This the multi-page printable view of this section. Click here to print.
Kubernetes Blog
- Updated: Dockershim Removal FAQ
- SIG Node CI Subproject Celebrates Two Years of Test Improvements
- Spotlight on SIG Multicluster
- Securing Admission Controllers
- Meet Our Contributors - APAC (India region)
- Kubernetes is Moving on From Dockershim: Commitments and Next Steps
- Kubernetes-in-Kubernetes and the WEDOS PXE bootable server farm
- Using Admission Controllers to Detect Container Drift at Runtime
- What's new in Security Profiles Operator v0.4.0
- Kubernetes 1.23: StatefulSet PVC Auto-Deletion (alpha)
- Kubernetes 1.23: Prevent PersistentVolume leaks when deleting out of order
- Kubernetes 1.23: Kubernetes In-Tree to CSI Volume Migration Status Update
- Kubernetes 1.23: Pod Security Graduates to Beta
- Kubernetes 1.23: Dual-stack IPv4/IPv6 Networking Reaches GA
- Kubernetes 1.23: The Next Frontier
- Contribution, containers and cricket: the Kubernetes 1.22 release interview
- Quality-of-Service for Memory Resources
- Dockershim removal is coming. Are you ready?
- Non-root Containers And Devices
- Announcing the 2021 Steering Committee Election Results
- Use KPNG to Write Specialized kube-proxiers
- Introducing ClusterClass and Managed Topologies in Cluster API
- A Closer Look at NSA/CISA Kubernetes Hardening Guidance
- How to Handle Data Duplication in Data-Heavy Kubernetes Environments
- Spotlight on SIG Node
- Introducing Single Pod Access Mode for PersistentVolumes
- Alpha in Kubernetes v1.22: API Server Tracing
- Kubernetes 1.22: A New Design for Volume Populators
- Minimum Ready Seconds for StatefulSets
- Enable seccomp for all workloads with a new v1.22 alpha feature
- Alpha in v1.22: Windows HostProcess Containers
- Kubernetes Memory Manager moves to beta
- Kubernetes 1.22: CSI Windows Support (with CSI Proxy) reaches GA
- New in Kubernetes v1.22: alpha support for using swap memory
- Kubernetes 1.22: Server Side Apply moves to GA
- Kubernetes 1.22: Reaching New Peaks
- Roorkee robots, releases and racing: the Kubernetes 1.21 release interview
- Updating NGINX-Ingress to use the stable Ingress API
- Kubernetes Release Cadence Change: Here’s What You Need To Know
- Spotlight on SIG Usability
- Kubernetes API and Feature Removals In 1.22: Here’s What You Need To Know
- Announcing Kubernetes Community Group Annual Reports
- Writing a Controller for Pod Labels
- Using Finalizers to Control Deletion
- Kubernetes 1.21: Metrics Stability hits GA
- Evolving Kubernetes networking with the Gateway API
- Graceful Node Shutdown Goes Beta
- Annotating Kubernetes Services for Humans
- Defining Network Policy Conformance for Container Network Interface (CNI) providers
- Introducing Indexed Jobs
- Volume Health Monitoring Alpha Update
- Three Tenancy Models For Kubernetes
- Local Storage: Storage Capacity Tracking, Distributed Provisioning and Generic Ephemeral Volumes hit Beta
- kube-state-metrics goes v2.0
- Introducing Suspended Jobs
- Kubernetes 1.21: CronJob Reaches GA
- Kubernetes 1.21: Power to the Community
- PodSecurityPolicy Deprecation: Past, Present, and Future
- The Evolution of Kubernetes Dashboard
- A Custom Kubernetes Scheduler to Orchestrate Highly Available Applications
- Kubernetes 1.20: Pod Impersonation and Short-lived Volumes in CSI Drivers
- Third Party Device Metrics Reaches GA
- Kubernetes 1.20: Granular Control of Volume Permission Changes
- Kubernetes 1.20: Kubernetes Volume Snapshot Moves to GA
- Kubernetes 1.20: The Raddest Release
- GSoD 2020: Improving the API Reference Experience
- Dockershim Deprecation FAQ
- Don't Panic: Kubernetes and Docker
- Cloud native security for your clusters
- Remembering Dan Kohn
- Announcing the 2020 Steering Committee Election Results
- Contributing to the Development Guide
- GSoC 2020 - Building operators for cluster addons
- Introducing Structured Logs
- Warning: Helpful Warnings Ahead
- Scaling Kubernetes Networking With EndpointSlices
- Ephemeral volumes with storage capacity tracking: EmptyDir on steroids
- Increasing the Kubernetes Support Window to One Year
- Kubernetes 1.19: Accentuate the Paw-sitive
- Moving Forward From Beta
- Introducing Hierarchical Namespaces
- Physics, politics and Pull Requests: the Kubernetes 1.18 release interview
- Music and math: the Kubernetes 1.17 release interview
- SIG-Windows Spotlight
- Working with Terraform and Kubernetes
- A Better Docs UX With Docsy
- Supporting the Evolving Ingress Specification in Kubernetes 1.18
- K8s KPIs with Kuberhealthy
- My exciting journey into Kubernetes’ history
- An Introduction to the K8s-Infrastructure Working Group
- WSL+Docker: Kubernetes on the Windows Desktop
- How Docs Handle Third Party and Dual Sourced Content
- Introducing PodTopologySpread
- Two-phased Canary Rollout with Open Source Gloo
- Cluster API v1alpha3 Delivers New Features and an Improved User Experience
- How Kubernetes contributors are building a better communication process
- API Priority and Fairness Alpha
- Introducing Windows CSI support alpha for Kubernetes
- Improvements to the Ingress API in Kubernetes 1.18
- Kubernetes 1.18 Feature Server-side Apply Beta 2
- Kubernetes Topology Manager Moves to Beta - Align Up!
- Kubernetes 1.18: Fit & Finish
- Join SIG Scalability and Learn Kubernetes the Hard Way
- Kong Ingress Controller and Service Mesh: Setting up Ingress to Istio on Kubernetes
- Contributor Summit Amsterdam Postponed
- Bring your ideas to the world with kubectl plugins
- Contributor Summit Amsterdam Schedule Announced
- Deploying External OpenStack Cloud Provider with Kubeadm
- KubeInvaders - Gamified Chaos Engineering Tool for Kubernetes
- CSI Ephemeral Inline Volumes
- Reviewing 2019 in Docs
- Kubernetes on MIPS
- Announcing the Kubernetes bug bounty program
- Remembering Brad Childs
- Testing of CSI drivers
- Kubernetes 1.17: Stability
- Kubernetes 1.17 Feature: Kubernetes Volume Snapshot Moves to Beta
- Kubernetes 1.17 Feature: Kubernetes In-Tree to CSI Volume Migration Moves to Beta
- When you're in the release team, you're family: the Kubernetes 1.16 release interview
- Gardener Project Update
- Develop a Kubernetes controller in Java
- Running Kubernetes locally on Linux with Microk8s
- Grokkin' the Docs
- Kubernetes Documentation Survey
- Contributor Summit San Diego Schedule Announced!
- 2019 Steering Committee Election Results
- Contributor Summit San Diego Registration Open!
- Kubernetes 1.16: Custom Resources, Overhauled Metrics, and Volume Extensions
- Announcing etcd 3.4
- OPA Gatekeeper: Policy and Governance for Kubernetes
- Get started with Kubernetes (using Python)
- Deprecated APIs Removed In 1.16: Here’s What You Need To Know
- Recap of Kubernetes Contributor Summit Barcelona 2019
- Automated High Availability in kubeadm v1.15: Batteries Included But Swappable
- Introducing Volume Cloning Alpha for Kubernetes
- Future of CRDs: Structural Schemas
- Kubernetes 1.15: Extensibility and Continuous Improvement
- Join us at the Contributor Summit in Shanghai
- Kyma - extend and build on Kubernetes with ease
- Kubernetes, Cloud Native, and the Future of Software
- Expanding our Contributor Workshops
- Cat shirts and Groundhog Day: the Kubernetes 1.14 release interview
- Join us for the 2019 KubeCon Diversity Lunch & Hack
- How You Can Help Localize Kubernetes Docs
- Hardware Accelerated SSL/TLS Termination in Ingress Controllers using Kubernetes Device Plugins and RuntimeClass
- Introducing kube-iptables-tailer: Better Networking Visibility in Kubernetes Clusters
- The Future of Cloud Providers in Kubernetes
- Pod Priority and Preemption in Kubernetes
- Process ID Limiting for Stability Improvements in Kubernetes 1.14
- Kubernetes 1.14: Local Persistent Volumes GA
- Kubernetes v1.14 delivers production-level support for Windows nodes and Windows containers
- kube-proxy Subtleties: Debugging an Intermittent Connection Reset
- Running Kubernetes locally on Linux with Minikube - now with Kubernetes 1.14 support
- Kubernetes 1.14: Production-level support for Windows Nodes, Kubectl Updates, Persistent Local Volumes GA
- Kubernetes End-to-end Testing for Everyone
- A Guide to Kubernetes Admission Controllers
- A Look Back and What's in Store for Kubernetes Contributor Summits
- KubeEdge, a Kubernetes Native Edge Computing Framework
- Kubernetes Setup Using Ansible and Vagrant
- Raw Block Volume support to Beta
- Automate Operations on your Cluster with OperatorHub.io
- Building a Kubernetes Edge (Ingress) Control Plane for Envoy v2
- Runc and CVE-2019-5736
- Poseidon-Firmament Scheduler – Flow Network Graph Based Scheduler
- Update on Volume Snapshot Alpha for Kubernetes
- Container Storage Interface (CSI) for Kubernetes GA
- APIServer dry-run and kubectl diff
- Kubernetes Federation Evolution
- etcd: Current status and future roadmap
- New Contributor Workshop Shanghai
- Production-Ready Kubernetes Cluster Creation with kubeadm
- Kubernetes 1.13: Simplified Cluster Management with Kubeadm, Container Storage Interface (CSI), and CoreDNS as Default DNS are Now Generally Available
- Kubernetes Docs Updates, International Edition
- gRPC Load Balancing on Kubernetes without Tears
- Tips for Your First Kubecon Presentation - Part 2
- Tips for Your First Kubecon Presentation - Part 1
- Kubernetes 2018 North American Contributor Summit
- 2018 Steering Committee Election Results
- Topology-Aware Volume Provisioning in Kubernetes
- Kubernetes v1.12: Introducing RuntimeClass
- Introducing Volume Snapshot Alpha for Kubernetes
- Support for Azure VMSS, Cluster-Autoscaler and User Assigned Identity
- Introducing the Non-Code Contributor’s Guide
- KubeDirector: The easy way to run complex stateful applications on Kubernetes
- Building a Network Bootable Server Farm for Kubernetes with LTSP
- Health checking gRPC servers on Kubernetes
- Kubernetes 1.12: Kubelet TLS Bootstrap and Azure Virtual Machine Scale Sets (VMSS) Move to General Availability
- Hands On With Linkerd 2.0
- 2018 Steering Committee Election Cycle Kicks Off
- The Machines Can Do the Work, a Story of Kubernetes Testing, CI, and Automating the Contributor Experience
- Introducing Kubebuilder: an SDK for building Kubernetes APIs using CRDs
- Out of the Clouds onto the Ground: How to Make Kubernetes Production Grade Anywhere
- Dynamically Expand Volume with CSI and Kubernetes
- KubeVirt: Extending Kubernetes with CRDs for Virtualized Workloads
- Feature Highlight: CPU Manager
- The History of Kubernetes & the Community Behind It
- Kubernetes Wins the 2018 OSCON Most Impact Award
- 11 Ways (Not) to Get Hacked
- How the sausage is made: the Kubernetes 1.11 release interview, from the Kubernetes Podcast
- Resizing Persistent Volumes using Kubernetes
- Dynamic Kubelet Configuration
- CoreDNS GA for Kubernetes Cluster DNS
- Meet Our Contributors - Monthly Streaming YouTube Mentoring Series
- IPVS-Based In-Cluster Load Balancing Deep Dive
- Airflow on Kubernetes (Part 1): A Different Kind of Operator
- Kubernetes 1.11: In-Cluster Load Balancing and CoreDNS Plugin Graduate to General Availability
- Dynamic Ingress in Kubernetes
- 4 Years of K8s
- Say Hello to Discuss Kubernetes
- Introducing kustomize; Template-free Configuration Customization for Kubernetes
- Kubernetes Containerd Integration Goes GA
- Getting to Know Kubevirt
- Gardener - The Kubernetes Botanist
- Docs are Migrating from Jekyll to Hugo
- Announcing Kubeflow 0.1
- Current State of Policy in Kubernetes
- Developing on Kubernetes
- Zero-downtime Deployment in Kubernetes with Jenkins
- Kubernetes Community - Top of the Open Source Charts in 2017
- Kubernetes Application Survey 2018 Results
- Local Persistent Volumes for Kubernetes Goes Beta
- Migrating the Kubernetes Blog
- Container Storage Interface (CSI) for Kubernetes Goes Beta
- Fixing the Subpath Volume Vulnerability in Kubernetes
- Kubernetes 1.10: Stabilizing Storage, Security, and Networking
- Principles of Container-based Application Design
- Expanding User Support with Office Hours
- How to Integrate RollingUpdate Strategy for TPR in Kubernetes
- Apache Spark 2.3 with Native Kubernetes Support
- Kubernetes: First Beta Version of Kubernetes 1.10 is Here
- Reporting Errors from Control Plane to Applications Using Kubernetes Events
- Core Workloads API GA
- Introducing client-go version 6
- Extensible Admission is Beta
- Introducing Container Storage Interface (CSI) Alpha for Kubernetes
- Kubernetes v1.9 releases beta support for Windows Server Containers
- Five Days of Kubernetes 1.9
- Introducing Kubeflow - A Composable, Portable, Scalable ML Stack Built for Kubernetes
- Kubernetes 1.9: Apps Workloads GA and Expanded Ecosystem
- Using eBPF in Kubernetes
- PaddlePaddle Fluid: Elastic Deep Learning on Kubernetes
- Autoscaling in Kubernetes
- Certified Kubernetes Conformance Program: Launch Celebration Round Up
- Kubernetes is Still Hard (for Developers)
- Securing Software Supply Chain with Grafeas
- Containerd Brings More Container Runtime Options for Kubernetes
- Kubernetes the Easy Way
- Enforcing Network Policies in Kubernetes
- Using RBAC, Generally Available in Kubernetes v1.8
- It Takes a Village to Raise a Kubernetes
- kubeadm v1.8 Released: Introducing Easy Upgrades for Kubernetes Clusters
- Five Days of Kubernetes 1.8
- Introducing Software Certification for Kubernetes
- Request Routing and Policy Management with the Istio Service Mesh
- Kubernetes Community Steering Committee Election Results
- Kubernetes 1.8: Security, Workloads and Feature Depth
- Kubernetes StatefulSets & DaemonSets Updates
- Introducing the Resource Management Working Group
- Windows Networking at Parity with Linux for Kubernetes
- Kubernetes Meets High-Performance Computing
- High Performance Networking with EC2 Virtual Private Clouds
- Kompose Helps Developers Move Docker Compose Files to Kubernetes
- Happy Second Birthday: A Kubernetes Retrospective
- How Watson Health Cloud Deploys Applications with Kubernetes
- Kubernetes 1.7: Security Hardening, Stateful Application Updates and Extensibility
- Managing microservices with the Istio service mesh
- Draft: Kubernetes container development made easy
- Kubernetes: a monitoring guide
- Kubespray Ansible Playbooks foster Collaborative Kubernetes Ops
- Dancing at the Lip of a Volcano: The Kubernetes Security Process - Explained
- How Bitmovin is Doing Multi-Stage Canary Deployments with Kubernetes in the Cloud and On-Prem
- RBAC Support in Kubernetes
- Configuring Private DNS Zones and Upstream Nameservers in Kubernetes
- Advanced Scheduling in Kubernetes
- Scalability updates in Kubernetes 1.6: 5,000 node and 150,000 pod clusters
- Dynamic Provisioning and Storage Classes in Kubernetes
- Five Days of Kubernetes 1.6
- Kubernetes 1.6: Multi-user, Multi-workloads at Scale
- The K8sPort: Engaging Kubernetes Community One Activity at a Time
- Deploying PostgreSQL Clusters using StatefulSets
- Containers as a Service, the foundation for next generation PaaS
- Inside JD.com's Shift to Kubernetes from OpenStack
- Run Deep Learning with PaddlePaddle on Kubernetes
- Highly Available Kubernetes Clusters
- Fission: Serverless Functions as a Service for Kubernetes
- Running MongoDB on Kubernetes with StatefulSets
- How we run Kubernetes in Kubernetes aka Kubeception
- Scaling Kubernetes deployments with Policy-Based Networking
- A Stronger Foundation for Creating and Managing Kubernetes Clusters
- Kubernetes UX Survey Infographic
- Kubernetes supports OpenAPI
- Cluster Federation in Kubernetes 1.5
- Windows Server Support Comes to Kubernetes
- StatefulSet: Run and Scale Stateful Applications Easily in Kubernetes
- Five Days of Kubernetes 1.5
- Introducing Container Runtime Interface (CRI) in Kubernetes
- Kubernetes 1.5: Supporting Production Workloads
- From Network Policies to Security Policies
- Kompose: a tool to go from Docker-compose to Kubernetes
- Kubernetes Containers Logging and Monitoring with Sematext
- Visualize Kubelet Performance with Node Dashboard
- CNCF Partners With The Linux Foundation To Launch New Kubernetes Certification, Training and Managed Service Provider Program
- Bringing Kubernetes Support to Azure Container Service
- Modernizing the Skytap Cloud Micro-Service Architecture with Kubernetes
- Introducing Kubernetes Service Partners program and a redesigned Partners page
- Tail Kubernetes with Stern
- How We Architected and Run Kubernetes on OpenStack at Scale at Yahoo! JAPAN
- Building Globally Distributed Services using Kubernetes Cluster Federation
- Helm Charts: making it simple to package and deploy common applications on Kubernetes
- Dynamic Provisioning and Storage Classes in Kubernetes
- How we improved Kubernetes Dashboard UI in 1.4 for your production needs
- How we made Kubernetes insanely easy to install
- How Qbox Saved 50% per Month on AWS Bills Using Kubernetes and Supergiant
- Kubernetes 1.4: Making it easy to run on Kubernetes anywhere
- High performance network policies in Kubernetes clusters
- Creating a PostgreSQL Cluster using Helm
- Deploying to Multiple Kubernetes Clusters with kit
- Cloud Native Application Interfaces
- Security Best Practices for Kubernetes Deployment
- Scaling Stateful Applications using Kubernetes Pet Sets and FlexVolumes with Datera Elastic Data Fabric
- Kubernetes Namespaces: use cases and insights
- SIG Apps: build apps for and operate them in Kubernetes
- Create a Couchbase cluster using Kubernetes
- Challenges of a Remotely Managed, On-Premises, Bare-Metal Kubernetes Cluster
- Why OpenStack's embrace of Kubernetes is great for both communities
- A Very Happy Birthday Kubernetes
- Happy Birthday Kubernetes. Oh, the places you’ll go!
- The Bet on Kubernetes, a Red Hat Perspective
- Bringing End-to-End Kubernetes Testing to Azure (Part 2)
- Dashboard - Full Featured Web Interface for Kubernetes
- Steering an Automation Platform at Wercker with Kubernetes
- Citrix + Kubernetes = A Home Run
- Cross Cluster Services - Achieving Higher Availability for your Kubernetes Applications
- Stateful Applications in Containers!? Kubernetes 1.3 Says “Yes!”
- Thousand Instances of Cassandra using Kubernetes Pet Set
- Autoscaling in Kubernetes
- Kubernetes in Rancher: the further evolution
- Five Days of Kubernetes 1.3
- Minikube: easily run Kubernetes locally
- rktnetes brings rkt container engine to Kubernetes
- Updates to Performance and Scalability in Kubernetes 1.3 -- 2,000 node 60,000 pod clusters
- Kubernetes 1.3: Bridging Cloud Native and Enterprise Workloads
- Container Design Patterns
- The Illustrated Children's Guide to Kubernetes
- Bringing End-to-End Kubernetes Testing to Azure (Part 1)
- Hypernetes: Bringing Security and Multi-tenancy to Kubernetes
- CoreOS Fest 2016: CoreOS and Kubernetes Community meet in Berlin (& San Francisco)
- Introducing the Kubernetes OpenStack Special Interest Group
- SIG-UI: the place for building awesome user interfaces for Kubernetes
- SIG-ClusterOps: Promote operability and interoperability of Kubernetes clusters
- SIG-Networking: Kubernetes Network Policy APIs Coming in 1.3
- How to deploy secure, auditable, and reproducible Kubernetes clusters on AWS
- Adding Support for Kubernetes in Rancher
- Container survey results - March 2016
- Configuration management with Containers
- Using Deployment objects with Kubernetes 1.2
- Kubernetes 1.2 and simplifying advanced networking with Ingress
- Using Spark and Zeppelin to process big data on Kubernetes 1.2
- AppFormix: Helping Enterprises Operationalize Kubernetes
- Building highly available applications using Kubernetes new multi-zone clusters (a.k.a. 'Ubernetes Lite')
- 1000 nodes and beyond: updates to Kubernetes performance and scalability in 1.2
- Five Days of Kubernetes 1.2
- How container metadata changes your point of view
- Scaling neural network image classification using Kubernetes with TensorFlow Serving
- Kubernetes 1.2: Even more performance upgrades, plus easier application deployment and management
- ElasticBox introduces ElasticKube to help manage Kubernetes within the enterprise
- Kubernetes in the Enterprise with Fujitsu’s Cloud Load Control
- Kubernetes Community Meeting Notes - 20160225
- State of the Container World, February 2016
- KubeCon EU 2016: Kubernetes Community in London
- Kubernetes Community Meeting Notes - 20160218
- Kubernetes Community Meeting Notes - 20160211
- ShareThis: Kubernetes In Production
- Kubernetes Community Meeting Notes - 20160204
- Kubernetes Community Meeting Notes - 20160128
- State of the Container World, January 2016
- Kubernetes Community Meeting Notes - 20160114
- Kubernetes Community Meeting Notes - 20160121
- Why Kubernetes doesn’t use libnetwork
- Simple leader election with Kubernetes and Docker
- Creating a Raspberry Pi cluster running Kubernetes, the installation (Part 2)
- Managing Kubernetes Pods, Services and Replication Controllers with Puppet
- How Weave built a multi-deployment solution for Scope using Kubernetes
- Creating a Raspberry Pi cluster running Kubernetes, the shopping list (Part 1)
- Monitoring Kubernetes with Sysdig
- One million requests per second: Dependable and dynamic distributed systems at scale
- Kubernetes 1.1 Performance upgrades, improved tooling and a growing community
- Kubernetes as Foundation for Cloud Native PaaS
- Some things you didn’t know about kubectl
- Kubernetes Performance Measurements and Roadmap
- Using Kubernetes Namespaces to Manage Environments
- Weekly Kubernetes Community Hangout Notes - July 31 2015
- The Growing Kubernetes Ecosystem
- Weekly Kubernetes Community Hangout Notes - July 17 2015
- Strong, Simple SSL for Kubernetes Services
- Weekly Kubernetes Community Hangout Notes - July 10 2015
- Announcing the First Kubernetes Enterprise Training Course
- How did the Quake demo from DockerCon Work?
- Kubernetes 1.0 Launch Event at OSCON
- The Distributed System ToolKit: Patterns for Composite Containers
- Slides: Cluster Management with Kubernetes, talk given at the University of Edinburgh
- Cluster Level Logging with Kubernetes
- Weekly Kubernetes Community Hangout Notes - May 22 2015
- Kubernetes on OpenStack
- Docker and Kubernetes and AppC
- Weekly Kubernetes Community Hangout Notes - May 15 2015
- Kubernetes Release: 0.17.0
- Resource Usage Monitoring in Kubernetes
- Kubernetes Release: 0.16.0
- Weekly Kubernetes Community Hangout Notes - May 1 2015
- AppC Support for Kubernetes through RKT
- Weekly Kubernetes Community Hangout Notes - April 24 2015
- Borg: The Predecessor to Kubernetes
- Kubernetes and the Mesosphere DCOS
- Weekly Kubernetes Community Hangout Notes - April 17 2015
- Introducing Kubernetes API Version v1beta3
- Kubernetes Release: 0.15.0
- Weekly Kubernetes Community Hangout Notes - April 10 2015
- Faster than a speeding Latte
- Weekly Kubernetes Community Hangout Notes - April 3 2015
- Participate in a Kubernetes User Experience Study
- Weekly Kubernetes Community Hangout Notes - March 27 2015
- Kubernetes Gathering Videos
- Welcome to the Kubernetes Blog!
Updated: Dockershim Removal FAQ
This is an update to the original Dockershim Deprecation FAQ article, published in late 2020.
This document goes over some frequently asked questions regarding the deprecation and removal of dockershim, that was announced as a part of the Kubernetes v1.20 release. For more detail on what that means, check out the blog post Don't Panic: Kubernetes and Docker.
Also, you can read check whether dockershim removal affects you to determine how much impact the removal of dockershim would have for you or for your organization.
As the Kubernetes 1.24 release has become imminent, we've been working hard to try to make this a smooth transition.
- We've written a blog post detailing our commitment and next steps.
- We believe there are no major blockers to migration to other container runtimes.
- There is also a Migrating from dockershim guide available.
- We've also created a page to list articles on dockershim removal and on using CRI-compatible runtimes. That list includes some of the already mentioned docs, and also covers selected external sources (including vendor guides).
Why is the dockershim being removed from Kubernetes?
Early versions of Kubernetes only worked with a specific container runtime: Docker Engine. Later, Kubernetes added support for working with other container runtimes. The CRI standard was created to enable interoperability between orchestrators (like Kubernetes) and many different container runtimes. Docker Engine doesn't implement that interface (CRI), so the Kubernetes project created special code to help with the transition, and made that dockershim code part of Kubernetes itself.
The dockershim code was always intended to be a temporary solution (hence the name: shim). You can read more about the community discussion and planning in the Dockershim Removal Kubernetes Enhancement Proposal. In fact, maintaining dockershim had become a heavy burden on the Kubernetes maintainers.
Additionally, features that were largely incompatible with the dockershim, such as cgroups v2 and user namespaces are being implemented in these newer CRI runtimes. Removing support for the dockershim will allow further development in those areas.
Can I still use Docker Engine in Kubernetes 1.23?
Yes, the only thing changed in 1.20 is a single warning log printed at kubelet startup if using Docker Engine as the runtime. You'll see this warning in all versions up to 1.23. The dockershim removal occurs in Kubernetes 1.24.
When will dockershim be removed?
Given the impact of this change, we are using an extended deprecation timeline. Removal of dockershim is scheduled for Kubernetes v1.24, see Dockershim Removal Kubernetes Enhancement Proposal. The Kubernetes project will be working closely with vendors and other ecosystem groups to ensure a smooth transition and will evaluate things as the situation evolves.
Can I still use Docker Engine as my container runtime?
First off, if you use Docker on your own PC to develop or test containers: nothing changes. You can still use Docker locally no matter what container runtime(s) you use for your Kubernetes clusters. Containers make this kind of interoperability possible.
Mirantis and Docker have committed to maintaining a replacement adapter for
Docker Engine, and to maintain that adapter even after the in-tree dockershim is removed
from Kubernetes. The replacement adapter is named cri-dockerd.
Will my existing container images still work?
Yes, the images produced from docker build will work with all CRI implementations.
All your existing images will still work exactly the same.
What about private images?
Yes. All CRI runtimes support the same pull secrets configuration used in Kubernetes, either via the PodSpec or ServiceAccount.
Are Docker and containers the same thing?
Docker popularized the Linux containers pattern and has been instrumental in developing the underlying technology, however containers in Linux have existed for a long time. The container ecosystem has grown to be much broader than just Docker. Standards like OCI and CRI have helped many tools grow and thrive in our ecosystem, some replacing aspects of Docker while others enhance existing functionality.
Are there examples of folks using other runtimes in production today?
All Kubernetes project produced artifacts (Kubernetes binaries) are validated with each release.
Additionally, the kind project has been using containerd for some time and has seen an improvement in stability for its use case. Kind and containerd are leveraged multiple times every day to validate any changes to the Kubernetes codebase. Other related projects follow a similar pattern as well, demonstrating the stability and usability of other container runtimes. As an example, OpenShift 4.x has been using the CRI-O runtime in production since June 2019.
For other examples and references you can look at the adopters of containerd and CRI-O, two container runtimes under the Cloud Native Computing Foundation (CNCF).
People keep referencing OCI, what is that?
OCI stands for the Open Container Initiative, which standardized many of the interfaces between container tools and technologies. They maintain a standard specification for packaging container images (OCI image-spec) and running containers (OCI runtime-spec). They also maintain an actual implementation of the runtime-spec in the form of runc, which is the underlying default runtime for both containerd and CRI-O. The CRI builds on these low-level specifications to provide an end-to-end standard for managing containers.
Which CRI implementation should I use?
That’s a complex question and it depends on a lot of factors. If Docker is working for you, moving to containerd should be a relatively easy swap and will have strictly better performance and less overhead. However, we encourage you to explore all the options from the CNCF landscape in case another would be an even better fit for your environment.
What should I look out for when changing CRI implementations?
While the underlying containerization code is the same between Docker and most CRIs (including containerd), there are a few differences around the edges. Some common things to consider when migrating are:
- Logging configuration
- Runtime resource limitations
- Node provisioning scripts that call docker or use docker via it's control socket
- Kubectl plugins that require docker CLI or the control socket
- Tools from the Kubernetes project that require direct access to Docker Engine
(for example: the deprecated
kube-imagepullertool) - Configuration of functionality like
registry-mirrorsand insecure registries - Other support scripts or daemons that expect Docker Engine to be available and are run outside of Kubernetes (for example, monitoring or security agents)
- GPUs or special hardware and how they integrate with your runtime and Kubernetes
If you use Kubernetes resource requests/limits or file-based log collection
DaemonSets then they will continue to work the same, but if you’ve customized
your dockerd configuration, you’ll need to adapt that for your new container
runtime where possible.
Another thing to look out for is anything expecting to run for system maintenance
or nested inside a container when building images will no longer work. For the
former, you can use the crictl tool as a drop-in replacement (see mapping from docker cli to crictl) and for the
latter you can use newer container build options like img, buildah,
kaniko, or buildkit-cli-for-kubectl that don’t require Docker.
For containerd, you can start with their documentation to see what configuration options are available as you migrate things over.
For instructions on how to use containerd and CRI-O with Kubernetes, see the Kubernetes documentation on Container Runtimes
What if I have more questions?
If you use a vendor-supported Kubernetes distribution, you can ask them about upgrade plans for their products. For end-user questions, please post them to our end user community forum: https://discuss.kubernetes.io/.
You can also check out the excellent blog post Wait, Docker is deprecated in Kubernetes now? a more in-depth technical discussion of the changes.
Can I have a hug?
Yes, we're still giving hugs as requested. 🤗🤗🤗
SIG Node CI Subproject Celebrates Two Years of Test Improvements
Authors: Sergey Kanzhelev (Google), Elana Hashman (Red Hat)
Ensuring the reliability of SIG Node upstream code is a continuous effort that takes a lot of behind-the-scenes effort from many contributors. There are frequent releases of Kubernetes, base operating systems, container runtimes, and test infrastructure that result in a complex matrix that requires attention and steady investment to "keep the lights on." In May 2020, the Kubernetes node special interest group ("SIG Node") organized a new subproject for continuous integration (CI) for node-related code and tests. Since its inauguration, the SIG Node CI subproject has run a weekly meeting, and even the full hour is often not enough to complete triage of all bugs, test-related PRs and issues, and discuss all related ongoing work within the subgroup.
Over the past two years, we've fixed merge-blocking and release-blocking tests, reducing time to merge Kubernetes contributors' pull requests thanks to reduced test flakes. When we started, Node test jobs only passed 42% of the time, and through our efforts, we now ensure a consistent >90% job pass rate. We've closed 144 test failure issues and merged 176 pull requests just in kubernetes/kubernetes. And we've helped subproject participants ascend the Kubernetes contributor ladder, with 3 new org members, 6 new reviewers, and 2 new approvers.
The Node CI subproject is an approachable first stop to help new contributors get started with SIG Node. There is a low barrier to entry for new contributors to address high-impact bugs and test fixes, although there is a long road before contributors can climb the entire contributor ladder: it took over a year to establish two new approvers for the group. The complexity of all the different components that power Kubernetes nodes and its test infrastructure requires a sustained investment over a long period for developers to deeply understand the entire system, both at high and low levels of detail.
We have several regular contributors at our meetings, however; our reviewers and approvers pool is still small. It is our goal to continue to grow contributors to ensure a sustainable distribution of work that does not just fall to a few key approvers.
It's not always obvious how subprojects within SIGs are formed, operate, and work. Each is unique to its sponsoring SIG and tailored to the projects that the group is intended to support. As a group that has welcomed many first-time SIG Node contributors, we'd like to share some of the details and accomplishments over the past two years, helping to demystify our inner workings and celebrate the hard work of all our dedicated contributors!
Timeline
May 2020. SIG Node CI group was formed on May 11, 2020, with more than 30 volunteers signed up, to improve SIG Node CI signal and overall observability. Victor Pickard focused on getting testgrid jobs passing when Ning Liao suggested forming a group around this effort and came up with the original group charter document. The SIG Node chairs sponsored group creation with Victor as a subproject lead. Sergey Kanzhelev joined Victor shortly after as a co-lead.
At the kick-off meeting, we discussed which tests to concentrate on fixing first and discussed merge-blocking and release-blocking tests, many of which were failing due to infrastructure issues or buggy test code.
The subproject launched weekly hour-long meetings to discuss ongoing work discussion and triage.
June 2020. Morgan Bauer, Karan Goel, and Jorge Alarcon Ochoa were recognized as reviewers for the SIG Node CI group for their contributions, helping significantly with the early stages of the subproject. David Porter and Roy Yang also joined the SIG test failures GitHub team.
August 2020. All merge-blocking and release-blocking tests were passing, with some flakes. However, only 42% of all SIG Node test jobs were green, as there were many flakes and failing tests.
October 2020. Amim Knabben becomes a Kubernetes org member for his contributions to the subproject.
January 2021. With healthy presubmit and critical periodic jobs passing, the subproject discussed its goal for cleaning up the rest of periodic tests and ensuring they passed without flakes.
Elana Hashman joined the subproject, stepping up to help lead it after Victor's departure.
February 2021. Artyom Lukianov becomes a Kubernetes org member for his contributions to the subproject.
August 2021. After SIG Node successfully ran a bug scrub to clean up its bug backlog, the scope of the meeting was extended to include bug triage to increase overall reliability, anticipating issues before they affect the CI signal.
Subproject leads Elana Hashman and Sergey Kanzhelev are both recognized as approvers on all node test code, supported by SIG Node and SIG Testing.
September 2021. After significant deflaking progress with serial tests in the 1.22 release spearheaded by Francesco Romani, the subproject set a goal for getting the serial job fully passing by the 1.23 release date.
Mike Miranda becomes a Kubernetes org member for his contributions to the subproject.
November 2021. Throughout 2021, SIG Node had no merge or release-blocking test failures. Many flaky tests from past releases are removed from release-blocking dashboards as they had been fully cleaned up.
Danielle Lancashire was recognized as a reviewer for SIG Node's subgroup, test code.
The final node serial tests were completely fixed. The serial tests consist of many disruptive and slow tests which tend to be flakey and are hard to troubleshoot. By the 1.23 release freeze, the last serial tests were fixed and the job was passing without flakes.

The 1.23 release got a special shout out for the tests quality and CI signal. The SIG Node CI subproject was proud to have helped contribute to such a high-quality release, in part due to our efforts in identifying and fixing flakes in Node and beyond.

December 2021. An estimated 90% of test jobs were passing at the time of the 1.23 release (up from 42% in August 2020).
Dockershim code was removed from Kubernetes. This affected nearly half of SIG Node's test jobs and the SIG Node CI subproject reacted quickly and retargeted all the tests. SIG Node was the first SIG to complete test migrations off dockershim, providing examples for other affected SIGs. The vast majority of new jobs passed at the time of introduction without further fixes required. The effort of removing dockershim) from Kubernetes is ongoing. There are still some wrinkles from the dockershim removal as we uncover more dependencies on dockershim, but we plan to stabilize all test jobs by the 1.24 release.
Statistics
Our regular meeting attendees and subproject participants for the past few months:
- Aditi Sharma
- Artyom Lukianov
- Arnaud Meukam
- Danielle Lancashire
- David Porter
- Davanum Srinivas
- Elana Hashman
- Francesco Romani
- Matthias Bertschy
- Mike Miranda
- Paco Xu
- Peter Hunt
- Ruiwen Zhao
- Ryan Phillips
- Sergey Kanzhelev
- Skyler Clark
- Swati Sehgal
- Wenjun Wu
The kubernetes/test-infra source code repository contains test definitions. The number of Node PRs just in that repository:
Triaged issues and PRs on CI board (including triaging away from the subgroup scope):
Future
Just "keeping the lights on" is a bold task and we are committed to improving this experience. We are working to simplify the triage and review processes for SIG Node.
Specifically, we are working on better test organization, naming, and tracking:
- https://github.com/kubernetes/enhancements/pull/3042
- https://github.com/kubernetes/test-infra/issues/24641
- Kubernetes SIG-Node CI Testgrid Tracker
We are also constantly making progress on improved tests debuggability and de-flaking.
If any of this interests you, we'd love for you to join us! There's plenty to learn in debugging test failures, and it will help you gain familiarity with the code that SIG Node maintains.
You can always find information about the group on the SIG Node page. We give group updates at our maintainer track sessions, such as KubeCon + CloudNativeCon Europe 2021 and KubeCon + CloudNative North America 2021. Join us in our mission to keep the kubelet and other SIG Node components reliable and ensure smooth and uneventful releases!
Spotlight on SIG Multicluster
Authors: Dewan Ahmed (Aiven) and Chris Short (AWS)
Introduction
SIG Multicluster is the SIG focused on how Kubernetes concepts are expanded and used beyond the cluster boundary. Historically, Kubernetes resources only interacted within that boundary - KRU or Kubernetes Resource Universe (not an actual Kubernetes concept). Kubernetes clusters, even now, don't really know anything about themselves or, about other clusters. Absence of cluster identifiers is a case in point. With the growing adoption of multicloud and multicluster deployments, the work SIG Multicluster doing is gaining a lot of attention. In this blog, Jeremy Olmsted-Thompson, Google and Chris Short, AWS discuss the interesting problems SIG Multicluster is solving and how you can get involved. Their initials JOT and CS will be used for brevity.
A summary of their conversation
CS: How long has the SIG Multicluster existed and how was the SIG in its infancy? How long have you been with this SIG?
JOT: I've been around for almost two years in the SIG Multicluster. All I know about the infancy years is from the lore but even in the early days, it was always about solving this same problem. Early efforts have been things like KubeFed. I think there are still folks using KubeFed but it's a smaller slice. Back then, I think people out there deploying large numbers of Kubernetes clusters were really not at a point where we had a ton of real concrete use cases. Projects like KubeFed and Cluster Registry were developed around that time and the need back then can be associated to these projects. The motivation for these projects were how do we solve the problems that we think people are going to have, when they start expanding to multiple clusters. Honestly, in some ways, it was trying to do too much at that time.
CS: How does KubeFed differ from the current state of SIG Multicluster? How does the lore differ from the now?
JOT: Yeah, it was like trying to get ahead of potential problems instead of addressing specific problems. I think towards the end of 2019, there was a slow down in SIG multicluster work and we kind of picked it back up with one of the most active recent projects that is the SIG Multicluster services (MCS).
Now this is the shift to solving real specific problems. For example,
I've got workloads that are spread across multiple clusters and I need them to talk to each other.
Okay, that's very straightforward and we know that we need to solve that. To get started, let's make sure that these projects can work together on a common API so you get the same kind of portability that you get with Kubernetes.
There's a few implementations of the MCS API out there and more are being developed. But, we didn't build an implementation because depending on how you're deploying things there could be hundreds of implementations. As long as you only need the basic Multicluster service functionality, it'll just work on whatever background you want, whether it's Submariner, GKE, or a service mesh.
My favorite example of "then vs. now" is cluster ID. A few years ago, there was an effort to define a cluster ID. A lot of really good thought went into this concept, for example, how do we make a cluster ID is unique across multiple clusters. How do we make this ID globally unique so it'll work in every contact? Let's say, there's an acquisition or merger of teams - does the cluster IDs still remain unique for those teams?
With Multicluster services, we found the need for an actual cluster ID, and it has a very specific need. To address this specific need, we're no longer considering every single Kubernetes cluster out there rather the ClusterSets - a grouping of clusters that work together in some kind of bounds. That's a much narrower scope than considering clusters everywhere in time and space. It also leaves flexibility for an implementer to define the boundary (a ClusterSet) beyond which this cluster ID will no longer be unique.
CS: How do you feel about the current state of SIG Multicluster versus where you're hoping to be in future?
JOT: There's a few projects that are kind of getting started, for example, Work API. In the future, I think that some common practices around how do we deploy things across clusters are going to develop.
If I have clusters deployed in a bunch of different regions; what's the best way to actually do that?
The answer is, almost always, "it depends". Why are you doing this? Is it because there's some kind of compliance that makes you care about locality? Is it performance? Is it availability?
I think revisiting registry patterns will probably be a natural step after we have cluster IDs, that is, how do you actually associate these clusters together? Maybe you've got a distributed deployment that you run in your own data centers all over the world. I imagine that expanding the API in that space is going to be important as more multi cluster features develop. It really depends on what the community starts doing with these tools.
CS: In the early days of Kubernetes, we used to have a few large Kubernetes clusters and now we're dealing with many small Kubernetes clusters - even multiple clusters for our own dev environments. How has this shift from a few large clusters to many small clusters affected the SIG? Has it accelerated the work or make it challenging in any way?
JOT: I think that it has created a lot of ambiguity that needs solving. Originally, you'd have a dev cluster, a staging cluster, and a prod cluster. When the multi region thing came in, we started needing dev/staging/prod clusters, per region. And then, sometimes clusters really need more isolation due to compliance or some regulations issues. Thus, we're ending up with a lot of clusters. I think figuring out the right balance on how many clusters should you actually have is important. The power of Kubernetes is being able to deploy a lot of things managed by a single control plane. So, it's not like every single workload that gets deployed should be in its own cluster. But I think it's pretty clear that we can't put every single workload in a single cluster.
CS: What are some of your favorite things about this SIG?
JOT: The complexity of the problems, the people and the newness of the space. We don't have right answers and we have to figure this out. At the beginning, we couldn't even think about multi clusters because there was no way to connect services across clusters. Now there is and we're starting to go tackle those problems, I think that this is a really fun place to be in because I expect that the SIG is going to get a lot busier the next couple of years. It's a very collaborative group and we definitely would like more people to come join us, get involved, raise their problems and bring their ideas.
CS: What do you think keeps people in this group? How has the pandemic affected you?
JOT: I think it definitely got a little bit quieter during the pandemic. But for the most part; it's a very distributed group so whether you're calling in to our weekly meetings from a conference room or from your home, it doesn't make that huge of a difference. During the pandemic, a lot of people had time to focus on what's next for their scale and growth. I think that's what keeps people in the group - we have real problems that need to be solved which are very new in this space. And it's fun :)
Wrap up
CS: That's all we have for today. Thanks Jeremy for your time.
JOT: Thanks Chris. Everybody is welcome at our bi-weekly meetings. We love as many people to come as possible and welcome all questions and all ideas. It's a new space and it'd be great to grow the community.
Securing Admission Controllers
Author: Rory McCune (Aqua Security)
Admission control is a key part of Kubernetes security, alongside authentication and authorization. Webhook admission controllers are extensively used to help improve the security of Kubernetes clusters in a variety of ways including restricting the privileges of workloads and ensuring that images deployed to the cluster meet organization’s security requirements.
However, as with any additional component added to a cluster, security risks can present themselves. A security risk example is if the deployment and management of the admission controller are not handled correctly. To help admission controller users and designers manage these risks appropriately, the security documentation subgroup of SIG Security has spent some time developing a threat model for admission controllers. This threat model looks at likely risks which may arise from the incorrect use of admission controllers, which could allow security policies to be bypassed, or even allow an attacker to get unauthorised access to the cluster.
From the threat model, we developed a set of security best practices that should be adopted to ensure that cluster operators can get the security benefits of admission controllers whilst avoiding any risks from using them.
Admission controllers and good practices for security
From the threat model, a couple of themes emerged around how to ensure the security of admission controllers.
Secure webhook configuration
It’s important to ensure that any security component in a cluster is well configured and admission controllers are no different here. There are a couple of security best practices to consider when using admission controllers
- Correctly configured TLS for all webhook traffic. Communications between the API server and the admission controller webhook should be authenticated and encrypted to ensure that attackers who may be in a network position to view or modify this traffic cannot do so. To achieve this access the API server and webhook must be using certificates from a trusted certificate authority so that they can validate their mutual identities
- Only authenticated access allowed. If an attacker can send an admission controller large numbers of requests, they may be able to overwhelm the service causing it to fail. Ensuring all access requires strong authentication should mitigate that risk.
- Admission controller fails closed. This is a security practice that has a tradeoff, so whether a cluster operator wants to configure it will depend on the cluster’s threat model. If an admission controller fails closed, when the API server can’t get a response from it, all deployments will fail. This stops attackers bypassing the admission controller by disabling it, but, can disrupt the cluster’s operation. As clusters can have multiple webhooks, one approach to hit a middle ground might be to have critical controls on a fail closed setups and less critical controls allowed to fail open.
- Regular reviews of webhook configuration. Configuration mistakes can lead to security issues, so it’s important that the admission controller webhook configuration is checked to make sure the settings are correct. This kind of review could be done automatically by an Infrastructure As Code scanner or manually by an administrator.
Secure cluster configuration for admission control
In most cases, the admission controller webhook used by a cluster will be installed as a workload in the cluster. As a result, it’s important to ensure that Kubernetes' security features that could impact its operation are well configured.
- Restrict RBAC rights. Any user who has rights which would allow them to modify the configuration of the webhook objects or the workload that the admission controller uses could disrupt its operation. So it’s important to make sure that only cluster administrators have those rights.
- Prevent privileged workloads. One of the realities of container systems is that if a workload is given certain privileges, it will be possible to break out to the underlying cluster node and impact other containers on that node. Where admission controller services run in the cluster they’re protecting, it’s important to ensure that any requirement for privileged workloads is carefully reviewed and restricted as much as possible.
- Strictly control external system access. As a security service in a cluster admission controller systems will have access to sensitive information like credentials. To reduce the risk of this information being sent outside the cluster, network policies should be used to restrict the admission controller services access to external networks.
- Each cluster has a dedicated webhook. Whilst it may be possible to have admission controller webhooks that serve multiple clusters, there is a risk when using that model that an attack on the webhook service would have a larger impact where it’s shared. Also where multiple clusters use an admission controller there will be increased complexity and access requirements, making it harder to secure.
Admission controller rules
A key element of any admission controller used for Kubernetes security is the rulebase it uses. The rules need to be able to accurately meet their goals avoiding false positive and false negative results.
- Regularly test and review rules. Admission controller rules need to be tested to ensure their accuracy. They also need to be regularly reviewed as the Kubernetes API will change with each new version, and rules need to be assessed with each Kubernetes release to understand any changes that may be required to keep them up to date.
Meet Our Contributors - APAC (India region)
Authors & Interviewers: Anubhav Vardhan, Atharva Shinde, Avinesh Tripathi, Debabrata Panigrahi, Kunal Verma, Pranshu Srivastava, Pritish Samal, Purneswar Prasad, Vedant Kakde
Editor: Priyanka Saggu
Good day, everyone 👋
Welcome to the first episode of the APAC edition of the "Meet Our Contributors" blog post series.
In this post, we'll introduce you to five amazing folks from the India region who have been actively contributing to the upstream Kubernetes projects in a variety of ways, as well as being the leaders or maintainers of numerous community initiatives.
💫 Let's get started, so without further ado…
Arsh Sharma
Arsh is currently employed with Okteto as a Developer Experience engineer. As a new contributor, he realised that 1:1 mentorship opportunities were quite beneficial in getting him started with the upstream project.
He is presently a CI Signal shadow on the Kubernetes 1.23 release team. He is also contributing to the SIG Testing and SIG Docs projects, as well as to the cert-manager tools development work that is being done under the aegis of SIG Architecture.
To the newcomers, Arsh helps plan their early contributions sustainably.
I would encourage folks to contribute in a way that's sustainable. What I mean by that is that it's easy to be very enthusiastic early on and take up more stuff than one can actually handle. This can often lead to burnout in later stages. It's much more sustainable to work on things iteratively.
Kunal Kushwaha
Kunal Kushwaha is a core member of the Kubernetes marketing council. He is also a CNCF ambassador and one of the founders of the CNCF Students Program.. He also served as a Communications role shadow during the 1.22 release cycle.
At the end of his first year, Kunal began contributing to the fabric8io kubernetes-client project. He was then selected to work on the same project as part of Google Summer of Code. Kunal mentored people on the same project, first through Google Summer of Code then through Google Code-in.
As an open-source enthusiast, he believes that diverse participation in the community is beneficial since it introduces new perspectives and opinions and respect for one's peers. He has worked on various open-source projects, and his participation in communities has considerably assisted his development as a developer.
I believe if you find yourself in a place where you do not know much about the project, that's a good thing because now you can learn while contributing and the community is there to help you. It has helped me a lot in gaining skills, meeting people from around the world and also helping them. You can learn on the go, you don't have to be an expert. Make sure to also check out no code contributions because being a beginner is a skill and you can bring new perspectives to the organisation.
Madhav Jivarajani
Madhav Jivarajani works on the VMware Upstream Kubernetes stability team. He began contributing to the Kubernetes project in January 2021 and has since made significant contributions to several areas of work under SIG Architecture, SIG API Machinery, and SIG ContribEx (contributor experience).
Among several significant contributions are his recent efforts toward the Archival of design proposals, refactoring the "groups" codebase under k8s-infra repository to make it mockable and testable, and improving the functionality of the GitHub k8s bot.
In addition to his technical efforts, Madhav oversees many projects aimed at assisting new contributors. He organises bi-weekly "KEP reading club" sessions to help newcomers understand the process of adding new features, deprecating old ones, and making other key changes to the upstream project. He has also worked on developing Katacoda scenarios to assist new contributors to become acquainted with the process of contributing to k/k. In addition to his current efforts to meet with community members every week, he has organised several new contributors workshops (NCW).
I initially did not know much about Kubernetes. I joined because the community was super friendly. But what made me stay was not just the people, but the project itself. My solution to not feeling overwhelmed in the community was to gain as much context and knowledge into the topics that I was interested in and were being discussed. And as a result I continued to dig deeper into Kubernetes and the design of it. I am a systems nut & thus Kubernetes was an absolute goldmine for me.
Rajas Kakodkar
Rajas Kakodkar currently works at VMware as a Member of Technical Staff. He has been engaged in many aspects of the upstream Kubernetes project since 2019.
He is now a key contributor to the Testing special interest group. He is also active in the SIG Network community. Lately, Rajas has contributed significantly to the NetworkPolicy++ and kpng sub-projects.
One of the first challenges he ran across was that he was in a different time zone than the upstream project's regular meeting hours. However, async interactions on community forums progressively corrected that problem.
I enjoy contributing to Kubernetes not just because I get to work on cutting edge tech but more importantly because I get to work with awesome people and help in solving real world problems.
Rajula Vineet Reddy
Rajula Vineet Reddy, a Junior Engineer at CERN, is a member of the Marketing Council team under SIG ContribEx . He also served as a release shadow for SIG Release during the 1.22 and 1.23 Kubernetes release cycles.
He started looking at the Kubernetes project as part of a university project with the help of one of his professors. Over time, he spent a significant amount of time reading the project's documentation, Slack discussions, GitHub issues, and blogs, which helped him better grasp the Kubernetes project and piqued his interest in contributing upstream. One of his key contributions was his assistance with automation in the SIG ContribEx Upstream Marketing subproject.
According to Rajula, attending project meetings and shadowing various project roles are vital for learning about the community.
I find the community very helpful and it's always “you get back as much as you contribute”. The more involved you are, the more you will understand, get to learn and contribute new things.
The first step to “come forward and start” is hard. But it's all gonna be smooth after that. Just take that jump.
If you have any recommendations/suggestions for who we should interview next, please let us know in #sig-contribex. We're thrilled to have other folks assisting us in reaching out to even more wonderful individuals of the community. Your suggestions would be much appreciated.
We'll see you all in the next one. Everyone, till then, have a happy contributing! 👋
Kubernetes is Moving on From Dockershim: Commitments and Next Steps
Authors: Sergey Kanzhelev (Google), Jim Angel (Google), Davanum Srinivas (VMware), Shannon Kularathna (Google), Chris Short (AWS), Dawn Chen (Google)
Kubernetes is removing dockershim in the upcoming v1.24 release. We're excited to reaffirm our community values by supporting open source container runtimes, enabling a smaller kubelet, and increasing engineering velocity for teams using Kubernetes. If you use Docker Engine as a container runtime for your Kubernetes cluster, get ready to migrate in 1.24! To check if you're affected, refer to Check whether dockershim deprecation affects you.
Why we’re moving away from dockershim
Docker was the first container runtime used by Kubernetes. This is one of the reasons why Docker is so familiar to many Kubernetes users and enthusiasts. Docker support was hardcoded into Kubernetes – a component the project refers to as dockershim. As containerization became an industry standard, the Kubernetes project added support for additional runtimes. This culminated in the implementation of the container runtime interface (CRI), letting system components (like the kubelet) talk to container runtimes in a standardized way. As a result, dockershim became an anomaly in the Kubernetes project. Dependencies on Docker and dockershim have crept into various tools and projects in the CNCF ecosystem ecosystem, resulting in fragile code.
By removing the dockershim CRI, we're embracing the first value of CNCF: "Fast is better than slow". Stay tuned for future communications on the topic!
Deprecation timeline
We formally announced the dockershim deprecation in December 2020. Full removal is targeted in Kubernetes 1.24, in April 2022. This timeline aligns with our deprecation policy, which states that deprecated behaviors must function for at least 1 year after their announced deprecation.
We'll support Kubernetes version 1.23, which includes dockershim, for another year in the Kubernetes project. For managed Kubernetes providers, vendor support is likely to last even longer, but this is dependent on the companies themselves. Regardless, we're confident all cluster operations will have time to migrate. If you have more questions about the dockershim removal, refer to the Dockershim Deprecation FAQ.
We asked you whether you feel prepared for the migration from dockershim in this survey: Are you ready for Dockershim removal. We had over 600 responses. To everybody who took time filling out the survey, thank you.
The results show that we still have a lot of ground to cover to help you to migrate smoothly. Other container runtimes exist, and have been promoted extensively. However, many users told us they still rely on dockershim, and sometimes have dependencies that need to be re-worked. Some of these dependencies are outside of your control. Based on your feedback, here are some of the steps we are taking to help.
Our next steps
Based on the feedback you provided:
- CNCF and the 1.24 release team are committed to delivering documentation in time for the 1.24 release. This includes more informative blog posts like this one, updating existing code samples, tutorials, and tasks, and producing a migration guide for cluster operators.
- We are reaching out to the rest of the CNCF community to help prepare them for this change.
If you're part of a project with dependencies on dockershim, or if you're interested in helping with the migration effort, please join us! There's always room for more contributors, whether to our transition tools or to our documentation. To get started, say hello in the #sig-node channel on Kubernetes Slack!
Final thoughts
As a project, we've already seen cluster operators increasingly adopt other container runtimes through 2021. We believe there are no major blockers to migration. The steps we're taking to improve the migration experience will light the path more clearly for you.
We understand that migration from dockershim is yet another action you may need to do to keep your Kubernetes infrastructure up to date. For most of you, this step will be straightforward and transparent. In some cases, you will encounter hiccups or issues. The community has discussed at length whether postponing the dockershim removal would be helpful. For example, we recently talked about it in the SIG Node discussion on November 11th and in the Kubernetes Steering committee meeting held on December 6th. We already postponed it once in 2021 because the adoption rate of other runtimes was lower than we wanted, which also gave us more time to identify potential blocking issues.
At this point, we believe that the value that you (and Kubernetes) gain from dockershim removal makes up for the migration effort you'll have. Start planning now to avoid surprises. We'll have more updates and guides before Kubernetes 1.24 is released.
Kubernetes-in-Kubernetes and the WEDOS PXE bootable server farm
Author: Andrei Kvapil (WEDOS)
When you own two data centers, thousands of physical servers, virtual machines and hosting for hundreds of thousands sites, Kubernetes can actually simplify the management of all these things. As practice has shown, by using Kubernetes, you can declaratively describe and manage not only applications, but also the infrastructure itself. I work for the largest Czech hosting provider WEDOS Internet a.s and today I'll show you two of my projects — Kubernetes-in-Kubernetes and Kubefarm.
With their help you can deploy a fully working Kubernetes cluster inside another Kubernetes using Helm in just a couple of commands. How and why?
Let me introduce you to how our infrastructure works. All our physical servers can be divided into two groups: control-plane and compute nodes. Control plane nodes are usually set up manually, have a stable OS installed, and designed to run all cluster services including Kubernetes control-plane. The main task of these nodes is to ensure the smooth operation of the cluster itself. Compute nodes do not have any operating system installed by default, instead they are booting the OS image over the network directly from the control plane nodes. Their work is to carry out the workload.

Once nodes have downloaded their image, they can continue to work without keeping connection to the PXE server. That is, a PXE server is just keeping rootfs image and does not hold any other complex logic. After our nodes have booted, we can safely restart the PXE server, nothing critical will happen to them.

After booting, the first thing our nodes do is join to the existing Kubernetes cluster, namely, execute the kubeadm join command so that kube-scheduler could schedule some pods on them and launch various workloads afterwards. From the beginning we used the scheme when nodes were joined into the same cluster used for the control-plane nodes.

This scheme worked stably for over two years. However later we decided to add containerized Kubernetes to it. And now we can spawn new Kubernetes-clusters very easily right on our control-plane nodes which are now member special admin-clusters. Now, compute nodes can be joined directly to their own clusters - depending on the configuration.

Kubefarm
This project came with the goal of enabling anyone to deploy such an infrastructure in just a couple of commands using Helm and get about the same in the end.
At this time, we moved away from the idea of a monocluster. Because it turned out to be not very convenient for managing work of several development teams in the same cluster. The fact is that Kubernetes was never designed as a multi-tenant solution and at the moment it does not provide sufficient means of isolation between projects. Therefore, running separate clusters for each team turned out to be a good idea. However, there should not be too many clusters, to let them be convenient to manage. Nor is it too small to have sufficient independence between development teams.
The scalability of our clusters became noticeably better after that change. The more clusters you have per number of nodes, the smaller the failure domain and the more stable they work. And as a bonus, we got a fully declaratively described infrastructure. Thus, now you can deploy a new Kubernetes cluster in the same way as deploying any other application in Kubernetes.
It uses Kubernetes-in-Kubernetes as a basis, LTSP as PXE-server from which the nodes are booted, and automates the DHCP server configuration using dnsmasq-controller:
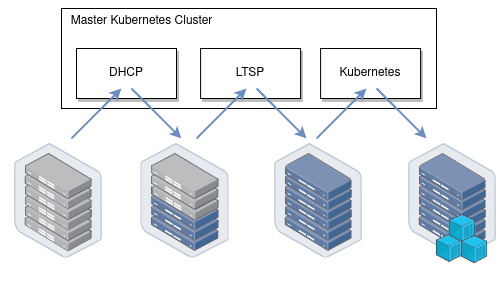
How it works
Now let's see how it works. In general, if you look at Kubernetes as from an application perspective, you can note that it follows all the principles of The Twelve-Factor App, and is actually written very well. Thus, it means running Kubernetes as an app in a different Kubernetes shouldn't be a big deal.
Running Kubernetes in Kubernetes
Now let's take a look at the Kubernetes-in-Kubernetes project, which provides a ready-made Helm chart for running Kubernetes in Kubernetes.
Here is the parameters that you can pass to Helm in the values file:

Beside persistence (storage parameters for the cluster), the Kubernetes control-plane components are described here: namely: etcd cluster, apiserver, controller-manager and scheduler. These are pretty much standard Kubernetes components. There is a light-hearted saying that “Kubernetes is just five binaries”. So here is where the configuration for these binaries is located.
If you ever tried to bootstrap a cluster using kubeadm, then this config will remind you it's configuration. But in addition to Kubernetes entities, you also have an admin container. In fact, it is a container which holds two binaries inside: kubectl and kubeadm. They are used to generate kubeconfig for the above components and to perform the initial configuration for the cluster. Also, in an emergency, you can always exec into it to check and manage your cluster.
After the release has been deployed, you can see a list of pods: admin-container, apiserver in two replicas, controller-manager, etcd-cluster, scheduller and the initial job that initializes the cluster. In the end you have a command, which allows you to get shell into the admin container, you can use it to see what is happening inside:

Also, let's take look at the certificates. If you've ever installed Kubernetes, then you know that it has a scary directory /etc/kubernetes/pki with a bunch of some certificates. In case of Kubernetes-in-Kubernetes, you have fully automated management of them with cert-manager. Thus, it is enough to pass all certificates parameters to Helm during installation, and all the certificates will automatically be generated for your cluster.

Looking at one of the certificates, eg. apiserver, you can see that it has a list of DNS names and IP addresses. If you want to make this cluster accessible outside, then just describe the additional DNS names in the values file and update the release. This will update the certificate resource, and cert-manager will regenerate the certificate. You'll no longer need to think about this. If kubeadm certificates need to be renewed at least once a year, here the cert-manager will take care and automatically renew them.

Now let's log into the admin container and look at the cluster and nodes. Of course, there are no nodes, yet, because at the moment you have deployed just the blank control-plane for Kubernetes. But in kube-system namespace you can see some coredns pods waiting for scheduling and configmaps already appeared. That is, you can conclude that the cluster is working:

Here is the diagram of the deployed cluster. You can see services for all Kubernetes components: apiserver, controller-manager, etcd-cluster and scheduler. And the pods on right side to which they forward traffic.
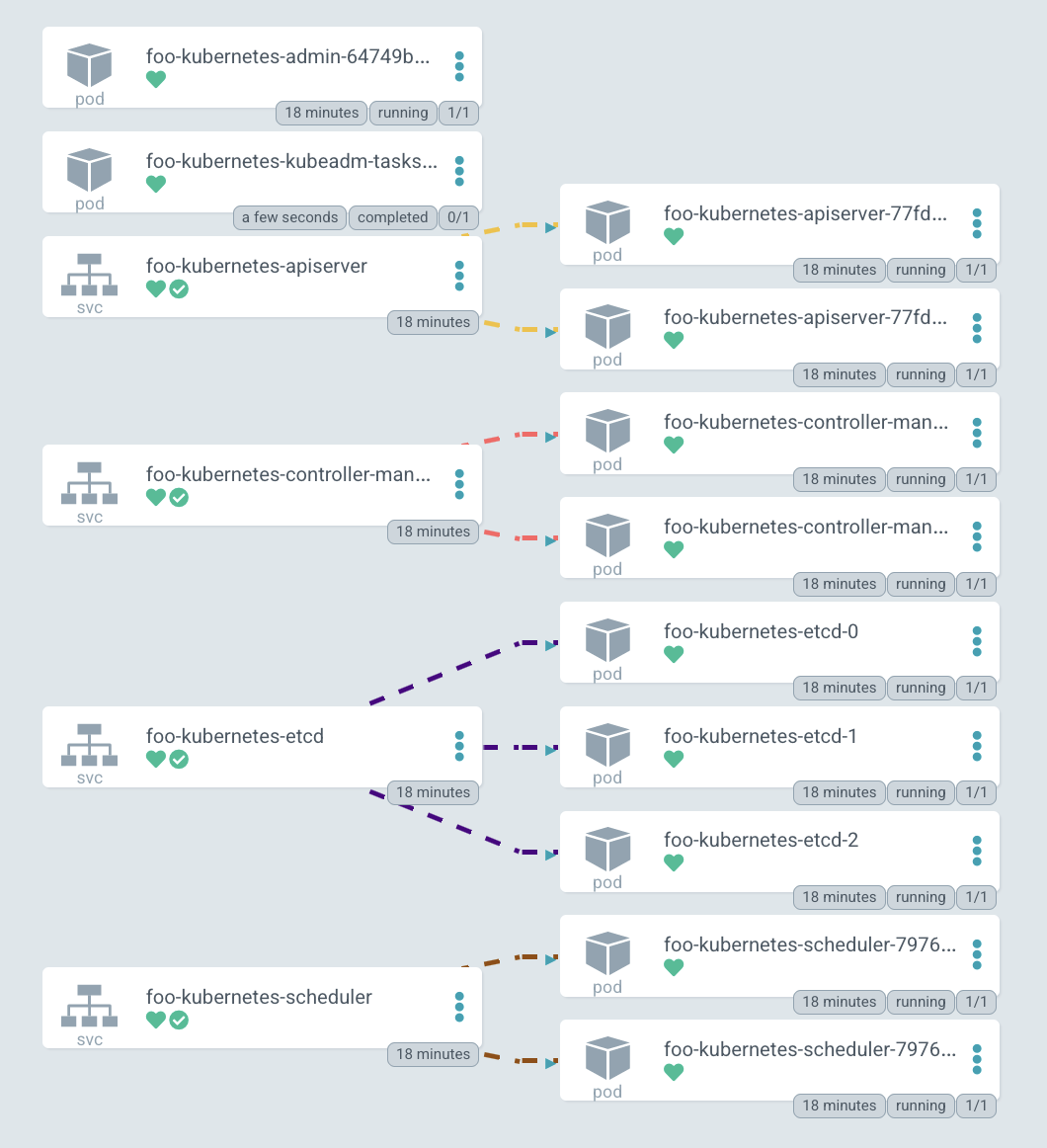
By the way, the diagram, is drawn in ArgoCD — the GitOps tool we use to manage our clusters, and cool diagrams are one of its features.
Orchestrating physical servers
OK, now you can see the way how is our Kubernetes control-plane deployed, but what about worker nodes, how are we adding them? As I already said, all our servers are bare metal. We do not use virtualization to run Kubernetes, but we orchestrate all physical servers by ourselves.
Also, we do use Linux network boot feature very actively. Moreover, this is exactly the booting, not some kind of automation of the installation. When the nodes are booting, they just run a ready-made system image for them. That is, to update any node, we just need to reboot it - and it will download a new image. It is very easy, simple and convenient.
For this, the Kubefarm project was created, which allows you to automate this. The most commonly used examples can be found in the examples directory. The most standard of them named generic. Let's take a look at values.yaml:
Here you can specify the parameters which are passed into the upstream Kubernetes-in-Kubernetes chart. In order for you control-plane to be accessible from the outside, it is enough to specify the IP address here, but if you wish, you can specify some DNS name here.
In the PXE server configuration you can specify a timezone. You can also add an SSH key for logging in without a password (but you can also specify a password), as well as kernel modules and parameters that should be applied during booting the system.
Next comes the nodePools configuration, i.e. the nodes themselves. If you've ever used a terraform module for gke, then this logic will remind you of it. Here you statically describe all nodes with a set of parameters:
-
Name (hostname);
-
MAC-addresses — we have nodes with two network cards, and each one can boot from any of the MAC addresses specified here.
-
IP-address, which the DHCP server should issue to this node.
In this example, you have two pools: the first has five nodes, the second has only one, the second pool has also two tags assigned. Tags are the way to describe configuration for specific nodes. For example, you can add specific DHCP options for some pools, options for the PXE server for booting (e.g. here is debug option enabled) and set of kubernetesLabels and kubernetesTaints options. What does that mean?
For example, in this configuration you have a second nodePool with one node. The pool has debug and foo tags assigned. Now see the options for foo tag in kubernetesLabels. This means that the m1c43 node will boot with these two labels and taint assigned. Everything seems to be simple. Now let's try this in practice.
Demo
Go to examples and update previously deployed chart to Kubefarm. Just use the generic parameters and look at the pods. You can see that a PXE server and one more job were added. This job essentially goes to the deployed Kubernetes cluster and creates a new token. Now it will run repeatedly every 12 hours to generate a new token, so that the nodes can connect to your cluster.

In a graphical representation, it looks about the same, but now apiserver started to be exposed outside.
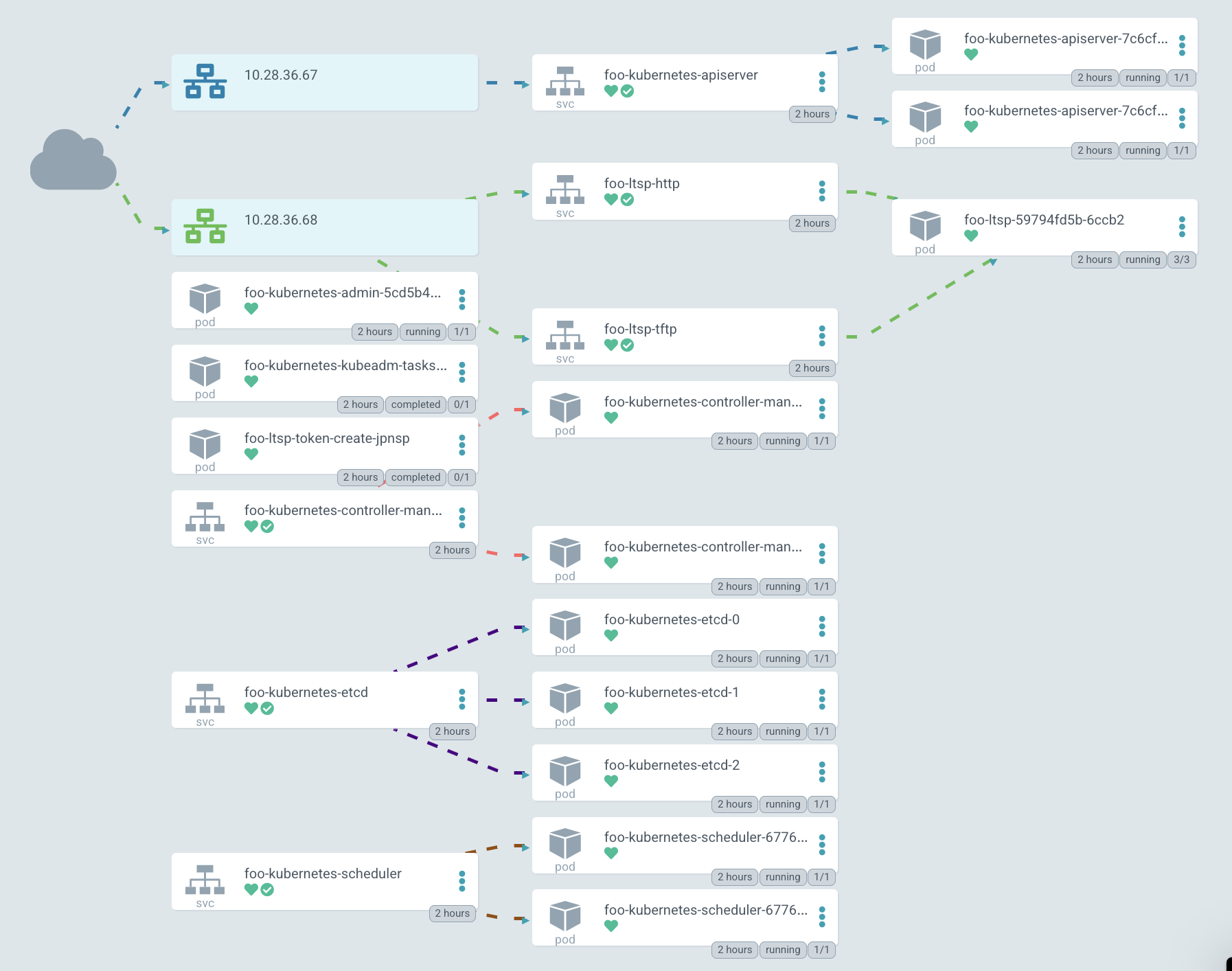
In the diagram, the IP is highlighted in green, the PXE server can be reached through it. At the moment, Kubernetes does not allow creating a single LoadBalancer service for TCP and UDP protocols by default, so you have to create two different services with the same IP address. One is for TFTP, and the second for HTTP, through which the system image is downloaded.
But this simple example is not always enough, sometimes you might need to modify the logic at boot. For example, here is a directory advanced_network, inside which there is a values file with a simple shell script. Let's call it network.sh:
All this script does is take environment variables at boot time, and generates a network configuration based on them. It creates a directory and puts the netplan config inside. For example, a bonding interface is created here. Basically, this script can contain everything you need. It can hold the network configuration or generate the system services, add some hooks or describe any other logic. Anything that can be described in bash or shell languages will work here, and it will be executed at boot time.
Let's see how it can be deployed. Let's pass the generic values file as the first parameter, and an additional values file as the second parameter. This is a standard Helm feature. This way you can also pass the secrets, but in this case, the configuration is just expanded by the second file:

Let's look at the configmap foo-kubernetes-ltsp for the netboot server and make sure that network.sh script is really there. These commands used to configure the network at boot time:

Here you can see how it works in principle. The chassis interface (we use HPE Moonshots 1500) have the nodes, you can enter show node list command to get a list of all the nodes. Now you can see the booting process.

You can also get their MAC addresses by show node macaddr all command. We have a clever operator that collects MAC-addresses from chassis automatically and passes them to the DHCP server. Actually, it's just creating custom configuration resources for dnsmasq-controller which is running in same admin Kubernetes cluster. Also, trough this interface you can control the nodes themselves, e.g. turn them on and off.
If you have no such opportunity to enter the chassis through iLO and collect a list of MAC addresses for your nodes, you can consider using catchall cluster pattern. Purely speaking, it is just a cluster with a dynamic DHCP pool. Thus, all nodes that are not described in the configuration to other clusters will automatically join to this cluster.

For example, you can see a special cluster with some nodes. They are joined to the cluster with an auto-generated name based on their MAC address. Starting from this point you can connect to them and see what happens there. Here you can somehow prepare them, for example, set up the file system and then rejoin them to another cluster.
Now let's try connecting to the node terminal and see how it is booting. After the BIOS, the network card is configured, here it sends a request to the DHCP server from a specific MAC address, which redirects it to a specific PXE server. Later the kernel and initrd image are downloaded from the server using the standard HTTP protocol:

After loading the kernel, the node downloads the rootfs image and transfers control to systemd. Then the booting proceeds as usual, and after that the node joins Kubernetes:

If you take a look at fstab, you can see only two entries there: /var/lib/docker and /var/lib/kubelet, they are mounted as tmpfs (in fact, from RAM). At the same time, the root partition is mounted as overlayfs, so all changes that you make here on the system will be lost on the next reboot.
Looking into the block devices on the node, you can see some nvme disk, but it has not yet been mounted anywhere. There is also a loop device - this is the exact rootfs image downloaded from the server. At the moment it is located in RAM, occupies 653 MB and mounted with the loop option.
If you look in /etc/ltsp, you find the network.sh file that was executed at boot. From containers, you can see running kube-proxy and pause container for it.

Details
Network Boot Image
But where does the main image come from? There is a little trick here. The image for the nodes is built through the Dockerfile along with the server. The Docker multi-stage build feature allows you to easily add any packages and kernel modules exactly at the stage of the image build. It looks like this:
What's going on here? First, we take a regular Ubuntu 20.04 and install all the packages we need. First of all we install the kernel, lvm, systemd, ssh. In general, everything that you want to see on the final node should be described here. Here we also install docker with kubelet and kubeadm, which are used to join the node to the cluster.
And then we perform an additional configuration. In the last stage, we simply install tftp and nginx (which serves our image to clients), grub (bootloader). Then root of the previous stages copied into the final image and generate squashed image from it. That is, in fact, we get a docker image, which has both the server and the boot image for our nodes. At the same time, it can be easily updated by changing the Dockerfile.
Webhooks and API aggregation layer
I want to pay special attention to the problem of webhooks and aggregation layer. In general, webhooks is a Kubernetes feature that allows you to respond to the creation or modification of any resources. Thus, you can add a handler so that when resources are applied, Kubernetes must send request to some pod and check if configuration of this resource is correct, or make additional changes to it.
But the point is, in order for the webhooks to work, the apiserver must have direct access to the cluster for which it is running. And if it is started in a separate cluster, like our case, or even separately from any cluster, then Konnectivity service can help us here. Konnectivity is one of the optional but officially supported Kubernetes components.
Let's take cluster of four nodes for example, each of them is running a kubelet and we have other Kubernetes components running outside: kube-apiserver, kube-scheduler and kube-controller-manager. By default, all these components interact with the apiserver directly - this is the most known part of the Kubernetes logic. But in fact, there is also a reverse connection. For example, when you want to view the logs or run a kubectl exec command, the API server establishes a connection to the specific kubelet independently:

But the problem is that if we have a webhook, then it usually runs as a standard pod with a service in our cluster. And when apiserver tries to reach it, it will fail because it will try to access an in-cluster service named webhook.namespace.svc being outside of the cluster where it is actually running:

And here Konnectivity comes to our rescue. Konnectivity is a tricky proxy server developed especially for Kubernetes. It can be deployed as a server next to the apiserver. And Konnectivity-agent is deployed in several replicas directly in the cluster you want to access. The agent establishes a connection to the server and sets up a stable channel to make apiserver able to access all webhooks and all kubelets in the cluster. Thus, now all communication with the cluster will take place through the Konnectivity-server:

Our plans
Of course, we are not going to stop at this stage. People interested in the project often write to me. And if there will be a sufficient number of interested people, I hope to move Kubernetes-in-Kubernetes project under Kubernetes SIGs, by representing it in form of the official Kubernetes Helm chart. Perhaps, by making this project independent we'll gather an even larger community.
I am also thinking of integrating it with the Machine Controller Manager, which would allow creating worker nodes, not only of physical servers, but also, for example, for creating virtual machines using kubevirt and running them in the same Kubernetes cluster. By the way, it also allows to spawn virtual machines in the clouds, and have a control-plane deployed locally.
I am also considering the option of integrating with the Cluster-API so that you can create physical Kubefarm clusters directly through the Kubernetes environment. But at the moment I'm not completely sure about this idea. If you have any thoughts on this matter, I'll be happy to listen to them.
Using Admission Controllers to Detect Container Drift at Runtime
Author: Saifuding Diliyaer (Box)
Illustration by Munire Aireti
At Box, we use Kubernetes (K8s) to manage hundreds of micro-services that enable Box to stream data at a petabyte scale. When it comes to the deployment process, we run kube-applier as part of the GitOps workflows with declarative configuration and automated deployment. Developers declare their K8s apps manifest into a Git repository that requires code reviews and automatic checks to pass, before any changes can get merged and applied inside our K8s clusters. With kubectl exec and other similar commands, however, developers are able to directly interact with running containers and alter them from their deployed state. This interaction could then subvert the change control and code review processes that are enforced in our CI/CD pipelines. Further, it allows such impacted containers to continue receiving traffic long-term in production.
To solve this problem, we developed our own K8s component called kube-exec-controller along with its corresponding kubectl plugin. They function together in detecting and terminating potentially mutated containers (caused by interactive kubectl commands), as well as revealing the interaction events directly to the target Pods for better visibility.
Admission control for interactive kubectl commands
Once a request is sent to K8s, it needs to be authenticated and authorized by the API server to proceed. Additionally, K8s has a separate layer of protection called admission controllers, which can intercept the request before an object is persisted in etcd. There are various predefined admission controls compiled into the API server binary (e.g. ResourceQuota to enforce hard resource usage limits per namespace). Besides, there are two dynamic admission controls named MutatingAdmissionWebhook and ValidatingAdmissionWebhook, used for mutating or validating K8s requests respectively. The latter is what we adopted to detect container drift at runtime caused by interactive kubectl commands. This whole process can be divided into three steps as explained in detail below.
1. Admit interactive kubectl command requests
First of all, we needed to enable a validating webhook that sends qualified requests to kube-exec-controller. To add the new validation mechanism applying to interactive kubectl commands specifically, we configured the webhook’s rules with resources as [pods/exec, pods/attach], and operations as CONNECT. These rules tell the cluster's API server that all exec and attach requests should be subject to our admission control webhook. In the ValidatingAdmissionWebhook that we configured, we specified a service reference (could also be replaced with url that gives the location of the webhook) and caBundle to allow validating its X.509 certificate, both under the clientConfig stanza.
Here is a short example of what our ValidatingWebhookConfiguration object looks like:
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: example-validating-webhook-config
webhooks:
- name: validate-pod-interaction.example.com
sideEffects: None
rules:
- apiGroups: ["*"]
apiVersions: ["*"]
operations: ["CONNECT"]
resources: ["pods/exec", "pods/attach"]
failurePolicy: Fail
clientConfig:
service:
# reference to kube-exec-controller service deployed inside the K8s cluster
name: example-service
namespace: kube-exec-controller
path: "/admit-pod-interaction"
caBundle: "{{VALUE}}" # PEM encoded CA bundle to validate kube-exec-controller's certificate
admissionReviewVersions: ["v1", "v1beta1"]
2. Label the target Pod with potentially mutated containers
Once a request of kubectl exec comes in, kube-exec-controller makes an internal note to label the associated Pod. The added labels mean that we can not only query all the affected Pods, but also enable the security mechanism to retrieve previously identified Pods, in case the controller service itself gets restarted.
The admission control process cannot directly modify the targeted in its admission response. This is because the pods/exec request is against a subresource of the Pod API, and the API kind for that subresource is PodExecOptions. As a result, there is a separate process in kube-exec-controller that patches the labels asynchronously. The admission control always permits the exec request, then acts as a client of the K8s API to label the target Pod and to log related events. Developers can check whether their Pods are affected or not using kubectl or similar tools. For example:
$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
test-pod 1/1 Running 0 2s box.com/podInitialInteractionTimestamp=1632524400,box.com/podInteractorUsername=username-1,box.com/podTTLDuration=1h0m0s
$ kubectl describe pod test-pod
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning PodInteraction 5s admission-controller-service Pod was interacted with 'kubectl exec' command by user 'username-1' initially at time 2021-09-24 16:00:00 -0800 PST
Warning PodInteraction 5s admission-controller-service Pod will be evicted at time 2021-09-24 17:00:00 -0800 PST (in about 1h0m0s).
3. Evict the target Pod after a predefined period
As you can see in the above event messages, the affected Pod is not evicted immediately. At times, developers might have to get into their running containers necessarily for debugging some live issues. Therefore, we define a time to live (TTL) of affected Pods based on the environment of clusters they are running. In particular, we allow a longer time in our dev clusters as it is more common to run kubectl exec or other interactive commands for active development.
For our production clusters, we specify a lower time limit so as to avoid the impacted Pods serving traffic abidingly. The kube-exec-controller internally sets and tracks a timer for each Pod that matches the associated TTL. Once the timer is up, the controller evicts that Pod using K8s API. The eviction (rather than deletion) is to ensure service availability, since the cluster respects any configured PodDisruptionBudget (PDB). Let's say if a user has defined x number of Pods as critical in their PDB, the eviction (as requested by kube-exec-controller) does not continue when the target workload has fewer than x Pods running.
Here comes a sequence diagram of the entire workflow mentioned above:

A new kubectl plugin for better user experience
Our admission controller component works great for solving the container drift issue we had on the platform. It is also able to submit all related Events to the target Pod that has been affected. However, K8s clusters don't retain Events very long (the default retention period is one hour). We need to provide other ways for developers to get their Pod interaction activity. A kubectl plugin is a perfect choice for us to expose this information. We named our plugin kubectl pi (short for pod-interaction) and provide two subcommands: get and extend.
When the get subcommand is called, the plugin checks the metadata attached by our admission controller and transfers it to human-readable information. Here is an example output from running kubectl pi get:
$ kubectl pi get test-pod
POD-NAME INTERACTOR POD-TTL EXTENSION EXTENSION-REQUESTER EVICTION-TIME
test-pod username-1 1h0m0s / / 2021-09-24 17:00:00 -0800 PST
The plugin can also be used to extend the TTL for a Pod that is marked for future eviction. This is useful in case developers need extra time to debug ongoing issues. To achieve this, a developer uses the kubectl pi extend subcommand, where the plugin patches the relevant annotations for the given Pod. These annotations include the duration and username who made the extension request for transparency (displayed in the table returned from the kubectl pi get command).
Correspondingly, there is another webhook defined in kube-exec-controller which admits valid annotation updates. Once admitted, those updates reset the eviction timer of the target Pod as requested. An example of requesting the extension from the developer side would be:
$ kubectl pi extend test-pod --duration=30m
Successfully extended the termination time of pod/test-pod with a duration=30m
$ kubectl pi get test-pod
POD-NAME INTERACTOR POD-TTL EXTENSION EXTENSION-REQUESTER EVICTION-TIME
test-pod username-1 1h0m0s 30m username-2 2021-09-24 17:30:00 -0800 PST
Future improvement
Although our admission controller service works great in handling interactive requests to a Pod, it could as well evict the Pod while the actual commands are no-op in these requests. For instance, developers sometimes run kubectl exec merely to check their service logs stored on hosts. Nevertheless, the target Pods would still get bounced despite the state of their containers not changing at all. One of the improvements here could be adding the ability to distinguish the commands that are passed to the interactive requests, so that no-op commands should not always force a Pod eviction. However, this becomes challenging when developers get a shell to a running container and execute commands inside the shell, since they will no longer be visible to our admission controller service.
Another item worth pointing out here is the choice of using K8s labels and annotations. In our design, we decided to have all immutable metadata attached as labels for better enforcing the immutability in our admission control. Yet some of these metadata could fit better as annotations. For instance, we had a label with the key box.com/podInitialInteractionTimestamp used to list all affected Pods in kube-exec-controller code, although its value would be unlikely to query for. As a more ideal design in the K8s world, a single label could be preferable in our case for identification with other metadata applied as annotations instead.
Summary
With the power of admission controllers, we are able to secure our K8s clusters by detecting potentially mutated containers at runtime, and evicting their Pods without affecting service availability. We also utilize kubectl plugins to provide flexibility of the eviction time and hence, bringing a better and more self-independent experience to service owners. We are proud to announce that we have open-sourced the whole project for the community to leverage in their own K8s clusters. Any contribution is more than welcomed and appreciated. You can find this project hosted on GitHub at https://github.com/box/kube-exec-controller
Special thanks to Ayush Sobti and Ethan Goldblum for their technical guidance on this project.
What's new in Security Profiles Operator v0.4.0
Authors: Jakub Hrozek, Juan Antonio Osorio, Paulo Gomes, Sascha Grunert
The Security Profiles Operator (SPO) is an out-of-tree Kubernetes enhancement to make the management of seccomp, SELinux and AppArmor profiles easier and more convenient. We're happy to announce that we recently released v0.4.0 of the operator, which contains a ton of new features, fixes and usability improvements.
What's new
It has been a while since the last v0.3.0 release of the operator. We added new features, fine-tuned existing ones and reworked our documentation in 290 commits over the past half year.
One of the highlights is that we're now able to record seccomp and SELinux
profiles using the operators log enricher.
This allows us to reduce the dependencies required for profile recording to have
auditd or
syslog (as fallback) running on the
nodes. All profile recordings in the operator work in the same way by using the
ProfileRecording CRD as well as their corresponding label
selectors. The log
enricher itself can be also used to gather meaningful insights about seccomp and
SELinux messages of a node. Checkout the official
documentation
to learn more about it.
seccomp related improvements
Beside the log enricher based recording we now offer an alternative to record
seccomp profiles by utilizing ebpf. This optional feature can
be enabled by setting enableBpfRecorder to true. This results in running a
dedicated container, which ships a custom bpf module on every node to collect
the syscalls for containers. It even supports older Kernel versions which do not
expose the BPF Type Format (BTF) per
default as well as the amd64 and arm64 architectures. Checkout
our documentation
to see it in action. By the way, we now add the seccomp profile architecture of
the recorder host to the recorded profile as well.
We also graduated the seccomp profile API from v1alpha1 to v1beta1. This
aligns with our overall goal to stabilize the CRD APIs over time. The only thing
which has changed is that the seccomp profile type Architectures now points to
[]Arch instead of []*Arch.
SELinux enhancements
Managing SELinux policies (an equivalent to using semodule that
you would normally call on a single server) is not done by SPO
itself, but by another container called selinuxd to provide better
isolation. This release switched to using selinuxd containers from
a personal repository to images located under our team's quay.io
repository.
The selinuxd repository has moved as well to the containers GitHub
organization.
Please note that selinuxd links dynamically to libsemanage and mounts the
SELinux directories from the nodes, which means that the selinuxd container
must be running the same distribution as the cluster nodes. SPO defaults
to using CentOS-8 based containers, but we also build Fedora based ones.
If you are using another distribution and would like us to add support for
it, please file an issue against selinuxd.
Profile Recording
This release adds support for recording of SELinux profiles.
The recording itself is managed via an instance of a ProfileRecording Custom
Resource as seen in an
example
in our repository. From the user's point of view it works pretty much the same
as recording of seccomp profiles.
Under the hood, to know what the workload is doing SPO installs a special
permissive policy called selinuxrecording
on startup which allows everything and logs all AVCs to audit.log.
These AVC messages are scraped by the log enricher component and when
the recorded workload exits, the policy is created.
SELinuxProfile CRD graduation
An v1alpha2 version of the SelinuxProfile object has been introduced. This
removes the raw Common Intermediate Language (CIL) from the object itself and
instead adds a simple policy language to ease the writing and parsing
experience.
Alongside, a RawSelinuxProfile object was also introduced. This contains a
wrapped and raw representation of the policy. This was intended for folks to be
able to take their existing policies into use as soon as possible. However, on
validations are done here.
AppArmor support
This version introduces the initial support for AppArmor, allowing users to load and unload AppArmor profiles into cluster nodes by using the new AppArmorProfile CRD.
To enable AppArmor support use the enableAppArmor feature gate switch of your SPO configuration. Then use our apparmor example to deploy your first profile across your cluster.
Metrics
The operator now exposes metrics, which are described in detail in
our new metrics documentation.
We decided to secure the metrics retrieval process by using
kube-rbac-proxy, while we ship an
additional spo-metrics-client cluster role (and binding) to retrieve the
metrics from within the cluster. If you're using
OpenShift,
then we provide an out of the box working
ServiceMonitor
to access the metrics.
Debuggability and robustness
Beside all those new features, we decided to restructure parts of the Security
Profiles Operator internally to make it better to debug and more robust. For
example, we now maintain an internal gRPC API to communicate
within the operator across different features. We also improved the performance
of the log enricher, which now caches results for faster retrieval of the log
data. The operator can be put into a more verbose log mode
by setting verbosity from 0 to 1.
We also print the used libseccomp and libbpf versions on startup, as well as
expose CPU and memory profiling endpoints for each container via the
enableProfiling option.
Dedicated liveness and startup probes inside of the operator daemon will now
additionally improve the life cycle of the operator.
Conclusion
Thank you for reading this update. We're looking forward to future enhancements of the operator and would love to get your feedback about the latest release. Feel free to reach out to us via the Kubernetes slack #security-profiles-operator for any feedback or question.
Kubernetes 1.23: StatefulSet PVC Auto-Deletion (alpha)
Author: Matthew Cary (Google)
Kubernetes v1.23 introduced a new, alpha-level policy for StatefulSets that controls the lifetime of PersistentVolumeClaims (PVCs) generated from the StatefulSet spec template for cases when they should be deleted automatically when the StatefulSet is deleted or pods in the StatefulSet are scaled down.
What problem does this solve?
A StatefulSet spec can include Pod and PVC templates. When a replica is first created, the Kubernetes control plane creates a PVC for that replica if one does not already exist. The behavior before Kubernetes v1.23 was that the control plane never cleaned up the PVCs created for StatefulSets - this was left up to the cluster administrator, or to some add-on automation that you’d have to find, check suitability, and deploy. The common pattern for managing PVCs, either manually or through tools such as Helm, is that the PVCs are tracked by the tool that manages them, with explicit lifecycle. Workflows that use StatefulSets must determine on their own what PVCs are created by a StatefulSet and what their lifecycle should be.
Before this new feature, when a StatefulSet-managed replica disappears, either because the StatefulSet is reducing its replica count, or because its StatefulSet is deleted, the PVC and its backing volume remains and must be manually deleted. While this behavior is appropriate when the data is critical, in many cases the persistent data in these PVCs is either temporary, or can be reconstructed from another source. In those cases, PVCs and their backing volumes remaining after their StatefulSet or replicas have been deleted are not necessary, incur cost, and require manual cleanup.
The new StatefulSet PVC retention policy
If you enable the alpha feature, a StatefulSet spec includes a PersistentVolumeClaim retention
policy. This is used to control if and when PVCs created from a StatefulSet’s volumeClaimTemplate
are deleted. This first iteration of the retention policy contains two situations where PVCs may be
deleted.
The first situation is when the StatefulSet resource is deleted (which implies that all replicas are
also deleted). This is controlled by the whenDeleted policy. The second situation, controlled by
whenScaled is when the StatefulSet is scaled down, which removes some but not all of the replicas
in a StatefulSet. In both cases the policy can either be Retain, where the corresponding PVCs are
not touched, or Delete, which means that PVCs are deleted. The deletion is done with a normal
object deletion, so that, for example, all
retention policies for the underlying PV are respected.
This policy forms a matrix with four cases. I’ll walk through and give an example for each one.
-
whenDeletedandwhenScaledare bothRetain. This matches the existing behavior for StatefulSets, where no PVCs are deleted. This is also the default retention policy. It’s appropriate to use when data on StatefulSet volumes may be irreplaceable and should only be deleted manually. -
whenDeletedisDeleteandwhenScaledisRetain. In this case, PVCs are deleted only when the entire StatefulSet is deleted. If the StatefulSet is scaled down, PVCs are not touched, meaning they are available to be reattached if a scale-up occurs with any data from the previous replica. This might be used for a temporary StatefulSet, such as in a CI instance or ETL pipeline, where the data on the StatefulSet is needed only during the lifetime of the StatefulSet lifetime, but while the task is running the data is not easily reconstructible. Any retained state is needed for any replicas that scale down and then up. -
whenDeletedandwhenScaledare bothDelete. PVCs are deleted immediately when their replica is no longer needed. Note this does not include when a Pod is deleted and a new version rescheduled, for example when a node is drained and Pods need to migrate elsewhere. The PVC is deleted only when the replica is no longer needed as signified by a scale-down or StatefulSet deletion. This use case is for when data does not need to live beyond the life of its replica. Perhaps the data is easily reconstructable and the cost savings of deleting unused PVCs is more important than quick scale-up, or perhaps that when a new replica is created, any data from a previous replica is not usable and must be reconstructed anyway. -
whenDeletedisRetainandwhenScaledisDelete. This is similar to the previous case, when there is little benefit to keeping PVCs for fast reuse during scale-up. An example of a situation where you might use this is an Elasticsearch cluster. Typically you would scale that workload up and down to match demand, whilst ensuring a minimum number of replicas (for example: 3). When scaling down, data is migrated away from removed replicas and there is no benefit to retaining those PVCs. However, it can be useful to bring the entire Elasticsearch cluster down temporarily for maintenance. If you need to take the Elasticsearch system offline, you can do this by temporarily deleting the StatefulSet, and then bringing the Elasticsearch cluster back by recreating the StatefulSet. The PVCs holding the Elasticsearch data will still exist and the new replicas will automatically use them.
Visit the documentation to see all the details.
What’s next?
Enable the feature and try it out! Enable the StatefulSetAutoDeletePVC feature gate on a cluster,
then create a StatefulSet using the new policy. Test it out and tell us what you think!
I'm very curious to see if this owner reference mechanism works well in practice. For example, we realized there is no mechanism in Kubernetes for knowing who set a reference, so it’s possible that the StatefulSet controller may fight with custom controllers that set their own references. Fortunately, maintaining the existing retention behavior does not involve any new owner references, so default behavior will be compatible.
Please tag any issues you report with the label sig/apps and assign them to Matthew Cary
(@mattcary at GitHub).
Enjoy!
Kubernetes 1.23: Prevent PersistentVolume leaks when deleting out of order
Author: Deepak Kinni (VMware)
PersistentVolume (or PVs for short) are
associated with Reclaim Policy.
The Reclaim Policy is used to determine the actions that need to be taken by the storage
backend on deletion of the PV.
Where the reclaim policy is Delete, the expectation is that the storage backend
releases the storage resource that was allocated for the PV. In essence, the reclaim
policy needs to honored on PV deletion.
With the recent Kubernetes v1.23 release, an alpha feature lets you configure your cluster to behave that way and honor the configured reclaim policy.
How did reclaim work in previous Kubernetes releases?
PersistentVolumeClaim (or PVC for short) is a request for storage by a user. A PV and PVC are considered Bound if there is a newly created PV or a matching PV is found. The PVs themselves are backed by a volume allocated by the storage backend.
Normally, if the volume is to be deleted, then the expectation is to delete the PVC for a bound PV-PVC pair. However, there are no restrictions to delete a PV prior to deleting a PVC.
First, I'll demonstrate the behavior for clusters that are running an older version of Kubernetes.
Retrieve an PVC that is bound to a PV
Retrieve an existing PVC example-vanilla-block-pvc
kubectl get pvc example-vanilla-block-pvc
The following output shows the PVC and it's Bound PV, the PV is shown under the VOLUME column:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
example-vanilla-block-pvc Bound pvc-6791fdd4-5fad-438e-a7fb-16410363e3da 5Gi RWO example-vanilla-block-sc 19s
Delete PV
When I try to delete a bound PV, the cluster blocks and the kubectl tool does
not return back control to the shell; for example:
kubectl delete pv pvc-6791fdd4-5fad-438e-a7fb-16410363e3da
persistentvolume "pvc-6791fdd4-5fad-438e-a7fb-16410363e3da" deleted
^C
Retrieving the PV:
kubectl get pv pvc-6791fdd4-5fad-438e-a7fb-16410363e3da
It can be observed that the PV is in Terminating state
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-6791fdd4-5fad-438e-a7fb-16410363e3da 5Gi RWO Delete Terminating default/example-vanilla-block-pvc example-vanilla-block-sc 2m23s
Delete PVC
kubectl delete pvc example-vanilla-block-pvc
The following output is seen if the PVC gets successfully deleted:
persistentvolumeclaim "example-vanilla-block-pvc" deleted
The PV object from the cluster also gets deleted. When attempting to retrieve the PV it will be observed that the PV is no longer found:
kubectl get pv pvc-6791fdd4-5fad-438e-a7fb-16410363e3da
Error from server (NotFound): persistentvolumes "pvc-6791fdd4-5fad-438e-a7fb-16410363e3da" not found
Although the PV is deleted the underlying storage resource is not deleted, and needs to be removed manually.
To sum it up, the reclaim policy associated with the Persistent Volume is currently
ignored under certain circumstance. For a Bound PV-PVC pair the ordering of PV-PVC
deletion determines whether the PV reclaim policy is honored. The reclaim policy
is honored if the PVC is deleted first, however, if the PV is deleted prior to
deleting the PVC then the reclaim policy is not exercised. As a result of this behavior,
the associated storage asset in the external infrastructure is not removed.
PV reclaim policy with Kubernetes v1.23
The new behavior ensures that the underlying storage object is deleted from the backend when users attempt to delete a PV manually.
How to enable new behavior?
To make use of the new behavior, you must have upgraded your cluster to the v1.23 release of Kubernetes.
You need to make sure that you are running the CSI external-provisioner version 4.0.0, or later.
You must also enable the HonorPVReclaimPolicy feature gate for the
external-provisioner and for the kube-controller-manager.
If you're not using a CSI driver to integrate with your storage backend, the fix isn't available. The Kubernetes project doesn't have a current plan to fix the bug for in-tree storage drivers: the future of those in-tree drivers is deprecation and migration to CSI.
How does it work?
The new behavior is achieved by adding a finalizer external-provisioner.volume.kubernetes.io/finalizer on new and existing PVs, the finalizer is only removed after the storage from backend is deleted.
An example of a PV with the finalizer, notice the new finalizer in the finalizers list
kubectl get pv pvc-a7b7e3ba-f837-45ba-b243-dec7d8aaed53 -o yaml
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: csi.vsphere.vmware.com
creationTimestamp: "2021-11-17T19:28:56Z"
finalizers:
- kubernetes.io/pv-protection
- external-provisioner.volume.kubernetes.io/finalizer
name: pvc-a7b7e3ba-f837-45ba-b243-dec7d8aaed53
resourceVersion: "194711"
uid: 087f14f2-4157-4e95-8a70-8294b039d30e
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 1Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: example-vanilla-block-pvc
namespace: default
resourceVersion: "194677"
uid: a7b7e3ba-f837-45ba-b243-dec7d8aaed53
csi:
driver: csi.vsphere.vmware.com
fsType: ext4
volumeAttributes:
storage.kubernetes.io/csiProvisionerIdentity: 1637110610497-8081-csi.vsphere.vmware.com
type: vSphere CNS Block Volume
volumeHandle: 2dacf297-803f-4ccc-afc7-3d3c3f02051e
persistentVolumeReclaimPolicy: Delete
storageClassName: example-vanilla-block-sc
volumeMode: Filesystem
status:
phase: Bound
The presence of the finalizer prevents the PV object from being removed from the cluster. As stated previously, the finalizer is only removed from the PV object after it is successfully deleted from the storage backend. To learn more about finalizers, please refer to Using Finalizers to Control Deletion.
What about CSI migrated volumes?
The fix is applicable to CSI migrated volumes as well. However, when the feature
HonorPVReclaimPolicy is enabled on 1.23, and CSI Migration is disabled, the finalizer
is removed from the PV object if it exists.
Some caveats
- The fix is applicable only to CSI volumes and migrated volumes. In-tree volumes will exhibit older behavior.
- The fix is introduced as an alpha feature in the external-provisioner under the feature gate
HonorPVReclaimPolicy. The feature is disabled by default, and needs to be enabled explicitly.
References
How do I get involved?
The Kubernetes Slack channel SIG Storage communication channels are great mediums to reach out to the SIG Storage and migration working group teams.
Special thanks to the following people for the insightful reviews, thorough consideration and valuable contribution:
- Jan Šafránek (jsafrane)
- Xing Yang (xing-yang)
- Matthew Wong (wongma7)
Those interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Kubernetes 1.23: Kubernetes In-Tree to CSI Volume Migration Status Update
Author: Jiawei Wang (Google)
The Kubernetes in-tree storage plugin to Container Storage Interface (CSI) migration infrastructure has already been beta since v1.17. CSI migration was introduced as alpha in Kubernetes v1.14.
Since then, SIG Storage and other Kubernetes special interest groups are working to ensure feature stability and compatibility in preparation for GA. This article is intended to give a status update to the feature as well as changes between Kubernetes 1.17 and 1.23. In addition, I will also cover the future roadmap for the CSI migration feature GA for each storage plugin.
Quick recap: What is CSI Migration, and why migrate?
The Container Storage Interface (CSI) was designed to help Kubernetes replace its existing, in-tree storage driver mechanisms - especially vendor specific plugins. Kubernetes support for the Container Storage Interface has been generally available since Kubernetes v1.13. Support for using CSI drivers was introduced to make it easier to add and maintain new integrations between Kubernetes and storage backend technologies. Using CSI drivers allows for for better maintainability (driver authors can define their own release cycle and support lifecycle) and reduce the opportunity for vulnerabilities (with less in-tree code, the risks of a mistake are reduced, and cluster operators can select only the storage drivers that their cluster requires).
As more CSI Drivers were created and became production ready, SIG Storage group wanted all Kubernetes users to benefit from the CSI model. However, we cannot break API compatibility with the existing storage API types. The solution we came up with was CSI migration: a feature that translates in-tree APIs to equivalent CSI APIs and delegates operations to a replacement CSI driver.
The CSI migration effort enables the replacement of existing in-tree storage plugins such as kubernetes.io/gce-pd or kubernetes.io/aws-ebs with a corresponding CSI driver from the storage backend.
If CSI Migration is working properly, Kubernetes end users shouldn’t notice a difference. Existing StorageClass, PersistentVolume and PersistentVolumeClaim objects should continue to work.
When a Kubernetes cluster administrator updates a cluster to enable CSI migration, existing workloads that utilize PVCs which are backed by in-tree storage plugins will continue to function as they always have.
However, behind the scenes, Kubernetes hands control of all storage management operations (previously targeting in-tree drivers) to CSI drivers.
For example, suppose you are a kubernetes.io/gce-pd user, after CSI migration, you can still use kubernetes.io/gce-pd to provision new volumes, mount existing GCE-PD volumes or delete existing volumes. All existing API/Interface will still function correctly. However, the underlying function calls are all going through the GCE PD CSI driver instead of the in-tree Kubernetes function.
This enables a smooth transition for end users. Additionally as storage plugin developers, we can reduce the burden of maintaining the in-tree storage plugins and eventually remove them from the core Kubernetes binary.
What has been changed, and what's new?
Building on the work done in Kubernetes v1.17 and earlier, the releases since then have made a series of changes:
New feature gates
The Kubernetes v1.21 release deprecated the CSIMigration{provider}Complete feature flags, and stopped honoring them. In their place came new feature flags named InTreePlugin{vendor}Unregister, that replace the old feature flag and retain all the functionality that CSIMigration{provider}Complete provided.
CSIMigration{provider}Complete was introduced before as a supplementary feature gate once CSI migration is enabled on all of the nodes. This flag unregisters the in-tree storage plugin you specify with the {provider} part of the flag name.
When you enable that feature gate, then instead of using the in-tree driver code, your cluster directly selects and uses the relevant CSI driver. This happens without any check for whether CSI migration is enabled on the node, or whether you have in fact deployed that CSI driver.
While this feature gate is a great helper, SIG Storage (and, I'm sure, lots of cluster operators) also wanted a feature gate that lets you disable an in-tree storage plugin, even without also enabling CSI migration. For example, you might want to disable the EBS storage plugin on a GCE cluster, because EBS volumes are specific to a different vendor's cloud (AWS).
To make this possible, Kubernetes v1.21 introduced a new feature flag set: InTreePlugin{vendor}Unregister.
InTreePlugin{vendor}Unregister is a standalone feature gate that can be enabled and disabled independently from CSI Migration. When enabled, the component will not register the specific in-tree storage plugin to the supported list. If the cluster operator only enables this flag, end users will get an error from PVC saying it cannot find the plugin when the plugin is used. The cluster operator may want to enable this regardless of CSI Migration if they do not want to support the legacy in-tree APIs and only support CSI moving forward.
Observability
Kubernetes v1.21 introduced metrics for tracking CSI migration. You can use these metrics to observe how your cluster is using storage services and whether access to that storage is using the legacy in-tree driver or its CSI-based replacement.
| Components | Metrics | Notes |
|---|---|---|
| Kube-Controller-Manager | storage_operation_duration_seconds | A new label migrated is added to the metric to indicate whether this storage operation is a CSI migration operation(string value true for enabled and false for not enabled). |
| Kubelet | csi_operations_seconds | The new metric exposes labels including driver_name, method_name, grpc_status_code and migrated. The meaning of these labels is identical to csi_sidecar_operations_seconds. |
| CSI Sidecars(provisioner, attacher, resizer) | csi_sidecar_operations_seconds | A new label migrated is added to the metric to indicate whether this storage operation is a CSI migration operation(string value true for enabled and false for not enabled). |
Bug fixes and feature improvement
We have fixed numerous bugs like dangling attachment, garbage collection, incorrect topology label through the help of our beta testers.
Cloud Provider && Cluster Lifecycle Collaboration
SIG Storage has been working closely with SIG Cloud Provider and SIG Cluster Lifecycle on the rollout of CSI migration.
If you are a user of a managed Kubernetes service, check with your provider if anything needs to be done. In many cases, the provider will manage the migration and no additional work is required.
If you use a distribution of Kubernetes, check its official documentation for information about support for this feature. For the CSI Migration feature graduation to GA, SIG Storage and SIG Cluster Lifecycle are collaborating towards making the migration mechanisms available in tooling (such as kubeadm) as soon as they're available in Kubernetes itself.
What is the timeline / status?
The current and targeted releases for each individual driver is shown in the table below:
| Driver | Alpha | Beta (in-tree deprecated) | Beta (on-by-default) | GA | Target "in-tree plugin" removal |
|---|---|---|---|---|---|
| AWS EBS | 1.14 | 1.17 | 1.23 | 1.24 (Target) | 1.26 (Target) |
| GCE PD | 1.14 | 1.17 | 1.23 | 1.24 (Target) | 1.26 (Target) |
| OpenStack Cinder | 1.14 | 1.18 | 1.21 | 1.24 (Target) | 1.26 (Target) |
| Azure Disk | 1.15 | 1.19 | 1.23 | 1.24 (Target) | 1.26 (Target) |
| Azure File | 1.15 | 1.21 | 1.24 (Target) | 1.25 (Target) | 1.27 (Target) |
| vSphere | 1.18 | 1.19 | 1.24 (Target) | 1.25 (Target) | 1.27 (Target) |
| Ceph RBD | 1.23 | ||||
| Portworx | 1.23 |
The following storage drivers will not have CSI migration support. The ScaleIO driver was already removed; the others are deprecated and will be removed from core Kubernetes.
| Driver | Deprecated | Code Removal |
|---|---|---|
| ScaleIO | 1.16 | 1.22 |
| Flocker | 1.22 | 1.25 (Target) |
| Quobyte | 1.22 | 1.25 (Target) |
| StorageOS | 1.22 | 1.25 (Target) |
What's next?
With more CSI drivers graduating to GA, we hope to soon mark the overall CSI Migration feature as GA. We are expecting cloud provider in-tree storage plugins code removal to happen by Kubernetes v1.26 and v1.27.
What should I do as a user?
Note that all new features for the Kubernetes storage system (such as volume snapshotting) will only be added to the CSI interface. Therefore, if you are starting up a new cluster, creating stateful applications for the first time, or require these new features we recommend using CSI drivers natively (instead of the in-tree volume plugin API). Follow the updated user guides for CSI drivers and use the new CSI APIs.
However, if you choose to roll a cluster forward or continue using specifications with the legacy volume APIs, CSI Migration will ensure we continue to support those deployments with the new CSI drivers. However, if you want to leverage new features like snapshot, it will require a manual migration to re-import an existing intree PV as a CSI PV.
How do I get involved?
The Kubernetes Slack channel #csi-migration along with any of the standard SIG Storage communication channels are great mediums to reach out to the SIG Storage and migration working group teams.
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together. We offer a huge thank you to the contributors who stepped up these last quarters to help move the project forward:
- Michelle Au (msau42)
- Jan Šafránek (jsafrane)
- Hemant Kumar (gnufied)
Special thanks to the following people for the insightful reviews, thorough consideration and valuable contribution to the CSI migration feature:
- Andy Zhang (andyzhangz)
- Divyen Patel (divyenpatel)
- Deep Debroy (ddebroy)
- Humble Devassy Chirammal (humblec)
- Jing Xu (jingxu97)
- Jordan Liggitt (liggitt)
- Matthew Cary (mattcary)
- Matthew Wong (wongma7)
- Neha Arora (nearora-msft)
- Oksana Naumov (trierra)
- Saad Ali (saad-ali)
- Tim Bannister (sftim)
- Xing Yang (xing-yang)
Those interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Kubernetes 1.23: Pod Security Graduates to Beta
Authors: Jim Angel (Google), Lachlan Evenson (Microsoft)
With the release of Kubernetes v1.23, Pod Security admission has now entered beta. Pod Security is a built-in admission controller that evaluates pod specifications against a predefined set of Pod Security Standards and determines whether to admit or deny the pod from running.
Pod Security is the successor to PodSecurityPolicy which was deprecated in the v1.21 release, and will be removed in Kubernetes v1.25. In this article, we cover the key concepts of Pod Security along with how to use it. We hope that cluster administrators and developers alike will use this new mechanism to enforce secure defaults for their workloads.
Why Pod Security
The overall aim of Pod Security is to let you isolate workloads. You can run a cluster that runs different workloads and, without adding extra third-party tooling, implement controls that require Pods for a workload to restrict their own privileges to a defined bounding set.
Pod Security overcomes key shortcomings of Kubernetes' existing, but deprecated, PodSecurityPolicy (PSP) mechanism:
- Policy authorization model — challenging to deploy with controllers.
- Risks around switching — a lack of dry-run/audit capabilities made it hard to enable PodSecurityPolicy.
- Inconsistent and Unbounded API — the large configuration surface and evolving constraints led to a complex and confusing API.
The shortcomings of PSP made it very difficult to use which led the community to reevaluate whether or not a better implementation could achieve the same goals. One of those goals was to provide an out-of-the-box solution to apply security best practices. Pod Security ships with predefined Pod Security levels that a cluster administrator can configure to meet the desired security posture.
It's important to note that Pod Security doesn't have complete feature parity with the deprecated PodSecurityPolicy. Specifically, it doesn't have the ability to mutate or change Kubernetes resources to auto-remediate a policy violation on behalf of the user. Additionally, it doesn't provide fine-grained control over each allowed field and value within a pod specification or any other Kubernetes resource that you may wish to evaluate. If you need more fine-grained policy control then take a look at these other projects which support such use cases.
Pod Security also adheres to Kubernetes best practices of declarative object management by denying resources that violate the policy. This requires resources to be updated in source repositories, and tooling to be updated prior to being deployed to Kubernetes.
How Does Pod Security Work?
Pod Security is a built-in admission controller starting with Kubernetes v1.22, but can also be run as a standalone webhook. Admission controllers function by intercepting requests in the Kubernetes API server prior to persistence to storage. They can either admit or deny a request. In the case of Pod Security, pod specifications will be evaluated against a configured policy in the form of a Pod Security Standard. This means that security sensitive fields in a pod specification will only be allowed to have specific values.
Configuring Pod Security
Pod Security Standards
In order to use Pod Security we first need to understand Pod Security Standards. These standards define three different policy levels that range from permissive to restrictive. These levels are as follows:
privileged— open and unrestrictedbaseline— Covers known privilege escalations while minimizing restrictionsrestricted— Highly restricted, hardening against known and unknown privilege escalations. May cause compatibility issues
Each of these policy levels define which fields are restricted within a pod specification and the allowed values. Some of the fields restricted by these policies include:
spec.securityContext.sysctlsspec.hostNetworkspec.volumes[*].hostPathspec.containers[*].securityContext.privileged
Policy levels are applied via labels on Namespace resources, which allows for granular per-namespace policy selection. The AdmissionConfiguration in the API server can also be configured to set cluster-wide default levels and exemptions.
Policy modes
Policies are applied in a specific mode. Multiple modes (with different policy levels) can be set on the same namespace. Here is a list of modes:
enforce— Any Pods that violate the policy will be rejectedaudit— Violations will be recorded as an annotation in the audit logs, but don't affect whether the pod is allowed.warn— Violations will send a warning message back to the user, but don't affect whether the pod is allowed.
In addition to modes you can also pin the policy to a specific version (for example v1.22). Pinning to a specific version allows the behavior to remain consistent if the policy definition changes in future Kubernetes releases.
Hands on demo
Prerequisites
Deploy a kind cluster
kind create cluster --image kindest/node:v1.23.0
It might take a while to start and once it's started it might take a minute or so before the node becomes ready.
kubectl cluster-info --context kind-kind
Wait for the node STATUS to become ready.
kubectl get nodes
The output is similar to this:
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready control-plane,master 54m v1.23.0
Confirm Pod Security is enabled
The best way to confirm the API's default enabled plugins is to check the Kubernetes API container's help arguments.
kubectl -n kube-system exec kube-apiserver-kind-control-plane -it -- kube-apiserver -h | grep "default enabled ones"
The output is similar to this:
...
--enable-admission-plugins strings
admission plugins that should be enabled in addition
to default enabled ones (NamespaceLifecycle, LimitRanger,
ServiceAccount, TaintNodesByCondition, PodSecurity, Priority,
DefaultTolerationSeconds, DefaultStorageClass,
StorageObjectInUseProtection, PersistentVolumeClaimResize,
RuntimeClass, CertificateApproval, CertificateSigning,
CertificateSubjectRestriction, DefaultIngressClass,
MutatingAdmissionWebhook, ValidatingAdmissionWebhook,
ResourceQuota).
...
PodSecurity is listed in the group of default enabled admission plugins.
If using a cloud provider, or if you don't have access to the API server, the best way to check would be to run a quick end-to-end test:
kubectl create namespace verify-pod-security
kubectl label namespace verify-pod-security pod-security.kubernetes.io/enforce=restricted
# The following command does NOT create a workload (--dry-run=server)
kubectl -n verify-pod-security run test --dry-run=server --image=busybox --privileged
kubectl delete namespace verify-pod-security
The output is similar to this:
Error from server (Forbidden): pods "test" is forbidden: violates PodSecurity "restricted:latest": privileged (container "test" must not set securityContext.privileged=true), allowPrivilegeEscalation != false (container "test" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "test" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "test" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "test" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
Configure Pod Security
Policies are applied to a namespace via labels. These labels are as follows:
pod-security.kubernetes.io/<MODE>: <LEVEL>(required to enable pod security)pod-security.kubernetes.io/<MODE>-version: <VERSION>(optional, defaults to latest)
A specific version can be supplied for each enforcement mode. The version pins the policy to the version that was shipped as part of the Kubernetes release. Pinning to a specific Kubernetes version allows for deterministic policy behavior while allowing flexibility for future updates to Pod Security Standards. The possible <MODE(S)> are enforce, audit and warn.
When to use warn?
The typical uses for warn are to get ready for a future change where you want to enforce a different policy. The most two common cases would be:
warnat the same level but a different version (e.g. pinenforceto restricted+v1.23 andwarnat restricted+latest)warnat a stricter level (e.g.enforcebaseline,warnrestricted)
It's not recommended to use warn for the exact same level+version of the policy as enforce. In the admission sequence, if enforce fails, the entire sequence fails before evaluating the warn.
First, create a namespace called verify-pod-security if not created earlier. For the demo, --overwrite is used when labeling to allow repurposing a single namespace for multiple examples.
kubectl create namespace verify-pod-security
Deploy demo workloads
Each workload represents a higher level of security that would not pass the profile that comes after it.
For the following examples, use the busybox container runs a sleep command for 1 million seconds (≅11 days) or until deleted. Pod Security is not interested in which container image you chose, but rather the Pod level settings and their implications for security.
Privileged level and workload
For the privileged pod, use the privileged policy. This allows the process inside a container to gain new processes (also known as "privilege escalation") and can be dangerous if untrusted.
First, let's apply a restricted Pod Security level for a test.
# enforces a "restricted" security policy and audits on restricted
kubectl label --overwrite ns verify-pod-security \
pod-security.kubernetes.io/enforce=restricted \
pod-security.kubernetes.io/audit=restricted
Next, try to deploy a privileged workload in the namespace.
cat <<EOF | kubectl -n verify-pod-security apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-privileged
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
securityContext:
allowPrivilegeEscalation: true
EOF
The output is similar to this:
Error from server (Forbidden): error when creating "STDIN": pods "busybox-privileged" is forbidden: violates PodSecurity "restricted:latest": allowPrivilegeEscalation != false (container "busybox" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "busybox" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "busybox" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "busybox" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
Now let's apply the privileged Pod Security level and try again.
# enforces a "privileged" security policy and warns / audits on baseline
kubectl label --overwrite ns verify-pod-security \
pod-security.kubernetes.io/enforce=privileged \
pod-security.kubernetes.io/warn=baseline \
pod-security.kubernetes.io/audit=baseline
cat <<EOF | kubectl -n verify-pod-security apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-privileged
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
securityContext:
allowPrivilegeEscalation: true
EOF
The output is similar to this:
pod/busybox-privileged created
We can run kubectl -n verify-pod-security get pods to verify it is running. Clean up with:
kubectl -n verify-pod-security delete pod busybox-privileged
Baseline level and workload
The baseline policy demonstrates sensible defaults while preventing common container exploits.
Let's revert back to a restricted Pod Security level for a quick test.
# enforces a "restricted" security policy and audits on restricted
kubectl label --overwrite ns verify-pod-security \
pod-security.kubernetes.io/enforce=restricted \
pod-security.kubernetes.io/audit=restricted
Apply the workload.
cat <<EOF | kubectl -n verify-pod-security apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-baseline
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
- CHOWN
EOF
The output is similar to this:
Error from server (Forbidden): error when creating "STDIN": pods "busybox-baseline" is forbidden: violates PodSecurity "restricted:latest": unrestricted capabilities (container "busybox" must set securityContext.capabilities.drop=["ALL"]; container "busybox" must not include "CHOWN" in securityContext.capabilities.add), runAsNonRoot != true (pod or container "busybox" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "busybox" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
Let's apply the baseline Pod Security level and try again.
# enforces a "baseline" security policy and warns / audits on restricted
kubectl label --overwrite ns verify-pod-security \
pod-security.kubernetes.io/enforce=baseline \
pod-security.kubernetes.io/warn=restricted \
pod-security.kubernetes.io/audit=restricted
cat <<EOF | kubectl -n verify-pod-security apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-baseline
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
- CHOWN
EOF
The output is similar to the following. Note that the warnings match the error message from the test above, but the pod is still successfully created.
Warning: would violate PodSecurity "restricted:latest": unrestricted capabilities (container "busybox" must set securityContext.capabilities.drop=["ALL"]; container "busybox" must not include "CHOWN" in securityContext.capabilities.add), runAsNonRoot != true (pod or container "busybox" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "busybox" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
pod/busybox-baseline created
Remember, we set the verify-pod-security namespace to warn based on the restricted profile. We can run kubectl -n verify-pod-security get pods to verify it is running. Clean up with:
kubectl -n verify-pod-security delete pod busybox-baseline
Restricted level and workload
The restricted policy requires rejection of all privileged parameters. It is the most secure with a trade-off for complexity.
The restricted policy allows containers to add the NET_BIND_SERVICE capability only.
While we've already tested restricted as a blocking function, let's try to get something running that meets all the criteria.
First we need to reapply the restricted profile, for the last time.
# enforces a "restricted" security policy and audits on restricted
kubectl label --overwrite ns verify-pod-security \
pod-security.kubernetes.io/enforce=restricted \
pod-security.kubernetes.io/audit=restricted
cat <<EOF | kubectl -n verify-pod-security apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-restricted
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
EOF
The output is similar to this:
Error from server (Forbidden): error when creating "STDIN": pods "busybox-restricted" is forbidden: violates PodSecurity "restricted:latest": unrestricted capabilities (container "busybox" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "busybox" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "busybox" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
This is because the restricted profile explicitly requires that certain values are set to the most secure parameters.
By requiring explicit values, manifests become more declarative and your entire security model can shift left. With the restricted level of enforcement, a company could audit their cluster's compliance based on permitted manifests.
Let's fix each warning resulting in the following file:
cat <<EOF | kubectl -n verify-pod-security apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-restricted
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
securityContext:
seccompProfile:
type: RuntimeDefault
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
EOF
The output is similar to this:
pod/busybox-restricted created
Run kubectl -n verify-pod-security get pods to verify it is running. The output is similar to this:
NAME READY STATUS RESTARTS AGE
busybox-restricted 0/1 CreateContainerConfigError 0 2m26s
Let's figure out why the container is not starting with kubectl -n verify-pod-security describe pod busybox-restricted. The output is similar to this:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Failed 2m29s (x8 over 3m55s) kubelet Error: container has runAsNonRoot and image will run as root (pod: "busybox-restricted_verify-pod-security(a4c6a62d-2166-41a9-b288-20df17cf5c90)", container: busybox)
To solve this, set the effective UID (runAsUser) to a non-zero (root) value or use the nobody UID (65534).
# delete the original pod
kubectl -n verify-pod-security delete pod busybox-restricted
# create the pod again with new runAsUser
cat <<EOF | kubectl -n verify-pod-security apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-restricted
spec:
securityContext:
runAsUser: 65534
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
securityContext:
seccompProfile:
type: RuntimeDefault
runAsNonRoot: true
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
EOF
Run kubectl -n verify-pod-security get pods to verify it is running. The output is similar to this:
NAME READY STATUS RESTARTS AGE
busybox-restricted 1/1 Running 0 25s
Clean up the demo (restricted pod and namespace) with:
kubectl delete namespace verify-pod-security
At this point, if you wanted to dive deeper into linux permissions or what is permitted for a certain container, exec into the control plane and play around with containerd and crictl inspect.
# if using docker, shell into the control plane
docker exec -it kind-control-plane bash
# list running containers
crictl ps
# inspect each one by container ID
crictl inspect <CONTAINER ID>
Applying a cluster-wide policy
In addition to applying labels to namespaces to configure policy you can also configure cluster-wide policies and exemptions using the AdmissionConfiguration resource.
Using this resource, policy definitions are applied cluster-wide by default and any policy that is applied via namespace labels will take precedence.
There is no runtime configurable API for the AdmissionConfiguration configuration file so a cluster administrator would need to specify a path to the file below via the --admission-control-config-file flag on the API server.
In the following resource we are enforcing the baseline policy and warning and auditing the baseline policy. We are also making the kube-system namespace exempt from this policy.
It's not recommended to alter control plane / clusters after install, so let's build a new cluster with a default policy on all namespaces.
First, delete the current cluster.
kind delete cluster
Create a Pod Security configuration that enforce and audit baseline policies while using a restricted profile to warn the end user.
cat <<EOF > pod-security.yaml
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: PodSecurity
configuration:
apiVersion: pod-security.admission.config.k8s.io/v1beta1
kind: PodSecurityConfiguration
defaults:
enforce: "baseline"
enforce-version: "latest"
audit: "baseline"
audit-version: "latest"
warn: "restricted"
warn-version: "latest"
exemptions:
# Array of authenticated usernames to exempt.
usernames: []
# Array of runtime class names to exempt.
runtimeClasses: []
# Array of namespaces to exempt.
namespaces: [kube-system]
EOF
For additional options, check out the official standards admission controller docs.
We now have a default baseline policy. Next pass it to the kind configuration to enable the --admission-control-config-file API server argument and pass the policy file. To pass a file to a kind cluster, use a configuration file to pass additional setup instructions. Kind uses kubeadm to provision the cluster and the configuration file has the ability to pass kubeadmConfigPatches for further customization. In our case, the local file is mounted into the control plane node as /etc/kubernetes/policies/pod-security.yaml which is then mounted into the apiServer container. We also pass the --admission-control-config-file argument pointing to the policy's location.
cat <<EOF > kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
apiServer:
# enable admission-control-config flag on the API server
extraArgs:
admission-control-config-file: /etc/kubernetes/policies/pod-security.yaml
# mount new file / directories on the control plane
extraVolumes:
- name: policies
hostPath: /etc/kubernetes/policies
mountPath: /etc/kubernetes/policies
readOnly: true
pathType: "DirectoryOrCreate"
# mount the local file on the control plane
extraMounts:
- hostPath: ./pod-security.yaml
containerPath: /etc/kubernetes/policies/pod-security.yaml
readOnly: true
EOF
Create a new cluster using the kind configuration file defined above.
kind create cluster --image kindest/node:v1.23.0 --config kind-config.yaml
Let's look at the default namespace.
kubectl describe namespace default
The output is similar to this:
Name: default
Labels: kubernetes.io/metadata.name=default
Annotations: <none>
Status: Active
No resource quota.
No LimitRange resource.
Let's create a new namespace and see if the labels apply there.
kubectl create namespace test-defaults
kubectl describe namespace test-defaults
Same.
Name: test-defaults
Labels: kubernetes.io/metadata.name=test-defaults
Annotations: <none>
Status: Active
No resource quota.
No LimitRange resource.
Can a privileged workload be deployed?
cat <<EOF | kubectl -n test-defaults apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-privileged
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
securityContext:
allowPrivilegeEscalation: true
EOF
Hmm... yep. The default warn level is working at least.
Warning: would violate PodSecurity "restricted:latest": allowPrivilegeEscalation != false (container "busybox" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "busybox" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot != true (pod or container "busybox" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "busybox" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")
pod/busybox-privileged created
Let's delete the pod with kubectl -n test-defaults delete pod/busybox-privileged.
Is my config even working?
# if using docker, shell into the control plane
docker exec -it kind-control-plane bash
# cat out the file we mounted
cat /etc/kubernetes/policies/pod-security.yaml
# check the api server logs
cat /var/log/containers/kube-apiserver*.log
# check the api server config
cat /etc/kubernetes/manifests/kube-apiserver.yaml
UPDATE: The baseline policy permits allowPrivilegeEscalation. While I cannot see the Pod Security default levels of enforcement, they are there. Let's try to provide a manifest that violates the baseline by requesting hostNetwork access.
# delete the original pod
kubectl -n test-defaults delete pod busybox-privileged
cat <<EOF | kubectl -n test-defaults apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-privileged
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
hostNetwork: true
EOF
The output is similar to this:
Error from server (Forbidden): error when creating "STDIN": pods "busybox-privileged" is forbidden: violates PodSecurity "baseline:latest": host namespaces (hostNetwork=true)
Yes!!! It worked! 🎉🎉🎉
I later found out, another way to check if things are operating as intended is to check the raw API server metrics endpoint.
Run the following command:
kubectl get --raw /metrics | grep pod_security_evaluations_total
The output is similar to this:
# HELP pod_security_evaluations_total [ALPHA] Number of policy evaluations that occurred, not counting ignored or exempt requests.
# TYPE pod_security_evaluations_total counter
pod_security_evaluations_total{decision="allow",mode="enforce",policy_level="baseline",policy_version="latest",request_operation="create",resource="pod",subresource=""} 2
pod_security_evaluations_total{decision="allow",mode="enforce",policy_level="privileged",policy_version="latest",request_operation="create",resource="pod",subresource=""} 0
pod_security_evaluations_total{decision="allow",mode="enforce",policy_level="privileged",policy_version="latest",request_operation="update",resource="pod",subresource=""} 0
pod_security_evaluations_total{decision="deny",mode="audit",policy_level="baseline",policy_version="latest",request_operation="create",resource="pod",subresource=""} 1
pod_security_evaluations_total{decision="deny",mode="enforce",policy_level="baseline",policy_version="latest",request_operation="create",resource="pod",subresource=""} 1
pod_security_evaluations_total{decision="deny",mode="warn",policy_level="restricted",policy_version="latest",request_operation="create",resource="controller",subresource=""} 2
pod_security_evaluations_total{decision="deny",mode="warn",policy_level="restricted",policy_version="latest",request_operation="create",resource="pod",subresource=""} 2
A monitoring tool could ingest these metrics too for reporting, assessments, or measuring trends.
Clean up
When finished, delete the kind cluster.
kind delete cluster
Auditing
Auditing is another way to track what policies are being enforced in your cluster. To set up auditing with kind, review the official docs for enabling auditing. As of version 1.11, Kubernetes audit logs include two annotations that indicate whether or not a request was authorized (authorization.k8s.io/decision) and the reason for the decision (authorization.k8s.io/reason). Audit events can be streamed to a webhook for monitoring, tracking, or alerting.
The audit events look similar to the following:
{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"","pod-security.kubernetes.io/audit":"allowPrivilegeEscalation != false (container \"busybox\" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container \"busybox\" must set securityContext.capabilities.drop=[\"ALL\"]), runAsNonRoot != true (pod or container \"busybox\" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container \"busybox\" must set securityContext.seccompProfile.type to \"RuntimeDefault\" or \"Localhost\")"}}
Auditing is also a good first step in evaluating your cluster's current compliance with Pod Security. The Kubernetes Enhancement Proposal (KEP) hints at a future where baseline could be the default for unlabeled namespaces.
Example audit-policy.yaml configuration tuned for Pod Security events:
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: RequestResponse
resources:
- group: "" # core API group
resources: ["pods", "pods/ephemeralcontainers", "podtemplates", "replicationcontrollers"]
- group: "apps"
resources: ["daemonsets", "deployments", "replicasets", "statefulsets"]
- group: "batch"
resources: ["cronjobs", "jobs"]
verbs: ["create", "update"]
omitStages:
- "RequestReceived"
- "ResponseStarted"
- "Panic"
Once auditing is enabled, look at the configured local file if using --audit-log-path or the destination of a webhook if using --audit-webhook-config-file.
If using a file (--audit-log-path), run cat /PATH/TO/API/AUDIT.log | grep "is forbidden:" to see all rejected workloads audited.
PSP migrations
If you're already using PSP, SIG Auth has created a guide and published the steps to migrate off of PSP.
To summarize the process:
- Update all existing PSPs to be non-mutating
- Apply Pod Security policies in
warnorauditmode - Upgrade Pod Security policies to
enforcemode - Remove
PodSecurityPolicyfrom--enable-admission-plugins
Listed as "optional future extensions" and currently out of scope, SIG Auth has kicked around the idea of providing a tool to assist with migrations. More details in the KEP.
Wrap up
Pod Security is a promising new feature that provides an out-of-the-box way to allow users to improve the security posture of their workloads. Like any new enhancement that has matured to beta, we ask that you try it out, provide feedback, or share your experience via either raising a Github issue or joining SIG Auth community meetings. It's our hope that Pod Security will be deployed on every cluster in our ongoing pursuit as a community to make Kubernetes security a priority.
For a step by step guide on how to enable "baseline" Pod Security Standards with Pod Security Admission feature please refer to these dedicated tutorials that cover the configuration needed at cluster level and namespace level.
Additional resources
- Official Pod Security Docs
- Enforce Pod Security Standards with Namespace Labels
- Enforce Pod Security Standards by Configuring the Built-in Admission Controller
- Official Kubernetes Enhancement Proposal (KEP)
- PodSecurityPolicy Deprecation: Past, Present, and Future
- Hands on with Kubernetes Pod Security
Kubernetes 1.23: Dual-stack IPv4/IPv6 Networking Reaches GA
Author: Bridget Kromhout (Microsoft)
"When will Kubernetes have IPv6?" This question has been asked with increasing frequency ever since alpha support for IPv6 was first added in k8s v1.9. While Kubernetes has supported IPv6-only clusters since v1.18, migration from IPv4 to IPv6 was not yet possible at that point. At long last, dual-stack IPv4/IPv6 networking has reached general availability (GA) in Kubernetes v1.23.
What does dual-stack networking mean for you? Let’s take a look…
Service API updates
Services were single-stack before 1.20, so using both IP families meant creating one Service per IP family. The user experience was simplified in 1.20, when Services were re-implemented to allow both IP families, meaning a single Service can handle both IPv4 and IPv6 workloads. Dual-stack load balancing is possible between services running any combination of IPv4 and IPv6.
The Service API now has new fields to support dual-stack, replacing the single ipFamily field.
- You can select your choice of IP family by setting
ipFamilyPolicyto one of three options: SingleStack, PreferDualStack, or RequireDualStack. A service can be changed between single-stack and dual-stack (within some limits). - Setting
ipFamiliesto a list of families assigned allows you to set the order of families used. clusterIPsis inclusive of the previousclusterIPbut allows for multiple entries, so it’s no longer necessary to run duplicate services, one in each of the two IP families. Instead, you can assign cluster IP addresses in both IP families.
Note that Pods are also dual-stack. For a given pod, there is no possibility of setting multiple IP addresses in the same family.
Default behavior remains single-stack
Starting in 1.20 with the re-implementation of dual-stack services as alpha, the underlying networking for Kubernetes has included dual-stack whether or not a cluster was configured with the feature flag to enable dual-stack.
Kubernetes 1.23 removed that feature flag as part of graduating the feature to stable. Dual-stack networking is always available if you want to configure it. You can set your cluster network to operate as single-stack IPv4, as single-stack IPv6, or as dual-stack IPv4/IPv6.
While Services are set according to what you configure, Pods default to whatever the CNI plugin sets. If your CNI plugin assigns single-stack IPs, you will have single-stack unless ipFamilyPolicy specifies PreferDualStack or RequireDualStack. If your CNI plugin assigns dual-stack IPs, pod.status.PodIPs defaults to dual-stack.
Even though dual-stack is possible, it is not mandatory to use it. Examples in the documentation show the variety possible in dual-stack service configurations.
Try dual-stack right now
While upstream Kubernetes now supports dual-stack networking as a GA or stable feature, each provider’s support of dual-stack Kubernetes may vary. Nodes need to be provisioned with routable IPv4/IPv6 network interfaces. Pods need to be dual-stack. The network plugin is what assigns the IP addresses to the Pods, so it's the network plugin being used for the cluster that needs to support dual-stack. Some Container Network Interface (CNI) plugins support dual-stack, as does kubenet.
Ecosystem support of dual-stack is increasing; you can create dual-stack clusters with kubeadm, try a dual-stack cluster locally with KIND, and deploy dual-stack clusters in cloud providers (after checking docs for CNI or kubenet availability).
Get involved with SIG Network
SIG-Network wants to learn from community experiences with dual-stack networking to find out more about evolving needs and your use cases. The SIG-network update video from KubeCon NA 2021 summarizes the SIG’s recent updates, including dual-stack going to stable in 1.23.
The current SIG-Network KEPs and issues on GitHub illustrate the SIG’s areas of emphasis. The dual-stack API server is one place to consider contributing.
SIG-Network meetings are a friendly, welcoming venue for you to connect with the community and share your ideas. Looking forward to hearing from you!
Acknowledgments
The dual-stack networking feature represents the work of many Kubernetes contributors. Thanks to all who contributed code, experience reports, documentation, code reviews, and everything in between. Bridget Kromhout details this community effort in Dual-Stack Networking in Kubernetes. KubeCon keynotes by Tim Hockin & Khaled (Kal) Henidak in 2019 (The Long Road to IPv4/IPv6 Dual-stack Kubernetes) and by Lachlan Evenson in 2021 (And Here We Go: Dual-stack Networking in Kubernetes) talk about the dual-stack journey, spanning five years and a great many lines of code.
Kubernetes 1.23: The Next Frontier
Authors: Kubernetes 1.23 Release Team
We’re pleased to announce the release of Kubernetes 1.23, the last release of 2021!
This release consists of 47 enhancements: 11 enhancements have graduated to stable, 17 enhancements are moving to beta, and 19 enhancements are entering alpha. Also, 1 feature has been deprecated.
Major Themes
Deprecation of FlexVolume
FlexVolume is deprecated. The out-of-tree CSI driver is the recommended way to write volume drivers in Kubernetes. See this doc for more information. Maintainers of FlexVolume drivers should implement a CSI driver and move users of FlexVolume to CSI. Users of FlexVolume should move their workloads to the CSI driver.
Deprecation of klog specific flags
To simplify the code base, several logging flags were marked as deprecated in Kubernetes 1.23. The code which implements them will be removed in a future release, so users of those need to start replacing the deprecated flags with some alternative solutions.
Software Supply Chain SLSA Level 1 Compliance in the Kubernetes Release Process
Kubernetes releases now generate provenance attestation files describing the staging and release phases of the release process. Artifacts are now verified as they are handed over from one phase to the next. This final piece completes the work needed to comply with Level 1 of the SLSA security framework (Supply-chain Levels for Software Artifacts).
IPv4/IPv6 Dual-stack Networking graduates to GA
IPv4/IPv6 dual-stack networking graduates to GA. Since 1.21, Kubernetes clusters have been enabled to support dual-stack networking by default. In 1.23, the IPv6DualStack feature gate is removed. The use of dual-stack networking is not mandatory. Although clusters are enabled to support dual-stack networking, Pods and Services continue to default to single-stack. To use dual-stack networking Kubernetes nodes must have routable IPv4/IPv6 network interfaces, a dual-stack capable CNI network plugin must be used, Pods must be configured to be dual-stack and Services must have their .spec.ipFamilyPolicy field set to either PreferDualStack or RequireDualStack.
HorizontalPodAutoscaler v2 graduates to GA
The HorizontalPodAutscaler autoscaling/v2 stable API moved to GA in 1.23. The HorizontalPodAutoscaler autoscaling/v2beta2 API has been deprecated.
Generic Ephemeral Volume feature graduates to GA
The generic ephemeral volume feature moved to GA in 1.23. This feature allows any existing storage driver that supports dynamic provisioning to be used as an ephemeral volume with the volume’s lifecycle bound to the Pod. All StorageClass parameters for volume provisioning and all features supported with PersistentVolumeClaims are supported.
Skip Volume Ownership change graduates to GA
The feature to configure volume permission and ownership change policy for Pods moved to GA in 1.23. This allows users to skip recursive permission changes on mount and speeds up the pod start up time.
Allow CSI drivers to opt-in to volume ownership and permission change graduates to GA
The feature to allow CSI Drivers to declare support for fsGroup based permissions graduates to GA in 1.23.
PodSecurity graduates to Beta
PodSecurity moves to Beta. PodSecurity replaces the deprecated PodSecurityPolicy admission controller. PodSecurity is an admission controller that enforces Pod Security Standards on Pods in a Namespace based on specific namespace labels that set the enforcement level. In 1.23, the PodSecurity feature gate is enabled by default.
Container Runtime Interface (CRI) v1 is default
The Kubelet now supports the CRI v1 API, which is now the project-wide default.
If a container runtime does not support the v1 API, Kubernetes will fall back to the v1alpha2 implementation. There is no intermediate action required by end-users, because v1 and v1alpha2 do not differ in their implementation. It is likely that v1alpha2 will be removed in one of the future Kubernetes releases to be able to develop v1.
Structured logging graduate to Beta
Structured logging reached its Beta milestone. Most log messages from kubelet and kube-scheduler have been converted. Users are encouraged to try out JSON output or parsing of the structured text format and provide feedback on possible solutions for the open issues, such as handling of multi-line strings in log values.
Simplified Multi-point plugin configuration for scheduler
The kube-scheduler is adding a new, simplified config field for Plugins to allow multiple extension points to be enabled in one spot. The new multiPoint plugin field is intended to simplify most scheduler setups for administrators. Plugins that are enabled via multiPoint will automatically be registered for each individual extension point that they implement. For example, a plugin that implements Score and Filter extensions can be simultaneously enabled for both. This means entire plugins can be enabled and disabled without having to manually edit individual extension point settings. These extension points can now be abstracted away due to their irrelevance for most users.
CSI Migration updates
CSI Migration enables the replacement of existing in-tree storage plugins such as kubernetes.io/gce-pd or kubernetes.io/aws-ebs with a corresponding CSI driver.
If CSI Migration is working properly, Kubernetes end users shouldn’t notice a difference.
After migration, Kubernetes users may continue to rely on all the functionality of in-tree storage plugins using the existing interface.
- CSI Migration feature is turned on by default but stays in Beta for GCE PD, AWS EBS, and Azure Disk in 1.23.
- CSI Migration is introduced as an Alpha feature for Ceph RBD and Portworx in 1.23.
Expression language validation for CRD is alpha
Expression language validation for CRD is in alpha starting in 1.23. If the CustomResourceValidationExpressions feature gate is enabled, custom resources will be validated by validation rules using the Common Expression Language (CEL).
Server Side Field Validation is Alpha
If the ServerSideFieldValidation feature gate is enabled starting 1.23, users will receive warnings from the server when they send Kubernetes objects in the request that contain unknown or duplicate fields. Previously unknown fields and all but the last duplicate fields would be dropped by the server.
With the feature gate enabled, we also introduce the fieldValidation query parameter so that users can specify the desired behavior of the server on a per request basis. Valid values for the fieldValidation query parameter are:
- Ignore (default when feature gate is disabled, same as pre-1.23 behavior of dropping/ignoring unkonwn fields)
- Warn (default when feature gate is enabled).
- Strict (this will fail the request with an Invalid Request error)
OpenAPI v3 is Alpha
If the OpenAPIV3 feature gate is enabled starting 1.23, users will be able to request the OpenAPI v3.0 spec for all Kubernetes types. OpenAPI v3 aims to be fully transparent and includes support for a set of fields that are dropped when publishing OpenAPI v2: default, nullable, oneOf, anyOf. A separate spec is published per Kubernetes group version (at the $cluster/openapi/v3/apis/<group>/<version> endpoint) for improved performance and discovery, for all group versions can be found at the $cluster/openapi/v3 path.
Other Updates
Graduated to Stable
- IPv4/IPv6 Dual-Stack Support
- Skip Volume Ownership Change
- TTL After Finished Controller
- Config FSGroup Policy in CSI Driver object
- Generic Ephemeral Inline Volumes
- Defend Against Logging Secrets via Static Analysis
- Namespace Scoped Ingress Class Parameters
- Reducing Kubernetes Build Maintenance
- Graduate HPA API to GA
Major Changes
Release Notes
Check out the full details of the Kubernetes 1.23 release in our release notes.
Availability
Kubernetes 1.23 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials or run local Kubernetes clusters using Docker container “nodes” with kind. You can also easily install 1.23 using kubeadm.
Release Team
This release was made possible by a very dedicated group of individuals, who came together as a team to deliver technical content, documentation, code, and a host of other components that go into every Kubernetes release.
A huge thank you to the release lead Rey Lejano for leading us through a successful release cycle, and to everyone else on the release team for supporting each other, and working so hard to deliver the 1.23 release for the community.
Release Theme and Logo
Kubernetes 1.23: The Next Frontier

"The Next Frontier" theme represents the new and graduated enhancements in 1.23, Kubernetes' history of Star Trek references, and the growth of community members in the release team.
Kubernetes has a history of Star Trek references. The original codename for Kubernetes within Google is Project 7, a reference to Seven of Nine from Star Trek Voyager. And of course Borg was the name for the predecessor to Kubernetes. "The Next Frontier" theme continues the Star Trek references. "The Next Frontier" is a fusion of two Star Trek titles, Star Trek V: The Final Frontier and Star Trek the Next Generation.
"The Next Frontier" represents a line in the SIG Release charter, "Ensure there is a consistent group of community members in place to support the release process across time." With each release team, we grow the community with new release team members and for many it's their first contribution in their open source frontier.
Reference: https://kubernetes.io/blog/2015/04/borg-predecessor-to-kubernetes/ Reference: https://github.com/kubernetes/community/blob/master/sig-release/charter.md
The Kubernetes 1.23 release logo continues with the theme's Star Trek reference. Every star is a helm from the Kubernetes logo. The ship represents the collective teamwork of the release team.
Rey Lejano designed the logo.
User Highlights
- Findings of the latest CNCF End User Technology Radar were themed around DevSecOps. Check out the Radar Page for the full details and findings.
- Learn about how end user Aegon Life India migrated core processes from its traditional monolith to a microservice-based architecture in its effort to transform into a leading digital service company.
- Utilizing multiple cloud native projects, Seagate engineered edgerX to run Real-time Analytics at the Edge.
- Check out how Zambon worked with SparkFabrik to develop 16 websites, with cloud native technologies, to enable stakeholders to easily update content while maintaining a consistent brand identity.
- Using Kubernetes, InfluxData was able to deliver on the promise of multi-cloud, multi-region service availability by creating a true cloud abstraction layer that allows for the seamless delivery of InfluxDB as a single application to multiple global clusters across three major cloud providers.
Ecosystem Updates
- KubeCon + CloudNativeCon NA 2021 was held in October 2021, both online and in person. All talks are now available on-demand for anyone that would like to catch up!
- Kubernetes and Cloud Native Essentials Training and KCNA Certification are now generally available for enrollment and scheduling. Additionally, a new online training course, Kubernetes and Cloud Native Essentials (LFS250), has been released to both prepare individuals for entry-level cloud roles and to sit for the KCNA exam.
- New resources are now available from the Inclusive Naming Initiative, including an Inclusive Strategies for Open Source (LFC103) course, Language Evaluation Framework, and Implementation Path.
Project Velocity
The CNCF K8s DevStats project aggregates a number of interesting data points related to the velocity of Kubernetes and various sub-projects. This includes everything from individual contributions to the number of companies that are contributing, and is an illustration of the depth and breadth of effort that goes into evolving this ecosystem.
In the v1.23 release cycle, which ran for 16 weeks (August 23 to December 7), we saw contributions from 1032 companies and 1084 individuals.
Event Update
- KubeCon + CloudNativeCon China 2021 is happening this month from December 9 - 11. After taking a break last year, the event will be virtual this year and includes 105 sessions. Check out the event schedule here.
- KubeCon + CloudNativeCon Europe 2022 will take place in Valencia, Spain, May 4 – 7, 2022! You can find more information about the conference and registration on the event site.
- Kubernetes Community Days has upcoming events scheduled in Pakistan, Brazil, Chengdu, and in Australia.
Upcoming Release Webinar
Join members of the Kubernetes 1.23 release team on January 4, 2022 to learn about the major features of this release, as well as deprecations and removals to help plan for upgrades. For more information and registration, visit the event page on the CNCF Online Programs site.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below:
- Find out more about contributing to Kubernetes at the Kubernetes Contributors website
- Follow us on Twitter @Kubernetesio for the latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Post questions (or answer questions) on Stack Overflow
- Share your Kubernetes story
- Read more about what’s happening with Kubernetes on the blog
- Learn more about the Kubernetes Release Team
Contribution, containers and cricket: the Kubernetes 1.22 release interview
Author: Craig Box (Google)
The Kubernetes release train rolls on, and we look ahead to the release of 1.23 next week. As is our tradition, I'm pleased to bring you a look back at the process that brought us the previous version.
The release team for 1.22 was led by Savitha Raghunathan, who was, at the time, a Senior Platform Engineer at MathWorks. I spoke to Savitha on the Kubernetes Podcast from Google, the weekly
Our release conversations shine a light on the team that puts together each Kubernetes release. Make sure you subscribe, wherever you get your podcasts so you catch the story of 1.23.
And in case you're interested in why the show has been on a hiatus the last few weeks, all will be revealed in the next episode!
This transcript has been lightly edited and condensed for clarity.
CRAIG BOX: Welcome to the show, Savitha.
SAVITHA RAGHUNATHAN: Hey, Craig. Thanks for having me on the show. How are you today?
CRAIG BOX: I'm very well, thank you. I've interviewed a lot of people on the show, and you're actually the first person who's asked that of me.
SAVITHA RAGHUNATHAN: I'm glad. It's something that I always do. I just want to make sure the other person is good and happy.
CRAIG BOX: That's very kind of you. Thank you for kicking off on a wonderful foot there. I want to ask first of all — you grew up in Chennai. My association with Chennai is the Super Kings cricket team. Was cricket part of your upbringing?
SAVITHA RAGHUNATHAN: Yeah. Actually, a lot. My mom loves watching cricket. I have a younger brother, and when we were growing up, we used to play cricket on the terrace. Everyone surrounding me, my best friends — and even now, my partner — loves watching cricket, too. Cricket is a part of my life.
I stopped watching it a while ago, but I still enjoy a good game.
CRAIG BOX: It's probably a bit harder in the US. Everything's in a different time zone. I find, with my cricket team being on the other side of the world, that it's a lot easier when they're playing near me, as opposed to trying to keep up with what they're doing when they're playing at 3:00 in the morning.
SAVITHA RAGHUNATHAN: That is actually one of the things that made me lose touch with cricket. I'm going to give you a piece of interesting information. I never supported Chennai Super Kings. I always supported Royal Challengers of Bangalore.
I once went to the stadium, and it was a match between the Chennai Super Kings and the RCB. I was the only one who was cheering whenever the RCB hit a 6, or when they were scoring. I got the stares of thousands of people looking at me. I'm like, "what are you doing?" My friends are like, "you're going to get us killed! Just stop screaming!"
CRAIG BOX: I hear you. As a New Zealander in the UK, there are a lot of international cricket matches I've been to where I am one of the few people dressed in the full beige kit. But I have to ask, why an affiliation with a different team?
SAVITHA RAGHUNATHAN: I'm not sure. When the IPL came out, I really liked Virat Kohli. He was playing for RCB at that time, and I think pretty much that's it.
CRAIG BOX: Well, what I know about the Chennai Super Kings is that their coach is New Zealand's finest batsmen and air conditioning salesman, Stephen Fleming.
SAVITHA RAGHUNATHAN: Oh, really?
CRAIG BOX: Yeah, he's a dead ringer for the guy who played the yellow Wiggle back in the day.
SAVITHA RAGHUNATHAN: Oh, interesting. I remember the name, but I cannot put the picture and the name together. I stopped watching cricket once I moved to the States. Then, all my focus was on studies and extracurriculars. I have always been an introvert. The campus — it was a new thing for me — they had international festivals.
And every week, they'd have some kind of new thing going on, so I'd go check them out. I wouldn't participate, but I did go out and check them out. That was a big feat for me around that time because a lot of people — and still, even now, a lot of people — they kind of scare me. I don't know how to make a conversation with everyone.
I'll just go and say, "hi, how are you? OK, I'm good. I'm just going to move on". And I'll just go to the next person. And after two hours, I'm out of that place.
CRAIG BOX: Perhaps a pleasant side effect of the last 12 months — a lot fewer gatherings of people.
SAVITHA RAGHUNATHAN: Could be that, but I'm so excited about KubeCon. But when I think about it, I'm like "oh my God. There's going to be a lot of people. What am I going to do? I'm going to meet all my friends over there".
Sometimes I have social anxiety like, what's going to happen?
CRAIG BOX: What's going to happen is you're going to ask them how they are at the beginning, and they're immediately going to be set at ease.
SAVITHA RAGHUNATHAN: laughs I hope so.
CRAIG BOX: Let's talk a little bit, then, about your transition from India to the US. You did your undergraduate degree in computer science at the SSN College of Engineering. How did you end up at Arizona State?
SAVITHA RAGHUNATHAN: I always wanted to pursue higher studies when I was in India, and I didn't have the opportunity immediately. Once I graduated from my school there, I went and I worked for a couple of years. My aim was always to get out of there and come here, do my graduate studies.
Eventually, I want to do a PhD. I have an idea of what I want to do. I always wanted to keep studying. If there's an option that I could just keep studying and not do work or anything of that sort, I'd just pick that other one — I'll just keep studying.
But unfortunately, you need money and other things to live and sustain in this world. So I'm like, OK, I'll take a break from studies, and I will work for a while.
CRAIG BOX: The road to success is littered with dreams of PhDs. I have a lot of friends who thought that that was the path they were going to take, and they've had a beautiful career and probably aren't going to go back to study. Did you use the Matlab software at all while you were going through your schooling?
SAVITHA RAGHUNATHAN: No, unfortunately. That is a question that everyone asks. I have not used Matlab. I haven't used it even now. I don't use it for work. I didn't have any necessity for my school work. I didn't have anything to do with Matlab. I never analysed, or did data processing, or anything, with Matlab. So unfortunately, no.
Everyone asks me like, you're working at MathWorks. Have you used Matlab? I'm like, no.
CRAIG BOX: Fair enough. Nor have I. But it's been around since the late 1970s, so I imagine there are a lot of people who will have come across it at some point. Do you work with a lot of people who have been working on it that whole time?
SAVITHA RAGHUNATHAN: Kind of. Not all the time, but I get to meet some folks who work on the product itself. Most of my interactions are with the infrastructure team and platform engineering teams at MathWorks. One other interesting fact is that when I joined the company — MathWorks has an extensive internal curriculum for training and learning, which I really love. They have an "Intro to Matlab" course, and that's on my bucket of things to do.
It was like 500 years ago. I added it, and I never got to it. I'm like, OK, maybe this year at least I want to get to it and I want to learn something new. My partner used Matlab extensively. He misses it right now at his current employer. And he's like, "you have the entire licence! You have access to the entire suite and you haven't used it?" I'm like, "no!"
CRAIG BOX: Well, I have bad news for the idea of you doing a PhD, I'm sorry.
SAVITHA RAGHUNATHAN: Another thing is that none of my family knew about the company MathWorks and Matlab. The only person who knew was my younger brother. He was so proud. He was like, "oh my God".
When he was 12 years old, he started getting involved in robotics and all that stuff. That's how he got introduced to Matlab. He goes absolutely bananas for the swag. So all the t-shirts, all the hoodies — any swag that I get from MathWorks goes to him, without saying.
Over the five, six years, the things that I've got — there was only one sweatshirt that I kept for myself. Everything else I've just given to him. And he cherishes it. He's the only one in my family who knew about Matlab and MathWorks.
Now, everyone knows, because I'm working there. They were initially like, I don't even know that company name. Is it like Amazon? I'm like, no, we make software that can send people to the moon. And we also make software that can do amazing robotic surgeries and even make a car drive on its own. That's something that I take immense pride in.
I know I don't directly work on the product, but I'm enabling the people who are creating the product. I'm really, really proud of that.
CRAIG BOX: I think Jeff Bezos is working on at least two out of three of those disciplines that you mentioned before, so it's maybe a little bit like Amazon. One thing I've always thought about Matlab is that, because it's called Matlab, it solves that whole problem where Americans call it math, and the rest of the world call it maths. Why do Americans think there's only one math?
SAVITHA RAGHUNATHAN: Definitely. I had trouble — growing up in India, it's always British English. And I had so much trouble when I moved here. So many things changed.
One of the things is maths. I always got used to writing maths, physics, and everything.
CRAIG BOX: They don't call it "physic" in the US, do they?
SAVITHA RAGHUNATHAN: No, no, they don't. Luckily, they don't. That still stays "physics". But math — I had trouble. It's maths. Even when you do the full abbreviations like mathematics and you are still calling it math, I'm like, mm.
CRAIG BOX: They can do the computer science abbreviation thing and call it math-7-S or whatever the number of letters is.
SAVITHA RAGHUNATHAN: Just like Kubernetes. K-8-s.
CRAIG BOX: Your path to Kubernetes is through MathWorks. They started out as a company making software which was distributed in a physical sense — boxed copies, if you will. I understand now there is a cloud version. Can I assume that that is where the two worlds intersect?
SAVITHA RAGHUNATHAN: Kind of. I have interaction with the team that supports Matlab on the cloud, but I don't get to work with them on a day-to-day basis. They use Docker containers, and they are building the platform using Kubernetes. So yeah, a little bit of that.
CRAIG BOX: So what exactly is the platform that you are engineering day to day?
SAVITHA RAGHUNATHAN: Providing Kubernetes as a platform, obviously — that goes without saying — to some of the internal development teams. In the future we might expand it to more teams within the company. That is a focus area right now, so that's what we are doing. In the process, we might even get to work with the people who are deploying Matlab on the cloud, which is exciting.
CRAIG BOX: Now, your path to contribution to Kubernetes, you've said before, was through fixing a 404 error on the Kubernetes.io website. Do you remember what the page was?
SAVITHA RAGHUNATHAN: I do. I was going to something for work, and I came across this changelog. In Kubernetes there's a nice page — once you got to the release page, there would be a long list of changelogs.
One of the things that I fixed was, the person who worked on the feature had changed their GitHub handle, and that wasn't reflected on this page. So that was my first. I got curious and clicked on the links. One of the links was the handle, and that went to a 404. And I was like "Yeah, I'll just fix that. They have done all the hard work. They can get the credit that's due".
It was easy. It wasn't overwhelming for me to pick it up as my first issue. Before that I logged on around Kubernetes for about six to eight months without doing anything because it was just a lot.
CRAIG BOX: One of the other things that you said about your initial contribution is that you had to learn how to use Git. As a very powerful tool, I find Git is a high barrier to entry for even contributing code to a project. When you want to contribute a blog post or documentation or a fix like you did before, I find it almost impossible to think how a new user would come along and do that. What was your process? Do you think that there's anything we can do to make that barrier lower for new contributors?
SAVITHA RAGHUNATHAN: Of course. There are more and more tutorials available these days. There is a new contributor workshop. They actually have a GitHub workflow section, how to do a pull request and stuff like that. I know a couple of folks from SIG Docs that are working on which Git commands that you need, or how to get to writing something small and getting it committed. But more tutorials or more links to intro to Git would definitely help.
The thing is also, someone like a documentation writer — they don't actually want to know the entirety of Git. Honestly, it's an ocean. I don't know how to do it. Most of the time, I still ask for help even though I work with Git on a day to day basis. There are several articles and a lot of help is available already within the community. Maybe we could just add a couple more to kubernetes.dev. That is an amazing site for all the new contributors and existing contributors who want to build code, who want to write documentation.
We could just add a tutorial there like, "hey, don't know Git, you are new to Git? You just need to know these main things".
CRAIG BOX: I find it a shame, to be honest, that people need to use Git for that, by comparison to Wikipedia where you can come along, and even though it might be written in Markdown or something like it, it seems like the barrier is a lot lower. Similar to you, I always have to look up anything more complicated than the five or six Git commands that I use on a day to day basis. Even to do simple things, I basically just go and follow a recipe which I find on the internet.
SAVITHA RAGHUNATHAN: This is how I got introduced to one of the amazing mentors in Kubernetes. Everyone knows him by his handle, Dims. It was my second PR to the Kubernetes website, and I made a mistake. I destroyed the Git history. I could not push my reviews and comments — I addressed them. I couldn't push them back.
My immediate thought was to delete it and recreate, do another pull request. But then I was like, "what happens to others who have already put effort into reviewing them?" I asked for help, and Dims was there.
I would say I just got lucky he was there. And he was like, "OK, let me walk you through". We did troubleshooting through Slack messages. I copied and pasted all the errors. Every single command that he said, I copied and pasted. And then he was like, "OK, run this one. Try this one. And do this one".
Finally, I got it fixed. So you know what I did? I went and I stored the command history somewhere local for the next time when I run into this problem. Luckily, I haven't. But I find the contributors so helpful. They are busy. They have a lot of things to do, but they take moments to stop and help someone who's new.
That is also another part of the reason why I stay — I want to contribute more. It's mainly the community. It's the Kubernetes community. I know you asked me about Git, and I just took the conversation to the Kubernetes community. That's how my brain works.
CRAIG BOX: A lot of people in the community do that and think that's fantastic, obviously, people like Dims who are just floating around on Slack and seem to have endless time. I don't know how they do it.
SAVITHA RAGHUNATHAN: I really want to know the secret for endless time. If I only had 48 hours in a day. I would sleep for 16 hours, and I would use the rest of the time for doing the things that I want.
CRAIG BOX: If I had a chance to sleep up to 48 hours a day, I think it'd be a lot more than 16.
Now, one of the areas that you've been contributing to Kubernetes is in the release team. In 1.18, you were a shadow for the docs role. You led that role in 1.19. And you were a release lead shadow for versions 1,20 and 1.21 before finally leading this release, 1.22, which we will talk about soon.
How did you get involved? And how did you decide which roles to take as you went through that process?
SAVITHA RAGHUNATHAN: That is a topic I love to talk about. This was fresh when I started learning about Kubernetes and using Kubernetes at work. And I got so much help from the community, I got interested in contributing back.
At the first KubeCon that I attended in 2018, in Seattle, they had a speed mentoring session. Now they call it "pod mentoring". I went to the session, and said, "hey, I want to contribute. I don't know where to start". And I got a lot of information on how to get started.
One of the places was SIG Release and the release team. I came back and diligently attended all the SIG Release meetings for four to six months. And in between, I applied to the Kubernetes release team — 1.14 and 1.15. I didn't get through. So I took a little bit of a break, and I focused on doing some documentation work. Then I applied for 1.18.
Since I was already working on some kinds of — not like full fledged "documentation" documentation, I still don't write. I eventually want to write something really nice and full fledged documentation like other awesome folks.
CRAIG BOX: You'll need a lot more than 48 hours in your day to do that.
SAVITHA RAGHUNATHAN: laughing That's how I applied for the docs role, because I know a little bit about the website. I've done a few pull requests and commits. That's how I got started. I applied for that one role, and I got selected for the 1.18 team. That's how my journey just took off.
And the next release, I was leading the documentation team. And as everyone knows, the pandemic hit. It was one of the longest releases. I could lean back on the community. I would just wait for the release team meetings.
It was my way of coping with the pandemic. It took my mind off. It was actually more than a release team, they were people. They were all people first, and we took care of each other. So it felt good.
And then, I became a release lead shadow for 1.20 and 1.21 because I wanted to know more. I wanted to learn more. I wasn't ready. I still don't feel ready, but I have led 1.22. So if I could do it, anyone could do it.
CRAIG BOX: How much of this work is day job?
SAVITHA RAGHUNATHAN: I am lucky to be blessed with an awesome team. I do most of my work after work, but there have been times where I have to take meetings and attend to immediate urgent stuff. During the time of exception requests and stuff like that, I take a little bit of time from my work.
My team has been wonderful: they support me in all possible ways, and the management as well. Other than the meetings, I don't do much of the work during the day job. It just takes my focus and attention away too much, and I end up having to spend a lot of time sitting in front of the computer, which I don't like.
Before the pandemic I had a good work life balance. I'd just go to work at 7:00, 7:30, and I'd be back by 4 o'clock. I never touched my laptop ever again. I left all work behind when I came home. So right now, I'm still learning how to get through.
I try to limit the amount of open source work that I do during work time. The release lead shadow and the release lead job — they require a lot of time, effort. So on average, I'd be spending two to three hours post work time on the release activities.
CRAIG BOX: Before the pandemic, everyone was worried that if we let people work from home, they wouldn't work enough. I think the opposite has actually happened, is that now we're worried that if we let people work from home, they will just get on the computer in the morning and you'll have to pry it out of their hands at midnight.
SAVITHA RAGHUNATHAN: Yeah, I think the productivity has increased at least twofold, I would say, for everyone, once they started working from home.
CRAIG BOX: But at the expense of work-life balance, though, because as you say, when you're sitting in the same chair in front of, perhaps, the same computer doing your MathWorks work and then your open source work, they kind of can blur into one perhaps?
SAVITHA RAGHUNATHAN: That is a challenge. I face it every day. But so many others are also facing it. I implemented a few little tricks to help me. When I used to come back home from work, the first thing I would do is remove my watch. That was an indication that OK, I'm done.
That's the thing that I still do. I just remove my watch, and I just keep it right where my workstation is. And I just close the door so that I never look back. Even going past the room, I don't get a glimpse of my work office. I start implementing tiny little things like that to avoid burnout.
I think I'm still facing a little bit of burnout. I don't know if I have fully recovered from it. I constantly feel like I need a vacation. And I could just take a vacation for like a month or two. If it's possible, I will just do it.
CRAIG BOX: I do hope that travel opens up for everyone as an opportunity because I know that, for a lot of people, it's not so much they've been working from home but they've been living at work. The idea of taking vacation effectively means, well, I've been stuck in the same place, if I've been under a lockdown. It's hard to justify that. It will be good as things improve worldwide for us to be able to start focusing more on mental health and perhaps getting away from the "everything room," as I sometimes call it.
SAVITHA RAGHUNATHAN: I'm totally looking forward to it. I hope that travel opens up and I could go home and I could meet my siblings and my aunt and my parents.
CRAIG BOX: Catch a cricket match?
SAVITHA RAGHUNATHAN: Yeah. Probably yes, if I have company and if there is anything interesting happening around the time. I don't mind going back to the Chepauk Stadium and catching a match or two.
CRAIG BOX: Let's turn now to the recently released Kubernetes 1.22. Congratulations on the launch.
SAVITHA RAGHUNATHAN: Thank you.
CRAIG BOX: Each launch comes with a theme and a mascot or a logo. What is the theme for this release?
SAVITHA RAGHUNATHAN: The theme for the release is reaching new peaks. I am fascinated with a lot of space travel and chasing stars, the Milky Way. The best place to do that is over the top of a mountain. So that is the release logo, basically. It's a mountain — Mount Rainier. On top of that, there is a Kubernetes flag, and it's overlooking the Milky Way.
It's also symbolic that with every release, that we are achieving something new, bigger, and better, and we are making the release awesome. So I just wanted to incorporate that into the team as to say, we are achieving new things with every release. That's the "reaching new peaks" theme.
CRAIG BOX: The last couple of releases have both been incrementally larger — as a result, perhaps, of the fact there are now only three releases per year rather than four. There were also changes to the process, where the work has been driven a lot more by the SIGs than by the release team having to go and ask the SIGs what was going on. What can you say about the size and scope of the 1.22 release?
SAVITHA RAGHUNATHAN: The 1.22 release is the largest release to date. We have 56 enhancements if I'm not wrong, and we have a good amount of features that's graduated as stable. You can now say that Kubernetes as a project has become more mature because you see new features coming in. At the same time, you see the features that weren't used getting deprecated — we have like three deprecations in this release.
Aside from that fact, we also have a big team that's supporting one of the longest releases. This is the first official release cycle after the cadence KEP got approved. Officially, we are at four months, even though 1.19 was six months, and 1.21 was like 3 and 1/2 months, I think, this is the first one after the official KEP approval.
CRAIG BOX: What changes did you make to the process knowing that you had that extra month?
SAVITHA RAGHUNATHAN: One of the things the community had asked for is more time for development. We tried to incorporate that in the release schedule. We had about six weeks between the enhancements freeze and the code freeze. That's one.
It might not be visible to everyone, but one of the things that I wanted to make sure of was the health of the team — since it was a long, long release, we had time to plan out, and not have everyone work during the weekends or during their evenings or time off. That actually helped everyone keep their sanity, and also in making good progress and delivering good results at the end of the release. That's one of the process improvements that I'd call out.
We got better by making a post during the exception request process. Everyone works around the world. People from the UK start a little earlier than the people in the US East Coast. The West Coast starts three hours later than the East Coast. We used to make a post every Friday evening saying "hey, we actually received this many requests. We have addressed a number of them. We are waiting on a couple, or whatever. All the release team members are done for the day. We will see you around on Monday. Have a good weekend." Something like that.
We set the expectations from the community as well. We understand things are really important and urgent, but we are done. This gave everyone their time back. They don't have to worry over the weekend thinking like, hey, what's happening? What's happening in the release? They could spend time with their family, or they could do whatever they want to do, like go on a hike, or just sit and watch TV.
There have been weekends that I just did that. I just binge-watched a series. That's what I did.
CRAIG BOX: Any recommendations?
SAVITHA RAGHUNATHAN: I'm a big fan of Marvel, so I have watched the new Loki, which I really love. Loki is one of my favourite characters in Marvel. And I also liked WandaVision. That was good, too.
CRAIG BOX: I've not seen Loki yet, but I've heard it described as the best series of Doctor Who in the last few years.
SAVITHA RAGHUNATHAN: Really?
CRAIG BOX: There must be an element of time-travelling in there if that's how people are describing it.
SAVITHA RAGHUNATHAN: You should really go and watch it whenever you have time. It's really amazing. I might go back and watch it again because I might have missed bits and pieces. That always happens in Marvel movies and the episodes; you need to watch them a couple of times to catch, "oh, this is how they relate".
CRAIG BOX: Yes, the mark of good media that you want to immediately go back and watch it again once you've seen it.
Let's look now at some of the new features in Kubernetes 1.22. A couple of things that have graduated to general availability — server-side apply, external credential providers, a couple of new security features — the replacement for pod security policy has been announced, and seccomp is now available by default.
Do you have any favourite features in 1.22 that you'd like to discuss?
SAVITHA RAGHUNATHAN: I have a lot of them. All my favourite features are related to security. OK, one of them is not security, but a major theme of my favourite KEPs is security. I'll start with the default seccomp. I think it will help make clusters secure by default, and may assist in preventing more vulnerabilities, which means less headaches for the cluster administrators.
This is close to my heart because the base of the MathWorks platform is provisioning Kubernetes clusters. Knowing that they are secure by default will definitely provide me with some good sleep. And also, I'm paranoid about security most of the time. I'm super interested in making everything secure. It might get in the way of making the users of the platform angry because it's not usable in any way.
My next one is rootless Kubelet. That feature's going to enable the cluster admin, the platform developers to deploy Kubernetes components to run in a user namespace. And I think that is also a great addition.
Like you mention, the most awaited drop in for the PSP replacement is here. It's pod admission control. It lets cluster admins apply the pod security standards. And I think it's just not related to the cluster admins. I might have to go back and check on that. Anyone can probably use it — the developers and the admins alike.
It also supports various modes, which is most welcome. There are times where you don't want to just cut the users off because they are trying to do something which is not securely correct. You just want to warn them, hey, this is what you are doing. This might just cause a security issue later, so you might want to correct it. But you just don't want to cut them off from using the platform, or them trying to attempt to do something — deploy their workload and get their day-to-day job done. That is something that I really like, that it also supports a warning mechanism.
Another one which is not security is node swap support. Kubernetes didn't have support for swap before, but it is taken into consideration now. This is an alpha feature. With this, you can take advantage of the swap, which is provisioned on the Linux VMs.
Some of the workloads — when they are deployed, they might need a lot of swap for the start-up — example, like Node and Java applications, which I just took out of their KEP user stories. So if anyone's interested, they can go and look in the KEP. That's useful. And it also increases the node stability and whatnot. So I think it's going to be beneficial for a lot of folks.
We know how Java and containers work. I think it has gotten better, but five years ago, it was so hard to get a Java application to fit in a small container. It always needed a lot of memory, swap, and everything to start up and run. I think this will help the users and help the admins and keep the cost low, and it will tie into so many other things as well. I'm excited about that feature.
Another feature that I want to just call out — I don't use Windows that much, but I just want to give a shout out to the folks who are doing an amazing job bringing all the Kubernetes features to Windows as well, to give a seamless experience.
One of the things is Windows privileged containers. I think it went alpha this release. And that is a wonderful addition, if you ask me. It can take advantage of whatever that's happening on the Linux side. And they can also port it over and see, OK, I can now run Windows containers in a privileged mode.
So whatever they are trying to achieve, they can do it. So that's a noteworthy mention. I need to give a shout out for the folks who work and make things happen in the Windows ecosystem as well.
CRAIG BOX: One of the things that's great about the release process is the continuity between groups and teams. There's always an emeritus advisor who was a lead from a previous release. One thing that I always ask when I do these interviews is, what is the advice that you give to the next person? When we talked to Nabarun for the 1.21 interview, he said that his advice to you would be "do, delegate, and defer". Figure out what you can do, figure out what you can ask other people to do, and figure out what doesn't need to be done. Were you able to take that advice on board?
SAVITHA RAGHUNATHAN: Yeah, you won't believe it. I have it right here stuck to my monitor.
CRAIG BOX: Next to your Git cheat sheet?
SAVITHA RAGHUNATHAN: laughs Absolutely. I just have it stuck there. I just took a look at it.
CRAIG BOX: Someone that you will have been able to delegate and defer to is Rey Lejano from Rancher Labs and SUSE, who is the release lead to be for 1.23.
SAVITHA RAGHUNATHAN: I want to tell Rey to beware of the team's mental health. Schedule in such a way that it avoids burnout. Check in, and make sure that everyone is doing good. If they need some kind of help, create a safe space where they can actually ask for help, if they want to step back, if they need someone to cover.
I think that is most important. The releases are successful based on the thousands and thousands of contributors. But when it comes to a release team, you need to have a healthy team where people feel they are in a good place and they just want to make good contributions, which means they want to be heard. That's one thing that I want to tell Rey.
Also collaborate and learn from each other. I constantly learn. I think the team was 39 folks, including me. Every day I learned something or the other, even starting from how to interact.
Sometimes I have learned more leadership skills from my release lead shadows. They are awesome, and they are mature. I constantly learn from them, and I admire them a lot.
It also helps to have good, strong individuals in the team who can step up and help when needed. For example, unfortunately, we lost one of our teammates after the start of the release cycle. That was tragic. His name was Peeyush Gupta. He was an awesome and wonderful human — very warm.
I didn't get more of a chance to interact with him. I had exchanged a few Slack messages, but I got his warm personality. I just want to take a couple of seconds to remember him. He was awesome.
After we lost him, we had this strong person from the team step up and lead the communications, who had never been a part of the release team before at all. He was a shadow for the first time. His name is Jesse Butler. So he stepped up, and he just took it away. He ran the comms show for 1.22.
That's what the community is about. You take care of team members, and the team will take care of you. So that's one other thing that I want to let Rey know, and maybe whoever — I think it's applicable overall.
CRAIG BOX: There's a link to a family education fund for Peeyush Gupta, which you can find in the show notes.
Five releases in a row now you've been a member of the release team. Will you be putting your feet up now for 1.23?
SAVITHA RAGHUNATHAN: I am going to take a break for a while. In the future, I want to be contributing, if not the release team, the SIG Release and the release management effort. But right now, I have been there for five releases. And I feel like, OK, I just need a little bit of fresh air.
And also the pandemic and the burnout has caught up, so I'm going to take a break from certain contributions. You will see me in the future. I will be around, but I might not be actively participating in the release team activities. I will be around the community. Anyone can reach out to me. They all know my Slack, so they can just reach out to me via Slack or Twitter.
CRAIG BOX: Yes, your Twitter handle is CoffeeArtGirl. Does that mean that you'll be spending some time working on your lattes?
SAVITHA RAGHUNATHAN: I am very bad at making lattes. The coffee art means that I used to make art with coffee. You get instant coffee powder and just mix it with water. You get the colours, very beautiful brown colours. I used to make art using that.
And I love coffee. So I just combined all the words together. And I had to come up with it in a span of one hour or so because I was joining this 'meet our contributors' panel. And Paris asked me, "do you have a Twitter handle?" I was planning to create one, but I didn't have the time.
I'm like, well, let me just think what I could just come up with real quick. So I just came up with that. So that's the story behind my Twitter handle. Everyone's interested in it. You are not the first person you have asked me or mentioned about it. So many others are like, why coffee art?
CRAIG BOX: And you are also interested in art with perhaps other materials?
SAVITHA RAGHUNATHAN: Yes. My interests keep changing. I used to do pebble art. It's just collecting pebbles from wherever I go, and I used to paint on them. I used to use watercolour, but I want to come back to watercolour sometime.
My recent interests are coloured pencils, which came back. When I was very young, I used to do a lot of coloured pencils. And then I switched to watercolours and oil painting. So I just go around in circles.
One of the hobbies that I picked up during a pandemic is crochet. I made a scarf for Mother's Day. My mum and my dad were here last year. They got stuck because of the pandemic, and they couldn't go back home. So they stayed with me for 10 months. That is the jackpot that I had, that I got to spend so much time with my parents after I moved to the US.
CRAIG BOX: And they got rewarded with a scarf.
SAVITHA RAGHUNATHAN: Yeah.
CRAIG BOX: One to share between them.
SAVITHA RAGHUNATHAN: I started making a blanket for my dad. And it became so heavy, I might have to just pick up some lighter yarn. I still don't know the differences between different kinds of yarns, but I'm getting better.
I started out because I wanted to make these little toys. They call them amigurumi in the crochet world. I wanted to make them. That's why I started out. I'm trying. I made a little cat which doesn't look like a cat, but it is a cat. I have to tell everyone that it's a cat so that they don't mock me later, but.
CRAIG BOX: It's an artistic interpretation of a cat.
SAVITHA RAGHUNATHAN: It definitely is!
Savitha Raghunathan, now a Senior Software Engineer at Red Hat, served as the Kubernetes 1.22 release team lead.
You can find the Kubernetes Podcast from Google at @KubernetesPod on Twitter, and you can subscribe so you never miss an episode.
Quality-of-Service for Memory Resources
Authors: Tim Xu (Tencent Cloud)
Kubernetes v1.22, released in August 2021, introduced a new alpha feature that improves how Linux nodes implement memory resource requests and limits.
In prior releases, Kubernetes did not support memory quality guarantees. For example, if you set container resources as follows:
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
containers:
- name: nginx
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "64Mi"
cpu: "500m"
spec.containers[].resources.requests(e.g. cpu, memory) is designed for scheduling. When you create a Pod, the Kubernetes scheduler selects a node for the Pod to run on. Each node has a maximum capacity for each of the resource types: the amount of CPU and memory it can provide for Pods. The scheduler ensures that, for each resource type, the sum of the resource requests of the scheduled Containers is less than the capacity of the node.
spec.containers[].resources.limits is passed to the container runtime when the kubelet starts a container. CPU is considered a "compressible" resource. If your app starts hitting your CPU limits, Kubernetes starts throttling your container, giving your app potentially worse performance. However, it won’t be terminated. That is what "compressible" means.
In cgroup v1, and prior to this feature, the container runtime never took into account and effectively ignored spec.containers[].resources.requests["memory"]. This is unlike CPU, in which the container runtime consider both requests and limits. Furthermore, memory actually can't be compressed in cgroup v1. Because there is no way to throttle memory usage, if a container goes past its memory limit it will be terminated by the kernel with an OOM (Out of Memory) kill.
Fortunately, cgroup v2 brings a new design and implementation to achieve full protection on memory. The new feature relies on cgroups v2 which most current operating system releases for Linux already provide. With this experimental feature, quality-of-service for pods and containers extends to cover not just CPU time but memory as well.
How does it work?
Memory QoS uses the memory controller of cgroup v2 to guarantee memory resources in Kubernetes. Memory requests and limits of containers in pod are used to set specific interfaces memory.min and memory.high provided by the memory controller. When memory.min is set to memory requests, memory resources are reserved and never reclaimed by the kernel; this is how Memory QoS ensures the availability of memory for Kubernetes pods. And if memory limits are set in the container, this means that the system needs to limit container memory usage, Memory QoS uses memory.high to throttle workload approaching it's memory limit, ensuring that the system is not overwhelmed by instantaneous memory allocation.

The following table details the specific functions of these two parameters and how they correspond to Kubernetes container resources.
| File | Description |
|---|---|
| memory.min | memory.min specifies a minimum amount of memory the cgroup must always retain, i.e., memory that can never be reclaimed by the system. If the cgroup's memory usage reaches this low limit and can’t be increased, the system OOM killer will be invoked.
We map it to the container's memory request |
| memory.high | memory.high is the memory usage throttle limit. This is the main mechanism to control a cgroup's memory use. If a cgroup's memory use goes over the high boundary specified here, the cgroup’s processes are throttled and put under heavy reclaim pressure. The default is max, meaning there is no limit.
We use a formula to calculate memory.high, depending on container's memory limit or node allocatable memory (if container's memory limit is empty) and a throttling factor. Please refer to the KEP for more details on the formula.
|
When container memory requests are made, kubelet passes memory.min to the back-end CRI runtime (possibly containerd, cri-o) via the Unified field in CRI during container creation. The memory.min in container level cgroup will be set to:

i: the ith container in one pod
Since the memory.min interface requires that the ancestor cgroup directories are all set, the pod and node cgroup directories need to be set correctly.
memory.min in pod level cgroup:

i: the ith container in one pod
memory.min in node level cgroup:

i: the ith pod in one node, j: the jth container in one pod
Kubelet will manage the cgroup hierarchy of the pod level and node level cgroups directly using runc libcontainer library, while container cgroup limits are managed by the container runtime.
For memory limits, in addition to the original way of limiting memory usage, Memory QoS adds an additional feature of throttling memory allocation. A throttling factor is introduced as a multiplier (default is 0.8). If the result of multiplying memory limits by the factor is greater than memory requests, kubelet will set memory.high to the value and use Unified via CRI. And if the container does not specify memory limits, kubelet will use node allocatable memory instead. The memory.high in container level cgroup is set to:

i: the ith container in one pod
This can can help improve stability when pod memory usage increases, ensuring that memory is throttled as it approaches the memory limit.
How do I use it?
Here are the prerequisites for enabling Memory QoS on your Linux node, some of these are related to Kubernetes support for cgroup v2.
- Kubernetes since v1.22
- runc since v1.0.0-rc93; containerd since 1.4; cri-o since 1.20
- Linux kernel minimum version: 4.15, recommended version: 5.2+
- Linux image with cgroupv2 enabled or enabling cgroupv2 unified_cgroup_hierarchy manually
OCI runtimes such as runc and crun already support cgroups v2 Unified, and Kubernetes CRI has also made the desired changes to support passing Unified. However, CRI Runtime support is required as well. Memory QoS in Alpha phase is designed to support containerd and cri-o. Related PR Feature: containerd-cri support LinuxContainerResources.Unified #5627 has been merged and will be released in containerd 1.6. CRI-O implement kube alpha features for 1.22 #5207 is still in WIP.
With those prerequisites met, you can enable the memory QoS feature gate (see Set kubelet parameters via a config file).
How can I learn more?
You can find more details as follows:
How do I get involved?
You can reach SIG Node by several means:
You can also contact me directly:
- GitHub / Slack: @xiaoxubeii
- Email: xiaoxubeii@gmail.com
Dockershim removal is coming. Are you ready?
Author: Sergey Kanzhelev, Google. With reviews from Davanum Srinivas, Elana Hashman, Noah Kantrowitz, Rey Lejano.
Poll closed
This poll closed on January 7, 2022.Last year we announced that Dockershim is being deprecated: Dockershim Deprecation FAQ. Our current plan is to remove dockershim from the Kubernetes codebase soon. We are looking for feedback from you whether you are ready for dockershim removal and to ensure that you are ready when the time comes.
Please fill out this survey: https://forms.gle/svCJmhvTv78jGdSx8
The dockershim component that enables Docker as a Kubernetes container runtime is being deprecated in favor of runtimes that directly use the Container Runtime Interface created for Kubernetes. Many Kubernetes users have migrated to other container runtimes without problems. However we see that dockershim is still very popular. You may see some public numbers in recent Container Report from DataDog. Some Kubernetes hosting vendors just recently enabled other runtimes support (especially for Windows nodes). And we know that many third party tools vendors are still not ready: migrating telemetry and security agents.
At this point, we believe that there is feature parity between Docker and the other runtimes. Many end-users have used our migration guide and are running production workload using these different runtimes. The plan of record today is that dockershim will be removed in version 1.24, slated for release around April of next year. For those developing or running alpha and beta versions, dockershim will be removed in December at the beginning of the 1.24 release development cycle.
There is only one month left to give us feedback. We want you to tell us how ready you are.
We are collecting opinions through this survey: https://forms.gle/svCJmhvTv78jGdSx8
To better understand preparedness for the dockershim removal, our survey is
asking the version of Kubernetes you are currently using, and an estimate of
when you think you will adopt Kubernetes 1.24. All the aggregated information
on dockershim removal readiness will be published.
Free form comments will be reviewed by SIG Node leadership. If you want to
discuss any details of migrating from dockershim, report bugs or adoption
blockers, you can use one of the SIG Node contact options any time:
https://github.com/kubernetes/community/tree/master/sig-node#contact
Kubernetes is a mature project. This deprecation is another step in the effort to get away from permanent beta features and providing more stability and compatibility guarantees. With the migration from dockershim you will get more flexibility and choice of container runtime features as well as less dependencies of your apps on specific underlying technology. Please take time to review the dockershim migration documentation and consult your Kubernetes hosting vendor (if you have one) what container runtime options are available for you. Read up container runtime documentation with instructions on how to use containerd and CRI-O to help prepare you when you're ready to upgrade to 1.24. CRI-O, containerd, and Docker with Mirantis cri-dockerd are not the only container runtime options, we encourage you to explore the CNCF landscape on container runtimes in case another suits you better.
Thank you!
Non-root Containers And Devices
Author: Mikko Ylinen (Intel)
The user/group ID related security settings in Pod's securityContext trigger a problem when users want to
deploy containers that use accelerator devices (via Kubernetes Device Plugins) on Linux. In this blog
post I talk about the problem and describe the work done so far to address it. It's not meant to be a long story about getting the k/k issue fixed.
Instead, this post aims to raise awareness of the issue and to highlight important device use-cases too. This is needed as Kubernetes works on new related features such as support for user namespaces.
Why non-root containers can't use devices and why it matters
One of the key security principles for running containers in Kubernetes is the
principle of least privilege. The Pod/container securityContext specifies the config
options to set, e.g., Linux capabilities, MAC policies, and user/group ID values to achieve this.
Furthermore, the cluster admins are supported with tools like PodSecurityPolicy (deprecated) or
Pod Security Admission (alpha) to enforce the desired security settings for pods that are being deployed in
the cluster. These settings could, for instance, require that containers must be runAsNonRoot or
that they are forbidden from running with root's group ID in runAsGroup or supplementalGroups.
In Kubernetes, the kubelet builds the list of Device resources to be made available to a container
(based on inputs from the Device Plugins) and the list is included in the CreateContainer CRI message
sent to the CRI container runtime. Each Device contains little information: host/container device
paths and the desired devices cgroups permissions.
The OCI Runtime Spec for Linux Container Configuration expects that in addition to the devices cgroup fields, more detailed information about the devices must be provided:
{
"type": "<string>",
"path": "<string>",
"major": <int64>,
"minor": <int64>,
"fileMode": <uint32>,
"uid": <uint32>,
"gid": <uint32>
},
The CRI container runtimes (containerd, CRI-O) are responsible for obtaining this information
from the host for each Device. By default, the runtimes copy the host device's user and group IDs:
uid(uint32, OPTIONAL) - id of device owner in the container namespace.gid(uint32, OPTIONAL) - id of device group in the container namespace.
Similarly, the runtimes prepare other mandatory config.json sections based on the CRI fields,
including the ones defined in securityContext: runAsUser/runAsGroup, which become part of the POSIX
platforms user structure via:
uid(int, REQUIRED) specifies the user ID in the container namespace.gid(int, REQUIRED) specifies the group ID in the container namespace.additionalGids(array of ints, OPTIONAL) specifies additional group IDs in the container namespace to be added to the process.
However, the resulting config.json triggers a problem when trying to run containers with
both devices added and with non-root uid/gid set via runAsUser/runAsGroup: the container user process
has no permission to use the device even when its group id (gid, copied from host) was permissive to
non-root groups. This is because the container user does not belong to that host group (e.g., via additionalGids).
Being able to run applications that use devices as non-root user is normal and expected to work so that the security principles can be met. Therefore, several alternatives were considered to get the gap filled with what the PodSec/CRI/OCI supports today.
What was done to solve the issue?
You might have noticed from the problem definition that it would at least be possible to workaround
the problem by manually adding the device gid(s) to supplementalGroups, or in
the case of just one device, set runAsGroup to the device's group id. However, this is problematic because the device gid(s) may have
different values depending on the nodes' distro/version in the cluster. For example, with GPUs the following commands for different distros and versions return different gids:
Fedora 33:
$ ls -l /dev/dri/
total 0
drwxr-xr-x. 2 root root 80 19.10. 10:21 by-path
crw-rw----+ 1 root video 226, 0 19.10. 10:42 card0
crw-rw-rw-. 1 root render 226, 128 19.10. 10:21 renderD128
$ grep -e video -e render /etc/group
video:x:39:
render:x:997:
Ubuntu 20.04:
$ ls -l /dev/dri/
total 0
drwxr-xr-x 2 root root 80 19.10. 17:36 by-path
crw-rw---- 1 root video 226, 0 19.10. 17:36 card0
crw-rw---- 1 root render 226, 128 19.10. 17:36 renderD128
$ grep -e video -e render /etc/group
video:x:44:
render:x:133:
Which number to choose in your securityContext? Also, what if the runAsGroup/runAsUser values cannot be hard-coded because
they are automatically assigned during pod admission time via external security policies?
Unlike volumes with fsGroup, the devices have no official notion of deviceGroup/deviceUser that the CRI runtimes (or kubelet)
would be able to use. We considered using container annotations set by the device plugins (e.g., io.kubernetes.cri.hostDeviceSupplementalGroup/) to get custom OCI config.json uid/gid values.
This would have required changes to all existing device plugins which was not ideal.
Instead, a solution that is seamless to end-users without getting the device plugin vendors involved was preferred. The selected approach was
to re-use runAsUser and runAsGroup values in config.json for devices:
{
"type": "c",
"path": "/dev/foo",
"major": 123,
"minor": 4,
"fileMode": 438,
"uid": <runAsUser>,
"gid": <runAsGroup>
},
With runc OCI runtime (in non-rootless mode), the device is created (mknod(2)) in
the container namespace and the ownership is changed to runAsUser/runAsGroup using chmod(2).
runAsUser/runAsGroup
are taken into account, and, e.g., the USER setting in the container is currently ignored.
While it is likely that the "faulty" deployments (i.e., non-root securityContext + devices) do not exist, to be absolutely sure no
deployments break, an opt-in config entry in both containerd and CRI-O to enable the new behavior was added. The following:
device_ownership_from_security_context (bool)
defaults to false and must be enabled to use the feature.
See non-root containers using devices after the fix
To demonstrate the new behavior, let's use a Data Plane Development Kit (DPDK) application using hardware accelerators, Kubernetes CPU manager, and HugePages as an example. The cluster runs containerd with:
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
device_ownership_from_security_context = true
or CRI-O with:
[crio.runtime]
device_ownership_from_security_context = true
and the Guaranteed QoS Class Pod that runs DPDK's crypto-perf test utility with this YAML:
...
metadata:
name: qat-dpdk
spec:
securityContext:
runAsUser: 1000
runAsGroup: 2000
fsGroup: 3000
containers:
- name: crypto-perf
image: intel/crypto-perf:devel
...
resources:
requests:
cpu: "3"
memory: "128Mi"
qat.intel.com/generic: '4'
hugepages-2Mi: "128Mi"
limits:
cpu: "3"
memory: "128Mi"
qat.intel.com/generic: '4'
hugepages-2Mi: "128Mi"
...
To verify the results, check the user and group ID that the container runs as:
$ kubectl exec -it qat-dpdk -c crypto-perf -- id
They are set to non-zero values as expected:
uid=1000 gid=2000 groups=2000,3000
Next, check the device node permissions (qat.intel.com/generic exposes /dev/vfio/ devices) are accessible to runAsUser/runAsGroup:
$ kubectl exec -it qat-dpdk -c crypto-perf -- ls -la /dev/vfio
total 0
drwxr-xr-x 2 root root 140 Sep 7 10:55 .
drwxr-xr-x 7 root root 380 Sep 7 10:55 ..
crw------- 1 1000 2000 241, 0 Sep 7 10:55 58
crw------- 1 1000 2000 241, 2 Sep 7 10:55 60
crw------- 1 1000 2000 241, 10 Sep 7 10:55 68
crw------- 1 1000 2000 241, 11 Sep 7 10:55 69
crw-rw-rw- 1 1000 2000 10, 196 Sep 7 10:55 vfio
Finally, check the non-root container is also allowed to create HugePages:
$ kubectl exec -it qat-dpdk -c crypto-perf -- ls -la /dev/hugepages/
fsGroup gives a runAsUser writable HugePages emptyDir mountpoint:
total 0
drwxrwsr-x 2 root 3000 0 Sep 7 10:55 .
drwxr-xr-x 7 root root 380 Sep 7 10:55 ..
Help us test it and provide feedback!
The functionality described here is expected to help with cluster security and the configurability of device permissions. To allow
non-root containers to use devices requires cluster admins to opt-in to the functionality by setting
device_ownership_from_security_context = true. To make it a default setting, please test it and provide your feedback (via SIG-Node meetings or issues)!
The flag is available in CRI-O v1.22 release and queued for containerd v1.6.
More work is needed to get it properly supported. It is known to work with runc but it also needs to be made to function
with other OCI runtimes too, where applicable. For instance, Kata Containers supports device passthrough and allows it to make devices
available to containers in VM sandboxes too.
Moreover, the additional challenge comes with support of user names and devices. This problem is still open and requires more brainstorming.
Finally, it needs to be understood whether runAsUser/runAsGroup are enough or if device specific settings similar to fsGroups are needed in PodSpec/CRI v2.
Thanks
My thanks goes to Mike Brown (IBM, containerd), Peter Hunt (Redhat, CRI-O), and Alexander Kanevskiy (Intel) for providing all the feedback and good conversations.
Announcing the 2021 Steering Committee Election Results
Author: Kaslin Fields
The 2021 Steering Committee Election is now complete. The Kubernetes Steering Committee consists of 7 seats, 4 of which were up for election in 2021. Incoming committee members serve a term of 2 years, and all members are elected by the Kubernetes Community.
This community body is significant since it oversees the governance of the entire Kubernetes project. With that great power comes great responsibility. You can learn more about the steering committee’s role in their charter.
Results
Congratulations to the elected committee members whose two year terms begin immediately (listed in alphabetical order by GitHub handle):
- Christoph Blecker (@cblecker), Red Hat
- Stephen Augustus (@justaugustus), Cisco
- Paris Pittman (@parispittman), Apple
- Tim Pepper (@tpepper), VMware
They join continuing members:
- Davanum Srinivas (@dims), VMware
- Jordan Liggitt (@liggitt), Google
- Bob Killen (@mrbobbytables), Google
Paris Pittman and Christoph Blecker are returning Steering Committee Members.
Big Thanks
Thank you and congratulations on a successful election to this round’s election officers:
- Alison Dowdney, (@alisondy)
- Noah Kantrowitz (@coderanger)
- Josh Berkus (@jberkus)
Special thanks to Arnaud Meukam (@ameukam), k8s-infra liaison, who enabled our voting software on community-owned infrastructure.
Thanks to the Emeritus Steering Committee Members. Your prior service is appreciated by the community:
- Derek Carr (@derekwaynecarr)
- Nikhita Raghunath (@nikhita)
And thank you to all the candidates who came forward to run for election.
Get Involved with the Steering Committee
This governing body, like all of Kubernetes, is open to all. You can follow along with Steering Committee backlog items and weigh in by filing an issue or creating a PR against their repo. They have an open meeting on the first Monday at 9:30am PT of every month and regularly attend Meet Our Contributors. They can also be contacted at their public mailing list steering@kubernetes.io.
You can see what the Steering Committee meetings are all about by watching past meetings on the YouTube Playlist.
This post was written by the Upstream Marketing Working Group. If you want to write stories about the Kubernetes community, learn more about us.
Use KPNG to Write Specialized kube-proxiers
Author: Lars Ekman (Ericsson)
The post will show you how to create a specialized service kube-proxy style network proxier using Kubernetes Proxy NG kpng without interfering with the existing kube-proxy. The kpng project aims at renewing the the default Kubernetes Service implementation, the "kube-proxy". An important feature of kpng is that it can be used as a library to create proxiers outside K8s. While this is useful for CNI-plugins that replaces the kube-proxy it also opens the possibility for anyone to create a proxier for a special purpose.
Define a service that uses a specialized proxier
apiVersion: v1
kind: Service
metadata:
name: kpng-example
labels:
service.kubernetes.io/service-proxy-name: kpng-example
spec:
clusterIP: None
ipFamilyPolicy: RequireDualStack
externalIPs:
- 10.0.0.55
- 1000::55
selector:
app: kpng-alpine
ports:
- port: 6000
If the service.kubernetes.io/service-proxy-name label is defined the
kube-proxy will ignore the service. A custom controller can watch
services with the label set to it's own name, "kpng-example" in
this example, and setup specialized load-balancing.
The service.kubernetes.io/service-proxy-name label is not
new,
but so far is has been quite hard to write a specialized proxier.
The common use for a specialized proxier is assumed to be handling
external traffic for some use-case not supported by K8s. In that
case ClusterIP is not needed, so we use a "headless" service in this
example.
Specialized proxier using kpng
A kpng based proxier
consists of the kpng controller handling all the K8s api related
functions, and a "backend" implementing the load-balancing. The
backend can be linked with the kpng controller binary or be a
separate program communicating with the controller using gRPC.
kpng kube --service-proxy-name=kpng-example to-api
This starts the kpng controller and tell it to watch only services
with the "kpng-example" service proxy name. The "to-api" parameter
will open a gRPC server for backends.
You can test this yourself outside your cluster. Please see the example below.
Now we start a backend that simply prints the updates from the controller.
$ kubectl apply -f kpng-example.yaml
$ kpng-json | jq # (this is the backend)
{
"Service": {
"Namespace": "default",
"Name": "kpng-example",
"Type": "ClusterIP",
"IPs": {
"ClusterIPs": {},
"ExternalIPs": {
"V4": [
"10.0.0.55"
],
"V6": [
"1000::55"
]
},
"Headless": true
},
"Ports": [
{
"Protocol": 1,
"Port": 6000,
"TargetPort": 6000
}
]
},
"Endpoints": [
{
"IPs": {
"V6": [
"1100::202"
]
},
"Local": true
},
{
"IPs": {
"V4": [
"11.0.2.2"
]
},
"Local": true
},
{
"IPs": {
"V4": [
"11.0.1.2"
]
}
},
{
"IPs": {
"V6": [
"1100::102"
]
}
}
]
}
A real backend would use some mechanism to load-balance traffic from the external IPs to the endpoints.
Writing a backend
The kpng-json backend looks like this:
package main
import (
"os"
"encoding/json"
"sigs.k8s.io/kpng/client"
)
func main() {
client.Run(jsonPrint)
}
func jsonPrint(items []*client.ServiceEndpoints) {
enc := json.NewEncoder(os.Stdout)
for _, item := range items {
_ = enc.Encode(item)
}
}
(yes, that is the entire program)
A real backend would of course be much more complex, but this
illustrates how kpng let you focus on load-balancing.
You can have several backends connected to a kpng controller, so
during development or debug it can be useful to let something like the
kpng-json backend run in parallel with your real backend.
Example
The complete example can be found here.
As an example we implement an "all-ip" backend. It direct all traffic for the externalIPs to a local endpoint, regardless of ports and upper layer protocols. There is a KEP for this function and this example is a much simplified version.
To direct all traffic from an external address to a local POD only one iptables rule is needed, for instance;
ip6tables -t nat -A PREROUTING -d 1000::55/128 -j DNAT --to-destination 1100::202
As you can see the addresses are in the call to the backend and all it have to do is:
- Extract the addresses with
Local: true - Setup iptables rules for the
ExternalIPs
A script doing that may look like:
xip=$(cat /tmp/out | jq -r .Service.IPs.ExternalIPs.V6[0])
podip=$(cat /tmp/out | jq -r '.Endpoints[]|select(.Local == true)|select(.IPs.V6 != null)|.IPs.V6[0]')
ip6tables -t nat -A PREROUTING -d $xip/128 -j DNAT --to-destination $podip
Assuming the JSON output above is stored in /tmp/out (jq is an awesome program!).
As this is an example we make it really simple for ourselves by using
a minor variation of the kpng-json backend above. Instead of just
printing, a program is called and the JSON output is passed as stdin
to that program. The backend can be tested stand-alone:
CALLOUT=jq kpng-callout
Where jq can be replaced with your own program or script. A script
may look like the example above. For more info and the complete
example please see https://github.com/kubernetes-sigs/kpng/tree/master/examples/pipe-exec.
Summary
While kpng is in early
stage of development this post wants to show how you may build your
own specialized K8s proxiers in the future. The only thing your
applications need to do is to add the
service.kubernetes.io/service-proxy-name label in the Service
manifest.
It is a tedious process to get new features into the kube-proxy and
it is not unlikely that they will be rejected, so to write a
specialized proxier may be the only option.
Introducing ClusterClass and Managed Topologies in Cluster API
Author: Fabrizio Pandini (VMware)
The Cluster API community is happy to announce the implementation of ClusterClass and Managed Topologies, a new feature that will greatly simplify how you can provision, upgrade, and operate multiple Kubernetes clusters in a declarative way.
A little bit of context…
Before getting into the details, let's take a step back and look at the history of Cluster API.
The Cluster API project started three years ago, and the first releases focused on extensibility and implementing a declarative API that allows a seamless experience across infrastructure providers. This was a success with many cloud providers: AWS, Azure, Digital Ocean, GCP, Metal3, vSphere and still counting.
With extensibility addressed, the focus shifted to features, like automatic control plane and etcd management, health-based machine remediation, machine rollout strategies and more.
Fast forwarding to 2021, with lots of companies using Cluster API to manage fleets of Kubernetes clusters running workloads in production, the community focused its effort on stabilization of both code, APIs, documentation, and on extensive test signals which inform Kubernetes releases.
With solid foundations in place, and a vibrant and welcoming community that still continues to grow, it was time to plan another iteration on our UX for both new and advanced users.
Enter ClusterClass and Managed Topologies, tada!
ClusterClass
As the name suggests, ClusterClass and managed topologies are built in two parts.
The idea behind ClusterClass is simple: define the shape of your cluster once, and reuse it many times, abstracting the complexities and the internals of a Kubernetes cluster away.

ClusterClass, at its heart, is a collection of Cluster and Machine templates. You can use it as a “stamp” that can be leveraged to create many clusters of a similar shape.
---
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: my-amazing-cluster-class
spec:
controlPlane:
ref:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlaneTemplate
name: high-availability-control-plane
machineInfrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
name: control-plane-machine
workers:
machineDeployments:
- class: type1-workers
template:
bootstrap:
ref:
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
name: type1-bootstrap
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
name: type1-machine
- class: type2-workers
template:
bootstrap:
ref:
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
name: type2-bootstrap
infrastructure:
ref:
kind: DockerMachineTemplate
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
name: type2-machine
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerClusterTemplate
name: cluster-infrastructure
The possibilities are endless; you can get a default ClusterClass from the community, “off-the-shelf” classes from your vendor of choice, “certified” classes from the platform admin in your company, or even create custom ones for advanced scenarios.
Managed Topologies
Managed Topologies let you put the power of ClusterClass into action.
Given a ClusterClass, you can create many Clusters of a similar shape by providing a single resource, the Cluster.

Here is an example:
---
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: my-amazing-cluster
namespace: bar
spec:
topology: # define a managed topology
class: my-amazing-cluster-class # use the ClusterClass mentioned earlier
version: v1.21.2
controlPlane:
replicas: 3
workers:
machineDeployments:
- class: type1-workers
name: big-pool-of-machines
replicas: 5
- class: type2-workers
name: small-pool-of-machines
replicas: 1
But there is more than simplified cluster creation. Now the Cluster acts as a single control point for your entire topology.
All the power of Cluster API, extensibility, lifecycle automation, stability, all the features required for managing an enterprise grade Kubernetes cluster on the infrastructure provider of your choice are now at your fingertips: you can create your Cluster, add new machines, upgrade to the next Kubernetes version, and all from a single place.
It is just as simple as it looks!
What’s next
While the amazing Cluster API community is working hard to deliver the first version of ClusterClass and managed topologies later this year, we are already looking forward to what comes next for the project and its ecosystem.
There are a lot of great ideas and opportunities ahead!
We want to make managed topologies even more powerful and flexible, allowing users to dynamically change bits of a ClusterClass according to the specific needs of a Cluster; this will ensure the same simple and intuitive UX for solving complex problems like e.g. selecting machine image for a specific Kubernetes version and for a specific region of your infrastructure provider, or injecting proxy configurations in the entire Cluster, and so on.
Stay tuned for what comes next, and if you have any questions, comments or suggestions:
- Chat with us on the Kubernetes Slack:#cluster-api
- Join the SIG Cluster Lifecycle Google Group to receive calendar invites and gain access to documents
- Join our Zoom meeting, every Wednesday at 10:00 Pacific Time
- Check out the ClusterClass quick-start for the Docker provider (CAPD) in the Cluster API book.
- UPDATE: Check out the ClusterClass experimental feature documentation in the Cluster API book.
A Closer Look at NSA/CISA Kubernetes Hardening Guidance
Authors: Jim Angel (Google), Pushkar Joglekar (VMware), and Savitha Raghunathan (Red Hat)
Disclaimer
The open source tools listed in this article are to serve as examples only and are in no way a direct recommendation from the Kubernetes community or authors.Background
USA's National Security Agency (NSA) and the Cybersecurity and Infrastructure Security Agency (CISA) released, "Kubernetes Hardening Guidance" on August 3rd, 2021. The guidance details threats to Kubernetes environments and provides secure configuration guidance to minimize risk.
The following sections of this blog correlate to the sections in the NSA/CISA guidance. Any missing sections are skipped because of limited opportunities to add anything new to the existing content.
Note: This blog post is not a substitute for reading the guide. Reading the published guidance is recommended before proceeding as the following content is complementary.
Introduction and Threat Model
Note that the threats identified as important by the NSA/CISA, or the intended audience of this guidance, may be different from the threats that other enterprise users of Kubernetes consider important. This section is still useful for organizations that care about data, resource theft and service unavailability.
The guidance highlights the following three sources of compromises:
- Supply chain risks
- Malicious threat actors
- Insider threats (administrators, users, or cloud service providers)
The threat model tries to take a step back and review threats that not only exist within the boundary of a Kubernetes cluster but also include the underlying infrastructure and surrounding workloads that Kubernetes does not manage.
For example, when a workload outside the cluster shares the same physical network, it has access to the kubelet and to control plane components: etcd, controller manager, scheduler and API server. Therefore, the guidance recommends having network level isolation separating Kubernetes clusters from other workloads that do not need connectivity to Kubernetes control plane nodes. Specifically, scheduler, controller-manager, etcd only need to be accessible to the API server. Any interactions with Kubernetes from outside the cluster can happen by providing access to API server port.
List of ports and protocols for each of these components are defined in Ports and Protocols within the Kubernetes documentation.
Special note: kube-scheduler and kube-controller-manager uses different ports than the ones mentioned in the guidance
The Threat modelling section from the CNCF Cloud Native Security Whitepaper + Map provides another perspective on approaching threat modelling Kubernetes, from a cloud native lens.
Kubernetes Pod security
Kubernetes by default does not guarantee strict workload isolation between pods running in the same node in a cluster. However, the guidance provides several techniques to enhance existing isolation and reduce the attack surface in case of a compromise.
"Non-root" containers and "rootless" container engines
Several best practices related to basic security principle of least privilege i.e. provide only the permissions are needed; no more, no less, are worth a second look.
The guide recommends setting non-root user at build time instead of relying on
setting runAsUser at runtime in your Pod spec. This is a good practice and provides
some level of defense in depth. For example, if the container image is built with user 10001
and the Pod spec misses adding the runAsuser field in its Deployment object. In this
case there are certain edge cases that are worth exploring for awareness:
- Pods can fail to start, if the user defined at build time is different from the one defined in pod spec and some files are as a result inaccessible.
- Pods can end up sharing User IDs unintentionally. This can be problematic even if the User IDs are non-zero in a situation where a container escape to host file system is possible. Once the attacker has access to the host file system, they get access to all the file resources that are owned by other unrelated pods that share the same UID.
- Pods can end up sharing User IDs, with other node level processes not managed by Kubernetes e.g. node level daemons for auditing, vulnerability scanning, telemetry. The threat is similar to the one above where host file system access can give attacker full access to these node level daemons without needing to be root on the node.
However, none of these cases will have as severe an impact as a container running as root being able to escape as a root user on the host, which can provide an attacker with complete control of the worker node, further allowing lateral movement to other worker or control plane nodes.
Kubernetes 1.22 introduced an alpha feature that specifically reduces the impact of such a control plane component running as root user to a non-root user through user namespaces.
That (alpha stage) support for user namespaces / rootless mode is available with the following container runtimes:
Some distributions support running in rootless mode, like the following:
Immutable container filesystems
The NSA/CISA Kubernetes Hardening Guidance highlights an often overlooked feature readOnlyRootFileSystem, with a
working example in Appendix B. This example limits execution and tampering of
containers at runtime. Any read/write activity can then be limited to few
directories by using tmpfs volume mounts.
However, some applications that modify the container filesystem at runtime, like exploding a WAR or JAR file at container startup, could face issues when enabling this feature. To avoid this issue, consider making minimal changes to the filesystem at runtime when possible.
Building secure container images
Kubernetes Hardening Guidance also recommends running a scanner at deploy time as an admission controller, to prevent vulnerable or misconfigured pods from running in the cluster. Theoretically, this sounds like a good approach but there are several caveats to consider before this can be implemented in practice:
- Depending on network bandwidth, available resources and scanner of choice, scanning for vulnerabilities for an image can take an indeterminate amount of time. This could lead to slower or unpredictable pod start up times, which could result in spikes of unavailability when apps are serving peak load.
- If the policy that allows or denies pod startup is made using incorrect or
incomplete data it could result in several false positive or false negative
outcomes like the following:
- inside a container image, the
opensslpackage is detected as vulnerable. However, the application is written in Golang and uses the Gocryptopackage for TLS. Therefore, this vulnerability is not in the code execution path and as such has minimal impact if it remains unfixed. - A vulnerability is detected in the
opensslpackage for a Debian base image. However, the upstream Debian community considers this as a Minor impact vulnerability and as a result does not release a patch fix for this vulnerability. The owner of this image is now stuck with a vulnerability that cannot be fixed and a cluster that does not allow the image to run because of predefined policy that does not take into account whether the fix for a vulnerability is available or not - A Golang app is built on top of a distroless image, but it is compiled with a Golang version that uses a vulnerable standard library. The scanner has no visibility into golang version but only on OS level packages. So it allows the pod to run in the cluster in spite of the image containing an app binary built on vulnerable golang.
- inside a container image, the
To be clear, relying on vulnerability scanners is absolutely a good idea but policy definitions should be flexible enough to allow:
- Creation of exception lists for images or vulnerabilities through labelling
- Overriding the severity with a risk score based on impact of a vulnerability
- Applying the same policies at build time to catch vulnerable images with fixable vulnerabilities before they can be deployed into Kubernetes clusters
Special considerations like offline vulnerability database fetch, may also be needed, if the clusters run in an air-gapped environment and the scanners require internet access to update the vulnerability database.
Pod Security Policies
Since Kubernetes v1.21, the PodSecurityPolicy API and related features are deprecated, but some of the guidance in this section will still apply for the next few years, until cluster operators upgrade their clusters to newer Kubernetes versions.
The Kubernetes project is working on a replacement for PodSecurityPolicy. Kubernetes v1.22 includes an alpha feature called Pod Security Admission that is intended to allow enforcing a minimum level of isolation between pods.
The built-in isolation levels for Pod Security Admission are derived from Pod Security Standards, which is a superset of all the components mentioned in Table I page 10 of the guidance.
Information about migrating from PodSecurityPolicy to the Pod Security Admission feature is available in Migrate from PodSecurityPolicy to the Built-In PodSecurity Admission Controller.
One important behavior mentioned in the guidance that remains the same between Pod Security Policy and its replacement is that enforcing either of them does not affect pods that are already running. With both PodSecurityPolicy and Pod Security Admission, the enforcement happens during the pod creation stage.
Hardening container engines
Some container workloads are less trusted than others but may need to run in the same cluster. In those cases, running them on dedicated nodes that include hardened container runtimes that provide stricter pod isolation boundaries can act as a useful security control.
Kubernetes supports an API called RuntimeClass that is stable / GA (and, therefore, enabled by default) stage as of Kubernetes v1.20. RuntimeClass allows you to ensure that Pods requiring strong isolation are scheduled onto nodes that can offer it.
Some third-party projects that you can use in conjunction with RuntimeClass are:
As discussed here and in the guidance, many features and tooling exist in and around Kubernetes that can enhance the isolation boundaries between pods. Based on relevant threats and risk posture, you should pick and choose between them, instead of trying to apply all the recommendations. Having said that, cluster level isolation i.e. running workloads in dedicated clusters, remains the strictest workload isolation mechanism, in spite of improvements mentioned earlier here and in the guide.
Network Separation and Hardening
Kubernetes Networking can be tricky and this section focuses on how to secure and harden the relevant configurations. The guide identifies the following as key takeaways:
- Using NetworkPolicies to create isolation between resources,
- Securing the control plane
- Encrypting traffic and sensitive data
Network Policies
Network policies can be created with the help of network plugins. In order to make the creation and visualization easier for users, Cilium supports a web GUI tool. That web GUI lets you create Kubernetes NetworkPolicies (a generic API that nevertheless requires a compatible CNI plugin), and / or Cilium network policies (CiliumClusterwideNetworkPolicy and CiliumNetworkPolicy, which only work in clusters that use the Cilium CNI plugin). You can use these APIs to restrict network traffic between pods, and therefore minimize the attack vector.
Another scenario that is worth exploring is the usage of external IPs. Some services, when misconfigured, can create random external IPs. An attacker can take advantage of this misconfiguration and easily intercept traffic. This vulnerability has been reported in CVE-2020-8554. Using externalip-webhook can mitigate this vulnerability by preventing the services from using random external IPs. externalip-webhook only allows creation of services that don't require external IPs or whose external IPs are within the range specified by the administrator.
CVE-2020-8554 - Kubernetes API server in all versions allow an attacker who is able to create a ClusterIP service and set the
spec.externalIPsfield, to intercept traffic to that IP address. Additionally, an attacker who is able to patch thestatus(which is considered a privileged operation and should not typically be granted to users) of a LoadBalancer service can set thestatus.loadBalancer.ingress.ipto similar effect.
Resource Policies
In addition to configuring ResourceQuotas and limits, consider restricting how many process IDs (PIDs) a given Pod can use, and also to reserve some PIDs for node-level use to avoid resource exhaustion. More details to apply these limits can be found in Process ID Limits And Reservations.
Control Plane Hardening
In the next section, the guide covers control plane hardening. It is worth noting that from Kubernetes 1.20, insecure port from API server, has been removed.
Etcd
As a general rule, the etcd server should be configured to only trust certificates assigned to the API server. It limits the attack surface and prevents a malicious attacker from gaining access to the cluster. It might be beneficial to use a separate CA for etcd, as it by default trusts all the certificates issued by the root CA.
Kubeconfig Files
In addition to specifying the token and certificates directly, .kubeconfig
supports dynamic retrieval of temporary tokens using auth provider plugins.
Beware of the possibility of malicious
shell code execution in a
kubeconfig file. Once attackers gain access to the cluster, they can steal ssh
keys/secrets or more.
Secrets
Kubernetes Secrets is the native way of managing secrets as a Kubernetes API object. However, in some scenarios such as a desire to have a single source of truth for all app secrets, irrespective of whether they run on Kubernetes or not, secrets can be managed loosely coupled with Kubernetes and consumed by pods through side-cars or init-containers with minimal usage of Kubernetes Secrets API.
External secrets providers and csi-secrets-store are some of these alternatives to Kubernetes Secrets
Log Auditing
The NSA/CISA guidance stresses monitoring and alerting based on logs. The key points include logging at the host level, application level, and on the cloud. When running Kubernetes in production, it's important to understand who's responsible, and who's accountable, for each layer of logging.
Kubernetes API auditing
One area that deserves more focus is what exactly should alert or be logged. The document outlines a sample policy in Appendix L: Audit Policy that logs all RequestResponse's including metadata and request / response bodies. While helpful for a demo, it may not be practical for production.
Each organization needs to evaluate their
own threat model and build an audit policy that complements or helps troubleshooting incident response. Think
about how someone would attack your organization and what audit trail could identify it. Review more advanced options for tuning audit logs in the official audit logging documentation.
It's crucial to tune your audit logs to only include events that meet your threat model. A minimal audit policy that logs everything at metadata level can also be a good starting point.
Audit logging configurations can also be tested with kind following these instructions.
Streaming logs and auditing
Logging is important for threat and anomaly detection. As the document outlines, it's a best practice to scan and alert on logs as close to real time as possible and to protect logs from tampering if a compromise occurs. It's important to reflect on the various levels of logging and identify the critical areas such as API endpoints.
Kubernetes API audit logging can stream to a webhook and there's an example in Appendix N: Webhook configuration. Using a webhook could be a method that stores logs off cluster and/or centralizes all audit logs. Once logs are centrally managed, look to enable alerting based on critical events. Also ensure you understand what the baseline is for normal activities.
Alert identification
While the guide stressed the importance of notifications, there is not a blanket event list to alert from. The alerting requirements vary based on your own requirements and threat model. Examples include the following events:
- Changes to the
securityContextof a Pod - Updates to admission controller configs
- Accessing certain files / URLs
Additional logging resources
- Seccomp Security Profiles and You: A Practical Guide - Duffie Cooley
- TGI Kubernetes 119: Gatekeeper and OPA
- Abusing The Lack of Kubernetes Auditing Policies
- Enable seccomp for all workloads with a new v1.22 alpha feature
- This Week in Cloud Native: Auditing / Pod Security
Upgrading and Application Security practices
Kubernetes releases three times per year, so upgrade-related toil is a common problem for people running production clusters. In addition to this, operators must regularly upgrade the underlying node's operating system and running applications. This is a best practice to ensure continued support and to reduce the likelihood of bugs or vulnerabilities.
Kubernetes supports the three most recent stable releases. While each Kubernetes release goes through a large number of tests before being published, some teams aren't comfortable running the latest stable release until some time has passed. No matter what version you're running, ensure that patch upgrades happen frequently or automatically. More information can be found in the version skew policy pages.
When thinking about how you'll manage node OS upgrades, consider ephemeral nodes. Having the ability to destroy and add nodes allows your team to respond quicker to node issues. In addition, having deployments that tolerate node instability (and a culture that encourages frequent deployments) allows for easier cluster upgrades.
Additionally, it's worth reiterating from the guidance that periodic vulnerability scans and penetration tests can be performed on the various system components to proactively look for insecure configurations and vulnerabilities.
Finding release & security information
To find the most recent Kubernetes supported versions, refer to https://k8s.io/releases, which includes minor versions. It's good to stay up to date with your minor version patches.
If you're running a managed Kubernetes offering, look for their release documentation and find their various security channels.
Subscribe to the Kubernetes Announce mailing list. The Kubernetes Announce mailing list is searchable for terms such as "Security Advisories". You can set up alerts and email notifications as long as you know what key words to alert on.
Conclusion
In summary, it is fantastic to see security practitioners sharing this level of detailed guidance in public. This guidance further highlights Kubernetes going mainstream and how securing Kubernetes clusters and the application containers running on Kubernetes continues to need attention and focus of practitioners. Only a few weeks after the guidance was published, an open source tool kubescape to validate cluster against this guidance became available.
This tool can be a great starting point to check the current state of your clusters, after which you can use the information in this blog post and in the guidance to assess where improvements can be made.
Finally, it is worth reiterating that not all controls in this guidance will make sense for all practitioners. The best way to know which controls matter is to rely on the threat model of your own Kubernetes environment.
A special shout out and thanks to Rory McCune (@raesene) for his inputs to this blog post
How to Handle Data Duplication in Data-Heavy Kubernetes Environments
Authors: Augustinas Stirbis (CAST AI)
Why Duplicate Data?
It’s convenient to create a copy of your application with a copy of its state for each team. For example, you might want a separate database copy to test some significant schema changes or develop other disruptive operations like bulk insert/delete/update...
Duplicating data takes a lot of time. That’s because you need first to download all the data from a source block storage provider to compute and then send it back to a storage provider again. There’s a lot of network traffic and CPU/RAM used in this process. Hardware acceleration by offloading certain expensive operations to dedicated hardware is always a huge performance boost. It reduces the time required to complete an operation by orders of magnitude.
Volume Snapshots to the rescue
Kubernetes introduced VolumeSnapshots as alpha in 1.12, beta in 1.17, and the Generally Available version in 1.20. VolumeSnapshots use specialized APIs from storage providers to duplicate volume of data.
Since data is already in the same storage device (array of devices), duplicating data is usually a metadata operation for storage providers with local snapshots (majority of on-premise storage providers). All you need to do is point a new disk to an immutable snapshot and only save deltas (or let it do a full-disk copy). As an operation that is inside the storage back-end, it’s much quicker and usually doesn’t involve sending traffic over the network. Public Clouds storage providers under the hood work a bit differently. They save snapshots to Object Storage and then copy back from Object storage to Block storage when "duplicating" disk. Technically there is a lot of Compute and network resources spent on Cloud providers side, but from Kubernetes user perspective VolumeSnapshots work the same way whether is it local or remote snapshot storage provider and no Compute and Network resources are involved in this operation.
Sounds like we have our solution, right?
Actually, VolumeSnapshots are namespaced, and Kubernetes protects namespaced data from being shared between tenants (Namespaces). This Kubernetes limitation is a conscious design decision so that a Pod running in a different namespace can’t mount another application’s PersistentVolumeClaim (PVC).
One way around it would be to create multiple volumes with duplicate data in one namespace. However, you could easily reference the wrong copy.
So the idea is to separate teams/initiatives by namespaces to avoid that and generally limit access to the production namespace.
Solution? Creating a Golden Snapshot externally
Another way around this design limitation is to create Snapshot externally (not through Kubernetes). This is also called pre-provisioning a snapshot manually. Next, I will import it as a multi-tenant golden snapshot that can be used for many namespaces. Below illustration will be for AWS EBS (Elastic Block Storage) and GCE PD (Persistent Disk) services.
High-level plan for preparing the Golden Snapshot
- Identify Disk (EBS/Persistent Disk) that you want to clone with data in the cloud provider
- Make a Disk Snapshot (in cloud provider console)
- Get Disk Snapshot ID
High-level plan for cloning data for each team
- Create Namespace “sandbox01”
- Import Disk Snapshot (ID) as VolumeSnapshotContent to Kubernetes
- Create VolumeSnapshot in the Namespace "sandbox01" mapped to VolumeSnapshotContent
- Create the PersistentVolumeClaim from VolumeSnapshot
- Install Deployment or StatefulSet with PVC
Step 1: Identify Disk
First, you need to identify your golden source. In my case, it’s a PostgreSQL database on PersistentVolumeClaim “postgres-pv-claim” in the “production” namespace.
kubectl -n <namespace> get pvc <pvc-name> -o jsonpath='{.spec.volumeName}'
The output will look similar to:
pvc-3096b3ba-38b6-4fd1-a42f-ec99176ed0d90
Step 2: Prepare your golden source
You need to do this once or every time you want to refresh your golden data.
Make a Disk Snapshot
Go to AWS EC2 or GCP Compute Engine console and search for an EBS volume
(on AWS) or Persistent Disk (on GCP), that has a label matching the last output.
In this case I saw: pvc-3096b3ba-38b6-4fd1-a42f-ec99176ed0d9.
Click on Create snapshot and give it a name. You can do it in Console manually,
in AWS CloudShell / Google Cloud Shell, or in the terminal. To create a snapshot in the
terminal you must have the AWS CLI tool (aws) or Google's CLI (gcloud)
installed and configured.
Here’s the command to create snapshot on GCP:
gcloud compute disks snapshot <cloud-disk-id> --project=<gcp-project-id> --snapshot-names=<set-new-snapshot-name> --zone=<availability-zone> --storage-location=<region>

GCP snapshot creation
GCP identifies the disk by its PVC name, so it’s direct mapping. In AWS, you need to find volume by the CSIVolumeName AWS tag with PVC name value first that will be used for snapshot creation.
Identify disk ID on AWS
Mark done Volume (volume-id) vol-00c7ecd873c6fb3ec and ether create EBS snapshot in AWS Console, or use aws cli.
aws ec2 create-snapshot --volume-id '<volume-id>' --description '<set-new-snapshot-name>' --tag-specifications 'ResourceType=snapshot'
Step 3: Get your Disk Snapshot ID
In AWS, the command above will output something similar to:
"SnapshotId": "snap-09ed24a70bc19bbe4"
If you’re using the GCP cloud, you can get the snapshot ID from the gcloud command by querying for the snapshot’s given name:
gcloud compute snapshots --project=<gcp-project-id> describe <new-snapshot-name> | grep id:
You should get similar output to:
id: 6645363163809389170
Step 4: Create a development environment for each team
Now I have my Golden Snapshot, which is immutable data. Each team will get a copy of this data, and team members can modify it as they see fit, given that a new EBS/persistent disk will be created for each team.
Below I will define a manifest for each namespace. To save time, you can replace
the namespace name (such as changing “sandbox01” → “sandbox42”) using tools
such as sed or yq, with Kubernetes-aware templating tools like
Kustomize,
or using variable substitution in a CI/CD pipeline.
Here's an example manifest:
---
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: postgresql-orders-db-sandbox01
namespace: sandbox01
spec:
deletionPolicy: Retain
driver: pd.csi.storage.gke.io
source:
snapshotHandle: 'gcp/projects/staging-eu-castai-vt5hy2/global/snapshots/6645363163809389170'
volumeSnapshotRef:
kind: VolumeSnapshot
name: postgresql-orders-db-snap
namespace: sandbox01
---
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: postgresql-orders-db-snap
namespace: sandbox01
spec:
source:
volumeSnapshotContentName: postgresql-orders-db-sandbox01
In Kubernetes, VolumeSnapshotContent (VSC) objects are not namespaced.
However, I need a separate VSC for each different namespace to use, so the
metadata.name of each VSC must also be different. To make that straightfoward,
I used the target namespace as part of the name.
Now it’s time to replace the driver field with the CSI (Container Storage Interface) driver installed in your K8s cluster. Major cloud providers have CSI driver for block storage that support VolumeSnapshots but quite often CSI drivers are not installed by default, consult with your Kubernetes provider.
That manifest above defines a VSC that works on GCP. On AWS, driver and SnashotHandle values might look like:
driver: ebs.csi.aws.com
source:
snapshotHandle: "snap-07ff83d328c981c98"
At this point, I need to use the Retain policy, so that the CSI driver doesn’t try to delete my manually created EBS disk snapshot.
For GCP, you will have to build this string by hand - add a full project ID and snapshot ID. For AWS, it’s just a plain snapshot ID.
VSC also requires specifying which VolumeSnapshot (VS) will use it, so VSC and VS are referencing each other.
Now I can create PersistentVolumeClaim from VS above. It’s important to set this first:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pv-claim
namespace: sandbox01
spec:
dataSource:
kind: VolumeSnapshot
name: postgresql-orders-db-snap
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 21Gi
If default StorageClass has WaitForFirstConsumer policy, then the actual Cloud Disk will be created from the Golden Snapshot only when some Pod bounds that PVC.
Now I assign that PVC to my Pod (in my case, it’s Postgresql) as I would with any other PVC.
kubectl -n <namespace> get volumesnapshotContent,volumesnapshot,pvc,pod
Both VS and VSC should be READYTOUSE true, PVC bound, and the Pod (from Deployment or StatefulSet) running.
To keep on using data from my Golden Snapshot, I just need to repeat this for the next namespace and voilà! No need to waste time and compute resources on the duplication process.
Spotlight on SIG Node
Author: Dewan Ahmed, Red Hat
Introduction
In Kubernetes, a Node is a representation of a single machine in your cluster. SIG Node owns that very important Node component and supports various subprojects such as Kubelet, Container Runtime Interface (CRI) and more to support how the pods and host resources interact. In this blog, we have summarized our conversation with Elana Hashman (EH) & Sergey Kanzhelev (SK), who walk us through the various aspects of being a part of the SIG and share some insights about how others can get involved.
A summary of our conversation
Could you tell us a little about what SIG Node does?
SK: SIG Node is a vertical SIG responsible for the components that support the controlled interactions between the pods and host resources. We manage the lifecycle of pods that are scheduled to a node. This SIG's focus is to enable a broad set of workload types, including workloads with hardware specific or performance sensitive requirements. All while maintaining isolation boundaries between pods on a node, as well as the pod and the host. This SIG maintains quite a few components and has many external dependencies (like container runtimes or operating system features), which makes the complexity we deal with huge. We tame the complexity and aim to continuously improve node reliability.
"SIG Node is a vertical SIG" could you explain a bit more?
EH: There are two kinds of SIGs: horizontal and vertical. Horizontal SIGs are concerned with a particular function of every component in Kubernetes: for example, SIG Security considers security aspects of every component in Kubernetes, or SIG Instrumentation looks at the logs, metrics, traces and events of every component in Kubernetes. Such SIGs don't tend to own a lot of code.
Vertical SIGs, on the other hand, own a single component, and are responsible for approving and merging patches to that code base. SIG Node owns the "Node" vertical, pertaining to the kubelet and its lifecycle. This includes the code for the kubelet itself, as well as the node controller, the container runtime interface, and related subprojects like the node problem detector.
How did the CI subproject start? Is this specific to SIG Node and how does it help the SIG?
SK: The subproject started as a follow up after one of the releases was blocked by numerous test failures of critical tests. These tests haven’t started falling all at once, rather continuous lack of attention led to slow degradation of tests quality. SIG Node was always prioritizing quality and reliability, and forming of the subproject was a way to highlight this priority.
As the 3rd largest SIG in terms of number of issues and PRs, how does your SIG juggle so much work?
EH: It helps to be organized. When I increased my contributions to the SIG in January of 2021, I found myself overwhelmed by the volume of pull requests and issues and wasn't sure where to start. We were already tracking test-related issues and pull requests on the CI subproject board, but that was missing a lot of our bugfixes and feature work. So I began putting together a triage board for the rest of our pull requests, which allowed me to sort each one by status and what actions to take, and documented its use for other contributors. We closed or merged over 500 issues and pull requests tracked by our two boards in each of the past two releases. The Kubernetes devstats showed that we have significantly increased our velocity as a result.
In June, we ran our first bug scrub event to work through the backlog of issues filed against SIG Node, ensuring they were properly categorized. We closed over 130 issues over the course of this 48 hour global event, but as of writing we still have 333 open issues.
Why should new and existing contributors consider joining SIG Node?
SK: Being a SIG Node contributor gives you skills and recognition that are rewarding and useful. Understanding under the hood of a kubelet helps architecting better apps, tune and optimize those apps, and gives leg up in issues troubleshooting. If you are a new contributor, SIG Node gives you the foundational knowledge that is key to understanding why other Kubernetes components are designed the way they are. Existing contributors may benefit as many features will require SIG Node changes one way or another. So being a SIG Node contributor helps building features in other SIGs faster.
SIG Node maintains numerous components, many of which have dependency on external projects or OS features. This makes the onboarding process quite lengthy and demanding. But if you are up for a challenge, there is always a place for you, and a group of people to support.
What do you do to help new contributors get started?
EH: Getting started in SIG Node can be intimidating, since there is so much work to be done, our SIG meetings are very large, and it can be hard to find a place to start.
I always encourage new contributors to work on things that they have some investment in already. In SIG Node, that might mean volunteering to help fix a bug that you have personally been affected by, or helping to triage bugs you care about by priority.
To come up to speed on any open source code base, there are two strategies you can take: start by exploring a particular issue deeply, and follow that to expand the edges of your knowledge as needed, or briefly review as many issues and change requests as you possibly can to get a higher level picture of how the component works. Ultimately, you will need to do both if you want to become a Node reviewer or approver.
Davanum Srinivas and I each ran a cohort of group mentoring to help teach new contributors the skills to become Node reviewers, and if there's interest we can work to find a mentor to run another session. I also encourage new contributors to attend our Node CI Subproject meeting: it's a smaller audience and we don't record the triage sessions, so it can be a less intimidating way to get started with the SIG.
Are there any particular skills you’d like to recruit for? What skills are contributors to SIG Usability likely to learn?
SK: SIG Node works on many workstreams in very different areas. All of these areas are on system level. For the typical code contributions you need to have a passion for building and utilizing low level APIs and writing performant and reliable components. Being a contributor you will learn how to debug and troubleshoot, profile, and monitor these components, as well as user workload that is run by these components. Often, with the limited to no access to Nodes, as they are running production workloads.
The other way of contribution is to help document SIG node features. This type of contribution requires a deep understanding of features, and ability to explain them in simple terms.
Finally, we are always looking for feedback on how best to run your workload. Come and explain specifics of it, and what features in SIG Node components may help to run it better.
What are you getting positive feedback on, and what’s coming up next for SIG Node?
EH: Over the past year SIG Node has adopted some new processes to help manage our feature development and Kubernetes enhancement proposals, and other SIGs have looked to us for inspiration in managing large workloads. I hope that this is an area we can continue to provide leadership in and further iterate on.
We have a great balance of new features and deprecations in flight right now. Deprecations of unused or difficult to maintain features help us keep technical debt and maintenance load under control, and examples include the dockershim and DynamicKubeletConfiguration deprecations. New features will unlock additional functionality in end users' clusters, and include exciting features like support for cgroups v2, swap memory, graceful node shutdowns, and device management policies.
Any closing thoughts/resources you’d like to share?
SK/EH: It takes time and effort to get to any open source community. SIG Node may overwhelm you at first with the number of participants, volume of work, and project scope. But it is totally worth it. Join our welcoming community! SIG Node GitHub Repo contains many useful resources including Slack, mailing list and other contact info.
Wrap Up
SIG Node hosted a KubeCon + CloudNativeCon Europe 2021 talk with an intro and deep dive to their awesome SIG. Join the SIG's meetings to find out about the most recent research results, what the plans are for the forthcoming year, and how to get involved in the upstream Node team as a contributor!
Introducing Single Pod Access Mode for PersistentVolumes
Author: Chris Henzie (Google)
Last month's release of Kubernetes v1.22 introduced a new ReadWriteOncePod access mode for PersistentVolumes and PersistentVolumeClaims. With this alpha feature, Kubernetes allows you to restrict volume access to a single pod in the cluster.
What are access modes and why are they important?
When using storage, there are different ways to model how that storage is consumed.
For example, a storage system like a network file share can have many users all reading and writing data simultaneously. In other cases maybe everyone is allowed to read data but not write it. For highly sensitive data, maybe only one user is allowed to read and write data but nobody else.
In the world of Kubernetes, access modes are the way you can define how durable storage is consumed. These access modes are a part of the spec for PersistentVolumes (PVs) and PersistentVolumeClaims (PVCs).
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: shared-cache
spec:
accessModes:
- ReadWriteMany # Allow many nodes to access shared-cache simultaneously.
resources:
requests:
storage: 1Gi
Before v1.22, Kubernetes offered three access modes for PVs and PVCs:
- ReadWriteOnce – the volume can be mounted as read-write by a single node
- ReadOnlyMany – the volume can be mounted read-only by many nodes
- ReadWriteMany – the volume can be mounted as read-write by many nodes
These access modes are enforced by Kubernetes components like the kube-controller-manager and kubelet to ensure only certain pods are allowed to access a given PersistentVolume.
What is this new access mode and how does it work?
Kubernetes v1.22 introduced a fourth access mode for PVs and PVCs, that you can use for CSI volumes:
- ReadWriteOncePod – the volume can be mounted as read-write by a single pod
If you create a pod with a PVC that uses the ReadWriteOncePod access mode, Kubernetes ensures that pod is the only pod across your whole cluster that can read that PVC or write to it.
If you create another pod that references the same PVC with this access mode, the pod will fail to start because the PVC is already in use by another pod. For example:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 1s default-scheduler 0/1 nodes are available: 1 node has pod using PersistentVolumeClaim with the same name and ReadWriteOncePod access mode.
How is this different than the ReadWriteOnce access mode?
The ReadWriteOnce access mode restricts volume access to a single node, which means it is possible for multiple pods on the same node to read from and write to the same volume. This could potentially be a major problem for some applications, especially if they require at most one writer for data safety guarantees.
With ReadWriteOncePod these issues go away. Set the access mode on your PVC, and Kubernetes guarantees that only a single pod has access.
How do I use it?
The ReadWriteOncePod access mode is in alpha for Kubernetes v1.22 and is only supported for CSI volumes.
As a first step you need to enable the ReadWriteOncePod feature gate for kube-apiserver, kube-scheduler, and kubelet.
You can enable the feature by setting command line arguments:
--feature-gates="...,ReadWriteOncePod=true"
You also need to update the following CSI sidecars to these versions or greater:
Creating a PersistentVolumeClaim
In order to use the ReadWriteOncePod access mode for your PVs and PVCs, you will need to create a new PVC with the access mode:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: single-writer-only
spec:
accessModes:
- ReadWriteOncePod # Allow only a single pod to access single-writer-only.
resources:
requests:
storage: 1Gi
If your storage plugin supports dynamic provisioning, new PersistentVolumes will be created with the ReadWriteOncePod access mode applied.
Migrating existing PersistentVolumes
If you have existing PersistentVolumes, they can be migrated to use ReadWriteOncePod.
In this example, we already have a "cat-pictures-pvc" PersistentVolumeClaim that is bound to a "cat-pictures-pv" PersistentVolume, and a "cat-pictures-writer" Deployment that uses this PersistentVolumeClaim.
As a first step, you need to edit your PersistentVolume's spec.persistentVolumeReclaimPolicy and set it to Retain.
This ensures your PersistentVolume will not be deleted when we delete the corresponding PersistentVolumeClaim:
kubectl patch pv cat-pictures-pv -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'
Next you need to stop any workloads that are using the PersistentVolumeClaim bound to the PersistentVolume you want to migrate, and then delete the PersistentVolumeClaim.
Once that is done, you need to clear your PersistentVolume's spec.claimRef.uid to ensure PersistentVolumeClaims can bind to it upon recreation:
kubectl scale --replicas=0 deployment cat-pictures-writer
kubectl delete pvc cat-pictures-pvc
kubectl patch pv cat-pictures-pv -p '{"spec":{"claimRef":{"uid":""}}}'
After that you need to replace the PersistentVolume's access modes with ReadWriteOncePod:
kubectl patch pv cat-pictures-pv -p '{"spec":{"accessModes":["ReadWriteOncePod"]}}'
Next you need to modify your PersistentVolumeClaim to set ReadWriteOncePod as the only access mode.
You should also set your PersistentVolumeClaim's spec.volumeName to the name of your PersistentVolume.
Once this is done, you can recreate your PersistentVolumeClaim and start up your workloads:
# IMPORTANT: Make sure to edit your PVC in cat-pictures-pvc.yaml before applying. You need to:
# - Set ReadWriteOncePod as the only access mode
# - Set spec.volumeName to "cat-pictures-pv"
kubectl apply -f cat-pictures-pvc.yaml
kubectl apply -f cat-pictures-writer-deployment.yaml
Lastly you may edit your PersistentVolume's spec.persistentVolumeReclaimPolicy and set to it back to Delete if you previously changed it.
kubectl patch pv cat-pictures-pv -p '{"spec":{"persistentVolumeReclaimPolicy":"Delete"}}'
You can read Configure a Pod to Use a PersistentVolume for Storage for more details on working with PersistentVolumes and PersistentVolumeClaims.
What volume plugins support this?
The only volume plugins that support this are CSI drivers. SIG Storage does not plan to support this for in-tree plugins because they are being deprecated as part of CSI migration. Support may be considered for beta for users that prefer to use the legacy in-tree volume APIs with CSI migration enabled.
As a storage vendor, how do I add support for this access mode to my CSI driver?
The ReadWriteOncePod access mode will work out of the box without any required updates to CSI drivers, but does require updates to CSI sidecars. With that being said, if you would like to stay up to date with the latest changes to the CSI specification (v1.5.0+), read on.
Two new access modes were introduced to the CSI specification in order to disambiguate the legacy SINGLE_NODE_WRITER access mode.
They are SINGLE_NODE_SINGLE_WRITER and SINGLE_NODE_MULTI_WRITER.
In order to communicate to sidecars (like the external-provisioner) that your driver understands and accepts these two new CSI access modes, your driver will also need to advertise the SINGLE_NODE_MULTI_WRITER capability for the controller service and node service.
If you'd like to read up on the motivation for these access modes and capability bits, you can also read the CSI Specification Changes, Volume Capabilities section of KEP-2485 (ReadWriteOncePod PersistentVolume Access Mode).
Update your CSI driver to use the new interface
As a first step you will need to update your driver's container-storage-interface dependency to v1.5.0+, which contains support for these new access modes and capabilities.
Accept new CSI access modes
If your CSI driver contains logic for validating CSI access modes for requests , it may need updating.
If it currently accepts SINGLE_NODE_WRITER, it should be updated to also accept SINGLE_NODE_SINGLE_WRITER and SINGLE_NODE_MULTI_WRITER.
Using the GCP PD CSI driver validation logic as an example, here is how it can be extended:
diff --git a/pkg/gce-pd-csi-driver/utils.go b/pkg/gce-pd-csi-driver/utils.go
index 281242c..b6c5229 100644
--- a/pkg/gce-pd-csi-driver/utils.go
+++ b/pkg/gce-pd-csi-driver/utils.go
@@ -123,6 +123,8 @@ func validateAccessMode(am *csi.VolumeCapability_AccessMode) error {
case csi.VolumeCapability_AccessMode_SINGLE_NODE_READER_ONLY:
case csi.VolumeCapability_AccessMode_MULTI_NODE_READER_ONLY:
case csi.VolumeCapability_AccessMode_MULTI_NODE_MULTI_WRITER:
+ case csi.VolumeCapability_AccessMode_SINGLE_NODE_SINGLE_WRITER:
+ case csi.VolumeCapability_AccessMode_SINGLE_NODE_MULTI_WRITER:
default:
return fmt.Errorf("%v access mode is not supported for for PD", am.GetMode())
}
Advertise new CSI controller and node service capabilities
Your CSI driver will also need to return the new SINGLE_NODE_MULTI_WRITER capability as part of the ControllerGetCapabilities and NodeGetCapabilities RPCs.
Using the GCP PD CSI driver capability advertisement logic as an example, here is how it can be extended:
diff --git a/pkg/gce-pd-csi-driver/gce-pd-driver.go b/pkg/gce-pd-csi-driver/gce-pd-driver.go
index 45903f3..0d7ea26 100644
--- a/pkg/gce-pd-csi-driver/gce-pd-driver.go
+++ b/pkg/gce-pd-csi-driver/gce-pd-driver.go
@@ -56,6 +56,8 @@ func (gceDriver *GCEDriver) SetupGCEDriver(name, vendorVersion string, extraVolu
csi.VolumeCapability_AccessMode_SINGLE_NODE_WRITER,
csi.VolumeCapability_AccessMode_MULTI_NODE_READER_ONLY,
csi.VolumeCapability_AccessMode_MULTI_NODE_MULTI_WRITER,
+ csi.VolumeCapability_AccessMode_SINGLE_NODE_SINGLE_WRITER,
+ csi.VolumeCapability_AccessMode_SINGLE_NODE_MULTI_WRITER,
}
gceDriver.AddVolumeCapabilityAccessModes(vcam)
csc := []csi.ControllerServiceCapability_RPC_Type{
@@ -67,12 +69,14 @@ func (gceDriver *GCEDriver) SetupGCEDriver(name, vendorVersion string, extraVolu
csi.ControllerServiceCapability_RPC_EXPAND_VOLUME,
csi.ControllerServiceCapability_RPC_LIST_VOLUMES,
csi.ControllerServiceCapability_RPC_LIST_VOLUMES_PUBLISHED_NODES,
+ csi.ControllerServiceCapability_RPC_SINGLE_NODE_MULTI_WRITER,
}
gceDriver.AddControllerServiceCapabilities(csc)
ns := []csi.NodeServiceCapability_RPC_Type{
csi.NodeServiceCapability_RPC_STAGE_UNSTAGE_VOLUME,
csi.NodeServiceCapability_RPC_EXPAND_VOLUME,
csi.NodeServiceCapability_RPC_GET_VOLUME_STATS,
+ csi.NodeServiceCapability_RPC_SINGLE_NODE_MULTI_WRITER,
}
gceDriver.AddNodeServiceCapabilities(ns)
Implement NodePublishVolume behavior
The CSI spec outlines expected behavior for the NodePublishVolume RPC when called more than once for the same volume but with different arguments (like the target path).
Please refer to the second table in the NodePublishVolume section of the CSI spec for more details on expected behavior when implementing in your driver.
Update your CSI sidecars
When deploying your CSI drivers, you must update the following CSI sidecars to versions that depend on CSI spec v1.5.0+ and the Kubernetes v1.22 API. The minimum required versions are:
What’s next?
As part of the beta graduation for this feature, SIG Storage plans to update the Kubenetes scheduler to support pod preemption in relation to ReadWriteOncePod storage. This means if two pods request a PersistentVolumeClaim with ReadWriteOncePod, the pod with highest priority will gain access to the PersistentVolumeClaim and any pod with lower priority will be preempted from the node and be unable to access the PersistentVolumeClaim.
How can I learn more?
Please see KEP-2485 for more details on the ReadWriteOncePod access mode and motivations for CSI spec changes.
How do I get involved?
The Kubernetes #csi Slack channel and any of the standard SIG Storage communication channels are great mediums to reach out to the SIG Storage and the CSI teams.
Special thanks to the following people for their insightful reviews and design considerations:
- Abdullah Gharaibeh (ahg-g)
- Aldo Culquicondor (alculquicondor)
- Ben Swartzlander (bswartz)
- Deep Debroy (ddebroy)
- Hemant Kumar (gnufied)
- Humble Devassy Chirammal (humblec)
- James DeFelice (jdef)
- Jan Šafránek (jsafrane)
- Jing Xu (jingxu97)
- Jordan Liggitt (liggitt)
- Michelle Au (msau42)
- Saad Ali (saad-ali)
- Tim Hockin (thockin)
- Xing Yang (xing-yang)
If you’re interested in getting involved with the design and development of CSI or any part of the Kubernetes storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Alpha in Kubernetes v1.22: API Server Tracing
Authors: David Ashpole (Google)
In distributed systems, it can be hard to figure out where problems are. You grep through one component's logs just to discover that the source of your problem is in another component. You search there only to discover that you need to enable debug logs to figure out what really went wrong... And it goes on. The more complex the path your request takes, the harder it is to answer questions about where it went. I've personally spent many hours doing this dance with a variety of Kubernetes components. Distributed tracing is a tool which is designed to help in these situations, and the Kubernetes API Server is, perhaps, the most important Kubernetes component to be able to debug. At Kubernetes' Sig Instrumentation, our mission is to make it easier to understand what's going on in your cluster, and we are happy to announce that distributed tracing in the Kubernetes API Server reached alpha in 1.22.
What is Tracing?
Distributed tracing links together a bunch of super-detailed information from multiple different sources, and structures that telemetry into a single tree for that request. Unlike logging, which limits the quantity of data ingested by using log levels, tracing collects all of the details and uses sampling to collect only a small percentage of requests. This means that once you have a trace which demonstrates an issue, you should have all the information you need to root-cause the problem--no grepping for object UID required! My favorite aspect, though, is how useful the visualizations of traces are. Even if you don't understand the inner workings of the API Server, or don't have a clue what an etcd "Transaction" is, I'd wager you (yes, you!) could tell me roughly what the order of events was, and which components were involved in the request. If some step takes a long time, it is easy to tell where the problem is.
Why OpenTelemetry?
It's important that Kubernetes works well for everyone, regardless of who manages your infrastructure, or which vendors you choose to integrate with. That is particularly true for Kubernetes' integrations with telemetry solutions. OpenTelemetry, being a CNCF project, shares these core values, and is creating exactly what we need in Kubernetes: A set of open standards for Tracing client library APIs and a standard trace format. By using OpenTelemetry, we can ensure users have the freedom to choose their backend, and ensure vendors have a level playing field. The timing couldn't be better: the OpenTelemetry golang API and SDK are very close to their 1.0 release, and will soon offer backwards-compatibility for these open standards.
Why instrument the API Server?
The Kubernetes API Server is a great candidate for tracing for a few reasons:
- It follows the standard "RPC" model (serve a request by making requests to downstream components), which makes it easy to instrument.
- Users are latency-sensitive: If a request takes more than 10 seconds to complete, many clients will time-out.
- It has a complex service topology: A single request could require consulting a dozen webhooks, or involve multiple requests to etcd.
Trying out APIServer Tracing with a webhook
Enabling API Server Tracing
-
Enable the APIServerTracing feature-gate.
-
Set our configuration for tracing by pointing the
--tracing-config-fileflag on the kube-apiserver at our config file, which contains:
apiVersion: apiserver.config.k8s.io/v1alpha1
kind: TracingConfiguration
# 1% sampling rate
samplingRatePerMillion: 10000
Enabling Etcd Tracing
Add --experimental-enable-distributed-tracing, --experimental-distributed-tracing-address=0.0.0.0:4317, --experimental-distributed-tracing-service-name=etcd flags to etcd to enable tracing. Note that this traces every request, so it will probably generate a lot of traces if you enable it.
Example Trace: List Nodes
I could've used any trace backend, but decided to use Jaeger, since it is one of the most popular open-source tracing projects. I deployed the Jaeger All-in-one container in my cluster, deployed the OpenTelemetry collector on my control-plane node (example), and captured traces like this one:

The teal lines are from the API Server, and includes it serving a request to /api/v1/nodes, and issuing a grpc Range RPC to ETCD. The yellow-ish line is from ETCD handling the Range RPC.
Example Trace: Create Pod with Mutating Webhook
I instrumented the example webhook with OpenTelemetry (I had to patch controller-runtime, but it makes a neat demo), and routed traces to Jaeger as well. I collected traces like this one:

Compared with the previous trace, there are two new spans: A teal span from the API Server making a request to the admission webhook, and a brown span from the admission webhook serving the request. Even if you didn't instrument your webhook, you would still get the span from the API Server making the request to the webhook.
Get involved!
As this is our first attempt at adding distributed tracing to a Kubernetes component, there is probably a lot we can improve! If my struggles resonated with you, or if you just want to try out the latest Kubernetes has to offer, please give the feature a try and open issues with any problem you encountered and ways you think the feature could be improved.
This is just the very beginning of what we can do with distributed tracing in Kubernetes. If there are other components you think would benefit from distributed tracing, or want to help bring API Server Tracing to GA, join sig-instrumentation at our regular meetings and get involved!
Kubernetes 1.22: A New Design for Volume Populators
Authors: Ben Swartzlander (NetApp)
Kubernetes v1.22, released earlier this month, introduced a redesigned approach for volume
populators. Originally implemented
in v1.18, the API suffered from backwards compatibility issues. Kubernetes v1.22 includes a new API
field called dataSourceRef that fixes these problems.
Data sources
Earlier Kubernetes releases already added a dataSource field into the
PersistentVolumeClaim API,
used for cloning volumes and creating volumes from snapshots. You could use the dataSource field when
creating a new PVC, referencing either an existing PVC or a VolumeSnapshot in the same namespace.
That also modified the normal provisioning process so that instead of yielding an empty volume, the
new PVC contained the same data as either the cloned PVC or the cloned VolumeSnapshot.
Volume populators embrace the same design idea, but extend it to any type of object, as long
as there exists a custom resource
to define the data source, and a populator controller to implement the logic. Initially,
the dataSource field was directly extended to allow arbitrary objects, if the AnyVolumeDataSource
feature gate was enabled on a cluster. That change unfortunately caused backwards compatibility
problems, and so the new dataSourceRef field was born.
In v1.22 if the AnyVolumeDataSource feature gate is enabled, the dataSourceRef field is
added, which behaves similarly to the dataSource field except that it allows arbitrary
objects to be specified. The API server ensures that the two fields always have the same
contents, and neither of them are mutable. The differences is that at creation time
dataSource allows only PVCs or VolumeSnapshots, and ignores all other values, while
dataSourceRef allows most types of objects, and in the few cases it doesn't allow an
object (core objects other than PVCs) a validation error occurs.
When this API change graduates to stable, we would deprecate using dataSource and recommend
using dataSourceRef field for all use cases.
In the v1.22 release, dataSourceRef is available (as an alpha feature) specifically for cases
where you want to use for custom volume populators.
Using populators
Every volume populator must have one or more CRDs that it supports. Administrators may
install the CRD and the populator controller and then PVCs with a dataSourceRef specifies
a CR of the type that the populator supports will be handled by the populator controller
instead of the CSI driver directly.
Underneath the covers, the CSI driver is still invoked to create an empty volume, which the populator controller fills with the appropriate data. The PVC doesn't bind to the PV until it's fully populated, so it's safe to define a whole application manifest including pod and PVC specs and the pods won't begin running until everything is ready, just as if the PVC was a clone of another PVC or VolumeSnapshot.
How it works
PVCs with data sources are still noticed by the external-provisioner sidecar for the related storage class (assuming a CSI provisioner is used), but because the sidecar doesn't understand the data source kind, it doesn't do anything. The populator controller is also watching for PVCs with data sources of a kind that it understands and when it sees one, it creates a temporary PVC of the same size, volume mode, storage class, and even on the same topology (if topology is used) as the original PVC. The populator controller creates a worker pod that attaches to the volume and writes the necessary data to it, then detaches from the volume and the populator controller rebinds the PV from the temporary PVC to the orignal PVC.
Trying it out
The following things are required to use volume populators:
- Enable the
AnyVolumeDataSourcefeature gate - Install a CRD for the specific data source / populator
- Install the populator controller itself
Populator controllers may use the lib-volume-populator library to do most of the Kubernetes API level work. Individual populators only need to provide logic for actually writing data into the volume based on a particular CR instance. This library provides a sample populator implementation.
These optional components improve user experience:
- Install the VolumePopulator CRD
- Create a VolumePopulator custom respource for each specific data source
- Install the volume data source validator controller (alpha)
The purpose of these components is to generate warning events on PVCs with data sources for which there is no populator.
Putting it all together
To see how this works, you can install the sample "hello" populator and try it out.
First install the volume-data-source-validator controller.
kubectl apply -f https://github.com/kubernetes-csi/volume-data-source-validator/blob/master/deploy/kubernetes/rbac-data-source-validator.yaml
kubectl apply -f https://github.com/kubernetes-csi/volume-data-source-validator/blob/master/deploy/kubernetes/setup-data-source-validator.yaml
Next install the example populator.
kubectl apply -f https://github.com/kubernetes-csi/lib-volume-populator/blob/master/example/hello-populator/crd.yaml
kubectl apply -f https://github.com/kubernetes-csi/lib-volume-populator/blob/master/example/hello-populator/deploy.yaml
Create an instance of the Hello CR, with some text.
apiVersion: hello.k8s.io/v1alpha1
kind: Hello
metadata:
name: example-hello
spec:
fileName: example.txt
fileContents: Hello, world!
Create a PVC that refers to that CR as its data source.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: example-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Mi
dataSourceRef:
apiGroup: hello.k8s.io
kind: Hello
name: example-hello
volumeMode: Filesystem
Next, run a job that reads the file in the PVC.
apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
template:
spec:
containers:
- name: example-container
image: busybox:latest
command:
- cat
- /mnt/example.txt
volumeMounts:
- name: vol
mountPath: /mnt
restartPolicy: Never
volumes:
- name: vol
persistentVolumeClaim:
claimName: example-pvc
Wait for the job to complete (including all of its dependencies).
kubectl wait --for=condition=Complete job/example-job
And last examine the log from the job.
kubectl logs job/example-job
Hello, world!
Note that the volume already contained a text file with the string contents from the CR. This is only the simplest example. Actual populators can set up the volume to contain arbitrary contents.
How to write your own volume populator
Developers interested in writing new poplators are encouraged to use the lib-volume-populator library and to only supply a small controller wrapper around the library, and a pod image capable of attaching to volumes and writing the appropriate data to the volume.
Individual populators can be extremely generic such that they work with every type of PVC, or they can do vendor specific things to rapidly fill a volume with data if the volume was provisioned by a specific CSI driver from the same vendor, for example, by communicating directly with the storage for that volume.
The future
As this feature is still in alpha, we expect to update the out of tree controllers with more tests and documentation. The community plans to eventually re-implement the populator library as a sidecar, for ease of operations.
We hope to see some official community-supported populators for some widely-shared use cases. Also, we expect that volume populators will be used by backup vendors as a way to "restore" backups to volumes, and possibly a standardized API to do this will evolve.
How can I learn more?
The enhancement proposal, Volume Populators, includes lots of detail about the history and technical implementation of this feature.
Volume populators and data sources, within the documentation topic about persistent volumes, explains how to use this feature in your cluster.
Please get involved by joining the Kubernetes storage SIG to help us enhance this feature. There are a lot of good ideas already and we'd be thrilled to have more!
Minimum Ready Seconds for StatefulSets
Authors: Ravi Gudimetla (Red Hat), Maciej Szulik (Red Hat)
This blog describes the notion of Availability for StatefulSet workloads, and a new alpha feature in Kubernetes 1.22 which adds minReadySeconds configuration for StatefulSets.
What problems does this solve?
Prior to Kubernetes 1.22 release, once a StatefulSet Pod is in the Ready state it is considered Available to receive traffic. For some of the StatefulSet workloads, it may not be the case. For example, a workload like Prometheus with multiple instances of Alertmanager, it should be considered Available only when Alertmanager's state transfer is complete, not when the Pod is in Ready state. Since minReadySeconds adds buffer, the state transfer may be complete before the Pod becomes Available. While this is not a fool proof way of identifying if the state transfer is complete or not, it gives a way to the end user to express their intention of waiting for sometime before the Pod is considered Available and it is ready to serve requests.
Another case, where minReadySeconds helps is when using LoadBalancer Services with cloud providers. Since minReadySeconds adds latency after a Pod is Ready, it provides buffer time to prevent killing pods in rotation before new pods show up. Imagine a load balancer in unhappy path taking 10-15s to propagate. If you have 2 replicas then, you'd kill the second replica only after the first one is up but in reality, first replica cannot be seen because it is not yet ready to serve requests.
So, in general, the notion of Availability in StatefulSets is pretty useful and this feature helps in solving the above problems. This is a feature that already exists for Deployments and DaemonSets and we now have them for StatefulSets too to give users consistent workload experience.
How does it work?
The statefulSet controller watches for both StatefulSets and the Pods associated with them. When the feature gate associated with this feature is enabled, the statefulSet controller identifies how long a particular Pod associated with a StatefulSet has been in the Running state.
If this value is greater than or equal to the time specified by the end user in .spec.minReadySeconds field, the statefulSet controller updates a field called availableReplicas in the StatefulSet's status subresource to include this Pod. The status.availableReplicas in StatefulSet's status is an integer field which tracks the number of pods that are Available.
How do I use it?
You are required to prepare the following things in order to try out the feature:
- Download and install a kubectl greater than v1.22.0 version
- Switch on the feature gate with the command line flag
--feature-gates=StatefulSetMinReadySeconds=trueonkube-apiserverandkube-controller-manager
After successfully starting kube-apiserver and kube-controller-manager, you will see AvailableReplicas in the status and minReadySeconds of spec (with a default value of 0).
Specify a value for minReadySeconds for any StatefulSet and you can check if Pods are available or not by checking AvailableReplicas field using:
kubectl get statefulset/<name_of_the_statefulset> -o yaml
How can I learn more?
- Read the KEP: minReadySeconds for StatefulSets
- Read the documentation: Minimum ready seconds for StatefulSet
- Review the API definition for StatefulSet
How do I get involved?
Please reach out to us in the #sig-apps channel on Slack (visit https://slack.k8s.io/ for an invitation if you need one), or on the SIG Apps mailing list: kubernetes-sig-apps@googlegroups.com
Enable seccomp for all workloads with a new v1.22 alpha feature
Author: Sascha Grunert, Red Hat
This blog post is about a new Kubernetes feature introduced in v1.22, which adds an additional security layer on top of the existing seccomp support. Seccomp is a security mechanism for Linux processes to filter system calls (syscalls) based on a set of defined rules. Applying seccomp profiles to containerized workloads is one of the key tasks when it comes to enhancing the security of the application deployment. Developers, site reliability engineers and infrastructure administrators have to work hand in hand to create, distribute and maintain the profiles over the applications life-cycle.
You can use the securityContext field of Pods and their
containers can be used to adjust security related configurations of the
workload. Kubernetes introduced dedicated seccomp related API
fields in this SecurityContext with the graduation of seccomp to
General Availability (GA) in v1.19.0. This enhancement allowed an easier
way to specify if the whole pod or a specific container should run as:
Unconfined: seccomp will not be enabledRuntimeDefault: the container runtimes default profile will be usedLocalhost: a node local profile will be applied, which is being referenced by a relative path to the seccomp profile root (<kubelet-root-dir>/seccomp) of the kubelet
With the graduation of seccomp, nothing has changed from an overall security
perspective, because Unconfined is still the default. This is totally fine if
you consider this from the upgrade path and backwards compatibility perspective of
Kubernetes releases. But it also means that it is more likely that a workload
runs without seccomp at all, which should be fixed in the long term.
SeccompDefault to the rescue
Kubernetes v1.22.0 introduces a new kubelet feature gate
SeccompDefault, which has been added in alpha state as every other new
feature. This means that it is disabled by default and can be enabled manually
for every single Kubernetes node.
What does the feature do? Well, it just changes the default seccomp profile from
Unconfined to RuntimeDefault. If not specified differently in the pod
manifest, then the feature will add a higher set of security constraints by
using the default profile of the container runtime. These profiles may differ
between runtimes like CRI-O or containerd. They also differ for
its used hardware architectures. But generally speaking, those default profiles
allow a common amount of syscalls while blocking the more dangerous ones, which
are unlikely or unsafe to be used in a containerized application.
Enabling the feature
Two kubelet configuration changes have to be made to enable the feature:
- Enable the feature gate by setting the
SeccompDefault=truevia the command line (--feature-gates) or the kubelet configuration file. - Turn on the feature by enabling the feature by adding the
--seccomp-defaultcommand line flag or via the kubelet configuration file (seccompDefault: true).
The kubelet will error on startup if only one of the above steps have been done.
Trying it out
If the feature is enabled on a node, then you can create a new workload like this:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-container
image: nginx:1.21
Now it is possible to inspect the used seccomp profile by using
crictl while investigating the containers runtime
specification:
CONTAINER_ID=$(sudo crictl ps -q --name=test-container)
sudo crictl inspect $CONTAINER_ID | jq .info.runtimeSpec.linux.seccomp
{
"defaultAction": "SCMP_ACT_ERRNO",
"architectures": ["SCMP_ARCH_X86_64", "SCMP_ARCH_X86", "SCMP_ARCH_X32"],
"syscalls": [
{
"names": ["_llseek", "_newselect", "accept", …, "write", "writev"],
"action": "SCMP_ACT_ALLOW"
},
…
]
}
You can see that the lower level container runtime (CRI-O and
runc in our case), successfully applied the default seccomp profile.
This profile denies all syscalls per default, while allowing commonly used ones
like accept or write.
Please note that the feature will not influence any Kubernetes API for now.
Therefore, it is not possible to retrieve the used seccomp profile via kubectl
get or describe if the SeccompProfile field is unset within the
SecurityContext.
The feature also works when using multiple containers within a pod, for example if you create a pod like this:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-container-nginx
image: nginx:1.21
securityContext:
seccompProfile:
type: Unconfined
- name: test-container-redis
image: redis:6.2
then you should see that the test-container-nginx runs without a seccomp profile:
sudo crictl inspect $(sudo crictl ps -q --name=test-container-nginx) |
jq '.info.runtimeSpec.linux.seccomp == null'
true
Whereas the container test-container-redis runs with RuntimeDefault:
sudo crictl inspect $(sudo crictl ps -q --name=test-container-redis) |
jq '.info.runtimeSpec.linux.seccomp != null'
true
The same applies to the pod itself, which also runs with the default profile:
sudo crictl inspectp (sudo crictl pods -q --name test-pod) |
jq '.info.runtimeSpec.linux.seccomp != null'
true
Upgrade strategy
It is recommended to enable the feature in multiple steps, whereas different risks and mitigations exist for each one.
Feature gate enabling
Enabling the feature gate at the kubelet level will not turn on the feature, but
will make it possible by using the SeccompDefault kubelet configuration or the
--seccomp-default CLI flag. This can be done by an administrator for the whole
cluster or only a set of nodes.
Testing the Application
If you're trying this within a dedicated test environment, you have to ensure
that the application code does not trigger syscalls blocked by the
RuntimeDefault profile before enabling the feature on a node. This can be done
by:
-
Recommended: Analyzing the code (manually or by running the application with strace) for any executed syscalls which may be blocked by the default profiles. If that's the case, then you can override the default by explicitly setting the pod or container to run as
Unconfined. Alternatively, you can create a custom seccomp profile (see optional step below). profile based on the default by adding the additional syscalls to the"action": "SCMP_ACT_ALLOW"section. -
Recommended: Manually set the profile to the target workload and use a rolling upgrade to deploy into production. Rollback the deployment if the application does not work as intended.
-
Optional: Run the application against an end-to-end test suite to trigger all relevant code paths with
RuntimeDefaultenabled. If a test fails, use the same mitigation as mentioned above. -
Optional: Create a custom seccomp profile based on the default and change its default action from
SCMP_ACT_ERRNOtoSCMP_ACT_LOG. This means that the seccomp filter for unknown syscalls will have no effect on the application at all, but the system logs will now indicate which syscalls may be blocked. This requires at least a Kernel version 4.14 as well as a recent runc release. Monitor the application hosts audit logs (defaults to/var/log/audit/audit.log) or syslog entries (defaults to/var/log/syslog) for syscalls viatype=SECCOMP(for audit) ortype=1326(for syslog). Compare the syscall ID with those listed in the Linux Kernel sources and add them to the custom profile. Be aware that custom audit policies may lead into missing syscalls, depending on the configuration of auditd. -
Optional: Use cluster additions like the Security Profiles Operator for profiling the application via its log enrichment capabilities or recording a profile by using its recording feature. This makes the above mentioned manual log investigation obsolete.
Deploying the modified application
Based on the outcome of the application tests, it may be required to change the
application deployment by either specifying Unconfined or a custom seccomp
profile. This is not the case if the application works as intended with
RuntimeDefault.
Enable the kubelet configuration
If everything went well, then the feature is ready to be enabled by the kubelet configuration or its corresponding CLI flag. This should be done on a per-node basis to reduce the overall risk of missing a syscall during the investigations when running the application tests. If it's possible to monitor audit logs within the cluster, then it's recommended to do this for eventually missed seccomp events. If the application works as intended then the feature can be enabled for further nodes within the cluster.
Conclusion
Thank you for reading this blog post! I hope you enjoyed to see how the usage of
seccomp profiles has been evolved in Kubernetes over the past releases as much
as I do. On your own cluster, change the default seccomp profile to
RuntimeDefault (using this new feature) and see the security benefits, and, of
course, feel free to reach out any time for feedback or questions.
Editor's note: If you have any questions or feedback about this blog post, feel free to reach out via the Kubernetes slack in #sig-node.
Alpha in v1.22: Windows HostProcess Containers
Authors: Brandon Smith (Microsoft)
Kubernetes v1.22 introduced a new alpha feature for clusters that include Windows nodes: HostProcess containers.
HostProcess containers aim to extend the Windows container model to enable a wider range of Kubernetes cluster management scenarios. HostProcess containers run directly on the host and maintain behavior and access similar to that of a regular process. With HostProcess containers, users can package and distribute management operations and functionalities that require host access while retaining versioning and deployment methods provided by containers. This allows Windows containers to be used for a variety of device plugin, storage, and networking management scenarios in Kubernetes. With this comes the enablement of host network mode—allowing HostProcess containers to be created within the host's network namespace instead of their own. HostProcess containers can also be built on top of existing Windows server 2019 (or later) base images, managed through the Windows container runtime, and run as any user that is available on or in the domain of the host machine.
Linux privileged containers are currently used for a variety of key scenarios in Kubernetes, including kube-proxy (via kubeadm), storage, and networking scenarios. Support for these scenarios in Windows previously required workarounds via proxies or other implementations. Using HostProcess containers, cluster operators no longer need to log onto and individually configure each Windows node for administrative tasks and management of Windows services. Operators can now utilize the container model to deploy management logic to as many clusters as needed with ease.
How does it work?
Windows HostProcess containers are implemented with Windows Job Objects, a break from the previous container model using server silos. Job objects are components of the Windows OS which offer the ability to manage a group of processes as a group (a.k.a. jobs) and assign resource constraints to the group as a whole. Job objects are specific to the Windows OS and are not associated with the Kubernetes Job API. They have no process or file system isolation, enabling the privileged payload to view and edit the host file system with the correct permissions, among other host resources. The init process, and any processes it launches or that are explicitly launched by the user, are all assigned to the job object of that container. When the init process exits or is signaled to exit, all the processes in the job will be signaled to exit, the job handle will be closed and the storage will be unmounted.
HostProcess and Linux privileged containers enable similar scenarios but differ greatly in their implementation (hence the naming difference). HostProcess containers have their own pod security policies. Those used to configure Linux privileged containers do not apply. Enabling privileged access to a Windows host is a fundamentally different process than with Linux so the configuration and capabilities of each differ significantly. Below is a diagram detailing the overall architecture of Windows HostProcess containers:
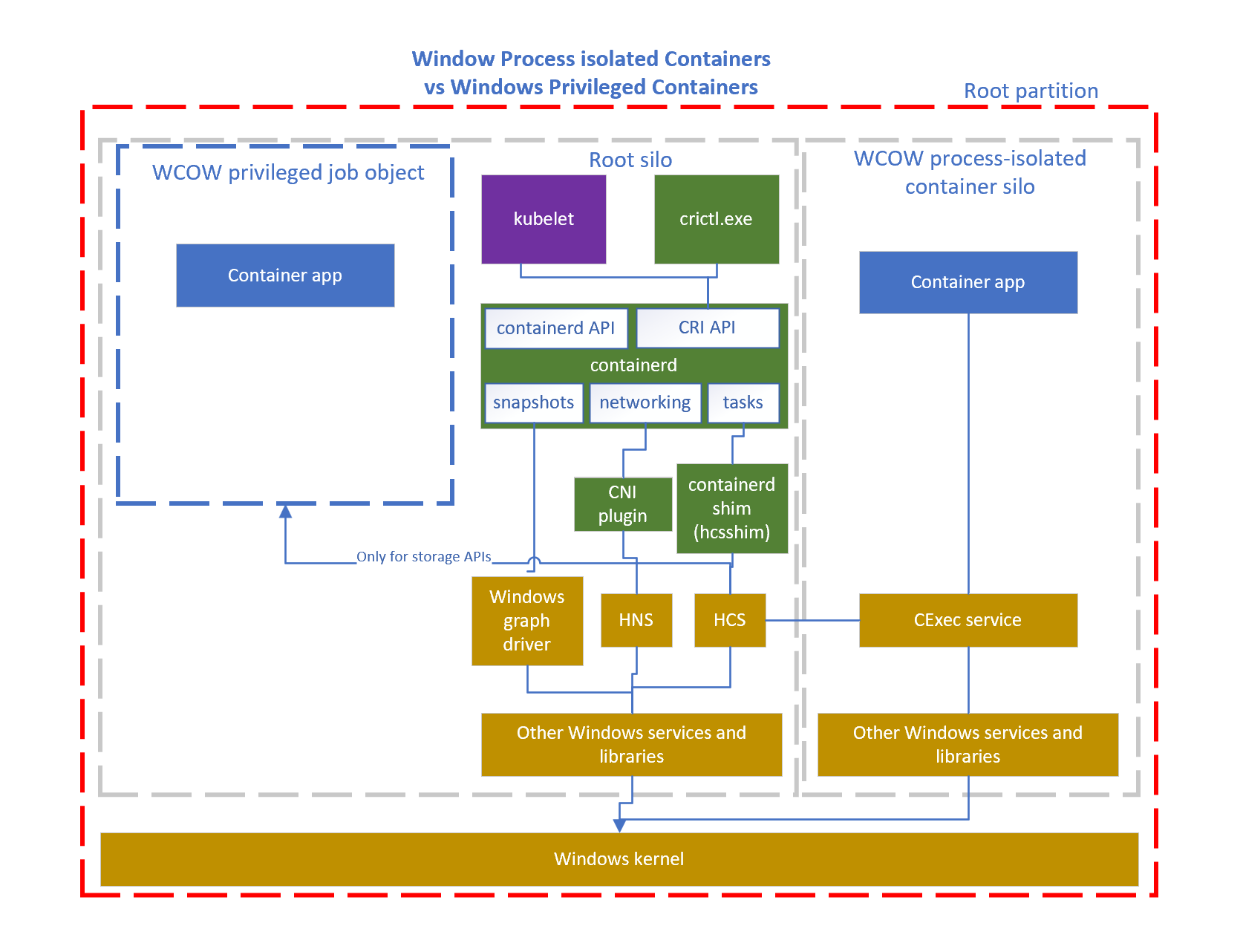
How do I use it?
HostProcess containers can be run from within a HostProcess Pod. With the feature enabled on Kubernetes version 1.22, a containerd container runtime of 1.5.4 or higher, and the latest version of hcsshim, deploying a pod spec with the correct HostProcess configuration will enable you to run HostProcess containers. To get started with running Windows containers see the general guidance for Windows in Kubernetes
How can I learn more?
-
Work through Create a Windows HostProcess Pod
-
Read about Kubernetes Pod Security Standards
-
Read the enhancement proposal Windows Privileged Containers and Host Networking Mode (KEP-1981)
How do I get involved?
HostProcess containers are in active development. SIG Windows welcomes suggestions from the community. Get involved with SIG Windows to contribute!
Kubernetes Memory Manager moves to beta
Authors: Artyom Lukianov (Red Hat), Cezary Zukowski (Samsung)
The blog post explains some of the internals of the Memory manager, a beta feature
of Kubernetes 1.22. In Kubernetes, the Memory Manager is a
kubelet subcomponent.
The memory manage provides guaranteed memory (and hugepages)
allocation for pods in the Guaranteed QoS class.
This blog post covers:
- Why do you need it?
- The internal details of how the MemoryManager works
- Current limitations of the MemoryManager
- Future work for the MemoryManager
Why do you need it?
Some Kubernetes workloads run on nodes with non-uniform memory access (NUMA). Suppose you have NUMA nodes in your cluster. In that case, you'll know about the potential for extra latency when compute resources need to access memory on the different NUMA locality.
To get the best performance and latency for your workload, container CPUs, peripheral devices, and memory should all be aligned to the same NUMA locality. Before Kubernetes v1.22, the kubelet already provided a set of managers to align CPUs and PCI devices, but you did not have a way to align memory. The Linux kernel was able to make best-effort attempts to allocate memory for tasks from the same NUMA node where the container is executing are placed, but without any guarantee about that placement.
How does it work?
The memory manager is doing two main things:
- provides the topology hint to the Topology Manager
- allocates the memory for containers and updates the state
The overall sequence of the Memory Manager under the Kubelet

During the Admission phase:
- When first handling a new pod, the kubelet calls the TopologyManager's
Admit()method. - The Topology Manager is calling
GetTopologyHints()for every hint provider including the Memory Manager. - The Memory Manager calculates all possible NUMA nodes combinations for every container inside the pod and returns hints to the Topology Manager.
- The Topology Manager calls to
Allocate()for every hint provider including the Memory Manager. - The Memory Manager allocates the memory under the state according to the hint that the Topology Manager chose.
During Pod creation:
- The kubelet calls
PreCreateContainer(). - For each container, the Memory Manager looks the NUMA nodes where it allocated the memory for the container and then returns that information to the kubelet.
- The kubelet creates the container, via CRI, using a container specification that incorporates information from the Memory Manager information.
Let's talk about the configuration
By default, the Memory Manager runs with the None policy, meaning it will just
relax and not do anything. To make use of the Memory Manager, you should set
two command line options for the kubelet:
--memory-manager-policy=Static--reserved-memory="<numaNodeID>:<resourceName>=<quantity>"
The value for --memory-manager-policy is straightforward: Static. Deciding what to specify for --reserved-memory takes more thought. To configure it correctly, you should follow two main rules:
- The amount of reserved memory for the
memoryresource must be greater than zero. - The amount of reserved memory for the resource type must be equal
to NodeAllocatable
(
kube-reserved + system-reserved + eviction-hard) for the resource. You can read more about memory reservations in Reserve Compute Resources for System Daemons.

Current limitations
The 1.22 release and promotion to beta brings along enhancements and fixes, but the Memory Manager still has several limitations.
Single vs Cross NUMA node allocation
The NUMA node can not have both single and cross NUMA node allocations. When the container memory is pinned to two or more NUMA nodes, we can not know from which NUMA node the container will consume the memory.

- The
container1started on the NUMA node 0 and requests 5Gi of the memory but currently is consuming only 3Gi of the memory. - For container2 the memory request is 10Gi, and no single NUMA node can satisfy it.
- The
container2consumes 3.5Gi of the memory from the NUMA node 0, but once thecontainer1will require more memory, it will not have it, and the kernel will kill one of the containers with the OOM error.
To prevent such issues, the Memory Manager will fail the admission of the container2 until the machine has two NUMA nodes without a single NUMA node allocation.
Works only for Guaranteed pods
The Memory Manager can not guarantee memory allocation for Burstable pods, also when the Burstable pod has specified equal memory limit and request.
Let's assume you have two Burstable pods: pod1 has containers with
equal memory request and limits, and pod2 has containers only with a
memory request set. You want to guarantee memory allocation for the pod1.
To the Linux kernel, processes in either pod have the same OOM score,
once the kernel finds that it does not have enough memory, it can kill
processes that belong to pod pod1.
Memory fragmentation
The sequence of Pods and containers that start and stop can fragment the memory on NUMA nodes. The alpha implementation of the Memory Manager does not have any mechanism to balance pods and defragment memory back.
Future work for the Memory Manager
We do not want to stop with the current state of the Memory Manager and are looking to make improvements, including in the following areas.
Make the Memory Manager allocation algorithm smarter
The current algorithm ignores distances between NUMA nodes during the calculation of the allocation. If same-node placement isn't available, we can still provide better performance compared to the current implementation, by changing the Memory Manager to prefer the closest NUMA nodes for cross-node allocation.
Reduce the number of admission errors
The default Kubernetes scheduler is not aware of the node's NUMA topology, and it can be a reason for many admission errors during the pod start. We're hoping to add a KEP (Kubernetes Enhancement Proposal) to cover improvements in this area. Follow Topology aware scheduler plugin in kube-scheduler to see how this idea progresses.
Conclusion
With the promotion of the Memory Manager to beta in 1.22, we encourage everyone to give it a try and look forward to any feedback you may have. While there are still several limitations, we have a set of enhancements planned to address them and look forward to providing you with many new features in upcoming releases. If you have ideas for additional enhancements or a desire for certain features, please let us know. The team is always open to suggestions to enhance and improve the Memory Manager. We hope you have found this blog informative and helpful! Let us know if you have any questions or comments.
You can contact us via:
- The Kubernetes #sig-node channel in Slack (visit https://slack.k8s.io/ for an invitation if you need one)
- The SIG Node mailing list, kubernetes-sig-node@googlegroups.com
Kubernetes 1.22: CSI Windows Support (with CSI Proxy) reaches GA
Authors: Mauricio Poppe (Google), Jing Xu (Google), and Deep Debroy (Apple)
The stable version of CSI Proxy for Windows has been released alongside Kubernetes 1.22. CSI Proxy enables CSI Drivers running on Windows nodes to perform privileged storage operations.
Background
Container Storage Interface (CSI) for Kubernetes went GA in the Kubernetes 1.13 release. CSI has become the standard for exposing block and file storage to containerized workloads on Container Orchestration systems (COs) like Kubernetes. It enables third-party storage providers to write and deploy plugins without the need to alter the core Kubernetes codebase. Legacy in-tree drivers are deprecated and new storage features are introduced in CSI, therefore it is important to get CSI Drivers to work on Windows.
A CSI Driver in Kubernetes has two main components: a controller plugin which runs in the control plane and a node plugin which runs on every node.
-
The controller plugin generally does not need direct access to the host and can perform all its operations through the Kubernetes API and external control plane services.
-
The node plugin, however, requires direct access to the host for making block devices and/or file systems available to the Kubernetes kubelet. Due to the missing capability of running privileged operations from containers on Windows nodes CSI Proxy was introduced as alpha in Kubernetes 1.18 as a way to enable containers to perform privileged storage operations. This enables containerized CSI Drivers to run on Windows nodes.
What's CSI Proxy and how do CSI drivers interact with it?
When a workload that uses persistent volumes is scheduled, it'll go through a sequence of steps defined in the CSI Spec. First, the workload will be scheduled to run on a node. Then the controller component of a CSI Driver will attach the persistent volume to the node. Finally the node component of a CSI Driver will mount the persistent volume on the node.
The node component of a CSI Driver needs to run on Windows nodes to support Windows workloads. Various privileged operations like scanning of disk devices, mounting of file systems, etc. cannot be done from a containerized application running on Windows nodes yet (Windows HostProcess containers introduced in Kubernetes 1.22 as alpha enable functionalities that require host access like the operations mentioned before). However, we can perform these operations through a binary (CSI Proxy) that's pre-installed on the Window nodes. CSI Proxy has a client-server architecture and allows CSI drivers to issue privileged storage operations through a gRPC interface exposed over named pipes created during the startup of CSI Proxy.
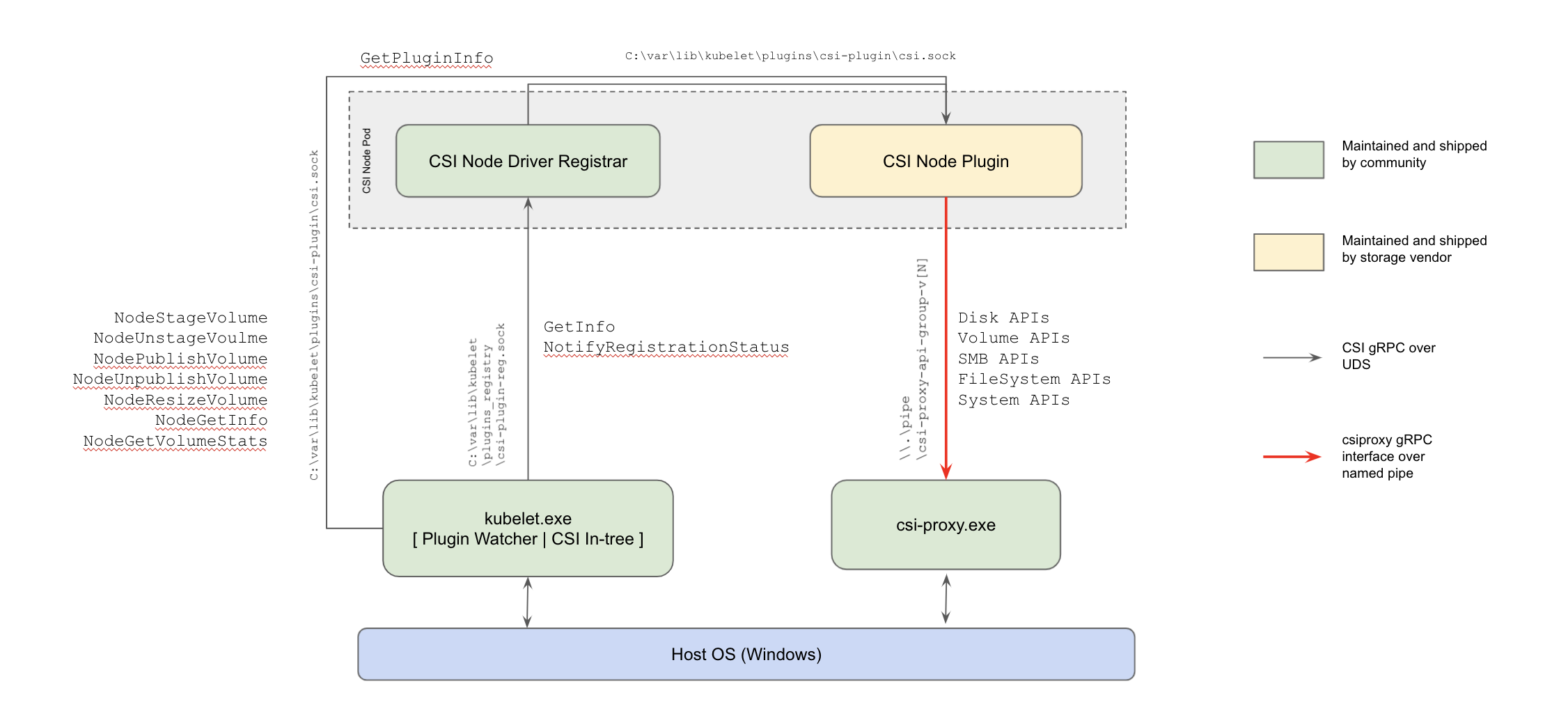
CSI Proxy reaches GA
The CSI Proxy development team has worked closely with storage vendors, many of whom started integrating CSI Proxy into their CSI Drivers and provided feedback as early as CSI Proxy design proposal. This cooperation uncovered use cases where additional APIs were needed, found bugs, and identified areas for documentation improvement.
The CSI Proxy design KEP has been updated to reflect the current CSI Proxy architecture. Additional development documentation is included for contributors interested in helping with new features or bug fixes.
Before we reached GA we wanted to make sure that our API is simple and consistent. We went through an extensive API review of the v1beta API groups where we made sure that the CSI Proxy API methods and messages are consistent with the naming conventions defined in the CSI Spec. As part of this effort we're graduating the Disk, Filesystem, SMB and Volume API groups to v1.
Additional Windows system APIs to get information from the Windows nodes and support to mount iSCSI targets in Windows nodes, are available as alpha APIs in the System API and the iSCSI API. These APIs will continue to be improved before we graduate them to v1.
CSI Proxy v1 is compatible with all the previous v1betaX releases. The GA csi-proxy.exe binary can handle requests from v1betaX clients thanks to the autogenerated conversion layer that transforms any versioned client request to a version-agnostic request that the server can process. Several integration tests were added for all the API versions of the API groups that are graduating to v1 to ensure that CSI Proxy is backwards compatible.
Version drift between CSI Proxy and the CSI Drivers that interact with it was also carefully considered. A connection fallback mechanism has been provided for CSI Drivers to handle multiple versions of CSI Proxy for a smooth upgrade to v1. This allows CSI Drivers, like the GCE PD CSI Driver, to recognize which version of the CSI Proxy binary is running and handle multiple versions of the CSI Proxy binary deployed on the node.
CSI Proxy v1 is already being used by many CSI Drivers, including the AWS EBS CSI Driver, Azure Disk CSI Driver, GCE PD CSI Driver, and SMB CSI Driver.
Future plans
We're very excited for the future of CSI Proxy. With the upcoming Windows HostProcess containers, we are considering converting the CSI Proxy in to a library consumed by CSI Drivers in addition to the current client/server design. This will allow us to iterate faster on new features because the csi-proxy.exe binary will no longer be needed.
How to get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together. Those interested in getting involved with the design and development of CSI Proxy, or any part of the Kubernetes Storage system, may join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
For those interested in more details about CSI support in Windows please reach out in the #csi-windows Kubernetes slack channel.
Acknowledgments
CSI-Proxy received many contributions from members of the Kubernetes community. We thank all of the people that contributed to CSI Proxy with design reviews, bug reports, bug fixes, and for their continuous support in reaching this milestone:
New in Kubernetes v1.22: alpha support for using swap memory
Author: Elana Hashman (Red Hat)
The 1.22 release introduced alpha support for configuring swap memory usage for Kubernetes workloads on a per-node basis.
In prior releases, Kubernetes did not support the use of swap memory on Linux, as it is difficult to provide guarantees and account for pod memory utilization when swap is involved. As part of Kubernetes' earlier design, swap support was considered out of scope, and a kubelet would by default fail to start if swap was detected on a node.
However, there are a number of use cases that would benefit from Kubernetes nodes supporting swap, including improved node stability, better support for applications with high memory overhead but smaller working sets, the use of memory-constrained devices, and memory flexibility.
Hence, over the past two releases, SIG Node has been working to gather appropriate use cases and feedback, and propose a design for adding swap support to nodes in a controlled, predictable manner so that Kubernetes users can perform testing and provide data to continue building cluster capabilities on top of swap. The alpha graduation of swap memory support for nodes is our first milestone towards this goal!
How does it work?
There are a number of possible ways that one could envision swap use on a node. To keep the scope manageable for this initial implementation, when swap is already provisioned and available on a node, we have proposed the kubelet should be able to be configured such that:
- It can start with swap on.
- It will direct the Container Runtime Interface to allocate zero swap memory to Kubernetes workloads by default.
- You can configure the kubelet to specify swap utilization for the entire node.
Swap configuration on a node is exposed to a cluster admin via the
memorySwap in the KubeletConfiguration.
As a cluster administrator, you can specify the node's behaviour in the
presence of swap memory by setting memorySwap.swapBehavior.
This is possible through the addition of a memory_swap_limit_in_bytes field
to the container runtime interface (CRI). The kubelet's config will control how
much swap memory the kubelet instructs the container runtime to allocate to
each container via the CRI. The container runtime will then write the swap
settings to the container level cgroup.
How do I use it?
On a node where swap memory is already provisioned, Kubernetes use of swap on a
node can be enabled by enabling the NodeSwap feature gate on the kubelet, and
disabling the failSwapOn configuration setting
or the --fail-swap-on command line flag.
You can also optionally configure memorySwap.swapBehavior in order to
specify how a node will use swap memory. For example,
memorySwap:
swapBehavior: LimitedSwap
The available configuration options for swapBehavior are:
LimitedSwap(default): Kubernetes workloads are limited in how much swap they can use. Workloads on the node not managed by Kubernetes can still swap.UnlimitedSwap: Kubernetes workloads can use as much swap memory as they request, up to the system limit.
If configuration for memorySwap is not specified and the feature gate is
enabled, by default the kubelet will apply the same behaviour as the
LimitedSwap setting.
The behaviour of the LimitedSwap setting depends if the node is running with
v1 or v2 of control groups (also known as "cgroups"):
- cgroups v1: Kubernetes workloads can use any combination of memory and swap, up to the pod's memory limit, if set.
- cgroups v2: Kubernetes workloads cannot use swap memory.
Caveats
Having swap available on a system reduces predictability. Swap's performance is worse than regular memory, sometimes by many orders of magnitude, which can cause unexpected performance regressions. Furthermore, swap changes a system's behaviour under memory pressure, and applications cannot directly control what portions of their memory usage are swapped out. Since enabling swap permits greater memory usage for workloads in Kubernetes that cannot be predictably accounted for, it also increases the risk of noisy neighbours and unexpected packing configurations, as the scheduler cannot account for swap memory usage.
The performance of a node with swap memory enabled depends on the underlying physical storage. When swap memory is in use, performance will be significantly worse in an I/O operations per second (IOPS) constrained environment, such as a cloud VM with I/O throttling, when compared to faster storage mediums like solid-state drives or NVMe.
Hence, we do not recommend the use of swap for certain performance-constrained workloads or environments. Cluster administrators and developers should benchmark their nodes and applications before using swap in production scenarios, and we need your help with that!
Looking ahead
The Kubernetes 1.22 release introduces alpha support for swap memory on nodes, and we will continue to work towards beta graduation in the 1.23 release. This will include:
- Adding support for controlling swap consumption at the Pod level via cgroups.
- This will include the ability to set a system-reserved quantity of swap from what kubelet detects on the host.
- Determining a set of metrics for node QoS in order to evaluate the performance and stability of nodes with and without swap enabled.
- Collecting feedback from test user cases.
- We will consider introducing new configuration modes for swap, such as a node-wide swap limit for workloads.
How can I learn more?
You can review the current documentation on the Kubernetes website.
For more information, and to assist with testing and provide feedback, please see KEP-2400 and its design proposal.
How do I get involved?
Your feedback is always welcome! SIG Node meets regularly and can be reached via Slack (channel #sig-node), or the SIG's mailing list. Feel free to reach out to me, Elana Hashman (@ehashman on Slack and GitHub) if you'd like to help.
Kubernetes 1.22: Server Side Apply moves to GA
Authors: Jeffrey Ying, Google & Joe Betz, Google
Server-side Apply (SSA) has been promoted to GA in the Kubernetes v1.22 release. The GA milestone means you can depend on the feature and its API, without fear of future backwards-incompatible changes. GA features are protected by the Kubernetes deprecation policy.
What is Server-side Apply?
Server-side Apply helps users and controllers manage their resources through declarative configurations. Server-side Apply replaces the client side apply feature implemented by “kubectl apply” with a server-side implementation, permitting use by tools/clients other than kubectl. Server-side Apply is a new merging algorithm, as well as tracking of field ownership, running on the Kubernetes api-server. Server-side Apply enables new features like conflict detection, so the system knows when two actors are trying to edit the same field. Refer to the Server-side Apply Documentation and Beta 2 release announcement for more information.
What’s new since Beta?
Since the Beta 2 release subresources support has been added, and both client-go and Kubebuilder have added comprehensive support for Server-side Apply. This completes the Server-side Apply functionality required to make controller development practical.
Support for subresources
Server-side Apply now fully supports subresources like status and scale. This is particularly important for controllers, which are often responsible for writing to subresources.
Server-side Apply support in client-go
Previously, Server-side Apply could only be called from the client-go typed client using the Patch function, with PatchType set to ApplyPatchType. Now, Apply functions are included in the client to allow for a more direct and typesafe way of calling Server-side Apply. Each Apply function takes an "apply configuration" type as an argument, which is a structured representation of an Apply request. For example:
import (
...
v1ac "k8s.io/client-go/applyconfigurations/autoscaling/v1"
)
hpaApplyConfig := v1ac.HorizontalPodAutoscaler(autoscalerName, ns).
WithSpec(v1ac.HorizontalPodAutoscalerSpec().
WithMinReplicas(0)
)
return hpav1client.Apply(ctx, hpaApplyConfig, metav1.ApplyOptions{FieldManager: "mycontroller", Force: true})
Note in this example that HorizontalPodAutoscaler is imported from an "applyconfigurations" package. Each "apply configuration" type represents the same Kubernetes object kind as the corresponding go struct, but where all fields are pointers to make them optional, allowing apply requests to be accurately represented. For example, when the apply configuration in the above example is marshalled to YAML, it produces:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myHPA
namespace: myNamespace
spec:
minReplicas: 0
To understand why this is needed, the above YAML cannot be produced by the v1.HorizontalPodAutoscaler go struct. Take for example:
hpa := v1.HorizontalPodAutoscaler{
TypeMeta: metav1.TypeMeta{
APIVersion: "autoscaling/v1",
Kind: "HorizontalPodAutoscaler",
},
ObjectMeta: ObjectMeta{
Namespace: ns,
Name: autoscalerName,
},
Spec: v1.HorizontalPodAutoscalerSpec{
MinReplicas: pointer.Int32Ptr(0),
},
}
The above code attempts to declare the same apply configuration as shown in the previous examples, but when marshalled to YAML, produces:
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v1
metadata
name: myHPA
namespace: myNamespace
creationTimestamp: null
spec:
scaleTargetRef:
kind: ""
name: ""
minReplicas: 0
maxReplicas: 0
Which, among other things, contains spec.maxReplicas set to 0. This is almost certainly not what the caller intended (the intended apply configuration says nothing about the maxReplicas field), and could have serious consequences on a production system: it directs the autoscaler to downscale to zero pods. The problem here originates from the fact that the go structs contain required fields that are zero valued if not set explicitly. The go structs work as intended for create and update operations, but are fundamentally incompatible with apply, which is why we have introduced the generated "apply configuration" types.
The "apply configurations" also have convenience With<FieldName> functions that make it easier to build apply requests. This allows developers to set fields without having to deal with the fact that all the fields in the "apply configuration" types are pointers, and are inconvenient to set using go. For example MinReplicas: &0 is not legal go code, so without the With functions, developers would work around this problem by using a library, e.g. MinReplicas: pointer.Int32Ptr(0), but string enumerations like corev1.Protocol are still a problem since they cannot be supported by a general purpose library. In addition to the convenience, the With functions also isolate developers from the underlying representation, which makes it safer for the underlying representation to be changed to support additional features in the future.
Using Server-side Apply in a controller
You can use the new support for Server-side Apply no matter how you implemented your controller. However, the new client-go support makes it easier to use Server-side Apply in controllers.
When authoring new controllers to use Server-side Apply, a good approach is to have the controller recreate the apply configuration for an object each time it reconciles that object. This ensures that the controller fully reconciles all the fields that it is responsible for. Controllers typically should unconditionally set all the fields they own by setting Force: true in the ApplyOptions. Controllers must also provide a FieldManager name that is unique to the reconciliation loop that apply is called from.
When upgrading existing controllers to use Server-side Apply the same approach often works well--migrate the controllers to recreate the apply configuration each time it reconciles any object. Unfortunately, the controller might have multiple code paths that update different parts of an object depending on various conditions. Migrating a controller like this to Server-side Apply can be risky because if the controller forgets to include any fields in an apply configuration that is included in a previous apply request, a field can be accidently deleted. To ease this type of migration, client-go apply support provides a way to replace any controller reconciliation code that performs a "read/modify-in-place/update" (or patch) workflow with a "extract/modify-in-place/apply" workflow. Here's an example of the new workflow:
fieldMgr := "my-field-manager"
deploymentClient := clientset.AppsV1().Deployments("default")
// read, could also be read from a shared informer
deployment, err := deploymentClient.Get(ctx, "example-deployment", metav1.GetOptions{})
if err != nil {
// handle error
}
// extract
deploymentApplyConfig, err := appsv1ac.ExtractDeployment(deployment, fieldMgr)
if err != nil {
// handle error
}
// modify-in-place
deploymentApplyConfig.Spec.Template.Spec.WithContainers(corev1ac.Container().
WithName("modify-slice").
WithImage("nginx:1.14.2"),
)
// apply
applied, err := deploymentClient.Apply(ctx, deploymentApplyConfig, metav1.ApplyOptions{FieldManager: fieldMgr})
For developers using Custom Resource Definitions (CRDs), the Kubebuilder apply support will provide the same capabilities. Documentation will be included in the Kubebuilder book when available.
Server-side Apply and CustomResourceDefinitions
It is strongly recommended that all Custom Resource Definitions (CRDs) have a schema. CRDs without a schema are treated as unstructured data by Server-side Apply. Keys are treated as fields in a struct and lists are assumed to be atomic.
CRDs that specify a schema are able to specify additional annotations in the schema. Please refer to the documentation on the full list of available annotations.
New annotations since beta:
Defaulting: Values for fields that appliers do not express explicit interest in should be defaulted. This prevents an applier from unintentionally owning a defaulted field that might cause conflicts with other appliers. If unspecified, the default value is nil or the nil equivalent for the corresponding type.
- Usage: see the CRD Defaulting documentation for more details.
- Golang:
+default=<value> - OpenAPI extension:
default: <value>
Atomic for maps and structs:
Maps: By default maps are granular. A different manager is able to manage each map entry. They can also be configured to be atomic such that a single manager owns the entire map.
- Usage: Refer to Merge Strategy for a more detailed overview
- Golang:
+mapType=granular/atomic - OpenAPI extension:
x-kubernetes-map-type: granular/atomic
Structs: By default structs are granular and a separate applier may own each field. For certain kinds of structs, atomicity may be desired. This is most commonly seen in small coordinate-like structs such as Field/Object/Namespace Selectors, Object References, RGB values, Endpoints (Protocol/Port pairs), etc.
- Usage: Refer to Merge Strategy for a more detailed overview
- Golang:
+structType=granular/atomic - OpenAPI extension:
x-kubernetes-map-type:atomic/granular
What's Next?
After Server Side Apply, the next focus for the API Expression working-group is around improving the expressiveness and size of the published Kubernetes API schema. To see the full list of items we are working on, please join our working group and refer to the work items document.
How to get involved?
The working-group for apply is wg-api-expression. It is available on slack #wg-api-expression, through the mailing list and we also meet every other Tuesday at 9.30 PT on Zoom.
We would also like to use the opportunity to thank the hard work of all the contributors involved in making this promotion to GA possible:
- Andrea Nodari
- Antoine Pelisse
- Daniel Smith
- Jeffrey Ying
- Jenny Buckley
- Joe Betz
- Julian Modesto
- Kevin Delgado
- Kevin Wiesmüller
- Maria Ntalla
Kubernetes 1.22: Reaching New Peaks
Authors: Kubernetes 1.22 Release Team
We’re pleased to announce the release of Kubernetes 1.22, the second release of 2021!
This release consists of 53 enhancements: 13 enhancements have graduated to stable, 24 enhancements are moving to beta, and 16 enhancements are entering alpha. Also, three features have been deprecated.
In April of this year, the Kubernetes release cadence was officially changed from four to three releases yearly. This is the first longer-cycle release related to that change. As the Kubernetes project matures, the number of enhancements per cycle grows. This means more work, from version to version, for the contributor community and Release Engineering team, and it can put pressure on the end-user community to stay up-to-date with releases containing increasingly more features.
Changing the release cadence from four to three releases yearly balances many aspects of the project, both in how contributions and releases are managed, and also in the community's ability to plan for upgrades and stay up to date.
You can read more in the official blog post Kubernetes Release Cadence Change: Here’s What You Need To Know.
Major Themes
Server-side Apply graduates to GA
Server-side Apply is a new field ownership and object merge algorithm running on the Kubernetes API server. Server-side Apply helps users and controllers manage their resources via declarative configurations. It allows them to create and/or modify their objects declaratively, simply by sending their fully specified intent. After being in beta for a couple releases, Server-side Apply is now generally available.
External credential providers now stable
Support for Kubernetes client credential plugins has been in beta since 1.11, and with the release of Kubernetes 1.22 now graduates to stable. The GA feature set includes improved support for plugins that provide interactive login flows, as well as a number of bug fixes. Aspiring plugin authors can look at sample-exec-plugin to get started.
etcd moves to 3.5.0
Kubernetes' default backend storage, etcd, has a new release: 3.5.0. The new release comes with improvements to the security, performance, monitoring, and developer experience. There are numerous bug fixes and some critical new features like the migration to structured logging and built-in log rotation. The release comes with a detailed future roadmap to implement a solution to traffic overload. You can read a full and detailed list of changes in the 3.5.0 release announcement.
Quality of Service for memory resources
Originally, Kubernetes used the v1 cgroups API. With that design, the QoS class for a Pod only applied to CPU resources (such as cpu_shares). As an alpha feature, Kubernetes v1.22 can now use the cgroups v2 API to control memory allocation and isolation. This feature is designed to improve workload and node availability when there is contention for memory resources, and to improve the predictability of container lifecycle.
Node system swap support
Every system administrator or Kubernetes user has been in the same boat regarding setting up and using Kubernetes: disable swap space. With the release of Kubernetes 1.22, alpha support is available to run nodes with swap memory. This change lets administrators opt in to configuring swap on Linux nodes, treating a portion of block storage as additional virtual memory.
Windows enhancements and capabilities
Continuing to support the growing developer community, SIG Windows has released their Development Environment. These new tools support multiple CNI providers and can run on multiple platforms. There is also a new way to run bleeding-edge Windows features from scratch by compiling the Windows kubelet and kube-proxy, then using them along with daily builds of other Kubernetes components.
CSI support for Windows nodes moves to GA in the 1.22 release. In Kubernetes v1.22, Windows privileged containers are an alpha feature. To allow using CSI storage on Windows nodes, CSIProxy enables CSI node plugins to be deployed as unprivileged pods, using the proxy to perform privileged storage operations on the node.
Default profiles for seccomp
An alpha feature for default seccomp profiles has been added to the kubelet, along with a new command line flag and configuration. When in use, this new feature provides cluster-wide seccomp defaults, using the RuntimeDefault seccomp profile rather than Unconfined by default. This enhances the default security of the Kubernetes Deployment. Security administrators will now sleep better knowing that workloads are more secure by default. To learn more about the feature, please refer to the official seccomp tutorial.
More secure control plane with kubeadm
A new alpha feature allows running the kubeadm control plane components as non-root users. This is a long requested security measure in kubeadm. To try it you must enable the kubeadm specific RootlessControlPlane feature gate. When you deploy a cluster using this alpha feature, your control plane runs with lower privileges.
For kubeadm, Kubernetes 1.22 also brings a new v1beta3 configuration API. This iteration adds some long requested features and deprecates some existing ones. The v1beta3 version is now the preferred API version; the v1beta2 API also remains available and is not yet deprecated.
Major Changes
Removal of several deprecated beta APIs
A number of deprecated beta APIs have been removed in 1.22 in favor of the GA version of those same APIs. All existing objects can be interacted with via stable APIs. This removal includes beta versions of the Ingress, IngressClass, Lease, APIService, ValidatingWebhookConfiguration, MutatingWebhookConfiguration, CustomResourceDefinition, TokenReview, SubjectAccessReview, and CertificateSigningRequest APIs.
For the full list, check out the Deprecated API Migration Guide as well as the blog post Kubernetes API and Feature Removals In 1.22: Here’s What You Need To Know.
API changes and improvements for ephemeral containers
The API used to create Ephemeral Containers changes in 1.22. The Ephemeral Containers feature is alpha and disabled by default, and the new API does not work with clients that attempt to use the old API.
For stable features, the kubectl tool follows the Kubernetes version skew policy; however, kubectl v1.21 and older do not support the new API for ephemeral containers. If you plan to use kubectl debug to create ephemeral containers, and your cluster is running Kubernetes v1.22, you cannot do so with kubectl v1.21 or earlier. Please update kubectl to 1.22 if you wish to use kubectl debug with a mix of cluster versions.
Other Updates
Graduated to Stable
- Bound Service Account Token Volumes
- CSI Service Account Token
- Windows Support for CSI Plugins
- Warning mechanism for deprecated API use
- PodDisruptionBudget Eviction
Notable Feature Updates
- A new PodSecurity admission alpha feature is introduced, intended as a replacement for PodSecurityPolicy
- The Memory Manager moves to beta
- A new alpha feature to enable API Server Tracing
- A new v1beta3 version of the kubeadm configuration format
- Generic data populators for PersistentVolumes are now available in alpha
- The Kubernetes control plane will now always use the CronJobs v2 controller
- As an alpha feature, all Kubernetes node components (including the kubelet, kube-proxy, and container runtime) can be run as a non-root user
Release notes
You can check out the full details of the 1.22 release in the release notes.
Availability of release
Kubernetes 1.22 is available for download and also on the GitHub project.
There are some great resources out there for getting started with Kubernetes. You can check out some interactive tutorials on the main Kubernetes site, or run a local cluster on your machine using Docker containers with kind. If you’d like to try building a cluster from scratch, check out the Kubernetes the Hard Way tutorial by Kelsey Hightower.
Release Team
This release was made possible by a very dedicated group of individuals, who came together as a team to deliver technical content, documentation, code, and a host of other components that go into every Kubernetes release.
A huge thank you to the release lead Savitha Raghunathan for leading us through a successful release cycle, and to everyone else on the release team for supporting each other, and working so hard to deliver the 1.22 release for the community.
We would also like to take this opportunity to remember Peeyush Gupta, a member of our team that we lost earlier this year. Peeyush was actively involved in SIG ContribEx and the Kubernetes Release Team, most recently serving as the 1.22 Communications lead. His contributions and efforts will continue to reflect in the community he helped build. A CNCF memorial page has been created where thoughts and memories can be shared by the community.
Release Logo

Amidst the ongoing pandemic, natural disasters, and ever-present shadow of burnout, the 1.22 release of Kubernetes includes 53 enhancements. This makes it the largest release to date. This accomplishment was only made possible due to the hard-working and passionate Release Team members and the amazing contributors of the Kubernetes ecosystem. The release logo is our reminder to keep reaching for new milestones and setting new records. And it is dedicated to all the Release Team members, hikers, and stargazers!
The logo is designed by Boris Zotkin. Boris is a Mac/Linux Administrator at the MathWorks. He enjoys simple things in life and loves spending time with his family. This tech-savvy individual is always up for a challenge and happy to help a friend!
User Highlights
- In May, the CNCF welcomed 27 new organizations across the globe as members of the diverse cloud native ecosystem. These new members will participate in CNCF events, including the upcoming KubeCon + CloudNativeCon NA in Los Angeles from October 12 – 15, 2021.
- The CNCF granted Spotify the Top End User Award during KubeCon + CloudNativeCon EU – Virtual 2021.
Project Velocity
The CNCF K8s DevStats project aggregates a number of interesting data points related to the velocity of Kubernetes and various sub-projects. This includes everything from individual contributions to the number of companies that are contributing, and is an illustration of the depth and breadth of effort that goes into evolving this ecosystem.
In the v1.22 release cycle, which ran for 15 weeks (April 26 to August 4), we saw contributions from 1063 companies and 2054 individuals.
Ecosystem Updates
- KubeCon + CloudNativeCon Europe 2021 was held in May, the third such event to be virtual. All talks are now available on-demand for anyone that would like to catch up!
- Spring Term LFX Program had the largest graduating class with 28 successful CNCF interns!
- CNCF launched livestreaming on Twitch at the beginning of the year targeting definitive interactive media experience for anyone wanting to learn, grow, and collaborate with others in the Cloud Native community from anywhere in the world.
Event Updates
- KubeCon + CloudNativeCon North America 2021 will take place in Los Angeles, October 12 – 15, 2021! You can find more information about the conference and registration on the event site.
- Kubernetes Community Days has upcoming events scheduled in Italy, the UK, and in Washington DC.
Upcoming release webinar
Join members of the Kubernetes 1.22 release team on October 5, 2021 to learn about the major features of this release, as well as deprecations and removals to help plan for upgrades. For more information and registration, visit the event page on the CNCF Online Programs site.
Get Involved
If you’re interested in contributing to the Kubernetes community, Special Interest Groups (SIGs) are a great starting point. Many of them may align with your interests! If there are things you’d like to share with the community, you can join the weekly community meeting, or use any of the following channels:
- Find out more about contributing to Kubernetes at the Kubernetes Contributors website.
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Share your Kubernetes story
- Read more about what’s happening with Kubernetes on the blog
- Learn more about the Kubernetes Release Team
Roorkee robots, releases and racing: the Kubernetes 1.21 release interview
Author: Craig Box (Google)
With Kubernetes 1.22 due out next week, now is a great time to look back on 1.21. The release team for that version was led by Nabarun Pal from VMware.
Back in April I interviewed Nabarun on the weekly Kubernetes Podcast from Google; the latest in a series of release lead conversations that started back with 1.11, not long after the show started back in 2018.
In these interviews we learn a little about the release, but also about the process behind it, and the story behind the person chosen to lead it. Getting to know a community member is my favourite part of the show each week, and so I encourage you to subscribe wherever you get your podcasts. With a release coming next week, you can probably guess what our next topic will be!
This transcript has been edited and condensed for clarity.
CRAIG BOX: You have a Bachelor of Technology in Metallurgical and Materials Engineering. How are we doing at turning lead into gold?
NABARUN PAL: Well, last I checked, we have yet to find the philosopher's stone!
CRAIG BOX: One of the more important parts of the process?
NABARUN PAL: We're not doing that well in terms of getting alchemists up and running. There is some improvement in nuclear technology, where you can turn lead into gold, but I would guess buying gold would be much more efficient.
CRAIG BOX: Or Bitcoin? It depends what you want to do with the gold.
NABARUN PAL: Yeah, seeing the increasing prices of Bitcoin, you'd probably prefer to bet on that. But, don't take this as a suggestion. I'm not a registered investment advisor, and I don't give investment advice!
CRAIG BOX: But you are, of course, a trained materials engineer. How did you get into that line of education?
NABARUN PAL: We had a graded and equated exam structure, where you sit a single exam, and then based on your performance in that exam, you can try any of the universities which take those scores into account. I went to the Indian Institute of Technology, Roorkee.
Materials engineering interested me a lot. I had a passion for computer science since childhood, but I also liked material science, so I wanted to explore that field. I did a lot of exploration around material science and metallurgy in my freshman and sophomore years, but then computing, since it was a passion, crept into the picture.
CRAIG BOX: Let's dig in there a little bit. What did computing look like during your childhood?
NABARUN PAL: It was a very interesting journey. I started exploring computers back when I was seven or eight. For my first programming language, if you call it a programming language, I explored LOGO.
You have a turtle on the screen, and you issue commands to it, like move forward or rotate or pen up or pen down. You basically draw geometric figures. I could visually see how I could draw a square and how I could draw a triangle. It was an interesting journey after that. I learned BASIC, then went to some amount of HTML, JavaScript.
CRAIG BOX: It's interesting to me because Logo and BASIC were probably my first two programming languages, but I think there was probably quite a gap in terms of when HTML became a thing after those two! Did your love of computing always lead you down the path towards programming, or were you interested as a child in using computers for games or application software? What led you specifically into programming?
NABARUN PAL: Programming came in late. Not just in computing, but in life, I'm curious with things. When my parents got me my first computer, I was curious. I was like, "how does this operating system work?" What even is running it? Using a television and using a computer is a different experience, but usability is kind of the same thing. The HCI device for a television is a remote, whereas with a computer, I had a keyboard and a mouse. I used to tinker with the box and reinstall operating systems.
We used to get magazines back then. They used to bundle OpenSuse or Debian, and I used to install them. It was an interesting experience, 15 years back, how Linux used to be. I have been a tinkerer all around, and that's what eventually led me to programming.
CRAIG BOX: With an interest in both the physical and ethereal aspects of technology, you did a lot of robotics challenges during university. That's something that I am not surprised to hear from someone who has a background in Logo, to be honest. There's Mindstorms, and a lot of other technology that is based around robotics that a lot of LOGO people got into. How was that something that came about for you?
NABARUN PAL: When I joined my university, apart from studying materials, one of the things they used to really encourage was to get involved in a lot of extracurricular activities. One which interested me was robotics. I joined my college robotics team and participated in a lot of challenges.
Predominantly, we used to participate in this competition called ABU Robocon, which is an event conducted by the Asia-Pacific Broadcasting Union. What they used to do was, every year, one of the participating countries in the contest would provide a problem statement. For example, one year, they asked us to build a badminton-playing robot. They asked us to build a rugby playing robot or a Frisbee thrower, and there are some interesting problem statements around the challenge: you can't do this. You can't do that. Weight has to be like this. Dimensions have to be like that.
I got involved in that, and most of my time at university, I used to spend there. Material science became kind of a backburner for me, and my hobby became my full time thing.
CRAIG BOX: And you were not only involved there in terms of the project and contributions to it, but you got involved as a secretary of the team, effectively, doing a lot of the organization, which is a thread that will come up as we speak about Kubernetes.
NABARUN PAL: Over the course of time, when I gained more knowledge into how the team works, it became very natural that I graduated up the ladder and then managed juniors. I became the joint secretary of the robotics club in our college. This was more of a broad, engaging role in evangelizing robotics at the university, to promote events, to help students to see the value in learning robotics - what you gain out of that mechanically or electronically, or how do you develop your logic by programming robots.
CRAIG BOX: Your first job after graduation was working at a company called Algoshelf, but you were also an intern there while you were at school?
NABARUN PAL: Algoshelf was known as Rorodata when I joined them as an intern. This was also an interesting opportunity for me in the sense that I was always interested in writing programs which people would use. One of the things that I did there was build an open source Function as a Service framework, if I may call it that - it was mostly turning Python functions into web servers without even writing any code. The interesting bit there was that it was targeted toward data scientists, and not towards programmers. We had to understand the pain of data scientists, that they had to learn a lot of programming in order to even deploy their machine learning models, and we wanted to solve that problem.
They offered me a job after my internship, and I kept on working for them after I graduated from university. There, I got introduced to Kubernetes, so we pivoted into a product structure where the very same thing I told you, the Functions as a Service thing, could be deployed in Kubernetes. I was exploring Kubernetes to use it as a scalable platform. Instead of managing pets, we wanted to manage cattle, as in, we wanted to have a very highly distributed architecture.
CRAIG BOX: Not actual cattle. I've been to India. There are a lot of cows around.
NABARUN PAL: Yeah, not actual cattle. That is a bit tough.
CRAIG BOX: When Algoshelf we're looking at picking up Kubernetes, what was the evaluation process like? Were you looking at other tools at the time? Or had enough time passed that Kubernetes was clearly the platform that everyone was going to use?
NABARUN PAL: Algoshelf was a natural evolution. Before Kubernetes, we used to deploy everything on a single big AWS server, using systemd. Everything was a systemd service, and everything was deployed using Fabric. Fabric is a Python package which essentially is like Ansible, but much leaner, as it does not have all the shims and things that Ansible has.
Then we asked "what if we need to scale out to different machines?" Kubernetes was in the hype. We hopped onto the hype train to see whether Kubernetes was worth it for us. And that's where my journey started, exploring the ecosystem, exploring the community. How can we improve the community in essence?
CRAIG BOX: A couple of times now you've mentioned as you've grown in a role, becoming part of the organization and the arranging of the group. You've talked about working in Python. You had submitted some talks to Pycon India. And I understand you're now a tech lead for that conference. What does the tech community look like in India and how do you describe your involvement in it?
NABARUN PAL: My involvement with the community began when I was at university. When I was working as an intern at Algoshelf, I was introduced to this-- I never knew about PyCon India, or tech conferences in general.
The person that I was working with just asked me, like hey, did you submit a talk to PyCon India? It's very useful, the library that we were making. So I submitted a talk to PyCon India in 2017. Eventually the talk got selected. That was not my first speaking opportunity, it was my second. I also spoke at PyData Delhi on a similar thing that I worked on in my internship.
It has been a journey since then. I talked about the same thing at FOSSASIA Summit in Singapore, and got really involved with the Python community because it was what I used to work on back then.
After giving all those talks at conferences, I got also introduced to this amazing group called dgplug, which is an acronym for the Durgapur Linux Users Group. It is a group started in-- I don't remember the exact year, but it was around 12 to 13 years back, by someone called Kushal Das, with the ideology of training students into being better open source contributors.
I liked the idea and got involved with in teaching last year. It is not limited to students. Professionals can also join in. It's about making anyone better at upstream contributions, making things sustainable. I started training people on Vim, on how to use text editors. so they are more efficient and productive. In general life, text editors are a really good tool.
The other thing was the shell. How do you navigate around the Linux shell and command line? That has been a fun experience.
CRAIG BOX: It's very interesting to think about that, because my own involvement with a Linux User Group was probably around the year 2000. And back then we were teaching people how to install things-- Linux on CD was kinda new at that point in time. There was a lot more of, what is this new thing and how do we get involved? When the internet took off around that time, all of that stuff moved online - you no longer needed to go meet a group of people in a room to talk about Linux. And I haven't really given much thought to the concept of a LUG since then, but it's great to see it having turned into something that's now about contributing, rather than just about how you get things going for yourself.
NABARUN PAL: Exactly. So as I mentioned earlier, my journey into Linux was installing SUSE from DVDs that came bundled with magazines. Back then it was a pain installing things because you did not get any instructions. There has certainly been a paradigm shift now. People are more open to reading instructions online, downloading ISOs, and then just installing them. So we really don't need to do that as part of LUGs.
We have shifted more towards enabling people to contribute to whichever project that they use. For example, if you're using Fedora, contribute to Fedora; make things better. It's just about giving back to the community in any way possible.
CRAIG BOX: You're also involved in the Kubernetes Bangalore meetup group. Does that group have a similar mentality?
NABARUN PAL: The Kubernetes Bangalore meetup group is essentially focused towards spreading the knowledge of Kubernetes and the aligned products in the ecosystem, whatever there is in the Cloud Native Landscape, in various ways. For example, to evangelize about using them in your company or how people use them in existing ways.
So a few months back in February, we did something like a Kubernetes contributor workshop. It was one of its kind in India. It was the first one if I recall correctly. We got a lot of traction and community members interested in contributing to Kubernetes and a lot of other projects. And this is becoming a really valuable thing.
I'm not much involved in the organization of the group. There are really great people already organizing it. I keep on being around and attending the meetups and trying to answer any questions if people have any.
CRAIG BOX: One way that it is possible to contribute to the Kubernetes ecosystem is through the release process. You've written a blog which talks about your journey through that. It started in Kubernetes 1.17, where you took a shadow role for that release. Tell me about what it was like to first take that plunge.
NABARUN PAL: Taking the plunge was a big step, I would say. It should not have been that way. After getting into the team, I saw that it is really encouraged that you should just apply to the team - but then write truthfully about yourself. What do you want? Write your passionate goal, why you want to be in the team.
So even right now the shadow applications are open for the next release. I wanted to give that a small shoutout. If you want to contribute to the Kubernetes release team, please do apply. The form is pretty simple. You just need to say why do you want to contribute to the release team.
CRAIG BOX: What was your answer to that question?
NABARUN PAL: It was a bit tricky. I have this philosophy of contributing to projects that I use in my day-to-day life. I use a lot of open source projects daily, and I started contributing to Kubernetes primarily because I was using the Kubernetes Python client. That was one of my first contributions.
When I was contributing to that, I explored the release team and it interested me a lot, particularly how interesting and varied the mechanics of releasing Kubernetes are. For most software projects, it's usually whenever you decide that you have made meaningful progress in terms of features, you release it. But Kubernetes is not like that. We follow a regular release cadence. And all those aspects really interested me. I actually applied for the first time in Kubernetes 1.16, but got rejected.
But I still applied to Kubernetes 1.17, and I got into the enhancements team. That team was led by MrBobbyTables, Bob Killen, back then, and Jeremy Rickard was one of my co-shadows in the team. I shadowed enhancements again. Then I lead enhancements in 1.19. I then shadowed the lead in 1.20 and eventually led the 1.21 team. That's what my journey has been.
My suggestion to people is don't be afraid of failure. Even if you don't get selected, it's perfectly fine. You can still contribute to the release team. Just hop on the release calls, raise your hand, and introduce yourself.
CRAIG BOX: Between the 1.20 and 1.21 releases, you moved to work on the upstream contribution team at VMware. I've noticed that VMware is hiring a lot of great upstream contributors at the moment. Is this something that Stephen Augustus had his fingerprints all over? Is there something in the water?
NABARUN PAL: A lot of people have fingerprints on this process. Stephen certainly had his fingerprints on it, I would say. We are expanding the team of upstream contributors primarily because the product that we are working for is based on Kubernetes. It helps us a lot in driving processes upstream and helping out the community as a whole, because everyone then gets enabled and benefits from what we contribute to the community.
CRAIG BOX: I understand that the Tanzu team is being built out in India at the moment, but I guess you probably haven't been able to meet them in person yet?
NABARUN PAL: Yes and no. I did not meet any of them after joining VMware, but I met a lot of my teammates, before I joined VMware, at KubeCons. For example, I met Nikhita, I met Dims, I met Stephen at KubeCon. I am yet to meet other members of the team and I'm really excited to catch up with them once everything comes out of lockdown and we go back to our normal lives.
CRAIG BOX: Yes, everyone that I speak to who has changed jobs in the pandemic says it's a very odd experience, just nothing really being different. And the same perhaps for people who are working on open source moving companies as well. They're doing the same thing, perhaps just for a different employer.
NABARUN PAL: As we say in the community, see you in another Slack in some time.
CRAIG BOX: We now turn to the recent release of Kubernetes 1.21. First of all, congratulations on that.
NABARUN PAL: Thank you.
CRAIG BOX: The announcement says the release consists of 51 enhancements, 13 graduating to stable, 16 moving to beta, 20 entering alpha, and then two features that have been deprecated. How would you summarize this release?
NABARUN PAL: One of the big points for this release is that it is the largest release of all time.
CRAIG BOX: Really?
NABARUN PAL: Yep. 1.20 was the largest release back then, but 1.21 got more enhancements, primarily due to a lot of changes that we did to the process.
In the 1.21 release cycle, we did a few things differently compared to other release cycles-- for example, in the enhancement process. An enhancement, in the Kubernetes context, is basically a feature proposal. You will hear the terminology Kubernetes Enhancement Proposals, or KEP, a lot in the community. An enhancement is a broad thing encapsulated in a specific document.
CRAIG BOX: I like to think of it as a thing that's worth having a heading in the release notes.
NABARUN PAL: Indeed. Until the 1.20 release cycle, what we used to do was-- the release team has a vertical called enhancements. The enhancements team members used to ping each of the enhancement issues and ask whether they want to be part of the release cycle or not. The authors would decide, or talk to their SIG, and then come back with the answer, as to whether they wanted to be part of the cycle.
In this release, what we did was we eliminated that process and asked the SIGs proactively to discuss amongst themselves, what they wanted to pitch in for this release cycle. What set of features did they want to graduate this release? They may introduce things in alpha, graduate things to beta or stable, or they may also deprecate features.
What this did was promote a lot of async processes, and at the same time, give power back to the community. The community decides what they want in the release and then comes back collectively. It also reduces a lot of stress on the release team who previously had to ask people consistently what they wanted to pitch in for the release. You now have a deadline. You discuss amongst your SIG what your roadmap is and what it looks like for the near future. Maybe this release, and the next two. And you put all of those answers into a Google spreadsheet. Spreadsheets are still a thing.
CRAIG BOX: The Kubernetes ecosystem runs entirely on Google Spreadsheets.
NABARUN PAL: It does, and a lot of Google Docs for meeting notes! We did a lot of process improvements, which essentially led to a better release. This release cycle we had 13 enhancements graduating to stable, 16 which moved to beta, and 20 enhancements which were net new features into the ecosystem, and came in as alpha.
Along with that are features set for deprecation. One of them was PodSecurityPolicy. That has been a point of discussion in the Kubernetes user base and we also published a blog post about it. All credit to SIG Security who have been on top of things as to find a replacement for PodSecurityPolicy even before this release cycle ended, so that they could at least have a proposal of what will happen next.
CRAIG BOX: Let's talk about some old things and some new things. You mentioned PodSecurityPolicy there. That's a thing that's been around a long time and is being deprecated. Two things that have been around a long time and that are now being promoted to stable are CronJobs and PodDisruptionBudgets, both of which were introduced in Kubernetes 1.4, which came out in 2016. Why do you think it took so long for them both to go stable?
NABARUN PAL: I might not have a definitive answer to your question. One of the things that I feel is they might be already so good that nobody saw that they were beta features, and just kept on using them.
One of the things that I noticed when reading for the CronJobs graduation from beta to stable was the new controller. Users might not see this, but there has been a drastic change in the CronJob controller v2. What it essentially does is goes from a poll-based method of checking what users have defined as CronJobs to a queue architecture, which is the modern method of defining controllers. That has been one of the really good improvements in the case of CronJobs. Instead of the controller working in O(N) time, you now have constant time complexity.
CRAIG BOX: A lot of these features that have been in beta for a long time, like you say, people have an expectation that they are complete. With PodSecurityPolicy, it's being deprecated, which is allowed because it's a feature that never made it out of beta. But how do you think people will react to it going away? And does that say something about the need for the process to make sure that features don't just languish in beta forever, which has been introduced recently?
NABARUN PAL: That's true. One of the driving factors, when contributors are thinking of graduating beta features has been the "prevention of perma-beta" KEP. Back in 1.19 we introduced this process where each of the beta resources were marked for deprecation and removal in a certain time frame-- three releases for deprecation and another release for removal. That's also a motivating factor for eventually rethinking as to how beta resources work for us in the community. That is also very effective, I would say.
CRAIG BOX: Do remember that Gmail was in beta for eight years.
NABARUN PAL: I did not know that!
CRAIG BOX: Nothing in Kubernetes is quite that old yet, but we'll get there. Of the 20 new enhancements, do you have a favorite or any that you'd like to call out?
NABARUN PAL: There are two specific features in 1.21 that I'm really interested in, and are coming as net new features. One of them is the persistent volume health monitor, which gives the users the capability to actually see whether the backing volumes, which power persistent volumes in Kubernetes, are deleted or not. For example, the volumes may get deleted due to an inadvertent event, or they may get corrupted. That information is basically surfaced out as a field so that the user can leverage it in any way.
The other feature is the proposal for adding headers with the command name to kubectl requests. We have always set the user-agent information when doing those kind of requests, but the proposal is to add what command the user put in so that we can enable more telemetry, and cluster administrators can determine the usage patterns of how people are using the cluster. I'm really excited about these kind of features coming into play.
CRAIG BOX: You're the first release lead from the Asia-Pacific region, or more accurately, outside of the US and Europe. Most meetings in the Kubernetes ecosystem are traditionally in the window of overlap between the US and Europe, in the morning in California and the evening here in the UK. What's it been like to work outside of the time zones that the community had previously been operating in?
NABARUN PAL: It has been a fun and a challenging proposition, I would say. In the last two-ish years that I have been contributing to Kubernetes, the community has also transformed from a lot of early morning Pacific calls to more towards async processes. For example, we in the release team have transformed our processes so we don't do updates in the calls anymore. What we do is ask for updates ahead of time, and then in the call, we just discuss things which need to be discussed synchronously in the team.
We leverage the meetings right now more for discussions. But we also don't come to decisions in those discussions, because if any stakeholder is not present on the call, it puts them at a disadvantage. We are trying to talk more on Slack, publicly, or talk on mailing lists. That's where most of the discussion should happen, and also to gain lazy consensus. What I mean by lazy consensus is come up with a pre-decision kind of thing, but then also invite feedback from the broader community about what people would like them to see about that specific thing being discussed. This is where we as a community are also transforming a lot, but there is a lot more headroom to grow.
The release team also started to have EU/APAC burndown meetings. In addition to having one meeting focused towards the US and European time zones, we also do a meeting which is more suited towards European and Asia-Pacific time zones. One of the driving factors for those decisions was that the release team is seeing a lot of participation from a variety of time zones. To give you one metric, we had release team members this cycle from UTC+8 all through UTC-8 - 16 hours of span. It's really difficult to accommodate all of those zones in a single meeting. And it's not just those 16 hours of span - what about the other eight hours?
CRAIG BOX: Yeah, you're missing New Zealand. You could add another 5 hours of span right there.
NABARUN PAL: Exactly. So we will always miss people in meetings, and that's why we should also innovate more, have different kinds of meetings. But that also may not be very sustainable in the future. Will people attend duplicate meetings? Will people follow both of the meetings? More meetings is one of the solutions.
The other solution is you have threaded discussions on some medium, be it Slack or be it a mailing list. Then, people can just pitch in whenever it is work time for them. Then, at the end of the day, a 24-hour rolling period, you digest it, and then push it out as meeting notes. That's what the Contributor Experience Special Interest Group is doing - shout-out to them for moving to that process. I may be wrong here, but I think once every two weeks, they do async updates on Slack. And that is a really nice thing to have, improving variety of geographies that people can contribute from.
CRAIG BOX: Once you've put everything together that you hope to be in your release, you create a release candidate build. How do you motivate people to test those?
NABARUN PAL: That's a very interesting question. It is difficult for us to motivate people into trying out these candidates. It's mostly people who are passionate about Kubernetes who try out the release candidates and see for themselves what the bugs are. I remember Dims tweeting out a call that if somebody tries out the release candidate and finds a good bug or caveat, they could get a callout in the KubeCon keynote. That's one of the incentives - if you want to be called out in a KubeCon keynote, please try our release candidates.
CRAIG BOX: Or get a new pair of Kubernetes socks?
NABARUN PAL: We would love to give out goodies to people who try out our release candidates and find bugs. For example, if you want the brand new release team logo as a sticker, just hit me up. If you find a bug in a 1.22 release candidate, I would love to be able to send you some coupon codes for the store. Don't quote me on this, but do reach out.
CRAIG BOX: Now the release is out, is it time for you to put your feet up? What more things do you have to do, and how do you feel about the path ahead for yourself?
NABARUN PAL: I was discussing this with the team yesterday. Even after the release, we had kind of a water-cooler conversation. I just pasted in a Zoom link to all the release team members and said, hey, do you want to chat? One of the things that I realized that I'm really missing is the daily burndowns right now. I will be around in the release team and the SIG Release meetings, helping out the new lead in transitioning. And even my job, right now, is not over. I'm working with Taylor, who is the emeritus advisor for 1.21, on figuring out some of the mechanics for the next release cycle. I'm also documenting what all we did as part of the process and as part of the process changes, and making sure the next release cycle is up and running.
CRAIG BOX: We've done a lot of these release lead interviews now, and there's a question which we always like to ask, which is, what will you write down in the transition envelope? Savitha Raghunathan is the release lead for 1.22. What is the advice that you will pass on to her?
NABARUN PAL: Three words-- Do, Delegate, and Defer. Categorize things into those three buckets as to what you should do right away, what you need to defer, and things that you can delegate to your shadows or other release team members. That's one of the mantras that works really well when leading a team. It is not just in the context of the release team, but it's in the context of managing any team.
The other bit is over-communicate. No amount of communication is enough. What I've realized is the community is always willing to help you. One of the big examples that I can give is the day before release was supposed to happen, we were seeing a lot of test failures, and then one of the community members had an idea-- why don't you just send an email? I was like, "that sounds good. We can send an email mentioning all the flakes and call out for help to the broader Kubernetes developer community." And eventually, once we sent out the email, lots of people came in to help us in de-flaking the tests and trying to find out the root cause as to why those tests were failing so often. Big shout out to Antonio and all the SIG Network folks who came to pitch in.
No matter how many names I mention, it will never be enough. A lot of people, even outside the release team, have helped us a lot with this release. And that's where the release theme comes in - Power to the Community. I'm really stoked by how this community behaves and how people are willing to help you all the time. It's not about what they're telling you to do, but it's what they're also interested in, they're passionate about.
CRAIG BOX: One of the things you're passionate about is Formula One. Do you think Lewis Hamilton is going to take it away this year?
NABARUN PAL: It's a fair probability that Lewis will win the title this year as well.
CRAIG BOX: Which would take him to eight all time career wins. And thus-- he's currently tied with Michael Schumacher-- would pull him ahead.
NABARUN PAL: Yes. Michael Schumacher was my first favorite F1 driver, I would say. It feels a bit heartbreaking to see someone break Michael's record.
CRAIG BOX: How do you feel about Michael Schumacher's son joining the contest?
NABARUN PAL: I feel good. Mick Schumacher is in the fray right now. And I wish we could see him, in a few years, in a Ferrari. The Schumacher family back to Ferrari would be really great to see. But then, my fan favorite has always been McLaren, partly because I like the chemistry of Lando and Carlos over the last two years. It was heartbreaking to see Carlos go to Ferrari. But then we have Lando and Daniel Ricciardo in the team. They're also fun people.
Nabarun Pal is on the Tanzu team at VMware and served as the Kubernetes 1.21 release team lead.
You can find the Kubernetes Podcast from Google at @KubernetesPod on Twitter, and you can subscribe so you never miss an episode.
Updating NGINX-Ingress to use the stable Ingress API
Authors: James Strong, Ricardo Katz
With all Kubernetes APIs, there is a process to creating, maintaining, and ultimately deprecating them once they become GA. The networking.k8s.io API group is no different. The upcoming Kubernetes 1.22 release will remove several deprecated APIs that are relevant to networking:
- the
networking.k8s.io/v1beta1API version of IngressClass - all beta versions of Ingress:
extensions/v1beta1andnetworking.k8s.io/v1beta1
On a v1.22 Kubernetes cluster, you'll be able to access Ingress and IngressClass objects through the stable (v1) APIs, but access via their beta APIs won't be possible. This change has been in in discussion since 2017, 2019 with 1.16 Kubernetes API deprecations, and most recently in KEP-1453: Graduate Ingress API to GA.
During community meetings, the networking Special Interest Group has decided to continue supporting Kubernetes versions older than 1.22 with Ingress-NGINX version 0.47.0. Support for Ingress-NGINX will continue for six months after Kubernetes 1.22 is released. Any additional bug fixes and CVEs for Ingress-NGINX will be addressed on a need-by-need basis.
Ingress-NGINX will have separate branches and releases of Ingress-NGINX to support this model, mirroring the Kubernetes project process. Future releases of the Ingress-NGINX project will track and support the latest versions of Kubernetes.
| Kubernetes version | Ingress-NGINX version | Notes |
|---|---|---|
| v1.22 | v1.0.0-alpha.2 | New features, plus bug fixes. |
| v1.21 | v0.47.x | Bugfixes only, and just for security issues or crashes. No end-of-support date announced. |
| v1.20 | v0.47.x | Bugfixes only, and just for security issues or crashes. No end-of-support date announced. |
| v1.19 | v0.47.x | Bugfixes only, and just for security issues or crashes. Fixes only provided until 6 months after Kubernetes v1.22.0 is released. |
Because of the updates in Kubernetes 1.22, v0.47.0 will not work with Kubernetes 1.22.
What you need to do
The team is currently in the process of upgrading ingress-nginx to support
the v1 migration, you can track the progress
here.
We're not making feature improvements to ingress-nginx until after the support for
Ingress v1 is complete.
In the meantime to ensure no compatibility issues:
- Update to the latest version of Ingress-NGINX; currently v0.47.0
- After Kubernetes 1.22 is released, ensure you are using the latest version of Ingress-NGINX that supports the stable APIs for Ingress and IngressClass.
- Test Ingress-NGINX version v1.0.0-alpha.2 with Cluster versions >= 1.19 and report any issues to the projects Github page.
The community’s feedback and support in this effort is welcome. The Ingress-NGINX Sub-project regularly holds community meetings where we discuss this and other issues facing the project. For more information on the sub-project, please see SIG Network.
Kubernetes Release Cadence Change: Here’s What You Need To Know
Authors: Celeste Horgan, Adolfo García Veytia, James Laverack, Jeremy Rickard
On April 23, 2021, the Release Team merged a Kubernetes Enhancement Proposal (KEP) changing the Kubernetes release cycle from four releases a year (once a quarter) to three releases a year.
This blog post provides a high level overview about what this means for the Kubernetes community's contributors and maintainers.
What's changing and when
Starting with the Kubernetes 1.22 release, a lightweight policy will drive the creation of each release schedule. This policy states:
- The first Kubernetes release of a calendar year should start at the second or third week of January to provide people more time for contributors coming back from the end of year holidays.
- The last Kubernetes release of a calendar year should be finished by the middle of December.
- A Kubernetes release cycle has a length of approximately 15 weeks.
- The week of KubeCon + CloudNativeCon is not considered a 'working week' for SIG Release. The Release Team will not hold meetings or make decisions in this period.
- An explicit SIG Release break of at least two weeks between each cycle will be enforced.
As a result, Kubernetes will follow a three releases per year cadence. Kubernetes 1.23 will be the final release of the 2021 calendar year. This new policy results in a very predictable release schedule, allowing us to forecast upcoming release dates:
Proposed Kubernetes Release Schedule for the remainder of 2021
| Week Number in Year | Release Number | Release Week | Note |
|---|---|---|---|
| 35 | 1.23 | 1 (August 23) | |
| 50 | 1.23 | 16 (December 07) | KubeCon + CloudNativeCon NA Break (Oct 11-15) |
Proposed Kubernetes Release Schedule for 2022
| Week Number in Year | Release Number | Release Week | Note |
|---|---|---|---|
| 1 | 1.24 | 1 (January 03) | |
| 15 | 1.24 | 15 (April 12) | |
| 17 | 1.25 | 1 (April 26) | KubeCon + CloudNativeCon EU likely to occur |
| 32 | 1.25 | 15 (August 09) | |
| 34 | 1.26 | 1 (August 22 | KubeCon + CloudNativeCon NA likely to occur |
| 49 | 1.26 | 14 (December 06) |
These proposed dates reflect only the start and end dates, and they are subject to change. The Release Team will select dates for enhancement freeze, code freeze, and other milestones at the start of each release. For more information on these milestones, please refer to the release phases documentation. Feedback from prior releases will feed into this process.
What this means for end users
The major change end users will experience is a slower release cadence and a slower rate of enhancement graduation. Kubernetes release artifacts, release notes, and all other aspects of any given release will stay the same.
Prior to this change an enhancement could graduate from alpha to stable in 9 months. With the change in cadence, this will stretch to 12 months. Additionally, graduation of features over the last few releases has in some part been driven by release team activities.
With fewer releases, users can expect to see the rate of feature graduation slow. Users can also expect releases to contain a larger number of enhancements that they need to be aware of during upgrades. However, with fewer releases to consume per year, it's intended that end user organizations will spend less time on upgrades and gain more time on supporting their Kubernetes clusters. It also means that Kubernetes releases are in support for a slightly longer period of time, so bug fixes and security patches will be available for releases for a longer period of time.
What this means for Kubernetes contributors
With a lower release cadence, contributors have more time for project enhancements, feature development, planning, and testing. A slower release cadence also provides more room for maintaining their mental health, preparing for events like KubeCon + CloudNativeCon or work on downstream integrations.
Why we decided to change the release cadence
The Kubernetes 1.19 cycle was far longer than usual. SIG Release extended it to lessen the burden on both Kubernetes contributors and end users due the COVID-19 pandemic. Following this extended release, the Kubernetes 1.20 release became the third, and final, release for 2020.
As the Kubernetes project matures, the number of enhancements per cycle grows, along with the burden on contributors, the Release Engineering team. Downstream consumers and integrators also face increased challenges keeping up with ever more feature-packed releases. A wider project adoption means the complexity of supporting a rapidly evolving platform affects a bigger downstream chain of consumers.
Changing the release cadence from four to three releases per year balances a variety of factors for stakeholders: while it's not strictly an LTS policy, consumers and integrators will get longer support terms for each minor version as the extended release cycles lead to the previous three releases being supported for a longer period. Contributors get more time to mature enhancements and get them ready for production.
Finally, the management overhead for SIG Release and the Release Engineering team diminishes allowing the team to spend more time on improving the quality of the software releases and the tooling that drives them.
How you can help
Join the discussion about communicating future release dates and be sure to be on the lookout for post release surveys.
Where you can find out more
- Read the KEP here
- Join the kubernetes-dev mailing list
- Join Kubernetes Slack and follow the #announcements channel
Spotlight on SIG Usability
Author: Kunal Kushwaha, Civo
Introduction
Are you interested in learning about what SIG Usability does and how you can get involved? Well, you're at the right place. SIG Usability is all about making Kubernetes more accessible to new folks, and its main activity is conducting user research for the community. In this blog, we have summarized our conversation with Gaby Moreno, who walks us through the various aspects of being a part of the SIG and shares some insights about how others can get involved.
Gaby is a co-lead for SIG Usability. She works as a Product Designer at IBM and enjoys working on the user experience of open, hybrid cloud technologies like Kubernetes, OpenShift, Terraform, and Cloud Foundry.
A summary of our conversation
Q. Could you tell us a little about what SIG Usability does?
A. SIG Usability at a high level started because there was no dedicated user experience team for Kubernetes. The extent of SIG Usability is focussed on the end-client ease of use of the Kubernetes project. The main activity is user research for the community, which includes speaking to Kubernetes users.
This covers points like user experience and accessibility. The objectives of the SIG are to guarantee that the Kubernetes project is maximally usable by people of a wide range of foundations and capacities, such as incorporating internationalization and ensuring the openness of documentation.
Q. Why should new and existing contributors consider joining SIG Usability?
A. There are plenty of territories where new contributors can begin. For example:
- User research projects, where people can help understand the usability of the end-user experiences, including error messages, end-to-end tasks, etc.
- Accessibility guidelines for Kubernetes community artifacts, examples include: internationalization of documentation, color choices for people with color blindness, ensuring compatibility with screen reader technology, user interface design for core components with user interfaces, and more.
Q. What do you do to help new contributors get started?
A. New contributors can get started by shadowing one of the user interviews, going through user interview transcripts, analyzing them, and designing surveys.
SIG Usability is also open to new project ideas. If you have an idea, we’ll do what we can to support it. There are regular SIG Meetings where people can ask their questions live. These meetings are also recorded for those who may not be able to attend. As always, you can reach out to us on Slack as well.
Q. What does the survey include?
A. In simple terms, the survey gathers information about how people use Kubernetes, such as trends in learning to deploy a new system, error messages they receive, and workflows.
One of our goals is to standardize the responses accordingly. The ultimate goal is to analyze survey responses for important user stories whose needs aren't being met.
Q. Are there any particular skills you’d like to recruit for? What skills are contributors to SIG Usability likely to learn?
A. Although contributing to SIG Usability does not have any pre-requisites as such, experience with user research, qualitative research, or prior experience with how to conduct an interview would be great plus points. Quantitative research, like survey design and screening, is also helpful and something that we expect contributors to learn.
Q. What are you getting positive feedback on, and what’s coming up next for SIG Usability?
A. We have had new members joining and coming to monthly meetings regularly and showing interests in becoming a contributor and helping the community. We have also had a lot of people reach out to us via Slack showcasing their interest in the SIG.
Currently, we are focused on finishing the study mentioned in our talk, also our project for this year. We are always happy to have new contributors join us.
Q: Any closing thoughts/resources you’d like to share?
A. We love meeting new contributors and assisting them in investigating different Kubernetes project spaces. We will work with and team up with other SIGs to facilitate engaging with end-users, running studies, and help them integrate accessible design practices into their development practices.
Here are some resources for you to get started:
Wrap Up
SIG Usability hosted a KubeCon talk about studying Kubernetes users' experiences. The talk focuses on updates to the user study projects, understanding who is using Kubernetes, what they are trying to achieve, how the project is addressing their needs, and where we need to improve the project and the client experience. Join the SIG's update to find out about the most recent research results, what the plans are for the forthcoming year, and how to get involved in the upstream usability team as a contributor!
Kubernetes API and Feature Removals In 1.22: Here’s What You Need To Know
Authors: Krishna Kilari (Amazon Web Services), Tim Bannister (The Scale Factory)
As the Kubernetes API evolves, APIs are periodically reorganized or upgraded. When APIs evolve, the old APIs they replace are deprecated, and eventually removed. See Kubernetes API removals to read more about Kubernetes' policy on removing APIs.
We want to make sure you're aware of some upcoming removals. These are beta APIs that you can use in current, supported Kubernetes versions, and they are already deprecated. The reason for all of these removals is that they have been superseded by a newer, stable (“GA”) API.
Kubernetes 1.22, due for release in August 2021, will remove a number of deprecated APIs. Update: Kubernetes 1.22: Reaching New Peaks has details on the v1.22 release.
API removals for Kubernetes v1.22
The v1.22 release will stop serving the API versions we've listed immediately below. These are all beta APIs that were previously deprecated in favor of newer and more stable API versions.
- Beta versions of the
ValidatingWebhookConfigurationandMutatingWebhookConfigurationAPI (the admissionregistration.k8s.io/v1beta1 API versions) - The beta
CustomResourceDefinitionAPI (apiextensions.k8s.io/v1beta1) - The beta
APIServiceAPI (apiregistration.k8s.io/v1beta1) - The beta
TokenReviewAPI (authentication.k8s.io/v1beta1) - Beta API versions of
SubjectAccessReview,LocalSubjectAccessReview,SelfSubjectAccessReview(API versions from authorization.k8s.io/v1beta1) - The beta
CertificateSigningRequestAPI (certificates.k8s.io/v1beta1) - The beta
LeaseAPI (coordination.k8s.io/v1beta1) - All beta
IngressAPIs (the extensions/v1beta1 and networking.k8s.io/v1beta1 API versions)
The Kubernetes documentation covers these API removals for v1.22 and explains how each of those APIs change between beta and stable.
What to do
We're going to run through each of the resources that are affected by these removals and explain the steps you'll need to take.
Ingress- Migrate to use the networking.k8s.io/v1
Ingress API,
available since v1.19.
The related API IngressClass is designed to complement the Ingress concept, allowing you to configure multiple kinds of Ingress within one cluster. If you're currently using the deprecatedkubernetes.io/ingress.classannotation, plan to switch to using the.spec.ingressClassNamefield instead.
On any cluster running Kubernetes v1.19 or later, you can use the v1 API to retrieve or update existing Ingress objects, even if they were created using an older API version.When you convert an Ingress to the v1 API, you should review each rule in that Ingress. Older Ingresses use the legacy
ImplementationSpecificpath type. Instead ofImplementationSpecific, switch path matching to eitherPrefixorExact. One of the benefits of moving to these alternative path types is that it becomes easier to migrate between different Ingress classes.ⓘ As well as upgrading your own use of the Ingress API as a client, make sure that every ingress controller that you use is compatible with the v1 Ingress API. Read Ingress Prerequisites for more context about Ingress and ingress controllers.
ValidatingWebhookConfigurationandMutatingWebhookConfiguration- Migrate to use the admissionregistration.k8s.io/v1 API versions of
ValidatingWebhookConfiguration
and MutatingWebhookConfiguration,
available since v1.16.
You can use the v1 API to retrieve or update existing objects, even if they were created using an older API version. CustomResourceDefinition- Migrate to use the CustomResourceDefinition
apiextensions.k8s.io/v1 API, available since v1.16.
You can use the v1 API to retrieve or update existing objects, even if they were created using an older API version. If you defined any custom resources in your cluster, those are still served after you upgrade.If you're using external CustomResourceDefinitions, you can use
kubectl convertto translate existing manifests to use the newer API. Because there are some functional differences between beta and stable CustomResourceDefinitions, our advice is to test out each one to make sure it works how you expect after the upgrade. APIService- Migrate to use the apiregistration.k8s.io/v1 APIService
API, available since v1.10.
You can use the v1 API to retrieve or update existing objects, even if they were created using an older API version. If you already have API aggregation using an APIService object, this aggregation continues to work after you upgrade. TokenReview- Migrate to use the authentication.k8s.io/v1 TokenReview
API, available since v1.10.
As well as serving this API via HTTP, the Kubernetes API server uses the same format to send TokenReviews to webhooks. The v1.22 release continues to use the v1beta1 API for TokenReviews sent to webhooks by default. See Looking ahead for some specific tips about switching to the stable API.
SubjectAccessReview,SelfSubjectAccessReviewandLocalSubjectAccessReview- Migrate to use the authorization.k8s.io/v1 versions of those authorization APIs, available since v1.6.
CertificateSigningRequest- Migrate to use the certificates.k8s.io/v1
CertificateSigningRequest
API, available since v1.19.
You can use the v1 API to retrieve or update existing objects, even if they were created using an older API version. Existing issued certificates retain their validity when you upgrade. Lease- Migrate to use the coordination.k8s.io/v1 Lease
API, available since v1.14.
You can use the v1 API to retrieve or update existing objects, even if they were created using an older API version.
kubectl convert
There is a plugin to kubectl that provides the kubectl convert subcommand.
It's an official plugin that you can download as part of Kubernetes.
See Download Kubernetes for more details.
You can use kubectl convert to update manifest files to use a different API
version. For example, if you have a manifest in source control that uses the beta
Ingress API, you can check that definition out,
and run
kubectl convert -f <manifest> --output-version <group>/<version>.
You can use the kubectl convert command to automatically convert an
existing manifest.
For example, to convert an older Ingress definition to
networking.k8s.io/v1, you can run:
kubectl convert -f ./legacy-ingress.yaml --output-version networking.k8s.io/v1
The automatic conversion uses a similar technique to how the Kubernetes control plane updates objects that were originally created using an older API version. Because it's a mechanical conversion, you might need to go in and change the manifest to adjust defaults etc.
Rehearse for the upgrade
If you manage your cluster's API server component, you can try out these API removals before you upgrade to Kubernetes v1.22.
To do that, add the following to the kube-apiserver command line arguments:
--runtime-config=admissionregistration.k8s.io/v1beta1=false,apiextensions.k8s.io/v1beta1=false,apiregistration.k8s.io/v1beta1=false,authentication.k8s.io/v1beta1=false,authorization.k8s.io/v1beta1=false,certificates.k8s.io/v1beta1=false,coordination.k8s.io/v1beta1=false,extensions/v1beta1/ingresses=false,networking.k8s.io/v1beta1=false
(as a side effect, this also turns off v1beta1 of EndpointSlice - watch out for that when you're testing).
Once you've switched all the kube-apiservers in your cluster to use that setting,
those beta APIs are removed. You can test that API clients (kubectl, deployment
tools, custom controllers etc) still work how you expect, and you can revert if
you need to without having to plan a more disruptive downgrade.
Advice for software authors
Maybe you're reading this because you're a developer of an addon or other component that integrates with Kubernetes?
If you develop an Ingress controller, webhook authenticator, an API aggregation, or any other tool that relies on these deprecated APIs, you should already have started to switch your software over.
You can use the tips in Rehearse for the upgrade to run your own Kubernetes cluster that only uses the new APIs, and make sure that your code works OK. For your documentation, make sure readers are aware of any steps they should take for the Kubernetes v1.22 upgrade.
Where possible, give your users a hand to adopt the new APIs early - perhaps in a test environment - so they can give you feedback about any problems.
There are some more deprecations coming in Kubernetes v1.25, so plan to have those covered too.
Kubernetes API removals
Here's some background about why Kubernetes removes some APIs, and also a promise about stable APIs in Kubernetes.
Kubernetes follows a defined deprecation policy for its features, including the Kubernetes API. That policy allows for replacing stable (“GA”) APIs from Kubernetes. Importantly, this policy means that a stable API only be deprecated when a newer stable version of that same API is available.
That stability guarantee matters: if you're using a stable Kubernetes API, there won't ever be a new version released that forces you to switch to an alpha or beta feature.
Earlier stages are different. Alpha features are under test and potentially incomplete. Almost always, alpha features are disabled by default. Kubernetes releases can and do remove alpha features that haven't worked out.
After alpha, comes beta. These features are typically enabled by default; if the testing works out, the feature can graduate to stable. If not, it might need a redesign.
Last year, Kubernetes officially adopted a policy for APIs that have reached their beta phase:
For Kubernetes REST APIs, when a new feature's API reaches beta, that starts a countdown. The beta-quality API now has three releases … to either:
- reach GA, and deprecate the beta, or
- have a new beta version (and deprecate the previous beta).
At the time of that article, three Kubernetes releases equated to roughly nine calendar months. Later that same month, Kubernetes adopted a new release cadence of three releases per calendar year, so the countdown period is now roughly twelve calendar months.
Whether an API removal is because of a beta feature graduating to stable, or because that API hasn't proved successful, Kubernetes will continue to remove APIs by following its deprecation policy and making sure that migration options are documented.
Looking ahead
There's a setting that's relevant if you use webhook authentication checks.
A future Kubernetes release will switch to sending TokenReview objects
to webhooks using the authentication.k8s.io/v1 API by default. At the moment,
the default is to send authentication.k8s.io/v1beta1 TokenReviews to webhooks,
and that's still the default for Kubernetes v1.22.
However, you can switch over to the stable API right now if you want:
add --authentication-token-webhook-version=v1 to the command line options for
the kube-apiserver, and check that webhooks for authentication still work how you
expected.
Once you're happy it works OK, you can leave the --authentication-token-webhook-version=v1
option set across your control plane.
The v1.25 release that's planned for next year will stop serving beta versions of several Kubernetes APIs that are stable right now and have been for some time. The same v1.25 release will remove PodSecurityPolicy, which is deprecated and won't graduate to stable. See PodSecurityPolicy Deprecation: Past, Present, and Future for more information.
The official list of API removals planned for Kubernetes 1.25 is:
- The beta
CronJobAPI (batch/v1beta1) - The beta
EndpointSliceAPI (networking.k8s.io/v1beta1) - The beta
PodDisruptionBudgetAPI (policy/v1beta1) - The beta
PodSecurityPolicyAPI (policy/v1beta1)
Want to know more?
Deprecations are announced in the Kubernetes release notes. You can see the announcements of pending deprecations in the release notes for 1.19, 1.20, and 1.21.
For information on the process of deprecation and removal, check out the official Kubernetes deprecation policy document.
Announcing Kubernetes Community Group Annual Reports
Authors: Divya Mohan

Given the growth and scale of the Kubernetes project, the existing reporting mechanisms were proving to be inadequate and challenging. Kubernetes is a large open source project. With over 100000 commits just to the main k/kubernetes repository, hundreds of other code repositories in the project, and thousands of contributors, there's a lot going on. In fact, there are 37 contributor groups at the time of writing. We also value all forms of contribution and not just code changes.
With that context in mind, the challenge of reporting on all this activity was a call to action for exploring better options. Therefore inspired by the Apache Software Foundation’s open guide to PMC Reporting and the CNCF project Annual Reporting, the Kubernetes project is proud to announce the Kubernetes Community Group Annual Reports for Special Interest Groups (SIGs) and Working Groups (WGs). In its flagship edition, the 2020 Summary report focuses on bettering the Kubernetes ecosystem by assessing and promoting the healthiness of the groups within the upstream community.
Previously, the mechanisms for the Kubernetes project overall to report on groups and their activities were devstats, GitHub data, issues, to measure the healthiness of a given UG/WG/SIG/Committee. As a project spanning several diverse communities, it was essential to have something that captured the human side of things. With 50,000+ contributors, it’s easy to assume that the project has enough help and this report surfaces more information than /help-wanted and /good-first-issue for end users. This is how we sustain the project. Paraphrasing one of the Steering Committee members, Paris Pittman, “There was a requirement for tighter feedback loops - ones that involved more than just GitHub data and issues. Given that Kubernetes, as a project, has grown in scale and number of contributors over the years, we have outgrown the existing reporting mechanisms."
The existing communication channels between the Steering committee members and the folks leading the groups and committees were also required to be made as open and as bi-directional as possible. Towards achieving this very purpose, every group and committee has been assigned a liaison from among the steering committee members for kick off, help, or guidance needed throughout the process. According to Davanum Srinivas a.k.a. dims, “... That was one of the main motivations behind this report. People (leading the groups/committees) know that they can reach out to us and there’s a vehicle for them to reach out to us… This is our way of setting up a two-way feedback for them." The progress on these action items would be updated and tracked on the monthly Steering Committee meetings ensuring that this is not a one-off activity. Quoting Nikhita Raghunath, one of the Steering Committee members, “... Once we have a base, the liaisons will work with these groups to ensure that the problems are resolved. When we have a report next year, we’ll have a look at the progress made and how we could still do better. But the idea is definitely to not stop at the report.”
With this report, we hope to empower our end user communities with information that they can use to identify ways in which they can support the project as well as a sneak peek into the roadmap for upcoming features. As a community, we thrive on feedback and would love to hear your views about the report. You can get in touch with the Steering Committee via Slack or via the mailing list.
Writing a Controller for Pod Labels
Authors: Arthur Busser (Padok)
Operators are proving to be an excellent solution to running stateful distributed applications in Kubernetes. Open source tools like the Operator SDK provide ways to build reliable and maintainable operators, making it easier to extend Kubernetes and implement custom scheduling.
Kubernetes operators run complex software inside your cluster. The open source community has already built many operators for distributed applications like Prometheus, Elasticsearch, or Argo CD. Even outside of open source, operators can help to bring new functionality to your Kubernetes cluster.
An operator is a set of custom resources and a set of controllers. A controller watches for changes to specific resources in the Kubernetes API and reacts by creating, updating, or deleting resources.
The Operator SDK is best suited for building fully-featured operators.
Nonetheless, you can use it to write a single controller. This post will walk
you through writing a Kubernetes controller in Go that will add a pod-name
label to pods that have a specific annotation.
Why do we need a controller for this?
I recently worked on a project where we needed to create a Service that routed traffic to a specific Pod in a ReplicaSet. The problem is that a Service can only select pods by label, and all pods in a ReplicaSet have the same labels. There are two ways to solve this problem:
- Create a Service without a selector and manage the Endpoints or EndpointSlices for that Service directly. We would need to write a custom controller to insert our Pod's IP address into those resources.
- Add a label to the Pod with a unique value. We could then use this label in our Service's selector. Again, we would need to write a custom controller to add this label.
A controller is a control loop that tracks one or more Kubernetes resource
types. The controller from option n°2 above only needs to track pods, which
makes it simpler to implement. This is the option we are going to walk through
by writing a Kubernetes controller that adds a pod-name label to our pods.
StatefulSets do this natively by adding a
pod-name label to each Pod in the set. But what if we don't want to or can't
use StatefulSets?
We rarely create pods directly; most often, we use a Deployment, ReplicaSet, or
another high-level resource. We can specify labels to add to each Pod in the
PodSpec, but not with dynamic values, so no way to replicate a StatefulSet's
pod-name label.
We tried using a mutating admission webhook. When
anyone creates a Pod, the webhook patches the Pod with a label containing the
Pod's name. Disappointingly, this does not work: not all pods have a name before
being created. For instance, when the ReplicaSet controller creates a Pod, it
sends a namePrefix to the Kubernetes API server and not a name. The API
server generates a unique name before persisting the new Pod to etcd, but only
after calling our admission webhook. So in most cases, we can't know a Pod's
name with a mutating webhook.
Once a Pod exists in the Kubernetes API, it is mostly immutable, but we can still add a label. We can even do so from the command line:
kubectl label my-pod my-label-key=my-label-value
We need to watch for changes to any pods in the Kubernetes API and add the label we want. Rather than do this manually, we are going to write a controller that does it for us.
Bootstrapping a controller with the Operator SDK
A controller is a reconciliation loop that reads the desired state of a resource from the Kubernetes API and takes action to bring the cluster's actual state closer to the desired state.
In order to write this controller as quickly as possible, we are going to use the Operator SDK. If you don't have it installed, follow the official documentation.
$ operator-sdk version
operator-sdk version: "v1.4.2", commit: "4b083393be65589358b3e0416573df04f4ae8d9b", kubernetes version: "v1.19.4", go version: "go1.15.8", GOOS: "darwin", GOARCH: "amd64"
Let's create a new directory to write our controller in:
mkdir label-operator && cd label-operator
Next, let's initialize a new operator, to which we will add a single controller. To do this, you will need to specify a domain and a repository. The domain serves as a prefix for the group your custom Kubernetes resources will belong to. Because we are not going to be defining custom resources, the domain does not matter. The repository is going to be the name of the Go module we are going to write. By convention, this is the repository where you will be storing your code.
As an example, here is the command I ran:
# Feel free to change the domain and repo values.
operator-sdk init --domain=padok.fr --repo=github.com/busser/label-operator
Next, we need a create a new controller. This controller will handle pods and not a custom resource, so no need to generate the resource code. Let's run this command to scaffold the code we need:
operator-sdk create api --group=core --version=v1 --kind=Pod --controller=true --resource=false
We now have a new file: controllers/pod_controller.go. This file contains a
PodReconciler type with two methods that we need to implement. The first is
Reconcile, and it looks like this for now:
func (r *PodReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
_ = r.Log.WithValues("pod", req.NamespacedName)
// your logic here
return ctrl.Result{}, nil
}
The Reconcile method is called whenever a Pod is created, updated, or deleted.
The name and namespace of the Pod are in the ctrl.Request the method receives
as a parameter.
The second method is SetupWithManager and for now it looks like this:
func (r *PodReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
// Uncomment the following line adding a pointer to an instance of the controlled resource as an argument
// For().
Complete(r)
}
The SetupWithManager method is called when the operator starts. It serves to
tell the operator framework what types our PodReconciler needs to watch. To
use the same Pod type used by Kubernetes internally, we need to import some of
its code. All of the Kubernetes source code is open source, so you can import
any part you like in your own Go code. You can find a complete list of available
packages in the Kubernetes source code or here on pkg.go.dev. To
use pods, we need the k8s.io/api/core/v1 package.
package controllers
import (
// other imports...
corev1 "k8s.io/api/core/v1"
// other imports...
)
Lets use the Pod type in SetupWithManager to tell the operator framework we
want to watch pods:
func (r *PodReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&corev1.Pod{}).
Complete(r)
}
Before moving on, we should set the RBAC permissions our controller needs. Above
the Reconcile method, we have some default permissions:
// +kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=core,resources=pods/status,verbs=get;update;patch
// +kubebuilder:rbac:groups=core,resources=pods/finalizers,verbs=update
We don't need all of those. Our controller will never interact with a Pod's status or its finalizers. It only needs to read and update pods. Lets remove the unnecessary permissions and keep only what we need:
// +kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;watch;update;patch
We are now ready to write our controller's reconciliation logic.
Implementing reconciliation
Here is what we want our Reconcile method to do:
- Use the Pod's name and namespace from the
ctrl.Requestto fetch the Pod from the Kubernetes API. - If the Pod has an
add-pod-name-labelannotation, add apod-namelabel to the Pod; if the annotation is missing, don't add the label. - Update the Pod in the Kubernetes API to persist the changes made.
Lets define some constants for the annotation and label:
const (
addPodNameLabelAnnotation = "padok.fr/add-pod-name-label"
podNameLabel = "padok.fr/pod-name"
)
The first step in our reconciliation function is to fetch the Pod we are working on from the Kubernetes API:
// Reconcile handles a reconciliation request for a Pod.
// If the Pod has the addPodNameLabelAnnotation annotation, then Reconcile
// will make sure the podNameLabel label is present with the correct value.
// If the annotation is absent, then Reconcile will make sure the label is too.
func (r *PodReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
log := r.Log.WithValues("pod", req.NamespacedName)
/*
Step 0: Fetch the Pod from the Kubernetes API.
*/
var pod corev1.Pod
if err := r.Get(ctx, req.NamespacedName, &pod); err != nil {
log.Error(err, "unable to fetch Pod")
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}
Our Reconcile method will be called when a Pod is created, updated, or
deleted. In the deletion case, our call to r.Get will return a specific error.
Let's import the package that defines this error:
package controllers
import (
// other imports...
apierrors "k8s.io/apimachinery/pkg/api/errors"
// other imports...
)
We can now handle this specific error and — since our controller does not care about deleted pods — explicitly ignore it:
/*
Step 0: Fetch the Pod from the Kubernetes API.
*/
var pod corev1.Pod
if err := r.Get(ctx, req.NamespacedName, &pod); err != nil {
if apierrors.IsNotFound(err) {
// we'll ignore not-found errors, since we can get them on deleted requests.
return ctrl.Result{}, nil
}
log.Error(err, "unable to fetch Pod")
return ctrl.Result{}, err
}
Next, lets edit our Pod so that our dynamic label is present if and only if our annotation is present:
/*
Step 1: Add or remove the label.
*/
labelShouldBePresent := pod.Annotations[addPodNameLabelAnnotation] == "true"
labelIsPresent := pod.Labels[podNameLabel] == pod.Name
if labelShouldBePresent == labelIsPresent {
// The desired state and actual state of the Pod are the same.
// No further action is required by the operator at this moment.
log.Info("no update required")
return ctrl.Result{}, nil
}
if labelShouldBePresent {
// If the label should be set but is not, set it.
if pod.Labels == nil {
pod.Labels = make(map[string]string)
}
pod.Labels[podNameLabel] = pod.Name
log.Info("adding label")
} else {
// If the label should not be set but is, remove it.
delete(pod.Labels, podNameLabel)
log.Info("removing label")
}
Finally, let's push our updated Pod to the Kubernetes API:
/*
Step 2: Update the Pod in the Kubernetes API.
*/
if err := r.Update(ctx, &pod); err != nil {
log.Error(err, "unable to update Pod")
return ctrl.Result{}, err
}
When writing our updated Pod to the Kubernetes API, there is a risk that the Pod has been updated or deleted since we first read it. When writing a Kubernetes controller, we should keep in mind that we are not the only actors in the cluster. When this happens, the best thing to do is start the reconciliation from scratch, by requeuing the event. Lets do exactly that:
/*
Step 2: Update the Pod in the Kubernetes API.
*/
if err := r.Update(ctx, &pod); err != nil {
if apierrors.IsConflict(err) {
// The Pod has been updated since we read it.
// Requeue the Pod to try to reconciliate again.
return ctrl.Result{Requeue: true}, nil
}
if apierrors.IsNotFound(err) {
// The Pod has been deleted since we read it.
// Requeue the Pod to try to reconciliate again.
return ctrl.Result{Requeue: true}, nil
}
log.Error(err, "unable to update Pod")
return ctrl.Result{}, err
}
Let's remember to return successfully at the end of the method:
return ctrl.Result{}, nil
}
And that's it! We are now ready to run the controller on our cluster.
Run the controller on your cluster
To run our controller on your cluster, we need to run the operator. For that,
all you will need is kubectl. If you don't have a Kubernetes cluster at hand,
I recommend you start one locally with KinD (Kubernetes in Docker).
All it takes to run the operator from your machine is this command:
make run
After a few seconds, you should see the operator's logs. Notice that our
controller's Reconcile method was called for all pods already running in the
cluster.
Let's keep the operator running and, in another terminal, create a new Pod:
kubectl run --image=nginx my-nginx
The operator should quickly print some logs, indicating that it reacted to the Pod's creation and subsequent changes in status:
INFO controllers.Pod no update required {"pod": "default/my-nginx"}
INFO controllers.Pod no update required {"pod": "default/my-nginx"}
INFO controllers.Pod no update required {"pod": "default/my-nginx"}
INFO controllers.Pod no update required {"pod": "default/my-nginx"}
Lets check the Pod's labels:
$ kubectl get pod my-nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
my-nginx 1/1 Running 0 11m run=my-nginx
Let's add an annotation to the Pod so that our controller knows to add our dynamic label to it:
kubectl annotate pod my-nginx padok.fr/add-pod-name-label=true
Notice that the controller immediately reacted and produced a new line in its logs:
INFO controllers.Pod adding label {"pod": "default/my-nginx"}
$ kubectl get pod my-nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
my-nginx 1/1 Running 0 13m padok.fr/pod-name=my-nginx,run=my-nginx
Bravo! You just successfully wrote a Kubernetes controller capable of adding labels with dynamic values to resources in your cluster.
Controllers and operators, both big and small, can be an important part of your Kubernetes journey. Writing operators is easier now than it has ever been. The possibilities are endless.
What next?
If you want to go further, I recommend starting by deploying your controller or
operator inside a cluster. The Makefile generated by the Operator SDK will do
most of the work.
When deploying an operator to production, it is always a good idea to implement robust testing. The first step in that direction is to write unit tests. This documentation will guide you in writing tests for your operator. I wrote tests for the operator we just wrote; you can find all of my code in this GitHub repository.
How to learn more?
The Operator SDK documentation goes into detail on how you can go further and implement more complex operators.
When modeling a more complex use-case, a single controller acting on built-in Kubernetes types may not be enough. You may need to build a more complex operator with Custom Resource Definitions (CRDs) and multiple controllers. The Operator SDK is a great tool to help you do this.
If you want to discuss building an operator, join the #kubernetes-operator channel in the Kubernetes Slack workspace!
Using Finalizers to Control Deletion
Authors: Aaron Alpar (Kasten)
Deleting objects in Kubernetes can be challenging. You may think you’ve deleted something, only to find it still persists. While issuing a kubectl delete command and hoping for the best might work for day-to-day operations, understanding how Kubernetes delete commands operate will help you understand why some objects linger after deletion.
In this post, I’ll look at:
- What properties of a resource govern deletion
- How finalizers and owner references impact object deletion
- How the propagation policy can be used to change the order of deletions
- How deletion works, with examples
For simplicity, all examples will use ConfigMaps and basic shell commands to demonstrate the process. We’ll explore how the commands work and discuss repercussions and results from using them in practice.
The basic delete
Kubernetes has several different commands you can use that allow you to create, read, update, and delete objects. For the purpose of this blog post, we’ll focus on four kubectl commands: create, get, patch, and delete.
Here are examples of the basic kubectl delete command:
kubectl create configmap mymap
configmap/mymap created
kubectl get configmap/mymap
NAME DATA AGE
mymap 0 12s
kubectl delete configmap/mymap
configmap "mymap" deleted
kubectl get configmap/mymap
Error from server (NotFound): configmaps "mymap" not found
Shell commands preceded by $ are followed by their output. You can see that we begin with a kubectl create configmap mymap, which will create the empty configmap mymap. Next, we need to get the configmap to prove it exists. We can then delete that configmap. Attempting to get it again produces an HTTP 404 error, which means the configmap is not found.
The state diagram for the basic delete command is very simple:
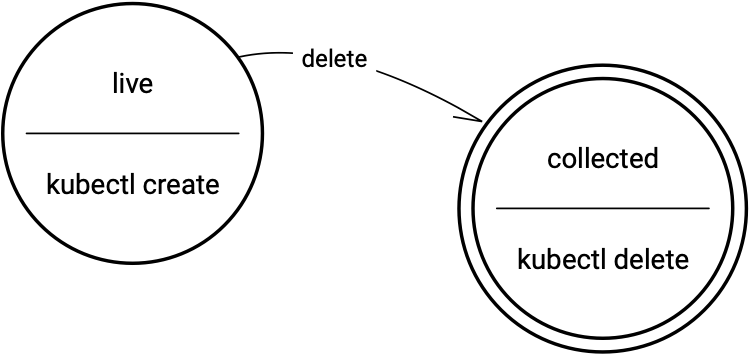
State diagram for delete
Although this operation is straightforward, other factors may interfere with the deletion, including finalizers and owner references.
Understanding Finalizers
When it comes to understanding resource deletion in Kubernetes, knowledge of how finalizers work is helpful and can help you understand why some objects don’t get deleted.
Finalizers are keys on resources that signal pre-delete operations. They control the garbage collection on resources, and are designed to alert controllers what cleanup operations to perform prior to removing a resource. However, they don’t necessarily name code that should be executed; finalizers on resources are basically just lists of keys much like annotations. Like annotations, they can be manipulated.
Some common finalizers you’ve likely encountered are:
kubernetes.io/pv-protectionkubernetes.io/pvc-protection
The finalizers above are used on volumes to prevent accidental deletion. Similarly, some finalizers can be used to prevent deletion of any resource but are not managed by any controller.
Below with a custom configmap, which has no properties but contains a finalizer:
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: mymap
finalizers:
- kubernetes
EOF
The configmap resource controller doesn't understand what to do with the kubernetes finalizer key. I term these “dead” finalizers for configmaps as it is normally used on namespaces. Here’s what happen upon attempting to delete the configmap:
kubectl delete configmap/mymap &
configmap "mymap" deleted
jobs
[1]+ Running kubectl delete configmap/mymap
Kubernetes will report back that the object has been deleted, however, it hasn’t been deleted in a traditional sense. Rather, it’s in the process of deletion. When we attempt to get that object again, we discover the object has been modified to include the deletion timestamp.
kubectl get configmap/mymap -o yaml
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: "2020-10-22T21:30:18Z"
deletionGracePeriodSeconds: 0
deletionTimestamp: "2020-10-22T21:30:34Z"
finalizers:
- kubernetes
name: mymap
namespace: default
resourceVersion: "311456"
selfLink: /api/v1/namespaces/default/configmaps/mymap
uid: 93a37fed-23e3-45e8-b6ee-b2521db81638
In short, what’s happened is that the object was updated, not deleted. That’s because Kubernetes saw that the object contained finalizers and put it into a read-only state. The deletion timestamp signals that the object can only be read, with the exception of removing the finalizer key updates. In other words, the deletion will not be complete until we edit the object and remove the finalizer.
Here's a demonstration of using the patch command to remove finalizers. If we want to delete an object, we can simply patch it on the command line to remove the finalizers. In this way, the deletion that was running in the background will complete and the object will be deleted. When we attempt to get that configmap, it will be gone.
kubectl patch configmap/mymap \
--type json \
--patch='[ { "op": "remove", "path": "/metadata/finalizers" } ]'
configmap/mymap patched
[1]+ Done kubectl delete configmap/mymap
kubectl get configmap/mymap -o yaml
Error from server (NotFound): configmaps "mymap" not found
Here's a state diagram for finalization:
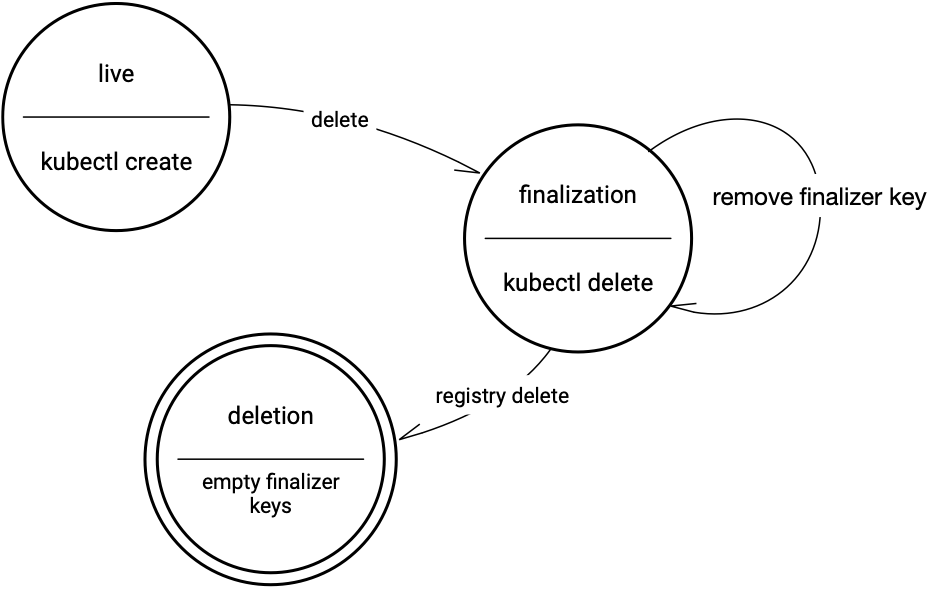
State diagram for finalize
So, if you attempt to delete an object that has a finalizer on it, it will remain in finalization until the controller has removed the finalizer keys or the finalizers are removed using Kubectl. Once that finalizer list is empty, the object can actually be reclaimed by Kubernetes and put into a queue to be deleted from the registry.
Owner References
Owner references describe how groups of objects are related. They are properties on resources that specify the relationship to one another, so entire trees of resources can be deleted.
Finalizer rules are processed when there are owner references. An owner reference consists of a name and a UID. Owner references link resources within the same namespace, and it also needs a UID for that reference to work. Pods typically have owner references to the owning replica set. So, when deployments or stateful sets are deleted, then the child replica sets and pods are deleted in the process.
Here are some examples of owner references and how they work. In the first example, we create a parent object first, then the child. The result is a very simple configmap that contains an owner reference to its parent:
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: mymap-parent
EOF
CM_UID=$(kubectl get configmap mymap-parent -o jsonpath="{.metadata.uid}")
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: mymap-child
ownerReferences:
- apiVersion: v1
kind: ConfigMap
name: mymap-parent
uid: $CM_UID
EOF
Deleting the child object when an owner reference is involved does not delete the parent:
kubectl get configmap
NAME DATA AGE
mymap-child 0 12m4s
mymap-parent 0 12m4s
kubectl delete configmap/mymap-child
configmap "mymap-child" deleted
kubectl get configmap
NAME DATA AGE
mymap-parent 0 12m10s
In this example, we re-created the parent-child configmaps from above. Now, when deleting from the parent (instead of the child) with an owner reference from the child to the parent, when we get the configmaps, none are in the namespace:
kubectl get configmap
NAME DATA AGE
mymap-child 0 10m2s
mymap-parent 0 10m2s
kubectl delete configmap/mymap-parent
configmap "mymap-parent" deleted
kubectl get configmap
No resources found in default namespace.
To sum things up, when there's an override owner reference from a child to a parent, deleting the parent deletes the children automatically. This is called cascade. The default for cascade is true, however, you can use the --cascade=orphan option for kubectl delete to delete an object and orphan its children. Update: starting with kubectl v1.20, the default for cascade is background.
In the following example, there is a parent and a child. Notice the owner references are still included. If I delete the parent using --cascade=orphan, the parent is deleted but the child still exists:
kubectl get configmap
NAME DATA AGE
mymap-child 0 13m8s
mymap-parent 0 13m8s
kubectl delete --cascade=orphan configmap/mymap-parent
configmap "mymap-parent" deleted
kubectl get configmap
NAME DATA AGE
mymap-child 0 13m21s
The --cascade option links to the propagation policy in the API, which allows you to change the order in which objects are deleted within a tree. In the following example uses API access to craft a custom delete API call with the background propagation policy:
kubectl proxy --port=8080 &
Starting to serve on 127.0.0.1:8080
curl -X DELETE \
localhost:8080/api/v1/namespaces/default/configmaps/mymap-parent \
-d '{ "kind":"DeleteOptions", "apiVersion":"v1", "propagationPolicy":"Background" }' \
-H "Content-Type: application/json"
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Success",
"details": { ... }
}
Note that the propagation policy cannot be specified on the command line using kubectl. You have to specify it using a custom API call. Simply create a proxy, so you have access to the API server from the client, and execute a curl command with just a URL to execute that delete command.
There are three different options for the propagation policy:
Foreground: Children are deleted before the parent (post-order)Background: Parent is deleted before the children (pre-order)Orphan: Owner references are ignored
Keep in mind that when you delete an object and owner references have been specified, finalizers will be honored in the process. This can result in trees of objects persisting, and you end up with a partial deletion. At that point, you have to look at any existing owner references on your objects, as well as any finalizers, to understand what’s happening.
Forcing a Deletion of a Namespace
There's one situation that may require forcing finalization for a namespace. If you've deleted a namespace and you've cleaned out all of the objects under it, but the namespace still exists, deletion can be forced by updating the namespace subresource, finalize. This informs the namespace controller that it needs to remove the finalizer from the namespace and perform any cleanup:
cat <<EOF | curl -X PUT \
localhost:8080/api/v1/namespaces/test/finalize \
-H "Content-Type: application/json" \
--data-binary @-
{
"kind": "Namespace",
"apiVersion": "v1",
"metadata": {
"name": "test"
},
"spec": {
"finalizers": null
}
}
EOF
This should be done with caution as it may delete the namespace only and leave orphan objects within the, now non-exiting, namespace - a confusing state for Kubernetes. If this happens, the namespace can be re-created manually and sometimes the orphaned objects will re-appear under the just-created namespace which will allow manual cleanup and recovery.
Key Takeaways
As these examples demonstrate, finalizers can get in the way of deleting resources in Kubernetes, especially when there are parent-child relationships between objects. Often, there is a reason for adding a finalizer into the code, so you should always investigate before manually deleting it. Owner references allow you to specify and remove trees of resources, although finalizers will be honored in the process. Finally, the propagation policy can be used to specify the order of deletion via a custom API call, giving you control over how objects are deleted. Now that you know a little more about how deletions work in Kubernetes, we recommend you try it out on your own, using a test cluster.
Kubernetes 1.21: Metrics Stability hits GA
Authors: Han Kang (Google), Elana Hashman (Red Hat)
Kubernetes 1.21 marks the graduation of the metrics stability framework and along with it, the first officially supported stable metrics. Not only do stable metrics come with supportability guarantees, the metrics stability framework brings escape hatches that you can use if you encounter problematic metrics.
See the list of stable Kubernetes metrics here
What are stable metrics and why do we need them?
A stable metric is one which, from a consumption point of view, can be reliably consumed across a number of Kubernetes versions without risk of ingestion failure.
Metrics stability is an ongoing community concern. Cluster monitoring infrastructure often assumes the stability of some control plane metrics, so we have introduced a mechanism for versioning metrics as a proper API, with stability guarantees around a formal metrics deprecation process.
What are the stability levels for metrics?
Metrics can currently have one of two stability levels: alpha or stable.
Alpha metrics have no stability guarantees; as such they can be modified or deleted at any time. At this time, all Kubernetes metrics implicitly fall into this category.
Stable metrics can be guaranteed to not change, except that the metric may become marked deprecated for a future Kubernetes version. By not change, we mean three things:
- the metric itself will not be deleted or renamed
- the type of metric will not be modified
- no labels can be added or removed from this metric
From an ingestion point of view, it is backwards-compatible to add or remove possible values for labels which already do exist, but not labels themselves. Therefore, adding or removing values from an existing label is permitted. Stable metrics can also be marked as deprecated for a future Kubernetes version, since this is tracked in a metadata field and does not actually change the metric itself.
Removing or adding labels from stable metrics is not permitted. In order to add or remove a label from an existing stable metric, one would have to introduce a new metric and deprecate the stable one; otherwise this would violate compatibility agreements.
How are metrics deprecated?
While deprecation policies only affect stability guarantees for stable metrics (and not alpha ones), deprecation information may be optionally provided on alpha metrics to help component owners inform users of future intent and assist with transition plans.
A stable metric undergoing the deprecation process signals that the metric will eventually be deleted. The metrics deprecation lifecycle looks roughly like this (with each stage representing a Kubernetes release):

Deprecated metrics have the same stability guarantees of their stable counterparts. If a stable metric is deprecated, then a deprecated stable metric is guaranteed to not change. When deprecating a stable metric, a future Kubernetes release is specified as the point from which the metric will be considered deprecated.
Deprecated metrics will have their description text prefixed with a deprecation notice string “(Deprecated from x.y)” and a warning log will be emitted during metric registration, in the spirit of the official Kubernetes deprecation policy.
Like their stable metric counterparts, deprecated metrics will be automatically registered to the metrics endpoint. On a subsequent release (when the metric's deprecatedVersion is equal to current_kubernetes_version - 4)), a deprecated metric will become a hidden metric. Hidden metrics are not automatically registered, and hence are hidden by default from end users. These hidden metrics can be explicitly re-enabled for one release after they reach the hidden state, to provide a migration path for cluster operators.
As an owner of a Kubernetes component, how do I add stable metrics?
During metric instantiation, stability can be specified by setting the metadata field, StabilityLevel, to “Stable”. When a StabilityLevel is not explicitly set, metrics default to “Alpha” stability. Note that metrics which have fields determined at runtime cannot be marked as Stable. Stable metrics will be detected during static analysis during the pre-commit phase, and must be reviewed by sig-instrumentation.
var metricDefinition = kubemetrics.CounterOpts{
Name: "some_metric",
Help: "some description",
StabilityLevel: kubemetrics.STABLE,
}
For more examples of setting metrics stability and deprecation, see the Metrics Stability KEP.
How do I get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together. We offer a huge thank you to all the contributors in Kubernetes community who helped review the design and implementation of the project, including but not limited to the following:
- Han Kang (logicalhan)
- Frederic Branczyk (brancz)
- Marek Siarkowicz (serathius)
- Elana Hashman (ehashman)
- Solly Ross (DirectXMan12)
- Stefan Schimanski (sttts)
- David Ashpole (dashpole)
- Yuchen Zhou (yoyinzyc)
- Yu Yi (erain)
If you’re interested in getting involved with the design and development of instrumentation or any part of the Kubernetes metrics system, join the Kubernetes Instrumentation Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Evolving Kubernetes networking with the Gateway API
Authors: Mark Church (Google), Harry Bagdi (Kong), Daneyon Hanson (Red Hat), Nick Young (VMware), Manuel Zapf (Traefik Labs)
The Ingress resource is one of the many Kubernetes success stories. It created a diverse ecosystem of Ingress controllers which were used across hundreds of thousands of clusters in a standardized and consistent way. This standardization helped users adopt Kubernetes. However, five years after the creation of Ingress, there are signs of fragmentation into different but strikingly similar CRDs and overloaded annotations. The same portability that made Ingress pervasive also limited its future.
It was at Kubecon 2019 San Diego when a passionate group of contributors gathered to discuss the evolution of Ingress. The discussion overflowed to the hotel lobby across the street and what came out of it would later be known as the Gateway API. This discussion was based on a few key assumptions:
- The API standards underlying route matching, traffic management, and service exposure are commoditized and provide little value to their implementers and users as custom APIs
- It’s possible to represent L4/L7 routing and traffic management through common core API resources
- It’s possible to provide extensibility for more complex capabilities in a way that does not sacrifice the user experience of the core API
Introducing the Gateway API
This led to design principles that allow the Gateway API to improve upon Ingress:
- Expressiveness - In addition to HTTP host/path matching and TLS, Gateway API can express capabilities like HTTP header manipulation, traffic weighting & mirroring, TCP/UDP routing, and other capabilities that were only possible in Ingress through custom annotations.
- Role-oriented design - The API resource model reflects the separation of responsibilities that is common in routing and Kubernetes service networking.
- Extensibility - The resources allow arbitrary configuration attachment at various layers within the API. This makes granular customization possible at the most appropriate places.
- Flexible conformance - The Gateway API defines varying conformance levels - core (mandatory support), extended (portable if supported), and custom (no portability guarantee), known together as flexible conformance. This promotes a highly portable core API (like Ingress) that still gives flexibility for Gateway controller implementers.
What does the Gateway API look like?
The Gateway API introduces a few new resource types:
- GatewayClasses are cluster-scoped resources that act as templates to explicitly define behavior for Gateways derived from them. This is similar in concept to StorageClasses, but for networking data-planes.
- Gateways are the deployed instances of GatewayClasses. They are the logical representation of the data-plane which performs routing, which may be in-cluster proxies, hardware LBs, or cloud LBs.
- Routes are not a single resource, but represent many different protocol-specific Route resources. The HTTPRoute has matching, filtering, and routing rules that get applied to Gateways that can process HTTP and HTTPS traffic. Similarly, there are TCPRoutes, UDPRoutes, and TLSRoutes which also have protocol-specific semantics. This model also allows the Gateway API to incrementally expand its protocol support in the future.

Gateway Controller Implementations
The good news is that although Gateway is in Alpha, there are already several Gateway controller implementations that you can run. Since it’s a standardized spec, the following example could be run on any of them and should function the exact same way. Check out getting started to see how to install and use one of these Gateway controllers.
Getting Hands-on with the Gateway API
In the following example, we’ll demonstrate the relationships between the different API Resources and walk you through a common use case:
- Team foo has their app deployed in the foo Namespace. They need to control the routing logic for the different pages of their app.
- Team bar is running in the bar Namespace. They want to be able to do blue-green rollouts of their application to reduce risk.
- The platform team is responsible for managing the load balancer and network security of all the apps in the Kubernetes cluster.
The following foo-route does path matching to various Services in the foo Namespace and also has a default route to a 404 server. This exposes foo-auth and foo-home Services via foo.example.com/login and foo.example.com/home respectively.:
kind: HTTPRoute
apiVersion: networking.x-k8s.io/v1alpha1
metadata:
name: foo-route
namespace: foo
labels:
gateway: external-https-prod
spec:
hostnames:
- "foo.example.com"
rules:
- matches:
- path:
type: Prefix
value: /login
forwardTo:
- serviceName: foo-auth
port: 8080
- matches:
- path:
type: Prefix
value: /home
forwardTo:
- serviceName: foo-home
port: 8080
- matches:
- path:
type: Prefix
value: /
forwardTo:
- serviceName: foo-404
port: 8080
The bar team, operating in the bar Namespace of the same Kubernetes cluster, also wishes to expose their application to the internet, but they also want to control their own canary and blue-green rollouts. The following HTTPRoute is configured for the following behavior:
-
For traffic to
bar.example.com:- Send 90% of the traffic to bar-v1
- Send 10% of the traffic to bar-v2
-
For traffic to
bar.example.comwith the HTTP headerenv: canary:- Send all the traffic to bar-v2

kind: HTTPRoute
apiVersion: networking.x-k8s.io/v1alpha1
metadata:
name: bar-route
namespace: bar
labels:
gateway: external-https-prod
spec:
hostnames:
- "bar.example.com"
rules:
- forwardTo:
- serviceName: bar-v1
port: 8080
weight: 90
- serviceName: bar-v2
port: 8080
weight: 10
- matches:
- headers:
values:
env: canary
forwardTo:
- serviceName: bar-v2
port: 8080
Route and Gateway Binding
So we have two HTTPRoutes matching and routing traffic to different Services. You might be wondering, where are these Services accessible? Through which networks or IPs are they exposed?
How Routes are exposed to clients is governed by Route binding, which describes how Routes and Gateways create a bidirectional relationship between each other. When Routes are bound to a Gateway it means their collective routing rules are configured on the underlying load balancers or proxies and the Routes are accessible through the Gateway. Thus, a Gateway is a logical representation of a networking data plane that can be configured through Routes.

Administrative Delegation
The split between Gateway and Route resources allows the cluster administrator to delegate some of the routing configuration to individual teams while still retaining centralized control. The following Gateway resource exposes HTTPS on port 443 and terminates all traffic on the port with a certificate controlled by the cluster administrator.
kind: Gateway
apiVersion: networking.x-k8s.io/v1alpha1
metadata:
name: prod-web
spec:
gatewayClassName: acme-lb
listeners:
- protocol: HTTPS
port: 443
routes:
kind: HTTPRoute
selector:
matchLabels:
gateway: external-https-prod
namespaces:
from: All
tls:
certificateRef:
name: admin-controlled-cert
The following HTTPRoute shows how the Route can ensure it matches the Gateway's selector via it’s kind (HTTPRoute) and resource labels (gateway=external-https-prod).
# Matches the required kind selector on the Gateway
kind: HTTPRoute
apiVersion: networking.x-k8s.io/v1alpha1
metadata:
name: foo-route
namespace: foo-ns
labels:
# Matches the required label selector on the Gateway
gateway: external-https-prod
...
Role Oriented Design
When you put it all together, you have a single load balancing infrastructure that can be safely shared by multiple teams. The Gateway API is not only a more expressive API for advanced routing, but is also a role-oriented API, designed for multi-tenant infrastructure. Its extensibility ensures that it will evolve for future use-cases while preserving portability. Ultimately these characteristics will allow the Gateway API to adapt to different organizational models and implementations well into the future.
Try it out and get involved
There are many resources to check out to learn more.
- Check out the user guides to see what use-cases can be addressed.
- Try out one of the existing Gateway controllers
- Or get involved and help design and influence the future of Kubernetes service networking!
Graceful Node Shutdown Goes Beta
Authors: David Porter (Google), Mrunal Patel (Red Hat), and Tim Bannister (The Scale Factory)
Graceful node shutdown, beta in 1.21, enables kubelet to gracefully evict pods during a node shutdown.
Kubernetes is a distributed system and as such we need to be prepared for inevitable failures — nodes will fail, containers might crash or be restarted, and - ideally - your workloads will be able to withstand these catastrophic events.
One of the common classes of issues are workload failures on node shutdown or restart. The best practice prior to bringing your node down is to safely drain and cordon your node. This will ensure that all pods running on this node can safely be evicted. An eviction will ensure your pods can follow the expected pod termination lifecycle meaning receiving a SIGTERM in your container and/or running preStopHooks.
Prior to Kubernetes 1.20 (when graceful node shutdown was introduced as an alpha feature), safe node draining was not easy: it required users to manually take action and drain the node beforehand. If someone or something shut down your node without draining it first, most likely your pods would not be safely evicted from your node and shutdown abruptly. Other services talking to those pods might see errors due to the pods exiting abruptly. Some examples of this situation may be caused by a reboot due to security patches or preemption of short lived cloud compute instances.
Kubernetes 1.21 brings graceful node shutdown to beta. Graceful node shutdown gives you more control over some of those unexpected shutdown situations. With graceful node shutdown, the kubelet is aware of underlying system shutdown events and can propagate these events to pods, ensuring containers can shut down as gracefully as possible. This gives the containers a chance to checkpoint their state or release back any resources they are holding.
Note, that for the best availability, even with graceful node shutdown, you should still design your deployments to be resilient to node failures.
How does it work?
On Linux, your system can shut down in many different situations. For example:
- A user or script running
shutdown -h noworsystemctl powerofforsystemctl reboot. - Physically pressing a power button on the machine.
- Stopping a VM instance on a cloud provider, e.g.
gcloud compute instances stopon GCP. - A Preemptible VM or Spot Instance that your cloud provider can terminate unexpectedly, but with a brief warning.
Many of these situations can be unexpected and there is no guarantee that a cluster administrator drained the node prior to these events. With the graceful node shutdown feature, kubelet uses a systemd mechanism called "Inhibitor Locks" to allow draining in most cases. Using Inhibitor Locks, kubelet instructs systemd to postpone system shutdown for a specified duration, giving a chance for the node to drain and evict pods on the system.
Kubelet makes use of this mechanism to ensure your pods will be terminated cleanly. When the kubelet starts, it acquires a systemd delay-type inhibitor lock. When the system is about to shut down, the kubelet can delay that shutdown for a configurable, short duration utilizing the delay-type inhibitor lock it acquired earlier. This gives your pods extra time to terminate. As a result, even during unexpected shutdowns, your application will receive a SIGTERM, preStop hooks will execute, and kubelet will properly update Ready node condition and respective pod statuses to the api-server.
For example, on a node with graceful node shutdown enabled, you can see that the inhibitor lock is taken by the kubelet:
kubelet-node ~ # systemd-inhibit --list
Who: kubelet (UID 0/root, PID 1515/kubelet)
What: shutdown
Why: Kubelet needs time to handle node shutdown
Mode: delay
1 inhibitors listed.
One important consideration we took when designing this feature is that not all pods are created equal. For example, some of the pods running on a node such as a logging related daemonset should stay running as long as possible to capture important logs during the shutdown itself. As a result, pods are split into two categories: "regular" and "critical". Critical pods are those that have priorityClassName set to system-cluster-critical or system-node-critical; all other pods are considered regular.
In our example, the logging DaemonSet would run as a critical pod. During the graceful node shutdown, regular pods are terminated first, followed by critical pods. As an example, this would allow a critical pod associated with a logging daemonset to continue functioning, and collecting logs during the termination of regular pods.
We will evaluate during the beta phase if we need more flexibility for different pod priority classes and add support if needed, please let us know if you have some scenarios in mind.
How do I use it?
Graceful node shutdown is controlled with the GracefulNodeShutdown feature gate and is enabled by default in Kubernetes 1.21.
You can configure the graceful node shutdown behavior using two kubelet configuration options: ShutdownGracePeriod and ShutdownGracePeriodCriticalPods. To configure these options, you edit the kubelet configuration file that is passed to kubelet via the --config flag; for more details, refer to Set kubelet parameters via a configuration file.
During a shutdown, kubelet terminates pods in two phases. You can configure how long each of these phases lasts.
- Terminate regular pods running on the node.
- Terminate critical pods running on the node.
The settings that control the duration of shutdown are:
ShutdownGracePeriod- Specifies the total duration that the node should delay the shutdown by. This is the total grace period for pod termination for both regular and critical pods.
ShutdownGracePeriodCriticalPods- Specifies the duration used to terminate critical pods during a node shutdown. This should be less than
ShutdownGracePeriod.
- Specifies the duration used to terminate critical pods during a node shutdown. This should be less than
For example, if ShutdownGracePeriod=30s, and ShutdownGracePeriodCriticalPods=10s, kubelet will delay the node shutdown by 30 seconds. During this time, the first 20 seconds (30-10) would be reserved for gracefully terminating normal pods, and the last 10 seconds would be reserved for terminating critical pods.
Note that by default, both configuration options described above, ShutdownGracePeriod and ShutdownGracePeriodCriticalPods are set to zero, so you will need to configure them as appropriate for your environment to activate graceful node shutdown functionality.
How can I learn more?
- Read the documentation
- Read the enhancement proposal, KEP 2000
- View the code
How do I get involved?
Your feedback is always welcome! SIG Node meets regularly and can be reached via Slack (channel #sig-node), or the SIG's mailing list
Annotating Kubernetes Services for Humans
Author: Richard Li, Ambassador Labs
Have you ever been asked to troubleshoot a failing Kubernetes service and struggled to find basic information about the service such as the source repository and owner?
One of the problems as Kubernetes applications grow is the proliferation of services. As the number of services grows, developers start to specialize working with specific services. When it comes to troubleshooting, however, developers need to be able to find the source, understand the service and dependencies, and chat with the owning team for any service.
Human service discovery
Troubleshooting always begins with information gathering. While much attention has been paid to centralizing machine data (e.g., logs, metrics), much less attention has been given to the human aspect of service discovery. Who owns a particular service? What Slack channel does the team work on? Where is the source for the service? What issues are currently known and being tracked?
Kubernetes annotations
Kubernetes annotations are designed to solve exactly this problem. Oft-overlooked, Kubernetes annotations are designed to add metadata to Kubernetes objects. The Kubernetes documentation says annotations can “attach arbitrary non-identifying metadata to objects.” This means that annotations should be used for attaching metadata that is external to Kubernetes (i.e., metadata that Kubernetes won’t use to identify objects. As such, annotations can contain any type of data. This is a contrast to labels, which are designed for uses internal to Kubernetes. As such, label structure and values are constrained so they can be efficiently used by Kubernetes.
Kubernetes annotations in action
Here is an example. Imagine you have a Kubernetes service for quoting, called the quote service. You can do the following:
kubectl annotate service quote a8r.io/owner=”@sally”
In this example, we've just added an annotation called a8r.io/owner with the value of @sally. Now, we can use kubectl describe to get the information.
Name: quote
Namespace: default
Labels: <none>
Annotations: a8r.io/owner: @sally
Selector: app=quote
Type: ClusterIP
IP: 10.109.142.131
Port: http 80/TCP
TargetPort: 8080/TCP
Endpoints: <none>
Session Affinity: None
Events: <none>
If you’re practicing GitOps (and you should be!) you’ll want to code these values directly into your Kubernetes manifest, e.g.,
apiVersion: v1
kind: Service
metadata:
name: quote
annotations:
a8r.io/owner: “@sally”
spec:
ports:
- name: http
port: 80
targetPort: 8080
selector:
app: quote
A Convention for Annotations
Adopting a common convention for annotations ensures consistency and understandability. Typically, you’ll want to attach the annotation to the service object, as services are the high-level resource that maps most clearly to a team’s responsibility. Namespacing your annotations is also very important. Here is one set of conventions, documented at a8r.io, and reproduced below:
| Annotation | Description |
|---|---|
a8r.io/description |
Unstructured text description of the service for humans. |
a8r.io/owner |
SSO username (GitHub), email address (linked to GitHub account), or unstructured owner description. |
a8r.io/chat |
Slack channel, or link to external chat system. |
a8r.io/bugs |
Link to external bug tracker. |
a8r.io/logs |
Link to external log viewer. |
a8r.io/documentation |
Link to external project documentation. |
a8r.io/repository |
Link to external VCS repository. |
a8r.io/support |
Link to external support center. |
a8r.io/runbook |
Link to external project runbook. |
a8r.io/incidents |
Link to external incident dashboard. |
a8r.io/uptime |
Link to external uptime dashboard. |
a8r.io/performance |
Link to external performance dashboard. |
a8r.io/dependencies |
Unstructured text describing the service dependencies for humans. |
Visualizing annotations: Service Catalogs
As the number of microservices and annotations proliferate, running kubectl describe can get tedious. Moreover, using kubectl describe requires every developer to have some direct access to the Kubernetes cluster. Over the past few years, service catalogs have gained greater visibility in the Kubernetes ecosystem. Popularized by tools such as Shopify's ServicesDB and Spotify's System Z, service catalogs are internally-facing developer portals that present critical information about microservices.
Note that these service catalogs should not be confused with the Kubernetes Service Catalog project. Built on the Open Service Broker API, the Kubernetes Service Catalog enables Kubernetes operators to plug in different services (e.g., databases) to their cluster.
Annotate your services now and thank yourself later
Much like implementing observability within microservice systems, you often don’t realize that you need human service discovery until it’s too late. Don't wait until something is on fire in production to start wishing you had implemented better metrics and also documented how to get in touch with the part of your organization that looks after it.
There's enormous benefits to building an effective “version 0” service: a dancing skeleton application with a thin slice of complete functionality that can be deployed to production with a minimal yet effective continuous delivery pipeline.
Adding service annotations should be an essential part of your “version 0” for all of your services. Add them now, and you’ll thank yourself later.
Defining Network Policy Conformance for Container Network Interface (CNI) providers
Authors: Matt Fenwick (Synopsys), Jay Vyas (VMWare), Ricardo Katz, Amim Knabben (Loadsmart), Douglas Schilling Landgraf (Red Hat), Christopher Tomkins (Tigera)
Special thanks to Tim Hockin and Bowie Du (Google), Dan Winship and Antonio Ojea (Red Hat), Casey Davenport and Shaun Crampton (Tigera), and Abhishek Raut and Antonin Bas (VMware) for being supportive of this work, and working with us to resolve issues in different Container Network Interfaces (CNIs) over time.
A brief conversation around "node local" Network Policies in April of 2020 inspired the creation of a NetworkPolicy subproject from SIG Network. It became clear that as a community, we need a rock-solid story around how to do pod network security on Kubernetes, and this story needed a community around it, so as to grow the cultural adoption of enterprise security patterns in K8s.
In this post we'll discuss:
- Why we created a subproject for Network Policies
- How we changed the Kubernetes e2e framework to
visualizeNetworkPolicy implementation of your CNI provider - The initial results of our comprehensive NetworkPolicy conformance validator, Cyclonus, built around these principles
- Improvements subproject contributors have made to the NetworkPolicy user experience
Why we created a subproject for NetworkPolicies
In April of 2020 it was becoming clear that many CNIs were emerging, and many vendors implement these CNIs in subtly different ways. Users were beginning to express a little bit of confusion around how to implement policies for different scenarios, and asking for new features. It was clear that we needed to begin unifying the way we think about Network Policies in Kubernetes, to avoid API fragmentation and unnecessary complexity.
For example:
- In order to be flexible to the user’s environment, Calico as a CNI provider can be run using IPIP or VXLAN mode, or without encapsulation overhead. CNIs such as Antrea and Cilium offer similar configuration options as well.
- Some CNI plugins offer iptables for NetworkPolicies amongst other options, whereas other CNIs use a completely different technology stack (for example, the Antrea project uses Open vSwitch rules).
- Some CNI plugins only implement a subset of the Kubernetes NetworkPolicy API, and some a superset. For example, certain plugins don't support the ability to target a named port; others don't work with certain IP address types, and there are diverging semantics for similar policy types.
- Some CNI plugins combine with OTHER CNI plugins in order to implement NetworkPolicies (canal), some CNI's might mix implementations (multus), and some clouds do routing separately from NetworkPolicy implementation.
Although this complexity is to some extent necessary to support different environments, end-users find that they need to follow a multistep process to implement Network Policies to secure their applications:
- Confirm that their network plugin supports NetworkPolicies (some don't, such as Flannel)
- Confirm that their cluster's network plugin supports the specific NetworkPolicy features that they are interested in (again, the named port or port range examples come to mind here)
- Confirm that their application's Network Policy definitions are doing the right thing
- Find out the nuances of a vendor's implementation of policy, and check whether or not that implementation has a CNI neutral implementation (which is sometimes adequate for users)
The NetworkPolicy project in upstream Kubernetes aims at providing a community where people can learn about, and contribute to, the Kubernetes NetworkPolicy API and the surrounding ecosystem.
The First step: A validation framework for NetworkPolicies that was intuitive to use and understand
The Kubernetes end to end suite has always had NetworkPolicy tests, but these weren't run in CI, and the way they were implemented didn't provide holistic, easily consumable information about how a policy was working in a cluster. This is because the original tests didn't provide any kind of visual summary of connectivity across a cluster. We thus initially set out to make it easy to confirm CNI support for NetworkPolicies by making the end to end tests (which are often used by administrators or users to diagnose cluster conformance) easy to interpret.
To solve the problem of confirming that CNIs support the basic features most users care about for a policy, we built a new NetworkPolicy validation tool into the Kubernetes e2e framework which allows for visual inspection of policies and their effect on a standard set of pods in a cluster. For example, take the following test output. We found a bug in OVN Kubernetes. This bug has now been resolved. With this tool the bug was really easy to characterize, wherein certain policies caused a state-modification that, later on, caused traffic to incorrectly be blocked (even after all Network Policies were deleted from the cluster).
This is the network policy for the test in question:
metadata:
creationTimestamp: null
name: allow-ingress-port-80
spec:
ingress:
- ports:
- port: serve-80-tcp
podSelector: {}
These are the expected connectivity results. The test setup is 9 pods (3 namespaces: x, y, and z; and 3 pods in each namespace: a, b, and c); each pod runs a server on the same port and protocol that can be reached through HTTP calls in the absence of network policies. Connectivity is verified by using the agnhost network utility to issue HTTP calls on a port and protocol that other pods are expected to be serving. A test scenario first runs a connectivity check to ensure that each pod can reach each other pod, for 81 (= 9 x 9) data points. This is the "control". Then perturbations are applied, depending on the test scenario: policies are created, updated, and deleted; labels are added and removed from pods and namespaces, and so on. After each change, the connectivity matrix is recollected and compared to the expected connectivity.
These results give a visual indication of connectivity in a simple matrix. Going down the leftmost column is the "source"
pod, or the pod issuing the request; going across the topmost row is the "destination" pod, or the pod
receiving the request. A . means that the connection was allowed; an X means the connection was
blocked. For example:
Nov 4 16:58:43.449: INFO: expected:
- x/a x/b x/c y/a y/b y/c z/a z/b z/c
x/a . . . . . . . . .
x/b . . . . . . . . .
x/c . . . . . . . . .
y/a . . . . . . . . .
y/b . . . . . . . . .
y/c . . . . . . . . .
z/a . . . . . . . . .
z/b . . . . . . . . .
z/c . . . . . . . . .
Below are the observed connectivity results in the case of the OVN Kubernetes bug. Notice how the top three rows indicate that all requests from namespace x regardless of pod and destination were blocked. Since these experimental results do not match the expected results, a failure will be reported. Note how the specific pattern of failure provides clear insight into the nature of the problem -- since all requests from a specific namespace fail, we have a clear clue to start our investigation.
Nov 4 16:58:43.449: INFO: observed:
- x/a x/b x/c y/a y/b y/c z/a z/b z/c
x/a X X X X X X X X X
x/b X X X X X X X X X
x/c X X X X X X X X X
y/a . . . . . . . . .
y/b . . . . . . . . .
y/c . . . . . . . . .
z/a . . . . . . . . .
z/b . . . . . . . . .
z/c . . . . . . . . .
This was one of our earliest wins in the Network Policy group, as we were able to identify and work with the OVN Kubernetes group to fix a bug in egress policy processing.
However, even though this tool has made it easy to validate roughly 30 common scenarios, it doesn't validate all Network Policy scenarios - because there are an enormous number of possible permutations that one might create (technically, we might say this number is infinite given that there's an infinite number of possible namespace/pod/port/protocol variations one can create).
Once these tests were in play, we worked with the Upstream SIG Network and SIG Testing communities (thanks to Antonio Ojea and Ben Elder) to put a testgrid Network Policy job in place. This job continuously runs the entire suite of Network Policy tests against GCE with Calico as a Network Policy provider.
Part of our role as a subproject is to help make sure that, when these tests break, we can help triage them effectively.
Cyclonus: The next step towards Network Policy conformance
Around the time that we were finishing the validation work, it became clear from the community that, in general, we needed to solve the overall problem of testing ALL possible Network Policy implementations. For example, a KEP was recently written which introduced the concept of micro versioning to Network Policies to accommodate describing this at the API level, by Dan Winship.
In response to this increasingly obvious need to comprehensively evaluate Network Policy implementations from all vendors, Matt Fenwick decided to evolve our approach to Network Policy validation again by creating Cyclonus.
Cyclonus is a comprehensive Network Policy fuzzing tool which verifies a CNI provider against hundreds of different Network Policy scenarios, by defining similar truth table/policy combinations as demonstrated in the end to end tests, while also providing a hierarchical representation of policy "categories". We've found some interesting nuances and issues in almost every CNI we've tested so far, and have even contributed some fixes back.
To perform a Cyclonus validation run, you create a Job manifest similar to:
apiVersion: batch/v1
kind: Job
metadata:
name: cyclonus
spec:
template:
spec:
restartPolicy: Never
containers:
- command:
- ./cyclonus
- generate
- --perturbation-wait-seconds=15
- --server-protocol=tcp,udp
name: cyclonus
imagePullPolicy: IfNotPresent
image: mfenwick100/cyclonus:latest
serviceAccount: cyclonus
Cyclonus outputs a report of all the test cases it will run:
test cases to run by tag:
- target: 6
- peer-ipblock: 4
- udp: 16
- delete-pod: 1
- conflict: 16
- multi-port/protocol: 14
- ingress: 51
- all-pods: 14
- egress: 51
- all-namespaces: 10
- sctp: 10
- port: 56
- miscellaneous: 22
- direction: 100
- multi-peer: 0
- any-port-protocol: 2
- set-namespace-labels: 1
- upstream-e2e: 0
- allow-all: 6
- namespaces-by-label: 6
- deny-all: 10
- pathological: 6
- action: 6
- rule: 30
- policy-namespace: 4
- example: 0
- tcp: 16
- target-namespace: 3
- named-port: 24
- update-policy: 1
- any-peer: 2
- target-pod-selector: 3
- IP-block-with-except: 2
- pods-by-label: 6
- numbered-port: 28
- protocol: 42
- peer-pods: 20
- create-policy: 2
- policy-stack: 0
- any-port: 14
- delete-namespace: 1
- delete-policy: 1
- create-pod: 1
- IP-block-no-except: 2
- create-namespace: 1
- set-pod-labels: 1
testing 112 cases
Note that Cyclonus tags its tests based on the type of policy being created, because the policies themselves are auto-generated, and thus have no meaningful names to be recognized by.
For each test, Cyclonus outputs a truth table, which is again similar to that of the E2E tests, along with the policy being validated:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
creationTimestamp: null
name: base
namespace: x
spec:
egress:
- ports:
- port: 81
to:
- namespaceSelector:
matchExpressions:
- key: ns
operator: In
values:
- "y"
- z
podSelector:
matchExpressions:
- key: pod
operator: In
values:
- a
- b
- ports:
- port: 53
protocol: UDP
ingress:
- from:
- namespaceSelector:
matchExpressions:
- key: ns
operator: In
values:
- x
- "y"
podSelector:
matchExpressions:
- key: pod
operator: In
values:
- b
- c
ports:
- port: 80
protocol: TCP
podSelector:
matchLabels:
pod: a
policyTypes:
- Ingress
- Egress
0 wrong, 0 ignored, 81 correct
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| TCP/80 | X/A | X/B | X/C | Y/A | Y/B | Y/C | Z/A | Z/B | Z/C |
| TCP/81 | | | | | | | | | |
| UDP/80 | | | | | | | | | |
| UDP/81 | | | | | | | | | |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| x/a | X | X | X | X | X | X | X | X | X |
| | X | X | X | . | . | X | . | . | X |
| | X | X | X | X | X | X | X | X | X |
| | X | X | X | X | X | X | X | X | X |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| x/b | . | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| x/c | . | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| y/a | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| y/b | . | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| y/c | . | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| z/a | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| z/b | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| z/c | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
| | X | . | . | . | . | . | . | . | . |
+--------+-----+-----+-----+-----+-----+-----+-----+-----+-----+
Both Cyclonus and the e2e tests use the same strategy to validate a Network Policy - probing pods over TCP or UDP, with SCTP support available as well for CNIs that support it (such as Calico).
As examples of how we use Cyclonus to help make CNI implementations better from a Network Policy perspective, you can see the following issues:
- Antrea: NetworkPolicy: unable to allow ingress by CIDR
- Calico: default missing protocol to TCP; don't let single port overwrite all ports
- Cilium: Egress Network Policy allows traffic that should be denied
The good news is that Antrea and Calico have already merged fixes for all the issues found and other CNI providers are working on it, with the support of SIG Network and the Network Policy subproject.
Are you interested in verifying NetworkPolicy functionality on your cluster? (if you care about security or offer multi-tenant SaaS, you should be) If so, you can run the upstream end to end tests, or Cyclonus, or both.
- If you're just getting started with NetworkPolicies and want to simply verify the "common" NetworkPolicy cases that most CNIs should be implementing correctly, in a way that is quick to diagnose, then you're better off running the e2e tests only.
- If you are deeply curious about your CNI provider's NetworkPolicy implementation, and want to verify it: use Cyclonus.
- If you want to test hundreds of policies, and evaluate your CNI plugin for comprehensive functionality, for deep discovery of potential security holes: use Cyclonus, and also consider running end-to-end cluster tests.
- If you're thinking of getting involved with the upstream NetworkPolicy efforts: use Cyclonus, and read at least an outline of which e2e tests are relevant.
Where to start with NetworkPolicy testing?
- Cyclonus is easy to run on your cluster, check out the instructions on github, and determine whether your specific CNI configuration is fully conformant to the hundreds of different Kubernetes Network Policy API constructs.
- Alternatively, you can use a tool like sonobuoy
to run the existing E2E tests in Kubernetes, with the
--ginkgo.focus=NetworkPolicyflag. Make sure that you use the K8s conformance image for K8s 1.21 or above (for example, by using the--kube-conformance-image-version v1.21.0flag), as older images will not have the new Network Policy tests in them.
Improvements to the NetworkPolicy API and user experience
In addition to cleaning up the validation story for CNI plugins that implement NetworkPolicies, subproject contributors have also spent some time improving the Kubernetes NetworkPolicy API for a few commonly requested features. After months of deliberation, we eventually settled on a few core areas for improvement:
-
Port Range policies: We now allow you to specify a range of ports for a policy. This allows users interested in scenarios like FTP or virtualization to enable advanced policies. The port range option for network policies will be available to use in Kubernetes 1.21. Read more in targeting a range of ports.
-
Namespace as name policies: Allowing users in Kubernetes >= 1.21 to target namespaces using names, when building Network Policy objects. This was done in collaboration with Jordan Liggitt and Tim Hockin on the API Machinery side. This change allowed us to improve the Network Policy user experience without actually changing the API! For more details, you can read Automatic labelling in the page about Namespaces. The TL,DR; is that for Kubernetes 1.21 and later, all namespaces have the following label added by default:
kubernetes.io/metadata.name: <name-of-namespace>
This means you can write a namespace policy against this namespace, even if you can't edit its labels.
For example, this policy, will 'just work', without needing to run a command such as kubectl edit namespace.
In fact, it will even work if you can't edit or view this namespace's data at all, because of the magic of API server defaulting.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
# Allow inbound traffic to Pods labelled role=db, in the namespace 'default'
# provided that the source is a Pod in the namespace 'my-namespace'
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: my-namespace
Results
In our tests, we found that:
- Antrea and Calico are at a point where they support all of cyclonus's scenarios, modulo a few very minor tweaks which we've made.
- Cilium also conformed to the majority of the policies, outside known features that aren't fully supported (for example, related to the way Cilium deals with pod CIDR policies).
If you are a CNI provider and interested in helping us to do a better job curating large tests of network policies, please reach out! We are continuing to curate the Network Policy conformance results from Cyclonus here, but we are not capable of maintaining all of the subtleties in NetworkPolicy testing data on our own. For now, we use github actions and Kind to test in CI.
The Future
We're also working on some improvements for the future of Network Policies, including:
- Fully qualified Domain policies: The Google Cloud team created a prototype (which we are really excited about) of FQDN policies. This tool uses the Network Policy API to enforce policies against L7 URLs, by finding their IPs and blocking them proactively when requests are made.
- Cluster Administrative policies: We're working hard at enabling administrative or cluster scoped Network Policies for the future. These are being presented iteratively to the NetworkPolicy subproject. You can read about them here in Cluster Scoped Network Policy.
The Network Policy subproject meets on mondays at 4PM EST. For details, check out the SIG Network community repo. We'd love to hang out with you, hack on stuff, and help you adopt K8s Network Policies for your cluster wherever possible.
A quick note on User Feedback
We've gotten a lot of ideas and feedback from users on Network Policies. A lot of people have interesting ideas about Network Policies, but we've found that as a subproject, very few people were deeply interested in implementing these ideas to the full extent.
Almost every change to the NetworkPolicy API includes weeks or months of discussion to cover different cases, and ensure no CVEs are being introduced. Thus, long term ownership is the biggest impediment in improving the NetworkPolicy user experience for us, over time.
- We've documented a lot of the history of the Network Policy dialogue here.
- We've also taken a poll of users, for what they'd like to see in the Network Policy API here.
We encourage anyone to provide us with feedback, but our most pressing issues right now involve finding long term owners to help us drive changes.
This doesn't require a lot of technical knowledge, but rather, just a long term commitment to helping us stay organized, do paperwork, and iterate through the many stages of the K8s feature process. If you want to help us and get involved, please reach out on the SIG Network mailing list, or in the SIG Network room in the k8s.io slack channel!
Anyone can put an oar in the water and help make NetworkPolices better!
Introducing Indexed Jobs
Author: Aldo Culquicondor (Google)
Once you have containerized a non-parallel Job, it is quite easy to get it up and running on Kubernetes without modifications to the binary. In most cases, when running parallel distributed Jobs, you had to set a separate system to partition the work among the workers. For example, you could set up a task queue to assign one work item to each Pod or multiple items to each Pod until the queue is emptied.
The Kubernetes 1.21 release introduces a new field to control Job completion mode, a configuration option that allows you to control how Pod completions affect the overall progress of a Job, with two possible options (for now):
NonIndexed(default): the Job is considered complete when there has been a number of successfully completed Pods equal to the specified number in.spec.completions. In other words, each Pod completion is homologous to each other. Any Job you might have created before the introduction of completion modes is implicitly NonIndexed.Indexed: the Job is considered complete when there is one successfully completed Pod associated with each index from 0 to.spec.completions-1. The index is exposed to each Pod in thebatch.kubernetes.io/job-completion-indexannotation and theJOB_COMPLETION_INDEXenvironment variable.
You can start using Jobs with Indexed completion mode, or Indexed Jobs, for short, to easily start parallel Jobs. Then, each worker Pod can have a statically assigned partition of the data based on the index. This saves you from having to set up a queuing system or even having to modify your binary!
Creating an Indexed Job
To create an Indexed Job, you just have to add completionMode: Indexed to the
Job spec and make use of the JOB_COMPLETION_INDEX environment variable.
apiVersion: batch/v1
kind: Job
metadata:
name: 'sample-job'
spec:
completions: 3
parallelism: 3
completionMode: Indexed
template:
spec:
restartPolicy: Never
containers:
- command:
- 'bash'
- '-c'
- 'echo "My partition: ${JOB_COMPLETION_INDEX}"'
image: 'docker.io/library/bash'
name: 'sample-load'
Note that completion mode is an alpha feature in the 1.21 release. To be able to
use it in your cluster, make sure to enable the IndexedJob feature
gate on the
API server and
the controller manager.
When you run the example, you will see that each of the three created Pods gets a
different completion index. For the user's convenience, the control plane sets the
JOB_COMPLETION_INDEX environment variable, but you can choose to set your
own
or expose the index as a file.
See Indexed Job for parallel processing with static work assignment for a step-by-step guide, and a few more examples.
Future plans
SIG Apps envisions that there might be more completion modes that enable more use cases for the Job API. We welcome you to open issues in kubernetes/kubernetes with your suggestions.
In particular, we are considering an IndexedAndUnique mode where the indexes
are not just available as annotation, but they are part of the Pod names,
similar to StatefulSet.
This should facilitate inter-Pod communication for tightly coupled Pods.
You can join the discussion in the open issue.
Wrap-up
Indexed Jobs allows you to statically partition work among the workers of your parallel Jobs. SIG Apps hopes that this feature facilitates the migration of more batch workloads to Kubernetes.
Volume Health Monitoring Alpha Update
Author: Xing Yang (VMware)
The CSI Volume Health Monitoring feature, originally introduced in 1.19 has undergone a large update for the 1.21 release.
Why add Volume Health Monitoring to Kubernetes?
Without Volume Health Monitoring, Kubernetes has no knowledge of the state of the underlying volumes of a storage system after a PVC is provisioned and used by a Pod. Many things could happen to the underlying storage system after a volume is provisioned in Kubernetes. For example, the volume could be deleted by accident outside of Kubernetes, the disk that the volume resides on could fail, it could be out of capacity, the disk may be degraded which affects its performance, and so on. Even when the volume is mounted on a pod and used by an application, there could be problems later on such as read/write I/O errors, file system corruption, accidental unmounting of the volume outside of Kubernetes, etc. It is very hard to debug and detect root causes when something happened like this.
Volume health monitoring can be very beneficial to Kubernetes users. It can communicate with the CSI driver to retrieve errors detected by the underlying storage system. PVC events can be reported up to the user to take action. For example, if the volume is out of capacity, they could request a volume expansion to get more space.
What is Volume Health Monitoring?
CSI Volume Health Monitoring allows CSI Drivers to detect abnormal volume conditions from the underlying storage systems and report them as events on PVCs or Pods.
The Kubernetes components that monitor the volumes and report events with volume health information include the following:
- Kubelet, in addition to gathering the existing volume stats will watch the volume health of the PVCs on that node. If a PVC has an abnormal health condition, an event will be reported on the pod object using the PVC. If multiple pods are using the same PVC, events will be reported on all pods using that PVC.
- An External Volume Health Monitor Controller watches volume health of the PVCs and reports events on the PVCs.
Note that the node side volume health monitoring logic was an external agent when this feature was first introduced in the Kubernetes 1.19 release. In Kubernetes 1.21, the node side volume health monitoring logic was moved from the external agent into the Kubelet, to avoid making duplicate CSI function calls. With this change in 1.21, a new alpha feature gate CSIVolumeHealth was introduced for the volume health monitoring logic in Kubelet.
Currently the Volume Health Monitoring feature is informational only as it only reports abnormal volume health events on PVCs or Pods. Users will need to check these events and manually fix the problems. This feature serves as a stepping stone towards programmatic detection and resolution of volume health issues by Kubernetes in the future.
How do I use Volume Health on my Kubernetes Cluster?
To use the Volume Health feature, first make sure the CSI driver you are using supports this feature. Refer to this CSI drivers doc to find out which CSI drivers support this feature.
To enable Volume Health Monitoring from the node side, the alpha feature gate CSIVolumeHealth needs to be enabled.
If a CSI driver supports the Volume Health Monitoring feature from the controller side, events regarding abnormal volume conditions will be recorded on PVCs.
If a CSI driver supports the Volume Health Monitoring feature from the controller side, user can also get events regarding node failures if the enable-node-watcher flag is set to true when deploying the External Health Monitor Controller. When a node failure event is detected, an event will be reported on the PVC to indicate that pods using this PVC are on a failed node.
If a CSI driver supports the Volume Health Monitoring feature from the node side, events regarding abnormal volume conditions will be recorded on pods using the PVCs.
As a storage vendor, how do I add support for volume health to my CSI driver?
Volume Health Monitoring includes two parts:
- An External Volume Health Monitoring Controller monitors volume health from the controller side.
- Kubelet monitors volume health from the node side.
For details, see the CSI spec and the Kubernetes-CSI Driver Developer Guide.
There is a sample implementation for volume health in CSI host path driver.
Controller Side Volume Health Monitoring
To learn how to deploy the External Volume Health Monitoring controller, see CSI external-health-monitor-controller in the CSI documentation.
The External Health Monitor Controller calls either ListVolumes or ControllerGetVolume CSI RPC and reports VolumeConditionAbnormal events with messages on PVCs if abnormal volume conditions are detected. Only CSI drivers with LIST_VOLUMES and VOLUME_CONDITION controller capability or GET_VOLUME and VOLUME_CONDITION controller capability support Volume Health Monitoring in the external controller.
To implement the volume health feature from the controller side, a CSI driver must add support for the new controller capabilities.
If a CSI driver supports LIST_VOLUMES and VOLUME_CONDITION controller capabilities, it must implement controller RPC ListVolumes and report the volume condition in the response.
If a CSI driver supports GET_VOLUME and VOLUME_CONDITION controller capability, it must implement controller PRC ControllerGetVolume and report the volume condition in the response.
If a CSI driver supports LIST_VOLUMES, GET_VOLUME, and VOLUME_CONDITION controller capabilities, only ListVolumes CSI RPC will be invoked by the External Health Monitor Controller.
Node Side Volume Health Monitoring
Kubelet calls NodeGetVolumeStats CSI RPC and reports VolumeConditionAbnormal events with messages on Pods if abnormal volume conditions are detected. Only CSI drivers with VOLUME_CONDITION node capability support Volume Health Monitoring in Kubelet.
To implement the volume health feature from the node side, a CSI driver must add support for the new node capabilities.
If a CSI driver supports VOLUME_CONDITION node capability, it must report the volume condition in node RPC NodeGetVoumeStats.
What’s next?
Depending on feedback and adoption, the Kubernetes team plans to push the CSI volume health implementation to beta in either 1.22 or 1.23.
We are also exploring how to use volume health information for programmatic detection and automatic reconcile in Kubernetes.
How can I learn more?
To learn the design details for Volume Health Monitoring, read the Volume Health Monitor enhancement proposal.
The Volume Health Monitor controller source code is at https://github.com/kubernetes-csi/external-health-monitor.
There are also more details about volume health checks in the Container Storage Interface Documentation.
How do I get involved?
The Kubernetes Slack channel #csi and any of the standard SIG Storage communication channels are great mediums to reach out to the SIG Storage and the CSI team.
We offer a huge thank you to the contributors who helped release this feature in 1.21. We want to thank Yuquan Ren (NickrenREN) who implemented the initial volume health monitor controller and agent in the external health monitor repo, thank Ran Xu (fengzixu) who moved the volume health monitoring logic from the external agent to Kubelet in 1.21, and we offer special thanks to the following people for their insightful reviews: David Ashpole (dashpole), Michelle Au (msau42), David Eads (deads2k), Elana Hashman (ehashman), Seth Jennings (sjenning), and Jiawei Wang (Jiawei0227).
Those interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Three Tenancy Models For Kubernetes
Authors: Ryan Bezdicek (Medtronic), Jim Bugwadia (Nirmata), Tasha Drew (VMware), Fei Guo (Alibaba), Adrian Ludwin (Google)
Kubernetes clusters are typically used by several teams in an organization. In other cases, Kubernetes may be used to deliver applications to end users requiring segmentation and isolation of resources across users from different organizations. Secure sharing of Kubernetes control plane and worker node resources allows maximizing productivity and saving costs in both cases.
The Kubernetes Multi-Tenancy Working Group is chartered with defining tenancy models for Kubernetes and making it easier to operationalize tenancy related use cases. This blog post, from the working group members, describes three common tenancy models and introduces related working group projects.
We will also be presenting on this content and discussing different use cases at our Kubecon EU 2021 panel session, Multi-tenancy vs. Multi-cluster: When Should you Use What?.
Namespaces as a Service
With the namespaces-as-a-service model, tenants share a cluster and tenant workloads are restricted to a set of Namespaces assigned to the tenant. The cluster control plane resources like the API server and scheduler, and worker node resources like CPU, memory, etc. are available for use across all tenants.
To isolate tenant workloads, each namespace must also contain:
- role bindings: for controlling access to the namespace
- network policies: to prevent network traffic across tenants
- resource quotas: to limit usage and ensure fairness across tenants
With this model, tenants share cluster-wide resources like ClusterRoles and CustomResourceDefinitions (CRDs) and hence cannot create or update these cluster-wide resources.
The Hierarchical Namespace Controller (HNC) project makes it easier to manage namespace based tenancy by allowing users to create additional namespaces under a namespace, and propagating resources within the namespace hierarchy. This allows self-service namespaces for tenants, without requiring cluster-wide permissions.
The Multi-Tenancy Benchmarks (MTB) project provides benchmarks and a command-line tool that performs several configuration and runtime checks to report if tenant namespaces are properly isolated and the necessary security controls are implemented.
Clusters as a Service
With the clusters-as-a-service usage model, each tenant gets their own cluster. This model allows tenants to have different versions of cluster-wide resources such as CRDs, and provides full isolation of the Kubernetes control plane.
The tenant clusters may be provisioned using projects like Cluster API (CAPI) where a management cluster is used to provision multiple workload clusters. A workload cluster is assigned to a tenant and tenants have full control over cluster resources. Note that in most enterprises a central platform team may be responsible for managing required add-on services such as security and monitoring services, and for providing cluster lifecycle management services such as patching and upgrades. A tenant administrator may be restricted from modifying the centrally managed services and other critical cluster information.
Control planes as a Service
In a variation of the clusters-as-a-service model, the tenant cluster may be a virtual cluster where each tenant gets their own dedicated Kubernetes control plane but share worker node resources. As with other forms of virtualization, users of a virtual cluster see no significant differences between a virtual cluster and other Kubernetes clusters. This is sometimes referred to as Control Planes as a Service (CPaaS).
A virtual cluster of this type shares worker node resources and workload state independent control plane components, like the scheduler. Other workload aware control-plane components, like the API server, are created on a per-tenant basis to allow overlaps, and additional components are used to synchronize and manage state across the per-tenant control plane and the underlying shared cluster resources. With this model users can manage their own cluster-wide resources.
The Virtual Cluster project implements this model, where a supercluster is shared by multiple virtual clusters. The Cluster API Nested project is extending this work to conform to the CAPI model, allowing use of familiar API resources to provision and manage virtual clusters.
Security considerations
Cloud native security involves different system layers and lifecycle phases as described in the Cloud Native Security Whitepaper from CNCF SIG Security. Without proper security measures implemented across all layers and phases, Kubernetes tenant isolation can be compromised and a security breach with one tenant can threaten other tenants.
It is important for any new user to Kubernetes to realize that the default installation of a new upstream Kubernetes cluster is not secure, and you are going to need to invest in hardening it in order to avoid security issues.
At a minimum, the following security measures are required:
- image scanning: container image vulnerabilities can be exploited to execute commands and access additional resources.
- RBAC: for namespaces-as-a-service user roles and permissions must be properly configured at a per-namespace level; for other models tenants may need to be restricted from accessing centrally managed add-on services and other cluster-wide resources.
- network policies: for namespaces-as-a-service default network policies that deny all ingress and egress traffic are recommended to prevent cross-tenant network traffic and may also be used as a best practice for other tenancy models.
- Kubernetes Pod Security Standards: to enforce Pod hardening best practices the
Restrictedpolicy is recommended as the default for tenant workloads with exclusions configured only as needed. - CIS Benchmarks for Kubernetes: the CIS Benchmarks for Kubernetes guidelines should be used to properly configure Kubernetes control-plane and worker node components.
Additional recommendations include using:
- policy engines: for configuration security best practices, such as only allowing trusted registries.
- runtime scanners: to detect and report runtime security events.
- VM-based container sandboxing: for stronger data plane isolation.
While proper security is required independently of tenancy models, not having essential security controls like pod security in a shared cluster provides attackers with means to compromise tenancy models and possibly access sensitive information across tenants increasing the overall risk profile.
Summary
A 2020 CNCF survey showed that production Kubernetes usage has increased by over 300% since 2016. As an increasing number of Kubernetes workloads move to production, organizations are looking for ways to share Kubernetes resources across teams for agility and cost savings.
The namespaces as a service tenancy model allows sharing clusters and hence enables resource efficiencies. However, it requires proper security configurations and has limitations as all tenants share the same cluster-wide resources.
The clusters as a service tenancy model addresses these limitations, but with higher management and resource overhead.
The control planes as a service model provides a way to share resources of a single Kubernetes cluster and also let tenants manage their own cluster-wide resources. Sharing worker node resources increases resource effeciencies, but also exposes cross tenant security and isolation concerns that exist for shared clusters.
In many cases, organizations will use multiple tenancy models to address different use cases and as different product and development teams will have varying needs. Following security and management best practices, such as applying Pod Security Standards and not using the default namespace, makes it easer to switch from one model to another.
The Kubernetes Multi-Tenancy Working Group has created several projects like Hierarchical Namespaces Controller, Virtual Cluster / CAPI Nested, and Multi-Tenancy Benchmarks to make it easier to provision and manage multi-tenancy models.
If you are interested in multi-tenancy topics, or would like to share your use cases, please join us in an upcoming community meeting or reach out on the wg-multitenancy channel on the Kubernetes slack.
Local Storage: Storage Capacity Tracking, Distributed Provisioning and Generic Ephemeral Volumes hit Beta
Authors: Patrick Ohly (Intel)
The "generic ephemeral volumes" and "storage capacity tracking" features in Kubernetes are getting promoted to beta in Kubernetes 1.21. Together with the distributed provisioning support in the CSI external-provisioner, development and deployment of Container Storage Interface (CSI) drivers which manage storage locally on a node become a lot easier.
This blog post explains how such drivers worked before and how these features can be used to make drivers simpler.
Problems we are solving
There are drivers for local storage, like TopoLVM for traditional disks and PMEM-CSI for persistent memory. They work and are ready for usage today also on older Kubernetes releases, but making that possible was not trivial.
Central component required
The first problem is volume provisioning: it is handled through the Kubernetes control plane. Some component must react to PersistentVolumeClaims (PVCs) and create volumes. Usually, that is handled by a central deployment of the CSI external-provisioner and a CSI driver component that then connects to the storage backplane. But for local storage, there is no such backplane.
TopoLVM solved this by having its different components communicate with each other through the Kubernetes API server by creating and reacting to custom resources. So although TopoLVM is based on CSI, a standard that is independent of a particular container orchestrator, TopoLVM only works on Kubernetes.
PMEM-CSI created its own storage backplane with communication through gRPC calls. Securing that communication depends on TLS certificates, which made driver deployment more complicated.
Informing Pod scheduler about capacity
The next problem is scheduling. When volumes get created independently
of pods ("immediate binding"), the CSI driver must pick a node without
knowing anything about the pod(s) that are going to use it. Topology
information then forces those pods to run on the node where the volume
was created. If other resources like RAM or CPU are exhausted there,
the pod cannot start. This can be avoided by configuring in the
StorageClass that volume creation is meant to wait for the first pod
that uses a volume (volumeBinding: WaitForFirstConsumer). In that
mode, the Kubernetes scheduler tentatively picks a node based on other
constraints and then the external-provisioner is asked to create a
volume such that it is usable there. If local storage is exhausted,
the provisioner can
ask
for another scheduling round. But without information about available
capacity, the scheduler might always pick the same unsuitable node.
Both TopoLVM and PMEM-CSI solved this with scheduler extenders. This works, but it is hard to configure when deploying the driver because communication between kube-scheduler and the driver is very dependent on how the cluster was set up.
Rescheduling
A common use case for local storage is scratch space. A better fit for that use case than persistent volumes are ephemeral volumes that get created for a pod and destroyed together with it. The initial API for supporting ephemeral volumes with CSI drivers (hence called "CSI ephemeral volumes") was designed for light-weight volumes where volume creation is unlikely to fail. Volume creation happens after pods have been permanently scheduled onto a node, in contrast to the traditional provisioning where volume creation is tried before scheduling a pod onto a node. CSI drivers must be modified to support "CSI ephemeral volumes", which was done for TopoLVM and PMEM-CSI. But due to the design of the feature in Kubernetes, pods can get stuck permanently if storage capacity runs out on a node. The scheduler extenders try to avoid that, but cannot be 100% reliable.
Enhancements in Kubernetes 1.21
Distributed provisioning
Starting with external-provisioner v2.1.0, released for Kubernetes 1.20, provisioning can be handled by external-provisioner instances that get deployed together with the CSI driver on each node and then cooperate to provision volumes ("distributed provisioning"). There is no need any more to have a central component and thus no need for communication between nodes, at least not for provisioning.
Storage capacity tracking
A scheduler extender still needs some way to find out about capacity
on each node. When PMEM-CSI switched to distributed provisioning in
v0.9.0, this was done by querying the metrics data exposed by the
local driver containers. But it is better also for users to eliminate
the need for a scheduler extender completely because the driver
deployment becomes simpler. Storage capacity
tracking, introduced in
1.19
and promoted to beta in Kubernetes 1.21, achieves that. It works by
publishing information about capacity in CSIStorageCapacity
objects. The scheduler itself then uses that information to filter out
unsuitable nodes. Because information might be not quite up-to-date,
pods may still get assigned to nodes with insufficient storage, it's
just less likely and the next scheduling attempt for a pod should work
better once the information got refreshed.
Generic ephemeral volumes
So CSI drivers still need the ability to recover from a bad scheduling decision, something that turned out to be impossible to implement for "CSI ephemeral volumes". "Generic ephemeral volumes", another feature that got promoted to beta in 1.21, don't have that limitation. This feature adds a controller that will create and manage PVCs with the lifetime of the Pod and therefore the normal recovery mechanism also works for them. Existing storage drivers will be able to process these PVCs without any new logic to handle this new scenario.
Known limitations
Both generic ephemeral volumes and storage capacity tracking increase the load on the API server. Whether that is a problem depends a lot on the kind of workload, in particular how many pods have volumes and how often those need to be created and destroyed.
No attempt was made to model how scheduling decisions affect storage capacity. That's because the effect can vary considerably depending on how the storage system handles storage. The effect is that multiple pods with unbound volumes might get assigned to the same node even though there is only sufficient capacity for one pod. Scheduling should recover, but it would be more efficient if the scheduler knew more about storage.
Because storage capacity gets published by a running CSI driver and the cluster autoscaler needs information about a node that hasn't been created yet, it will currently not scale up a cluster for pods that need volumes. There is an idea how to provide that information, but more work is needed in that area.
Distributed snapshotting and resizing are not currently supported. It should be doable to adapt the respective sidecar and there are tracking issues for external-snapshotter and external-resizer open already, they just need some volunteer.
The recovery from a bad scheduling decising can fail for pods with multiple volumes, in particular when those volumes are local to nodes: if one volume can be created and then storage is insufficient for another volume, the first volume continues to exist and forces the scheduler to put the pod onto the node of that volume. There is an idea how do deal with this, rolling back the provision of the volume, but this is only in the very early stages of brainstorming and not even a merged KEP yet. For now it is better to avoid creating pods with more than one persistent volume.
Enabling the new features and next steps
With the feature entering beta in the 1.21 release, no additional actions are needed to enable it. Generic ephemeral volumes also work without changes in CSI drivers. For more information, see the documentation and the previous blog post about it. The API has not changed at all between alpha and beta.
For the other two features, the external-provisioner documentation explains how CSI driver developers must change how their driver gets deployed to support storage capacity tracking and distributed provisioning. These two features are independent, therefore it is okay to enable only one of them.
SIG
Storage
would like to hear from you if you are using these new features. We
can be reached through
email,
Slack (channel #sig-storage) and in the
regular SIG
meeting.
A description of your workload would be very useful to validate design
decisions, set up performance tests and eventually promote these
features to GA.
Acknowledgements
Thanks a lot to the members of the community who have contributed to these features or given feedback including members of SIG Scheduling, SIG Auth, and of course SIG Storage!
kube-state-metrics goes v2.0
Authors: Lili Cosic (Red Hat), Frederic Branczyk (Polar Signals), Manuel Rüger (Sony Interactive Entertainment), Tariq Ibrahim (Salesforce)
What?
kube-state-metrics, a project under the Kubernetes organization, generates Prometheus format metrics based on the current state of the Kubernetes native resources. It does this by listening to the Kubernetes API and gathering information about resources and objects, e.g. Deployments, Pods, Services, and StatefulSets. A full list of resources is available in the documentation of kube-state-metrics.
Why?
There are numerous useful metrics and insights provided by kube-state-metrics right out of the box! These metrics can be used to serve as an insight into your cluster: Either through metrics alone, in the form of dashboards, or through an alerting pipeline. To provide a few examples:
kube_pod_container_status_restarts_totalcan be used to alert on a crashing pod.kube_deployment_status_replicaswhich together withkube_deployment_status_replicas_availablecan be used to alert on whether a deployment is rolled out successfully or stuck.kube_pod_container_resource_requestsandkube_pod_container_resource_limitscan be used in capacity planning dashboards.
And there are many more metrics available! To learn more about the other metrics and their details, please check out the documentation.
What is new in v2.0?
So now that we know what kube-state-metrics is, we are excited to announce the next release: kube-state-metrics v2.0! This release was long-awaited and started with an alpha release in September 2020. To ease maintenance we removed tech debt and also adjusted some confusing wording around user-facing flags and APIs. We also removed some metrics that caused unnecessarily high cardinality in Prometheus! For the 2.0 release, we took the time to set up scale and performance testing. This allows us to better understand if we hit any issues in large clusters and also to document resource request recommendations for your clusters. In this release (and v1.9.8) container builds providing support for multiple architectures were introduced allowing you to run kube-state-metrics on ARM, ARM64, PPC64 and S390x as well!
So without further ado, here is the list of more noteworthy user-facing breaking changes. A full list of changes, features and bug fixes is available in the changelog at the end of this post.
- Flag
--namespacewas renamed to--namespaces. If you are using the former, please make sure to update the flag before deploying the latest release. - Flag
--collectorswas renamed to--resources. - Flags
--metric-blacklistand--metric-whitelistwere renamed to--metric-denylistand--metric-allowlist. - Flag
--metric-labels-allowlistallows you to specify a list of Kubernetes labels that get turned into the dimensions of thekube_<resource-name>_labelsmetrics. By default, the metric contains only name and namespace labels. - All metrics with a prefix of
kube_hpa_*were renamed tokube_horizontalpodautoscaler_*. - Metric labels that relate to Kubernetes were converted to snake_case.
- If you are importing kube-state-metrics as a library, we have updated our go module path to
k8s.io/kube-state-metrics/v2 - All deprecated stable metrics were removed as per the notice in the v1.9 release.
quay.io/coreos/kube-state-metricsimages will no longer be updated.k8s.gcr.io/kube-state-metrics/kube-state-metricsis the new canonical location.- The helm chart that is part of the kubernetes/kube-state-metrics repository is deprecated. https://github.com/prometheus-community/helm-charts will be its new location.
For the full list of v2.0 release changes includes features, bug fixes and other breaking changes see the full CHANGELOG.
Found a problem?
Thanks to all our users for testing so far and thank you to all our contributors for your issue reports as well as code and documentation changes! If you find any problems, we the maintainers are more than happy to look into them, so please report them by opening a GitHub issue.
Introducing Suspended Jobs
Author: Adhityaa Chandrasekar (Google)
Jobs are a crucial part of Kubernetes' API. While other kinds of workloads such as Deployments, ReplicaSets, StatefulSets, and DaemonSets solve use-cases that require Pods to run forever, Jobs are useful when Pods need to run to completion. Commonly used in parallel batch processing, Jobs can be used in a variety of applications ranging from video rendering and database maintenance to sending bulk emails and scientific computing.
While the amount of parallelism and the conditions for Job completion are configurable, the Kubernetes API lacked the ability to suspend and resume Jobs. This is often desired when cluster resources are limited and a higher priority Job needs to execute in the place of another Job. Deleting the lower priority Job is a poor workaround as Pod completion history and other metrics associated with the Job will be lost.
With the recent Kubernetes 1.21 release, you will be able to suspend a Job by
updating its spec. The feature is currently in alpha and requires you to
enable the SuspendJob feature gate
on the API server
and the controller manager
in order to use it.
API changes
We introduced a new boolean field suspend into the .spec of Jobs. Let's say
I create the following Job:
apiVersion: batch/v1
kind: Job
metadata:
name: my-job
spec:
suspend: true
parallelism: 2
completions: 10
template:
spec:
containers:
- name: my-container
image: busybox
command: ["sleep", "5"]
restartPolicy: Never
Jobs are not suspended by default, so I'm explicitly setting the suspend field
to true in the .spec of the above Job manifest. In the above example, the
Job controller will refrain from creating Pods until I'm ready to start the Job,
which I can do by updating suspend to false.
As another example, consider a Job that was created with the suspend field
omitted. The Job controller will happily create Pods to work towards Job
completion. However, before the Job completes, if I explicitly set the field to
true with a Job update, the Job controller will terminate all active Pods that
are running and will wait indefinitely for the flag to be flipped back to false.
Typically, Pod termination is done by sending a SIGTERM signal to all container
processes in the Pod; the graceful termination period
defined in the Pod spec will be honoured. Pods terminated this way will not be
counted as failures by the Job controller.
It is important to understand that succeeded and failed Pods from the past will continue to exist after you suspend a Job. That is, that they will count towards Job completion once you resume it. You can verify this by looking at Job's status before and after suspension.
Read the documentation for a full overview of this new feature.
Where is this useful?
Let's say I'm the operator of a large cluster. I have many users submitting Jobs to the cluster, but not all Jobs are created equal — some Jobs are more important than others. Cluster resources aren't infinite either, so all users must share resources. If all Jobs were created in the suspended state and placed in a pending queue, I can achieve priority-based Job scheduling by resuming Jobs in the right order.
As another motivational use-case, consider a cloud provider where compute resources are cheaper at night than in the morning. If I have a long-running Job that takes multiple days to complete, being able to suspend the Job in the morning and then resume it in the evening every day can reduce costs.
Since this field is a part of the Job spec, CronJobs automatically get this feature for free too.
References and next steps
If you're interested in a deeper dive into the rationale behind this feature and the decisions we have taken, consider reading the enhancement proposal. There's more detail on suspending and resuming jobs in the documentation for Job.
As previously mentioned, this feature is currently in alpha and is available
only if you explicitly opt-in through the SuspendJob feature gate.
If this is a feature you're interested in, please consider testing suspended
Jobs in your cluster and providing feedback. You can discuss this enhancement on GitHub.
The SIG Apps community also meets regularly
and can be reached through Slack or the mailing list.
Barring any unexpected changes to the API, we intend to graduate the feature to
beta in Kubernetes 1.22, so that the feature becomes available by default.
Kubernetes 1.21: CronJob Reaches GA
Authors: Alay Patel (Red Hat), and Maciej Szulik (Red Hat)
In Kubernetes v1.21, the CronJob resource reached general availability (GA). We've also substantially improved the performance of CronJobs since Kubernetes v1.19, by implementing a new controller.
In Kubernetes v1.20 we launched a revised v2 controller for CronJobs,
initially as an alpha feature. Kubernetes 1.21 uses the newer controller by
default, and the CronJob resource itself is now GA (group version: batch/v1).
In this article, we'll take you through the driving forces behind this new development, give you a brief description of controller design for core Kubernetes, and we'll outline what you will gain from this improved controller.
The driving force behind promoting the API was Kubernetes' policy choice to ensure APIs move beyond beta. That policy aims to prevent APIs from being stuck in a “permanent beta” state. Over the years the old CronJob controller implementation had received healthy feedback from the community, with reports of several widely recognized issues.
If the beta API for CronJob was to be supported as GA, the existing controller code would need substantial rework. Instead, the SIG Apps community decided to introduce a new controller and gradually replace the old one.
How do controllers work?
Kubernetes controllers are control loops that watch the state of resource(s) in your cluster, then make or request changes where needed. Each controller tries to move part of the current cluster state closer to the desired state.
The v1 CronJob controller works by performing a periodic poll and sweep of all the CronJob objects in your cluster, in order to act on them. It is a single worker implementation that gets all CronJobs every 10 seconds, iterates over each one of them, and syncs them to their desired state. This was the default way of doing things almost 5 years ago when the controller was initially written. In hindsight, we can certainly say that such an approach can overload the API server at scale.
These days, every core controller in kubernetes must follow the guidelines described in Writing Controllers. Among many details, that document prescribes using shared informers to “receive notifications of adds, updates, and deletes for a particular resource”. Upon any such events, the related object(s) is placed in a queue. Workers pull items from the queue and process them one at a time. This approach ensures consistency and scalability.
The picture below shows the flow of information from kubernetes API server, through shared informers and queue, to the main part of a controller - a reconciliation loop which is responsible for performing the core functionality.

The CronJob controller V2 uses a queue that implements the DelayingInterface to handle the scheduling aspect. This queue allows processing an element after a specific time interval. Every time there is a change in a CronJob or its related Jobs, the key that represents the CronJob is pushed to the queue. The main handler pops the key, processes the CronJob, and after completion pushes the key back into the queue for the next scheduled time interval. This is immediately a more performant implementation, as it no longer requires a linear scan of all the CronJobs. On top of that, this controller can be scaled by increasing the number of workers processing the CronJobs in parallel.
Performance impact of the new controller
In order to test the performance difference of the two controllers a VM instance with 128 GiB RAM and 64 vCPUs was used to set up a single node Kubernetes cluster. Initially, a sample workload was created with 20 CronJob instances with a schedule to run every minute, and 2100 CronJobs running every 20 hours. Additionally, over the next few minutes we added 1000 CronJobs with a schedule to run every 20 hours, until we reached a total of 5120 CronJobs.

We observed that for every 1000 CronJobs added, the old controller used around 90 to 120 seconds more wall-clock time to schedule 20 Jobs every cycle. That is, at 5120 CronJobs, the old controller took approximately 9 minutes to create 20 Jobs. Hence, during each cycle, about 8 schedules were missed. The new controller, implemented with architectural change explained above, created 20 Jobs without any delay, even when we created an additional batch of 1000 CronJobs reaching a total of 6120.
As a closing remark, the new controller exposes a histogram metric
cronjob_controller_cronjob_job_creation_skew_duration_seconds which helps
monitor the time difference between when a CronJob is meant to run and when
the actual Job is created.
Hopefully the above description is a sufficient argument to follow the
guidelines and standards set in the Kubernetes project, even for your own
controllers. As mentioned before, the new controller is on by default starting
from Kubernetes v1.21; if you want to check it out in the previous release (1.20),
you can enable the CronJobControllerV2
feature gate
for the kube-controller-manager: --feature-gate="CronJobControllerV2=true".
Kubernetes 1.21: Power to the Community
Authors: Kubernetes 1.21 Release Team
We’re pleased to announce the release of Kubernetes 1.21, our first release of 2021! This release consists of 51 enhancements: 13 enhancements have graduated to stable, 16 enhancements are moving to beta, 20 enhancements are entering alpha, and 2 features have been deprecated.
This release cycle, we saw a major shift in ownership of processes around the release team. We moved from a synchronous mode of communication, where we periodically asked the community for inputs, to a mode where the community opts-in to contribute features and/or blogs to the release. These changes have resulted in an increase in collaboration and teamwork across the community. The result of all that is reflected in Kubernetes 1.21 having the most number of features in the recent times.
Major Themes
CronJobs Graduate to Stable!
CronJobs (previously ScheduledJobs) has been a beta feature since Kubernetes 1.8! With 1.21 we get to finally see this widely used API graduate to stable.
CronJobs are meant for performing regular scheduled actions such as backups, report generation, and so on. Each of those tasks should be configured to recur indefinitely (for example: once a day / week / month); you can define the point in time within that interval when the job should start.
Immutable Secrets and ConfigMaps
Immutable Secrets and ConfigMaps add a new field to those resource types that will reject changes to those objects if set. Secrets and ConfigMaps by default are mutable which is beneficial for pods that are able to consume changes. Mutating Secrets and ConfigMaps can also cause problems if a bad configuration is pushed for pods that use them.
By marking Secrets and ConfigMaps as immutable you can be sure your application configuration won't change. If you want to make changes you'll need to create a new, uniquly named Secret or ConfigMap and deploy a new pod to consume that resource. Immutable resources also have scaling benefits because controllers do not need to poll the API server to watch for changes.
This feature has graduated to stable in Kubernetes 1.21.
IPv4/IPv6 dual-stack support
IP addresses are a consumable resource that cluster operators and administrators need to make sure are not exhausted. In particular, public IPv4 addresses are now scarce. Having dual-stack support enables native IPv6 routing to pods and services, whilst still allowing your cluster to talk IPv4 where needed. Dual-stack cluster networking also improves a possible scaling limitation for workloads.
Dual-stack support in Kubernetes means that pods, services, and nodes can get IPv4 addresses and IPv6 addresses. In Kubernetes 1.21 dual-stack networking has graduated from alpha to beta, and is now enabled by default.
Graceful Node Shutdown
Graceful Node shutdown also graduated to beta with this release (and will now be available to a much larger group of users)! This is a hugely beneficial feature that allows the kubelet to be aware of node shutdown, and gracefully terminate pods that are scheduled to that node.
Currently, when a node shuts down, pods do not follow the expected termination lifecycle and are not shut down gracefully. This can introduce problems with a lot of different workloads. Going forward, the kubelet will be able to detect imminent system shutdown through systemd, then inform running pods so they can terminate as gracefully as possible.
PersistentVolume Health Monitor
Persistent Volumes (PV) are commonly used in applications to get local, file-based storage. They can be used in many different ways and help users migrate applications without needing to re-write storage backends.
Kubernetes 1.21 has a new alpha feature which allows PVs to be monitored for health of the volume and marked accordingly if the volume becomes unhealthy. Workloads will be able to react to the health state to protect data from being written or read from a volume that is unhealthy.
Reducing Kubernetes Build Maintenance
Previously Kubernetes has maintained multiple build systems. This has often been a source of friction and complexity for new and current contributors.
Over the last release cycle, a lot of work has been put in to simplify the build process, and standardize on the native Golang build tools. This should empower broader community maintenance, and lower the barrier to entry for new contributors.
Major Changes
PodSecurityPolicy Deprecation
In Kubernetes 1.21, PodSecurityPolicy is deprecated. As with all Kubernetes feature deprecations, PodSecurityPolicy will continue to be available and fully-functional for several more releases. PodSecurityPolicy, previously in the beta stage, is planned for removal in Kubernetes 1.25.
What's next? We're developing a new built-in mechanism to help limit Pod privileges, with a working title of “PSP Replacement Policy.” Our plan is for this new mechanism to cover the key PodSecurityPolicy use cases, with greatly improved ergonomics and maintainability. To learn more, read PodSecurityPolicy Deprecation: Past, Present, and Future.
TopologyKeys Deprecation
The Service field topologyKeys is now deprecated; all the component features that used this field were previously alpha, and are now also deprecated.
We've replaced topologyKeys with a way to implement topology-aware routing, called topology-aware hints. Topology-aware hints are an alpha feature in Kubernetes 1.21. You can read more details about the replacement feature in Topology Aware Hints; the related KEP explains the context for why we switched.
Other Updates
Graduated to Stable
Notable Feature Updates
- External client-go credential providers - beta in 1.21
- Structured logging - graduating to beta in 1.22
- TTL after finish cleanup for Jobs and Pods - graduated to beta
Release notes
You can check out the full details of the 1.21 release in the release notes.
Availability of release
Kubernetes 1.21 is available for download on GitHub. There are some great resources out there for getting started with Kubernetes. You can check out some interactive tutorials on the main Kubernetes site, or run a local cluster on your machine using Docker containers with kind. If you’d like to try building a cluster from scratch, check out the Kubernetes the Hard Way tutorial by Kelsey Hightower.
Release Team
This release was made possible by a very dedicated group of individuals, who came together as a team in the midst of a lot of things happening out in the world. A huge thank you to the release lead Nabarun Pal, and to everyone else on the release team for supporting each other, and working so hard to deliver the 1.21 release for the community.
Release Logo

The Kubernetes 1.21 Release Logo portrays the global nature of the Release Team, with release team members residing in timezones from UTC+8 all the way to UTC-8. The diversity of the release team brought in a lot of challenges, but the team tackled them all by adopting more asynchronous communication practices. The heptagonal globe in the release logo signifies the sheer determination of the community to overcome the challenges as they come. It celebrates the amazing teamwork of the release team over the last 3 months to bring in a fun packed Kubernetes release!
The logo is designed by Aravind Sekar, an independent designer based out of India. Aravind helps open source communities like PyCon India in their design efforts.
User Highlights
- CNCF welcomes 47 new organizations across the globe as members to advance Cloud Native technology further at the start of 2021! These new members will join CNCF at the upcoming 2021 KubeCon + CloudNativeCon events, including KubeCon + CloudNativeCom EU – Virtual from May 4 – 7, 2021, and KubeCon + CloudNativeCon NA in Los Angeles from October 12 – 15, 2021.
Project Velocity
The CNCF K8s DevStats project aggregates a number of interesting data points related to the velocity of Kubernetes and various sub-projects. This includes everything from individual contributions to the number of companies that are contributing, and is a neat illustration of the depth and breadth of effort that goes into evolving this ecosystem.
In the v1.21 release cycle, which ran for 12 weeks (January 11 to April 8), we saw contributions from 999 companies and 1279 individuals.
Ecosystem Updates
- In the wake of rising racism & attacks on global Asian communities, read the statement from CNCF General Priyanka Sharma on the CNCF blog reinstating the community's commitment towards inclusive values & diversity-powered resilience.
- We now have a process in place for migration of the default branch from master → main. Learn more about the guidelines here
- CNCF and the Linux Foundation have announced the availability of their new training course, LFS260 – Kubernetes Security Essentials. In addition to providing skills and knowledge on a broad range of best practices for securing container-based applications and Kubernetes platforms, the course is also a great way to prepare for the recently launched Certified Kubernetes Security Specialist certification exam.
Event Updates
- KubeCon + CloudNativeCon Europe 2021 will take place May 4 - 7, 2021! You can find more information about the conference here.
- Kubernetes Community Days are being relaunched! Q2 2021 will start with Africa and Bengaluru.
Upcoming release webinar
Join the members of the Kubernetes 1.21 release team on May 13th, 2021 to learn about the major features in this release including IPv4/IPv6 dual-stack support, PersistentVolume Health Monitor, Immutable Secrets and ConfigMaps, and many more. Register here: https://community.cncf.io/events/details/cncf-cncf-online-programs-presents-cncf-live-webinar-kubernetes-121-release/
Get Involved
If you’re interested in contributing to the Kubernetes community, Special Interest Groups (SIGs) are a great starting point. Many of them may align with your interests! If there are things you’d like to share with the community, you can join the weekly community meeting, or use any of the following channels:
- Find out more about contributing to Kubernetes at the Kubernetes Contributor website
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Share your Kubernetes story
- Read more about what’s happening with Kubernetes on the blog
- Learn more about the Kubernetes Release Team
PodSecurityPolicy Deprecation: Past, Present, and Future
Author: Tabitha Sable (Kubernetes SIG Security)
PodSecurityPolicy (PSP) is being deprecated in Kubernetes 1.21, to be released later this week. This starts the countdown to its removal, but doesn’t change anything else. PodSecurityPolicy will continue to be fully functional for several more releases before being removed completely. In the meantime, we are developing a replacement for PSP that covers key use cases more easily and sustainably.
What are Pod Security Policies? Why did we need them? Why are they going away, and what’s next? How does this affect you? These key questions come to mind as we prepare to say goodbye to PSP, so let’s walk through them together. We’ll start with an overview of how features get removed from Kubernetes.
What does deprecation mean in Kubernetes?
Whenever a Kubernetes feature is set to go away, our deprecation policy is our guide. First the feature is marked as deprecated, then after enough time has passed, it can finally be removed.
Kubernetes 1.21 starts the deprecation process for PodSecurityPolicy. As with all feature deprecations, PodSecurityPolicy will continue to be fully functional for several more releases. The current plan is to remove PSP from Kubernetes in the 1.25 release.
Until then, PSP is still PSP. There will be at least a year during which the newest Kubernetes releases will still support PSP, and nearly two years until PSP will pass fully out of all supported Kubernetes versions.
What is PodSecurityPolicy?
PodSecurityPolicy is a built-in admission controller that allows a cluster administrator to control security-sensitive aspects of the Pod specification.
First, one or more PodSecurityPolicy resources are created in a cluster to define the requirements Pods must meet. Then, RBAC rules are created to control which PodSecurityPolicy applies to a given pod. If a pod meets the requirements of its PSP, it will be admitted to the cluster as usual. In some cases, PSP can also modify Pod fields, effectively creating new defaults for those fields. If a Pod does not meet the PSP requirements, it is rejected, and cannot run.
One more important thing to know about PodSecurityPolicy: it’s not the same as PodSecurityContext.
A part of the Pod specification, PodSecurityContext (and its per-container counterpart SecurityContext) is the collection of fields that specify many of the security-relevant settings for a Pod. The security context dictates to the kubelet and container runtime how the Pod should actually be run. In contrast, the PodSecurityPolicy only constrains (or defaults) the values that may be set on the security context.
The deprecation of PSP does not affect PodSecurityContext in any way.
Why did we need PodSecurityPolicy?
In Kubernetes, we define resources such as Deployments, StatefulSets, and Services that represent the building blocks of software applications. The various controllers inside a Kubernetes cluster react to these resources, creating further Kubernetes resources or configuring some software or hardware to accomplish our goals.
In most Kubernetes clusters, RBAC (Role-Based Access Control) rules control access to these resources. list, get, create, edit, and delete are the sorts of API operations that RBAC cares about, but RBAC does not consider what settings are being put into the resources it controls. For example, a Pod can be almost anything from a simple webserver to a privileged command prompt offering full access to the underlying server node and all the data. It’s all the same to RBAC: a Pod is a Pod is a Pod.
To control what sorts of settings are allowed in the resources defined in your cluster, you need Admission Control in addition to RBAC. Since Kubernetes 1.3, PodSecurityPolicy has been the built-in way to do that for security-related Pod fields. Using PodSecurityPolicy, you can prevent “create Pod” from automatically meaning “root on every cluster node,” without needing to deploy additional external admission controllers.
Why is PodSecurityPolicy going away?
In the years since PodSecurityPolicy was first introduced, we have realized that PSP has some serious usability problems that can’t be addressed without making breaking changes.
The way PSPs are applied to Pods has proven confusing to nearly everyone that has attempted to use them. It is easy to accidentally grant broader permissions than intended, and difficult to inspect which PSP(s) apply in a given situation. The “changing Pod defaults” feature can be handy, but is only supported for certain Pod settings and it’s not obvious when they will or will not apply to your Pod. Without a “dry run” or audit mode, it’s impractical to retrofit PSP to existing clusters safely, and it’s impossible for PSP to ever be enabled by default.
For more information about these and other PSP difficulties, check out SIG Auth’s KubeCon NA 2019 Maintainer Track session video:
Today, you’re not limited only to deploying PSP or writing your own custom admission controller. Several external admission controllers are available that incorporate lessons learned from PSP to provide a better user experience. K-Rail, Kyverno, and OPA/Gatekeeper are all well-known, and each has its fans.
Although there are other good options available now, we believe there is still value in having a built-in admission controller available as a choice for users. With this in mind, we turn toward building what’s next, inspired by the lessons learned from PSP.
What’s next?
Kubernetes SIG Security, SIG Auth, and a diverse collection of other community members have been working together for months to ensure that what’s coming next is going to be awesome. We have developed a Kubernetes Enhancement Proposal (KEP 2579) and a prototype for a new feature, currently being called by the temporary name "PSP Replacement Policy." We are targeting an Alpha release in Kubernetes 1.22.
PSP Replacement Policy starts with the realization that since there is a robust ecosystem of external admission controllers already available, PSP’s replacement doesn’t need to be all things to all people. Simplicity of deployment and adoption is the key advantage a built-in admission controller has compared to an external webhook, so we have focused on how to best utilize that advantage.
PSP Replacement Policy is designed to be as simple as practically possible while providing enough flexibility to really be useful in production at scale. It has soft rollout features to enable retrofitting it to existing clusters, and is configurable enough that it can eventually be active by default. It can be deactivated partially or entirely, to coexist with external admission controllers for advanced use cases.
What does this mean for you?
What this all means for you depends on your current PSP situation. If you’re already using PSP, there’s plenty of time to plan your next move. Please review the PSP Replacement Policy KEP and think about how well it will suit your use case.
If you’re making extensive use of the flexibility of PSP with numerous PSPs and complex binding rules, you will likely find the simplicity of PSP Replacement Policy too limiting. Use the next year to evaluate the other admission controller choices in the ecosystem. There are resources available to ease this transition, such as the Gatekeeper Policy Library.
If your use of PSP is relatively simple, with a few policies and straightforward binding to service accounts in each namespace, you will likely find PSP Replacement Policy to be a good match for your needs. Evaluate your PSPs compared to the Kubernetes Pod Security Standards to get a feel for where you’ll be able to use the Restricted, Baseline, and Privileged policies. Please follow along with or contribute to the KEP and subsequent development, and try out the Alpha release of PSP Replacement Policy when it becomes available.
If you’re just beginning your PSP journey, you will save time and effort by keeping it simple. You can approximate the functionality of PSP Replacement Policy today by using the Pod Security Standards’ PSPs. If you set the cluster default by binding a Baseline or Restricted policy to the system:serviceaccounts group, and then make a more-permissive policy available as needed in certain Namespaces using ServiceAccount bindings, you will avoid many of the PSP pitfalls and have an easy migration to PSP Replacement Policy. If your needs are much more complex than this, your effort is probably better spent adopting one of the more fully-featured external admission controllers mentioned above.
We’re dedicated to making Kubernetes the best container orchestration tool we can, and sometimes that means we need to remove longstanding features to make space for better things to come. When that happens, the Kubernetes deprecation policy ensures you have plenty of time to plan your next move. In the case of PodSecurityPolicy, several options are available to suit a range of needs and use cases. Start planning ahead now for PSP’s eventual removal, and please consider contributing to its replacement! Happy securing!
Acknowledgment: It takes a wonderful group to make wonderful software. Thanks are due to everyone who has contributed to the PSP replacement effort, especially (in alphabetical order) Tim Allclair, Ian Coldwater, and Jordan Liggitt. It’s been a joy to work with y’all on this.
The Evolution of Kubernetes Dashboard
Authors: Marcin Maciaszczyk, Kubermatic & Sebastian Florek, Kubermatic
In October 2020, the Kubernetes Dashboard officially turned five. As main project maintainers, we can barely believe that so much time has passed since our very first commits to the project. However, looking back with a bit of nostalgia, we realize that quite a lot has happened since then. Now it’s due time to celebrate “our baby” with a short recap.
How It All Began
The initial idea behind the Kubernetes Dashboard project was to provide a web interface for Kubernetes. We wanted to reflect the kubectl functionality through an intuitive web UI. The main benefit from using the UI is to be able to quickly see things that do not work as expected (monitoring and troubleshooting). Also, the Kubernetes Dashboard is a great starting point for users that are new to the Kubernetes ecosystem.
The very first commit to the Kubernetes Dashboard was made by Filip Grządkowski from Google on 16th October 2015 – just a few months from the initial commit to the Kubernetes repository. Our initial commits go back to November 2015 (Sebastian committed on 16 November 2015; Marcin committed on 23 November 2015). Since that time, we’ve become regular contributors to the project. For the next two years, we worked closely with the Googlers, eventually becoming main project maintainers ourselves.
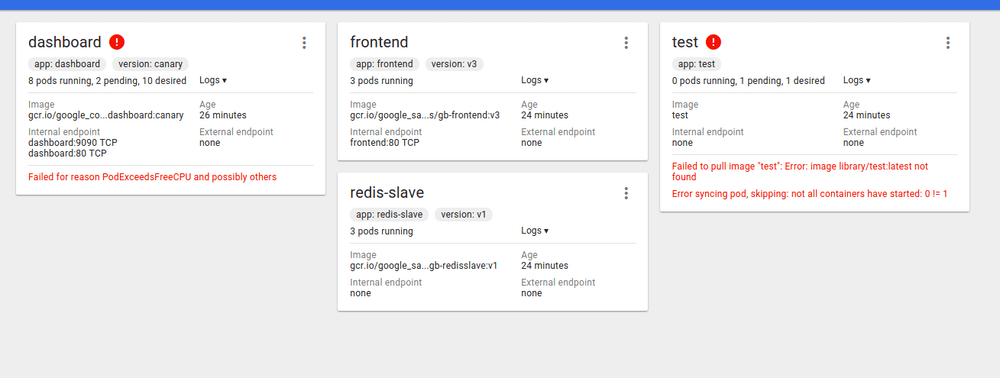
The First Version of the User Interface
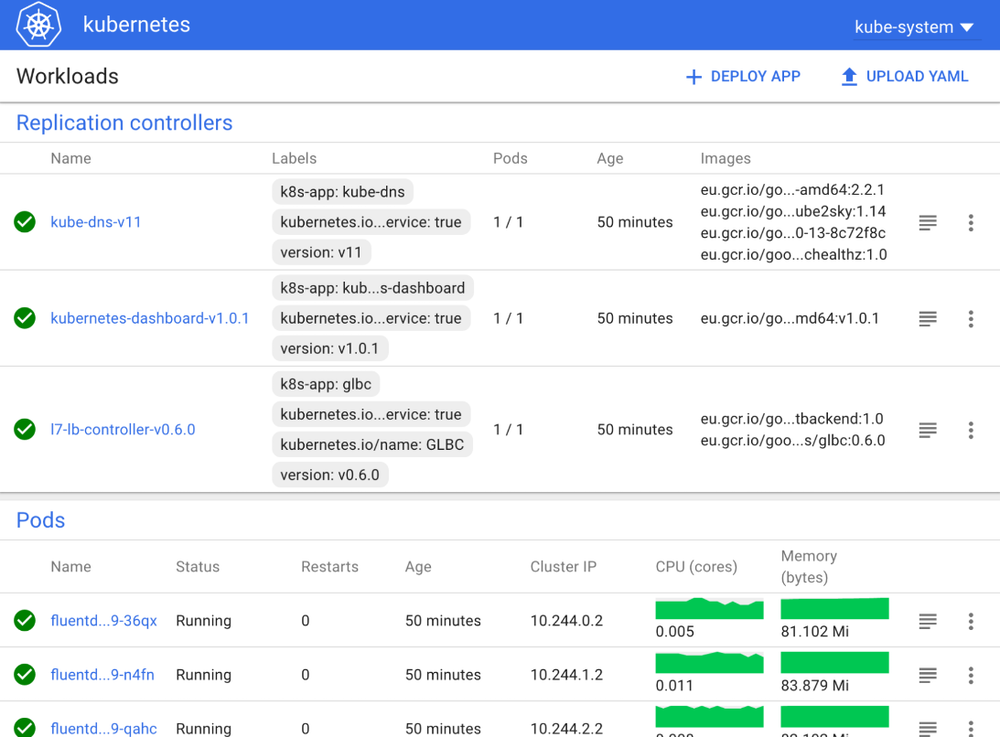
Prototype of the New User Interface
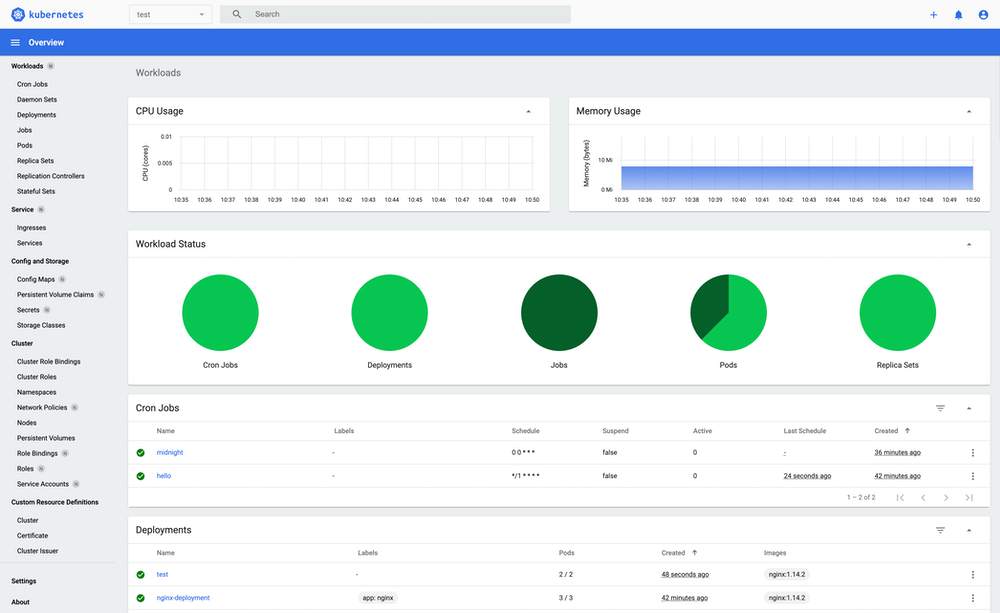
The Current User Interface
As you can see, the initial look and feel of the project were completely different from the current one. We have changed the design multiple times. The same has happened with the code itself.
Growing Up - The Big Migration
At the beginning of 2018, we reached a point where AngularJS was getting closer to the end of its life, while the new Angular versions were published quite often. A lot of the libraries and the modules that we were using were following the trend. That forced us to spend a lot of the time rewriting the frontend part of the project to make it work with newer technologies.
The migration came with many benefits like being able to refactor a lot of the code, introduce design patterns, reduce code complexity, and benefit from the new modules. However, you can imagine that the scale of the migration was huge. Luckily, there were a number of contributions from the community helping us with the resource support, new Kubernetes version support, i18n, and much more. After many long days and nights, we finally released the first beta version in July 2019, followed by the 2.0 release in April 2020 — our baby had grown up.
Where Are We Standing in 2021?
Due to limited resources, unfortunately, we were not able to offer extensive support for many different Kubernetes versions. So, we’ve decided to always try and support the latest Kubernetes version available at the time of the Kubernetes Dashboard release. The latest release, Dashboard v2.2.0 provides support for Kubernetes v1.20.
On top of that, we put in a great deal of effort into improving resource support. Meanwhile, we do offer support for most of the Kubernetes resources. Also, the Kubernetes Dashboard supports multiple languages: English, German, French, Japanese, Korean, Chinese (Traditional, Simplified, Traditional Hong Kong). Persian and Russian localizations are currently in progress. Moreover, we are working on the support for 3rd party themes and the design of the app in general. As you can see, quite a lot of things are going on.
Luckily, we do have regular contributors with domain knowledge who are taking care of the project, updating the Helm charts, translations, Go modules, and more. But as always, there could be many more hands on deck. So if you are thinking about contributing to Kubernetes, keep us in mind ;)
What’s Next
The Kubernetes Dashboard has been growing and prospering for more than 5 years now. It provides the community with an intuitive Web UI, thereby decreasing the complexity of Kubernetes and increasing its accessibility to new community members. We are proud of what the project has achieved so far, but this is by far not the end. These are our priorities for the future:
- Keep providing support for the new Kubernetes versions
- Keep improving the support for the existing resources
- Keep working on auth system improvements
- Rewrite the API to use gRPC and shared informers: This will allow us to improve the performance of the application but, most importantly, to support live updates coming from the Kubernetes project. It is one of the most requested features from the community.
- Split the application into two containers, one with the UI and the second with the API running inside.
The Kubernetes Dashboard in Numbers
- Initial commit made on October 16, 2015
- Over 100 million pulls from Dockerhub since the v2 release
- 8 supported languages and the next 2 in progress
- Over 3360 closed PRs
- Over 2260 closed issues
- 100% coverage of the supported core Kubernetes resources
- Over 9000 stars on GitHub
- Over 237 000 lines of code
Join Us
As mentioned earlier, we are currently looking for more people to help us further develop and grow the project. We are open to contributions in multiple areas, i.e., issues with help wanted label. Please feel free to reach out via GitHub or the #sig-ui channel in the Kubernetes Slack.
A Custom Kubernetes Scheduler to Orchestrate Highly Available Applications
Author: Chris Seto (Cockroach Labs)
As long as you're willing to follow the rules, deploying on Kubernetes and air travel can be quite pleasant. More often than not, things will "just work". However, if one is interested in travelling with an alligator that must remain alive or scaling a database that must remain available, the situation is likely to become a bit more complicated. It may even be easier to build one's own plane or database for that matter. Travelling with reptiles aside, scaling a highly available stateful system is no trivial task.
Scaling any system has two main components:
- Adding or removing infrastructure that the system will run on, and
- Ensuring that the system knows how to handle additional instances of itself being added and removed.
Most stateless systems, web servers for example, are created without the need to be aware of peers. Stateful systems, which includes databases like CockroachDB, have to coordinate with their peer instances and shuffle around data. As luck would have it, CockroachDB handles data redistribution and replication. The tricky part is being able to tolerate failures during these operations by ensuring that data and instances are distributed across many failure domains (availability zones).
One of Kubernetes' responsibilities is to place "resources" (e.g, a disk or container) into the cluster and satisfy the constraints they request. For example: "I must be in availability zone A" (see Running in multiple zones), or "I can't be placed onto the same node as this other Pod" (see Affinity and anti-affinity).
As an addition to those constraints, Kubernetes offers Statefulsets that provide identity to Pods as well as persistent storage that "follows" these identified pods. Identity in a StatefulSet is handled by an increasing integer at the end of a pod's name. It's important to note that this integer must always be contiguous: in a StatefulSet, if pods 1 and 3 exist then pod 2 must also exist.
Under the hood, CockroachCloud deploys each region of CockroachDB as a StatefulSet in its own Kubernetes cluster - see Orchestrate CockroachDB in a Single Kubernetes Cluster. In this article, I'll be looking at an individual region, one StatefulSet and one Kubernetes cluster which is distributed across at least three availability zones.
A three-node CockroachCloud cluster would look something like this:

When adding additional resources to the cluster we also distribute them across zones. For the speediest user experience, we add all Kubernetes nodes at the same time and then scale up the StatefulSet.

Note that anti-affinities are satisfied no matter the order in which pods are assigned to Kubernetes nodes. In the example, pods 0, 1 and 2 were assigned to zones A, B, and C respectively, but pods 3 and 4 were assigned in a different order, to zones B and A respectively. The anti-affinity is still satisfied because the pods are still placed in different zones.
To remove resources from a cluster, we perform these operations in reverse order.
We first scale down the StatefulSet and then remove from the cluster any nodes lacking a CockroachDB pod.

Now, remember that pods in a StatefulSet of size n must have ids in the range [0,n). When scaling down a StatefulSet by m, Kubernetes removes m pods, starting from the highest ordinals and moving towards the lowest, the reverse in which they were added.
Consider the cluster topology below:

As ordinals 5 through 3 are removed from this cluster, the statefulset continues to have a presence across all 3 availability zones.

However, Kubernetes' scheduler doesn't guarantee the placement above as we expected at first.
Our combined knowledge of the following is what lead to this misconception.
- Kubernetes' ability to automatically spread Pods across zone
- The behavior that a StatefulSet with n replicas, when Pods are being deployed, they are created sequentially, in order from
{0..n-1}. See StatefulSet for more details.
Consider the following topology:

These pods were created in order and they are spread across all availability zones in the cluster. When ordinals 5 through 3 are terminated, this cluster will lose its presence in zone C!

Worse yet, our automation, at the time, would remove Nodes A-2, B-2, and C-2. Leaving CRDB-1 in an unscheduled state as persistent volumes are only available in the zone they are initially created in.
To correct the latter issue, we now employ a "hunt and peck" approach to removing machines from a cluster. Rather than blindly removing Kubernetes nodes from the cluster, only nodes without a CockroachDB pod would be removed. The much more daunting task was to wrangle the Kubernetes scheduler.
A session of brainstorming left us with 3 options:
1. Upgrade to kubernetes 1.18 and make use of Pod Topology Spread Constraints
While this seems like it could have been the perfect solution, at the time of writing Kubernetes 1.18 was unavailable on the two most common managed Kubernetes services in public cloud, EKS and GKE. Furthermore, pod topology spread constraints were still a beta feature in 1.18 which meant that it wasn't guaranteed to be available in managed clusters even when v1.18 became available. The entire endeavour was concerningly reminiscent of checking caniuse.com when Internet Explorer 8 was still around.
2. Deploy a statefulset per zone.
Rather than having one StatefulSet distributed across all availability zones, a single StatefulSet with node affinities per zone would allow manual control over our zonal topology. Our team had considered this as an option in the past which made it particularly appealing. Ultimately, we decided to forego this option as it would have required a massive overhaul to our codebase and performing the migration on existing customer clusters would have been an equally large undertaking.
3. Write a custom Kubernetes scheduler.
Thanks to an example from Kelsey Hightower and a blog post from Banzai Cloud, we decided to dive in head first and write our own custom Kubernetes scheduler.
Once our proof-of-concept was deployed and running, we quickly discovered that the Kubernetes' scheduler is also responsible for mapping persistent volumes to the Pods that it schedules.
The output of kubectl get events had led us to believe there was another system at play.
In our journey to find the component responsible for storage claim mapping, we discovered the kube-scheduler plugin system. Our next POC was a Filter plugin that determined the appropriate availability zone by pod ordinal, and it worked flawlessly!
Our custom scheduler plugin is open source and runs in all of our CockroachCloud clusters.
Having control over how our StatefulSet pods are being scheduled has let us scale out with confidence.
We may look into retiring our plugin once pod topology spread constraints are available in GKE and EKS, but the maintenance overhead has been surprisingly low.
Better still: the plugin's implementation is orthogonal to our business logic. Deploying it, or retiring it for that matter, is as simple as changing the schedulerName field in our StatefulSet definitions.
Chris Seto is a software engineer at Cockroach Labs and works on their Kubernetes automation for CockroachCloud, CockroachDB.
Kubernetes 1.20: Pod Impersonation and Short-lived Volumes in CSI Drivers
Author: Shihang Zhang (Google)
Typically when a CSI driver mounts credentials such as secrets and certificates, it has to authenticate against storage providers to access the credentials. However, the access to those credentials are controlled on the basis of the pods' identities rather than the CSI driver's identity. CSI drivers, therefore, need some way to retrieve pod's service account token.
Currently there are two suboptimal approaches to achieve this, either by granting CSI drivers the permission to use TokenRequest API or by reading tokens directly from the host filesystem.
Both of them exhibit the following drawbacks:
- Violating the principle of least privilege
- Every CSI driver needs to re-implement the logic of getting the pod’s service account token
The second approach is more problematic due to:
- The audience of the token defaults to the kube-apiserver
- The token is not guaranteed to be available (e.g.
AutomountServiceAccountToken=false) - The approach does not work for CSI drivers that run as a different (non-root) user from the pods. See file permission section for service account token
- The token might be legacy Kubernetes service account token which doesn’t expire if
BoundServiceAccountTokenVolume=false
Kubernetes 1.20 introduces an alpha feature, CSIServiceAccountToken, to improve the security posture. The new feature allows CSI drivers to receive pods' bound service account tokens.
This feature also provides a knob to re-publish volumes so that short-lived volumes can be refreshed.
Pod Impersonation
Using GCP APIs
Using Workload Identity, a Kubernetes service account can authenticate as a Google service account when accessing Google Cloud APIs. If a CSI driver needs to access GCP APIs on behalf of the pods that it is mounting volumes for, it can use the pod's service account token to exchange for GCP tokens. The pod's service account token is plumbed through the volume context in NodePublishVolume RPC calls when the feature CSIServiceAccountToken is enabled. For example: accessing Google Secret Manager via a secret store CSI driver.
Using Vault
If users configure Kubernetes as an auth method, Vault uses the TokenReview API to validate the Kubernetes service account token. For CSI drivers using Vault as resources provider, they need to present the pod's service account to Vault. For example, secrets store CSI driver and cert manager CSI driver.
Short-lived Volumes
To keep short-lived volumes such as certificates effective, CSI drivers can specify RequiresRepublish=true in theirCSIDriver object to have the kubelet periodically call NodePublishVolume on mounted volumes. These republishes allow CSI drivers to ensure that the volume content is up-to-date.
Next steps
This feature is alpha and projected to move to beta in 1.21. See more in the following KEP and CSI documentation:
Your feedback is always welcome!
- SIG-Auth meets regularly and can be reached via Slack and the mailing list
- SIG-Storage meets regularly and can be reached via Slack and the mailing list.
Third Party Device Metrics Reaches GA
Authors: Renaud Gaubert (NVIDIA), David Ashpole (Google), and Pramod Ramarao (NVIDIA)
With Kubernetes 1.20, infrastructure teams who manage large scale Kubernetes clusters, are seeing the graduation of two exciting and long awaited features:
- The Pod Resources API (introduced in 1.13) is finally graduating to GA. This allows Kubernetes plugins to obtain information about the node’s resource usage and assignment; for example: which pod/container consumes which device.
- The
DisableAcceleratorMetricsfeature (introduced in 1.19) is graduating to beta and will be enabled by default. This removes device metrics reported by the kubelet in favor of the new plugin architecture.
Many of the features related to fundamental device support (device discovery, plugin, and monitoring) are reaching a strong level of stability. Kubernetes users should see these features as stepping stones to enable more complex use cases (networking, scheduling, storage, etc.)!
One such example is Non Uniform Memory Access (NUMA) placement where, when selecting a device, an application typically wants to ensure that data transfer between CPU Memory and Device Memory is as fast as possible. In some cases, incorrect NUMA placement can nullify the benefit of offloading compute to an external device.
If these are topics of interest to you, consider joining the Kubernetes Node Special Insterest Group (SIG) for all topics related to the Kubernetes node, the COD (container orchestrated device) workgroup for topics related to runtimes, or the resource management forum for topics related to resource management!
The Pod Resources API - Why does it need to exist?
Kubernetes is a vendor neutral platform. If we want it to support device monitoring, adding vendor-specific code in the Kubernetes code base is not an ideal solution. Ultimately, devices are a domain where deep expertise is needed and the best people to add and maintain code in that area are the device vendors themselves.
The Pod Resources API was built as a solution to this issue. Each vendor can build and maintain their own out-of-tree monitoring plugin. This monitoring plugin, often deployed as a separate pod within a cluster, can then associate the metrics a device emits with the associated pod that's using it.
For example, use the NVIDIA GPU dcgm-exporter to scrape metrics in Prometheus format:
$ curl -sL http://127.0.01:8080/metrics
# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).
# TYPE DCGM_FI_DEV_SM_CLOCK gauge
# HELP DCGM_FI_DEV_MEM_CLOCK Memory clock frequency (in MHz).
# TYPE DCGM_FI_DEV_MEM_CLOCK gauge
# HELP DCGM_FI_DEV_MEMORY_TEMP Memory temperature (in C).
# TYPE DCGM_FI_DEV_MEMORY_TEMP gauge
...
DCGM_FI_DEV_SM_CLOCK{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="foo",namespace="bar",pod="baz"} 139
DCGM_FI_DEV_MEM_CLOCK{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="foo",namespace="bar",pod="baz"} 405
DCGM_FI_DEV_MEMORY_TEMP{gpu="0", UUID="GPU-604ac76c-d9cf-fef3-62e9-d92044ab6e52",container="foo",namespace="bar",pod="baz"} 9223372036854775794
Each agent is expected to adhere to the node monitoring guidelines. In other words, plugins are expected to generate metrics in Prometheus format, and new metrics should not have any dependency on the Kubernetes base directly.
This allows consumers of the metrics to use a compatible monitoring pipeline to collect and analyze metrics from a variety of agents, even if they are maintained by different vendors.
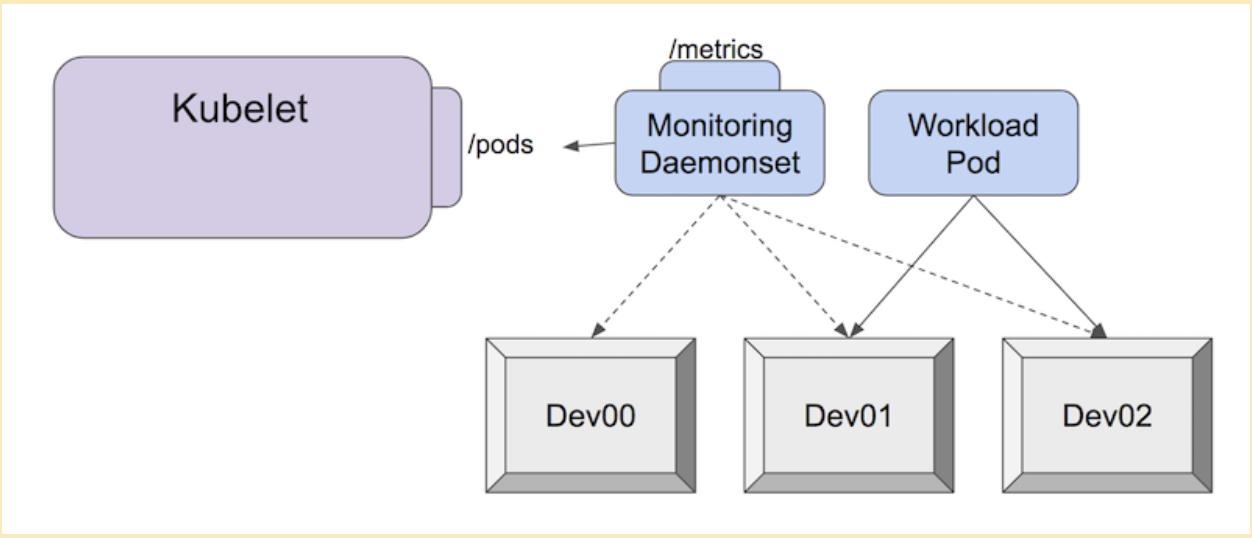
Disabling the NVIDIA GPU metrics - Warning
With the graduation of the plugin monitoring system, Kubernetes is deprecating the NVIDIA GPU metrics that are being reported by the kubelet.
With the DisableAcceleratorMetrics feature being enabled by default in Kubernetes 1.20, NVIDIA GPUs are no longer special citizens in Kubernetes. This is a good thing in the spirit of being vendor-neutral, and enables the most suited people to maintain their plugin on their own release schedule!
Users will now need to either install the NVIDIA GDGM exporter or use bindings to gather more accurate and complete metrics about NVIDIA GPUs. This deprecation means that you can no longer rely on metrics that were reported by kubelet, such as container_accelerator_duty_cycle or container_accelerator_memory_used_bytes which were used to gather NVIDIA GPU memory utilization.
This means that users who used to rely on the NVIDIA GPU metrics reported by the kubelet, will need to update their reference and deploy the NVIDIA plugin. Namely the different metrics reported by Kubernetes map to the following metrics:
| Kubernetes Metrics | NVIDIA dcgm-exporter metric |
|---|---|
container_accelerator_duty_cycle |
DCGM_FI_DEV_GPU_UTIL |
container_accelerator_memory_used_bytes |
DCGM_FI_DEV_FB_USED |
container_accelerator_memory_total_bytes |
DCGM_FI_DEV_FB_FREE + DCGM_FI_DEV_FB_USED |
You might also be interested in other metrics such as DCGM_FI_DEV_GPU_TEMP (the GPU temperature) or DCGM_FI_DEV_POWER_USAGE (the power usage). The default set is available in Nvidia's Data Center GPU Manager documentation.
Note that for this release you can still set the DisableAcceleratorMetrics feature gate to false, effectively re-enabling the ability for the kubelet to report NVIDIA GPU metrics.
Paired with the graduation of the Pod Resources API, these tools can be used to generate GPU telemetry that can be used in visualization dashboards, below is an example:
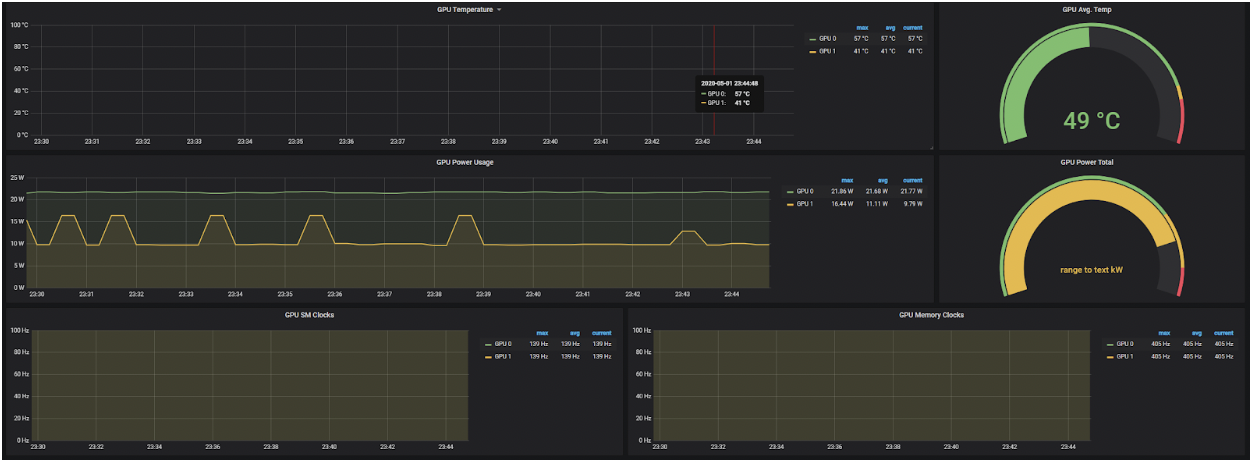
The Pod Resources API - What can I go on to do with this?
As soon as this interface was introduced, many vendors started using it for widely different use cases! To list a few examples:
The kuryr-kubernetes CNI plugin in tandem with intel-sriov-device-plugin. This allowed the CNI plugin to know which allocation of SR-IOV Virtual Functions (VFs) the kubelet made and use that information to correctly setup the container network namespace and use a device with the appropriate NUMA node. We also expect this interface to be used to track the allocated and available resources with information about the NUMA topology of the worker node.
Another use-case is GPU telemetry, where GPU metrics can be associated with the containers and pods that the GPU is assigned to. One such example is the NVIDIA dcgm-exporter, but others can be easily built in the same paradigm.
The Pod Resources API is a simple gRPC service which informs clients of the pods the kubelet knows. The information concerns the devices assignment the kubelet made and the assignment of CPUs. This information is obtained from the internal state of the kubelet's Device Manager and CPU Manager respectively.
You can see below a sample example of the API and how a go client could use that information in a few lines:
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
// Kubernetes 1.21
rpc Watch(WatchPodResourcesRequest) returns (stream WatchPodResourcesResponse) {}
}
func main() {
ctx, cancel := context.WithTimeout(context.Background(), connectionTimeout)
defer cancel()
socket := "/var/lib/kubelet/pod-resources/kubelet.sock"
conn, err := grpc.DialContext(ctx, socket, grpc.WithInsecure(), grpc.WithBlock(),
grpc.WithDialer(func(addr string, timeout time.Duration) (net.Conn, error) {
return net.DialTimeout("unix", addr, timeout)
}),
)
if err != nil {
panic(err)
}
client := podresourcesapi.NewPodResourcesListerClient(conn)
resp, err := client.List(ctx, &podresourcesapi.ListPodResourcesRequest{})
if err != nil {
panic(err)
}
net.Printf("%+v\n", resp)
}
Finally, note that you can watch the number of requests made to the Pod Resources endpoint by watching the new kubelet metric called pod_resources_endpoint_requests_total on the kubelet's /metrics endpoint.
Is device monitoring suitable for production? Can I extend it? Can I contribute?
Yes! This feature released in 1.13, almost 2 years ago, has seen broad adoption, is already used by different cloud managed services, and with its graduation to G.A in Kubernetes 1.20 is production ready!
If you are a device vendor, you can start using it today! If you just want to monitor the devices in your cluster, go get the latest version of your monitoring plugin!
If you feel passionate about that area, join the kubernetes community, help improve the API or contribute the device monitoring plugins!
Acknowledgements
We thank the members of the community who have contributed to this feature or given feedback including members of WG-Resource-Management, SIG-Node and the Resource management forum!
Kubernetes 1.20: Granular Control of Volume Permission Changes
Authors: Hemant Kumar, Red Hat & Christian Huffman, Red Hat
Kubernetes 1.20 brings two important beta features, allowing Kubernetes admins and users alike to have more adequate control over how volume permissions are applied when a volume is mounted inside a Pod.
Allow users to skip recursive permission changes on mount
Traditionally if your pod is running as a non-root user (which you should), you must specify a fsGroup inside the pod’s security context so that the volume can be readable and writable by the Pod. This requirement is covered in more detail in here.
But one side-effect of setting fsGroup is that, each time a volume is mounted, Kubernetes must recursively chown() and chmod() all the files and directories inside the volume - with a few exceptions noted below. This happens even if group ownership of the volume already matches the requested fsGroup, and can be pretty expensive for larger volumes with lots of small files, which causes pod startup to take a long time. This scenario has been a known problem for a while, and in Kubernetes 1.20 we are providing knobs to opt-out of recursive permission changes if the volume already has the correct permissions.
When configuring a pod’s security context, set fsGroupChangePolicy to "OnRootMismatch" so if the root of the volume already has the correct permissions, the recursive permission change can be skipped. Kubernetes ensures that permissions of the top-level directory are changed last the first time it applies permissions.
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
fsGroupChangePolicy: "OnRootMismatch"
You can learn more about this in Configure volume permission and ownership change policy for Pods.
Allow CSI Drivers to declare support for fsGroup based permissions
Although the previous section implied that Kubernetes always recursively changes permissions of a volume if a Pod has a fsGroup, this is not strictly true. For certain multi-writer volume types, such as NFS or Gluster, the cluster doesn’t perform recursive permission changes even if the pod has a fsGroup. Other volume types may not even support chown()/chmod(), which rely on Unix-style permission control primitives.
So how do we know when to apply recursive permission changes and when we shouldn't? For in-tree storage drivers, this was relatively simple. For CSI drivers that could span a multitude of platforms and storage types, this problem can be a bigger challenge.
Previously, whenever a CSI volume was mounted to a Pod, Kubernetes would attempt to automatically determine if the permissions and ownership should be modified. These methods were imprecise and could cause issues as we already mentioned, depending on the storage type.
The CSIDriver custom resource now has a .spec.fsGroupPolicy field, allowing storage drivers to explicitly opt in or out of these recursive modifications. By having the CSI driver specify a policy for the backing volumes, Kubernetes can avoid needless modification attempts. This optimization helps to reduce volume mount time and also cuts own reporting errors about modifications that would never succeed.
CSIDriver FSGroupPolicy API
Three FSGroupPolicy values are available as of Kubernetes 1.20, with more planned for future releases.
- ReadWriteOnceWithFSType - This is the default policy, applied if no
fsGroupPolicyis defined; this preserves the behavior from previous Kubernetes releases. Each volume is examined at mount time to determine if permissions should be recursively applied. - File - Always attempt to apply permission modifications, regardless of the filesystem type or PersistentVolumeClaim’s access mode.
- None - Never apply permission modifications.
How do I use it?
The only configuration needed is defining fsGroupPolicy inside of the .spec for a CSIDriver. Once that element is defined, any subsequently mounted volumes will automatically use the defined policy. There’s no additional deployment required!
What’s next?
Depending on feedback and adoption, the Kubernetes team plans to push these implementations to GA in either 1.21 or 1.22.
How can I learn more?
This feature is explained in more detail in Kubernetes project documentation: CSI Driver fsGroup Support and Configure volume permission and ownership change policy for Pods .
How do I get involved?
The Kubernetes Slack channel #csi and any of the standard SIG Storage communication channels are great mediums to reach out to the SIG Storage and the CSI team.
Those interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Kubernetes 1.20: Kubernetes Volume Snapshot Moves to GA
Authors: Xing Yang, VMware & Xiangqian Yu, Google
The Kubernetes Volume Snapshot feature is now GA in Kubernetes v1.20. It was introduced as alpha in Kubernetes v1.12, followed by a second alpha with breaking changes in Kubernetes v1.13, and promotion to beta in Kubernetes 1.17. This blog post summarizes the changes releasing the feature from beta to GA.
What is a volume snapshot?
Many storage systems (like Google Cloud Persistent Disks, Amazon Elastic Block Storage, and many on-premise storage systems) provide the ability to create a “snapshot” of a persistent volume. A snapshot represents a point-in-time copy of a volume. A snapshot can be used either to rehydrate a new volume (pre-populated with the snapshot data) or to restore an existing volume to a previous state (represented by the snapshot).
Why add volume snapshots to Kubernetes?
Kubernetes aims to create an abstraction layer between distributed applications and underlying clusters so that applications can be agnostic to the specifics of the cluster they run on and application deployment requires no “cluster-specific” knowledge.
The Kubernetes Storage SIG identified snapshot operations as critical functionality for many stateful workloads. For example, a database administrator may want to snapshot a database’s volumes before starting a database operation.
By providing a standard way to trigger volume snapshot operations in Kubernetes, this feature allows Kubernetes users to incorporate snapshot operations in a portable manner on any Kubernetes environment regardless of the underlying storage.
Additionally, these Kubernetes snapshot primitives act as basic building blocks that unlock the ability to develop advanced enterprise-grade storage administration features for Kubernetes, including application or cluster level backup solutions.
What’s new since beta?
With the promotion of Volume Snapshot to GA, the feature is enabled by default on standard Kubernetes deployments and cannot be turned off.
Many enhancements have been made to improve the quality of this feature and to make it production-grade.
-
The Volume Snapshot APIs and client library were moved to a separate Go module.
-
A snapshot validation webhook has been added to perform necessary validation on volume snapshot objects. More details can be found in the Volume Snapshot Validation Webhook Kubernetes Enhancement Proposal.
-
Along with the validation webhook, the volume snapshot controller will start labeling invalid snapshot objects that already existed. This allows users to identify, remove any invalid objects, and correct their workflows. Once the API is switched to the v1 type, those invalid objects will not be deletable from the system.
-
To provide better insights into how the snapshot feature is performing, an initial set of operation metrics has been added to the volume snapshot controller.
-
There are more end-to-end tests, running on GCP, that validate the feature in a real Kubernetes cluster. Stress tests (based on Google Persistent Disk and
hostPathCSI Drivers) have been introduced to test the robustness of the system.
Other than introducing tightening validation, there is no difference between the v1beta1 and v1 Kubernetes volume snapshot API. In this release (with Kubernetes 1.20), both v1 and v1beta1 are served while the stored API version is still v1beta1. Future releases will switch the stored version to v1 and gradually remove v1beta1 support.
Which CSI drivers support volume snapshots?
Snapshots are only supported for CSI drivers, not for in-tree or FlexVolume drivers. Ensure the deployed CSI driver on your cluster has implemented the snapshot interfaces. For more information, see Container Storage Interface (CSI) for Kubernetes GA.
Currently more than 50 CSI drivers support the Volume Snapshot feature. The GCE Persistent Disk CSI Driver has gone through the tests for upgrading from volume snapshots beta to GA. GA level support for other CSI drivers should be available soon.
Who builds products using volume snapshots?
As of the publishing of this blog, the following participants from the Kubernetes Data Protection Working Group are building products or have already built products using Kubernetes volume snapshots.
- Dell-EMC: PowerProtect
- Druva
- Kasten K10
- NetApp: Project Astra
- Portworx (PX-Backup)
- Pure Storage (Pure Service Orchestrator)
- Red Hat OpenShift Container Storage
- Robin Cloud Native Storage
- TrilioVault for Kubernetes
- Velero plugin for CSI
How to deploy volume snapshots?
Volume Snapshot feature contains the following components:
- Kubernetes Volume Snapshot CRDs
- Volume snapshot controller
- Snapshot validation webhook
- CSI Driver along with CSI Snapshotter sidecar
It is strongly recommended that Kubernetes distributors bundle and deploy the volume snapshot controller, CRDs, and validation webhook as part of their Kubernetes cluster management process (independent of any CSI Driver).
If your cluster does not come pre-installed with the correct components, you may manually install them. See the CSI Snapshotter README for details.
How to use volume snapshots?
Assuming all the required components (including CSI driver) have been already deployed and running on your cluster, you can create volume snapshots using the VolumeSnapshot API object, or use an existing VolumeSnapshot to restore a PVC by specifying the VolumeSnapshot data source on it. For more details, see the volume snapshot documentation.
Dynamically provision a volume snapshot
To dynamically provision a volume snapshot, create a VolumeSnapshotClass API object first.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: test-snapclass
driver: testdriver.csi.k8s.io
deletionPolicy: Delete
parameters:
csi.storage.k8s.io/snapshotter-secret-name: mysecret
csi.storage.k8s.io/snapshotter-secret-namespace: mysecretnamespace
Then create a VolumeSnapshot API object from a PVC by specifying the volume snapshot class.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: test-snapshot
namespace: ns1
spec:
volumeSnapshotClassName: test-snapclass
source:
persistentVolumeClaimName: test-pvc
Importing an existing volume snapshot with Kubernetes
To import a pre-existing volume snapshot into Kubernetes, manually create a VolumeSnapshotContent object first.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: test-content
spec:
deletionPolicy: Delete
driver: testdriver.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-xxx
volumeSnapshotRef:
name: test-snapshot
namespace: default
Then create a VolumeSnapshot object pointing to the VolumeSnapshotContent object.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: test-snapshot
spec:
source:
volumeSnapshotContentName: test-content
Rehydrate volume from snapshot
A bound and ready VolumeSnapshot object can be used to rehydrate a new volume with data pre-populated from snapshotted data as shown here:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-restore
namespace: demo-namespace
spec:
storageClassName: test-storageclass
dataSource:
name: test-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
How to add support for snapshots in a CSI driver?
See the CSI spec and the Kubernetes-CSI Driver Developer Guide for more details on how to implement the snapshot feature in a CSI driver.
What are the limitations?
The GA implementation of volume snapshots for Kubernetes has the following limitations:
- Does not support reverting an existing PVC to an earlier state represented by a snapshot (only supports provisioning a new volume from a snapshot).
How to learn more?
The code repository for snapshot APIs and controller is here: https://github.com/kubernetes-csi/external-snapshotter
Check out additional documentation on the snapshot feature here: http://k8s.io/docs/concepts/storage/volume-snapshots and https://kubernetes-csi.github.io/docs/
How to get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together.
We offer a huge thank you to the contributors who stepped up these last few quarters to help the project reach GA. We want to thank Saad Ali, Michelle Au, Tim Hockin, and Jordan Liggitt for their insightful reviews and thorough consideration with the design, thank Andi Li for his work on adding the support of the snapshot validation webhook, thank Grant Griffiths on implementing metrics support in the snapshot controller and handling password rotation in the validation webhook, thank Chris Henzie, Raunak Shah, and Manohar Reddy for writing critical e2e tests to meet the scalability and stability requirements for graduation, thank Kartik Sharma for moving snapshot APIs and client lib to a separate go module, and thank Raunak Shah and Prafull Ladha for their help with upgrade testing from beta to GA.
There are many more people who have helped to move the snapshot feature from beta to GA. We want to thank everyone who has contributed to this effort:
- Andi Li
- Ben Swartzlander
- Chris Henzie
- Christian Huffman
- Grant Griffiths
- Humble Devassy Chirammal
- Jan Šafránek
- Jiawei Wang
- Jing Xu
- Jordan Liggitt
- Kartik Sharma
- Madhu Rajanna
- Manohar Reddy
- Michelle Au
- Patrick Ohly
- Prafull Ladha
- Prateek Pandey
- Raunak Shah
- Saad Ali
- Saikat Roychowdhury
- Tim Hockin
- Xiangqian Yu
- Xing Yang
- Zhu Can
For those interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
We also hold regular Data Protection Working Group meetings. New attendees are welcome to join in discussions.
Kubernetes 1.20: The Raddest Release
Authors: Kubernetes 1.20 Release Team
We’re pleased to announce the release of Kubernetes 1.20, our third and final release of 2020! This release consists of 42 enhancements: 11 enhancements have graduated to stable, 15 enhancements are moving to beta, and 16 enhancements are entering alpha.
The 1.20 release cycle returned to its normal cadence of 11 weeks following the previous extended release cycle. This is one of the most feature dense releases in a while: the Kubernetes innovation cycle is still trending upward. This release has more alpha than stable enhancements, showing that there is still much to explore in the cloud native ecosystem.
Major Themes
Volume Snapshot Operations Goes Stable
This feature provides a standard way to trigger volume snapshot operations and allows users to incorporate snapshot operations in a portable manner on any Kubernetes environment and supported storage providers.
Additionally, these Kubernetes snapshot primitives act as basic building blocks that unlock the ability to develop advanced, enterprise-grade, storage administration features for Kubernetes, including application or cluster level backup solutions.
Note that snapshot support requires Kubernetes distributors to bundle the Snapshot controller, Snapshot CRDs, and validation webhook. A CSI driver supporting the snapshot functionality must also be deployed on the cluster.
Kubectl Debug Graduates to Beta
The kubectl alpha debug features graduates to beta in 1.20, becoming kubectl debug. The feature provides support for common debugging workflows directly from kubectl. Troubleshooting scenarios supported in this release of kubectl include:
- Troubleshoot workloads that crash on startup by creating a copy of the pod that uses a different container image or command.
- Troubleshoot distroless containers by adding a new container with debugging tools, either in a new copy of the pod or using an ephemeral container. (Ephemeral containers are an alpha feature that are not enabled by default.)
- Troubleshoot on a node by creating a container running in the host namespaces and with access to the host’s filesystem.
Note that as a new built-in command, kubectl debug takes priority over any kubectl plugin named “debug”. You must rename the affected plugin.
Invocations using kubectl alpha debug are now deprecated and will be removed in a subsequent release. Update your scripts to use kubectl debug. For more information about kubectl debug, see Debugging Running Pods.
Beta: API Priority and Fairness
Introduced in 1.18, Kubernetes 1.20 now enables API Priority and Fairness (APF) by default. This allows kube-apiserver to categorize incoming requests by priority levels.
Alpha with updates: IPV4/IPV6
The IPv4/IPv6 dual stack has been reimplemented to support dual stack services based on user and community feedback. This allows both IPv4 and IPv6 service cluster IP addresses to be assigned to a single service, and also enables a service to be transitioned from single to dual IP stack and vice versa.
GA: Process PID Limiting for Stability
Process IDs (pids) are a fundamental resource on Linux hosts. It is trivial to hit the task limit without hitting any other resource limits and cause instability to a host machine.
Administrators require mechanisms to ensure that user pods cannot induce pid exhaustion that prevents host daemons (runtime, kubelet, etc) from running. In addition, it is important to ensure that pids are limited among pods in order to ensure they have limited impact to other workloads on the node.
After being enabled-by-default for a year, SIG Node graduates PID Limits to GA on both SupportNodePidsLimit (node-to-pod PID isolation) and SupportPodPidsLimit (ability to limit PIDs per pod).
Alpha: Graceful node shutdown
Users and cluster administrators expect that pods will adhere to expected pod lifecycle including pod termination. Currently, when a node shuts down, pods do not follow the expected pod termination lifecycle and are not terminated gracefully which can cause issues for some workloads.
The GracefulNodeShutdown feature is now in Alpha. GracefulNodeShutdown makes the kubelet aware of node system shutdowns, enabling graceful termination of pods during a system shutdown.
Major Changes
Dockershim Deprecation
Dockershim, the container runtime interface (CRI) shim for Docker is being deprecated. Support for Docker is deprecated and will be removed in a future release. Docker-produced images will continue to work in your cluster with all CRI compliant runtimes as Docker images follow the Open Container Initiative (OCI) image specification. The Kubernetes community has written a detailed blog post about deprecation with a dedicated FAQ page for it.
Exec Probe Timeout Handling
A longstanding bug regarding exec probe timeouts that may impact existing pod definitions has been fixed. Prior to this fix, the field timeoutSeconds was not respected for exec probes. Instead, probes would run indefinitely, even past their configured deadline, until a result was returned. With this change, the default value of 1 second will be applied if a value is not specified and existing pod definitions may no longer be sufficient if a probe takes longer than one second. A feature gate, called ExecProbeTimeout, has been added with this fix that enables cluster operators to revert to the previous behavior, but this will be locked and removed in subsequent releases. In order to revert to the previous behavior, cluster operators should set this feature gate to false.
Please review the updated documentation regarding configuring probes for more details.
Other Updates
Graduated to Stable
- RuntimeClass
- Built-in API Types Defaults
- Add Pod-Startup Liveness-Probe Holdoff
- Support CRI-ContainerD On Windows
- SCTP Support for Services
- Adding AppProtocol To Services And Endpoints
Notable Feature Updates
Release notes
You can check out the full details of the 1.20 release in the release notes.
Availability of release
Kubernetes 1.20 is available for download on GitHub. There are some great resources out there for getting started with Kubernetes. You can check out some interactive tutorials on the main Kubernetes site, or run a local cluster on your machine using Docker containers with kind. If you’d like to try building a cluster from scratch, check out the Kubernetes the Hard Way tutorial by Kelsey Hightower.
Release Team
This release was made possible by a very dedicated group of individuals, who came together as a team in the midst of a lot of things happening out in the world. A huge thank you to the release lead Jeremy Rickard, and to everyone else on the release team for supporting each other, and working so hard to deliver the 1.20 release for the community.
Release Logo

raddest: adjective, Slang. excellent; wonderful; cool:
The Kubernetes 1.20 Release has been the raddest release yet.
2020 has been a challenging year for many of us, but Kubernetes contributors have delivered a record-breaking number of enhancements in this release. That is a great accomplishment, so the release lead wanted to end the year with a little bit of levity and pay homage to Kubernetes 1.14 - Caturnetes with a "rad" cat named Humphrey.
Humphrey is the release lead's cat and has a permanent blep. Rad was pretty common slang in the 1990s in the United States, and so were laser backgrounds. Humphrey in a 1990s style school picture felt like a fun way to end the year. Hopefully, Humphrey and his blep bring you a little joy at the end of 2020!
The release logo was created by Henry Hsu - @robotdancebattle.
User Highlights
- Apple is operating multi-thousand node Kubernetes clusters in data centers all over the world. Watch Alena Prokharchyk's KubeCon NA Keynote to learn more about their cloud native journey.
Project Velocity
The CNCF K8s DevStats project aggregates a number of interesting data points related to the velocity of Kubernetes and various sub-projects. This includes everything from individual contributions to the number of companies that are contributing, and is a neat illustration of the depth and breadth of effort that goes into evolving this ecosystem.
In the v1.20 release cycle, which ran for 11 weeks (September 25 to December 9), we saw contributions from 967 companies and 1335 individuals (44 of whom made their first Kubernetes contribution) from 26 countries.
Ecosystem Updates
- KubeCon North America just wrapped up three weeks ago, the second such event to be virtual! All talks are now available to all on-demand for anyone still needing to catch up!
- In June, the Kubernetes community formed a new working group as a direct response to the Black Lives Matter protests occurring across America. WG Naming's goal is to remove harmful and unclear language in the Kubernetes project as completely as possible and to do so in a way that is portable to other CNCF projects. A great introductory talk on this important work and how it is conducted was given at KubeCon 2020 North America, and the initial impact of this labor can actually be seen in the v1.20 release.
- Previously announced this summer, The Certified Kubernetes Security Specialist (CKS) Certification was released during Kubecon NA for immediate scheduling! Following the model of CKA and CKAD, the CKS is a performance-based exam, focused on security-themed competencies and domains. This exam is targeted at current CKA holders, particularly those who want to round out their baseline knowledge in securing cloud workloads (which is all of us, right?).
Event Updates
KubeCon + CloudNativeCon Europe 2021 will take place May 4 - 7, 2021! Registration will open on January 11. You can find more information about the conference here. Remember that the CFP closes on Sunday, December 13, 11:59pm PST!
Upcoming release webinar
Stay tuned for the upcoming release webinar happening this January.
Get Involved
If you’re interested in contributing to the Kubernetes community, Special Interest Groups (SIGs) are a great starting point. Many of them may align with your interests! If there are things you’d like to share with the community, you can join the weekly community meeting, or use any of the following channels:
- Find out more about contributing to Kubernetes at the new Kubernetes Contributor website
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Share your Kubernetes story
- Read more about what’s happening with Kubernetes on the blog
- Learn more about the Kubernetes Release Team
GSoD 2020: Improving the API Reference Experience
Author: Philippe Martin
Editor's note: Better API references have been my goal since I joined Kubernetes docs three and a half years ago. Philippe has succeeded fantastically. More than a better API reference, though, Philippe embodied the best of the Kubernetes community in this project: excellence through collaboration, and a process that made the community itself better. Thanks, Google Season of Docs, for making Philippe's work possible. —Zach Corleissen
Introduction
The Google Season of Docs project brings open source organizations and technical writers together to work closely on a specific documentation project.
I was selected by the CNCF to work on Kubernetes documentation, specifically to make the API Reference documentation more accessible.
I'm a software developer with a great interest in documentation systems. In the late 90's I started translating Linux-HOWTO documents into French. From one thing to another, I learned about documentation systems. Eventually, I wrote a Linux-HOWTO to help documentarians learn the language used at that time for writing documents, LinuxDoc/SGML.
Shortly afterward, Linux documentation adopted the DocBook language. I helped some writers rewrite their documents in this format; for example, the Advanced Bash-Scripting Guide. I also worked on the GNU makeinfo program to add DocBook output, making it possible to transform GNU Info documentation into Docbook format.
Background
The Kubernetes website is built with Hugo from documentation written in Markdown format in the website repository, using the Docsy Hugo theme.
The existing API reference documentation is a large HTML file generated from the Kubernetes OpenAPI specification.
On my side, I wanted for some time to make the API Reference more accessible, by:
- building individual and autonomous pages for each Kubernetes resource
- adapting the format to mobile reading
- reusing the website's assets and theme to build, integrate, and display the reference pages
- allowing the search engines to reference the content of the pages
Around one year ago, I started to work on the generator building the current unique HTML page, to add a DocBook output, so the API Reference could be generated first in DocBook format, and after that in PDF or other formats supported by DocBook processors. The first result has been some Ebook files for the API Reference and an auto-edited paper book.
I decided later to add another output to this generator, to generate Markdown files and create a website with the API Reference.
When the CNCF proposed a project for the Google Season of Docs to work on the API Reference, I applied, and the match occurred.
The Project
swagger-ui
The first idea of the CNCF members that proposed this project was to test the swagger-ui tool, to try and document the Kubernetes API Reference with this standard tool.
Because the Kubernetes API is much larger than many other APIs, it has been necessary to write a tool to split the complete API Reference by API Groups, and insert in the Documentation website several swagger-ui components, one for each API Group.
Generally, APIs are used by developers by calling endpoints with a specific HTTP verb, with specific parameters and waiting for a response. The swagger-ui interface is built for this usage: the interface displays a list of endpoints and their associated verbs, and for each the parameters and responses formats.
The Kubernetes API is most of the time used differently: users create manifest files containing resources definitions in YAML format, and use the kubectl CLI to apply these manifests to the cluster. In this case, the most important information is the description of the structures used as parameters and responses (the Kubernetes Resources).
Because of this specificity, we realized that it would be difficult to adapt the swagger-ui interface to satisfy the users of the Kubernetes API and this direction has been abandoned.
Markdown pages
The second stage of the project has been to adapt the work I had done to create the k8sref.io website, to include it in the official documentation website.
The main changes have been to:
- use go-templates to represent the output pages, so non-developers can adapt the generated pages without having to edit the generator code
- create a new custom shortcode, to easily create links from inside the website to specific pages of the API reference
- improve the navigation between the sections of the API reference
- add the code of the generator to the Kubernetes GitHub repository containing the different reference generators
All the discussions and work done can be found in website pull request #23294.
Adding the generator code to the Kubernetes project happened in kubernetes-sigs/reference-docs#179.
Here are the features of the new API Reference to be included in the official documentation website:
- the resources are categorized, in the categories Workloads, Services, Config & Storage, Authentication, Authorization, Policies, Extend, Cluster. This structure is configurable with a simple
toc.yamlfile - each page displays associated resources at the first level ; for example: Pod, PodSpec, PodStatus, PodList
- most resource pages inline relevant definitions ; the exceptions are when those definitions are common to several resources, or are too complex to be displayed inline. With the old approach, you had to follow a hyperlink to read each extra detail.
- some widely used definitions, such as
ObjectMeta, are documented in a specific page - required fields are indicated, and placed first
- fields of a resource can be categorized and ordered, with the help of a
fields.yamlfile mapfields are indicated. For example the.spec.nodeSelectorfor aPodismap[string]string, instead ofobject, using the value ofx-kubernetes-list-type- patch strategies are indicated
apiVersionandkinddisplay the value, not thestringtype- At the top of a reference page, the page displays the Go import necessary to use these resources from a Go program.
The work is currently on hold pending the 1.20 release. When the release finishes and the work is integrated, the API reference will be available at https://kubernetes.io/docs/reference/.
Future Work
There are points to improve, particularly:
- Some Kubernetes resources are deeply nested. Inlining the definition of these resources makes them difficult to understand.
- The created
shortcodeuses the URL of the page to reference a Resource page. It would be easier for documentarians if they could reference a Resource by its group and name.
Appreciation
I would like to thank my mentor Zach Corleissen and the lead writers Karen Bradshaw, Celeste Horgan, Tim Bannister and Qiming Teng who supervised me during all the season. They all have been very encouraging and gave me tons of great advice.
Dockershim Deprecation FAQ
Update: There is a newer version of this article available.
This document goes over some frequently asked questions regarding the Dockershim deprecation announced as a part of the Kubernetes v1.20 release. For more detail on the deprecation of Docker as a container runtime for Kubernetes kubelets, and what that means, check out the blog post Don't Panic: Kubernetes and Docker.
Also, you can read check whether Dockershim deprecation affects you to check whether it does.
Why is dockershim being deprecated?
Maintaining dockershim has become a heavy burden on the Kubernetes maintainers. The CRI standard was created to reduce this burden and allow smooth interoperability of different container runtimes. Docker itself doesn't currently implement CRI, thus the problem.
Dockershim was always intended to be a temporary solution (hence the name: shim). You can read more about the community discussion and planning in the Dockershim Removal Kubernetes Enhancement Proposal.
Additionally, features that were largely incompatible with the dockershim, such as cgroups v2 and user namespaces are being implemented in these newer CRI runtimes. Removing support for the dockershim will allow further development in those areas.
Can I still use Docker in Kubernetes 1.20?
Yes, the only thing changing in 1.20 is a single warning log printed at kubelet startup if using Docker as the runtime.
When will dockershim be removed?
Given the impact of this change, we are using an extended deprecation timeline. It will not be removed before Kubernetes 1.22, meaning the earliest release without dockershim would be 1.23 in late 2021. Update: removal of dockershim is scheduled for Kubernetes v1.24, see Dockershim Removal Kubernetes Enhancement Proposal. We will be working closely with vendors and other ecosystem groups to ensure a smooth transition and will evaluate things as the situation evolves.
Can I still use dockershim after it is removed from Kubernetes?
Update: Mirantis and Docker have committed to maintaining the dockershim after it is removed from Kubernetes.
Will my existing Docker images still work?
Yes, the images produced from docker build will work with all CRI implementations.
All your existing images will still work exactly the same.
What about private images?
Yes. All CRI runtimes support the same pull secrets configuration used in Kubernetes, either via the PodSpec or ServiceAccount.
Are Docker and containers the same thing?
Docker popularized the Linux containers pattern and has been instrumental in developing the underlying technology, however containers in Linux have existed for a long time. The container ecosystem has grown to be much broader than just Docker. Standards like OCI and CRI have helped many tools grow and thrive in our ecosystem, some replacing aspects of Docker while others enhance existing functionality.
Are there examples of folks using other runtimes in production today?
All Kubernetes project produced artifacts (Kubernetes binaries) are validated with each release.
Additionally, the kind project has been using containerd for some time and has seen an improvement in stability for its use case. Kind and containerd are leveraged multiple times every day to validate any changes to the Kubernetes codebase. Other related projects follow a similar pattern as well, demonstrating the stability and usability of other container runtimes. As an example, OpenShift 4.x has been using the CRI-O runtime in production since June 2019.
For other examples and references you can look at the adopters of containerd and CRI-O, two container runtimes under the Cloud Native Computing Foundation (CNCF).
People keep referencing OCI, what is that?
OCI stands for the Open Container Initiative, which standardized many of the interfaces between container tools and technologies. They maintain a standard specification for packaging container images (OCI image-spec) and running containers (OCI runtime-spec). They also maintain an actual implementation of the runtime-spec in the form of runc, which is the underlying default runtime for both containerd and CRI-O. The CRI builds on these low-level specifications to provide an end-to-end standard for managing containers.
Which CRI implementation should I use?
That’s a complex question and it depends on a lot of factors. If Docker is working for you, moving to containerd should be a relatively easy swap and will have strictly better performance and less overhead. However, we encourage you to explore all the options from the CNCF landscape in case another would be an even better fit for your environment.
What should I look out for when changing CRI implementations?
While the underlying containerization code is the same between Docker and most CRIs (including containerd), there are a few differences around the edges. Some common things to consider when migrating are:
- Logging configuration
- Runtime resource limitations
- Node provisioning scripts that call docker or use docker via it's control socket
- Kubectl plugins that require docker CLI or the control socket
- Kubernetes tools that require direct access to Docker (e.g. kube-imagepuller)
- Configuration of functionality like
registry-mirrorsand insecure registries - Other support scripts or daemons that expect Docker to be available and are run outside of Kubernetes (e.g. monitoring or security agents)
- GPUs or special hardware and how they integrate with your runtime and Kubernetes
If you use Kubernetes resource requests/limits or file-based log collection DaemonSets then they will continue to work the same, but if you’ve customized your dockerd configuration, you’ll need to adapt that for your new container runtime where possible.
Another thing to look out for is anything expecting to run for system maintenance
or nested inside a container when building images will no longer work. For the
former, you can use the crictl tool as a drop-in replacement (see mapping from docker cli to crictl) and for the
latter you can use newer container build options like img, buildah,
kaniko, or buildkit-cli-for-kubectl that don’t require Docker.
For containerd, you can start with their documentation to see what configuration options are available as you migrate things over.
For instructions on how to use containerd and CRI-O with Kubernetes, see the Kubernetes documentation on Container Runtimes
What if I have more questions?
If you use a vendor-supported Kubernetes distribution, you can ask them about upgrade plans for their products. For end-user questions, please post them to our end user community forum: https://discuss.kubernetes.io/.
You can also check out the excellent blog post Wait, Docker is deprecated in Kubernetes now? a more in-depth technical discussion of the changes.
Can I have a hug?
Always and whenever you want! 🤗🤗
Don't Panic: Kubernetes and Docker
Authors: Jorge Castro, Duffie Cooley, Kat Cosgrove, Justin Garrison, Noah Kantrowitz, Bob Killen, Rey Lejano, Dan “POP” Papandrea, Jeffrey Sica, Davanum “Dims” Srinivas
Kubernetes is deprecating Docker as a container runtime after v1.20.
You do not need to panic. It’s not as dramatic as it sounds.
TL;DR Docker as an underlying runtime is being deprecated in favor of runtimes that use the Container Runtime Interface (CRI) created for Kubernetes. Docker-produced images will continue to work in your cluster with all runtimes, as they always have.
If you’re an end-user of Kubernetes, not a whole lot will be changing for you.
This doesn’t mean the death of Docker, and it doesn’t mean you can’t, or
shouldn’t, use Docker as a development tool anymore. Docker is still a useful
tool for building containers, and the images that result from running docker build can still run in your Kubernetes cluster.
If you’re using a managed Kubernetes service like GKE, EKS, or AKS (which defaults to containerd) you will need to make sure your worker nodes are using a supported container runtime before Docker support is removed in a future version of Kubernetes. If you have node customizations you may need to update them based on your environment and runtime requirements. Please work with your service provider to ensure proper upgrade testing and planning.
If you’re rolling your own clusters, you will also need to make changes to avoid your clusters breaking. At v1.20, you will get a deprecation warning for Docker. When Docker runtime support is removed in a future release (currently planned for the 1.22 release in late 2021) of Kubernetes it will no longer be supported and you will need to switch to one of the other compliant container runtimes, like containerd or CRI-O. Just make sure that the runtime you choose supports the docker daemon configurations you currently use (e.g. logging).
So why the confusion and what is everyone freaking out about?
We’re talking about two different environments here, and that’s creating confusion. Inside of your Kubernetes cluster, there’s a thing called a container runtime that’s responsible for pulling and running your container images. Docker is a popular choice for that runtime (other common options include containerd and CRI-O), but Docker was not designed to be embedded inside Kubernetes, and that causes a problem.
You see, the thing we call “Docker” isn’t actually one thing—it’s an entire tech stack, and one part of it is a thing called “containerd,” which is a high-level container runtime by itself. Docker is cool and useful because it has a lot of UX enhancements that make it really easy for humans to interact with while we’re doing development work, but those UX enhancements aren’t necessary for Kubernetes, because it isn’t a human.
As a result of this human-friendly abstraction layer, your Kubernetes cluster has to use another tool called Dockershim to get at what it really needs, which is containerd. That’s not great, because it gives us another thing that has to be maintained and can possibly break. What’s actually happening here is that Dockershim is being removed from Kubelet as early as v1.23 release, which removes support for Docker as a container runtime as a result. You might be thinking to yourself, but if containerd is included in the Docker stack, why does Kubernetes need the Dockershim?
Docker isn’t compliant with CRI, the Container Runtime Interface. If it were, we wouldn’t need the shim, and this wouldn’t be a thing. But it’s not the end of the world, and you don’t need to panic—you just need to change your container runtime from Docker to another supported container runtime.
One thing to note: If you are relying on the underlying docker socket
(/var/run/docker.sock) as part of a workflow within your cluster today, moving
to a different runtime will break your ability to use it. This pattern is often
called Docker in Docker. There are lots of options out there for this specific
use case including things like
kaniko,
img, and
buildah.
What does this change mean for developers, though? Do we still write Dockerfiles? Do we still build things with Docker?
This change addresses a different environment than most folks use to interact with Docker. The Docker installation you’re using in development is unrelated to the Docker runtime inside your Kubernetes cluster. It’s confusing, we understand. As a developer, Docker is still useful to you in all the ways it was before this change was announced. The image that Docker produces isn’t really a Docker-specific image—it’s an OCI (Open Container Initiative) image. Any OCI-compliant image, regardless of the tool you use to build it, will look the same to Kubernetes. Both containerd and CRI-O know how to pull those images and run them. This is why we have a standard for what containers should look like.
So, this change is coming. It’s going to cause issues for some, but it isn’t catastrophic, and generally it’s a good thing. Depending on how you interact with Kubernetes, this could mean nothing to you, or it could mean a bit of work. In the long run, it’s going to make things easier. If this is still confusing for you, that’s okay—there’s a lot going on here; Kubernetes has a lot of moving parts, and nobody is an expert in 100% of it. We encourage any and all questions regardless of experience level or complexity! Our goal is to make sure everyone is educated as much as possible on the upcoming changes. We hope this has answered most of your questions and soothed some anxieties! ❤️
Looking for more answers? Check out our accompanying Dockershim Removal FAQ (updated February 2022).
Cloud native security for your clusters
Author: Pushkar Joglekar
Over the last few years a small, security focused community has been working diligently to deepen our understanding of security, given the evolving cloud native infrastructure and corresponding iterative deployment practices. To enable sharing of this knowledge with the rest of the community, members of CNCF SIG Security (a group which reports into CNCF TOC and who are friends with Kubernetes SIG Security) led by Emily Fox, collaborated on a whitepaper outlining holistic cloud native security concerns and best practices. After over 1200 comments, changes, and discussions from 35 members across the world, we are proud to share cloud native security whitepaper v1.0 that serves as essential reading for security leadership in enterprises, financial and healthcare industries, academia, government, and non-profit organizations.
The paper attempts to not focus on any specific cloud native project. Instead, the intent is to model and inject security into four logical phases of cloud native application lifecycle: Develop, Distribute, Deploy, and Runtime.

Kubernetes native security controls
When using Kubernetes as a workload orchestrator, some of the security controls this version of the whitepaper recommends are:
- Pod Security Policies: Implement a single source of truth for “least privilege” workloads across the entire cluster
- Resource requests and limits: Apply requests (soft constraint) and limits (hard constraint) for shared resources such as memory and CPU
- Audit log analysis: Enable Kubernetes API auditing and filtering for security relevant events
- Control plane authentication and certificate root of trust: Enable mutual TLS authentication with a trusted CA for communication within the cluster
- Secrets management: Integrate with a built-in or external secrets store
Cloud native complementary security controls
Kubernetes has direct involvement in the deploy phase and to a lesser extent in the runtime phase. Ensuring the artifacts are securely developed and distributed is necessary for, enabling workloads in Kubernetes to run “secure by default”. Throughout all phases of the Cloud native application life cycle, several complementary security controls exist for Kubernetes orchestrated workloads, which includes but are not limited to:
- Develop:
- Image signing and verification
- Image vulnerability scanners
- Distribute:
- Pre-deployment checks for detecting excessive privileges
- Enabling observability and logging
- Deploy:
- Using a service mesh for workload authentication and authorization
- Enforcing “default deny” network policies for inter-workload communication via network plugins
- Runtime:
- Deploying security monitoring agents for workloads
- Isolating applications that run on the same node using SELinux, AppArmor, etc.
- Scanning configuration against recognized secure baselines for node, workload and orchestrator
Understand first, secure next
The cloud native way, including containers, provides great security benefits for its users: immutability, modularity, faster upgrades and consistent state across the environment. Realizing this fundamental change in “the way things are done”, motivates us to look at security with a cloud native lens. One of the things that was evident for all the authors of the paper was the fact that it’s tough to make smarter decisions on how and what to secure in a cloud native ecosystem if you do not understand the tools, patterns, and frameworks at hand (in addition to knowing your own critical assets). Hence, for all the security practitioners out there who want to be partners rather than a gatekeeper for your friends in Operations, Product Development, and Compliance, let’s make an attempt to learn more so we can secure better.
We recommend following this 7 step R.U.N.T.I.M.E. path to get started on cloud native security:
- Read the paper and any linked material in it
- Understand challenges and constraints for your environment
- Note the content and controls that apply to your environment
- Talk about your observations with your peers
- Involve your leadership and ask for help
- Make a risk profile based on existing and missing security controls
- Expend time, money, and resources that improve security posture and reduce risk where appropriate.
Acknowledgements
Huge shout out to Emily Fox, Tim Bannister (The Scale Factory), Chase Pettet (Mirantis), and Wayne Haber (GitLab) for contributing with their wonderful suggestions for this blog post.
Remembering Dan Kohn
Author: The Kubernetes Steering Committee
Dan Kohn was instrumental in getting Kubernetes and CNCF community to where it is today. He shared our values, motivations, enthusiasm, community spirit, and helped the Kubernetes community to become the best that it could be. Dan loved getting people together to solve problems big and small. He enabled people to grow their individual scope in the community which often helped launch their career in open source software.
Dan built a coalition around the nascent Kubernetes project and turned that into a cornerstone to build the larger cloud native space. He loved challenges, especially ones where the payoff was great like building worldwide communities, spreading the love of open source, and helping diverse, underprivileged communities and students to get a head start in technology.
Our heart goes out to his family. Thank you, Dan, for bringing your boys to events in India and elsewhere as we got to know how great you were as a father. Dan, your thoughts and ideas will help us make progress in our journey as a community. Thank you for your life's work!
If Dan has made an impact on you in some way, please consider adding a memory of him in his CNCF memorial.
Announcing the 2020 Steering Committee Election Results
Author: Kaslin Fields
The 2020 Steering Committee Election is now complete. In 2019, the committee arrived at its final allocation of 7 seats, 3 of which were up for election in 2020. Incoming committee members serve a term of 2 years, and all members are elected by the Kubernetes Community.
This community body is significant since it oversees the governance of the entire Kubernetes project. With that great power comes great responsibility. You can learn more about the steering committee’s role in their charter.
Results
Congratulations to the elected committee members whose two year terms begin immediately (listed in alphabetical order by GitHub handle):
- Davanum Srinivas (@dims), VMware
- Jordan Liggitt (@liggitt), Google
- Bob Killen (@mrbobbytables), Google
They join continuing members Christoph Blecker (@cblecker), Red Hat; Derek Carr (@derekwaynecarr), Red Hat; Nikhita Raghunath (@nikhita), VMware; and Paris Pittman (@parispittman), Apple. Davanum Srinivas is returning for his second term on the committee.
Big Thanks!
- Thank you and congratulations on a successful election to this round’s election officers:
- Jaice Singer DuMars (@jdumars), Apple
- Ihor Dvoretskyi (@idvoretskyi), CNCF
- Josh Berkus (@jberkus), Red Hat
- Thanks to the Emeritus Steering Committee Members. Your prior service is appreciated by the community:
- Aaron Crickenberger (@spiffxp), Google
- and Lachlan Evenson(@lachie83)), Microsoft
- And thank you to all the candidates who came forward to run for election. As Jorge Castro put it: we are spoiled with capable, kind, and selfless volunteers who put the needs of the project first.
Get Involved with the Steering Committee
This governing body, like all of Kubernetes, is open to all. You can follow along with Steering Committee backlog items and weigh in by filing an issue or creating a PR against their repo. They have an open meeting on the first Monday of the month at 6pm UTC and regularly attend Meet Our Contributors. They can also be contacted at their public mailing list steering@kubernetes.io.
You can see what the Steering Committee meetings are all about by watching past meetings on the YouTube Playlist.
This post was written by the Upstream Marketing Working Group. If you want to write stories about the Kubernetes community, learn more about us.
Contributing to the Development Guide
When most people think of contributing to an open source project, I suspect they probably think of contributing code changes, new features, and bug fixes. As a software engineer and a long-time open source user and contributor, that's certainly what I thought. Although I have written a good quantity of documentation in different workflows, the massive size of the Kubernetes community was a new kind of "client." I just didn't know what to expect when Google asked my compatriots and me at Lion's Way to make much-needed updates to the Kubernetes Development Guide.
This article originally appeared on the Kubernetes Contributor Community blog.
The Delights of Working With a Community
As professional writers, we are used to being hired to write very specific pieces. We specialize in marketing, training, and documentation for technical services and products, which can range anywhere from relatively fluffy marketing emails to deeply technical white papers targeted at IT and developers. With this kind of professional service, every deliverable tends to have a measurable return on investment. I knew this metric wouldn't be present when working on open source documentation, but I couldn't predict how it would change my relationship with the project.
One of the primary traits of the relationship between our writing and our traditional clients is that we always have one or two primary points of contact inside a company. These contacts are responsible for reviewing our writing and making sure it matches the voice of the company and targets the audience they're looking for. It can be stressful -- which is why I'm so glad that my writing partner, eagle-eyed reviewer, and bloodthirsty editor Joel handles most of the client contact.
I was surprised and delighted that all of the stress of client contact went out the window when working with the Kubernetes community.
"How delicate do I have to be? What if I screw up? What if I make a developer angry? What if I make
enemies?" These were all questions that raced through my mind and made me feel like I was
approaching a field of eggshells when I first joined the #sig-contribex channel on the Kubernetes
Slack and announced that I would be working on the
Development Guide.
"The Kubernetes Code of Conduct is in effect, so please be excellent to each other." — Jorge Castro, SIG ContribEx co-chair
My fears were unfounded. Immediately, I felt welcome. I like to think this isn't just because I was working on a much needed task, but rather because the Kubernetes community is filled with friendly, welcoming people. During the weekly SIG ContribEx meetings, our reports on progress with the Development Guide were included immediately. In addition, the leader of the meeting would always stress that the Kubernetes Code of Conduct was in effect, and that we should, like Bill and Ted, be excellent to each other.
This Doesn't Mean It's All Easy
The Development Guide needed a pretty serious overhaul. When we got our hands on it, it was already packed with information and lots of steps for new developers to go through, but it was getting dusty with age and neglect. Documentation can really require a global look, not just point fixes. As a result, I ended up submitting a gargantuan pull request to the Community repo: 267 additions and 88 deletions.
The life cycle of a pull request requires a certain number of Kubernetes organization members to review and approve changes before they can be merged. This is a great practice, as it keeps both documentation and code in pretty good shape, but it can be tough to cajole the right people into taking the time for such a hefty review. As a result, that massive PR took 26 days from my first submission to final merge. But in the end, it was successful.
Since Kubernetes is a pretty fast-moving project, and since developers typically aren't really excited about writing documentation, I also ran into the problem that sometimes, the secret jewels that describe the workings of a Kubernetes subsystem are buried deep within the labyrinthine mind of a brilliant engineer, and not in plain English in a Markdown file. I ran headlong into this issue when it came time to update the getting started documentation for end-to-end (e2e) testing.
This portion of my journey took me out of documentation-writing territory and into the role of a
brand new user of some unfinished software. I ended up working with one of the developers of the new
kubetest2 framework to document the latest process of
getting up-and-running for e2e testing, but it required a lot of head scratching on my part. You can
judge the results for yourself by checking out my
completed pull request.
Nobody Is the Boss, and Everybody Gives Feedback
But while I secretly expected chaos, the process of contributing to the Kubernetes Development Guide and interacting with the amazing Kubernetes community went incredibly smoothly. There was no contention. I made no enemies. Everybody was incredibly friendly and welcoming. It was enjoyable.
With an open source project, there is no one boss. The Kubernetes project, which approaches being gargantuan, is split into many different special interest groups (SIGs), working groups, and communities. Each has its own regularly scheduled meetings, assigned duties, and elected chairpersons. My work intersected with the efforts of both SIG ContribEx (who watch over and seek to improve the contributor experience) and SIG Testing (who are in charge of testing). Both of these SIGs proved easy to work with, eager for contributions, and populated with incredibly friendly and welcoming people.
In an active, living project like Kubernetes, documentation continues to need maintenance, revision, and testing alongside the code base. The Development Guide will continue to be crucial to onboarding new contributors to the Kubernetes code base, and as our efforts have shown, it is important that this guide keeps pace with the evolution of the Kubernetes project.
Joel and I really enjoy interacting with the Kubernetes community and contributing to the Development Guide. I really look forward to continuing to not only contributing more, but to continuing to build the new friendships I've made in this vast open source community over the past few months.
GSoC 2020 - Building operators for cluster addons
Author: Somtochi Onyekwere
Introduction
Google Summer of Code is a global program that is geared towards introducing students to open source. Students are matched with open-source organizations to work with them for three months during the summer.
My name is Somtochi Onyekwere from the Federal University of Technology, Owerri (Nigeria) and this year, I was given the opportunity to work with Kubernetes (under the CNCF organization) and this led to an amazing summer spent learning, contributing and interacting with the community.
Specifically, I worked on the Cluster Addons: Package all the things! project. The project focused on building operators for better management of various cluster addons, extending the tooling for building these operators and making the creation of these operators a smooth process.
Background
Kubernetes has progressed greatly in the past few years with a flourishing community and a large number of contributors. The codebase is gradually moving away from the monolith structure where all the code resides in the kubernetes/kubernetes repository to being split into multiple sub-projects. Part of the focus of cluster-addons is to make some of these sub-projects work together in an easy to assemble, self-monitoring, self-healing and Kubernetes-native way. It enables them to work seamlessly without human intervention.
The community is exploring the use of operators as a mechanism to monitor various resources in the cluster and properly manage these resources. In addition to this, it provides self-healing and it is a kubernetes-native pattern that can encode how best these addons work and manage them properly.
What are cluster addons? Cluster addons are a collection of resources (like Services and deployment) that are used to give a Kubernetes cluster additional functionalities. They range from things as simple as the Kubernetes dashboards (for visualization) to more complex ones like Calico (for networking). These addons are essential to different applications running in the cluster and the cluster itself. The addon operator provides a nicer way of managing these addons and understanding the health and status of the various resources that comprise the addon. You can get a deeper overview in this article.
Operators are custom controllers with custom resource definitions that encode application-specific knowledge and are used for managing complex stateful applications. It is a widely accepted pattern. Managing addons via operators, with these operators encoding knowledge of how best the addons work, introduces a lot of advantages while setting standards that will be easy to follow and scale. This article does a good job of explaining operators.
The addon operators can solve a lot of problems, but they have their challenges. Those under the cluster-addons project had missing pieces and were still a proof of concept. Generating the RBAC configuration for the operators was a pain and sometimes the operators were given too much privilege. The operators weren’t very extensible as it only pulled manifests from local filesystems or HTTP(s) servers and a lot of simple addons were generating the same code. I spent the summer working on these issues, looking at them with fresh eyes and coming up with solutions for both the known and unknown issues.
Various additions to kubebuilder-declarative-pattern
The kubebuilder-declarative-pattern (from here on referred to as KDP) repo is an extra layer of addon specific tooling on top of the kubebuilder SDK that is enabled by passing the experimental --pattern=addon flag to kubebuilder create command. Together, they create the base code for the addon operator. During the internship, I worked on a couple of features in KDP and cluster-addons.
Operator version checking
Enabling version checks for operators helped in making upgrades/downgrades safer to different versions of the addon, even though the operator had complex logic. It is a way of matching the version of an addon to the version of the operator that knows how to manage it well. Most addons have different versions and these versions might need to be managed differently. This feature checks the custom resource for the addons.k8s.io/min-operator-version annotation which states the minimum operator version that is needed to manage the version against the version of the operator. If the operator version is below the minimum version required, the operator pauses with an error telling the user that the version of the operator is too low. This helps to ensure that the correct operator is being used for the addon.
Git repository for storing the manifests
Previously, there was support for only local file directories and HTTPS repositories for storing manifests. Giving creators of addon operators the ability to store manifest in GitHub repository enables faster development and version control. When starting the controller, you can pass a flag to specify the location of your channels directory. The channels directory contains the manifests for different versions, the controller pulls the manifest from this directory and applies it to the cluster. During the internship period, I extended it to include Git repositories.
Annotations to temporarily disable reconciliation
The reconciliation loop that ensures that the desired state matches the actual state prevents modification of objects in the cluster. This makes it hard to experiment or investigate what might be wrong in the cluster as any changes made are promptly reverted. I resolved this by allowing users to place an addons.k8s.io/ignore annotation on the resource that they don’t want the controller to reconcile. The controller checks for this annotation and doesn’t reconcile that object. To resume reconciliation, the annotation can be removed from the resource.
Unstructured support in kubebuilder-declarative-pattern
One of the operators that I worked on is a generic controller that could manage more than one cluster addon that did not require extra configuration. To do this, the operator couldn’t use a particular type and needed the kubebuilder-declarative-repo to support using the unstructured.Unstructured type. There were various functions in the kubebuilder-declarative-pattern that couldn’t handle this type and returned an error if the object passed in was not of type addonsv1alpha1.CommonObject. The functions were modified to handle both unstructured.Unstructured and addonsv1alpha.CommonObject.
Tools and CLI programs
There were also some command-line programs I wrote that could be used to make working with addon operators easier. Most of them have uses outside the addon operators as they try to solve a specific problem that could surface anywhere while working with Kubernetes. I encourage you to check them out when you have the chance!
RBAC Generator
One of the biggest concerns with the operator was RBAC. You had to manually look through the manifest and add the RBAC rule for each resource as it needs to have RBAC permissions to create, get, update and delete the resources in the manifest when running in-cluster. Building the RBAC generator automated the process of writing the RBAC roles and role bindings. The function of the RBAC generator is simple. It accepts the file name of the manifest as a flag. Then, it parses the manifest and gets the API group and resource name of the resources and adds it to a role. It outputs the role and role binding to stdout or a file if the --out flag is parsed.
Additionally, the tool enables you to split the RBAC by separating the cluster roles in the manifest. This lessened the security concern of an operator being over-privileged as it needed to have all the permissions that the clusterrole has. If you want to apply the clusterrole yourself and not give the operator these permissions, you can pass in a --supervisory boolean flag so that the generator does not add these permissions to the role. The CLI program resides here.
Kubectl Ownerref
It is hard to find out at a glance which objects were created by an addon custom resource. This kubectl plugin alleviates that pain by displaying all the objects in the cluster that a resource has ownerrefs on. You simply pass the kind and the name of the resource as arguments to the program and it checks the cluster for the objects and gives the kind, name, the namespace of such an object. It could be useful to get a general overview of all the objects that the controller is reconciling by passing in the name and kind of custom resource. The CLI program resides here.
Addon Operators
To fully understand addons operators and make changes to how they are being created, you have to try creating and using them. Part of the summer was spent building operators for some popular addons like the Kubernetes dashboard, flannel, NodeLocalDNS and so on. Please check the cluster-addons repository for the different addon operators. In this section, I will just highlight one that is a little different from the others.
Generic Controller
The generic controller can be shared between addons that don’t require much configuration. This minimizes resource consumption on the cluster as it reduces the number of controllers that need to be run. Also instead of building your own operator, you can just use the generic controller and whenever you feel that your needs have grown and you need a more complex operator, you can always scaffold the code with kubebuilder and continue from where the generic operator stopped. To use the generic controller, you can generate the CustomResourceDefinition(CRD) using this tool (generic-addon). You pass in the kind, group, and the location of your channels directory (it could be a Git repository too!). The tool generates the - CRD, RBAC manifest and two custom resources for you.
The process is as follows:
- Create the Generic CRD
- Generate all the manifests needed with the
generic-addon tool.
This tool creates:
- The CRD for your addon
- The RBAC rules for the CustomResourceDefinitions
- The RBAC rules for applying the manifests
- The custom resource for your addon
- A Generic custom resource
The Generic custom resource looks like this:
apiVersion: addons.x-k8s.io/v1alpha1
kind: Generic
metadata:
name: generic-sample
spec:
objectKind:
kind: NodeLocalDNS
version: "v1alpha1"
group: addons.x-k8s.io
channel: "../nodelocaldns/channels"
Apply these manifests but ensure to apply the CRD before the CR. Then, run the Generic controller, either on your machine or in-cluster.
If you are interested in building an operator, Please check out this guide.
Relevant Links
- Detailed breakdown of work done during the internship
- Addon Operator (KEP)
- Original GSoC Issue
- Proposal Submitted for GSoC
- All commits to kubernetes-sigs/cluster-addons
- All commits to kubernetes-sigs/kubebuidler-declarative-pattern
Further Work
A lot of work was definitely done on the cluster addons during the GSoC period. But we need more people building operators and using them in the cluster. We need wider adoption in the community. Build operators for your favourite addons and tell us how it went and if you had any issues. Check out this README.md to get started.
Appreciation
I really want to appreciate my mentors Justin Santa Barbara (Google) and Leigh Capili (Weaveworks). My internship was awesome because they were awesome. They set a golden standard for what mentorship should be. They were accessible and always available to clear any confusion. I think what I liked best was that they didn’t just dish out tasks, instead, we had open discussions about what was wrong and what could be improved. They are really the best and I hope I get to work with them again! Also, I want to say a huge thanks to Lubomir I. Ivanov for reviewing this blog post!
Conclusion
So far I have learnt a lot about Go, the internals of Kubernetes, and operators. I want to conclude by encouraging people to contribute to open-source (especially Kubernetes :)) regardless of your level of experience. It has been a well-rounded experience for me and I have come to love the community. It is a great initiative and it is a great way to learn and meet awesome people. Special shoutout to Google for organizing this program.
If you are interested in cluster addons and finding out more on addon operators, you are welcome to join our slack channel on the Kubernetes #cluster-addons.
Somtochi Onyekwere is a software engineer that loves contributing to open-source and exploring cloud native solutions.
Introducing Structured Logs
Authors: Marek Siarkowicz (Google), Nathan Beach (Google)
Logs are an essential aspect of observability and a critical tool for debugging. But Kubernetes logs have traditionally been unstructured strings, making any automated parsing difficult and any downstream processing, analysis, or querying challenging to do reliably.
In Kubernetes 1.19, we are adding support for structured logs, which natively support (key, value) pairs and object references. We have also updated many logging calls such that over 99% of logging volume in a typical deployment are now migrated to the structured format.
To maintain backwards compatibility, structured logs will still be outputted as a string where the string contains representations of those "key"="value" pairs. Starting in alpha in 1.19, logs can also be outputted in JSON format using the --logging-format=json flag.
Using Structured Logs
We've added two new methods to the klog library: InfoS and ErrorS. For example, this invocation of InfoS:
klog.InfoS("Pod status updated", "pod", klog.KObj(pod), "status", status)
will result in this log:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
Or, if the --logging-format=json flag is set, it will result in this output:
{
"ts": 1580306777.04728,
"msg": "Pod status updated",
"pod": {
"name": "coredns",
"namespace": "kube-system"
},
"status": "ready"
}
This means downstream logging tools can easily ingest structured logging data and instead of using regular expressions to parse unstructured strings. This also makes processing logs easier, querying logs more robust, and analyzing logs much faster.
With structured logs, all references to Kubernetes objects are structured the same way, so you can filter the output and only log entries referencing the particular pod. You can also find logs indicating how the scheduler was scheduling the pod, how the pod was created, the health probes of the pod, and all other changes in the lifecycle of the pod.
Suppose you are debugging an issue with a pod. With structured logs, you can filter to only those log entries referencing the pod of interest, rather than needing to scan through potentially thousands of log lines to find the relevant ones.
Not only are structured logs more useful when manual debugging of issues, they also enable richer features like automated pattern recognition within logs or tighter correlation of log and trace data.
Finally, structured logs can help reduce storage costs for logs because most storage systems are more efficiently able to compress structured key=value data than unstructured strings.
Get Involved
While we have updated over 99% of the log entries by log volume in a typical deployment, there are still thousands of logs to be updated. Pick a file or directory that you would like to improve and migrate existing log calls to use structured logs. It's a great and easy way to make your first contribution to Kubernetes!
Warning: Helpful Warnings Ahead
Author: Jordan Liggitt (Google)
As Kubernetes maintainers, we're always looking for ways to improve usability while preserving compatibility. As we develop features, triage bugs, and answer support questions, we accumulate information that would be helpful for Kubernetes users to know. In the past, sharing that information was limited to out-of-band methods like release notes, announcement emails, documentation, and blog posts. Unless someone knew to seek out that information and managed to find it, they would not benefit from it.
In Kubernetes v1.19, we added a feature that allows the Kubernetes API server to
send warnings to API clients.
The warning is sent using a standard Warning response header,
so it does not change the status code or response body in any way.
This allows the server to send warnings easily readable by any API client, while remaining compatible with previous client versions.
Warnings are surfaced by kubectl v1.19+ in stderr output, and by the k8s.io/client-go client library v0.19.0+ in log output.
The k8s.io/client-go behavior can be overridden per-process or per-client.
Deprecation Warnings
The first way we are using this new capability is to send warnings for use of deprecated APIs.
Kubernetes is a big, fast-moving project. Keeping up with the changes in each release can be daunting, even for people who work on the project full-time. One important type of change is API deprecations. As APIs in Kubernetes graduate to GA versions, pre-release API versions are deprecated and eventually removed.
Even though there is an extended deprecation period, and deprecations are included in release notes, they can still be hard to track. During the deprecation period, the pre-release API remains functional, allowing several releases to transition to the stable API version. However, we have found that users often don't even realize they are depending on a deprecated API version until they upgrade to the release that stops serving it.
Starting in v1.19, whenever a request is made to a deprecated REST API, a warning is returned along with the API response. This warning includes details about the release in which the API will no longer be available, and the replacement API version.
Because the warning originates at the server, and is intercepted at the client level, it works for all kubectl commands,
including high-level commands like kubectl apply, and low-level commands like kubectl get --raw:

This helps people affected by the deprecation to know the request they are making is deprecated, how long they have to address the issue, and what API they should use instead. This is especially helpful when the user is applying a manifest they didn't create, so they have time to reach out to the authors to ask for an updated version.
We also realized that the person using a deprecated API is often not the same person responsible for upgrading the cluster, so we added two administrator-facing tools to help track use of deprecated APIs and determine when upgrades are safe.
Metrics
Starting in Kubernetes v1.19, when a request is made to a deprecated REST API endpoint,
an apiserver_requested_deprecated_apis gauge metric is set to 1 in the kube-apiserver process.
This metric has labels for the API group, version, resource, and subresource,
and a removed_version label that indicates the Kubernetes release in which the API will no longer be served.
This is an example query using kubectl, prom2json,
and jq to determine which deprecated APIs have been requested
from the current instance of the API server:
kubectl get --raw /metrics | prom2json | jq '
.[] | select(.name=="apiserver_requested_deprecated_apis").metrics[].labels
'
Output:
{
"group": "extensions",
"removed_release": "1.22",
"resource": "ingresses",
"subresource": "",
"version": "v1beta1"
}
{
"group": "rbac.authorization.k8s.io",
"removed_release": "1.22",
"resource": "clusterroles",
"subresource": "",
"version": "v1beta1"
}
This shows the deprecated extensions/v1beta1 Ingress and rbac.authorization.k8s.io/v1beta1 ClusterRole APIs
have been requested on this server, and will be removed in v1.22.
We can join that information with the apiserver_request_total metrics to get more details about the requests being made to these APIs:
kubectl get --raw /metrics | prom2json | jq '
# set $deprecated to a list of deprecated APIs
[
.[] |
select(.name=="apiserver_requested_deprecated_apis").metrics[].labels |
{group,version,resource}
] as $deprecated
|
# select apiserver_request_total metrics which are deprecated
.[] | select(.name=="apiserver_request_total").metrics[] |
select(.labels | {group,version,resource} as $key | $deprecated | index($key))
'
Output:
{
"labels": {
"code": "0",
"component": "apiserver",
"contentType": "application/vnd.kubernetes.protobuf;stream=watch",
"dry_run": "",
"group": "extensions",
"resource": "ingresses",
"scope": "cluster",
"subresource": "",
"verb": "WATCH",
"version": "v1beta1"
},
"value": "21"
}
{
"labels": {
"code": "200",
"component": "apiserver",
"contentType": "application/vnd.kubernetes.protobuf",
"dry_run": "",
"group": "extensions",
"resource": "ingresses",
"scope": "cluster",
"subresource": "",
"verb": "LIST",
"version": "v1beta1"
},
"value": "1"
}
{
"labels": {
"code": "200",
"component": "apiserver",
"contentType": "application/json",
"dry_run": "",
"group": "rbac.authorization.k8s.io",
"resource": "clusterroles",
"scope": "cluster",
"subresource": "",
"verb": "LIST",
"version": "v1beta1"
},
"value": "1"
}
The output shows that only read requests are being made to these APIs, and the most requests have been made to watch the deprecated Ingress API.
You can also find that information through the following Prometheus query, which returns information about requests made to deprecated APIs which will be removed in v1.22:
apiserver_requested_deprecated_apis{removed_version="1.22"} * on(group,version,resource,subresource)
group_right() apiserver_request_total
Audit Annotations
Metrics are a fast way to check whether deprecated APIs are being used, and at what rate,
but they don't include enough information to identify particular clients or API objects.
Starting in Kubernetes v1.19, audit events
for requests to deprecated APIs include an audit annotation of "k8s.io/deprecated":"true".
Administrators can use those audit events to identify specific clients or objects that need to be updated.
Custom Resource Definitions
Along with the API server ability to warn about deprecated API use, starting in v1.19, a CustomResourceDefinition can indicate a particular version of the resource it defines is deprecated. When API requests to a deprecated version of a custom resource are made, a warning message is returned, matching the behavior of built-in APIs.
The author of the CustomResourceDefinition can also customize the warning for each version if they want to. This allows them to give a pointer to a migration guide or other information if needed.
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
name: crontabs.example.com
spec:
versions:
- name: v1alpha1
# This indicates the v1alpha1 version of the custom resource is deprecated.
# API requests to this version receive a warning in the server response.
deprecated: true
# This overrides the default warning returned to clients making v1alpha1 API requests.
deprecationWarning: "example.com/v1alpha1 CronTab is deprecated; use example.com/v1 CronTab (see http://example.com/v1alpha1-v1)"
...
- name: v1beta1
# This indicates the v1beta1 version of the custom resource is deprecated.
# API requests to this version receive a warning in the server response.
# A default warning message is returned for this version.
deprecated: true
...
- name: v1
...
Admission Webhooks
Admission webhooks are the primary way to integrate custom policies or validation with Kubernetes. Starting in v1.19, admission webhooks can return warning messages that are passed along to the requesting API client. Warnings can be returned with allowed or rejected admission responses.
As an example, to allow a request but warn about a configuration known not to work well, an admission webhook could send this response:
{
"apiVersion": "admission.k8s.io/v1",
"kind": "AdmissionReview",
"response": {
"uid": "<value from request.uid>",
"allowed": true,
"warnings": [
".spec.memory: requests >1GB do not work on Fridays"
]
}
}
If you are implementing a webhook that returns a warning message, here are some tips:
- Don't include a "Warning:" prefix in the message (that is added by clients on output)
- Use warning messages to describe problems the client making the API request should correct or be aware of
- Be brief; limit warnings to 120 characters if possible
There are many ways admission webhooks could use this new feature, and I'm looking forward to seeing what people come up with. Here are a couple ideas to get you started:
- webhook implementations adding a "complain" mode, where they return warnings instead of rejections, to allow trying out a policy to verify it is working as expected before starting to enforce it
- "lint" or "vet"-style webhooks, inspecting objects and surfacing warnings when best practices are not followed
Customize Client Handling
Applications that use the k8s.io/client-go library to make API requests can customize
how warnings returned from the server are handled. By default, warnings are logged to
stderr as they are received, but this behavior can be customized
per-process
or per-client.
This example shows how to make your application behave like kubectl,
overriding message handling process-wide to deduplicate warnings
and highlighting messages using colored output where supported:
import (
"os"
"k8s.io/client-go/rest"
"k8s.io/kubectl/pkg/util/term"
...
)
func main() {
rest.SetDefaultWarningHandler(
rest.NewWarningWriter(os.Stderr, rest.WarningWriterOptions{
// only print a given warning the first time we receive it
Deduplicate: true,
// highlight the output with color when the output supports it
Color: term.AllowsColorOutput(os.Stderr),
},
),
)
...
The next example shows how to construct a client that ignores warnings. This is useful for clients that operate on metadata for all resource types (found dynamically at runtime using the discovery API) and do not benefit from warnings about a particular resource being deprecated. Suppressing deprecation warnings is not recommended for clients that require use of particular APIs.
import (
"k8s.io/client-go/rest"
"k8s.io/client-go/kubernetes"
)
func getClientWithoutWarnings(config *rest.Config) (kubernetes.Interface, error) {
// copy to avoid mutating the passed-in config
config = rest.CopyConfig(config)
// set the warning handler for this client to ignore warnings
config.WarningHandler = rest.NoWarnings{}
// construct and return the client
return kubernetes.NewForConfig(config)
}
Kubectl Strict Mode
If you want to be sure you notice deprecations as soon as possible and get a jump start on addressing them,
kubectl added a --warnings-as-errors option in v1.19. When invoked with this option,
kubectl treats any warnings it receives from the server as errors and exits with a non-zero exit code:

This could be used in a CI job to apply manifests to a current server, and required to pass with a zero exit code in order for the CI job to succeed.
Future Possibilities
Now that we have a way to communicate helpful information to users in context, we're already considering other ways we can use this to improve people's experience with Kubernetes. A couple areas we're looking at next are warning about known problematic values we cannot reject outright for compatibility reasons, and warning about use of deprecated fields or field values (like selectors using beta os/arch node labels, deprecated in v1.14). I'm excited to see progress in this area, continuing to make it easier to use Kubernetes.
Jordan Liggitt is a software engineer at Google, and helps lead Kubernetes authentication, authorization, and API efforts.
Scaling Kubernetes Networking With EndpointSlices
Author: Rob Scott (Google)
EndpointSlices are an exciting new API that provides a scalable and extensible alternative to the Endpoints API. EndpointSlices track IP addresses, ports, readiness, and topology information for Pods backing a Service.
In Kubernetes 1.19 this feature is enabled by default with kube-proxy reading from EndpointSlices instead of Endpoints. Although this will mostly be an invisible change, it should result in noticeable scalability improvements in large clusters. It also enables significant new features in future Kubernetes releases like Topology Aware Routing.
Scalability Limitations of the Endpoints API
With the Endpoints API, there was only one Endpoints resource for a Service. That meant that it needed to be able to store IP addresses and ports (network endpoints) for every Pod that was backing the corresponding Service. This resulted in huge API resources. To compound this problem, kube-proxy was running on every node and watching for any updates to Endpoints resources. If even a single network endpoint changed in an Endpoints resource, the whole object would have to be sent to each of those instances of kube-proxy.
A further limitation of the Endpoints API is that it limits the number of network endpoints that can be tracked for a Service. The default size limit for an object stored in etcd is 1.5MB. In some cases that can limit an Endpoints resource to 5,000 Pod IPs. This is not an issue for most users, but it becomes a significant problem for users with Services approaching this size.
To show just how significant these issues become at scale it helps to have a simple example. Think about a Service which has 5,000 Pods, it might end up with a 1.5MB Endpoints resource. If even a single network endpoint in that list changes, the full Endpoints resource will need to be distributed to each Node in the cluster. This becomes quite an issue in a large cluster with 3,000 Nodes. Each update would involve sending 4.5GB of data (1.5MB Endpoints * 3,000 Nodes) across the cluster. That's nearly enough to fill up a DVD, and it would happen for each Endpoints change. Imagine a rolling update that results in all 5,000 Pods being replaced - that's more than 22TB (or 5,000 DVDs) worth of data transferred.
Splitting endpoints up with the EndpointSlice API
The EndpointSlice API was designed to address this issue with an approach similar to sharding. Instead of tracking all Pod IPs for a Service with a single Endpoints resource, we split them into multiple smaller EndpointSlices.
Consider an example where a Service is backed by 15 pods. We'd end up with a single Endpoints resource that tracked all of them. If EndpointSlices were configured to store 5 endpoints each, we'd end up with 3 different EndpointSlices:

By default, EndpointSlices store as many as 100 endpoints each, though this can be configured with the --max-endpoints-per-slice flag on kube-controller-manager.
EndpointSlices provide 10x scalability improvements
This API dramatically improves networking scalability. Now when a Pod is added or removed, only 1 small EndpointSlice needs to be updated. This difference becomes quite noticeable when hundreds or thousands of Pods are backing a single Service.
Potentially more significant, now that all Pod IPs for a Service don't need to be stored in a single resource, we don't have to worry about the size limit for objects stored in etcd. EndpointSlices have already been used to scale Services beyond 100,000 network endpoints.
All of this is brought together with some significant performance improvements that have been made in kube-proxy. When using EndpointSlices at scale, significantly less data will be transferred for endpoints updates and kube-proxy should be faster to update iptables or ipvs rules. Beyond that, Services can now scale to at least 10 times beyond any previous limitations.
EndpointSlices enable new functionality
Introduced as an alpha feature in Kubernetes v1.16, EndpointSlices were built to enable some exciting new functionality in future Kubernetes releases. This could include dual-stack Services, topology aware routing, and endpoint subsetting.
Dual-Stack Services are an exciting new feature that has been in development alongside EndpointSlices. They will utilize both IPv4 and IPv6 addresses for Services and rely on the addressType field on EndpointSlices to track these addresses by IP family.
Topology aware routing will update kube-proxy to prefer routing requests within the same zone or region. This makes use of the topology fields stored for each endpoint in an EndpointSlice. As a further refinement of that, we're exploring the potential of endpoint subsetting. This would allow kube-proxy to only watch a subset of EndpointSlices. For example, this might be combined with topology aware routing so that kube-proxy would only need to watch EndpointSlices containing endpoints within the same zone. This would provide another very significant scalability improvement.
What does this mean for the Endpoints API?
Although the EndpointSlice API is providing a newer and more scalable alternative to the Endpoints API, the Endpoints API will continue to be considered generally available and stable. The most significant change planned for the Endpoints API will involve beginning to truncate Endpoints that would otherwise run into scalability issues.
The Endpoints API is not going away, but many new features will rely on the EndpointSlice API. To take advantage of the new scalability and functionality that EndpointSlices provide, applications that currently consume Endpoints will likely want to consider supporting EndpointSlices in the future.
Ephemeral volumes with storage capacity tracking: EmptyDir on steroids
Author: Patrick Ohly (Intel)
Some applications need additional storage but don't care whether that data is stored persistently across restarts. For example, caching services are often limited by memory size and can move infrequently used data into storage that is slower than memory with little impact on overall performance. Other applications expect some read-only input data to be present in files, like configuration data or secret keys.
Kubernetes already supports several kinds of such ephemeral volumes, but the functionality of those is limited to what is implemented inside Kubernetes.
CSI ephemeral volumes made it possible to extend Kubernetes with CSI drivers that provide light-weight, local volumes. These inject arbitrary states, such as configuration, secrets, identity, variables or similar information. CSI drivers must be modified to support this Kubernetes feature, i.e. normal, standard-compliant CSI drivers will not work, and by design such volumes are supposed to be usable on whatever node is chosen for a pod.
This is problematic for volumes which consume significant resources on
a node or for special storage that is only available on some nodes.
Therefore, Kubernetes 1.19 introduces two new alpha features for
volumes that are conceptually more like the EmptyDir volumes:
The advantages of the new approach are:
- Storage can be local or network-attached.
- Volumes can have a fixed size that applications are never able to exceed.
- Works with any CSI driver that supports provisioning of persistent
volumes and (for capacity tracking) implements the CSI
GetCapacitycall. - Volumes may have some initial data, depending on the driver and parameters.
- All of the typical volume operations (snapshotting, resizing, the future storage capacity tracking, etc.) are supported.
- The volumes are usable with any app controller that accepts a Pod or volume specification.
- The Kubernetes scheduler itself picks suitable nodes, i.e. there is no need anymore to implement and configure scheduler extenders and mutating webhooks.
This makes generic ephemeral volumes a suitable solution for several use cases:
Use cases
Persistent Memory as DRAM replacement for memcached
Recent releases of memcached added support for using Persistent Memory (PMEM) instead of standard DRAM. When deploying memcached through one of the app controllers, generic ephemeral volumes make it possible to request a PMEM volume of a certain size from a CSI driver like PMEM-CSI.
Local LVM storage as scratch space
Applications working with data sets that exceed the RAM size can
request local storage with performance characteristics or size that is
not met by the normal Kubernetes EmptyDir volumes. For example,
TopoLVM was written for that
purpose.
Read-only access to volumes with data
Provisioning a volume might result in a non-empty volume:
Such volumes can be mounted read-only.
How it works
Generic ephemeral volumes
The key idea behind generic ephemeral volumes is that a new volume
source, the so-called
EphemeralVolumeSource
contains all fields that are needed to created a volume claim
(historically called persistent volume claim, PVC). A new controller
in the kube-controller-manager waits for Pods which embed such a
volume source and then creates a PVC for that pod. To a CSI driver
deployment, that PVC looks like any other, so no special support is
needed.
As long as these PVCs exist, they can be used like any other volume claim. In particular, they can be referenced as data source in volume cloning or snapshotting. The PVC object also holds the current status of the volume.
Naming of the automatically created PVCs is deterministic: the name is
a combination of Pod name and volume name, with a hyphen (-) in the
middle. This deterministic naming makes it easier to
interact with the PVC because one does not have to search for it once
the Pod name and volume name are known. The downside is that the name might
be in use already. This is detected by Kubernetes and then blocks Pod
startup.
To ensure that the volume gets deleted together with the pod, the controller makes the Pod the owner of the volume claim. When the Pod gets deleted, the normal garbage-collection mechanism also removes the claim and thus the volume.
Claims select the storage driver through the normal storage class
mechanism. Although storage classes with both immediate and late
binding (aka WaitForFirstConsumer) are supported, for ephemeral
volumes it makes more sense to use WaitForFirstConsumer: then Pod
scheduling can take into account both node utilization and
availability of storage when choosing a node. This is where the other
new feature comes in.
Storage capacity tracking
Normally, the Kubernetes scheduler has no information about where a CSI driver might be able to create a volume. It also has no way of talking directly to a CSI driver to retrieve that information. It therefore tries different nodes until it finds one where all volumes can be made available (late binding) or leaves it entirely to the driver to choose a location (immediate binding).
The new CSIStorageCapacity alpha
API
allows storing the necessary information in etcd where it is available to the
scheduler. In contrast to support for generic ephemeral volumes,
storage capacity tracking must be enabled when deploying a CSI
driver:
the external-provisioner must be told to publish capacity
information that it then retrieves from the CSI driver through the normal
GetCapacity call.
When the Kubernetes scheduler needs to choose a node for a Pod with an
unbound volume that uses late binding and the CSI driver deployment
has opted into the feature by setting the CSIDriver.storageCapacity
flag
flag, the scheduler automatically filters out nodes that do not have
access to enough storage capacity. This works for generic ephemeral
and persistent volumes but not for CSI ephemeral volumes because the
parameters of those are opaque for Kubernetes.
As usual, volumes with immediate binding get created before scheduling pods, with their location chosen by the storage driver. Therefore, the external-provisioner's default configuration skips storage classes with immediate binding as the information wouldn't be used anyway.
Because the Kubernetes scheduler must act on potentially outdated information, it cannot be ensured that the capacity is still available when a volume is to be created. Still, the chances that it can be created without retries should be higher.
Security
CSIStorageCapacity
CSIStorageCapacity objects are namespaced. When deploying each CSI drivers in its own namespace and, as recommended, limiting the RBAC permissions for CSIStorageCapacity to that namespace, it is always obvious where the data came from. However, Kubernetes does not check that and typically drivers get installed in the same namespace anyway, so ultimately drivers are expected to behave and not publish incorrect data.
Generic ephemeral volumes
If users have permission to create a Pod (directly or indirectly), then they can also create generic ephemeral volumes even when they do not have permission to create a volume claim. That's because RBAC permission checks are applied to the controller which creates the PVC, not the original user. This is a fundamental change that must be taken into account before enabling the feature in clusters where untrusted users are not supposed to have permission to create volumes.
Example
A special branch in PMEM-CSI contains all the necessary changes to bring up a Kubernetes 1.19 cluster inside QEMU VMs with both alpha features enabled. The PMEM-CSI driver code is used unchanged, only the deployment was updated.
On a suitable machine (Linux, non-root user can use Docker - see the QEMU and Kubernetes section in the PMEM-CSI documentation), the following commands bring up a cluster and install the PMEM-CSI driver:
git clone --branch=kubernetes-1-19-blog-post https://github.com/intel/pmem-csi.git
cd pmem-csi
export TEST_KUBERNETES_VERSION=1.19 TEST_FEATURE_GATES=CSIStorageCapacity=true,GenericEphemeralVolume=true TEST_PMEM_REGISTRY=intel
make start && echo && test/setup-deployment.sh
If all goes well, the output contains the following usage instructions:
The test cluster is ready. Log in with [...]/pmem-csi/_work/pmem-govm/ssh.0, run
kubectl once logged in. Alternatively, use kubectl directly with the
following env variable:
KUBECONFIG=[...]/pmem-csi/_work/pmem-govm/kube.config
secret/pmem-csi-registry-secrets created
secret/pmem-csi-node-secrets created
serviceaccount/pmem-csi-controller created
...
To try out the pmem-csi driver ephemeral volumes:
cat deploy/kubernetes-1.19/pmem-app-ephemeral.yaml |
[...]/pmem-csi/_work/pmem-govm/ssh.0 kubectl create -f -
The CSIStorageCapacity objects are not meant to be human-readable, so some post-processing is needed. The following Golang template filters all objects by the storage class that the example uses and prints the name, topology and capacity:
kubectl get \
-o go-template='{{range .items}}{{if eq .storageClassName "pmem-csi-sc-late-binding"}}{{.metadata.name}} {{.nodeTopology.matchLabels}} {{.capacity}}
{{end}}{{end}}' \
csistoragecapacities
csisc-2js6n map[pmem-csi.intel.com/node:pmem-csi-pmem-govm-worker2] 30716Mi
csisc-sqdnt map[pmem-csi.intel.com/node:pmem-csi-pmem-govm-worker1] 30716Mi
csisc-ws4bv map[pmem-csi.intel.com/node:pmem-csi-pmem-govm-worker3] 30716Mi
One individual object has the following content:
kubectl describe csistoragecapacities/csisc-6cw8j
Name: csisc-sqdnt
Namespace: default
Labels: <none>
Annotations: <none>
API Version: storage.k8s.io/v1alpha1
Capacity: 30716Mi
Kind: CSIStorageCapacity
Metadata:
Creation Timestamp: 2020-08-11T15:41:03Z
Generate Name: csisc-
Managed Fields:
...
Owner References:
API Version: apps/v1
Controller: true
Kind: StatefulSet
Name: pmem-csi-controller
UID: 590237f9-1eb4-4208-b37b-5f7eab4597d1
Resource Version: 2994
Self Link: /apis/storage.k8s.io/v1alpha1/namespaces/default/csistoragecapacities/csisc-sqdnt
UID: da36215b-3b9d-404a-a4c7-3f1c3502ab13
Node Topology:
Match Labels:
pmem-csi.intel.com/node: pmem-csi-pmem-govm-worker1
Storage Class Name: pmem-csi-sc-late-binding
Events: <none>
Now let's create the example app with one generic ephemeral
volume. The pmem-app-ephemeral.yaml file contains:
# This example Pod definition demonstrates
# how to use generic ephemeral inline volumes
# with a PMEM-CSI storage class.
kind: Pod
apiVersion: v1
metadata:
name: my-csi-app-inline-volume
spec:
containers:
- name: my-frontend
image: intel/pmem-csi-driver-test:v0.7.14
command: [ "sleep", "100000" ]
volumeMounts:
- mountPath: "/data"
name: my-csi-volume
volumes:
- name: my-csi-volume
ephemeral:
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
storageClassName: pmem-csi-sc-late-binding
After creating that as shown in the usage instructions above, we have one additional Pod and PVC:
kubectl get pods/my-csi-app-inline-volume -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-csi-app-inline-volume 1/1 Running 0 6m58s 10.36.0.2 pmem-csi-pmem-govm-worker1 <none> <none>
kubectl get pvc/my-csi-app-inline-volume-my-csi-volume
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-csi-app-inline-volume-my-csi-volume Bound pvc-c11eb7ab-a4fa-46fe-b515-b366be908823 4Gi RWO pmem-csi-sc-late-binding 9m21s
That PVC is owned by the Pod:
kubectl get -o yaml pvc/my-csi-app-inline-volume-my-csi-volume
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
pv.kubernetes.io/bind-completed: "yes"
pv.kubernetes.io/bound-by-controller: "yes"
volume.beta.kubernetes.io/storage-provisioner: pmem-csi.intel.com
volume.kubernetes.io/selected-node: pmem-csi-pmem-govm-worker1
creationTimestamp: "2020-08-11T15:44:57Z"
finalizers:
- kubernetes.io/pvc-protection
managedFields:
...
name: my-csi-app-inline-volume-my-csi-volume
namespace: default
ownerReferences:
- apiVersion: v1
blockOwnerDeletion: true
controller: true
kind: Pod
name: my-csi-app-inline-volume
uid: 75c925bf-ca8e-441a-ac67-f190b7a2265f
...
Eventually, the storage capacity information for pmem-csi-pmem-govm-worker1 also gets updated:
csisc-2js6n map[pmem-csi.intel.com/node:pmem-csi-pmem-govm-worker2] 30716Mi
csisc-sqdnt map[pmem-csi.intel.com/node:pmem-csi-pmem-govm-worker1] 26620Mi
csisc-ws4bv map[pmem-csi.intel.com/node:pmem-csi-pmem-govm-worker3] 30716Mi
If another app needs more than 26620Mi, the Kubernetes
scheduler will not pick pmem-csi-pmem-govm-worker1 anymore.
Next steps
Both features are under development. Several open questions were already raised during the alpha review process. The two enhancement proposals document the work that will be needed for migration to beta and what alternatives were already considered and rejected:
Your feedback is crucial for driving that development. SIG-Storage meets regularly and can be reached via Slack and a mailing list.
Increasing the Kubernetes Support Window to One Year
Authors: Tim Pepper (VMware), Nick Young (VMware)
Starting with Kubernetes 1.19, the support window for Kubernetes versions will increase from 9 months to one year. The longer support window is intended to allow organizations to perform major upgrades at a time of the year that works the best for them.
This is a big change. For many years, the Kubernetes project has delivered a new minor release (e.g.: 1.13 or 1.14) every 3 months. The project provides bugfix support via patch releases (e.g.: 1.13.Y) for three parallel branches of the codebase. Combined, this led to each minor release (e.g.: 1.13) having a patch release stream of support for approximately 9 months. In the end, a cluster operator had to upgrade at least every 9 months to remain supported.
A survey conducted in early 2019 by the WG LTS showed that a significant subset of Kubernetes end-users fail to upgrade within the 9-month support period.
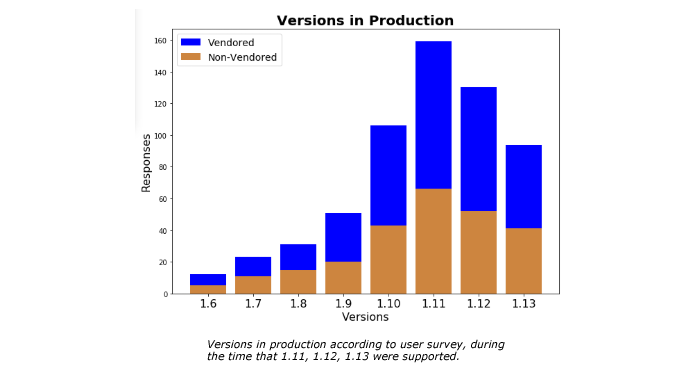
This, and other responses from the survey, suggest that a considerable portion of our community would better be able to manage their deployments on supported versions if the patch support period were extended to 12-14 months. It appears to be true regardless of whether the users are on DIY builds or commercially vendored distributions. An extension in the patch support length of time would thus lead to a larger percentage of our user base running supported versions compared to what we have now.
A yearly support period provides the cushion end-users appear to desire, and is more aligned with familiar annual planning cycles. There are many unknowns about changing the support windows for a project with as many moving parts as Kubernetes. Keeping the change relatively small (relatively being the important word), gives us the chance to find out what those unknowns are in detail and address them. From Kubernetes version 1.19 on, the support window will be extended to one year. For Kubernetes versions 1.16, 1.17, and 1.18, the story is more complicated.
All of these versions still fall under the older “three releases support” model, and will drop out of support when 1.19, 1.20 and 1.21 are respectively released. However, because the 1.19 release has been delayed due to the events of 2020, they will end up with close to a year of support (depending on their exact release dates).
For example, 1.19 was released on the 26th of August 2020, which is 11 months since the release of 1.16. Since 1.16 is still under the old release policy, this means that it is now out of support.
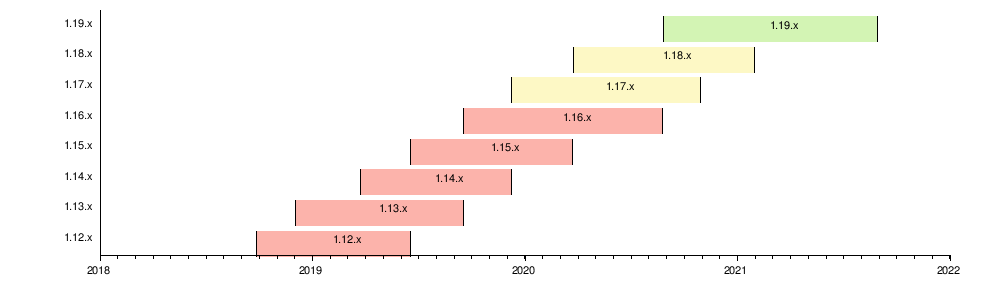
If you’ve got thoughts or feedback, we’d love to hear them. Please contact us on #wg-lts on the Kubernetes Slack, or to the kubernetes-wg-lts mailing list.
Kubernetes 1.19: Accentuate the Paw-sitive
Authors: Kubernetes 1.19 Release Team
Finally, we have arrived with Kubernetes 1.19, the second release for 2020, and by far the longest release cycle lasting 20 weeks in total. It consists of 34 enhancements: 10 enhancements are moving to stable, 15 enhancements in beta, and 9 enhancements in alpha.
The 1.19 release was quite different from a regular release due to COVID-19, the George Floyd protests, and several other global events that we experienced as a release team. Due to these events, we made the decision to adjust our timeline and allow the SIGs, Working Groups, and contributors more time to get things done. The extra time also allowed for people to take time to focus on their lives outside of the Kubernetes project, and ensure their mental wellbeing was in a good place.
Contributors are the heart of Kubernetes, not the other way around. The Kubernetes code of conduct asks that people be excellent to one another and despite the unrest in our world, we saw nothing but greatness and humility from the community.
Major Themes
Increase Kubernetes support window to one year
A survey conducted in early 2019 by the Long Term Support (LTS) working group showed that a significant subset of Kubernetes end-users fail to upgrade within the current 9-month support period. This, and other responses from the survey, suggest that 30% of users would be able to keep their deployments on supported versions if the patch support period were extended to 12-14 months. This appears to be true regardless of whether the users are on self build or commercially vendored distributions. An extension would thus lead to more than 80% of users being on supported versions, instead of the 50-60% we have now. A yearly support period provides the cushion end-users appear to desire, and is more in harmony with familiar annual planning cycles. From Kubernetes version 1.19 on, the support window will be extended to one year.
Storage capacity tracking
Traditionally, the Kubernetes scheduler was based on the assumptions that additional persistent storage is available everywhere in the cluster and has infinite capacity. Topology constraints addressed the first point, but up to now pod scheduling was still done without considering that the remaining storage capacity may not be enough to start a new pod. Storage capacity tracking, a new alpha feature, addresses that by adding an API for a CSI driver to report storage capacity and uses that information in the Kubernetes scheduler when choosing a node for a pod. This feature serves as a stepping stone for supporting dynamic provisioning for local volumes and other volume types that are more capacity constrained.
Generic ephemeral volumes
Kubernetes provides volume plugins whose lifecycle is tied to a pod and can be used as scratch space (e.g. the builtin emptydir volume type) or to load some data in to a pod (e.g. the builtin configmap and secret volume types, or “CSI inline volumes”). The new generic ephemeral volumes alpha feature allows any existing storage driver that supports dynamic provisioning to be used as an ephemeral volume with the volume’s lifecycle bound to the Pod.
It can be used to provide scratch storage that is different from the root disk, for example persistent memory, or a separate local disk on that node.
All StorageClass parameters for volume provisioning are supported.
All features supported with PersistentVolumeClaims are supported, such as storage capacity tracking, snapshots and restore, and volume resizing.
CSI Volume Health Monitoring
The alpha version of CSI health monitoring is being released with Kubernetes 1.19. This feature enables CSI Drivers to share abnormal volume conditions from the underlying storage systems with Kubernetes so that they can be reported as events on PVCs or Pods. This feature serves as a stepping stone towards programmatic detection and resolution of individual volume health issues by Kubernetes.
Ingress graduates to General Availability
In terms of moving the Ingress API towards GA, the API itself has been available in beta for so long that it has attained de facto GA status through usage and adoption (both by users and by load balancer / ingress controller providers). Abandoning it without a full replacement is not a viable approach. It is clearly a useful API and captures a non-trivial set of use cases. At this point, it seems more prudent to declare the current API as something the community will support as a V1, codifying its status, while working on either a V2 Ingress API or an entirely different API with a superset of features.
Structured logging
Before v1.19, logging in the Kubernetes control plane couldn't guarantee any uniform structure for log messages and references to Kubernetes objects in those logs. This makes parsing, processing, storing, querying and analyzing logs hard and forces administrators and developers to rely on ad-hoc solutions in most cases based on some regular expressions. Due to those problems any analytical solution based on those logs is hard to implement and maintain.
New klog methods
This Kubernetes release introduces new methods to the klog library that provide a more structured interface for formatting log messages. Each existing formatted log method (Infof, Errorf) is now matched by a structured method (InfoS, ErrorS). The new logging methods accept log messages as a first argument and a list of key-values pairs as a variadic second argument. This approach allows incremental adoption of structured logging without converting all of Kubernetes to a new API at one time.
Client TLS certificate rotation for kubelet
A kubelet authenticates the kubelet to the kube-apiserver using a private key and certificate. The certificate is supplied to the kubelet when it is first booted, via an out-of-cluster mechanism. Since Kubernetes v1.8, clusters have included a (beta) process for obtaining the initial cert/key pair and rotating it as expiration of the certificate approaches. In Kubernetes v1.19 this graduates to stable.
During the kubelet start-up sequence, the filesystem is scanned for an existing cert/key pair, which is managed by the certificate manager. In the case that a cert/key is available it will be loaded. If not, the kubelet checks its config file for an encoded certificate value or a file reference in the kubeconfig. If the certificate is a bootstrap certificate, this will be used to generate a key, create a certificate signing request and request a signed certificate from the API server.
When an expiration approaches the cert manager takes care of providing the correct certificate, generating new private keys and requesting new certificates. With the kubelet requesting certificates be signed as part of its boot sequence, and on an ongoing basis, certificate signing requests from the kubelet need to be auto approved to make cluster administration manageable.
Other Updates
Graduated to Stable
- Seccomp
- Kubelet client TLS certificate rotation
- Limit node access to API
- Redesign Event API
- Graduate Ingress to V1
- CertificateSigningRequest API
- Building Kubelet without Docker
Major Changes
Other Notable Features
Release Notes
Check out the full details of the Kubernetes 1.19 release in our release notes.
Availability
Kubernetes 1.19 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials or run local Kubernetes clusters using Docker container “nodes” with KinD (Kubernetes in Docker). You can also easily install 1.19 using kubeadm.
Release Team
This release is made possible through the efforts of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Taylor Dolezal, Senior Developer Advocate at HashiCorp. The 34 release team members coordinated many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid pace. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has had over 49,000 individual contributors to date and an active community of more than 3,000 people.
Release Logo
All of you inspired this Kubernetes 1.19 release logo! This release was a bit more of a marathon and a testament to when the world is a wild place, we can come together and do unbelievable things.

"Accentuate the Paw-sitive" was chosen as the release theme because it captures the positive outlook that the release team had, despite the state of the world. The characters pictured in the 1.19 logo represent everyone's personalities on our release team, from emo to peppy, and beyond!
About the designer: Hannabeth Lagerlof is a Visual Designer based in Los Angeles, California, and she has an extensive background in Environments and Graphic Design. Hannabeth creates art and user experiences that inspire connection. You can find Hannabeth on Twitter as @emanate_design.
The Long Run
The release was also different from the enhancements side of things. Traditionally, we have had 3-4 weeks between the call for enhancements and Enhancements Freeze, which ends the phase in which contributors can acknowledge whether a particular feature will be part of the cycle. This release cycle, being unique, we had five weeks for the same milestone. The extended duration gave the contributors more time to plan and decide about the graduation of their respective features.
The milestone until which contributors implement the features was extended from the usual five weeks to 7 weeks. Contributors were provided with 40% more time to work on their features, resulting in reduced fatigue and more to think through about the implementation. We also noticed a considerable reduction in last-minute hustles. There were also a lesser number of exception requests this cycle - 6 compared to 14 the previous release cycle.
User Highlights
- The CNCF grants Zalando, Europe’s leading online platform for fashion and lifestyle, the Top End User Award. Zalando leverages numerous CNCF projects and open sourced multiple of their own development.
Ecosystem Updates
- The CNCF just concluded its very first Virtual KubeCon. All talks are on-demand for anyone registered, it's not too late!
- The Certified Kubernetes Security Specialist (CKS) coming in November! CKS focuses on cluster & system hardening, minimizing microservice vulnerabilities and the security of the supply chain.
- CNCF published the second State of Cloud Native Development, showing the massively growing number of cloud native developer using container and serverless technology.
- Kubernetes.dev, a Kubernetes contributor focused website has been launched. It brings the contributor documentation, resources and project event information into one central location.
Project Velocity
The Kubernetes DevStats dashboard illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. If you want to gather numbers, facts and figures from Kubernetes and the CNCF community it is the best place to start.
During this release cycle from April till August, 382 different companies and over 2,464 individuals contributed to Kubernetes. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
Upcoming release webinar
Join the members of the Kubernetes 1.19 release team on September 25th, 2020 to learn about the major features in this release including storage capacity tracking, structured logging, Ingress V1 GA, and many more. Register here: https://www.cncf.io/webinars/kubernetes-1-19/.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our monthly community meeting, and through the channels below. Thank you for your continued feedback and support.
- Find out more about contributing to Kubernetes at the new Kubernetes Contributor website
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Share your Kubernetes story
- Read more about what’s happening with Kubernetes on the blog
- Learn more about the Kubernetes Release Team
Moving Forward From Beta
Author: Tim Bannister, The Scale Factory
In Kubernetes, features follow a defined lifecycle. First, as the twinkle of an eye in an interested developer. Maybe, then, sketched in online discussions, drawn on the online equivalent of a cafe napkin. This rough work typically becomes a Kubernetes Enhancement Proposal (KEP), and from there it usually turns into code.
For Kubernetes v1.20 and onwards, we're focusing on helping that code graduate into stable features.
That lifecycle I mentioned runs as follows:

Usually, alpha features aren't enabled by default. You turn them on by setting a feature gate; usually, by setting a command line flag on each of the components that use the feature.
(If you use Kubernetes through a managed service offering such as AKS, EKS, GKE, etc then the vendor who runs that service may have decided what feature gates are enabled for you).
There's a defined process for graduating an existing, alpha feature into the beta phase. This is important because beta features are enabled by default, with the feature flag still there so cluster operators can opt out if they want.
A similar but more thorough set of graduation criteria govern the transition to general availability (GA), also known as "stable". GA features are part of Kubernetes, with a commitment that they are staying in place throughout the current major version.
Having beta features on by default lets Kubernetes and its contributors get valuable real-world feedback. However, there's a mismatch of incentives. Once a feature is enabled by default, people will use it. Even if there might be a few details to shake out, the way Kubernetes' REST APIs and conventions work mean that any future stable API is going to be compatible with the most recent beta API: your API objects won't stop working when a beta feature graduates to GA.
For the API and its resources in particular, there's a much less strong incentive to move features from beta to GA than from alpha to beta. Vendors who want a particular feature have had good reason to help get code to the point where features are enabled by default, and beyond that the journey has been less clear.
KEPs track more than code improvements. Essentially, anything that would need communicating to the wider community merits a KEP. That said, most KEPs cover Kubernetes features (and the code to implement them).
You might know that Ingress has been in Kubernetes for a while, but did you realize that it actually went beta in 2015? To help drive things forward, Kubernetes' Architecture Special Interest Group (SIG) have a new approach in mind.
Avoiding permanent beta
For Kubernetes REST APIs, when a new feature's API reaches beta, that starts a countdown. The beta-quality API now has three releases (about nine calendar months) to either:
- reach GA, and deprecate the beta, or
- have a new beta version (and deprecate the previous beta).
To be clear, at this point only REST APIs are affected. For example, APIListChunking is a beta feature but isn't itself a REST API. Right now there are no plans to automatically deprecate APIListChunking nor any other features that aren't REST APIs.
If a beta API has not graduated to GA after three Kubernetes releases, then the next Kubernetes release will deprecate that API version. There's no option for the REST API to stay at the same beta version beyond the first Kubernetes release to come out after the release window.
What this means for you
If you're using Kubernetes, there's a good chance that you're using a beta feature. Like I said, there are lots of them about. As well as Ingress, you might be using CronJob, or PodSecurityPolicy, or others. There's an even bigger chance that you're running on a control plane with at least one beta feature enabled.
If you're using or generating Kubernetes manifests that use beta APIs like Ingress, you'll need to plan to revise those. The current APIs are going to be deprecated following a schedule (the 9 months I mentioned earlier) and after a further 9 months those deprecated APIs will be removed. At that point, to stay current with Kubernetes, you should already have migrated.
What this means for Kubernetes contributors
The motivation here seems pretty clear: get features stable. Guaranteeing that beta features will be deprecated adds a pretty big incentive so that people who want the feature continue their effort until the code, documentation and tests are ready for this feature to graduate to stable, backed by several Kubernetes' releases of evidence in real-world use.
What this means for the ecosystem
In my opinion, these harsh-seeming measures make a lot of sense, and are going to be good for Kubernetes. Deprecating existing APIs, through a rule that applies across all the different Special Interest Groups (SIGs), helps avoid stagnation and encourages fixes.
Let's say that an API goes to beta and then real-world experience shows that it just isn't right - that, fundamentally, the API has shortcomings. With that 9 month countdown ticking, the people involved have the means and the justification to revise and release an API that deals with the problem cases. Anyone who wants to live with the deprecated API is welcome to - Kubernetes is open source - but their needs do not have to hold up progress on the feature.
Introducing Hierarchical Namespaces
Author: Adrian Ludwin (Google)
Safely hosting large numbers of users on a single Kubernetes cluster has always been a troublesome task. One key reason for this is that different organizations use Kubernetes in different ways, and so no one tenancy model is likely to suit everyone. Instead, Kubernetes offers you building blocks to create your own tenancy solution, such as Role Based Access Control (RBAC) and NetworkPolicies; the better these building blocks, the easier it is to safely build a multitenant cluster.
Namespaces for tenancy
By far the most important of these building blocks is the namespace, which forms the backbone of almost all Kubernetes control plane security and sharing policies. For example, RBAC, NetworkPolicies and ResourceQuotas all respect namespaces by default, and objects such as Secrets, ServiceAccounts and Ingresses are freely usable within any one namespace, but fully segregated from other namespaces.
Namespaces have two key properties that make them ideal for policy enforcement. Firstly, they can be used to represent ownership. Most Kubernetes objects must be in a namespace, so if you use namespaces to represent ownership, you can always count on there being an owner.
Secondly, namespaces have authorized creation and use. Only highly-privileged users can create namespaces, and other users require explicit permission to use those namespaces - that is, create, view or modify objects in those namespaces. This allows them to be carefully created with appropriate policies, before unprivileged users can create “regular” objects like pods and services.
The limits of namespaces
However, in practice, namespaces are not flexible enough to meet some common use cases. For example, let’s say that one team owns several microservices with different secrets and quotas. Ideally, they should place these services into different namespaces in order to isolate them from each other, but this presents two problems.
Firstly, these namespaces have no common concept of ownership, even though they’re both owned by the same team. This means that if the team controls multiple namespaces, not only does Kubernetes not have any record of their common owner, but namespaced-scoped policies cannot be applied uniformly across them.
Secondly, teams generally work best if they can operate autonomously, but since namespace creation is highly privileged, it’s unlikely that any member of the dev team is allowed to create namespaces. This means that whenever a team wants a new namespace, they must raise a ticket to the cluster administrator. While this is probably acceptable for small organizations, it generates unnecessary toil as the organization grows.
Introducing hierarchical namespaces
Hierarchical namespaces are a new concept developed by the Kubernetes Working Group for Multi-Tenancy (wg-multitenancy) in order to solve these problems. In its simplest form, a hierarchical namespace is a regular Kubernetes namespace that contains a small custom resource that identifies a single, optional, parent namespace. This establishes the concept of ownership across namespaces, not just within them.
This concept of ownership enables two additional types of behaviours:
- Policy inheritance: if one namespace is a child of another, policy objects such as RBAC RoleBindings are copied from the parent to the child.
- Delegated creation: you usually need cluster-level privileges to create a namespace, but hierarchical namespaces adds an alternative: subnamespaces, which can be manipulated using only limited permissions in the parent namespace.
This solves both of the problems for our dev team. The cluster administrator can create a single “root” namespace for the team, along with all necessary policies, and then delegate permission to create subnamespaces to members of that team. Those team members can then create subnamespaces for their own use, without violating the policies that were imposed by the cluster administrators.
Hands-on with hierarchical namespaces
Hierarchical namespaces are provided by a Kubernetes extension known as the Hierarchical Namespace Controller, or HNC. The HNC consists of two components:
- The manager runs on your cluster, manages subnamespaces, propagates policy objects, ensures that your hierarchies are legal and manages extension points.
- The kubectl plugin, called
kubectl-hns, makes it easy for users to interact with the manager.
Both can be easily installed from the releases page of our repo.
Let’s see HNC in action. Imagine that I do not have namespace creation
privileges, but I can view the namespace team-a and create subnamespaces
within it1. Using the plugin, I can now say:
$ kubectl hns create svc1-team-a -n team-a
This creates a subnamespace called svc1-team-a. Note that since subnamespaces
are just regular Kubernetes namespaces, all subnamespace names must still be
unique.
I can view the structure of these namespaces by asking for a tree view:
$ kubectl hns tree team-a
# Output:
team-a
└── svc1-team-a
And if there were any policies in the parent namespace, these now appear in the
child as well2. For example, let’s say that team-a had
an RBAC RoleBinding called sres. This rolebinding will also be present in the
subnamespace:
$ kubectl describe rolebinding sres -n svc1-team-a
# Output:
Name: sres
Labels: hnc.x-k8s.io/inheritedFrom=team-a # inserted by HNC
Annotations: <none>
Role:
Kind: ClusterRole
Name: admin
Subjects: ...
Finally, HNC adds labels to these namespaces with useful information about the hierarchy which you can use to apply other policies. For example, you can create the following NetworkPolicy:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-team-a
namespace: team-a
spec:
ingress:
- from:
- namespaceSelector:
matchExpressions:
- key: 'team-a.tree.hnc.x-k8s.io/depth' # Label created by HNC
operator: Exists
This policy will both be propagated to all descendants of team-a, and will
also allow ingress traffic between all of those namespaces. The “tree” label
can only be applied by HNC, and is guaranteed to reflect the latest hierarchy.
You can learn all about the features of HNC from the user guide.
Next steps and getting involved
If you think that hierarchical namespaces can work for your organization, HNC v0.5.1 is available on GitHub. We’d love to know what you think of it, what problems you’re using it to solve and what features you’d most like to see added. As with all early software, you should be cautious about using HNC in production environments, but the more feedback we get, the sooner we’ll be able to drive to HNC 1.0.
We’re also open to additional contributors, whether it’s to fix or report bugs, or help prototype new features such as exceptions, improved monitoring, hierarchical resource quotas or fine-grained configuration.
Please get in touch with us via our repo, mailing list or on Slack - we look forward to hearing from you!
Adrian Ludwin is a software engineer and the tech lead for the Hierarchical Namespace Controller.
Note 1: technically, you create a small object called a "subnamespace anchor" in the parent namespace, and then HNC creates the subnamespace for you.
Note 2: By default, only RBAC Roles and RoleBindings are propagated, but you can configure HNC to propagate any namespaced Kubernetes object.
Physics, politics and Pull Requests: the Kubernetes 1.18 release interview
Author: Craig Box (Google)
The start of the COVID-19 pandemic couldn't delay the release of Kubernetes 1.18, but unfortunately a small bug could — thankfully only by a day. This was the last cat that needed to be herded by 1.18 release lead Jorge Alarcón before the release on March 25.
One of the best parts about co-hosting the weekly Kubernetes Podcast from Google is the conversations we have with the people who help bring Kubernetes releases together. Jorge was our guest on episode 96 back in March, and just like last week we are delighted to bring you the transcript of this interview.
If you'd rather enjoy the "audiobook version", including another interview when 1.19 is released later this month, subscribe to the show wherever you get your podcasts.
In the last few weeks, we've talked to long-time Kubernetes contributors and SIG leads David Oppenheimer, David Ashpole and Wojciech Tyczynski. All are worth taking the dog for a longer walk to listen to!
ADAM GLICK: You're a former physicist. I have to ask, what kind of physics did you work on?
JORGE ALARCÓN: Back in my days of math and all that, I used to work in computational biology and a little bit of high energy physics. Computational biology was, for the most part, what I spent most of my time on. And it was essentially exploring the big idea of we have the structure of proteins. We know what they're made of. Now, based on that structure, we want to be able to predict how they're going to fold and how they're going to behave, which essentially translates into the whole idea of designing pharmaceuticals, designing vaccines, or anything that you can possibly think of that has any connection whatsoever to a living organism.
ADAM GLICK: That would seem to ladder itself well into maybe going to something like bioinformatics. Did you take a tour into that, or did you decide to go elsewhere directly?
JORGE ALARCÓN: It is related, and I worked a little bit with some people that did focus on bioinformatics on the field specifically, but I never took a detour into it. Really, my big idea with computational biology, to be honest, it wasn't even the biology. That's usually what sells it, what people are really interested in, because protein engineering, all the cool and amazing things that you can do.
Which is definitely good, and I don't want to take away from it. But my big thing is because biology is such a real thing, it is amazingly complicated. And the math— the models that you have to design to study those systems, to be able to predict something that people can actually experiment and measure, it just captivated me. The level of complexity, the beauty, the mechanisms, all the structures that you see once you got through the math and look at things, it just kind of got to me.
ADAM GLICK: How did you go from that world into the world of Kubernetes?
JORGE ALARCÓN: That's both a really boring story and an interesting one.
[LAUGHING]
I did my thing with physics, and it was good. It was fun. But at some point, I wanted— working in academia— at least my feeling for it is that generally all the people that you're surrounded with are usually academics. Just another bunch of physics, a bunch of mathematicians.
But very seldom do you actually get the opportunity to take what you're working on and give it to someone else to use. Even with the mathematicians and physicists, the things that we're working on are super specialized, and you can probably find three, four, five people that can actually understand everything that you're saying. A lot of people are going to get the gist of it, but understanding the details, it's somewhat rare.
One of the things that I absolutely love about tech, about software engineering, coding, all that, is how open and transparent everything is. You can write your library in Python, you can publish it, and suddenly the world is going to actually use it, actually consume it. And because normally, I've seen that it has a large avenue where you can work in something really complicated, you can communicate it, and people can actually go ahead and take it and run with it in their given direction. And that is kind of what happened.
At some point, by pure accident and chance, I came across this group of people on the internet, and they were in the stages of making up this new group that's called Data for Democracy, a non-profit. And the whole idea was the internet, especially Twitter— that's how we congregated— Twitter, the internet. We have a ton of data scientists, people who work as software engineers, and the like. What if we all come together and try to solve some issues that actually affect the daily lives of people. And there were a ton of projects. Helping the ACLU gather data for something interesting that they were doing, gather data and analyze it for local governments— where do you have potholes, how much water is being consumed.
Try to apply all the science that we knew, combined with all the code that we could write, and offer a good and digestible idea for people to say, OK, this makes sense, let's do something about it— policy, action, whatever. And I started working with this group, Data for Democracy— wonderful set of people. And the person who I believe we can blame for Data for Democracy— the one who got the idea and got it up and running, his name is Jonathan Morgan. And eventually, we got to work together. He started a startup, and I went to work with the startup. And that was essentially the thing that took me away from physics and into the world of software engineering— Data for Democracy, definitely.
ADAM GLICK: Were you using Kubernetes as part of that work there?
JORGE ALARCÓN: No, it was simple as it gets. You just try to get some data. You create a couple IPython notebooks, some setting up of really simple MySQL databases, and that was it.
ADAM GLICK: Where did you get started using Kubernetes? And was it before you started contributing to it and being a part, or did you decide to jump right in?
JORGE ALARCÓN: When I first started using Kubernetes, it was also on my first job. So there wasn't a lot of specific training in regards to software engineering or anything of the sort that I did before I actually started working as a software engineer. I just went from physicist to engineer. And in my days of physics, at least on the computer side, I was completely trained in the super old school system administrator, where you have your 10, 20 computers. You know physically where they are, and you have to connect the cables.
ADAM GLICK: All pets— all pets all the time.
JORGE ALARCÓN: [LAUGHING] You have to have your huge Python, bash scripts, three, five major versions, all because doing an upgrade will break something really important and you have no idea how to work on it. And that was my training. That was the way that I learned how to do things. Those were the kind of things that I knew how to do.
And when I got to this company— startup— we were pretty much starting from scratch. We were building a couple applications. We work testing them, we were deploying them on a couple of managed instances. But like everything, there was a lot of toil that we wanted to automate. The whole issue of, OK, after days of work, we finally managed to get this version of the application up and running in these machines.
It's open to the internet. People can test it out. But it turns out that it is now two weeks behind the latest on all the master branches for this repo, so now we want to update. And we have to go through the process of bringing it back up, creating new machines, do that whole thing. And I had no idea what Kubernetes was, to be honest. My boss at the moment mentioned it to me like, hey, we should use Kubernetes because apparently, Kubernetes is something that might be able to help us here. And we did some— I want to call it research and development.
It was actually just making— again, startup, small company, small team, so really me just playing around with Kubernetes trying to get it to work, trying to get it to run. I was so lost. I had no idea what I was doing— not enough. I didn't have an idea of how Kubernetes was supposed to help me. And at that point, I did the best Googling that I could manage. Didn't really find a lot of examples. Didn't find a lot of blog posts. It was early.
ADAM GLICK: What time frame was this?
JORGE ALARCÓN: Three, four years ago, so definitely not 1.13. That's the best guesstimate that I can give at this point. But I wasn't able to find any good examples, any tutorials. The only book that I was able to get my hands on was the one written by Joe Beda, Kelsey Hightower, and I forget the other author. But what is it? "Kubernetes— Up and Running"?
And in general, right now I use it as reference— it's really good. But as a beginner, I still was lost. They give all these amazing examples, they provide the applications, but I had no idea why someone might need a Pod, why someone might need a Deployment. So my last resort was to try and find someone who actually knew Kubernetes.
By accident, during my eternal Googling, I actually found a link to the Kubernetes Slack. I jumped into the Kubernetes Slack hoping that someone might be able to help me out. And that was my entry point into the Kubernetes community. I just kept on exploring the Slack, tried to see what people were talking about, what they were asking to try to make sense of it, and just kept on iterating. And at some point, I think I got the hang of it.
ADAM GLICK: What made you decide to be a release lead?
JORGE ALARCÓN: The answer to this is my answer to why I have been contributing to Kubernetes. I really just want to be able to help out the community. Kubernetes is something that I absolutely adore.
Comparing Kubernetes to old school system administration, a handful of years ago, it took me like a week to create a node for an application to run. It took me months to get something that vaguely looked like an Ingress resource— just setting up the Nginx, and allowing someone else to actually use my application. And the fact that I could do all of that in five minutes, it really captivated me. Plus I've got to blame it on the physics. The whole idea with physics, I really like the patterns, and I really like the design of Kubernetes.
Once I actually got the hang of it, I loved the idea of how everything was designed, and I just wanted to learn a lot more about it. And I wanted to help the contributors. I wanted to help the people who actually build it. I wanted to help maintain it, and help provide the information for new contributors or new users. So instead of taking months for them to be up and running, let's just chat about what your issue is, and let's try to get a fix within the next hour or so.
ADAM GLICK: You work for a stealth startup right now. Is it fair to assume that they're using Kubernetes?
JORGE ALARCÓN: Yes—
[LAUGHING]
—for everything.
ADAM GLICK: Are you able to say what Searchable does?
JORGE ALARCÓN: The thing that we are trying to build is kind of like a search engine for your documents. Usually, if people have a question, they jump on Google. And for the most part, you're going to be able to get a good answer. You can ask something really random, like 'what is the weight of an elephant?'
Which, if you think about it, it's kind of random, but Google is going to give you an answer. And the thing that we are trying to build is something similar to that, but for files. So essentially, a search engine for your files. And most people, you have your local machine loaded up with— at least mine, I have a couple tens of gigabytes of different files.
I have Google Drive. I have a lot of documents that live in my email and the like. So the idea is to kind of build a search engine that is going to be able to connect all of those pieces. And besides doing simple word searches— for example, 'Kubernetes interview', and bring me the documents that we're looking at with all the questions— I can also ask things like what issue did I find last week while testing Prometheus. And it's going to be able to read my files, like through natural language processing, understand it, and be able to give me an answer.
ADAM GLICK: It is a Google for your personal and non-public information, essentially?
JORGE ALARCÓN: Hopefully.
ADAM GLICK: Is the work that you do with Kubernetes as the release lead— is that part of your day job, or is that something that you're doing kind of nights and weekends separate from your day job?
JORGE ALARCÓN: Both. Strictly speaking, my day job is just keep working on the application, build the things that it needs, maintain the infrastructure, and all that. When I started working at the company— which by the way, the person who brought me into the company was also someone that I met from my days in Data for Democracy— we started talking about the work.
I mentioned that I do a lot of work with the Kubernetes community and if it was OK that I continue doing it. And to my surprise, the answer was not only a yes, but yeah, you can do it during your day work. And at least for the time being, I just balance— I try to keep things organized.
Some days I just focus on Kubernetes. Some mornings I do Kubernetes. And then afternoon, I do Searchable, vice-versa, or just go back and forth, and try to balance the work as much as possible. But being release lead, definitely, it is a lot, so nights and weekends.
ADAM GLICK: How much time does it take to be the release lead?
JORGE ALARCÓN: It varies, but probably, if I had to give an estimate, at the very least you have to be able to dedicate four hours most days.
ADAM GLICK: Four hours a day?
JORGE ALARCÓN: Yeah, most days. It varies a lot. For example, at the beginning of the release cycle, you don't need to put in that much work because essentially, you're just waiting and helping people get set up, and people are writing their Kubernetes Enhancement Proposals, they are implementing it, and you can answer some questions. It's relatively easy, but for the most part, a lot of the time the four hours go into talking with people, just making sure that, hey, are people actually writing their enhancements, do we have all the enhancements that we want. And most of those fours hours, going around, chatting with people, and making sure that things are being done. And if, for some reason, someone needs help, just directing them to the right place to get their answer.
ADAM GLICK: What does Searchable get out of you doing this work?
JORGE ALARCÓN: Physically, nothing. The thing that we're striving for is to give back to the community. My manager/boss/homeslice— I told him I was going to call him my homeslice— both of us have experience working in open source. At some point, he was also working on a project that I'm probably going to mispronounce, but Mahout with Apache.
And he also has had this experience. And both of us have this general idea and strive to build something for Searchable that's going to be useful for people, but also build knowledge, build guides, build applications that are going to be useful for the community. And at least one of the things that I was able to do right now is be the lead for the Kubernetes team. And this is a way of giving back to the community. We're using Kubernetes to run our things, so let's try to balance how things work.
ADAM GLICK: Lachlan Evenson was the release lead on 1.16 as well as our guest back in episode 72, and he's returned on this release as the emeritus advisor. What did you learn from him?
JORGE ALARCÓN: Oh, everything. And it actually all started back on 1.16. So like you said, an amazing person— he's an amazing individual. And it's truly an opportunity to be able to work with him. During 1.16, I was the CI Signal lead, and Lachie is very hands on.
He's not the kind of person to just give you a list of things and say, do them. He actually comes to you, has a conversation, and he works with you more than anything. And when we were working together on 1.16, I got to learn a lot from him in terms of CI Signal. And especially because we talked about everything just to make sure that 1.16 was ready to go, I also got to pick up a couple of things that a release lead has to know, has to be able to do, has to work on to get a release out the door.
And now, during this release, there is a lot of information that's really useful, and there's a lot of advice and general wisdom that comes in handy. For most of the things that impact a lot of things, we are always in communication. Like, I'm doing this, you're doing that, advice. And essentially, every single thing that we do is pretty much a code review. You do it, and then you wait for someone else to give you comments. And that's been a strong part of our relationship working.
ADAM GLICK: What would you say the theme for this release is?
JORGE ALARCÓN: I think one of the themes is "fit and finish". There are a lot of features that we are bumping from alpha to beta, from beta to stable. And we want to make sure that people have a good user experience. Operators and developers alike just want to get rid of as many bugs as possible, improve the flow of things.
But the other really cool thing is we have about an equal distribution between alpha, beta, and stable. We are also bringing up a lot of new features. So besides making Kubernetes more stable for all the users that are already using it, we are working on bringing up new things that people can try out for the next release and see how it goes in the future.
ADAM GLICK: Did you have a release team mascot?
JORGE ALARCÓN: Kind of.
ADAM GLICK: Who/what was it?
JORGE ALARCÓN: [LAUGHING] I say kind of because I'm using the mascot in the logo, and the logo is inspired by the Large Hadron Collider.
ADAM GLICK: Oh, fantastic.
JORGE ALARCÓN: Being the release lead, I really had to take a chance on this opportunity to use the LHC as the mascot.
ADAM GLICK: We've had some of the folks from the LHC on the show, and I know they listen, and they will be thrilled with that.
JORGE ALARCÓN: [LAUGHING] Hopefully, they like the logo.
ADAM GLICK: If you look at this release, what part of this release, what thing that has been added to it are you personally most excited about?
JORGE ALARCÓN: Like a parent can't choose which child is his or her favorite, you really can't choose a specific thing.
ADAM GLICK: We have been following online and in the issues an enhancement that's called sidecar containers. You'd be able to mark the order of containers starting in a pod. Tim Hockin posted a long comment on behalf of a number of SIG Node contributors citing social, procedural, and technical concerns about what's going on with that— in particular, that it moved out of 1.18 and is now moving to 1.19. Did you have any thoughts on that?
JORGE ALARCÓN: The sidecar enhancement has definitely been an interesting one. First off, thank you very much to Joseph Irving, the author of the KEP. And thank you very much to Tim Hockin, who voiced out the point of view of the approvers, maintainers of SIG Node. And I guess a little bit of context before we move on is, in the Kubernetes community, we have contributors, we have reviewers, and we have approvers.
Contributors are people who write PRs, who file issues, who troubleshoot issues. Reviewers are contributors who focus on one or multiple specific areas within the project, and then approvers are maintainers for the specific area, for one or multiple specific areas, of the project. So you can think of approvers as people who have write access in a repo or someplace within a repo.
The issue with the sidecar enhancement is that it has been deferred for multiple releases now, and that's been because there hasn't been a lot of collaboration between the KEP authors and the approvers for specific parts of the project. Something worthwhile to mention— and this was brought up during the original discussion— is this can obviously be frustrating for both contributors and for approvers. From the contributor's side of things, you are working on something. You are doing your best to make sure that it works.
And to build something that's going to be used by people, both from the approver side of things and, I think, for the most part, every single person in the Kubernetes community, we are all really excited to see this project grow. We want to help improve it, and we love when new people come in and work on new enhancements, bug fixes, and the like.
But one of the limitations is the day only has so many hours, and there are only so many things that we can work on at a time. So people prioritize in whatever way works best, and some things just fall behind. And a lot of the time, the things that fall behind are not because people don't want them to continue moving forward, but it's just a limited amount of resources, a limited amount of people.
And I think this discussion around the sidecar enhancement proposal has been very useful, and it points us to the need for more standardized mentoring programs. This is something that multiple SIGs are working on. For example, SIG Contribex, SIG Cluster Lifecycle, SIG Release. The idea is to standardize some sort of mentoring experience so that we can better prepare new contributors to become reviewers and ultimately approvers.
Because ultimately at the end of the day, if we have more people who are knowledgeable about Kubernetes, or even some specific area of Kubernetes, we can better distribute the load, and we can better collaborate on whatever new things come up. I think the sidecar enhancement has shown us mentoring is something worthwhile, and we need a lot more of it. Because as much work as we do, more things are going to continue popping in throughout the project. And the more people we have who are comfortable working in these really complicated areas of Kubernetes, the better off that we are going to be.
ADAM GLICK: Was there any talk of delaying 1.18 due to the current worldwide health situation?
JORGE ALARCÓN: We thought about it, and the plan was to just wait and see how people felt. Tried make sure that people were comfortable continuing to work and all the people were landing in new enhancements, or fixing tests, or members of the release team who were making sure that things were happening. We wanted to see that people were comfortable, that they could continue doing their job. And for a moment, I actually thought about delaying just outright— we're going to give it more time, and hopefully at some point, things are going to work out.
But people just continue doing their amazing work. There was no delay. There was no hitch throughout the process. So at some point, I just figured we stay with the current timeline and see how we went. And at this point, things are more or less set.
ADAM GLICK: Amazing power of a distributed team.
JORGE ALARCÓN: Yeah, definitely.
[LAUGHING]
ADAM GLICK: Taylor Dolezal was announced as the 1.19 release lead. Do you know how that choice was made, and by whom?
JORGE ALARCÓN: I actually got to choose the lead. The practice is the current lead for the release team is going to look at people and see, first off, who's interested and out of the people interested, who can do the job, who's comfortable enough with the release team, with the Kubernetes community at large who can actually commit the amount of hours throughout the next, hopefully, three months.
And for one, I think Taylor has been part of my team. So there is the release team. Then the release team has multiple subgroups. One of those subgroups is actually just for me and my shadows. So for this release, it was mrbobbytables and Taylor. And Taylor volunteered to take over 1.19, and I'm sure that he will do an amazing job.
ADAM GLICK: I am as well. What advice will you give Taylor?
JORGE ALARCÓN: Over-communicate as much as possible. Normally, if you made it to the point that you are the lead for a release, or even the shadow for a release, you more or less are familiar with a lot of the work— CI Signal, enhancements, documentation, and the like. And a lot of people, if they know how to do their job, they might tell themselves, yeah, I could do it— no need to worry about it. I'm just going to go ahead and sign this PR, debug this test, whatever.
But one of the interesting aspects is whenever we are actually working in a release, 50% of the work has to go into actually making the release happen. The other 50% of the work has to go into mentoring people, and making sure the newcomers, new members are able to learn everything that they need to learn to do your job, you being in the lead for a subgroup or the entire team. And whenever you actually see that things need to happen, just over-communicate.
Try to provide the opportunity for someone else to do the work, and over-communicate with them as much as possible to make sure that they are learning whatever it is that they need to learn. If neither you or the other person knows what's going on, then I can over-communicate, so someone hopefully will see your messages and come to the rescue. That happens a lot. There's a lot of really nice and kind people who will come out and tell you how something works, help you fix it.
ADAM GLICK: If you were to sum up your experience running this release, what would it be?
JORGE ALARCÓN: It's been super fun and a little bit stressing, to be honest. Being the release lead is definitely amazing. You're kind of sitting at the center of Kubernetes.
You not only see the people who are working on things— the things that are broken, and the users filling out issues, and saying what broke, and the like. But you also get the opportunity to work with a lot of people who do a lot of non-code related work. Docs is one of the most obvious things. There's a lot of work that goes into communications, contributor experience, public relations.
And being connected, getting to talk with those people mostly every other day, it's really fun. It's a really good experience in terms of becoming a better contributor to the community, but also taking some of that knowledge home with you and applying it somewhere else. If you are a software engineer, if you are a project manager, whatever, it's amazing how much you can learn.
ADAM GLICK: I know the community likes to rotate around who are the release leads. But if you were given the opportunity to be a release lead for a future release of Kubernetes, would you do it again?
JORGE ALARCÓN: Yeah, it's a fun job. To be honest, it can be really stressing. Especially, as I mentioned, at some point, most of that work is just going to be talking with people, and talking requires a lot more thought and effort than just sitting down and thinking about things sometimes. And some of that can be really stressful.
But the job itself, it is definitely fun. And at some distant point in the future, if for some reason it was a possibility, I will think about it. But definitely, as you mentioned, one thing that we try to do is cycle out, because I can have fun in it, and that's all good and nice. And hopefully I can help another release go out the door. But providing the opportunity for other people to learn I think is a lot more important than just being the lead itself.
Jorge Alarcón is a site reliability engineer with Searchable AI and served as the Kubernetes 1.18 release team lead.
You can find the Kubernetes Podcast from Google at @KubernetesPod on Twitter, and you can subscribe so you never miss an episode.
Music and math: the Kubernetes 1.17 release interview
Author: Adam Glick (Google)
Every time the Kubernetes release train stops at the station, we like to ask the release lead to take a moment to reflect on their experience. That takes the form of an interview on the weekly Kubernetes Podcast from Google that I co-host with Craig Box. If you're not familiar with the show, every week we summarise the new in the Cloud Native ecosystem, and have an insightful discussion with an interesting guest from the broader Kubernetes community.
At the time of the 1.17 release in December, we talked to release team lead Guinevere Saenger. We have shared the transcripts of previous interviews on the Kubernetes blog, and we're very happy to share another today.
Next week we will bring you up to date with the story of Kubernetes 1.18, as we gear up for the release of 1.19 next month. Subscribe to the show wherever you get your podcasts to make sure you don't miss that chat!
ADAM GLICK: You have a nontraditional background for someone who works as a software engineer. Can you explain that background?
GUINEVERE SAENGER: My first career was as a collaborative pianist, which is an academic way of saying "piano accompanist". I was a classically trained pianist who spends most of her time onstage, accompanying other people and making them sound great.
ADAM GLICK: Is that the piano equivalent of pair-programming?
GUINEVERE SAENGER: No one has said it to me like that before, but all sorts of things are starting to make sense in my head right now. I think that's a really great way of putting it.
ADAM GLICK: That's a really interesting background, as someone who also has a background with music. What made you decide to get into software development?
GUINEVERE SAENGER: I found myself in a life situation where I needed more stable source of income, and teaching music, and performing for various gig opportunities, was really just not cutting it anymore. And I found myself to be working really, really hard with not much to show for it. I had a lot of friends who were software engineers. I live in Seattle. That's sort of a thing that happens to you when you live in Seattle — you get to know a bunch of software engineers, one way or the other.
The ones I met were all lovely people, and they said, hey, I'm happy to show you how to program in Python. And so I did that for a bit, and then I heard about this program called Ada Developers Academy. That's a year long coding school, targeted at women and non-binary folks that are looking for a second career in tech. And so I applied for that.
CRAIG BOX: What can you tell us about that program?
GUINEVERE SAENGER: It's incredibly selective, for starters. It's really popular in Seattle and has gotten quite a good reputation. It took me three tries to get in. They do two classes a year, and so it was a while before I got my response saying 'congratulations, we are happy to welcome you into Cohort 6'. I think what sets Ada Developers Academy apart from other bootcamp style coding programs are three things, I think? The main important one is that if you get in, you pay no tuition. The entire program is funded by company sponsors.
CRAIG BOX: Right.
GUINEVERE SAENGER: The other thing that really convinced me is that five months of the 11-month program are an industry internship, which means you get both practical experience, mentorship, and potential job leads at the end of it.
CRAIG BOX: So very much like a condensed version of the University of Waterloo degree, where you do co-op terms.
GUINEVERE SAENGER: Interesting. I didn't know about that.
CRAIG BOX: Having lived in Waterloo for a while, I knew a lot of people who did that. But what would you say the advantages were of going through such a condensed schooling process in computer science?
GUINEVERE SAENGER: I'm not sure that the condensed process is necessarily an advantage. I think it's a necessity, though. People have to quit their jobs to go do this program. It's not an evening school type of thing.
CRAIG BOX: Right.
GUINEVERE SAENGER: And your internship is basically a full-time job when you do it. One thing that Ada was really, really good at is giving us practical experience that directly relates to the workplace. We learned how to use Git. We learned how to design websites using Rails. And we also learned how to collaborate, how to pair-program. We had a weekly retrospective, so we sort of got a soft introduction to workflows at a real workplace. Adding to that, the internship, and I think the overall experience is a little bit more 'practical workplace oriented' and a little bit less academic.
When you're done with it, you don't have to relearn how to be an adult in a working relationship with other people. You come with a set of previous skills. There are Ada graduates who have previously been campaign lawyers, and veterinarians, and nannies, cooks, all sorts of people. And it turns out these skills tend to translate, and they tend to matter.
ADAM GLICK: With your background in music, what do you think that that allows you to bring to software development that could be missing from, say, standard software development training that people go through?
GUINEVERE SAENGER: People tend to really connect the dots when I tell them I used to be a musician. Of course, I still consider myself a musician, because you don't really ever stop being a musician. But they say, 'oh, yeah, music and math', and that's just a similar sort of brain. And that makes so much sense. And I think there's a little bit of a point to that. When you learn a piece of music, you have to start recognizing patterns incredibly quickly, almost intuitively.
And I think that is the main skill that translates into programming— recognizing patterns, finding the things that work, finding the things that don't work. And for me, especially as a collaborative pianist, it's the communicating with people, the finding out what people really want, where something is going, how to figure out what the general direction is that we want to take, before we start writing the first line of code.
CRAIG BOX: In your experience at Ada or with other experiences you've had, have you been able to identify patterns in other backgrounds for people that you'd recommend, 'hey, you're good at music, so therefore you might want to consider doing something like a course in computer science'?
GUINEVERE SAENGER: Overall, I think ultimately writing code is just giving a set of instructions to a computer. And we do that in daily life all the time. We give instructions to our kids, we give instructions to our students. We do math, we write textbooks. We give instructions to a room full of people when you're in court as a lawyer.
Actually, the entrance exam to Ada Developers Academy used to have questions from the LSAT on it to see if you were qualified to join the program. They changed that when I applied, but I think that's a thing that happened at one point. So, overall, I think software engineering is a much more varied field than we give it credit for, and that there are so many ways in which you can apply your so-called other skills and bring them under the umbrella of software engineering.
CRAIG BOX: I do think that programming is effectively half art and half science. There's creativity to be applied. There is perhaps one way to solve a problem most efficiently. But there are many different ways that you can choose to express how you compiled something down to that way.
GUINEVERE SAENGER: Yeah, I mean, that's definitely true. I think one way that you could probably prove that is that if you write code at work and you're working on something with other people, you can probably tell which one of your co-workers wrote which package, just by the way it's written, or how it is documented, or how it is styled, or any of those things. I really do think that the human character shines through.
ADAM GLICK: What got you interested in Kubernetes and open source?
GUINEVERE SAENGER: The honest answer is absolutely nothing. Going back to my programming school— and remember that I had to do a five-month internship as part of my training— the way that the internship works is that sponsor companies for the program get interns in according to how much they sponsored a specific cohort of students.
So at the time, Samsung and SDS offered to host two interns for five months on their Cloud Native Computing team and have that be their practical experience. So I go out of a Ruby on Rails full stack web development bootcamp and show up at my internship, and they said, "Welcome to Kubernetes. Try to bring up a cluster." And I said, "Kuber what?"
CRAIG BOX: We've all said that on occasion.
ADAM GLICK: Trial by fire, wow.
GUINEVERE SAENGER: I will say that that entire team was absolutely wonderful, delightful to work with, incredibly helpful. And I will forever be grateful for all of the help and support that I got in that environment. It was a great place to learn.
CRAIG BOX: You now work on GitHub's Kubernetes infrastructure. Obviously, there was GitHub before there was a Kubernetes, so a migration happened. What can you tell us about the transition that GitHub made to running on Kubernetes?
GUINEVERE SAENGER: A disclaimer here— I was not at GitHub at the time that the transition to Kubernetes was made. However, to the best of my knowledge, the decision to transition to Kubernetes was made and people decided, yes, we want to try Kubernetes. We want to use Kubernetes. And mostly, the only decision left was, which one of our applications should we move over to Kubernetes?
CRAIG BOX: I thought GitHub was written on Rails, so there was only one application.
GUINEVERE SAENGER: [LAUGHING] We have a lot of supplementary stuff under the covers.
CRAIG BOX: I'm sure.
GUINEVERE SAENGER: But yes, GitHub is written in Rails. It is still written in Rails. And most of the supplementary things are currently running on Kubernetes. We have a fair bit of stuff that currently does not run on Kubernetes. Mainly, that is GitHub Enterprise related things. I would know less about that because I am on the platform team that helps people use the Kubernetes infrastructure. But back to your question, leadership at the time decided that it would be a good idea to start with GitHub the Rails website as the first project to move to Kubernetes.
ADAM GLICK: High stakes!
GUINEVERE SAENGER: The reason for this was that they decided if they were going to not start big, it really wasn't going to transition ever. It was really not going to happen. So they just decided to go all out, and it was successful, for which I think the lesson would probably be commit early, commit big.
CRAIG BOX: Are there any other lessons that you would take away or that you've learned kind of from the transition that the company made, and might be applicable to other people who are looking at moving their companies from a traditional infrastructure to a Kubernetes infrastructure?
GUINEVERE SAENGER: I'm not sure this is a lesson specifically, but I was on support recently, and it turned out that, due to unforeseen circumstances and a mix of human error, a bunch of the namespaces on one of our Kubernetes clusters got deleted.
ADAM GLICK: Oh, my.
GUINEVERE SAENGER: It should not have affected any customers, I should mention, at this point. But all in all, it took a few of us a few hours to almost completely recover from this event. I think that, without Kubernetes, this would not have been possible.
CRAIG BOX: Generally, deleting something like that is quite catastrophic. We've seen a number of other vendors suffer large outages when someone's done something to that effect, which is why we get #hugops on Twitter all the time.
GUINEVERE SAENGER: People did send me #hugops, that is a thing that happened. But overall, something like this was an interesting stress test and sort of proved that it wasn't nearly as catastrophic as a worst case scenario.
CRAIG BOX: GitHub runs its own data centers. Kubernetes was largely built for running on the cloud, but a lot of people do choose to run it on their own, bare metal. How do you manage clusters and provisioning of the machinery you run?
GUINEVERE SAENGER: When I started, my onboarding project was to deprovision an old cluster, make sure all the traffic got moved to somewhere where it would keep running, provision a new cluster, and then move website traffic onto the new cluster. That was a really exciting onboarding project. At the time, we provisioned bare metal machines using Puppet. We still do that to a degree, but I believe the team that now runs our computing resources actually inserts virtual machines as an extra layer between the bare metal and the Kubernetes nodes.
Again, I was not intrinsically part of that decision, but my understanding is that it just makes for a greater reliability and reproducibility across the board. We've had some interesting hardware dependency issues come up, and the virtual machines basically avoid those.
CRAIG BOX: You've been working with Kubernetes for a couple of years now. How did you get involved in the release process?
GUINEVERE SAENGER: When I first started in the project, I started at the special interest group for contributor experience, namely because one of my co-workers at the time, Aaron Crickenberger, was a big Kubernetes community person. Still is.
CRAIG BOX: We've had him on the show for one of these very release interviews!
GUINEVERE SAENGER: In fact, this is true! So Aaron and I actually go way back to Samsung SDS. Anyway, Aaron suggested that I should write up a contribution to the Kubernetes project, and I said, me? And he said, yes, of course. You will be speaking at KubeCon, so you should probably get started with a PR or something. So I tried, and it was really, really hard. And I complained about it in a public GitHub issue, and people said, yeah. Yeah, we know it's hard. Do you want to help with that?
And so I started getting really involved with the process for new contributors to get started and have successes, kind of getting a foothold into a project that's as large and varied as Kubernetes. From there on, I began to talk to people, get to know people. The great thing about the Kubernetes community is that there is so much mentorship to go around.
ADAM GLICK: Right.
GUINEVERE SAENGER: There are so many friendly people willing to help. It's really funny when I talk to other people about it. They say, what do you mean, your coworker? And I said, well, he's really a colleague. He really works for another company.
CRAIG BOX: He's sort-of officially a competitor.
GUINEVERE SAENGER: Yeah.
CRAIG BOX: But we're friends.
GUINEVERE SAENGER: But he totally helped me when I didn't know how to git patch my borked pull request. So that happened. And eventually, somebody just suggested that I start following along in the release process and shadow someone on their release team role. And that, at the time, was Tim Pepper, who was bug triage lead, and I shadowed him for that role.
CRAIG BOX: Another podcast guest on the interview train.
GUINEVERE SAENGER: This is a pattern that probably will make more sense once I explain to you about the shadow process of the release team.
ADAM GLICK: Well, let's turn to the Kubernetes release and the release process. First up, what's new in this release of 1.17?
GUINEVERE SAENGER: We have only a very few new things. The one that I'm most excited about is that we have moved IPv4 and IPv6 dual stack support to alpha. That is the most major change, and it has been, I think, a year and a half in coming. So this is the very first cut of that feature, and I'm super excited about that.
CRAIG BOX: The people who have been promised IPv6 for many, many years and still don't really see it, what will this mean for them?
ADAM GLICK: And most importantly, why did we skip IPv5 support?
GUINEVERE SAENGER: I don't know!
CRAIG BOX: Please see the appendix to this podcast for technical explanations.
GUINEVERE SAENGER: Having a dual stack configuration obviously enables people to have a much more flexible infrastructure and not have to worry so much about making decisions that will become outdated or that may be over-complicated. This basically means that pods can have dual stack addresses, and nodes can have dual stack addresses. And that basically just makes communication a lot easier.
CRAIG BOX: What about features that didn't make it into the release? We had a conversation with Lachie in the 1.16 interview, where he mentioned sidecar containers. They unfortunately didn't make it into that release. And I see now that they haven't made this one either.
GUINEVERE SAENGER: They have not, and we are actually currently undergoing an effort of tracking features that flip multiple releases.
As a community, we need everyone's help. There are a lot of features that people want. There is also a lot of cleanup that needs to happen. And we have started talking at previous KubeCons repeatedly about problems with maintainer burnout, reviewer burnout, have a hard time finding reviews for your particular contributions, especially if you are not an entrenched member of the community. And it has become very clear that this is an area where the entire community needs to improve.
So the unfortunate reality is that sometimes life happens, and people are busy. This is an open source project. This is not something that has company mandated OKRs. Particularly during the fourth quarter of the year in North America, but around the world, we have a lot of holidays. It is the end of the year. Kubecon North America happened as well. This makes it often hard to find a reviewer in time or to rally the support that you need for your enhancement proposal. Unfortunately, slipping releases is fairly common and, at this point, expected. We started out with having 42 enhancements and landed with roughly half of that.
CRAIG BOX: I was going to ask about the truncated schedule due to the fourth quarter of the year, where there are holidays in large parts of the world. Do you find that the Q4 release on the whole is smaller than others, if not for the fact that it's some week shorter?
GUINEVERE SAENGER: Q4 releases are shorter by necessity because we are trying to finish the final release of the year before the end of the year holidays. Often, releases are under pressure of KubeCons, during which finding reviewers or even finding the time to do work can be hard to do, if you are attending. And even if you're not attending, your reviewers might be attending.
It has been brought up last year to make the final release more of a stability release, meaning no new alpha features. In practice, for this release, this is actually quite close to the truth. We have four features graduating to beta and most of our features are graduating to stable. I am hoping to use this as a precedent to change our process to make the final release a stability release from here on out. The timeline fits. The past experience fits this model.
ADAM GLICK: On top of all of the release work that was going on, there was also KubeCon that happened. And you were involved in the contributor summit. How was the summit?
GUINEVERE SAENGER: This was the first contributor summit where we had an organized events team with events organizing leads, and handbooks, and processes. And I have heard from multiple people— this is just word of mouth— that it was their favorite contributor summit ever.
CRAIG BOX: Was someone allocated to hat production? Everyone had sailor hats.
GUINEVERE SAENGER: Yes, the entire event staff had sailor hats with their GitHub handle on them, and it was pretty fantastic. You can probably see me wearing one in some of the pictures from the contributor summit. That literally was something that was pulled out of a box the morning of the contributor summit, and no one had any idea. But at first, I was a little skeptical, but then I put it on and looked at myself in the mirror. And I was like, yes. Yes, this is accurate. We should all wear these.
ADAM GLICK: Did getting everyone together for the contributor summit help with the release process?
GUINEVERE SAENGER: It did not. It did quite the opposite, really. Well, that's too strong.
ADAM GLICK: Is that just a matter of the time taken up?
GUINEVERE SAENGER: It's just a completely different focus. Honestly, it helped getting to know people face-to-face that I had currently only interacted with on video. But we did have to cancel the release team meeting the day of the contributor summit because there was kind of no sense in having it happen. We moved it to the Tuesday, I believe.
CRAIG BOX: The role of the release team leader has been described as servant leadership. Do you consider the position proactive or reactive?
GUINEVERE SAENGER: Honestly, I think that depends on who's the release team lead, right? There are some people who are very watchful and look for trends, trying to detect problems before they happen. I tend to be in that camp, but I also know that sometimes it's not possible to predict things. There will be last minute bugs sometimes, sometimes not. If there is a last minute bug, you have to be ready to be on top of that. So for me, the approach has been I want to make sure that I have my priorities in order and also that I have backups in case I can't be available.
ADAM GLICK: What was the most interesting part of the release process for you?
GUINEVERE SAENGER: A release lead has to have served in other roles on the release team prior to being release team lead. To me, it was very interesting to see what other roles were responsible for, ones that I hadn't seen from the inside before, such as docs, CI signal. I had helped out with CI signal for a bit, but I want to give a big shout out to CI signal lead, Alena Varkockova, who was able to communicate effectively and kindly with everyone who was running into broken tests, failing tests. And she was very effective in getting all of our tests up and running.
So that was actually really cool to see. And yeah, just getting to see more of the workings of the team, for me, it was exciting. The other big exciting thing, of course, was to see all the changes that were going in and all the efforts that were being made.
CRAIG BOX: The release lead for 1.18 has just been announced as Jorge Alarcon. What are you going to put in the proverbial envelope as advice for him?
GUINEVERE SAENGER: I would want Jorge to be really on top of making sure that every Special Interest Group that enters a change, that has an enhancement for 1.18, is on top of the timelines and is responsive. Communication tends to be a problem. And I had hinted at this earlier, but some enhancements slipped simply because there wasn't enough reviewer bandwidth.
Greater communication of timelines and just giving people more time and space to be able to get in their changes, or at least, seemingly give them more time and space by sending early warnings, is going to be helpful. Of course, he's going to have a slightly longer release, too, than I did. This might be related to a unique Q4 challenge. Overall, I would encourage him to take more breaks, to rely more on his release shadows, and split out the work in a fashion that allows everyone to have a turn and everyone to have a break as well.
ADAM GLICK: What would your advice be to someone who is hearing your experience and is inspired to get involved with the Kubernetes release or contributer process?
GUINEVERE SAENGER: Those are two separate questions. So let me tackle the Kubernetes release question first. Kubernetes SIG Release has, in my opinion, a really excellent onboarding program for new members. We have what is called the Release Team Shadow Program. We also have the Release Engineering Shadow Program, or the Release Management Shadow Program. Those are two separate subprojects within SIG Release. And each subproject has a team of roles, and each role can have two to four shadows that are basically people who are part of that role team, and they are learning that role as they are doing it.
So for example, if I am the lead for bug triage on the release team, I may have two, three or four people that I closely work with on the bug triage tasks. These people are my shadows. And once they have served one release cycle as a shadow, they are now eligible to be lead in that role. We have an application form for this process, and it should probably be going up in January. It usually happens the first week of the release once all the release leads are put together.
CRAIG BOX: Do you think being a member of the release team is something that is a good first contribution to the Kubernetes project overall?
GUINEVERE SAENGER: It depends on what your goals are, right? I believe so. I believe, for me, personally, it has been incredibly helpful looking into corners of the project that I don't know very much about at all, like API machinery, storage. It's been really exciting to look over all the areas of code that I normally never touch.
It depends on what you want to get out of it. In general, I think that being a release team shadow is a really, really great on-ramp to being a part of the community because it has a paved path solution to contributing. All you have to do is show up to the meetings, ask questions of your lead, who is required to answer those questions.
And you also do real work. You really help, you really contribute. If you go across the issues and pull requests in the repo, you will see, 'Hi, my name is so-and-so. I am shadowing the CI signal lead for the current release. Can you help me out here?' And that's a valuable contribution, and it introduces people to others. And then people will recognize your name. They'll see a pull request by you, and they're like oh yeah, I know this person. They're legit.
Guinevere Saenger is a software engineer for GitHub and served as the Kubernetes 1.17 release team lead.
You can find the Kubernetes Podcast from Google at @KubernetesPod on Twitter, and you can subscribe so you never miss an episode.
SIG-Windows Spotlight
This post tells the story of how Kubernetes contributors work together to provide a container orchestrator that works for both Linux and Windows.

Most people who are familiar with Kubernetes are probably used to associating it with Linux. The connection makes sense, since Kubernetes ran on Linux from its very beginning. However, many teams and organizations working on adopting Kubernetes need the ability to orchestrate containers on Windows. Since the release of Docker and rise to popularity of containers, there have been efforts both from the community and from Microsoft itself to make container technology as accessible in Windows systems as it is in Linux systems.
Within the Kubernetes community, those who are passionate about making Kubernetes accessible to the Windows community can find a home in the Windows Special Interest Group. To learn more about SIG-Windows and the future of Kubernetes on Windows, I spoke to co-chairs Mark Rossetti and Michael Michael about the SIG's goals and how others can contribute.
Intro to Windows Containers & Kubernetes
Kubernetes is the most popular tool for orchestrating container workloads, so to understand the Windows Special Interest Group (SIG) within the Kubernetes project, it's important to first understand what we mean when we talk about running containers on Windows.
"When looking at Windows support in Kubernetes," says SIG (Special Interest Group) Co-chairs Mark Rossetti and Michael Michael, "many start drawing comparisons to Linux containers. Although some of the comparisons that highlight limitations are fair, it is important to distinguish between operational limitations and differences between the Windows and Linux operating systems. Windows containers run the Windows operating system and Linux containers run Linux."
In essence, any "container" is simply a process being run on its host operating system, with some key tooling in place to isolate that process and its dependencies from the rest of the environment. The goal is to make that running process safely isolated, while taking up minimal resources from the system to perform that isolation. On Linux, the tooling used to isolate processes to create "containers" commonly boils down to cgroups and namespaces (among a few others), which are themselves tools built in to the Linux Kernel.

If dogs were processes: containerization would be like giving each dog their own resources like toys and food using cgroups, and isolating troublesome dogs using namespaces.
Native Windows processes are processes that are or must be run on a Windows operating system. This makes them fundamentally different from a process running on a Linux operating system. Since Linux containers are Linux processes being isolated by the Linux kernel tools known as cgroups and namespaces, containerizing native Windows processes meant implementing similar isolation tools within the Windows kernel itself. Thus, "Windows Containers" and "Linux Containers" are fundamentally different technologies, even though they have the same goals (isolating processes) and in some ways work similarly (using kernel level containerization).
So when it comes to running containers on Windows, there are actually two very important concepts to consider:
- Native Windows processes running as native Windows Server style containers,
- and traditional Linux containers running on a Linux Kernel, generally hosted on a lightweight Hyper-V Virtual Machine.
You can learn more about Linux and Windows containers in this tutorial from Microsoft.
Kubernetes on Windows
Kubernetes was initially designed with Linux containers in mind and was itself designed to run on Linux systems. Because of that, much of the functionality of Kubernetes involves unique Linux functionality. The Linux-specific work is intentional--we all want Kubernetes to run optimally on Linux--but there is a growing demand for similar optimization for Windows servers. For cases where users need container orchestration on Windows, the Kubernetes contributor community of SIG-Windows has incorporated functionality for Windows-specific use cases.
"A common question we get is, will I be able to have a Windows-only cluster. The answer is NO. Kubernetes control plane components will continue to be based on Linux, while SIG-Windows is concentrating on the experience of having Windows worker nodes in a Kubernetes cluster."
Rather than separating out the concepts of "Windows Kubernetes," and "Linux Kubernetes," the community of SIG-Windows works toward adding functionality to the main Kubernetes project which allows it to handle use cases for Windows. These Windows capabilities mirror, and in some cases add unique functionality to, the Linux use cases Kubernetes has served since its release in 2014 (want to learn more history? Scroll through this original design document.
What Does SIG-Windows Do?
"SIG-Windows is really the center for all things Windows in Kubernetes," SIG chairs Mark and Michael said, "We mainly focus on the compute side of things, but really anything related to running Kubernetes on Windows is in scope for SIG-Windows."
In order to best serve users, SIG-Windows works to make the Kubernetes user experience as consistent as possible for users of Windows and Linux. However some use cases simply only apply to one Operating System, and as such, the SIG-Windows group also works to create functionality that is unique to Windows-only workloads.
Many SIGs, or "Special Interest Groups" within Kubernetes have a narrow focus, allowing members to dive deep on a certain facet of the technology. While specific expertise is welcome, those interested in SIG-Windows will find it to be a great community to build broad understanding across many focus areas of Kubernetes. "Members from our SIG interface with storage, network, testing, cluster-lifecycle and others groups in Kubernetes."
Who are SIG-Windows' Users?
The best way to understand the technology a group makes, is often to understand who their customers or users are.
"A majority of the users we've interacted with have business-critical infrastructure running on Windows developed over many years and can't move those workloads to Linux for various reasons (cost, time, compliance, etc)," the SIG chairs shared. "By transporting those workloads into Windows containers and running them in Kubernetes they are able to quickly modernize their infrastructure and help migrate it to the cloud."
As anyone in the Kubernetes space can attest, companies around the world, in many different industries, see Kubernetes as their path to modernizing their infrastructure. Often this involves re-architecting or event totally re-inventing many of the ways they've been doing business. With the goal being to make their systems more scalable, more robust, and more ready for anything the future may bring. But not every application or workload can or should change the core operating system it runs on, so many teams need the ability to run containers at scale on Windows, or Linux, or both.
"Sometimes the driver to Windows containers is a modernization effort and sometimes it’s because of expiring hardware warranties or end-of-support cycles for the current operating system. Our efforts in SIG-Windows enable Windows developers to take advantage of cloud native tools and Kubernetes to build and deploy distributed applications faster. That’s exciting! In essence, users can retain the benefits of application availability while decreasing costs."
Who are SIG-Windows?
Who are these contributors working on enabling Windows workloads for Kubernetes? It could be you!
Like with other Kubernetes SIGs, contributors to SIG-Windows can be anyone from independent hobbyists to professionals who work at many different companies. They come from many different parts of the world and bring to the table many different skill sets.

"Like most other Kubernetes SIGs, we are a very welcome and open community," explained the SIG co-chairs Michael Michael and Mark Rosetti.
Becoming a contributor
For anyone interested in getting started, the co-chairs added, "New contributors can view old community meetings on GitHub (we record every single meeting going back three years), read our documentation, attend new community meetings, ask questions in person or on Slack, and file some issues on Github. We also attend all KubeCon conferences and host 1-2 sessions, a contributor session, and meet-the-maintainer office hours."
The co-chairs also shared a glimpse into what the path looks like to becoming a member of the SIG-Windows community:
"We encourage new contributors to initially just join our community and listen, then start asking some questions and get educated on Windows in Kubernetes. As they feel comfortable, they could graduate to improving our documentation, file some bugs/issues, and eventually they can be a code contributor by fixing some bugs. If they have long-term and sustained substantial contributions to Windows, they could become a technical lead or a chair of SIG-Windows. You won't know if you love this area unless you get started :) To get started, visit this getting-started page. It's a one stop shop with links to everything related to SIG-Windows in Kubernetes."
When asked if there were any useful skills for new contributors, the co-chairs said,
"We are always looking for expertise in Go and Networking and Storage, along with a passion for Windows. Those are huge skills to have. However, we don’t require such skills, and we welcome any and all contributors, with varying skill sets. If you don’t know something, we will help you acquire it."
You can get in touch with the folks at SIG-Windows in their Slack channel or attend one of their regular meetings - currently 30min long on Tuesdays at 12:30PM EST! You can find links to their regular meetings as well as past meeting notes and recordings from the SIG-Windows README on GitHub.
As a closing message from SIG-Windows:
"We welcome you to get involved and join our community to share feedback and deployment stories, and contribute to code, docs, and improvements of any kind."
Working with Terraform and Kubernetes
Author: Philipp Strube, Kubestack
Maintaining Kubestack, an open-source Terraform GitOps Framework for Kubernetes, I unsurprisingly spend a lot of time working with Terraform and Kubernetes. Kubestack provisions managed Kubernetes services like AKS, EKS and GKE using Terraform but also integrates cluster services from Kustomize bases into the GitOps workflow. Think of cluster services as everything that's required on your Kubernetes cluster, before you can deploy application workloads.
Hashicorp recently announced better integration between Terraform and Kubernetes. I took this as an opportunity to give an overview of how Terraform can be used with Kubernetes today and what to be aware of.
In this post I will however focus only on using Terraform to provision Kubernetes API resources, not Kubernetes clusters.
Terraform is a popular infrastructure as code solution, so I will only introduce it very briefly here. In a nutshell, Terraform allows declaring a desired state for resources as code, and will determine and execute a plan to take the infrastructure from its current state, to the desired state.
To be able to support different resources, Terraform requires providers that integrate the respective API. So, to create Kubernetes resources we need a Kubernetes provider. Here are our options:
Terraform kubernetes provider (official)
First, the official Kubernetes provider. This provider is undoubtedly the most mature of the three. However, it comes with a big caveat that's probably the main reason why using Terraform to maintain Kubernetes resources is not a popular choice.
Terraform requires a schema for each resource and this means the maintainers have to translate the schema of each Kubernetes resource into a Terraform schema. This is a lot of effort and was the reason why for a long time the supported resources where pretty limited. While this has improved over time, still not everything is supported. And especially custom resources are not possible to support this way.
This schema translation also results in some edge cases to be aware of. For example, metadata in the Terraform schema is a list of maps. Which means you have to refer to the metadata.name of a Kubernetes resource like this in Terraform: kubernetes_secret.example.metadata.0.name.
On the plus side however, having a Terraform schema means full integration between Kubernetes and other Terraform resources. Like for example, using Terraform to create a Kubernetes service of type LoadBalancer and then use the returned ELB hostname in a Route53 record to configure DNS.
The biggest benefit when using Terraform to maintain Kubernetes resources is integration into the Terraform plan/apply life-cycle. So you can review planned changes before applying them. Also, using kubectl, purging of resources from the cluster is not trivial without manual intervention. Terraform does this reliably.
Terraform kubernetes-alpha provider
Second, the new alpha Kubernetes provider. As a response to the limitations of the current Kubernetes provider the Hashicorp team recently released an alpha version of a new provider.
This provider uses dynamic resource types and server-side-apply to support all Kubernetes resources. I personally think this provider has the potential to be a game changer - even if managing Kubernetes resources in HCL may still not be for everyone. Maybe the Kustomize provider below will help with that.
The only downside really is, that it's explicitly discouraged to use it for anything but testing. But the more people test it, the sooner it should be ready for prime time. So I encourage everyone to give it a try.
Terraform kustomize provider
Last, we have the kustomize provider. Kustomize provides a way to do customizations of Kubernetes resources using inheritance instead of templating. It is designed to output the result to stdout, from where you can apply the changes using kubectl. This approach means that kubectl edge cases like no purging or changes to immutable attributes still make full automation difficult.
Kustomize is a popular way to handle customizations. But I was looking for a more reliable way to automate applying changes. Since this is exactly what Terraform is great at the Kustomize provider was born.
Not going into too much detail here, but from Terraform's perspective, this provider treats every Kubernetes resource as a JSON string. This way it can handle any Kubernetes resource resulting from the Kustomize build. But it has the big disadvantage that Kubernetes resources can not easily be integrated with other Terraform resources. Remember the load balancer example from above.
Under the hood, similarly to the new Kubernetes alpha provider, the Kustomize provider also uses the dynamic Kubernetes client and server-side-apply. Going forward, I plan to deprecate this part of the Kustomize provider that overlaps with the new Kubernetes provider and only keep the Kustomize integration.
Conclusion
For teams that are already invested into Terraform, or teams that are looking for ways to replace kubectl in automation, Terraform's plan/apply life-cycle has always been a promising option to automate changes to Kubernetes resources. However, the limitations of the official Kubernetes provider resulted in this not seeing significant adoption.
The new alpha provider removes the limitations and has the potential to make Terraform a prime option to automate changes to Kubernetes resources.
Teams that have already adopted Kustomize, may find integrating Kustomize and Terraform using the Kustomize provider beneficial over kubectl because it avoids common edge cases. Even if in this set up, Terraform can only easily be used to plan and apply the changes, not to adapt the Kubernetes resources. In the future, this issue may be resolved by combining the Kustomize provider with the new Kubernetes provider.
If you have any questions regarding these three options, feel free to reach out to me on the Kubernetes Slack in either the #kubestack or the #kustomize channel. If you happen to give any of the providers a try and encounter a problem, please file a GitHub issue to help the maintainers fix it.
A Better Docs UX With Docsy
Author: Zach Corleissen, Cloud Native Computing Foundation
Editor's note: Zach is one of the chairs for the Kubernetes documentation special interest group (SIG Docs).
I'm pleased to announce that the Kubernetes website now features the Docsy Hugo theme.
The Docsy theme improves the site's organization and navigability, and opens a path to improved API references. After over 4 years with few meaningful UX improvements, Docsy implements some best practices for technical content. The theme makes the Kubernetes site easier to read and makes individual pages easier to navigate. It gives the site a much-needed facelift.
For example: adding a right-hand rail for navigating topics on the page. No more scrolling up to navigate!
The theme opens a path for future improvements to the website. The Docsy functionality I'm most excited about is the theme's swaggerui shortcode, which provides native support for generating API references from an OpenAPI spec. The CNCF is partnering with Google Season of Docs (GSoD) for staffing to make better API references a reality in Q4 this year. We're hopeful to be chosen, and we're looking forward to Google's list of announced projects on August 16th. Better API references have been a personal goal since I first started working with SIG Docs in 2017. It's exciting to see the goal within reach.
One of SIG Docs' tech leads, Karen Bradshaw did a lot of heavy lifting to fix a wide range of site compatibility issues, including a fix to the last of our legacy pieces when we migrated from Jekyll to Hugo in 2018. Our other tech leads, Tim Bannister and Taylor Dolezal provided extensive reviews.
Thanks also to Björn-Erik Pedersen, who provided invaluable advice about how to navigate a Hugo upgrade beyond version 0.60.0.
The CNCF contracted with Gearbox in Victoria, BC to apply the theme to the site. Thanks to Aidan, Troy, and the rest of the team for all their work!
Supporting the Evolving Ingress Specification in Kubernetes 1.18
Authors: Alex Gervais (Datawire.io)
Earlier this year, the Kubernetes team released Kubernetes 1.18, which extended Ingress. In this blog post, we’ll walk through what’s new in the new Ingress specification, what it means for your applications, and how to upgrade to an ingress controller that supports this new specification.
What is Kubernetes Ingress
When deploying your applications in Kubernetes, one of the first challenges many people encounter is how to get traffic into their cluster. Kubernetes ingress is a collection of routing rules that govern how external users access services running in a Kubernetes cluster. There are three general approaches for exposing your application:
- Using a
NodePortto expose your application on a port across each of your nodes - Using a
LoadBalancerservice to create an external load balancer that points to a Kubernetes service in your cluster - Using a Kubernetes Ingress resource
What’s new in Kubernetes 1.18 Ingress
There are three significant additions to the Ingress API in Kubernetes 1.18:
- A new
pathTypefield - A new
IngressClassresource - Support for wildcards in hostnames
The new pathType field allows you to specify how Ingress paths should match.
The field supports three types: ImplementationSpecific (default), exact, and prefix. Explicitly defining the expected behavior of path matching will allow every ingress-controller to support a user’s needs and will increase portability between ingress-controller implementation solutions.
The IngressClass resource specifies how Ingresses should be implemented by controllers. This was added to formalize the commonly used but never standardized kubernetes.io/ingress.class annotation and allow for implementation-specific extensions and configuration.
You can read more about these changes, as well as the support for wildcards in hostnames in more detail in a previous blog post.
Supporting Kubernetes ingress
Ambassador is an open-source Envoy-based ingress controller. We believe strongly in supporting common standards such as Kubernetes ingress, which we adopted and announced our initial support for back in 2019.
Every Ambassador release goes through rigorous testing. Therefore, we also contributed an open conformance test suite, supporting Kubernetes ingress. We wrote the initial bits of test code and will keep iterating over the newly added features and different versions of the Ingress specification as it evolves to a stable v1 GA release. Documentation and usage samples, is one of our top priorities. We understand how complex usage can be, especially when transitioning from a previous version of an API.
Following a test-driven development approach, the first step we took in supporting Ingress improvements in Ambassador was to translate the revised specification -- both in terms of API and behavior -- into a comprehensible test suite. The test suite, although still under heavy development and going through multiple iterations, was rapidly added to the Ambassador CI infrastructure and acceptance criteria. This means every change to the Ambassador codebase going forward will be compliant with the Ingress API and be tested end-to-end in a lightweight KIND cluster. Using KIND allowed us to make rapid improvements while limiting our cloud provider infrastructure bill and testing out unreleased Kubernetes features with pre-release builds.
Adopting a new specification
With a global comprehension of additions to Ingress introduced in Kubernetes 1.18 and a test suite on hand, we tackled the task of adapting the Ambassador code so that it would support translating the high-level Ingress API resources into Envoy configurations and constructs. Luckily Ambassador already supported previous versions of ingress functionalities so the development effort was incremental.
We settled on a controller name of getambassador.io/ingress-controller. This value, consistent with Ambassador's domain and CRD versions, must be used to tie in an IngressClass spec.controller with an Ambassador deployment. The new IngressClass resource allows for extensibility by setting a spec.parameters field. At the moment Ambassador makes no use of this field and its usage is reserved for future development.
Paths can now define different matching behaviors using the pathType field. The field will default to a value of ImplementationSpecific, which uses the same matching rules as the Ambassador Mappings prefix field and previous Ingress specification for backward compatibility reasons.
Kubernetes Ingress Controllers
A comprehensive list of Kubernetes ingress controllers is available in the Kubernetes documentation. Currently, Ambassador is the only ingress controller that supports these new additions to the ingress specification. Powered by the Envoy Proxy, Ambassador is the fastest way for you to try out the new ingress specification today.
Check out the following resources:
- Ambassador on GitHub
- The Ambassador documentation
- Improvements to the Ingress API
Or join the community on Slack!
K8s KPIs with Kuberhealthy
Authors: Joshulyne Park (Comcast), Eric Greer (Comcast)
Building Onward from Kuberhealthy v2.0.0
Last November at KubeCon San Diego 2019, we announced the release of Kuberhealthy 2.0.0 - transforming Kuberhealthy into a Kubernetes operator for synthetic monitoring. This new ability granted developers the means to create their own Kuberhealthy check containers to synthetically monitor their applications and clusters. The community was quick to adopt this new feature and we're grateful for everyone who implemented and tested Kuberhealthy 2.0.0 in their clusters. Thanks to all of you who reported issues and contributed to discussions on the #kuberhealthy Slack channel. We quickly set to work to address all your feedback with a newer version of Kuberhealthy. Additionally, we created a guide on how to easily install and use Kuberhealthy in order to capture some helpful synthetic KPIs.
Deploying Kuberhealthy
To install Kuberhealthy, make sure you have Helm 3 installed. If not, you can use the generated flat spec files located in this deploy folder. You should use kuberhealthy-prometheus.yaml if you don't use the Prometheus Operator, and kuberhealthy-prometheus-operator.yaml if you do. If you don't use Prometheus at all, you can still use Kuberhealthy with a JSON status page and/or InfluxDB integration using this spec.
To install using Helm 3:
1. Create namespace "kuberhealthy" in the desired Kubernetes cluster/context:
kubectl create namespace kuberhealthy
2. Set your current namespace to "kuberhealthy":
kubectl config set-context --current --namespace=kuberhealthy
3. Add the kuberhealthy repo to Helm:
helm repo add kuberhealthy https://comcast.github.io/kuberhealthy/helm-repos
4. Depending on your Prometheus implementation, install Kuberhealthy using the appropriate command for your cluster:
- If you use the Prometheus Operator:
helm install kuberhealthy kuberhealthy/kuberhealthy --set prometheus.enabled=true,prometheus.enableAlerting=true,prometheus.enableScraping=true,prometheus.serviceMonitor=true
- If you use Prometheus, but NOT Prometheus Operator:
helm install kuberhealthy kuberhealthy/kuberhealthy --set prometheus.enabled=true,prometheus.enableAlerting=true,prometheus.enableScraping=true
See additional details about configuring the appropriate scrape annotations in the section Prometheus Integration Details below.
- Finally, if you don't use Prometheus:
helm install kuberhealthy kuberhealthy/kuberhealthy
Running the Helm command should automatically install the newest version of Kuberhealthy (v2.2.0) along with a few basic checks. If you run kubectl get pods, you should see two Kuberhealthy pods. These are the pods that create, coordinate, and track test pods. These two Kuberhealthy pods also serve a JSON status page as well as a /metrics endpoint. Every other pod you see created is a checker pod designed to execute and shut down when done.
Configuring Additional Checks
Next, you can run kubectl get khchecks. You should see three Kuberhealthy checks installed by default:
- daemonset: Deploys and tears down a daemonset to ensure all nodes in the cluster are functional.
- deployment: Creates a deployment and then triggers a rolling update. Tests that the deployment is reachable via a service and then deletes everything. Any problem in this process will cause this check to report a failure.
- dns-status-internal: Validates that internal cluster DNS is functioning as expected.
To view other available external checks, check out the external checks registry where you can find other yaml files you can apply to your cluster to enable various checks.
Kuberhealthy check pods should start running shortly after Kuberhealthy starts running (1-2 minutes). Additionally, the check-reaper cronjob runs every few minutes to ensure there are no more than 5 completed checker pods left lying around at a time.
To get status page view of these checks, you'll need to either expose the kuberhealthy service externally by editing the service kuberhealthy and setting Type: LoadBalancer or use kubectl port-forward service/kuberhealthy 8080:80. When viewed, the service endpoint will display a JSON status page that looks like this:
{
"OK": true,
"Errors": [],
"CheckDetails": {
"kuberhealthy/daemonset": {
"OK": true,
"Errors": [],
"RunDuration": "22.512278967s",
"Namespace": "kuberhealthy",
"LastRun": "2020-04-06T23:20:31.7176964Z",
"AuthoritativePod": "kuberhealthy-67bf8c4686-mbl2j",
"uuid": "9abd3ec0-b82f-44f0-b8a7-fa6709f759cd"
},
"kuberhealthy/deployment": {
"OK": true,
"Errors": [],
"RunDuration": "29.142295647s",
"Namespace": "kuberhealthy",
"LastRun": "2020-04-06T23:20:31.7176964Z",
"AuthoritativePod": "kuberhealthy-67bf8c4686-mbl2j",
"uuid": "5f0d2765-60c9-47e8-b2c9-8bc6e61727b2"
},
"kuberhealthy/dns-status-internal": {
"OK": true,
"Errors": [],
"RunDuration": "2.43940936s",
"Namespace": "kuberhealthy",
"LastRun": "2020-04-06T23:20:44.6294547Z",
"AuthoritativePod": "kuberhealthy-67bf8c4686-mbl2j",
"uuid": "c85f95cb-87e2-4ff5-b513-e02b3d25973a"
}
},
"CurrentMaster": "kuberhealthy-7cf79bdc86-m78qr"
}
This JSON page displays all Kuberhealthy checks running in your cluster. If you have Kuberhealthy checks running in different namespaces, you can filter them by adding the GET variable namespace parameter: ?namespace=kuberhealthy,kube-system onto the status page URL.
Writing Your Own Checks
Kuberhealthy is designed to be extended with custom check containers that can be written by anyone to check anything. These checks can be written in any language as long as they are packaged in a container. This makes Kuberhealthy an excellent platform for creating your own synthetic checks!
Creating your own check is a great way to validate your client library, simulate real user workflow, and create a high level of confidence in your service or system uptime.
To learn more about writing your own checks, along with simple examples, check the custom check creation documentation.
Prometheus Integration Details
When enabling Prometheus (not the operator), the Kuberhealthy service gets the following annotations added:
prometheus.io/path: /metrics
prometheus.io/port: "80"
prometheus.io/scrape: "true"
In your prometheus configuration, add the following example scrape_config that scrapes the Kuberhealthy service given the added prometheus annotation:
- job_name: 'kuberhealthy'
scrape_interval: 1m
honor_labels: true
metrics_path: /metrics
kubernetes_sd_configs:
- role: service
namespaces:
names:
- kuberhealthy
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
You can also specify the target endpoint to be scraped using this example job:
- job_name: kuberhealthy
scrape_interval: 1m
honor_labels: true
metrics_path: /metrics
static_configs:
- targets:
- kuberhealthy.kuberhealthy.svc.cluster.local:80
Once the appropriate prometheus configurations are applied, you should be able to see the following Kuberhealthy metrics:
kuberhealthy_checkkuberhealthy_check_duration_secondskuberhealthy_cluster_stateskuberhealthy_running
Creating Key Performance Indicators
Using these Kuberhealthy metrics, our team has been able to collect KPIs based on the following definitions, calculations, and PromQL queries.
Availability
We define availability as the K8s cluster control plane being up and functioning as expected. This is measured by our ability to create a deployment, do a rolling update, and delete the deployment within a set period of time.
We calculate this by measuring Kuberhealthy's deployment check successes and failures.
-
Availability = Uptime / (Uptime * Downtime)
-
Uptime = Number of Deployment Check Passes * Check Run Interval
-
Downtime = Number of Deployment Check Fails * Check Run Interval
-
Check Run Interval = how often the check runs (
runIntervalset in your KuberhealthyCheck Spec) -
PromQL Query (Availability % over the past 30 days):
1 - (sum(count_over_time(kuberhealthy_check{check="kuberhealthy/deployment", status="0"}[30d])) OR vector(0)) / sum(count_over_time(kuberhealthy_check{check="kuberhealthy/deployment", status="1"}[30d]))
Utilization
We define utilization as user uptake of product (k8s) and its resources (pods, services, etc.). This is measured by how many nodes, deployments, statefulsets, persistent volumes, services, pods, and jobs are being utilized by our customers. We calculate this by counting the total number of nodes, deployments, statefulsets, persistent volumes, services, pods, and jobs.
Duration (Latency)
We define duration as the control plane's capacity and utilization of throughput. We calculate this by capturing the average run duration of a Kuberhealthy deployment check run.
- PromQL Query (Deployment check average run duration):
avg(kuberhealthy_check_duration_seconds{check="kuberhealthy/deployment"})
Errors / Alerts
We define errors as all k8s cluster and Kuberhealthy related alerts. Every time one of our Kuberhealthy check fails, we are alerted of this failure.
Thank You!
Thanks again to everyone in the community for all of your contributions and help! We are excited to see what you build. As always, if you find an issue, have a feature request, or need to open a pull request, please open an issue on the Github project.
My exciting journey into Kubernetes’ history
Author: Sascha Grunert, SUSE Software Solutions
Editor's note: Sascha is part of SIG Release and is working on many other different container runtime related topics. Feel free to reach him out on Twitter @saschagrunert.
A story of data science-ing 90,000 GitHub issues and pull requests by using Kubeflow, TensorFlow, Prow and a fully automated CI/CD pipeline.
- Introduction
- Getting the Data
- Exploring the Data
- Building the Machine Learning Model
- Automate Everything
- Automatic Labeling of new PRs
- Summary
Introduction
Choosing the right steps when working in the field of data science is truly no silver bullet. Most data scientists might have their custom workflow, which could be more or less automated, depending on their area of work. Using Kubernetes can be a tremendous enhancement when trying to automate workflows on a large scale. In this blog post, I would like to take you on my journey of doing data science while integrating the overall workflow into Kubernetes.
The target of the research I did in the past few months was to find any useful information about all those thousands of GitHub issues and pull requests (PRs) we have in the Kubernetes repository. What I ended up with was a fully automated, in Kubernetes running Continuous Integration (CI) and Deployment (CD) data science workflow powered by Kubeflow and Prow. You may not know both of them, but we get to the point where I explain what they’re doing in detail. The source code of my work can be found in the kubernetes-analysis GitHub repository, which contains everything source code-related as well as the raw data. But how to retrieve this data I’m talking about? Well, this is where the story begins.
Getting the Data
The foundation for my experiments is the raw GitHub API data in plain JSON
format. The necessary data can be retrieved via the GitHub issues
endpoint, which returns all pull requests as well as regular issues in the
REST API. I exported roughly 91000 issues and pull requests in
the first iteration into a massive 650 MiB data blob. This took me about 8
hours of data retrieval time because for sure, the GitHub API is rate
limited. To be able to put this data into a GitHub repository, I’d chosen
to compress it via xz(1). The result was a roundabout 25 MiB sized
tarball, which fits well into the repository.
I had to find a way to regularly update the dataset because the Kubernetes issues and pull requests are updated by the users over time as well as new ones are created. To achieve the continuous update without having to wait 8 hours over and over again, I now fetch the delta GitHub API data between the last update and the current time. This way, a Continuous Integration job can update the data on a regular basis, whereas I can continue my research with the latest available set of data.
From a tooling perspective, I’ve written an all-in-one Python executable, which allows us to trigger the different steps during the data science experiments separately via dedicated subcommands. For example, to run an export of the whole data set, we can call:
> export GITHUB_TOKEN=<MY-SECRET-TOKEN>
> ./main export
INFO | Getting GITHUB_TOKEN from environment variable
INFO | Dumping all issues
INFO | Pulling 90929 items
INFO | 1: Unit test coverage in Kubelet is lousy. (~30%)
INFO | 2: Better error messages if go isn't installed, or if gcloud is old.
INFO | 3: Need real cluster integration tests
INFO | 4: kubelet should know which containers it is managing
… [just wait 8 hours] …
To update the data between the last time stamp stored in the repository we can run:
> ./main export --update-api
INFO | Getting GITHUB_TOKEN from environment variable
INFO | Retrieving issues and PRs
INFO | Updating API
INFO | Got update timestamp: 2020-05-09T10:57:40.854151
INFO | 90786: Automated cherry pick of #90749: fix: azure disk dangling attach issue
INFO | 90674: Switch core master base images from debian to distroless
INFO | 90086: Handling error returned by request.Request.ParseForm()
INFO | 90544: configurable weight on the CPU and memory
INFO | 87746: Support compiling Kubelet w/o docker/docker
INFO | Using already extracted data from data/data.pickle
INFO | Loading pickle dataset
INFO | Parsed 34380 issues and 55832 pull requests (90212 items)
INFO | Updating data
INFO | Updating issue 90786 (updated at 2020-05-09T10:59:43Z)
INFO | Updating issue 90674 (updated at 2020-05-09T10:58:27Z)
INFO | Updating issue 90086 (updated at 2020-05-09T10:58:26Z)
INFO | Updating issue 90544 (updated at 2020-05-09T10:57:51Z)
INFO | Updating issue 87746 (updated at 2020-05-09T11:01:51Z)
INFO | Saving data
This gives us an idea of how fast the project is actually moving: On a Saturday at noon (European time), 5 issues and pull requests got updated within literally 5 minutes!
Funnily enough, Joe Beda, one of the founders of Kubernetes, created the first GitHub issue mentioning that the unit test coverage is too low. The issue has no further description than the title, and no enhanced labeling applied, like we know from more recent issues and pull requests. But now we have to explore the exported data more deeply to do something useful with it.
Exploring the Data
Before we can start creating machine learning models and train them, we have to get an idea about how our data is structured and what we want to achieve in general.
To get a better feeling about the amount of data, let’s look at how many issues and pull requests have been created over time inside the Kubernetes repository:
> ./main analyze --created
INFO | Using already extracted data from data/data.pickle
INFO | Loading pickle dataset
INFO | Parsed 34380 issues and 55832 pull requests (90212 items)
The Python matplotlib module should pop up a graph which looks like this:

Okay, this looks not that spectacular but gives us an impression on how the project has grown over the past 6 years. To get a better idea about the speed of development of the project, we can look at the created-vs-closed metric. This means on our timeline, we add one to the y-axis if an issue or pull request got created and subtracts one if closed. Now the chart looks like this:
> ./main analyze --created-vs-closed

At the beginning of 2018, the Kubernetes projects introduced some more enhanced life-cycle management via the glorious fejta-bot. This automatically closes issues and pull requests after they got stale over a longer period of time. This resulted in a massive closing of issues, which does not apply to pull requests in the same amount. For example, if we look at the created-vs-closed metric only for pull requests.
> ./main analyze --created-vs-closed --pull-requests

The overall impact is not that obvious. What we can see is that the increasing number of peaks in the PR chart indicates that the project is moving faster over time. Usually, a candlestick chart would be a better choice for showing this kind of volatility-related information. I’d also like to highlight that it looks like the development of the project slowed down a bit in the beginning of 2020.
Parsing raw JSON in every analysis iteration is not the fastest approach to do in Python. This means that I decided to parse the more important information, for example the content, title and creation time into dedicated issue and PR classes. This data will be pickle serialized into the repository as well, which allows an overall faster startup independently of the JSON blob.
A pull request is more or less the same as an issue in my analysis, except that it contains a release note.
Release notes in Kubernetes are written in the PRs description into a separate
release-note block like this:
```release-note
I changed something extremely important and you should note that.
```
Those release notes are parsed by dedicated Release Engineering Tools like
krel during the release creation process and will be part of the various
CHANGELOG.md files and the Release Notes Website. That seems like a
lot of magic, but in the end, the quality of the overall release notes is much
higher because they’re easy to edit, and the PR reviewers can ensure that we
only document real user-facing changes and nothing else.
The quality of the input data is a key aspect when doing data science. I decided to focus on the release notes because they seem to have the highest amount of overall quality when comparing them to the plain descriptions in issues and PRs. Besides that, they’re easy to parse, and we would not need to strip away the various issue and PR template text noise.
Labels, Labels, Labels
Issues and pull requests in Kubernetes get different labels applied during its
life-cycle. They are usually grouped via a single slash (/). For example, we
have kind/bug and kind/api-change or sig/node and sig/network. An easy
way to understand which label groups exist and how they’re distributed across
the repository is to plot them into a bar chart:
> ./main analyze --labels-by-group

It looks like that sig/, kind/ and area/ labels are pretty common.
Something like size/ can be ignored for now because these labels are
automatically applied based on the amount of the code changes for a pull
request. We said that we want to focus on release notes as input data, which
means that we have to check out the distribution of the labels for the PRs. This
means that the top 25 labels on pull requests are:
> ./main analyze --labels-by-name --pull-requests

Again, we can ignore labels like lgtm (looks good to me), because every PR
which now should get merged has to look good. Pull requests containing release
notes automatically get the release-note label applied, which enables further
filtering more easily. This does not mean that every PR containing that label
also contains the release notes block. The label could have been applied
manually and the parsing of the release notes block did not exist since the
beginning of the project. This means we will probably loose a decent amount of
input data on one hand. On the other hand we can focus on the highest possible
data quality, because applying labels the right way needs some enhanced maturity
of the project and its contributors.
From a label group perspective I have chosen to focus on the kind/ labels.
Those labels are something which has to be applied manually by the author of the
PR, they are available on a good amount of pull requests and they’re related to
user-facing changes as well. Besides that, the kind/ choice has to be done for
every pull request because it is part of the PR template.
Alright, how does the distribution of those labels look like when focusing only on pull requests which have release notes?
> ./main analyze --release-notes-stats

Interestingly, we have approximately 7,000 overall pull requests containing
release notes, but only ~5,000 have a kind/ label applied. The distribution of
the labels is not equal, and one-third of them are labeled as kind/bug. This
brings me to the next decision in my data science journey: I will build a binary
classifier which, for the sake of simplicity, is only able to distinguish between
bugs (via kind/bug) and non-bugs (where the label is not applied).
The main target is now to be able to classify newly incoming release notes if they are related to a bug or not, based on the historical data we already have from the community.
Before doing that, I recommend that you play around with the ./main analyze -h
subcommand as well to explore the latest set of data. You can also check out all
the continuously updated assets I provide within the analysis repository.
For example, those are the top 25 PR creators inside the Kubernetes repository:

Building the Machine Learning Model
Now we have an idea what the data set is about, and we can start building a first machine learning model. Before actually building the model, we have to pre-process all the extracted release notes from the PRs. Otherwise, the model would not be able to understand our input.
Doing some first Natural Language Processing (NLP)
In the beginning, we have to define a vocabulary for which we want to train. I
decided to choose the TfidfVectorizer from the Python scikit-learn machine
learning library. This vectorizer is able to take our input texts and create a
single huge vocabulary out of it. This is our so-called bag-of-words,
which has a chosen n-gram range of (1, 2) (unigrams and bigrams). Practically
this means that we always use the first word and the next one as a single
vocabulary entry (bigrams). We also use the single word as vocabulary entry
(unigram). The TfidfVectorizer is able to skip words that occur multiple times
(max_df), and requires a minimum amount (min_df) to add a word to the
vocabulary. I decided not to change those values in the first place, just
because I had the intuition that release notes are something unique to a
project.
Parameters like min_df, max_df and the n-gram range can be seen as some of
our hyperparameters. Those parameters have to be optimized in a dedicated step
after the machine learning model has been built. This step is called
hyperparameter tuning and basically means that we train multiple times with
different parameters and compare the accuracy of the model. Afterwards, we choose
the parameters with the best accuracy.
During the training, the vectorizer will produce a data/features.json which
contains the whole vocabulary. This gives us a good understanding of how such a
vocabulary may look like:
[
…
"hostname",
"hostname address",
"hostname and",
"hostname as",
"hostname being",
"hostname bug",
…
]
This produces round about 50,000 entries in the overall bag-of-words, which is pretty much. Previous analyses between different data sets showed that it is simply not necessary to take so many features into account. Some general data sets state that an overall vocabulary of 20,000 is enough and higher amounts do not influence the accuracy any more. To do so we can use the SelectKBest feature selector to strip down the vocabulary to only choose the top features. Anyway, I still decided to stick to the top 50,000 to not negatively influence the model accuracy. We have a relatively low amount of data (appr. 7,000 samples) and a low number of words per sample (~15) which already made me wonder if we have enough data at all.
The vectorizer is not only able to create our bag-of-words, but it is also able to encode the features in term frequency–inverse document frequency (tf-idf) format. That is where the vectorizer got its name, whereas the output of that encoding is something the machine learning model can directly consume. All the details of the vectorization process can be found in the source code.
Creating the Multi-Layer Perceptron (MLP) Model
I decided to choose a simple MLP based model which is built with the help of the popular TensorFlow framework. Because we do not have that much input data, we just use two hidden layers, so that the model basically looks like this:
There have to be multiple other hyperparameters to be taken into account when creating the model. I will not discuss them in detail here, but they’re important to be optimized also in relation to the number of classes we want to have in the model (only two in our case).
Training the Model
Before starting the actual training, we have to split up our input data into training and validation data sets. I’ve chosen to use ~80% of the data for training and 20% for validation purposes. We have to shuffle our input data as well to ensure that the model is not affected by ordering issues. The technical details of the training process can be found in the GitHub sources. So now we’re ready to finally start the training:
> ./main train
INFO | Using already extracted data from data/data.pickle
INFO | Loading pickle dataset
INFO | Parsed 34380 issues and 55832 pull requests (90212 items)
INFO | Training for label 'kind/bug'
INFO | 6980 items selected
INFO | Using 5584 training and 1395 testing texts
INFO | Number of classes: 2
INFO | Vocabulary len: 51772
INFO | Wrote features to file data/features.json
INFO | Using units: 1
INFO | Using activation function: sigmoid
INFO | Created model with 2 layers and 64 units
INFO | Compiling model
INFO | Starting training
Train on 5584 samples, validate on 1395 samples
Epoch 1/1000
5584/5584 - 3s - loss: 0.6895 - acc: 0.6789 - val_loss: 0.6856 - val_acc: 0.6860
Epoch 2/1000
5584/5584 - 2s - loss: 0.6822 - acc: 0.6827 - val_loss: 0.6782 - val_acc: 0.6860
Epoch 3/1000
…
Epoch 68/1000
5584/5584 - 2s - loss: 0.2587 - acc: 0.9257 - val_loss: 0.4847 - val_acc: 0.7728
INFO | Confusion matrix:
[[920 32]
[291 152]]
INFO | Confusion matrix normalized:
[[0.966 0.034]
[0.657 0.343]]
INFO | Saving model to file data/model.h5
INFO | Validation accuracy: 0.7727598547935486, loss: 0.48470408514836355
The output of the Confusion Matrix shows us that we’re pretty good on
training accuracy, but the validation accuracy could be a bit higher. We now
could start a hyperparameter tuning to see if we can optimize the output of the
model even further. I will leave that experiment up to you with the hint to the
./main train --tune flag.
We saved the model (data/model.h5), the vectorizer (data/vectorizer.pickle)
and the feature selector (data/selector.pickle) to disk to be able to use them
later on for prediction purposes without having a need for additional training
steps.
A first Prediction
We are now able to test the model by loading it from disk and predicting some input text:
> ./main predict --test
INFO | Testing positive text:
Fix concurrent map access panic
Don't watch .mount cgroups to reduce number of inotify watches
Fix NVML initialization race condition
Fix brtfs disk metrics when using a subdirectory of a subvolume
INFO | Got prediction result: 0.9940581321716309
INFO | Matched expected positive prediction result
INFO | Testing negative text:
action required
1. Currently, if users were to explicitly specify CacheSize of 0 for
KMS provider, they would end-up with a provider that caches up to
1000 keys. This PR changes this behavior.
Post this PR, when users supply 0 for CacheSize this will result in
a validation error.
2. CacheSize type was changed from int32 to *int32. This allows
defaulting logic to differentiate between cases where users
explicitly supplied 0 vs. not supplied any value.
3. KMS Provider's endpoint (path to Unix socket) is now validated when
the EncryptionConfiguration files is loaded. This used to be handled
by the GRPCService.
INFO | Got prediction result: 0.1251964420080185
INFO | Matched expected negative prediction result
Both tests are real-world examples which already exist. We could also try something completely different, like this random tweet I found a couple of minutes ago:
./main predict "My dudes, if you can understand SYN-ACK, you can understand consent"
INFO | Got prediction result: 0.1251964420080185
ERROR | Result is lower than selected threshold 0.6
Looks like it is not classified as bug for a release note, which seems to work. Selecting a good threshold is also not that easy, but sticking to something > 50% should be the bare minimum.
Automate Everything
The next step is to find some way of automation to continuously update the model with new data. If I change any source code within my repository, then I’d like to get feedback about the test results of the model without having a need to run the training on my own machine. I would like to utilize the GPUs in my Kubernetes cluster to train faster and automatically update the data set if a PR got merged.
With the help of Kubeflow pipelines we can fulfill most of these requirements. The pipeline I built looks like this:
First, we check out the source code of the PR, which will be passed on as output artifact to all other steps. Then we incrementally update the API and internal data before we run the training on an always up-to-date data set. The prediction test verifies after the training that we did not badly influence the model with our changes.
We also built a container image within our pipeline. This container image
copies the previously built model, vectorizer, and selector into a container and
runs ./main serve. When doing this, we spin up a kfserving web server,
which can be used for prediction purposes. Do you want to try it out by yourself? Simply
do a JSON POST request like this and run the prediction against the endpoint:
> curl https://kfserving.k8s.saschagrunert.de/v1/models/kubernetes-analysis:predict \
-d '{"text": "my test text"}'
{"result": 0.1251964420080185}
The custom kfserving implementation is pretty straightforward, whereas the deployment utilizes Knative Serving and an Istio ingress gateway under the hood to correctly route the traffic into the cluster and provide the right set of services.
The commit-changes and rollout step will only run if the pipeline runs on
the master branch. Those steps make sure that we always have the latest data
set available on the master branch as well as in the kfserving deployment. The
rollout step creates a new canary deployment, which only accepts 50% of the
incoming traffic in the first place. After the canary got deployed successfully,
it will be promoted as the new main instance of the service. This is a great way
to ensure that the deployment works as intended and allows additional testing
after rolling out the canary.
But how to trigger Kubeflow pipelines when creating a pull request? Kubeflow has no feature for that right now. That’s why I decided to use Prow, Kubernetes test-infrastructure project for CI/CD purposes.
First of all, a 24h periodic job ensures that we have at least daily up-to-date data available within the repository. Then, if we create a pull request, Prow will run the whole Kubeflow pipeline without committing or rolling out any changes. If we merge the pull request via Prow, another job runs on the master and updates the data as well as the deployment. That’s pretty neat, isn’t it?
Automatic Labeling of new PRs
The prediction API is nice for testing, but now we need a real-world use case. Prow supports external plugins which can be used to take action on any GitHub event. I wrote a plugin which uses the kfserving API to make predictions based on new pull requests. This means if we now create a new pull request in the kubernetes-analysis repository, we will see the following:
Okay cool, so now let’s change the release note based on a real bug from the already existing dataset:
The bot edits its own comment, predicts it with round about 90% as kind/bug
and automatically adds the correct label! Now, if we change it back to some
different - obviously wrong - release note:
The bot does the work for us, removes the label and informs us what it did!
Finally, if we change the release note to None:
The bot removed the comment, which is nice and reduces the text noise on the PR. Everything I demonstrated is running inside a single Kubernetes cluster, which would make it unnecessary at all to expose the kfserving API to the public. This introduces an indirect API rate limiting because the only usage would be possible via the Prow bot user.
If you want to try it out for yourself, feel free to open a new test
issue in kubernetes-analysis. This works because I enabled the plugin
also for issues rather than only for pull requests.
So then, we have a running CI bot which is able to classify new release notes based on a machine learning model. If the bot would run in the official Kubernetes repository, then we could correct wrong label predictions manually. This way, the next training iteration would pick up the correction and result in a continuously improved model over time. All totally automated!
Summary
Thank you for reading down to here! This was my little data science journey
through the Kubernetes GitHub repository. There are a lot of other things to
optimize, for example introducing more classes (than just kind/bug or nothing)
or automatic hyperparameter tuning with Kubeflows Katib. If you have any
questions or suggestions, then feel free to get in touch with me anytime. See you
soon!
An Introduction to the K8s-Infrastructure Working Group
Author: Kiran "Rin" Oliver Storyteller, Kubernetes Upstream Marketing Team
An Introduction to the K8s-Infrastructure Working Group
Welcome to part one of a new series introducing the K8s-Infrastructure working group!
When Kubernetes was formed in 2014, Google undertook the task of building and maintaining the infrastructure necessary for keeping the project running smoothly. The tools itself were open source, but the Google Cloud Platform project used to run the infrastructure was internal-only, preventing contributors from being able to help out. In August 2018, Google granted the Cloud Native Computing Foundation $9M in credits for the operation of Kubernetes. The sentiment behind this was that a project such as Kubernetes should be both maintained and operated by the community itself rather than by a single vendor.
A group of community members enthusiastically undertook the task of collaborating on the path forward, realizing that there was a more formal infrastructure necessary. They joined together as a cross-team working group with ownership spanning across multiple Kubernetes SIGs (Architecture, Contributor Experience, Release, and Testing). Aaron Crickenberger worked with the Kubernetes Steering Committee to enable the formation of the working group, co-drafting a charter alongside long-time collaborator Davanum Srinivas, and by 2019 the working group was official.
What Issues Does the K8s-Infrastructure Working Group Tackle?
The team took on the complex task of managing the many moving parts of the infrastructure that sustains Kubernetes as a project.
The need started with necessity: the first problem they took on was a complete migration of all of the project's infrastructure from Google-owned infrastructure to the Cloud Native Computing Foundation (CNCF). This is being done so that the project is self-sustainable without the need of any direct assistance from individual vendors. This breaks down in the following ways:
- Identifying what infrastructure the Kubernetes project depends on.
- What applications are running?
- Where does it run?
- Where is its source code?
- What is custom built?
- What is off-the-shelf?
- What services depend on each other?
- How is it administered?
- Documenting guidelines and policies for how to run the infrastructure as a community.
- What are our access policies?
- How do we keep track of billing?
- How do we ensure privacy and security?
- Migrating infrastructure over to the CNCF as-is.
- What is the path of least resistance to migration?
- Improving the state of the infrastructure for sustainability.
- Moving from humans running scripts to a more automated GitOps model (YAML all the things!)
- Supporting community members who wish to develop new infrastructure
- Documenting the state of our efforts, better defining goals, and completeness indicators.
- The project and program management necessary to communicate this work to our massive community of contributors
The challenge of K8s-Infrastructure is documentation
The most crucial problem the working group is trying to tackle is that the project is all volunteer-led. This leads to contributors, chairs, and others involved in the project quickly becoming overscheduled. As a result of this, certain areas such as documentation and organization often lack information, and efforts to progress are taking longer than the group would like to complete.
Some of the infrastructure that is being migrated over hasn't been updated in a while, and its original authors or directly responsible individuals have moved on from working on Kubernetes. While this is great from the perspective of the fact that the code was able to run untouched for a long period of time, from the perspective of trying to migrate, this makes it difficult to identify how to operate these components, and how to move these infrastructure pieces where they need to be effectively.
The lack of documentation is being addressed head-on by group member Bart Smykla, but there is a definite need for others to support. If you're looking for a way to get involved and learn the infrastructure, you can become a new contributor to the working group!
Celebrating some Working Group wins
The team has made progress in the last few months that is well worth celebrating.
- The K8s-Infrastructure Working Group released an automated billing report that they start every meeting off by reviewing as a group.
- DNS for k8s.io and kubernetes.io are also fully community-owned, with community members able to file issues to manage records.
- The container registry k8s.gcr.io is also fully community-owned and available for all Kubernetes subprojects to use.
- The Kubernetes publishing-bot responsible for keeping k8s.io/kubernetes/staging repositories published to their own top-level repos (For example: kubernetes/api) runs on a community-owned cluster.
- The gcsweb.k8s.io service used to provide anonymous access to GCS buckets for kubernetes artifacts runs on a community-owned cluster.
- There is also an automated process of promoting all our container images. This includes a fully documented infrastructure, managed by the Kubernetes community, with automated processes for provisioning permissions.
These are just a few of the things currently happening in the K8s Infrastructure working group.
If you're interested in getting involved, be sure to join the #wg-K8s-infra Slack Channel. Meetings are 60 minutes long, and are held every other Wednesday at 8:30 AM PT/16:30 UTC.
Join to help with the documentation, stay to learn about the amazing infrastructure supporting the Kubernetes community.
WSL+Docker: Kubernetes on the Windows Desktop
Authors: Nuno do Carmo Docker Captain and WSL Corsair; Ihor Dvoretskyi, Developer Advocate, Cloud Native Computing Foundation
Introduction
New to Windows 10 and WSL2, or new to Docker and Kubernetes? Welcome to this blog post where we will install from scratch Kubernetes in Docker KinD and Minikube.
Why Kubernetes on Windows?
For the last few years, Kubernetes became a de-facto standard platform for running containerized services and applications in distributed environments. While a wide variety of distributions and installers exist to deploy Kubernetes in the cloud environments (public, private or hybrid), or within the bare metal environments, there is still a need to deploy and run Kubernetes locally, for example, on the developer's workstation.
Kubernetes has been originally designed to be deployed and used in the Linux environments. However, a good number of users (and not only application developers) use Windows OS as their daily driver. When Microsoft revealed WSL - the Windows Subsystem for Linux, the line between Windows and Linux environments became even less visible.
Also, WSL brought an ability to run Kubernetes on Windows almost seamlessly!
Below, we will cover in brief how to install and use various solutions to run Kubernetes locally.
Prerequisites
Since we will explain how to install KinD, we won't go into too much detail around the installation of KinD's dependencies.
However, here is the list of the prerequisites needed and their version/lane:
- OS: Windows 10 version 2004, Build 19041
- WSL2 enabled
- In order to install the distros as WSL2 by default, once WSL2 installed, run the command
wsl.exe --set-default-version 2in Powershell
- In order to install the distros as WSL2 by default, once WSL2 installed, run the command
- WSL2 distro installed from the Windows Store - the distro used is Ubuntu-18.04
- Docker Desktop for Windows, stable channel - the version used is 2.2.0.4
- [Optional] Microsoft Terminal installed from the Windows Store
- Open the Windows store and type "Terminal" in the search, it will be (normally) the first option
And that's actually it. For Docker Desktop for Windows, no need to configure anything yet as we will explain it in the next section.
WSL2: First contact
Once everything is installed, we can launch the WSL2 terminal from the Start menu, and type "Ubuntu" for searching the applications and documents:
Once found, click on the name and it will launch the default Windows console with the Ubuntu bash shell running.
Like for any normal Linux distro, you need to create a user and set a password:
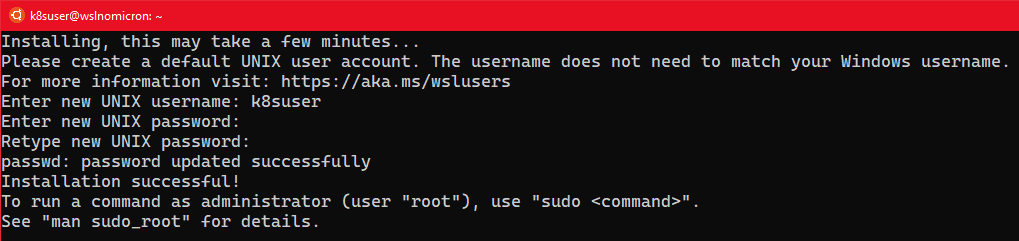
[Optional] Update the sudoers
As we are working, normally, on our local computer, it might be nice to update the sudoers and set the group %sudo to be password-less:
# Edit the sudoers with the visudo command
sudo visudo
# Change the %sudo group to be password-less
%sudo ALL=(ALL:ALL) NOPASSWD: ALL
# Press CTRL+X to exit
# Press Y to save
# Press Enter to confirm
Update Ubuntu
Before we move to the Docker Desktop settings, let's update our system and ensure we start in the best conditions:
# Update the repositories and list of the packages available
sudo apt update
# Update the system based on the packages installed > the "-y" will approve the change automatically
sudo apt upgrade -y
Docker Desktop: faster with WSL2
Before we move into the settings, let's do a small test, it will display really how cool the new integration with Docker Desktop is:
# Try to see if the docker cli and daemon are installed
docker version
# Same for kubectl
kubectl version
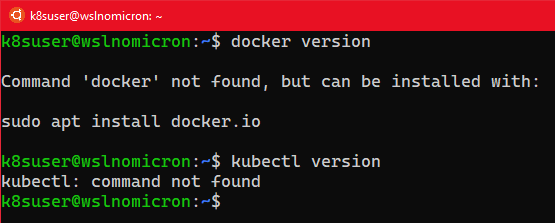
You got an error? Perfect! It's actually good news, so let's now move on to the settings.
Docker Desktop settings: enable WSL2 integration
First let's start Docker Desktop for Windows if it's not still the case. Open the Windows start menu and type "docker", click on the name to start the application:
You should now see the Docker icon with the other taskbar icons near the clock:

Now click on the Docker icon and choose settings. A new window will appear:
By default, the WSL2 integration is not active, so click the "Enable the experimental WSL 2 based engine" and click "Apply & Restart":
What this feature did behind the scenes was to create two new distros in WSL2, containing and running all the needed backend sockets, daemons and also the CLI tools (read: docker and kubectl command).
Still, this first setting is still not enough to run the commands inside our distro. If we try, we will have the same error as before.
In order to fix it, and finally be able to use the commands, we need to tell the Docker Desktop to "attach" itself to our distro also:
Let's now switch back to our WSL2 terminal and see if we can (finally) launch the commands:
# Try to see if the docker cli and daemon are installed
docker version
# Same for kubectl
kubectl version
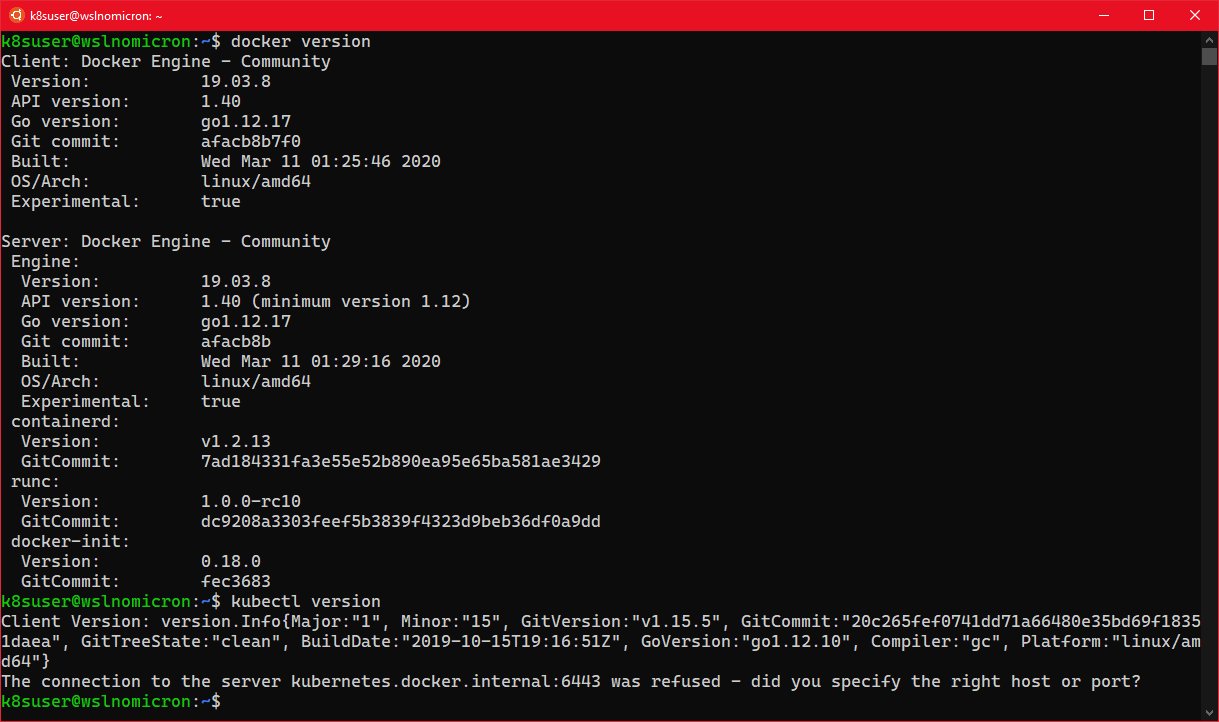
Tip: if nothing happens, restart Docker Desktop and restart the WSL process in Powershell:
Restart-Service LxssManagerand launch a new Ubuntu session
And success! The basic settings are now done and we move to the installation of KinD.
KinD: Kubernetes made easy in a container
Right now, we have Docker that is installed, configured and the last test worked fine.
However, if we look carefully at the kubectl command, it found the "Client Version" (1.15.5), but it didn't find any server.
This is normal as we didn't enable the Docker Kubernetes cluster. So let's install KinD and create our first cluster.
And as sources are always important to mention, we will follow (partially) the how-to on the official KinD website:
# Download the latest version of KinD
curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/download/v0.7.0/kind-linux-amd64
# Make the binary executable
chmod +x ./kind
# Move the binary to your executable path
sudo mv ./kind /usr/local/bin/

KinD: the first cluster
We are ready to create our first cluster:
# Check if the KUBECONFIG is not set
echo $KUBECONFIG
# Check if the .kube directory is created > if not, no need to create it
ls $HOME/.kube
# Create the cluster and give it a name (optional)
kind create cluster --name wslkind
# Check if the .kube has been created and populated with files
ls $HOME/.kube
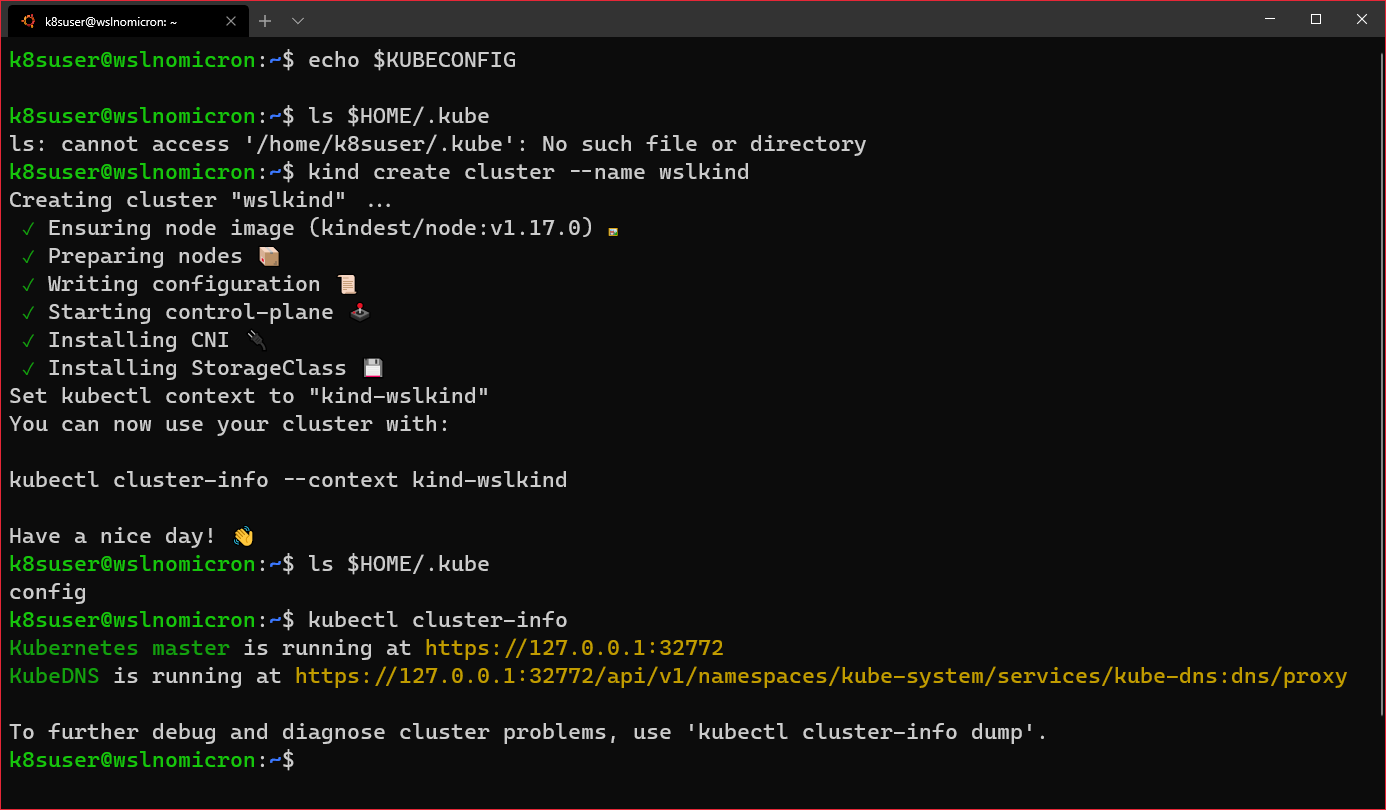
Tip: as you can see, the Terminal was changed so the nice icons are all displayed
The cluster has been successfully created, and because we are using Docker Desktop, the network is all set for us to use "as is".
So we can open the Kubernetes master URL in our Windows browser:
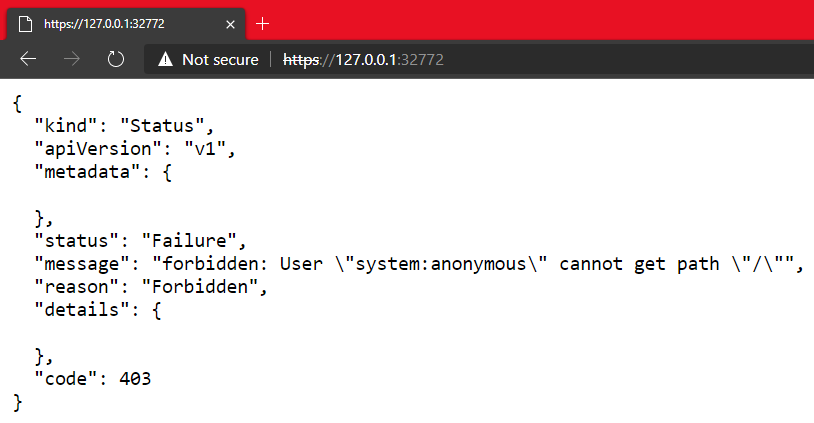
And this is the real strength from Docker Desktop for Windows with the WSL2 backend. Docker really did an amazing integration.
KinD: counting 1 - 2 - 3
Our first cluster was created and it's the "normal" one node cluster:
# Check how many nodes it created
kubectl get nodes
# Check the services for the whole cluster
kubectl get all --all-namespaces
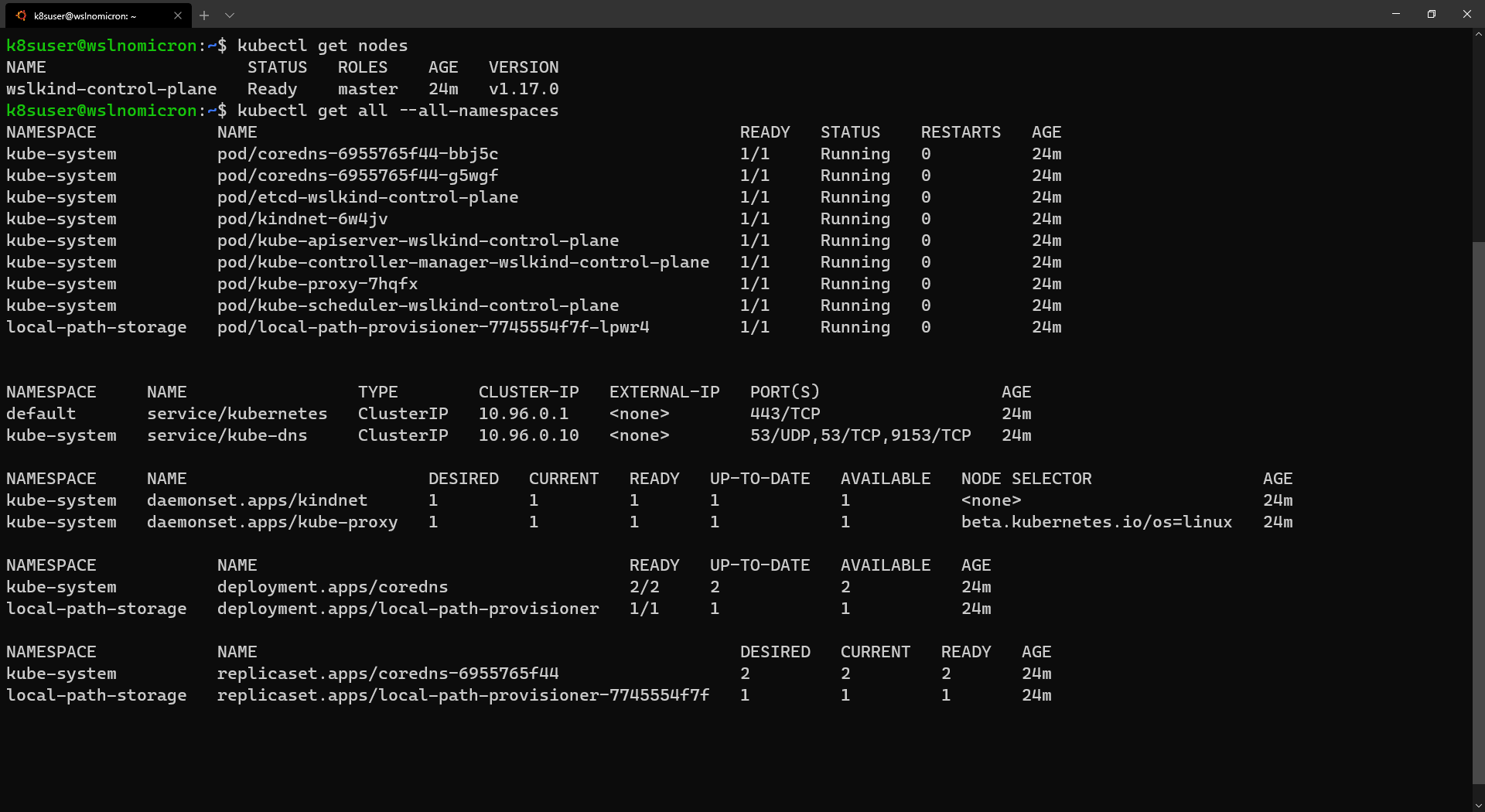
While this will be enough for most people, let's leverage one of the coolest feature, multi-node clustering:
# Delete the existing cluster
kind delete cluster --name wslkind
# Create a config file for a 3 nodes cluster
cat << EOF > kind-3nodes.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
EOF
# Create a new cluster with the config file
kind create cluster --name wslkindmultinodes --config ./kind-3nodes.yaml
# Check how many nodes it created
kubectl get nodes
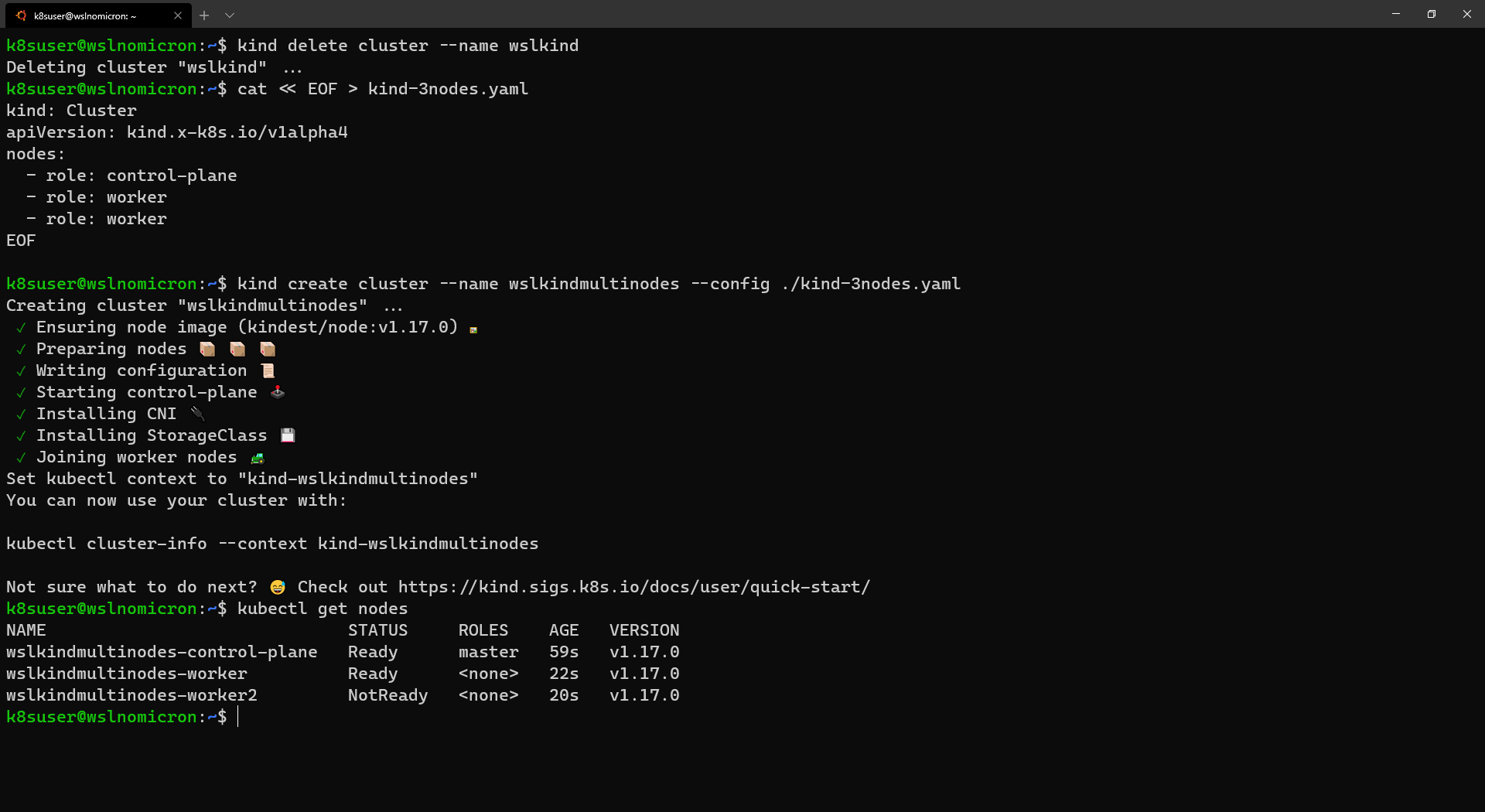
Tip: depending on how fast we run the "get nodes" command, it can be that not all the nodes are ready, wait few seconds and run it again, everything should be ready
And that's it, we have created a three-node cluster, and if we look at the services one more time, we will see several that have now three replicas:
# Check the services for the whole cluster
kubectl get all --all-namespaces
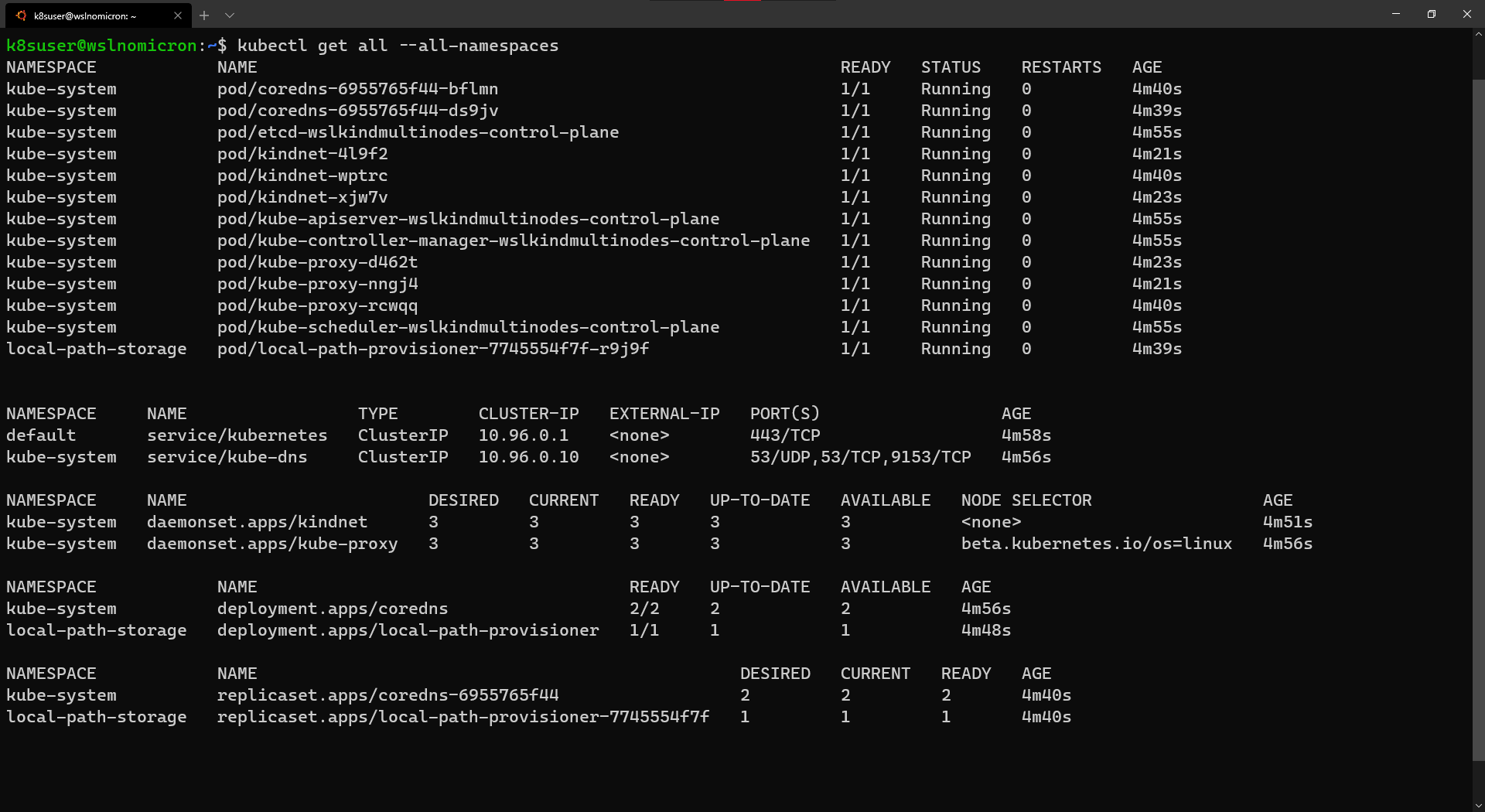
KinD: can I see a nice dashboard?
Working on the command line is always good and very insightful. However, when dealing with Kubernetes we might want, at some point, to have a visual overview.
For that, the Kubernetes Dashboard project has been created. The installation and first connection test is quite fast, so let's do it:
# Install the Dashboard application into our cluster
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc6/aio/deploy/recommended.yaml
# Check the resources it created based on the new namespace created
kubectl get all -n kubernetes-dashboard
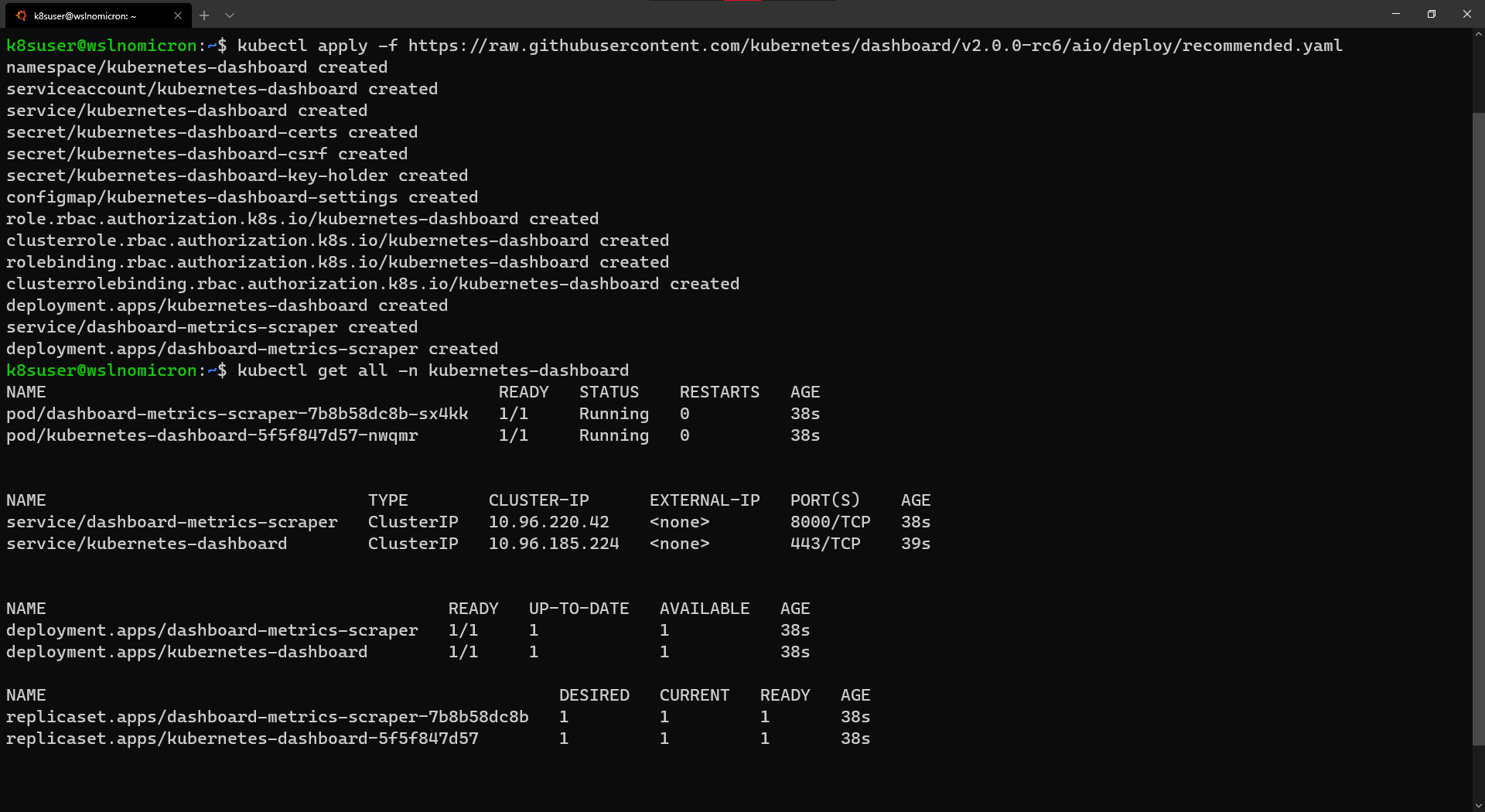
As it created a service with a ClusterIP (read: internal network address), we cannot reach it if we type the URL in our Windows browser:
That's because we need to create a temporary proxy:
# Start a kubectl proxy
kubectl proxy
# Enter the URL on your browser: http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
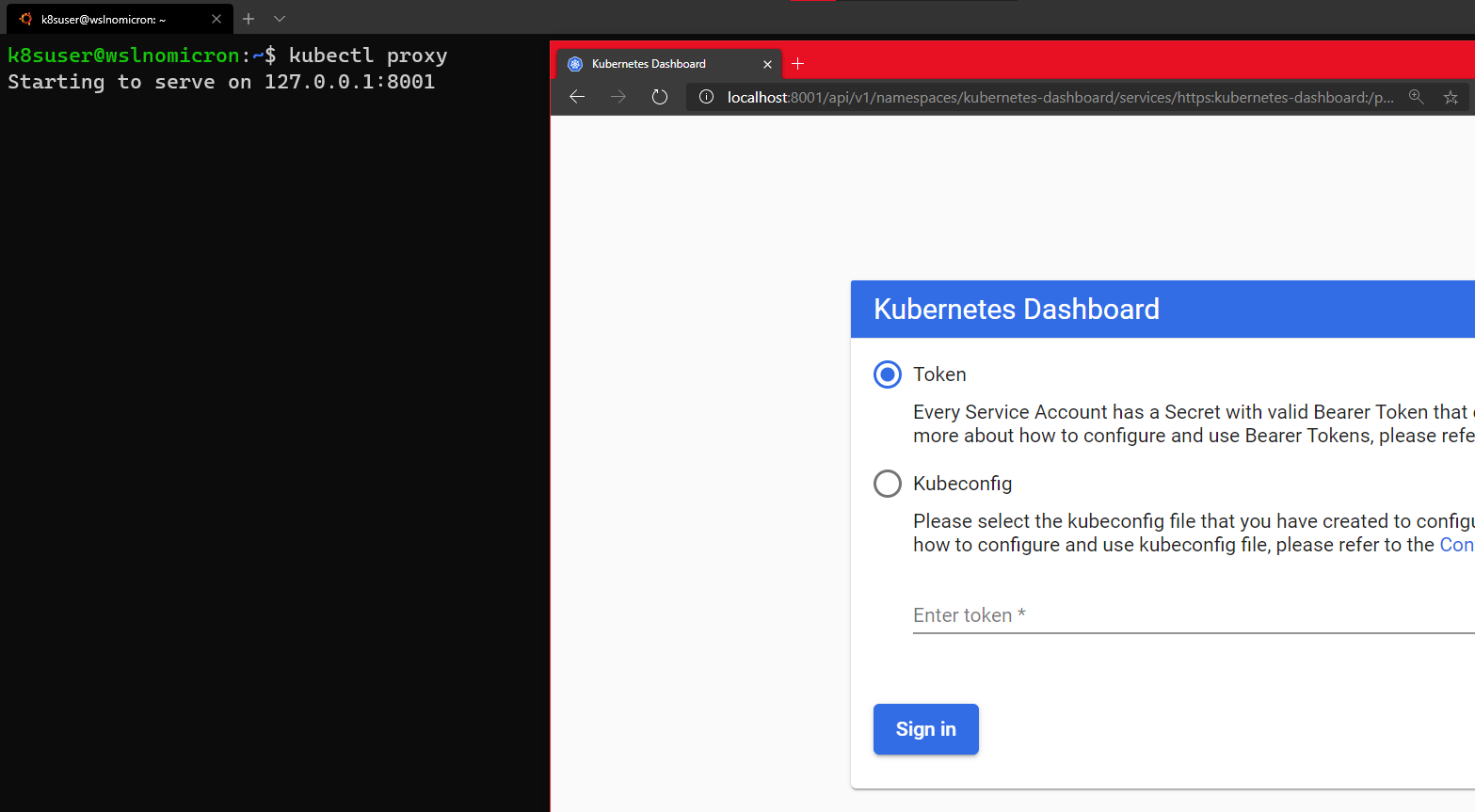
Finally to login, we can either enter a Token, which we didn't create, or enter the kubeconfig file from our Cluster.
If we try to login with the kubeconfig, we will get the error "Internal error (500): Not enough data to create auth info structure". This is due to the lack of credentials in the kubeconfig file.
So to avoid you ending with the same error, let's follow the recommended RBAC approach.
Let's open a new WSL2 session:
# Create a new ServiceAccount
kubectl apply -f - <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
EOF
# Create a ClusterRoleBinding for the ServiceAccount
kubectl apply -f - <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
# Get the Token for the ServiceAccount
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
# Copy the token and copy it into the Dashboard login and press "Sign in"
Success! And let's see our nodes listed also:
A nice and shiny three nodes appear.
Minikube: Kubernetes from everywhere
Right now, we have Docker that is installed, configured and the last test worked fine.
However, if we look carefully at the kubectl command, it found the "Client Version" (1.15.5), but it didn't find any server.
This is normal as we didn't enable the Docker Kubernetes cluster. So let's install Minikube and create our first cluster.
And as sources are always important to mention, we will follow (partially) the how-to from the Kubernetes.io website:
# Download the latest version of Minikube
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
# Make the binary executable
chmod +x ./minikube
# Move the binary to your executable path
sudo mv ./minikube /usr/local/bin/

Minikube: updating the host
If we follow the how-to, it states that we should use the --driver=none flag in order to run Minikube directly on the host and Docker.
Unfortunately, we will get an error about "conntrack" being required to run Kubernetes v 1.18:
# Create a minikube one node cluster
minikube start --driver=none

Tip: as you can see, the Terminal was changed so the nice icons are all displayed
So let's fix the issue by installing the missing package:
# Install the conntrack package
sudo apt install -y conntrack
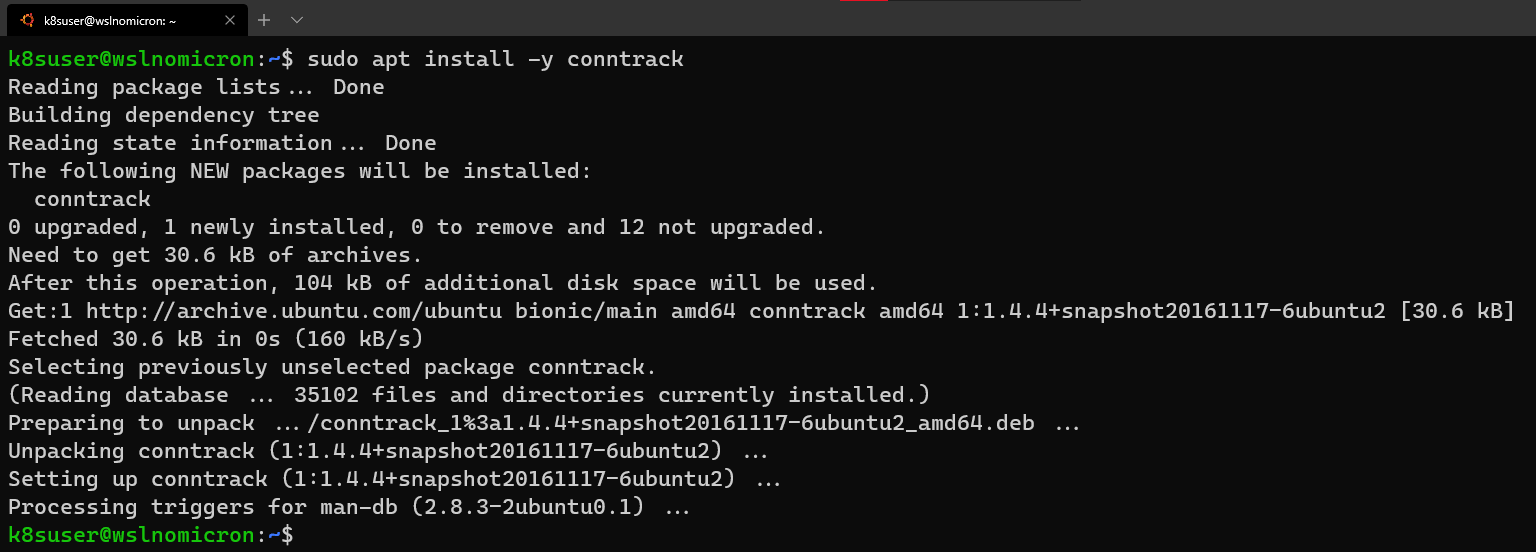
Let's try to launch it again:
# Create a minikube one node cluster
minikube start --driver=none
# We got a permissions error > try again with sudo
sudo minikube start --driver=none
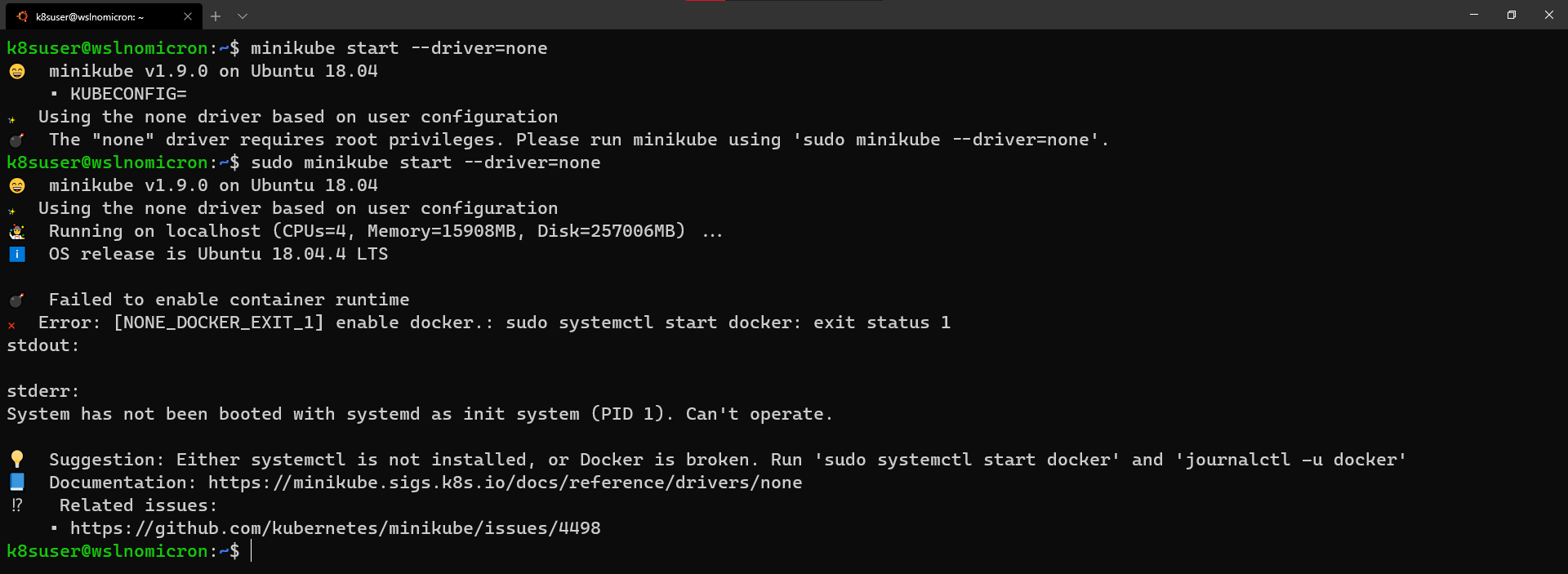
Ok, this error cloud be problematic ... in the past. Luckily for us, there's a solution
Minikube: enabling SystemD
In order to enable SystemD on WSL2, we will apply the scripts from Daniel Llewellyn.
I invite you to read the full blog post and how he came to the solution, and the various iterations he did to fix several issues.
So in a nutshell, here are the commands:
# Install the needed packages
sudo apt install -yqq daemonize dbus-user-session fontconfig
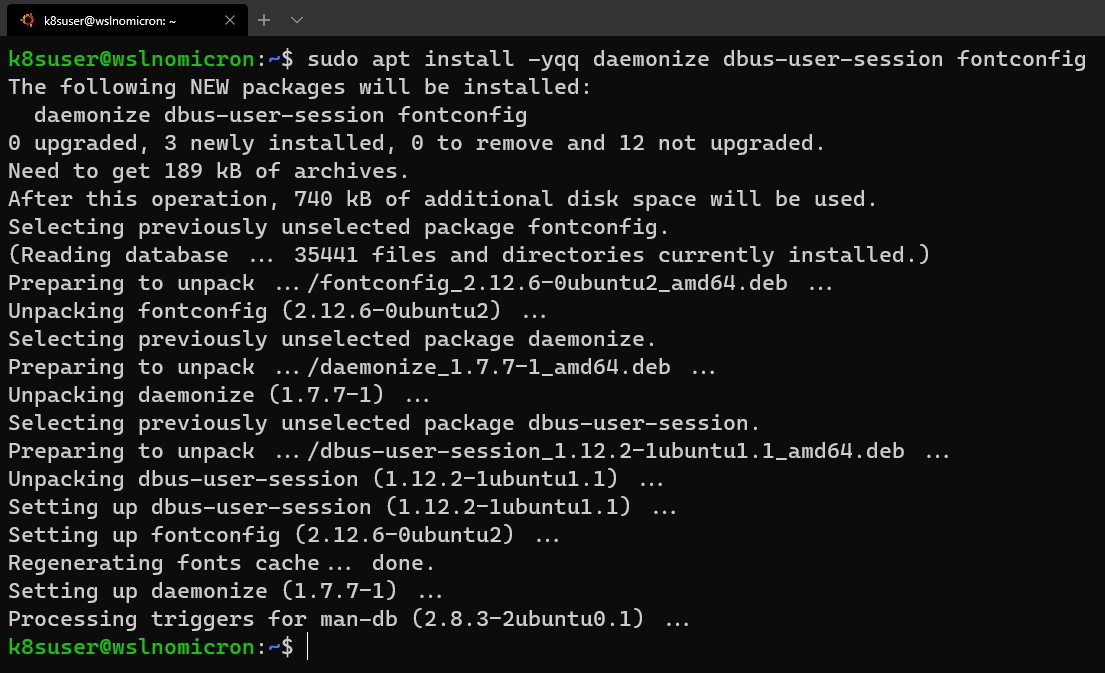
# Create the start-systemd-namespace script
sudo vi /usr/sbin/start-systemd-namespace
#!/bin/bash
SYSTEMD_PID=$(ps -ef | grep '/lib/systemd/systemd --system-unit=basic.target$' | grep -v unshare | awk '{print $2}')
if [ -z "$SYSTEMD_PID" ] || [ "$SYSTEMD_PID" != "1" ]; then
export PRE_NAMESPACE_PATH="$PATH"
(set -o posix; set) | \
grep -v "^BASH" | \
grep -v "^DIRSTACK=" | \
grep -v "^EUID=" | \
grep -v "^GROUPS=" | \
grep -v "^HOME=" | \
grep -v "^HOSTNAME=" | \
grep -v "^HOSTTYPE=" | \
grep -v "^IFS='.*"$'\n'"'" | \
grep -v "^LANG=" | \
grep -v "^LOGNAME=" | \
grep -v "^MACHTYPE=" | \
grep -v "^NAME=" | \
grep -v "^OPTERR=" | \
grep -v "^OPTIND=" | \
grep -v "^OSTYPE=" | \
grep -v "^PIPESTATUS=" | \
grep -v "^POSIXLY_CORRECT=" | \
grep -v "^PPID=" | \
grep -v "^PS1=" | \
grep -v "^PS4=" | \
grep -v "^SHELL=" | \
grep -v "^SHELLOPTS=" | \
grep -v "^SHLVL=" | \
grep -v "^SYSTEMD_PID=" | \
grep -v "^UID=" | \
grep -v "^USER=" | \
grep -v "^_=" | \
cat - > "$HOME/.systemd-env"
echo "PATH='$PATH'" >> "$HOME/.systemd-env"
exec sudo /usr/sbin/enter-systemd-namespace "$BASH_EXECUTION_STRING"
fi
if [ -n "$PRE_NAMESPACE_PATH" ]; then
export PATH="$PRE_NAMESPACE_PATH"
fi
# Create the enter-systemd-namespace
sudo vi /usr/sbin/enter-systemd-namespace
#!/bin/bash
if [ "$UID" != 0 ]; then
echo "You need to run $0 through sudo"
exit 1
fi
SYSTEMD_PID="$(ps -ef | grep '/lib/systemd/systemd --system-unit=basic.target$' | grep -v unshare | awk '{print $2}')"
if [ -z "$SYSTEMD_PID" ]; then
/usr/sbin/daemonize /usr/bin/unshare --fork --pid --mount-proc /lib/systemd/systemd --system-unit=basic.target
while [ -z "$SYSTEMD_PID" ]; do
SYSTEMD_PID="$(ps -ef | grep '/lib/systemd/systemd --system-unit=basic.target$' | grep -v unshare | awk '{print $2}')"
done
fi
if [ -n "$SYSTEMD_PID" ] && [ "$SYSTEMD_PID" != "1" ]; then
if [ -n "$1" ] && [ "$1" != "bash --login" ] && [ "$1" != "/bin/bash --login" ]; then
exec /usr/bin/nsenter -t "$SYSTEMD_PID" -a \
/usr/bin/sudo -H -u "$SUDO_USER" \
/bin/bash -c 'set -a; source "$HOME/.systemd-env"; set +a; exec bash -c '"$(printf "%q" "$@")"
else
exec /usr/bin/nsenter -t "$SYSTEMD_PID" -a \
/bin/login -p -f "$SUDO_USER" \
$(/bin/cat "$HOME/.systemd-env" | grep -v "^PATH=")
fi
echo "Existential crisis"
fi
# Edit the permissions of the enter-systemd-namespace script
sudo chmod +x /usr/sbin/enter-systemd-namespace
# Edit the bash.bashrc file
sudo sed -i 2a"# Start or enter a PID namespace in WSL2\nsource /usr/sbin/start-systemd-namespace\n" /etc/bash.bashrc
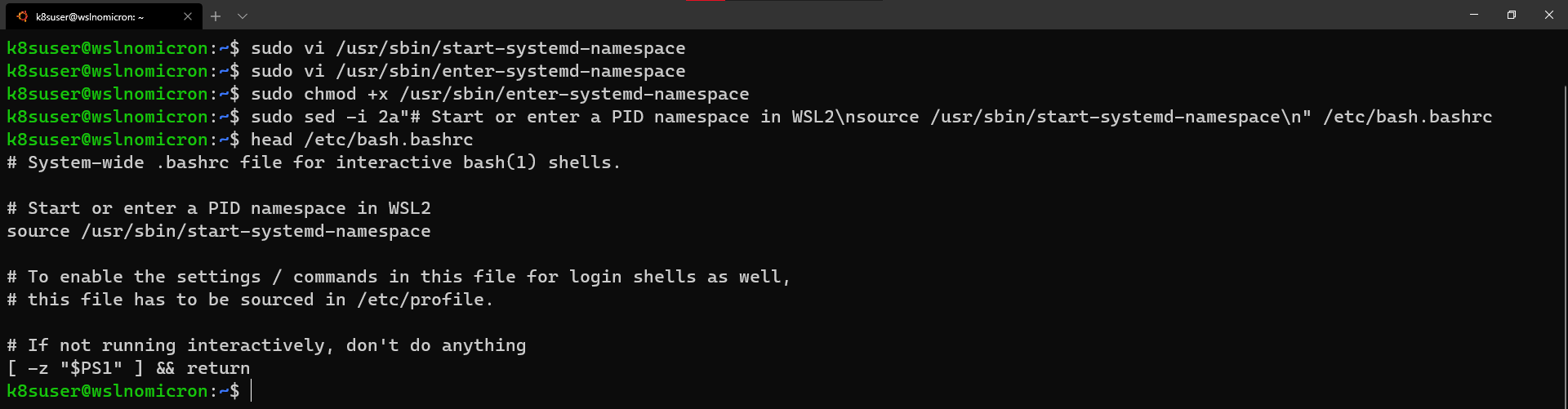
Finally, exit and launch a new session. You do not need to stop WSL2, a new session is enough:
Minikube: the first cluster
We are ready to create our first cluster:
# Check if the KUBECONFIG is not set
echo $KUBECONFIG
# Check if the .kube directory is created > if not, no need to create it
ls $HOME/.kube
# Check if the .minikube directory is created > if yes, delete it
ls $HOME/.minikube
# Create the cluster with sudo
sudo minikube start --driver=none
In order to be able to use kubectl with our user, and not sudo, Minikube recommends running the chown command:
# Change the owner of the .kube and .minikube directories
sudo chown -R $USER $HOME/.kube $HOME/.minikube
# Check the access and if the cluster is running
kubectl cluster-info
# Check the resources created
kubectl get all --all-namespaces
The cluster has been successfully created, and Minikube used the WSL2 IP, which is great for several reasons, and one of them is that we can open the Kubernetes master URL in our Windows browser:
And the real strength of WSL2 integration, the port 8443 once open on WSL2 distro, it actually forwards it to Windows, so instead of the need to remind the IP address, we can also reach the Kubernetes master URL via localhost:
Minikube: can I see a nice dashboard?
Working on the command line is always good and very insightful. However, when dealing with Kubernetes we might want, at some point, to have a visual overview.
For that, Minikube embeded the Kubernetes Dashboard. Thanks to it, running and accessing the Dashboard is very simple:
# Enable the Dashboard service
sudo minikube dashboard
# Access the Dashboard from a browser on Windows side
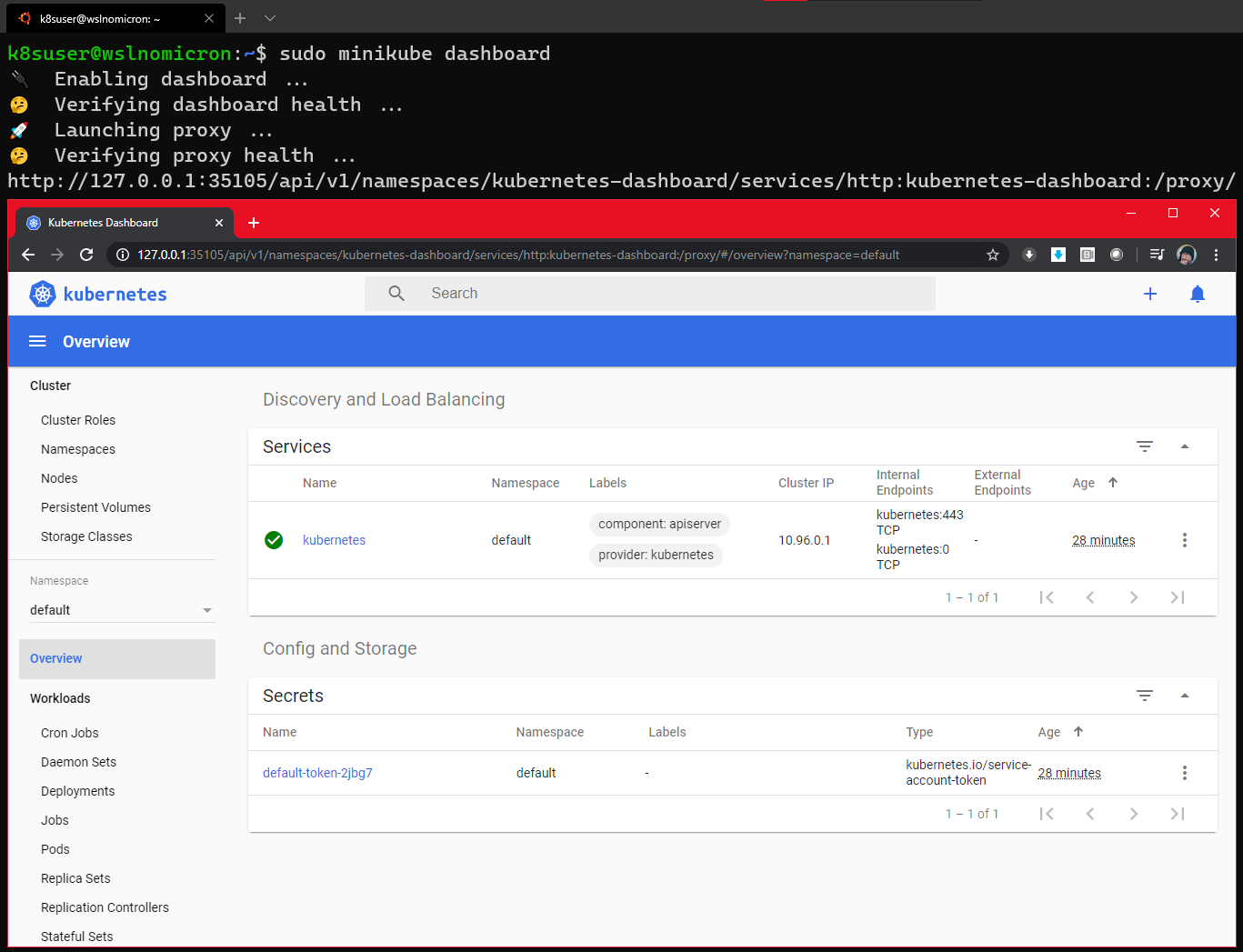
The command creates also a proxy, which means that once we end the command, by pressing CTRL+C, the Dashboard will no more be accessible.
Still, if we look at the namespace kubernetes-dashboard, we will see that the service is still created:
# Get all the services from the dashboard namespace
kubectl get all --namespace kubernetes-dashboard
Let's edit the service and change it's type to LoadBalancer:
# Edit the Dashoard service
kubectl edit service/kubernetes-dashboard --namespace kubernetes-dashboard
# Go to the very end and remove the last 2 lines
status:
loadBalancer: {}
# Change the type from ClusterIO to LoadBalancer
type: LoadBalancer
# Save the file
Check again the Dashboard service and let's access the Dashboard via the LoadBalancer:
# Get all the services from the dashboard namespace
kubectl get all --namespace kubernetes-dashboard
# Access the Dashboard from a browser on Windows side with the URL: localhost:<port exposed>
Conclusion
It's clear that we are far from done as we could have some LoadBalancing implemented and/or other services (storage, ingress, registry, etc...).
Concerning Minikube on WSL2, as it needed to enable SystemD, we can consider it as an intermediate level to be implemented.
So with two solutions, what could be the "best for you"? Both bring their own advantages and inconveniences, so here an overview from our point of view solely:
| Criteria | KinD | Minikube |
|---|---|---|
| Installation on WSL2 | Very Easy | Medium |
| Multi-node | Yes | No |
| Plugins | Manual install | Yes |
| Persistence | Yes, however not designed for | Yes |
| Alternatives | K3d | Microk8s |
We hope you could have a real taste of the integration between the different components: WSL2 - Docker Desktop - KinD/Minikube. And that gave you some ideas or, even better, some answers to your Kubernetes workflows with KinD and/or Minikube on Windows and WSL2.
See you soon for other adventures in the Kubernetes ocean.
How Docs Handle Third Party and Dual Sourced Content
Author: Zach Corleissen, Cloud Native Computing Foundation
Editor's note: Zach is one of the chairs for the Kubernetes documentation special interest group (SIG Docs).
Late last summer, SIG Docs started a community conversation about third party content in Kubernetes docs. This conversation became a Kubernetes Enhancement Proposal (KEP) and, after five months for review and comment, SIG Architecture approved the KEP as a content guide for Kubernetes docs.
Here's how Kubernetes docs handle third party content now:
Links to active content in the Kubernetes project (projects in the kubernetes and kubernetes-sigs GitHub orgs) are always allowed.
Kubernetes requires some third party content to function. Examples include container runtimes (containerd, CRI-O, Docker), networking policy (CNI plugins), Ingress controllers, and logging.
Docs can link to third party open source software (OSS) outside the Kubernetes project if it’s necessary for Kubernetes to function.
These common sense guidelines make sure that Kubernetes docs document Kubernetes.
Keeping the docs focused
Our goal is for Kubernetes docs to be a trustworthy guide to Kubernetes features. To achieve this goal, SIG Docs is tracking third party content and removing any third party content that isn't both in the Kubernetes project and required for Kubernetes to function.
Re-homing content
Some content will be removed that readers may find helpful. To make sure readers have continous access to information, we're giving stakeholders until the 1.19 release deadline for docs, July 9th, 2020 to re-home any content slated for removal.
Over the next few months you'll see less third party content in the docs as contributors open PRs to remove content.
Background
Over time, SIG Docs observed increasing vendor content in the docs. Some content took the form of vendor-specific implementations that aren't required for Kubernetes to function in-project. Other content was thinly-disguised advertising with minimal to no feature content. Some vendor content was new; other content had been in the docs for years. It became clear that the docs needed clear, well-bounded guidelines for what kind of third party content is and isn't allowed. The content guide emerged from an extensive period for review and comment from the community.
Docs work best when they're accurate, helpful, trustworthy, and remain focused on features. In our experience, vendor content dilutes trust and accuracy.
Put simply: feature docs aren't a place for vendors to advertise their products. Our content policy keeps the docs focused on helping developers and cluster admins, not on marketing.
Dual sourced content
Less impactful but also important is how Kubernetes docs handle dual-sourced content. Dual-sourced content is content published in more than one location, or from a non-canonical source.
From the Kubernetes content guide:
Wherever possible, Kubernetes docs link to canonical sources instead of hosting dual-sourced content.
Minimizing dual-sourced content streamlines the docs and makes content across the Web more searchable. We're working to consolidate and redirect dual-sourced content in the Kubernetes docs as well.
Ways to contribute
We're tracking third-party content in an issue in the Kubernetes website repository. If you see third party content that's out of project and isn't required for Kubernetes to function, please comment on the tracking issue.
Feel free to open a PR that removes non-conforming content once you've identified it!
Want to know more?
For more information, read the issue description for tracking third party content.
Introducing PodTopologySpread
Author: Wei Huang (IBM), Aldo Culquicondor (Google)
Managing Pods distribution across a cluster is hard. The well-known Kubernetes features for Pod affinity and anti-affinity, allow some control of Pod placement in different topologies. However, these features only resolve part of Pods distribution use cases: either place unlimited Pods to a single topology, or disallow two Pods to co-locate in the same topology. In between these two extreme cases, there is a common need to distribute the Pods evenly across the topologies, so as to achieve better cluster utilization and high availability of applications.
The PodTopologySpread scheduling plugin (originally proposed as EvenPodsSpread) was designed to fill that gap. We promoted it to beta in 1.18.
API changes
A new field topologySpreadConstraints is introduced in the Pod's spec API:
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
As this API is embedded in Pod's spec, you can use this feature in all the high-level workload APIs, such as Deployment, DaemonSet, StatefulSet, etc.
Let's see an example of a cluster to understand this API.
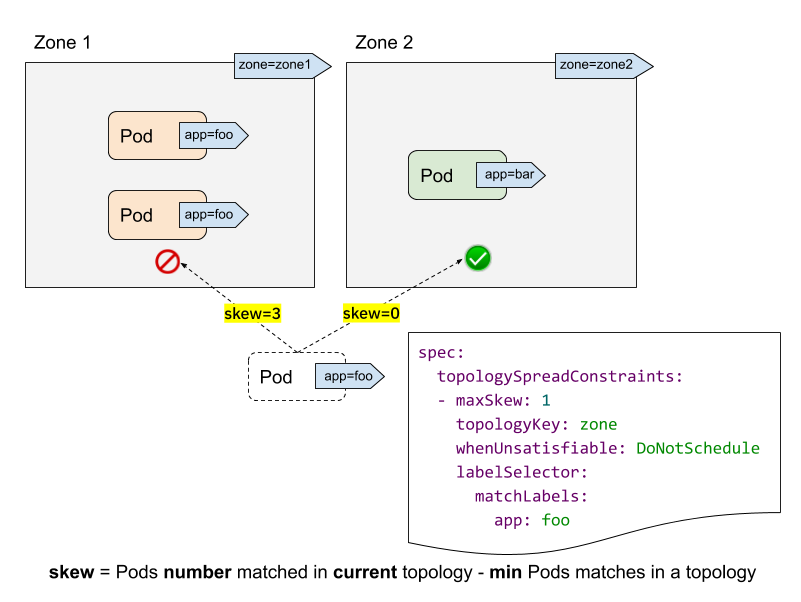
- labelSelector is used to find matching Pods. For each topology, we count the number of Pods that match this label selector. In the above example, given the labelSelector as "app: foo", the matching number in "zone1" is 2; while the number in "zone2" is 0.
- topologyKey is the key that defines a topology in the Nodes' labels. In the above example, some Nodes are grouped into "zone1" if they have the label "zone=zone1" label; while other ones are grouped into "zone2".
- maxSkew describes the maximum degree to which Pods can be unevenly
distributed. In the above example:
- if we put the incoming Pod to "zone1", the skew on "zone1" will become 3 (3 Pods matched in "zone1"; global minimum of 0 Pods matched on "zone2"), which violates the "maxSkew: 1" constraint.
- if the incoming Pod is placed to "zone2", the skew on "zone2" is 0 (1 Pod matched in "zone2"; global minimum of 1 Pod matched on "zone2" itself), which satisfies the "maxSkew: 1" constraint. Note that the skew is calculated per each qualified Node, instead of a global skew.
- whenUnsatisfiable specifies, when "maxSkew" can't be satisfied, what
action should be taken:
DoNotSchedule(default) tells the scheduler not to schedule it. It's a hard constraint.ScheduleAnywaytells the scheduler to still schedule it while prioritizing Nodes that reduce the skew. It's a soft constraint.
Advanced usage
As the feature name "PodTopologySpread" implies, the basic usage of this feature is to run your workload with an absolute even manner (maxSkew=1), or relatively even manner (maxSkew>=2). See the official document for more details.
In addition to this basic usage, there are some advanced usage examples that enable your workloads to benefit on high availability and cluster utilization.
Usage along with NodeSelector / NodeAffinity
You may have found that we didn't have a "topologyValues" field to limit which topologies the Pods are going to be scheduled to. By default, it is going to search all Nodes and group them by "topologyKey". Sometimes this may not be the ideal case. For instance, suppose there is a cluster with Nodes tagged with "env=prod", "env=staging" and "env=qa", and now you want to evenly place Pods to the "qa" environment across zones, is it possible?
The answer is yes. You can leverage the NodeSelector or NodeAffinity API spec. Under the hood, the PodTopologySpread feature will honor that and calculate the spread constraints among the nodes that satisfy the selectors.
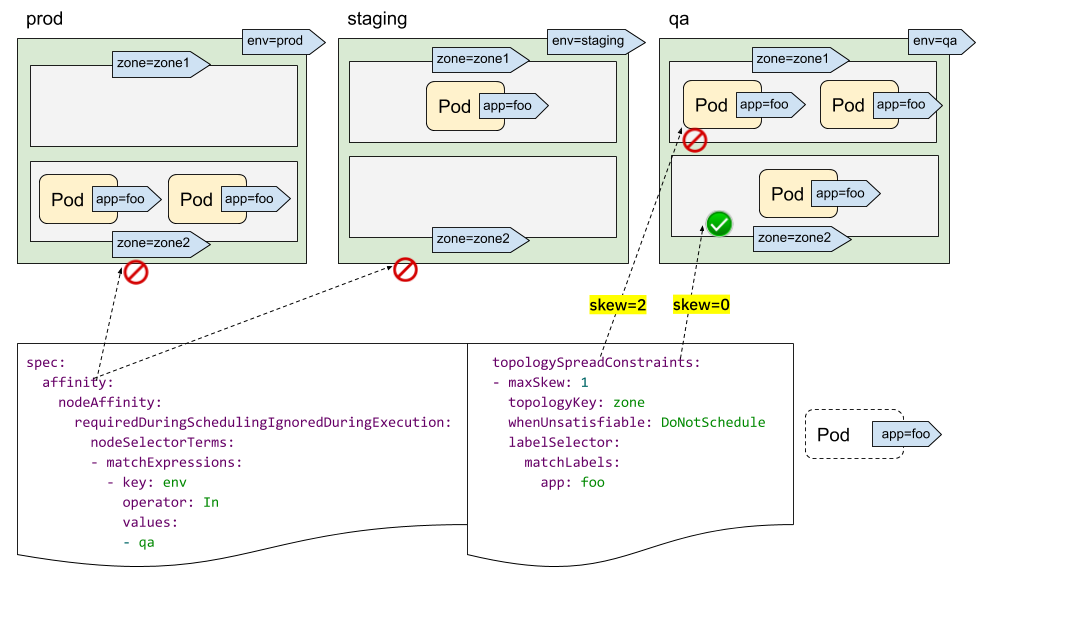
As illustrated above, you can specify spec.affinity.nodeAffinity to limit the
"searching scope" to be "qa" environment, and within that scope, the Pod will be
scheduled to one zone which satisfies the topologySpreadConstraints. In this
case, it's "zone2".
Multiple TopologySpreadConstraints
It's intuitive to understand how one single TopologySpreadConstraint works. What's the case for multiple TopologySpreadConstraints? Internally, each TopologySpreadConstraint is calculated independently, and the result sets will be merged to generate the eventual result set - i.e., suitable Nodes.
In the following example, we want to schedule a Pod to a cluster with 2 requirements at the same time:
- place the Pod evenly with Pods across zones
- place the Pod evenly with Pods across nodes
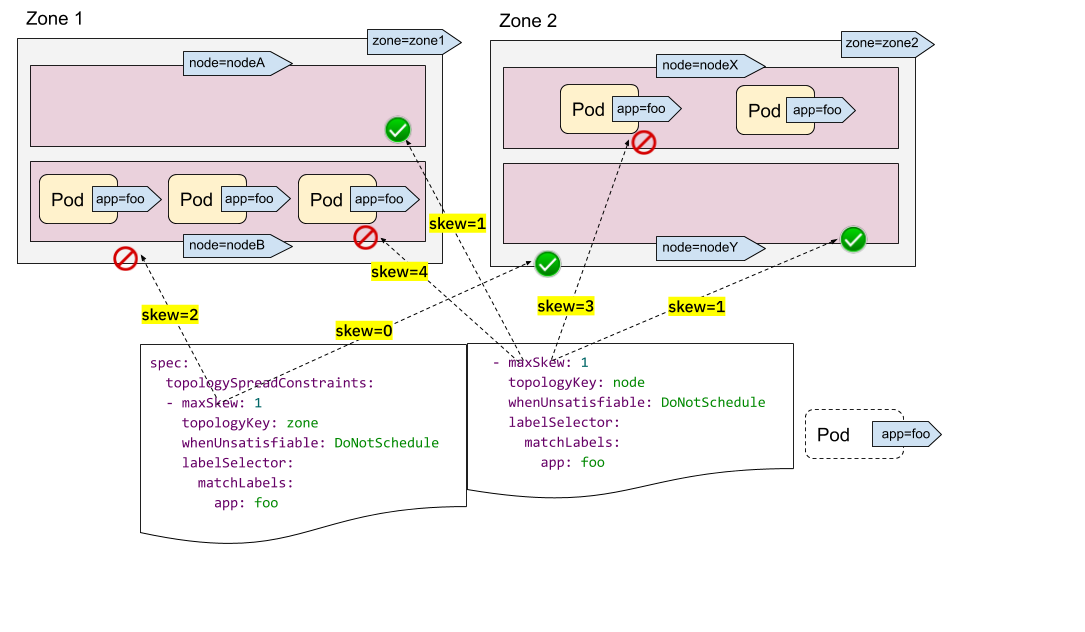
For the first constraint, there are 3 Pods in zone1 and 2 Pods in zone2, so the incoming Pod can be only put to zone2 to satisfy the "maxSkew=1" constraint. In other words, the result set is nodeX and nodeY.
For the second constraint, there are too many Pods in nodeB and nodeX, so the incoming Pod can be only put to nodeA and nodeY.
Now we can conclude the only qualified Node is nodeY - from the intersection of the sets {nodeX, nodeY} (from the first constraint) and {nodeA, nodeY} (from the second constraint).
Multiple TopologySpreadConstraints is powerful, but be sure to understand the difference with the preceding "NodeSelector/NodeAffinity" example: one is to calculate result set independently and then interjoined; while the other is to calculate topologySpreadConstraints based on the filtering results of node constraints.
Instead of using "hard" constraints in all topologySpreadConstraints, you can also combine using "hard" constraints and "soft" constraints to adhere to more diverse cluster situations.
PodTopologySpread defaults
PodTopologySpread is a Pod level API. As such, to use the feature, workload
authors need to be aware of the underlying topology of the cluster, and then
specify proper topologySpreadConstraints in the Pod spec for every workload.
While the Pod-level API gives the most flexibility it is also possible to
specify cluster-level defaults.
The default PodTopologySpread constraints allow you to specify spreading for all the workloads in the cluster, tailored for its topology. The constraints can be specified by an operator/admin as PodTopologySpread plugin arguments in the scheduling profile configuration API when starting kube-scheduler.
A sample configuration could look like this:
apiVersion: kubescheduler.config.k8s.io/v1alpha2
kind: KubeSchedulerConfiguration
profiles:
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: example.com/rack
whenUnsatisfiable: ScheduleAnyway
When configuring default constraints, label selectors must be left empty. kube-scheduler will deduce the label selectors from the membership of the Pod to Services, ReplicationControllers, ReplicaSets or StatefulSets. Pods can always override the default constraints by providing their own through the PodSpec.
Wrap-up
PodTopologySpread allows you to define spreading constraints for your workloads with a flexible and expressive Pod-level API. In the past, workload authors used Pod AntiAffinity rules to force or hint the scheduler to run a single Pod per topology domain. In contrast, the new PodTopologySpread constraints allow Pods to specify skew levels that can be required (hard) or desired (soft). The feature can be paired with Node selectors and Node affinity to limit the spreading to specific domains. Pod spreading constraints can be defined for different topologies such as hostnames, zones, regions, racks, etc.
Lastly, cluster operators can define default constraints to be applied to all Pods. This way, Pods don't need to be aware of the underlying topology of the cluster.
Two-phased Canary Rollout with Open Source Gloo
Author: Rick Ducott | GitHub | Twitter
Every day, my colleagues and I are talking to platform owners, architects, and engineers who are using Gloo as an API gateway to expose their applications to end users. These applications may span legacy monoliths, microservices, managed cloud services, and Kubernetes clusters. Fortunately, Gloo makes it easy to set up routes to manage, secure, and observe application traffic while supporting a flexible deployment architecture to meet the varying production needs of our users.
Beyond the initial set up, platform owners frequently ask us to help design the operational workflows within their organization: How do we bring a new application online? How do we upgrade an application? How do we divide responsibilities across our platform, ops, and development teams?
In this post, we're going to use Gloo to design a two-phased canary rollout workflow for application upgrades:
- In the first phase, we'll do canary testing by shifting a small subset of traffic to the new version. This allows you to safely perform smoke and correctness tests.
- In the second phase, we'll progressively shift traffic to the new version, allowing us to monitor the new version under load, and eventually, decommission the old version.
To keep it simple, we're going to focus on designing the workflow using open source Gloo, and we're going to deploy the gateway and application to Kubernetes. At the end, we'll talk about a few extensions and advanced topics that could be interesting to explore in a follow up.
Initial setup
To start, we need a Kubernetes cluster. This example doesn't take advantage of any cloud specific
features, and can be run against a local test cluster such as minikube.
This post assumes a basic understanding of Kubernetes and how to interact with it using kubectl.
We'll install the latest open source Gloo to the gloo-system namespace and deploy
version v1 of an example application to the echo namespace. We'll expose this application outside the cluster
by creating a route in Gloo, to end up with a picture like this:
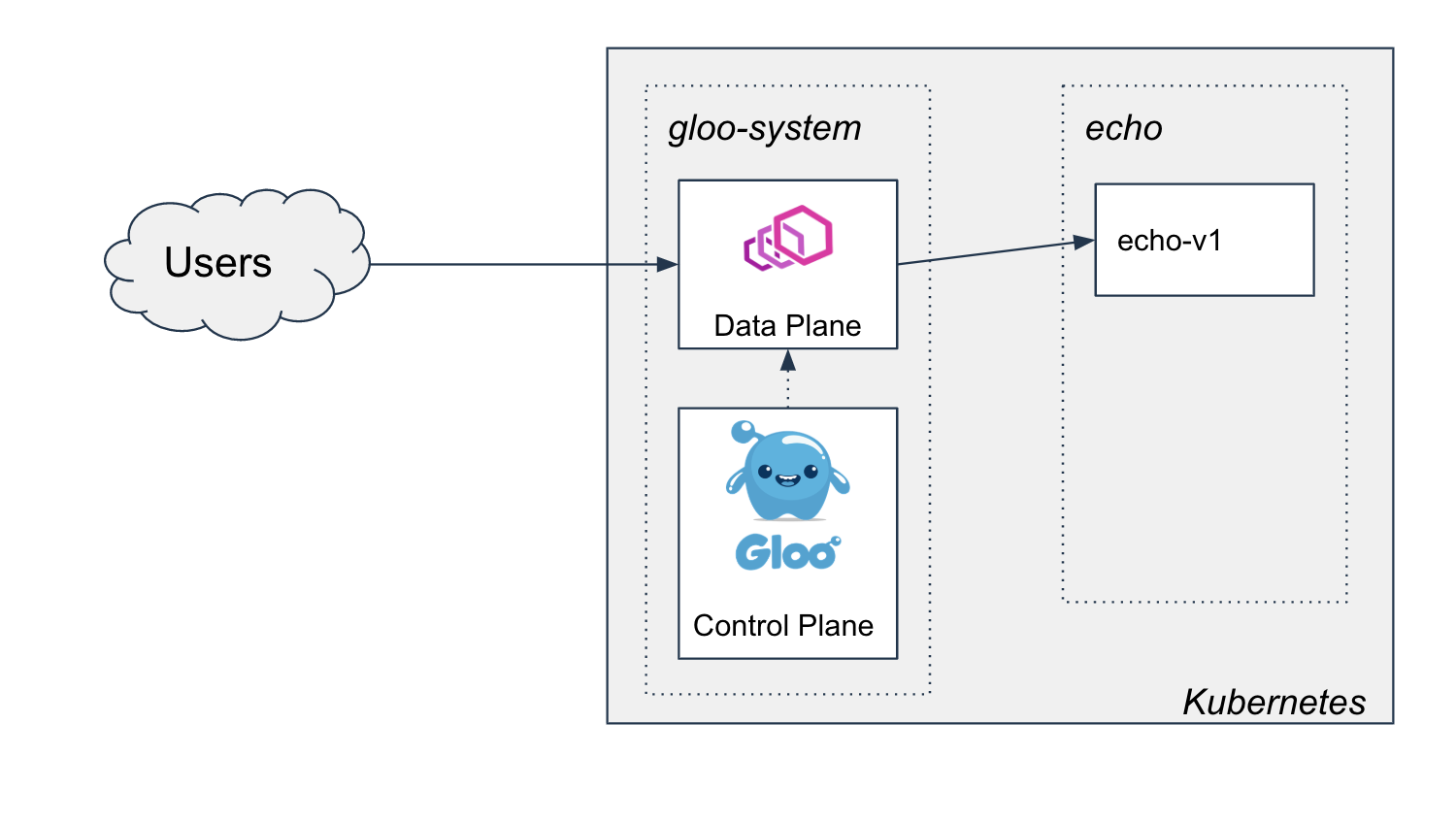
Deploying Gloo
We'll install gloo with the glooctl command line tool, which we can download and add to the PATH with the following
commands:
curl -sL https://run.solo.io/gloo/install | sh
export PATH=$HOME/.gloo/bin:$PATH
Now, you should be able to run glooctl version to see that it is installed correctly:
➜ glooctl version
Client: {"version":"1.3.15"}
Server: version undefined, could not find any version of gloo running
Now we can install the gateway to our cluster with a simple command:
glooctl install gateway
The console should indicate the install finishes successfully:
Creating namespace gloo-system... Done.
Starting Gloo installation...
Gloo was successfully installed!
Before long, we can see all the Gloo pods running in the gloo-system namespace:
➜ kubectl get pod -n gloo-system
NAME READY STATUS RESTARTS AGE
discovery-58f8856bd7-4fftg 1/1 Running 0 13s
gateway-66f86bc8b4-n5crc 1/1 Running 0 13s
gateway-proxy-5ff99b8679-tbp65 1/1 Running 0 13s
gloo-66b8dc8868-z5c6r 1/1 Running 0 13s
Deploying the application
Our echo application is a simple container (thanks to our friends at HashiCorp) that will
respond with the application version, to help demonstrate our canary workflows as we start testing and
shifting traffic to a v2 version of the application.
Kubernetes gives us a lot of flexibility in terms of modeling this application. We'll adopt the following conventions:
- We'll include the version in the deployment name so we can run two versions of the application side-by-side and manage their lifecycle differently.
- We'll label pods with an app label (
app: echo) and a version label (version: v1) to help with our canary rollout. - We'll deploy a single Kubernetes
Servicefor the application to set up networking. Instead of updating this or using multiple services to manage routing to different versions, we'll manage the rollout with Gloo configuration.
The following is our v1 echo application:
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-v1
spec:
replicas: 1
selector:
matchLabels:
app: echo
version: v1
template:
metadata:
labels:
app: echo
version: v1
spec:
containers:
# Shout out to our friends at Hashi for this useful test server
- image: hashicorp/http-echo
args:
- "-text=version:v1"
- -listen=:8080
imagePullPolicy: Always
name: echo-v1
ports:
- containerPort: 8080
And here is the echo Kubernetes Service object:
apiVersion: v1
kind: Service
metadata:
name: echo
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
selector:
app: echo
For convenience, we've published this yaml in a repo so we can deploy it with the following command:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/1-setup/echo.yaml
We should see the following output:
namespace/echo created
deployment.apps/echo-v1 created
service/echo created
And we should be able to see all the resources healthy in the echo namespace:
➜ kubectl get all -n echo
NAME READY STATUS RESTARTS AGE
pod/echo-v1-66dbfffb79-287s5 1/1 Running 0 6s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/echo ClusterIP 10.55.252.216 <none> 80/TCP 6s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/echo-v1 1/1 1 1 7s
NAME DESIRED CURRENT READY AGE
replicaset.apps/echo-v1-66dbfffb79 1 1 1 7s
Exposing outside the cluster with Gloo
We can now expose this service outside the cluster with Gloo. First, we'll model the application as a Gloo Upstream, which is Gloo's abstraction for a traffic destination:
apiVersion: gloo.solo.io/v1
kind: Upstream
metadata:
name: echo
namespace: gloo-system
spec:
kube:
selector:
app: echo
serviceName: echo
serviceNamespace: echo
servicePort: 8080
subsetSpec:
selectors:
- keys:
- version
Here, we're setting up subsets based on the version label. We don't have to use this in our routes, but later
we'll start to use it to support our canary workflow.
We can now create a route to this upstream in Gloo by defining a Virtual Service:
apiVersion: gateway.solo.io/v1
kind: VirtualService
metadata:
name: echo
namespace: gloo-system
spec:
virtualHost:
domains:
- "*"
routes:
- matchers:
- prefix: /
routeAction:
single:
upstream:
name: echo
namespace: gloo-system
We can apply these resources with the following commands:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/1-setup/upstream.yaml
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/1-setup/vs.yaml
Once we apply these two resources, we can start to send traffic to the application through Gloo:
➜ curl $(glooctl proxy url)/
version:v1
Our setup is complete, and our cluster now looks like this:
Two-Phased Rollout Strategy
Now we have a new version v2 of the echo application that we wish to roll out. We know that when the
rollout is complete, we are going to end up with this picture:
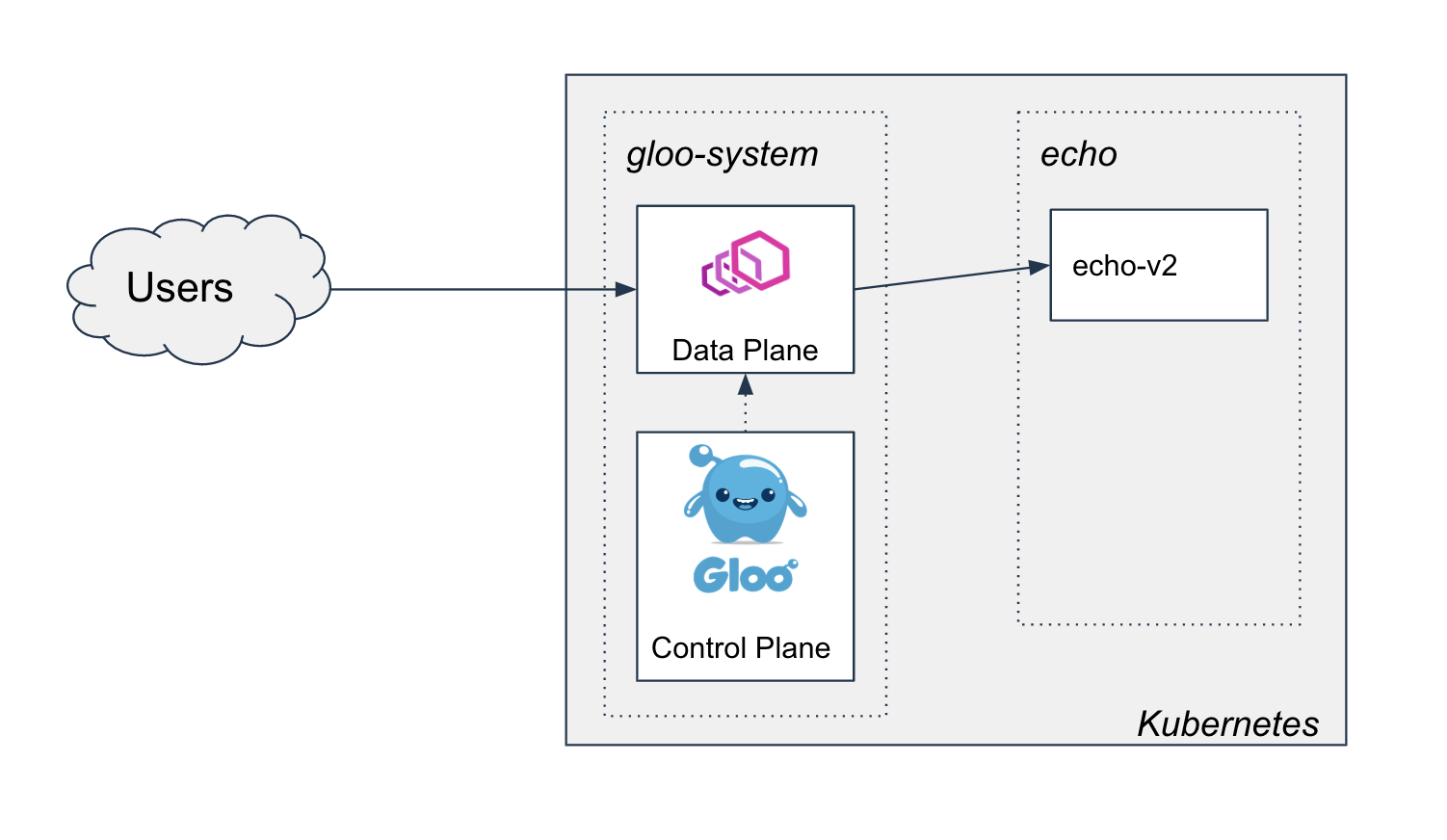
However, to get there, we may want to perform a few rounds of testing to ensure the new version of the application meets certain correctness and/or performance acceptance criteria. In this post, we'll introduce a two-phased approach to canary rollout with Gloo, that could be used to satisfy the vast majority of acceptance tests.
In the first phase, we'll perform smoke and correctness tests by routing a small segment of the traffic to the new version
of the application. In this demo, we'll use a header stage: canary to trigger routing to the new service, though in
practice it may be desirable to make this decision based on another part of the request, such as a claim in a verified JWT.
In the second phase, we've already established correctness, so we are ready to shift all of the traffic over to the new version of the application. We'll configure weighted destinations, and shift the traffic while monitoring certain business metrics to ensure the service quality remains at acceptable levels. Once 100% of the traffic is shifted to the new version, the old version can be decommissioned.
In practice, it may be desirable to only use one of the phases for testing, in which case the other phase can be skipped.
Phase 1: Initial canary rollout of v2
In this phase, we'll deploy v2, and then use a header stage: canary to start routing a small amount of specific
traffic to the new version. We'll use this header to perform some basic smoke testing and make sure v2 is working the
way we'd expect:
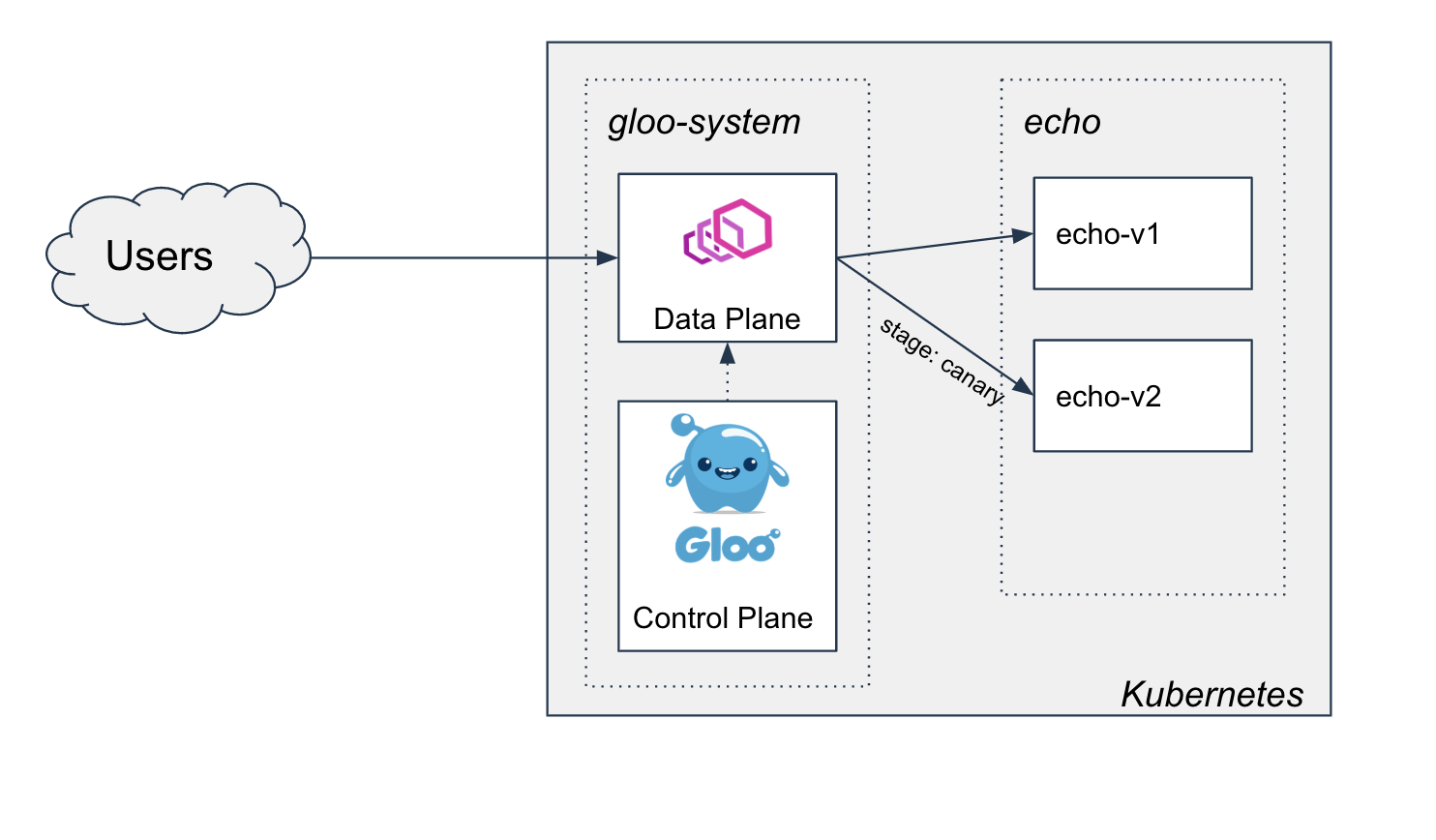
Setting up subset routing
Before deploying our v2 service, we'll update our virtual service to only route to pods that have the subset label
version: v1, using a Gloo feature called subset routing.
apiVersion: gateway.solo.io/v1
kind: VirtualService
metadata:
name: echo
namespace: gloo-system
spec:
virtualHost:
domains:
- "*"
routes:
- matchers:
- prefix: /
routeAction:
single:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v1
We can apply them to the cluster with the following commands:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/2-initial-subset-routing-to-v2/vs-1.yaml
The application should continue to function as before:
➜ curl $(glooctl proxy url)/
version:v1
Deploying echo v2
Now we can safely deploy v2 of the echo application:
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-v2
spec:
replicas: 1
selector:
matchLabels:
app: echo
version: v2
template:
metadata:
labels:
app: echo
version: v2
spec:
containers:
- image: hashicorp/http-echo
args:
- "-text=version:v2"
- -listen=:8080
imagePullPolicy: Always
name: echo-v2
ports:
- containerPort: 8080
We can deploy with the following command:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/2-initial-subset-routing-to-v2/echo-v2.yaml
Since our gateway is configured to route specifically to the v1 subset, this should have no effect. However, it does enable
v2 to be routable from the gateway if the v2 subset is configured for a route.
Make sure v2 is running before moving on:
➜ kubectl get pod -n echo
NAME READY STATUS RESTARTS AGE
echo-v1-66dbfffb79-2qw86 1/1 Running 0 5m25s
echo-v2-86584fbbdb-slp44 1/1 Running 0 93s
The application should continue to function as before:
➜ curl $(glooctl proxy url)/
version:v1
Adding a route to v2 for canary testing
We'll route to the v2 subset when the stage: canary header is supplied on the request. If the header isn't
provided, we'll continue to route to the v1 subset as before.
apiVersion: gateway.solo.io/v1
kind: VirtualService
metadata:
name: echo
namespace: gloo-system
spec:
virtualHost:
domains:
- "*"
routes:
- matchers:
- headers:
- name: stage
value: canary
prefix: /
routeAction:
single:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v2
- matchers:
- prefix: /
routeAction:
single:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v1
We can deploy with the following command:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/2-initial-subset-routing-to-v2/vs-2.yaml
Canary testing
Now that we have this route, we can do some testing. First let's ensure that the existing route is working as expected:
➜ curl $(glooctl proxy url)/
version:v1
And now we can start to canary test our new application version:
➜ curl $(glooctl proxy url)/ -H "stage: canary"
version:v2
Advanced use cases for subset routing
We may decide that this approach, using user-provided request headers, is too open. Instead, we may want to restrict canary testing to a known, authorized user.
A common implementation of this that we've seen is for the canary route to require a valid JWT that contains a specific claim to indicate the subject is authorized for canary testing. Enterprise Gloo has out of the box support for verifying JWTs, updating the request headers based on the JWT claims, and recomputing the routing destination based on the updated headers. We'll save that for a future post covering more advanced use cases in canary testing.
Phase 2: Shifting all traffic to v2 and decommissioning v1
At this point, we've deployed v2, and created a route for canary testing. If we are satisfied with the
results of the testing, we can move on to phase 2 and start shifting the load from v1 to v2. We'll use
weighted destinations
in Gloo to manage the load during the migration.
Setting up the weighted destinations
We can change the Gloo route to route to both of these destinations, with weights to decide how much of the traffic should
go to the v1 versus the v2 subset. To start, we're going to set it up so 100% of the traffic continues to get routed to the
v1 subset, unless the stage: canary header was provided as before.
apiVersion: gateway.solo.io/v1
kind: VirtualService
metadata:
name: echo
namespace: gloo-system
spec:
virtualHost:
domains:
- "*"
routes:
# We'll keep our route from before if we want to continue testing with this header
- matchers:
- headers:
- name: stage
value: canary
prefix: /
routeAction:
single:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v2
# Now we'll route the rest of the traffic to the upstream, load balanced across the two subsets.
- matchers:
- prefix: /
routeAction:
multi:
destinations:
- destination:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v1
weight: 100
- destination:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v2
weight: 0
We can apply this virtual service update to the cluster with the following commands:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/3-progressive-traffic-shift-to-v2/vs-1.yaml
Now the cluster looks like this, for any request that doesn't have the stage: canary header:
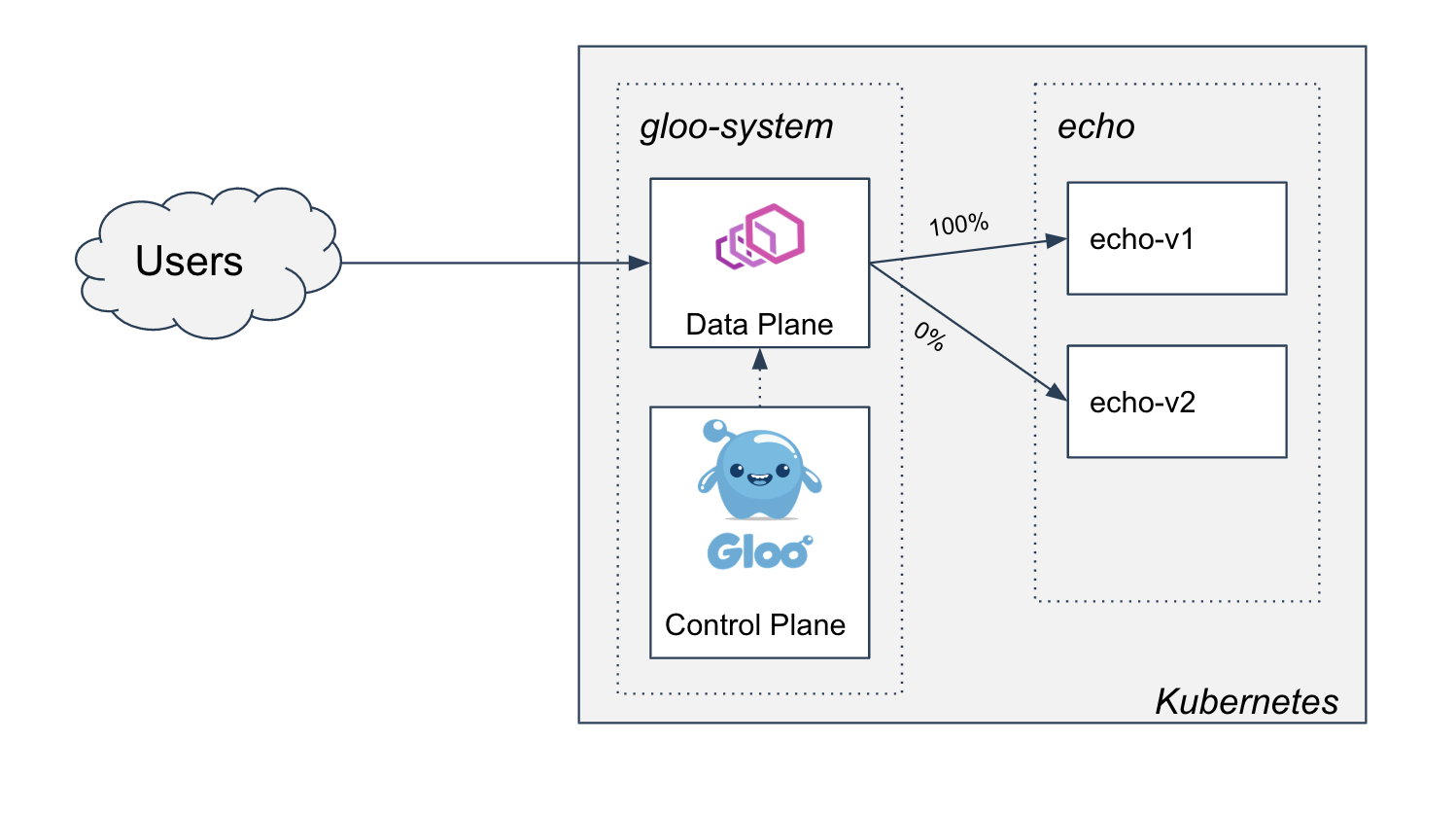
With the initial weights, we should see the gateway continue to serve v1 for all traffic.
➜ curl $(glooctl proxy url)/
version:v1
Commence rollout
To simulate a load test, let's shift half the traffic to v2:
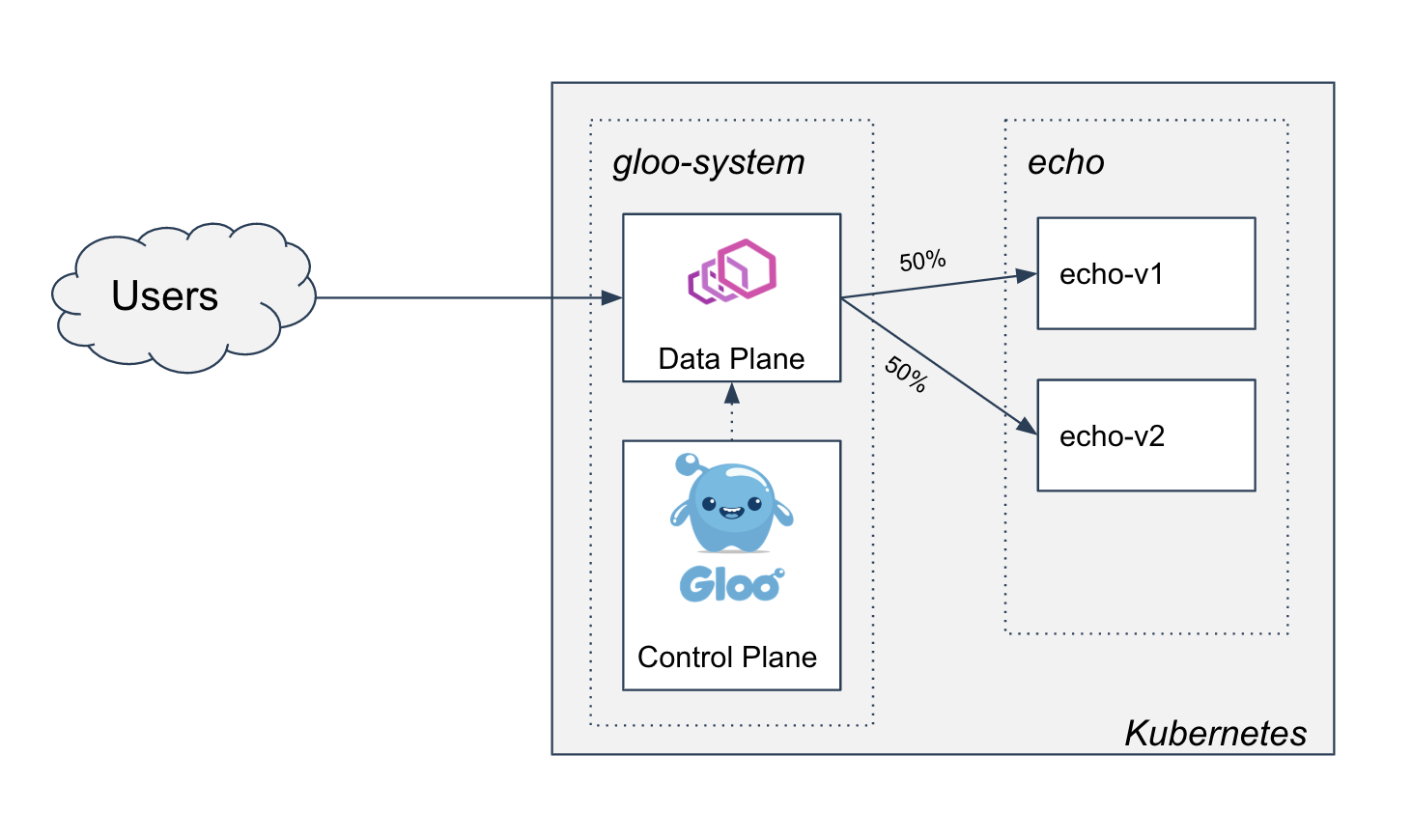
This can be expressed on our virtual service by adjusting the weights:
apiVersion: gateway.solo.io/v1
kind: VirtualService
metadata:
name: echo
namespace: gloo-system
spec:
virtualHost:
domains:
- "*"
routes:
- matchers:
- headers:
- name: stage
value: canary
prefix: /
routeAction:
single:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v2
- matchers:
- prefix: /
routeAction:
multi:
destinations:
- destination:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v1
# Update the weight so 50% of the traffic hits v1
weight: 50
- destination:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v2
# And 50% is routed to v2
weight: 50
We can apply this to the cluster with the following command:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/3-progressive-traffic-shift-to-v2/vs-2.yaml
Now when we send traffic to the gateway, we should see half of the requests return version:v1 and the
other half return version:v2.
➜ curl $(glooctl proxy url)/
version:v1
➜ curl $(glooctl proxy url)/
version:v2
➜ curl $(glooctl proxy url)/
version:v1
In practice, during this process it's likely you'll be monitoring some performance and business metrics to ensure the traffic shift isn't resulting in a decline in the overall quality of service. We can even leverage operators like Flagger to help automate this Gloo workflow. Gloo Enterprise integrates with your metrics backend and provides out of the box and dynamic, upstream-based dashboards that can be used to monitor the health of the rollout. We will save these topics for a future post on advanced canary testing use cases with Gloo.
Finishing the rollout
We will continue adjusting weights until eventually, all of the traffic is now being routed to v2:
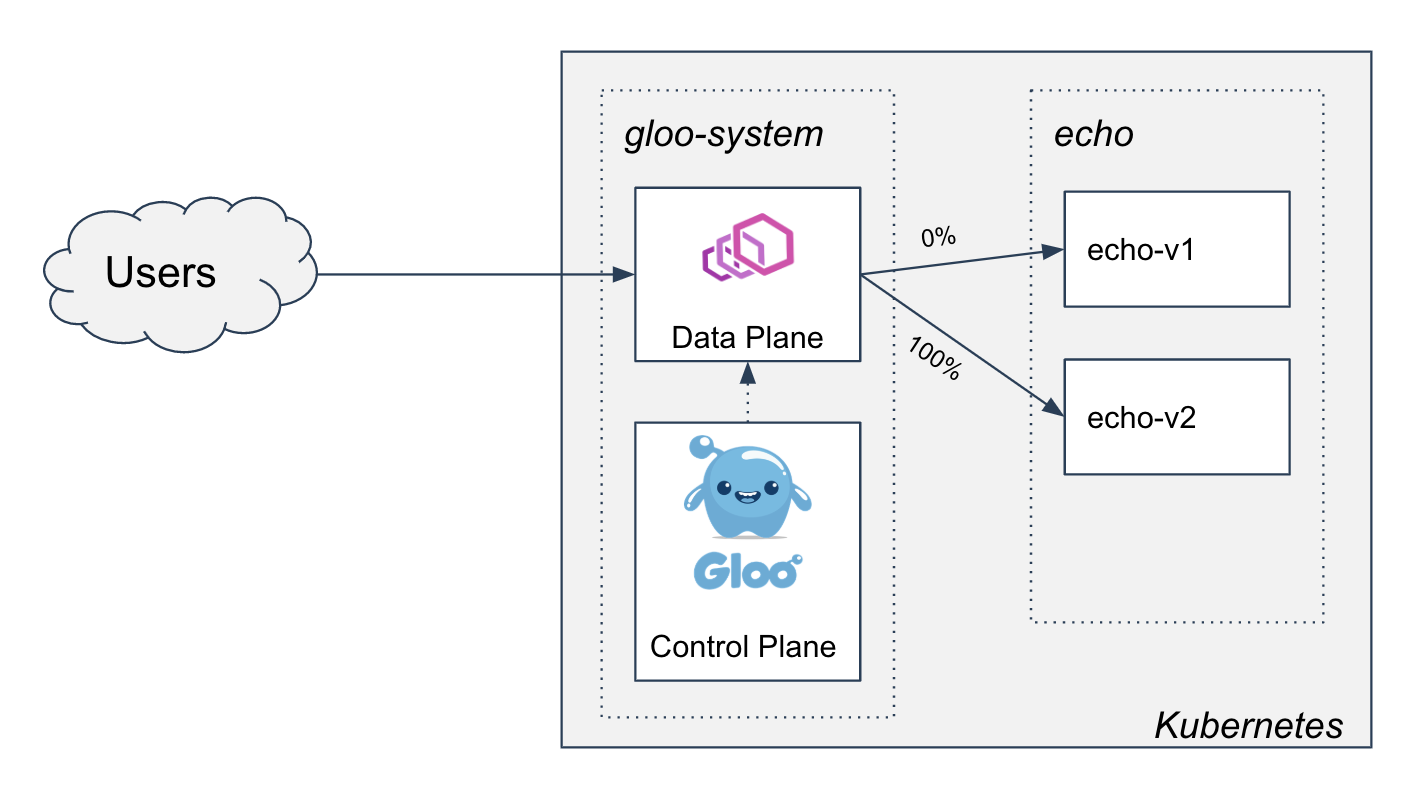
Our virtual service will look like this:
apiVersion: gateway.solo.io/v1
kind: VirtualService
metadata:
name: echo
namespace: gloo-system
spec:
virtualHost:
domains:
- "*"
routes:
- matchers:
- headers:
- name: stage
value: canary
prefix: /
routeAction:
single:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v2
- matchers:
- prefix: /
routeAction:
multi:
destinations:
- destination:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v1
# No traffic will be sent to v1 anymore
weight: 0
- destination:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v2
# Now all the traffic will be routed to v2
weight: 100
We can apply that to the cluster with the following command:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/3-progressive-traffic-shift-to-v2/vs-3.yaml
Now when we send traffic to the gateway, we should see all of the requests return version:v2.
➜ curl $(glooctl proxy url)/
version:v2
➜ curl $(glooctl proxy url)/
version:v2
➜ curl $(glooctl proxy url)/
version:v2
Decommissioning v1
At this point, we have deployed the new version of our application, conducted correctness tests using subset routing,
conducted load and performance tests by progressively shifting traffic to the new version, and finished
the rollout. The only remaining task is to clean up our v1 resources.
First, we'll clean up our routes. We'll leave the subset specified on the route so we are all setup for future upgrades.
apiVersion: gateway.solo.io/v1
kind: VirtualService
metadata:
name: echo
namespace: gloo-system
spec:
virtualHost:
domains:
- "*"
routes:
- matchers:
- prefix: /
routeAction:
single:
upstream:
name: echo
namespace: gloo-system
subset:
values:
version: v2
We can apply this update with the following command:
kubectl apply -f https://raw.githubusercontent.com/solo-io/gloo-ref-arch/blog-30-mar-20/platform/prog-delivery/two-phased-with-os-gloo/4-decommissioning-v1/vs.yaml
And we can delete the v1 deployment, which is no longer serving any traffic.
kubectl delete deploy -n echo echo-v1
Now our cluster looks like this:
And requests to the gateway return this:
➜ curl $(glooctl proxy url)/
version:v2
We have now completed our two-phased canary rollout of an application update using Gloo!
Other Advanced Topics
Over the course of this post, we collected a few topics that could be a good starting point for advanced exploration:
- Using the JWT filter to verify JWTs, extract claims onto headers, and route to canary versions depending on a claim value.
- Looking at Prometheus metrics and Grafana dashboards created by Gloo to monitor the health of the rollout.
- Automating the rollout by integrating Flagger with Gloo.
A few other topics that warrant further exploration:
- Supporting self-service upgrades by giving teams ownership over their upstream and route configuration
- Utilizing Gloo's delegation feature and Kubernetes RBAC to decentralize the configuration management safely
- Fully automating the continuous delivery process by applying GitOps principles and using tools like Flux to push config to the cluster
- Supporting hybrid or non-Kubernetes application use-cases by setting up Gloo with a different deployment pattern
- Utilizing traffic shadowing to begin testing the new version with realistic data before shifting production traffic to it
Get Involved in the Gloo Community
Gloo has a large and growing community of open source users, in addition to an enterprise customer base. To learn more about Gloo:
- Check out the repo, where you can see the code and file issues
- Check out the docs, which have an extensive collection of guides and examples
- Join the slack channel and start chatting with the Solo engineering team and user community
If you'd like to get in touch with me (feedback is always appreciated!), you can find me on the Solo slack or email me at rick.ducott@solo.io.
Cluster API v1alpha3 Delivers New Features and an Improved User Experience
Author: Daniel Lipovetsky (D2IQ)

The Cluster API is a Kubernetes project to bring declarative, Kubernetes-style APIs to cluster creation, configuration, and management. It provides optional, additive functionality on top of core Kubernetes to manage the lifecycle of a Kubernetes cluster.
Following the v1alpha2 release in October 2019, many members of the Cluster API community met in San Francisco, California, to plan the next release. The project had just gone through a major transformation, delivering a new architecture that promised to make the project easier for users to adopt, and faster for the community to build. Over the course of those two days, we found our common goals: To implement the features critical to managing production clusters, to make its user experience more intuitive, and to make it a joy to develop.
The v1alpha3 release of Cluster API brings significant features for anyone running Kubernetes in production and at scale. Among the highlights:
- Declarative Control Plane Management
- Support for Distributing Control Plane Nodes Across Failure Domains To Reduce Risk
- Automated Replacement of Unhealthy Nodes
- Support for Infrastructure-Managed Node Groups
For anyone who wants to understand the API, or prizes a simple, but powerful, command-line interface, the new release brings:
- Redesigned clusterctl, a command-line tool (and go library) for installing and managing the lifecycle of Cluster API
- Extensive and up-to-date documentation in The Cluster API Book
Finally, for anyone extending the Cluster API for their custom infrastructure or software needs:
- New End-to-End (e2e) Test Framework
- Documentation for integrating Cluster API into your cluster lifecycle stack
All this was possible thanks to the hard work of many contributors.
Declarative Control Plane Management
Special thanks to Jason DeTiberus, Naadir Jeewa, and Chuck Ha
The Kubeadm-based Control Plane (KCP) provides a declarative API to deploy and scale the Kubernetes control plane, including etcd. This is the feature many Cluster API users have been waiting for! Until now, to deploy and scale up the control plane, users had to create specially-crafted Machine resources. To scale down the control plane, they had to manually remove members from the etcd cluster. KCP automates deployment, scaling, and upgrades.
What is the Kubernetes Control Plane? The Kubernetes control plane is, at its core, kube-apiserver and etcd. If either of these are unavailable, no API requests can be handled. This impacts not only core Kubernetes APIs, but APIs implemented with CRDs. Other components, like kube-scheduler and kube-controller-manager, are also important, but do not have the same impact on availability.
The control plane was important in the beginning because it scheduled workloads. However, some workloads could continue to run during a control plane outage. Today, workloads depend on operators, service meshes, and API gateways, which all use the control plane as a platform. Therefore, the control plane's availability is more important than ever.
Managing the control plane is one of the most complex parts of cluster operation. Because the typical control plane includes etcd, it is stateful, and operations must be done in the correct sequence. Control plane replicas can and do fail, and maintaining control plane availability means being able to replace failed nodes.
The control plane can suffer a complete outage (e.g. permanent loss of quorum in etcd), and recovery (along with regular backups) is sometimes the only feasible option.
For more details, read about Kubernetes Components in the Kubernetes documentation.
Here's an example of a 3-replica control plane for the Cluster API Docker Infrastructure, which the project maintains for testing and development. For brevity, other required resources, like Cluster, and Infrastructure Template, referenced by its name and namespace, are not shown.
apiVersion: controlplane.cluster.x-k8s.io/v1alpha3
kind: KubeadmControlPlane
metadata:
name: example
spec:
infrastructureTemplate:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
kind: DockerMachineTemplate
name: example
namespace: default
kubeadmConfigSpec:
clusterConfiguration:
replicas: 3
version: 1.16.3
Deploy this control plane with kubectl:
kubectl apply -f example-docker-control-plane.yaml
Scale the control plane the same way you scale other Kubernetes resources:
kubectl scale kubeadmcontrolplane example --replicas=5
kubeadmcontrolplane.controlplane.cluster.x-k8s.io/example scaled
Upgrade the control plane to a newer patch of the Kubernetes release:
kubectl patch kubeadmcontrolplane example --type=json -p '[{"op": "replace", "path": "/spec/version", "value": "1.16.4"}]'
Number of Control Plane Replicas By default, KCP is configured to manage etcd, and requires an odd number of replicas. If KCP is configured to not manage etcd, an odd number is recommended, but not required. An odd number of replicas ensures optimal etcd configuration. To learn why your etcd cluster should have an odd number of members, see the etcd FAQ.
Because it is a core Cluster API component, KCP can be used with any v1alpha3-compatible Infrastructure Provider that provides a fixed control plane endpoint, i.e., a load balancer or virtual IP. This endpoint enables requests to reach multiple control plane replicas.
What is an Infrastructure Provider? A source of computational resources (e.g. machines, networking, etc.). The community maintains providers for AWS, Azure, Google Cloud, and VMWare. For details, see the list of providers in the Cluster API Book.
Distributing Control Plane Nodes To Reduce Risk
Special thanks to Vince Prignano, and Chuck Ha
Cluster API users can now deploy nodes in different failure domains, reducing the risk of a cluster failing due to a domain outage. This is especially important for the control plane: If nodes in one domain fail, the cluster can continue to operate as long as the control plane is available to nodes in other domains.
What is a Failure Domain? A failure domain is a way to group the resources that would be made unavailable by some failure. For example, in many public clouds, an "availability zone" is the default failure domain. A zone corresponds to a data center. So, if a specific data center is brought down by a power outage or natural disaster, all resources in that zone become unavailable. If you run Kubernetes on your own hardware, your failure domain might be a rack, a network switch, or power distribution unit.
The Kubeadm-based ControlPlane distributes nodes across failure domains. To minimize the chance of losing multiple nodes in the event of a domain outage, it tries to distribute them evenly: it deploys a new node in the failure domain with the fewest existing nodes, and it removes an existing node in the failure domain with the most existing nodes.
MachineDeployments and MachineSets do not distribute nodes across failure domains. To deploy your worker nodes across multiple failure domains, create a MachineDeployment or MachineSet for each failure domain.
The Failure Domain API works on any infrastructure. That's because every Infrastructure Provider maps failure domains in its own way. The API is optional, so if your infrastructure is not complex enough to need failure domains, you do not need to support it. This example is for the Cluster API Docker Infrastructure Provider. Note that two of the domains are marked as suitable for control plane nodes, while a third is not. The Kubeadm-based ControlPlane will only deploy nodes to domains marked suitable.
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
kind: DockerCluster
metadata:
name: example
spec:
controlPlaneEndpoint:
host: 172.17.0.4
port: 6443
failureDomains:
domain-one:
controlPlane: true
domain-two:
controlPlane: true
domain-three:
controlPlane: false
The AWS Infrastructure Provider (CAPA), maintained by the Cluster API project, maps failure domains to AWS Availability Zones. Using CAPA, you can deploy a cluster across multiple Availability Zones. First, define subnets for multiple Availability Zones. The CAPA controller will define a failure domain for each Availability Zone. Deploy the control plane with the KubeadmControlPlane: it will distribute replicas across the failure domains. Finally, create a separate MachineDeployment for each failure domain.
Automated Replacement of Unhealthy Nodes
Special thanks to Alberto García Lamela, and Joel Speed
There are many reasons why a node might be unhealthy. The kubelet process may stop. The container runtime might have a bug. The kernel might have a memory leak. The disk may run out of space. CPU, disk, or memory hardware may fail. A power outage may happen. Failures like these are especially common in larger clusters.
Kubernetes is designed to tolerate them, and to help your applications tolerate them as well. Nevertheless, only a finite number of nodes can be unhealthy before the cluster runs out of resources, and Pods are evicted or not scheduled in the first place. Unhealthy nodes should be repaired or replaced at the earliest opportunity.
The Cluster API now includes a MachineHealthCheck resource, and a controller that monitors node health. When it detects an unhealthy node, it removes it. (Another Cluster API controller detects the node has been removed and replaces it.) You can configure the controller to suit your needs. You can configure how long to wait before removing the node. You can also set a threshold for the number of unhealthy nodes. When the threshold is reached, no more nodes are removed. The wait can be used to tolerate short-lived outages, and the threshold to prevent too many nodes from being replaced at the same time.
The controller will remove only nodes managed by a Cluster API MachineSet. The controller does not remove control plane nodes, whether managed by the Kubeadm-based Control Plane, or by the user, as in v1alpha2. For more, see Limits and Caveats of a MachineHealthCheck.
Here is an example of a MachineHealthCheck. For more details, see Configure a MachineHealthCheck in the Cluster API book.
apiVersion: cluster.x-k8s.io/v1alpha3
kind: MachineHealthCheck
metadata:
name: example-node-unhealthy-5m
spec:
clusterName: example
maxUnhealthy: 33%
nodeStartupTimeout: 10m
selector:
matchLabels:
nodepool: nodepool-0
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
Infrastructure-Managed Node Groups
Special thanks to Juan-Lee Pang and Cecile Robert-Michon
If you run large clusters, you need to create and destroy hundreds of nodes, sometimes in minutes. Although public clouds make it possible to work with large numbers of nodes, having to make a separate API request to create or delete every node may scale poorly. For example, API requests may have to be delayed to stay within rate limits.
Some public clouds offer APIs to manage groups of nodes as one single entity. For example, AWS has AutoScaling Groups, Azure has Virtual Machine Scale Sets, and GCP has Managed Instance Groups. With this release of Cluster API, Infrastructure Providers can add support for these APIs, and users can deploy groups of Cluster API Machines by using the MachinePool Resource. For more information, see the proposal in the Cluster API repository.
Experimental Feature The MachinePool API is an experimental feature that is not enabled by default. Users are encouraged to try it and report on how well it meets their needs.
The Cluster API User Experience, Reimagined
clusterctl
Special thanks to Fabrizio Pandini
If you are new to Cluster API, your first experience will probably be with the project's command-line tool, clusterctl. And with the new Cluster API release, it has been re-designed to be more pleasing to use than before. The tool is all you need to deploy your first workload cluster in just a few steps.
First, use clusterctl init to fetch the configuration for your Infrastructure and Bootstrap Providers and deploy all of the components that make up the Cluster API. Second, use clusterctl config cluster to create the workload cluster manifest. This manifest is just a collection of Kubernetes objects. To create the workload cluster, just kubectl apply the manifest. Don't be surprised if this workflow looks familiar: Deploying a workload cluster with Cluster API is just like deploying an application workload with Kubernetes!
Clusterctl also helps with the "day 2" operations. Use clusterctl move to migrate Cluster API custom resources, such as Clusters, and Machines, from one Management Cluster to another. This step--also known as a pivot--is necessary to create a workload cluster that manages itself with Cluster API. Finally, use clusterctl upgrade to upgrade all of the installed components when a new Cluster API release becomes available.
One more thing! Clusterctl is not only a command-line tool. It is also a Go library! Think of the library as an integration point for projects that build on top of Cluster API. All of clusterctl's command-line functionality is available in the library, making it easy to integrate into your stack. To get started with the library, please read its documentation.
The Cluster API Book
Thanks to many contributors!
The project's documentation is extensive. New users should get some background on the architecture, and then create a cluster of their own with the Quick Start. The clusterctl tool has its own reference. The Developer Guide has plenty of information for anyone interested in contributing to the project.
Above and beyond the content itself, the project's documentation site is a pleasure to use. It is searchable, has an outline, and even supports different color themes. If you think the site a lot like the documentation for a different community project, Kubebuilder, that is no coincidence! Many thanks to Kubebuilder authors for creating a great example of documentation. And many thanks to the mdBook authors for creating a great tool for building documentation.
Integrate & Customize
End-to-End Test Framework
Special thanks to Chuck Ha
The Cluster API project is designed to be extensible. For example, anyone can develop their own Infrastructure and Bootstrap Providers. However, it's important that Providers work in a uniform way. And, because the project is still evolving, it takes work to make sure that Providers are up-to-date with new releases of the core.
The End-to-End Test Framework provides a set of standard tests for developers to verify that their Providers integrate correctly with the current release of Cluster API, and help identify any regressions that happen after a new release of the Cluster API, or the Provider.
For more details on the Framework, see Testing in the Cluster API Book, and the README in the repository.
Provider Implementer's Guide
Thanks to many contributors!
The community maintains Infrastructure Providers for a many popular infrastructures. However, if you want to build your own Infrastructure or Bootstrap Provider, the Provider Implementer's guide explains the entire process, from creating a git repository, to creating CustomResourceDefinitions for your Providers, to designing, implementing, and testing the controllers.
Under Active Development The Provider Implementer's Guide is actively under development, and may not yet reflect all of the changes in the v1alpha3 release.
Join Us!
The Cluster API project is a very active project, and covers many areas of interest. If you are an infrastructure expert, you can contribute to one of the Infrastructure Providers. If you like building controllers, you will find opportunities to innovate. If you're curious about testing distributed systems, you can help develop the project's end-to-end test framework. Whatever your interests and background, you can make a real impact on the project.
Come introduce yourself to the community at our weekly meeting, where we dedicate a block of time for a Q&A session. You can also find maintainers and users on the Kubernetes Slack, and in the Kubernetes forum. Please check out the links below. We look forward to seeing you!
- Chat with us on the Kubernetes Slack: #cluster-api
- Join the sig-cluster-lifecycle Google Group to receive calendar invites and gain access to documents
- Join our Zoom meeting, every Wednesday at 10:00 Pacific Time
- Post to the Cluster API community forum
How Kubernetes contributors are building a better communication process
Authors: Paris Pittman
"Perhaps we just need to use a different word. We may need to use community development or project advocacy as a word in the open source realm as opposed to marketing, and perhaps then people will realize that they need to do it." ~ Nithya Ruff (from TODO Group)
A common way to participate in the Kubernetes contributor community is to be everywhere.
We have an active Slack, many mailing lists, Twitter account(s), and dozens of community-driven podcasts and newsletters that highlight all end-user, contributor, and ecosystem topics. And to add on to that, we also have repositories of amazing documentation, tons of meetings that drive the project forward, and recorded code deep dives. All of this information is incredibly valuable, but it can be too much.
Keeping up with thousands of contributors can be a challenge for anyone, but this task of consuming information straight from the firehose is particularly challenging for new community members. It's no secret that the project is vast for contributors and users alike.
To paint a picture with numbers:
- 43,000 contributors
- 6,579 members in #kubernetes-dev slack channel
- 52 mailing lists (kubernetes-dev@ has thousands of members; sig-networking@ has 1000 alone)
- 40 community groups
- 30 upstream meetings this week alone
All of these numbers are only growing in scale, and with that comes the need to simplify how contributors get the information right information front-and-center.
How we got here
Kubernetes (K8s for short) communication grew out of a need for people to connect in our growing community. With the best of intentions, the community spun up channels for people to connect. This energy was part of what helped Kubernetes grow so fast, and it also had us in sprawling out far and wide. As adoption grew, contributors knew there was a need for standardization.
This new attention to how the community communicates led to the discovery of a complex web of options. There were so many options, and it was a challenge for anyone to be sure they were in the right place to receive the right information. We started taking immediate action combining communication streams and thinking about how to reach out best to serve our community. We also asked for feedback from all our contributors directly via annual surveys to see where folks were actually reading the news that influences their experiences here in our community.
With over 43,000 contributors, our contributor base is larger than many enterprise companies. You can imagine what it's like getting important messages across to make sure they are landing and folks are taking action.
Contributing to better communication
Think about how your company/employer solves for this kind of communication challenge. Many have done so by building internal marketing and communication focus areas in marketing departments. So that's what we are doing. This has also been applied at Fedora and at a smaller scale in our very own release and contributor summit planning teams as roles.
We have hit the accelerator on an upstream marketing group under SIG Contributor Experience and we want to tackle this challenge straight on. We've learned in other contributor areas that creating roles for contributors is super helpful - onboarding, breaking down work, and ownership. Here's our team charting the course.
Journey your way through our other documents like our charter if you are interested in our mission and scope.
Many of you close to the ecosystem might be scratching your head - isn't this what CNCF does?
Yes and no. The CNCF has 40+ other projects that need to be marketed to a countless number of different types of community members in distinct ways and they aren't responsible for the day to day operations of their projects. They absolutely do partner with us to highlight what we need and when we need it, and they do a fantastic job of it (one example is the @kubernetesio Twitter account and its 200,000 followers).
Where this group differs is in its scope: we are entirely focused on elevating the hard work being done throughout the Kubernetes community by its contributors.
What to expect from us
You can expect to see us on the Kubernetes communication channels supporting you by:
- Finding ways of adding our human touch to potentially overwhelming quantities of info by storytelling and other methods - we want to highlight the work you are doing and provide useful information!
- Keeping you in the know of the comings and goings of contributor community events, activities, mentoring initiatives, KEPs, and more.
- Creating a presence on Twitter specifically for contributors via @k8scontributors that is all about being a contributor in all its forms.
What does this look like in the wild? Our first post in a series about our 36 community groups landed recently. Did you see it? More articles like this and additional themes of stories to flow through our storytellers.
We will deliver this with an ethos behind us aligned to the Kubernetes project as a whole, and we're committed to using the same tools as all the other SIGs to do so. Check out our project board to view our roadmap of upcoming work.
Join us and be part of the story
This initiative is in an early phase and we still have important roles to fill to make it successful.
If you are interested in open sourcing marketing functions – it's a fun ride – join us! Specific immediate roles include storytelling through blogs and as a designer. We also have plenty of work in progress on our project board. Add a comment to any open issue to let us know you're interested in getting involved.
Also, if you're reading this, you're exactly the type of person we are here to support. We would love to hear about how to improve, feedback, or how we can work together.
Reach out at one of the contact methods listed on our README. We would love to hear from you.
API Priority and Fairness Alpha
Authors: Min Kim (Ant Financial), Mike Spreitzer (IBM), Daniel Smith (Google)
This blog describes “API Priority And Fairness”, a new alpha feature in Kubernetes 1.18. API Priority And Fairness permits cluster administrators to divide the concurrency of the control plane into different weighted priority levels. Every request arriving at a kube-apiserver will be categorized into one of the priority levels and get its fair share of the control plane’s throughput.
What problem does this solve?
Today the apiserver has a simple mechanism for protecting itself against CPU and memory overloads: max-in-flight limits for mutating and for readonly requests. Apart from the distinction between mutating and readonly, no other distinctions are made among requests; consequently, there can be undesirable scenarios where one subset of the requests crowds out other requests.
In short, it is far too easy for Kubernetes workloads to accidentally DoS the apiservers, causing other important traffic--like system controllers or leader elections---to fail intermittently. In the worst cases, a few broken nodes or controllers can push a busy cluster over the edge, turning a local problem into a control plane outage.
How do we solve the problem?
The new feature “API Priority and Fairness” is about generalizing the existing max-in-flight request handler in each apiserver, to make the behavior more intelligent and configurable. The overall approach is as follows.
- Each request is matched by a Flow Schema. The Flow Schema states the Priority Level for requests that match it, and assigns a “flow identifier” to these requests. Flow identifiers are how the system determines whether requests are from the same source or not.
- Priority Levels may be configured to behave in several ways. Each Priority Level gets its own isolated concurrency pool. Priority levels also introduce the concept of queuing requests that cannot be serviced immediately.
- To prevent any one user or namespace from monopolizing a Priority Level, they may be configured to have multiple queues. “Shuffle Sharding” is used to assign each flow of requests to a subset of the queues.
- Finally, when there is capacity to service a request, a “Fair Queuing” algorithm is used to select the next request. Within each priority level the queues compete with even fairness.
Early results have been very promising! Take a look at this analysis.
How do I try this out?
You are required to prepare the following things in order to try out the feature:
- Download and install a kubectl greater than v1.18.0 version
- Enabling the new API groups with the command line flag
--runtime-config="flowcontrol.apiserver.k8s.io/v1alpha1=true"on the kube-apiservers - Switch on the feature gate with the command line flag
--feature-gates=APIPriorityAndFairness=trueon the kube-apiservers
After successfully starting your kube-apiservers, you will see a few default FlowSchema and PriorityLevelConfiguration resources in the cluster. These default configurations are designed for a general protection and traffic management for your cluster. You can examine and customize the default configuration by running the usual tools, e.g.:
kubectl get flowschemaskubectl get prioritylevelconfigurations
How does this work under the hood?
Upon arrival at the handler, a request is assigned to exactly one priority level and exactly one flow within that priority level. Hence understanding how FlowSchema and PriorityLevelConfiguration works will be helping you manage the request traffic going through your kube-apiservers.
-
FlowSchema: FlowSchema will identify a PriorityLevelConfiguration object and the way to compute the request’s “flow identifier”. Currently we support matching requests according to: the identity making the request, the verb, and the target object. The identity can match in terms of: a username, a user group name, or a ServiceAccount. And as for the target objects, we can match by apiGroup, resource[/subresource], and namespace.
- The flow identifier is used for shuffle sharding, so it’s important that requests have the same flow identifier if they are from the same source! We like to consider scenarios with “elephants” (which send many/heavy requests) vs “mice” (which send few/light requests): it is important to make sure the elephant’s requests all get the same flow identifier, otherwise they will look like many different mice to the system!
- See the API Documentation here!
-
PriorityLevelConfiguration: Defines a priority level.
- For apiserver self requests, and any reentrant traffic (e.g., admission webhooks which themselves make API requests), a Priority Level can be marked “exempt”, which means that no queueing or limiting of any sort is done. This is to prevent priority inversions.
- Each non-exempt Priority Level is configured with a number of "concurrency shares" and gets an isolated pool of concurrency to use. Requests of that Priority Level run in that pool when it is not full, never anywhere else. Each apiserver is configured with a total concurrency limit (taken to be the sum of the old limits on mutating and readonly requests), and this is then divided among the Priority Levels in proportion to their concurrency shares.
- A non-exempt Priority Level may select a number of queues and a "hand size" to use for the shuffle sharding. Shuffle sharding maps flows to queues in a way that is better than consistent hashing. A given flow has access to a small collection of queues, and for each incoming request the shortest queue is chosen. When a Priority Level has queues, it also sets a limit on queue length. There is also a limit placed on how long a request can wait in its queue; this is a fixed fraction of the apiserver's request timeout. A request that cannot be executed and cannot be queued (any longer) is rejected.
- Alternatively, a non-exempt Priority Level may select immediate rejection instead of waiting in a queue.
- See the API documentation for this feature.
What’s missing? When will there be a beta?
We’re already planning a few enhancements based on alpha and there will be more as users send feedback to our community. Here’s a list of them:
- Traffic management for WATCH and EXEC requests
- Adjusting and improving the default set of FlowSchema/PriorityLevelConfiguration
- Enhancing observability on how this feature works
- Join the discussion here
Possibly treat LIST requests differently depending on an estimate of how big their result will be.
How can I get involved?
As always! Reach us on slack #sig-api-machinery, or through the mailing list. We have lots of exciting features to build and can use all sorts of help.
Many thanks to the contributors that have gotten this feature this far: Aaron Prindle, Daniel Smith, Jonathan Tomer, Mike Spreitzer, Min Kim, Bruce Ma, Yu Liao, Mengyi Zhou!
Introducing Windows CSI support alpha for Kubernetes
Authors: Authors: Deep Debroy [Docker], Jing Xu [Google], Krishnakumar R (KK) [Microsoft]
The alpha version of CSI Proxy for Windows is being released with Kubernetes 1.18. CSI proxy enables CSI Drivers on Windows by allowing containers in Windows to perform privileged storage operations.
Background
Container Storage Interface (CSI) for Kubernetes went GA in the Kubernetes 1.13 release. CSI has become the standard for exposing block and file storage to containerized workloads on Container Orchestration systems (COs) like Kubernetes. It enables third-party storage providers to write and deploy plugins without the need to alter the core Kubernetes codebase. All new storage features will utilize CSI, therefore it is important to get CSI drivers to work on Windows.
A CSI driver in Kubernetes has two main components: a controller plugin and a node plugin. The controller plugin generally does not need direct access to the host and can perform all its operations through the Kubernetes API and external control plane services (e.g. cloud storage service). The node plugin, however, requires direct access to the host for making block devices and/or file systems available to the Kubernetes kubelet. This was previously not possible for containers on Windows. With the release of CSIProxy, CSI drivers can now perform storage operations on the node. This inturn enables containerized CSI Drivers to run on Windows.
CSI support for Windows clusters
CSI drivers (e.g. AzureDisk, GCE PD, etc.) are recommended to be deployed as containers. CSI driver’s node plugin typically runs on every worker node in the cluster (as a DaemonSet). Node plugin containers need to run with elevated privileges to perform storage related operations. However, Windows currently does not support privileged containers. To solve this problem, CSIProxy makes it so that node plugins can now be deployed as unprivileged pods and then use the proxy to perform privileged storage operations on the node.
Node plugin interactions with CSIProxy
The design of the CSI proxy is captured in this KEP. The following diagram depicts the interactions with the CSI node plugin and CSI proxy.
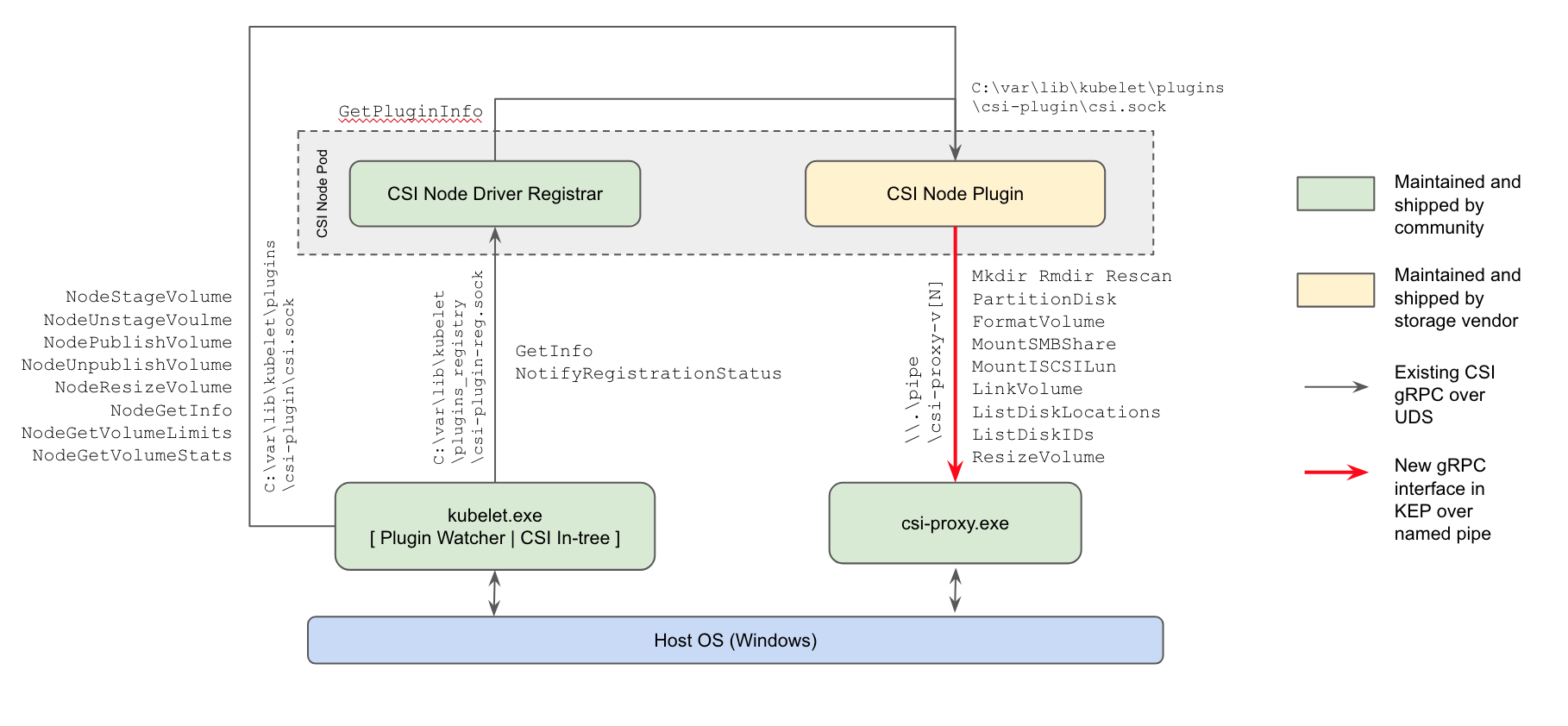
The CSI proxy runs as a process directly on the host on every windows node - very similar to kubelet. The CSI code in kubelet interacts with the node driver registrar component and the CSI node plugin. The node driver registrar is a community maintained CSI project which handles the registration of vendor specific node plugins. The kubelet initiates CSI gRPC calls like NodeStageVolume/NodePublishVolume on the node plugin as described in the figure. Node plugins interface with the CSIProxy process to perform local host OS storage related operations such as creation/enumeration of volumes, mounting/unmounting, etc.
CSI proxy architecture and implementation
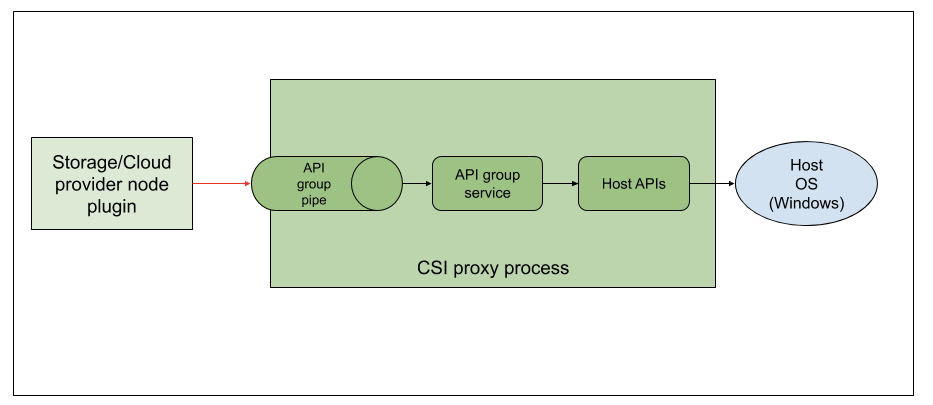
In the alpha release, CSIProxy supports the following API groups:
- Filesystem
- Disk
- Volume
- SMB
CSI proxy exposes each API group via a Windows named pipe. The communication is performed using gRPC over these pipes. The client library from the CSI proxy project uses these pipes to interact with the CSI proxy APIs. For example, the filesystem APIs are exposed via a pipe like \.\pipe\csi-proxy-filesystem-v1alpha1 and volume APIs under the \.\pipe\csi-proxy-volume-v1alpha1, and so on.
From each API group service, the calls are routed to the host API layer. The host API calls into the host Windows OS by either Powershell or Go standard library calls. For example, when the filesystem API Rmdir is called the API group service would decode the grpc structure RmdirRequest and find the directory to be removed and call into the Host APIs layer. This would result in a call to os.Remove, a Go standard library call, to perform the remove operation.
Control flow details
The following figure uses CSI call NodeStageVolume as an example to explain the interaction between kubelet, CSI plugin, and CSI proxy for provisioning a fresh volume. After the node plugin receives a CSI RPC call, it makes a few calls to CSIproxy accordingly. As a result of the NodeStageVolume call, first the required disk is identified using either of the Disk API calls: ListDiskLocations (in AzureDisk driver) or GetDiskNumberByName (in GCE PD driver). If the disk is not partitioned, then the PartitionDisk (Disk API group) is called. Subsequently, Volume API calls such as ListVolumesOnDisk, FormatVolume and MountVolume are called to perform the rest of the required operations. Similar operations are performed in case of NodeUnstageVolume, NodePublishVolume, NodeUnpublishedVolume, etc.
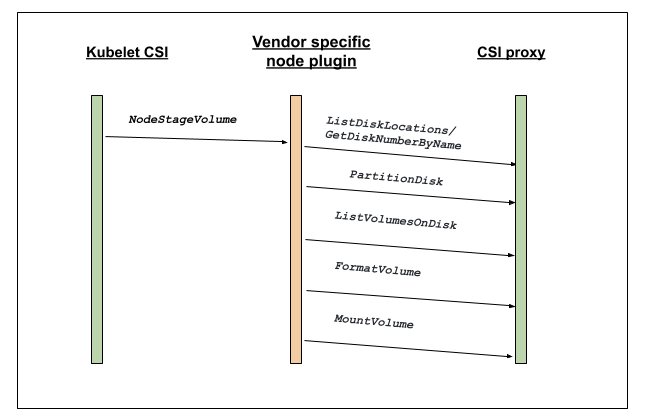
Current support
CSI proxy is now available as alpha. You can find more details on the CSIProxy GitHub repository. There are currently two cloud providers that provide alpha support for CSI drivers on Windows: Azure and GCE.
Future plans
One key area of focus in beta is going to be Windows based build and CI/CD setup to improve the stability and quality of the code base. Another area is using Go based calls directly instead of Powershell commandlets to improve performance. Enhancing debuggability and adding more tests are other areas which the team will be looking into.
How to get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together. Those interested in getting involved with the design and development of CSI Proxy, or any part of the Kubernetes Storage system, may join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
For those interested in more details, the CSIProxy GitHub repository is a good place to start. In addition, the #csi-windows channel on kubernetes slack is available for discussions specific to the CSI on Windows.
Acknowledgments
We would like to thank Michelle Au for guiding us throughout this journey to alpha. We would like to thank Jean Rougé for contributions during the initial CSI proxy effort. We would like to thank Saad Ali for all the guidance with respect to the project and review/feedback on a draft of this blog. We would like to thank Patrick Lang and Mark Rossetti for helping us with Windows specific questions and details. Special thanks to Andy Zhang for reviews and guidance with respect to Azuredisk and Azurefile work. A big thank you to Paul Burt and Karen Chu for the review and suggestions on improving this blog post.
Last but not the least, we would like to thank the broader Kubernetes community who contributed at every step of the project.
Improvements to the Ingress API in Kubernetes 1.18
Authors: Rob Scott (Google), Christopher M Luciano (IBM)
The Ingress API in Kubernetes has enabled a large number of controllers to provide simple and powerful ways to manage inbound network traffic to Kubernetes workloads. In Kubernetes 1.18, we've made 3 significant additions to this API:
- A new
pathTypefield that can specify how Ingress paths should be matched. - A new
IngressClassresource that can specify how Ingresses should be implemented by controllers. - Support for wildcards in hostnames.
Better Path Matching With Path Types
The new concept of a path type allows you to specify how a path should be matched. There are three supported types:
- ImplementationSpecific (default): With this path type, matching is up to the controller implementing the
IngressClass. Implementations can treat this as a separatepathTypeor treat it identically to thePrefixorExactpath types. - Exact: Matches the URL path exactly and with case sensitivity.
- Prefix: Matches based on a URL path prefix split by
/. Matching is case sensitive and done on a path element by element basis.
Extended Configuration With Ingress Classes
The Ingress resource was designed with simplicity in mind, providing a simple set of fields that would be applicable in all use cases. Over time, as use cases evolved, implementations began to rely on a long list of custom annotations for further configuration. The new IngressClass resource provides a way to replace some of those annotations.
Each IngressClass specifies which controller should implement Ingresses of the class and can reference a custom resource with additional parameters.
apiVersion: "networking.k8s.io/v1beta1"
kind: "IngressClass"
metadata:
name: "external-lb"
spec:
controller: "example.com/ingress-controller"
parameters:
apiGroup: "k8s.example.com/v1alpha"
kind: "IngressParameters"
name: "external-lb"
Specifying the Class of an Ingress
A new ingressClassName field has been added to the Ingress spec that is used to reference the IngressClass that should be used to implement this Ingress.
Deprecating the Ingress Class Annotation
Before the IngressClass resource was added in Kubernetes 1.18, a similar concept of Ingress class was often specified with a kubernetes.io/ingress.class annotation on the Ingress. Although this annotation was never formally defined, it was widely supported by Ingress controllers, and should now be considered formally deprecated.
Setting a Default IngressClass
It’s possible to mark a specific IngressClass as default in a cluster. Setting the
ingressclass.kubernetes.io/is-default-class annotation to true on an
IngressClass resource will ensure that new Ingresses without an ingressClassName specified will be assigned this default IngressClass.
Support for Hostname Wildcards
Many Ingress providers have supported wildcard hostname matching like *.foo.com matching app1.foo.com, but until now the spec assumed an exact FQDN match of the host. Hosts can now be precise matches (for example “foo.bar.com”) or a wildcard (for example “*.foo.com”). Precise matches require that the http host header matches the Host setting. Wildcard matches require the http host header is equal to the suffix of the wildcard rule.
| Host | Host header | Match? |
|---|---|---|
*.foo.com |
bar.foo.com |
Matches based on shared suffix |
*.foo.com |
baz.bar.foo.com |
No match, wildcard only covers a single DNS label |
*.foo.com |
foo.com |
No match, wildcard only covers a single DNS label |
Putting it All Together
These new Ingress features allow for much more configurability. Here’s an example of an Ingress that makes use of pathType, ingressClassName, and a hostname wildcard:
apiVersion: "networking.k8s.io/v1beta1"
kind: "Ingress"
metadata:
name: "example-ingress"
spec:
ingressClassName: "external-lb"
rules:
- host: "*.example.com"
http:
paths:
- path: "/example"
pathType: "Prefix"
backend:
serviceName: "example-service"
servicePort: 80
Ingress Controller Support
Since these features are new in Kubernetes 1.18, each Ingress controller implementation will need some time to develop support for these new features. Check the documentation for your preferred Ingress controllers to see when they will support this new functionality.
The Future of Ingress
The Ingress API is on pace to graduate from beta to a stable API in Kubernetes 1.19. It will continue to provide a simple way to manage inbound network traffic for Kubernetes workloads. This API has intentionally been kept simple and lightweight, but there has been a desire for greater configurability for more advanced use cases.
Work is currently underway on a new highly configurable set of APIs that will provide an alternative to Ingress in the future. These APIs are being referred to as the new “Service APIs”. They are not intended to replace any existing APIs, but instead provide a more configurable alternative for complex use cases. For more information, check out the Service APIs repo on GitHub.
Kubernetes 1.18 Feature Server-side Apply Beta 2
Authors: Antoine Pelisse (Google)
What is Server-side Apply?
Server-side Apply is an important effort to migrate “kubectl apply” to the apiserver. It was started in 2018 by the Apply working group.
The use of kubectl to declaratively apply resources has exposed the following challenges:
-
One needs to use the kubectl go code, or they have to shell out to kubectl.
-
Strategic merge-patch, the patch format used by kubectl, grew organically and was challenging to fix while maintaining compatibility with various api-server versions.
-
Some features are hard to implement directly on the client, for example, unions.
Server-side Apply is a new merging algorithm, as well as tracking of field ownership, running on the Kubernetes api-server. Server-side Apply enables new features like conflict detection, so the system knows when two actors are trying to edit the same field.
How does it work, what’s managedFields?
Server-side Apply works by keeping track of which actor of the system has changed each field of an object. It does so by diffing all updates to objects, and recording all the fields that have changed as well the time of the operation. All this information is stored in the managedFields in the metadata of objects. Since objects can have many fields, this field can be quite large.
When someone applies, we can then use the information stored within managedFields to report relevant conflicts and help the merge algorithm to do the right thing.
Wasn’t it already Beta before 1.18?
Yes, Server-side Apply has been Beta since 1.16, but it didn’t track the owner for fields associated with objects that had not been applied. This means that most objects didn’t have the managedFields metadata stored, and conflicts for these objects cannot be resolved. With Kubernetes 1.18, all new objects will have the managedFields attached to them and provide accurate information on conflicts.
How do I use it?
The most common way to use this is through kubectl: kubectl apply --server-side. This is likely to show conflicts with other actors, including client-side apply. When that happens, conflicts can be forced by using the --force-conflicts flag, which will grab the ownership for the fields that have changed.
Current limitations
We have two important limitations right now, especially with sub-resources. The first is that if you apply with a status, the status is going to be ignored. We are still going to try and acquire the fields, which may lead to invalid conflicts. The other is that we do not update the managedFields on some sub-resources, including scale, so you may not see information about a horizontal pod autoscaler changing the number of replicas.
What’s next?
We are working hard to improve the experience of using server-side apply with kubectl, and we are trying to make it the default. As part of that, we want to improve the migration from client-side to server-side.
Can I help?
Of course! The working-group apply is available on slack #wg-apply, through the mailing list and we also meet every other Tuesday at 9.30 PT on Zoom. We have lots of exciting features to build and can use all sorts of help.
We would also like to use the opportunity to thank the hard work of all the contributors involved in making this new beta possible:
- Daniel Smith
- Jenny Buckley
- Joe Betz
- Julian Modesto
- Kevin Wiesmüller
- Maria Ntalla
Kubernetes Topology Manager Moves to Beta - Align Up!
Authors: Kevin Klues (NVIDIA), Victor Pickard (Red Hat), Conor Nolan (Intel)
This blog post describes the TopologyManager, a beta feature of Kubernetes in release 1.18. The TopologyManager feature enables NUMA alignment of CPUs and peripheral devices (such as SR-IOV VFs and GPUs), allowing your workload to run in an environment optimized for low-latency.
Prior to the introduction of the TopologyManager, the CPU and Device Manager would make resource allocation decisions independent of each other. This could result in undesirable allocations on multi-socket systems, causing degraded performance on latency critical applications. With the introduction of the TopologyManager, we now have a way to avoid this.
This blog post covers:
- A brief introduction to NUMA and why it is important
- The policies available to end-users to ensure NUMA alignment of CPUs and devices
- The internal details of how the
TopologyManagerworks - Current limitations of the
TopologyManager - Future directions of the
TopologyManager
So, what is NUMA and why do I care?
The term NUMA stands for Non-Uniform Memory Access. It is a technology available on multi-cpu systems that allows different CPUs to access different parts of memory at different speeds. Any memory directly connected to a CPU is considered "local" to that CPU and can be accessed very fast. Any memory not directly connected to a CPU is considered "non-local" and will have variable access times depending on how many interconnects must be passed through in order to reach it. On modern systems, the idea of having "local" vs. "non-local" memory can also be extended to peripheral devices such as NICs or GPUs. For high performance, CPUs and devices should be allocated such that they have access to the same local memory.
All memory on a NUMA system is divided into a set of "NUMA nodes", with each node representing the local memory for a set of CPUs or devices. We talk about an individual CPU as being part of a NUMA node if its local memory is associated with that NUMA node.
We talk about a peripheral device as being part of a NUMA node based on the shortest number of interconnects that must be passed through in order to reach it.
For example, in Figure 1, CPUs 0-3 are said to be part of NUMA node 0, whereas CPUs 4-7 are part of NUMA node 1. Likewise GPU 0 and NIC 0 are said to be part of NUMA node 0 because they are attached to Socket 0, whose CPUs are all part of NUMA node 0. The same is true for GPU 1 and NIC 1 on NUMA node 1.
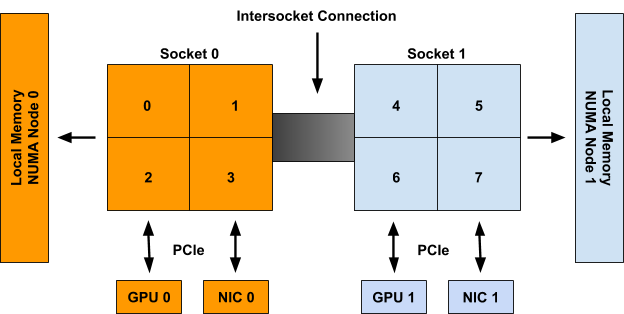
Figure 1: An example system with 2 NUMA nodes, 2 Sockets with 4 CPUs each, 2 GPUs, and 2 NICs. CPUs on Socket 0, GPU 0, and NIC 0 are all part of NUMA node 0. CPUs on Socket 1, GPU 1, and NIC 1 are all part of NUMA node 1.
Although the example above shows a 1-1 mapping of NUMA Node to Socket, this is not necessarily true in the general case. There may be multiple sockets on a single NUMA node, or individual CPUs of a single socket may be connected to different NUMA nodes. Moreover, emerging technologies such as Sub-NUMA Clustering (available on recent intel CPUs) allow single CPUs to be associated with multiple NUMA nodes so long as their memory access times to both nodes are the same (or have a negligible difference).
The TopologyManager has been built to handle all of these scenarios.
Align Up! It's a TeaM Effort!
As previously stated, the TopologyManager allows users to align their CPU and peripheral device allocations by NUMA node. There are several policies available for this:
none:this policy will not attempt to do any alignment of resources. It will act the same as if theTopologyManagerwere not present at all. This is the default policy.best-effort:with this policy, theTopologyManagerwill attempt to align allocations on NUMA nodes as best it can, but will always allow the pod to start even if some of the allocated resources are not aligned on the same NUMA node.restricted:this policy is the same as thebest-effortpolicy, except it will fail pod admission if allocated resources cannot be aligned properly. Unlike with thesingle-numa-nodepolicy, some allocations may come from multiple NUMA nodes if it is impossible to ever satisfy the allocation request on a single NUMA node (e.g. 2 devices are requested and the only 2 devices on the system are on different NUMA nodes).single-numa-node:this policy is the most restrictive and will only allow a pod to be admitted if all requested CPUs and devices can be allocated from exactly one NUMA node.
It is important to note that the selected policy is applied to each container in a pod spec individually, rather than aligning resources across all containers together.
Moreover, a single policy is applied to all pods on a node via a global kubelet flag, rather than allowing users to select different policies on a pod-by-pod basis (or a container-by-container basis). We hope to relax this restriction in the future.
The kubelet flag to set one of these policies can be seen below:
--topology-manager-policy=
[none | best-effort | restricted | single-numa-node]
Additionally, the TopologyManager is protected by a feature gate. This feature gate has been available since Kubernetes 1.16, but has only been enabled by default since 1.18.
The feature gate can be enabled or disabled as follows (as described in more detail here):
--feature-gates="...,TopologyManager=<true|false>"
In order to trigger alignment according to the selected policy, a user must request CPUs and peripheral devices in their pod spec, according to a certain set of requirements.
For peripheral devices, this means requesting devices from the available resources provided by a device plugin (e.g. intel.com/sriov, nvidia.com/gpu, etc.). This will only work if the device plugin has been extended to integrate properly with the TopologyManager. Currently, the only plugins known to have this extension are the Nvidia GPU device plugin, and the Intel SRIOV network device plugin. Details on how to extend a device plugin to integrate with the TopologyManager can be found here.
For CPUs, this requires that the CPUManager has been configured with its --static policy enabled and that the pod is running in the Guaranteed QoS class (i.e. all CPU and memory limits are equal to their respective CPU and memory requests). CPUs must also be requested in whole number values (e.g. 1, 2, 1000m, etc). Details on how to set the CPUManager policy can be found here.
For example, assuming the CPUManager is running with its --static policy enabled and the device plugins for gpu-vendor.com, and nic-vendor.com have been extended to integrate with the TopologyManager properly, the pod spec below is sufficient to trigger the TopologyManager to run its selected policy:
spec:
containers:
- name: numa-aligned-container
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
Following Figure 1 from the previous section, this would result in one of the following aligned allocations:
{cpu: {0, 1}, gpu: 0, nic: 0}
{cpu: {0, 2}, gpu: 0, nic: 0}
{cpu: {0, 3}, gpu: 0, nic: 0}
{cpu: {1, 2}, gpu: 0, nic: 0}
{cpu: {1, 3}, gpu: 0, nic: 0}
{cpu: {2, 3}, gpu: 0, nic: 0}
{cpu: {4, 5}, gpu: 1, nic: 1}
{cpu: {4, 6}, gpu: 1, nic: 1}
{cpu: {4, 7}, gpu: 1, nic: 1}
{cpu: {5, 6}, gpu: 1, nic: 1}
{cpu: {5, 7}, gpu: 1, nic: 1}
{cpu: {6, 7}, gpu: 1, nic: 1}
And that’s it! Just follow this pattern to have the TopologyManager ensure NUMA alignment across containers that request topology-aware devices and exclusive CPUs.
**NOTE:** if a pod is rejected by one of the **TopologyManager** policies, it will be placed in a **Terminated** state with a pod admission error and a reason of "TopologyAffinityError". Once a pod is in this state, the Kubernetes scheduler will not attempt to reschedule it. It is therefore recommended to use a Deployment with replicas to trigger a redeploy of the pod on such a failure. An external control loop can also be implemented to trigger a redeployment of pods that have a TopologyAffinityError.
This is great, so how does it work under the hood?
Pseudocode for the primary logic carried out by the TopologyManager can be seen below:
for container := range append(InitContainers, Containers...) {
for provider := range HintProviders {
hints += provider.GetTopologyHints(container)
}
bestHint := policy.Merge(hints)
for provider := range HintProviders {
provider.Allocate(container, bestHint)
}
}
The following diagram summarizes the steps taken during this loop:
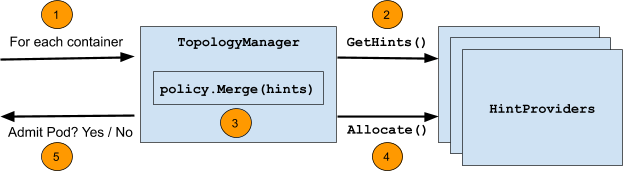
The steps themselves are:
- Loop over all containers in a pod.
- For each container, gather "
TopologyHints" from a set of "HintProviders" for each topology-aware resource type requested by the container (e.g.gpu-vendor.com/gpu,nic-vendor.com/nic,cpu, etc.). - Using the selected policy, merge the gathered
TopologyHintsto find the "best" hint that aligns resource allocations across all resource types. - Loop back over the set of hint providers, instructing them to allocate the resources they control using the merged hint as a guide.
- This loop runs at pod admission time and will fail to admit the pod if any of these steps fail or alignment cannot be satisfied according to the selected policy. Any resources allocated before the failure are cleaned up accordingly.
The following sections go into more detail on the exact structure of TopologyHints and HintProviders, as well as some details on the merge strategies used by each policy.
TopologyHints
A TopologyHint encodes a set of constraints from which a given resource request can be satisfied. At present, the only constraint we consider is NUMA alignment. It is defined as follows:
type TopologyHint struct {
NUMANodeAffinity bitmask.BitMask
Preferred bool
}
The NUMANodeAffinity field contains a bitmask of NUMA nodes where a resource request can be satisfied. For example, the possible masks on a system with 2 NUMA nodes include:
{00}, {01}, {10}, {11}
The Preferred field contains a boolean that encodes whether the given hint is "preferred" or not. With the best-effort policy, preferred hints will be given preference over non-preferred hints when generating a "best" hint. With the restricted and single-numa-node policies, non-preferred hints will be rejected.
In general, HintProviders generate TopologyHints by looking at the set of currently available resources that can satisfy a resource request. More specifically, they generate one TopologyHint for every possible mask of NUMA nodes where that resource request can be satisfied. If a mask cannot satisfy the request, it is omitted. For example, a HintProvider might provide the following hints on a system with 2 NUMA nodes when being asked to allocate 2 resources. These hints encode that both resources could either come from a single NUMA node (either 0 or 1), or they could each come from different NUMA nodes (but we prefer for them to come from just one).
{01: True}, {10: True}, {11: False}
At present, all HintProviders set the Preferred field to True if and only if the NUMANodeAffinity encodes a minimal set of NUMA nodes that can satisfy the resource request. Normally, this will only be True for TopologyHints with a single NUMA node set in their bitmask. However, it may also be True if the only way to ever satisfy the resource request is to span multiple NUMA nodes (e.g. 2 devices are requested and the only 2 devices on the system are on different NUMA nodes):
{0011: True}, {0111: False}, {1011: False}, {1111: False}
NOTE: Setting of the Preferred field in this way is not based on the set of currently available resources. It is based on the ability to physically allocate the number of requested resources on some minimal set of NUMA nodes.
In this way, it is possible for a HintProvider to return a list of hints with all Preferred fields set to False if an actual preferred allocation cannot be satisfied until other containers release their resources. For example, consider the following scenario from the system in Figure 1:
- All but 2 CPUs are currently allocated to containers
- The 2 remaining CPUs are on different NUMA nodes
- A new container comes along asking for 2 CPUs
In this case, the only generated hint would be {11: False} and not {11: True}. This happens because it is possible to allocate 2 CPUs from the same NUMA node on this system (just not right now, given the current allocation state). The idea being that it is better to fail pod admission and retry the deployment when the minimal alignment can be satisfied than to allow a pod to be scheduled with sub-optimal alignment.
HintProviders
A HintProvider is a component internal to the kubelet that coordinates aligned resource allocations with the TopologyManager. At present, the only HintProviders in Kubernetes are the CPUManager and the DeviceManager. We plan to add support for HugePages soon.
As discussed previously, the TopologyManager both gathers TopologyHints from HintProviders as well as triggers aligned resource allocations on them using a merged "best" hint. As such, HintProviders implement the following interface:
type HintProvider interface {
GetTopologyHints(*v1.Pod, *v1.Container) map[string][]TopologyHint
Allocate(*v1.Pod, *v1.Container) error
}
Notice that the call to GetTopologyHints() returns a map[string][]TopologyHint. This allows a single HintProvider to provide hints for multiple resource types instead of just one. For example, the DeviceManager requires this in order to pass hints back for every resource type registered by its plugins.
As HintProviders generate their hints, they only consider how alignment could be satisfied for currently available resources on the system. Any resources already allocated to other containers are not considered.
For example, consider the system in Figure 1, with the following two containers requesting resources from it:
Container0
|
Container1
|
spec:
containers:
- name: numa-aligned-container0
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
|
spec:
containers:
- name: numa-aligned-container1
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
|
If Container0 is the first container considered for allocation on the system, the following set of hints will be generated for the three topology-aware resource types in the spec.
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{01: True}, {10: True}}
nic-vendor.com/nic: {{01: True}, {10: True}}
With a resulting aligned allocation of:
{cpu: {0, 1}, gpu: 0, nic: 0}
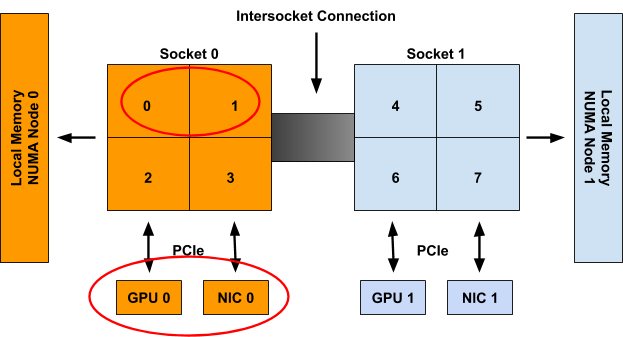
When considering Container1 these resources are then presumed to be unavailable, and thus only the following set of hints will be generated:
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{10: True}}
nic-vendor.com/nic: {{10: True}}
With a resulting aligned allocation of:
{cpu: {4, 5}, gpu: 1, nic: 1}
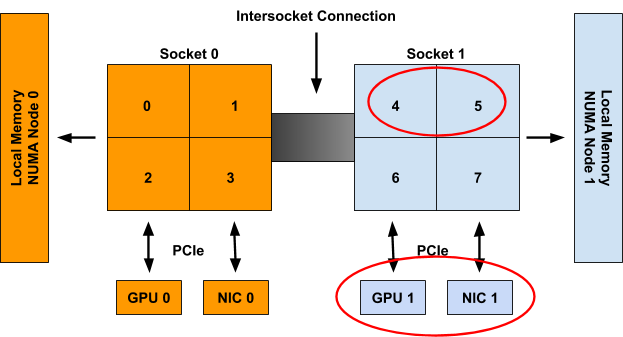
NOTE: Unlike the pseudocode provided at the beginning of this section, the call to Allocate() does not actually take a parameter for the merged "best" hint directly. Instead, the TopologyManager implements the following Store interface that HintProviders can query to retrieve the hint generated for a particular container once it has been generated:
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
Separating this out into its own API call allows one to access this hint outside of the pod admission loop. This is useful for debugging as well as for reporting generated hints in tools such as kubectl(not yet available).
Policy.Merge
The merge strategy defined by a given policy dictates how it combines the set of TopologyHints generated by all HintProviders into a single TopologyHint that can be used to inform aligned resource allocations.
The general merge strategy for all supported policies begins the same:
- Take the cross-product of
TopologyHintsgenerated for each resource type - For each entry in the cross-product,
bitwise-andthe NUMA affinities of eachTopologyHinttogether. Set this as the NUMA affinity in a resulting "merged" hint. - If all of the hints in an entry have
Preferredset toTrue, setPreferredtoTruein the resulting "merged" hint. - If even one of the hints in an entry has
Preferredset toFalse, setPreferredtoFalsein the resulting "merged" hint. Also setPreferredtoFalsein the "merged" hint if its NUMA affinity contains all 0s.
Following the example from the previous section with hints for Container0 generated as:
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{01: True}, {10: True}}
nic-vendor.com/nic: {{01: True}, {10: True}}
The above algorithm results in the following set of cross-product entries and "merged" hints:
| cross-product entry
|
"merged" hint |
{{01: True}, {01: True}, {01: True}}
|
{01: True}
|
{{01: True}, {01: True}, {10: True}}
|
{00: False}
|
{{01: True}, {10: True}, {01: True}}
|
{00: False}
|
{{01: True}, {10: True}, {10: True}}
|
{00: False}
|
{{10: True}, {01: True}, {01: True}}
|
{00: False}
|
{{10: True}, {01: True}, {10: True}}
|
{00: False}
|
{{10: True}, {10: True}, {01: True}}
|
{00: False}
|
{{10: True}, {10: True}, {10: True}}
|
{01: True}
|
{{11: False}, {01: True}, {01: True}}
|
{01: False}
|
{{11: False}, {01: True}, {10: True}}
|
{00: False}
|
{{11: False}, {10: True}, {01: True}}
|
{00: False}
|
{{11: False}, {10: True}, {10: True}}
|
{10: False}
|
Once this list of "merged" hints has been generated, it is the job of the specific TopologyManager policy in use to decide which one to consider as the "best" hint.
In general, this involves:
- Sorting merged hints by their "narrowness". Narrowness is defined as the number of bits set in a hint’s NUMA affinity mask. The fewer bits set, the narrower the hint. For hints that have the same number of bits set in their NUMA affinity mask, the hint with the most low order bits set is considered narrower.
- Sorting merged hints by their
Preferredfield. Hints that havePreferredset toTrueare considered more likely candidates than hints withPreferredset toFalse. - Selecting the narrowest hint with the best possible setting for
Preferred.
In the case of the best-effort policy this algorithm will always result in some hint being selected as the "best" hint and the pod being admitted. This "best" hint is then made available to HintProviders so they can make their resource allocations based on it.
However, in the case of the restricted and single-numa-node policies, any selected hint with Preferred set to False will be rejected immediately, causing pod admission to fail and no resources to be allocated. Moreover, the single-numa-node will also reject a selected hint that has more than one NUMA node set in its affinity mask.
In the example above, the pod would be admitted by all policies with a hint of {01: True}.
Upcoming enhancements
While the 1.18 release and promotion to Beta brings along some great enhancements and fixes, there are still a number of limitations, described here. We are already underway working to address these limitations and more.
This section walks through the set of enhancements we plan to implement for the TopologyManager in the near future. This list is not exhaustive, but it gives a good idea of the direction we are moving in. It is ordered by the timeframe in which we expect to see each enhancement completed.
If you would like to get involved in helping with any of these enhancements, please join the weekly Kubernetes SIG-node meetings to learn more and become part of the community effort!
Supporting device-specific constraints
Currently, NUMA affinity is the only constraint considered by the TopologyManager for resource alignment. Moreover, the only scalable extensions that can be made to a TopologyHint involve node-level constraints, such as PCIe bus alignment across device types. It would be intractable to try and add any device-specific constraints to this struct (e.g. the internal NVLINK topology among a set of GPU devices).
As such, we propose an extension to the device plugin interface that will allow a plugin to state its topology-aware allocation preferences, without having to expose any device-specific topology information to the kubelet. In this way, the TopologyManager can be restricted to only deal with common node-level topology constraints, while still having a way of incorporating device-specific topology constraints into its allocation decisions.
Details of this proposal can be found here, and should be available as soon as Kubernetes 1.19.
NUMA alignment for hugepages
As stated previously, the only two HintProviders currently available to the TopologyManager are the CPUManager and the DeviceManager. However, work is currently underway to add support for hugepages as well. With the completion of this work, the TopologyManager will finally be able to allocate memory, hugepages, CPUs and PCI devices all on the same NUMA node.
A KEP for this work is currently under review, and a prototype is underway to get this feature implemented very soon.
Scheduler awareness
Currently, the TopologyManager acts as a Pod Admission controller. It is not directly involved in the scheduling decision of where a pod will be placed. Rather, when the kubernetes scheduler (or whatever scheduler is running in the deployment), places a pod on a node to run, the TopologyManager will decide if the pod should be "admitted" or "rejected". If the pod is rejected due to lack of available NUMA aligned resources, things can get a little interesting. This kubernetes issue highlights and discusses this situation well.
So how do we go about addressing this limitation? We have the Kubernetes Scheduling Framework to the rescue! This framework provides a new set of plugin APIs that integrate with the existing Kubernetes Scheduler and allow scheduling features, such as NUMA alignment, to be implemented without having to resort to other, perhaps less appealing alternatives, including writing your own scheduler, or even worse, creating a fork to add your own scheduler secret sauce.
The details of how to implement these extensions for integration with the TopologyManager have not yet been worked out. We still need to answer questions like:
- Will we require duplicated logic to determine device affinity in the
TopologyManagerand the scheduler? - Do we need a new API to get
TopologyHintsfrom theTopologyManagerto the scheduler plugin?
Work on this feature should begin in the next couple of months, so stay tuned!
Per-pod alignment policy
As stated previously, a single policy is applied to all pods on a node via a global kubelet flag, rather than allowing users to select different policies on a pod-by-pod basis (or a container-by-container basis).
While we agree that this would be a great feature to have, there are quite a few hurdles that need to be overcome before it is achievable. The biggest hurdle being that this enhancement will require an API change to be able to express the desired alignment policy in either the Pod spec or its associated RuntimeClass.
We are only now starting to have serious discussions around this feature, and it is still a few releases away, at the best, from being available.
Conclusion
With the promotion of the TopologyManager to Beta in 1.18, we encourage everyone to give it a try and look forward to any feedback you may have. Many fixes and enhancements have been worked on in the past several releases, greatly improving the functionality and reliability of the TopologyManager and its HintProviders. While there are still a number of limitations, we have a set of enhancements planned to address them, and look forward to providing you with a number of new features in upcoming releases.
If you have ideas for additional enhancements or a desire for certain features, don’t hesitate to let us know. The team is always open to suggestions to enhance and improve the TopologyManager.
We hope you have found this blog informative and useful! Let us know if you have any questions or comments. And, happy deploying…..Align Up!
Kubernetes 1.18: Fit & Finish
Authors: Kubernetes 1.18 Release Team
We're pleased to announce the delivery of Kubernetes 1.18, our first release of 2020! Kubernetes 1.18 consists of 38 enhancements: 15 enhancements are moving to stable, 11 enhancements in beta, and 12 enhancements in alpha.
Kubernetes 1.18 is a "fit and finish" release. Significant work has gone into improving beta and stable features to ensure users have a better experience. An equal effort has gone into adding new developments and exciting new features that promise to enhance the user experience even more. Having almost as many enhancements in alpha, beta, and stable is a great achievement. It shows the tremendous effort made by the community on improving the reliability of Kubernetes as well as continuing to expand its existing functionality.
Major Themes
Kubernetes Topology Manager Moves to Beta - Align Up!
A beta feature of Kubernetes in release 1.18, the Topology Manager feature enables NUMA alignment of CPU and devices (such as SR-IOV VFs) that will allow your workload to run in an environment optimized for low-latency. Prior to the introduction of the Topology Manager, the CPU and Device Manager would make resource allocation decisions independent of each other. This could result in undesirable allocations on multi-socket systems, causing degraded performance on latency critical applications.
Serverside Apply Introduces Beta 2
Server-side Apply was promoted to Beta in 1.16, but is now introducing a second Beta in 1.18. This new version will track and manage changes to fields of all new Kubernetes objects, allowing you to know what changed your resources and when.
Extending Ingress with and replacing a deprecated annotation with IngressClass
In Kubernetes 1.18, there are two significant additions to Ingress: A new pathType field and a new IngressClass resource. The pathType field allows specifying how paths should be matched. In addition to the default ImplementationSpecific type, there are new Exact and Prefix path types.
The IngressClass resource is used to describe a type of Ingress within a Kubernetes cluster. Ingresses can specify the class they are associated with by using a new ingressClassName field on Ingresses. This new resource and field replace the deprecated kubernetes.io/ingress.class annotation.
SIG-CLI introduces kubectl alpha debug
SIG-CLI was debating the need for a debug utility for quite some time already. With the development of ephemeral containers, it became more obvious how we can support developers with tooling built on top of kubectl exec. The addition of the kubectl alpha debug command (it is alpha but your feedback is more than welcome), allows developers to easily debug their Pods inside the cluster. We think this addition is invaluable. This command allows one to create a temporary container which runs next to the Pod one is trying to examine, but also attaches to the console for interactive troubleshooting.
Introducing Windows CSI support alpha for Kubernetes
The alpha version of CSI Proxy for Windows is being released with Kubernetes 1.18. CSI proxy enables CSI Drivers on Windows by allowing containers in Windows to perform privileged storage operations.
Other Updates
Graduated to Stable 💯
- Taint Based Eviction
kubectl diff- CSI Block storage support
- API Server dry run
- Pass Pod information in CSI calls
- Support Out-of-Tree vSphere Cloud Provider
- Support GMSA for Windows workloads
- Skip attach for non-attachable CSI volumes
- PVC cloning
- Moving kubectl package code to staging
- RunAsUserName for Windows
- AppProtocol for Services and Endpoints
- Extending Hugepage Feature
- client-go signature refactor to standardize options and context handling
- Node-local DNS cache
Major Changes
- EndpointSlice API
- Moving kubectl package code to staging
- CertificateSigningRequest API
- Extending Hugepage Feature
- client-go signature refactor to standardize options and context handling
Release Notes
Check out the full details of the Kubernetes 1.18 release in our release notes.
Availability
Kubernetes 1.18 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials or run local Kubernetes clusters using Docker container “nodes” with kind. You can also easily install 1.18 using kubeadm.
Release Team
This release is made possible through the efforts of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Jorge Alarcon Ochoa, Site Reliability Engineer at Searchable AI. The 34 release team members coordinated many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid pace. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has had over 40,000 individual contributors to date and an active community of more than 3,000 people.
Release Logo
![]()
Why the LHC?
The LHC is the world’s largest and most powerful particle accelerator. It is the result of the collaboration of thousands of scientists from around the world, all for the advancement of science. In a similar manner, Kubernetes has been a project that has united thousands of contributors from hundreds of organizations – all to work towards the same goal of improving cloud computing in all aspects! "A Bit Quarky" as the release name is meant to remind us that unconventional ideas can bring about great change and keeping an open mind to diversity will lead help us innovate.
About the designer
Maru Lango is a designer currently based in Mexico City. While her area of expertise is Product Design, she also enjoys branding, illustration and visual experiments using CSS + JS and contributing to diversity efforts within the tech and design communities. You may find her in most social media as @marulango or check her website: https://marulango.com
User Highlights
- Ericsson is using Kubernetes and other cloud native technology to deliver a highly demanding 5G network that resulted in up to 90 percent CI/CD savings.
- Zendesk is using Kubernetes to run around 70% of its existing applications. It’s also building all new applications to also run on Kubernetes, which has brought time savings, greater flexibility, and increased velocity to its application development.
- LifeMiles has reduced infrastructure spending by 50% because of its move to Kubernetes. It has also allowed them to double its available resource capacity.
Ecosystem Updates
- The CNCF published the results of its annual survey showing that Kubernetes usage in production is skyrocketing. The survey found that 78% of respondents are using Kubernetes in production compared to 58% last year.
- The “Introduction to Kubernetes” course hosted by the CNCF surpassed 100,000 registrations.
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times.
This past quarter, 641 different companies and over 6,409 individuals contributed to Kubernetes. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
Event Update
Kubecon + CloudNativeCon EU 2020 is being pushed back – for the more most up-to-date information, please check the Novel Coronavirus Update page.
Upcoming Release Webinar
Join members of the Kubernetes 1.18 release team on April 23rd, 2020 to learn about the major features in this release including kubectl debug, Topography Manager, Ingress to V1 graduation, and client-go. Register here: https://www.cncf.io/webinars/kubernetes-1-18/.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below. Thank you for your continued feedback and support.
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Post questions (or answer questions) on Stack Overflow
- Share your Kubernetes story
- Read more about what’s happening with Kubernetes on the blog
- Learn more about the Kubernetes Release Team
Join SIG Scalability and Learn Kubernetes the Hard Way
Authors: Alex Handy
Contributing to SIG Scalability is a great way to learn Kubernetes in all its depth and breadth, and the team would love to have you join as a contributor. I took a look at the value of learning the hard way and interviewed the current SIG chairs to give you an idea of what contribution feels like.
The value of Learning The Hard Way
There is a belief in the software development community that pushes for the most challenging and rigorous possible method of learning a new language or system. These tend to go by the moniker of "Learn __ the Hard Way." Examples abound: Learn Code the Hard Way, Learn Python the Hard Way, and many others originating with Zed Shaw's courses in the topic.
While there are folks out there who offer you a "Learn Kubernetes the Hard Way" type experience (most notably Kelsey Hightower's), any "Hard Way" project should attempt to cover every aspect of the core topic's principles.
Therefore, the real way to "Learn Kubernetes the Hard Way," is to join the CNCF and get involved in the project itself. And there is only one SIG that could genuinely offer a full-stack learning experience for Kubernetes: SIG Scalability.
The team behind SIG Scalability is responsible for detecting and dealing with issues that arise when Kubernetes clusters are working with upwards of a thousand nodes. Said Wojiciech Tyczynski, a staff software engineer at Google and a member of SIG Scalability, the standard size for a test cluster for this SIG is over 5,000 nodes.
And yet, this SIG is not composed of Ph.D.'s in highly scalable systems designs. Many of the folks working with Tyczynski, for example, joined the SIG knowing very little about these types of issues, and often, very little about Kubernetes.
Working on SIG Scalability is like jumping into the deep end of the pool to learn to swim, and the SIG is inherently concerned with the entire Kubernetes project. SIG Scalability focuses on how Kubernetes functions as a whole and at scale. The SIG Scalability team members have an impetus to learn about every system and to understand how all systems interact with one another.
A complex and rewarding contributor experience
While that may sound complicated (and it is!), that doesn't mean it's outside the reach of an average developer, tester, or administrator. Google software developer Matt Matejczyk has only been on the team since the beginning of 2019, and he's been a valued member of the team since then, ferreting out bugs.
"I am new here," said Matejczyk. "I joined the team in January [2019]. Before that, I worked on AdWords at Google in New York. Why did I join? I knew some people there, so that was one of the decisions for me to move. I thought at that time that Kubernetes is a unique, cutting edge technology. I thought it'd be cool to work on that."
Matejczyk was correct about the coolness. "It's cool," he said. "So actually, ramping up on scalability is not easy. There are many things you need to understand. You need to understand Kubernetes very well. It can use every part of Kubernetes. I am still ramping up after these 8 months. I think it took me maybe 3 months to get up to decent speed."
When Matejczyk spoke to what he had worked on during those 8 months, he answered, "An interesting example is a regression I have been working on recently. We noticed the overall slowness of Kubernetes control plane in specific scenarios, and we couldn't attribute it to any particular component. In the end, we realized that everything boiled down to the memory allocation on the golang level. It was very counterintuitive to have two completely separate pieces of code (running as a part of the same binary) affecting the performance of each other only because one of them was allocating memory too fast. But connecting all the dots and getting to the bottom of regression like this gives great satisfaction."
Tyczynski said that "It's not only debugging regressions, but it's also debugging and finding bottlenecks. In general, those can be regressions, but those can be things we can improve. The other significant area is extending what we want to guarantee to users. Extending SLA and SLO coverage of the system so users can rely on what they can expect from the system in terms of performance and scalability. Matt is doing much work in extending our tests to be more representative and cover more Kubernetes concepts."
Give SIG Scalability a try
The SIG Scalability team is always in need of new members, and if you're the sort of developer or tester who loves taking on new complex challenges, and perhaps loves learning things the hard way, consider joining this SIG. As the team points out, adding Kubernetes expertise to your resume is never a bad idea, and this is the one SIG where you can learn it all from top to bottom.
See the SIG's documentation to learn about upcoming meetings, its charter, and more. You can also join the #sig-scalability Slack channel to see what it's like. We hope to see you join in to take advantage of this great opportunity to learn Kubernetes and contribute back at the same time.
Kong Ingress Controller and Service Mesh: Setting up Ingress to Istio on Kubernetes
Author: Kevin Chen, Kong
Kubernetes has become the de facto way to orchestrate containers and the services within services. But how do we give services outside our cluster access to what is within? Kubernetes comes with the Ingress API object that manages external access to services within a cluster.
Ingress is a group of rules that will proxy inbound connections to endpoints defined by a backend. However, Kubernetes does not know what to do with Ingress resources without an Ingress controller, which is where an open source controller can come into play. In this post, we are going to use one option for this: the Kong Ingress Controller. The Kong Ingress Controller was open-sourced a year ago and recently reached one million downloads. In the recent 0.7 release, service mesh support was also added. Other features of this release include:
- Built-In Kubernetes Admission Controller, which validates Custom Resource Definitions (CRD) as they are created or updated and rejects any invalid configurations.
- In-memory Mode - Each pod’s controller actively configures the Kong container in its pod, which limits the blast radius of failure of a single container of Kong or controller container to that pod only.
- Native gRPC Routing - gRPC traffic can now be routed via Kong Ingress Controller natively with support for method-based routing.
If you would like a deeper dive into Kong Ingress Controller 0.7, please check out the GitHub repository.
But let’s get back to the service mesh support since that will be the main focal point of this blog post. Service mesh allows organizations to address microservices challenges related to security, reliability, and observability by abstracting inter-service communication into a mesh layer. But what if our mesh layer sits within Kubernetes and we still need to expose certain services beyond our cluster? Then you need an Ingress controller such as the Kong Ingress Controller. In this blog post, we’ll cover how to deploy Kong Ingress Controller as your Ingress layer to an Istio mesh. Let’s dive right in:
Part 0: Set up Istio on Kubernetes
This blog will assume you have Istio set up on Kubernetes. If you need to catch up to this point, please check out the Istio documentation. It will walk you through setting up Istio on Kubernetes.
1. Install the Bookinfo Application
First, we need to label the namespaces that will host our application and Kong proxy. To label our default namespace where the bookinfo app sits, run this command:
$ kubectl label namespace default istio-injection=enabled
namespace/default labeled
Then create a new namespace that will be hosting our Kong gateway and the Ingress controller:
$ kubectl create namespace kong
namespace/kong created
Because Kong will be sitting outside the default namespace, be sure you also label the Kong namespace with istio-injection enabled as well:
$ kubectl label namespace kong istio-injection=enabled
namespace/kong labeled
Having both namespaces labeled istio-injection=enabled is necessary. Or else the default configuration will not inject a sidecar container into the pods of your namespaces.
Now deploy your BookInfo application with the following command:
$ kubectl apply -f http://bit.ly/bookinfoapp
service/details created
serviceaccount/bookinfo-details created
deployment.apps/details-v1 created
service/ratings created
serviceaccount/bookinfo-ratings created
deployment.apps/ratings-v1 created
service/reviews created
serviceaccount/bookinfo-reviews created
deployment.apps/reviews-v1 created
deployment.apps/reviews-v2 created
deployment.apps/reviews-v3 created
service/productpage created
serviceaccount/bookinfo-productpage created
deployment.apps/productpage-v1 created
Let’s double-check our Services and Pods to make sure that we have it all set up correctly:
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
details ClusterIP 10.97.125.254 <none> 9080/TCP 29s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 29h
productpage ClusterIP 10.97.62.68 <none> 9080/TCP 28s
ratings ClusterIP 10.96.15.180 <none> 9080/TCP 28s
reviews ClusterIP 10.104.207.136 <none> 9080/TCP 28s
You should see four new services: details, productpage, ratings, and reviews. None of them have an external IP so we will use the Kong gateway to expose the necessary services. And to check pods, run the following command:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
details-v1-c5b5f496d-9wm29 2/2 Running 0 101s
productpage-v1-7d6cfb7dfd-5mc96 2/2 Running 0 100s
ratings-v1-f745cf57b-hmkwf 2/2 Running 0 101s
reviews-v1-85c474d9b8-kqcpt 2/2 Running 0 101s
reviews-v2-ccffdd984-9jnsj 2/2 Running 0 101s
reviews-v3-98dc67b68-nzw97 2/2 Running 0 101s
This command outputs useful data, so let’s take a second to understand it. If you examine the READY column, each pod has two containers running: the service and an Envoy sidecar injected alongside it. Another thing to highlight is that there are three review pods but only 1 review service. The Envoy sidecar will load balance the traffic to three different review pods that contain different versions, giving us the ability to A/B test our changes. We have one step before we can access the deployed application. We need to add an additional annotation to the productpage service. To do so, run:
$ kubectl annotate service productpage ingress.kubernetes.io/service-upstream=true
service/productpage annotated
Both the API gateway (Kong) and the service mesh (Istio) can handle the load-balancing. Without the additional ingress.kubernetes.io/service-upstream: "true" annotation, Kong will try to load-balance by selecting its own endpoint/target from the productpage service. This causes Envoy to receive that pod’s IP as the upstream local address, instead of the service’s cluster IP. But we want the service's cluster IP so that Envoy can properly load balance.
With that added, you should now be able to access your product page!
$ kubectl exec -it $(kubectl get pod -l app=ratings -o jsonpath='{.items[0].metadata.name}') -c ratings -- curl productpage:9080/productpage | grep -o "<title>.*</title>"
<title>Simple Bookstore App</title>
2. Kong Kubernetes Ingress Controller Without Database
To expose your services to the world, we will deploy Kong as the north-south traffic gateway. Kong 1.1 released with declarative configuration and DB-less mode. Declarative configuration allows you to specify the desired system state through a YAML or JSON file instead of a sequence of API calls. Using declarative config provides several key benefits to reduce complexity, increase automation and enhance system performance. And with the Kong Ingress Controller, any Ingress rules you apply to the cluster will automatically be configured on the Kong proxy. Let’s set up the Kong Ingress Controller and the actual Kong proxy first like this:
$ kubectl apply -f https://bit.ly/k4k8s
namespace/kong configured
customresourcedefinition.apiextensions.k8s.io/kongconsumers.configuration.konghq.com created
customresourcedefinition.apiextensions.k8s.io/kongcredentials.configuration.konghq.com created
customresourcedefinition.apiextensions.k8s.io/kongingresses.configuration.konghq.com created
customresourcedefinition.apiextensions.k8s.io/kongplugins.configuration.konghq.com created
serviceaccount/kong-serviceaccount created
clusterrole.rbac.authorization.k8s.io/kong-ingress-clusterrole created
clusterrolebinding.rbac.authorization.k8s.io/kong-ingress-clusterrole-nisa-binding created
configmap/kong-server-blocks created
service/kong-proxy created
service/kong-validation-webhook created
deployment.apps/ingress-kong created
To check if the Kong pod is up and running, run:
$ kubectl get pods -n kong
NAME READY STATUS RESTARTS AGE
pod/ingress-kong-8b44c9856-9s42v 3/3 Running 0 2m26s
There will be three containers within this pod. The first container is the Kong Gateway that will be the Ingress point to your cluster. The second container is the Ingress controller. It uses Ingress resources and updates the proxy to follow rules defined in the resource. And lastly, the third container is the Envoy proxy injected by Istio. Kong will route traffic through the Envoy sidecar proxy to the appropriate service. To send requests into the cluster via our newly deployed Kong Gateway, setup an environment variable with the a URL based on the IP address at which Kong is accessible.
$ export PROXY_URL="$(minikube service -n kong kong-proxy --url | head -1)"
$ echo $PROXY_URL
http://192.168.99.100:32728
Next, we need to change some configuration so that the side-car Envoy process can route the request correctly based on the host/authority header of the request. Run the following to stop the route from preserving host:
$ echo "
apiVersion: configuration.konghq.com/v1
kind: KongIngress
metadata:
name: do-not-preserve-host
route:
preserve_host: false
upstream:
host_header: productpage.default.svc
" | kubectl apply -f -
kongingress.configuration.konghq.com/do-not-preserve-host created
And annotate the existing productpage service to set service-upstream as true:
$ kubectl annotate svc productpage Ingress.kubernetes.io/service-upstream="true"
service/productpage annotated
Now that we have everything set up, we can look at how to use the Ingress resource to help route external traffic to the services within your Istio mesh. We’ll create an Ingress rule that routes all traffic with the path of / to our productpage service:
$ echo "
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: productpage
annotations:
configuration.konghq.com: do-not-preserve-host
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: productpage
servicePort: 9080
" | kubectl apply -f -
ingress.extensions/productpage created
And just like that, the Kong Ingress Controller is able to understand the rules you defined in the Ingress resource and routes it to the productpage service! To view the product page service’s GUI, go to $PROXY_URL/productpage in your browser. Or to test it in your command line, try:
$ curl $PROXY_URL/productpage
That is all I have for this walk-through. If you enjoyed the technologies used in this post, please check out their repositories since they are all open source and would love to have more contributors! Here are their links for your convenience:
- Kong: [GitHub] [Twitter]
- Kubernetes: [GitHub] [Twitter]
- Istio: [GitHub] [Twitter]
- Envoy: [GitHub] [Twitter]
Thank you for following along!
Contributor Summit Amsterdam Postponed
Authors: Dawn Foster (VMware), Jorge Castro (VMware)
The CNCF has announced that KubeCon + CloudNativeCon EU has been delayed until July/August of 2020. As a result the Contributor Summit planning team is weighing options for how to proceed. Here’s the current plan:
- There will be an in-person Contributor Summit as planned when KubeCon + CloudNativeCon is rescheduled.
- We are looking at options for having additional virtual contributor activities in the meantime.
We will communicate via this blog and the usual communications channels on the final plan. Please bear with us as we adapt when we get more information. Thank you for being patient as the team pivots to bring you a great Contributor Summit!
Bring your ideas to the world with kubectl plugins
Author: Cornelius Weig (TNG Technology Consulting GmbH)
kubectl is the most critical tool to interact with Kubernetes and has to address multiple user personas, each with their own needs and opinions.
One way to make kubectl do what you need is to build new functionality into kubectl.
Challenges with building commands into kubectl
However, that's easier said than done. Being such an important cornerstone of
Kubernetes, any meaningful change to kubectl needs to undergo a Kubernetes
Enhancement Proposal (KEP) where the intended change is discussed beforehand.
When it comes to implementation, you'll find that kubectl is an ingenious and
complex piece of engineering. It might take a long time to get used to
the processes and style of the codebase to get done what you want to achieve. Next
comes the review process which may go through several rounds until it meets all
the requirements of the Kubernetes maintainers -- after all, they need to take
over ownership of this feature and maintain it from the day it's merged.
When everything goes well, you can finally rejoice. Your code will be shipped
with the next Kubernetes release. Well, that could mean you need to wait
another 3 months to ship your idea in kubectl if you are unlucky.
So this was the happy path where everything goes well. But there are good
reasons why your new functionality may never make it into kubectl. For one,
kubectl has a particular look and feel and violating that style will not be
acceptable by the maintainers. For example, an interactive command that
produces output with colors would be inconsistent with the rest of kubectl.
Also, when it comes to tools or commands useful only to a minuscule proportion
of users, the maintainers may simply reject your proposal as kubectl needs to
address common needs.
But this doesn’t mean you can’t ship your ideas to kubectl users.
What if you didn’t have to change kubectl to add functionality?
This is where kubectl plugins shine.
Since kubectl v1.12, you can simply
drop executables into your PATH, which follows the naming pattern
kubectl-myplugin. Then you can execute this plugin as kubectl myplugin, and
it will just feel like a normal sub-command of kubectl.
Plugins give you the opportunity to try out new experiences like terminal UIs, colorful output, specialized functionality, or other innovative ideas. You can go creative, as you’re the owner of your own plugin.
Further, plugins offer safe experimentation space for commands you’d like to
propose to kubectl. By pre-releasing as a plugin, you can push your
functionality faster to the end-users and quickly gather feedback. For example,
the kubectl-debug plugin is proposed
to become a built-in command in kubectl in a
KEP).
In the meanwhile, the plugin author can ship the functionality and collect
feedback using the plugin mechanism.
How to get started with developing plugins
If you already have an idea for a plugin, how do you best make it happen?
First you have to ask yourself if you can implement it as a wrapper around
existing kubectl functionality. If so, writing the plugin as a shell script
is often the best way forward, because the resulting plugin will be small,
works cross-platform, and has a high level of trust because it is not
compiled.
On the other hand, if the plugin logic is complex, a general-purpose language
is usually better. The canonical choice here is Go, because you can use the
excellent client-go library to interact with the Kubernetes API. The Kubernetes
maintained sample-cli-plugin
demonstrates some best practices and can be used as a template for new plugin
projects.
When the development is done, you just need to ship your plugin to the
Kubernetes users. For the best plugin installation experience and discoverability,
you should consider doing so via the
krew plugin manager. For an in-depth
discussion about the technical details around kubectl plugins, refer to the
documentation on kubernetes.io.
Contributor Summit Amsterdam Schedule Announced
Authors: Jeffrey Sica (Red Hat), Amanda Katona (VMware)
tl;dr Registration is open and the schedule is live so register now and we’ll see you in Amsterdam!
Kubernetes Contributor Summit
Sunday, March 29, 2020
- Evening Contributor Celebration: ZuidPool
- Address: Europaplein 22, 1078 GZ Amsterdam, Netherlands
- Time: 18:00 - 21:00
Monday, March 30, 2020
- All Day Contributor Summit:
- Amsterdam RAI
- Address: Europaplein 24, 1078 GZ Amsterdam, Netherlands
- Time: 09:00 - 17:00 (Breakfast at 08:00)

Hello everyone and Happy 2020! It’s hard to believe that KubeCon EU 2020 is less than six weeks away, and with that another contributor summit! This year we have the pleasure of being in Amsterdam in early spring, so be sure to pack some warmer clothing. This summit looks to be exciting with a lot of fantastic community-driven content. We received 26 submissions from the CFP. From that, the events team selected 12 sessions. Each of the sessions falls into one of four categories:
- Community
- Contributor Improvement
- Sustainability
- In-depth Technical
On top of the presentations, there will be a dedicated Docs Sprint as well as the New Contributor Workshop 101 and 201 Sessions. All told, we will have five separate rooms of content throughout the day on Monday. Please see the full schedule to see what sessions you’d be interested in. We hope between the content provided and the inevitable hallway track, everyone has a fun and enriching experience.
Speaking of fun, the social Sunday night should be a blast! We’re hosting this summit’s social close to the conference center, at ZuidPool. There will be games, bingo, and unconference sign-up throughout the evening. It should be a relaxed way to kick off the week.
Registration is open! Space is limited so it’s always a good idea to register early.
If you have any questions, reach out to the Amsterdam Team on Slack in the #contributor-summit channel.
Hope to see you there!
Deploying External OpenStack Cloud Provider with Kubeadm
This document describes how to install a single control-plane Kubernetes cluster v1.15 with kubeadm on CentOS, and then deploy an external OpenStack cloud provider and Cinder CSI plugin to use Cinder volumes as persistent volumes in Kubernetes.
Preparation in OpenStack
This cluster runs on OpenStack VMs, so let's create a few things in OpenStack first.
- A project/tenant for this Kubernetes cluster
- A user in this project for Kubernetes, to query node information and attach volumes etc
- A private network and subnet
- A router for this private network and connect it to a public network for floating IPs
- A security group for all Kubernetes VMs
- A VM as a control-plane node and a few VMs as worker nodes
The security group will have the following rules to open ports for Kubernetes.
Control-Plane Node
| Protocol | Port Number | Description |
|---|---|---|
| TCP | 6443 | Kubernetes API Server |
| TCP | 2379-2380 | etcd server client API |
| TCP | 10250 | Kubelet API |
| TCP | 10251 | kube-scheduler |
| TCP | 10252 | kube-controller-manager |
| TCP | 10255 | Read-only Kubelet API |
Worker Nodes
| Protocol | Port Number | Description |
|---|---|---|
| TCP | 10250 | Kubelet API |
| TCP | 10255 | Read-only Kubelet API |
| TCP | 30000-32767 | NodePort Services |
CNI ports on both control-plane and worker nodes
| Protocol | Port Number | Description |
|---|---|---|
| TCP | 179 | Calico BGP network |
| TCP | 9099 | Calico felix (health check) |
| UDP | 8285 | Flannel |
| UDP | 8472 | Flannel |
| TCP | 6781-6784 | Weave Net |
| UDP | 6783-6784 | Weave Net |
CNI specific ports are only required to be opened when that particular CNI plugin is used. In this guide, we will use Weave Net. Only the Weave Net ports (TCP 6781-6784 and UDP 6783-6784), will need to be opened in the security group.
The control-plane node needs at least 2 cores and 4GB RAM. After the VM is launched, verify its hostname and make sure it is the same as the node name in Nova.
If the hostname is not resolvable, add it to /etc/hosts.
For example, if the VM is called master1, and it has an internal IP 192.168.1.4. Add that to /etc/hosts and set hostname to master1.
echo "192.168.1.4 master1" >> /etc/hosts
hostnamectl set-hostname master1
Install Docker and Kubernetes
Next, we'll follow the official documents to install docker and Kubernetes using kubeadm.
Install Docker following the steps from the container runtime documentation.
Note that it is a best practice to use systemd as the cgroup driver for Kubernetes. If you use an internal container registry, add them to the docker config.
# Install Docker CE
## Set up the repository
### Install required packages.
yum install yum-utils device-mapper-persistent-data lvm2
### Add Docker repository.
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
## Install Docker CE.
yum update && yum install docker-ce-18.06.2.ce
## Create /etc/docker directory.
mkdir /etc/docker
# Configure the Docker daemon
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
# Restart Docker
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
Install kubeadm following the steps from the Installing Kubeadm documentation.
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
# Set SELinux in permissive mode (effectively disabling it)
# Caveat: In a production environment you may not want to disable SELinux, please refer to Kubernetes documents about SELinux
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
systemctl enable --now kubelet
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
# check if br_netfilter module is loaded
lsmod | grep br_netfilter
# if not, load it explicitly with
modprobe br_netfilter
The official document about how to create a single control-plane cluster can be found from the Creating a single control-plane cluster with kubeadm documentation.
We'll largely follow that document but also add additional things for the cloud provider.
To make things more clear, we'll use a kubeadm-config.yml for the control-plane node.
In this config we specify to use an external OpenStack cloud provider, and where to find its config.
We also enable storage API in API server's runtime config so we can use OpenStack volumes as persistent volumes in Kubernetes.
apiVersion: kubeadm.k8s.io/v1beta1
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
cloud-provider: "external"
---
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: "v1.15.1"
apiServer:
extraArgs:
enable-admission-plugins: NodeRestriction
runtime-config: "storage.k8s.io/v1=true"
controllerManager:
extraArgs:
external-cloud-volume-plugin: openstack
extraVolumes:
- name: "cloud-config"
hostPath: "/etc/kubernetes/cloud-config"
mountPath: "/etc/kubernetes/cloud-config"
readOnly: true
pathType: File
networking:
serviceSubnet: "10.96.0.0/12"
podSubnet: "10.224.0.0/16"
dnsDomain: "cluster.local"
Now we'll create the cloud config, /etc/kubernetes/cloud-config, for OpenStack.
Note that the tenant here is the one we created for all Kubernetes VMs in the beginning.
All VMs should be launched in this project/tenant.
In addition you need to create a user in this tenant for Kubernetes to do queries.
The ca-file is the CA root certificate for OpenStack's API endpoint, for example https://openstack.cloud:5000/v3
At the time of writing the cloud provider doesn't allow insecure connections (skip CA check).
[Global]
region=RegionOne
username=username
password=password
auth-url=https://openstack.cloud:5000/v3
tenant-id=14ba698c0aec4fd6b7dc8c310f664009
domain-id=default
ca-file=/etc/kubernetes/ca.pem
[LoadBalancer]
subnet-id=b4a9a292-ea48-4125-9fb2-8be2628cb7a1
floating-network-id=bc8a590a-5d65-4525-98f3-f7ef29c727d5
[BlockStorage]
bs-version=v2
[Networking]
public-network-name=public
ipv6-support-disabled=false
Next run kubeadm to initiate the control-plane node
kubeadm init --config=kubeadm-config.yml
With the initialization completed, copy admin config to .kube
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
At this stage, the control-plane node is created but not ready. All the nodes have the taint node.cloudprovider.kubernetes.io/uninitialized=true:NoSchedule and are waiting to be initialized by the cloud-controller-manager.
# kubectl describe no master1
Name: master1
Roles: master
......
Taints: node-role.kubernetes.io/master:NoSchedule
node.cloudprovider.kubernetes.io/uninitialized=true:NoSchedule
node.kubernetes.io/not-ready:NoSchedule
......
Now deploy the OpenStack cloud controller manager into the cluster, following using controller manager with kubeadm.
Create a secret with the cloud-config for the openstack cloud provider.
kubectl create secret -n kube-system generic cloud-config --from-literal=cloud.conf="$(cat /etc/kubernetes/cloud-config)" --dry-run -o yaml > cloud-config-secret.yaml
kubectl apply -f cloud-config-secret.yaml
Get the CA certificate for OpenStack API endpoints and put that into /etc/kubernetes/ca.pem.
Create RBAC resources.
kubectl apply -f https://github.com/kubernetes/cloud-provider-openstack/raw/release-1.15/cluster/addons/rbac/cloud-controller-manager-roles.yaml
kubectl apply -f https://github.com/kubernetes/cloud-provider-openstack/raw/release-1.15/cluster/addons/rbac/cloud-controller-manager-role-bindings.yaml
We'll run the OpenStack cloud controller manager as a DaemonSet rather than a pod.
The manager will only run on the control-plane node, so if there are multiple control-plane nodes, multiple pods will be run for high availability.
Create openstack-cloud-controller-manager-ds.yaml containing the following manifests, then apply it.
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: openstack-cloud-controller-manager
namespace: kube-system
labels:
k8s-app: openstack-cloud-controller-manager
spec:
selector:
matchLabels:
k8s-app: openstack-cloud-controller-manager
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
k8s-app: openstack-cloud-controller-manager
spec:
nodeSelector:
node-role.kubernetes.io/master: ""
securityContext:
runAsUser: 1001
tolerations:
- key: node.cloudprovider.kubernetes.io/uninitialized
value: "true"
effect: NoSchedule
- key: node-role.kubernetes.io/master
effect: NoSchedule
- effect: NoSchedule
key: node.kubernetes.io/not-ready
serviceAccountName: cloud-controller-manager
containers:
- name: openstack-cloud-controller-manager
image: docker.io/k8scloudprovider/openstack-cloud-controller-manager:v1.15.0
args:
- /bin/openstack-cloud-controller-manager
- --v=1
- --cloud-config=$(CLOUD_CONFIG)
- --cloud-provider=openstack
- --use-service-account-credentials=true
- --address=127.0.0.1
volumeMounts:
- mountPath: /etc/kubernetes/pki
name: k8s-certs
readOnly: true
- mountPath: /etc/ssl/certs
name: ca-certs
readOnly: true
- mountPath: /etc/config
name: cloud-config-volume
readOnly: true
- mountPath: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
name: flexvolume-dir
- mountPath: /etc/kubernetes
name: ca-cert
readOnly: true
resources:
requests:
cpu: 200m
env:
- name: CLOUD_CONFIG
value: /etc/config/cloud.conf
hostNetwork: true
volumes:
- hostPath:
path: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
type: DirectoryOrCreate
name: flexvolume-dir
- hostPath:
path: /etc/kubernetes/pki
type: DirectoryOrCreate
name: k8s-certs
- hostPath:
path: /etc/ssl/certs
type: DirectoryOrCreate
name: ca-certs
- name: cloud-config-volume
secret:
secretName: cloud-config
- name: ca-cert
secret:
secretName: openstack-ca-cert
When the controller manager is running, it will query OpenStack to get information about the nodes and remove the taint. In the node info you'll see the VM's UUID in OpenStack.
# kubectl describe no master1
Name: master1
Roles: master
......
Taints: node-role.kubernetes.io/master:NoSchedule
node.kubernetes.io/not-ready:NoSchedule
......
sage:docker: network plugin is not ready: cni config uninitialized
......
PodCIDR: 10.224.0.0/24
ProviderID: openstack:///548e3c46-2477-4ce2-968b-3de1314560a5
Now install your favourite CNI and the control-plane node will become ready.
For example, to install Weave Net, run this command:
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
Next we'll set up worker nodes.
Firstly, install docker and kubeadm in the same way as how they were installed in the control-plane node. To join them to the cluster we need a token and ca cert hash from the output of control-plane node installation. If it is expired or lost we can recreate it using these commands.
# check if token is expired
kubeadm token list
# re-create token and show join command
kubeadm token create --print-join-command
Create kubeadm-config.yml for worker nodes with the above token and ca cert hash.
apiVersion: kubeadm.k8s.io/v1beta2
discovery:
bootstrapToken:
apiServerEndpoint: 192.168.1.7:6443
token: 0c0z4p.dnafh6vnmouus569
caCertHashes: ["sha256:fcb3e956a6880c05fc9d09714424b827f57a6fdc8afc44497180905946527adf"]
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
cloud-provider: "external"
apiServerEndpoint is the control-plane node, token and caCertHashes can be taken from the join command printed in the output of 'kubeadm token create' command.
Run kubeadm and the worker nodes will be joined to the cluster.
kubeadm join --config kubeadm-config.yml
At this stage we'll have a working Kubernetes cluster with an external OpenStack cloud provider. The provider tells Kubernetes about the mapping between Kubernetes nodes and OpenStack VMs. If Kubernetes wants to attach a persistent volume to a pod, it can find out which OpenStack VM the pod is running on from the mapping, and attach the underlying OpenStack volume to the VM accordingly.
Deploy Cinder CSI
The integration with Cinder is provided by an external Cinder CSI plugin, as described in the Cinder CSI documentation.
We'll perform the following steps to install the Cinder CSI plugin. Firstly, create a secret with CA certs for OpenStack's API endpoints. It is the same cert file as what we use in cloud provider above.
kubectl create secret -n kube-system generic openstack-ca-cert --from-literal=ca.pem="$(cat /etc/kubernetes/ca.pem)" --dry-run -o yaml > openstack-ca-cert.yaml
kubectl apply -f openstack-ca-cert.yaml
Then create RBAC resources.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/cloud-provider-openstack/release-1.15/manifests/cinder-csi-plugin/cinder-csi-controllerplugin-rbac.yaml
kubectl apply -f https://github.com/kubernetes/cloud-provider-openstack/raw/release-1.15/manifests/cinder-csi-plugin/cinder-csi-nodeplugin-rbac.yaml
The Cinder CSI plugin includes a controller plugin and a node plugin.
The controller communicates with Kubernetes APIs and Cinder APIs to create/attach/detach/delete Cinder volumes. The node plugin in-turn runs on each worker node to bind a storage device (attached volume) to a pod, and unbind it during deletion.
Create cinder-csi-controllerplugin.yaml and apply it to create csi controller.
kind: Service
apiVersion: v1
metadata:
name: csi-cinder-controller-service
namespace: kube-system
labels:
app: csi-cinder-controllerplugin
spec:
selector:
app: csi-cinder-controllerplugin
ports:
- name: dummy
port: 12345
---
kind: StatefulSet
apiVersion: apps/v1
metadata:
name: csi-cinder-controllerplugin
namespace: kube-system
spec:
serviceName: "csi-cinder-controller-service"
replicas: 1
selector:
matchLabels:
app: csi-cinder-controllerplugin
template:
metadata:
labels:
app: csi-cinder-controllerplugin
spec:
serviceAccount: csi-cinder-controller-sa
containers:
- name: csi-attacher
image: quay.io/k8scsi/csi-attacher:v1.0.1
args:
- "--v=5"
- "--csi-address=$(ADDRESS)"
env:
- name: ADDRESS
value: /var/lib/csi/sockets/pluginproxy/csi.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /var/lib/csi/sockets/pluginproxy/
- name: csi-provisioner
image: quay.io/k8scsi/csi-provisioner:v1.0.1
args:
- "--provisioner=csi-cinderplugin"
- "--csi-address=$(ADDRESS)"
env:
- name: ADDRESS
value: /var/lib/csi/sockets/pluginproxy/csi.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /var/lib/csi/sockets/pluginproxy/
- name: csi-snapshotter
image: quay.io/k8scsi/csi-snapshotter:v1.0.1
args:
- "--connection-timeout=15s"
- "--csi-address=$(ADDRESS)"
env:
- name: ADDRESS
value: /var/lib/csi/sockets/pluginproxy/csi.sock
imagePullPolicy: Always
volumeMounts:
- mountPath: /var/lib/csi/sockets/pluginproxy/
name: socket-dir
- name: cinder-csi-plugin
image: docker.io/k8scloudprovider/cinder-csi-plugin:v1.15.0
args :
- /bin/cinder-csi-plugin
- "--v=5"
- "--nodeid=$(NODE_ID)"
- "--endpoint=$(CSI_ENDPOINT)"
- "--cloud-config=$(CLOUD_CONFIG)"
- "--cluster=$(CLUSTER_NAME)"
env:
- name: NODE_ID
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: CSI_ENDPOINT
value: unix://csi/csi.sock
- name: CLOUD_CONFIG
value: /etc/config/cloud.conf
- name: CLUSTER_NAME
value: kubernetes
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: secret-cinderplugin
mountPath: /etc/config
readOnly: true
- mountPath: /etc/kubernetes
name: ca-cert
readOnly: true
volumes:
- name: socket-dir
hostPath:
path: /var/lib/csi/sockets/pluginproxy/
type: DirectoryOrCreate
- name: secret-cinderplugin
secret:
secretName: cloud-config
- name: ca-cert
secret:
secretName: openstack-ca-cert
Create cinder-csi-nodeplugin.yaml and apply it to create csi node.
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: csi-cinder-nodeplugin
namespace: kube-system
spec:
selector:
matchLabels:
app: csi-cinder-nodeplugin
template:
metadata:
labels:
app: csi-cinder-nodeplugin
spec:
serviceAccount: csi-cinder-node-sa
hostNetwork: true
containers:
- name: node-driver-registrar
image: quay.io/k8scsi/csi-node-driver-registrar:v1.1.0
args:
- "--v=5"
- "--csi-address=$(ADDRESS)"
- "--kubelet-registration-path=$(DRIVER_REG_SOCK_PATH)"
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "rm -rf /registration/cinder.csi.openstack.org /registration/cinder.csi.openstack.org-reg.sock"]
env:
- name: ADDRESS
value: /csi/csi.sock
- name: DRIVER_REG_SOCK_PATH
value: /var/lib/kubelet/plugins/cinder.csi.openstack.org/csi.sock
- name: KUBE_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: registration-dir
mountPath: /registration
- name: cinder-csi-plugin
securityContext:
privileged: true
capabilities:
add: ["SYS_ADMIN"]
allowPrivilegeEscalation: true
image: docker.io/k8scloudprovider/cinder-csi-plugin:v1.15.0
args :
- /bin/cinder-csi-plugin
- "--nodeid=$(NODE_ID)"
- "--endpoint=$(CSI_ENDPOINT)"
- "--cloud-config=$(CLOUD_CONFIG)"
env:
- name: NODE_ID
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: CSI_ENDPOINT
value: unix://csi/csi.sock
- name: CLOUD_CONFIG
value: /etc/config/cloud.conf
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: pods-mount-dir
mountPath: /var/lib/kubelet/pods
mountPropagation: "Bidirectional"
- name: kubelet-dir
mountPath: /var/lib/kubelet
mountPropagation: "Bidirectional"
- name: pods-cloud-data
mountPath: /var/lib/cloud/data
readOnly: true
- name: pods-probe-dir
mountPath: /dev
mountPropagation: "HostToContainer"
- name: secret-cinderplugin
mountPath: /etc/config
readOnly: true
- mountPath: /etc/kubernetes
name: ca-cert
readOnly: true
volumes:
- name: socket-dir
hostPath:
path: /var/lib/kubelet/plugins/cinder.csi.openstack.org
type: DirectoryOrCreate
- name: registration-dir
hostPath:
path: /var/lib/kubelet/plugins_registry/
type: Directory
- name: kubelet-dir
hostPath:
path: /var/lib/kubelet
type: Directory
- name: pods-mount-dir
hostPath:
path: /var/lib/kubelet/pods
type: Directory
- name: pods-cloud-data
hostPath:
path: /var/lib/cloud/data
type: Directory
- name: pods-probe-dir
hostPath:
path: /dev
type: Directory
- name: secret-cinderplugin
secret:
secretName: cloud-config
- name: ca-cert
secret:
secretName: openstack-ca-cert
When they are both running, create a storage class for Cinder.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-sc-cinderplugin
provisioner: csi-cinderplugin
Then we can create a PVC with this class.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myvol
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: csi-sc-cinderplugin
When the PVC is created, a Cinder volume is created correspondingly.
# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
myvol Bound pvc-14b8bc68-6c4c-4dc6-ad79-4cb29a81faad 1Gi RWO csi-sc-cinderplugin 3s
In OpenStack the volume name will match the Kubernetes persistent volume generated name. In this example it would be: pvc-14b8bc68-6c4c-4dc6-ad79-4cb29a81faad
Now we can create a pod with the PVC.
apiVersion: v1
kind: Pod
metadata:
name: web
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
hostPort: 8081
protocol: TCP
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myvol
When the pod is running, the volume will be attached to the pod. If we go back to OpenStack, we can see the Cinder volume is mounted to the worker node where the pod is running on.
# openstack volume show 6b5f3296-b0eb-40cd-bd4f-2067a0d6287f
+--------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Field | Value |
+--------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| attachments | [{u'server_id': u'1c5e1439-edfa-40ed-91fe-2a0e12bc7eb4', u'attachment_id': u'11a15b30-5c24-41d4-86d9-d92823983a32', u'attached_at': u'2019-07-24T05:02:34.000000', u'host_name': u'compute-6', u'volume_id': u'6b5f3296-b0eb-40cd-bd4f-2067a0d6287f', u'device': u'/dev/vdb', u'id': u'6b5f3296-b0eb-40cd-bd4f-2067a0d6287f'}] |
| availability_zone | nova |
| bootable | false |
| consistencygroup_id | None |
| created_at | 2019-07-24T05:02:18.000000 |
| description | Created by OpenStack Cinder CSI driver |
| encrypted | False |
| id | 6b5f3296-b0eb-40cd-bd4f-2067a0d6287f |
| migration_status | None |
| multiattach | False |
| name | pvc-14b8bc68-6c4c-4dc6-ad79-4cb29a81faad |
| os-vol-host-attr:host | rbd:volumes@rbd#rbd |
| os-vol-mig-status-attr:migstat | None |
| os-vol-mig-status-attr:name_id | None |
| os-vol-tenant-attr:tenant_id | 14ba698c0aec4fd6b7dc8c310f664009 |
| properties | attached_mode='rw', cinder.csi.openstack.org/cluster='kubernetes' |
| replication_status | None |
| size | 1 |
| snapshot_id | None |
| source_volid | None |
| status | in-use |
| type | rbd |
| updated_at | 2019-07-24T05:02:35.000000 |
| user_id | 5f6a7a06f4e3456c890130d56babf591 |
+--------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
Summary
In this walk-through, we deployed a Kubernetes cluster on OpenStack VMs and integrated it with OpenStack using an external OpenStack cloud provider. Then on this Kubernetes cluster we deployed Cinder CSI plugin which can create Cinder volumes and expose them in Kubernetes as persistent volumes.
KubeInvaders - Gamified Chaos Engineering Tool for Kubernetes
Authors Eugenio Marzo, Sourcesense
Some months ago, I released my latest project called KubeInvaders. The first time I shared it with the community was during an Openshift Commons Briefing session. Kubenvaders is a Gamified Chaos Engineering tool for Kubernetes and Openshift and helps test how resilient your Kubernetes cluster is, in a fun way.
It is like Space Invaders, but the aliens are pods.

During my presentation at Codemotion Milan 2019, I started saying "of course you can do it with few lines of Bash, but it is boring."

Using the code above you can kill random pods across a Kubernetes cluster, but I think it is much more fun with the spaceship of KubeInvaders.
I published the code at https://github.com/lucky-sideburn/KubeInvaders and there is a little community that is growing gradually. Some people love to use it for demo sessions killing pods on a big screen.

How to install KubeInvaders
I defined multiples modes to install it:
-
Helm Chart https://github.com/lucky-sideburn/KubeInvaders/tree/master/helm-charts/kubeinvaders
-
Manual Installation for Openshift using a template https://github.com/lucky-sideburn/KubeInvaders#install-kubeinvaders-on-openshift
-
Manual Installation for Kubernetes https://github.com/lucky-sideburn/KubeInvaders#install-kubeinvaders-on-kubernetes
The preferred way, of course, is with a Helm chart:
# Please set target_namespace to set your target namespace!
helm install --set-string target_namespace="namespace1,namespace2" \
--name kubeinvaders --namespace kubeinvaders ./helm-charts/kubeinvaders
How to use KubeInvaders
Once it is installed on your cluster you can use the following functionalities:
- Key 'a' — Switch to automatic pilot
- Key 'm' — Switch to manual pilot
- Key 'i' — Show pod's name. Move the ship towards an alien
- Key 'h' — Print help
- Key 'n' — Jump between different namespaces (my favorite feature!)
Tuning KubeInvaders
At Codemotion Milan 2019, my colleagues and I organized a desk with a game station for playing KubeInvaders. People had to fight with Kubernetes to win a t-shirt.
If you have pods that require a few seconds to start, you may lose. It is possible to set the complexity of the game with these parameters as environmment variables in the Kubernetes deployment:
- ALIENPROXIMITY — Reduce this value to increase the distance between aliens;
- HITSLIMIT — Seconds of CPU time to wait before shooting;
- UPDATETIME — Seconds to wait before updating pod status (you can set also 0.x Es: 0.5);
The result is a harder game experience against the machine.
Use cases
Adopting chaos engineering strategies for your production environment is really useful, because it is the only way to test if a system supports unexpected destructive events.
KubeInvaders is a game — so please do not take it too seriously! — but it demonstrates some important use cases:
- Test how resilient Kubernetes clusters are on unexpected pod deletion
- Collect metrics like pod restart time
- Tune readiness probes
Next steps
I want to continue to add some cool features and integrate it into a Kubernetes dashboard because I am planning to transform it into a "Gamified Chaos Engineering and Development Tool for Kubernetes", to help developer to interact with deployments in a Kubernetes environment. For example:
- Point to the aliens to get pod logs
- Deploy Helm charts by shooting some particular objects
- Read messages stored in a specific label present in a deployment
Please feel free to contribute to https://github.com/lucky-sideburn/KubeInvaders and stay updated following #kubeinvaders news on Twitter.
CSI Ephemeral Inline Volumes
Author: Patrick Ohly (Intel)
Typically, volumes provided by an external storage driver in Kubernetes are persistent, with a lifecycle that is completely independent of pods or (as a special case) loosely coupled to the first pod which uses a volume (late binding mode). The mechanism for requesting and defining such volumes in Kubernetes are Persistent Volume Claim (PVC) and Persistent Volume (PV) objects. Originally, volumes that are backed by a Container Storage Interface (CSI) driver could only be used via this PVC/PV mechanism.
But there are also use cases for data volumes whose content and lifecycle is tied to a pod. For example, a driver might populate a volume with dynamically created secrets that are specific to the application running in the pod. Such volumes need to be created together with a pod and can be deleted as part of pod termination (ephemeral). They get defined as part of the pod spec (inline).
Since Kubernetes 1.15, CSI drivers can also be used for such ephemeral inline volumes. The CSIInlineVolume feature gate had to be set to enable it in 1.15 because support was still in alpha state. In 1.16, the feature reached beta state, which typically means that it is enabled in clusters by default.
CSI drivers have to be adapted to support this because although two
existing CSI gRPC calls are used (NodePublishVolume and NodeUnpublishVolume),
the way how they are
used is different and not covered by the CSI spec: for ephemeral
volumes, only NodePublishVolume is invoked by kubelet when asking
the CSI driver for a volume. All other calls
(like CreateVolume, NodeStageVolume, etc.) are skipped. The volume
parameters are provided in the pod spec and from there copied into the
NodePublishVolumeRequest.volume_context field. There are currently
no standardized parameters; even common ones like size must be
provided in a format that is defined by the CSI driver. Likewise, only
NodeUnpublishVolume gets called after the pod has terminated and the
volume needs to be removed.
Initially, the assumption was that CSI drivers would be specifically written to provide either persistent or ephemeral volumes. But there are also drivers which provide storage that is useful in both modes: for example, PMEM-CSI manages persistent memory (PMEM), a new kind of local storage that is provided by Intel® Optane™ DC Persistent Memory. Such memory is useful both as persistent data storage (faster than normal SSDs) and as ephemeral scratch space (higher capacity than DRAM).
Therefore the support in Kubernetes 1.16 was extended:
- Kubernetes and users can determine which kind of volumes a driver
supports via the
volumeLifecycleModesfield in theCSIDriverobject. - Drivers can get information about the volume mode by enabling the
"pod info on
mount" feature
which then will add the new
csi.storage.k8s.io/ephemeralentry to theNodePublishRequest.volume_context.
For more information about implementing support of ephemeral inline volumes in a CSI driver, see the Kubernetes-CSI documentation and the original design document.
What follows in this blog post are usage examples based on real drivers and a summary at the end.
Examples
PMEM-CSI
Support for ephemeral inline volumes was added in release v0.6.0. The driver can be used on hosts with real Intel® Optane™ DC Persistent Memory, on special machines in GCE or with hardware emulated by QEMU. The latter is fully integrated into the makefile and only needs Go, Docker and KVM, so that approach was used for this example:
git clone --branch release-0.6 https://github.com/intel/pmem-csi
cd pmem-csi
TEST_DISTRO=clear TEST_DISTRO_VERSION=32080 TEST_PMEM_REGISTRY=intel make start
Bringing up the four-node cluster can take a while but eventually should end with:
The test cluster is ready. Log in with /work/pmem-csi/_work/pmem-govm/ssh-pmem-govm, run kubectl once logged in.
Alternatively, KUBECONFIG=/work/pmem-csi/_work/pmem-govm/kube.config can also be used directly.
To try out the pmem-csi driver persistent volumes:
...
To try out the pmem-csi driver ephemeral volumes:
cat deploy/kubernetes-1.17/pmem-app-ephemeral.yaml | /work/pmem-csi/_work/pmem-govm/ssh-pmem-govm kubectl create -f -
deploy/kubernetes-1.17/pmem-app-ephemeral.yaml specifies one volume:
kind: Pod
apiVersion: v1
metadata:
name: my-csi-app-inline-volume
spec:
containers:
- name: my-frontend
image: busybox
command: [ "sleep", "100000" ]
volumeMounts:
- mountPath: "/data"
name: my-csi-volume
volumes:
- name: my-csi-volume
csi:
driver: pmem-csi.intel.com
fsType: "xfs"
volumeAttributes:
size: "2Gi"
nsmode: "fsdax"
Once we have created that pod, we can inspect the result:
kubectl describe pods/my-csi-app-inline-volume
Name: my-csi-app-inline-volume
...
Volumes:
my-csi-volume:
Type: CSI (a Container Storage Interface (CSI) volume source)
Driver: pmem-csi.intel.com
FSType: xfs
ReadOnly: false
VolumeAttributes: nsmode=fsdax
size=2Gi
kubectl exec my-csi-app-inline-volume -- df -h /data
Filesystem Size Used Available Use% Mounted on
/dev/ndbus0region0fsdax/d7eb073f2ab1937b88531fce28e19aa385e93696
1.9G 34.2M 1.8G 2% /data
Image Populator
The image populator automatically unpacks a container image and makes its content available as an ephemeral volume. It's still in development, but canary images are already available which can be installed with:
kubectl create -f https://github.com/kubernetes-csi/csi-driver-image-populator/raw/master/deploy/kubernetes-1.16/csi-image-csidriverinfo.yaml
kubectl create -f https://github.com/kubernetes-csi/csi-driver-image-populator/raw/master/deploy/kubernetes-1.16/csi-image-daemonset.yaml
This example pod will run nginx and have it serve data that
comes from the kfox1111/misc:test image:
kubectl create -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.16-alpine
ports:
- containerPort: 80
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumes:
- name: data
csi:
driver: image.csi.k8s.io
volumeAttributes:
image: kfox1111/misc:test
EOF
kubectl exec nginx -- cat /usr/share/nginx/html/test
That test file just contains a single word:
testing
Such data containers can be built with Dockerfiles such as:
FROM scratch
COPY index.html /index.html
cert-manager-csi
cert-manager-csi works together with cert-manager. The goal for this driver is to facilitate requesting and mounting certificate key pairs to pods seamlessly. This is useful for facilitating mTLS, or otherwise securing connections of pods with guaranteed present certificates whilst having all of the features that cert-manager provides. This project is experimental.
Next steps
One of the issues with ephemeral inline volumes is that pods get scheduled by Kubernetes onto nodes without knowing anything about the currently available storage on that node. Once the pod has been scheduled, the CSI driver must make the volume available one that node. If that is currently not possible, the pod cannot start. This will be retried until eventually the volume becomes ready. The storage capacity tracking KEP is an attempt to address this problem.
A related KEP introduces a standardized size parameter.
Currently, CSI ephemeral inline volumes stay in beta while issues like these are getting discussed. Your feedback is needed to decide how to proceed with this feature. For the KEPs, the two PRs linked to above is a good place to comment. The SIG Storage also meets regularly and can be reached via Slack and a mailing list.
Reviewing 2019 in Docs
Author: Zach Corleissen (Cloud Native Computing Foundation)
Hi, folks! I'm one of the co-chairs for the Kubernetes documentation special interest group (SIG Docs). This blog post is a review of SIG Docs in 2019. Our contributors did amazing work last year, and I want to highlight their successes.
Although I review 2019 in this post, my goal is to point forward to 2020. I observe some trends in SIG Docs–some good, others troubling. I want to raise visibility before those challenges increase in severity.
The good
There was much to celebrate in SIG Docs in 2019.
Kubernetes docs started the year with three localizations in progress. By the end of the year, we ended with ten localizations available, four of which (Chinese, French, Japanese, Korean) are reasonably complete. The Korean and French teams deserve special mentions for their contributions to git best practices across all localizations (Korean team) and help bootstrapping other localizations (French team).
Despite significant transition over the year, SIG Docs improved its review velocity, with a median review time from PR open to merge of just over 24 hours.
Issue triage improved significantly in both volume and speed, largely due to the efforts of GitHub users @sftim, @tengqm, and @kbhawkey.
Doc sprints remain valuable at KubeCon contributor days, introducing new contributors to Kubernetes documentation.
The docs component of Kubernetes quarterly releases improved over 2019, thanks to iterative playbook improvements from release leads and their teams.
Site traffic increased over the year. The website ended the year with ~6 million page views per month in December, up from ~5M page views in January. The kubernetes.io website had 851k site visitors in October, a new all-time high. Reader satisfaction remains general.
We onboarded a new SIG chair: @jimangel, a Cloud Architect at General Motors. Jim was a docs contributor for a year, during which he led the 1.14 docs release, before stepping up as chair.
The not so good
While reader satisfaction is decent, most respondents indicated dissatisfaction with stale content in every area: concepts, tasks, tutorials, and reference. Additionally, readers requested more diagrams, advanced conceptual content, and code samples—things that technical writers excel at providing.
SIG Docs continues to solve how best to handle third-party content. There's too much vendor content on kubernetes.io, and guidelines for adding or rejecting third-party content remain unclear. The discussion so far has been powerful, including pushback demanding greater collaborative input—a powerful reminder that Kubernetes is in all ways a communal effort.
We're in the middle of our third chair transition in 18 months. Each chair transition has been healthy and collegial, but it's still a lot of turnover in a short time. Chairing any open source project is difficult, but especially so with SIG Docs. Chairship of SIG Docs requires a steep learning curve across multiple domains: docs (both written and generated from spec), information architecture, specialized contribution paths (for example, localization), how to run a release cycle, website development, CI/CD, community management, on and on. It's a role that requires multiple people to function successfully without burning people out. Training replacements is time-intensive.
Perhaps most pressing in the Not So Good category is that SIG Docs currently has only one technical writer dedicated full-time to Kubernetes docs. This has impacts on Kubernetes docs: some obvious, some less so.
Impacts of understaffing on Kubernetes docs
Me today: pic.twitter.com/cDpHOWEsjf
— Benjamin Elder (@BenTheElder) January 10, 2020
If Kubernetes continues through 2020 without more technical writers dedicated to the docs, here's what I see as the most likely possibilities.
But first, a disclaimer
Some of my predictions are almost certainly wrong. Any errors are mine alone.
That said...
Effects in 2020
Current levels of function aren't self-sustaining. Even with a strong playbook, the release cycle still requires expert support from at least one (and usually two) chairs during every cycle. Without fail, each release breaks in new and unexpected ways, and it requires familiarity and expertise to diagnose and resolve. As chairs continue to cycle—and to be clear, regular transitions are part of a healthy project—we accrue the risks associated with a pool lacking sufficient professional depth and employer support.
Oddly enough, one of the challenges to staffing is that the docs appear good enough. Based on site analytics and survey responses, readers are pleased with the quality of the docs. When folks visit the site, they generally find what they need and behave like satisfied visitors.
The danger is that this will change over time: slowly with occasional losses of function, annoying at first, then increasingly critical. The more time passes without adequate staffing, the more difficult and costly fixes will become.
I suspect this is true because the challenges we face now at decent levels of reader satisfaction are already difficult to fix. API reference generation is complex and brittle; the site's UI is outdated; and our most consistent requests are for more tutorials, advanced concepts, diagrams, and code samples, all of which require ongoing, dedicated time to create.
Release support remains strong.
The release team continues a solid habit of leaving each successive team with better support than the previous release. This mostly takes the form of iterative improvements to the docs release playbook, producing better documentation and reducing siloed knowledge.
Staleness accelerates.
Conceptual content becomes less accurate or relevant as features change or deprecate. Tutorial content degrades for the same reason.
The content structure will also degrade: the categories of concepts, tasks, and tutorials are legacy categories that may not best fit the needs of current readers, let alone future ones.
Cruft accumulates for both readers and contributors. Reference docs become increasingly brittle without intervention.
Critical knowledge vanishes.
As I mentioned previously, SIG Docs has a wide range of functions, some with a steep learning curve. As contributors change roles or jobs, their expertise and availability will diminish or reduce to zero. Contributors with specific knowledge may not be available for consultation, exposing critical vulnerabilities in docs function. Specific examples include reference generation and chair leadership.
That's a lot to take in
It's difficult to strike a balance between the importance of SIG Docs' work to the community and our users, the joy it brings me personally, and the fact that things can't remain as they are without significant negative impacts (eventually). SIG Docs is by no means dying; it's a vibrant community with active contributors doing cool things. It's also a community with some critical knowledge and capacity shortages that can only be remedied with trained, paid staff dedicated to documentation.
What the community can do for healthy docs
Hire technical writers dedicated to Kubernetes docs. Support advanced content creation, not just release docs and incremental feature updates.
Thanks, and Happy 2020.
Kubernetes on MIPS
Authors: TimYin Shi, Dominic Yin, Wang Zhan, Jessica Jiang, Will Cai, Jeffrey Gao, Simon Sun (Inspur)
Background
MIPS (Microprocessor without Interlocked Pipelined Stages) is a reduced instruction set computer (RISC) instruction set architecture (ISA), appeared in 1981 and developed by MIPS Technologies. Now MIPS architecture is widely used in many electronic products.
Kubernetes has officially supported a variety of CPU architectures such as x86, arm/arm64, ppc64le, s390x. However, it's a pity that Kubernetes doesn't support MIPS. With the widespread use of cloud native technology, users under MIPS architecture also have an urgent demand for Kubernetes on MIPS.
Achievements
For many years, to enrich the ecology of the open-source community, we have been working on adjusting MIPS architecture for Kubernetes use cases. With the continuous iterative optimization and the performance improvement of the MIPS CPU, we have made some breakthrough progresses on the mips64el platform.
Over the years, we have been actively participating in the Kubernetes community and have rich experience in the using and optimization of Kubernetes technology. Recently, we tried to adapt the MIPS architecture platform for Kubernetes and achieved a new a stage on that journey. The team has completed migration and adaptation of Kubernetes and related components, built not only a stable and highly available MIPS cluster but also completed the conformance test for Kubernetes v1.16.2.
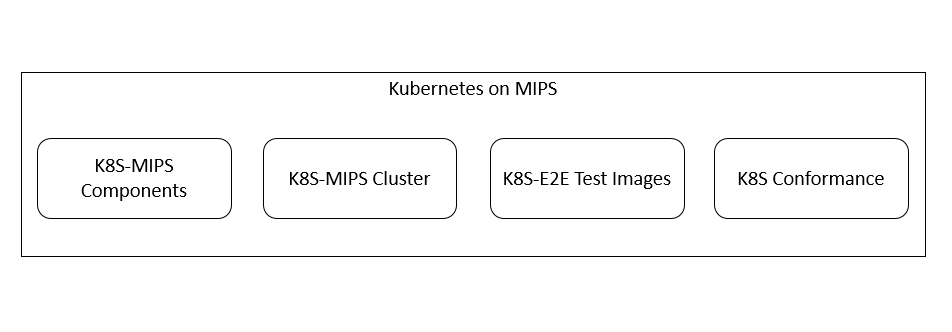
Figure 1 Kubernetes on MIPS
K8S-MIPS component build
Almost all native cloud components related to Kubernetes do not provide a MIPS version installation package or image. The prerequisite of deploying Kubernetes on the MIPS platform is to compile and build all required components on the mips64el platform. These components include:
- golang
- docker-ce
- hyperkube
- pause
- etcd
- calico
- coredns
- metrics-server
Thanks to the excellent design of Golang and its good support for the MIPS platform, the compilation processes of the above cloud native components are greatly simplified. First of all, we compiled Golang on the latest stable version for the mips64el platform, and then we compiled most of the above components with source code.
During the compilation processes, we inevitably encountered many platform compatibility problems, such as a Golang system call compatibility problem (syscall), typecasting of syscall. Stat_t from uint32 to uint64, patching for EpollEvent, and so on.
To build K8S-MIPS components, we used cross-compilation technology. Our process involved integrating a QEMU tool to translate MIPS CPU instructions and modifying the build script of Kubernetes and E2E image script of Kubernetes, Hyperkube, and E2E test images on MIPS architecture.
After successfully building the above components, we use tools such as kubespray and kubeadm to complete kubernetes cluster construction.
| Name | Version | MIPS Repository |
|---|---|---|
| golang on MIPS | 1.12.5 | - |
| docker-ce on MIPS | 18.09.8 | - |
| metrics-server for CKE on MIPS | 0.3.2 | registry.inspurcloud.cn/library/cke/kubernetes/metrics-server-mips64el:v0.3.2 |
| etcd for CKE on MIPS | 3.2.26 | registry.inspurcloud.cn/library/cke/etcd/etcd-mips64el:v3.2.26 |
| pause for CKE on MIPS | 3.1 | registry.inspurcloud.cn/library/cke/kubernetes/pause-mips64el:3.1 |
| hyperkube for CKE on MIPS | 1.14.3 | registry.inspurcloud.cn/library/cke/kubernetes/hyperkube-mips64el:v1.14.3 |
| coredns for CKE on MIPS | 1.6.5 | registry.inspurcloud.cn/library/cke/kubernetes/coredns-mips64el:v1.6.5 |
| calico for CKE on MIPS | 3.8.0 | registry.inspurcloud.cn/library/cke/calico/cni-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/ctl-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/node-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/kube-controllers-mips64el:v3.8.0 |
Note: CKE is a Kubernetes-based cloud container engine launched by Inspur
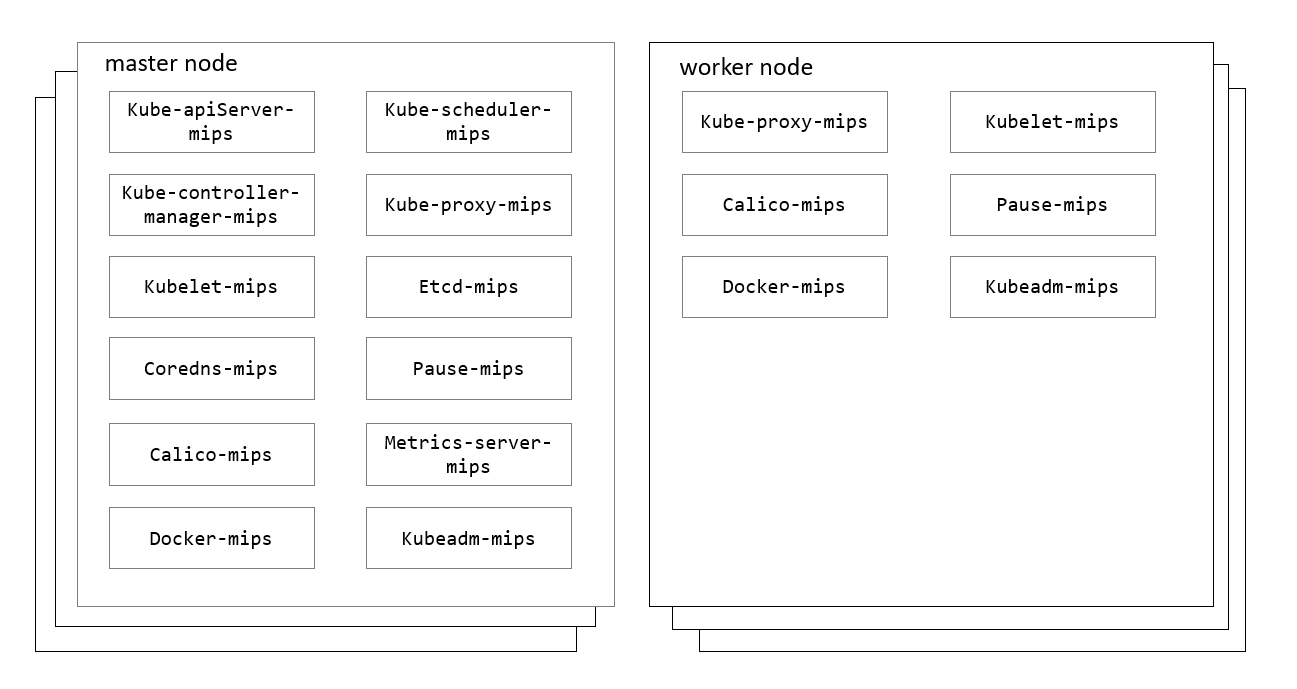
Figure 2 K8S-MIPS Cluster Components

Figure 3 CPU Architecture
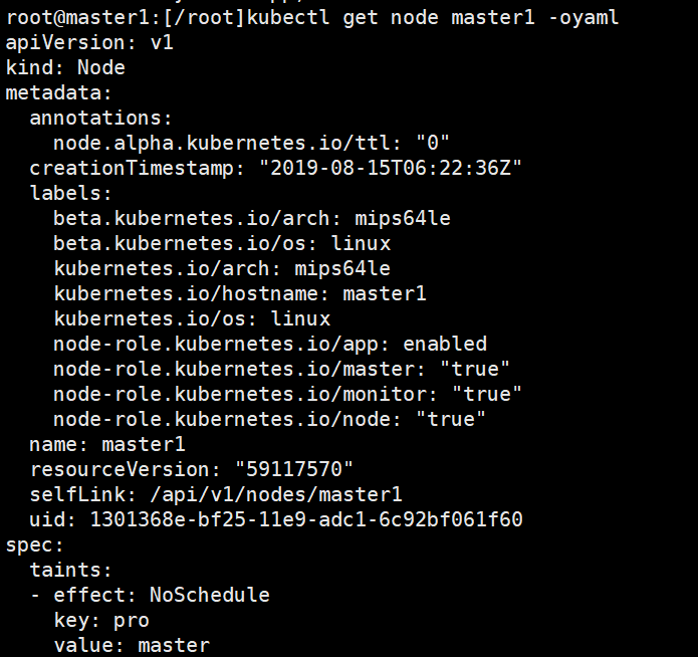
Figure 4 Cluster Node Information
Run K8S Conformance Test
The most straightforward way to verify the stability and availability of the K8S-MIPS cluster is to run a Kubernetes conformance test.
Conformance is a standalone container to launch Kubernetes end-to-end tests for conformance testing.
Once the test has started, it launches several pods for various end-to-end tests. The source code of those images used by these pods is mostly from kubernetes/test/images, and the built images are at gcr.io/kubernetes-e2e-test-images. Since there are no MIPS images in the repository, we must first build all needed images to run the test.
Build needed images for test
The first step is to find all needed images for the test. We can run sonobuoy images-p e2e command to list all images, or we can find those images in /test/utils/image/manifest.go. Although Kubernetes officially has a complete Makefile and shell-script that provides commands for building test images, there are still a number of architecture-related issues that have not been resolved, such as the incompatibilities of base images and dependencies. So we cannot directly build mips64el architecture images by executing these commands.
Most test images are in golang, then compiled into binaries and built as Docker image based on the corresponding Dockerfile. These images are easy to build. But note that most images are using alpine as their base image, which does not officially support mips64el architecture for now. For this moment, we are unable to make mips64el version of alpine, so we have to replace the alpine to existing MIPS images, such as Debian-stretch, fedora, ubuntu. Replacing the base image also requires replacing the command to install the dependencies, even the version of these dependencies.
Some images are not in kubernetes/test/images, such as gcr.io/google-samples/gb-frontend:v6. There is no clear documentation explaining where these images are locaated, though we found the source code in repository github.com/GoogleCloudPlatform/kubernetes-engine-samples. We soon ran into new problems: to build these google sample images, we have to build the base image it uses, even the base image of the base images, such as php:5-apache, redis, and perl.
After a long process of building an image, we finished with about four dozen images, including the images used by the test pod, and the base images. The last step before we run the tests is to place all those images into every node in the cluster and make sure the Pod image pull policy is imagePullPolicy: ifNotPresent.
Here are some of the images we built:
docker.io/library/busybox:1.29docker.io/library/nginx:1.14-alpinedocker.io/library/nginx:1.15-alpinedocker.io/library/perl:5.26docker.io/library/httpd:2.4.38-alpinedocker.io/library/redis:5.0.5-alpinegcr.io/google-containers/conformance:v1.16.2gcr.io/google-containers/hyperkube:v1.16.2gcr.io/google-samples/gb-frontend:v6gcr.io/kubernetes-e2e-test-images/agnhost:2.6gcr.io/kubernetes-e2e-test-images/apparmor-loader:1.0gcr.io/kubernetes-e2e-test-images/dnsutils:1.1gcr.io/kubernetes-e2e-test-images/echoserver:2.2gcr.io/kubernetes-e2e-test-images/ipc-utils:1.0gcr.io/kubernetes-e2e-test-images/jessie-dnsutils:1.0gcr.io/kubernetes-e2e-test-images/kitten:1.0gcr.io/kubernetes-e2e-test-images/metadata-concealment:1.2gcr.io/kubernetes-e2e-test-images/mounttest-user:1.0gcr.io/kubernetes-e2e-test-images/mounttest:1.0gcr.io/kubernetes-e2e-test-images/nautilus:1.0gcr.io/kubernetes-e2e-test-images/nonewprivs:1.0gcr.io/kubernetes-e2e-test-images/nonroot:1.0gcr.io/kubernetes-e2e-test-images/resource-consumer-controller:1.0gcr.io/kubernetes-e2e-test-images/resource-consumer:1.5gcr.io/kubernetes-e2e-test-images/sample-apiserver:1.10gcr.io/kubernetes-e2e-test-images/test-webserver:1.0gcr.io/kubernetes-e2e-test-images/volume/gluster:1.0gcr.io/kubernetes-e2e-test-images/volume/iscsi:2.0gcr.io/kubernetes-e2e-test-images/volume/nfs:1.0gcr.io/kubernetes-e2e-test-images/volume/rbd:1.0.1k8s.gcr.io/etcd:3.3.15k8s.gcr.io/pause:3.1
Finally, we ran the tests and got the test result, include e2e.log, which showed that all test cases passed. Additionally, we submitted our test result to k8s-conformance as a pull request.
Figure 5 Pull request for conformance test results
What's next
We built the kubernetes-MIPS component manually and finished the conformance test, which verified the feasibility of Kubernetes On the MIPS platform and greatly enhanced our confidence in promoting the support of the MIPS architecture by Kubernetes.
In the future, we plan to actively contribute our experience and achievements to the community, submit PR, and patch for MIPS. We hope that more developers and companies in the community join us and promote Kubernetes on MIPS.
Contribution plan:
- contribute the source of e2e test images for MIPS
- contribute the source of hyperkube for MIPS
- contribute the source of deploy tools like kubeadm for MIPS
Announcing the Kubernetes bug bounty program
Authors: Maya Kaczorowski and Tim Allclair, Google, on behalf of the Kubernetes Product Security Committee
Today, the Kubernetes Product Security Committee is launching a new bug bounty program, funded by the CNCF, to reward researchers finding security vulnerabilities in Kubernetes.
Setting up a new bug bounty program
We aimed to set up this bug bounty program as transparently as possible, with an initial proposal, evaluation of vendors, and working draft of the components in scope. Once we onboarded the selected bug bounty program vendor, HackerOne, these documents were further refined based on the feedback from HackerOne, as well as what was learned in the recent Kubernetes security audit. The bug bounty program has been in a private release for several months now, with invited researchers able to submit bugs and help us test the triage process. After almost two years since the initial proposal, the program is now ready for all security researchers to contribute!
What’s exciting is that this is rare: a bug bounty for an open-source infrastructure tool. Some open-source bug bounty programs exist, such as the Internet Bug Bounty, this mostly covers core components that are consistently deployed across environments; but most bug bounties are still for hosted web apps. In fact, with more than 100 certified distributions of Kubernetes, the bug bounty program needs to apply to the Kubernetes code that powers all of them. By far, the most time-consuming challenge here has been ensuring that the program provider (HackerOne) and their researchers who do the first line triage have the awareness of Kubernetes and the ability to easily test the validity of a reported bug. As part of the bootstrapping process, HackerOne had their team pass the Certified Kubernetes Administrator (CKA) exam.
What’s in scope
The bug bounty scope covers code from the main Kubernetes organizations on GitHub, as well as continuous integration, release, and documentation artifacts. Basically, most content you’d think of as ‘core’ Kubernetes, included at https://github.com/kubernetes, is in scope. We’re particularly interested in cluster attacks, such as privilege escalations, authentication bugs, and remote code execution in the kubelet or API server. Any information leak about a workload, or unexpected permission changes is also of interest. Stepping back from the cluster admin’s view of the world, you’re also encouraged to look at the Kubernetes supply chain, including the build and release processes, which would allow any unauthorized access to commits, or the ability to publish unauthorized artifacts.
Notably out of scope is the community management tooling, e.g., the Kubernetes mailing lists or Slack channel. Container escapes, attacks on the Linux kernel, or other dependencies, such as etcd, are also out of scope and should be reported to the appropriate party. We would still appreciate that any Kubernetes vulnerability, even if not in scope for the bug bounty, be disclosed privately to the Kubernetes Product Security Committee. See the full scope on the program reporting page.
How Kubernetes handles vulnerabilities and disclosures
Kubernetes’ Product Security Committee is a group of security-focused maintainers who are responsible for receiving and responding to reports of security issues in Kubernetes. This follows the documented security vulnerability response process, which includes initial triage, assessing impact, generating and rolling out a fix.
With our bug bounty program, initial triage and initial assessment are handled by the bug bounty provider, in this case, HackerOne, enabling us better scale our limited Kubernetes security experts to handle only valid reports. Nothing else in this process is changing - the Product Security Committee will continue to develop fixes, build private patches, and coordinate special security releases. New releases with security patches will be announced at kubernetes-security-announce@googlegroups.com.
If you want to report a bug, you don’t need to use the bug bounty - you can still follow the existing process and report what you’ve found at security@kubernetes.io.
Get started
Just as many organizations support open source by hiring developers, paying bug bounties directly supports security researchers. This bug bounty is a critical step for Kubernetes to build up its community of security researchers and reward their hard work.
If you’re a security researcher, and new to Kubernetes, check out these resources to learn more and get started bug hunting:
- Hardening guides
- Frameworks
- CIS benchmarks: https://www.cisecurity.org/benchmark/kubernetes/
- NIST 800-190: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-190.pdf
- Talks
- The Devil in the Details: Kubernetes’ First Security Assessment (KubeCon NA 2019): https://www.youtube.com/watch?v=vknE5XEa_Do
- Crafty Requests: Deep Dive into Kubernetes CVE-2018-1002105 (KubeCon EU 2019): https://www.youtube.com/watch?v=VjSJqc13PNk
- A Hacker’s Guide to Kubernetes and the Cloud (KubeCon EU 2018): https://www.youtube.com/watch?v=dxKpCO2dAy8
- Shipping in pirate-infested waters (KubeCon NA 2017): https://www.youtube.com/watch?v=ohTq0no0ZVU
- Hacking and Hardening Kubernetes clusters by example (KubeCon NA 2017): https://www.youtube.com/watch?v=vTgQLzeBfRU
If you find something, please report a security bug to the Kubernetes bug bounty at https://hackerone.com/kubernetes.
Remembering Brad Childs
Authors: Paul Morie, Red Hat
Last year, the Kubernetes family lost one of its own. Brad Childs was a SIG Storage chair and long time contributor to the project. Brad worked on a number of features in storage and was known as much for his friendliness and sense of humor as for his technical contributions and leadership.
We recently spent time remembering Brad at Kubecon NA:
Our hearts go out to Brad’s friends and family and others whose lives he touched inside and outside the Kubernetes community.
Thank you for everything, Brad. We’ll miss you.
Testing of CSI drivers
Author: Patrick Ohly (Intel)
When developing a Container Storage Interface (CSI) driver, it is useful to leverage as much prior work as possible. This includes source code (like the sample CSI hostpath driver) but also existing tests. Besides saving time, using tests written by someone else has the advantage that it can point out aspects of the specification that might have been overlooked otherwise.
An earlier blog post about end-to-end testing already showed how to use the Kubernetes storage tests for testing of a third-party CSI driver. That approach makes sense when the goal to also add custom E2E tests, but depends on quite a bit of effort for setting up and maintaining a test suite.
When the goal is to merely run the existing tests, then there are simpler approaches. This blog post introduces those.
Sanity testing
csi-test sanity ensures that a CSI driver conforms to the CSI specification by calling the gRPC methods in various ways and checking that the outcome is as required. Despite its current hosting under the Kubernetes-CSI organization, it is completely independent of Kubernetes. Tests connect to a running CSI driver through its Unix domain socket, so although the tests are written in Go, the driver itself can be implemented in any language.
The main README explains how to include those tests into an existing Go test suite. The simpler alternative is to just invoke the csi-sanity command.
Installation
Starting with csi-test v3.0.0, you can build the csi-sanity command
with go get github.com/kubernetes-csi/csi-test/cmd/csi-sanity and
you'll find the compiled binary in $GOPATH/bin/csi-sanity.
go get always builds the latest revision from the master branch. To
build a certain release, get the source
code and run
make -C cmd/csi-sanity. This produces cmd/csi-sanity/csi-sanity.
Usage
The csi-sanity binary is a full Ginkgo test
suite and thus has the usual -gingko
command line flags. In particular, -ginkgo.focus and
-ginkgo.skip can be used to select which tests are run resp. not
run.
During a test run, csi-sanity simulates the behavior of a container
orchestrator (CO) by creating staging and target directories as required by the CSI spec
and calling a CSI driver via gRPC. The driver must be started before
invoking csi-sanity. Although the tests currently only check the gRPC
return codes, that might change and so the driver really should make
the changes requested by a call, like mounting a filesystem. That may
mean that it has to run as root.
At least one gRPC
endpoint must
be specified via the -csi.endpoint parameter when invoking
csi-sanity, either as absolute path (unix:/tmp/csi.sock) for a Unix
domain socket or as host name plus port (dns:///my-machine:9000) for
TCP. csi-sanity then uses that endpoint for both node and controller
operations. A separate endpoint for controller operations can be
specified with -csi.controllerendpoint. Directories are created in
/tmp by default. This can be changed via -csi.mountdir and
-csi.stagingdir.
Some drivers cannot be deployed such that everything is guaranteed to run on the same host. In such a case, custom scripts have to be used to handle directories: they log into the host where the CSI node controller runs and create or remove the directories there.
For example, during CI testing the CSI hostpath example
driver gets
deployed on a real Kubernetes cluster before invoking csi-sanity and then
csi-sanity connects to it through port forwarding provided by
socat.
Scripts
are used to create and remove the directories.
Here's how one can replicate that, using the v1.2.0 release of the CSI hostpath driver:
$ cd csi-driver-host-path
$ git describe --tags HEAD
v1.2.0
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
127.0.0.1 Ready <none> 42m v1.16.0
$ deploy/kubernetes-1.16/deploy-hostpath.sh
applying RBAC rules
kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/external-provisioner/v1.4.0/deploy/kubernetes/rbac.yaml
...
deploying hostpath components
deploy/kubernetes-1.16/hostpath/csi-hostpath-attacher.yaml
using image: quay.io/k8scsi/csi-attacher:v2.0.0
service/csi-hostpath-attacher created
statefulset.apps/csi-hostpath-attacher created
deploy/kubernetes-1.16/hostpath/csi-hostpath-driverinfo.yaml
csidriver.storage.k8s.io/hostpath.csi.k8s.io created
deploy/kubernetes-1.16/hostpath/csi-hostpath-plugin.yaml
using image: quay.io/k8scsi/csi-node-driver-registrar:v1.2.0
using image: quay.io/k8scsi/hostpathplugin:v1.2.0
using image: quay.io/k8scsi/livenessprobe:v1.1.0
...
service/hostpath-service created
statefulset.apps/csi-hostpath-socat created
07:38:46 waiting for hostpath deployment to complete, attempt #0
deploying snapshotclass
volumesnapshotclass.snapshot.storage.k8s.io/csi-hostpath-snapclass created
$ cat >mkdir_in_pod.sh <<EOF
#!/bin/sh
kubectl exec csi-hostpathplugin-0 -c hostpath -- mktemp -d /tmp/csi-sanity.XXXXXX
EOF
$ cat >rmdir_in_pod.sh <<EOF
#!/bin/sh
kubectl exec csi-hostpathplugin-0 -c hostpath -- rmdir "\$@"
EOF
$ chmod u+x *_in_pod.sh
$ csi-sanity -ginkgo.v \
-csi.endpoint dns:///127.0.0.1:$(kubectl get "services/hostpath-service" -o "jsonpath={..nodePort}") \
-csi.createstagingpathcmd ./mkdir_in_pod.sh \
-csi.createmountpathcmd ./mkdir_in_pod.sh \
-csi.removestagingpathcmd ./rmdir_in_pod.sh \
-csi.removemountpathcmd ./rmdir_in_pod.sh
Running Suite: CSI Driver Test Suite
====================================
Random Seed: 1570540138
Will run 72 of 72 specs
...
Controller Service [Controller Server] ControllerGetCapabilities
should return appropriate capabilities
/nvme/gopath/src/github.com/kubernetes-csi/csi-test/pkg/sanity/controller.go:111
STEP: connecting to CSI driver
STEP: creating mount and staging directories
STEP: checking successful response
•
------------------------------
Controller Service [Controller Server] GetCapacity
should return capacity (no optional values added)
/nvme/gopath/src/github.com/kubernetes-csi/csi-test/pkg/sanity/controller.go:149
STEP: reusing connection to CSI driver at dns:///127.0.0.1:30056
STEP: creating mount and staging directories
...
Ran 53 of 72 Specs in 148.206 seconds
SUCCESS! -- 53 Passed | 0 Failed | 0 Pending | 19 Skipped
PASS
Some comments:
- The source code of these tests is in the
pkg/sanitypackage. - How to determine the external IP address of the node depends on the
cluster. In this example, the cluster was brought up with
hack/local-up-cluster.shand thus runs on the local host (127.0.0.1). It uses a port allocated by Kubernetes, obtained above withkubectl get "services/hostpath-service". The Kubernetes-CSI CI uses kind and there a Docker command can be used. - The create script must print the final directory. Using a unique directory for each test case has the advantage that if something goes wrong in one test case, others still start with a clean slate.
- The "staging directory", aka
NodePublishVolumeRequest.target_pathin the CSI spec, must be created and deleted by the CSI driver while the CO is responsible for the parent directory.csi-sanityhandles that by creating a directory and then giving the CSI driver that directory path with/targetappended at the end. Kubernetes got this wrong and creates the actualtarget_pathdirectory, so CSI drivers which want to work with Kubernetes currently have to be lenient and must not fail when that directory already exists. - The "mount directory" corresponds to
NodeStageVolumeRequest.staging_target_pathand really gets created by the CO, i.e.csi-sanity.
End-to-end testing
In contrast to csi-sanity, end-to-end testing interacts with the CSI
driver through the Kubernetes API, i.e. it simulates operations from a
normal user, like creating a PersistentVolumeClaim. Support for testing external CSI
drivers was
added
in Kubernetes 1.14.0.
Installation
For each Kubernetes release, a test tar archive is published. It's not
listed in the release notes (for example, the ones for
1.16),
so one has to know that the full URL is
https://dl.k8s.io/<version>/kubernetes-test-linux-amd64.tar.gz (like
for
v1.16.0).
These include a e2e.test binary for Linux on x86-64. Archives for
other platforms are also available, see this
KEP. The
e2e.test binary is completely self-contained, so one can "install"
it and the ginkgo test runner with:
curl --location https://dl.k8s.io/v1.16.0/kubernetes-test-linux-amd64.tar.gz | \
tar --strip-components=3 -zxf - kubernetes/test/bin/e2e.test kubernetes/test/bin/ginkgo
Each e2e.test binary contains tests that match the features
available in the corresponding release. In particular, the [Feature: xyz] tags change between releases: they separate tests of alpha
features from tests of non-alpha features. Also, the tests from an
older release might rely on APIs that were removed in more recent
Kubernetes releases. To avoid problems, it's best to simply use the
e2e.test binary that matches the Kubernetes release that is used for
testing.
Usage
Not all features of a CSI driver can be discovered through the Kubernetes API. Therefore a configuration file in YAML or JSON format is needed which describes the driver that is to be tested. That file is used to populate the driverDefinition struct and the DriverInfo struct that is embedded inside it. For detailed usage instructions of individual fields refer to these structs.
A word of warning: tests are often only run when setting some fields and the file parser does not warn about unknown fields, so always check that the file really matches those structs.
Here is an example that tests the
csi-driver-host-path:
$ cat >test-driver.yaml <<EOF
StorageClass:
FromName: true
SnapshotClass:
FromName: true
DriverInfo:
Name: hostpath.csi.k8s.io
Capabilities:
block: true
controllerExpansion: true
exec: true
multipods: true
persistence: true
pvcDataSource: true
snapshotDataSource: true
InlineVolumes:
- Attributes: {}
EOF
At a minimum, you need to define the storage class you want to use in
the test, the name of your driver, and what capabilities you want to
test.
As with csi-sanity, the driver has to be running in the cluster
before testing it.
The actual e2e.test invocation then enables tests for this driver
with -storage.testdriver and selects the storage tests for it with
-ginkgo.focus:
$ ./e2e.test -ginkgo.v \
-ginkgo.focus='External.Storage' \
-storage.testdriver=test-driver.yaml
Oct 8 17:17:42.230: INFO: The --provider flag is not set. Continuing as if --provider=skeleton had been used.
I1008 17:17:42.230210 648569 e2e.go:92] Starting e2e run "90b9adb0-a3a2-435f-80e0-640742d56104" on Ginkgo node 1
Running Suite: Kubernetes e2e suite
===================================
Random Seed: 1570547861 - Will randomize all specs
Will run 163 of 5060 specs
Oct 8 17:17:42.237: INFO: >>> kubeConfig: /var/run/kubernetes/admin.kubeconfig
Oct 8 17:17:42.241: INFO: Waiting up to 30m0s for all (but 0) nodes to be schedulable
...
------------------------------
SSSSSSSSSSSSSSSSSSSS
------------------------------
External Storage [Driver: hostpath.csi.k8s.io] [Testpattern: Dynamic PV (filesystem volmode)] multiVolume [Slow]
should access to two volumes with different volume mode and retain data across pod recreation on the same node
/workspace/anago-v1.16.0-rc.2.1+2bd9643cee5b3b/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/storage/testsuites/multivolume.go:191
[BeforeEach] [Testpattern: Dynamic PV (filesystem volmode)] multiVolume [Slow]
...
You can use ginkgo to run some kinds of test in parallel.
Alpha feature tests or those that by design have to be run
sequentially then need to be run separately:
$ ./ginkgo -p -v \
-focus='External.Storage' \
-skip='\[Feature:|\[Disruptive\]|\[Serial\]' \
./e2e.test \
-- \
-storage.testdriver=test-driver.yaml
$ ./ginkgo -v \
-focus='External.Storage.*(\[Feature:|\[Disruptive\]|\[Serial\])' \
./e2e.test \
-- \
-storage.testdriver=test-driver.yaml
Getting involved
Both the Kubernetes storage tests and the sanity tests are meant to be applicable to arbitrary CSI drivers. But perhaps tests are based on additional assumptions and your driver does not pass the testing although it complies with the CSI specification. If that happens then please file issues (links below).
These are open source projects which depend on the help of those using them, so once a problem has been acknowledged, a pull request addressing it will be highly welcome.
The same applies to writing new tests. The following searches in the issue trackers select issues that have been marked specifically as something that needs someone's help:
Happy testing! May the issues it finds be few and easy to fix.
Kubernetes 1.17: Stability
Authors: Kubernetes 1.17 Release Team
We’re pleased to announce the delivery of Kubernetes 1.17, our fourth and final release of 2019! Kubernetes v1.17 consists of 22 enhancements: 14 enhancements have graduated to stable, 4 enhancements are moving to beta, and 4 enhancements are entering alpha.
Major Themes
Cloud Provider Labels reach General Availability
Added as a beta feature way back in v1.2, v1.17 sees the general availability of cloud provider labels.
Volume Snapshot Moves to Beta
The Kubernetes Volume Snapshot feature is now beta in Kubernetes v1.17. It was introduced as alpha in Kubernetes v1.12, with a second alpha with breaking changes in Kubernetes v1.13.
CSI Migration Beta
The Kubernetes in-tree storage plugin to Container Storage Interface (CSI) migration infrastructure is now beta in Kubernetes v1.17. CSI migration was introduced as alpha in Kubernetes v1.14.
Cloud Provider Labels reach General Availability
When nodes and volumes are created, a set of standard labels are applied based on the underlying cloud provider of the Kubernetes cluster. Nodes get a label for the instance type. Both nodes and volumes get two labels describing the location of the resource in the cloud provider topology, usually organized in zones and regions.
Standard labels are used by Kubernetes components to support some features. For example, the scheduler would ensure that pods are placed on the same zone as the volumes they claim; and when scheduling pods belonging to a deployment, the scheduler would prioritize spreading them across zones. You can also use the labels in your pod specs to configure things as such node affinity. Standard labels allow you to write pod specs that are portable among different cloud providers.
The labels are reaching general availability in this release. Kubernetes components have been updated to populate the GA and beta labels and to react to both. However, if you are using the beta labels in your pod specs for features such as node affinity, or in your custom controllers, we recommend that you start migrating them to the new GA labels. You can find the documentation for the new labels here:
Volume Snapshot Moves to Beta
The Kubernetes Volume Snapshot feature is now beta in Kubernetes v1.17. It was introduced as alpha in Kubernetes v1.12, with a second alpha with breaking changes in Kubernetes v1.13. This post summarizes the changes in the beta release.
What is a Volume Snapshot?
Many storage systems (like Google Cloud Persistent Disks, Amazon Elastic Block Storage, and many on-premise storage systems) provide the ability to create a “snapshot” of a persistent volume. A snapshot represents a point-in-time copy of a volume. A snapshot can be used either to provision a new volume (pre-populated with the snapshot data) or to restore an existing volume to a previous state (represented by the snapshot).
Why add Volume Snapshots to Kubernetes?
The Kubernetes volume plugin system already provides a powerful abstraction that automates the provisioning, attaching, and mounting of block and file storage.
Underpinning all these features is the Kubernetes goal of workload portability: Kubernetes aims to create an abstraction layer between distributed systems applications and underlying clusters so that applications can be agnostic to the specifics of the cluster they run on and application deployment requires no “cluster specific” knowledge.
The Kubernetes Storage SIG identified snapshot operations as critical functionality for many stateful workloads. For example, a database administrator may want to snapshot a database volume before starting a database operation.
By providing a standard way to trigger snapshot operations in the Kubernetes API, Kubernetes users can now handle use cases like this without having to go around the Kubernetes API (and manually executing storage system specific operations).
Instead, Kubernetes users are now empowered to incorporate snapshot operations in a cluster agnostic way into their tooling and policy with the comfort of knowing that it will work against arbitrary Kubernetes clusters regardless of the underlying storage.
Additionally these Kubernetes snapshot primitives act as basic building blocks that unlock the ability to develop advanced, enterprise grade, storage administration features for Kubernetes: including application or cluster level backup solutions.
You can read more in the blog entry about releasing CSI volume snapshots to beta.
CSI Migration Beta
Why are we migrating in-tree plugins to CSI?
Prior to CSI, Kubernetes provided a powerful volume plugin system. These volume plugins were “in-tree” meaning their code was part of the core Kubernetes code and shipped with the core Kubernetes binaries. However, adding support for new volume plugins to Kubernetes was challenging. Vendors that wanted to add support for their storage system to Kubernetes (or even fix a bug in an existing volume plugin) were forced to align with the Kubernetes release process. In addition, third-party storage code caused reliability and security issues in core Kubernetes binaries and the code was often difficult (and in some cases impossible) for Kubernetes maintainers to test and maintain. Using the Container Storage Interface in Kubernetes resolves these major issues.
As more CSI Drivers were created and became production ready, we wanted all Kubernetes users to reap the benefits of the CSI model. However, we did not want to force users into making workload/configuration changes by breaking the existing generally available storage APIs. The way forward was clear - we would have to replace the backend of the “in-tree plugin” APIs with CSI. What is CSI migration?
The CSI migration effort enables the replacement of existing in-tree storage plugins such as kubernetes.io/gce-pd or kubernetes.io/aws-ebs with a corresponding CSI driver. If CSI Migration is working properly, Kubernetes end users shouldn’t notice a difference. After migration, Kubernetes users may continue to rely on all the functionality of in-tree storage plugins using the existing interface.
When a Kubernetes cluster administrator updates a cluster to enable CSI migration, existing stateful deployments and workloads continue to function as they always have; however, behind the scenes Kubernetes hands control of all storage management operations (previously targeting in-tree drivers) to CSI drivers.
The Kubernetes team has worked hard to ensure the stability of storage APIs and for the promise of a smooth upgrade experience. This involves meticulous accounting of all existing features and behaviors to ensure backwards compatibility and API stability. You can think of it like changing the wheels on a racecar while it’s speeding down the straightaway.
You can read more in the blog entry about CSI migration going to beta.
Other Updates
Graduated to Stable 💯
- Taint Node by Condition
- Configurable Pod Process Namespace Sharing
- Schedule DaemonSet Pods by kube-scheduler
- Dynamic Maximum Volume Count
- Kubernetes CSI Topology Support
- Provide Environment Variables Expansion in SubPath Mount
- Defaulting of Custom Resources
- Move Frequent Kubelet Heartbeats To Lease Api
- Break Apart The Kubernetes Test Tarball
- Add Watch Bookmarks Support
- Behavior-Driven Conformance Testing
- Finalizer Protection For Service Loadbalancers
- Avoid Serializing The Same Object Independently For Every Watcher
Major Changes
Other Notable Features
Availability
Kubernetes 1.17 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials. You can also easily install 1.17 using kubeadm.
Release Team
This release is made possible through the efforts of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Guinevere Saenger. The 35 individuals on the release team coordinated many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid pace. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has had over 39,000 individual contributors to date and an active community of more than 66,000 people.
Webinar
Join members of the Kubernetes 1.17 release team on Jan 7th, 2020 to learn about the major features in this release. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below. Thank you for your continued feedback and support.
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Post questions (or answer questions) on Stack Overflow
- Share your Kubernetes story
Kubernetes 1.17 Feature: Kubernetes Volume Snapshot Moves to Beta
Authors: Xing Yang, VMware & Xiangqian Yu, Google
The Kubernetes Volume Snapshot feature is now beta in Kubernetes v1.17. It was introduced as alpha in Kubernetes v1.12, with a second alpha with breaking changes in Kubernetes v1.13. This post summarizes the changes in the beta release.
What is a Volume Snapshot?
Many storage systems (like Google Cloud Persistent Disks, Amazon Elastic Block Storage, and many on-premise storage systems) provide the ability to create a “snapshot” of a persistent volume. A snapshot represents a point-in-time copy of a volume. A snapshot can be used either to provision a new volume (pre-populated with the snapshot data) or to restore an existing volume to a previous state (represented by the snapshot).
Why add Volume Snapshots to Kubernetes?
The Kubernetes volume plugin system already provides a powerful abstraction that automates the provisioning, attaching, and mounting of block and file storage.
Underpinning all these features is the Kubernetes goal of workload portability: Kubernetes aims to create an abstraction layer between distributed applications and underlying clusters so that applications can be agnostic to the specifics of the cluster they run on and application deployment requires no “cluster specific” knowledge.
The Kubernetes Storage SIG identified snapshot operations as critical functionality for many stateful workloads. For example, a database administrator may want to snapshot a database volume before starting a database operation.
By providing a standard way to trigger snapshot operations in the Kubernetes API, Kubernetes users can now handle use cases like this without having to go around the Kubernetes API (and manually executing storage system specific operations).
Instead, Kubernetes users are now empowered to incorporate snapshot operations in a cluster agnostic way into their tooling and policy with the comfort of knowing that it will work against arbitrary Kubernetes clusters regardless of the underlying storage.
Additionally these Kubernetes snapshot primitives act as basic building blocks that unlock the ability to develop advanced, enterprise grade, storage administration features for Kubernetes: including application or cluster level backup solutions.
What’s new in Beta?
With the promotion of Volume Snapshot to beta, the feature is now enabled by default on standard Kubernetes deployments instead of being opt-in.
The move of the Kubernetes Volume Snapshot feature to beta also means:
- A revamp of volume snapshot APIs.
- The CSI external-snapshotter sidecar is split into two controllers, a common snapshot controller and a CSI external-snapshotter sidecar.
- Deletion secret is added as an annotation to the volume snapshot content.
- A new finalizer is added to the volume snapshot API object to prevent it from being deleted when it is bound to a volume snapshot content API object.
Kubernetes Volume Snapshots Requirements
As mentioned above, with the promotion of Volume Snapshot to beta, the feature is now enabled by default on standard Kubernetes deployments instead of being opt-in.
In order to use the Kubernetes Volume Snapshot feature, you must ensure the following components have been deployed on your Kubernetes cluster:
- Kubernetes Volume Snapshot CRDs
- Volume snapshot controller
- CSI Driver supporting Kubernetes volume snapshot beta
See the deployment section below for details.
Which drivers support Kubernetes Volume Snapshots?
Kubernetes supports three types of volume plugins: in-tree, Flex, and CSI. See Kubernetes Volume Plugin FAQ for details.
Snapshots are only supported for CSI drivers (not for in-tree or Flex). To use the Kubernetes snapshots feature, ensure that a CSI Driver that implements snapshots is deployed on your cluster.
Read the “Container Storage Interface (CSI) for Kubernetes GA” blog post to learn more about CSI and how to deploy CSI drivers.
As of the publishing of this blog, the following CSI drivers have been updated to support volume snapshots beta:
Beta level Volume Snapshot support for other CSI drivers is pending, and should be available soon.
Kubernetes Volume Snapshot Beta API
A number of changes were made to the Kubernetes volume snapshot API between alpha to beta. These changes are not backward compatible. The purpose of these changes was to make API definitions clear and easier to use.
The following changes are made:
DeletionPolicyis now a required field rather than optional in bothVolumeSnapshotClassandVolumeSnapshotContent. This way the user has to explicitly specify it, leaving no room for confusion.VolumeSnapshotSpechas a new requiredSourcefield.Sourcemay be either aPersistentVolumeClaimName(if dynamically provisioning a snapshot) orVolumeSnapshotContentName(if pre-provisioning a snapshot).VolumeSnapshotContentSpecalso has a new requiredSourcefield. ThisSourcemay be either aVolumeHandle(if dynamically provisioning a snapshot) or aSnapshotHandle(if pre-provisioning volume snapshots).VolumeSnapshotStatusnow contains aBoundVolumeSnapshotContentNameto indicate theVolumeSnapshotobject is bound to aVolumeSnapshotContent.VolumeSnapshotContentnow contains aStatusto indicate the current state of the content. It has a fieldSnapshotHandleto indicate that theVolumeSnapshotContentrepresents a snapshot on the storage system.
The beta Kubernetes VolumeSnapshot API object:
type VolumeSnapshot struct {
metav1.TypeMeta
metav1.ObjectMeta
Spec VolumeSnapshotSpec
Status *VolumeSnapshotStatus
}
type VolumeSnapshotSpec struct {
Source VolumeSnapshotSource
VolumeSnapshotClassName *string
}
// Exactly one of its members MUST be specified
type VolumeSnapshotSource struct {
// +optional
PersistentVolumeClaimName *string
// +optional
VolumeSnapshotContentName *string
}
type VolumeSnapshotStatus struct {
BoundVolumeSnapshotContentName *string
CreationTime *metav1.Time
ReadyToUse *bool
RestoreSize *resource.Quantity
Error *VolumeSnapshotError
}
The beta Kubernetes VolumeSnapshotContent API object:
type VolumeSnapshotContent struct {
metav1.TypeMeta
metav1.ObjectMeta
Spec VolumeSnapshotContentSpec
Status *VolumeSnapshotContentStatus
}
type VolumeSnapshotContentSpec struct {
VolumeSnapshotRef core_v1.ObjectReference
Source VolumeSnapshotContentSource
DeletionPolicy DeletionPolicy
Driver string
VolumeSnapshotClassName *string
}
type VolumeSnapshotContentSource struct {
// +optional
VolumeHandle *string
// +optional
SnapshotHandle *string
}
type VolumeSnapshotContentStatus struct {
CreationTime *int64
ReadyToUse *bool
RestoreSize *int64
Error *VolumeSnapshotError
SnapshotHandle *string
}
The beta Kubernetes VolumeSnapshotClass API object:
type VolumeSnapshotClass struct {
metav1.TypeMeta
metav1.ObjectMeta
Driver string
Parameters map[string]string
DeletionPolicy DeletionPolicy
}
How do I deploy support for Volume Snapshots on my Kubernetes Cluster?
Please note that the Volume Snapshot feature now depends on a new, common volume snapshot controller in addition to the volume snapshot CRDs. Both the volume snapshot controller and the CRDs are independent of any CSI driver. Regardless of the number of CSI drivers deployed on the cluster, there must be only one instance of the volume snapshot controller running and one set of volume snapshot CRDs installed per cluster.
Therefore, it is strongly recommended that Kubernetes distributors bundle and deploy the controller and CRDs as part of their Kubernetes cluster management process (independent of any CSI Driver).
If your cluster does not come pre-installed with the correct components, you may manually install these components by executing the following steps.
Install Snapshot Beta CRDs
kubectl create -f config/crd- https://github.com/kubernetes-csi/external-snapshotter/tree/53469c21962339229dd150cbba50c34359acec73/config/crd
- Do this once per cluster
Install Common Snapshot Controller
kubectl create -f deploy/kubernetes/snapshot-controller- https://github.com/kubernetes-csi/external-snapshotter/tree/master/deploy/kubernetes/snapshot-controller
- Do this once per cluster
Install CSI Driver
Follow instructions provided by your CSI Driver vendor.
How do I use Kubernetes Volume Snapshots?
Assuming all the required components (including CSI driver) are already deployed and running on your cluster, you can create volume snapshots using the VolumeSnapshot API object, and restore them by specifying a VolumeSnapshot data source on a PVC.
Creating a New Volume Snapshot with Kubernetes
You can enable creation/deletion of volume snapshots in a Kubernetes cluster, by creating a VolumeSnapshotClass API object pointing to a CSI Driver that support volume snapshots.
The following VolumeSnapshotClass, for example, tells the Kubernetes cluster that a CSI driver, testdriver.csi.k8s.io, can handle volume snapshots, and that when these snapshots are created, their deletion policy should be to delete.
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshotClass
metadata:
name: test-snapclass
driver: testdriver.csi.k8s.io
deletionPolicy: Delete
parameters:
csi.storage.k8s.io/snapshotter-secret-name: mysecret
csi.storage.k8s.io/snapshotter-secret-namespace: mysecretnamespace
The common snapshot controller reserves the parameter keys csi.storage.k8s.io/snapshotter-secret-name and csi.storage.k8s.io/snapshotter-secret-namespace. If specified, it fetches the referenced Kubernetes secret and sets it as an annotation on the volume snapshot content object. The CSI external-snapshotter sidecar retrieves it from the content annotation and passes it to the CSI driver during snapshot creation.
Creation of a volume snapshot is triggered by the creation of a VolumeSnapshot API object.
The VolumeSnapshot object must specify the following source type:
persistentVolumeClaimName - The name of the PVC to snapshot. Please note that the source PVC, PV, and VolumeSnapshotClass for a VolumeSnapshot object must point to the same CSI driver.
The following VolumeSnapshot, for example, triggers the creation of a snapshot for a PVC called test-pvc using the VolumeSnapshotClass above.
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshot
metadata:
name: test-snapshot
spec:
volumeSnapshotClassName: test-snapclass
source:
persistentVolumeClaimName: test-pvc
When volume snapshot creation is invoked, the common snapshot controller first creates a VolumeSnapshotContent object with the volumeSnapshotRef, source volumeHandle, volumeSnapshotClassName if specified, driver, and deletionPolicy.
The CSI external-snapshotter sidecar then passes the VolumeSnapshotClass parameters, the source volume ID, and any referenced secret(s) to the CSI driver (in this case testdriver.csi.k8s.io) via a CSI CreateSnapshot call. In response, the CSI driver creates a new snapshot for the specified volume, and returns the ID for that snapshot. The CSI external-snapshotter sidecar then updates the snapshotHandle, creationTime, restoreSize, and readyToUse in the status field of the VolumeSnapshotContent object that represents the new snapshot. For a storage system that needs to upload the snapshot after it has been cut, the CSI external-snapshotter sidecar will keep calling the CSI CreateSnapshot to check the status until upload is complete and set readyToUse to true.
The common snapshot controller binds the VolumeSnapshotContent object to the VolumeSnapshot (sets BoundVolumeSnapshotContentName), and updates the creationTime, restoreSize, and readyToUse in the status field of the VolumeSnapshot object based on the status field of the VolumeSnapshotContent object.
If no volumeSnapshotClassName is specified, one is automatically selected as follows:
The StorageClass from PVC or PV of the source volume is fetched. The default VolumeSnapshotClass is fetched, if available. A default VolumeSnapshotClass is a snapshot class created by the admin with the snapshot.storage.kubernetes.io/is-default-class annotation. If the Driver field of the default VolumeSnapshotClass is the same as the Provisioner field in the StorageClass, the default VolumeSnapshotClass is used. If there is no default VolumeSnapshotClass or more than one default VolumeSnapshotClass for a snapshot, an error will be returned.
Please note that the Kubernetes Snapshot API does not provide any consistency guarantees. You have to prepare your application (pause application, freeze filesystem etc.) before taking the snapshot for data consistency either manually or using some other higher level APIs/controllers.
You can verify that the VolumeSnapshot object is created and bound with VolumeSnapshotContent by running kubectl describe volumesnapshot:
Bound Volume Snapshot Content Name - field in the Status indicates the volume is bound to the specified VolumeSnapshotContent.
Ready To Use - field in the Status indicates this volume snapshot is ready for use.
Creation Time - field in the Status indicates when the snapshot was actually created (cut).
Restore Size - field in the Status indicates the minimum volume size required when restoring a volume from this snapshot.
Name: test-snapshot
Namespace: default
Labels: <none>
Annotations: <none>
API Version: snapshot.storage.k8s.io/v1beta1
Kind: VolumeSnapshot
Metadata:
Creation Timestamp: 2019-11-16T00:36:04Z
Finalizers:
snapshot.storage.kubernetes.io/volumesnapshot-as-source-protection
snapshot.storage.kubernetes.io/volumesnapshot-bound-protection
Generation: 1
Resource Version: 1294
Self Link: /apis/snapshot.storage.k8s.io/v1beta1/namespaces/default/volumesnapshots/new-snapshot-demo
UID: 32ceaa2a-3802-4edd-a808-58c4f1bd7869
Spec:
Source:
Persistent Volume Claim Name: test-pvc
Volume Snapshot Class Name: test-snapclass
Status:
Bound Volume Snapshot Content Name: snapcontent-32ceaa2a-3802-4edd-a808-58c4f1bd7869
Creation Time: 2019-11-16T00:36:04Z
Ready To Use: true
Restore Size: 1Gi
As a reminder to any developers building controllers using volume snapshot APIs: before using a VolumeSnapshot API object, validate the bi-directional binding between the VolumeSnpashot and the VolumeSnapshotContent it is bound to, to ensure the binding is complete and correct (not doing so may result in security issues).
kubectl describe volumesnapshotcontent
Name: snapcontent-32ceaa2a-3802-4edd-a808-58c4f1bd7869
Namespace:
Labels: <none>
Annotations: <none>
API Version: snapshot.storage.k8s.io/v1beta1
Kind: VolumeSnapshotContent
Metadata:
Creation Timestamp: 2019-11-16T00:36:04Z
Finalizers:
snapshot.storage.kubernetes.io/volumesnapshotcontent-bound-protection
Generation: 1
Resource Version: 1292
Self Link: /apis/snapshot.storage.k8s.io/v1beta1/volumesnapshotcontents/snapcontent-32ceaa2a-3802-4edd-a808-58c4f1bd7869
UID: 7dfdf22e-0b0c-4b71-9ddf-2f1612ca2aed
Spec:
Deletion Policy: Delete
Driver: testdriver.csi.k8s.io
Source:
Volume Handle: d1b34a5f-0808-11ea-808a-0242ac110003
Volume Snapshot Class Name: test-snapclass
Volume Snapshot Ref:
API Version: snapshot.storage.k8s.io/v1beta1
Kind: VolumeSnapshot
Name: test-snapshot
Namespace: default
Resource Version: 1286
UID: 32ceaa2a-3802-4edd-a808-58c4f1bd7869
Status:
Creation Time: 1573864564608810101
Ready To Use: true
Restore Size: 1073741824
Snapshot Handle: 127c5798-0809-11ea-808a-0242ac110003
Events: <none>
Importing an existing volume snapshot with Kubernetes
You can always expose a pre-existing volume snapshot in Kubernetes by manually creating a VolumeSnapshotContent object to represent the existing volume snapshot. Because VolumeSnapshotContent is a non-namespace API object, only a cluster admin may have the permission to create it. By specifying the volumeSnapshotRef the cluster admin specifies exactly which user can use the snapshot.
The following VolumeSnapshotContent, for example exposes a volume snapshot with the name 7bdd0de3-aaeb-11e8-9aae-0242ac110002 belonging to a CSI driver called testdriver.csi.k8s.io.
A VolumeSnapshotContent object should be created by a cluster admin with the following fields to represent an existing snapshot:
driver- CSI driver used to handle this volume. This field is required.source- Snapshot identifying informationsnapshotHandle- name/identifier of the snapshot. This field is required.volumeSnapshotRef- Pointer to the VolumeSnapshot object this content should bind to.nameandnamespace- Specifies the name and namespace of the VolumeSnapshot object which the content is bound to.deletionPolicy- Valid values areDeleteandRetain. If thedeletionPolicyisDelete, then the underlying storage snapshot will be deleted along with the VolumeSnapshotContent object. If the -deletionPolicyisRetain, then both the underlying snapshot and VolumeSnapshotContent remain.
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshotContent
metadata:
name: manually-created-snapshot-content
spec:
deletionPolicy: Delete
driver: testdriver.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-aaeb-11e8-9aae-0242ac110002
volumeSnapshotRef:
name: test-snapshot
namespace: default
Once a VolumeSnapshotContent object is created, a user can create a VolumeSnapshot object pointing to the VolumeSnapshotContent object. The name and namespace of the VolumeSnapshot object must match the name/namespace specified in the volumeSnapshotRef of the VolumeSnapshotContent. It specifies the following fields:
volumeSnapshotContentName - name of the volume snapshot content specified above. This field is required.
volumeSnapshotClassName - name of the volume snapshot class. This field is optional.
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshot
metadata:
name: manually-created-snapshot
spec:
source:
volumeSnapshotContentName: test-content
Once both objects are created, the common snapshot controller verifies the binding between VolumeSnapshot and VolumeSnapshotContent objects is correct and marks the VolumeSnapshot as ready (if the CSI driver supports the ListSnapshots call, the controller also validates that the referenced snapshot exists). The CSI external-snapshotter sidecar checks if the snapshot exists if ListSnapshots CSI method is implemented, otherwise it assumes the snapshot exists. The external-snapshotter sidecar sets readyToUse to true in the status field of VolumeSnapshotContent. The common snapshot controller marks the snapshot as ready accordingly.
Create Volume From Snapshot
Once you have a bound and ready VolumeSnapshot object, you can use that object to provision a new volume that is pre-populated with data from the snapshot.
To provision a new volume pre-populated with data from a snapshot, use the dataSource field in the PersistentVolumeClaim. It has three parameters:
name - name of the VolumeSnapshot object representing the snapshot to use as source
kind - must be VolumeSnapshot
apiGroup - must be snapshot.storage.k8s.io
The namespace of the source VolumeSnapshot object is assumed to be the same as the namespace of the PersistentVolumeClaim object.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-restore
namespace: demo-namespace
spec:
storageClassName: testdriver.csi.k8s.io
dataSource:
name: manually-created-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
When the PersistentVolumeClaim object is created, it will trigger provisioning of a new volume that is pre-populated with data from the specified snapshot.
As a storage vendor, how do I add support for snapshots to my CSI driver?
To implement the snapshot feature, a CSI driver MUST add support for additional controller capabilities CREATE_DELETE_SNAPSHOT and LIST_SNAPSHOTS, and implement additional controller RPCs: CreateSnapshot, DeleteSnapshot, and ListSnapshots. For details, see the CSI spec and the Kubernetes-CSI Driver Developer Guide.
Although Kubernetes is as minimally prescriptive on the packaging and deployment of a CSI Volume Driver as possible, it provides a suggested mechanism for deploying an arbitrary containerized CSI driver on Kubernetes to simplify deployment of containerized CSI compatible volume drivers.
As part of this recommended deployment process, the Kubernetes team provides a number of sidecar (helper) containers, including the external-snapshotter sidecar container.
The external-snapshotter watches the Kubernetes API server for VolumeSnapshotContent object and triggers CreateSnapshot and DeleteSnapshot operations against a CSI endpoint. The CSI external-provisioner sidecar container has also been updated to support restoring volume from snapshot using the dataSource PVC field.
In order to support snapshot feature, it is recommended that storage vendors deploy the external-snapshotter sidecar containers in addition to the external provisioner, along with their CSI driver.
What are the limitations of beta?
The beta implementation of volume snapshots for Kubernetes has the following limitations:
- Does not support reverting an existing volume to an earlier state represented by a snapshot (beta only supports provisioning a new volume from a snapshot).
- No snapshot consistency guarantees beyond any guarantees provided by storage system (e.g. crash consistency). These are the responsibility of higher level APIs/controllers
What’s next?
Depending on feedback and adoption, the Kubernetes team plans to push the CSI Snapshot implementation to GA in either 1.18 or 1.19. Some of the features we are interested in supporting include consistency groups, application consistent snapshots, workload quiescing, in-place restores, volume backups, and more.
How can I learn more?
You can also have a look at the external-snapshotter source code repository.
Check out additional documentation on the snapshot feature here and here.
How do I get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together.
We offer a huge thank you to the contributors who stepped up these last few quarters to help the project reach Beta:
- Xing Yang (xing-yang)
- Xiangqian Yu (yuxiangqian)
- Jing Xu (jingxu97)
- Grant Griffiths (ggriffiths)
- Can Zhu (zhucan)
With special thanks to the following people for their insightful reviews and thorough consideration with the design:
- Michelle Au (msau42)
- Saad Ali (saadali)
- Patrick Ohly (pohly)
- Tim Hockin (thockin)
- Jordan Liggitt (liggitt).
Those interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
We also hold regular SIG-Storage Snapshot Working Group meetings. New attendees are welcome to join for design and development discussions.
Kubernetes 1.17 Feature: Kubernetes In-Tree to CSI Volume Migration Moves to Beta
Authors: David Zhu, Software Engineer, Google
The Kubernetes in-tree storage plugin to Container Storage Interface (CSI) migration infrastructure is now beta in Kubernetes v1.17. CSI migration was introduced as alpha in Kubernetes v1.14.
Kubernetes features are generally introduced as alpha and moved to beta (and eventually to stable/GA) over subsequent Kubernetes releases. This process allows Kubernetes developers to get feedback, discover and fix issues, iterate on the designs, and deliver high quality, production grade features.
Why are we migrating in-tree plugins to CSI?
Prior to CSI, Kubernetes provided a powerful volume plugin system. These volume plugins were “in-tree” meaning their code was part of the core Kubernetes code and shipped with the core Kubernetes binaries. However, adding support for new volume plugins to Kubernetes was challenging. Vendors that wanted to add support for their storage system to Kubernetes (or even fix a bug in an existing volume plugin) were forced to align with the Kubernetes release process. In addition, third-party storage code caused reliability and security issues in core Kubernetes binaries and the code was often difficult (and in some cases impossible) for Kubernetes maintainers to test and maintain. Using the Container Storage Interface in Kubernetes resolves these major issues.
As more CSI Drivers were created and became production ready, we wanted all Kubernetes users to reap the benefits of the CSI model. However, we did not want to force users into making workload/configuration changes by breaking the existing generally available storage APIs. The way forward was clear - we would have to replace the backend of the “in-tree plugin” APIs with CSI.
What is CSI migration?
The CSI migration effort enables the replacement of existing in-tree storage plugins such as kubernetes.io/gce-pd or kubernetes.io/aws-ebs with a corresponding CSI driver. If CSI Migration is working properly, Kubernetes end users shouldn’t notice a difference. After migration, Kubernetes users may continue to rely on all the functionality of in-tree storage plugins using the existing interface.
When a Kubernetes cluster administrator updates a cluster to enable CSI migration, existing stateful deployments and workloads continue to function as they always have; however, behind the scenes Kubernetes hands control of all storage management operations (previously targeting in-tree drivers) to CSI drivers.
The Kubernetes team has worked hard to ensure the stability of storage APIs and for the promise of a smooth upgrade experience. This involves meticulous accounting of all existing features and behaviors to ensure backwards compatibility and API stability. You can think of it like changing the wheels on a racecar while it’s speeding down the straightaway.
How to try out CSI migration for existing plugins?
If you are Kubernetes distributor that deploys in one of the environments listed below, now would be a good time to start testing the CSI migration and figuring out how to deploy/manage the appropriate CSI driver.
To try out CSI migration in beta for an existing plugin you must be using Kubernetes v1.17 or higher. First, you must update/create a Kubernetes cluster with the feature flags CSIMigration (on by default in 1.17) and CSIMigration{provider} (off by default) enabled on all Kubernetes components (master and node). Where {provider} is the in-tree cloud provider storage type that is used in your cluster. Please note that during a cluster upgrade you must drain each node (remove running workloads) before updating or changing configuration of your Kubelet. You may also see an optional CSIMigration{provider}Complete flag that you may enable if all of your nodes have CSI migration enabled.
You must also install the requisite CSI driver on your cluster - instructions for this can generally be found from you provider of choice. CSI migration is available for GCE Persistent Disk and AWS Elastic Block Store in beta as well as for Azure File/Disk and Openstack Cinder in alpha. Kubernetes distributors should look at automating the deployment and management (upgrade, downgrade, etc.) of the CSI Drivers they will depend on.
To verify the feature flag is enabled and driver installed on a particular node you can get the CSINode object. You should see the in-tree plugin name of the migrated plugin as well as your [installed] driver in the drivers list.
kubectl get csinodes -o yaml
- apiVersion: storage.k8s.io/v1
kind: CSINode
metadata:
annotations:
storage.alpha.kubernetes.io/migrated-plugins: kubernetes.io/gce-pd
name: test-node
...
spec:
drivers:
name: pd.csi.storage.gke.io
...
After the above set up is complete you can confirm that your cluster has functioning CSI migration by deploying a stateful workload using the legacy APIs.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-disk
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: Pod
metadata:
name: web-server
spec:
containers:
- name: web-server
image: nginx
volumeMounts:
- mountPath: /var/lib/www/html
name: mypvc
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: test-disk
Verify that the pod is RUNNING after some time
kubectl get pods web-server
NAME READY STATUS RESTARTS AGE
web-server 1/1 Running 0 39s
To confirm that the CSI driver is actually serving your requests it may be prudent to check the container logs of the CSI Driver after exercising the storage management operations. Note that your container logs may look different depending on the provider used.
kubectl logs {CSIdriverPodName} --container={CSIdriverContainerName}
/csi.v1.Controller/ControllerPublishVolume called with request: ...
Attaching disk ... to ...
ControllerPublishVolume succeeded for disk ... to instance ...
Current limitations
Although CSI migration is now beta there is one major limitation that prevents us from turning it on by default. Turning on migration still requires a cluster administrator to install a CSI driver before storage functionality is seamlessly handed over. We are currently working with SIG-CloudProvider to provide a frictionless experience of bundling the required CSI Drivers with cloud distributions.
What is the timeline/status?
The timeline for CSI migration is actually set by the cloud provider extraction project. It is part of the effort to remove all cloud provider code from Kubernetes. By migrating cloud storage plugins to external CSI drivers we are able to extract out all the cloud provider dependencies.
Although the overall feature is beta and not on by default, there is still work to be done on a per-plugin basis. Currently only GCE PD and AWS EBS have gone beta with Migration and yet both are still off by default since they depend on a manual installation of their respective CSI Drivers. Azure File/Disk, OpenStack, and VMWare plugins are currently in less mature states and non-cloud plugins such as NFS, Portworx, RBD etc are still in the planning stages.
The current and targeted releases for each individual cloud driver is shown in the table below:
| Driver | Alpha | Beta (in-tree deprecated) | GA | Target "in-tree plugin" removal |
|---|---|---|---|---|
| AWS EBS | 1.14 | 1.17 | 1.19 (Target) | 1.21 |
| GCE PD | 1.14 | 1.17 | 1.19 (Target) | 1.21 |
| OpenStack Cinder | 1.14 | 1.18 (Target) | 1.19 (Target) | 1.21 |
| Azure Disk + File | 1.15 | 1.18 (Target) | 1.19 (Target) | 1.21 |
| VSphere | 1.18 (Target) | 1.19 (Target) | 1.20 (Target) | 1.22 |
What's next?
Major upcoming work includes implementing and hardening CSI migration for the remaining in-tree plugins, installing CSI Drivers by default in distributions, turning on CSI migration by default, and finally removing all in-tree plugin code as a part of cloud provider extraction. We expect to complete this project including the full switch to “on-by-default” migration by Kubernetes v1.21.
What should I do as a user?
Note that all new features for the Kubernetes storage system (like volume snapshotting) will only be added to the CSI interface. Therefore, if you are starting up a new cluster, creating stateful applications for the first time, or require these new features we recommend using CSI drivers natively (instead of the in-tree volume plugin API). Follow the updated user guides for CSI drivers and use the new CSI APIs.
However, if you choose to roll a cluster forward or continue using specifications with the legacy volume APIs, CSI Migration will ensure we continue to support those deployments with the new CSI drivers.
How do I get involved?
The Kubernetes Slack channel csi-migration along with any of the standard SIG Storage communication channels are great mediums to reach out to the SIG Storage and migration working group teams.
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together. We offer a huge thank you to the contributors who stepped up these last quarters to help the project reach Beta:
- David Zhu
- Deep Debroy
- Cheng Pan
- Jan Šafránek
With special thanks to:
- Michelle Au
- Saad Ali
- Jonathan Basseri
- Fabio Bertinatto
- Ben Elder
- Andrew Sy Kim
- Hemant Kumar
For fruitful dialogues, insightful reviews, and thorough consideration of CSI migration in other features.
When you're in the release team, you're family: the Kubernetes 1.16 release interview
Author: Craig Box (Google)
It is a pleasure to co-host the weekly Kubernetes Podcast from Google with Adam Glick. We get to talk to friends old and new from the community, as well as give people a download on the Cloud Native news every week.
It was also a pleasure to see Lachlan Evenson, the release team lead for Kubernetes 1.16, win the CNCF "Top Ambassador" award at KubeCon. We talked with Lachie when 1.16 was released, and as is becoming a tradition, we are delighted to share an abridged version of that interview with the readers of the Kubernetes Blog.
If you're paying attention to the release calendar, you'll see 1.17 is due out soon. Subscribe to our show in your favourite podcast player for another release interview!
CRAIG BOX: Lachie, I've been looking forward to chatting to you for some time. We first met at KubeCon Berlin in 2017 when you were with Deis. Let's start with a question on everyone's ears-- which part of England are you from?
LACHLAN EVENSON: The prison part! See, we didn't have a choice about going to Australia, but I'd like to say we got the upper hand in the long run. We got that beautiful country, so yes, from Australia, the southern part of England-- the southern tip.
CRAIG BOX: We did set that question up a little bit. I'm actually in Australia this week, and I'll let you know it's quite a nice place. I can't imagine why you would have left.
LACHLAN EVENSON: Yeah, it seems fitting that you're interviewing an Australian from Australia, and that Australian is in San Francisco.
CRAIG BOX: Oh, well, thank you very much for joining us and making it work. This is the third in our occasional series of release lead interviews. We talked to Josh and Tim from Red Hat and VMware, respectively, in episode 10, and we talked to Aaron from Google in episode 46. And we asked all three how their journey in cloud-native started. What was your start in cloud-native?
LACHLAN EVENSON: I remember back in early 2014, I was working for a company called Lithium Technologies. We'd been using containers for quite some time, and my boss at the time had put a challenge out to me-- go and find a way to orchestrate these containers, because they seem to be providing quite a bit of value to our developer velocity.
He gave me a week, and he said, go and check out both Mesos and Kubernetes. And at the end of that week, I had Kubernetes up and running, and I had workloads scheduled. I was a little bit more challenged on the Mesos side, but Kubernetes was there, and I had it up and running. And from there, I actually went and was offered to speak at the Kubernetes 1.0 launch in OSCOM in Portland in 2014, I believe.
CRAIG BOX: So, a real early adopter?
LACHLAN EVENSON: Really, really early. I remember, I think, I started in 0.8, before CrashLoopBackOff was a thing. I remember writing that thing myself.
[LAUGHING]
CRAIG BOX: You were contributing to the code at that point as well?
LACHLAN EVENSON: I was just a user. I was part of the community at that point, but from a user perspective. I showed up to things like the community meeting. I remember meeting Sarah Novotny in the very early years of the community meeting, and I spent some time in SIG Apps, so really looking at how people were putting workloads onto Kubernetes-- so going through that whole process.
It turned out we built some tools like Helm, before Helm existed, to facilitate rollout and putting applications onto Kubernetes. And then, once Helm existed, that's when I met the folks from Deis, and I said, hey, I think you want to get rid of this code that we've built internally and then go and use the open-source code that Helm provided.
So we got into the Helm ecosystem there, and I subsequently went and worked for Deis, specifically on professional services-- helping people out in the community with their Kubernetes journey. And that was when we actually met, Craig, back in Berlin. It seems, you know, I say container years are like dog years; it's 7:1.
CRAIG BOX: Right.
LACHLAN EVENSON: Seven years ago, we were about 50 years-- much younger.
CRAIG BOX: That sounds like the same ratio as kangaroos to people in Australia.
LACHLAN EVENSON: It's much the same arithmetic, yes.
ADAM GLICK: What was the most interesting implementation that you ran into at that time?
LACHLAN EVENSON: There wasn't a lot of the workload APIs. Back in 1.0, there wasn't even Deployments. There wasn't Ingress. Back in the day, there were a lot of people in those points trying to build those workload APIs on top of Kubernetes, but they didn't actually have any way to extend Kubernetes itself. There were no third-party resources. There were no operators, no custom resources.
A lot of people are actually trying to figure out how to interact with the Kubernetes API and deliver things like deployments, because you just had-- in those days, you didn't have replica sets. You had a ReplicationController that we called the RC, back in the day. You didn't have a lot of these things that we take for granted today. There wasn't RBAC. There wasn't a lot of the things that we have today.
So it's great to have seen and been a part of the Kubernetes community from 0.8 to 1.16, and actually leading that release. So I've seen a lot, and it's been a wonderful part of my adventures in open-source.
ADAM GLICK: You were also part of the Deis team that transitioned and became a part of the Microsoft team. What was that transition like, from small startup to joining a large player in the cloud and technology community?
LACHLAN EVENSON: It was fantastic. When we came on board with Microsoft, they didn't have a managed Kubernetes offering, and we were brought on to try and seed that. There was also a bigger part that we were actually building open-source tools to help people in the community integrate. We had the autonomy with-- Brendan Burns was on the team. We had Gabe Monroy. And we really had that top-down autonomy that was believing and placing a bet on open-source and helping us build tools and give us that autonomy to go and solve problems in open-source, along with contributing to things like Kubernetes.
I'm part of the upstream team from a PM perspective, and we have a bunch of engineers, a bunch of PMs that are actually working on these things in the Cloud Native Compute Foundation to help folks integrate their workloads into things like Kubernetes and build and aid their cloud-native journeys.
CRAIG BOX: There are a number of new tools, and specifications, and so on that are still coming out from Microsoft under the Deis brand. That must be exciting to you as one of the people who joined from Deis initially.
LACHLAN EVENSON: Yeah, absolutely. We really took that Deis brand-- it's now Deis Labs-- but we really wanted this a home to signal to the community that we were building things in the hope to put them out into foundation. You may see things like CNAB, Cloud Native Application Bundles. I know you've had both Ralph and Jeremy on the show before talking about CNAB, SMI - Service Mesh Interface, other tooling in the ecosystem where we want to signal to the community that we want to go give that to a foundation. We really want a neutral place to begin that nascent work, but then things, for example, Virtual Kubelet started there as well, and it went out into the Cloud Native Compute Foundation.
ADAM GLICK: Is there any consternation about the fact that Phippy has become the character people look to rather than the actual "Captain Kube" owl, in the family of donated characters?
LACHLAN EVENSON: Yes, so it's interesting because I didn't actually work on that project back at Deis, but the Deis folks, Karen Chu and Matt Butcher actually created "The Children's Guide to Kubernetes," which I thought was fantastic.
ADAM GLICK: Totally.
LACHLAN EVENSON: Because I could sit down and read it to my parents, as well, and tell them-- it wasn't for children. It was more for the adults in my life, I like to say. And so when I give out a copy of that book, I'm like, take it home and read it to mum. She might actually understand what you do by the end of that book.
But it was really a creative way, because this was back in that nascent Kubernetes where people were trying to get their head around those concepts-- what is a pod? What is a secret? What is a namespace? Having that vehicle of a fun set of characters--
ADAM GLICK: Yep.
LACHLAN EVENSON: And Phippy is a PHP app. Remember them? So yeah, it's totally in line with the things that we're seeing people want to containerize and put onto Kubernetes at that. But Phippy is still cute. I was questioned last week about Captain Kube, as well, on the release logo, so we could talk about that a little bit more. But there's a swag of characters in there that are quite cute and illustrate the fun concept behind the Kubernetes community.
CRAIG BOX: 1.16 has just been released. You were the release team lead for that-- congratulations.
LACHLAN EVENSON: Thank you very much. It was a pleasure to serve the community.
CRAIG BOX: What are the headline announcements in Kubernetes 1.16?
LACHLAN EVENSON: Well, I think there are a few. Custom Resources hit GA. Now, that is a big milestone for extensibility and Kubernetes. I know we've spoken about them for some time-- custom resources were introduced in 1.7, and we've been trying to work through that ecosystem to bring the API up to a GA standard. So it hit GA, and I think a lot of the features that went in as part of the GA release will help people in the community that are writing operators.
There's a lot of lifecycle management, a lot of tooling that you can put into the APIs themselves. Doing strict dependency checks-- you can do typing, you can do validation, you can do pruning superfluous fields, and allowing for that ecosystem of operators and extensibility in the community to exist on top of Kubernetes.
It's been a long road to get to GA for Custom Resources, but it's great now that they're here and people can really bank on that being an API they can use to extend Kubernetes. So I'd say that's a large headline feature. The metrics overhaul, as well-- I know this was on the release blog.
The metrics team have actually tried to standardize the metrics in Kubernetes and put them through the same paces as all other enhancements that go into Kubernetes. So they're really trying to put through, what are the criteria? How do we make them standard? How do we test them? How to make sure that they're extensible? So it was great to see that team actually step up and create stable metrics that everybody can build and stack on.
Finally, there were some other additions to CSI, as well. Volume resizing was added. This is a maturity story around the Container Storage Interface, which was introduced several releases ago in GA. But really, you've seen volume providers actually build on that interface and that interface get a little bit more broader to adopt things like "I want to resize dynamically at runtime on my storage volume". That's a great story as well, for those providers out there.
I think they're the big headline features for 1.16, but there are a slew. There were 31 enhancements that went into Kubernetes 1.16. And I know there have been questions out there in the community saying, well, how do we decide what's stable? Eight of those were stable, eight of those were beta, and the rest of those features, the 15 remaining, were actually in alpha. There were quite a few things that went from alpha into beta and beta into stable, so I think that's a good progression for the release, as well.
ADAM GLICK: As you've looked at all these, which of them is your personal favorite?
LACHLAN EVENSON: I probably have two. One is a little bit biased, but I personally worked on, with the dual-stack team in the community. Dual-stack is the ability to give IPv4 and IPv6 addresses to both pods and services. And I think where this is interesting in the community is Kubernetes is becoming a runtime that is going to new spaces. Think IoT, think edge, think cloud edge.
When you're pushing Kubernetes into these new operational environments, things like addressing may become a problem, where you might want to run thousands and thousands of pods which all need IP addresses. So, having that same crossover point where I can have v4 and v6 at the same time, get comfortable with v6, I think Kubernetes may be an accelerator to v6 adoption through things like IoT workloads on top of Kubernetes.
The other one is Endpoint Slices. Endpoint slices is about scaling. As you may know, services have endpoints attached to them, and endpoints are all the pod IPs that actually match that label selector on a service. Now, when you have large clusters, you can imagine the number of pod IPs being attached to that service growing to tens of thousands. And when you update that, everything that actually watches those service endpoints needs to get an update, which is the delta change over time, which gets rather large as things are being attached, added, and removed, as is the dynamic nature of Kubernetes.
But what endpoint slices makes available is you can actually slice those endpoints up into groups of 100 and then only update the ones that you really need to worry about, which means as a scaling factor, we don't need to update everybody listening into tens of thousands of updates. We only need to update a subsection. So I'd say they're my two highlights, yeah.
CRAIG BOX: Are there any early stage or alpha features that you're excited to see where they go personally?
LACHLAN EVENSON: Personally, ephemeral containers. The tooling that you have available at runtime in a pod is dependent on the constituents or the containers that are part of that pod. And what we've seen in containers being built by scratch and tools like distroless from the folks out of Google, where you can build scratch containers that don't actually have any tooling inside them but just the raw compiled binaries, if you want to go in and debug that at runtime, it's incredibly difficult to insert something in.
And this is where ephemeral containers come in. I can actually insert a container into a running pod-- and let's just call that a debug container-- that has all my slew of tools that I need to debug that running workload, and I can insert that into a pod at runtime. So I think ephemeral containers is a really interesting feature that's been included in 1.16 in alpha, which allows a greater debugging story for the Kubernetes community.
ADAM GLICK: What feature that slipped do you wish would have made it into the release?
LACHLAN EVENSON: The feature that slipped that I was a little disappointed about was sidecar containers.
ADAM GLICK: Right.
LACHLAN EVENSON: In the world of service meshes, you may want to order the start of some containers, and it's very specific to things like service meshes in the case of the data plane. I need the Envoy sidecar to start before everything else so that it can wire up the networking.
The inverse is true as well. I need it to stop last. Sidecar containers gave you that ordered start. And what we see a lot of people doing in the ecosystem is just laying down one sidecar per node as a DaemonSet, and they want that to start before all the other pods on the machine. Or if it's inside the pod, or the context of one pod, they want to say that sidecar needs to stop before all the other containers in a pod. So giving you that ordered guarantee, I think, is really interesting and is really hot, especially given the service mesh ecosystem heating up.
CRAIG BOX: This release deprecates a few beta API groups, for things like ReplicaSets and Deployments. That will break deployment for the group of people who have just taken example code off the web and don't really understand it. The GA version of these APIs were released in 1.9, so it's obviously a long time ago. There's been a lot of preparation going into this. But what considerations and concerns have we had about the fact that these are now being deprecated in this particular release?
LACHLAN EVENSON: Let me start by saying that this is the first release that we've had a big API deprecation, so the proof is going to be in the pudding. And we do have an API deprecation policy. So as you mentioned, Craig, the apps/v1 group has been around since 1.9. If you go and read the API deprecation policy, you can see that we have a three-release announcement. Around the 1.12, 1.13 time frame, we actually went and announced this deprecation, and over the last few releases, we've been reiterating that.
But really, what we want to do is get the whole community on those stable APIs because it really starts to become a problem when we're supporting all these many now-deprecated APIs, and people are building tooling around them and trying to build reliable tooling. So this is the first test for us to move people, and I'm sure it will break a lot of tools that depend on things. But I think in the long run, once we get onto those stable APIs, people can actually guarantee that their tools work, and it's going to become easier in the long run.
So we've put quite a bit of work in announcing this. There was a blog sent out about six months ago by Valerie Lancey in the Kubernetes community which said, hey, go use 'kubectl convert', where you can actually say, I want to convert this resource from this API version to that API version, and it actually makes that really easy. But I think there'll be some problems in the ecosystem, but we need to do this going forward, pruning out the old APIs and making sure that people are on the stable ones.
ADAM GLICK: Congratulations on the release of 1.16. Obviously, that's a big thing. It must have been a lot of work for you. Can you talk a little bit about what went into leading this release?
LACHLAN EVENSON: The job of the release lead is to oversee throughout the process of the release and make sure that the release gets out the door on a specific schedule. So really, what that is is wrangling a lot of different resources and a lot of different people in the community, and making sure that they show up and do the things that they are committed to as part of their duties as either SIG chairs or other roles in the community, and making sure that enhancements are in the right state, and code shows up at the right time, and that things are looking green.
A lot of it is just making sure you know who to contact and how to contact them, and ask them to actually show up. But when I was asked at the end of the 1.15 release cycle if I would lead, you have to consider how much time it's going to take and the scheduling, where hours a week are dedicated to making sure that this release actually hits the shelves on time and is of a certain quality. So there is lots of pieces to that.
ADAM GLICK: Had you been on the path through the shadow program for release management?
LACHLAN EVENSON: Yeah, I had. I actually joined the shadow program-- so the shadow program for the release team. The Kubernetes release team is tasked with staffing a specific release, and I came in the 1.14 release under the lead of Aaron Crickenberger. And I was an enhancement shadow at that point. I was really interested in how KEPs worked, so the Kubernetes Enhancement Proposal work. I wanted to make sure that I understood that part of the release team, and I came in and helped in that release.
And then, in 1.15, I was asked if I could be a lead shadow. And the lead shadow is to stand alongside the lead and help the lead fill their duties. So if they're out, if they need people to wrangle different parts of the community, I would go out and do that. I've served on three releases at this point-- 1.14, 1.15, and 1.16.
CRAIG BOX: Thank you for your service.
LACHLAN EVENSON: Absolutely, it's my pleasure.
ADAM GLICK: Release lead emeritus is the next role for you, I assume?
LACHLAN EVENSON: [LAUGHS] Yes. We also have a new role on the release lead team called Emeritus Advisors, which are actually to go back and help answer the questions of, why was this decision made? How can we do better? What was this like in the previous release? So we do have that continuity, and in 1.17, we have the old release lead from 1.15. Claire Lawrence is coming back to fill in as emeritus advisor. So that is something we do take.
And I think for the shadow program in general, the release team is a really good example of how you can actually build continuity across releases in an open-source fashion. We actually have a session at KubeCon San Diego on how that shadowing program works. But it's really to get people excited about how we can do mentoring in open-source communities and make sure that the project goes on after all of us have rolled on and off the team.
ADAM GLICK: Speaking of the team, there were 32 people involved, including yourself, in this release. What is it like to coordinate that group? That sounds like a full time job.
LACHLAN EVENSON: It is a full time job. And let me say that this release team in 1.16 represented five different continents. We can count Antarctica as not having anybody, but we didn't have anybody from South America for that release, which was unfortunate. But we had people from Australia, China, India, Tanzania. We have a good spread-- Europe, North America. It's great to have that spread and that continuity, which allowed for us to get things done throughout the day.
CRAIG BOX: Until you want to schedule a meeting.
LACHLAN EVENSON: Scheduling a meeting was extremely difficult. Typically, on the release team, we run one Europe, Western Europe, and North American-friendly meeting, and then we ask the team if they would like to hold another meeting. Now, in the case of 1.16, they didn't want to hold another meeting. We actually put it out to survey. But in previous releases, we held an EU in the morning so that people in India, as well, or maybe even late-night in China, could be involved.
ADAM GLICK: Any interesting facts about the team, besides the incredible geographic diversity that you had, to work around that?
LACHLAN EVENSON: I really appreciate about the release team that we're from all different backgrounds, from all different parts of the world and all different companies. There are people who are doing this on their own time, There are people who are doing this on company time, but we all come together with that shared common goal of shipping that release.
This release was we had the five continents. It was really exciting in 1.17 that we have in the lead roles, it was represented mainly by women. So 1.17, watch out-- most of the leads for 1.17 are women, which is a great result, and that's through that shadow program that we can foster different types of talent. I'm excited to see future releases benefiting from different diverse groups of people from the Kubernetes community.
CRAIG BOX: What are you going to put in the proverbial envelope for the 1.17 team?
LACHLAN EVENSON: We've had this theme of a lot of roles in the release team being cut and dry, right? We have these release handbooks, so for each of the members of the team, they're cut into different roles. There's seven different roles on the team. There's the lead. There's the CI signal role. There's bug triage. There's comms. There's docs. And there's release notes. And there's also the release branch managers who actually cut the code and make sure that they have shipped and it ends up in all the repositories.
What we did in the previous 1.15, we actually had a role call the test-infra role. And thanks to the wonderful work of the folks of the test-infra team out of Google-- Katharine Berry, and Ben Elder, and other folks-- they actually automated this role completely that we could get rid of it in the 1.16 release and still have our same-- and be able to get a release out the door.
I think a lot of these things are ripe for automation, and therefore, we can have a lot less of a footprint going forward. Let's automate the bits of the process that we can and actually refine the process to make sure that the people that are involved are not doing the repetitive tasks over and over again. In the era of enhancements, we could streamline that process. CI signal and bug triage, there are places we could actually go in and automate that as well. I think one place that's been done really well in 1.16 was in the release notes.
I don't know if you've seen relnotes.k8s.io, but you can go and check out the release notes and now, basically, annotated PRs show up as release notes that are searchable and sortable, all through an automated means, whereas that was previously some YAML jockeying to make sure that that would actually happen and be digestible to the users.
CRAIG BOX: Come on, Lachie, all Kubernetes is just YAML jockeying.
[LAUGHING]
LACHLAN EVENSON: Yeah, but it's great to have an outcome where we can actually make that searchable and get people out of the mundaneness of things like, let's make sure we're copying and pasting YAML from left to right.
ADAM GLICK: After the release, you had a retrospective meeting. What was the takeaway from that meeting?
LACHLAN EVENSON: At the end of each release, we do have a retrospective. It's during the community meeting. That retrospective, it was good. I was just really excited to see that there were so many positives. It's a typical retrospective where we go, what did we say we were going to do last release? Did we do that? What was great? What can we do better? And some actions out of that.
It was great to see people giving other people on the team so many compliments. It was really, really deep and rich, saying, thank you for doing this, thank you for doing that. People showed up and pulled their weight in the release team, and other people were acknowledging that. That was great.
I think one thing we want to do is-- we have a code freeze as part of the release process, which is where we make sure that code basically stops going into master in Kubernetes. Only things destined for the release can actually be put in there. But we don't actually stop the test infrastructure from changing, so the test infrastructure has a lifecycle of its own.
One of the things that was proposed was that we actually code freeze the test infrastructure as well, to make sure that we're not actually looking at changes in the test-infra causing jobs to fail while we're trying to stabilize the code. I think that's something we have some high level agreement about, but getting down into the low-level nitty-gritty would be great in 1.17 and beyond.
ADAM GLICK: We talked about sidecar containers slipping out of this release. Most of the features are on a release train, and are put in when they're ready. What does it mean for the process of managing a release when those things happen?
LACHLAN EVENSON: Basically, we have an enhancements freeze, and that says that enhancements-- so the KEPs that are backing these enhancements-- so the sidecar containers would have had an enhancement proposal. And the SIG that owns that code would then need to sign off and say that this is in a state called "implementable." When we've agreed on the high-level details, you can go and proceed and implement that.
Now, that had actually happened in the case of sidecar containers. The challenge was you still need to write the code and get the code actually implemented, and there's a month gap between enhancement freeze and code freeze. If the code doesn't show up, or the code shows up and needs to be reviewed a little bit more, you may miss that deadline.
I think that's what happened in the case of this specific feature. It went all the way through to code freeze, the code wasn't complete at that time, and we basically had to make a call-- do we want to grant it an exception? In this case, they didn't ask for an exception. They said, let's just move it to 1.17.
There's still a lot of people and SIGs show up at the start of a new release and put forward the whole release of all the things they want to ship, and obviously, throughout the release, a lot of those things get plucked off. I think we started with something like 60 enhancements, and then what we got out the door was 31. They either fall off as part of the enhancement freeze or as part of the code freeze, and that is absolutely typical of any release.
ADAM GLICK: Do you think that a three-month wait is acceptable for something that might have had a one- or two-week slip, or would you like to see enhancements be able to be released in point releases between the three-month releases?
LACHLAN EVENSON: Yeah, there's back and forth about this in the community, about how can we actually roll things at different cadences, I think, is the high-level question. Tim Hockin actually put out, how about we do stability cycles as well? Because there are a lot of new features going in, and there are a lot of stability features going in. But if you look at it, half of the features were beta or stable, and the other half were alpha, which means we're still introducing a lot more complexity and largely untested code into alpha state-- which, as much as we wouldn't like to admit, it does affect the stability of the system.
There's talk of LTS. There's talk of stability releases as well. I think they're all things that are interesting now that Kubernetes has that momentum, and you are seeing a lot of things go to GA. People are like, "I don't need to be drinking from the firehose as fast. I have CRDs in GA. I have all these other things in GA. Do I actually need to consume this at the rate?" So I think-- stay tuned. If you're interested in those discussions, the upstream community is having those. Show up there and voice your opinion.
CRAIG BOX: Is this the first release with its own release mascot?
LACHLAN EVENSON: I think that release mascot goes back to-- I would like to say 1.11? If you go back to 1.11, you can actually see the different mascots. I remember 1.11 being "The Hobbit." So it's the Hobbiton front door of Bilbo Baggins with the Kubernetes Helm on the front of it, and that was called 11ty-one--
CRAIG BOX: Uh-huh.
LACHLAN EVENSON: A long-expected release. So they go through from each release, and you can actually go check them out on the SIG release repository upstream.
CRAIG BOX: I do think this is the first time that's managed to make it into a blog post, though.
LACHLAN EVENSON: I do think it is the case. I wanted to have a little bit of fun with the release team, so typically you will see the release teams have a t-shirt. I have, from 1.14, the Caternetes, which Aaron designed, which has a bunch of cats kind of trying to look at a Kubernetes logo.
CRAIG BOX: We had a fun conversation with Aaron about his love of cats.
LACHLAN EVENSON: [LAUGHS] And it becomes a token of, hey, remember this hard work that you put together? It becomes a badge of honor for everybody that participated in the release. I wanted to highlight it as a release mascot. I don't think a lot of people knew that we did have those across the last few releases. But it's just a bit of fun, and I wanted to put my own spin on things just so that the team could come together. A lot of it was around the laughs that we had as a team throughout this release-- and my love of Olive Garden.
CRAIG BOX: Your love of Olive Garden feels like it may have become a meme to a community which might need a little explanation for our audience. For those who are not familiar with American fine dining, can we start with-- what exactly is Olive Garden?
LACHLAN EVENSON: Olive Garden is the finest Italian dining experience you will have in the continental United States. I see everybody's faces saying, is he sure about that? I'm sure.
CRAIG BOX: That might require a slight justification on behalf of some of our Italian-American listeners.
ADAM GLICK: Is it the unlimited breadsticks and salad that really does it for you, or is the plastic boat that it comes in?
LACHLAN EVENSON: I think it's a combination of all three things. You know, the tour of Italy, you can't go past. The free breadsticks are fantastic. But Olive Garden just represents the large chain restaurant and that kind of childhood I had growing up and thinking about these large-scale chain restaurants. You don't get to choose your meme. And the legacy-- I would have liked to have had a different mascot.
But I just had a run with the meme of Olive Garden. And this came about, I would like to say, about three or four months ago. Paris Pittman from Google, who is another member of the Kubernetes community, kind of put out there, what's your favorite sit-down large-scale restaurant? And of course, I pitched in very early and said, it's got to be the Olive Garden.
And then everybody kind of jumped onto that. And my inbox is full of free Olive Garden gift certificates now, and it's taken on a life of its own. And at this point, I'm just embracing it-- so much so that we might even have the 1.16 release party at an Olive Garden in San Diego, if it can accommodate 10,000 people.
ADAM GLICK: When you're there, are you family?
LACHLAN EVENSON: Yes. Absolutely, absolutely. And I would have loved to put that. I think the release name was "unlimited breadsticks for all." I would have liked to have done, "When you're here, you're family," but that is, sadly, trademarked.
ADAM GLICK: Aww. What's next for you in the community?
LACHLAN EVENSON: I've really been looking at Cluster API a lot-- so building Kubernetes clusters on top of a declarative approach. I've been taking a look at what we can do in the Cluster API ecosystem. I'm also a chair of SIG PM, so helping foster the KEP process as well-- making sure that that continues to happen and continues to be fruitful for the community.
Lachlan Evenson is a Principal Program Manager at Microsoft and an Australian living in the US, and most recently served as the Kubernetes 1.16 release team lead.
You can find the Kubernetes Podcast from Google at @kubernetespod on Twitter, and you can subscribe so you never miss an episode.
Gardener Project Update
Authors: Rafael Franzke (SAP), Vasu Chandrasekhara (SAP)
Last year, we introduced Gardener in the Kubernetes Community Meeting and in a post on the Kubernetes Blog. At SAP, we have been running Gardener for more than two years, and are successfully managing thousands of conformant clusters in various versions on all major hyperscalers as well as in numerous infrastructures and private clouds that typically join an enterprise via acquisitions.
We are often asked why a handful of dynamically scalable clusters would not suffice. We also started our journey into Kubernetes with a similar mindset. But we realized that applying the architecture and principles of Kubernetes to productive scenarios, our internal and external customers very quickly required the rational separation of concerns and ownership, which in most circumstances led to the use of multiple clusters. Therefore, a scalable and managed Kubernetes as a service solution is often also the basis for adoption. Particularly, when a larger organization runs multiple products on different providers and in different regions, the number of clusters will quickly rise to the hundreds or even thousands.
Today, we want to give an update on what we have implemented in the past year regarding extensibility and customizability, and what we plan to work on for our next milestone.
Short Recap: What Is Gardener?
Gardener's main principle is to leverage Kubernetes primitives for all of its
operations, commonly described as inception or kubeception. The feedback from
the community was that initially our architecture
diagram looks
"overwhelming", but after some little digging into the material, everything we
do is the "Kubernetes way". One can re-use all learnings with respect to APIs,
control loops, etc.
The essential idea is that so-called seed clusters are used to host the
control planes of end-user clusters (botanically named shoots).
Gardener provides vanilla Kubernetes clusters as a service independent of the
underlying infrastructure provider in a homogenous way, utilizing the upstream
provided k8s.gcr.io/* images as open distribution. The project is built
entirely on top of Kubernetes extension concepts, and as such adds a custom API
server, a controller-manager, and a scheduler to create and manage the lifecycle
of Kubernetes clusters. It extends the Kubernetes API with custom resources,
most prominently the Gardener cluster specification (Shoot resource), that can
be used to "order" a Kubernetes cluster in a declarative way (for day-1, but
also reconcile all management activities for day-2).
By leveraging Kubernetes as base infrastructure, we were able to devise a combined Horizontal and Vertical Pod Autoscaler (HVPA) that, when configured with custom heuristics, scales all control plane components up/down or out/in automatically. This enables a fast scale-out, even beyond the capacity of typically some fixed number of master nodes. This architectural feature is one of the main differences compared to many other Kubernetes cluster provisioning tools. But in our production, Gardener does not only effectively reduce the total costs of ownership by bin-packing control planes. It also simplifies implementation of "day-2 operations" (like cluster updates or robustness qualities). Again, essentially by relying on all the mature Kubernetes features and capabilities.
The newly introduced extension concepts for Gardener now enable providers to only maintain their specific extension without the necessity to develop inside the core source tree.
Extensibility
As result of its growth over the past years, the Kubernetes code base contained a numerous amount of provider-specific code that is now being externalized from its core source tree. The same has happened with Project Gardener: over time, lots of specifics for cloud providers, operating systems, network plugins, etc. have been accumulated. Generally, this leads to a significant increase of efforts when it comes to maintainability, testability, or to new releases. Our community member Packet contributed Gardener support for their infrastructure in-tree, and suffered from the mentioned downsides.
Consequently, similar to how the Kubernetes community decided to move their cloud-controller-managers out-of-tree, or volumes plugins to CSI, etc., the Gardener community proposed and implemented likewise extension concepts. The Gardener core source-tree is now devoid of any provider specifics, allowing vendors to solely focus on their infrastructure specifics, and enabling core contributors becoming more agile again.
Typically, setting up a cluster requires a flow of interdependent steps, beginning with the generation of certificates and preparation of the infrastructure, continuing with the provisioning of the control plane and the worker nodes, and ending with the deployment of system components. We would like to emphasize here that all these steps are necessary (cf. Kubernetes the Hard Way) and all Kubernetes cluster creation tools implement the same steps (automated to some degree) in one way or another.
The general idea of Gardener's extensibility concept was to make this flow more generic and to carve out custom resources for each step which can serve as ideal extension points.
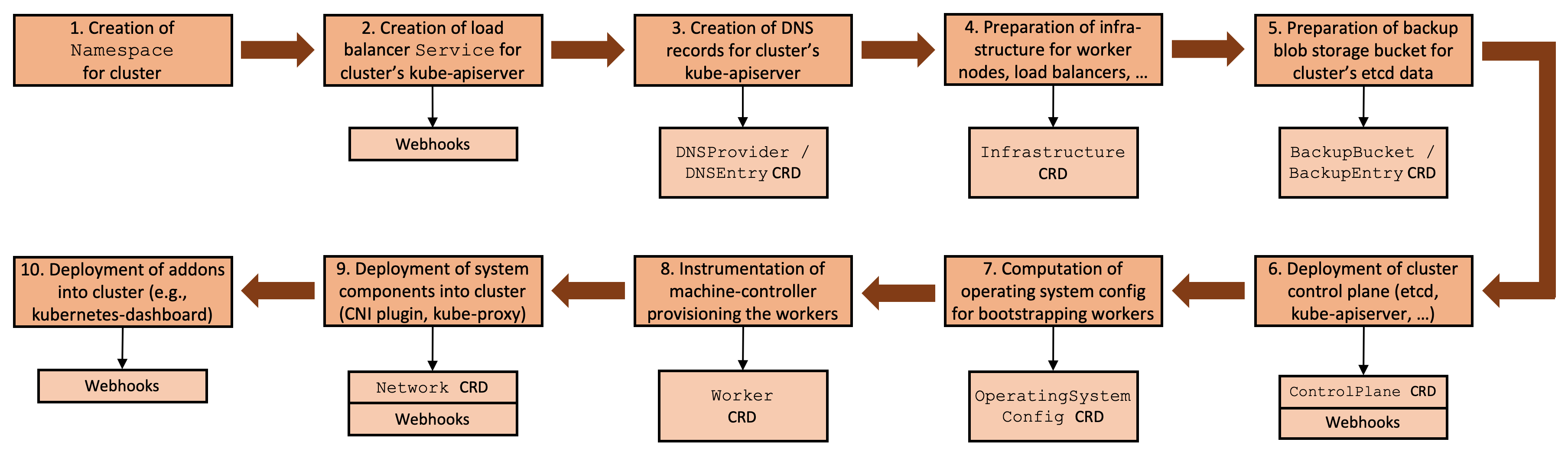
Figure 1 Cluster reconciliation flow with extension points.
With Gardener's flow framework we implicitly have a reproducible state machine for all infrastructures and all possible states of a cluster.
The Gardener extensibility approach defines custom resources that serve as ideal extension points for the following categories:
- DNS providers (e.g., Route53, CloudDNS, ...),
- Blob storage providers (e.g., S3, GCS, ABS,...),
- Infrastructure providers (e.g., AWS, GCP, Azure, ...),
- Operating systems (e.g., CoreOS Container Linux, Ubuntu, FlatCar Linux, ...),
- Network plugins (e.g., Calico, Flannel, Cilium, ...),
- Non-essential extensions (e.g., Let's Encrypt certificate service).
Extension Points
Besides leveraging custom resource definitions, we also effectively use mutating
/ validating webhooks in the seed clusters. Extension controllers themselves run
in these clusters and react on CRDs and workload resources (like Deployment,
StatefulSet, etc.) they are responsible for. Similar to the Cluster
API's approach, these CRDs may also contain
provider specific information.
The steps 2. - 10. [cf. Figure 1] involve infrastructure specific meta data
referring to infrastructure specific implementations, e.g. for DNS records there
might be aws-route53, google-clouddns, or for isolated networks even
openstack-designate, and many more. We are going to examine the steps 4 and 6
in the next paragraphs as examples for the general concepts (based on the
implementation for AWS). If you're interested you can read up the fully
documented API contract in our extensibility
documents.
Example: Infrastructure CRD
Kubernetes clusters on AWS require a certain infrastructure preparation before
they can be used. This includes, for example, the creation of a VPC, subnets,
etc. The purpose of the Infrastructure CRD is to trigger this preparation:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: Infrastructure
metadata:
name: infrastructure
namespace: shoot--foobar--aws
spec:
type: aws
region: eu-west-1
secretRef:
name: cloudprovider
namespace: shoot--foobar—aws
sshPublicKey: c3NoLXJzYSBBQUFBQ...
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 10.250.0.0/16
zones:
- name: eu-west-1a
internal: 10.250.112.0/22
public: 10.250.96.0/22
workers: 10.250.0.0/19
Based on the Shoot resource, Gardener creates this Infrastructure resource
as part of its reconciliation flow. The AWS-specific providerConfig is part of
the end-user's configuration in the Shoot resource and not evaluated by
Gardener but just passed to the extension controller in the seed cluster.
In its current implementation, the AWS extension creates a new VPC and three
subnets in the eu-west-1a zones. Also, it creates a NAT and an internet
gateway, elastic IPs, routing tables, security groups, IAM roles, instances
profiles, and an EC2 key pair.
After it has completed its tasks it will report the status and some provider-specific output:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: Infrastructure
metadata:
name: infrastructure
namespace: shoot--foobar--aws
spec: ...
status:
lastOperation:
type: Reconcile
state: Succeeded
providerStatus:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureStatus
ec2:
keyName: shoot--foobar--aws-ssh-publickey
iam:
instanceProfiles:
- name: shoot--foobar--aws-nodes
purpose: nodes
roles:
- arn: "arn:aws:iam::<accountID>:role/shoot..."
purpose: nodes
vpc:
id: vpc-0815
securityGroups:
- id: sg-0246
purpose: nodes
subnets:
- id: subnet-1234
purpose: nodes
zone: eu-west-1b
- id: subnet-5678
purpose: public
zone: eu-west-1b
The information inside the providerStatus can be used in subsequent steps,
e.g. to configure the cloud-controller-manager or to instrument the
machine-controller-manager.
Example: Deployment of the Cluster Control Plane
One of the major features of Gardener is the homogeneity of the clusters it
manages across different infrastructures. Consequently, it is still in charge of
deploying the provider-independent control plane components into the seed
cluster (like etcd, kube-apiserver). The deployment of provider-specific control
plane components like cloud-controller-manager or CSI controllers is triggered
by a dedicated ControlPlane CRD. In this paragraph, however, we want to focus
on the customization of the standard components.
Let's focus on both the kube-apiserver and the kube-controller-manager
Deployments. Our AWS extension for Gardener is not yet using CSI but relying
on the in-tree EBS volume plugin. Hence, it needs to enable the
PersistentVolumeLabel admission plugin and to provide the cloud provider
config to the kube-apiserver. Similarly, the kube-controller-manager will be
instructed to use its in-tree volume plugin.
The kube-apiserver Deployment incorporates the kube-apiserver container and
is deployed by Gardener like this:
containers:
- command:
- /hyperkube
- apiserver
- --enable-admission-plugins=Priority,...,NamespaceLifecycle
- --allow-privileged=true
- --anonymous-auth=false
...
Using a MutatingWebhookConfiguration the AWS extension injects the mentioned
flags and modifies the spec as follows:
containers:
- command:
- /hyperkube
- apiserver
- --enable-admission-plugins=Priority,...,NamespaceLifecycle,PersistentVolumeLabel
- --allow-privileged=true
- --anonymous-auth=false
...
- --cloud-provider=aws
- --cloud-config=/etc/kubernetes/cloudprovider/cloudprovider.conf
- --endpoint-reconciler-type=none
...
volumeMounts:
- mountPath: /etc/kubernetes/cloudprovider
name: cloud-provider-config
volumes:
- configMap:
defaultMode: 420
name: cloud-provider-config
name: cloud-provider-config
The kube-controller-manager Deployment is handled in a similar way.
Webhooks in the seed cluster can be used to mutate anything related to the shoot cluster control plane deployed by Gardener or any other extension. There is a similar webhook concept for resources in shoot clusters in case extension controllers need to customize system components deployed by Gardener.
Registration of Extension Controllers
The Gardener API uses two special resources to register and install extensions.
The registration itself is declared via the ControllerRegistration resource.
The easiest option is to define the Helm chart as well as some values to render
the chart, however, any other deployment mechanism is supported via custom code
as well.
Gardener determines whether an extension controller is required in a specific
seed cluster, and creates a ControllerInstallation that is used to trigger the
deployment.
To date, every registered extension controller is deployed to every seed cluster which is not necessary in general. In the future, Gardener will become more selective to only deploy those extensions required on the specific seed clusters.
Our dynamic registration approach allows to add or remove extensions in the running system - without the necessity to rebuild or restart any component.
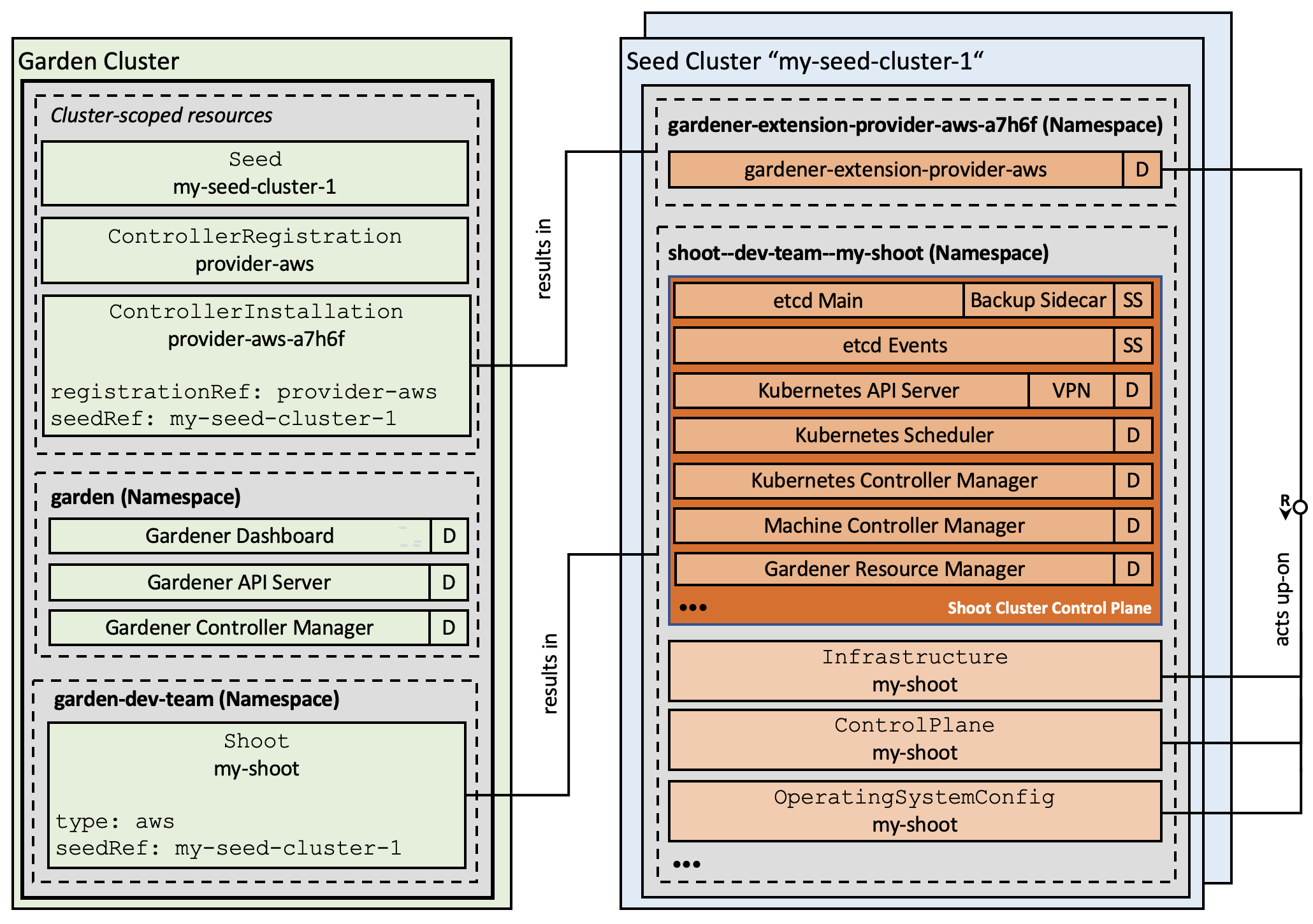
Figure 2 Gardener architecture with extension controllers.
Status Quo
We have recently introduced the new core.gardener.cloud API group that
incorporates fully forwards and backwards compatible Shoot resources, and that
allows providers to use Gardener without modifying anything in its core source
tree.
We have already adapted all controllers to use this new API group and have deprecated the old API. Eventually, after a few months we will remove it, so end-users are advised to start migrating to the new API soon.
Apart from that, we have enabled all relevant extensions to contribute to the
shoot health status and implemented the respective contract. The basic idea is
that the CRDs may have .status.conditions that are picked up by Gardener and
merged with its standard health checks into the Shoot status field.
Also, we want to implement some easy-to-use library functions facilitating
defaulting and validation webhooks for the CRDs in order to validate the
providerConfig field controlled by end-users.
Finally, we will split the
gardener/gardener-extensions
repository into separate repositories and keep it only for the generic library
functions that can be used to write extension controllers.
Next Steps
Kubernetes has externalized many of the infrastructural management challenges. The inception design solves most of them by delegating lifecycle operations to a separate management plane (seed clusters). But what if the garden cluster or a seed cluster goes down? How do we scale beyond tens of thousands of managed clusters that need to be reconciled in parallel? We are further investing into hardening the Gardener scalability and disaster recovery features. Let's briefly highlight three of the features in more detail:
Gardenlet
Right from the beginning of the Gardener Project we started implementing the operator pattern: We have a custom controller-manager that acts on our own custom resources. Now, when you start thinking about the Gardener architecture, you will recognize some interesting similarity with respect to the Kubernetes architecture: Shoot clusters can be compared with pods, and seed clusters can be seen as worker nodes. Guided by this observation we introduced the gardener-scheduler. Its main task is to find an appropriate seed cluster to host the control-plane for newly ordered clusters, similar to how the kube-scheduler finds an appropriate node for newly created pods. By providing multiple seed clusters for a region (or provider) and distributing the workload, we reduce the blast-radius of potential hick-ups as well.
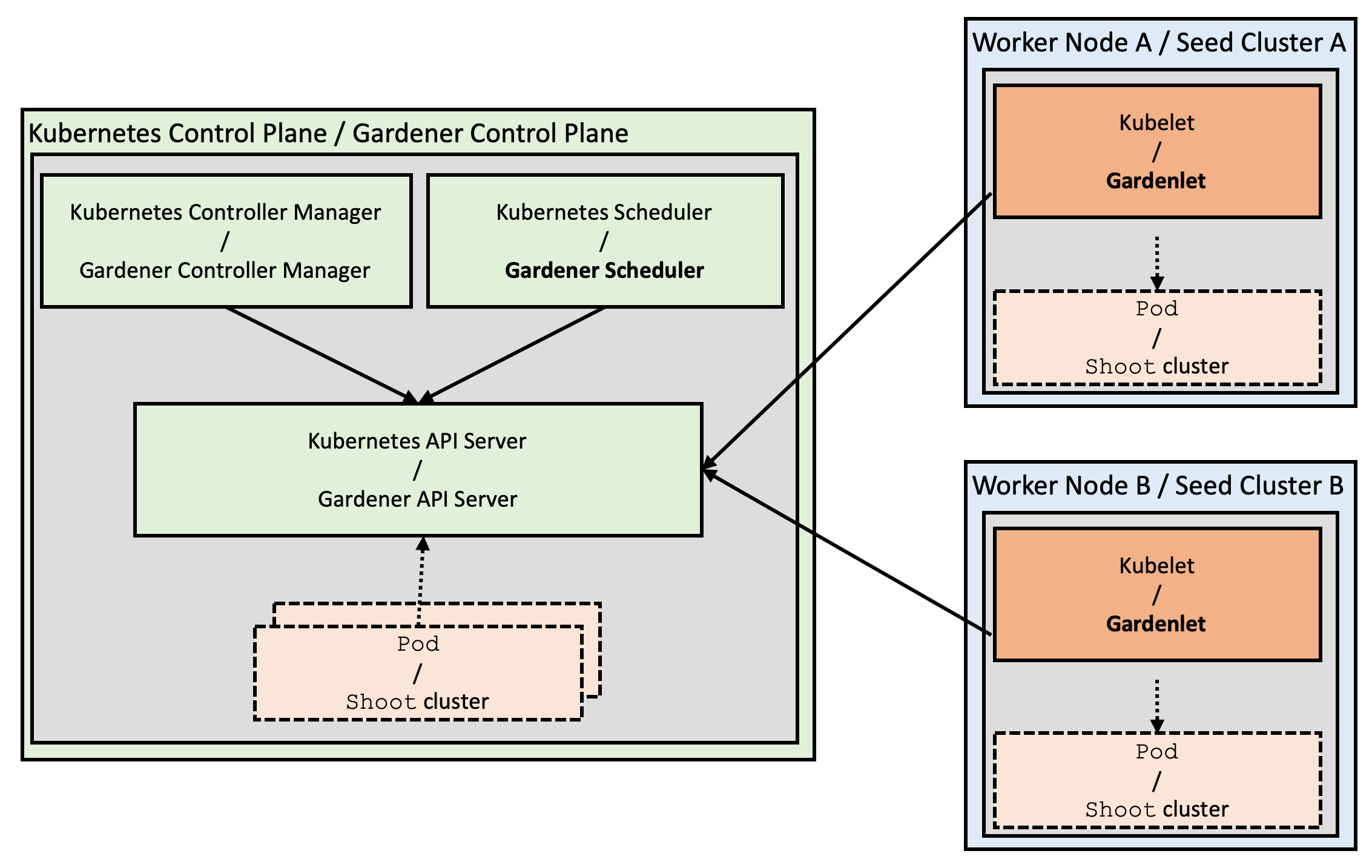
Figure 3 Similarities between Kubernetes and Gardener architecture.
Yet, there is still a significant difference between the Kubernetes and the Gardener architectures: Kubernetes runs a primary "agent" on every node, the kubelet, which is mainly responsible for managing pods and containers on its particular node. Gardener uses its controller-manager which is responsible for all shoot clusters on all seed clusters, and it is performing its reconciliation loops centrally from the garden cluster.
While this works well at scale for thousands of clusters today, our goal is to enable true scalability following the Kubernetes principles (beyond the capacity of a single controller-manager): We are now working on distributing the logic (or the Gardener operator) into the seed cluster and will introduce a corresponding component, adequately named the gardenlet. It will be Gardener's primary "agent" on every seed cluster and will be only responsible for shoot clusters located in its particular seed cluster.
The gardener-controller-manager will still keep its control loops for other resources of the Gardener API, however, it will no longer talk to seed/shoot clusters.
Reversing the control flow will even allow placing seed/shoot clusters behind firewalls without the necessity of direct accessibility (via VPN tunnels) anymore.
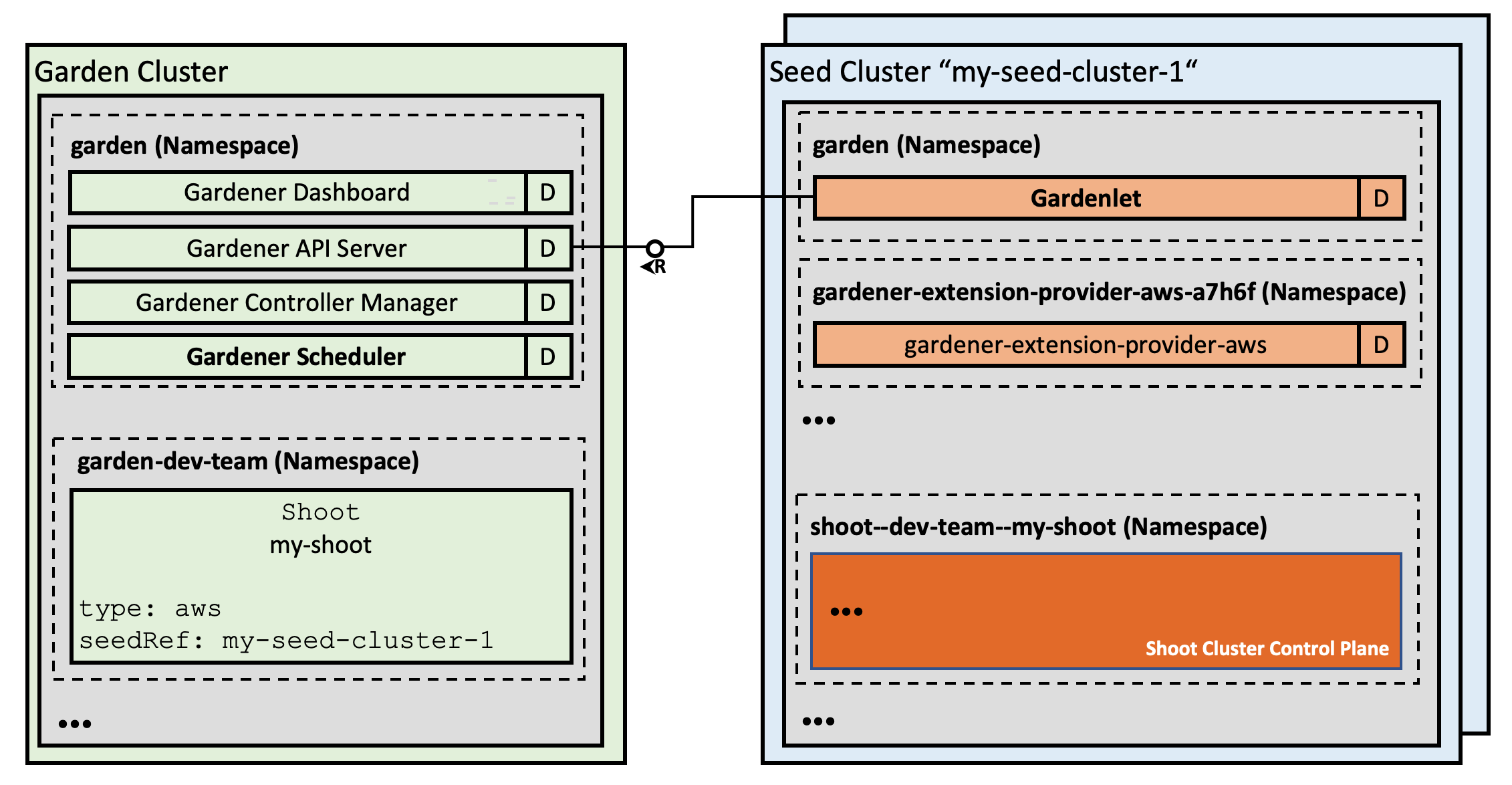
Figure 4 Detailed architecture with Gardenlet.
Control Plane Migration between Seed Clusters
When a seed cluster fails, the user's static workload will continue to operate. However, administrating the cluster won't be possible anymore because the shoot cluster's API server running in the failed seed is no longer reachable.
We have implemented the relocation of failed control planes hit by some seed disaster to another seed and are now working on fully automating this unique capability. In fact, this approach is not only feasible, we have performed the fail-over procedure multiple times in our production.
The automated failover capability will enable us to implement even more comprehensive disaster recovery and scalability qualities, e.g., the automated provisioning and re-balancing of seed clusters or automated migrations for all non-foreseeable cases. Again, think about the similarities with Kubernetes with respect to pod eviction and node drains.
Gardener Ring
The Gardener Ring is our novel approach for provisioning and managing Kubernetes clusters without relying on an external provision tool for the initial cluster. By using Kubernetes in a recursive manner, we can drastically reduce the management complexity by avoiding imperative tool sets, while creating new qualities with a self-stabilizing circular system.
The Ring approach is conceptually different from self-hosting and static pod based deployments. The idea is to create a ring of three (or more) shoot clusters that each host the control plane of its successor.
An outage of one cluster will not affect the stability and availability of the
Ring, and as the control plane is externalized the failed cluster can be
automatically recovered by Gardener's self-healing capabilities. As long as
there is a quorum of at least n/2+1 available clusters the Ring will always
stabilize itself. Running these clusters on different cloud providers (or at
least in different regions / data centers) reduces the potential for quorum
losses.
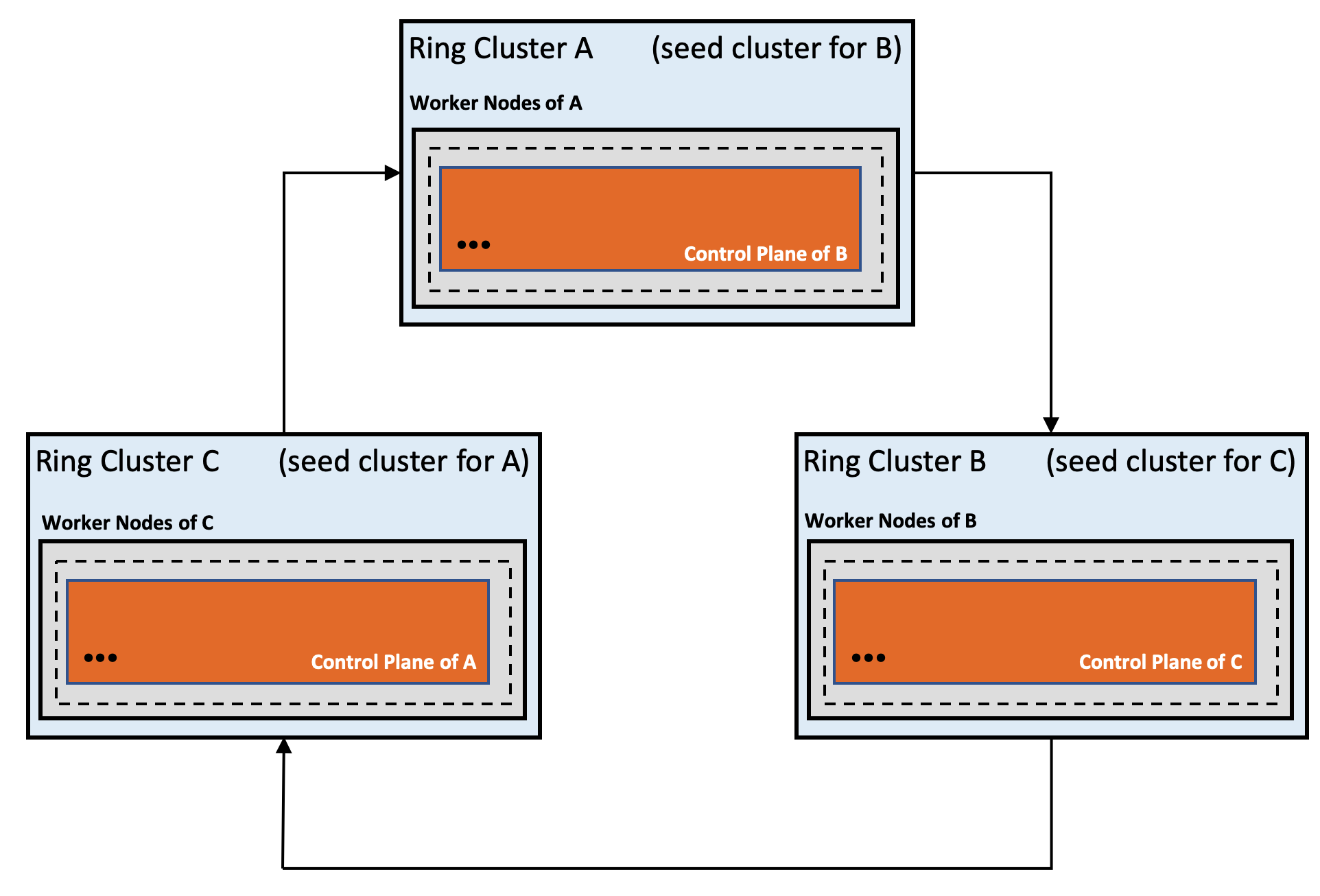
Figure 5 Self-stabilizing ring of Kubernetes clusters.
The way how the distributed instances of Gardener can share the same data is by deploying separate kube-apiserver instances talking to the same etcd cluster. These kube-apiservers are forming a node-less Kubernetes cluster that can be used as "data container" for Gardener and its associated applications.
We are running test landscapes internally protected by the ring and it has saved us from manual interventions. With the automated control plane migration in place we can easily bootstrap the Ring and will solve the "initial cluster problem" as well as improve the overall robustness.
Getting Started!
If you are interested in writing an extension, you might want to check out the following resources:
- GEP-1: Extensibility proposal document
- GEP-4: New
core.gardener.cloud/v1alpha1API - Example extension controller implementation for AWS
- Gardener Extensions Golang library
- Extension contract documentation
- Gardener API Reference
Of course, any other contribution to our project is very welcome as well! We are always looking for new community members.
If you want to try out Gardener, please check out our quick installation guide. This installer will setup a complete Gardener environment ready to be used for testing and evaluation within just a few minutes.
Contributions Welcome!
The Gardener project is developed as Open Source and hosted on GitHub: https://github.com/gardener
If you see the potential of the Gardener project, please join us via GitHub.
We are having a weekly public community meeting scheduled every Friday 10-11 a.m. CET, and a public #gardener Slack channel in the Kubernetes workspace. Also, we are planning a Gardener Hackathon in Q1 2020 and are looking forward meeting you there!
Develop a Kubernetes controller in Java
Authors: Min Kim (Ant Financial), Tony Ado (Ant Financial)
The official Kubernetes Java SDK project recently released their latest work on providing the Java Kubernetes developers a handy Kubernetes controller-builder SDK which is helpful for easily developing advanced workloads or systems.
Overall
Java is no doubt one of the most popular programming languages in the world but it's been difficult for a period time for those non-Golang developers to build up their customized controller/operator due to the lack of library resources in the community. In the world of Golang, there're already some excellent controller frameworks, for example, controller runtime, operator SDK. These existing Golang frameworks are relying on the various utilities from the Kubernetes Golang SDK proven to be stable over years. Driven by the emerging need of further integration into the platform of Kubernetes, we not only ported many essential toolings from the Golang SDK into the kubernetes Java SDK including informers, work-queues, leader-elections, etc. but also developed a controller-builder SDK which wires up everything into a runnable controller without hiccups.
Backgrounds
Why use Java to implement Kubernetes tooling? You might pick Java for:
-
Integrating legacy enterprise Java systems: Many companies have their legacy systems or frameworks written in Java in favor of stability. We are not able to move everything to Golang easily.
-
More open-source community resources: Java is mature and has accumulated abundant open-source libraries over decades, even though Golang is getting more and more fancy and popular for developers. Additionally, nowadays developers are able to develop their aggregated-apiservers over SQL-storage and Java has way better support on SQLs.
How to use?
Take maven project as example, adding the following dependencies into your dependencies:
<dependency>
<groupId>io.kubernetes</groupId>
<artifactId>client-java-extended</artifactId>
<version>6.0.1</version>
</dependency>
Then we can make use of the provided builder libraries to write your own controller. For example, the following one is a simple controller prints out node information on watch notification, see complete example here:
...
Reconciler reconciler = new Reconciler() {
@Override
public Result reconcile(Request request) {
V1Node node = nodeLister.get(request.getName());
System.out.println("triggered reconciling " + node.getMetadata().getName());
return new Result(false);
}
};
Controller controller =
ControllerBuilder.defaultBuilder(informerFactory)
.watch(
(workQueue) -> ControllerBuilder.controllerWatchBuilder(V1Node.class, workQueue).build())
.withReconciler(nodeReconciler) // required, set the actual reconciler
.withName("node-printing-controller") // optional, set name for controller for logging, thread-tracing
.withWorkerCount(4) // optional, set worker thread count
.withReadyFunc( nodeInformer::hasSynced) // optional, only starts controller when the cache has synced up
.build();
If you notice, the new Java controller framework learnt a lot from the design of controller-runtime which successfully encapsulates the complex components inside controller into several clean interfaces. With the help of Java Generics, we even move on a bit and simply the encapsulation in a better way.
As for more advanced usage, we can wrap multiple controllers into a controller-manager or a leader-electing controller which helps deploying in HA setup. In a word, we can basically find most of the equivalence implementations here from Golang SDK and more advanced features are under active development by us.
Future steps
The community behind the official Kubernetes Java SDK project will be focusing on providing more useful utilities for developers who hope to program cloud native Java applications to extend Kubernetes. If you are interested in more details, please look at our repo kubernetes-client/java. Feel free to share also your feedback with us, through Issues or Slack.
Running Kubernetes locally on Linux with Microk8s
Authors: Ihor Dvoretskyi, Developer Advocate, Cloud Native Computing Foundation; Carmine Rimi
This article, the second in a series about local deployment options on Linux, and covers MicroK8s. Microk8s is the click-and-run solution for deploying a Kubernetes cluster locally, originally developed by Canonical, the publisher of Ubuntu.
While Minikube usually spins up a local virtual machine (VM) for the Kubernetes cluster, MicroK8s doesn’t require a VM. It uses snap packages, an application packaging and isolation technology.
This difference has its pros and cons. Here we’ll discuss a few of the interesting differences, and comparing the benefits of a VM based approach with the benefits of a non-VM approach. One of the first factors is cross-platform portability. While a Minikube VM is portable across operating systems - it supports not only Linux, but Windows, macOS, and even FreeBSD - Microk8s requires Linux, and only on those distributions that support snaps. Most popular Linux distributions are supported.
Another factor to consider is resource consumption. While a VM appliance gives you greater portability, it does mean you’ll consume more resources to run the VM, primarily because the VM ships a complete operating system, and runs on top of a hypervisor. You’ll consume more disk space when the VM is dormant. You’ll consume more RAM and CPU while it is running. Since Microk8s doesn’t require spinning up a virtual machine you’ll have more resources to run your workloads and other applications. Given its smaller footprint, MicroK8s is ideal for IoT devices - you can even use it on a Raspberry Pi device!
Finally, the projects appear to follow a different release cadence and strategy. MicroK8s, and snaps in general provide channels that allow you to consume beta and release candidate versions of new releases of Kubernetes, as well as the previous stable release. Microk8s generally releases the stable release of upstream Kubernetes almost immediately.
But wait, there’s more! Minikube and MicroK8s both started as single-node clusters. Essentially, they allow you to create a Kubernetes cluster with a single worker node. That is about to change - there’s an early alpha release of MicroK8s that includes clustering. With this capability, you can create Kubernetes clusters with as many worker nodes as you wish. This is effectively an un-opinionated option for creating a cluster - the developer must create the network connectivity between the nodes, as well as integrate with other infrastructure that may be required, like an external load-balancer. In summary, MicroK8s offers a quick and easy way to turn a handful of computers or VMs into a multi-node Kubernetes cluster. We’ll write more about this kind of architecture in a future article.
Disclaimer
This is not an official guide to MicroK8s. You may find detailed information on running and using MicroK8s on it's official webpage, where different use cases, operating systems, environments, etc. are covered. Instead, the purpose of this post is to provide clear and easy guidelines for running MicroK8s on Linux.
Prerequisites
A Linux distribution that supports snaps, is required. In this guide, we’ll use Ubuntu 18.04 LTS, it supports snaps out-of-the-box. If you are interested in running Microk8s on Windows or Mac, you should check out Multipass to stand up a quick Ubuntu VM as the official way to run virtual Ubuntu on your system.
MicroK8s installation
MicroK8s installation is straightforward:
sudo snap install microk8s --classic
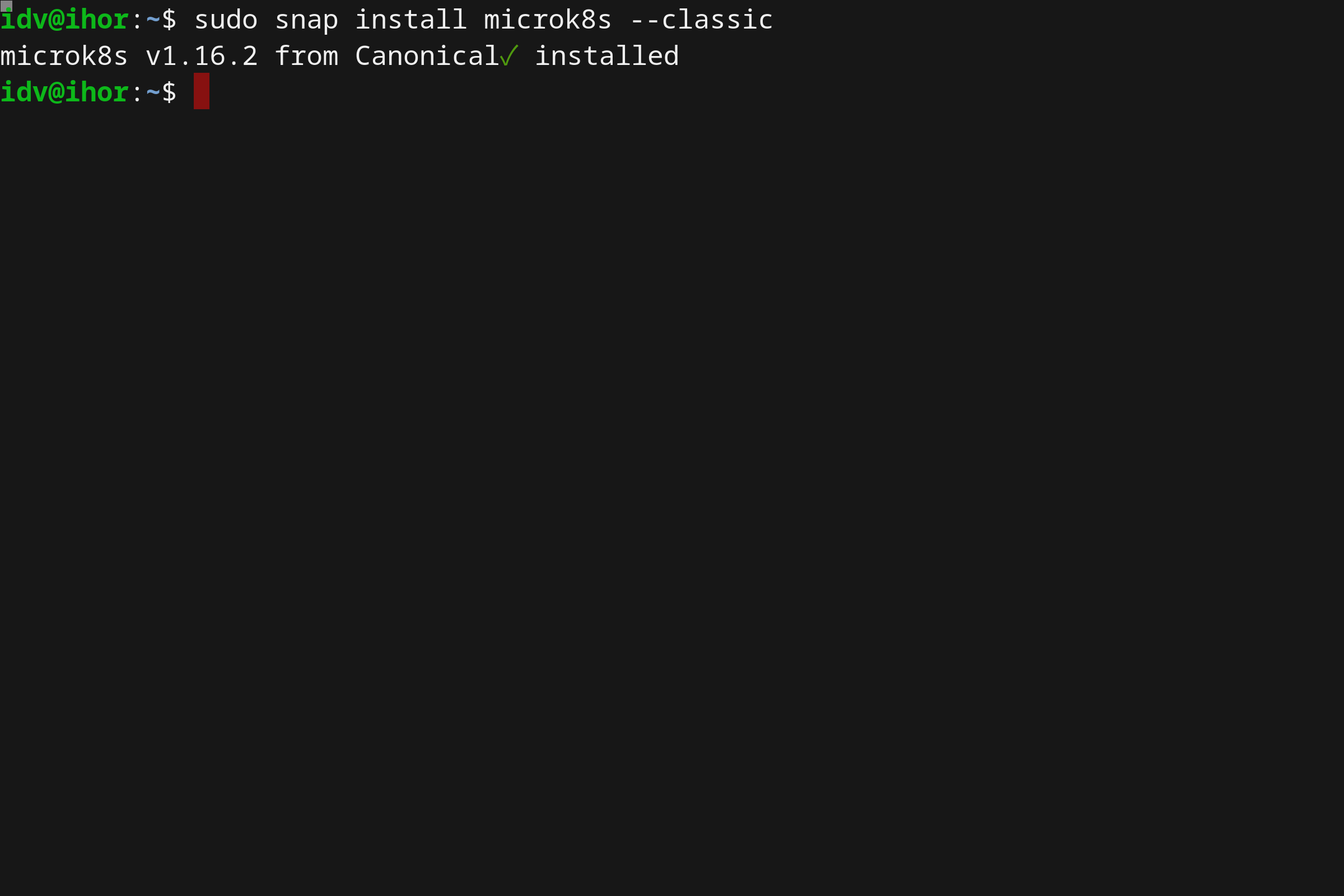
The command above installs a local single-node Kubernetes cluster in seconds. Once the command execution is finished, your Kubernetes cluster is up and running.
You may verify the MicroK8s status with the following command:
sudo microk8s.status
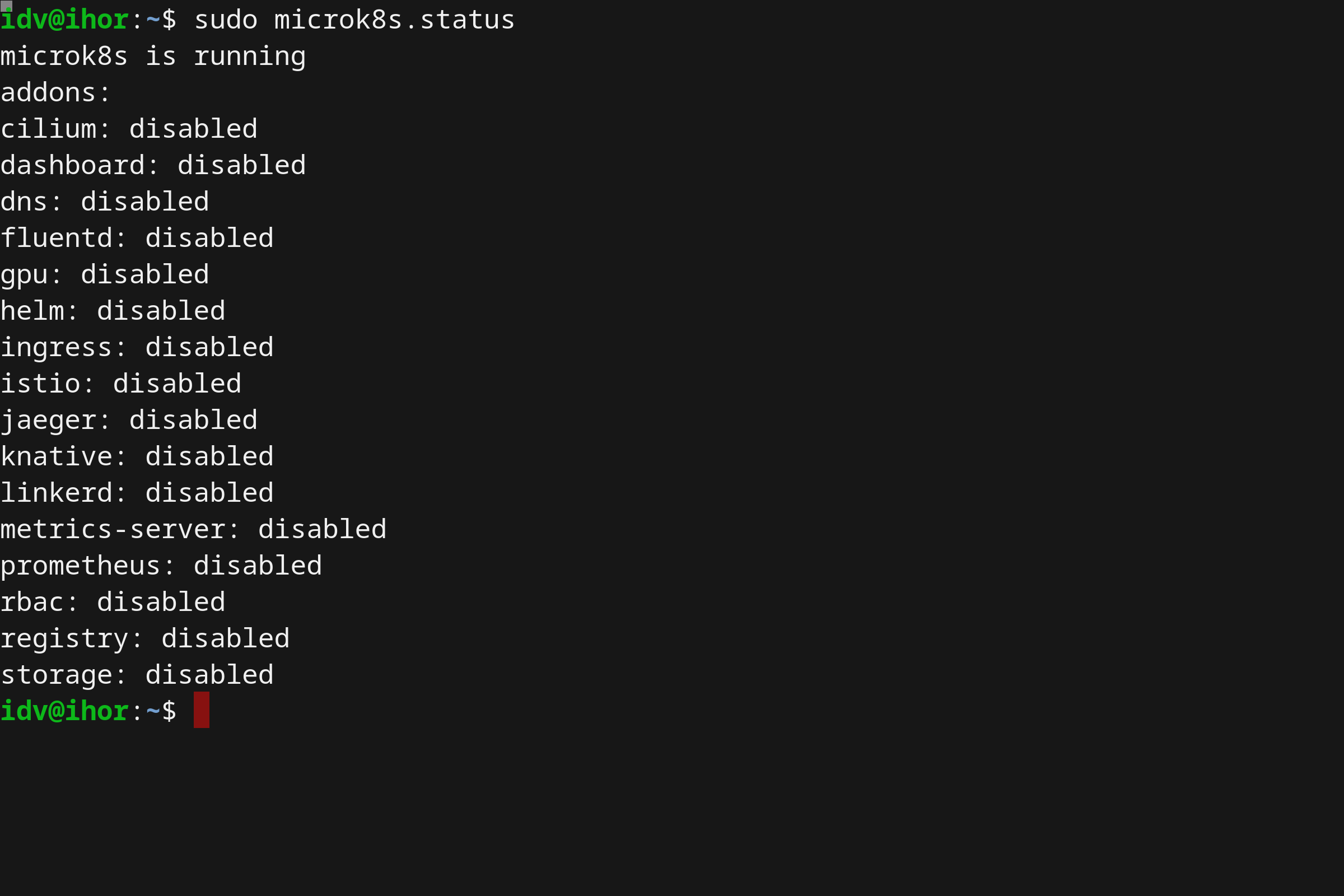
Using microk8s
Using MicroK8s is as straightforward as installing it. MicroK8s itself includes a kubectl binary, which can be accessed by running the microk8s.kubectl command. As an example:
microk8s.kubectl get nodes
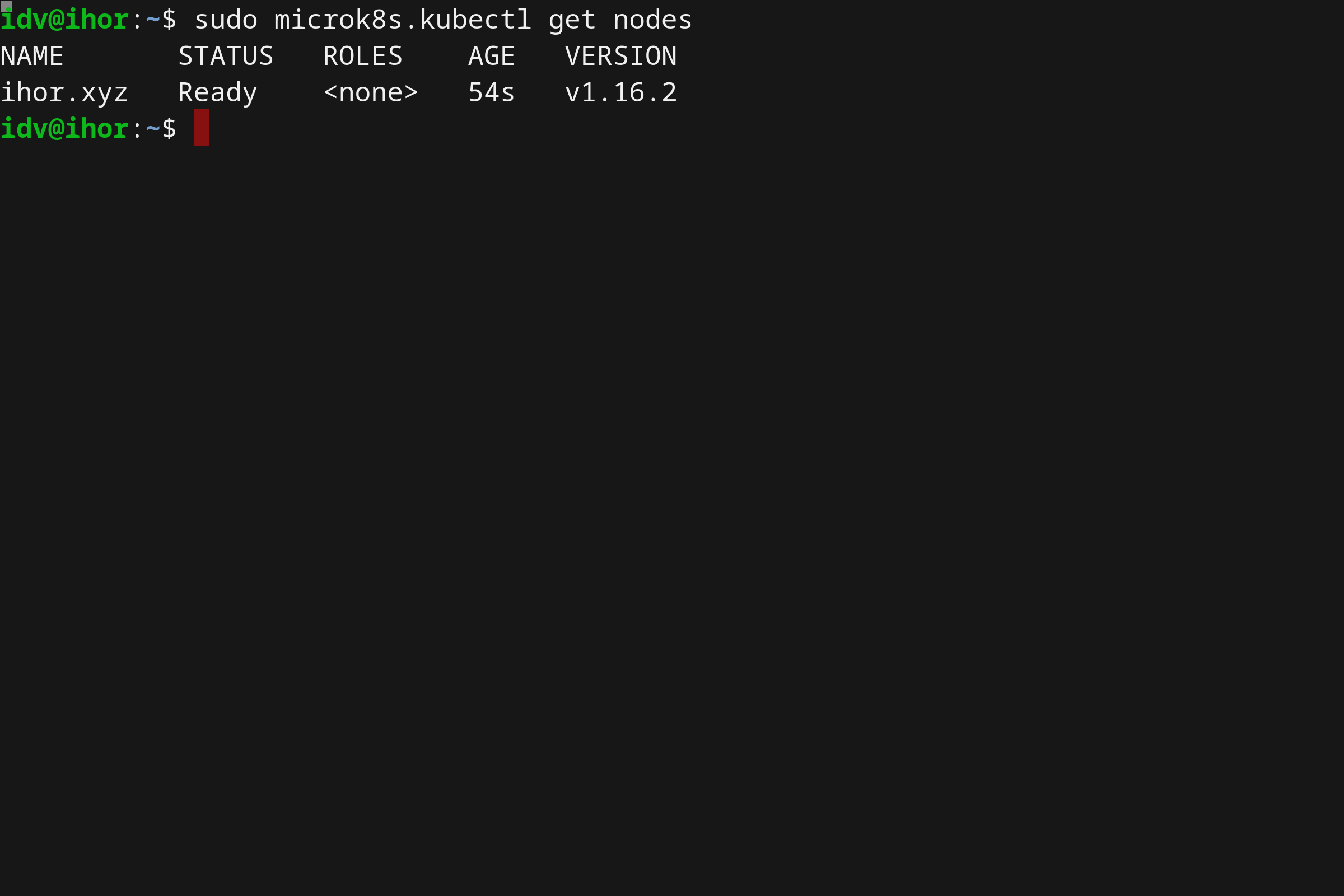
While using the prefix microk8s.kubectl allows for a parallel install of another system-wide kubectl without impact, you can easily get rid of it by using the snap alias command:
sudo snap alias microk8s.kubectl kubectl
This will allow you to simply use kubectl after. You can revert this change using the snap unalias command.
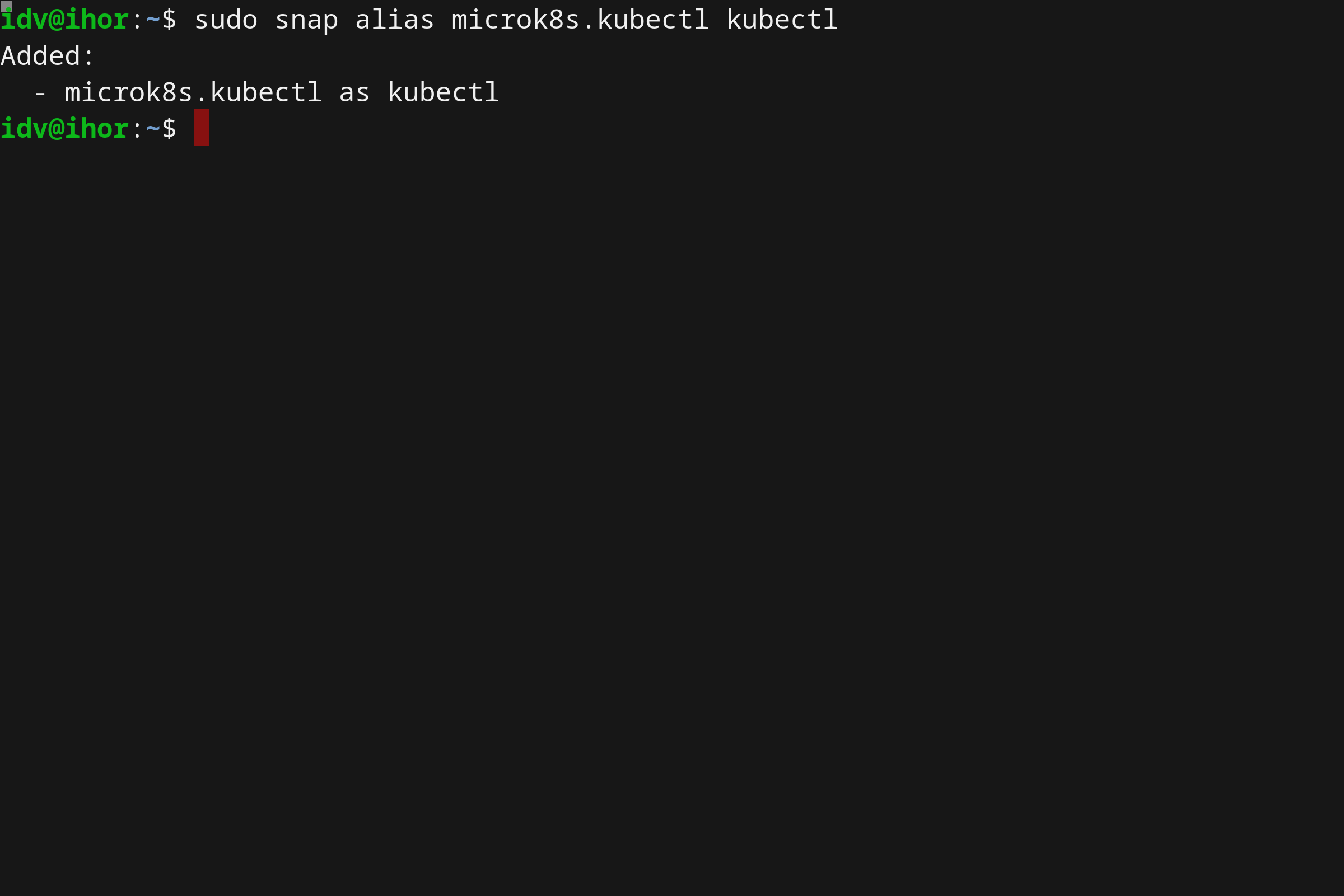
kubectl get nodes
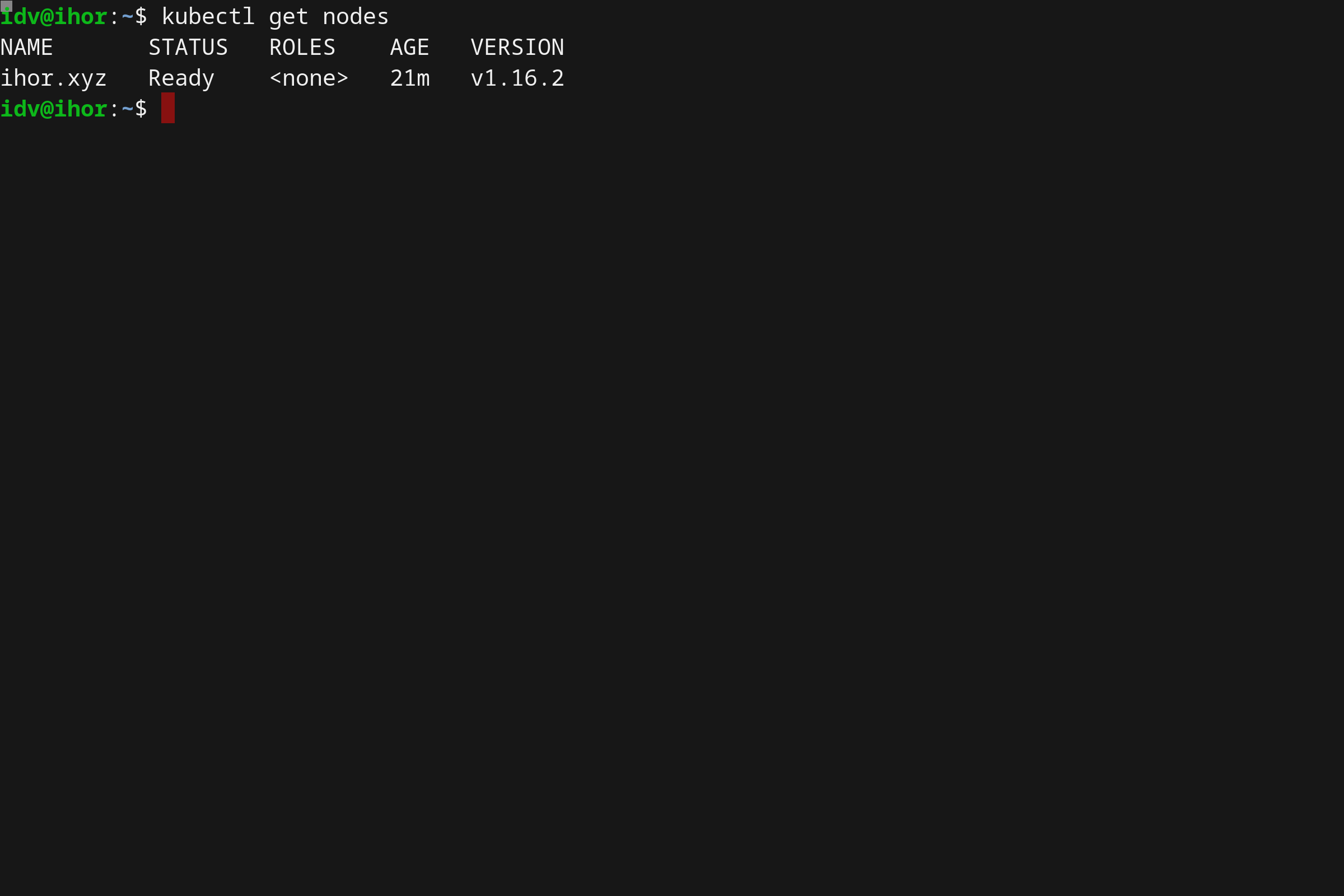
MicroK8s addons
One of the biggest benefits of using Microk8s is the fact that it also supports various add-ons and extensions. What is even more important is they are shipped out of the box, the user just has to enable them.
The full list of extensions can be checked by running the microk8s.status command:
sudo microk8s.status
As of the time of writing this article, the following add-ons are supported:
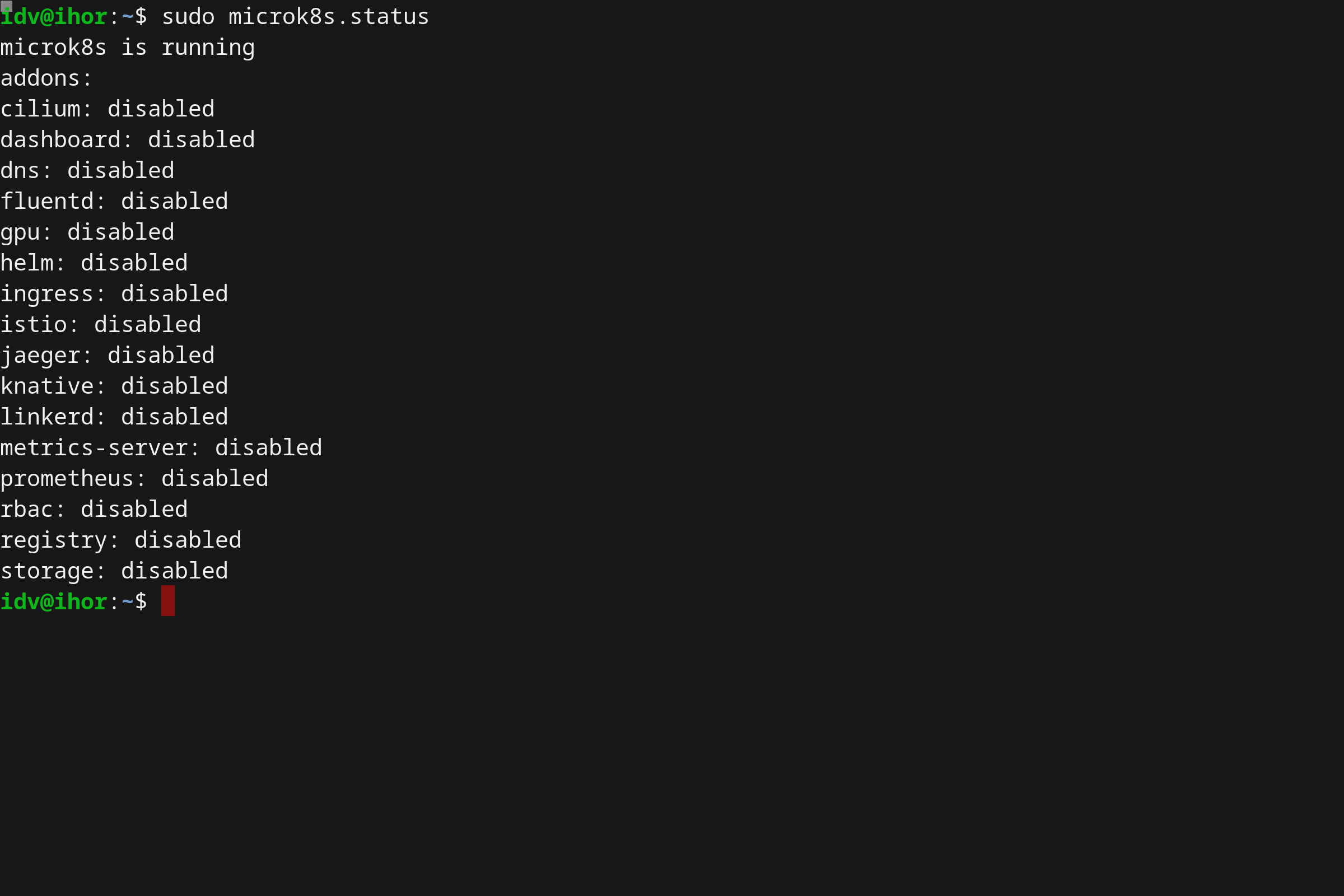
More add-ons are being created and contributed by the community all the time, it definitely helps to check often!
Release channels
sudo snap info microk8s
Installing the sample application
In this tutorial we’ll use NGINX as a sample application (the official Docker Hub image).
It will be installed as a Kubernetes deployment:
kubectl create deployment nginx --image=nginx
To verify the installation, let’s run the following:
kubectl get deployments
kubectl get pods
Also, we can retrieve the full output of all available objects within our Kubernetes cluster:
kubectl get all --all-namespaces
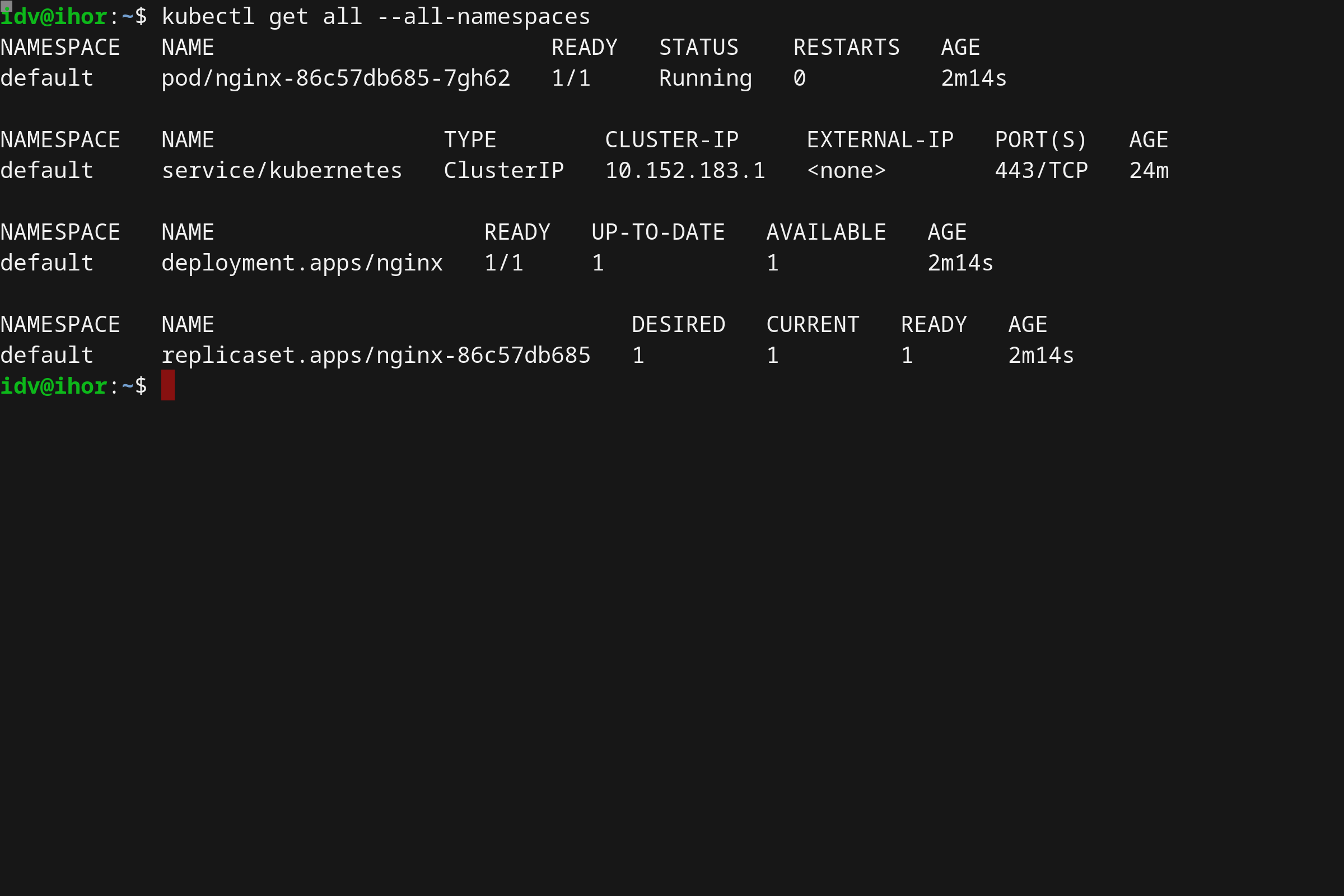
Uninstalling MicroK8s
Uninstalling your microk8s cluster is so easy as uninstalling the snap:
sudo snap remove microk8s
Screencast

Grokkin' the Docs
Author: Aimee Ukasick, Independent Contributor

Definition courtesy of Merriam Webster online dictionary
Intro - Observations of a new SIG Docs contributor
I began contributing to the SIG Docs community in August 2019. Sometimes I feel like I am a stranger in a strange land adapting to a new community: investigating community organization, understanding contributor society, learning new lessons, and incorporating new jargon. I'm an observer as well as a contributor.
Observation 01: Read the Contribute pages!
I contributed code and documentation to OpenStack, OPNFV, and Acumos, so I thought contributing to the Kubernetes documentation would be the same. I was wrong. I should have thoroughly read the Contribute to Kubernetes docs pages instead of skimming them.
I am very familiar with the git/gerrit workflow. With those tools, a contributor clones
the master repo and then creates a local branch. Kubernetes uses a different
approach, called Fork and Pull. Each contributor forks the master repo, and
then the contributor pushes work to their fork before creating a pull request. I
created a simple pull request (PR), following the instructions in the Start
contributing page's Submit a pull
request
section. This section describes how to make a documentation change using the
GitHub UI. I learned that this method is fine for a change that requires a
single commit to fix. However, this method becomes complicated when you have to
make additional updates to your PR. GitHub creates a new commit for each change
made using the GitHub UI. The Kubernetes GitHub org requires squashing commits.
The Start contributing page didn't mention squashing commits, so I looked at
the GitHub and git documentation. I could not squash my commits using the GitHub
UI. I had to git fetch and git checkout my pull request locally, squash the
commits using the command line, and then push my changes. If the Start
contributing had mentioned squashing commits, I would have worked from a local
clone instead of using the GitHub UI.
Observation 02: Reach out and ping someone
While working on my first PRs, I had questions about working from a local clone
and about keeping my fork updated from upstream master. I turned to searching
the internet instead of asking on the Kubernetes Slack
#sig-docs channel. I used the wrong process to update my fork, so I had to git rebase my PRs, which did not go well at all. As a result, I closed those PRs
and submitted new ones. When I asked for help on the #sig-docs channel,
contributors posted useful links, what my local git config file should look
like, and the exact set of git commands to run. The process used by contributors
was different than the one defined in the Intermediate contributing page.
I would have saved myself so much time if I had asked what GitHub workflow to
use. The more community knowledge that is documented, the easier it is for new
contributors to be productive quickly.
Observation 03: Don't let conflicting information ruin your day
The Kubernetes community has a contributor guide for
code
and another one for documentation. The
guides contain conflicting information on the same topic. For example, the SIG
Docs GitHub process recommends creating a local branch based on
upstream/master. The Kubernetes Community Contributor
Guide
advocates updating your fork from upstream and then creating a local branch
based on your fork. Which process should a new contributor follow? Are the two
processes interchangeable? The best place to ask questions about conflicting
information is the #sig-docs or #sig-contribex channels. I asked for
clarification about the GitHub workflows in the #sig-contribex channel.
@cblecker provided an extremely detailed response, which I used to update the
Intermediate contributing page.
Observation 04: Information may be scattered
It's common for large open source projects to have information scattered around various repos or duplicated between repos. Sometimes groups work in silos, and information is not shared. Other times, a person leaves to work on a different project without passing on specialized knowledge. Documentation gaps exist and may never be rectified because of higher priority items. So new contributors may have difficulty finding basic information, such as meeting details.
Attending SIG Docs meetings is a great way to become involved. However, people have had a hard time locating the meeting URL. Most new contributors ask in the #sig-docs channel, but I decided to locate the meeting information in the docs. This required several clicks over multiple pages. How many new contributors miss meetings because they can't locate the meeting details?
Observation 05: Patience is a virtue
A contributor may wait days for feedback on a larger PR. The process from submission to final approval may take weeks instead of days. There are two reasons for this: 1) most reviewers work part-time on SIG Docs; and 2) reviewers want to provide meaningful reviews. "Drive-by reviewing" doesn't happen in SIG Docs! Reviewers check for the following:
-
Do the commit message and PR description adequately describe the change?
-
Does the PR follow the guidelines in the style and content guides?
- Overall, is the grammar and punctuation correct?
- Is the content clear, concise, and appropriate for non-native speakers?
- Does the content stylistically fit in with the rest of the documentation?
- Does the flow of the content make sense?
- Can anything be changed to make the content better, such as using a Hugo shortcode?
- Does the content render correctly?
-
Is the content technically correct?
Sometimes the review process made me feel defensive, annoyed, and frustrated. I'm sure other contributors have felt the same way. Contributors need to be patient! Writing excellent documentation is an iterative process. Reviewers scrutinize PRs because they want to maintain a high level of quality in the documentation, not because they want to annoy contributors!
Observation 06: Make every word count
Non-native English speakers read and contribute to the Kubernetes documentation. When you are writing content, use simple, direct language in clear, concise sentences. Every sentence you write may be translated into another language, so remove words that don't add substance. I admit that implementing these guidelines is challenging at times.
Issues and pull requests aren't translated into other languages. However, you
should still follow the aforementioned guidelines when you write the description
for an issue or pull request. You should add details and background
information to an issue so the person doing triage doesn't have to apply the
triage/needs-information label. Likewise, when you create a pull request, you
should add enough information about the content change that reviewers don't have
to figure out the reason for the pull request. Providing details in clear,
concise language speeds up the process.
Observation 07: Triaging issues is more difficult than it should be
In SIG Docs, triaging issues requires the ability to distinguish between support, bug, and feature requests not only for the documentation but also for Kubernetes code projects. How to route, label, and prioritize issues has become easier week by week. I'm still not 100% clear on which SIG and/or project is responsible for which parts of the documentation. The SIGs and Working Groups page helps, but it is not enough. At a page level in the documentation, it's not always obvious which SIG or project has domain expertise. The page's front matter sometimes list reviewers but never lists a SIG or project. Each page should indicate who is responsible for content, so that SIG Docs triagers know where to route issues.
Observation 08: SIG Docs is understaffed
Documentation is the number one driver of software adoption1.
Many contributors devote a small amount of time to SIG Docs but only a handful are trained technical writers. Few companies have hired tech writers to work on Kubernetes docs at least half-time. That's very disheartening for online documentation that has had over 53 million unique page views from readers in 229 countries year to date in 2019.
SIG Docs faces challenges due to lack of technical writers:
- Maintaining a high quality in the Kubernetes documentation:
There are over 750 pages of documentation. That's 750 pages to check for
stale content on a regular basis. This involves more than running a link
checker against the
kubernetes/websiterepo. This involves people having a technical understanding of Kubernetes, knowing which code release changes impact documentation, and knowing where content is located in the documentation so that all impacted pages and example code files are updated in a timely fashion. Other SIGs help with this, but based on the number of issues created by readers, enough people aren't working on keeping the content fresh. - Reducing the time to review and merge a PR:
The larger the size of the PR, the longer it takes to get the
lgtmlabel and eventual approval. Mysize/Mand larger PRs took from five to thirty days to approve. Sometimes I politely poked reviewers to review again after I had pushed updates. Other times I asked on the #sig-docs channel for any approver to take a look and approve. People are busy. People go on vacation. People also move on to new roles that don't involve SIG Docs and forget to remove themselves from the reviewer and approver assignment file. A large part of the time-to-merge problem is not having enough reviewers and approvers. The other part is the high barrier to becoming a reviewer or approver, much higher than what I've seen on other open source projects. Experienced open source tech writers who want to contribute to SIG Docs aren't fast-tracked into approver and reviewer roles. On one hand, that high barrier ensures that those roles are filled by folks with a minimum level of Kubernetes documentation knowledge; on the other hand, it might deter experienced tech writers from contributing at all, or from a company allocating a tech writer to SIG Docs. Maybe SIG Docs should consider deviating from the Kubernetes community requirements by lowering the barrier to becoming a reviewer or approver, on a case-by-case basis, of course. - Ensuring consistent naming across all pages: Terms should be identical to what is used in the Standardized Glossary. Being consistent reduces confusion. Tracking down and fixing these occurrences is time-consuming but worthwhile for readers.
- Working with the Steering Committee to create project documentation guidelines:
The Kubernetes Repository Guidelines don't mention documentation at all. Between a
project's GitHub docs and the Kubernetes docs, some projects have almost
duplicate content, whereas others have conflicting content. Create clear
guidelines so projects know to put roadmaps, milestones, and comprehensive
feature details in the
kubernetes/<project>repo and to put installation, configuration, usage details, and tutorials in the Kubernetes docs. - Removing duplicate content: Kubernetes users install Docker, so a good example of duplicate content is Docker installation instructions. Rather than repeat what's in the Docker docs, state which version of Docker works with which version of Kubernetes and link to the Docker docs for installation. Then detail any Kubernetes-specific configuration. That idea is the same for the container runtimes that Kubernetes supports.
- Removing third-party vendor content: This is tightly coupled to removing duplicate content. Some third-party content consists of lists or tables detailing external products. Other third-party content is found in the Tasks and Tutorials sections. SIG Docs should not be responsible for verifying that third-party products work with the latest version of Kubernetes. Nor should SIG Docs be responsible for maintaining lists of training courses or cloud providers. Additionally, the Kubernetes documentation isn't the place to pitch vendor products. If SIG Docs is forced to reverse its policy on not allowing third-party content, there could be a tidal wave of vendor-or-commercially-oriented pull requests. Maintaining that content places an undue burden on SIG Docs.
- Indicating which version of Kubernetes works with each task and tutorial: This means reviewing each task and tutorial for every release. Readers assume if a task or tutorial is in the latest version of the docs, it works with the latest version of Kubernetes.
- Addressing issues:
There are 470 open issues in the
kubernetes/websiterepo. It's hard to keep up with all the issues that are created. We encourage those creating simpler issues to submit PRs: some do; most do not. - Creating more detailed content: Readers indicated they would like to see more detailed content across all sections of the documentation, including tutorials.
Kubernetes has seen unparalleled growth since its first release in 2015. Like any fast-growing project, it has growing pains. Providing consistently high-quality documentation is one of those pains, and one incredibly important to an open source project. SIG Docs needs a larger core team of tech writers who are allocated at least 50%. SIG Docs can then better achieve goals, move forward with new content, update existing content, and address open issues in a timely fashion.
Observation 09: Contributing to technical documentation projects requires, on average, more skills than developing software
When I said that to my former colleagues, the response was a healthy dose of skepticism and lots of laughter. It seems that many developers, as well as managers, don't fully know what tech writers contributing to open source projects actually do. Having done both development and technical writing for the better part of 22 years, I've noticed that tech writers are valued far less than software developers of comparative standing.
SIG Docs core team members do far more than write content based on requirements:
- We use some of the same processes and tools as developers, such as the terminal, git workflow, GitHub, and IDEs like Atom, Golang, and Visual Studio Code; we also use documentation-specific plugins and tools.
- We possess a good eye for detail as well as design and organization: the big picture and the little picture.
- We provide documentation which has a logical flow; it is not merely content on a page but the way pages fit into sections and sections fit into the overall structure.
- We write content that is comprehensive and uses language that readers not fluent in English can understand.
- We have a firm grasp of English composition using various markup languages.
- We are technical, sometimes to the level of a Kubernetes admin.
- We read, understand, and occasionally write code.
- We are project managers, able to plan new work as well as assign issues to releases.
- We are educators and diplomats with every review we do and with every comment we leave on an issue.
- We use site analytics to plan work based on which pages readers access most often as well as which pages readers say are unhelpful.
- We are surveyors, soliciting feedback from the community on a regular basis.
- We analyze the documentation as a whole, deciding what content should stay and what content should be removed based on available resources and reader needs.
- We have a working knowledge of Hugo and other frameworks used for online documentation; we know how to create, use, and debug Hugo shortcodes that enable content to be more robust than pure Markdown.
- We troubleshoot performance issues not only with Hugo but with Netlify.
- We grapple with the complex problem of API documentation.
- We are dedicated to providing the highest quality documentation that we can.
If you have any doubts about the complexity of the Kubernetes documentation project, watch presentations given by SIG Docs Chair Zach Corleissen:
- Multilingual Kubernetes - the kubernetes.io stack, how we got there, and what it took to get there
- Found in Translation: Lessons from a Year of Open Source Localization
Additionally, Docs as Code: The Missing Manual (Jennifer Rondeau, Margaret Eker; 2016) is an excellent presentation on the complexity of documentation projects in general.
The Write the Docs website and YouTube channel are fantastic places to delve into the good, the bad, and the ugly of technical writing.
Think what an open source project would be without talented, dedicated tech writers!
Observation 10: Community is everything
The SIG Docs community, and the larger Kubernetes community, is dedicated, intelligent, friendly, talented, fun, helpful, and a whole bunch of other positive adjectives! People welcomed me with open arms, and not only because SIG Docs needs more technical writers. I have never felt that my ideas and contributions were dismissed because I was the newbie. Humility and respect go a long way. Community members have a wealth of knowledge to share. Attend meetings, ask questions, propose improvements, thank people, and contribute in every way that you can!
Big shout out to those who helped me, and put up with me (LOL), during my break-in period: @zacharaysarah, @sftim, @kbhawkey, @jaypipes, @jrondeau, @jmangel, @bradtopol, @cody_clark, @thecrudge, @jaredb, @tengqm, @steveperry-53, @mrbobbytables, @cblecker, and @kbarnard10.
Outro
Do I grok SIG Docs? Not quite yet, but I do understand that SIG Docs needs more dedicated resources to continue to be successful.
Citations
1 @linuxfoundation. "Megan Byrd-Sanicki, Open Source Strategist, Google @megansanicki - documentation is the #1 driver of software adoption. #ossummit." Twitter, Oct 29, 2019, 3:54 a.m., twitter.com/linuxfoundation/status/1189103201439637510.
Kubernetes Documentation Survey
Author: Aimee Ukasick and SIG Docs
In September, SIG Docs conducted its first survey about the Kubernetes documentation. We'd like to thank the CNCF's Kim McMahon for helping us create the survey and access the results.
Key takeaways
Respondents would like more example code, more detailed content, and more diagrams in the Concepts, Tasks, and Reference sections.
74% of respondents would like the Tutorials section to contain advanced content.
69.70% said the Kubernetes documentation is the first place they look for information about Kubernetes.
Survey methodology and respondents
We conducted the survey in English. The survey was only available for 4 days due to time constraints. We announced the survey on Kubernetes mailing lists, in Kubernetes Slack channels, on Twitter, and in Kube Weekly. There were 23 questions, and respondents took an average of 4 minutes to complete the survey.
Quick facts about respondents:
- 48.48% are experienced Kubernetes users, 26.26% expert, and 25.25% beginner
- 57.58% use Kubernetes in both administrator and developer roles
- 64.65% have been using the Kubernetes documentation for more than 12 months
- 95.96% read the documentation in English
Question and response highlights
Why people access the Kubernetes documentation
The majority of respondents stated that they access the documentation for the Concepts.
This deviates only slightly from what we see in Google Analytics: of the top 10 most viewed pages this year, #1 is the kubectl cheatsheet in the Reference section, followed overwhelmingly by pages in the Concepts section.
Satisfaction with the documentation
We asked respondents to record their level of satisfaction with the detail in the Concepts, Tasks, Reference, and Tutorials sections:
- Concepts: 47.96% Moderately Satisfied
- Tasks: 50.54% Moderately Satisfied
- Reference: 40.86% Very Satisfied
- Tutorial: 47.25% Moderately Satisfied
How SIG Docs can improve each documentation section
We asked how we could improve each section, providing respondents with selectable answers as well as a text field. The clear majority would like more example code, more detailed content, more diagrams, and advanced tutorials:
- Personally, would like to see more analogies to help further understanding.
- Would be great if corresponding sections of code were explained too
- Expand on the concepts to bring them together - they're a bucket of separate eels moving in different directions right now
- More diagrams, and more example code
Respondents used the "Other" text box to record areas causing frustration:
- Keep concepts up to date and accurate
- Keep task topics up to date and accurate. Human testing.
- Overhaul the examples. Many times the output of commands shown is not actual.
- I've never understood how to navigate or interpret the reference section
- Keep the tutorials up to date, or remove them
How SIG Docs can improve the documentation overall
We asked respondents how we can improve the Kubernetes documentation overall. Some took the opportunity to tell us we are doing a good job:
- For me, it is the best documented open source project.
- Keep going!
- I find the documentation to be excellent.
- You [are] doing a great job. For real.
Other respondents provided feedback on the content:
- ...But since we're talking about docs, more is always better. More
advanced configuration examples would be, to me, the way to go. Like a Use Case page for each
configuration topic with beginner to advanced example scenarios. Something like that would be
awesome....
- More in-depth examples and use cases would be great. I often feel that the Kubernetes
documentation scratches the surface of a topic, which might be great for new users, but it leaves
more experienced users without much "official" guidance on how to implement certain things.
- More production like examples in the resource sections (notably secrets) or links to production like
examples
- It would be great to see a very clear "Quick Start" A->Z up and running like many other tech
projects. There are a handful of almost-quick-starts, but no single guidance. The result is
information overkill.
A few respondents provided technical suggestions:
- Make table columns sortable and filterable using a ReactJS or Angular component.
- For most, I think creating documentation with Hugo - a system for static site generation - is not
appropriate. There are better systems for documenting large software project. Specifically, I would
like to see k8s switch to Sphinx for documentation. It has an excellent built-in search, it is easy to
learn if you know markdown, it is widely adopted by other projects (e.g. every software project in
readthedocs.io, linux kernel, docs.python.org etc).
Overall, respondents provided constructive criticism focusing on the need for advanced use cases as well as more in-depth examples, guides, and walkthroughs.
Where to see more
Survey results summary, charts, and raw data are available in kubernetes/community sig-docs survey directory.
Contributor Summit San Diego Schedule Announced!
Authors: Josh Berkus (Red Hat), Paris Pittman (Google), Jonas Rosland (VMware)
tl;dr A week ago we announced that registration is open for the contributor summit , and we're now live with the full Contributor Summit schedule! Grab your spot while tickets are still available. There is currently a waitlist for new contributor workshop. (Register here!)
There are many great sessions planned for the Contributor Summit, spread across five rooms of current contributor content in addition to the new contributor workshops. Since this is an upstream contributor summit and we don't often meet, being a globally distributed team, most of these sessions are discussions or hands-on labs, not just presentations. We want folks to learn and have a good time meeting their OSS teammates.
Unconference tracks are returning from last year with sessions to be chosen Monday morning. These are ideal for the latest hot topics and specific discussions that contributors want to have. In previous years, we've covered flaky tests, cluster lifecycle, KEPs (Kubernetes Enhancement Proposals), mentoring, security, and more.

While the schedule contains difficult decisions in every timeslot, we've picked a few below to give you a taste of what you'll hear, see, and participate in, at the summit:
- Vision: SIG-Architecture will be sharing their vision of where we're going with Kubernetes development for the next year and beyond.
- Security: Tim Allclair and CJ Cullen will present on the current state of Kubernetes security. In another security talk, Vallery Lancey will lead a discussion about making our platform secure by default.
- Prow: Interested in working with Prow and contributing to Test-Infra, but not sure where to start? Rob Keilty will help you get a Prow test environment running on your laptop.
- Git: Staff from GitHub will be collaborating with Christoph Blecker to share practical Git tips for Kubernetes contributors.
- Reviewing: Tim Hockin will share the secrets of becoming a great code reviewer, and Jordan Liggitt will conduct a live API review so that you can do one, or at least pass one.
- End Users: Several end users from the CNCF partner ecosystem, invited by Cheryl Hung, will hold a Q&A with contributors to strengthen our feedback loop.
- Docs: As always, SIG-Docs will run a three-hour contributing-to-documentation workshop.
We're also giving out awards to contributors who distinguished themselves in 2019, and there will be a huge Meet & Greet for new contributors to find their SIG (and for existing contributors to ask about their PRs) at the end of the day on Monday.
Hope to see you all there, and make sure you register! San Diego team
2019 Steering Committee Election Results
Authors: Bob Killen (University of Michigan), Jorge Castro (VMware), Brian Grant (Google), and Ihor Dvoretskyi (CNCF)
The 2019 Steering Committee Election is a landmark milestone for the Kubernetes project. The initial bootstrap committee is graduating to emeritus and the committee has now shrunk to its final allocation of seven seats. All members of the Steering Committee are now fully elected by the Kubernetes Community.
Moving forward elections will elect either 3 or 4 people to the committee for two-year terms.
Results
The Kubernetes Steering Committee Election is now complete and the following candidates came ahead to secure two-year terms that start immediately (in alphabetical order by GitHub handle):
- Christoph Blecker (@cblecker), Red Hat
- Derek Carr (@derekwaynecarr), Red Hat
- Nikhita Raghunath (@nikhita), Loodse
- Paris Pittman (@parispittman), Google
They join Aaron Crickenberger (@spiffxp), Google; Davanum Srinivas (@dims), VMware; and Timothy St. Clair (@timothysc), VMware, to round out the committee. The seats held by Aaron, Davanum, and Timothy will be up for election around this time next year.
Big Thanks!
- Thanks to the initial bootstrap committee for establishing the initial
project governance and overseeing a multi-year transition period:
- Joe Beda (@jbeda), VMware
- Brendan Burns (@brendandburns), Microsoft
- Clayton Coleman (@smarterclayton), Red Hat
- Brian Grant (@bgrant0607), Google
- Tim Hockin (@thockin), Google
- Sarah Novotny (@sarahnovotny), Microsoft
- Brandon Philips (@philips), Red Hat
- And also thanks to the other Emeritus Steering Committee Members. Your
prior service is appreciated by the community:
- Quinton Hoole (@quinton-hoole), Huawei
- Michelle Noorali (@michelleN), Microsoft
- Phillip Wittrock (@pwittrock), Google
- Thanks to the candidates that came forward to run for election. May we always have a strong set of people who want to push the community forward like yours in every election.
- Thanks to all 377 voters who cast a ballot.
- And last but not least…Thanks to Cornell University for hosting CIVS!
Get Involved with the Steering Committee
You can follow along with Steering Committee backlog items and weigh in by filing an issue or creating a PR against their repo. They meet bi-weekly on Wednesdays at 8pm UTC and regularly attend Meet Our Contributors. They can also be contacted at their public mailing list steering@kubernetes.io.
Steering Committee Meetings:
Contributor Summit San Diego Registration Open!
Authors: Paris Pittman (Google), Jeffrey Sica (Red Hat), Jonas Rosland (VMware)
Contributor Summit San Diego 2019 Event Page
Registration is now open and in record time, we’ve hit capacity for the
new contributor workshop session of the event! Waitlist is now available.
Sunday, November 17
Evening Contributor Celebration:
QuartYard*
Address: 1301 Market Street, San Diego, CA 92101
Time: 6:00PM - 9:00PM
Monday, November 18
All Day Contributor Summit:
Marriott Marquis San Diego Marina
Address: 333 W Harbor Dr, San Diego, CA 92101
Time: 9:00AM - 5:00PM
While the Kubernetes project is only five years old, we’re already going into our 9th Contributor Summit this November in San Diego before KubeCon + CloudNativeCon. The rapid increase is thanks to adding European and Asian Contributor Summits to the North American events we’ve done previously. We will continue to run Contributor Summits across the globe, as it is important that our contributor base grows in all forms of diversity.
Kubernetes has a large distributed remote contributing team, from individuals and organizations all over the world. The Contributor Summits give the community three chances a year to get together, work on community topics, and have hallway track time. The upcoming San Diego summit is expected to bring over 450 attendees, and will contain multiple tracks with something for everyone. The focus will be around contributor growth and sustainability. We're going to stop here with capacity for future summits; we want this event to offer value to individuals and the project. We've heard from past summit attendee feedback that getting work done, learning, and meeting folks face to face is a priority. By capping attendance and offering the contributor gatherings in more locations, it will help us achieve those goals.
This summit is unique as we’ve taken big moves on sustaining ourselves, the contributor experience events team. Taking a page from the release team’s playbook, we have added additional core team and shadow roles making it a natural mentoring (watching+doing) relationship. The shadows are expected to fill another role at one of the three events in 2020, and core team members to take the lead. In preparation for this team, we’ve open sourced our rolebooks, guidelines, best practices and opened up our meetings and project board. Our team makes up many parts of the Kubernetes project and takes care of making sure all voices are represented.
Are you at KubeCon + CloudNativeCon but can’t make it to the summit? Check out the SIG Intro and Deep Dive sessions during KubeCon + CloudNativeCon to participate in Q&A and hear what’s up with each Special interest Group (SIG). We’ll also record all of Contributor Summit’s presentation sessions, take notes in discussions, and share it back with you, after the event is complete.
We hope to see you all at Kubernetes Contributor Summit San Diego, make sure you head over and register right now! This event will sell out - here’s your warning. :smiley:
Check out past blogs on persona building around our events and the Barcelona summit story.

*=QuartYard has a huge stage! Want to perform something in front of your contributor peers? Reach out to us! community@kubernetes.io
Kubernetes 1.16: Custom Resources, Overhauled Metrics, and Volume Extensions
Authors: Kubernetes 1.16 Release Team
We’re pleased to announce the delivery of Kubernetes 1.16, our third release of 2019! Kubernetes 1.16 consists of 31 enhancements: 8 enhancements moving to stable, 8 enhancements in beta, and 15 enhancements in alpha.
Major Themes
Custom resources
CRDs are in widespread use as a Kubernetes extensibility mechanism and have been available in beta since the 1.7 release. The 1.16 release marks the graduation of CRDs to general availability (GA).
Overhauled metrics
Kubernetes has previously made extensive use of a global metrics registry to register metrics to be exposed. By implementing a metrics registry, metrics are registered in more transparent means. Previously, Kubernetes metrics have been excluded from any kind of stability requirements.
Volume Extension
There are quite a few enhancements in this release that pertain to volumes and volume modifications. Volume resizing support in CSI specs is moving to beta which allows for any CSI spec volume plugin to be resizable.
Significant Changes to the Kubernetes API
As the Kubernetes API has evolved, we have promoted some API resources to stable, others have been reorganized to different groups. We deprecate older versions of a resource and make newer versions available in accordance with the API versioning policy.
An example of this is the Deployment resource. This was introduced under the extensions/v1beta1 group in 1.6 and as the project changed has been promoted to extensions/v1beta2, apps/v1beta2 and finally promoted to stable and moved to apps/v1 in 1.9.
It's important to note that until this release the project has not stopped serving any of the previous versions of the any of the deprecated resources.
This means that folks interacting with the Kubernetes API have not been required to move to the new version of any of the deprecated API objects.
In 1.16 if you submit a Deployment to the API server and specify extensions/v1beta1 as the API group it will be rejected with:
error: unable to recognize "deployment": no matches for kind "Deployment" in version "extensions/v1beta1"
With this release we are taking a very important step in the maturity of the Kubernetes API, and are no longer serving the deprecated APIs. Our earlier post Deprecated APIs Removed In 1.16: Here’s What You Need To Know tells you more, including which resources are affected.
Additional Enhancements
Custom Resources Reach General Availability
CRDs have become the basis for extensions in the Kubernetes ecosystem. Started as a ground-up redesign of the ThirdPartyResources prototype, they have finally reached GA in 1.16 with apiextensions.k8s.io/v1, as the hard-won lessons of API evolution in Kubernetes have been integrated. As we transition to GA, the focus is on data consistency for API clients.
As you upgrade to the GA API, you’ll notice that several of the previously optional guard rails have become required and/or default behavior. Things like structural schemas, pruning unknown fields, validation, and protecting the *.k8s.io group are important for ensuring the longevity of your APIs and are now much harder to accidentally miss. Defaulting is another important part of API evolution and that support will be on by default for CRD.v1. The combination of these, along with CRD conversion mechanisms are enough to build stable APIs that evolve over time, the same way that native Kubernetes resources have changed without breaking backward-compatibility.
Updates to the CRD API won’t end here. We have ideas for features like arbitrary subresources, API group migration, and maybe a more efficient serialization protocol, but the changes from here are expected to be optional and complementary in nature to what’s already here in the GA API. Happy operator writing!
Details on how to work with custom resources can be found in the Kubernetes documentation.
Opening Doors With Windows Enhancements
Beta: Enhancing the workload identity options for Windows containers
Active Directory Group Managed Service Account (GMSA) support is graduating to beta and certain annotations that were introduced with the alpha support are being deprecated. GMSA is a specific type of Active Directory account that enables Windows containers to carry an identity across the network and communicate with other resources. Windows containers can now gain authenticated access to external resources. In addition, GMSA provides automatic password management, simplified service principal name (SPN) management, and the ability to delegate the management to other administrators across multiple servers.
Adding support for RunAsUserName as an alpha release. The RunAsUserName is a string specifying the windows identity (or username) in Windows to run the entrypoint of the container and is a part of the newly introduced windowsOptions component of the securityContext (WindowsSecurityContextOptions).
Alpha: Improvements to setup & node join experience with kubeadm
Introducing alpha support for kubeadm, enabling Kubernetes users to easily join (and reset) Windows worker nodes to an existing cluster the same way they do for Linux nodes. Users can utilize kubeadm to prepare and add a Windows node to cluster. When the operations are complete, the node will be in a Ready state and able to run Windows containers. In addition, we will also provide a set of Windows-specific scripts to enable the installation of prerequisites and CNIs ahead of joining the node to the cluster.
Alpha: Introducing support for Container Storage Interface (CSI)
Introducing CSI plugin support for out-of-tree providers, enabling Windows nodes in a Kubernetes cluster to leverage persistent storage capabilities for Windows-based workloads. This significantly expands the storage options of Windows workloads, adding onto a list that included FlexVolume and in-tree storage plugins. This capability is achieved through a host OS proxy that enables the execution of privileged operations on the Windows node on behalf of containers.
Introducing Endpoint Slices
The release of Kubernetes 1.16 includes an exciting new alpha feature: the EndpointSlice API. This API provides a scalable and extensible alternative to the Endpoints resource, which dates back to the very first versions of Kubernetes. Behind the scenes, Endpoints play a big role in network routing within Kubernetes. Each Service endpoint is tracked within these resources - kube-proxy uses them for generating proxy rules that allow pods to communicate with each other so easily in Kubernetes, and many ingress controllers use them to route HTTP traffic directly to pods.
Providing Greater Scalability
A key goal for EndpointSlices is to enable greater scalability for Kubernetes Services. With the existing Endpoints API, a single instance must include network endpoints representing all pods matching a Service. As Services start to scale to thousands of pods, the corresponding Endpoints resources become quite large. Simply adding or removing one endpoint from a Service at this scale can be quite costly. As the Endpoints instance is updated, every piece of code watching Endpoints will need to be sent a full copy of the resource. With kube-proxy running on every node in a cluster, a copy needs to be sent to every single node. At a small scale, this is not an issue, but it becomes increasingly noticeable as clusters get larger.
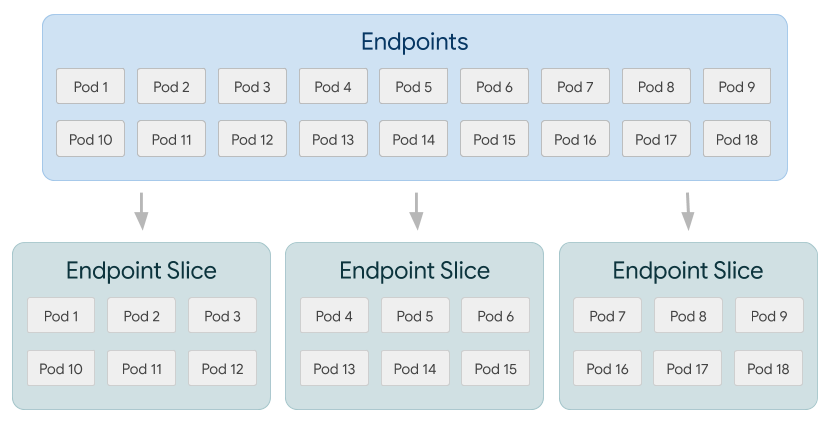
With EndpointSlices, network endpoints for a Service are split into multiple instances, significantly decreasing the amount of data required for updates at scale. By default, EndpointSlices are limited to 100 endpoints each.
For example, let’s take a cluster with 10,000 Service endpoints spread over 5,000 nodes. A single Pod update would result in approximately 5GB transmitted with the Endpoints API (that’s enough to fill a DVD). This becomes increasingly significant given how frequently Endpoints can change during events like rolling updates on Deployments. The same update will be much more efficient with EndpointSlices since each one includes only a tiny portion of the total number of Service endpoints. Instead of transferring a big Endpoints object to each node, only the small EndpointSlice that’s been changed has to be transferred. In this example, EndpointSlices would decrease data transferred by approximately 100x.
| Endpoints | Endpoint Slices | |
| # of resources | 1 | 20k / 100 = 200 |
| # of network endpoints stored | 1 * 20k = 20k | 200 * 100 = 20k |
| size of each resource | 20k * const = ~2.0 MB | 100 * const = ~10 kB |
| watch event data transferred | ~2.0MB * 5k = 10GB | ~10kB * 5k = 50MB |
Providing Greater Extensibility
A second goal for EndpointSlices was to provide a resource that would be highly extensible and useful across a wide variety of use cases. One of the key additions with EndpointSlices involves a new topology attribute. By default, this will be populated with the existing topology labels used throughout Kubernetes indicating attributes such as region and zone. Of course, this field can be populated with custom labels as well for more specialized use cases.
EndpointSlices also include greater flexibility for address types. Each contains a list of addresses. An initial use case for multiple addresses would be to support dual-stack endpoints with both IPv4 and IPv6 addresses. As an example, here’s a simple EndpointSlice showing how one could be represented:
apiVersion: discovery.k8s.io/v1alpha
kind: EndpointSlice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IP
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
- "2001:db8::1234:5678"
topology:
kubernetes.io/hostname: node-1
topology.kubernetes.io/zone: us-west2-a
More About Endpoint Slices
EndpointSlices are an alpha feature in Kubernetes 1.16 and not enabled by default. The Endpoints API will continue to be enabled by default, but we’re working to move the largest Endpoints consumers to the new EndpointSlice API. Notably, kube-proxy in Kubernetes 1.16 includes alpha support for EndpointSlices.
The official Kubernetes documentation contains more information about EndpointSlices as well as how to enable them in your cluster. There’s also a great KubeCon talk that provides more background on the initial rationale for developing this API.
Notable Feature Updates
- Topology Manager, a new Kubelet component, aims to co-ordinate resource assignment decisions to provide optimized resource allocations.
- IPv4/IPv6 dual-stack enables the allocation of both IPv4 and IPv6 addresses to Pods and Services.
- Extensions for Cloud Controller Manager Migration.
Availability
Kubernetes 1.16 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials. You can also easily install 1.16 using kubeadm.
Release Team
This release is made possible through the efforts of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Lachlan Evenson, Principal Program Manager at Microsoft. The 32 individuals on the release team coordinated many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid pace. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has had over 32,000 individual contributors to date and an active community of more than 66,000 people.
Release Mascot
The Kubernetes 1.16 release crest was loosely inspired by the Apollo 16 mission crest. It represents the hard work of the release-team and the community alike and is an ode to the challenges and fun times we shared as a team throughout the release cycle. Many thanks to Ronan Flynn-Curran of Microsoft for creating this magnificent piece.

Kubernetes Updates
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. This past year, 1,147 different companies and over 3,149 individuals contribute to Kubernetes each month. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
Ecosystem
- The Kubernetes project leadership created the Security Audit Working Group to oversee the very first third-part Kubernetes security audit, in an effort to improve the overall security of the ecosystem.
- The Kubernetes Certified Service Providers program (KCSP) reached 100 member companies, ranging from the largest multinational cloud, enterprise software, and consulting companies to tiny startups.
- The first Kubernetes Project Journey Report was released, showcasing the massive growth of the project.
KubeCon + CloudNativeCon
The Cloud Native Computing Foundation’s flagship conference gathers adopters and technologists from leading open source and cloud native communities in San Diego, California from November 18-21, 2019. Join Kubernetes, Prometheus, Envoy, CoreDNS, containerd, Fluentd, OpenTracing, gRPC, CNI, Jaeger, Notary, TUF, Vitess, NATS, Linkerd, Helm, Rook, Harbor, etcd, Open Policy Agent, CRI-O, and TiKV as the community gathers for four days to further the education and advancement of cloud native computing. Register today!
Webinar
Join members of the Kubernetes 1.16 release team on Oct 22, 2019 to learn about the major features in this release. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below. Thank you for your continued feedback and support.
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Post questions (or answer questions) on Stack Overflow
- Share your Kubernetes story
Announcing etcd 3.4
Authors: Gyuho Lee (Amazon Web Services, @gyuho), Jingyi Hu (Google, @jingyih)
etcd 3.4 focuses on stability, performance and ease of operation, with features like pre-vote and non-voting member and improvements to storage backend and client balancer.
Please see CHANGELOG for full lists of changes.
Better Storage Backend
etcd v3.4 includes a number of performance improvements for large scale Kubernetes workloads.
In particular, etcd experienced performance issues with a large number of concurrent read transactions even when there is no write (e.g. “read-only range request ... took too long to execute”). Previously, the storage backend commit operation on pending writes blocks incoming read transactions, even when there was no pending write. Now, the commit does not block reads which improve long-running read transaction performance.
We further made backend read transactions fully concurrent. Previously, ongoing long-running read transactions block writes and upcoming reads. With this change, write throughput is increased by 70% and P99 write latency is reduced by 90% in the presence of long-running reads. We also ran Kubernetes 5000-node scalability test on GCE with this change and observed similar improvements. For example, in the very beginning of the test where there are a lot of long-running “LIST pods”, the P99 latency of “POST clusterrolebindings” is reduced by 97.4%.
More improvements have been made to lease storage. We enhanced lease expire/revoke performance by storing lease objects more efficiently, and made lease look-up operation non-blocking with current lease grant/revoke operation. And etcd v3.4 introduces lease checkpoint as an experimental feature to persist remaining time-to-live values through consensus. This ensures short-lived lease objects are not auto-renewed after leadership election. This also prevents lease object pile-up when the time-to-live value is relatively large (e.g. 1-hour TTL never expired in Kubernetes use case).
Improved Raft Voting Process
etcd server implements Raft consensus algorithm for data replication. Raft is a leader-based protocol. Data is replicated from leader to follower; a follower forwards proposals to a leader, and the leader decides what to commit or not. Leader persists and replicates an entry, once it has been agreed by the quorum of cluster. The cluster members elect a single leader, and all other members become followers. The elected leader periodically sends heartbeats to its followers to maintain its leadership, and expects responses from each follower to keep track of its progress.
In its simplest form, a Raft leader steps down to a follower when it receives a message with higher terms without any further cluster-wide health checks. This behavior can affect the overall cluster availability.
For instance, a flaky (or rejoining) member drops in and out, and starts campaign. This member ends up with higher terms, ignores all incoming messages with lower terms, and sends out messages with higher terms. When the leader receives this message of a higher term, it reverts back to follower.
This becomes more disruptive when there’s a network partition. Whenever the partitioned node regains its connectivity, it can possibly trigger the leader re-election. To address this issue, etcd Raft introduces a new node state pre-candidate with the pre-vote feature. The pre-candidate first asks other servers whether it's up-to-date enough to get votes. Only if it can get votes from the majority, it increments its term and starts an election. This extra phase improves the robustness of leader election in general. And helps the leader remain stable as long as it maintains its connectivity with the quorum of its peers.
Similarly, etcd availability can be affected when a restarting node has not received the leader heartbeats in time (e.g. due to slow network), which triggers the leader election. Previously, etcd fast-forwards election ticks on server start, with only one tick left for leader election. For example, when the election timeout is 1-second, the follower only waits 100ms for leader contacts before starting an election. This speeds up initial server start, by not having to wait for the election timeouts (e.g. election is triggered in 100ms instead of 1-second). Advancing election ticks is also useful for cross datacenter deployments with larger election timeouts. However, in many cases, the availability is more critical than the speed of initial leader election. To ensure better availability with rejoining nodes, etcd now adjusts election ticks with more than one tick left, thus more time for the leader to prevent a disruptive restart.
Raft Non-Voting Member, Learner
The challenge with membership reconfiguration is that it often leads to quorum size changes, which are prone to cluster unavailabilities. Even if it does not alter the quorum, clusters with membership change are more likely to experience other underlying problems. To improve the reliability and confidence of reconfiguration, a new role - learner is introduced in etcd 3.4 release.
A new etcd member joins the cluster with no initial data, requesting all historical updates from the leader until it catches up to the leader’s logs. This means the leader’s network is more likely to be overloaded, blocking or dropping leader heartbeats to followers. In such cases, a follower may experience election-timeout and start a new leader election. That is, a cluster with a new member is more vulnerable to leader election. Both leader election and the subsequent update propagation to the new member are prone to causing periods of cluster unavailability (see Figure 1).
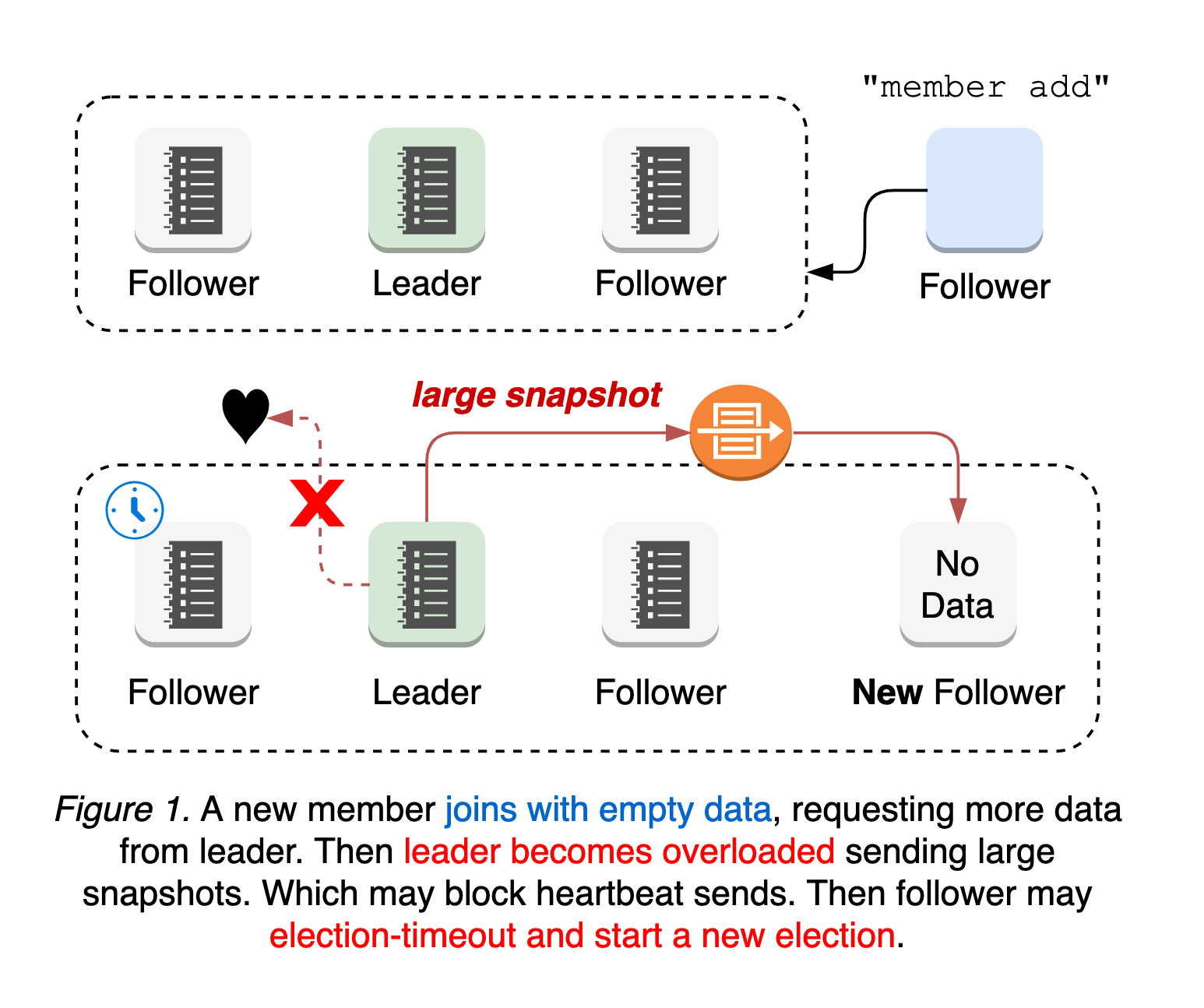
The worst case is a misconfigured membership add. Membership reconfiguration in etcd is a two-step process: etcdctl member add with peer URLs, and starting a new etcd to join the cluster. That is, member add command is applied whether the peer URL value is invalid or not. If the first step is to apply the invalid URLs and change the quorum size, it is possible that the cluster already loses the quorum until the new node connects. Since the node with invalid URLs will never become online and there’s no leader, it is impossible to revert the membership change (see Figure 2).
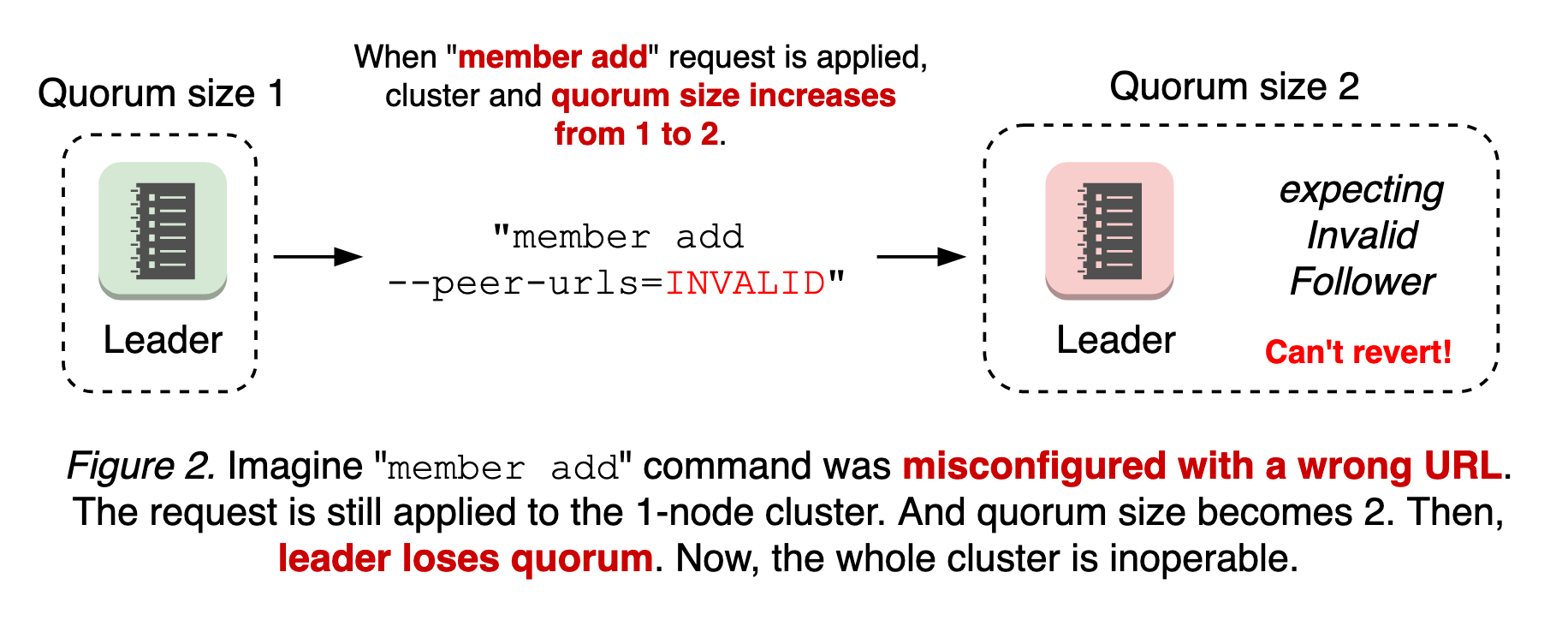
This becomes more complicated when there are partitioned nodes (see the design document for more).
In order to address such failure modes, etcd introduces a new node state “Learner”, which joins the cluster as a non-voting member until it catches up to leader’s logs. This means the learner still receives all updates from leader, while it does not count towards the quorum, which is used by the leader to evaluate peer activeness. The learner only serves as a standby node until promoted. This relaxed requirements for quorum provides the better availability during membership reconfiguration and operational safety (see Figure 3).
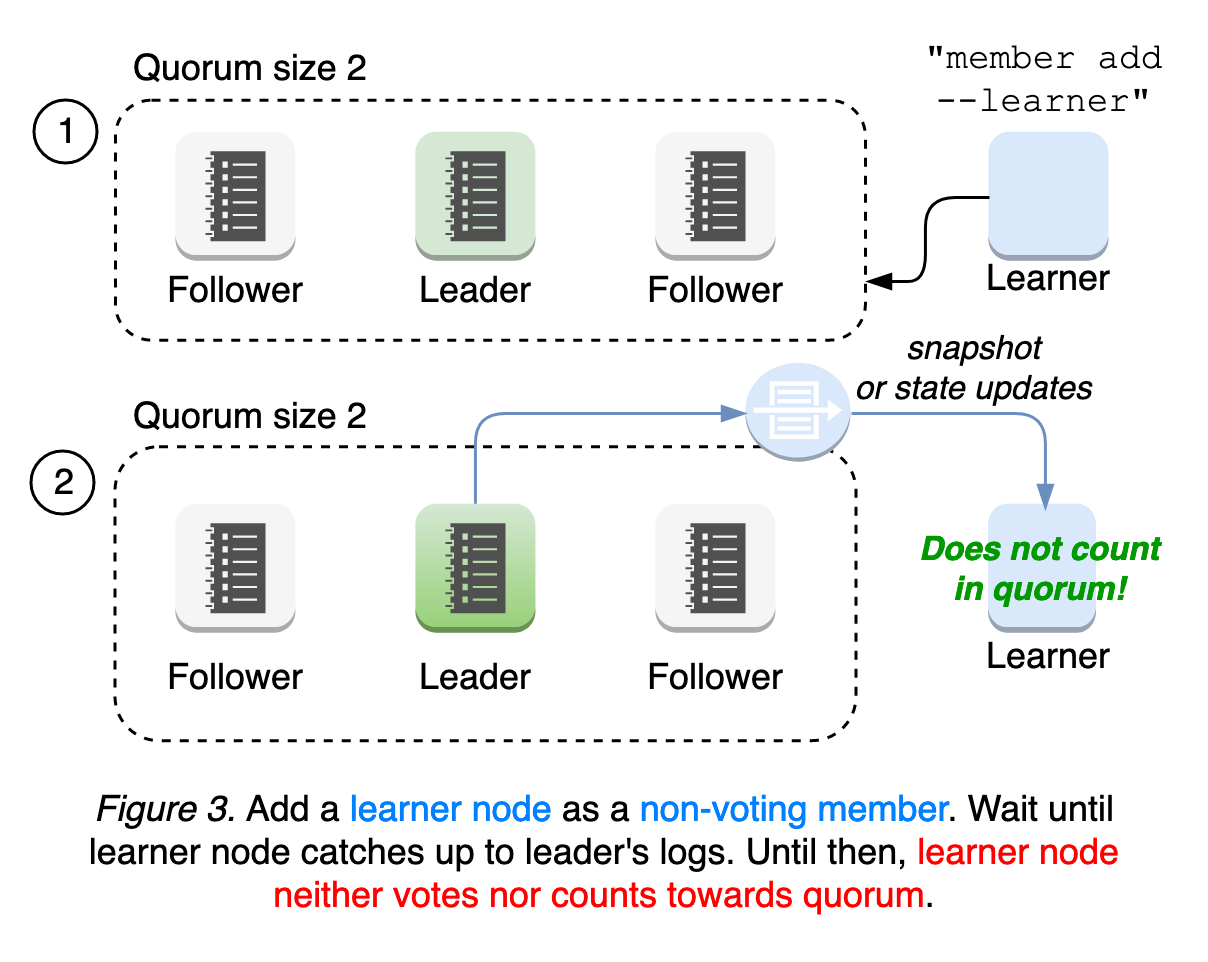
We will further improve learner robustness, and explore auto-promote mechanisms for easier and more reliable operation. Please read our learner design documentation and runtime-configuration document for user guides.
New Client Balancer
etcd is designed to tolerate various system and network faults. By design, even if one node goes down, the cluster “appears” to be working normally, by providing one logical cluster view of multiple servers. But, this does not guarantee the liveness of the client. Thus, etcd client has implemented a different set of intricate protocols to guarantee its correctness and high availability under faulty conditions.
Historically, etcd client balancer heavily relied on old gRPC interface: every gRPC dependency upgrade broke client behavior. A majority of development and debugging efforts were devoted to fixing those client behavior changes. As a result, its implementation has become overly complicated with bad assumptions on server connectivity. The primary goal was to simplify balancer failover logic in etcd v3.4 client; instead of maintaining a list of unhealthy endpoints, which may be stale, simply roundrobin to the next endpoint whenever client gets disconnected from the current endpoint. It does not assume endpoint status. Thus, no more complicated status tracking is needed.
Furthermore, the new client now creates its own credential bundle to fix balancer failover against secure endpoints. This resolves the year-long bug, where kube-apiserver loses its connectivity to etcd cluster when the first etcd server becomes unavailable.
Please see client balancer design documentation for more.
OPA Gatekeeper: Policy and Governance for Kubernetes
Authors: Rita Zhang (Microsoft), Max Smythe (Google), Craig Hooper (Commonwealth Bank AU), Tim Hinrichs (Styra), Lachie Evenson (Microsoft), Torin Sandall (Styra)
The Open Policy Agent Gatekeeper project can be leveraged to help enforce policies and strengthen governance in your Kubernetes environment. In this post, we will walk through the goals, history, and current state of the project.
The following recordings from the Kubecon EU 2019 sessions are a great starting place in working with Gatekeeper:
Motivations
If your organization has been operating Kubernetes, you probably have been looking for ways to control what end-users can do on the cluster and ways to ensure that clusters are in compliance with company policies. These policies may be there to meet governance and legal requirements or to enforce best practices and organizational conventions. With Kubernetes, how do you ensure compliance without sacrificing development agility and operational independence?
For example, you can enforce policies like:
- All images must be from approved repositories
- All ingress hostnames must be globally unique
- All pods must have resource limits
- All namespaces must have a label that lists a point-of-contact
Kubernetes allows decoupling policy decisions from the API server by means of admission controller webhooks to intercept admission requests before they are persisted as objects in Kubernetes. Gatekeeper was created to enable users to customize admission control via configuration, not code and to bring awareness of the cluster’s state, not just the single object under evaluation at admission time. Gatekeeper is a customizable admission webhook for Kubernetes that enforces policies executed by the Open Policy Agent (OPA), a policy engine for Cloud Native environments hosted by CNCF.
Evolution
Before we dive into the current state of Gatekeeper, let’s take a look at how the Gatekeeper project has evolved.
- Gatekeeper v1.0 - Uses OPA as the admission controller with the kube-mgmt sidecar enforcing configmap-based policies. It provides validating and mutating admission control. Donated by Styra.
- Gatekeeper v2.0 - Uses Kubernetes policy controller as the admission controller with OPA and kube-mgmt sidecars enforcing configmap-based policies. It provides validating and mutating admission control and audit functionality. Donated by Microsoft.
- Gatekeeper v3.0 - The admission controller is integrated with the OPA Constraint Framework to enforce CRD-based policies and allow declaratively configured policies to be reliably shareable. Built with kubebuilder, it provides validating and, eventually, mutating (to be implemented) admission control and audit functionality. This enables the creation of policy templates for Rego policies, creation of policies as CRDs, and storage of audit results on policy CRDs. This project is a collaboration between Google, Microsoft, Red Hat, and Styra.
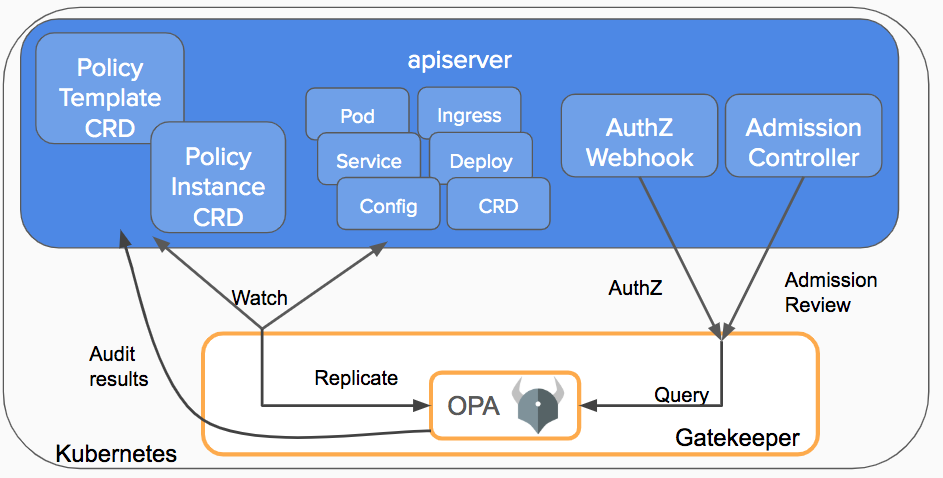
Gatekeeper v3.0 Features
Now let’s take a closer look at the current state of Gatekeeper and how you can leverage all the latest features. Consider an organization that wants to ensure all objects in a cluster have departmental information provided as part of the object’s labels. How can you do this with Gatekeeper?
Validating Admission Control
Once all the Gatekeeper components have been installed in your cluster, the API server will trigger the Gatekeeper admission webhook to process the admission request whenever a resource in the cluster is created, updated, or deleted.
During the validation process, Gatekeeper acts as a bridge between the API server and OPA. The API server will enforce all policies executed by OPA.
Policies and Constraints
With the integration of the OPA Constraint Framework, a Constraint is a declaration that its author wants a system to meet a given set of requirements. Each Constraint is written with Rego, a declarative query language used by OPA to enumerate instances of data that violate the expected state of the system. All Constraints are evaluated as a logical AND. If one Constraint is not satisfied, then the whole request is rejected.
Before defining a Constraint, you need to create a Constraint Template that allows people to declare new Constraints. Each template describes both the Rego logic that enforces the Constraint and the schema for the Constraint, which includes the schema of the CRD and the parameters that can be passed into a Constraint, much like arguments to a function.
For example, here is a Constraint template CRD that requires certain labels to be present on an arbitrary object.
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: k8srequiredlabels
spec:
crd:
spec:
names:
kind: K8sRequiredLabels
listKind: K8sRequiredLabelsList
plural: k8srequiredlabels
singular: k8srequiredlabels
validation:
# Schema for the `parameters` field
openAPIV3Schema:
properties:
labels:
type: array
items: string
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8srequiredlabels
deny[{"msg": msg, "details": {"missing_labels": missing}}] {
provided := {label | input.review.object.metadata.labels[label]}
required := {label | label := input.parameters.labels[_]}
missing := required - provided
count(missing) > 0
msg := sprintf("you must provide labels: %v", [missing])
}
Once a Constraint template has been deployed in the cluster, an admin can now create individual Constraint CRDs as defined by the Constraint template. For example, here is a Constraint CRD that requires the label hr to be present on all namespaces.
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-hr
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["hr"]
Similarly, another Constraint CRD that requires the label finance to be present on all namespaces can easily be created from the same Constraint template.
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-finance
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["finance"]
As you can see, with the Constraint framework, we can reliably share Regos via the Constraint templates, define the scope of enforcement with the match field, and provide user-defined parameters to the Constraints to create customized behavior for each Constraint.
Audit
The audit functionality enables periodic evaluations of replicated resources against the Constraints enforced in the cluster to detect pre-existing misconfigurations. Gatekeeper stores audit results as violations listed in the status field of the relevant Constraint.
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-hr
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["hr"]
status:
auditTimestamp: "2019-08-06T01:46:13Z"
byPod:
- enforced: true
id: gatekeeper-controller-manager-0
violations:
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: default
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: gatekeeper-system
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: kube-public
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: kube-system
Data Replication
Audit requires replication of Kubernetes resources into OPA before they can be evaluated against the enforced Constraints. Data replication is also required by Constraints that need access to objects in the cluster other than the object under evaluation. For example, a Constraint that enforces uniqueness of ingress hostname must have access to all other ingresses in the cluster.
To configure Kubernetes data to be replicated, create a sync config resource with the resources to be replicated into OPA. For example, the below configuration replicates all namespace and pod resources to OPA.
apiVersion: config.gatekeeper.sh/v1alpha1
kind: Config
metadata:
name: config
namespace: "gatekeeper-system"
spec:
sync:
syncOnly:
- group: ""
version: "v1"
kind: "Namespace"
- group: ""
version: "v1"
kind: "Pod"
Planned for Future
The community behind the Gatekeeper project will be focusing on providing mutating admission control to support mutation scenarios (for example: annotate objects automatically with departmental information when creating a new resource), support external data to inject context external to the cluster into the admission decisions, support dry run to see impact of a policy on existing resources in the cluster before enforcing it, and more audit functionalities.
If you are interested in learning more about the project, check out the Gatekeeper repo. If you are interested in helping define the direction of Gatekeeper, join the #kubernetes-policy channel on OPA Slack, and join our weekly meetings to discuss development, issues, use cases, etc.
Get started with Kubernetes (using Python)
Author: Jason Haley (Independent Consultant)
So, you know you want to run your application in Kubernetes but don’t know where to start. Or maybe you’re getting started but still don’t know what you don’t know. In this blog you’ll walk through how to containerize an application and get it running in Kubernetes.
This walk-through assumes you are a developer or at least comfortable with the command line (preferably bash shell).
What we’ll do
- Get the code and run the application locally
- Create an image and run the application in Docker
- Create a deployment and run the application in Kubernetes
Prerequisites
- A Kubernetes service - I'm using Docker Desktop with Kubernetes in this walkthrough, but you can use one of the others. See Getting Started for a full listing.
- Python 3.7 installed
- Git installed
Containerizing an application
In this section you’ll take some source code, verify it runs locally, and then create a Docker image of the application. The sample application used is a very simple Flask web application; if you want to test it locally, you’ll need Python installed. Otherwise, you can skip to the "Create a Dockerfile" section.
Get the application code
Use git to clone the repository to your local machine:
git clone https://github.com/JasonHaley/hello-python.git
Change to the app directory:
cd hello-python/app
There are only two files in this directory. If you look at the main.py file, you’ll see the application prints out a hello message. You can learn more about Flask on the Flask website.
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello from Python!"
if __name__ == "__main__":
app.run(host='0.0.0.0')
The requirements.txt file contains the list of packages needed by the main.py and will be used by pip to install the Flask library.
pip install and may want to use virtualenv (or pyenv) to install your dependencies in a virtual environment.
Run locally
Manually run the installer and application using the following commands:
pip install -r requirements.txt
python main.py
This will start a development web server hosting your application, which you will be able to see by navigating to http://localhost:5000. Because port 5000 is the default port for the development server, we didn’t need to specify it.
Create a Dockerfile
Now that you have verified the source code works, the first step in containerizing the application is to create a Dockerfile.
In the hello-python/app directory, create a file named Dockerfile with the following contents and save it:
FROM python:3.7
RUN mkdir /app
WORKDIR /app
ADD . /app/
RUN pip install -r requirements.txt
EXPOSE 5000
CMD ["python", "/app/main.py"]
This file is a set of instructions Docker will use to build the image. For this simple application, Docker is going to:
- Get the official Python Base Image for version 3.7 from Docker Hub.
- In the image, create a directory named app.
- Set the working directory to that new app directory.
- Copy the local directory’s contents to that new folder into the image.
- Run the pip installer (just like we did earlier) to pull the requirements into the image.
- Inform Docker the container listens on port 5000.
- Configure the starting command to use when the container starts.
Create an image
At your command line or shell, in the hello-python/app directory, build the image with the following command:
docker build -f Dockerfile -t hello-python:latest .
This will perform those seven steps listed above and create the image. To verify the image was created, run the following command:
docker image ls

The application is now containerized, which means it can now run in Docker and Kubernetes!
Running in Docker
Before jumping into Kubernetes, let’s verify it works in Docker. Run the following command to have Docker run the application in a container and map it to port 5001:
docker run -p 5001:5000 hello-python
Now navigate to http://localhost:5001, and you should see the “Hello from Python!” message.
More info
Running in Kubernetes
You are finally ready to get the application running in Kubernetes. Because you have a web application, you will create a service and a deployment.
First verify your kubectl is configured. At the command line, type the following:
kubectl version
If you don’t see a reply with a Client and Server version, you’ll need to install and configure it.
If you are running on Windows or Mac, make sure it is using the Docker for Desktop context by running the following:
kubectl config use-context docker-for-desktop
Now you are working with Kubernetes! You can see the node by typing:
kubectl get nodes
Now let’s have it run the application. Create a file named deployment.yaml and add the following contents to it and then save it:
apiVersion: v1
kind: Service
metadata:
name: hello-python-service
spec:
selector:
app: hello-python
ports:
- protocol: "TCP"
port: 6000
targetPort: 5000
type: LoadBalancer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-python
spec:
selector:
matchLabels:
app: hello-python
replicas: 4
template:
metadata:
labels:
app: hello-python
spec:
containers:
- name: hello-python
image: hello-python:latest
imagePullPolicy: Never
ports:
- containerPort: 5000
This YAML file is the instructions to Kubernetes for what you want running. It is telling Kubernetes the following:
- You want a load-balanced service exposing port 6000
- You want four instances of the hello-python container running
Use kubectl to send the YAML file to Kubernetes by running the following command:
kubectl apply -f deployment.yaml
You can see the pods are running if you execute the following command:
kubectl get pods
Now navigate to http://localhost:6000, and you should see the “Hello from Python!” message.
That’s it! The application is now running in Kubernetes!
More Info
Summary
In this walk-through, we containerized an application, and got it running in Docker and in Kubernetes. This simple application only scratches the surface of what’s possible (and what you’ll need to learn).
Next steps
If you are just getting started and this walk-through was useful to you, then the following resources should be good next steps for you to further expand your Kubernetes knowledge:
- Introduction to Microservices, Docker, and Kubernetes - 55-minute video by James Quigley
- This is a great place to start because it provides more information than I could here.
- Containerize your Apps with Docker and Kubernetes - free e-book by Dr Gabriel N Schenker
- This is my favorite book on Docker and Kubernetes.
- Kubernetes Learning Path: 50 days from zero to hero with Kubernetes - on Microsoft’s site
- This is a 10-page pdf that has tons of links to videos (with Brendan Burns), documentation sites, and a really good workshop for Azure Kubernetes Service.
How to enable Kubernetes in Docker Desktop
Once you have Docker Desktop installed, open the Settings:
Select the Kubernetes menu item on the left and verify that the Enable Kubernetes is checked. If it isn’t, check it and click the Apply button at the bottom right:
Deprecated APIs Removed In 1.16: Here’s What You Need To Know
Author: Vallery Lancey (Lyft)
As the Kubernetes API evolves, APIs are periodically reorganized or upgraded. When APIs evolve, the old API is deprecated and eventually removed.
The v1.16 release will stop serving the following deprecated API versions in favor of newer and more stable API versions:
- NetworkPolicy in the extensions/v1beta1 API version is no longer served
- Migrate to use the networking.k8s.io/v1 API version, available since v1.8. Existing persisted data can be retrieved/updated via the new version.
- PodSecurityPolicy in the extensions/v1beta1 API version
- Migrate to use the policy/v1beta1 API, available since v1.10. Existing persisted data can be retrieved/updated via the new version.
- DaemonSet in the extensions/v1beta1 and apps/v1beta2 API versions is no longer served
- Migrate to use the apps/v1 API version, available since v1.9. Existing persisted data can be retrieved/updated via the new version.
- Notable changes:
spec.templateGenerationis removedspec.selectoris now required and immutable after creation; use the existing template labels as the selector for seamless upgradesspec.updateStrategy.typenow defaults toRollingUpdate(the default inextensions/v1beta1wasOnDelete)
- Deployment in the extensions/v1beta1, apps/v1beta1, and apps/v1beta2 API versions is no longer served
- Migrate to use the apps/v1 API version, available since v1.9. Existing persisted data can be retrieved/updated via the new version.
- Notable changes:
spec.rollbackTois removedspec.selectoris now required and immutable after creation; use the existing template labels as the selector for seamless upgradesspec.progressDeadlineSecondsnow defaults to600seconds (the default inextensions/v1beta1was no deadline)spec.revisionHistoryLimitnow defaults to10(the default inapps/v1beta1was2, the default inextensions/v1beta1was to retain all)maxSurgeandmaxUnavailablenow default to25%(the default inextensions/v1beta1was1)
- StatefulSet in the apps/v1beta1 and apps/v1beta2 API versions is no longer served
- Migrate to use the apps/v1 API version, available since v1.9. Existing persisted data can be retrieved/updated via the new version.
- Notable changes:
spec.selectoris now required and immutable after creation; use the existing template labels as the selector for seamless upgradesspec.updateStrategy.typenow defaults toRollingUpdate(the default inapps/v1beta1wasOnDelete)
- ReplicaSet in the extensions/v1beta1, apps/v1beta1, and apps/v1beta2 API versions is no longer served
- Migrate to use the apps/v1 API version, available since v1.9. Existing persisted data can be retrieved/updated via the new version.
- Notable changes:
spec.selectoris now required and immutable after creation; use the existing template labels as the selector for seamless upgrades
The v1.22 release will stop serving the following deprecated API versions in favor of newer and more stable API versions:
- Ingress in the extensions/v1beta1 API version will no longer be served
- Migrate to use the networking.k8s.io/v1beta1 API version, available since v1.14. Existing persisted data can be retrieved/updated via the new version.
What To Do
Kubernetes 1.16 is due to be released in September 2019, so be sure to audit your configuration and integrations now!
- Change YAML files to reference the newer APIs
- Update custom integrations and controllers to call the newer APIs
- Update third party tools (ingress controllers, continuous delivery systems) to call the newer APIs
Migrating to the new Ingress API will only require changing the API path - the
API fields remain the same. However, migrating other resources (EG Deployments)
will require some updates based on changed fields. You can use the
kubectl convert command to automatically convert an existing object:
kubectl convert -f <file> --output-version <group>/<version>.
For example, to convert
an older Deployment to apps/v1, you can run:
kubectl convert -f ./my-deployment.yaml --output-version apps/v1
Note that this may use non-ideal default values. To learn more about a specific
resource, check the Kubernetes api reference.
You can test your clusters by starting an apiserver with the above resources disabled, to simulate the upcoming removal. Add the following flag to the apiserver startup arguments:
--runtime-config=apps/v1beta1=false,apps/v1beta2=false,extensions/v1beta1/daemonsets=false,extensions/v1beta1/deployments=false,extensions/v1beta1/replicasets=false,extensions/v1beta1/networkpolicies=false,extensions/v1beta1/podsecuritypolicies=false
Want To Know More?
Deprecations are announced in the Kubernetes release notes. You can see these announcements in 1.14 and 1.15.
You can read more in our deprecation policy document about the deprecation policies for Kubernetes APIs, and other Kubernetes components. Deprecation policies vary by component (for example, the primary APIs vs. admin CLIs) and by maturity (alpha, beta, or GA).
These details were also previously announced on the kubernetes-dev mailing list, along with the releases of Kubernetes 1.14 and 1.15. From Jordan Liggitt:
In case you missed it in the 1.15.0 release notes, the timelines for deprecated resources in the extensions/v1beta1, apps/v1beta1, and apps/v1beta2 API groups to no longer be served by default have been updated:
* NetworkPolicy resources will no longer be served from extensions/v1beta1 by default in v1.16. Migrate to the networking.k8s.io/v1 API, available since v1.8. Existing persisted data can be retrieved/updated via the networking.k8s.io/v1 API.
* PodSecurityPolicy resources will no longer be served from extensions/v1beta1 by default in v1.16. Migrate to the policy/v1beta1 API, available since v1.10. Existing persisted data can be retrieved/updated via the policy/v1beta1 API.
* DaemonSet, Deployment, StatefulSet, and ReplicaSet resources will no longer be served from extensions/v1beta1, apps/v1beta1, or apps/v1beta2 by default in v1.16. Migrate to the apps/v1 API, available since v1.9. Existing persisted data can be retrieved/updated via the apps/v1 API.
To start a v1.15.0 API server with these resources disabled to flush out dependencies on these deprecated APIs, and ensure your application/manifests will work properly against the v1.16 release, use the following --runtime-config argument:
--runtime-config=apps/v1beta1=false,apps/v1beta2=false,extensions/v1beta1/daemonsets=false,extensions/v1beta1/deployments=false,extensions/v1beta1/replicasets=false,extensions/v1beta1/networkpolicies=false,extensions/v1beta1/podsecuritypolicies=false
Recap of Kubernetes Contributor Summit Barcelona 2019
Author: Jonas Rosland (VMware)
First of all, THANK YOU to everyone who made the Kubernetes Contributor Summit in Barcelona possible. We had an amazing team of volunteers tasked with planning and executing the event, and it was so much fun meeting and talking to all new and current contributors during the main event and the pre-event celebration.
Contributor Summit in Barcelona kicked off KubeCon + CloudNativeCon in a big way as it was the largest contributor summit to date with 331 people signed up, and only 9 didn't pick up their badges!
Contributor Celebration
Sunday evening before the main event we held a Contributor Celebration, which was very well attended. We hope that all new and current contributors felt welcome and enjoyed the food, the music, and the company.


New Contributor Workshops
We had over 130 people registered for the New Contributor Workshops. This year the workshops were divided into 101-level content for people who were not familiar with contributing to an open source project, and 201-level content for those who were.
The workshops contained overviews of what SIGs are, deep-dives into the codebase, test builds of the Kubernetes project, and real contributions.
Did you miss something during the workshops? We now have them published on YouTube, with added closed captioning!


SIG Face-to-Face
We also tried a new thing for Barcelona, the SIG Face-to-Face meetings. We had over 170 people registered to attend the 11 SIG and one subproject meetings throughout the day, going over what they're working on and what they want to do in the near future.


SIG Meet and Greet
At the end of the summit, both new and current contributors had a chance to sit down with SIG chairs and members. The goal of this was to make sure that contributors got to know even more individuals in the project, hear what some of the SIGs actually do, and sign up to be a part of them and learn more.


Join us!
Interested in attending the Contributor Summit in San Diego? You can get more information on our event page, sign up and we will notify you when registration opens.
Thanks!
Again, thank you to everyone for making this an amazing event, and we're looking forward to seeing you next time!
To our Barcelona crew, you ROCK! 🥁
Paris Pittman, Bob Killen, Guinevere Saenger, Tim Pepper, Deb Giles, Ihor Dvoretskyi, Jorge Castro, Noah Kantrowitz, Dawn Foster, Ruben Orduz, Josh Berkus, Kiran Mova, Bart Smykla, Rostislav Georgiev, Jeffrey Sica, Rael Garcia, Silvia Moura Pina, Arnaud Meukam, Jason DeTiberius, Andy Goldstein, Suzanne Ambiel, Jonas Rosland
You can see many more pictures from the event over on CNCF's Flickr.
Automated High Availability in kubeadm v1.15: Batteries Included But Swappable
Authors:
- Lucas Käldström, @luxas, SIG Cluster Lifecycle co-chair & kubeadm subproject owner, Weaveworks
- Fabrizio Pandini, @fabriziopandini, kubeadm subproject owner, Independent
kubeadm is a tool that enables Kubernetes administrators to quickly and easily bootstrap minimum viable clusters that are fully compliant with Certified Kubernetes guidelines. It’s been under active development by SIG Cluster Lifecycle since 2016 and graduated it from beta to generally available (GA) at the end of 2018.
After this important milestone, the kubeadm team is now focused on the stability of the core feature set and working on maturing existing features.
With this post, we are introducing the improvements made in the v1.15 release of kubeadm.
The scope of kubeadm
kubeadm is focused on performing the actions necessary to get a minimum viable, secure cluster up and running in a user-friendly way. kubeadm's scope is limited to the local machine’s filesystem and the Kubernetes API, and it is intended to be a composable building block for higher-level tools.
The core of the kubeadm interface is quite simple: new control plane nodes are created by you running
kubeadm init, worker nodes are joined to the control plane by you running
kubeadm join. Also included are common utilities for managing already bootstrapped
clusters, such as control plane upgrades, token and certificate renewal.
To keep kubeadm lean, focused, and vendor/infrastructure agnostic, the following tasks are out of scope:
- Infrastructure provisioning
- Third-party networking
- Non-critical add-ons, e.g. monitoring, logging, and visualization
- Specific cloud provider integrations
Those tasks are addressed by other SIG Cluster Lifecycle projects, such as the Cluster API for infrastructure provisioning and management.
Instead, kubeadm covers only the common denominator in every Kubernetes cluster: the control plane.
What’s new in kubeadm v1.15?
High Availability to Beta
We are delighted to announce that automated support for High Availability clusters is graduating to Beta in kubeadm v1.15. Let’s give a great shout out to all the contributors that helped in this effort and to the early adopter users for the great feedback received so far!
But how does automated High Availability work in kubeadm?
The great news is that you can use the familiar kubeadm init or kubeadm join workflow for creating high availability cluster as well, with the only difference that you have to pass the --control-plane flag to kubeadm join when adding more control plane nodes.
A 3-minute screencast of this feature is here:

In a nutshell:
-
Set up a Load Balancer. You need an external load balancer; providing this however, is out of scope of kubeadm.
- The community will provide a set of reference implementations for this task though
- HAproxy, Envoy, or a similar Load Balancer from a cloud provider work well
-
Run kubeadm init on the first control plane node, with small modifications:
- Create a kubeadm Config File
- In the config file, set the
controlPlaneEndpointfield to where your Load Balancer can be reached at. - Run init, with the
--upload-certsflag like this:sudo kubeadm init --config=kubeadm-config.yaml --upload-certs
-
Run kubeadm join --control-plane at any time when you want to expand the set of control plane nodes
- Both control-plane- and normal nodes can be joined in any order, at any time
- The command to run will be given by
kubeadm initabove, and is of the form:
kubeadm join [LB endpoint] \ --token ... \ --discovery-token-ca-cert-hash sha256:... \ --control-plane --certificate-key ...
For those interested in the details, there are many things that make this functionality possible. Most notably:
-
Automated certificate transfer. kubeadm implements an automatic certificate copy feature to automate the distribution of all the certificate authorities/keys that must be shared across all the control-planes nodes in order to get your cluster to work. This feature can be activated by passing
--upload-certstokubeadm init; see configure and deploy an HA control plane for more details. This is an explicit opt-in feature, you can also distribute the certificates manually in your preferred way. \ -
Dynamically-growing etcd cluster. When you're not providing an external etcd cluster, kubeadm automatically adds a new etcd member, running as a static pod. All the etcd members are joined in a “stacked” etcd cluster that grows together with your high availability control-plane \
-
Concurrent joining. Similarly to what already implemented for worker nodes, you join control-plane nodes whenever, in any order, or even in parallel. \
-
Upgradable. The kubeadm upgrade workflow was improved in order to properly handle the HA scenario, and, after starting the upgrade with
kubeadm upgrade applyas usual, users can now complete the upgrade process by usingkubeadm upgrade nodeboth on the remaining control-plane nodes and worker nodes
Finally, it is also worthy to notice that an entirely new test suite has been created specifically for ensuring High Availability in kubeadm will stay stable over time.
Certificate Management
Certificate management has become more simple and robust in kubeadm v1.15.
If you perform Kubernetes version upgrades regularly, kubeadm will now take care of keeping your cluster up to date and reasonably secure by automatically rotating all your certificates at kubeadm upgrade time.
If instead, you prefer to renew your certificates manually, you can opt out from the automatic certificate renewal by passing --certificate-renewal=false to kubeadm upgrade commands. Then you can perform manual certificate renewal with the kubeadm alpha certs renew command.
But there is more.
A new command kubeadm alpha certs check-expiration was introduced to allow users to
check certificate expiration. The output is similar to this:
CERTIFICATE EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
admin.conf May 15, 2020 13:03 UTC 364d false
apiserver May 15, 2020 13:00 UTC 364d false
apiserver-etcd-client May 15, 2020 13:00 UTC 364d false
apiserver-kubelet-client May 15, 2020 13:00 UTC 364d false
controller-manager.conf May 15, 2020 13:03 UTC 364d false
etcd-healthcheck-client May 15, 2020 13:00 UTC 364d false
etcd-peer May 15, 2020 13:00 UTC 364d false
etcd-server May 15, 2020 13:00 UTC 364d false
front-proxy-client May 15, 2020 13:00 UTC 364d false
scheduler.conf May 15, 2020 13:03 UTC 364d false
You should expect also more work around certificate management in kubeadm in the next releases, with the introduction of ECDSA keys and with improved support for CA key rotation. Additionally, the commands staged under kubeadm alpha are expected to move top-level soon.
Improved Configuration File Format
You can argue that there are hardly two Kubernetes clusters that are configured equally, and hence there is a need to customize how the cluster is set up depending on the environment. One way of configuring a component is via flags. However, this has some scalability limitations:
- Hard to maintain. When a component’s flag set grows over 30+ flags, configuring it becomes really painful.
- Complex upgrades. When flags are removed, deprecated or changed, you need to upgrade of the binary at the same time as the arguments.
- Key-value limited. There are simply many types of configuration you can’t express with the
--key=valuesyntax. - Imperative. In contrast to Kubernetes API objects themselves that are declaratively specified, flag arguments are imperative by design.
This is a key problem for Kubernetes components in general, as some components have 150+ flags. With kubeadm we’re pioneering the ComponentConfig effort, and providing users with a small set of flags, but most importantly, a declarative and versioned configuration file for advance use-cases. We call this ComponentConfig. It has the following characteristics:
- Upgradable: You can upgrade the binary, and still use the existing, older schema. Automatic migrations.
- Programmable. Configuration expressed in JSON/YAML allows for consistent, and programmable manipulation
- Expressible. Advanced patterns of configuration can be used and applied.
- Declarative. OpenAPI information can easily be exposed / used for doc generation
In kubeadm v1.15, we have improved the structure and are releasing the new v1beta2 format. Important to note that the existing v1beta1 format released in v1.13 will still continue to work for several releases. This means you can upgrade kubeadm to v1.15, and still use your existing v1beta1 configuration files. When you’re ready to take advantage of the improvements made in v1beta2, you can perform an automatic schema migration using the kubeadm config migrate command.
During the course of the year, we’re looking forward to graduate the schema to General Availability v1.` If you’re interested in this effort, you can also join WG Component Standard.
What’s next?
2019 plans
We are focusing our efforts around graduating the configuration file format to GA (kubeadm.k8s.io/v1)`, graduating this super-easy High Availability flow to stable, and providing better tools around rotating certificates needed for running the cluster automatically.
In addition to these three key milestones of our charter, we want to improve the following areas:
- Support joining Windows nodes to a kubeadm cluster (with end-to-end tests)
- Improve the upstream CI signal, mainly for HA and upgrades
- Consolidate how Kubernetes artifacts are built and installed
- Utilize Kustomize to allow for advanced, layered and declarative configuration
We make no guarantees that these deliverables will ship this year though, as this is a community effort. If you want to see these things happen, please join our SIG and start contributing! The ComponentConfig issues in particular need more attention.
kubeadm now has a logo!
Dan Kohn offered CNCF’s help with creating a logo for kubeadm in this cycle. Alex Contini created 19 (!) different logo options for the community to vote on. The public poll was active for around a week, and we got 386 answers. The winning option got 17.4% of the votes. In other words, now we have an official logo!
![]()
Contributing
If this all sounds exciting, join us!
SIG Cluster Lifecycle has many different subprojects, where kubeadm is one of them. In the following picture you can see that there are many pieces in the puzzle, and we have a lot still to do.
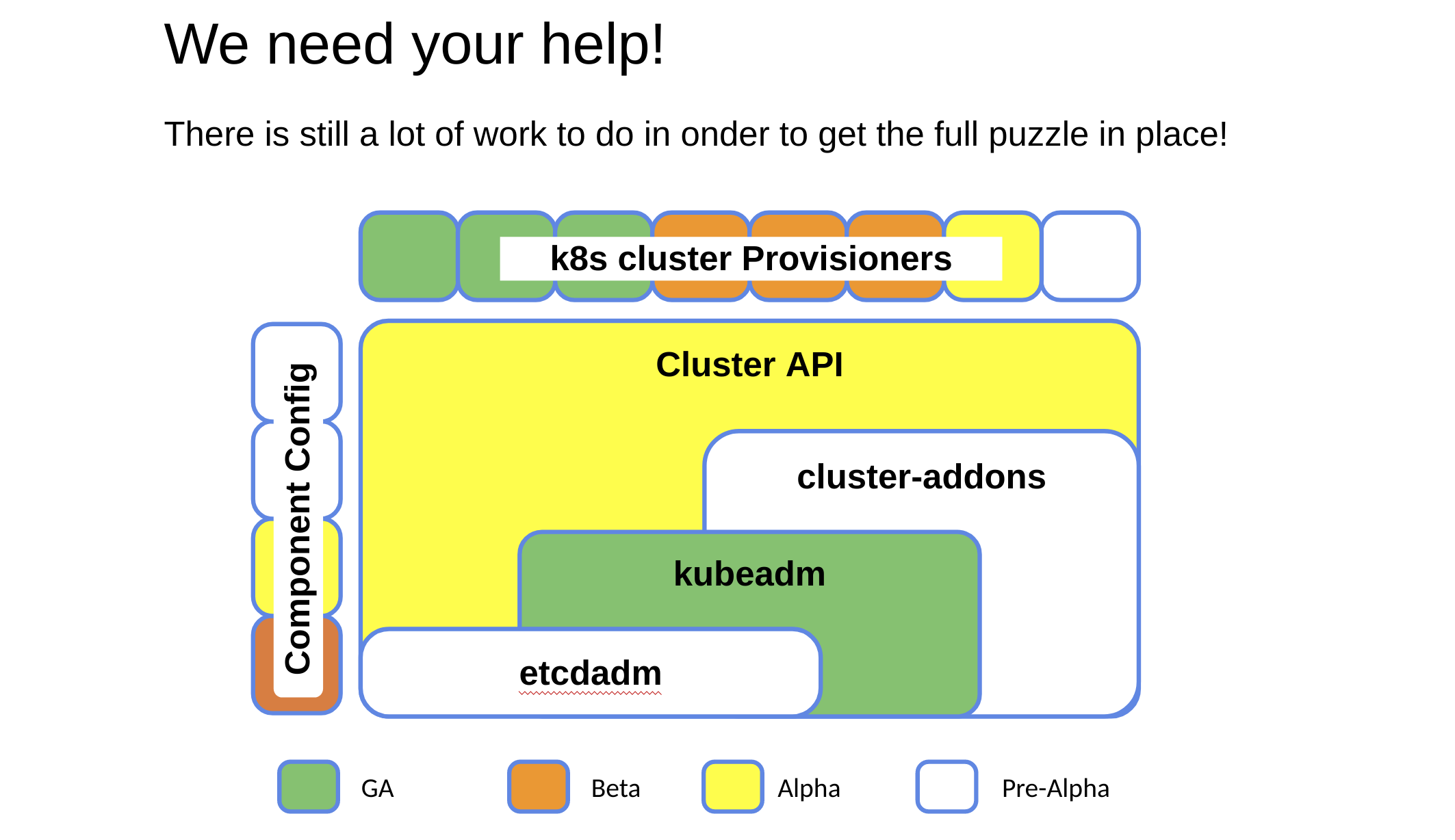
Some handy links if you want to start contribute:
- You can watch the SIG Cluster Lifecycle New Contributor Onboarding session on YouTube.
- Look out for “good first issue”, “help wanted” and “sig/cluster-lifecycle” labeled issues in our repositories (e.g. kubernetes/kubeadm)
- Join #sig-cluster-lifecycle, #kubeadm, #cluster-api, #minikube, #kind, etc. in Slack
- Join our public, bi-weekly SIG Cluster Lifecycle Zoom meeting at Tuesdays 9am PT
- Check out the Meeting Notes to join
- Join our public, weekly kubeadm Office Hours Zoom meeting at Wednesdays 9am PT
- Check out the Meeting Notes to join
- Check out the SIG Cluster Lifecycle Intro or the kubeadm Deep Dive sessions from KubeCon Barcelona
Thank You
This release wouldn’t have been possible without the help of the great people that have been contributing to SIG Cluster Lifecycle and kubeadm. We would like to thank all the kubeadm contributors and companies making it possible for their developers to work on Kubernetes!
In particular, we would like to thank the kubeadm subproject owners that made this possible:
- Tim St. Clair , @timothysc, SIG Cluster Lifecycle co-chair, VMware
- Lucas Käldström, @luxas, SIG Cluster Lifecycle co-chair, Weaveworks
- Fabrizio Pandini, @fabriziopandini, Independent
- Lubomir I. Ivanov, @neolit123, VMware
- Rostislav M. Georgiev, @rosti, VMware
Introducing Volume Cloning Alpha for Kubernetes
Author: John Griffith (Red Hat)
Kubernetes v1.15 introduces alpha support for volume cloning. This feature allows you to create new volumes using the contents of existing volumes in the user's namespace using the Kubernetes API.
What is a Clone?
Many storage systems provide the ability to create a "clone" of a volume. A clone is a duplicate of an existing volume that is its own unique volume on the system, but the data on the source is duplicated to the destination (clone). A clone is similar to a snapshot in that it's a point in time copy of a volume, however rather than creating a new snapshot object from a volume, we're instead creating a new independent volume, sometimes thought of as pre-populating the newly created volume.
Why add cloning to Kubernetes
The Kubernetes volume plugin system already provides a powerful abstraction that automates the provisioning, attaching, and mounting of block and file storage.
Underpinning all these features is the Kubernetes goal of workload portability: Kubernetes aims to create an abstraction layer between distributed systems applications and underlying clusters so that applications can be agnostic to the specifics of the cluster they run on and application deployment requires no specific storage device knowledge.
The Kubernetes Storage SIG identified clone operations as critical functionality for many stateful workloads. For example, a database administrator may want to duplicate a database volume and create another instance of an existing database.
By providing a standard way to trigger clone operations in the Kubernetes API, Kubernetes users can now handle use cases like this without having to go around the Kubernetes API (and manually executing storage system specific operations). While cloning is similar in behavior to creating a snapshot of a volume, then creating a volume from the snapshot, a clone operation is more streamlined and is more efficient for many backend devices.
Kubernetes users are now empowered to incorporate clone operations in a cluster agnostic way into their tooling and policy with the comfort of knowing that it will work against arbitrary Kubernetes clusters regardless of the underlying storage.
Kubernetes API and Cloning
The cloning feature in Kubernetes is enabled via the PersistentVolumeClaim.DataSource field. Prior to v1.15 the only valid object type permitted for use as a dataSource was a VolumeSnapshot. The cloning feature extends the allowed PersistentVolumeclaim.DataSource.Kind field to not only allow VolumeSnapshot but also PersistentVolumeClaim. The existing behavior is not changed.
There are no new objects introduced to enable cloning. Instead, the existing dataSource field in the PersistentVolumeClaim object is expanded to be able to accept the name of an existing PersistentVolumeClaim in the same namespace. It is important to note that from a users perspective a clone is just another PersistentVolume and PersistentVolumeClaim, the only difference being that that PersistentVolume is being populated with the contents of another PersistentVolume at creation time. After creation it behaves exactly like any other Kubernetes PersistentVolume and adheres to the same behaviors and rules.
Which volume plugins support Kubernetes Cloning?
Kubernetes supports three types of volume plugins: in-tree, Flex, and Container Storage Interface (CSI). See Kubernetes Volume Plugin FAQ for details.
Cloning is only supported for CSI drivers (not for in-tree or Flex). To use the Kubernetes cloning feature, ensure that a CSI Driver that implements cloning is deployed on your cluster. For a list of CSI drivers that currently support cloning see the CSI Drivers doc.
Kubernetes Cloning Requirements
Before using Kubernetes Volume Cloning, you must:
- Ensure a CSI driver implementing Cloning is deployed and running on your Kubernetes cluster.
- Enable the Kubernetes Volume Cloning feature via new Kubernetes feature gate (disabled by default for alpha):
- Set the following flag on the API server binary:
--feature-gates=VolumePVCDataSource=true
- Set the following flag on the API server binary:
- The source and destination claims must be in the same namespace.
Creating a clone with Kubernetes
To provision a new volume pre-populated with data from an existing Kubernetes Volume, use the dataSource field in the PersistentVolumeClaim. There are three parameters:
- name - name of the
PersistentVolumeClaimobject to use as source - kind - must be
PersistentVolumeClaim - apiGroup - must be
""
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-clone
Namespace: demo-namespace
spec:
storageClassName: csi-storageclass
dataSource:
name: src-pvc
kind: PersistentVolumeClaim
apiGroup: ""
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi # NOTE this capacity must be specified and must be >= the capacity of the source volume
When the PersistentVolumeClaim object is created, it will trigger provisioning of a new volume that is pre-populated with data from the specified dataSource volume. It is the sole responsbility of the CSI Plugin to implement the cloning of volumes.
As a storage vendor, how do I add support for cloning to my CSI driver?
For more information on how to implement cloning in your CSI Plugin, reference the developing a CSI driver for Kubernetes section of the CSI docs.
What are the limitations of alpha?
The alpha implementation of cloning for Kubernetes has the following limitations:
- Does not support cloning volumes across different namespaces
- Does not support cloning volumes across different storage classes (backends)
Future
Depending on feedback and adoption, the Kubernetes team plans to push the CSI cloning implementation to beta in 1.16.
A common question that users have regarding cloning is "what about cross namespace clones". As we've mentioned, the current release requires that source and destination be in the same namespace. There are however efforts underway to propose a namespace transfer API, future versions of Kubernetes may provide the ability to transfer volume resources from one namespace to another. This feature is still under discussion and design, and may or may not be available in a future release.
How can I learn more?
You can find additional documentation on the cloning feature in the storage concept docs and also the CSI docs.
How do I get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together.
We offer a huge thank you to all the contributors in Kubernetes Storage SIG and CSI community who helped review the design and implementation of the project, including but not limited to the following:
- Saad Ali (saadali)
- Tim Hockin (thockin)
- Jan Šafránek (jsafrane)
- Michelle Au (msau42)
- Xing Yang (xing-yang)
If you’re interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Future of CRDs: Structural Schemas
Authors: Stefan Schimanski (Red Hat)
CustomResourceDefinitions were introduced roughly two years ago as the primary way to extend the Kubernetes API with custom resources. From the beginning they stored arbitrary JSON data, with the exception that kind, apiVersion and metadata had to follow the Kubernetes API conventions. In Kubernetes 1.8 CRDs gained the ability to define an optional OpenAPI v3 based validation schema.
By the nature of OpenAPI specifications though—only describing what must be there, not what shouldn’t, and by being potentially incomplete specifications—the Kubernetes API server never knew the complete structure of CustomResource instances. As a consequence, kube-apiserver—until today—stores all JSON data received in an API request (if it validates against the OpenAPI spec). This especially includes anything that is not specified in the OpenAPI schema.
The story of malicious, unspecified data
To understand this, we assume a CRD for maintenance jobs by the operations team, running each night as a service user:
apiVersion: operations/v1
kind: MaintenanceNightlyJob
spec:
shell: >
grep backdoor /etc/passwd ||
echo “backdoor:76asdfh76:/bin/bash” >> /etc/passwd || true
machines: [“az1-master1”,”az1-master2”,”az2-master3”]
privileged: true
The privileged field is not specified by the operations team. Their controller does not know it, and their validating admission webhook does not know about it either. Nevertheless, kube-apiserver persists this suspicious, but unknown field without ever validating it.
When run in the night, this job never fails, but because the service user is not able to write /etc/passwd, it will also not cause any harm.
The maintenance team needs support for privileged jobs. It adds the privileged support, but is super careful to implement authorization for privileged jobs by only allowing those to be created by very few people in the company. That malicious job though has long been persisted to etcd. The next night arrives and the malicious job is executed.
Towards complete knowledge of the data structure
This example shows that we cannot trust CustomResource data in etcd. Without having complete knowledge about the JSON structure, the kube-apsierver cannot do anything to prevent persistence of unknown data.
Kubernetes 1.15 introduces the concept of a (complete) structural OpenAPI schema—an OpenAPI schema with a certain shape, more in a second—which will fill this knowledge gap.
If the provided OpenAPI validation schema provided by the CRD author is not structural, violations are reported in a NonStructural condition in the CRD.
A structural schema for CRDs in apiextensions.k8s.io/v1beta1 will not be required. But we plan to require structural schemas for every CRD created in apiextensions.k8s.io/v1, targeted for 1.16.
But now let us see what a structural schema looks like.
Structural Schema
The core of a structural schema is an OpenAPI v3 schema made out of
propertiesitemsadditionalPropertiestypenullabletitledescriptions.
In addition, all types must be non-empty, and in each sub-schema only one of properties, additionalProperties or items may be used.
Here is an example of our MaintenanceNightlyJob:
type: object
properties:
spec:
type: object
properties
command:
type: string
shell:
type: string
machines:
type: array
items:
type: string
This schema is structural because we only use the permitted OpenAPI constructs, and we specify each type.
Note that we leave out apiVersion, kind and metadata. These are implicitly defined for each object.
Starting from this structural core of our schema, we might enhance it for value validation purposes with nearly all other OpenAPI constructs, with only a few restrictions, for example:
type: object
properties:
spec:
type: object
properties
command:
type: string
minLength: 1 # value validation
shell:
type: string
minLength: 1 # value validation
machines:
type: array
items:
type: string
pattern: “^[a-z0-9]+(-[a-z0-9]+)*$” # value validation
oneOf: # value validation
- required: [“command”] # value validation
- required: [“shell”] # value validation
required: [“spec”] # value validation
Some notable restrictions for these additional value validations:
- the last 5 of the core constructs are not allowed:
additionalProperties,type,nullable,title,description - every properties field mentioned, must also show up in the core (without the blue value validations).
As you can see also logical constraints using oneOf, allOf, anyOf, not are allowed.
To sum up, an OpenAPI schema is structural if
- it has the core as defined above out of
properties,items,additionalProperties,type,nullable,title,description, - all types are defined,
- the core is extended with value validation following the constraints:
(i) inside of value validations noadditionalProperties,type,nullable,title,description
(ii) all fields mentioned in value validation are specified in the core.
Let us modify our example spec slightly, to make it non-structural:
properties:
spec:
type: object
properties
command:
type: string
minLength: 1
shell:
type: string
minLength: 1
machines:
type: array
items:
type: string
pattern: “^[a-z0-9]+(-[a-z0-9]+)*$”
oneOf:
- properties:
command:
type: string
required: [“command”]
- properties:
shell:
type: string
required: [“shell”]
not:
properties:
privileged: {}
required: [“spec”]
This spec is non-structural for many reasons:
type: objectat the root is missing (rule 2).- inside of
oneOfit is not allowed to usetype(rule 3-i). - inside of
notthe propertyprivilegedis mentioned, but it is not specified in the core (rule 3-ii).
Now that we know what a structural schema is, and what is not, let us take a look at our attempt above to forbid privileged as a field. While we have seen that this is not possible in a structural schema, the good news is that we don’t have to explicitly attempt to forbid unwanted fields in advance.
Pruning – don’t preserve unknown fields
In apiextensions.k8s.io/v1 pruning will be the default, with ways to opt-out of it. Pruning in apiextensions.k8s.io/v1beta1 is enabled via
apiVersion: apiextensions/v1beta1
kind: CustomResourceDefinition
spec:
…
preserveUnknownFields: false
Pruning can only be enabled if the global schema or the schemas of all versions are structural.
If pruning is enabled, the pruning algorithm
- assumes that the schema is complete, i.e. every field is mentioned and not-mentioned fields can be dropped
- is run on
(i) data received via an API request
(ii) after conversion and admission requests
(iii) when reading from etcd (using the schema version of the data in etcd).
As we don’t specify privileged in our structural example schema, the malicious field is pruned from before persisting to etcd:
apiVersion: operations/v1
kind: MaintenanceNightlyJob
spec:
shell: >
grep backdoor /etc/passwd ||
echo “backdoor:76asdfh76:/bin/bash” >> /etc/passwd || true
machines: [“az1-master1”,”az1-master2”,”az2-master3”]
# pruned: privileged: true
Extensions
While most Kubernetes-like APIs can be expressed with a structural schema, there are a few exceptions, notably intstr.IntOrString, runtime.RawExtensions and pure JSON fields.
Because we want CRDs to make use of these types as well, we introduce the following OpenAPI vendor extensions to the permitted core constructs:
-
x-kubernetes-embedded-resource: true— specifies that this is anruntime.RawExtension-like field, with a Kubernetes resource with apiVersion, kind and metadata. The consequence is that those 3 fields are not pruned and are automatically validated. -
x-kubernetes-int-or-string: true— specifies that this is either an integer or a string. No types must be specified, butoneOf: - type: integer - type: stringis permitted, though optional.
-
x-kubernetes-preserve-unknown-fields: true— specifies that the pruning algorithm should not prune any field. This can be combined withx-kubernetes-embedded-resource. Note that within a nestedpropertiesoradditionalPropertiesOpenAPI schema the pruning starts again.One can use
x-kubernetes-preserve-unknown-fields: trueat the root of the schema (and inside anyproperties,additionalProperties) to get the traditional CRD behaviour that nothing is pruned, despite settingspec.preserveUnknownProperties: false.
Conclusion
With this we conclude the discussion of the structural schema in Kubernetes 1.15 and beyond. To sum up:
- structural schemas are optional in
apiextensions.k8s.io/v1beta1. Non-structural CRDs will keep working as before. - pruning (enabled via
spec.preserveUnknownProperties: false) requires a structural schema. - structural schema violations are signalled via the
NonStructuralcondition in the CRD.
Structural schemas are the future of CRDs. apiextensions.k8s.io/v1 will require them. But
type: object
x-kubernetes-preserve-unknown-fields: true
is a valid structural schema that will lead to the old schema-less behaviour.
Any new feature for CRDs starting from Kubernetes 1.15 will require to have a structural schema:
- publishing of OpenAPI validation schemas and therefore support for kubectl client-side validation, and
kubectl explainsupport (beta in Kubernetes 1.15) - CRD conversion (beta in Kubernetes 1.15)
- CRD defaulting (alpha in Kubernetes 1.15)
- Server-side apply (alpha in Kubernetes 1.15, CRD support pending).
Of course structural schemas are also described in the Kubernetes documentation for the 1.15 release.
Kubernetes 1.15: Extensibility and Continuous Improvement
Authors: The 1.15 Release Team
We’re pleased to announce the delivery of Kubernetes 1.15, our second release of 2019! Kubernetes 1.15 consists of 25 enhancements: 2 moving to stable, 13 in beta, and 10 in alpha. The main themes of this release are:
- Continuous Improvement
- Project sustainability is not just about features. Many SIGs have been working on improving test coverage, ensuring the basics stay reliable, and stability of the core feature set and working on maturing existing features and cleaning up the backlog.
- Extensibility
- The community has been asking for continuing support of extensibility, so this cycle features more work around CRDs and API Machinery. Most of the enhancements in this cycle were from SIG API Machinery and related areas.
Let’s dive into the key features of this release:
Extensibility around core Kubernetes APIs
The theme of the new developments around CustomResourceDefinitions is data consistency and native behaviour. A user should not notice whether the interaction is with a CustomResource or with a Golang-native resource. With big steps we are working towards a GA release of CRDs and GA of admission webhooks in one of the next releases.
In this direction, we have rethought our OpenAPI based validation schemas in CRDs and from 1.15 on we check each schema against a restriction called “structural schema”. This basically enforces non-polymorphic and complete typing of each field in a CustomResource. We are going to require structural schemas in the future, especially for all new features including those listed below, and list violations in a NonStructural condition. Non-structural schemas keep working for the time being in the v1beta1 API group. But any serious CRD application is urged to migrate to structural schemas in the foreseeable future.
Details about what makes a schema structural will be published in a blog post on kubernetes.io later this week, and it is of course documented in the Kubernetes documentation.
beta: CustomResourceDefinition Webhook Conversion
CustomResourceDefinitions support multiple versions as beta since 1.14. With Kubernetes 1.15, they gain the ability to convert between different versions on-the-fly, just like users are used to from native resources for long term. Conversions for CRDs are implemented via webhooks, deployed inside the cluster by the cluster admin. This feature is promoted to beta in Kubernetes 1.15, lifting CRDs to a completely new level for serious CRD applications.
beta: CustomResourceDefinition OpenAPI Publishing
OpenAPI specs for native types have been served at /openapi/v2 by kube-apiserver for a long time, and they are consumed by a number of components, notably kubectl client-side validation, kubectl explain and OpenAPI based client generators.
OpenAPI publishing for CRDs will be available with Kubernetes 1.15 as beta, yet again only for structural schemas.
beta: CustomResourceDefinitions Pruning
Pruning is the automatic removal of unknown fields in objects sent to a Kubernetes API. A field is unknown if it is not specified in the OpenAPI validation schema. This is both a data consistency and security relevant feature. It enforces that only data structures specified by the CRD developer are persisted to etcd. This is the behaviour of native resources, and will be available for CRDs as well, starting as beta in Kubernetes 1.15.
Pruning is activated via spec.preserveUnknownFields: false in the CustomResourceDefinition. A future apiextensions.k8s.io/v1 variant of CRDs will enforce pruning (with a possible, but explicitly necessary opt-out).
Pruning requires that CRD developer provides complete, structural validation schemas, either top-level or for all versions of the CRD.
alpha: CustomResourceDefinition Defaulting
CustomResourceDefinitions get support for defaulting. Defaults are specified using the default keyword in the OpenAPI validation schema. Defaults are set for unspecified field in an object sent to the API, and when reading from etcd.
Defaulting will be available as alpha in Kubernetes 1.15 for structural schemas.
beta: Admission Webhook Reinvocation & Improvements
Mutating and validating admission webhooks become more and more mainstream for projects extending the Kubernetes API. Until now mutating webhooks were only called once, in alphabetical order. An earlier run webhook cannot react on the output of webhooks called later in the chain. With Kubernetes 1.15 this will change:
Mutating webhooks can opt-in into at least one re-invocation by specifying reinvocationPolicy: IfNeeded. If a later mutating webhook modifies the object, the earlier webhook will get a second chance.
This requires that webhooks have an idem-potent-like behaviour which can cope with this second invocation.
It is not planned to add another round of invocations such that webhook authors still have to be careful about the changes to admitted objects they implement. Finally the validating webhooks are called to verify that promised invariants are fulfilled.
There are more smaller changes to admission webhook, notably objectSelector to exclude objects with certain labels from admission, arbitrary port (not only 443) for the webhook server.
Cluster Lifecycle Stability and Usability Improvements
Work on making Kubernetes installation, upgrade and configuration even more robust has been a major focus for this cycle for SIG Cluster Lifecycle (see our last Community Update). Bug fixes across bare metal tooling and production-ready user stories, such as the high availability use cases have been given priority for 1.15.
kubeadm, the cluster lifecycle building block, continues to receive features and stability work required for bootstrapping production clusters efficiently. kubeadm has promoted high availability (HA) capability to beta, allowing users to use the familiar kubeadm init and kubeadm join commands to configure and deploy an HA control plane. An entire new test suite has been created specifically for ensuring these features will stay stable over time.
Certificate management has become more robust in 1.15, with kubeadm now seamlessly rotating all your certificates (on upgrades) before they expire. Check the kubeadm documentation for information on how to manage your certificates.
The kubeadm configuration file API is moving from v1beta1 to v1beta2 in 1.15.
Finally, let’s celebrate that kubeadm now has its own logo!
![]()
Continued improvement of CSI
In Kubernetes v1.15, SIG Storage continued work to enable migration of in-tree volume plugins to Container Storage Interface (CSI). SIG Storage worked on bringing CSI to feature parity with in-tree functionality, including functionality like resizing, inline volumes, and more. SIG Storage introduces new alpha functionality in CSI that doesn't exist in the Kubernetes Storage subsystem yet, like volume cloning.
Volume cloning enables users to specify another PVC as a "DataSource" when provisioning a new volume. If the underlying storage system supports this functionality and implements the "CLONE_VOLUME" capability in its CSI driver, then the new volume becomes a clone of the source volume.
Additional Notable Feature Updates
- Support for go modules in Kubernetes Core
- Continued preparation on cloud provider extraction and code organization. The cloud provider code has been moved to kubernetes/legacy-cloud-providers for easier removal later and external consumption.
- Kubectl get and describe now work with extensions
- Nodes now support third party monitoring plugins.
- A new Scheduling Framework for schedule plugins is now Alpha
- ExecutionHook API designed to trigger hook commands in the containers for different use cases is now Alpha.
- Continued deprecation of extensions/v1beta1, apps/v1beta1, and apps/v1beta2 APIs; these extensions will be retired in 1.16!
Check the release notes for a complete list of notable features and fixes.
Availability
Kubernetes 1.15 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials. You can also easily install 1.15 using kubeadm.
Features Blog Series
If you’re interested in exploring these features more in depth, check back this week and the next for our Days of Kubernetes series where we’ll highlight detailed walkthroughs of the following features:
- Future of CRDs: Structural Schemas
- Introducing Volume Cloning Alpha for Kubernetes
- Automated High Availability in Kubeadm
Release team
This release is made possible through the efforts of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Claire Laurence, Senior Technical Program Manager at Pivotal Software. The 38 individuals on the release team coordinated many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has had over 32,000 individual contributors to date and an active community of more than 66,000 people.
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. On average over the past year, 379 different companies and over 2,715 individuals contribute to Kubernetes each month. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
User Highlights
Established, global organizations are using Kubernetes in production at massive scale. Recently published user stories from the community include:
- China Unicom is using Kubernetes to increase their resource utilization 20-50%, lowering IT infrastructure costs, and cutting deployment time from hours to 10-15 minutes.
- The City of Montreal is using Kubernetes to decrease deployments from months to hours and run 200 application components on 8 machines with 5 people operating Kubernetes clusters.
- SLAMTEC is using Kubernetes along with other CNCF projects to achiever 18+ months of 100% uptime saving 50% time spent on troubleshooting and debugging and 30% time savings on CI/CD efforts.
- ThredUP has decreased deployment time by about 50% on average for key services and has shrunk lead time for deployment to under 20 minutes.
Is Kubernetes helping your team? Share your story with the community.
Ecosystem Updates
- Kubernetes recently celebrated its five-year anniversary at KubeCon + CloudNativeCon Barcelona
- The Certified Kubernetes Administrator (CKA) exam has become one of the most popular Linux Foundation certifications to date with over 9,000 registrations and over 1,700 individuals that passed and received the certification.
- Coming off the heels of a successful KubeCon + CloudNativeCon Europe 2019, the CNCF announced it has over 400 members with a 130 percent year-over-year growth rate.
KubeCon
The world’s largest Kubernetes gathering, KubeCon + CloudNativeCon is coming to Shanghai (co-located with Open Source Summit) from June 24-26, 2019 and San Diego from November 18-21. These conferences will feature technical sessions, case studies, developer deep dives, salons, and more! Register today!
Webinar
Join members of the Kubernetes 1.15 release team on July 23 at 10am PDT to learn about the major features in this release. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below. Thank you for your continued feedback and support.
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Post questions (or answer questions) on Stack Overflow
- Share your Kubernetes story
Join us at the Contributor Summit in Shanghai
Author: Josh Berkus (Red Hat)

For the second year, we will have a Contributor Summit event the day before KubeCon China in Shanghai. If you already contribute to Kubernetes or would like to contribute, please consider attending and register. The Summit will be held June 24th, at the Shanghai Expo Center (the same location where KubeCon will take place), and will include a Current Contributor Day as well as the New Contributor Workshop and the Documentation Sprints.
Current Contributor Day
After last year's Contributor Day, our team received feedback that many of our contributors in Asia and Oceania would like content for current contributors as well. As such, we have added a Current Contributor track to the schedule.
While we do not yet have a full schedule up, the topics covered in the current contributor track will include:
- How to write a KEP (Kubernetes Enhancement Proposal)
- Codebase and repository review
- Local Build & Test troubleshooting session
- Guide to Non-Code Contribution opportunities
- SIG-Azure face-to-face meeting
- SIG-Scheduling face-to-face meeting
- Other SIG face-to-face meetings as we confirm them
The schedule will be on the Community page once it is complete.
If your SIG wants to have a face-to-face meeting at Kubecon Shanghai, please contact Josh Berkus.
New Contributor Workshop
Students at last year's New Contributor Workshop (NCW) found it to be extremely valuable, and the event helped to orient a few of the many Asian and Pacific developers looking to participate in the Kubernetes community.
"It's a one-stop-shop for becoming familiar with the community." said one participant.
If you have not contributed to Kubernetes before, or have only done one or two things, please consider enrolling in the NCW.
"Got to know the process from signing CLA to PR and made friends with other contributors." said another.
Documentation Sprints
Both old and new contributors on our Docs Team will spend a day both improving our documentation and translating it into other languages. If you are interested in having better documentation, fully localized into Chinese and other languages, please sign up to help with the Doc Sprints.
Before you attend
Regardless of where you participate, everyone at the Contributor Summit should sign the Kubernetes Contributor License Agreement (CLA) before coming to the conference. You should also bring a laptop suitable for working on documentation or code development.
Kyma - extend and build on Kubernetes with ease
Authors: Lukasz Gornicki (SAP)
According to this recently completed CNCF Survey, the adoption rate of Cloud Native technologies in production is growing rapidly. Kubernetes is at the heart of this technological revolution. Naturally, the growth of cloud native technologies has been accompanied by the growth of the ecosystem that surrounds it. Of course, the complexity of cloud native technologies have increased as well. Just google for the phrase “Kubernetes is hard”, and you’ll get plenty of articles that explain this complexity problem. The best thing about the CNCF community is that problems like this can be solved by smart people building new tools to enable Kubernetes users: Projects like Knative and its Build resource extension, for example, serve to reduce complexity across a range of scenarios. Even though increasing complexity might seem like the most important issue to tackle, it is not the only challenge you face when transitioning to Cloud Native.
Problems to solve
Picking the right technology is hard
Now that you understand Kubernetes, your teams are trained and you’ve started building applications on top, it’s time to face a new layer of challenges. Cloud native doesn’t just mean deploying a platform for developers to build on top of. Developers also need storage, backup, monitoring, logging and a service mesh to enforce policies upon data in transit. Each of these individual systems must be properly configured and deployed, as well as logged, monitored and backed up on its own. The CNCF is here to help. We provide a landscape overview of all cloud-native technologies, but the list is huge and can be overwhelming.
This is where Kyma will make your life easier. Its mission statement is to enable a flexible and easy way of extending applications.
This project is designed to give you the tools you need to be able to write an end-to-end, production-grade cloud native application. Kyma was donated to the open-source community by SAP; a company with great experience in writing production-grade cloud native applications. That’s why we’re so excited to -- announce the first major release of Kyma 1.0!
Deciding on the path from monolith to cloud-native is hard
Try Googling monolith to cloud native or monolith to microservices and you’ll get a list of plenty of talks and papers that tackle this challenge. There are many different paths available for migrating a monolith to the cloud, and our experience has taught us to be quite opinionated in this area. First, let's answer the question of why you’d want to move from monolith to cloud native. The goals driving this move are typically:
- Increased scalability.
- Faster implementation of new features.
- More flexible approach to extensibility.
You do not have to rewrite your monolith to achieve these goals. Why spend all that time rewriting functionality that you already have? Just focus on enabling your monolith to support event-driven architecture.
How does Kyma solve your challenges?
What is Kyma?
Kyma runs on Kubernetes and consists of a number of different components, three of which are:
- Application connector that you can use to connect any application with a Kubernetes cluster and expose its APIs and Events through the Kubernetes Service Catalog.
- Serverless which enables you to easily write extensions for your application. Your function code can be triggered by API calls and also by events coming from external system. You can also securely call back the integrated system from your function.
- Service Catalog is here to expose integrated systems. This integration also enables you to use services from hyperscalers like Azure, AWS or Google Cloud. Kyma allows for easy integration of official service brokers maintained by Microsoft and Google.

You can watch this video for a short overview of Kyma key features that is based on a real demo scenario.
We picked the right technologies for you
You can provide reliable extensibility in a project like Kyma only if it is properly monitored and configured. We decided not to reinvent the wheel. There are many great projects in the CNCF landscape, most with huge communities behind them. We decided to pick the best ones and glue them all together in Kyma. You can see the same architecture diagram that is above but with a focus on the projects we put together to create Kyma:
- Monitoring and alerting is based on Prometheus and Grafana
- Logging is based on Loki
- Eventing uses Knative and NATS
- Asset management uses Minio as a storage
- Service Mesh is based on Istio
- Tracing is done with Jaeger
- Authentication is supported by dex
You don't have to integrate these tools: We made sure they all play together well, and are always up to date ( Kyma is already using Istio 1.1). With our custom Installer and Helm charts, we enabled easy installation and easy upgrades to new versions of Kyma.
Do not rewrite your monoliths
Rewriting is hard, costs a fortune, and in most cases is not needed. At the end of the day, what you need is to be able to write and put new features into production quicker. You can do it by connecting your monolith to Kyma using the Application Connector. In short, this component makes sure that:
- You can securely call back the registered monolith without the need to take care of authorization, as the Application Connector handles this.
- Events sent from your monolith get securely to the Kyma Event Bus.
At the moment, your monolith can consume three different types of services: REST (with OpenAPI specification) and OData (with Entity Data Model specification) for synchronous communication, and for asynchronous communication you can register a catalog of events based on AsyncAPI specification. Your events are later delivered internally using NATS Streaming channel with Knative eventing.
Once your monolith's services are connected, you can provision them in selected Namespaces thanks to the previously mentioned Service Catalog integration. You, as a developer, can go to the catalog and see a list of all the services you can consume. There are services from your monolith, and services from other 3rd party providers thanks to registered Service Brokers, like Azure's OSBA. It is the one single place with everything you need. If you want to stand up a new application, everything you need is already available in Kyma.
Finally some code
Check out some code I had to write to integrate a monolith with Azure services. I wanted to understand the sentiments shared by customers under the product's review section. On every event with a review comment, I wanted to use machine learning to call a sentiments analysis service, and in the case of a negative comment, I wanted to store it in a database for later review. This is the code of a function created thanks to our Serverless component. Pay attention to my code comments:
You can watch this short video for a full demo of sentiment analysis function.
/* It is a function powered by NodeJS runtime so I have to import some necessary dependencies. I choosed Azure's CosmoDB that is a Mongo-like database, so I could use a MongoClient */
const axios = require("axios");
const MongoClient = require('mongodb').MongoClient;
module.exports = { main: async function (event, context) {
/* My function was triggered because it was subscribed to customer review event. I have access to the payload of the event. */
let negative = await isNegative(event.data.comment)
if (negative) {
console.log("Customer sentiment is negative:", event.data)
await mongoInsert(event.data)
} else {
console.log("This positive comment was not saved:", event.data)
}
}}
/* Like in case of isNegative function, I focus of usage of the MongoClient API. The necessary information about the database location and an authorization needed to call it is injected into my function and I just need to pick a proper environment variable. */
async function mongoInsert(data) {
try {
client = await MongoClient.connect(process.env.connectionString, { useNewUrlParser: true });
db = client.db('mycommerce');
const collection = db.collection('comments');
return await collection.insertOne(data);
} finally {
client.close();
}
}
/* This function calls Azure's Text Analytics service to get information about the sentiment. Notice process.env.textAnalyticsEndpoint and process.env.textAnalyticsKey part. When I wrote this function I didn't have to go to Azure's console to get these details. I had these variables automatically injected into my function thanks to our integration with Service Catalog and our Service Binding Usage controller that pairs the binding with a function. */
async function isNegative(comment) {
let response = await axios.post(`${process.env.textAnalyticsEndpoint}/sentiment`,
{ documents: [{ id: '1', text: comment }] }, {headers:{ 'Ocp-Apim-Subscription-Key': process.env.textAnalyticsKey }})
return response.data.documents[0].score < 0.5
}
Thanks to Kyma, I don't have to worry about the infrastructure around my function. As I mentioned, I have all the tools needed in Kyma, and they are integrated together. I can quickly get access to my logs through Loki, and I can quickly get access to a preconfigured Grafana dashboard to see the metrics of my Lambda delivered thanks to Prometheus and Istio.
Such an approach gives you a lot of flexibility in adding new functionality. It also gives you time to rethink the need to rewrite old functions.
Contribute and give feedback
Kyma is an open source project, and we would love help it grow. The way that happens is with your help. After reading this post, you already know that we don't want to reinvent the wheel. We stay true to this approach in our work model, which enables community contributors. We work in Special Interest Groups and have publicly recorded meeting that you can join any time, so we have a setup similar to what you know from Kubernetes itself. Feel free to share also your feedback with us, through Twitter or Slack.
Kubernetes, Cloud Native, and the Future of Software
Authors: Brian Grant (Google), Jaice Singer DuMars (Google)
Kubernetes, Cloud Native, and the Future of Software
Five years ago this June, Google Cloud announced a new application management technology called Kubernetes. It began with a simple open source commit, followed the next day by a one-paragraph blog mention around container support. Later in the week, Eric Brewer talked about Kubernetes for the first time at DockerCon. And soon the world was watching.
We’re delighted to see Kubernetes become core to the creation and operation of modern software, and thereby a key part of the global economy. To us, the success of Kubernetes represents even more: A business transition with truly worldwide implications, thanks to the unprecedented cooperation afforded by the open source software movement.
Like any important technology, Kubernetes has become about more than just itself; it has positively affected the environment in which it arose, changing how software is deployed at scale, how work is done, and how corporations engage with big open-source projects.
Let’s take a look at how this happened, since it tells us a lot about where we are today, and what might be happening next.
Beginnings
The most important precursor to Kubernetes was the rise of application containers. Docker, the first tool to really make containers usable by a broad audience, began as an open source project in 2013. By containerizing an application, developers could achieve easier language runtime management, deployment, and scalability. This triggered a sea change in the application ecosystem. Containers made stateless applications easily scalable and provided an immutable deployment artifact that drastically reduced the number of variables previously encountered between test and production systems.
While containers presented strong stand-alone value for developers, the next challenge was how to deliver and manage services, applications, and architectures that spanned multiple containers and multiple hosts.
Google had already encountered similar issues within its own IT infrastructure. Running the world’s most popular search engine (and several other products with millions of users) lead to early innovation around, and adoption of, containers. Kubernetes was inspired by Borg, Google’s internal platform for scheduling and managing the hundreds of millions, and eventually billions, of containers that implement all of our services.
Kubernetes is more than just “Borg, for everyone” It distills the most successful architectural and API patterns of prior systems and couples them with load balancing, authorization policies, and other features needed to run and manage applications at scale. This in turn provides the groundwork for cluster-wide abstractions that allow true portability across clouds.
The November 2014 alpha launch of Google Cloud’s Google Kubernetes Engine (GKE) introduced managed Kubernetes. There was an explosion of innovation around Kubernetes, and companies from the enterprise down to the startup saw barriers to adoption fall away. Google, Red Hat, and others in the community increased their investment of people, experience, and architectural know-how to ensure it was ready for increasingly mission-critical workloads. The response was a wave of adoption that swept it to the forefront of the crowded container management space.
The Rise of Cloud Native
Every enterprise, regardless of its core business, is embracing more digital technology. The ability to rapidly adapt is fundamental to continued growth and competitiveness. Cloud-native technologies, and especially Kubernetes, arose to meet this need, providing the automation and observability necessary to manage applications at scale and with high velocity. Organizations previously constrained to quarterly deployments of critical applications can now deploy safely multiple times a day.
Kubernetes’s declarative, API-driven infrastructure empowers teams to operate independently, and enables them to focus on their business objectives. An inevitable cultural shift in the workplace has come from enabling greater autonomy and productivity and reducing the toil of development teams.
Increased engagement with open source
The ability for teams to rapidly develop and deploy new software creates a virtuous cycle of success for companies and technical practitioners alike. Companies have started to recognize that contributing back to the software projects they use not only improves the performance of the software for their use cases, but also builds critical skills and creates challenging opportunities that help them attract and retain new developers.
The Kubernetes project in particular curates a collaborative culture that encourages contribution and sharing of learning and development with the community. This fosters a positive-sum ecosystem that benefits both contributors and end-users equally.
What’s Next?
Where Kubernetes is concerned, five years seems like an eternity. That says much about the collective innovation we’ve seen in the community, and the rapid adoption of the technology.
In other ways, it is just the start. New applications such as machine learning, edge computing, and the Internet of Things are finding their way into the cloud native ecosystem via projects like Kubeflow. Kubernetes is almost certain to be at the heart of their success.
Kubernetes may be most successful if it becomes an invisible essential of daily life, like urban plumbing or electrical grids. True standards are dramatic, but they are also taken for granted. As Googler and KubeCon co-chair Janet Kuo said in a recent keynote, Kubernetes is going to become boring, and that’s a good thing, at least for the majority of people who don’t have to care about container management.
At Google Cloud, we’re still excited about the project, and we go to work on it every day. Yet it’s all of the solutions and extensions that expand from Kubernetes that will dramatically change the world as we know it.
So, as we all celebrate the continued success of Kubernetes, remember to take the time and thank someone you see helping make the community better. It’s up to all of us to foster a cloud-native ecosystem that prizes the efforts of everyone who helps maintain and nurture the work we do together.
And, to everyone who has been a part of the global success of Kubernetes, thank you. You have changed the world.
Expanding our Contributor Workshops
Authors: Guinevere Saenger (GitHub) and Paris Pittman (Google)
tl;dr - learn about the contributor community with us and land your first PR! We have spots available in Barcelona (registration closes on Wednesday May 15, so grab your spot!) and the upcoming Shanghai Summit. The Barcelona event is poised to be our biggest one yet, with more registered attendees than ever before!
Have you always wanted to contribute to Kubernetes, but not sure where to begin? Have you seen our community’s many code bases and seen places to improve? We have a workshop for you!
KubeCon + CloudNativeCon Barcelona’s new contributor workshop will be the fourth one of its kind, and we’re really looking forward to it! The workshop was kickstarted last year at KubeConEU in Copenhagen, and so far we have taken it to Shanghai and Seattle, and now Barcelona, as well as some non-KubeCon locations. We are constantly updating and improving the workshop content based on feedback from past sessions. This time, we’re breaking up the participants by their experience and comfort level with open source and Kubernetes. We’ll have developer setup and project workflow support for folks entirely new to open source and Kubernetes as part of the 101 track, and hope to set up each participant with their very own first issue to work on. In the 201 track, we will have a codebase walkthrough and local development and test demonstration for folks who have a bit more experience in open source but may be unfamiliar with our community’s development tools. For both tracks, you will have a chance to get your hands dirty and have some fun. Because not every contributor works with code, and not every contribution is technical, we will spend the beginning of the workshop learning how our project is structured and organized, where to find the right people, and where to get help when stuck.
Mentoring Opportunities
We will also bring back the SIG Meet-and-Greet where new contributors will have a chance to mingle with current contributors, perhaps find their dream SIG, learn what exciting areas they can help with, gain mentors, and make friends.
PS - there are also two mentoring sessions DURING KubeCon + CloudNativeCon on Thursday, May 23. Sign up here. 60% of the attendees during the Seattle event asked contributor questions.
Past Attendee Story - Vallery Lancy, Engineer at Lyft
We talked to a few of our past participants in a series of interviews that we will publish throughout the course of the year. In our first two clips, we meet Vallery Lancy, an Engineer at Lyft and one of 75 attendees at our recent Seattle edition of the workshop. She was poking around in the community for a while to see where she could jump in.
Watch Vallery talk about her experience here:
What does Vallery say to folks curious about the workshops, or those attending the Barcelona edition?
Be like Vallery and hundreds of previous New Contributor Workshop attendees: join us in Barcelona (or Shanghai - or San Diego!) for a unique experience without digging into our documentation! Have the opportunity to meet with the experts and go step by step into your journey with your peers around you. We’re looking forward to seeing you there! Register here
Cat shirts and Groundhog Day: the Kubernetes 1.14 release interview
Author: Craig Box (Google)
Last week we celebrated one year of the Kubernetes Podcast from Google. In this weekly show, my co-host Adam Glick and I focus on all the great things that are happening in the world of Kubernetes and Cloud Native. From the news of the week, to interviews with people in the community, we help you stay up to date on everything Kubernetes.
Every few cycles we check in on the release process for Kubernetes itself. Last year we interviewed the release managers for Kubernetes 1.11, and shared that transcript on the Kubernetes blog. We got such great feedback that we wanted to share the transcript of our recent conversation with Aaron Crickenberger, the release manager for Kubernetes 1.14.
As always, the canonical version can be enjoyed by listening to the podcast version. If you like what you hear, we encourage you to subscribe!
CRAIG BOX: We like to start with our guests into digging into their backgrounds a little bit. Kubernetes is built from contributors from many different companies. You worked on Kubernetes at Samsung SDS before joining Google. Does anything change in your position in the community and the work you do, when you change companies?
AARON CRICKENBERGER: Largely, no. I think the food's a little bit better at the current company! But by and large, I have gotten to work with basically the same people doing basically the same thing. I cared about the community first and Google second before I joined Google, and I kind of still operate that way mostly because I believe that Google's success depends upon the community's success, as does everybody else who depends upon Kubernetes. A good and healthy upstream makes a good and healthy downstream.
So that was largely why Samsung had me working on Kubernetes in the first place was because we thought the technology was legit. But we needed to make sure that the community and project as a whole was also legit. And so that's why you've seen me continue to advocate for transparency and community empowerment throughout my tenure in Kubernetes.
ADAM GLICK: You co-founded the Testing SIG. How did you decide that that was needed, and at what stage in the process did you come to that?
AARON CRICKENBERGER: This was very early on in the Kubernetes project. I'm actually a little hazy on specifically when it happened. But at the time, my boss, Bob Wise, worked with some folks within Google to co-found the Scalability SIG.
If you remember way, way back when Kubernetes first started, there was concern over whether or not Kubernetes was performance enough. Like, I believe it officially supported something on the order of 100 nodes. And there were some who thought, that's silly. I mean, come on, Google can do way more than that. And who in their right mind is going to use a container orchestrator that only supports 100 nodes?
And of course the thing is we're being super-conservative. We're trying to iterate, ship early and often. And so we helped push the boundaries to make sure that Kubernetes could prove that it worked up to a thousand nodes before it was even officially supported to say, look, it already does this, we're just trying to make sure we have all of the nuts and bolts tightened.
OK, so great. We decided we needed to create a thing called a SIG in the very first place to talk about these things and make sure that we were moving in the right direction. I then turned my personal attention to testing as the next thing that I believe needed a SIG. So I believe that testing was the second SIG ever to be created for Kubernetes. It was co-founded initially with Ike McCreary who, at the time I believe, was an SRE for Google, and then eventually it was handed over to some folks who work in the engineering productivity part of Google where I think it aligned really well with testing's interests.
It is like "I don't know what you people are trying to write here with Kubernetes, but I want to help you write it better, faster, and stronger". And so I want to make sure we, as a community and as a project, are making it easier for you to write tests, easier for you to run tests, and most importantly, easier for you to act based on those test results.
That came down to, let's make sure that Kubernetes gets tested on more than just Google Cloud. That was super important to me, as somebody who operated not in Google Cloud but in other clouds. I think it really helped sell the story and build confidence in Kubernetes as something that worked effectively on multiple clouds. And I also thought it was really helpful to see SIG Testing in the community's advocacy move us to a world today we can use test grids so that everybody see the same set of test results to understand what is allowed to prevent Kubernetes from going out the door.
The process was basically just saying, let's do it. The process was finding people who were motivated and suggesting that we meet on a recurring basis and we try to rally around a common set of work. This was sort of well before SIG governance was an official thing. And we gradually, after about a year, I think, settled on the pattern that most SIGs follow where you try to make sure you have a meeting agenda, you have a Slack channel, you have a mailing list, you discuss everything out in the open, you try to use sort a consistent set of milestones and move forward.
CRAIG BOX: A couple of things I wanted to ask about your life before Kubernetes. Why is there a Black Hawk flight simulator in a shipping container?
AARON CRICKENBERGER: As you may imagine, Black Hawk helicopters are flown in a variety of places around the world, not just next to a building that happens to have a parking lot next to it. And so in order to keep your pilots fresh, you may want to make sure they have good training hours and flight time, without spending fuel to fly an actual helicopter.
I was involved in helping make what's called a operation simulator, to train pilots on a bunch of the procedures using the same exact hardware that was deployed in Black Hawk helicopters, complete with motion seats that would shake to simulate movement and a full-fidelity visual system. This was all packed up in two shipping containers so that the simulator could be deployed wherever needed.
I definitely had a really fun experience working on this simulator in the field at an Air Force base prior to a conference where I got to experience F-16s doing takeoff drills, which was amazing. They would get off the runway, and then just slam the afterburners to max and go straight up into the air. And I got to work on graphic simulation bugs. It was really cool.
CRAIG BOX: And for a lot of people, when you click on the web page they have listed in the GitHub link, you get their resume, or you get the list of open source projects they work on. In your case, there is a SoundCloud page. What do people find on that page?
AARON CRICKENBERGER: They get to see me living my whole life. I find that music is a very important part of my life. It's a non-verbal voice that I have developed over time. I needed some place to host that. And then it came down between SoundCloud and Bandcamp, and SoundCloud was a much easier place to host my recordings.
So you get to hear the results of me having picked up a guitar and noodling with that about five years ago. You get to hear what I've learned messing around with Ableton Live. You get to hear some mixes that I've done of ambient music. And I haven't posted anything in a while there because I'm trying to get my recording of drums just right.
So if you go to my YouTube channel, mostly what you'll see are recordings of the various SIG meetings that I've participated in. But if you go back a little bit earlier than that, you'll see that I do, in fact, play the drums. I'm trying to get those folded into my next songs.
CRAIG BOX: Do you know who Hugh Padgham is?
AARON CRICKENBERGER: I do not.
CRAIG BOX: Hugh Padgham was the recording engineer who did the gated reverb drum sound that basically defined Phil Collins in the 1980s. I think you should call him up if you're having problems with your drum sound.
AARON CRICKENBERGER: That is awesome.
ADAM GLICK: You mentioned you can also find videos of the work that you're doing with the SIG. How did you become the release manager for 1.14?
AARON CRICKENBERGER: I've been involved in the Kubernetes release process way back in the 1.4 days. I started out as somebody who tried to help figure out, how do you write release notes for this thing? How do you take this whole mess and try to describe it in a sane way that makes sense to end users and developers? And I gradually became involved in other aspects of the release over time.
I helped out with CI Signal. I helped out with issue triage. When I helped out with CI Signal, I wrote the very first playbook to describe what it is I do around here. That's the model that has since been used for the rest of the release team, where every role describes what they do in a playbook that is used not just for their own benefit, but to help them train other people.
Formally how I became release lead was I served as release shadow in 1.13. And when release leads are looking to figure out who's going to lead the next release, they turn around and they look at their shadows, because those are who they have been helping out and training.
CRAIG BOX: If they don't have a shadow, do they have to wait another three months and do a release again?
AARON CRICKENBERGER: They do not. The way it works is the release lead can look at their shadows, then they take a look at the rest of their release team leads to see if there is sufficient experience there. And then if not, they consult with the chairs of SIG release.
So for example, for Kubernetes v1.15, I ended up in an unfortunate situation where neither of my shadows were available to step up and become the leads for 1.15. I consulted with Claire Lawrence, who was my enhancements lead for 1.14 and who was on the release team for two quarters, and so met the requirements to become a release lead that way. So she will be the release lead for v1.15.
CRAIG BOX: That was a fantastic answer to a throwaway Groundhog Day joke. I appreciate that.
AARON CRICKENBERGER: [LAUGHS]
ADAM GLICK: You can ask it again and see what the answer is, and then another time, and see how it evolves over time.
AARON CRICKENBERGER: I'm short on my Groundhog Day riffs. I'll come back to you.
ADAM GLICK: What are your responsibilities as the release lead?
AARON CRICKENBERGER: Don't Panic. I mean, essentially, a release lead's job is to make the final call, and then hold the line by making the final call. So what you shouldn't be doing as a release lead is attempting to dive in and fix all of the things, or do all of the things, or second-guess anybody else's work. You are there principally and primarily to listen to everybody else's advice and help them make the best decision. And only in the situations where there's not a clear consensus do you wade in and make the call yourself.
I feel like I was helped out by a very capable team in this regard, this release cycle. So it was super helpful. But as somebody who has what I like to call an "accomplishment monkey" on my back, it can be very difficult to resist the urge to dive right in and help out, because I have been there before. I have the boots-on-the-ground experience.
The release lead's job is not to be the boots on the ground, but to help make sure that everybody who is boots on the ground is actually doing what they need to do and unblocked in doing what they need to do. It also involves doing songs and dances and making funny pictures. So I view it more as like it's about effective communication. And doing a lot of songs and dances, and funny pictures, and memes is one way that I do that.
So one way that I thought it would help people pay attention to the release updates that I gave every week at the Kubernetes community meeting was to make sure that I wore a different cat T-shirt each week. After people riffed and joked out my first cat T-shirt where I said, I really need coffee right "meow", and somebody asked if I got that coffee from a "purr-colator", I decided to up the ante.
And I've heard that people will await those cat T-shirts. They want to know what the latest one is. I even got a special cat T-shirt just to signify that code freeze was coming.
We also decided that instead of imposing this crazy process that involved a lot of milestones, and labels, and whatnot that would cause the machinery to impose a bunch of additional friction, I would just post a lot of memes to Twitter about code freeze coming. And that seems to have worked out really well. So by and large, the release lead's job is communication, unblocking, and then doing nothing for as much as possible.
It's really kind of difficult and terrifying because you always have this feeling that you may have missed something, or that you're just not seeing something that's out there. So I'm sitting in this position with a release that has been extremely stable, and I spent a lot of time thinking, OK, what am I missing? Like, this looks too good. This is too quiet. There's usually something that blows up. Come on, what is it, what is it, what is it? And it's an exercise in keeping that all in and not sharing it with everybody until the release is over.
ADAM GLICK: He is here in a cat T-shirt, as well.
When a new US President takes over the office, it's customary that the outgoing president leaves them a note with advice in it. Aside from the shadow team, is there something similar that exists with Kubernetes release management?
AARON CRICKENBERGER: Yeah, I would say there's a very special-- I don't know what the word is I'm looking for here-- bond, relationship, or something where people who have been release leads in the past are very empathetic and very supportive of those who step into the role as release lead.
You know, I talked about release lead being a lot of uncertainty and second-guessing yourself, while on the outside you have to pretend like everything is OK. And having the support of people who have been there and who have gone through that experience is tremendously helpful.
So I was able to reach out to a previous release lead. Not to pull the game with-- what is it, like two envelopes? The first envelope, you blame the outgoing president. The second envelope, you write two letters. It's not quite like that.
I am totally happy to be blamed for all of the changes we made to the release process that didn't go well, but I'm also happy to help support my successor. I feel like my job as a release lead is, number one, make sure the release gets out the door, number two, make sure I set up my successor for success.
So I've already been meeting with Claire to describe what I would do as the introductory steps. And I plan on continuing to consult with Claire throughout the release process to make sure that things are going well.
CRAIG BOX: If you want to hear the perspective from some previous release leads, check out episode 10, where we interview Josh Berkus and Tim Pepper.
ADAM GLICK: What do you plan to put into that set of notes for Claire?
AARON CRICKENBERGER: That's a really good question. I would tell Claire to trust her team first and trust her gut second. Like I said, I think it is super important to establish trust with your team, because the release is this superhuman effort that involves consuming, or otherwise fielding, or shepherding the work of hundreds of contributors.
And your team is made up of at least 13 people. You could go all the way up to 40 or 50, if you include all of the people that are being trained by those people. There's so much work out there. It's just more work than any one person can possibly handle.
It's honestly the same thing I will tell new contributors to Kubernetes is that there's no way you can possibly understand all of it. You will not understand the shape of Kubernetes. You will never be the expert who knows literally all of the things, and that's OK. The important part is to make sure that you have people who, when you don't know the answer, you know who to ask for the answer. And it is really helpful if your team are those people.
CRAIG BOX: The specific version that you've been working on and the release that's just come out is Kubernetes 1.14. What are some of the new things in this release?
AARON CRICKENBERGER: This release of Kubernetes contains more stable enhancements than any other release of Kubernetes ever. And I'm pretty proud of that fact. I know in the past you may have heard other release leads talk about, like, this is the stability release, or this time we're really making things a little more mature. But I feel a lot of confidence in saying that this time around.
Like, I stood in a room, and it was a leadership summit, I think, back in 2017 where we said, look, we're really going to try and make Kubernetes more stable. And we're going to focus on sort of hardening the core of Kubernetes and defining what the core of Kubernetes is. And we're not going to accept a bunch of new features. And then we kind of went and accepted a bunch of new features. And that was a while ago. And here we are today.
But I think we are finally starting to see the results of work that was started back then. Windows Server Container Support is probably the biggest one. You can hear Michael Michael tell stories about how SIG Windows was started about three years ago. And today, they can finally announce that Windows Server containers have gone GA. That's a huge accomplishment.
A lot of the heavy lifting for this, I believe, came at the end. It started with a conversation in Kubernetes 1.13, and was really wrapped up this release where we define, what are Windows Server containers, exactly? How do they differ from Docker containers or other container runtimes that run on Linux?
Because today so much of the assumptions people make about the functionality that Kubernetes offers are also baked in with the functionality that Linux-based containers offer. And so we wanted to enable people to use the awesome Kubernetes orchestration capabilities that they have come to love, but to also use that to orchestrate some applications or capabilities that are only available on Windows.
So we put together what's called a Kubernetes Enhancement Proposal process, or a KEP, for short. And we said that we're going to use these KEPs to describe exactly what the criteria are to call something alpha, or beta, or stable. And so the Windows feature allowed us to use a KEP-- or in getting Windows in here, we used the KEP to describe everything that would and would not work for Windows Server containers. That was super huge. And that really, I think, helped us better understand or define what Kubernetes is in that context.
But OK, I've spent most of the time answering your question with just one single stable feature.
CRAIG BOX: Well, let's dig a little bit in to the KEP process then, because this is the first release where there's a new rule. It says, all proposed enhancements for this release must have an associated KEP. So that's a Kubernetes Enhancement Proposal, a one-page document that describes it. What has the process been like of A, getting engineers on-board with using that, and then B, building something based on these documents?
AARON CRICKENBERGER: It is a process of continued improvement. So it is by no means done, but it honestly required a lot of talking, and saying the same thing over and over to the same people or to different people, as is often the case when it comes to things that involve communication and process changes. But by and large, everybody was pretty much on-board with this.
There was a little bit of confusion, though, over how high the bar would be set and how rigorously or rigidly we would be enforcing these criteria. And that's where I feel like we have room to iterate and improve on. But we have collectively agreed that, yeah, we do like having all of the information about a particular enhancement in one place. Right?
The way the world used to operate before is we would throw around Google Docs, that were these design proposals, and then we'd comment on those a bunch. And then eventually, those were turned into markdown files. And those would end up in the community repo,
And then we'd have a bunch of associated issues that talked about that. And then maybe somebody would open up another issue that they'd call an umbrella issue. And then a bunch of comments would be put there. And then there's lots of discussion that goes on in the PRs. There's like seven different things that I just rattled off there.
So KEPs are about focusing all of the discussion about the design and implementation and reasoning behind enhancements in one single place. And I think there, we are fully on board. Do we have room to improve? Absolutely. Humans are involved, and it's a messy process. We could definitely find places to automate this better, structure it better. And I look forward to seeing those improvements happen.
You know, I think another one of the big things was a lot of these KEPs were mired across three different SIGs. There was sort of SIG architecture who had the technical vision for these. There was SIG PM, who-- you know, pick your P of choice-- product, project, process, program, people who are better about how to shepherd things forward, and then SIG release, who just wanted to figure out, what's landing in the release, and why, and how, and why is it important? And so taking the responsibilities across all of those three SIGs and putting it in the right place, which is SIG PM, I think really will help us iterate properly, moving forward.
CRAIG BOX: The other change in this release is that there is no code slush. What is a code slush, and why don't we have one anymore?
AARON CRICKENBERGER: That's a really good question. I had 10 different people ask me that question over the past couple of months, quarters, years. Take your pick. And so I finally decided, if nobody knows what a code slush is, why do we even have it?
CRAIG BOX: It's like a thawed freeze, but possibly with sugar?
AARON CRICKENBERGER: [LAUGHING] So code slush is about-- we want to slow the rate of change prior to code freeze. Like, let's accept code freeze as this big deadline where nothing's going to happen after a code freeze.
So while I really want to assume and aspire to live in a world where developers are super productive, and start their changes early, and get them done when they're done, today, I happen to live in a world where developers are driven by deadlines. And they get distracted. And there's other stuff going on. And then suddenly, they realize there's a code freeze ahead of them.
And this wonderful feature that they've been thinking about implementing over the past two months, they now have to get done in two weeks. And so suddenly, all sorts of code starts to fly in super fast and super quickly. And OK, that's great. I love empowering people to be productive.
But what we don't want to have happen is somebody decide to land some massive feature or enhancement that changes absolutely everything. Or maybe they decided they want to refactor the world. And if they do that, then they make everybody else's life super difficult because of merge conflicts and rebases. Or maybe all of the test signal that we had kind-of grown accustomed to and gotten used to, completely changes.
So code slush was about reminding people, hey, don't be jerks. Be kind of responsible. Please try not to land anything super huge at the last minute. But the way that we enforced this was with, like, make sure your PR has a milestone. And make sure that it has priority critical/urgent. In times past, we were like, make sure there is a label called status approved for milestone.
We were like, what do all these things even mean? People became obsessed with all the labels, and the milestones, and the process. And they never really paid attention to why we're asking people to pay attention to the fact that code freeze was coming soon.
ADAM GLICK: Process for process sake, they could start to build on top of each other. You mentioned that there is a number of other things in the release. Do you want to talk about some of the other pieces that are in there?
AARON CRICKENBERGER: Sure. I think two of the other stable features that I believe other people will find to be exciting are readiness gates and Pod priority and preemption. Today, Pods have the concept of liveliness and readiness. A live Pod has an application running in it, but it might not be ready to do anything. And so when a Pod is ready, that means it's ready to receive traffic.
So if you're thinking of some big application that's scaled out everywhere, you want to make sure your Pods are only handling traffic when they're good and ready to do so. But prior to 1.14, the only ways you could verify that were by using either TCP probes, HTTP probes, or exec probes. Either make sure that ports are open inside of the container, or run a command inside of the container and see what that command says.
And then you can definitely customize a fair amount there, but that requires that you put all of that information inside of the Pod. And it might be really useful for some cluster operators to signify some more overarching concerns that they have before a Pod could be ready. So just-- I don't know-- make sure a Pod has registered with some other system to make sure that it is authorized to serve traffic, or something of that nature. Pod readiness gates allow that sort of capability to happen-- to transparently extend the conditions that you use to figure out whether a Pod is ready for traffic. We believe this will enable more sophisticated orchestration and deployment mechanisms for people who are trying to manage their applications and services.
I feel like Pod priority and preemption will be interesting to consumers who like to oversubscribe their Kubernetes clusters. Instead of assuming everything is the same size and is the same priority, and first Pods win, you can now say that certain Pods are more important than other Pods. They get scheduled before other Pods, and maybe even so that they kick out other Pods to make room for the really important Pods.
You could think of it as if you have any super important agents or daemons that have to run on your cluster. Those should always be there. Now, you can describe them as high-priority to make sure that they are definitely always there and always scheduled before anything else is.
ADAM GLICK: Are there any other new features that are in alpha or beta that you're keeping your eye on?
AARON CRICKENBERGER: Yeah. So I feel like, on the beta side of things, a lot of what I am interested in-- if I go back to my theme of maturity, and stability, and defining the core of Kubernetes, I think that the storage SIG has been doing amazing work. They continue to ship out, quarter, after quarter, after quarter, after quarter, new and progressive enhancements to storage-- mostly these days through the CSI, Container Storage Interface project, which is fantastic. It allows you to plug in arbitrary pieces of storage functionality.
They have a number of things related to that that are in beta this time around, such as topology support. So you're going to be able to more accurately express how and where your CSI volumes need to live relative to your application. Block storage support is something I've heard a number of people asking for, as well as the ability to define durable local volumes.
Let's say you're running a Pod on a node, and you want to make sure it's writing directly to the node's local volumes. And that way, it could be super performant. Cool. Give it an emptydir. It'll be fine.
But if you destroy the Pod, then you lose all the data that the Pod wrote. And so again, I go back to the example of maybe it's an agent, and it's writing a bunch of useful, stateful information to disk. And you'd love for the agent to be able to go away and something to replace it, and be able to get all of that information off of disk. Local durable volumes allow you to do that. And you get to do that in the same way that you're used to specifying durable or persistent volumes that are given to you by a cloud provider, for example.
Since I did co-found SIG testing, I think I have to call out a testing feature that I like. It's really tiny and silly, but it has always bugged me that when you try to download the tests, you download something that's over a gigabyte in size. That's the way things used work for Kubernetes back in the old days for Kubernetes client and server stuff as well. And we have since broken that up into-- you only need to download the binaries that makes sense for your platform.
So say I'm developing Kubernetes on my MacBook. I probably don't need to download the Linux test binaries, or the Windows test binaries, or the ARM64 test binaries, or the s390x test binaries. Did I mention Kubernetes supports a lot of different architectures?
CRAIG BOX: I hadn't noticed s390 was a supported platform until now.
AARON CRICKENBERGER: It is definitely something that we build binaries for. I'm not sure if we've actually seen a certified conformant Kubernetes that runs on s390, but it is definitely one of the things we build Kubernetes against.
Not having to download an entire gigabyte plus of binaries just to run some tests is super great. I like to live in a world where I don't have to build the tests from scratch. Can I please just run a program that has all the tests? Maybe I can use that to soak test or sanity test my cluster to make sure that everything is OK. And downloading just the thing that I need is super great.
CRAIG BOX: You're talking about the idea of Kubernetes having a core and the idea of releases and stability. If you think back to Linux distributions maybe even 10 years ago, we didn't care so much about the version number releases of the kernel anymore, but we cared when there was a new feature in a Red Hat release. Do you think we're getting to that point with Kubernetes at the moment?
AARON CRICKENBERGER: I think that is one model that people really hope to see Kubernetes move toward. I'm not sure if it is the model that we will move toward, but I think it is an ongoing discussion. So you know, we've created a working group called WG LTS. I like to call it by its longer name-- WG "to LTS, or not to LTS". What does LTS even mean? What are we trying to release and support?
Because I think that when people think about distributions, they do naturally gravitate towards some distributions have higher velocity release cadences, and others have slower release cadences. And that's cool and great for people who want to live on a piece of software that never ever changes. But those of us who run software at scale find that you can't actually prevent change from happening. There will always be pieces of your infrastructure, or your environment, or your software, that are not under your control.
And so anything we can do to achieve what I like to call a dynamic stability is probably better for everybody involved. Make the cost of change as low as you possibly can. Make the pain of changing and upgrade as low as you possibly can, and accept that everything will always be changing all the time.
So yeah. Maybe that's where Linux lives, where the Kernel is always changing. And you can either care about that, or not. And you can go with a distribution that is super up-to-date with the Linux Kernel, or maybe has a slightly longer upgrade cadence. But I think it's about enabling both of those options. Because I think if we try to live in a world where there are only distributions and nothing else, that's going to actually harm everybody in the long term and maybe bring us away from all of these cloud-native ideals that we have, trying to accept change as a constant.
ADAM GLICK: We can't let you go without talking about the Beard. What is SIG Beard, and how critical was it in you becoming the 1.14 release manager?
AARON CRICKENBERGER: I feel like it's a new requirement for all release leads to be a member of SIG Beard. SIG Beard happened because, one day, I realized I had gotten lazy, and I had this just ginormous and magnificent beard. It was really flattering to have Brendan Burns up on stage at KubeCon Seattle compliment my beard in front of an audience of thousands of people. I cannot tell you what that feels like.
But to be serious for a moment, like OK, I'm a dude. I have a beard. There are a lot of dudes who work in tech, and many dudes are bearded. And this is by no means a way of being exclusionary, or calling that out, or anything like that. It was just noticing that while I was on camera, there seemed to be more beard than face at times. And what is that about?
And I had somebody start referring to me as "The Beard" in my company. It turns out they read Neil Stevenson's "Cryptonomicon," if you're familiar with that book at all.
ADAM GLICK: It's a great book.
AARON CRICKENBERGER: Yeah. It talks about how you have the beard, and you have the suit. The suit is the person who's responsible for doing all the talking, and the beard is responsible for doing all the walking. And I guess I have gained a reputation for doing an awful lot of walking and showing up in an awful lot of places. And so I thought I would embrace that.
When I showed up to Google my first day at work where I was looking for the name tag that shows what desk is mine, and my name tag was SIG Beard. And I don't know who did it, but I was like, all right, I'm running with it. And so I referred to myself as "Aaron of SIG Beard" from then on.
And so to me, the beard is not so much about being bearded on my face, but being bearded at heart-- being welcoming, being fun, embracing this community for all of the awesomeness that it has, and encouraging other people to do the same. So in that regard, I would like to see more people be members of SIG Beard. I'm trying to figure out ways to make that happen. And yeah, it's great.
Aaron Crickenberger is a senior test engineer with Google Cloud. He co-founded the Kubernetes Testing SIG, has participated in every Kubernetes release since version 1.4, has served on the Kubernetes steering committee since its inception in 2017, and most recently served as the Kubernetes 1.14 release lead.
You can find the Kubernetes Podcast from Google at @kubernetespod on Twitter, and you can subscribe so you never miss an episode. Please come and say Hello to us at KubeCon EU!
Join us for the 2019 KubeCon Diversity Lunch & Hack
Authors: Kiran Oliver, Podcast Producer, The New Stack
Join us for the 2019 KubeCon Diversity Lunch & Hack: Building Tech Skills & An Inclusive Community - Sponsored by Google Cloud and VMware
Registration for the Diversity Lunch opens today, May 2nd, 2019. To register, go to the main KubeCon + CloudNativeCon EU schedule, then log in to your Sched account, and confirm your attendance to the Diversity Lunch. Please sign up ASAP once the link is live, as spaces will fill quickly. We filled the event in just a few days last year, and anticipate doing so again this year.
The 2019 KubeCon Diversity Lunch & Hack will be held at the Fira Gran Via Barcelona Hall 8.0 Room F1 on May 22nd, 2019 from 12:30-14:00.
If you’ve never attended a Diversity Lunch before, not to worry. All are welcome, and there’s a variety of things to experience and discuss.
First things first, let’s establish some ground rules:
This is a safe space. What does that mean? Simple:
- Asking for and using people’s pronouns
- Absolutely no photography
- Awareness of your actions towards others. Do your best to ensure that you contribute towards making this environment welcoming, safe, and inclusive for all.
- Please avoid tech-heavy arbitrary community slang/jargon [keep in mind that not all of us are developers, many are tech-adjacent and/or new to the community]
- Act with care and empathy towards your fellow community members at all times.
This event also follows the Code of Conduct for all CNCF events.
We have run a very successful diversity lunch event before. This isn’t a trial run, nor is it a proof of concept. We had a fun, productive, and educational conversation last year in Seattle, and hope to do so again this year. As 2018’s KubeCon + CloudNativeCon in Seattle marked our first Diversity Lunch with pair programming, we hammered out a lot of kinks post-mortem, using that feedback to inform and improve upon our decision making, planning, and organizational process moving forward, to bring you an improved experience at the 2019 KubeCon + CloudNativeCon Diversity Lunch.
Tables not related to pair-programming or hands-on Kubernetes will be led by a moderator, where notes and feedback will then be taken and shared at the end of the lunch and in a post-mortem discussion after KubeCon+CloudNativeCon Barcelona ends, as part of our continuous improvement process. Some of last year’s tables were dedicated to topics that were submitted at registration, such as: security, D&I, service meshes, and more. You can suggest your own table topic on the registration form this year as well, and we highly encourage you to do so, particularly if you do not see your preferred topic or activity of choice listed. Your suggestions will then be used to determine the discussion table tracks that will be available at this year’s Diversity Lunch & Hack.
We hope you are also excited to participate in the ‘Hack’ portion of this ‘Lunch and Hack.’ This breakout track will include a variety of peer-programming exercises led by your fellow Kubernetes community members, with discussion leads working together with attendees hands-on to solve their Kubernetes-related problems in a welcoming, safe environment.
To make this all possible, we need you. Yes, you, to register. As much as we love having groups of diverse people all gather in the same room, we also need allies. If you’re a member of a privileged group or majority, you are welcome and encouraged to join us. Most importantly, we want you to take what you learn and experience at the Diversity Lunch back to both your companies and your open source communities, so that you can help us make positive changes not only within our industry, but beyond. No-one lives [or works] in a bubble. We hope that the things you learn here will carry over and bring about positive change in the world as a whole.
We look forward to seeing you!
Special thanks to Leah Petersen, Sarah Conway and Paris Pittman for their help in editing this post.
How You Can Help Localize Kubernetes Docs
Author: Zach Corleissen (Linux Foundation)
Last year we optimized the Kubernetes website for hosting multilingual content. Contributors responded by adding multiple new localizations: as of April 2019, Kubernetes docs are partially available in nine different languages, with six added in 2019 alone. You can see a list of available languages in the language selector at the top of each page.
By partially available, I mean that localizations are ongoing projects. They range from mostly complete (Chinese docs for 1.12) to brand new (1.14 docs in Portuguese). If you're interested in helping an existing localization, read on!
What is a localization?
Translation is about words and meaning. Localization is about words, meaning, process, and design.
A localization is like a translation, but more thorough. Instead of just translating words, a localization optimizes the framework for writing and publishing words. For example, most site navigation features (button text) on kubernetes.io are strings contained in a single file. Part of creating a new localization involves adding a language-specific version of that file and translating the strings it contains.
Localization matters because it reduces barriers to adoption and support. When we can read Kubernetes docs in our own language, it's easier to get started using Kubernetes and contributing to its development.
How do localizations happen?
The availability of docs in different languages is a feature—and like all Kubernetes features, contributors develop localized docs in a SIG, share them for review, and add them to the project.
Contributors work in teams to localize content. Because folks can't approve their own PRs, localization teams have a minimum size of two—for example, the Italian localization has two contributors. Teams can also be quite large: the Chinese team has several dozen contributors.
Each team has its own workflow. Some teams localize all content manually; others use editors with translation plugins and review machine output for accuracy. SIG Docs focuses on standards of output; this leaves teams free to adopt the workflow that works best for them. That said, teams frequently collaborate with each other on best practices, and sharing abounds in the best spirit of the Kubernetes community.
Helping with localizations
If you're interested in starting a new localization for Kubernetes docs, the Kubernetes contribution guide shows you how.
Existing localizations also need help. If you'd like to contribute to an existing project, join the localization team's Slack channel and introduce yourself. Folks on that team can help you get started.
| Localization | Slack channel |
|---|---|
| Chinese (中文) | #kubernetes-docs-zh |
| English | #sig-docs |
| French (Français) | #kubernetes-docs-fr |
| German (Deutsch) | #kubernetes-docs-de |
| Hindi | #kubernetes-docs-hi |
| Indonesian | #kubernetes-docs-id |
| Italian | #kubernetes-docs-it |
| Japanese (日本語) | #kubernetes-docs-ja |
| Korean (한국어) | #kubernetes-docs-ko |
| Portuguese (Português) | #kubernetes-docs-pt |
| Spanish (Español) | #kubernetes-docs-es |
What's next?
There's a new Hindi localization beginning. Why not add your language, too?
As a chair of SIG Docs, I'd love to see localization spread beyond the docs and into Kubernetes components. Is there a Kubernetes component you'd like to see supported in a different language? Consider making a Kubernetes Enhancement Proposal to support the change.
Hardware Accelerated SSL/TLS Termination in Ingress Controllers using Kubernetes Device Plugins and RuntimeClass
Authors: Mikko Ylinen (Intel)
Abstract
A Kubernetes Ingress is a way to connect cluster services to the world outside the cluster. In order to correctly route the traffic to service backends, the cluster needs an Ingress controller. The Ingress controller is responsible for setting the right destinations to backends based on the Ingress API objects’ information. The actual traffic is routed through a proxy server that is responsible for tasks such as load balancing and SSL/TLS (later “SSL” refers to both SSL or TLS ) termination. The SSL termination is a CPU heavy operation due to the crypto operations involved. To offload some of the CPU intensive work away from the CPU, OpenSSL based proxy servers can take the benefit of OpenSSL Engine API and dedicated crypto hardware. This frees CPU cycles for other things and improves the overall throughput of the proxy server.
In this blog post, we will show how easy it is to make hardware accelerated crypto available for containers running the Ingress controller proxy using some of the recently created Kubernetes building blocks: Device plugin framework and RuntimeClass. At the end, a reference setup is given using an HAproxy based Ingress controller accelerated using Intel® QuickAssist Technology cards.
About Proxies, OpenSSL Engine and Crypto Hardware
The proxy server plays a vital role in a Kubernetes Ingress Controller function. It proxies the traffic to the backends per Ingress objects routes. Under heavy traffic load, the performance becomes critical especially if the proxying involves CPU intensive operations like SSL crypto.
The OpenSSL project provides the widely adopted library for implementing the SSL protocol. Of the commonly known proxy servers used by Kubernetes Ingress controllers, Nginx and HAproxy use OpenSSL. The CNCF graduated Envoy proxy uses BoringSSL but there seems to be community interest in having OpenSSL as the alternative for it too.
The OpenSSL SSL protocol library relies on libcrypto that implements the cryptographic functions. For quite some time now (first introduced in 0.9.6 release), OpenSSL has provided an ENGINE concept that allows these cryptographic operations to be offloaded to a dedicated crypto acceleration hardware. Later, a special dynamic ENGINE enabled the crypto hardware specific pieces to be implemented in an independent loadable module that can be developed outside the OpenSSL code base and distributed separately. From the application’s perspective, this is also ideal because they don’t need to know the details of how to use the hardware, and the hardware specific module can be loaded/used when the hardware is available.
Hardware based crypto can greatly improve Cloud applications’ performance due to hardware accelerated processing in SSL operations as discussed, and can provide other crypto services like key/random number generation. Clouds can make the hardware easily available using the dynamic ENGINE and several loadable module implementations exist, for example, CloudHSM, IBMCA, or QAT Engine.
For Cloud deployments, the ideal scenario is for these modules to be shipped as part of the container workload. The workload would get scheduled on a node that provides the underlying hardware that the module needs to access. On the other hand, the workloads should run the same way and without code modifications regardless of the crypto acceleration hardware being available or not. The OpenSSL dynamic engine enables this. Figure 1 below illustrates these two scenarios using a typical Ingress Controller container as an example. The red colored boxes indicate the differences between a container with a crypto hardware engine enabled container vs. a “standard” one. It’s worth pointing out that the configuration changes shown do not necessarily require another version of the container since the configurations could be managed, e.g., using ConfigMaps.
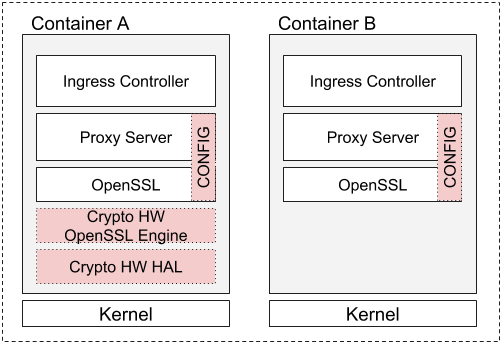
Figure 1. Examples of Ingress controller containers
Hardware Resources and Isolation
To be able to deploy workloads with hardware dependencies, Kubernetes provides excellent extension and configurability mechanisms. Let’s take a closer look into Kubernetes the device plugin framework (beta in 1.14) and RuntimeClass (beta in 1.14) and learn how they can be leveraged to expose crypto hardware to workloads.
The device plugin framework, first introduced in Kubernetes 1.8, provides a way for hardware vendors to register and allocate node hardware resources to Kubelets. The plugins implement the hardware specific initialization logic and resource management. The pods can request hardware resources in their PodSpec, which also guarantees the pod is scheduled on a node that can provide those resources.
The device resource allocation for containers is non-trivial. For applications dealing with security, the hardware level isolation is critical. The PCIe based crypto acceleration device functions can benefit from IO hardware virtualization, through an I/O Memory Management Unit (IOMMU), to provide the isolation: an IOMMU group the device belongs to provides the isolated resource for a workload (assuming the crypto cards do not share the IOMMU group with other devices). The number of isolated resources can be further increased if the PCIe device supports the Single-Root I/O Virtualization (SR-IOV) specification. SR-IOV allows the PCIe device to be split further to virtual functions (VF), derived from physical function (PF) devices, and each belonging to their own IOMMU group. To expose these IOMMU isolated device functions to user space and containers, the host kernel should bind them to a specific device driver. In Linux, this driver is vfio-pci and it makes each device available through a character device in user space. The kernel vfio-pci driver provides user space applications with a direct, IOMMU backed access to PCIe devices and functions, using a mechanism called PCI passthrough. The interface can be leveraged by user space frameworks, such as the Data Plane Development Kit (DPDK). Additionally, virtual machine (VM) hypervisors can provide these user space device nodes to VMs and expose them as PCI devices to the guest kernel. Assuming support from the guest kernel, the VM gets close to native performant direct access to the underlying host devices.
To advertise these device resources to Kubernetes, we can have a simple Kubernetes device plugin
that runs the initialization (i.e., binding), calls kubelet’s Registration gRPC service, and
implements the DevicePlugin gRPC service that kubelet calls to, e.g., to Allocate the resources
upon Pod creation.
Device Assignment and Pod Deployment
At this point, you may ask what the container could do with a VFIO device node? The answer comes after we first take a quick look into the Kubernetes RuntimeClass.
The Kubernetes RuntimeClass was created to provide better control and configurability over a variety of runtimes (an earlier blog post goes into the details of the needs, status and roadmap for it) that are available in the cluster. In essence, the RuntimeClass provides cluster users better tools to pick and use the runtime that best suits for the pod use case.
The OCI compatible Kata Containers runtime provides workloads with a hardware virtualized
isolation layer. In addition to workload isolation, the Kata Containers VM has the added
side benefit that the VFIO devices, as Allocate’d by the device plugin, can be passed
through to the container as hardware isolated devices. The only requirement is that the
Kata Containers kernel has driver for the exposed device enabled.
That’s all it really takes to enable hardware accelerated crypto for container workloads. To summarize:
- Cluster needs a device plugin running on the node that provides the hardware
- Device plugin exposes the hardware to user space using the VFIO driver
- Pod requests the device resources and Kata Containers as the RuntimeClass in the PodSpec
- The container has the hardware adaptation library and the OpenSSL engine module
Figure 2 shows the overall setup using the Container A illustrated earlier.
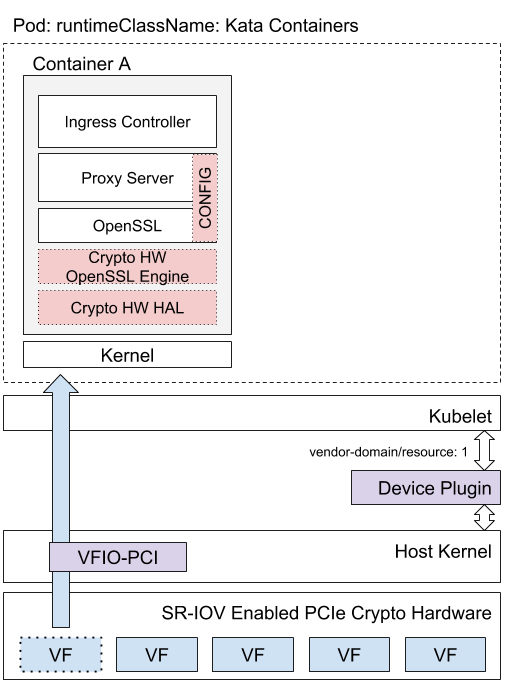
Figure 2. Deployment overview
Reference Setup
Finally, we describe the necessary building blocks and steps to build a functional setup described in Figure 2 that enables hardware accelerated SSL termination in an Ingress Controller using an Intel® QuickAssist Technology (QAT) PCIe device. It should be noted that the use cases are not limited to Ingress controllers, but any OpenSSL based workload can be accelerated.
Cluster configuration:
- Kubernetes 1.14 (
RuntimeClassandDevicePluginfeature gates enabled (both aretruein 1.14) - RuntimeClass ready runtime and Kata Containers configured
Host configuration:
- Intel® QAT driver release with the kernel drivers installed for both host kernel and Kata Containers kernel (or on a rootfs as loadable modules)
- QAT device plugin DaemonSet deployed
Ingress controller configuration and deployment:
- HAproxy-ingress ingress controller in a modified container that has
- the QAT HW HAL user space library (part of Intel® QAT SW release) and
- the OpenSSL QAT Engine built in
- Haproxy-ingress ConfigMap to enable QAT engine usage
ssl-engine=”qat”ssl-mode-async=true
- Haproxy-ingress deployment
.yamlto- Request
qat.intel.com: nresources - Request
runtimeClassName: kata-containers(name value depends on cluster config)
- Request
- (QAT device config file for each requested device resource with OpenSSL engine configured available in the container)
Once the building blocks are available, the hardware accelerated SSL/TLS can be tested by following the TLS termination
example steps. In order to verify the hardware is used, you can check /sys/kernel/debug/*/fw_counters files on host as they
get updated by the Intel® QAT firmware.
Haproxy-ingress and HAproxy are used because HAproxy can be directly configured to use the OpenSSL engine using
ssl-engine <name> [algo ALGOs] configuration flag without modifications to the global openssl configuration file.
Moreover, HAproxy can offload configured algorithms using asynchronous calls (with ssl-mode-async) to further improve performance.
Call to Action
In this blog post we have shown how Kubernetes Device Plugins and RuntimeClass can be used to provide isolated hardware access for applications in pods to offload crypto operations to hardware accelerators. Hardware accelerators can be used to speed up crypto operations and also save CPU cycles to other tasks. We demonstrated the setup using HAproxy that already supports asynchronous crypto offload with OpenSSL.
The next steps for our team is to repeat the same for Envoy (with an OpenSSL based TLS transport socket built as an extension). Furthermore, we are working to enhance Envoy to be able to offload BoringSSL asynchronous private key operations to a crypto acceleration hardware. Any review feedback or help is appreciated!
How many CPU cycles can your crypto application save for other tasks when offloading crypto processing to a dedicated accelerator?
Introducing kube-iptables-tailer: Better Networking Visibility in Kubernetes Clusters
Authors: Saifuding Diliyaer, Software Engineer, Box
At Box, we use Kubernetes to empower our engineers to own the whole lifecycle of their microservices. When it comes to networking, our engineers use Tigera’s Project Calico to declaratively manage network policies for their apps running in our Kubernetes clusters. App owners define a Calico policy in order to enable their Pods to send/receive network traffic, which is instantiated as iptables rules.
There may be times, however, when such network policy is missing or declared incorrectly by app owners. In this situation, the iptables rules will cause network packet drops between the affected Pods, which get logged in a file that is inaccessible to app owners. We needed a mechanism to seamlessly deliver alerts about those iptables packet drops based on their network policies to help app owners quickly diagnose the corresponding issues. To solve this, we developed a service called kube-iptables-tailer to detect packet drops from iptables logs and report them as Kubernetes events. We are proud to open-source kube-iptables-tailer for you to utilize in your own cluster, regardless of whether you use Calico or other network policy tools.
Improved Experience for App Owners
App owners do not have to apply any additional changes to utilize kube-iptables-tailer. They can simply run kubectl describe pods to check if any of their Pods' traffic has been dropped due to iptables rules. All the results sent from kube-iptables-tailer will be shown under the Events section, which is a much better experience for developers when compared to reading through raw iptables logs.
$ kubectl describe pods --namespace=YOUR_NAMESPACE
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning PacketDrop 5s kube-iptables-tailer Packet dropped when receiving traffic from example-service-2 (IP: 22.222.22.222).
Warning PacketDrop 10m kube-iptables-tailer Packet dropped when sending traffic to example-service-1 (IP: 11.111.11.111).
* output of events sent from kube-iptables-tailer to Kubernetes Pods having networking issues
Process behind kube-iptables-tailer
Before we had kube-iptables-tailer, the only way for Box’s engineers to get information about packet drops related to their network policies was parsing through the raw iptables logs and matching their service IPs. This was a suboptimal experience because iptables logs only contain basic IP address information. Mapping these IPs to specific Pods could be painful, especially in the Kubernetes world where Pods and containers are ephemeral and IPs are frequently changing. This process involved a bunch of manual commands for our engineers. Additionally, iptables logs could be noisy due to a number of drops, and if IP addresses were being reused, the app owners might even have some stale data. With the help of kube-iptables-tailer, life now becomes much easier for our developers. As shown in the following diagram, the principle of this service can be divided into three steps:

* sequence diagram for kube-iptables-tailer
1. Watch changes on iptables log file
Instead of requiring human engineers to manually decipher the raw iptables logs, we now use kube-iptables-tailer to help identify changes in that file. We run the service as a DaemonSet on every host node in our cluster, and it tails the iptables log file periodically. The service itself is written in Go, and it has multiple goroutines for the different service components running concurrently. We use channels to share information among those various components. In this step, for instance, the service will send out any changes it detected in iptables log file to a Go channel to be parsed later.
2. Parse iptables logs based on log prefix
Once the parser receives a new log message through a particular Go channel, it will first check whether the log message includes any network policy related packet drop information by parsing the log prefix. Packet drops based on our Calico policies will be logged containing “calico-drop:” as the log prefix in iptables log file. In this case, an object will be created by the parser with the data from the log message being stored as the object’s fields. These handy objects will be later used to locate the relevant Pods running in Kubernetes and post notifications directly to them. The parser is also able to identify duplicate logs and filter them to avoid causing confusion and consuming extra resources. After the parsing process, it will come to the final step for kube-iptables-tailer to send out the results.
3. Locate pods and send out events
Using the Kubernetes API, kube-iptables-tailer will try locating both senders and receivers in our cluster by matching the IPs stored in objects parsed from the previous step. As a result, an event will be posted to these affected Pods if they are located successfully. Kubernetes events are objects designed to provide information about what is happening inside a Kubernetes component. At Box, one of the use cases for Kubernetes events is to report errors directly to the corresponding applications (for more details, please refer to this blog post). The event generated by kube-iptables-tailer includes useful information such as traffic direction, IPs and the namespace of Pods from the other side. We have added DNS lookup as well because our Pods also send and receive traffic from services running on bare-metal hosts and VMs. Besides, exponential backoff is implemented to avoid overwhelming the Kubernetes API server.
Summary
At Box, kube-iptables-tailer has saved time as well as made life happier for many developers across various teams. Instead of flying blind with regards to packet drops based on network policies, the service is able to help detect changes in iptables log file and get the corresponding information delivered right to the Pods inside Kubernetes clusters. If you’re not using Calico, you can still apply any other log prefix (configured as an environment variable in the service) to match whatever is defined in your iptables rules and get notified about the network policy related packet drops. You may also find other cases where it is useful to make information from host systems available to Pods via the Kubernetes API. As an open-sourced project, every contribution is more than welcome to help improve the project together. You can find this project hosted on Github at https://github.com/box/kube-iptables-tailer
Special thanks to Kunal Parmar, Greg Lyons and Shrenik Dedhia for contributing to this project.
The Future of Cloud Providers in Kubernetes
Authors: Andrew Sy Kim (VMware), Mike Crute (AWS), Walter Fender (Google)
Approximately 9 months ago, the Kubernetes community agreed to form the Cloud Provider Special Interest Group (SIG). The justification was to have a single governing SIG to own and shape the integration points between Kubernetes and the many cloud providers it supported. A lot has been in motion since then and we’re here to share with you what has been accomplished so far and what we hope to see in the future.
The Mission
First and foremost, I want to share what the mission of the SIG is, because we use it to guide our present & future work. Taken straight from our charter, the mission of the SIG is to simplify, develop and maintain cloud provider integrations as extensions, or add-ons, to Kubernetes clusters. The motivation behind this is two-fold: to ensure Kubernetes remains extensible and cloud agnostic.
The Current State of Cloud Providers
In order to gain a forward looking perspective to our work, I think it’s important to take a step back to look at the current state of cloud providers. Today, each core Kubernetes component (except the scheduler and kube-proxy) has a --cloud-provider flag you can configure to enable a set of functionalities that integrate with the underlying infrastructure provider, a.k.a the cloud provider. Enabling this integration unlocks a wide set of features for your clusters such as: node address & zone discovery, cloud load balancers for Services with Type=LoadBalancer, IP address management, and cluster networking via VPC routing tables. Today, the cloud provider integrations can be done either in-tree or out-of-tree.
In-Tree & Out-of-Tree Providers
In-tree cloud providers are the providers we develop & release in the main Kubernetes repository. This results in embedding the knowledge and context of each cloud provider into most of the Kubernetes components. This enables more native integrations such as the kubelet requesting information about itself via a metadata service from the cloud provider.
In-Tree Cloud Provider Architecture (source: kubernetes.io)
Out-of-tree cloud providers are providers that can be developed, built, and released independent of Kubernetes core. This requires deploying a new component called the cloud-controller-manager which is responsible for running all the cloud specific controllers that were previously run in the kube-controller-manager.
Out-of-Tree Cloud Provider Architecture (source: kubernetes.io)
When cloud provider integrations were initially developed, they were developed natively (in-tree). We integrated each provider close to the core of Kubernetes and within the monolithic repository that is k8s.io/kubernetes today. As Kubernetes became more ubiquitous and more infrastructure providers wanted to support Kubernetes natively, we realized that this model was not going to scale. Each provider brings along a large set of dependencies which increases potential vulnerabilities in our code base and significantly increases the binary size of each component. In addition to this, more of the Kubernetes release notes started to focus on provider specific changes rather than core changes that impacted all Kubernetes users.
In late 2017, we developed a way for cloud providers to build integrations without adding them to the main Kubernetes tree (out-of-tree). This became the de-facto way for new infrastructure providers in the ecosystem to integrate with Kubernetes. Since then, we’ve been actively working towards migrating all cloud providers to use the out-of-tree architecture as most clusters today are still using the in-tree cloud providers.
Looking Ahead
Looking ahead, the goal of the SIG is to remove all existing in-tree cloud providers in favor of their out-of-tree equivalents with minimal impact to users. In addition to the core cloud provider integration mentioned above, there are more extension points for cloud integrations like CSI and the image credential provider that are actively being worked on for v1.15. Getting to this point would mean that Kubernetes is truly cloud-agnostic with no native integrations for any cloud provider. By doing this work we empower each cloud provider to develop and release new versions at their own cadence independent of Kubernetes. We’ve learned by now that this is a large feat with a unique set of challenges. Migrating workloads is never easy, especially when it’s an essential part of the control plane. Providing a safe and easy migration path between in-tree and out-of-tree cloud providers is of the highest priority for our SIG in the upcoming releases. If any of this sounds interesting to you, I encourage you to check out of some of our KEPs and get in touch with our SIG by joining the mailing list or our slack channel (#sig-cloud-provider in Kubernetes slack).
Pod Priority and Preemption in Kubernetes
Author: Bobby Salamat
Kubernetes is well-known for running scalable workloads. It scales your workloads based on their resource usage. When a workload is scaled up, more instances of the application get created. When the application is critical for your product, you want to make sure that these new instances are scheduled even when your cluster is under resource pressure. One obvious solution to this problem is to over-provision your cluster resources to have some amount of slack resources available for scale-up situations. This approach often works, but costs more as you would have to pay for the resources that are idle most of the time.
Pod priority and preemption is a scheduler feature made generally available in Kubernetes 1.14 that allows you to achieve high levels of scheduling confidence for your critical workloads without overprovisioning your clusters. It also provides a way to improve resource utilization in your clusters without sacrificing the reliability of your essential workloads.
Guaranteed scheduling with controlled cost
Kubernetes Cluster Autoscaler is an excellent tool in the ecosystem which adds more nodes to your cluster when your applications need them. However, cluster autoscaler has some limitations and may not work for all users:
- It does not work in physical clusters.
- Adding more nodes to the cluster costs more.
- Adding nodes is not instantaneous and could take minutes before those nodes become available for scheduling.
An alternative is Pod Priority and Preemption. In this approach, you combine multiple workloads in a single cluster. For example, you may run your CI/CD pipeline, ML workloads, and your critical service in the same cluster. When multiple workloads run in the same cluster, the size of your cluster is larger than a cluster that you would use to run only your critical service. If you give your critical service the highest priority and your CI/CD and ML workloads lower priority, when your service needs more computing resources, the scheduler preempts (evicts) enough pods of your lower priority workloads, e.g., ML workload, to allow all your higher priority pods to schedule.
With pod priority and preemption you can set a maximum size for your cluster in the Autoscaler configuration to ensure your costs get controlled without sacrificing availability of your service. Moreover, preemption is much faster than adding new nodes to the cluster. Within seconds your high priority pods are scheduled, which is critical for latency sensitive services.
Improve cluster resource utilization
Cluster operators who run critical services learn over time a rough estimate of the number of nodes that they need in their clusters to achieve high service availability. The estimate is usually conservative. Such estimates take bursts of traffic into account to find the number of required nodes. Cluster autoscaler can be configured never to reduce the size of the cluster below this level. The only problem is that such estimates are often conservative and cluster resources may remain underutilized most of the time. Pod priority and preemption allows you to improve resource utilization significantly by running a non-critical workload in the cluster.
The non-critical workload may have many more pods that can fit in the cluster. If you give a negative priority to your non-critical workload, Cluster Autoscaler does not add more nodes to your cluster when the non-critical pods are pending. Therefore, you won’t incur higher expenses. When your critical workload requires more computing resources, the scheduler preempts non-critical pods and schedules critical ones.
The non-critical pods fill the “holes” in your cluster resources which improves resource utilization without raising your costs.
Get Involved
If you have feedback for this feature or are interested in getting involved with the design and development, join the Scheduling Special Interest Group.
Process ID Limiting for Stability Improvements in Kubernetes 1.14
Author: Derek Carr
Have you ever seen someone take more than their fair share of the cookies? The one person who reaches in and grabs a half dozen fresh baked chocolate chip chunk morsels and skitters off like Cookie Monster exclaiming “Om nom nom nom.”
In some rare workloads, a similar occurrence was taking place inside Kubernetes clusters. With each Pod and Node, there comes a finite number of possible process IDs (PIDs) for all applications to share. While it is rare for any one process or pod to reach in and grab all the PIDs, some users were experiencing resource starvation due to this type of behavior. So in Kubernetes 1.14, we introduced an enhancement to mitigate the risk of a single pod monopolizing all of the PIDs available.
Can You Spare Some PIDs?
Here, we’re talking about the greed of certain containers. Outside the ideal, runaway processes occur from time to time, particularly in clusters where testing is taking place. Thus, some wildly non-production-ready activity is happening.
In such a scenario, it’s possible for something akin to a fork bomb taking place inside a node. As resources slowly erode, being taken over by some zombie-like process that continually spawns children, other legitimate workloads begin to get bumped in favor of this inflating balloon of wasted processing power. This could result in other processes on the same pod being starved of their needed PIDs. It could also lead to interesting side effects as a node could fail and a replica of that pod is scheduled to a new machine where the process repeats across your entire cluster.
Fixing the Problem
Thus, in Kubernetes 1.14, we have added a feature that allows for the configuration of a kubelet to limit the number of PIDs a given pod can consume. If that machine supports 32,768 PIDs and 100 pods, one can give each pod a budget of 300 PIDs to prevent total exhaustion of PIDs. If the admin wants to overcommit PIDs similar to cpu or memory, they may do so as well with some additional risks. Either way, no one pod can bring the whole machine down. This will generally prevent against simple fork bombs from taking over your cluster.
This change allows administrators to protect one pod from another, but does not ensure if all pods on the machine can protect the node, and the node agents themselves from falling over. Thus, we’ve introduced a feature in this release in alpha form that provides isolation of PIDs from end user workloads on a pod from the node agents (kubelet, runtime, etc.). The admin is able to reserve a specific number of PIDs--similar to how one reserves CPU or memory today--and ensure they are never consumed by pods on that machine. Once that graduates from alpha, to beta, then stable in future releases of Kubernetes, we’ll have protection against an easily starved Linux resource.
Get started with Kubernetes 1.14.
Get Involved
If you have feedback for this feature or are interested in getting involved with the design and development, join the Node Special Interest Group.
About the author:
Derek Carr is Senior Principal Software Engineer at Red Hat. He is a Kubernetes contributor and member of the Kubernetes Community Steering Committee.
Kubernetes 1.14: Local Persistent Volumes GA
Authors: Michelle Au (Google), Matt Schallert (Uber), Celina Ward (Uber)
The Local Persistent Volumes feature has been promoted to GA in Kubernetes 1.14. It was first introduced as alpha in Kubernetes 1.7, and then beta in Kubernetes 1.10. The GA milestone indicates that Kubernetes users may depend on the feature and its API for production use. GA features are protected by the Kubernetes deprecation policy.
What is a Local Persistent Volume?
A local persistent volume represents a local disk directly-attached to a single Kubernetes Node.
Kubernetes provides a powerful volume plugin system that enables Kubernetes workloads to use a wide variety of block and file storage to persist data. Most of these plugins enable remote storage -- these remote storage systems persist data independent of the Kubernetes node where the data originated. Remote storage usually can not offer the consistent high performance guarantees of local directly-attached storage. With the Local Persistent Volume plugin, Kubernetes workloads can now consume high performance local storage using the same volume APIs that app developers have become accustomed to.
How is it different from a HostPath Volume?
To better understand the benefits of a Local Persistent Volume, it is useful to compare it to a HostPath volume. HostPath volumes mount a file or directory from the host node’s filesystem into a Pod. Similarly a Local Persistent Volume mounts a local disk or partition into a Pod.
The biggest difference is that the Kubernetes scheduler understands which node a Local Persistent Volume belongs to. With HostPath volumes, a pod referencing a HostPath volume may be moved by the scheduler to a different node resulting in data loss. But with Local Persistent Volumes, the Kubernetes scheduler ensures that a pod using a Local Persistent Volume is always scheduled to the same node.
While HostPath volumes may be referenced via a Persistent Volume Claim (PVC) or directly inline in a pod definition, Local Persistent Volumes can only be referenced via a PVC. This provides additional security benefits since Persistent Volume objects are managed by the administrator, preventing Pods from being able to access any path on the host.
Additional benefits include support for formatting of block devices during mount, and volume ownership using fsGroup.
What's New With GA?
Since 1.10, we have mainly focused on improving stability and scalability of the feature so that it is production ready.
The only major feature addition is the ability to specify a raw block device and have Kubernetes automatically format and mount the filesystem. This reduces the previous burden of having to format and mount devices before giving it to Kubernetes.
Limitations of GA
At GA, Local Persistent Volumes do not support dynamic volume provisioning. However there is an external controller available to help manage the local PersistentVolume lifecycle for individual disks on your nodes. This includes creating the PersistentVolume objects, cleaning up and reusing disks once they have been released by the application.
How to Use a Local Persistent Volume?
Workloads can request a local persistent volume using the same PersistentVolumeClaim interface as remote storage backends. This makes it easy to swap out the storage backend across clusters, clouds, and on-prem environments.
First, a StorageClass should be created that sets volumeBindingMode: WaitForFirstConsumer to enable volume topology-aware
scheduling.
This mode instructs Kubernetes to wait to bind a PVC until a Pod using it is scheduled.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
Then, the external static provisioner can be configured and run to create PVs for all the local disks on your nodes.
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
local-pv-27c0f084 368Gi RWO Delete Available local-storage 8s
local-pv-3796b049 368Gi RWO Delete Available local-storage 7s
local-pv-3ddecaea 368Gi RWO Delete Available local-storage 7s
Afterwards, workloads can start using the PVs by creating a PVC and Pod or a StatefulSet with volumeClaimTemplates.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: local-test
spec:
serviceName: "local-service"
replicas: 3
selector:
matchLabels:
app: local-test
template:
metadata:
labels:
app: local-test
spec:
containers:
- name: test-container
image: k8s.gcr.io/busybox
command:
- "/bin/sh"
args:
- "-c"
- "sleep 100000"
volumeMounts:
- name: local-vol
mountPath: /usr/test-pod
volumeClaimTemplates:
- metadata:
name: local-vol
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "local-storage"
resources:
requests:
storage: 368Gi
Once the StatefulSet is up and running, the PVCs are all bound:
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
local-vol-local-test-0 Bound local-pv-27c0f084 368Gi RWO local-storage 3m45s
local-vol-local-test-1 Bound local-pv-3ddecaea 368Gi RWO local-storage 3m40s
local-vol-local-test-2 Bound local-pv-3796b049 368Gi RWO local-storage 3m36s
When the disk is no longer needed, the PVC can be deleted. The external static provisioner will clean up the disk and make the PV available for use again.
$ kubectl patch sts local-test -p '{"spec":{"replicas":2}}'
statefulset.apps/local-test patched
$ kubectl delete pvc local-vol-local-test-2
persistentvolumeclaim "local-vol-local-test-2" deleted
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
local-pv-27c0f084 368Gi RWO Delete Bound default/local-vol-local-test-0 local-storage 11m
local-pv-3796b049 368Gi RWO Delete Available local-storage 7s
local-pv-3ddecaea 368Gi RWO Delete Bound default/local-vol-local-test-1 local-storage 19m
You can find full documentation for the feature on the Kubernetes website.
What Are Suitable Use Cases?
The primary benefit of Local Persistent Volumes over remote persistent storage is performance: local disks usually offer higher IOPS and throughput and lower latency compared to remote storage systems.
However, there are important limitations and caveats to consider when using Local Persistent Volumes:
- Using local storage ties your application to a specific node, making your application harder to schedule. Applications which use local storage should specify a high priority so that lower priority pods, that don’t require local storage, can be preempted if necessary.
- If that node or local volume encounters a failure and becomes inaccessible, then that pod also becomes inaccessible. Manual intervention, external controllers, or operators may be needed to recover from these situations.
- While most remote storage systems implement synchronous replication, most local disk offerings do not provide data durability guarantees. Meaning loss of the disk or node may result in loss of all the data on that disk
For these reasons, local persistent storage should only be considered for workloads that handle data replication and backup at the application layer, thus making the applications resilient to node or data failures and unavailability despite the lack of such guarantees at the individual disk level.
Examples of good workloads include software defined storage systems and replicated databases. Other types of applications should continue to use highly available, remotely accessible, durable storage.
How Uber Uses Local Storage
M3, Uber’s in-house metrics platform, piloted Local Persistent Volumes at scale in an effort to evaluate M3DB — an open-source, distributed timeseries database created by Uber. One of M3DB’s notable features is its ability to shard its metrics into partitions, replicate them by a factor of three, and then evenly disperse the replicas across separate failure domains.
Prior to the pilot with local persistent volumes, M3DB ran exclusively in Uber-managed environments. Over time, internal use cases arose that required the ability to run M3DB in environments with fewer dependencies. So the team began to explore options. As an open-source project, we wanted to provide the community with a way to run M3DB as easily as possible, with an open-source stack, while meeting M3DB’s requirements for high throughput, low-latency storage, and the ability to scale itself out.
The Kubernetes Local Persistent Volume interface, with its high-performance, low-latency guarantees, quickly emerged as the perfect abstraction to build on top of. With Local Persistent Volumes, individual M3DB instances can comfortably handle up to 600k writes per-second. This leaves plenty of headroom for spikes on clusters that typically process a few million metrics per-second.
Because M3DB also gracefully handles losing a single node or volume, the limited data durability guarantees of Local Persistent Volumes are not an issue. If a node fails, M3DB finds a suitable replacement and the new node begins streaming data from its two peers.
Thanks to the Kubernetes scheduler’s intelligent handling of volume topology, M3DB is able to programmatically evenly disperse its replicas across multiple local persistent volumes in all available cloud zones, or, in the case of on-prem clusters, across all available server racks.
Uber's Operational Experience
As mentioned above, while Local Persistent Volumes provide many benefits, they also require careful planning and careful consideration of constraints before committing to them in production. When thinking about our local volume strategy for M3DB, there were a few things Uber had to consider.
For one, we had to take into account the hardware profiles of the nodes in our Kubernetes cluster. For example, how many local disks would each node cluster have? How would they be partitioned?
The local static provisioner provides guidance to help answer these questions. It’s best to be able to dedicate a full disk to each local volume (for IO isolation) and a full partition per-volume (for capacity isolation). This was easier in our cloud environments where we could mix and match local disks. However, if using local volumes on-prem, hardware constraints may be a limiting factor depending on the number of disks available and their characteristics.
When first testing local volumes, we wanted to have a thorough understanding of the effect disruptions (voluntary and involuntary) would have on pods using local storage, and so we began testing some failure scenarios. We found that when a local volume becomes unavailable while the node remains available (such as when performing maintenance on the disk), a pod using the local volume will be stuck in a ContainerCreating state until it can mount the volume. If a node becomes unavailable, for example if it is removed from the cluster or is drained, then pods using local volumes on that node are stuck in an Unknown or Pending state depending on whether or not the node was removed gracefully.
Recovering pods from these interim states means having to delete the PVC binding the pod to its local volume and then delete the pod in order for it to be rescheduled (or wait until the node and disk are available again). We took this into account when building our operator for M3DB, which makes changes to the cluster topology when a pod is rescheduled such that the new one gracefully streams data from the remaining two peers. Eventually we plan to automate the deletion and rescheduling process entirely.
Alerts on pod states can help call attention to stuck local volumes, and workload-specific controllers or operators can remediate them automatically. Because of these constraints, it’s best to exclude nodes with local volumes from automatic upgrades or repairs, and in fact some cloud providers explicitly mention this as a best practice.
Portability Between On-Prem and Cloud
Local Volumes played a big role in Uber’s decision to build orchestration for M3DB using Kubernetes, in part because it is a storage abstraction that works the same across on-prem and cloud environments. Remote storage solutions have different characteristics across cloud providers, and some users may prefer not to use networked storage at all in their own data centers. On the other hand, local disks are relatively ubiquitous and provide more predictable performance characteristics.
By orchestrating M3DB using local disks in the cloud, where it was easier to get up and running with Kubernetes, we gained confidence that we could still use our operator to run M3DB in our on-prem environment without any modifications. As we continue to work on how we’d run Kubernetes on-prem, having solved such an important pending question is a big relief.
What's Next for Local Persistent Volumes?
As we’ve seen with Uber’s M3DB, local persistent volumes have successfully been used in production environments. As adoption of local persistent volumes continues to increase, SIG Storage continues to seek feedback for ways to improve the feature.
One of the most frequent asks has been for a controller that can help with recovery from failed nodes or disks, which is currently a manual process (or something that has to be built into an operator). SIG Storage is investigating creating a common controller that can be used by workloads with simple and similar recovery processes.
Another popular ask has been to support dynamic provisioning using lvm. This can simplify disk management, and improve disk utilization. SIG Storage is evaluating the performance tradeoffs for the viability of this feature.
Getting Involved
If you have feedback for this feature or are interested in getting involved with the design and development, join the Kubernetes Storage Special-Interest-Group (SIG). We’re rapidly growing and always welcome new contributors.
Special thanks to all the contributors that helped bring this feature to GA, including Chuqiang Li (lichuqiang), Dhiraj Hedge (dhirajh), Ian Chakeres (ianchakeres), Jan Šafránek (jsafrane), Michelle Au (msau42), Saad Ali (saad-ali), Yecheng Fu (cofyc) and Yuquan Ren (nickrenren).
Kubernetes v1.14 delivers production-level support for Windows nodes and Windows containers
Authors: Michael Michael (VMware), Patrick Lang (Microsoft)
The first release of Kubernetes in 2019 brings a highly anticipated feature - production-level support for Windows workloads. Up until now Windows node support in Kubernetes has been in beta, allowing many users to experiment and see the value of Kubernetes for Windows containers. While in beta, developers in the Kubernetes community and Windows Server team worked together to improve the container runtime, build a continuous testing process, and complete features needed for a good user experience. Kubernetes now officially supports adding Windows nodes as worker nodes and scheduling Windows containers, enabling a vast ecosystem of Windows applications to leverage the power of our platform.
As Windows developers and devops engineers have been adopting containers over the last few years, they've been looking for a way to manage all their workloads with a common interface. Kubernetes has taken the lead for container orchestration, and this gives users a consistent way to manage their container workloads whether they need to run on Linux or Windows.
The journey to a stable release of Windows in Kubernetes was not a walk in the park. The community has been working on Windows support for 3 years, delivering an alpha release with v1.5, a beta with v1.9, and now a stable release with v1.14. We would not be here today without rallying broad support and getting significant contributions from companies including Microsoft, Docker, VMware, Pivotal, Cloudbase Solutions, Google and Apprenda. During this journey, there were 3 critical points in time that significantly advanced our progress.
- Advancements in Windows Server container networking that provided the infrastructure to create CNI (Container Network Interface) plugins
- Enhancements shipped in Windows Server semi-annual channel releases enabled Kubernetes development to move forward - culminating with Windows Server 2019 on the Long-Term Servicing Channel. This is the best release of Windows Server for running containers.
- The adoption of the KEP (Kubernetes Enhancement Proposals) process. The Windows KEP outlined a clear and agreed upon set of goals, expectations, and deliverables based on review and feedback from stakeholders across multiple SIGs. This created a clear plan that SIG-Windows could follow, paving the path towards this stable release.
With v1.14, we're declaring that Windows node support is stable, well-tested, and ready for adoption in production scenarios. This is a huge milestone for many reasons. For Kubernetes, it strengthens its position in the industry, enabling a vast ecosystem of Windows-based applications to be deployed on the platform. For Windows operators and developers, this means they can use the same tools and processes to manage their Windows and Linux workloads, taking full advantage of the efficiencies of the cloud-native ecosystem powered by Kubernetes. Let’s dig in a little bit into these.
Operator Advantages
- Gain operational efficiencies by leveraging existing investments in solutions, tools, and technologies to manage Windows containers the same way as Linux containers
- Knowledge, training and expertise on container orchestration transfers to Windows container support
- IT can deliver a scalable self-service container platform to Linux and Windows developers
Developer Advantages
- Containers simplify packaging and deploying applications during development and test. Now you also get to take advantage of Kubernetes’ benefits in creating reliable, secure, and scalable distributed applications.
- Windows developers can now take advantage of the growing ecosystem of cloud and container-native tools to build and deploy faster, resulting in a faster time to market for their applications
- Taking advantage of Kubernetes as the leader in container orchestration, developers only need to learn how to use Kubernetes and that skillset will transfer across development environments and across clouds
CIO Advantages
- Leverage the operational and cost efficiencies that are introduced with Kubernetes
- Containerize existing.NET applications or Windows-based workloads to eliminate old hardware or underutilized virtual machines, and streamline migration from end-of-support OS versions. You retain the benefit your application brings to the business, but decrease the cost of keeping it running
“Using Kubernetes on Windows allows us to run our internal web applications as microservices. This provides quick scaling in response to load, smoother upgrades, and allows for different development groups to build without worry of other group's version dependencies. We save money because development times are shorter and operation's time is not spent maintaining multiple virtual machine environments,” said Jeremy, a lead devops engineer working for a top multinational legal firm, one of the early adopters of Windows on Kubernetes.
There are many features that are surfaced with this release. We want to turn your attention to a few key features and enablers of Windows support in Kubernetes. For a detailed list of supported functionality, you can read our documentation.
- You can now add Windows Server 2019 worker nodes
- You can now schedule Windows containers utilizing deployments, pods, services, and workload controllers
- Out of tree CNI plugins are provided for Azure, OVN-Kubernetes, and Flannel
- Containers can utilize a variety of in and out-of-tree storage plugins
- Improved support for metrics/quotas closely matches the capabilities offered for Linux containers
When looking at Windows support in Kubernetes, many start drawing comparisons to Linux containers. Although some of the comparisons that highlight limitations are fair, it is important to distinguish between operational limitations and differences between the Windows and Linux operating systems. From a container management standpoint, we must strike a balance between preserving OS-specific behaviors required for application compatibility, and reaching operational consistency in Kubernetes across multiple operating systems. For example, some Linux-specific file system features, user IDs and permissions exposed through Kubernetes will not work on Windows today, and users are familiar with these fundamental differences. We will also be adding support for Windows-specific configurations to meet the needs of Windows customers that may not exist on Linux. The alpha support for Windows Group Managed Service Accounts is one example. Other areas such as memory reservations for Windows pods and the Windows kubelet are a work in progress and highlight an operational limitation. We will continue working on operational limitations based on what’s important to our community in future releases.
Today, Kubernetes master components will continue to run on Linux. That way users can add Windows nodes without having to create a separate Kubernetes cluster. As always, our future direction is set by the community, so more components, features and deployment methods will come over time. Users should understand the differences between Windows and Linux and utilize the advantages of each platform. Our goal with this release is not to make Windows interchangeable with Linux or to answer the question of Windows vs Linux. We offer consistency in management. Managing workloads without automation is tedious and expensive. Rewriting or re-architecting workloads is even more expensive. Containers provide a clear path forward whether your app runs on Linux or Windows, and Kubernetes brings an IT organization operational consistency.
As a community, our work is not complete. As already mentioned , we still have a fair bit of limitations and a healthy roadmap. We will continue making progress and enhancing Windows container support in Kubernetes, with some notable upcoming features including:
- Support for CRI-ContainerD and Hyper-V isolation, bringing hypervisor-level isolation between pods for additional security and extending our container-to-node compatibility matrix
- Additional network plugins, including the stable release of Flannel overlay support
- Simple heterogeneous cluster creation using kubeadm on Windows
We welcome you to get involved and join our community to share feedback and deployment stories, and contribute to code, docs, and improvements of any kind.
- Read our getting started and contributor guides, which include links to the community meetings and past recordings, at https://github.com/kubernetes/community/tree/master/sig-windows
- Explore our documentation at https://kubernetes.io/docs/setup/production-environment/windows/
- Join us on Slack or the Kubernetes Community Forums to chat about Windows containers on Kubernetes.
Thank you and feel free to reach us individually if you have any questions.
Michael Michael
SIG-Windows Chair
Director of Product Management, VMware
@michmike77 on Twitter
@m2 on Slack
Patrick Lang
SIG-Windows Chair
Senior Software Engineer, Microsoft
@PatrickLang on Slack
kube-proxy Subtleties: Debugging an Intermittent Connection Reset
Author: Yongkun Gui, Google
I recently came across a bug that causes intermittent connection resets. After some digging, I found it was caused by a subtle combination of several different network subsystems. It helped me understand Kubernetes networking better, and I think it’s worthwhile to share with a wider audience who are interested in the same topic.
The symptom
We received a user report claiming they were getting connection resets while using a Kubernetes service of type ClusterIP to serve large files to pods running in the same cluster. Initial debugging of the cluster did not yield anything interesting: network connectivity was fine and downloading the files did not hit any issues. However, when we ran the workload in parallel across many clients, we were able to reproduce the problem. Adding to the mystery was the fact that the problem could not be reproduced when the workload was run using VMs without Kubernetes. The problem, which could be easily reproduced by a simple app, clearly has something to do with Kubernetes networking, but what?
Kubernetes networking basics
Before digging into this problem, let’s talk a little bit about some basics of Kubernetes networking, as Kubernetes handles network traffic from a pod very differently depending on different destinations.
Pod-to-Pod
In Kubernetes, every pod has its own IP address. The benefit is that the applications running inside pods could use their canonical port, instead of remapping to a different random port. Pods have L3 connectivity between each other. They can ping each other, and send TCP or UDP packets to each other. CNI is the standard that solves this problem for containers running on different hosts. There are tons of different plugins that support CNI.
Pod-to-external
For the traffic that goes from pod to external addresses, Kubernetes simply uses SNAT. What it does is replace the pod’s internal source IP:port with the host’s IP:port. When the return packet comes back to the host, it rewrites the pod’s IP:port as the destination and sends it back to the original pod. The whole process is transparent to the original pod, who doesn’t know the address translation at all.
Pod-to-Service
Pods are mortal. Most likely, people want reliable service. Otherwise, it’s pretty much useless. So Kubernetes has this concept called "service" which is simply a L4 load balancer in front of pods. There are several different types of services. The most basic type is called ClusterIP. For this type of service, it has a unique VIP address that is only routable inside the cluster.
The component in Kubernetes that implements this feature is called kube-proxy.
It sits on every node, and programs complicated iptables rules to do all kinds
of filtering and NAT between pods and services. If you go to a Kubernetes node
and type iptables-save, you’ll see the rules that are inserted by Kubernetes
or other programs. The most important chains are KUBE-SERVICES, KUBE-SVC-*
and KUBE-SEP-*.
KUBE-SERVICESis the entry point for service packets. What it does is to match the destination IP:port and dispatch the packet to the correspondingKUBE-SVC-*chain.KUBE-SVC-*chain acts as a load balancer, and distributes the packet toKUBE-SEP-*chain equally. EveryKUBE-SVC-*has the same number ofKUBE-SEP-*chains as the number of endpoints behind it.KUBE-SEP-*chain represents a Service EndPoint. It simply does DNAT, replacing service IP:port with pod's endpoint IP:Port.
For DNAT, conntrack kicks in and tracks the connection state using a state machine. The state is needed because it needs to remember the destination address it changed to, and changed it back when the returning packet came back. Iptables could also rely on the conntrack state (ctstate) to decide the destiny of a packet. Those 4 conntrack states are especially important:
- NEW: conntrack knows nothing about this packet, which happens when the SYN packet is received.
- ESTABLISHED: conntrack knows the packet belongs to an established connection, which happens after handshake is complete.
- RELATED: The packet doesn’t belong to any connection, but it is affiliated to another connection, which is especially useful for protocols like FTP.
- INVALID: Something is wrong with the packet, and conntrack doesn’t know how to deal with it. This state plays a centric role in this Kubernetes issue.
Here is a diagram of how a TCP connection works between pod and service. The sequence of events are:
- Client pod from left hand side sends a packet to a service: 192.168.0.2:80
- The packet is going through iptables rules in client node and the destination is changed to pod IP, 10.0.1.2:80
- Server pod handles the packet and sends back a packet with destination 10.0.0.2
- The packet is going back to the client node, conntrack recognizes the packet and rewrites the source address back to 192.169.0.2:80
- Client pod receives the response packet
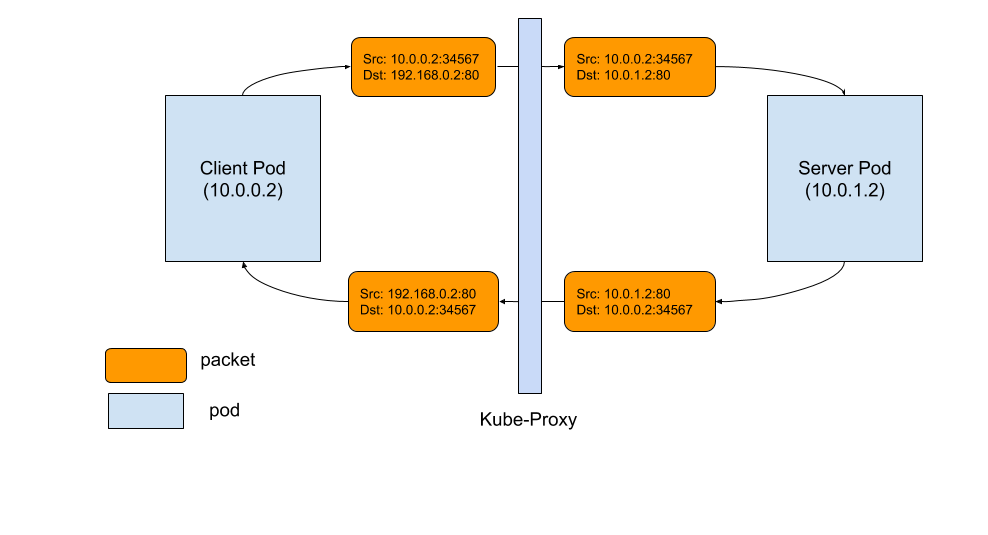
Good packet flow
What caused the connection reset?
Enough of the background, so what really went wrong and caused the unexpected connection reset?
As the diagram below shows, the problem is packet 3. When conntrack cannot recognize a returning packet, and mark it as INVALID. The most common reasons include: conntrack cannot keep track of a connection because it is out of capacity, the packet itself is out of a TCP window, etc. For those packets that have been marked as INVALID state by conntrack, we don’t have the iptables rule to drop it, so it will be forwarded to client pod, with source IP address not rewritten (as shown in packet 4)! Client pod doesn’t recognize this packet because it has a different source IP, which is pod IP, not service IP. As a result, client pod says, "Wait a second, I don't recall this connection to this IP ever existed, why does this dude keep sending this packet to me?" Basically, what the client does is simply send a RST packet to the server pod IP, which is packet 5. Unfortunately, this is a totally legit pod-to-pod packet, which can be delivered to server pod. Server pod doesn’t know all the address translations that happened on the client side. From its view, packet 5 is a totally legit packet, like packet 2 and 3. All server pod knows is, "Well, client pod doesn’t want to talk to me, so let’s close the connection!" Boom! Of course, in order for all these to happen, the RST packet has to be legit too, with the right TCP sequence number, etc. But when it happens, both parties agree to close the connection.
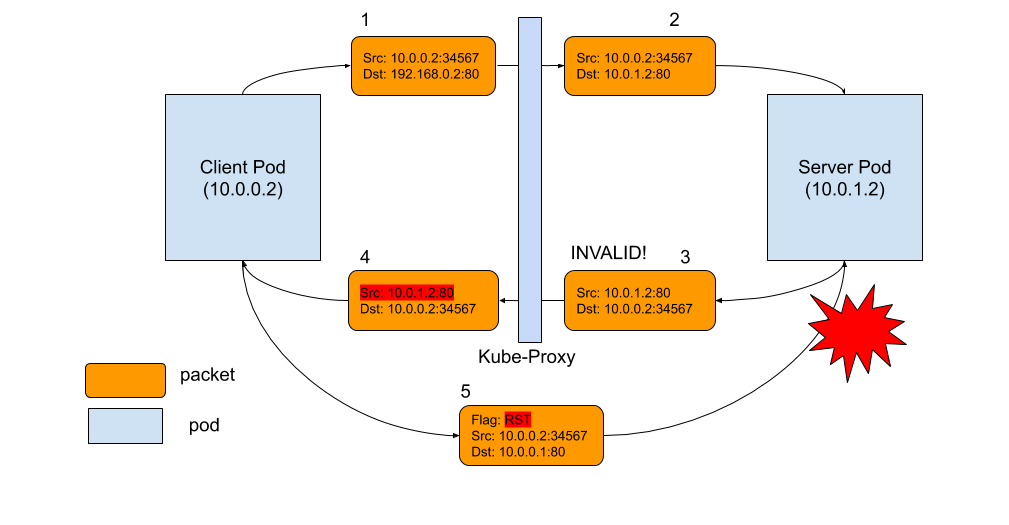
Connection reset packet flow
How to address it?
Once we understand the root cause, the fix is not hard. There are at least 2 ways to address it.
- Make conntrack more liberal on packets, and don’t mark the packets as
INVALID. In Linux, you can do this by
echo 1 > /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_be_liberal. - Specifically add an iptables rule to drop the packets that are marked as INVALID, so it won’t reach to client pod and cause harm.
The fix is available in v1.15+. However, for the users that are affected by this bug, there is a way to mitigate the problem by applying the following rule in your cluster.
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: startup-script
labels:
app: startup-script
spec:
template:
metadata:
labels:
app: startup-script
spec:
hostPID: true
containers:
- name: startup-script
image: gcr.io/google-containers/startup-script:v1
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
env:
- name: STARTUP_SCRIPT
value: |
#! /bin/bash
echo 1 > /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_be_liberal
echo done
Summary
Obviously, the bug has existed almost forever. I am surprised that it hasn’t been noticed until recently. I believe the reasons could be: (1) this happens more in a congested server serving large payloads, which might not be a common use case; (2) the application layer handles the retry to be tolerant of this kind of reset. Anyways, regardless of how fast Kubernetes has been growing, it’s still a young project. There are no other secrets than listening closely to customers’ feedback, not taking anything for granted but digging deep, we can make it the best platform to run applications.
Special thanks to bowei for the consulting for both debugging process and the blog, to tcarmet for reporting the issue and providing a reproduction.
Running Kubernetes locally on Linux with Minikube - now with Kubernetes 1.14 support
Author: Ihor Dvoretskyi, Developer Advocate, Cloud Native Computing Foundation

A few days ago, the Kubernetes community announced Kubernetes 1.14, the most recent version of Kubernetes. Alongside it, Minikube, a part of the Kubernetes project, recently hit the 1.0 milestone, which supports Kubernetes 1.14 by default.
Kubernetes is a real winner (and a de facto standard) in the world of distributed Cloud Native computing. While it can handle up to 5000 nodes in a single cluster, local deployment on a single machine (e.g. a laptop, a developer workstation, etc.) is an increasingly common scenario for using Kubernetes.
A few weeks ago I ran a poll on Twitter asking the community to specify their preferred option for running Kubernetes locally on Linux:
Ok, Twitter ✋
— ihor dvoretskyi (@idvoretskyi) February 6, 2019
Your local Kubernetes cluster on Linux is deployed by:
This is post #1 in a series about the local deployment options on Linux, and it will cover Minikube, the most popular community-built solution for running Kubernetes on a local machine.
Minikube is a cross-platform, community-driven Kubernetes distribution, which is targeted to be used primarily in local environments. It deploys a single-node cluster, which is an excellent option for having a simple Kubernetes cluster up and running on localhost.
Minikube is designed to be used as a virtual machine (VM), and the default VM runtime is VirtualBox. At the same time, extensibility is one of the critical benefits of Minikube, so it's possible to use it with drivers outside of VirtualBox.
By default, Minikube uses Virtualbox as a runtime for running the virtual machine. Virtualbox is a cross-platform solution, which can be used on a variety of operating systems, including GNU/Linux, Windows, and macOS.
At the same time, QEMU/KVM is a Linux-native virtualization solution, which may offer benefits compared to Virtualbox. For example, it's much easier to use KVM on a GNU/Linux server, so you can run a single-node Minikube cluster not only on a Linux workstation or laptop with GUI, but also on a remote headless server.
Unfortunately, Virtualbox and KVM can't be used simultaneously, so if you are already running KVM workloads on a machine and want to run Minikube there as well, using the KVM minikube driver is the preferred way to go.
In this guide, we'll focus on running Minikube with the KVM driver on Ubuntu 18.04 (I am using a bare metal machine running on packet.com.)

Minikube architecture (source: kubernetes.io)
Disclaimer
This is not an official guide to Minikube. You may find detailed information on running and using Minikube on it's official webpage, where different use cases, operating systems, environments, etc. are covered. Instead, the purpose of this guide is to provide clear and easy guidelines for running Minikube with KVM on Linux.
Prerequisites
- Any Linux you like (in this tutorial we'll use Ubuntu 18.04 LTS, and all the instructions below are applicable to it. If you prefer using a different Linux distribution, please check out the relevant documentation)
libvirtand QEMU-KVM installed and properly configured- The Kubernetes CLI (
kubectl) for operating the Kubernetes cluster
QEMU/KVM and libvirt installation
NOTE: skip if already installed
Before we proceed, we have to verify if our host can run KVM-based virtual machines. This can be easily checked using the kvm-ok tool, available on Ubuntu.
sudo apt install cpu-checker && sudo kvm-ok
If you receive the following output after running kvm-ok, you can use KVM on your machine (otherwise, please check out your configuration):
$ sudo kvm-ok
INFO: /dev/kvm exists
KVM acceleration can be used
Now let's install KVM and libvirt and add our current user to the libvirt group to grant sufficient permissions:
sudo apt install libvirt-clients libvirt-daemon-system qemu-kvm \
&& sudo usermod -a -G libvirt $(whoami) \
&& newgrp libvirt
After installing libvirt, you may verify the host validity to run the virtual machines with virt-host-validate tool, which is a part of libvirt.
sudo virt-host-validate
kubectl (Kubernetes CLI) installation
NOTE: skip if already installed
In order to manage the Kubernetes cluster, we need to install kubectl, the Kubernetes CLI tool.
The recommended way to install it on Linux is to download the pre-built binary and move it to a directory under the $PATH.
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl \
&& sudo install kubectl /usr/local/bin && rm kubectl
Alternatively, kubectl can be installed with a big variety of different methods (eg. as a .deb or snap package - check out the kubectl documentation to find the best one for you).
Minikube installation
Minikube KVM driver installation
A VM driver is an essential requirement for local deployment of Minikube. As we've chosen to use KVM as the Minikube driver in this tutorial, let's install the KVM driver with the following command:
curl -LO https://storage.googleapis.com/minikube/releases/latest/docker-machine-driver-kvm2 \
&& sudo install docker-machine-driver-kvm2 /usr/local/bin/ && rm docker-machine-driver-kvm2
Minikube installation
Now let's install Minikube itself:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 \
&& sudo install minikube-linux-amd64 /usr/local/bin/minikube && rm minikube-linux-amd64
Verify the Minikube installation
Before we proceed, we need to verify that Minikube is correctly installed. The simplest way to do this is to check Minikube’s status.
minikube version
To use the KVM2 driver:
Now let's run the local Kubernetes cluster with Minikube and KVM:
minikube start --vm-driver kvm2
Set KVM2 as a default VM driver for Minikube
If KVM is used as the single driver for Minikube on our machine, it's more convenient to set it as a default driver and run Minikube with fewer command-line arguments. The following command sets the KVM driver as the default:
minikube config set vm-driver kvm2
So now let's run Minikube as usual:
minikube start
Verify the Kubernetes installation
Let's check if the Kubernetes cluster is up and running:
kubectl get nodes
Now let's run a simple sample app (nginx in our case):
kubectl create deployment nginx --image=nginx
Let’s also check that the Kubernetes pods are correctly provisioned:
kubectl get pods
Screencast
Next steps
At this point, a Kubernetes cluster with Minikube and KVM is adequately set up and configured on your local machine.
To proceed, you may check out the Kubernetes tutorials on the project website:
It’s also worth checking out the "Introduction to Kubernetes" course by The Linux Foundation/Cloud Native Computing Foundation, available for free on EDX:
Kubernetes 1.14: Production-level support for Windows Nodes, Kubectl Updates, Persistent Local Volumes GA
Authors: The 1.14 Release Team
We’re pleased to announce the delivery of Kubernetes 1.14, our first release of 2019!
Kubernetes 1.14 consists of 31 enhancements: 10 moving to stable, 12 in beta, and 7 net new. The main themes of this release are extensibility and supporting more workloads on Kubernetes with three major features moving to general availability, and an important security feature moving to beta.
More enhancements graduated to stable in this release than any prior Kubernetes release. This represents an important milestone for users and operators in terms of setting support expectations. In addition, there are notable Pod and RBAC enhancements in this release, which are discussed in the “additional notable features” section below.
Let’s dive into the key features of this release:
Production-level Support for Windows Nodes
Up until now Windows Node support in Kubernetes has been in beta, allowing many users to experiment and see the value of Kubernetes for Windows containers. Kubernetes now officially supports adding Windows nodes as worker nodes and scheduling Windows containers, enabling a vast ecosystem of Windows applications to leverage the power of our platform. Enterprises with investments in Windows-based applications and Linux-based applications don’t have to look for separate orchestrators to manage their workloads, leading to increased operational efficiencies across their deployments, regardless of operating system.
Some of the key features of enabling Windows containers in Kubernetes include:
- Support for Windows Server 2019 for worker nodes and containers
- Support for out of tree networking with Azure-CNI, OVN-Kubernetes, and Flannel
- Improved support for pods, service types, workload controllers, and metrics/quotas to closely match the capabilities offered for Linux containers
Notable Kubectl Updates
New Kubectl Docs and Logo
The documentation for kubectl has been rewritten from the ground up with a focus on managing Resources using declarative Resource Config. The documentation has been published as a standalone site with the format of a book, and it is linked from the main k8s.io documentation (available at https://kubectl.docs.kubernetes.io).
The new kubectl logo and mascot (pronounced kubee-cuddle) are shown on the new docs site logo.
Kustomize Integration
The declarative Resource Config authoring capabilities of kustomize are now available in kubectl through the -k flag (e.g. for commands like apply, get) and the kustomize subcommand. Kustomize helps users author and reuse Resource Config using Kubernetes native concepts. Users can now apply directories with kustomization.yaml to a cluster using kubectl apply -k dir/. Users can also emit customized Resource Config to stdout without applying them via kubectl kustomize dir/. The new capabilities are documented in the new docs at https://kubectl.docs.kubernetes.io
The kustomize subcommand will continue to be developed in the Kubernetes owned kustomize repo. The latest kustomize features will be available from a standalone kustomize binary (published to the kustomize repo) at a frequent release cadence, and will be updated in kubectl prior to each Kubernetes releases.
kubectl Plugin Mechanism Graduating to Stable
The kubectl plugin mechanism allows developers to publish their own custom kubectl subcommands in the form of standalone binaries. This may be used to extend kubectl with new higher-level functionality and with additional porcelain (e.g. adding a set-ns command).
Plugins must have the kubectl- name prefix and exist on the user’s $PATH. The plugin mechanics have been simplified significantly for GA, and are similar to the git plugin system.
Persistent Local Volumes are Now GA
This feature, graduating to stable, makes locally attached storage available as a persistent volume source. Distributed file systems and databases are the primary use cases for persistent local storage due performance and cost. On cloud providers, local SSDs give better performance than remote disks. On bare metal, in addition to performance, local storage is typically cheaper and using it is a necessity to provision distributed file systems.
PID Limiting is Moving to Beta
Process IDs (PIDs) are a fundamental resource on Linux hosts. It is trivial to hit the task limit without hitting any other resource limits and cause instability to a host machine. Administrators require mechanisms to ensure that user pods cannot induce PID exhaustion that prevents host daemons (runtime, kubelet, etc) from running. In addition, it is important to ensure that PIDs are limited among pods in order to ensure they have limited impact to other workloads on the node.
Administrators are able to provide pod-to-pod PID isolation by defaulting the number of PIDs per pod as a beta feature. In addition, administrators can enable node-to-pod PID isolation as an alpha feature by reserving a number of allocatable PIDs to user pods via node allocatable. The community hopes to graduate this feature to beta in the next release.
Additional Notable Feature Updates
Pod priority and preemption enables Kubernetes scheduler to schedule more important Pods first and when cluster is out of resources, it removes less important pods to create room for more important ones. The importance is specified by priority.
Pod Readiness Gates introduce an extension point for external feedback on pod readiness.
Harden the default RBAC discovery clusterrolebindings removes discovery from the set of APIs which allow for unauthenticated access by default, improving privacy for CRDs and the default security posture of default clusters in general.
Availability
Kubernetes 1.14 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials. You can also easily install 1.14 using kubeadm.
Features Blog Series
If you’re interested in exploring these features more in depth, check back next week for our 5 Days of Kubernetes series where we’ll highlight detailed walkthroughs of the following features:
- Day 1 - Windows Server Containers
- Day 2 - Harden the default RBAC discovery clusterrolebindings
- Day 3 - Pod Priority and Preemption in Kubernetes
- Day 4 - PID Limiting
- Day 5 - Persistent Local Volumes
Release Team
This release is made possible through the efforts of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Aaron Crickenberger, Senior Test Engineer at Google. The 43 individuals on the release team coordinated many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has had over 28,000 individual contributors to date and an active community of more than 57,000 people.
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. On average over the past year, 381 different companies and over 2,458 individuals contribute to Kubernetes each month. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
User Highlights
Established, global organizations are using Kubernetes in production at massive scale. Recently published user stories from the community include:
- NetEase moving to Kubernetes has increased their R&D efficiency by more than 100% and deployment efficiency by 280%.
- VSCO found that moving to continuous integration, containerization, and Kubernetes, velocity was increased dramatically. The time from code-complete to deployment in production on real infrastructure went from 1-2 weeks to 2-4 hours for a typical service.
- NAV’s move to Kubernetes saved the company 50% in infrastructure costs, deployments increased 5x from 10 a day to 50 a day and resource utilization increased from 1% to 40%.
Is Kubernetes helping your team? Share your story with the community.
Ecosystem Updates
- Kubernetes is participating in GSoC 2019 under the CNCF. Check out the full list of project ideas for 2019 on CNCF’s GitHub page.
- The CNCF Annual report 2018 provides a look back at the growth of the Kubernetes and the foundation, community engagement, ecosystem tools, test conformance projects, KubeCon and more.
- Out of 8,000 attendees at KubeCon + CloudNativeCon North America 2018, 73% were first-time KubeCon-ers, highlighting massive growth and new interest in Kubernetes and cloud native technologies. Conference transparency report.
KubeCon
The world’s largest Kubernetes gathering, KubeCon + CloudNativeCon is coming to Barcelona from May 20-23, 2019 and Shanghai (co-located with Open Source Summit) from June 24-26, 2019. These conferences will feature technical sessions, case studies, developer deep dives, salons, and more! Register today!
Webinar
Join members of the Kubernetes 1.14 release team on April 23rd at 10am PDT to learn about the major features in this release. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
Thank you for your continued feedback and support.
- Post questions (or answer questions) on Stack Overflow
- Join the community discussion on Discuss
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community on Slack
- Share your Kubernetes story
Kubernetes End-to-end Testing for Everyone
Author: Patrick Ohly (Intel)
More and more components that used to be part of Kubernetes are now being developed outside of Kubernetes. For example, storage drivers used to be compiled into Kubernetes binaries, then were moved into stand-alone FlexVolume binaries on the host, and now are delivered as Container Storage Interface (CSI) drivers that get deployed in pods inside the Kubernetes cluster itself.
This poses a challenge for developers who work on such components: how can end-to-end (E2E) testing on a Kubernetes cluster be done for such external components? The E2E framework that is used for testing Kubernetes itself has all the necessary functionality. However, trying to use it outside of Kubernetes was difficult and only possible by carefully selecting the right versions of a large number of dependencies. E2E testing has become a lot simpler in Kubernetes 1.13.
This blog post summarizes the changes that went into Kubernetes 1.13. For CSI driver developers, it will cover the ongoing effort to also make the storage tests available for testing of third-party CSI drivers. How to use them will be shown based on two Intel CSI drivers:
Testing those drivers was the main motivation behind most of these enhancements.
E2E overview
E2E testing consists of several phases:
- Implementing a test suite. This is the main focus of this blog
post. The Kubernetes E2E framework is written in Go. It relies on
Ginkgo for managing tests and
Gomega for assertions. These tools
support “behavior driven development”, which describes expected
behavior in “specs”. In this blog post, “test” is used to reference
an individual
Ginkgo.Itspec. Tests interact with the Kubernetes cluster using client-go. - Bringing up a test cluster. Tools like kubetest can help here.
- Running an E2E test suite against that cluster. Ginkgo test suites
can be run with the
ginkgotool or as a normal Go test withgo test. Without any parameters, a Kubernetes E2E test suite will connect to the default cluster based on environment variables like KUBECONFIG, exactly like kubectl. Kubetest also knows how to run the Kubernetes E2E suite.
E2E framework enhancements in Kubernetes 1.13
All of the following enhancements follow the same basic pattern: they make the E2E framework more useful and easier to use outside of Kubernetes, without changing the behavior of the original Kubernetes e2e.test binary.
Splitting out provider support
The main reason why using the E2E framework from Kubernetes <= 1.12 was difficult were the dependencies on provider-specific SDKs, which pulled in a large number of packages. Just getting it compiled was non-trivial.
Many of these packages are only needed for certain tests. For example, testing the mounting of a pre-provisioned volume must first provision such a volume the same way as an administrator would, by talking directly to a specific storage backend via some non-Kubernetes API.
There is an effort to remove cloud provider-specific tests from core Kubernetes. The approach taken in PR #68483 can be seen as an incremental step towards that goal: instead of ripping out the code immediately and breaking all tests that depend on it, all cloud provider-specific code was moved into optional packages under test/e2e/framework/providers. The E2E framework then accesses it via an interface that gets implemented separately by each vendor package.
The author of a E2E test suite decides which of these packages get
imported into the test suite. The vendor support is then activated via
the --provider command line flag. The Kubernetes e2e.test binary in
1.13 and 1.14 still contains support for the same providers as in
1.12. It is also okay to include no packages, which means that only
the generic providers will be available:
- “skeleton”: cluster is accessed via the Kubernetes API and nothing else
- “local”: like “skeleton”, but in addition the scripts in kubernetes/kubernetes/cluster can retrieve logs via ssh after a test suite is run
External files
Tests may have to read additional files at runtime, like .yaml
manifests. But the Kubernetes e2e.test binary is supposed to be usable
and entirely stand-alone because that simplifies shipping and running
it. The solution in the Kubernetes build system is to link all files
under test/e2e/testing-manifests into the binary with
go-bindata. The
E2E framework used to have a hard dependency on the output of
go-bindata, now bindata support is
optional. When
accessing a file via the testfiles
package,
files will be retrieved from different sources:
- relative to the directory specified with
--repo-rootparameter - zero or more bindata chunks
Test parameters
The e2e.test binary takes additional parameters which control test execution. In 2016, an effort was started to replace all E2E command line parameters with a Viper configuration file. But that effort stalled, which left developers without clear guidance how they should handle test-specific parameters.
The approach in v1.12 was to add all flags to the central
test/e2e/framework/test_context.go,
which does not work for tests developed independently from the
framework. Since PR
#69105 the
recommendation has been to use the normal flag package to
define its parameters, in its own source code. Flag names must be
hierarchical with dots separating different levels, for example
my.test.parameter, and must be unique. Uniqueness is enforced by the
flag package which panics when registering a flag a second time. The
new
config
package simplifies the definition of multiple options, which are
stored in a single struct.
To summarize, this is how parameters are handled now:
- The init code in test packages defines tests and parameters. The actual parameter values are not available yet, so test definitions cannot use them.
- The init code of the test suite parses parameters and (optionally) the configuration file.
- The tests run and now can use parameter values.
However, recently it was pointed out that it is desirable and was possible to not expose test settings as command line flags and only set them via a configuration file. There is an open bug and a pending PR about this.
Viper support has been enhanced. Like the provider support, it is
completely optional. It gets pulled into a e2e.test binary by
importing the viperconfig package and calling
it
after parsing the normal command line flags. This has been implemented
so that all variables which can be set via command line flags are also
set when the flag appears in a Viper config file. For example, the
Kubernetes v1.13 e2e.test binary accepts
--viper-config=/tmp/my-config.yaml and that file will set the
my.test.parameter to value when it has this content: my: test:
parameter: value
In older Kubernetes releases, that option could only load a file from the current directory, the suffix had to be left out, and only a few parameters actually could be set this way. Beware that one limitation of Viper still exists: it works by matching config file entries against known flags, without warning about unknown config file entries and thus leaving typos undetected. A better config file parser for Kubernetes is still work in progress.
Creating items from .yaml manifests
In Kubernetes 1.12, there was some support for loading individual items from a .yaml file, but then creating that item had to be done by hand-written code. Now the framework has new methods for loading a .yaml file that has multiple items, patching those items (for example, setting the namespace created for the current test), and creating them. This is currently used to deploy CSI drivers anew for each test from exactly the same .yaml files that are also used for deployment via kubectl. If the CSI driver supports running under different names, then tests are completely independent and can run in parallel.
However, redeploying a driver slows down test execution and it does not cover concurrent operations against the driver. A more realistic test scenario is to deploy a driver once when bringing up the test cluster, then run all tests against that deployment. Eventually the Kubernetes E2E testing will move to that model, once it is clearer how test cluster bringup can be extended such that it also includes installing additional entities like CSI drivers.
Upcoming enhancements in Kubernetes 1.14
Reusing storage tests
Being able to use the framework outside of Kubernetes enables building a custom test suite. But a test suite without tests is still useless. Several of the existing tests, in particular for storage, can also be applied to out-of-tree components. Thanks to the work done by Masaki Kimura, storage tests in Kubernetes 1.13 are defined such that they can be instantiated multiple times for different drivers.
But history has a habit of repeating itself. As with providers, the package defining these tests also pulled in driver definitions for all in-tree storage backends, which in turn pulled in more additional packages than were needed. This has been fixed for the upcoming Kubernetes 1.14.
Skipping unsupported tests
Some of the storage tests depend on features of the cluster (like running on a host that supports XFS) or of the driver (like supporting block volumes). These conditions are checked while the test runs, leading to skipped tests when they are not satisfied. The good thing is that this records an explanation why the test did not run.
Starting a test is slow, in particular when it must first deploy the CSI driver, but also in other scenarios. Creating the namespace for a test has been measured at 5 seconds on a fast cluster, and it produces a lot of noisy test output. It would have been possible to address that by skipping the definition of unsupported tests, but then reporting why a test isn’t even part of the test suite becomes tricky. This approach has been dropped in favor of reorganizing the storage test suite such that it first checks conditions before doing the more expensive test setup steps.
More readable test definitions
The same PR also rewrites the tests to operate like conventional Ginkgo tests, with test cases and their local variables in a single function.
Testing external drivers
Building a custom E2E test suite is still quite a bit of work. The e2e.test binary that will get distributed in the Kubernetes 1.14 test archive will have the ability to test already installed storage drivers without rebuilding the test suite. See this README for further instructions.
E2E test suite HOWTO
Test suite initialization
The first step is to set up the necessary boilerplate code that
defines the test suite. In Kubernetes
E2E,
this is done in the e2e.go and e2e_test.go files. It could also be
done in a single e2e_test.go file. Kubernetes imports all of the
various providers, in-tree tests, Viper configuration support, and
bindata file lookup in e2e_test.go. e2e.go controls the actual
execution, including some cluster preparations and metrics collection.
A simpler starting point are the e2e_[test].go files from
PMEM-CSI. It
doesn’t use any providers, no Viper, no bindata, and imports just the
storage tests.
Like PMEM-CSI, OIM drops all of the extra features, but is a bit more
complex because it integrates a custom cluster startup directly into
the test
suite,
which was useful in this case because some additional components have
to run on the host side. By running them directly in the E2E binary,
interactive debugging with dlv becomes easier.
Both CSI drivers follow the Kubernetes example and use the test/e2e
directory for their test suites, but any other directory and other
file names would also work.
Adding E2E storage tests
Tests are defined by packages that get imported into a test suite. The
only thing specific to E2E tests is that they instantiate a
framework.Framework pointer (usually called f) with
framework.NewDefaultFramework. This variable gets initialized anew
in a BeforeEach for each test and freed in an AfterEach. It has a
f.ClientSet and f.Namespace at runtime (and only at runtime!)
which can be used by a test.
The PMEM-CSI storage test imports the Kubernetes storage test suite and sets up one instance of the provisioning tests for a PMEM-CSI driver which must be already installed in the test cluster. The storage test suite changes the storage class to run tests with different filesystem types. Because of this requirement, the storage class is created from a .yaml file.
Explaining all the various utility methods available in the framework is out of scope for this blog post. Reading existing tests and the source code of the framework is a good way to get started.
Vendoring
Vendoring Kubernetes code is still not trivial, even after eliminating
many of the unnecessary dependencies. k8s.io/kubernetes is not meant
to be included in other projects and does not define its dependencies
in a way that is understood by tools like dep. The other k8s.io
packages are meant to be included, but don’t follow semantic
versioning
yet or don’t
tag any releases (k8s.io/kube-openapi, k8s.io/utils).
PMEM-CSI uses dep. It’s
Gopkg.toml
file is a good starting point. It enables pruning (not enabled in dep
by default) and locks certain projects onto versions that are
compatible with the Kubernetes version that is used. When dep
doesn’t pick a compatible version, then checking Kubernetes’
Godeps.json
helps to determine which revision might be the right one.
Compiling and running the test suite
go test ./test/e2e -args -help is the fastest way to test that the
test suite compiles.
Once it does compile and a cluster has been set up, the command go test -timeout=0 -v ./test/e2e -ginkgo.v runs all tests. In order to
run tests in parallel, use the ginkgo -p ./test/e2e command instead.
Getting involved
The Kubernetes E2E framework is owned by the testing-commons sub-project in SIG-testing. See that page for contact information.
There are various tasks that could be worked on, including but not limited to:
- Moving test/e2e/framework into a staging repo and restructuring it so that it is more modular (#74352).
- Simplifying
e2e.goby moving more of its code intotest/e2e/framework(#74353). - Removing provider-specific code from the Kubernetes E2E test suite (#70194).
Special thanks to the reviewers of this article:
- Olev Kartau (https://github.com/okartau)
- Mary Camp (https://github.com/MCamp859)
A Guide to Kubernetes Admission Controllers
Author: Malte Isberner (StackRox)
Kubernetes has greatly improved the speed and manageability of backend clusters in production today. Kubernetes has emerged as the de facto standard in container orchestrators thanks to its flexibility, scalability, and ease of use. Kubernetes also provides a range of features that secure production workloads. A more recent introduction in security features is a set of plugins called “admission controllers.” Admission controllers must be enabled to use some of the more advanced security features of Kubernetes, such as pod security policies that enforce a security configuration baseline across an entire namespace. The following must-know tips and tricks will help you leverage admission controllers to make the most of these security capabilities in Kubernetes.
What are Kubernetes admission controllers?
In a nutshell, Kubernetes admission controllers are plugins that govern and enforce how the cluster is used. They can be thought of as a gatekeeper that intercept (authenticated) API requests and may change the request object or deny the request altogether. The admission control process has two phases: the mutating phase is executed first, followed by the validating phase. Consequently, admission controllers can act as mutating or validating controllers or as a combination of both. For example, the LimitRanger admission controller can augment pods with default resource requests and limits (mutating phase), as well as verify that pods with explicitly set resource requirements do not exceed the per-namespace limits specified in the LimitRange object (validating phase).
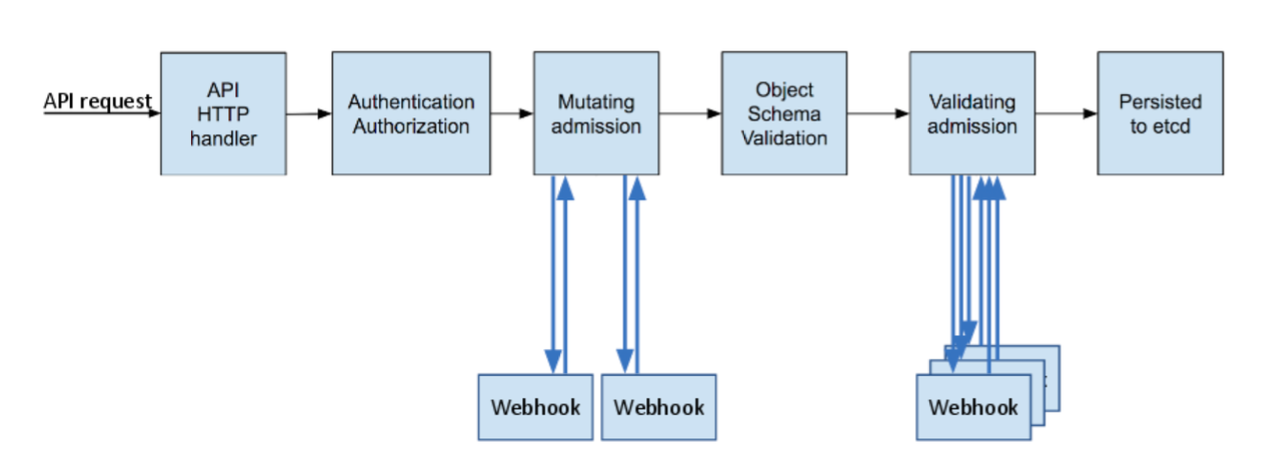
Admission Controller Phases
It is worth noting that some aspects of Kubernetes’ operation that many users would consider built-in are in fact governed by admission controllers. For example, when a namespace is deleted and subsequently enters the Terminating state, the NamespaceLifecycle admission controller is what prevents any new objects from being created in this namespace.
Among the more than 30 admission controllers shipped with Kubernetes, two take a special role because of their nearly limitless flexibility - ValidatingAdmissionWebhooks and MutatingAdmissionWebhooks, both of which are in beta status as of Kubernetes 1.13. We will examine these two admission controllers closely, as they do not implement any policy decision logic themselves. Instead, the respective action is obtained from a REST endpoint (a webhook) of a service running inside the cluster. This approach decouples the admission controller logic from the Kubernetes API server, thus allowing users to implement custom logic to be executed whenever resources are created, updated, or deleted in a Kubernetes cluster.
The difference between the two kinds of admission controller webhooks is pretty much self-explanatory: mutating admission webhooks may mutate the objects, while validating admission webhooks may not. However, even a mutating admission webhook can reject requests and thus act in a validating fashion. Validating admission webhooks have two main advantages over mutating ones: first, for security reasons it might be desirable to disable the MutatingAdmissionWebhook admission controller (or apply stricter RBAC restrictions as to who may create MutatingWebhookConfiguration objects) because of its potentially confusing or even dangerous side effects. Second, as shown in the previous diagram, validating admission controllers (and thus webhooks) are run after any mutating ones. As a result, whatever request object a validating webhook sees is the final version that would be persisted to etcd.
The set of enabled admission controllers is configured by passing a flag to the Kubernetes API server. Note that the old --admission-control flag was deprecated in 1.10 and replaced with --enable-admission-plugins.
--enable-admission-plugins=ValidatingAdmissionWebhook,MutatingAdmissionWebhook
Kubernetes recommends the following admission controllers to be enabled by default.
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,Priority,ResourceQuota,PodSecurityPolicy
The complete list of admission controllers with their descriptions can be found in the official Kubernetes reference. This discussion will focus only on the webhook-based admission controllers.
Why do I need admission controllers?
- Security: Admission controllers can increase security by mandating a reasonable security baseline across an entire namespace or cluster. The built-in
PodSecurityPolicyadmission controller is perhaps the most prominent example; it can be used for disallowing containers from running as root or making sure the container’s root filesystem is always mounted read-only, for example. Further use cases that can be realized by custom, webhook-based admission controllers include: - Allow pulling images only from specific registries known to the enterprise, while denying unknown image registries.
- Reject deployments that do not meet security standards. For example, containers using the
privilegedflag can circumvent a lot of security checks. This risk could be mitigated by a webhook-based admission controller that either rejects such deployments (validating) or overrides theprivilegedflag, setting it tofalse. - Governance: Admission controllers allow you to enforce the adherence to certain practices such as having good labels, annotations, resource limits, or other settings. Some of the common scenarios include:
- Enforce label validation on different objects to ensure proper labels are being used for various objects, such as every object being assigned to a team or project, or every deployment specifying an app label.
- Automatically add annotations to objects, such as attributing the correct cost center for a “dev” deployment resource.
- Configuration management: Admission controllers allow you to validate the configuration of the objects running in the cluster and prevent any obvious misconfigurations from hitting your cluster. Admission controllers can be useful in detecting and fixing images deployed without semantic tags, such as by:
- automatically adding resource limits or validating resource limits,
- ensuring reasonable labels are added to pods, or
- ensuring image references used in production deployments are not using the
latesttags, or tags with a-devsuffix.
In this way, admission controllers and policy management help make sure that applications stay in compliance within an ever-changing landscape of controls.
Example: Writing and Deploying an Admission Controller Webhook
To illustrate how admission controller webhooks can be leveraged to establish custom security policies, let’s consider an example that addresses one of the shortcomings of Kubernetes: a lot of its defaults are optimized for ease of use and reducing friction, sometimes at the expense of security. One of these settings is that containers are by default allowed to run as root (and, without further configuration and no USER directive in the Dockerfile, will also do so). Even though containers are isolated from the underlying host to a certain extent, running containers as root does increase the risk profile of your deployment— and should be avoided as one of many security best practices. The recently exposed runC vulnerability (CVE-2019-5736), for example, could be exploited only if the container ran as root.
You can use a custom mutating admission controller webhook to apply more secure defaults: unless explicitly requested, our webhook will ensure that pods run as a non-root user (we assign the user ID 1234 if no explicit assignment has been made). Note that this setup does not prevent you from deploying any workloads in your cluster, including those that legitimately require running as root. It only requires you to explicitly enable this riskier mode of operation in the deployment configuration, while defaulting to non-root mode for all other workloads.
The full code along with deployment instructions can be found in our accompanying GitHub repository. Here, we will highlight a few of the more subtle aspects about how webhooks work.
Mutating Webhook Configuration
A mutating admission controller webhook is defined by creating a MutatingWebhookConfiguration object in Kubernetes. In our example, we use the following configuration:
apiVersion: admissionregistration.k8s.io/v1beta1
kind: MutatingWebhookConfiguration
metadata:
name: demo-webhook
webhooks:
- name: webhook-server.webhook-demo.svc
clientConfig:
service:
name: webhook-server
namespace: webhook-demo
path: "/mutate"
caBundle: ${CA_PEM_B64}
rules:
- operations: [ "CREATE" ]
apiGroups: [""]
apiVersions: ["v1"]
resources: ["pods"]
This configuration defines a webhook webhook-server.webhook-demo.svc, and instructs the Kubernetes API server to consult the service webhook-server in namespace webhook-demo whenever a pod is created by making a HTTP POST request to the /mutate URL. For this configuration to work, several prerequisites have to be met.
Webhook REST API
The Kubernetes API server makes an HTTPS POST request to the given service and URL path, with a JSON-encoded AdmissionReview (with the Request field set) in the request body. The response should in turn be a JSON-encoded AdmissionReview, this time with the Response field set.
Our demo repository contains a function that takes care of the serialization/deserialization boilerplate code and allows you to focus on implementing the logic operating on Kubernetes API objects. In our example, the function implementing the admission controller logic is called applySecurityDefaults, and an HTTPS server serving this function under the /mutate URL can be set up as follows:
mux := http.NewServeMux()
mux.Handle("/mutate", admitFuncHandler(applySecurityDefaults))
server := &http.Server{
Addr: ":8443",
Handler: mux,
}
log.Fatal(server.ListenAndServeTLS(certPath, keyPath))
Note that for the server to run without elevated privileges, we have the HTTP server listen on port 8443. Kubernetes does not allow specifying a port in the webhook configuration; it always assumes the HTTPS port 443. However, since a service object is required anyway, we can easily map port 443 of the service to port 8443 on the container:
apiVersion: v1
kind: Service
metadata:
name: webhook-server
namespace: webhook-demo
spec:
selector:
app: webhook-server # specified by the deployment/pod
ports:
- port: 443
targetPort: webhook-api # name of port 8443 of the container
Object Modification Logic
In a mutating admission controller webhook, mutations are performed via JSON patches. While the JSON patch standard includes a lot of intricacies that go well beyond the scope of this discussion, the Go data structure in our example as well as its usage should give the user a good initial overview of how JSON patches work:
type patchOperation struct {
Op string `json:"op"`
Path string `json:"path"`
Value interface{} `json:"value,omitempty"`
}
For setting the field .spec.securityContext.runAsNonRoot of a pod to true, we construct the following patchOperation object:
patches = append(patches, patchOperation{
Op: "add",
Path: "/spec/securityContext/runAsNonRoot",
Value: true,
})
TLS Certificates
Since a webhook must be served via HTTPS, we need proper certificates for the server. These certificates can be self-signed (rather: signed by a self-signed CA), but we need Kubernetes to instruct the respective CA certificate when talking to the webhook server. In addition, the common name (CN) of the certificate must match the server name used by the Kubernetes API server, which for internal services is <service-name>.<namespace>.svc, i.e., webhook-server.webhook-demo.svc in our case. Since the generation of self-signed TLS certificates is well documented across the Internet, we simply refer to the respective shell script in our example.
The webhook configuration shown previously contains a placeholder ${CA_PEM_B64}. Before we can create this configuration, we need to replace this portion with the Base64-encoded PEM certificate of the CA. The openssl base64 -A command can be used for this purpose.
Testing the Webhook
After deploying the webhook server and configuring it, which can be done by invoking the ./deploy.sh script from the repository, it is time to test and verify that the webhook indeed does its job. The repository contains three examples:
- A pod that does not specify a security context (
pod-with-defaults). We expect this pod to be run as non-root with user id 1234. - A pod that does specify a security context, explicitly allowing it to run as root (
pod-with-override). - A pod with a conflicting configuration, specifying it must run as non-root but with a user id of 0 (
pod-with-conflict). To showcase the rejection of object creation requests, we have augmented our admission controller logic to reject such obvious misconfigurations.
Create one of these pods by running kubectl create -f examples/<name>.yaml. In the first two examples, you can verify the user id under which the pod ran by inspecting the logs, for example:
$ kubectl create -f examples/pod-with-defaults.yaml
$ kubectl logs pod-with-defaults
I am running as user 1234
In the third example, the object creation should be rejected with an appropriate error message:
$ kubectl create -f examples/pod-with-conflict.yaml
Error from server (InternalError): error when creating "examples/pod-with-conflict.yaml": Internal error occurred: admission webhook "webhook-server.webhook-demo.svc" denied the request: runAsNonRoot specified, but runAsUser set to 0 (the root user)
Feel free to test this with your own workloads as well. Of course, you can also experiment a little bit further by changing the logic of the webhook and see how the changes affect object creation. More information on how to do experiment with such changes can be found in the repository’s readme.
Summary
Kubernetes admission controllers offer significant advantages for security. Digging into two powerful examples, with accompanying available code, will help you get started on leveraging these powerful capabilities.
References:
- https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/
- https://docs.okd.io/latest/architecture/additional_concepts/dynamic_admission_controllers.html
- https://kubernetes.io/blog/2018/01/extensible-admission-is-beta/
- https://medium.com/ibm-cloud/diving-into-kubernetes-mutatingadmissionwebhook-6ef3c5695f74
- https://github.com/kubernetes/kubernetes/blob/v1.10.0-beta.1/test/images/webhook/main.go
- https://github.com/istio/istio
- https://www.stackrox.com/post/2019/02/the-runc-vulnerability-a-deep-dive-on-protecting-yourself/
A Look Back and What's in Store for Kubernetes Contributor Summits
Authors: Paris Pittman (Google), Jonas Rosland (VMware)
tl;dr - click here for Barcelona Contributor Summit information.

Seattle Contributor Summit
As our contributing community grows in great numbers, with more than 16,000 contributors this year across 150+ GitHub repositories, it’s important to provide face to face connections for our large distributed teams to have opportunities for collaboration and learning. In Contributor Experience, our methodology with planning events is a lot like our documentation; we build from personas -- interests, skills, and motivators to name a few. This way we ensure there is valuable content and learning for everyone.
We build the contributor summits around you:
- New Contributor
- Current Contributor
- docs
- code
- community management
- Subproject OWNERs - aka maintainers in other OSS circles.
- Special Interest Group (SIG) / Working Group (WG) Chair or Tech Lead
- Active Contributors
- Casual Contributors

New Contributor Workshop
These personas combined with ample feedback from previous events, produce the altogether experience that welcomed over 600 contributors in Copenhagen (May), Shanghai(November), and Seattle(December) in 2018. Seattle's event drew over 300+ contributors, equal to Shanghai and Copenhagen combined, for the 6th contributor event in Kubernetes history. In true Kubernetes fashion, we expect another record breaking year of attendance. We've pre-ordered 900+ contributor patches, a tradition, and we are looking forward to giving them to you!
With that said...
Save the Dates:
Barcelona: May 19th (evening) and 20th (all day)
Shanghai: June 24th (all day)
San Diego: November 18th, 19th, and activities in KubeCon/CloudNativeCon week
In an effort of continual improvement, here's what to expect from us this year:
- Large new contributor workshops and contributor socials at all three events expected to break previous attendance records
- A multiple track event in San Diego for all contributor types including workshops, birds of a feather, lightning talks and more
- Addition of a “201” / “Intermediate” edition of the new contributor workshop in San Diego
- An event website!
- Follow along with updates: kubernetes-dev@googlegroups.com is our main communication hub as always; however, we will also blog here, our Thursday Kubernetes Community Meeting, twitter, SIG meetings, event site, discuss.kubernetes.io, and #contributor-summit on Slack.
- Opportunities to get involved: We still have 2019 roles available! Reach out to Contributor Experience via community@kubernetes.io, stop by a Wednesday SIG update meeting, or catch us on Slack (#sig-contribex).

Unconference voting
Thanks!
Our 2018 crew 🥁
Jorge Castro, Paris Pittman, Bob Killen, Jeff Sica, Megan Lehn, Guinevere Saenger, Josh Berkus, Noah Abrahams, Yang Li, Xiangpeng Zhao, Puja Abbassi, Lindsey Tulloch, Zach Corleissen, Tim Pepper, Ihor Dvoretskyi, Nancy Mohamed, Chris Short, Mario Loria, Jason DeTiberus, Sahdev Zala, Mithra Raja
And an introduction to our 2019 crew (a thanks in advance ;) )...
Jonas Rosland, Josh Berkus, Paris Pittman, Jorge Castro, Bob Killen, Deb Giles, Guinevere Saenger, Noah Abrahams, Yang Li, Xiangpeng Zhao, Puja Abbassi, Rui Chen, Tim Pepper, Ihor Dvoretskyi, Dawn Foster
Relive Seattle Contributor Summit
📈 80% growth rate since the Austin 2017 December event
📜 Event waiting list: 103
🎓 76 contributors were on-boarded through the New Contributor Workshop
🎉 92% of the current contributors RSVPs attended and of those:
👩🏻🚒 25% were Special Interest Group or Working Group Chairs or Tech Leads
🗳 70% were eligible to vote in the last steering committee election - more than 50 contributions in 2018
📹 20+ Sessions
👀 Most watched to date: Technical Vision, Security, API Code Base Tour
🌟 Top 3 according to survey: Live API Code Review, Deflaking Unconference, Technical Vision
🎱 🎳 160 attendees for the social at Garage on Sunday night where we sunk eight balls and recorded strikes (out in some cases)
🏆 Special recognition: SIG Storage, @dims, and @jordan
📸 Pictures (special thanks to rdodev)
Garage Pic Reg Desk

Some of the group in Seattle
“I love Contrib Summit! The intros and deep dives during KubeCon were a great extension of Contrib Summit. Y'all did an excellent job in the morning to level set expectations and prime everyone.” -- julianv
“great work! really useful and fun!” - coffeepac
KubeEdge, a Kubernetes Native Edge Computing Framework
Author: Sanil Kumar D (Huawei), Jun Du(Huawei)
KubeEdge becomes the first Kubernetes Native Edge Computing Platform with both Edge and Cloud components open sourced!
Open source edge computing is going through its most dynamic phase of development in the industry. So many open source platforms, so many consolidations and so many initiatives for standardization! This shows the strong drive to build better platforms to bring cloud computing to the edges to meet ever increasing demand. KubeEdge, which was announced last year, now brings great news for cloud native computing! It provides a complete edge computing solution based on Kubernetes with separate cloud and edge core modules. Currently, both the cloud and edge modules are open sourced.
Unlike certain light weight kubernetes platforms available around, KubeEdge is made to build edge computing solutions extending the cloud. The control plane resides in cloud, though scalable and extendable. At the same time, the edge can work in offline mode. Also it is lightweight and containerized, and can support heterogeneous hardware at the edge. With the optimization in edge resource utlization, KubeEdge positions to save significant setup and operation cost for edge solutions. This makes it the most compelling edge computing platform in the world currently, based on Kubernetes!
Kube(rnetes)Edge! - Opening up a new Kubernetes-based ecosystem for Edge Computing
The key goal for KubeEdge is extending Kubernetes ecosystem from cloud to edge. From the time it was announced to the public at KubeCon in Shanghai in November 2018, the architecture direction for KubeEdge was aligned to Kubernetes, as its name!
It started with its v0.1 providing the basic edge computing features. Now, with its latest release v0.2, it brings the cloud components to connect and complete the loop. With consistent and scalable Kubernetes-based interfaces, KubeEdge enables the orchestration and management of edge clusters similar to how Kubernetes manages in the cloud. This opens up seamless possibilities of bringing cloud computing capabilities to the edge, quickly and efficiently.
![]()
KubeEdge Links:
Based on its roadmap and architecture, KubeEdge tries to support all edge nodes, applications, devices and even the cluster management consistent with the Kuberenetes interface. This will help the edge cloud act exactly like a cloud cluster. This can save a lot of time and cost on the edge cloud development deployment based on KubeEdge.
KubeEdge provides a containerized edge computing platform, which is inherently scalable. As it's modular and optimized, it is lightweight (66MB foot print and ~30MB running memory) and could be deployed on low resource devices. Similarly, the edge node can be of different hardware architecture and with different hardware configurations. For the device connectivity, it can support multiple protocols and it uses a standard MQTT-based communication. This helps in scaling the edge clusters with new nodes and devices efficiently.
You heard it right! KubeEdge Cloud Core modules are open sourced!
By open sourcing both the edge and cloud modules, KubeEdge brings a complete cloud vendor agnostic lightweight heterogeneous edge computing platform. It is now ready to support building a complete Kubernetes ecosystem for edge computing, exploiting most of the existing cloud native projects or software modules. This can enable a mini-cloud at the edge to support demanding use cases like data analytics, video analytics, machine learning and more.
KubeEdge Architecture: Building Kuberenetes Native Edge computing!
The core architecture tenet for KubeEdge is to build interfaces that are consistent with Kubernetes, be it on the cloud side or edge side.
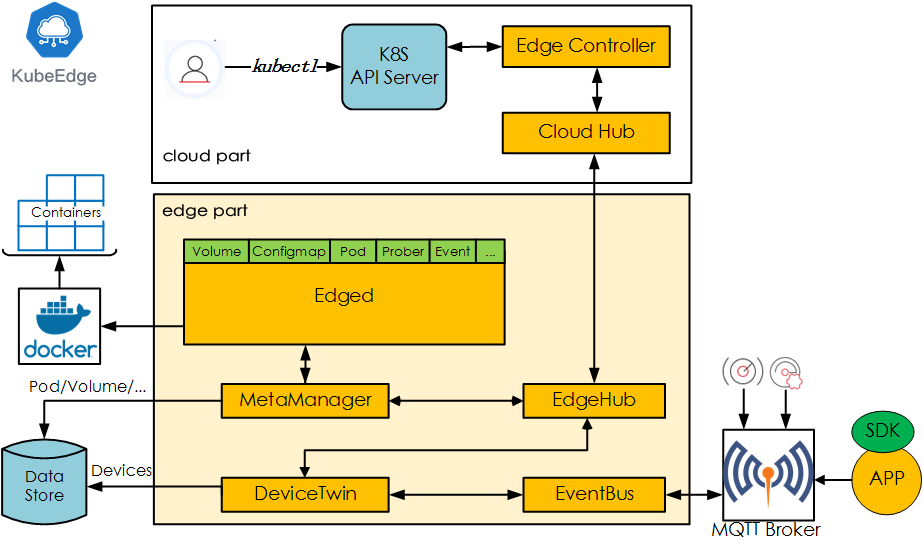
Edged: Manages containerized Applications at the Edge.
EdgeHub: Communication interface module at the Edge. It is a web socket client responsible for interacting with Cloud Service for edge computing.
CloudHub: Communication interface module at the Cloud. A web socket server responsible for watching changes on the cloud side, caching and sending messages to EdgeHub.
EdgeController: Manages the Edge nodes. It is an extended Kubernetes controller which manages edge nodes and pods metadata so that the data can be targeted to a specific edge node.
EventBus: Handles the internal edge communications using MQTT. It is an MQTT client to interact with MQTT servers (mosquitto), offering publish and subscribe capabilities to other components.
DeviceTwin: It is software mirror for devices that handles the device metadata. This module helps in handling device status and syncing the same to cloud. It also provides query interfaces for applications, as it interfaces to a lightweight database (SQLite).
MetaManager: It manages the metadata at the edge node. This is the message processor between edged and edgehub. It is also responsible for storing/retrieving metadata to/from a lightweight database (SQLite).
Even if you want to add more control plane modules based on the architecture refinement and improvement (for example enhanced security), it is simple as it uses consistent registration and modular communication within these modules.
KubeEdge provides scalable lightweight Kubernetes Native Edge Computing Platform which can work in offline mode.
It helps simplify edge application development and deployment.
Cloud vendor agnostic and can run the cloud core modules on any compute node.
Release 0.1 to 0.2 -- game changer!
KubeEdge v0.1 was released at the end of December 2018 with very basic edge features to manage edge applications along with Kubernetes API primitives for node, pod, config etc. In ~2 months, KubeEdge v0.2 was release on March 5th, 2019. This release provides the cloud core modules and enables the end to end open source edge computing solution. The cloud core modules can be deployed to any compute node from any cloud vendors or on-prem.
Now, the complete edge solution can be installed and tested very easily, also with a laptop.
Run Anywhere - Simple and Light
As described, the KubeEdge Edge and Cloud core components can be deployed easily and can run the user applications. The edge core has a foot print of 66MB and just needs 30MB memory to run. Similarly the cloud core can run on any cloud nodes. (User can experience by running it on a laptop as well)
The installation is simple and can be done in few steps:
- Setup the pre-requisites Docker, Kubernetes, MQTT and openssl
- Clone and Build KubeEdge Cloud and Edge
- Run Cloud
- Run Edge
The detailed steps for each are available at KubeEdge/kubeedge
Future: Taking off with competent features and community collaboration
KubeEdge has been developed by members from the community who are active contributors to Kubernetes/CNCF and doing research in edge computing. The KubeEdge team is also actively collaborating with Kubernetes IOT/EDGE WORKING GROUP. Within a few months of the KubeEdge announcement it has attracted members from different organizations including JingDong, Zhejiang University, SEL Lab, Eclipse, China Mobile, ARM, Intel to collaborate in building the platform and ecosystem.
KubeEdge has a clear roadmap for its upcoming major releases in 2019. vc1.0 targets to provide a complete edge cluster and device management solution with standard edge to edge communication, while v2.0 targets to have advanced features like service mesh, function service , data analytics etc at edge. Also, for all the features, KubeEdge architecture would attempt to utilize the existing CNCF projects/software.
The KubeEdge community needs varied organizations, their requirements, use cases and support to build it. Please join to make a kubernetes native edge computing platform which can extend the cloud native computing paradigm to edge cloud.
How to Get Involved?
We welcome more collaboration to build the Kubernetes native edge computing ecosystem. Please join us!
- Twitter: https://twitter.com/kubeedge
- Slack: kubeedge.slack.com
- Website: https://kubeedge.io
- GitHub: https://github.com/kubeedge/kubeedge
- Email: kubeedge@gmail.com
Kubernetes Setup Using Ansible and Vagrant
Author: Naresh L J (Infosys)
Objective
This blog post describes the steps required to setup a multi node Kubernetes cluster for development purposes. This setup provides a production-like cluster that can be setup on your local machine.
Why do we require multi node cluster setup?
Multi node Kubernetes clusters offer a production-like environment which has various advantages. Even though Minikube provides an excellent platform for getting started, it doesn't provide the opportunity to work with multi node clusters which can help solve problems or bugs that are related to application design and architecture. For instance, Ops can reproduce an issue in a multi node cluster environment, Testers can deploy multiple versions of an application for executing test cases and verifying changes. These benefits enable teams to resolve issues faster which make the more agile.
Why use Vagrant and Ansible?
Vagrant is a tool that will allow us to create a virtual environment easily and it eliminates pitfalls that cause the works-on-my-machine phenomenon. It can be used with multiple providers such as Oracle VirtualBox, VMware, Docker, and so on. It allows us to create a disposable environment by making use of configuration files.
Ansible is an infrastructure automation engine that automates software configuration management. It is agentless and allows us to use SSH keys for connecting to remote machines. Ansible playbooks are written in yaml and offer inventory management in simple text files.
Prerequisites
- Vagrant should be installed on your machine. Installation binaries can be found here.
- Oracle VirtualBox can be used as a Vagrant provider or make use of similar providers as described in Vagrant's official documentation.
- Ansible should be installed in your machine. Refer to the Ansible installation guide for platform specific installation.
Setup overview
We will be setting up a Kubernetes cluster that will consist of one master and two worker nodes. All the nodes will run Ubuntu Xenial 64-bit OS and Ansible playbooks will be used for provisioning.
Step 1: Creating a Vagrantfile
Use the text editor of your choice and create a file with named Vagrantfile, inserting the code below. The value of N denotes the number of nodes present in the cluster, it can be modified accordingly. In the below example, we are setting the value of N as 2.
IMAGE_NAME = "bento/ubuntu-16.04"
N = 2
Vagrant.configure("2") do |config|
config.ssh.insert_key = false
config.vm.provider "virtualbox" do |v|
v.memory = 1024
v.cpus = 2
end
config.vm.define "k8s-master" do |master|
master.vm.box = IMAGE_NAME
master.vm.network "private_network", ip: "192.168.50.10"
master.vm.hostname = "k8s-master"
master.vm.provision "ansible" do |ansible|
ansible.playbook = "kubernetes-setup/master-playbook.yml"
ansible.extra_vars = {
node_ip: "192.168.50.10",
}
end
end
(1..N).each do |i|
config.vm.define "node-#{i}" do |node|
node.vm.box = IMAGE_NAME
node.vm.network "private_network", ip: "192.168.50.#{i + 10}"
node.vm.hostname = "node-#{i}"
node.vm.provision "ansible" do |ansible|
ansible.playbook = "kubernetes-setup/node-playbook.yml"
ansible.extra_vars = {
node_ip: "192.168.50.#{i + 10}",
}
end
end
end
end
Step 2: Create an Ansible playbook for Kubernetes master.
Create a directory named kubernetes-setup in the same directory as the Vagrantfile. Create two files named master-playbook.yml and node-playbook.yml in the directory kubernetes-setup.
In the file master-playbook.yml, add the code below.
Step 2.1: Install Docker and its dependent components.
We will be installing the following packages, and then adding a user named “vagrant” to the “docker” group.
- docker-ce
- docker-ce-cli
- containerd.io
---
- hosts: all
become: true
tasks:
- name: Install packages that allow apt to be used over HTTPS
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
- apt-transport-https
- ca-certificates
- curl
- gnupg-agent
- software-properties-common
- name: Add an apt signing key for Docker
apt_key:
url: https://download.docker.com/linux/ubuntu/gpg
state: present
- name: Add apt repository for stable version
apt_repository:
repo: deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable
state: present
- name: Install docker and its dependecies
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
- docker-ce
- docker-ce-cli
- containerd.io
notify:
- docker status
- name: Add vagrant user to docker group
user:
name: vagrant
group: docker
Step 2.2: Kubelet will not start if the system has swap enabled, so we are disabling swap using the below code.
- name: Remove swapfile from /etc/fstab
mount:
name: "{{ item }}"
fstype: swap
state: absent
with_items:
- swap
- none
- name: Disable swap
command: swapoff -a
when: ansible_swaptotal_mb > 0
Step 2.3: Installing kubelet, kubeadm and kubectl using the below code.
- name: Add an apt signing key for Kubernetes
apt_key:
url: https://packages.cloud.google.com/apt/doc/apt-key.gpg
state: present
- name: Adding apt repository for Kubernetes
apt_repository:
repo: deb https://apt.kubernetes.io/ kubernetes-xenial main
state: present
filename: kubernetes.list
- name: Install Kubernetes binaries
apt:
name: "{{ packages }}"
state: present
update_cache: yes
vars:
packages:
- kubelet
- kubeadm
- kubectl
- name: Configure node ip
lineinfile:
path: /etc/default/kubelet
line: KUBELET_EXTRA_ARGS=--node-ip={{ node_ip }}
- name: Restart kubelet
service:
name: kubelet
daemon_reload: yes
state: restarted
Step 2.3: Initialize the Kubernetes cluster with kubeadm using the below code (applicable only on master node).
- name: Initialize the Kubernetes cluster using kubeadm
command: kubeadm init --apiserver-advertise-address="192.168.50.10" --apiserver-cert-extra-sans="192.168.50.10" --node-name k8s-master --pod-network-cidr=192.168.0.0/16
Step 2.4: Setup the kube config file for the vagrant user to access the Kubernetes cluster using the below code.
- name: Setup kubeconfig for vagrant user
command: "{{ item }}"
with_items:
- mkdir -p /home/vagrant/.kube
- cp -i /etc/kubernetes/admin.conf /home/vagrant/.kube/config
- chown vagrant:vagrant /home/vagrant/.kube/config
Step 2.5: Setup the container networking provider and the network policy engine using the below code.
- name: Install calico pod network
become: false
command: kubectl create -f https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/calico.yaml
Step 2.6: Generate kube join command for joining the node to the Kubernetes cluster and store the command in the file named join-command.
- name: Generate join command
command: kubeadm token create --print-join-command
register: join_command
- name: Copy join command to local file
local_action: copy content="{{ join_command.stdout_lines[0] }}" dest="./join-command"
Step 2.7: Setup a handler for checking Docker daemon using the below code.
handlers:
- name: docker status
service: name=docker state=started
Step 3: Create the Ansible playbook for Kubernetes node.
Create a file named node-playbook.yml in the directory kubernetes-setup.
Add the code below into node-playbook.yml
Step 3.1: Start adding the code from Steps 2.1 till 2.3.
Step 3.2: Join the nodes to the Kubernetes cluster using below code.
- name: Copy the join command to server location
copy: src=join-command dest=/tmp/join-command.sh mode=0777
- name: Join the node to cluster
command: sh /tmp/join-command.sh
Step 3.3: Add the code from step 2.7 to finish this playbook.
Step 4: Upon completing the Vagrantfile and playbooks follow the below steps.
$ cd /path/to/Vagrantfile
$ vagrant up
Upon completion of all the above steps, the Kubernetes cluster should be up and running. We can login to the master or worker nodes using Vagrant as follows:
$ ## Accessing master
$ vagrant ssh k8s-master
vagrant@k8s-master:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 18m v1.13.3
node-1 Ready <none> 12m v1.13.3
node-2 Ready <none> 6m22s v1.13.3
$ ## Accessing nodes
$ vagrant ssh node-1
$ vagrant ssh node-2
Raw Block Volume support to Beta
Authors: Ben Swartzlander (NetApp), Saad Ali (Google)
Kubernetes v1.13 moves raw block volume support to beta. This feature allows persistent volumes to be exposed inside containers as a block device instead of as a mounted file system.
What are block devices?
Block devices enable random access to data in fixed-size blocks. Hard drives, SSDs, and CD-ROMs drives are all examples of block devices.
Typically persistent storage is implemented in a layered maner with a file system (like ext4) on top of a block device (like a spinning disk or SSD). Applications then read and write files instead of operating on blocks. The operating systems take care of reading and writing files, using the specified filesystem, to the underlying device as blocks.
It's worth noting that while whole disks are block devices, so are disk partitions, and so are LUNs from a storage area network (SAN) device.
Why add raw block volumes to kubernetes?
There are some specialized applications that require direct access to a block device because, for example, the file system layer introduces unneeded overhead. The most common case is databases, which prefer to organize their data directly on the underlying storage. Raw block devices are also commonly used by any software which itself implements some kind of storage service (software defined storage systems).
From a programmer's perspective, a block device is a very large array of bytes, usually with some minimum granularity for reads and writes, often 512 bytes, but frequently 4K or larger.
As it becomes more common to run database software and storage infrastructure software inside of Kubernetes, the need for raw block device support in Kubernetes becomes more important.
Which volume plugins support raw blocks?
As of the publishing of this blog, the following in-tree volumes types support raw blocks:
- AWS EBS
- Azure Disk
- Cinder
- Fibre Channel
- GCE PD
- iSCSI
- Local volumes
- RBD (Ceph)
- Vsphere
Out-of-tree CSI volume drivers may also support raw block volumes. Kubernetes CSI support for raw block volumes is currently alpha. See documentation here.
Kubernetes raw block volume API
Raw block volumes share a lot in common with ordinary volumes. Both are requested by creating PersistentVolumeClaim objects which bind to PersistentVolume objects, and are attached to Pods in Kubernetes by including them in the volumes array of the PodSpec.
There are 2 important differences however. First, to request a raw block PersistentVolumeClaim, you must set volumeMode = "Block" in the PersistentVolumeClaimSpec. Leaving volumeMode blank is the same as specifying volumeMode = "Filesystem" which results in the traditional behavior. PersistentVolumes also have a volumeMode field in their PersistentVolumeSpec, and "Block" type PVCs can only bind to "Block" type PVs and "Filesystem" PVCs can only bind to "Filesystem" PVs.
Secondly, when using a raw block volume in your Pods, you must specify a VolumeDevice in the Container portion of the PodSpec rather than a VolumeMount. VolumeDevices have devicePaths instead of mountPaths, and inside the container, applications will see a device at that path instead of a mounted file system.
Applications open, read, and write to the device node inside the container just like they would interact with any block device on a system in a non-containerized or virtualized context.
Creating a new raw block PVC
First, ensure that the provisioner associated with the storage class you choose is one that support raw blocks. Then create the PVC.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteMany
volumeMode: Block
storageClassName: my-sc
resources:
requests:
storage: 1Gi
Using a raw block PVC
When you use the PVC in a pod definition, you get to choose the device path for the block device rather than the mount path for the file system.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: busybox
command:
- sleep
- “3600”
volumeDevices:
- devicePath: /dev/block
name: my-volume
imagePullPolicy: IfNotPresent
volumes:
- name: my-volume
persistentVolumeClaim:
claimName: my-pvc
As a storage vendor, how do I add support for raw block devices to my CSI plugin?
Raw block support for CSI plugins is still alpha, but support can be added today. The CSI specification details how to handle requests for volume that have the BlockVolume capability instead of the MountVolume capability. CSI plugins can support both kinds of volumes, or one or the other. For more details see documentation here.
Issues/gotchas
Because block devices are actually devices, it’s possible to do low-level actions on them from inside containers that wouldn’t be possible with file system volumes. For example, block devices that are actually SCSI disks support sending SCSI commands to the device using Linux ioctls.
By default, Linux won’t allow containers to send SCSI commands to disks from inside containers though. In order to do so, you must grant the SYS_RAWIO capability to the container security context to allow this. See documentation here.
Also, while Kubernetes is guaranteed to deliver a block device to the container, there’s no guarantee that it’s actually a SCSI disk or any other kind of disk for that matter. The user must either ensure that the desired disk type is used with his pods, or only deploy applications that can handle a variety of block device types.
How can I learn more?
Check out additional documentation on the snapshot feature here: Raw Block Volume Support
How do I get involved?
Join the Kubernetes storage SIG and the CSI community and help us add more great features and improve existing ones like raw block storage!
https://github.com/kubernetes/community/tree/master/sig-storage https://github.com/container-storage-interface/community/blob/master/README.md
Special thanks to all the contributors who helped add block volume support to Kubernetes including:
- Ben Swartzlander (https://github.com/bswartz)
- Brad Childs (https://github.com/childsb)
- Erin Boyd (https://github.com/erinboyd)
- Masaki Kimura (https://github.com/mkimuram)
- Matthew Wong (https://github.com/wongma7)
- Michelle Au (https://github.com/msau42)
- Mitsuhiro Tanino (https://github.com/mtanino)
- Saad Ali (https://github.com/saad-ali)
Automate Operations on your Cluster with OperatorHub.io
Author: Diane Mueller, Director of Community Development, Cloud Platforms, Red Hat
One of the important challenges facing developers and Kubernetes administrators has been a lack of ability to quickly find common services that are operationally ready for Kubernetes. Typically, the presence of an Operator for a specific service - a pattern that was introduced in 2016 and has gained momentum - is a good signal for the operational readiness of the service on Kubernetes. However, there has to date not existed a registry of Operators to simplify the discovery of such services.
To help address this challenge, today Red Hat is launching OperatorHub.io in collaboration with AWS, Google Cloud and Microsoft. OperatorHub.io enables developers and Kubernetes administrators to find and install curated Operator-backed services with a base level of documentation, active maintainership by communities or vendors, basic testing, and packaging for optimized life-cycle management on Kubernetes.
The Operators currently in OperatorHub.io are just the start. We invite the Kubernetes community to join us in building a vibrant community for Operators by developing, packaging, and publishing Operators on OperatorHub.io.
What does OperatorHub.io provide?
OperatorHub.io is designed to address the needs of both Kubernetes developers and users. For the former it provides a common registry where they can publish their Operators alongside with descriptions, relevant details like version, image, code repository and have them be readily packaged for installation. They can also update already published Operators to new versions when they are released.
Users get the ability to discover and download Operators at a central location, that has content which has been screened for the previously mentioned criteria and scanned for known vulnerabilities. In addition, developers can guide users of their Operators with prescriptive examples of the CustomResources that they introduce to interact with the application.
What is an Operator?
Operators were first introduced in 2016 by CoreOS and have been used by Red Hat and the Kubernetes community as a way to package, deploy and manage a Kubernetes-native application. A Kubernetes-native application is an application that is both deployed on Kubernetes and managed using the Kubernetes APIs and well-known tooling, like kubectl.
An Operator is implemented as a custom controller that watches for certain Kubernetes resources to appear, be modified or deleted. These are typically CustomResourceDefinitions that the Operator “owns.” In the spec properties of these objects the user declares the desired state of the application or the operation. The Operator’s reconciliation loop will pick these up and perform the required actions to achieve the desired state. For example, the intent to create a highly available etcd cluster could be expressed by creating an new resource of type EtcdCluster:
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "my-etcd-cluster"
spec:
size: 3
version: "3.3.12"
The EtcdOperator would be responsible for creating a 3-node etcd cluster running version v3.3.12 as a result. Similarly, an object of type EtcdBackup could be defined to express the intent to create a consistent backup of the etcd database to an S3 bucket.
How do I create and run an Operator?
One way to get started is with the Operator Framework, an open source toolkit that provides an SDK, lifecycle management, metering and monitoring capabilities. It enables developers to build, test, and package Operators. Operators can be implemented in several programming and automation languages, including Go, Helm, and Ansible, all three of which are supported directly by the SDK.
If you are interested in creating your own Operator, we recommend checking out the Operator Framework to get started.
Operators vary in where they fall along the capability spectrum ranging from basic functionality to having specific operational logic for an application to automate advanced scenarios like backup, restore or tuning. Beyond basic installation, advanced Operators are designed to handle upgrades more seamlessly and react to failures automatically. Currently, Operators on OperatorHub.io span the maturity spectrum, but we anticipate their continuing maturation over time.
While Operators on OperatorHub.io don’t need to be implemented using the SDK, they are packaged for deployment through the Operator Lifecycle Manager (OLM). The format mainly consists of a YAML manifest referred to as [ClusterServiceVersion](https://github.com/operator-framework/operator-lifecycle-manager/blob/master/doc/design/building-your-csv.md) which provides information about the CustomResourceDefinitions the Operator owns or requires, which RBAC definition it needs, where the image is stored, etc. This file is usually accompanied by additional YAML files which define the Operators’ own CRDs. This information is processed by OLM at the time a user requests to install an Operator to provide dependency resolution and automation.
What does listing of an Operator on OperatorHub.io mean?
To be listed, Operators must successfully show cluster lifecycle features, be packaged as a CSV to be maintained through OLM, and have acceptable documentation for its intended users.
Some examples of Operators that are currently listed on OperatorHub.io include: Amazon Web Services Operator, Couchbase Autonomous Operator, CrunchyData’s PostgreSQL, etcd Operator, Jaeger Operator for Kubernetes, Kubernetes Federation Operator, MongoDB Enterprise Operator, Percona MySQL Operator, PlanetScale’s Vitess Operator, Prometheus Operator, and Redis Operator.
Want to add your Operator to OperatorHub.io? Follow these steps
If you have an existing Operator, follow the contribution guide using a fork of the community-operators repository. Each contribution contains the CSV, all of the CustomResourceDefinitions, access control rules and references to the container image needed to install and run your Operator, plus other info like a description of its features and supported Kubernetes versions. A complete example, including multiple versions of the Operator, can be found with the EtcdOperator.
After testing out your Operator on your own cluster, submit a PR to the community repository with all of YAML files following this directory structure. Subsequent versions of the Operator can be published in the same way. At first this will be reviewed manually, but automation is on the way. After it’s merged by the maintainers, it will show up on OperatorHub.io along with its documentation and a convenient installation method.
Want to learn more?
- Attend one of the upcoming Kubernetes Operator Framework hands-on workshops at ScaleX in Pasadena on March 7 and at the OpenShift Commons Gathering on Operating at Scale in Santa Clara on March 11
- Listen to this OpenShift Commons Briefing on “The State of Operators” with Daniel Messer and Diane Mueller
- Join in on the online conversations in the community Kubernetes-Operator Slack Channel and the Operator Framework Google Group
- Finally, read up on how to add your Operator to OperatorHub.io: https://operatorhub.io/contribute
Building a Kubernetes Edge (Ingress) Control Plane for Envoy v2
Author: Daniel Bryant, Product Architect, Datawire; Flynn, Ambassador Lead Developer, Datawire; Richard Li, CEO and Co-founder, Datawire
Kubernetes has become the de facto runtime for container-based microservice applications, but this orchestration framework alone does not provide all of the infrastructure necessary for running a distributed system. Microservices typically communicate through Layer 7 protocols such as HTTP, gRPC, or WebSockets, and therefore having the ability to make routing decisions, manipulate protocol metadata, and observe at this layer is vital. However, traditional load balancers and edge proxies have predominantly focused on L3/4 traffic. This is where the Envoy Proxy comes into play.
Envoy proxy was designed as a universal data plane from the ground-up by the Lyft Engineering team for today's distributed, L7-centric world, with broad support for L7 protocols, a real-time API for managing its configuration, first-class observability, and high performance within a small memory footprint. However, Envoy's vast feature set and flexibility of operation also makes its configuration highly complicated -- this is evident from looking at its rich but verbose control plane syntax.
With the open source Ambassador API Gateway, we wanted to tackle the challenge of creating a new control plane that focuses on the use case of deploying Envoy as an forward-facing edge proxy within a Kubernetes cluster, in a way that is idiomatic to Kubernetes operators. In this article, we'll walk through two major iterations of the Ambassador design, and how we integrated Ambassador with Kubernetes.
Ambassador pre-2019: Envoy v1 APIs, Jinja Template Files, and Hot Restarts
Ambassador itself is deployed within a container as a Kubernetes service, and uses annotations added to Kubernetes Services as its core configuration model. This approach enables application developers to manage routing as part of the Kubernetes service definition. We explicitly decided to go down this route because of limitations in the current Ingress API spec, and we liked the simplicity of extending Kubernetes services, rather than introducing another custom resource type. An example of an Ambassador annotation can be seen here:
kind: Service
apiVersion: v1
metadata:
name: my-service
annotations:
getambassador.io/config: |
---
apiVersion: ambassador/v0
kind: Mapping
name: my_service_mapping
prefix: /my-service/
service: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
Translating this simple Ambassador annotation config into valid Envoy v1 config was not a trivial task. By design, Ambassador's configuration isn't based on the same conceptual model as Envoy's configuration -- we deliberately wanted to aggregate and simplify operations and config. Therefore, translating between one set of concepts to the other involves a fair amount of logic within Ambassador.
In this first iteration of Ambassador we created a Python-based service that watched the Kubernetes API for changes to Service objects. When new or updated Ambassador annotations were detected, these were translated from the Ambassador syntax into an intermediate representation (IR) which embodied our core configuration model and concepts. Next, Ambassador translated this IR into a representative Envoy configuration which was saved as a file within pods associated with the running Ambassador k8s Service. Ambassador then "hot-restarted" the Envoy process running within the Ambassador pods, which triggered the loading of the new configuration.
There were many benefits with this initial implementation. The mechanics involved were fundamentally simple, the transformation of Ambassador config into Envoy config was reliable, and the file-based hot restart integration with Envoy was dependable.
However, there were also notable challenges with this version of Ambassador. First, although the hot restart was effective for the majority of our customers' use cases, it was not very fast, and some customers (particularly those with huge application deployments) found it was limiting the frequency with which they could change their configuration. Hot restart can also drop connections, especially long-lived connections like WebSockets or gRPC streams.
More crucially, though, the first implementation of the IR allowed rapid prototyping but was primitive enough that it proved very difficult to make substantial changes. While this was a pain point from the beginning, it became a critical issue as Envoy shifted to the Envoy v2 API. It was clear that the v2 API would offer Ambassador many benefits -- as Matt Klein outlined in his blog post, "The universal data plane API" -- including access to new features and a solution to the connection-drop problem noted above, but it was also clear that the existing IR implementation was not capable of making the leap.
Ambassador >= v0.50: Envoy v2 APIs (ADS), Testing with KAT, and Golang
In consultation with the Ambassador community, the Datawire team undertook a redesign of the internals of Ambassador in 2018. This was driven by two key goals. First, we wanted to integrate Envoy's v2 configuration format, which would enable the support of features such as SNI, rate limiting and gRPC authentication APIs. Second, we also wanted to do much more robust semantic validation of Envoy configuration due to its increasing complexity (particularly when operating with large-scale application deployments).
Initial stages
We started by restructuring the Ambassador internals more along the lines of a multipass compiler. The class hierarchy was made to more closely mirror the separation of concerns between the Ambassador configuration resources, the IR, and the Envoy configuration resources. Core parts of Ambassador were also redesigned to facilitate contributions from the community outside Datawire. We decided to take this approach for several reasons. First, Envoy Proxy is a very fast moving project, and we realized that we needed an approach where a seemingly minor Envoy configuration change didn't result in days of reengineering within Ambassador. In addition, we wanted to be able to provide semantic verification of configuration.
As we started working more closely with Envoy v2, a testing challenge was quickly identified. As more and more features were being supported in Ambassador, more and more bugs appeared in Ambassador's handling of less common but completely valid combinations of features. This drove to creation of a new testing requirement that meant Ambassador's test suite needed to be reworked to automatically manage many combinations of features, rather than relying on humans to write each test individually. Moreover, we wanted the test suite to be fast in order to maximize engineering productivity.
Thus, as part of the Ambassador rearchitecture, we introduced the Kubernetes Acceptance Test (KAT) framework. KAT is an extensible test framework that:
- Deploys a bunch of services (along with Ambassador) to a Kubernetes cluster
- Run a series of verification queries against the spun up APIs
- Perform a bunch of assertions on those query results
KAT is designed for performance -- it batches test setup upfront, and then runs all the queries in step 3 asynchronously with a high performance client. The traffic driver in KAT runs locally using Telepresence, which makes it easier to debug issues.
Introducing Golang to the Ambassador Stack
With the KAT test framework in place, we quickly ran into some issues with Envoy v2 configuration and hot restart, which presented the opportunity to switch to use Envoy’s Aggregated Discovery Service (ADS) APIs instead of hot restart. This completely eliminated the requirement for restart on configuration changes, which we found could lead to dropped connection under high loads or long-lived connections.
However, we faced an interesting question as we considered the move to the ADS. The ADS is not as simple as one might expect: there are explicit ordering dependencies when sending updates to Envoy. The Envoy project has reference implementations of the ordering logic, but only in Go and Java, where Ambassador was primarily in Python. We agonized a bit, and decided that the simplest way forward was to accept the polyglot nature of our world, and do our ADS implementation in Go.
We also found, with KAT, that our testing had reached the point where Python’s performance with many network connections was a limitation, so we took advantage of Go here, as well, writing KAT’s querying and backend services primarily in Go. After all, what’s another Golang dependency when you’ve already taken the plunge?
With a new test framework, new IR generating valid Envoy v2 configuration, and the ADS, we thought we were done with the major architectural changes in Ambassador 0.50. Alas, we hit one more issue. On the Azure Kubernetes Service, Ambassador annotation changes were no longer being detected.
Working with the highly-responsive AKS engineering team, we were able to identify the issue -- namely, the Kubernetes API server in AKS is exposed through a chain of proxies, requiring clients to be updating to understand how to connect using the FQDN of the API server, which is provided through a mutating webhook in AKS. Unfortunately, support for this feature was not available in the official Kubernetes Python client, so this was the third spot where we chose to switch to Go instead of Python.
This raises the interesting question of, “why not ditch all the Python code, and just rewrite Ambassador entirely in Go?” It’s a valid question. The main concern with a rewrite is that Ambassador and Envoy operate at different conceptual levels rather than simply expressing the same concepts with different syntax. Being certain that we’ve expressed the conceptual bridges in a new language is not a trivial challenge, and not something to undertake without already having really excellent test coverage in place
At this point, we use Go to coverage very specific, well-contained functions that can be verified for correctness much more easily that we could verify a complete Golang rewrite. In the future, who knows? But for 0.50.0, this functional split let us both take advantage of Golang’s strengths, while letting us retain more confidence about all the changes already in 0.50.
Lessons Learned
We've learned a lot in the process of building Ambassador 0.50. Some of our key takeaways:
- Kubernetes and Envoy are very powerful frameworks, but they are also extremely fast moving targets -- there is sometimes no substitute for reading the source code and talking to the maintainers (who are fortunately all quite accessible!)
- The best supported libraries in the Kubernetes / Envoy ecosystem are written in Go. While we love Python, we have had to adopt Go so that we're not forced to maintain too many components ourselves.
- Redesigning a test harness is sometimes necessary to move your software forward.
- The real cost in redesigning a test harness is often in porting your old tests to the new harness implementation.
- Designing (and implementing) an effective control plane for the edge proxy use case has been challenging, and the feedback from the open source community around Kubernetes, Envoy and Ambassador has been extremely useful.
Migrating Ambassador to the Envoy v2 configuration and ADS APIs was a long and difficult journey that required lots of architecture and design discussions and plenty of coding, but early feedback from results have been positive. Ambassador 0.50 is available now, so you can take it for a test run and share your feedback with the community on our Slack channel or on Twitter.
Runc and CVE-2019-5736
This morning a container escape vulnerability in runc was announced. We wanted to provide some guidance to Kubernetes users to ensure everyone is safe and secure.
What Is Runc?
Very briefly, runc is the low-level tool which does the heavy lifting of spawning a Linux container. Other tools like Docker, Containerd, and CRI-O sit on top of runc to deal with things like data formatting and serialization, but runc is at the heart of all of these systems.
Kubernetes in turn sits on top of those tools, and so while no part of Kubernetes itself is vulnerable, most Kubernetes installations are using runc under the hood.
What Is The Vulnerability?
While full details are still embargoed to give people time to patch, the rough version is that when running a process as root (UID 0) inside a container, that process can exploit a bug in runc to gain root privileges on the host running the container. This then allows them unlimited access to the server as well as any other containers on that server.
If the process inside the container is either trusted (something you know is not hostile) or is not running as UID 0, then the vulnerability does not apply. It can also be prevented by SELinux, if an appropriate policy has been applied. RedHat Enterprise Linux and CentOS both include appropriate SELinux permissions with their packages and so are believed to be unaffected if SELinux is enabled.
The most common source of risk is attacker-controller container images, such as unvetted images from public repositories.
What Should I Do?
As with all security issues, the two main options are to mitigate the vulnerability or upgrade your version of runc to one that includes the fix.
As the exploit requires UID 0 within the container, a direct mitigation is to ensure all your containers are running as a non-0 user. This can be set within the container image, or via your pod specification:
apiVersion: v1
kind: Pod
metadata:
name: run-as-uid-1000
spec:
securityContext:
runAsUser: 1000
# ...
This can also be enforced globally using a PodSecurityPolicy:
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: non-root
spec:
privileged: false
allowPrivilegeEscalation: false
runAsUser:
# Require the container to run without root privileges.
rule: 'MustRunAsNonRoot'
Setting a policy like this is highly encouraged given the overall risks of running as UID 0 inside a container.
Another potential mitigation is to ensure all your container images are vetted and trusted. This can be accomplished by building all your images yourself, or by vetting the contents of an image and then pinning to the image version hash (image: external/someimage@sha256:7832659873hacdef).
Upgrading runc can generally be accomplished by upgrading the package runc for your distribution or by upgrading your OS image if using immutable images. This is a list of known safe versions for various distributions and platforms:
- Ubuntu -
runc 1.0.0~rc4+dfsg1-6ubuntu0.18.10.1 - Debian -
runc 1.0.0~rc6+dfsg1-2 - RedHat Enterprise Linux -
docker 1.13.1-91.git07f3374.el7(if SELinux is disabled) - Amazon Linux -
docker 18.06.1ce-7.25.amzn1.x86_64 - CoreOS - Stable:
1967.5.0/ Beta:2023.2.0/ Alpha:2051.0.0 - Kops Debian - in progress (see advisory for how to address until Kops Debian is patched)
- Docker -
18.09.2
Some platforms have also posted more specific instructions:
Google Container Engine (GKE)
Google has issued a security bulletin with more detailed information but in short, if you are using the default GKE node image then you are safe. If you are using an Ubuntu node image then you will need to mitigate or upgrade to an image with a fixed version of runc.
Amazon Elastic Container Service for Kubernetes (EKS)
Amazon has also issued a security bulletin with more detailed information. All EKS users should mitigate the issue or upgrade to a new node image.
Azure Kubernetes Service (AKS)
Microsoft has issued a security bulletin with detailed information on mitigating the issue. Microsoft recommends all AKS users to upgrade their cluster to mitigate the issue.
Kops
Kops has issued an advisory with detailed information on mitigating this issue.
Docker
We don't have specific confirmation that Docker for Mac and Docker for Windows are vulnerable, however it seems likely. Docker has released a fix in version 18.09.2 and it is recommended you upgrade to it. This also applies to other deploy systems using Docker under the hood.
If you are unable to upgrade Docker, the Rancher team has provided backports of the fix for many older versions at github.com/rancher/runc-cve.
Getting More Information
If you have any further questions about how this vulnerability impacts Kubernetes, please join us at discuss.kubernetes.io.
If you would like to get in contact with the runc team, you can reach them on Google Groups or #opencontainers on Freenode IRC.
Poseidon-Firmament Scheduler – Flow Network Graph Based Scheduler
Authors: Deepak Vij (Huawei), Shivram Shrivastava (Huawei)
Introduction
Cluster Management systems such as Mesos, Google Borg, Kubernetes etc. in a cloud scale datacenter environment (also termed as Datacenter-as-a-Computer or Warehouse-Scale Computing - WSC) typically manage application workloads by performing tasks such as tracking machine live-ness, starting, monitoring, terminating workloads and more importantly using a Cluster Scheduler to decide on workload placements.
A Cluster Scheduler essentially performs the scheduling of workloads to compute resources – combining the global placement of work across the WSC environment makes the “warehouse-scale computer” more efficient, increases utilization, and saves energy. Cluster Scheduler examples are Google Borg, Kubernetes, Firmament, Mesos, Tarcil, Quasar, Quincy, Swarm, YARN, Nomad, Sparrow, Apollo etc.
In this blog post, we briefly describe the novel Firmament flow network graph based scheduling approach (OSDI paper) in Kubernetes. We specifically describe the Firmament Scheduler and how it integrates with the Kubernetes cluster manager using Poseidon as the integration glue. We have seen extremely impressive scheduling throughput performance benchmarking numbers with this novel scheduling approach. Originally, Firmament Scheduler was conceptualized, designed and implemented by University of Cambridge researchers, Malte Schwarzkopf & Ionel Gog.
Poseidon-Firmament Scheduler – How It Works
At a very high level, Poseidon-Firmament scheduler augments the current Kubernetes scheduling capabilities by incorporating novel flow network graph based scheduling capabilities alongside the default Kubernetes Scheduler. It models the scheduling problem as a constraint-based optimization over a flow network graph – by reducing scheduling to a min-cost max-flow optimization problem. Due to the inherent rescheduling capabilities, the new scheduler enables a globally optimal scheduling environment that constantly keeps refining the workloads placements dynamically.
Key Advantages
Flow graph scheduling based Poseidon-Firmament scheduler provides the following key advantages:
-
Workloads (pods) are bulk scheduled to enable scheduling decisions at massive scale.
-
Based on the extensive performance test results, Poseidon-Firmament scales much better than Kubernetes default scheduler as the number of nodes increase in a cluster. This is due to the fact that Poseidon-Firmament is able to amortize more and more work across workloads.
-
Poseidon-Firmament Scheduler outperforms the Kubernetes default scheduler by a wide margin when it comes to throughput performance numbers for scenarios where compute resource requirements are somewhat uniform across jobs (Replicasets/Deployments/Jobs). Poseidon-Firmament scheduler end-to-end throughput performance numbers, including bind time, consistently get better as the number of nodes in a cluster increase. For example, for a 2,700 node cluster (shown in the graphs here), Poseidon-Firmament scheduler achieves a 7X or greater end-to-end throughput than the Kubernetes default scheduler, which includes bind time.
-
Availability of complex rule constraints.
-
Scheduling in Poseidon-Firmament is very dynamic; it keeps cluster resources in a global optimal state during every scheduling run.
-
Highly efficient resource utilizations.
Firmament Flow Network Graph – An Overview
Firmament scheduler runs a min-cost flow algorithm over the flow network to find an optimal flow, from which it extracts the implied workload (pod placements). A flow network is a directed graph whose arcs carry flow from source nodes (i.e. pod nodes) to a sink node. A cost and capacity associated with each arc constrain the flow, and specify preferential routes for it.
Figure 1 below shows an example of a flow network for a cluster with two tasks (workloads or pods) and four machines (nodes) – each workload on the left hand side, is a source of one unit of flow. All such flow must be drained into the sink node (S) for a feasible solution to the optimization problem.
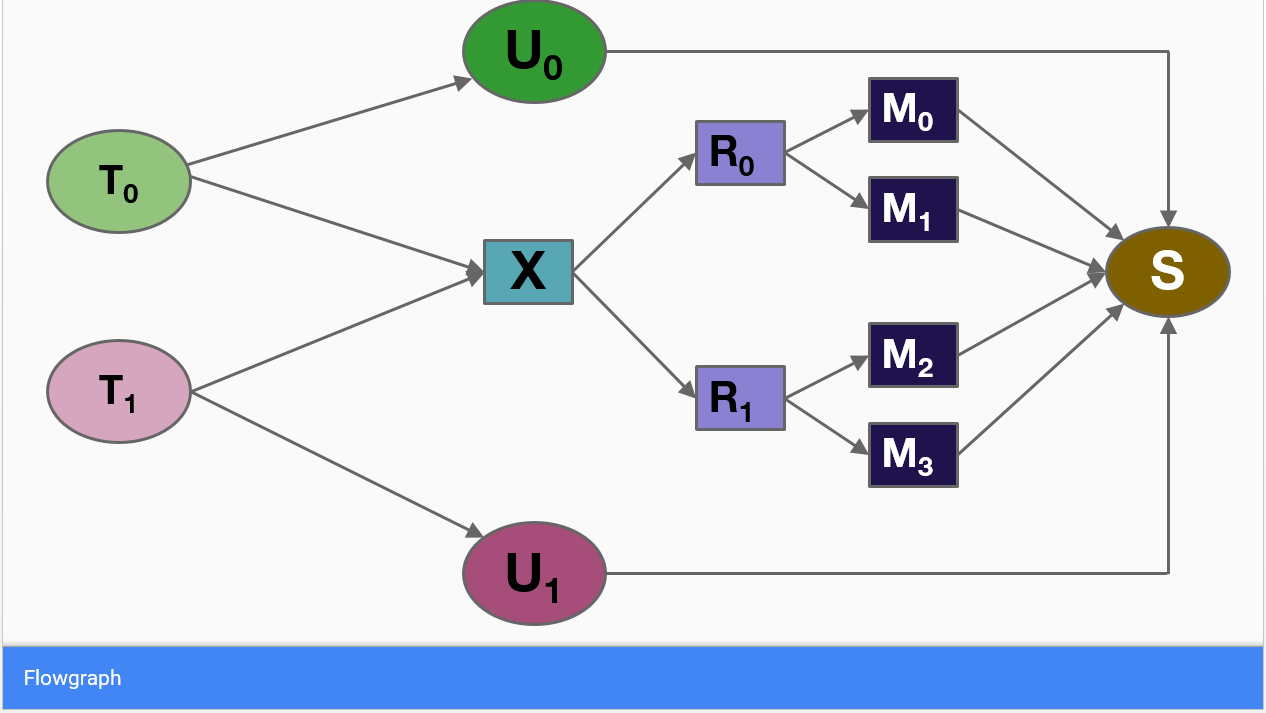
Figure 1. Example of a Flow Network
Poseidon Mediation Layer – An Overview
Poseidon is a service that acts as the integration glue for the Firmament scheduler with Kubernetes. It augments the current Kubernetes scheduling capabilities by incorporating new flow network graph based Firmament scheduling capabilities alongside the default Kubernetes Scheduler; multiple schedulers running simultaneously. Figure 2 below describes the high level overall design as far as how Poseidon integration glue works in conjunction with the underlying Firmament flow network graph based scheduler.
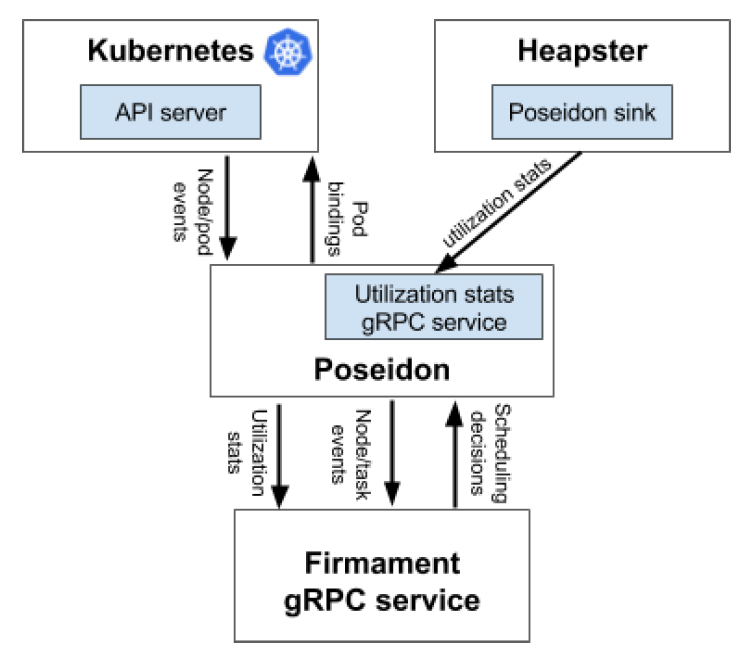
Figure 2. Firmament Kubernetes Integration Overview
As part of the Kubernetes multiple schedulers support, each new pod is typically scheduled by the default scheduler, but Kubernetes can be instructed to use another scheduler by specifying the name of another custom scheduler (in our case, Poseidon-Firmament) at the time of pod deployment. In this case, the default scheduler will ignore that Pod and allow Poseidon scheduler to schedule the Pod to a relevant node.
Possible Use Case Scenarios – When To Use It
Poseidon-Firmament scheduler enables extremely high throughput scheduling environment at scale due to its bulk scheduling approach superiority versus K8s pod-at-a-time approach. In our extensive tests, we have observed substantial throughput benefits as long as resource requirements (CPU/Memory) for incoming Pods is uniform across jobs (Replicasets/Deployments/Jobs), mainly due to efficient amortization of work across jobs.
Although, Poseidon-Firmament scheduler is capable of scheduling various types of workloads (service, batch, etc.), following are the few use cases where it excels the most:
-
For “Big Data/AI” jobs consisting of a large number of tasks, throughput benefits are tremendous.
-
Substantial throughput benefits also for service or batch job scenarios where workload resource requirements are uniform across jobs (Replicasets/Deplyments/Jobs).
Current Project Stage
Currently Poseidon-Firmament project is an incubation project. Alpha Release is available at https://github.com/kubernetes-sigs/poseidon.
Update on Volume Snapshot Alpha for Kubernetes
Authors: Jing Xu (Google), Xing Yang (Huawei), Saad Ali (Google)
Volume snapshotting support was introduced in Kubernetes v1.12 as an alpha feature. In Kubernetes v1.13, it remains an alpha feature, but a few enhancements were added and some breaking changes were made. This post summarizes the changes.
Breaking Changes
CSI spec v1.0 introduced a few breaking changes to the volume snapshot feature. CSI driver maintainers should be aware of these changes as they upgrade their drivers to support v1.0.
SnapshotStatus replaced with Boolean ReadyToUse
CSI v0.3.0, defined a SnapshotStatus enum in CreateSnapshotResponse which indicates whether the snapshot is READY, UPLOADING, or ERROR_UPLOADING. In CSI v1.0, SnapshotStatus has been removed from CreateSnapshotResponse and replaced with a boolean ReadyToUse. A ReadyToUse value of true indicates that post snapshot processing (such as uploading) is complete and the snapshot is ready to be used as a source to create a volume.
Storage systems that need to do post snapshot processing (such as uploading after the snapshot is cut) should return a successful CreateSnapshotResponse with the ReadyToUse field set to false as soon as the snapshot has been taken. This indicates that the Container Orchestration System (CO) can resume any workload that was quiesced for the snapshot to be taken. The CO can then repeatedly call CreateSnapshot until the ReadyToUse field is set to true or the call returns an error indicating a problem in processing. The CSI ListSnapshot call could be used along with snapshot_id filtering to determine if the snapshot is ready to use, but is not recommended because it provides no way to detect errors during processing (the ReadyToUse field simply remains false indefinitely).
The v1.x.x releases of the CSI external-snapshotter sidecar container already handle this change by calling CreateSnapshot instead of ListSnapshots to check if a snapshot is ready to use. When upgrading their drivers to CSI 1.0, driver maintainers should use the appropriate 1.0 compatible sidecar container.
To be consistent with the change in the CSI spec, the Ready field in the VolumeSnapshot API object has been renamed to ReadyToUse. This change is visible to the user when running kubectl describe volumesnapshot to view the details of a snapshot.
Timestamp Data Type
The creation time of a snapshot is available to Kubernetes admins as part of the VolumeSnapshotContent API object. This field is populated using the creation_time field in the CSI CreateSnapshotResponse. In CSI v1.0, this creation_time field type was changed to .google.protobuf.Timestamp instead of int64. When upgrading drivers to CSI 1.0, driver maintainers must make changes accordingly. The v1.x.x releases of the CSI external-snapshotter sidecar container has been updated to handle this change.
Deprecations
The following VolumeSnapshotClass parameters are deprecated and will be removed in a future release. They will be replaced with parameters listed in the Replacement section below.
Deprecated Replacement csiSnapshotterSecretName csi.storage.k8s.io/snapshotter-secret-name csiSnapshotterSecretNameSpace csi.storage.k8s.io/snapshotter-secret-namespace
New Features
SnapshotContent Deletion/Retain Policy
As described in the initial blog post announcing the snapshot alpha, the Kubernetes snapshot APIs are similar to the PV/PVC APIs: just like a volume is represented by a bound PVC and PV pair, a snapshot is represented by a bound VolumeSnapshot and VolumeSnapshotContent pair.
With PV/PVC pairs, when a user is done with a volume, they can delete the PVC. And the reclaim policy on the PV determines what happens to the PV (whether it is also deleted or retained).
In the initial alpha release, snapshots did not support the ability to specify a reclaim policy. Instead when a snapshot object was deleted it always resulted in the snapshot being deleted. In Kubernetes v1.13, a snapshot content DeletionPolicy was added. It enables an admin to configure what what happens to a VolumeSnapshotContent after the VolumeSnapshot object it is bound to is deleted. The DeletionPolicy of a volume snapshot can either be Retain or Delete. If the value is not specified, the default depends on whether the SnapshotContent object was created via static binding or dynamic provisioning.
Retain
The Retain policy allows for manual reclamation of the resource. If a VolumeSnapshotContent is statically created and bound, the default DeletionPolicy is Retain. When the VolumeSnapshot is deleted, the VolumeSnapshotContent continues to exist and the VolumeSnapshotContent is considered “released”. But it is not available for binding to other VolumeSnapshot objects because it contains data. It is up to an administrator to decide how to handle the remaining API object and resource cleanup.
Delete
A Delete policy enables automatic deletion of the bound VolumeSnapshotContent object from Kubernetes and the associated storage asset in the external infrastructure (such as an AWS EBS snapshot or GCE PD snapshot, etc.). Snapshots that are dynamically provisioned inherit the deletion policy of their VolumeSnapshotClass, which defaults to Delete. The administrator should configure the VolumeSnapshotClass with the desired retention policy. The policy may be changed for individual VolumeSnapshotContent after it is created by patching the object.
The following example demonstrates how to check the deletion policy of a dynamically provisioned VolumeSnapshotContent.
$ kubectl create -f ./examples/kubernetes/demo-defaultsnapshotclass.yaml
$ kubectl create -f ./examples/kubernetes/demo-snapshot.yaml
$ kubectl get volumesnapshots demo-snapshot-podpvc -o yaml
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshot
metadata:
creationTimestamp: "2018-11-27T23:57:09Z"
...
spec:
snapshotClassName: default-snapshot-class
snapshotContentName: snapcontent-26cd0db3-f2a0-11e8-8be6-42010a800002
source:
apiGroup: null
kind: PersistentVolumeClaim
name: podpvc
status:
…
$ kubectl get volumesnapshotcontent snapcontent-26cd0db3-f2a0-11e8-8be6-42010a800002 -o yaml
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshotContent
…
spec:
csiVolumeSnapshotSource:
creationTime: 1546469777852000000
driver: pd.csi.storage.gke.io
restoreSize: 6442450944
snapshotHandle: projects/jing-k8s-dev/global/snapshots/snapshot-26cd0db3-f2a0-11e8-8be6-42010a800002
deletionPolicy: Delete
persistentVolumeRef:
apiVersion: v1
kind: PersistentVolume
name: pvc-853622a4-f28b-11e8-8be6-42010a800002
resourceVersion: "21117"
uid: ae400e9f-f28b-11e8-8be6-42010a800002
snapshotClassName: default-snapshot-class
volumeSnapshotRef:
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshot
name: demo-snapshot-podpvc
namespace: default
resourceVersion: "6948065"
uid: 26cd0db3-f2a0-11e8-8be6-42010a800002
User can change the deletion policy by using patch:
$ kubectl patch volumesnapshotcontent snapcontent-26cd0db3-f2a0-11e8-8be6-42010a800002 -p '{"spec":{"deletionPolicy":"Retain"}}' --type=merge
$ kubectl get volumesnapshotcontent snapcontent-26cd0db3-f2a0-11e8-8be6-42010a800002 -o yaml
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshotContent
...
spec:
csiVolumeSnapshotSource:
...
deletionPolicy: Retain
persistentVolumeRef:
apiVersion: v1
kind: PersistentVolume
name: pvc-853622a4-f28b-11e8-8be6-42010a800002
...
Snapshot Object in Use Protection
The purpose of the Snapshot Object in Use Protection feature is to ensure that in-use snapshot API objects are not removed from the system (as this may result in data loss). There are two cases that require “in-use” protection:
- If a volume snapshot is in active use by a persistent volume claim as a source to create a volume.
- If a
VolumeSnapshotContentAPI object is bound to a VolumeSnapshot API object, the content object is considered in use.
If a user deletes a VolumeSnapshot API object in active use by a PVC, the VolumeSnapshot object is not removed immediately. Instead, removal of the VolumeSnapshot object is postponed until the VolumeSnapshot is no longer actively used by any PVCs. Similarly, if an admin deletes a VolumeSnapshotContent that is bound to a VolumeSnapshot, the VolumeSnapshotContent is not removed immediately. Instead, the VolumeSnapshotContent removal is postponed until the VolumeSnapshotContent is not bound to the VolumeSnapshot object.
Which volume plugins support Kubernetes Snapshots?
Snapshots are only supported for CSI drivers (not for in-tree or FlexVolume). To use the Kubernetes snapshots feature, ensure that a CSI Driver that implements snapshots is deployed on your cluster.
As of the publishing of this blog post, the following CSI drivers support snapshots:
- GCE Persistent Disk CSI Driver
- OpenSDS CSI Driver
- Ceph RBD CSI Driver
- Portworx CSI Driver
- GlusterFS CSI Driver
- DigitalOcean CSI Driver
- Ember CSI Driver
- Cinder CSI Driver
- Datera CSI Driver
- NexentaStor CSI Driver
Snapshot support for other drivers is pending, and should be available soon. Read the “Container Storage Interface (CSI) for Kubernetes GA” blog post to learn more about CSI and how to deploy CSI drivers.
What’s next?
Depending on feedback and adoption, the Kubernetes team plans to push the CSI Snapshot implementation to beta in either 1.15 or 1.16. Some of the features we are interested in supporting include consistency groups, application consistent snapshots, workload quiescing, in-place restores, and more.
How can I learn more?
The code repository for snapshot APIs and controller is here: https://github.com/kubernetes-csi/external-snapshotter
Check out additional documentation on the snapshot feature here: http://k8s.io/docs/concepts/storage/volume-snapshots and https://kubernetes-csi.github.io/docs/
How do I get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together.
Special thanks to all the contributors that helped add CSI v1.0 support and improve the snapshot feature in this release, including Saad Ali (saadali), Michelle Au (msau42), Deep Debroy (ddebroy), James DeFelice (jdef), John Griffith (j-griffith), Julian Hjortshoj (julian-hj), Tim Hockin (thockin), Patrick Ohly (pohly), Luis Pabon (lpabon), Cheng Xing (verult), Jing Xu (jingxu97), Shiwei Xu (wackxu), Xing Yang (xing-yang), Jie Yu (jieyu), David Zhu (davidz627).
Those interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
We also hold regular SIG-Storage Snapshot Working Group meetings. New attendees are welcome to join for design and development discussions.
Container Storage Interface (CSI) for Kubernetes GA

![]()
Author: Saad Ali, Senior Software Engineer, Google
The Kubernetes implementation of the Container Storage Interface (CSI) has been promoted to GA in the Kubernetes v1.13 release. Support for CSI was introduced as alpha in Kubernetes v1.9 release, and promoted to beta in the Kubernetes v1.10 release.
The GA milestone indicates that Kubernetes users may depend on the feature and its API without fear of backwards incompatible changes in future causing regressions. GA features are protected by the Kubernetes deprecation policy.
Why CSI?
Although prior to CSI Kubernetes provided a powerful volume plugin system, it was challenging to add support for new volume plugins to Kubernetes: volume plugins were “in-tree” meaning their code was part of the core Kubernetes code and shipped with the core Kubernetes binaries—vendors wanting to add support for their storage system to Kubernetes (or even fix a bug in an existing volume plugin) were forced to align with the Kubernetes release process. In addition, third-party storage code caused reliability and security issues in core Kubernetes binaries and the code was often difficult (and in some cases impossible) for Kubernetes maintainers to test and maintain.
CSI was developed as a standard for exposing arbitrary block and file storage storage systems to containerized workloads on Container Orchestration Systems (COs) like Kubernetes. With the adoption of the Container Storage Interface, the Kubernetes volume layer becomes truly extensible. Using CSI, third-party storage providers can write and deploy plugins exposing new storage systems in Kubernetes without ever having to touch the core Kubernetes code. This gives Kubernetes users more options for storage and makes the system more secure and reliable.
What’s new?
With the promotion to GA, the Kubernetes implementation of CSI introduces the following changes:
- Kubernetes is now compatible with CSI spec v1.0 and v0.3 (instead of CSI spec v0.2).
- There were breaking changes between CSI spec v0.3.0 and v1.0.0, but Kubernetes v1.13 supports both versions so either version will work with Kubernetes v1.13.
- Please note that with the release of the CSI 1.0 API, support for CSI drivers using 0.3 and older releases of the CSI API is deprecated, and is planned to be removed in Kubernetes v1.15.
- There were no breaking changes between CSI spec v0.2 and v0.3, so v0.2 drivers should also work with Kubernetes v1.10.0+.
- There were breaking changes between the CSI spec v0.1 and v0.2, so very old drivers implementing CSI 0.1 must be updated to be at least 0.2 compatible before use with Kubernetes v1.10.0+.
- The Kubernetes
VolumeAttachmentobject (introduced in v1.9 in the storage v1alpha1 group, and added to the v1beta1 group in v1.10) has been added to the storage v1 group in v1.13. - The Kubernetes
CSIPersistentVolumeSourcevolume type has been promoted to GA. - The Kubelet device plugin registration mechanism, which is the means by which kubelet discovers new CSI drivers, has been promoted to GA in Kubernetes v1.13.
How to deploy a CSI driver?
Kubernetes users interested in how to deploy or manage an existing CSI driver on Kubernetes should look at the documentation provided by the author of the CSI driver.
How to use a CSI volume?
Assuming a CSI storage plugin is already deployed on a Kubernetes cluster, users can use CSI volumes through the familiar Kubernetes storage API objects: PersistentVolumeClaims, PersistentVolumes, and StorageClasses. Documented here.
Although the Kubernetes implementation of CSI is a GA feature in Kubernetes v1.13, it may require the following flag:
- API server binary and kubelet binaries:
--allow-privileged=true- Most CSI plugins will require bidirectional mount propagation, which can only be enabled for privileged pods. Privileged pods are only permitted on clusters where this flag has been set to true (this is the default in some environments like GCE, GKE, and kubeadm).
Dynamic Provisioning
You can enable automatic creation/deletion of volumes for CSI Storage plugins that support dynamic provisioning by creating a StorageClass pointing to the CSI plugin.
The following StorageClass, for example, enables dynamic creation of “fast-storage” volumes by a CSI volume plugin called “csi-driver.example.com”.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast-storage
provisioner: csi-driver.example.com
parameters:
type: pd-ssd
csi.storage.k8s.io/provisioner-secret-name: mysecret
csi.storage.k8s.io/provisioner-secret-namespace: mynamespace
New for GA, the CSI external-provisioner (v1.0.1+) reserves the parameter keys prefixed with csi.storage.k8s.io/. If the keys do not correspond to a set of known keys the values are simply ignored (and not passed to the CSI driver). The older secret parameter keys (csiProvisionerSecretName, csiProvisionerSecretNamespace, etc.) are also supported by CSI external-provisioner v1.0.1 but are deprecated and may be removed in future releases of the CSI external-provisioner.
Dynamic provisioning is triggered by the creation of a PersistentVolumeClaim object. The following PersistentVolumeClaim, for example, triggers dynamic provisioning using the StorageClass above.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-request-for-storage
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: fast-storage
When volume provisioning is invoked, the parameter type: pd-ssd and the secret any referenced secret(s) are passed to the CSI plugin csi-driver.example.com via a CreateVolume call. In response, the external volume plugin provisions a new volume and then automatically create a PersistentVolume object to represent the new volume. Kubernetes then binds the new PersistentVolume object to the PersistentVolumeClaim, making it ready to use.
If the fast-storage StorageClass is marked as “default”, there is no need to include the storageClassName in the PersistentVolumeClaim, it will be used by default.
Pre-Provisioned Volumes
You can always expose a pre-existing volume in Kubernetes by manually creating a PersistentVolume object to represent the existing volume. The following PersistentVolume, for example, exposes a volume with the name “existingVolumeName” belonging to a CSI storage plugin called “csi-driver.example.com”.
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-manually-created-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
csi:
driver: csi-driver.example.com
volumeHandle: existingVolumeName
readOnly: false
fsType: ext4
volumeAttributes:
foo: bar
controllerPublishSecretRef:
name: mysecret1
namespace: mynamespace
nodeStageSecretRef:
name: mysecret2
namespace: mynamespace
nodePublishSecretRef
name: mysecret3
namespace: mynamespace
Attaching and Mounting
You can reference a PersistentVolumeClaim that is bound to a CSI volume in any pod or pod template.
kind: Pod
apiVersion: v1
metadata:
name: my-pod
spec:
containers:
- name: my-frontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: my-csi-volume
volumes:
- name: my-csi-volume
persistentVolumeClaim:
claimName: my-request-for-storage
When the pod referencing a CSI volume is scheduled, Kubernetes will trigger the appropriate operations against the external CSI plugin (ControllerPublishVolume, NodeStageVolume, NodePublishVolume, etc.) to ensure the specified volume is attached, mounted, and ready to use by the containers in the pod.
For more details please see the CSI implementation design doc and documentation.
How to write a CSI Driver?
The kubernetes-csi site details how to develop, deploy, and test a CSI driver on Kubernetes. In general, CSI Drivers should be deployed on Kubernetes along with the following sidecar (helper) containers:
- external-attacher
- Watches Kubernetes
VolumeAttachmentobjects and triggersControllerPublishandControllerUnpublishoperations against a CSI endpoint.
- Watches Kubernetes
- external-provisioner
- Watches Kubernetes
PersistentVolumeClaimobjects and triggersCreateVolumeandDeleteVolumeoperations against a CSI endpoint.
- Watches Kubernetes
- node-driver-registrar
- Registers the CSI driver with kubelet using the Kubelet device plugin mechanism.
- cluster-driver-registrar (Alpha)
- Registers a CSI Driver with the Kubernetes cluster by creating a
CSIDriverobject which enables the driver to customize how Kubernetes interacts with it.
- Registers a CSI Driver with the Kubernetes cluster by creating a
- external-snapshotter (Alpha)
- Watches Kubernetes
VolumeSnapshotCRD objects and triggersCreateSnapshotandDeleteSnapshotoperations against a CSI endpoint.
- Watches Kubernetes
- livenessprobe
- May be included in a CSI plugin pod to enable the Kubernetes Liveness Probe mechanism.
Storage vendors can build Kubernetes deployments for their plugins using these components, while leaving their CSI driver completely unaware of Kubernetes.
List of CSI Drivers
CSI drivers are developed and maintained by third parties. You can find a non-definitive list of CSI drivers here.
What about in-tree volume plugins?
There is a plan to migrate most of the persistent, remote in-tree volume plugins to CSI. For more details see design doc.
Limitations of GA
The GA implementation of CSI has the following limitations:
- Ephemeral local volumes must create a PVC (pod inline referencing of CSI volumes is not supported).
What’s next?
- Work on moving Kubernetes CSI features that are still alpha to beta:
- Raw block volumes
- Topology awareness (the ability for Kubernetes to understand and influence where a CSI volume is provisioned (zone, regions, etc.).
- Features depending on CSI CRDs (e.g. “Skip attach” and “Pod info on mount”).
- Volume Snapshots
- Work on completing support for local ephemeral volumes.
- Work on migrating remote persistent in-tree volume plugins to CSI.
How to get involved?
The Kubernetes Slack channel wg-csi and the Google group kubernetes-sig-storage-wg-csi along with any of the standard SIG storage communication channels are all great mediums to reach out to the SIG Storage team.
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together. We offer a huge thank you to the new contributors who stepped up this quarter to help the project reach GA:
- Saad Ali (saad-ali)
- Michelle Au (msau42)
- Serguei Bezverkhi (sbezverk)
- Masaki Kimura (mkimuram)
- Patrick Ohly (pohly)
- Luis Pabón (lpabon)
- Jan Šafránek (jsafrane)
- Vladimir Vivien (vladimirvivien)
- Cheng Xing (verult)
- Xing Yang (xing-yang)
- David Zhu (davidz627)
If you’re interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
APIServer dry-run and kubectl diff
Author: Antoine Pelisse (Google Cloud, @apelisse)
Declarative configuration management, also known as configuration-as-code, is
one of the key strengths of Kubernetes. It allows users to commit the desired state of
the cluster, and to keep track of the different versions, improve auditing and
automation through CI/CD pipelines. The Apply working-group
is working on fixing some of the gaps, and is happy to announce that Kubernetes
1.13 promoted server-side dry-run and kubectl diff to beta. These
two features are big improvements for the Kubernetes declarative model.
Challenges
A few pieces are still missing in order to have a seamless declarative experience with Kubernetes, and we tried to address some of these:
- While compilers and linters do a good job to detect errors in pull-requests
for code, a good validation is missing for Kubernetes configuration files.
The existing solution is to run
kubectl apply --dry-run, but this runs a local dry-run that doesn't talk to the server: it doesn't have server validation and doesn't go through validating admission controllers. As an example, Custom resource names are only validated on the server so a local dry-run won't help. - It can be difficult to know how your object is going to be applied by the
server for multiple reasons:
- Defaulting will set some fields to potentially unexpected values,
- Mutating webhooks might set fields or clobber/change some values.
- Patch and merges can have surprising effects and result in unexpected objects. For example, it can be hard to know how lists are going to be ordered once merged.
The working group has tried to address these problems.
APIServer dry-run
APIServer dry-run was implemented to address these two problems:
- it allows individual requests to the apiserver to be marked as "dry-run",
- the apiserver guarantees that dry-run requests won't be persisted to storage,
- the request is still processed as typical request: the fields are defaulted, the object is validated, it goes through the validation admission chain, and through the mutating admission chain, and then the final object is returned to the user as it normally would, without being persisted.
While dynamic admission controllers are not supposed to have side-effects on each request, dry-run requests are only processed if all admission controllers explicitly announce that they don't have any dry-run side-effects.
How to enable it
Server-side dry-run is enabled through a feature-gate. Now that the feature is
Beta in 1.13, it should be enabled by default, but still can be enabled/disabled
using kube-apiserver --feature-gates DryRun=true.
If you have dynamic admission controllers, you might have to fix them to:
- Remove any side-effects when the dry-run parameter is specified on the webhook request,
- Specify in the
sideEffectsfield of theadmissionregistration.k8s.io/v1beta1.Webhookobject to indicate that the object doesn't have side-effects on dry-run (or at all).
How to use it
You can trigger the feature from kubectl by using kubectl apply --server-dry-run, which will decorate the request with the dryRun flag
and return the object as it would have been applied, or an error if it would
have failed.
Kubectl diff
APIServer dry-run is convenient because it lets you see how the object would be
processed, but it can be hard to identify exactly what changed if the object is
big. kubectl diff does exactly what you want by showing the differences between
the current "live" object and the new "dry-run" object. It makes it very
convenient to focus on only the changes that are made to the object, how the
server has merged these and how the mutating webhooks affects the output.
How to use it
kubectl diff is meant to be as similar as possible to kubectl apply:
kubectl diff -f some-resources.yaml will show a diff for the resources in the yaml file. One can even use the diff program of their choice by using the KUBECTL_EXTERNAL_DIFF environment variable, for example:
KUBECTL_EXTERNAL_DIFF=meld kubectl diff -f some-resources.yaml
What's next
The working group is still busy trying to improve some of these things:
- Server-side apply is trying to improve the apply scenario, by adding owner semantics to fields! It's also going to improve support for CRDs and unions!
- Some kubectl apply features are missing from diff and could be useful, like the ability to filter by label, or to display pruned resources.
- Eventually, kubectl diff will use server-side apply!
kubectl apply --server-dry-run is deprecated in v1.18.
Use the flag --dry-run=server for using server-side dry-run in
kubectl apply and other subcommands.
Kubernetes Federation Evolution
Authors: Irfan Ur Rehman (Huawei), Paul Morie (RedHat) and Shashidhara T D (Huawei)
Kubernetes provides great primitives for deploying applications to a cluster: it can be as simple as kubectl create -f app.yaml. Deploy apps across multiple clusters has never been that simple. How should app workloads be distributed? Should the app resources be replicated into all clusters, replicated into selected clusters, or partitioned into clusters? How is access to the clusters managed? What happens if some of the resources that a user wants to distribute pre-exist, in some or all of the clusters, in some form?
In SIG Multicluster, our journey has revealed that there are multiple possible models to solve these problems and there probably is no single best-fit, all-scenario solution. Federation, however, is the single biggest Kubernetes open source sub-project, and has seen the maximum interest and contribution from the community in this problem space. The project initially reused the Kubernetes API to do away with any added usage complexity for an existing Kubernetes user. This approach was not viable, because of the problems summarised below:
- Difficulties in re-implementing the Kubernetes API at the cluster level, as federation-specific extensions were stored in annotations.
- Limited flexibility in federated types, placement and reconciliation, due to 1:1 emulation of the Kubernetes API.
- No settled path to GA, and general confusion on API maturity; for example, Deployments are GA in Kubernetes but not even Beta in Federation v1.
The ideas have evolved further with a federation-specific API architecture and a community effort which now continues as Federation v2.
Conceptual Overview
Because Federation attempts to address a complex set of problems, it pays to break the different parts of those problems down. Let’s take a look at the different high-level areas involved:
Kubernetes Federation v2 Concepts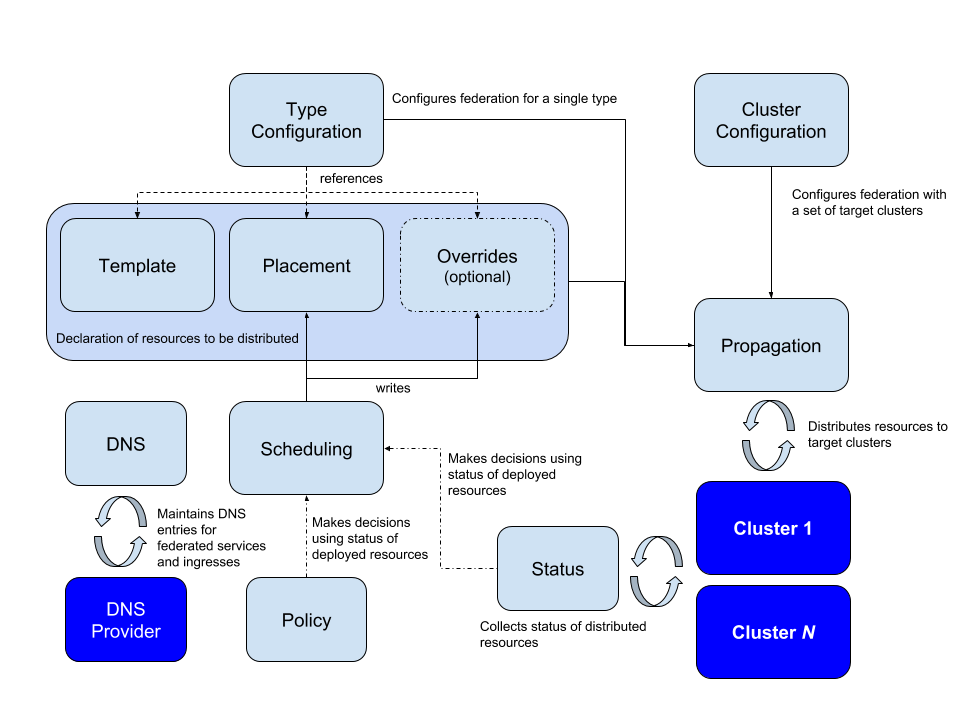
Federating arbitrary resources
One of the main goals of Federation is to be able to define the APIs and API groups which encompass basic tenets needed to federate any given Kubernetes resource. This is crucial, due to the popularity of CustomResourceDefinitions as a way to extend Kubernetes with new APIs.
The workgroup arrived at a common definition of the federation API and API groups as 'a mechanism that distributes “normal” Kubernetes API resources into different clusters'. The distribution in its most simple form could be imagined as simple propagation of this 'normal Kubernetes API resource' across the federated clusters. A thoughtful reader can certainly discern more complicated mechanisms, other than this simple propagation of the Kubernetes resources.
During the journey of defining building blocks of the federation APIs, one of the near term goals also evolved as 'to be able to create a simple federation a.k.a. simple propagation of any Kubernetes resource or a CRD, writing almost zero code'. What ensued further was a core API group defining the building blocks as a Template resource, a Placement resource and an Override resource per given Kubernetes resource, a TypeConfig to specify sync or no sync for the given resource and associated controller(s) to carry out the sync. More details follow in the next section. Further sections will also talk about being able to follow a layered behaviour with higher-level federation APIs consuming the behaviour of these core building blocks, and users being able to consume whole or part of the API and associated controllers. Lastly, this architecture also allows the users to write additional controllers or replace the available reference controllers with their own, to carry out desired behaviour.
The ability to 'easily federate arbitrary Kubernetes resources', and a decoupled API, divided into building blocks APIs, higher level APIs and possible user intended types, presented such that different users can consume parts and write controllers composing solutions specific to them, makes a compelling case for Federation v2.
Federating resources: the details
Fundamentally, federation must be configured with two types of information:
- Which API types federation should handle
- Which clusters federation should target for distributing those resources.
For each API type that federation handles, different parts of the declared state live in different API resources:
- A
Templatetype holds the base specification of the resource - for example, a type calledFederatedReplicaSetholds the base specification of aReplicaSetthat should be distributed to the targeted clusters - A
Placementtype holds the specification of the clusters the resource should be distributed to - for example, a type calledFederatedReplicaSetPlacementholds information about which clustersFederatedReplicaSetsshould be distributed to - An optional
Overridestype holds the specification of how theTemplateresource should be varied in some clusters - for example, a type calledFederatedReplicaSetOverridesholds information about how aFederatedReplicaSetshould be varied in certain clusters.
These types are all associated by name - meaning that for a particular Template resource with name foo, the Placement and Override information for that resource are contained by the Override and Placement resources with the name foo and in the same namespace as the Template.
Higher-level behaviour
The architecture of the v2 API allows higher-level APIs to be constructed using the mechanics provided by the core API types (Template, Placement and Override), and associated controllers, for a given resource. In the community we uncovered a few use cases and implemented the higher-level APIs and associated controllers useful for those cases. Some of these types described in further sections also provide an useful reference to anybody interested in solving more complex use cases, building on top of the mechanics already available with the v2 API.
ReplicaSchedulingPreference
ReplicaSchedulingPreference provides an automated mechanism of distributing and maintaining total number of replicas for Deployment or ReplicaSet-based federated workloads into federated clusters. This is based on high-level user preferences given by the user. These preferences include the semantics of weighted distribution and limits (min and max) for distributing the replicas. These also include semantics to allow redistribution of replicas dynamically in case some replica Pods remain unscheduled in some clusters, for example due to insufficient resources in that cluster.
More details can be found at the user guide for ReplicaSchedulingPreferences.
Federated services & cross-cluster service discovery
Kubernetes Services are very useful in constructing a microservices architecture. There is a clear desire to deploy services across cluster, zone, region and cloud boundaries. Services that span clusters provide geographic distribution, enable hybrid and multi-cloud scenarios and improve the level of high availability beyond single cluster deployments. Customers who want their services to span one or more (possibly remote) clusters, need them to be reachable in a consistent manner from both within and outside their clusters.
Federated Service, at its core, contains a Template (a definition of a Kubernetes Service), a Placement (which clusters to be deployed into), an Override (optional variation in particular clusters) and a ServiceDNSRecord (specifying details on how to discover it).
Note: The federated service has to be of type LoadBalancer in order for it to be discoverable across clusters.
Discovering a federated service from Pods inside your federated clusters
By default, Kubernetes clusters come preconfigured with a cluster-local DNS server, as well as an intelligently constructed DNS search path, which together ensure that DNS queries like myservice, myservice.mynamespace, or some-other-service.other-namespace, issued by software running inside Pods, are automatically expanded and resolved correctly to the appropriate IP of Services running in the local cluster.
With the introduction of federated services and cross-cluster service discovery, this concept is extended to cover Kubernetes Services running in any other cluster across your cluster federation, globally. To take advantage of this extended range, you use a slightly different DNS name (e.g. myservice.mynamespace.myfederation) to resolve federated services. Using a different DNS name also avoids having your existing applications accidentally traversing cross-zone or cross-region networks and you incurring perhaps unwanted network charges or latency, without you explicitly opting in to this behavior.
Lets consider an example, using a service named nginx.
A Pod in a cluster in the us-central1-a availability zone needs to contact our nginx service. Rather than use the service’s traditional cluster-local DNS name (nginx.mynamespace, which is automatically expanded to nginx.mynamespace.svc.cluster.local) it can now use the service’s federated DNS name, which is nginx.mynamespace.myfederation. This will be automatically expanded and resolved to the closest healthy shard of my nginx service, wherever in the world that may be. If a healthy shard exists in the local cluster, that service’s cluster-local IP address will be returned (by the cluster-local DNS). This is exactly equivalent to non-federated service resolution.
If the Service does not exist in the local cluster (or it exists but has no healthy backend pods), the DNS query is automatically expanded to nginx.mynamespace.myfederation.svc.us-central1-a.us-central1.example.com. Behind the scenes, this finds the external IP of one of the shards closest to my availability zone. This expansion is performed automatically by the cluster-local DNS server, which returns the associated CNAME record. This results in a traversal of the hierarchy of DNS records, and ends up at one of the external IP’s of the federated service nearby.
It is also possible to target service shards in availability zones and regions other than the ones local to a Pod by specifying the appropriate DNS names explicitly, and not relying on automatic DNS expansion. For example, nginx.mynamespace.myfederation.svc.europe-west1.example.comwill resolve to all of the currently healthy service shards in Europe, even if the Pod issuing the lookup is located in the U.S., and irrespective of whether or not there are healthy shards of the service in the U.S. This is useful for remote monitoring and other similar applications.
Discovering a federated service from other clients outside your federated clusters
For external clients, automatic DNS expansion described is not currently possible. External clients need to specify one of the fully qualified DNS names of the federated service, be that a zonal, regional or global name. For convenience reasons, it is often a good idea to manually configure additional static CNAME records in your service, for example:
| SHORT NAME | CNAME |
|---|---|
| eu.nginx.acme.com | nginx.mynamespace.myfederation.svc.europe-west1.example.com |
| us.nginx.acme.com | nginx.mynamespace.myfederation.svc.us-central1.example.com |
| nginx.acme.com | nginx.mynamespace.myfederation.svc.example.com |
That way, your clients can always use the short form on the left, and always be automatically routed to the closest healthy shard on their home continent. All of the required failover is handled for you automatically by Kubernetes cluster federation.
As further reading, a more elaborate example for users is available in the Multi-Cluster Service DNS with ExternalDNS guide.
Try it yourself
To get started with Federation v2, please refer to the user guide. Deployment can be accomplished with a Helm chart, and once the control plane is available, the user guide’s example can be used to get some hands-on experience with using Federation V2.
Federation v2 can be deployed in both cluster-scoped and namespace-scoped configurations. A cluster-scoped deployment will require cluster-admin privileges to both host and member clusters, and may be a good fit for evaluating federation on clusters that are not running critical workloads. Namespace-scoped deployment requires access to only a single namespace on host and member clusters, and is a better fit for evaluating federation on clusters running workloads. Most of the user guide refers to cluster-scoped deployment, with the namespaced federation section documenting how use of a namespaced deployment differs. The same cluster can host multiple federations, and clusters can be part of multiple federations when using namespaced federation.
Next Steps
As we noted in the beginning of this post, the multicluster problem space is extremely broad. It can be difficult to know exactly how to handle such broad problem spaces without concrete pieces of software to frame those conversations around. Our hope in the Federation working group is that Federation v2 can be a concrete artifact to frame discussions around. We would love to know experiences that folks have had in this problem space, how they feel about Federation v2, and what use-cases they’re interested in exploring in the future.
Please feel welcome to join us at the sig-multicluster slack channel or at Federation working group meetings on Wednesdays at 07:30 PST.
etcd: Current status and future roadmap
Author: Gyuho Lee (Amazon Container OSS Team, @gyuho), Joe Betz (Google Cloud, @jpbetz)
etcd is a distributed key value store that provides a reliable way to manage the coordination state of distributed systems. etcd was first announced in June 2013 by CoreOS (part of Red Hat as of 2018). Since its adoption in Kubernetes in 2014, etcd has become a fundamental part of the Kubernetes cluster management software design, and the etcd community has grown exponentially. etcd is now being used in production environments of multiple companies, including large cloud provider environments such as AWS, Google Cloud Platform, Azure, and other on-premises Kubernetes implementations. CNCF currently has 32 conformant Kubernetes platforms and distributions, all of which use etcd as the datastore.
In this blog post, we’ll review some of the milestones achieved in latest etcd releases, and go over the future roadmap for etcd. Share your thoughts and feedback on features you consider important on the mailing list: etcd-dev@googlegroups.com.
etcd, 2013
In June 2014, Kubernetes was released with etcd as a backing storage for all master states. Kubernetes v0.4 used etcd v0.2 API, which was in an alpha stage at the time. As Kubernetes reached the v1.0 milestone in 2015, etcd stabilized its v2.0 API. The widespread adoption of Kubernetes led to a dramatic increase in the scalability requirements for etcd. To handle large number of workloads and the growing requirements on scale, etcd released v3.0 API in June 2016. Kubernetes v1.13 finally dropped support for etcd v2.0 API and adopted the etcd v3.0 API. The table below gives a visual snapshot of the release cycles of etcd and Kubernetes.
| etcd | Kubernetes | |
|---|---|---|
| Initial Commit | June 2, 2013 | June 1, 2014 |
| First Stable Release | January 28, 2015 (v2.0.0) | July 13, 2015 (v1.0.0) |
| Latest Release | October 10, 2018 (v3.3.10) | December 3, 2018 (v1.13.0) |
etcd v3.1, early 2017
etcd v3.1 features provide better read performance and better availability during version upgrades. Given the high use of etcd in production even to this day, these features were very useful for users. It implements Raft read index, which bypasses Raft WAL disk writes for linearizable reads. The follower requests read index from the leader. Responses from the leader indicate whether a follower has advanced as much as the leader. When the follower's logs are up-to-date, quorum read is served locally without going through the full Raft protocol. Thus, no disk write is required for read requests. etcd v3.1 introduces automatic leadership transfer. When etcd leader receives an interrupt signal, it automatically transfers its leadership to a follower. This provides higher availability when the cluster adds or loses a member.
etcd v3.2 (summer 2017)
etcd v3.2 focuses on stability. Its client was shipped in Kubernetes v1.10, v1.11, and v1.12. The etcd team still actively maintains the branch by backporting all the bug fixes. This release introduces gRPC proxy to support, watch, and coalesce all watch event broadcasts into one gRPC stream. These event broadcasts can go up to one million events per second.
etcd v3.2 also introduces changes such as “snapshot-count” default value from 10,000 to 100,000. With higher snapshot count, etcd server holds Raft entries in-memory for longer periods before compacting the old ones. etcd v3.2 default configuration shows higher memory usage, while giving more time for slow followers to catch up. It is a trade-off between less frequent snapshot sends and higher memory usage. Users can employ lower etcd --snapshot-count value to reduce the memory usage or higher “snapshot-count” value to increase the availability of slow followers.
Another new feature backported to etcd v3.2.19 was etcd --initial-election-tick-advance flag. By default, a rejoining follower fast-forwards election ticks to speed up its initial cluster bootstrap. For example, the starting follower node only waits 200ms instead of full election timeout 1-second before starting an election. Ideally, within the 200ms, it receives a leader heartbeat and immediately joins the cluster as a follower. However, if network partition happens, heartbeat may drop and thus leadership election will be triggered. A vote request from a partitioned node is quite disruptive. If it contains a higher Raft term, current leader is forced to step down. With “initial-election-tick-advance” set to false, a rejoining node has more chance to receive leader heartbeats before disrupting the cluster.
etcd v3.3 (early 2018)
etcd v3.3 continues the theme of stability. Its client is included in Kubernetes v1.13. Previously, etcd client carelessly retried on network disconnects without any backoff or failover logic. The client was often stuck with a partitioned node, affecting several production users. v3.3 client balancer now maintains a list of unhealthy endpoints using gRPC health checking protocol, making more efficient retries and failover in the face of transient disconnects and network partitions. This was backported to etcd v3.2 and also included in Kubernetes v1.10 API server. etcd v3.3 also provides more predictable database size. etcd used to maintain a separate freelist DB to track pages that were no longer in use and freed after transactions, so that following transactions can reuse them. However, it turns out persisting freelist demands high disk space and introduces high latency for Kubernetes workloads. Especially when there were frequent snapshots with lots of read transactions, etcd database size quickly grew from 16 MB to 4 GB. etcd v3.3 disables freelist sync and rebuilds the freelist on restart. The overhead is so small that it is unnoticeable to most users. See "database space exceeded" issue for more information on this.
etcd v3.4 and beyond
etcd v3.4 focuses on improving the operational experience. It adds Raft pre-vote feature to improve the robustness of leadership election. When a node becomes isolated (e.g. network partition), this member will start an election requesting votes with increased Raft terms. When a leader receives a vote request with a higher term, it steps down to a follower. With pre-vote, Raft runs an additional election phase to check if the candidate can get enough votes to win an election. The isolated follower's vote request is rejected because it does not contain the latest log entries.
etcd v3.4 adds a Raft learner that joins the cluster as a non-voting member that still receives all the updates from leader. Adding a learner node does not increase the size of quorum and hence improves the cluster availability during membership reconfiguration. It only serves as a standby node until it gets promoted to a voting member. Moreover, to handle unexpected upgrade failures, v3.4 introduces etcd downgrade feature.
etcd v3 storage uses multi-version concurrency control model to preserve key updates as event history. Kubernetes runs compaction to discard the event history that is no longer needed, and reclaims the storage space. etcd v3.4 will improve this storage compact operation, boost backend concurrency for large read transactions, and optimize storage commit interval for Kubernetes use-case.
To further improve etcd client load balancer, the v3.4 balancer was rewritten to leverage the newly introduced gRPC load balancing API. By leveraging gPRC, the etcd client load balancer codebase was substantially simplified while retaining feature parity with the v3.3 implementation and improving overall load balancing by round-robining requests across healthy endpoints. See Client Architecture for more details.
Additionally, etcd maintainers will continue to make improvements to Kubernetes test frameworks: kubemark integration for scalability tests, Kubernetes API server conformance tests with etcd to provide release recommends and version skew policy, specifying conformance testing requirements for each cloud provider, etc.
etcd Joins CNCF
etcd now has a new home at etcd-io and joined CNCF as an incubating project.
The synergistic efforts with Kubernetes have driven the evolution of etcd. Without community feedback and contribution, etcd could not have achieved its maturity and reliability. We’re looking forward to continuing the growth of etcd as an open source project and are excited to work with the Kubernetes and the wider CNCF community.
Finally, we’d like to thank all contributors with special thanks to Xiang Li for his leadership in etcd and Kubernetes.
New Contributor Workshop Shanghai
Authors: Josh Berkus (Red Hat), Yang Li (The Plant), Puja Abbassi (Giant Swarm), XiangPeng Zhao (ZTE)

Kubecon Shanghai New Contributor Summit attendees. Photo by Jerry Zhang
We recently completed our first New Contributor Summit in China, at the first KubeCon in China. It was very exciting to see all of the Chinese and Asian developers (plus a few folks from around the world) interested in becoming contributors. Over the course of a long day, they learned how, why, and where to contribute to Kubernetes, created pull requests, attended a panel of current contributors, and got their CLAs signed.
This was our second New Contributor Workshop (NCW), building on the one created and led by SIG Contributor Experience members in Copenhagen. Because of the audience, it was held in both Chinese and English, taking advantage of the superb simultaneous interpretation services the CNCF sponsored. Likewise, the NCW team included both English and Chinese-speaking members of the community: Yang Li, XiangPeng Zhao, Puja Abbassi, Noah Abrahams, Tim Pepper, Zach Corleissen, Sen Lu, and Josh Berkus. In addition to presenting and helping students, the bilingual members of the team translated all of the slides into Chinese. Fifty-one students attended.

Noah Abrahams explains Kubernetes communications channels. Photo by Jerry Zhang
The NCW takes participants through the stages of contributing to Kubernetes, starting from deciding where to contribute, followed by an introduction to the SIG system and our repository structure. We also have "guest speakers" from Docs and Test Infrastructure who cover contributing in those areas. We finally wind up with some hands-on exercises in filing issues and creating and approving PRs.
Those hands-on exercises use a repository known as the contributor playground, created by SIG Contributor Experience as a place for new contributors to try out performing various actions on a Kubernetes repo. It has modified Prow and Tide automation, uses Owners files like in the real repositories. This lets students learn how the mechanics of contributing to our repositories work without disrupting normal development.

Yang Li talks about getting your PRs reviewed. Photo by Josh Berkus
Both the "Great Firewall" and the language barrier prevent contributing Kubernetes from China from being straightforward. What's more, because open source business models are not mature in China, the time for employees work on open source projects is limited.
Chinese engineers are eager to participate in the development of Kubernetes, but many of them don't know where to start since Kubernetes is such a large project. With this workshop, we hope to help those who want to contribute, whether they wish to fix some bugs they encountered, improve or localize documentation, or they need to work with Kubernetes at their work. We are glad to see more and more Chinese contributors joining the community in the past few years, and we hope to see more of them in the future.
"I have been participating in the Kubernetes community for about three years," said XiangPeng Zhao. "In the community, I notice that more and more Chinese developers are showing their interest in contributing to Kubernetes. However, it's not easy to start contributing to such a project. I tried my best to help those who I met in the community, but I think there might still be some new contributors leaving the community due to not knowing where to get help when in trouble. Fortunately, the community initiated NCW at KubeCon Copenhagen and held a second one at KubeCon Shanghai. I was so excited to be invited by Josh Berkus to help organize this workshop. During the workshop, I met community friends in person, mentored attendees in the exercises, and so on. All of this was a memorable experience for me. I also learned a lot as a contributor who already has years of contributing experience. I wish I had attended such a workshop when I started contributing to Kubernetes years ago."

Panel of contributors. Photo by Jerry Zhang
The workshop ended with a panel of current contributors, featuring Lucas Käldström, Janet Kuo, Da Ma, Pengfei Ni, Zefeng Wang, and Chao Xu. The panel aimed to give both new and current contributors a look behind the scenes on the day-to-day of some of the most active contributors and maintainers, both from China and around the world. Panelists talked about where to begin your contributor's journey, but also how to interact with reviewers and maintainers. They further touched upon the main issues of contributing from China and gave attendees an outlook into exciting features they can look forward to in upcoming releases of Kubernetes.
After the workshop, Xiang Peng Zhao chatted with some attendees on WeChat and Twitter about their experiences. They were very glad to have attended the NCW and had some suggestions on improving the workshop. One attendee, Mohammad, said, "I had a great time at the workshop and learned a lot about the entire process of k8s for a contributor." Another attendee, Jie Jia, said, "The workshop was wonderful. It systematically explained how to contribute to Kubernetes. The attendee could understand the process even if s/he knew nothing about that before. For those who were already contributors, they could also learn something new. Furthermore, I could make new friends from inside or outside of China in the workshop. It was awesome!"
SIG Contributor Experience will continue to run New Contributor Workshops at each upcoming Kubecon, including Seattle, Barcelona, and the return to Shanghai in June 2019. If you failed to get into one this year, register for one at a future Kubecon. And, when you meet an NCW attendee, make sure to welcome them to the community.
Links:
- English versions of the slides: PDF or Google Docs with speaker notes
- Chinese version of the slides: PDF
- Contributor playground
Production-Ready Kubernetes Cluster Creation with kubeadm
Authors: Lucas Käldström (CNCF Ambassador) and Luc Perkins (CNCF Developer Advocate)
kubeadm is a tool that enables Kubernetes administrators to quickly and easily bootstrap minimum viable clusters that are fully compliant with Certified Kubernetes guidelines. It's been under active development by SIG Cluster Lifecycle since 2016 and we're excited to announce that it has now graduated from beta to stable and generally available (GA)!
This GA release of kubeadm is an important event in the progression of the Kubernetes ecosystem, bringing stability to an area where stability is paramount.
The goal of kubeadm is to provide a foundational implementation for Kubernetes cluster setup and administration. kubeadm ships with best-practice defaults but can also be customized to support other ecosystem requirements or vendor-specific approaches. kubeadm is designed to be easy to integrate into larger deployment systems and tools.
The scope of kubeadm
kubeadm is focused on bootstrapping Kubernetes clusters on existing infrastructure and performing an essential set of maintenance tasks. The core of the kubeadm interface is quite simple: new control plane nodes are created by running kubeadm init and worker nodes are joined to the control plane by running kubeadm join. Also included are utilities for managing already bootstrapped clusters, such as control plane upgrades and token and certificate renewal.
To keep kubeadm lean, focused, and vendor/infrastructure agnostic, the following tasks are out of its scope:
- Infrastructure provisioning
- Third-party networking
- Non-critical add-ons, e.g. for monitoring, logging, and visualization
- Specific cloud provider integrations
Infrastructure provisioning, for example, is left to other SIG Cluster Lifecycle projects, such as the Cluster API. Instead, kubeadm covers only the common denominator in every Kubernetes cluster: the control plane. The user may install their preferred networking solution and other add-ons on top of Kubernetes after cluster creation.
What kubeadm's GA release means
General Availability means different things for different projects. For kubeadm, going GA means not only that the process of creating a conformant Kubernetes cluster is now stable, but also that kubeadm is flexible enough to support a wide variety of deployment options.
We now consider kubeadm to have achieved GA-level maturity in each of these important domains:
- Stable command-line UX --- The kubeadm CLI conforms to #5a GA rule of the Kubernetes Deprecation Policy, which states that a command or flag that exists in a GA version must be kept for at least 12 months after deprecation.
- Stable underlying implementation --- kubeadm now creates a new Kubernetes cluster using methods that shouldn't change any time soon. The control plane, for example, is run as a set of static Pods, bootstrap tokens are used for the
kubeadm joinflow, and ComponentConfig is used for configuring the kubelet. - Configuration file schema --- With the new v1beta1 API version, you can now tune almost every part of the cluster declaratively and thus build a "GitOps" flow around kubeadm-built clusters. In future versions, we plan to graduate the API to version v1 with minimal changes (and perhaps none).
- The "toolbox" interface of kubeadm --- Also known as phases. If you don't want to perform all
kubeadm inittasks, you can instead apply more fine-grained actions using thekubeadm init phasecommand (for example generating certificates or control plane Static Pod manifests). - Upgrades between minor versions --- The
kubeadm upgradecommand is now fully GA. It handles control plane upgrades for you, which includes upgrades to etcd, the API Server, the Controller Manager, and the Scheduler. You can seamlessly upgrade your cluster between minor or patch versions (e.g. v1.12.2 -> v1.13.1 or v1.13.1 -> v1.13.3). - etcd setup --- etcd is now set up in a way that is secure by default, with TLS communication everywhere, and allows for expanding to a highly available cluster when needed.
Who will benefit from a stable kubeadm
SIG Cluster Lifecycle has identified a handful of likely kubeadm user profiles, although we expect that kubeadm at GA can satisfy many other scenarios as well.
Here's our list:
- You're a new user who wants to take Kubernetes for a spin. kubeadm is the fastest way to get up and running on Linux machines. If you're using Minikube on a Mac or Windows workstation, you're actually already running kubeadm inside the Minikube VM!
- You're a system administrator responsible for setting up Kubernetes on bare metal machines and you want to quickly create Kubernetes clusters that are secure and in conformance with best practices but also highly configurable.
- You're a cloud provider who wants to add a Kubernetes offering to your suite of cloud services. kubeadm is the go-to tool for creating clusters at a low level.
- You're an organization that requires highly customized Kubernetes clusters. Existing public cloud offerings like Amazon EKS and Google Kubernetes Engine won't cut it for you; you need customized Kubernetes clusters tailored to your hardware, security, policy, and other needs.
- You're creating a higher-level cluster creation tool than kubeadm, building the cluster experience from the ground up, but you don't want to reinvent the wheel. You can "rebase" on top of kubeadm and utilize the common bootstrapping tools kubeadm provides for you. Several community tools have adopted kubeadm, and it's a perfect match for Cluster API implementations.
All these users can benefit from kubeadm graduating to a stable GA state.
kubeadm survey
Although kubeadm is GA, the SIG Cluster Lifecycle will continue to be committed to improving the user experience in managing Kubernetes clusters. We're launching a survey to collect community feedback about kubeadm for the sake of future improvement.
The survey is available at https://bit.ly/2FPfRiZ. Your participation would be highly valued!
Thanks to the community!
This release wouldn't have been possible without the help of the great people that have been contributing to the SIG. SIG Cluster Lifecycle would like to thank a few key kubeadm contributors:
| Name | Organization | Role |
|---|---|---|
| Tim St. Clair | Heptio | SIG co-chair |
| Robert Bailey | SIG co-chair | |
| Fabrizio Pandini | Independent | Approver |
| Lubomir Ivanov | VMware | Approver |
| Mike Danese | Emeritus approver | |
| Ilya Dmitrichenko | Weaveworks | Emeritus approver |
| Peter Zhao | ZTE | Reviewer |
| Di Xu | Ant Financial | Reviewer |
| Chuck Ha | Heptio | Reviewer |
| Liz Frost | Heptio | Reviewer |
| Jason DeTiberus | Heptio | Reviewer |
| Alexander Kanievsky | Intel | Reviewer |
| Ross Georgiev | VMware | Reviewer |
| Yago Nobre | Nubank | Reviewer |
We also want to thank all the companies making it possible for their developers to work on Kubernetes, and all the other people that have contributed in various ways towards making kubeadm as stable as it is today!
About the authors
Lucas Käldström
- kubeadm subproject owner and SIG Cluster Lifecycle co-chair
- Kubernetes upstream contractor, last two years contracting for Weaveworks
- CNCF Ambassador
- GitHub: luxas
Luc Perkins
- CNCF Developer Advocate
- Kubernetes SIG Docs contributor and SIG Docs tooling WG chair
- GitHub: lucperkins
Kubernetes 1.13: Simplified Cluster Management with Kubeadm, Container Storage Interface (CSI), and CoreDNS as Default DNS are Now Generally Available
Author: The 1.13 Release Team
We’re pleased to announce the delivery of Kubernetes 1.13, our fourth and final release of 2018!
Kubernetes 1.13 has been one of the shortest releases to date at 10 weeks. This release continues to focus on stability and extensibility of Kubernetes with three major features graduating to general availability this cycle in the areas of Storage and Cluster Lifecycle. Notable features graduating in this release include: simplified cluster management with kubeadm, Container Storage Interface (CSI), and CoreDNS as the default DNS.
These stable graduations are an important milestone for users and operators in terms of setting support expectations. In addition, there’s a continual and steady stream of internal improvements and new alpha features that are made available to the community in this release. These features are discussed in the “additional notable features” section below.
Let’s dive into the key features of this release:
Simplified Kubernetes Cluster Management with kubeadm in GA
Most people who have gotten hands-on with Kubernetes have at some point been hands-on with kubeadm. It's an essential tool for managing the cluster lifecycle, from creation to configuration to upgrade; and now kubeadm is officially GA. kubeadm handles the bootstrapping of production clusters on existing hardware and configuring the core Kubernetes components in a best-practice-manner to providing a secure yet easy joining flow for new nodes and supporting easy upgrades. What’s notable about this GA release are the now graduated advanced features, specifically around pluggability and configurability. The scope of kubeadm is to be a toolbox for both admins and automated, higher-level system and this release is a significant step in that direction.
Container Storage Interface (CSI) Goes GA
The Container Storage Interface (CSI) is now GA after being introduced as alpha in v1.9 and beta in v1.10. With CSI, the Kubernetes volume layer becomes truly extensible. This provides an opportunity for third party storage providers to write plugins that interoperate with Kubernetes without having to touch the core code. The specification itself has also reached a 1.0 status.
With CSI now stable, plugin authors are developing storage plugins out of core, at their own pace. You can find a list of sample and production drivers in the CSI Documentation.
CoreDNS is Now the Default DNS Server for Kubernetes
In 1.11, we announced CoreDNS had reached General Availability for DNS-based service discovery. In 1.13, CoreDNS is now replacing kube-dns as the default DNS server for Kubernetes. CoreDNS is a general-purpose, authoritative DNS server that provides a backwards-compatible, but extensible, integration with Kubernetes. CoreDNS has fewer moving parts than the previous DNS server, since it’s a single executable and a single process, and supports flexible use cases by creating custom DNS entries. It’s also written in Go making it memory-safe.
CoreDNS is now the recommended DNS solution for Kubernetes 1.13+. The project has switched the common test infrastructure to use CoreDNS by default and we recommend users switching as well. KubeDNS will still be supported for at least one more release, but it's time to start planning your migration. Many OSS installer tools have already made the switch, including Kubeadm in 1.11. If you use a hosted solution, please work with your vendor to understand how this will impact you.
Additional Notable Feature Updates
Support for 3rd party device monitoring plugins has been introduced as an alpha feature. This removes current device-specific knowledge from the kubelet to enable future use-cases requiring device-specific knowledge to be out-of-tree.
Kubelet Device Plugin Registration is graduating to stable. This creates a common Kubelet plugin discovery model that can be used by different types of node-level plugins, such as device plugins, CSI and CNI, to establish communication channels with Kubelet.
Topology Aware Volume Scheduling is now stable. This make the scheduler aware of a Pod's volume's topology constraints, such as zone or node.
APIServer DryRun is graduating to beta. This moves "apply" and declarative object management from kubectl to the apiserver in order to fix many of the existing bugs that can't be fixed today.
Kubectl Diff is graduating to beta. This allows users to run a kubectl command to view the difference between a locally declared object configuration and the current state of a live object.
Raw block device using persistent volume source is graduating to beta. This makes raw block devices (non-networked) available for consumption via a Persistent Volume Source.
Each Special Interest Group (SIG) within the community continues to deliver the most-requested enhancements, fixes, and functionality for their respective specialty areas. For a complete list of inclusions by SIG, please visit the release notes.
Availability
Kubernetes 1.13 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials. You can also easily install 1.13 using kubeadm.
Features Blog Series
If you’re interested in exploring these features more in depth, check back tomorrow for our 5 Days of Kubernetes series where we’ll highlight detailed walkthroughs of the following features:
- Day 1 - Simplified Kubernetes Cluster Creation with Kubeadm
- Day 2 - Out-of-tree CSI Volume Plugins
- Day 3 - Switch default DNS plugin to CoreDNS
- Day 4 - New CLI Tips and Tricks (Kubectl Diff and APIServer Dry run)
- Day 5 - Raw Block Volume
Release team
This release is made possible through the effort of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Aishwarya Sundar, Software Engineer at Google. The 39 individuals on the release team coordinate many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has over 25,000 individual contributors to date and an active community of more than 51,000 people.
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. On average over the past year, 347 different companies and over 2,372 individuals contribute to Kubernetes each month. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
User Highlights
Established, global organizations are using Kubernetes in production at massive scale. Recently published user stories from the community include:
- IBM Cloud, a leading provider of public, private, and hybrid cloud functionality, is using cloud native technology for high-availability deployments with three instances across two zones in each of the five regions, load balanced with failover support.
- The National Association of Insurance Commissioners (NAIC), the U.S. standard-setting and regulatory support organization, leverages Kubernetes to create rapid prototypes in two days that would have previously taken at least a month.
- Ocado, the world’s largest online-only grocery retailer, use 15-25% less hardware resources to host the same applications in Kubernetes in their test environments.
- Adform, a provider of advertising technology to enable digital ads across devices, uses Kubernetes to reduce utilization of hardware resources, with containers notching 2-3 times more efficiency over virtual machines.
Is Kubernetes helping your team? Share your story with the community.
Ecosystem Updates
- CNCF recently released the findings of their bi-annual CNCF survey in Mandarin, finding that cloud usage in Asia has grown 135% since March 2018.
- CNCF expanded its certification offerings to include a Certified Kubernetes Application Developer exam. The CKAD exam certifies an individual's ability to design, build, configure, and expose cloud native applications for Kubernetes. More information can be found here.
- CNCF added a new partner category, Kubernetes Training Partners (KTP). KTPs are a tier of vetted training providers who have deep experience in cloud native technology training. View partners and learn more here.
- CNCF also offers online training that teaches the skills needed to create and configure a real-world Kubernetes cluster.
- Kubernetes documentation now features user journeys: specific pathways for learning based on who readers are and what readers want to do. Learning Kubernetes is easier than ever for beginners, and more experienced users can find task journeys specific to cluster admins and application developers.
KubeCon
The world’s largest Kubernetes gathering, KubeCon + CloudNativeCon is coming to Seattle from December 10-13, 2018 and Barcelona from May 20-23, 2019. This conference will feature technical sessions, case studies, developer deep dives, salons, and more. Registration will open up in early 2019.
Webinar
Join members of the Kubernetes 1.13 release team on January 10th at 9am PDT to learn about the major features in this release. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
Thank you for your continued feedback and support.
- Post questions (or answer questions) on Stack Overflow
- Join the community discussion on Discuss Kubernetes
- Follow us on Twitter @Kubernetesio for latest updates
- Chat with the community on Slack
- Share your Kubernetes story.
Kubernetes Docs Updates, International Edition
Author: Zach Corleissen (Linux Foundation)
As a co-chair of SIG Docs, I'm excited to share that Kubernetes docs have a fully mature workflow for localization (l10n).
Abbreviations galore
L10n is an abbreviation for localization.
I18n is an abbreviation for internationalization.
I18n is what you do to make l10n easier. L10n is a fuller, more comprehensive process than translation (t9n).
Why localization matters
The goal of SIG Docs is to make Kubernetes easier to use for as many people as possible.
One year ago, we looked at whether it was possible to host the output of a Chinese team working independently to translate the Kubernetes docs. After many conversations (including experts on OpenStack l10n), much transformation, and renewed commitment to easier localization, we realized that open source documentation is, like open source software, an ongoing exercise at the edges of what's possible.
Consolidating workflows, language labels, and team-level ownership may seem like simple improvements, but these features make l10n scalable for increasing numbers of l10n teams. While SIG Docs continues to iterate improvements, we've paid off a significant amount of technical debt and streamlined l10n in a single workflow. That's great for the future as well as the present.
Consolidated workflow
Localization is now consolidated in the kubernetes/website repository. We've configured the Kubernetes CI/CD system, Prow, to handle automatic language label assignment as well as team-level PR review and approval.
Language labels
Prow automatically applies language labels based on file path. Thanks to SIG Docs contributor June Yi, folks can also manually assign language labels in pull request (PR) comments. For example, when left as a comment on an issue or PR, this command assigns the label language/ko (Korean).
/language ko
These repo labels let reviewers filter for PRs and issues by language. For example, you can now filter the k/website dashboard for PRs with Chinese content.
Team review
L10n teams can now review and approve their own PRs. For example, review and approval permissions for English are assigned in an OWNERS file in the top subfolder for English content.
Adding OWNERS files to subdirectories lets localization teams review and approve changes without requiring a rubber stamp approval from reviewers who may lack fluency.
What's next
We're looking forward to the doc sprint in Shanghai to serve as a resource for the Chinese l10n team.
We're excited to continue supporting the Japanese and Korean l10n teams, who are making excellent progress.
If you're interested in localizing Kubernetes for your own language or region, check out our guide to localizing Kubernetes docs and reach out to a SIG Docs chair for support.
Get involved with SIG Docs
If you're interested in Kubernetes documentation, come to a SIG Docs weekly meeting, or join #sig-docs in Kubernetes Slack.
gRPC Load Balancing on Kubernetes without Tears
Author: William Morgan (Buoyant)
Many new gRPC users are surprised to find that Kubernetes's default load balancing often doesn't work out of the box with gRPC. For example, here's what happens when you take a simple gRPC Node.js microservices app and deploy it on Kubernetes:
While the voting service displayed here has several pods, it's clear from
Kubernetes's CPU graphs that only one of the pods is actually doing any
work—because only one of the pods is receiving any traffic. Why?
In this blog post, we describe why this happens, and how you can easily fix it by adding gRPC load balancing to any Kubernetes app with Linkerd, a CNCF service mesh and service sidecar.
Why does gRPC need special load balancing?
First, let's understand why we need to do something special for gRPC.
gRPC is an increasingly common choice for application developers. Compared to alternative protocols such as JSON-over-HTTP, gRPC can provide some significant benefits, including dramatically lower (de)serialization costs, automatic type checking, formalized APIs, and less TCP management overhead.
However, gRPC also breaks the standard connection-level load balancing, including what's provided by Kubernetes. This is because gRPC is built on HTTP/2, and HTTP/2 is designed to have a single long-lived TCP connection, across which all requests are multiplexed—meaning multiple requests can be active on the same connection at any point in time. Normally, this is great, as it reduces the overhead of connection management. However, it also means that (as you might imagine) connection-level balancing isn't very useful. Once the connection is established, there's no more balancing to be done. All requests will get pinned to a single destination pod, as shown below:
Why doesn't this affect HTTP/1.1?
The reason why this problem doesn't occur in HTTP/1.1, which also has the concept of long-lived connections, is because HTTP/1.1 has several features that naturally result in cycling of TCP connections. Because of this, connection-level balancing is "good enough", and for most HTTP/1.1 apps we don't need to do anything more.
To understand why, let's take a deeper look at HTTP/1.1. In contrast to HTTP/2,
HTTP/1.1 cannot multiplex requests. Only one HTTP request can be active at a
time per TCP connection. The client makes a request, e.g. GET /foo, and then
waits until the server responds. While that request-response cycle is
happening, no other requests can be issued on that connection.
Usually, we want lots of requests happening in parallel. Therefore, to have concurrent HTTP/1.1 requests, we need to make multiple HTTP/1.1 connections, and issue our requests across all of them. Additionally, long-lived HTTP/1.1 connections typically expire after some time, and are torn down by the client (or server). These two factors combined mean that HTTP/1.1 requests typically cycle across multiple TCP connections, and so connection-level balancing works.
So how do we load balance gRPC?
Now back to gRPC. Since we can't balance at the connection level, in order to do gRPC load balancing, we need to shift from connection balancing to request balancing. In other words, we need to open an HTTP/2 connection to each destination, and balance requests across these connections, as shown below:
In network terms, this means we need to make decisions at L5/L7 rather than L3/L4, i.e. we need to understand the protocol sent over the TCP connections.
How do we accomplish this? There are a couple options. First, our application code could manually maintain its own load balancing pool of destinations, and we could configure our gRPC client to use this load balancing pool. This approach gives us the most control, but it can be very complex in environments like Kubernetes where the pool changes over time as Kubernetes reschedules pods. Our application would have to watch the Kubernetes API and keep itself up to date with the pods.
Alternatively, in Kubernetes, we could deploy our app as headless services. In this case, Kubernetes will create multiple A records in the DNS entry for the service. If our gRPC client is sufficiently advanced, it can automatically maintain the load balancing pool from those DNS entries. But this approach restricts us to certain gRPC clients, and it's rarely possible to only use headless services.
Finally, we can take a third approach: use a lightweight proxy.
gRPC load balancing on Kubernetes with Linkerd
Linkerd is a CNCF-hosted service mesh for Kubernetes. Most relevant to our purposes, Linkerd also functions as a service sidecar, where it can be applied to a single service—even without cluster-wide permissions. What this means is that when we add Linkerd to our service, it adds a tiny, ultra-fast proxy to each pod, and these proxies watch the Kubernetes API and do gRPC load balancing automatically. Our deployment then looks like this:
Using Linkerd has a couple advantages. First, it works with services written in any language, with any gRPC client, and any deployment model (headless or not). Because Linkerd's proxies are completely transparent, they auto-detect HTTP/2 and HTTP/1.x and do L7 load balancing, and they pass through all other traffic as pure TCP. This means that everything will just work.
Second, Linkerd's load balancing is very sophisticated. Not only does Linkerd maintain a watch on the Kubernetes API and automatically update the load balancing pool as pods get rescheduled, Linkerd uses an exponentially-weighted moving average of response latencies to automatically send requests to the fastest pods. If one pod is slowing down, even momentarily, Linkerd will shift traffic away from it. This can reduce end-to-end tail latencies.
Finally, Linkerd's Rust-based proxies are incredibly fast and small. They introduce <1ms of p99 latency and require <10mb of RSS per pod, meaning that the impact on system performance will be negligible.
gRPC Load Balancing in 60 seconds
Linkerd is very easy to try. Just follow the steps in the Linkerd Getting Started Instructions—install the CLI on your laptop, install the control plane on your cluster, and "mesh" your service (inject the proxies into each pod). You'll have Linkerd running on your service in no time, and should see proper gRPC balancing immediately.
Let's take a look at our sample voting service again, this time after
installing Linkerd:
As we can see, the CPU graphs for all pods are active, indicating that all pods are now taking traffic—without having to change a line of code. Voila, gRPC load balancing as if by magic!
Linkerd also gives us built-in traffic-level dashboards, so we don't even need to guess what's happening from CPU charts any more. Here's a Linkerd graph that's showing the success rate, request volume, and latency percentiles of each pod:
We can see that each pod is getting around 5 RPS. We can also see that, while we've solved our load balancing problem, we still have some work to do on our success rate for this service. (The demo app is built with an intentional failure—as an exercise to the reader, see if you can figure it out by using the Linkerd dashboard!)
Wrapping it up
If you're interested in a dead simple way to add gRPC load balancing to your Kubernetes services, regardless of what language it's written in, what gRPC client you're using, or how it's deployed, you can use Linkerd to add gRPC load balancing in a few commands.
There's a lot more to Linkerd, including security, reliability, and debugging and diagnostics features, but those are topics for future blog posts.
Want to learn more? We’d love to have you join our rapidly-growing community! Linkerd is a CNCF project, hosted on GitHub, and has a thriving community on Slack, Twitter, and the mailing lists. Come and join the fun!
Tips for Your First Kubecon Presentation - Part 2
Author: Michael Gasch (VMware)
Hello and welcome back to the second and final part about tips for KubeCon first-time speakers. If you missed the last post, please give it a read here.
The Day before the Show
Tip #13 - Get enough sleep. I don't know about you, but when I don't get enough sleep (especially when beer is in the game), the next day my brain power is around 80% at best. It's very easy to get distracted at KubeCon (in a positive sense). "Let's have dinner tonight and chat about XYZ". Get some food, beer or wine because you're so excited and all the good resolutions you had set for the day before your presentation are forgotten :)
OK, I'm slightly exaggerating here. But don't underestimate the dynamics of this conference, the amazing people you meet, the inspiring talks and of course the conference party. Be disciplined, at least that one day. There's enough time to party after your great presentation!
Tip #14 - A final dry-run. Usually, I do a final dry-run of my presentation the day before the talk. This helps me to recall the first few sentences I want to say so I keep the flow no matter what happens when the red recording light goes on. Especially when your talk is later during the conference, there's so much new stuff your brain has to digest which could "overwrite" the very important parts of your presentation. I think you know what I mean. So, if you're like me, a final dry-run is never a bad idea (also to check equipment, demos, etc.).
Tip #15 - Promote your session, again. Send out a final reminder on your social media channels so your followers (and KubeCon attendees) will recall to attend your session (again, KubeCon is busy and it's hard to keep up with all the talks you wanted to attend). I was surprised to see my attendee list jumping from ~80 at the beginning of the week to >300 the day before the talk. The number kept rising even an hour before going on stage. So don't worry about the stats too early.
Tip #16 - Ask your idols to attend. Steve Wong, a colleague of mine who I really admire for his knowledge and passion, gave me a great advise. Reach out to the people you always wanted to attend your talk and kindly ask them to come along.
So I texted the one and only Tim Hockin. Even though these well-respected community leaders are super busy and thus usually cannot attend many talks during the conference, the worst thing that can happen is that they cannot show up and will let you know. (see the end of this post to find out whether or not I was lucky :))
The show is on!
Your day has come and it doesn't make any sense to make big changes to your presentation now! Actually, that's a very bad idea unless you're an expert and your heartbeat at rest is around 40 BPM. (But even then many things can go horribly wrong).
So, without further ado, here are my final tips for you.
Tip #17 - Arrive ahead of time. Set an alert (or two) to not miss your presentation, e.g. because somebody caught you on the way to the room or you got a call/have been pulled in a meeting. It's a good idea to find out were your room is at least some hours before your talk. These conference buildings can be very large. Also look for last minute schedule (time/room) changes, just because you never know...
Tip #18 - Ask a friend to take photos. My dear colleague Bjoern, without me asking for it, took a lot of pictures and watched the audience during the talk. This was really helpful, not just because I now have some nice shots that will always remind me of this great day. He also gave me honest feedback, e.g. what people said, whether they liked it or what I could have done better.
Tip #19 - Restroom. If you're like me, when I'm nervous I could run every 15 minutes. The last thing you want is that you are fully cabled (microphone), everything is set up and two minutes before your presentation you feel like "oh oh"...nothing more to say here ;)
Tip #20 - The audience. I had many examples and references from other Kubernetes users (and their postmortem stories) in my talk. So I tried to give them credit and actually some of them were in the room and really liked that I did so. It gave them (and hopefully the rest of the audience as well) the feeling that I did not invent the wheel and we are all in the same boat. Also feel free to ask some questions in the beginning, e.g. to get a better feeling about who is attending your talk, or who would consider himself an expert in the area of what you are talking about, etc.
Tip #21 - Repeat questions. Always. Because of the time constraints, questions should be asked at the end of your presentation (unless you are giving a community meeting or panel of course). Always (always!) repeat the questions at the end. Sometimes people will not use the microphone. This is not only hard for the people in the back, but also it won't be captured on the recording. I am sure you also had that moment watching a recording and not getting what is being asked/discussed because the question was not captured.
Tip #22 - Feedback. Don't forget to ask the audience to fill out the survey. They're not always enforced/mandatory during conferences (especially not at KubeCon), so it's easy to forget to give the speaker feedback. Feedback is super critical (also for the committee) as sometimes people won't directly tell you but rather write their thoughts. Also, you might want to block your calendar to leave some time after the presentation for follow-up questions, so you are not in the hurry to catch your next meeting/session.
Tip #23 - Invite your audience. No, I don't mean to throw a round of beer for everyone attending your talk (I mean, you could). But you might let them know, at the end of your presentation, that you would like to hang out, have dinner, etc. A great opportunity to reflect and geek out with like-minded friends.
Final Tip - Your Voice matters. Don't underestimate the power of giving a talk at a conference. In my case I was lucky that the Zalando crew was in the room and took this talk as an opportunity for an ad hoc meeting after the conference. This drove an important performance fix forward, which eventually was merged (kudos to the Zalando team again!).
Embrace the opportunity to give a talk at a conference, take it serious, be professional and make the best use of your time. But I'm sure I don't have to tell you that ;)
Now it's on you :)
I hope some of these tips are useful for you as well. And I wish you all the best for your upcoming talk!!! Believing in and being yourself is key to success. And perhaps your Kubernetes idol is in the room and has some nice words for you after your presentation!
Besides my fantastic reviewers and the speaker support team already mentioned above, I also would like to thank the people who supported me along this KubeCon journey: Bjoern, Timo, Emad and Steve!
#KubeCon @embano1 is laying down an homage to an earlier @thockin presentation in his "Inside K8S Resource Management" session, if you didn't make it in the door, check out the deck here https://t.co/4xQq5CQ3aZ pic.twitter.com/ObFEuKskhB
— Steve Wong (@cantbewong) May 4, 2018
Tips for Your First Kubecon Presentation - Part 1
Author: Michael Gasch (VMware)
First of all, let me congratulate you to this outstanding achievement. Speaking at KubeCon, especially if it's your first time, is a tremendous honor and experience. Well done!
Congrats to everyone who got Kubecon talks accepted! 👏👏👏
— Justin Garrison (@rothgar) September 24, 2018
To everyone who got a rejection don't feel bad. Only 13% could be accepted. Keep trying. There will be other opportunities.
When I was informed that my KubeCon talk about Kubernetes Resource Management was accepted for KubeCon EU in Denmark (2018), I really could not believe it. By then, the chances to get your talk accepted were around 10% (or less, don't really remember the exact number). There were over a 1,000 submissions just for that KubeCon (recall that we now have three KubeCon events during the year - US, EU and Asia region). The popularity of Kubernetes is ever increasing and so is the number of people trying to get a talk accepted. Once again, outstanding achievement to get your talk in!
But now comes the tough part - research, write, practice, repeat, go on stage, perform :) Let me tell you that I went through several sleepless nights preparing for my first KubeCon talk. The day of the presentation, until I got on stage, was a mixture of every emotion I could have possibly gone through. Even though I had presented uncountable times before, including large industry conferences, KubeCon was very different. Different because it was the first time everything was recorded (including the presenter on stage) and I did not really know the audience, or more precisely: I was assuming everyone in the room is a Kubernetes expert and that my presentation not only had to be entertaining but also technically deep and 100% accurate. It's not seldom that maintainers and SIG (Special Interest Group) leads are in the room as well.
Another challenge for me was squeezing a topic, that can easily fill a full-day workshop, into a 35min presentation (including Q&A). Before KubeCon, I was used to giving breakouts which were typically 60 minutes long. This doesn't say anything about the quality of the presentation but I knew how many slides I can squeeze into 60 minutes, covering important details but not killing people with "Death by PowerPoint".
So I learned a lot going through this endless cycle of preparation, practicing, these doubts of failing and time pressure finishing your deck, and of course giving the talk. When I left Copenhagen, I took some notes based on my speaker experience during the flight, which my friend Bjoern encouraged me to share. Not all of them might apply to you, but I still hope some of them are useful for your first KubeCon talk.
Submitting a Good Talk
Some of you might read these lines even though you did not submit a talk or it wasn't accepted. I found these resources (not specifically targeted at KubeCon) for writing a good proposal very useful:
- How to write with Style
- Talk Framework by the incredible goinggodotnet
- Lachie’s 7 step guide to writing a winning tech conference CFP
Believe it or not, mine went through several reviews by Justin Garrison, Liz Rice, Bill Kennedy, Emad Benjamin and Kelsey Hightower (yes, THE Kelsey Hightower)! Some of them didn't know me before, they just live by our community values to grow newcomers and thus drive this great community forward every day.
I think, without their feedback my proposal wouldn't have been on point to be selected. Their feedback was often direct and required me to completely change the first revisions. But they were right and their feedback was useful to stay within the character limit while still standing out with the proposal.
Feel free to reach out for professional and/or experienced speakers. They know this stuff. And I was surprised by the support and help offered. Many had their DMs in Twitter open, so ask for help and you will be helped :) Besides Twitter, related forums to ask for assistance might be Discuss and Reddit.
Preparing for your Presentation
Tip #1 - Appreciate that you were selected and don't be upset about the slot your presentation was scheduled in. For example, my talk was put as second last presentation of final KubeCon day (Friday). I was like, who's going to stay there and not catch his/her flight or hang out and relax after this crazy week? The session stats, where speakers can see who signed up, were slowly increasing until the week of KubeCon. I think at the beginning of the week it showed ~80 people interested in my session (there is no mandatory sign-up). I was so happy, especially since there were some interesting talks running at the same time as my presentation.
Without spoiling (see below), the KubeCon community and attendees fully leverage the time and effort they've put into traveling to KubeCon. Rest assured that even if you have the last presentation at KubeCon, people will show up!
Tip #2 - Study the Masters on Youtube. Get some inspirations from great speakers (some of them already mentioned above) and top rated sessions of previous KubeCons. Observe how they present and interact with the audience, while still keeping the tough timing throughout the presentation.
Tip #3 - Find reviewers. Having experienced or professional speakers review your slides is super critical. Not only to check for language/translation (see below) but also to improve the flow of your presentation and get feedback on whether the content is logically structured and not too dense (too many slides, timing). They will help you to leave out less important information while also making the presentation fit for your audience (not everyone has the level of knowledge as you in your specific area).
Tip #4 - Language barriers. Nobody is perfect and the community encourages diversity. This makes us all better and is what I probably like the most about the Kubernetes community. However, make sure that the audience understands the message of your talk. For non-native speakers, it can be really hard to present in English (e.g. at the US/EU conferences), especially if you're not used to it. Add to that the tension during the talk and it can become really hard for the audience to follow.
I am not saying that everyone has to present in perfect business English. Nobody expects that, let me be very clear. But if you feel that this could be an issue for you, reach out for help. Reviewers can help fix grammar and wording in your slide deck. Practicing and recording yourself (see below) are helpful to reflect yourself. The slides should reflect your message so people can read along if they lost you. Simple, less busy slides are definitely recommended. Make sure to add speaker notes to your presentation. Not only does this help with getting better every time you run through your presentation (memory effect and the flow). It also serves as a safety net when you think language will definitely be an issue, or when you're suddenly completely lost during the presentation on stage.
Tip #5 - Study the Speaker Guidelines. Nothing to add here, take them seriously and reach out to the (fantastic) speaker support if you have questions. Also submit your presentation in time (plan ahead accordingly) to not risk any trouble with the committee.
Tip #6 - Practice like never before. Practicing is probably the most important tip I can give you. I don't know how many times I practiced my talk, e.g. at home but also at some local Meetups to get some early feedback. First I was shocked with timing. Even though I had my deck down to 40min in my dry runs at home, at the Meetup I completely run out of time (50min). I was shocked, as I didn't know what to leave out.
The feedback from these sessions helped me to trim down content as it helped me to understand what to leave out/shorten. Keep in mind to also leave room for questions as a best practice (requirement?) by the speaker guidelines.
Tip #7 - The Demo Gods are not always with you. Demos can and will go wrong. Not just because of the typical suspect like slow WiFi, etc. I heard horror stories about expired certificates, daylight saving times (for those traveling through time zones on their way to KubeCon) affecting deployments, the content of a variable in your BASH script changing (e.g. when curling stuff from the web), keyboards breaking (Mac lovers, can you believe that?), hard disks crashing (even the backup disk not working), and so on.
Never ever rely on the demo gods, especially when you're not Kelsey Hightower :) Take video recordings of your demos so you not only have a backup when the live demo breaks. But also in case you're afraid of running out of time. In order to avoid the primary and backup disks crashing (yes, it happened at that KubeCon I was told), store a copy at your trusted cloud provider.
Tip #8 - The right Tools for the job. Sometimes you want to highlight something on your slide. This has two potentially issues. First, you have to constantly turn away from the audience which does not necessarily look good (if you can avoid it). Second, it might not always work depending on the (laser) pointer and room equipment (light, background).
This presenter from Logitech has really served me well. It has several useful features, the "Spotlight" (that's why the name) being my favorite feature. You'll never want to go back.
Tip #9 - Being recorded. I am not sure if you can opt-out from being recorded (please check with speaker support on the latest guidelines here) if you don't want to appear on Youtube for the rest of your life. But audio definitely will be recorded so chose your words (jokes) wisely. Again, practicing and reviewing helps. If you're ok with being recorded, at least think about which shirt (logos and "art") you want to be remembered by the internet ;)
Tip #10 - Social media. Social media is great for promoting your session and you should definitely send out reminders on various channels for your presentation. Something that is missing almost every time in the presentation templates (if you want to use them) is placeholders for your social media account and, more importantly, for your session ID. Even if the conference does not use session IDs externally (in the schedule builder), you might still want to add a handle to every slide so people can refer to your presentation (or particular slide) on social media with a hashtag that you then can search for feedback, questions, etc.
Tip #11 - Be yourself. Be authentic and don't try to sound super smart or funny (unless you are ;)). Seriously. Just be yourself and people will love you. Authenticity is key for a great presentation and the audience will smell when you try to fool them. It also makes practicing and the live performance easier as you don't have to pay attention on acting like somebody else.
From a content perspective make sure that you own and develop the content and you did not copy and paste like crazy from the Kubernetes docs or other presentations. It's absolutely ok to reference other sources, but please give them credit. Again, the audience will smell if you make things up. You should know what you're speaking about (not saying that you have to be an expert, but experience is what makes your talk unique). The final proof is during Q&A and KubeCon is a sharp audience ;)
Tip #12 - Changes to the proposal. The committee, based on your proposal description and details, might change the audience level. For example, I put my talk in as intermediate, but it was changed to all skill levels. This is not bad per se. Just watch out for changes and adapt your presentation accordingly or reach out to speaker support. If you were not expecting beginners or architects in your talk (because you had chosen another skill level and target group), you might lose parts of your audience. This could also negatively affect your session feedback/scores.
Wrapping up
I hope some of these tips are already useful and will help you getting started to work on your presentation. In the next post we are going to cover speaker tips when you are finally at the KubeCon event.
Kubernetes 2018 North American Contributor Summit
Authors: Bob Killen (University of Michigan) Sahdev Zala (IBM), Ihor Dvoretskyi (CNCF)
The 2018 North American Kubernetes Contributor Summit to be hosted right before KubeCon + CloudNativeCon Seattle is shaping up to be the largest yet. It is an event that brings together new and current contributors alike to connect and share face-to-face; and serves as an opportunity for existing contributors to help shape the future of community development. For new community members, it offers a welcoming space to learn, explore and put the contributor workflow to practice.
Unlike previous Contributor Summits, the event now spans two-days with a more relaxed ‘hallway’ track and general Contributor get-together to be hosted from 5-8pm on Sunday December 9th at the Garage Lounge and Gaming Hall, just a short walk away from the Convention Center. There, contributors can enjoy billiards, bowling, trivia and more; accompanied by a variety of food and drink.
Things pick up the following day, Monday the 10th with three separate tracks:
New Contributor Workshop:
A half day workshop aimed at getting new and first time contributors onboarded and comfortable with working within the Kubernetes Community. Staying for the duration is required; this is not a workshop you can drop into.
Current Contributor Track:
Reserved for those that are actively engaged with the development of the project; the Current Contributor Track includes Talks, Workshops, Birds of a Feather, Unconferences, Steering Committee Sessions, and more! Keep an eye on the schedule in GitHub as content is frequently being updated.
Docs Sprint:
SIG-Docs will have a curated list of issues and challenges to be tackled closer to the event date.
To Register:
To register for the Contributor Summit, see the Registration section of the Event Details in GitHub. Please note that registrations are being reviewed. If you select the “Current Contributor Track” and are not an active contributor, you will be asked to attend the New Contributor Workshop, or asked to be put on a waitlist. With thousands of contributors and only 300 spots, we need to make sure the right folks are in the room.
If you have any questions or concerns, please don’t hesitate to reach out to the Contributor Summit Events Team at community@kubernetes.io.
Look forward to seeing everyone there!
2018 Steering Committee Election Results
Authors: Jorge Castro (Heptio), Ihor Dvoretskyi (CNCF), Paris Pittman (Google)
Results
The Kubernetes Steering Committee Election is now complete and the following candidates came ahead to secure two year terms that start immediately:
- Aaron Crickenberger, Google, @spiffxp
- Davanum Srinivas, Huawei, @dims
- Tim St. Clair, Heptio, @timothysc
Big Thanks!
- Steering Committee Member Emeritus Quinton Hoole for his service to the community over the past year. We look forward to
- The candidates that came forward to run for election. May we always have a strong set of people who want to push community forward like yours in every election.
- All 307 voters who cast a ballot.
- And last but not least...Cornell University for hosting CIVS!
Get Involved with the Steering Committee
You can follow along to Steering Committee backlog items and weigh in by filing an issue or creating a PR against their repo. They meet bi-weekly on Wednesdays at 8pm UTC and regularly attend Meet Our Contributors.
Steering Committee Meetings:
Meet Our Contributors Steering AMA’s:
Topology-Aware Volume Provisioning in Kubernetes
Author: Michelle Au (Google)
The multi-zone cluster experience with persistent volumes is improving in Kubernetes 1.12 with the topology-aware dynamic provisioning beta feature. This feature allows Kubernetes to make intelligent decisions when dynamically provisioning volumes by getting scheduler input on the best place to provision a volume for a pod. In multi-zone clusters, this means that volumes will get provisioned in an appropriate zone that can run your pod, allowing you to easily deploy and scale your stateful workloads across failure domains to provide high availability and fault tolerance.
Previous challenges
Before this feature, running stateful workloads with zonal persistent disks (such as AWS ElasticBlockStore, Azure Disk, GCE PersistentDisk) in multi-zone clusters had many challenges. Dynamic provisioning was handled independently from pod scheduling, which meant that as soon as you created a PersistentVolumeClaim (PVC), a volume would get provisioned. This meant that the provisioner had no knowledge of what pods were using the volume, and any pod constraints it had that could impact scheduling.
This resulted in unschedulable pods because volumes were provisioned in zones that:
- did not have enough CPU or memory resources to run the pod
- conflicted with node selectors, pod affinity or anti-affinity policies
- could not run the pod due to taints
Another common issue was that a non-StatefulSet pod using multiple persistent volumes could have each volume provisioned in a different zone, again resulting in an unschedulable pod.
Suboptimal workarounds included overprovisioning of nodes, or manual creation of volumes in the correct zones, making it difficult to dynamically deploy and scale stateful workloads.
The topology-aware dynamic provisioning feature addresses all of the above issues.
Supported Volume Types
In 1.12, the following drivers support topology-aware dynamic provisioning:
- AWS EBS
- Azure Disk
- GCE PD (including Regional PD)
- CSI (alpha) - currently only the GCE PD CSI driver has implemented topology support
Design Principles
While the initial set of supported plugins are all zonal-based, we designed this feature to adhere to the Kubernetes principle of portability across environments. Topology specification is generalized and uses a similar label-based specification like in Pod nodeSelectors and nodeAffinity. This mechanism allows you to define your own topology boundaries, such as racks in on-premise clusters, without requiring modifications to the scheduler to understand these custom topologies.
In addition, the topology information is abstracted away from the pod specification, so a pod does not need knowledge of the underlying storage system’s topology characteristics. This means that you can use the same pod specification across multiple clusters, environments, and storage systems.
Getting Started
To enable this feature, all you need to do is to create a StorageClass with volumeBindingMode set to WaitForFirstConsumer:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: topology-aware-standard
provisioner: kubernetes.io/gce-pd
volumeBindingMode: WaitForFirstConsumer
parameters:
type: pd-standard
This new setting instructs the volume provisioner to not create a volume immediately, and instead, wait for a pod using an associated PVC to run through scheduling. Note that previous StorageClass zone and zones parameters do not need to be specified anymore, as pod policies now drive the decision of which zone to provision a volume in.
Next, create a pod and PVC with this StorageClass. This sequence is the same as before, but with a different StorageClass specified in the PVC. The following is a hypothetical example, demonstrating the capabilities of the new feature by specifying many pod constraints and scheduling policies:
- multiple PVCs in a pod
- nodeAffinity across a subset of zones
- pod anti-affinity on zones
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- us-central1-a
- us-central1-f
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: nginx
image: gcr.io/google_containers/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
- name: logs
mountPath: /logs
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: topology-aware-standard
resources:
requests:
storage: 10Gi
- metadata:
name: logs
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: topology-aware-standard
resources:
requests:
storage: 1Gi
Afterwards, you can see that the volumes were provisioned in zones according to the policies set by the pod:
$ kubectl get pv -o=jsonpath='{range .items[*]}{.spec.claimRef.name}{"\t"}{.metadata.labels.failure\-domain\.beta\.kubernetes\.io/zone}{"\n"}{end}'
www-web-0 us-central1-f
logs-web-0 us-central1-f
www-web-1 us-central1-a
logs-web-1 us-central1-a
How can I learn more?
Official documentation on the topology-aware dynamic provisioning feature is available here
Documentation for CSI drivers is available at https://kubernetes-csi.github.io/docs/
What’s next?
We are actively working on improving this feature to support:
- more volume types, including dynamic provisioning for local volumes
- dynamic volume attachable count and capacity limits per node
How do I get involved?
If you have feedback for this feature or are interested in getting involved with the design and development, join the Kubernetes Storage Special-Interest-Group (SIG). We’re rapidly growing and always welcome new contributors.
Special thanks to all the contributors that helped bring this feature to beta, including Cheng Xing (verult), Chuqiang Li (lichuqiang), David Zhu (davidz627), Deep Debroy (ddebroy), Jan Šafránek (jsafrane), Jordan Liggitt (liggitt), Michelle Au (msau42), Pengfei Ni (feiskyer), Saad Ali (saad-ali), Tim Hockin (thockin), and Yecheng Fu (cofyc).
Kubernetes v1.12: Introducing RuntimeClass
Author: Tim Allclair (Google)
Kubernetes originally launched with support for Docker containers running native applications on a Linux host. Starting with rkt in Kubernetes 1.3 more runtimes were coming, which lead to the development of the Container Runtime Interface (CRI). Since then, the set of alternative runtimes has only expanded: projects like Kata Containers and gVisor were announced for stronger workload isolation, and Kubernetes' Windows support has been steadily progressing.
With runtimes targeting so many different use cases, a clear need for mixed runtimes in a cluster arose. But all these different ways of running containers have brought a new set of problems to deal with:
- How do users know which runtimes are available, and select the runtime for their workloads?
- How do we ensure pods are scheduled to the nodes that support the desired runtime?
- Which runtimes support which features, and how can we surface incompatibilities to the user?
- How do we account for the varying resource overheads of the runtimes?
RuntimeClass aims to solve these issues.
RuntimeClass in Kubernetes 1.12
RuntimeClass was recently introduced as an alpha feature in Kubernetes 1.12. The initial implementation focuses on providing a runtime selection API, and paves the way to address the other open problems.
The RuntimeClass resource represents a container runtime supported in a Kubernetes cluster. The cluster provisioner sets up, configures, and defines the concrete runtimes backing the RuntimeClass. In its current form, a RuntimeClassSpec holds a single field, the RuntimeHandler. The RuntimeHandler is interpreted by the CRI implementation running on a node, and mapped to the actual runtime configuration. Meanwhile the PodSpec has been expanded with a new field, RuntimeClassName, which names the RuntimeClass that should be used to run the pod.
Why is RuntimeClass a pod level concept? The Kubernetes resource model expects certain resources to be shareable between containers in the pod. If the pod is made up of different containers with potentially different resource models, supporting the necessary level of resource sharing becomes very challenging. For example, it is extremely difficult to support a loopback (localhost) interface across a VM boundary, but this is a common model for communication between two containers in a pod.
What's next?
The RuntimeClass resource is an important foundation for surfacing runtime properties to the control plane. For example, to implement scheduler support for clusters with heterogeneous nodes supporting different runtimes, we might add NodeAffinity terms to the RuntimeClass definition. Another area to address is managing the variable resource requirements to run pods of different runtimes. The Pod Overhead proposal was an early take on this that aligns nicely with the RuntimeClass design, and may be pursued further.
Many other RuntimeClass extensions have also been proposed, and will be revisited as the feature continues to develop and mature. A few more extensions that are being considered include:
- Surfacing optional features supported by runtimes, and better visibility into errors caused by incompatible features.
- Automatic runtime or feature discovery, to support scheduling decisions without manual configuration.
- Standardized or conformant RuntimeClass names that define a set of properties that should be supported across clusters with RuntimeClasses of the same name.
- Dynamic registration of additional runtimes, so users can install new runtimes on existing clusters with no downtime.
- "Fitting" a RuntimeClass to a pod's requirements. For instance, specifying runtime properties and letting the system match an appropriate RuntimeClass, rather than explicitly assigning a RuntimeClass by name.
RuntimeClass will be under active development at least through 2019, and we’re excited to see the feature take shape, starting with the RuntimeClass alpha in Kubernetes 1.12.
Learn More
- Take it for a spin! As an alpha feature, there are some additional setup steps to use RuntimeClass. Refer to the RuntimeClass documentation for how to get it running.
- Check out the RuntimeClass Kubernetes Enhancement Proposal for more nitty-gritty design details.
- The Sandbox Isolation Level Decision documents the thought process that initially went into making RuntimeClass a pod-level choice.
- Join the discussions and help shape the future of RuntimeClass with the SIG-Node community
Introducing Volume Snapshot Alpha for Kubernetes
Author: Jing Xu (Google) Xing Yang (Huawei), Saad Ali (Google)
Kubernetes v1.12 introduces alpha support for volume snapshotting. This feature allows creating/deleting volume snapshots, and the ability to create new volumes from a snapshot natively using the Kubernetes API.
What is a Snapshot?
Many storage systems (like Google Cloud Persistent Disks, Amazon Elastic Block Storage, and many on-premise storage systems) provide the ability to create a "snapshot" of a persistent volume. A snapshot represents a point-in-time copy of a volume. A snapshot can be used either to provision a new volume (pre-populated with the snapshot data) or to restore the existing volume to a previous state (represented by the snapshot).
Why add Snapshots to Kubernetes?
The Kubernetes volume plugin system already provides a powerful abstraction that automates the provisioning, attaching, and mounting of block and file storage.
Underpinning all these features is the Kubernetes goal of workload portability: Kubernetes aims to create an abstraction layer between distributed systems applications and underlying clusters so that applications can be agnostic to the specifics of the cluster they run on and application deployment requires no “cluster specific” knowledge.
The Kubernetes Storage SIG identified snapshot operations as critical functionality for many stateful workloads. For example, a database administrator may want to snapshot a database volume before starting a database operation.
By providing a standard way to trigger snapshot operations in the Kubernetes API, Kubernetes users can now handle use cases like this without having to go around the Kubernetes API (and manually executing storage system specific operations).
Instead, Kubernetes users are now empowered to incorporate snapshot operations in a cluster agnostic way into their tooling and policy with the comfort of knowing that it will work against arbitrary Kubernetes clusters regardless of the underlying storage.
Additionally these Kubernetes snapshot primitives act as basic building blocks that unlock the ability to develop advanced, enterprise grade, storage administration features for Kubernetes: such as data protection, data replication, and data migration.
Which volume plugins support Kubernetes Snapshots?
Kubernetes supports three types of volume plugins: in-tree, Flex, and CSI. See Kubernetes Volume Plugin FAQ for details.
Snapshots are only supported for CSI drivers (not for in-tree or Flex). To use the Kubernetes snapshots feature, ensure that a CSI Driver that implements snapshots is deployed on your cluster.
As of the publishing of this blog, the following CSI drivers support snapshots:
Snapshot support for other drivers is pending, and should be available soon. Read the “Container Storage Interface (CSI) for Kubernetes Goes Beta” blog post to learn more about CSI and how to deploy CSI drivers.
Kubernetes Snapshots API
Similar to the API for managing Kubernetes Persistent Volumes, Kubernetes Volume Snapshots introduce three new API objects for managing snapshots:
VolumeSnapshot- Created by a Kubernetes user to request creation of a snapshot for a specified volume. It contains information about the snapshot operation such as the timestamp when the snapshot was taken and whether the snapshot is ready to use.
- Similar to the
PersistentVolumeClaimobject, the creation and deletion of this object represents a user desire to create or delete a cluster resource (a snapshot).
VolumeSnapshotContent- Created by the CSI volume driver once a snapshot has been successfully created. It contains information about the snapshot including snapshot ID.
- Similar to the
PersistentVolumeobject, this object represents a provisioned resource on the cluster (a snapshot). - Like
PersistentVolumeClaimandPersistentVolumeobjects, once a snapshot is created, theVolumeSnapshotContentobject binds to the VolumeSnapshot for which it was created (with a one-to-one mapping).
VolumeSnapshotClass- Created by cluster administrators to describe how snapshots should be created. including the driver information, the secrets to access the snapshot, etc.
It is important to note that unlike the core Kubernetes Persistent Volume objects, these Snapshot objects are defined as CustomResourceDefinitions (CRDs). The Kubernetes project is moving away from having resource types pre-defined in the API server, and is moving towards a model where the API server is independent of the API objects. This allows the API server to be reused for projects other than Kubernetes, and consumers (like Kubernetes) can simply install the resource types they require as CRDs.
CSI Drivers that support snapshots will automatically install the required CRDs. Kubernetes end users only need to verify that a CSI driver that supports snapshots is deployed on their Kubernetes cluster.
In addition to these new objects, a new, DataSource field has been added to the PersistentVolumeClaim object:
type PersistentVolumeClaimSpec struct {
AccessModes []PersistentVolumeAccessMode
Selector *metav1.LabelSelector
Resources ResourceRequirements
VolumeName string
StorageClassName *string
VolumeMode *PersistentVolumeMode
DataSource *TypedLocalObjectReference
}
This new alpha field enables a new volume to be created and automatically pre-populated with data from an existing snapshot.
Kubernetes Snapshots Requirements
Before using Kubernetes Volume Snapshotting, you must:
- Ensure a CSI driver implementing snapshots is deployed and running on your Kubernetes cluster.
- Enable the Kubernetes Volume Snapshotting feature via new Kubernetes feature gate (disabled by default for alpha):
- Set the following flag on the API server binary:
--feature-gates=VolumeSnapshotDataSource=true
- Set the following flag on the API server binary:
Before creating a snapshot, you also need to specify CSI driver information for snapshots by creating a VolumeSnapshotClass object and setting the snapshotter field to point to your CSI driver. In the example of VolumeSnapshotClass below, the CSI driver is com.example.csi-driver. You need at least one VolumeSnapshotClass object per snapshot provisioner. You can also set a default VolumeSnapshotClass for each individual CSI driver by putting an annotation snapshot.storage.kubernetes.io/is-default-class: "true" in the class definition.
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshotClass
metadata:
name: default-snapclass
annotations:
snapshot.storage.kubernetes.io/is-default-class: "true"
snapshotter: com.example.csi-driver
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
snapshotter: com.example.csi-driver
parameters:
fakeSnapshotOption: foo
csiSnapshotterSecretName: csi-secret
csiSnapshotterSecretNamespace: csi-namespace
You must set any required opaque parameters based on the documentation for your CSI driver. As the example above shows, the parameter fakeSnapshotOption: foo and any referenced secret(s) will be passed to CSI driver during snapshot creation and deletion. The default CSI external-snapshotter reserves the parameter keys csiSnapshotterSecretName and csiSnapshotterSecretNamespace. If specified, it fetches the secret and passes it to the CSI driver when creating and deleting a snapshot.
And finally, before creating a snapshot, you must provision a volume using your CSI driver and populate it with some data that you want to snapshot (see the CSI blog post on how to create and use CSI volumes).
Creating a new Snapshot with Kubernetes
Once a VolumeSnapshotClass object is defined and you have a volume you want to snapshot, you may create a new snapshot by creating a VolumeSnapshot object.
The source of the snapshot specifies the volume to create a snapshot from. It has two parameters:
kind- must bePersistentVolumeClaimname- the PVC API object name
The namespace of the volume to snapshot is assumed to be the same as the namespace of the VolumeSnapshot object.
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshot
metadata:
name: new-snapshot-demo
namespace: demo-namespace
spec:
snapshotClassName: csi-snapclass
source:
name: mypvc
kind: PersistentVolumeClaim
In the VolumeSnapshot spec, user can specify the VolumeSnapshotClass which has the information about which CSI driver should be used for creating the snapshot . When the VolumeSnapshot object is created, the parameter fakeSnapshotOption: foo and any referenced secret(s) from the VolumeSnapshotClass are passed to the CSI plugin com.example.csi-driver via a CreateSnapshot call.
In response, the CSI driver triggers a snapshot of the volume and then automatically creates a VolumeSnapshotContent object to represent the new snapshot, and binds the new VolumeSnapshotContent object to the VolumeSnapshot, making it ready to use. If the CSI driver fails to create the snapshot and returns error, the snapshot controller reports the error in the status of VolumeSnapshot object and does not retry (this is different from other controllers in Kubernetes, and is to prevent snapshots from being taken at an unexpected time).
If a snapshot class is not specified, the external snapshotter will try to find and set a default snapshot class for the snapshot. The CSI driver specified by snapshotter in the default snapshot class must match the CSI driver specified by the provisioner in the storage class of the PVC.
Please note that the alpha release of Kubernetes Snapshot does not provide any consistency guarantees. You have to prepare your application (pause application, freeze filesystem etc.) before taking the snapshot for data consistency.
You can verify that the VolumeSnapshot object is created and bound with VolumeSnapshotContent by running kubectl describe volumesnapshot:
Readyshould be set to true underStatusto indicate this volume snapshot is ready for use.Creation Timefield indicates when the snapshot is actually created (cut).Restore Sizefield indicates the minimum volume size when restoring a volume from the snapshot.Snapshot Content Namefield in thespecpoints to theVolumeSnapshotContentobject created for this snapshot.
Importing an existing snapshot with Kubernetes
You can always import an existing snapshot to Kubernetes by manually creating a VolumeSnapshotContent object to represent the existing snapshot. Because VolumeSnapshotContent is a non-namespace API object, only a system admin may have the permission to create it. Once a VolumeSnapshotContent object is created, the user can create a VolumeSnapshot object pointing to the VolumeSnapshotContent object. The external-snapshotter controller will mark snapshot as ready after verifying the snapshot exists and the binding between VolumeSnapshot and VolumeSnapshotContent objects is correct. Once bound, the snapshot is ready to use in Kubernetes.
A VolumeSnapshotContent object should be created with the following fields to represent a pre-provisioned snapshot:
csiVolumeSnapshotSource- Snapshot identifying information.snapshotHandle- name/identifier of the snapshot. This field is required.driver- CSI driver used to handle this volume. This field is required. It must match the snapshotter name in the snapshot controller.creationTimeandrestoreSize- these fields are not required for pre-provisioned volumes. The external-snapshotter controller will automatically update them after creation.
volumeSnapshotRef- Pointer to theVolumeSnapshotobject this object should bind to.nameandnamespace- It specifies the name and namespace of theVolumeSnapshotobject which the content is bound to.UID- these fields are not required for pre-provisioned volumes.The external-snapshotter controller will update the field automatically after binding. If user specifies UID field, he/she must make sure that it matches with the binding snapshot’s UID. If the specified UID does not match the binding snapshot’s UID, the content is considered an orphan object and the controller will delete it and its associated snapshot.
snapshotClassName- This field is optional. The external-snapshotter controller will update the field automatically after binding.
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshotContent
metadata:
name: static-snapshot-content
spec:
csiVolumeSnapshotSource:
driver: com.example.csi-driver
snapshotHandle: snapshotcontent-example-id
volumeSnapshotRef:
kind: VolumeSnapshot
name: static-snapshot-demo
namespace: demo-namespace
A VolumeSnapshot object should be created to allow a user to use the snapshot:
snapshotClassName- name of the volume snapshot class. This field is optional. If set, the snapshotter field in the snapshot class must match the snapshotter name of the snapshot controller. If not set, the snapshot controller will try to find a default snapshot class.snapshotContentName- name of the volume snapshot content. This field is required for pre-provisioned volumes.
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshot
metadata:
name: static-snapshot-demo
namespace: demo-namespace
spec:
snapshotClassName: csi-snapclass
snapshotContentName: static-snapshot-content
Once these objects are created, the snapshot controller will bind them together, and set the field Ready (under Status) to True to indicate the snapshot is ready to use.
Provision a new volume from a snapshot with Kubernetes
To provision a new volume pre-populated with data from a snapshot object, use the new dataSource field in the PersistentVolumeClaim. It has three parameters:
- name - name of the
VolumeSnapshotobject representing the snapshot to use as source - kind - must be
VolumeSnapshot - apiGroup - must be
snapshot.storage.k8s.io
The namespace of the source VolumeSnapshot object is assumed to be the same as the namespace of the PersistentVolumeClaim object.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-restore
Namespace: demo-namespace
spec:
storageClassName: csi-storageclass
dataSource:
name: new-snapshot-demo
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
When the PersistentVolumeClaim object is created, it will trigger provisioning of a new volume that is pre-populated with data from the specified snapshot.
As a storage vendor, how do I add support for snapshots to my CSI driver?
To implement the snapshot feature, a CSI driver MUST add support for additional controller capabilities CREATE_DELETE_SNAPSHOT and LIST_SNAPSHOTS, and implement additional controller RPCs: CreateSnapshot, DeleteSnapshot, and ListSnapshots. For details, see the CSI spec.
Although Kubernetes is as minimally prescriptive on the packaging and deployment of a CSI Volume Driver as possible, it provides a suggested mechanism for deploying an arbitrary containerized CSI driver on Kubernetes to simplify deployment of containerized CSI compatible volume drivers.
As part of this recommended deployment process, the Kubernetes team provides a number of sidecar (helper) containers, including a new external-snapshotter sidecar container.
The external-snapshotter watches the Kubernetes API server for VolumeSnapshot and VolumeSnapshotContent objects and triggers CreateSnapshot and DeleteSnapshot operations against a CSI endpoint. The CSI external-provisioner sidecar container has also been updated to support restoring volume from snapshot using the new dataSource PVC field.
In order to support snapshot feature, it is recommended that storage vendors deploy the external-snapshotter sidecar containers in addition to the external provisioner the external attacher, along with their CSI driver in a statefulset as shown in the following diagram.
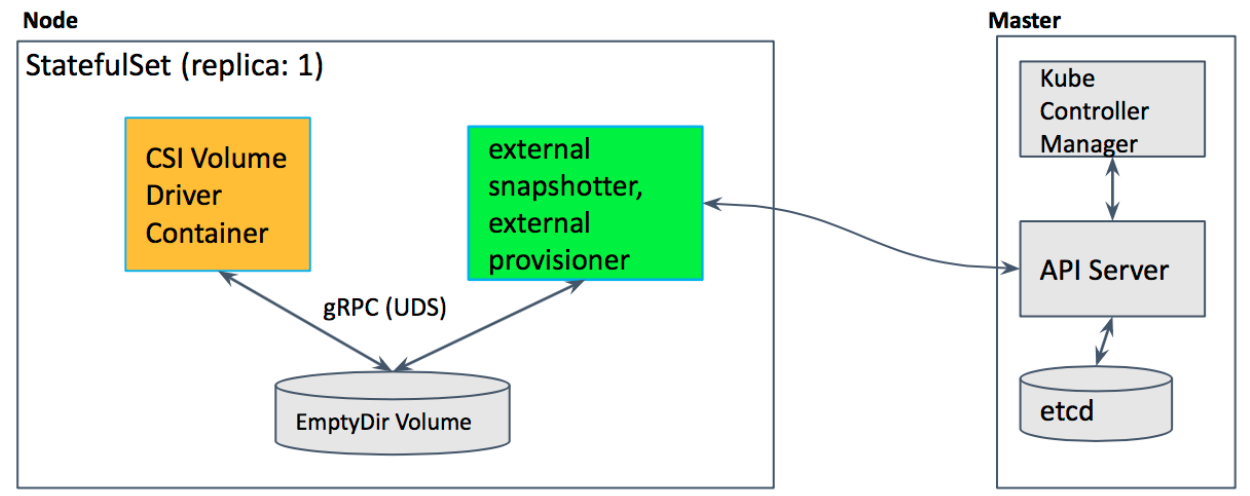
In this example deployment yaml file, two sidecar containers, the external provisioner and the external snapshotter, and CSI drivers are deployed together with the hostpath CSI plugin in the statefulset pod. Hostpath CSI plugin is a sample plugin, not for production.
What are the limitations of alpha?
The alpha implementation of snapshots for Kubernetes has the following limitations:
- Does not support reverting an existing volume to an earlier state represented by a snapshot (alpha only supports provisioning a new volume from a snapshot).
- Does not support “in-place restore” of an existing PersistentVolumeClaim from a snapshot: i.e. provisioning a new volume from a snapshot, but updating an existing PersistentVolumeClaim to point to the new volume and effectively making the PVC appear to revert to an earlier state (alpha only supports using a new volume provisioned from a snapshot via a new PV/PVC).
- No snapshot consistency guarantees beyond any guarantees provided by storage system (e.g. crash consistency).
What’s next?
Depending on feedback and adoption, the Kubernetes team plans to push the CSI Snapshot implementation to beta in either 1.13 or 1.14.
How can I learn more?
Check out additional documentation on the snapshot feature here: http://k8s.io/docs/concepts/storage/volume-snapshots and https://kubernetes-csi.github.io/docs/
How do I get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together.
In addition to the contributors who have been working on the Snapshot feature:
- Xing Yang (xing-yang)
- Jing Xu (jingxu97)
- Huamin Chen (rootfs)
- Tomas Smetana (tsmetana)
- Shiwei Xu (wackxu)
We offer a huge thank you to all the contributors in Kubernetes Storage SIG and CSI community who helped review the design and implementation of the project, including but not limited to the following:
- Saad Ali (saadali)
- Tim Hockin (thockin)
- Jan Šafránek (jsafrane)
- Luis Pabon (lpabon)
- Jordan Liggitt (liggitt)
- David Zhu (davidz627)
- Garth Bushell (garthy)
- Ardalan Kangarlou (kangarlou)
- Seungcheol Ko (sngchlko)
- Michelle Au (msau42)
- Humble Devassy Chirammal (humblec)
- Vladimir Vivien (vladimirvivien)
- John Griffith (j-griffith)
- Bradley Childs (childsb)
- Ben Swartzlander (bswartz)
If you’re interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Support for Azure VMSS, Cluster-Autoscaler and User Assigned Identity
Author: Krishnakumar R (KK) (Microsoft), Pengfei Ni (Microsoft)
Introduction
With Kubernetes v1.12, Azure virtual machine scale sets (VMSS) and cluster-autoscaler have reached their General Availability (GA) and User Assigned Identity is available as a preview feature.
Azure VMSS allow you to create and manage identical, load balanced VMs that automatically increase or decrease based on demand or a set schedule. This enables you to easily manage and scale multiple VMs to provide high availability and application resiliency, ideal for large-scale applications like container workloads [1].
Cluster autoscaler allows you to adjust the size of the Kubernetes clusters based on the load conditions automatically.
Another exciting feature which v1.12 brings to the table is the ability to use User Assigned Identities with Kubernetes clusters [12].
In this article, we will do a brief overview of VMSS, cluster autoscaler and user assigned identity features on Azure.
VMSS
Azure’s Virtual Machine Scale sets (VMSS) feature offers users an ability to automatically create VMs from a single central configuration, provide load balancing via L4 and L7 load balancing, provide a path to use availability zones for high availability, provides large-scale VM instances et. al.
VMSS consists of a group of virtual machines, which are identical and can be managed and configured at a group level. More details of this feature in Azure itself can be found at the following link [1].
With Kubernetes v1.12 customers can create k8s cluster out of VMSS instances and utilize VMSS features.
Cluster components on Azure
Generally, standalone Kubernetes cluster in Azure consists of the following parts
- Compute - the VM itself and its properties.
- Networking - this includes the IPs and load balancers.
- Storage - the disks which are associated with the VMs.
Compute
Compute in cloud k8s cluster consists of the VMs. These VMs are created by provisioning tools such as acs-engine or AKS (in case of managed service). Eventually, they run various system daemons such as kubelet, kube-api server etc. either as a process (in some versions) or as a docker container.
Networking
In Azure Kubernetes cluster various networking components are brought together to provide features required for users. Typically they consist of the network interfaces, network security groups, public IP resource, VNET (virtual networks), load balancers etc.
Storage
Kubernetes clusters are built on top of disks created in Azure. In a typical configuration, we have managed disks which are used to hold the regular OS images and a separate disk is used for etcd.
Cloud provider components
Kubernetes cloud provider interface provides interactions with clouds for managing cloud-specific resources, e.g. public IPs and routes. A good overview of these components is given in [2]. In case of Azure Kubernetes cluster, the Kubernetes interactions go through the Azure cloud provider layer and contact the various services running in the cloud.
The cloud provider implementation of K8s can be largely divided into the following component interfaces which we need to implement:
- Load Balancer
- Instances
- Zones
- Routes
In addition to the above interfaces, the storage services from the cloud provider is linked via the volume plugin layer.
Azure cloud provider implementation and VMSS
In the Azure cloud provider, for every type of cluster we implement, there is a VMType option which we specify. In case of VMSS, the VM type is “vmss”. The provisioning software (acs-engine, in future AKS etc.) would setup these values in /etc/kubernetes/azure.json file. Based on this type, various implementations would get instantiated [3]
The load balancer interface provides access to the underlying cloud provider load balancer service. The information about the load balancers and the control operations on them are required for Kubernetes to handle the services which gets hosted on the Kubernetes cluster. For VMSS support the changes ensure that the VMSS instances are part of the load balancer pool as required.
The instances interfaces help the cloud controller to get various details about a node from the cloud provider layer. For example, the details of a node like the IP address, the instance id etc, is obtained by the controller by means of the instances interfaces which the cloud provider layer registers with it. In case of VMSS support, we talk to VMSS service to gather information regarding the instances.
The zones interfaces help the cloud controller to get zone information for each node. Scheduler could spread pods to different availability zones with such information. It is also required for supporting topology aware dynamic provisioning features, e.g. AzureDisk. Each VMSS instances will be labeled with its current zone and region.
The routes interfaces help the cloud controller to setup advanced routes for Pod network. For example, a route with prefix node’s podCIDR and next hop node’s internal IP will be set for each node. In case of VMSS support, the next hops are VMSS virtual machines’ internal IP address.
The Azure volume plugin interfaces have been modified for VMSS to work properly. For example, the attach/detach to the AzureDisk have been modified to perform these operations at VMSS instance level.
Setting up a VMSS cluster on Azure
The following link [4] provides an example of acs-engine to create a Kubernetes cluster.
acs-engine deploy --subscription-id <subscription id> \
--dns-prefix <dns> --location <location> \
--api-model examples/kubernetes.json
API model file provides various configurations which acs-engine uses to create a cluster. The API model here [5] gives a good starting configuration to setup the VMSS cluster.
Once a VMSS cluster is created, here are some of the steps you can run to understand more about the cluster setup. Here is the output of kubectl get nodes from a cluster created using the above command:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-agentpool1-92998111-vmss000000 Ready agent 1h v1.12.0-rc.2
k8s-agentpool1-92998111-vmss000001 Ready agent 1h v1.12.0-rc.2
k8s-master-92998111-0 Ready master 1h v1.12.0-rc.2
This cluster consists of two worker nodes and one master. Now how do we check which node is which in Azure parlance? In VMSS listing, we can see a single VMSS:
$ az vmss list -o table -g k8sblogkk1
Name ResourceGroup Location Zones Capacity Overprovision UpgradePolicy
---------------------------- --------------- ---------- ------- ---------- --------------- ---------------
k8s-agentpool1-92998111-vmss k8sblogkk1 westus2 2 False Manual
The nodes which we see as agents (in the kubectl get nodes command) are part of this vmss. We can use the following command to list the instances which are part of the VM scale set:
$ az vmss list-instances -g k8sblogkk1 -n k8s-agentpool1-92998111-vmss -o table
InstanceId LatestModelApplied Location Name ProvisioningState ResourceGroup VmId
------------ -------------------- ---------- ------------------------------ ------------------- --------------- ------------------------------------
0 True westus2 k8s-agentpool1-92998111-vmss_0 Succeeded K8SBLOGKK1 21c57d6c-9c8f-4a62-970f-63ed0fcba53f
1 True westus2 k8s-agentpool1-92998111-vmss_1 Succeeded K8SBLOGKK1 840743b9-0076-4a2e-920e-5ba9da296665
The node name does not match the name in the vm scale set, but if we run the following command to list the providerID we can find the matching node which resembles the instance name:
$ kubectl describe nodes k8s-agentpool1-92998111-vmss000000| grep ProviderID
ProviderID: azure:///subscriptions/<subscription id>/resourceGroups/k8sblogkk1/providers/Microsoft.Compute/virtualMachineScaleSets/k8s-agentpool1-92998111-vmss/virtualMachines/0
Current Status and Future
Currently the following is supported:
- VMSS master nodes and worker nodes
- VMSS on worker nodes and Availability set on master nodes combination.
- Per vm disk attach
- Azure Disk & Azure File support
- Availability zones (Alpha)
In future there will be support for the following:
- AKS with VMSS support
- Per VM instance public IP
Cluster Autoscaler
A Kubernetes cluster consists of nodes. These nodes can be virtual machines, bare metal servers or could be even virtual node (virtual kubelet). To avoid getting lost in permutations and combinations of Kubernetes ecosystem ;-), let's consider that the cluster we are discussing consists of virtual machines, which are hosted in a cloud (eg: Azure, Google or AWS). What this effectively means is that you have access to virtual machines which run Kubernetes agents and a master node which runs k8s services like API server. A detailed version of k8s architecture can be found here [11].
The number of nodes which are required on a cluster depends on the workload on the cluster. When the load goes up there is a need to increase the nodes and when it subsides, there is a need to reduce the nodes and clean up the resources which are no longer in use. One way this can be taken care of is to manually scale up the nodes which are part of the Kubernetes cluster and manually scale down when the demand reduces. But shouldn’t this be done automatically ? Answer to this question is the Cluster Autoscaler (CA).
The cluster autoscaler itself runs as a pod within the kubernetes cluster. The following figure illustrates the high level view of the setup with respect to the k8s cluster:
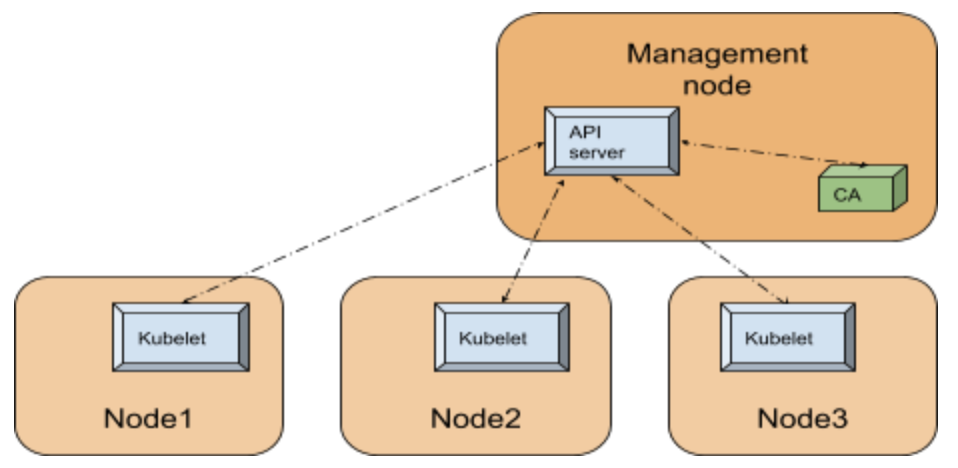
Since Cluster Autoscaler is a pod within the k8s cluster, it can use the in-cluster config and the Kubernetes go client [10] to contact the API server.
Internals
The API server is the central service which manages the state of the k8s cluster utilizing a backing store (an etcd database), runs on the management node or runs within the cloud (in case of managed service such as AKS). For any component within the Kubernetes cluster to figure out the state of the cluster, like for example the nodes registered in the cluster, contacting the API server is the way to go.
In order to simplify our discussion let’s divide the CA functionality into 3 parts as given below:
The main portion of the CA is a control loop which keeps running at every scan interval. This loop is responsible for updating the autoscaler metrics and health probes. Before this loop is entered auto scaler performs various operations such as claiming the leader state after performing a Kubernetes leader election. The main loop initializes static autoscaler component. This component initializes the underlying cloud provider based on the parameters passed onto the CA.
Various operations performed by the CA to manage the state of the cluster is passed onto the cloud provider component. Some examples like - increase target size, decrease target size etc, results in the cloud provider component talking to the cloud services internally and performing operations such as adding a node or deleting a node. These operations are performed on group of nodes in the cluster. The static autoscaler also keeps tab on the state of the system by querying the API server - operations such as list pods and list nodes are used to get hold of such information.
The decision to make a scale up is based on pods which remain unscheduled and a variety of checks and balances. The nodes which are free to be scaled down are deleted from the cluster and deleted from the cloud itself. The cluster autoscaler applies checks and balances before scaling up and scaling down - for example the nodes which have been recently added are given special consideration. During the deletion the nodes are drained to ensure that no disruption happens to the running pods.
Setting up CA on Azure:
Cluster Autoscaler is available as an add-on with acs-engine. The following link [15] has an example configuration file used to deploy autoscaler with acs-engine. The following link [8] provides details on manual step by step way to do the same.
In acs-engine case we use the regular command line to deploy:
acs-engine deploy --subscription-id <subscription id> \
--dns-prefix <dns> --location <location> \
--api-model examples/kubernetes.json
The main difference are the following lines in the config file at [15] makes sure that CA is deployed as an addon:
"addons": [
{
"name": "cluster-autoscaler",
"enabled": true,
"config": {
"minNodes": "1",
"maxNodes": "5"
}
}
]
The config section in the json above can be used to provide the configuration to the cluster autoscaler pod, eg: min and max nodes as above.
Once the setup completes we can see that the cluster-autoscaler pod is deployed in the system namespace:
$kubectl get pods -n kube-system | grep autoscaler
cluster-autoscaler-7bdc74d54c-qvbjs 1/1 Running 1 6m
Here is the output from the CA configmap and events from a sample cluster:
$kubectl -n kube-system describe configmap cluster-autoscaler-status
Name: cluster-autoscaler-status
Namespace: kube-system
Labels: <none>
Annotations: cluster-autoscaler.kubernetes.io/last-updated=2018-10-02 01:21:17.850010508 +0000 UTC
Data
====
status:
----
Cluster-autoscaler status at 2018-10-02 01:21:17.850010508 +0000 UTC:
Cluster-wide:
Health: Healthy (ready=3 unready=0 notStarted=0 longNotStarted=0 registered=3 longUnregistered=0)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:28:49.944222739 +0000 UTC m=+13.584675084
ScaleUp: NoActivity (ready=3 registered=3)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:28:49.944222739 +0000 UTC m=+13.584675084
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:39:50.493307405 +0000 UTC m=+674.133759650
NodeGroups:
Name: k8s-agentpool1-92998111-vmss
Health: Healthy (ready=2 unready=0 notStarted=0 longNotStarted=0 registered=2 longUnregistered=0 cloudProviderTarget=2 (minSize=1, maxSize=5))
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:28:49.944222739 +0000 UTC m=+13.584675084
ScaleUp: NoActivity (ready=2 cloudProviderTarget=2)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:28:49.944222739 +0000 UTC m=+13.584675084
ScaleDown: NoCandidates (candidates=0)
LastProbeTime: 2018-10-02 01:21:17.772229859 +0000 UTC m=+3161.412682204
LastTransitionTime: 2018-10-02 00:39:50.493307405 +0000 UTC m=+674.133759650
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScaleDownEmpty 42m cluster-autoscaler Scale-down: removing empty node k8s-agentpool1-92998111-vmss000002
As can be seen the events, the cluster autoscaler scaled down and deleted a node as there was no load on this cluster. The rest of the configmap in this case indicates that there are no further actions which the autoscaler is taking at this moment.
Current status and future:
Cluster Autoscaler currently supports four VM types: standard (VMAS), VMSS, ACS and AKS. In the future, Cluster Autoscaler will be integrated within AKS product, so that users can enable it by one-click.
User Assigned Identity
Inorder for the Kubernetes cluster components to securely talk to the cloud services, it needs to authenticate with the cloud provider. In Azure Kubernetes clusters, up until now this was done using two ways - Service Principals or Managed Identities. In case of service principal the credentials are stored within the cluster and there are password rotation and other challenges which user needs to incur to accommodate this model. Managed service identities takes out this burden from the user and manages the service instances directly [12].
There are two kinds of managed identities possible - one is system assigned and another is user assigned. In case of system assigned identity each vm in the Kubernetes cluster is assigned a managed identity during creation. This identity is used by various Kubernetes components needing access to Azure resources. Examples to these operations are getting/updating load balancer configuration, getting/updating vm information etc. With the system assigned managed identity, user has no control over the identity which is assigned to the underlying vm. The system automatically assigns it and this reduces the flexibility for the user.
With v1.12 we bring user assigned managed identity support for Kubernetes. With this support user does not have to manage any passwords but at the same time has the flexibility to manage the identity which is used by the cluster. For example if the user needs to allow access to a cluster for a specific storage account or a Azure key vault, the user assigned identity can be created in advance and key vault access provided.
Internals
To understand the internals, we will focus on a cluster created using acs-engine. This can be configured in other ways, but the basic interactions are of the same pattern.
The acs-engine sets up the cluster with the required configuration. The /etc/kubernetes/azure.json file provides a way for the cluster components (eg: kube-apiserver) to gather configuration on how to access the cloud resources. In a user managed identity cluster there is a value filled with the key as UserAssignedIdentityID. This value is filled with the client id of the user assigned identity created by acs-engine or provided by the user, however the case may be. The code which does the authentication for Kubernetes on azure can be found here [14]. This code uses Azure adal packages to get authenticated to access various resources in the cloud. In case of user assigned identity the following API call is made to get new token:
adal.NewServicePrincipalTokenFromMSIWithUserAssignedID(msiEndpoint,
env.ServiceManagementEndpoint,
config.UserAssignedIdentityID)
This calls hits either the instance metadata service or the vm extension [12] to gather the token which is then used to access various resources.
Setting up a cluster with user assigned identity
With the upstream support for user assigned identity in v1.12, it is now supported in the acs-engine to create a cluster with the user assigned identity. The json config files present here [13] can be used to create a cluster with user assigned identity. The same step used to create a vmss cluster can be used to create a cluster which has user assigned identity assigned.
acs-engine deploy --subscription-id <subscription id> \
--dns-prefix <dns> --location <location> \
--api-model examples/kubernetes-msi-userassigned/kube-vmss.json
The main config values here are the following:
"useManagedIdentity": true
"userAssignedID": "acsenginetestid"
The first one useManagedIdentity indicates to acs-engine that we are going to use the managed identity extension. This sets up the necessary packages and extensions required for the managed identities to work. The next one userAssignedID provides the information on the user identity which is to be used with the cluster.
Current status and future
Currently we support the user assigned identity creation with the cluster using deploy of the acs-engine. In future this will become part of AKS.
Get involved
For azure specific discussions - please checkout the Azure SIG page at [6] and come and join the #sig-azure slack channel for more.
For CA, please checkout the Autoscaler project here [7] and join the #sig-autoscaling Slack for more discussions.
For the acs-engine (the unmanaged variety) on Azure docs can be found here: [9]. More details about the managed service from Azure Kubernetes Service (AKS) here [5].
References
-
https://docs.microsoft.com/en-us/azure/virtual-machine-scale-sets/overview
-
/docs/concepts/architecture/cloud-controller/
-
https://github.com/Azure/acs-engine/blob/master/docs/kubernetes/deploy.md
-
https://github.com/kubernetes/community/tree/master/sig-azure
-
/docs/concepts/architecture/
-
https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview
-
https://github.com/Azure/acs-engine/tree/master/examples/kubernetes-msi-userassigned
14)https://github.com/kubernetes/kubernetes/blob/release-1.17/staging/src/k8s.io/legacy-cloud-providers/azure/auth/azure_auth.go
Introducing the Non-Code Contributor’s Guide
Author: Noah Abrahams (InfoSiftr), Jonas Rosland (VMware), Ihor Dvoretskyi (CNCF)
It was May 2018 in Copenhagen, and the Kubernetes community was enjoying the contributor summit at KubeCon/CloudNativeCon, complete with the first run of the New Contributor Workshop. As a time of tremendous collaboration between contributors, the topics covered ranged from signing the CLA to deep technical conversations. Along with the vast exchange of information and ideas, however, came continued scrutiny of the topics at hand to ensure that the community was being as inclusive and accommodating as possible. Over that spring week, some of the pieces under the microscope included the many themes being covered, and how they were being presented, but also the overarching characteristics of the people contributing and the skill sets involved. From the discussions and analysis that followed grew the idea that the community was not benefiting as much as it could from the many people who wanted to contribute, but whose strengths were in areas other than writing code.
This all led to an effort called the Non-Code Contributor’s Guide.
Now, it’s important to note that Kubernetes is rare, if not unique, in the open source world, in that it was defined very early on as both a project and a community. While the project itself is focused on the codebase, it is the community of people driving it forward that makes the project successful. The community works together with an explicit set of community values, guiding the day-to-day behavior of contributors whether on GitHub, Slack, Discourse, or sitting together over tea or coffee.
By having a community that values people first, and explicitly values a diversity of people, the Kubernetes project is building a product to serve people with diverse needs. The different backgrounds of the contributors bring different approaches to the problem solving, with different methods of collaboration, and all those different viewpoints ultimately create a better project.
The Non-Code Contributor’s Guide aims to make it easy for anyone to contribute to the Kubernetes project in a way that makes sense for them. This can be in many forms, technical and non-technical, based on the person's knowledge of the project and their available time. Most individuals are not developers, and most of the world’s developers are not paid to fully work on open source projects. Based on this we have started an ever-growing list of possible ways to contribute to the Kubernetes project in a Non-Code way!
Get Involved
Some of the ways that you can contribute to the Kubernetes community without writing a single line of code include:
- Community education, answering questions on Discuss, StackOverflow, and Slack
- Outward facing community work such as hosting meetups and events
- Writing project documentation
- Writing operational manuals, helping users understand how to run Kubernetes
- Helping deliver Kubernetes, as a part of the release team
- Project, program, and product management
- And many more!
The guide to get started with Kubernetes project contribution is documented on GitHub, and as the Non-Code Contributors Guide is a part of that Kubernetes Contributors Guide, it can be found here. As stated earlier, this list is not exhaustive and will continue to be a work in progress.
To date, the typical Non-Code contributions fall into the following categories:
- Roles that are based on skill sets other than “software developer”
- Non-Code contributions in primarily code-based roles
- “Post-Code” roles, that are not code-based, but require knowledge of either the code base or management of the code base
If you, dear reader, have any additional ideas for a Non-Code way to contribute, whether or not it fits in an existing category, the team will always appreciate if you could help us expand the list.
If a contribution of the Non-Code nature appeals to you, please read the Non-Code Contributions document, and then check the Contributor Role Board to see if there are any open positions where your expertise could be best used! If there are no listed open positions that match your skill set, drop on by the #sig-contribex channel on Slack, and we’ll point you in the right direction.
We hope to see you contributing to the Kubernetes community soon!
KubeDirector: The easy way to run complex stateful applications on Kubernetes
Author: Thomas Phelan (BlueData)
KubeDirector is an open source project designed to make it easy to run complex stateful scale-out application clusters on Kubernetes. KubeDirector is built using the custom resource definition (CRD) framework and leverages the native Kubernetes API extensions and design philosophy. This enables transparent integration with Kubernetes user/resource management as well as existing clients and tools.
We recently introduced the KubeDirector project, as part of a broader open source Kubernetes initiative we call BlueK8s. I’m happy to announce that the pre-alpha code for KubeDirector is now available. And in this blog post, I’ll show how it works.
KubeDirector provides the following capabilities:
- The ability to run non-cloud native stateful applications on Kubernetes without modifying the code. In other words, it’s not necessary to decompose these existing applications to fit a microservices design pattern.
- Native support for preserving application-specific configuration and state.
- An application-agnostic deployment pattern, minimizing the time to onboard new stateful applications to Kubernetes.
KubeDirector enables data scientists familiar with data-intensive distributed applications such as Hadoop, Spark, Cassandra, TensorFlow, Caffe2, etc. to run these applications on Kubernetes -- with a minimal learning curve and no need to write GO code. The applications controlled by KubeDirector are defined by some basic metadata and an associated package of configuration artifacts. The application metadata is referred to as a KubeDirectorApp resource.
To understand the components of KubeDirector, clone the repository on GitHub using a command similar to:
git clone http://<userid>@github.com/bluek8s/kubedirector.
The KubeDirectorApp definition for the Spark 2.2.1 application is located
in the file kubedirector/deploy/example_catalog/cr-app-spark221e2.json.
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{
"apiVersion": "kubedirector.bluedata.io/v1alpha1",
"kind": "KubeDirectorApp",
"metadata": {
"name" : "spark221e2"
},
"spec" : {
"systemctlMounts": true,
"config": {
"node_services": [
{
"service_ids": [
"ssh",
"spark",
"spark_master",
"spark_worker"
],
…
The configuration of an application cluster is referred to as a KubeDirectorCluster resource. The
KubeDirectorCluster definition for a sample Spark 2.2.1 cluster is located in the file
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml.
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1"
kind: "KubeDirectorCluster"
metadata:
name: "spark221e2"
spec:
app: spark221e2
roles:
- name: controller
replicas: 1
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: worker
replicas: 2
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: jupyter
…
Running Spark on Kubernetes with KubeDirector
With KubeDirector, it’s easy to run Spark clusters on Kubernetes.
First, verify that Kubernetes (version 1.9 or later) is running, using the command kubectl version
~> kubectl version
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Deploy the KubeDirector service and the example KubeDirectorApp resource definitions with the commands:
cd kubedirector
make deploy
These will start the KubeDirector pod:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
List the installed KubeDirector applications with kubectl get KubeDirectorApp
~> kubectl get KubeDirectorApp
NAME AGE
cassandra311 30m
spark211up 30m
spark221e2 30m
Now you can launch a Spark 2.2.1 cluster using the example KubeDirectorCluster file and the
kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml command.
Verify that the Spark cluster has been started:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-djdwl 1/1 Running 0 19m
spark221e2-controller-zbg4d-0 1/1 Running 0 23m
spark221e2-jupyter-2km7q-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-1 1/1 Running 0 23m
The running services now include the Spark services:
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
Pointing the browser at port 31533 connects to the Spark Master UI:
That’s all there is to it! In fact, in the example above we also deployed a Jupyter notebook along with the Spark cluster.
To start another application (e.g. Cassandra), just specify another KubeDirectorApp file:
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
See the running Cassandra cluster:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
cassandra311-seed-v24r6-0 1/1 Running 0 1m
cassandra311-seed-v24r6-1 1/1 Running 0 1m
cassandra311-worker-rqrhl-0 1/1 Running 0 1m
cassandra311-worker-rqrhl-1 1/1 Running 0 1m
kubedirector-58cf59869-djdwl 1/1 Running 0 1d
spark221e2-controller-tq8d6-0 1/1 Running 0 22m
spark221e2-jupyter-6989v-0 1/1 Running 0 22m
spark221e2-worker-d9892-0 1/1 Running 0 22m
spark221e2-worker-d9892-1 1/1 Running 0 22m
Now you have a Spark cluster (with a Jupyter notebook) and a Cassandra cluster running on Kubernetes.
Use kubectl get service to see the set of services.
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m
svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m
svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m
svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m
svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
Get Involved
KubeDirector is a fully open source, Apache v2 licensed, project – the first of multiple open source projects within a broader initiative we call BlueK8s. The pre-alpha code for KubeDirector has just been released and we would love for you to join the growing community of developers, contributors, and adopters. Follow @BlueK8s on Twitter and get involved through these channels:
- KubeDirector chat room on Slack
- KubeDirector GitHub repo
Building a Network Bootable Server Farm for Kubernetes with LTSP
Author: Andrei Kvapil (WEDOS)

In this post, I'm going to introduce you to a cool technology for Kubernetes, LTSP. It is useful for large baremetal Kubernetes deployments.
You don't need to think about installing an OS and binaries on each node anymore. Why? You can do that automatically through Dockerfile!
You can buy and put 100 new servers into a production environment and get them working immediately - it's really amazing!
Intrigued? Let me walk you through how it works.
Summary
Please note: this is a cool hack, but is not officially supported in Kubernetes.
First, we need to understand how exactly it works.
In short, for all nodes we have prepared the image with the OS, Docker, Kubelet and everything else that you need there. This image with the kernel is building automatically by CI using Dockerfile. End nodes are booting the kernel and OS from this image via the network.
Nodes are using overlays as the root filesystem and after reboot any changes will be lost (like in Docker containers). You have a config-file where you can describe mounts and some initial commands which should be executed during node boot (Example: set root user ssh-key and kubeadm join commands)
Image Preparation Process
We will use LTSP project because it's gives us everything we need to organize the network booting environment. Basically, LTSP is a pack of shell-scripts which makes our life much easier.
LTSP provides a initramfs module, a few helper-scripts, and the configuration system which prepare the system during the early state of boot, before the main init process call.
This is what the image preparation procedure looks like:
- You're deploying the basesystem in the chroot environment.
- Make any needed changes there, install software.
- Run the
ltsp-build-imagecommand
After that, you will get the squashed image from the chroot with all the software inside. Each node will download this image during the boot and use it as the rootfs. For the update node, you can just reboot it. The new squashed image will be downloaded and mounted into the rootfs.
Server Components
The server part of LTSP includes two components in our case:
- TFTP-server - TFTP is the initial protocol, it is used the download the kernel, initramfs and main config - lts.conf.
- NBD-server - NBD protocol is used to distribute the squashed rootfs image to the clients. It is the fastest way, but if you want, it can be replaced by the NFS or AoE protocol.
You should also have:
- DHCP-server - it will distribute the IP-settings and a few specific options to the clients to make it possible for them to boot from our LTSP-server.
Node Booting Process
This is how the node is booting up
- The first time, the node will ask DHCP for IP-settings and
next-server,filenameoptions. - Next, the node will apply settings and download bootloader (pxelinux or grub)
- Bootloader will download and read config with the kernel and initramfs image.
- Then bootloader will download the kernel and initramfs and execute it with specific cmdline options.
- During the boot, initramfs modules will handle options from cmdline and do some actions like connect NBD-device, prepare overlay rootfs, etc.
- Afterwards it will call the ltsp-init system instead of the normal init.
- ltsp-init scripts will prepare the system on the earlier stage, before the main init will be called. Basically it applies the setting from lts.conf (main config): write fstab and rc.local entries etc.
- Call the main init (systemd) which is booting the configured system as usual, mounts shares from fstab, start targets and services, executes commands from rc.local file.
- In the end you have a fully configured and booted system ready for further operations.
Preparing the Server
As I said before, I'm preparing the LTSP-server with the squashed image automatically using Dockerfile. This method is quite good because you have all steps described in your git repository. You have versioning, branches, CI and everything that you used to use for preparing your usual Docker projects.
Otherwise, you can deploy the LTSP server manually by executing all steps by hand. This is a good practice for learning and understanding the basic principles.
Just repeat all the steps listed here by hand, just to try to install LTSP without Dockerfile.
Used Patches List
LTSP still has some issues which authors don’t want to apply, yet. However LTSP is easy customizable so I prepared a few patches for myself and will share them here.
I’ll create a fork if the community will warmly accept my solution.
- feature-grub.diff LTSP does not support EFI by default, so I've prepared a patch which adds GRUB2 with EFI support.
- feature_preinit.diff This patch adds a PREINIT option to lts.conf, which allows you to run custom commands before the main init call. It may be useful to modify the systemd units and configure the network. It's remarkable that all environment variables from the boot environment are saved and you can use them in your scripts.
- feature_initramfs_params_from_lts_conf.diff Solves a problem with NBD_TO_RAM option, after this patch you can specify it on lts.conf inside chroot. (not in tftp directory)
- nbd-server-wrapper.sh This is not a patch but a special wrapper script which allows you to run NBD-server in the foreground. It is useful if you want to run it inside a Docker container.
Dockerfile Stages
We will use stage building in our Dockerfile to leave only the needed parts in our Docker image. The unused parts will be removed from the final image.
ltsp-base
(install basic LTSP server software)
|
|---basesystem
| (prepare chroot with main software and kernel)
| |
| |---builder
| | (build additional software from sources, if needed)
| |
| '---ltsp-image
| (install additional software, docker, kubelet and build squashed image)
|
'---final-stage
(copy squashed image, kernel and initramfs into first stage)
Stage 1: ltsp-base
Let's start writing our Dockerfile. This is the first part:
FROM ubuntu:16.04 as ltsp-base
ADD nbd-server-wrapper.sh /bin/
ADD /patches/feature-grub.diff /patches/feature-grub.diff
RUN apt-get -y update \
&& apt-get -y install \
ltsp-server \
tftpd-hpa \
nbd-server \
grub-common \
grub-pc-bin \
grub-efi-amd64-bin \
curl \
patch \
&& sed -i 's|in_target mount|in_target_nofail mount|' \
/usr/share/debootstrap/functions \
# Add EFI support and Grub bootloader (#1745251)
&& patch -p2 -d /usr/sbin < /patches/feature-grub.diff \
&& rm -rf /var/lib/apt/lists \
&& apt-get clean
At this stage our Docker image has already been installed:
- NBD-server
- TFTP-server
- LTSP-scripts with grub bootloader support (for EFI)
Stage 2: basesystem
In this stage we will prepare a chroot environment with basesystem, and install basic software with the kernel.
We will use the classic debootstrap instead of ltsp-build-client to prepare the base image, because ltsp-build-client will install GUI and few other things which we don't need for the server deployment.
FROM ltsp-base as basesystem
ARG DEBIAN_FRONTEND=noninteractive
# Prepare base system
RUN debootstrap --arch amd64 xenial /opt/ltsp/amd64
# Install updates
RUN echo "\
deb http://archive.ubuntu.com/ubuntu xenial main restricted universe multiverse\n\
deb http://archive.ubuntu.com/ubuntu xenial-updates main restricted universe multiverse\n\
deb http://archive.ubuntu.com/ubuntu xenial-security main restricted universe multiverse" \
> /opt/ltsp/amd64/etc/apt/sources.list \
&& ltsp-chroot apt-get -y update \
&& ltsp-chroot apt-get -y upgrade
# Installing LTSP-packages
RUN ltsp-chroot apt-get -y install ltsp-client-core
# Apply initramfs patches
# 1: Read params from /etc/lts.conf during the boot (#1680490)
# 2: Add support for PREINIT variables in lts.conf
ADD /patches /patches
RUN patch -p4 -d /opt/ltsp/amd64/usr/share < /patches/feature_initramfs_params_from_lts_conf.diff \
&& patch -p3 -d /opt/ltsp/amd64/usr/share < /patches/feature_preinit.diff
# Write new local client config for boot NBD image to ram:
RUN echo "[Default]\nLTSP_NBD_TO_RAM = true" \
> /opt/ltsp/amd64/etc/lts.conf
# Install packages
RUN echo 'APT::Install-Recommends "0";\nAPT::Install-Suggests "0";' \
>> /opt/ltsp/amd64/etc/apt/apt.conf.d/01norecommend \
&& ltsp-chroot apt-get -y install \
software-properties-common \
apt-transport-https \
ca-certificates \
ssh \
bridge-utils \
pv \
jq \
vlan \
bash-completion \
screen \
vim \
mc \
lm-sensors \
htop \
jnettop \
rsync \
curl \
wget \
tcpdump \
arping \
apparmor-utils \
nfs-common \
telnet \
sysstat \
ipvsadm \
ipset \
make
# Install kernel
RUN ltsp-chroot apt-get -y install linux-generic-hwe-16.04
Note that you may encounter problems with some packages, such as lvm2.
They have not fully optimized for installing in an unprivileged chroot.
Their postinstall scripts try to call some privileged commands which can fail with errors and block the package installation.
Solution:
- Some of them can be installed before the kernel without any problems (like
lvm2) - But for some of them you will need to use this workaround to install without the postinstall script.
Stage 3: builder
Now we can build all the necessary software and kernel modules. It's really cool that you can do that automatically in this stage. You can skip this stage if you have nothing to do here.
Here is example for install latest MLNX_EN driver:
FROM basesystem as builder
# Set cpuinfo (for building from sources)
RUN cp /proc/cpuinfo /opt/ltsp/amd64/proc/cpuinfo
# Compile Mellanox driver
RUN ltsp-chroot sh -cx \
' VERSION=4.3-1.0.1.0-ubuntu16.04-x86_64 \
&& curl -L http://www.mellanox.com/downloads/ofed/MLNX_EN-${VERSION%%-ubuntu*}/mlnx-en-${VERSION}.tgz \
| tar xzf - \
&& export \
DRIVER_DIR="$(ls -1 | grep "MLNX_OFED_LINUX-\|mlnx-en-")" \
KERNEL="$(ls -1t /lib/modules/ | head -n1)" \
&& cd "$DRIVER_DIR" \
&& ./*install --kernel "$KERNEL" --without-dkms --add-kernel-support \
&& cd - \
&& rm -rf "$DRIVER_DIR" /tmp/mlnx-en* /tmp/ofed*'
# Save kernel modules
RUN ltsp-chroot sh -c \
' export KERNEL="$(ls -1t /usr/src/ | grep -m1 "^linux-headers" | sed "s/^linux-headers-//g")" \
&& tar cpzf /modules.tar.gz /lib/modules/${KERNEL}/updates'
Stage 4: ltsp-image
In this stage we will install what we built in the previous step:
FROM basesystem as ltsp-image
# Retrieve kernel modules
COPY --from=builder /opt/ltsp/amd64/modules.tar.gz /opt/ltsp/amd64/modules.tar.gz
# Install kernel modules
RUN ltsp-chroot sh -c \
' export KERNEL="$(ls -1t /usr/src/ | grep -m1 "^linux-headers" | sed "s/^linux-headers-//g")" \
&& tar xpzf /modules.tar.gz \
&& depmod -a "${KERNEL}" \
&& rm -f /modules.tar.gz'
Then do some additional changes to finalize our ltsp-image:
# Install docker
RUN ltsp-chroot sh -c \
' curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - \
&& echo "deb https://download.docker.com/linux/ubuntu xenial stable" \
> /etc/apt/sources.list.d/docker.list \
&& apt-get -y update \
&& apt-get -y install \
docker-ce=$(apt-cache madison docker-ce | grep 18.06 | head -1 | awk "{print $ 3}")'
# Configure docker options
RUN DOCKER_OPTS="$(echo \
--storage-driver=overlay2 \
--iptables=false \
--ip-masq=false \
--log-driver=json-file \
--log-opt=max-size=10m \
--log-opt=max-file=5 \
)" \
&& sed "/^ExecStart=/ s|$| $DOCKER_OPTS|g" \
/opt/ltsp/amd64/lib/systemd/system/docker.service \
> /opt/ltsp/amd64/etc/systemd/system/docker.service
# Install kubeadm, kubelet and kubectl
RUN ltsp-chroot sh -c \
' curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - \
&& echo "deb http://apt.kubernetes.io/ kubernetes-xenial main" \
> /etc/apt/sources.list.d/kubernetes.list \
&& apt-get -y update \
&& apt-get -y install kubelet kubeadm kubectl cri-tools'
# Disable automatic updates
RUN rm -f /opt/ltsp/amd64/etc/apt/apt.conf.d/20auto-upgrades
# Disable apparmor profiles
RUN ltsp-chroot find /etc/apparmor.d \
-maxdepth 1 \
-type f \
-name "sbin.*" \
-o -name "usr.*" \
-exec ln -sf "{}" /etc/apparmor.d/disable/ \;
# Write kernel cmdline options
RUN KERNEL_OPTIONS="$(echo \
init=/sbin/init-ltsp \
forcepae \
console=tty1 \
console=ttyS0,9600n8 \
nvme_core.default_ps_max_latency_us=0 \
)" \
&& sed -i "/^CMDLINE_LINUX_DEFAULT=/ s|=.*|=\"${KERNEL_OPTIONS}\"|" \
"/opt/ltsp/amd64/etc/ltsp/update-kernels.conf"
Then we will make the squashed image from our chroot:
# Cleanup caches
RUN rm -rf /opt/ltsp/amd64/var/lib/apt/lists \
&& ltsp-chroot apt-get clean
# Build squashed image
RUN ltsp-update-image
Stage 5: Final Stage
In the final stage we will save only our squashed image and kernels with initramfs.
FROM ltsp-base
COPY --from=ltsp-image /opt/ltsp/images /opt/ltsp/images
COPY --from=ltsp-image /etc/nbd-server/conf.d /etc/nbd-server/conf.d
COPY --from=ltsp-image /var/lib/tftpboot /var/lib/tftpboot
Ok, now we have docker image which includes:
- TFTP-server
- NBD-server
- configured bootloader
- kernel with initramfs
- squashed rootfs image
Usage
OK, now when our docker-image with LTSP-server, kernel, initramfs and squashed rootfs fully prepared we can run the deployment with it.
We can do that as usual, but one more thing is networking. Unfortunately, we can't use the standard Kubernetes service abstraction for our deployment, because TFTP can't work behind the NAT. During the boot, our nodes are not part of Kubernetes cluster and they requires ExternalIP, but Kubernetes always enables NAT for ExternalIPs, and there is no way to override this behavior.
For now I have two ways for avoid this: use hostNetwork: true or use pipework. The second option will also provide you redundancy because, in case of failure, the IP will be moved with the Pod to another node. Unfortunately, pipework is not native and a less secure method.
If you have some better option for that please let me know.
Here is example for deployment with hostNetwork:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: ltsp-server
labels:
app: ltsp-server
spec:
selector:
matchLabels:
name: ltsp-server
replicas: 1
template:
metadata:
labels:
name: ltsp-server
spec:
hostNetwork: true
containers:
- name: tftpd
image: registry.example.org/example/ltsp:latest
command: [ "/usr/sbin/in.tftpd", "-L", "-u", "tftp", "-a", ":69", "-s", "/var/lib/tftpboot" ]
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "cd /var/lib/tftpboot/ltsp/amd64; ln -sf config/lts.conf ." ]
volumeMounts:
- name: config
mountPath: "/var/lib/tftpboot/ltsp/amd64/config"
- name: nbd-server
image: registry.example.org/example/ltsp:latest
command: [ "/bin/nbd-server-wrapper.sh" ]
volumes:
- name: config
configMap:
name: ltsp-config
As you can see it also requires configmap with lts.conf file. Here is example part from mine:
apiVersion: v1
kind: ConfigMap
metadata:
name: ltsp-config
data:
lts.conf: |
[default]
KEEP_SYSTEM_SERVICES = "ssh ureadahead dbus-org.freedesktop.login1 systemd-logind polkitd cgmanager ufw rpcbind nfs-kernel-server"
PREINIT_00_TIME = "ln -sf /usr/share/zoneinfo/Europe/Prague /etc/localtime"
PREINIT_01_FIX_HOSTNAME = "sed -i '/^127.0.0.2/d' /etc/hosts"
PREINIT_02_DOCKER_OPTIONS = "sed -i 's|^ExecStart=.*|ExecStart=/usr/bin/dockerd -H fd:// --storage-driver overlay2 --iptables=false --ip-masq=false --log-driver=json-file --log-opt=max-size=10m --log-opt=max-file=5|' /etc/systemd/system/docker.service"
FSTAB_01_SSH = "/dev/data/ssh /etc/ssh ext4 nofail,noatime,nodiratime 0 0"
FSTAB_02_JOURNALD = "/dev/data/journal /var/log/journal ext4 nofail,noatime,nodiratime 0 0"
FSTAB_03_DOCKER = "/dev/data/docker /var/lib/docker ext4 nofail,noatime,nodiratime 0 0"
# Each command will stop script execution when fail
RCFILE_01_SSH_SERVER = "cp /rofs/etc/ssh/*_config /etc/ssh; ssh-keygen -A"
RCFILE_02_SSH_CLIENT = "mkdir -p /root/.ssh/; echo 'ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDBSLYRaORL2znr1V4a3rjDn3HDHn2CsvUNK1nv8+CctoICtJOPXl6zQycI9KXNhANfJpc6iQG1ZPZUR74IiNhNIKvOpnNRPyLZ5opm01MVIDIZgi9g0DUks1g5gLV5LKzED8xYKMBmAfXMxh/nsP9KEvxGvTJB3OD+/bBxpliTl5xY3Eu41+VmZqVOz3Yl98+X8cZTgqx2dmsHUk7VKN9OZuCjIZL9MtJCZyOSRbjuo4HFEssotR1mvANyz+BUXkjqv2pEa0I2vGQPk1VDul5TpzGaN3nOfu83URZLJgCrX+8whS1fzMepUYrbEuIWq95esjn0gR6G4J7qlxyguAb9 admin@kubernetes' >> /root/.ssh/authorized_keys"
RCFILE_03_KERNEL_DEBUG = "sysctl -w kernel.unknown_nmi_panic=1 kernel.softlockup_panic=1; modprobe netconsole netconsole=@/vmbr0,@10.9.0.15/"
RCFILE_04_SYSCTL = "sysctl -w fs.file-max=20000000 fs.nr_open=20000000 net.ipv4.neigh.default.gc_thresh1=80000 net.ipv4.neigh.default.gc_thresh2=90000 net.ipv4.neigh.default.gc_thresh3=100000"
RCFILE_05_FORWARD = "echo 1 > /proc/sys/net/ipv4/ip_forward"
RCFILE_06_MODULES = "modprobe br_netfilter"
RCFILE_07_JOIN_K8S = "kubeadm join --token 2a4576.504356e45fa3d365 10.9.0.20:6443 --discovery-token-ca-cert-hash sha256:e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"
- KEEP_SYSTEM_SERVICES - during the boot, LTSP automatically removes some services, this variable is needed to prevent this behavior.
- **PREINIT_*** - commands listed here will be executed before systemd runs (this function was added by the feature_preinit.diff patch)
- **FSTAB_*** - entries written here will be added to the
/etc/fstabfile. As you can see, I use thenofailoption, that means that if a partition doesn't exist, it will continue to boot without error. If you have fully diskless nodes you can remove the FSTAB settings or configure the remote filesystem there. - **RCFILE_*** - those commands will be written to
rc.localfile, which will be called by systemd during the boot. Here I load the kernel modules and add some sysctl tunes, then call thekubeadm joincommand, which adds my node to the Kubernetes cluster.
You can get more details on all the variables used from lts.conf manpage.
Now you can configure your DHCP. Basically you should set the next-server and filename options.
I use ISC-DHCP server, and here is an example dhcpd.conf:
shared-network ltsp-netowrk {
subnet 10.9.0.0 netmask 255.255.0.0 {
authoritative;
default-lease-time -1;
max-lease-time -1;
option domain-name "example.org";
option domain-name-servers 10.9.0.1;
option routers 10.9.0.1;
next-server ltsp-1; # write LTSP-server hostname here
if option architecture = 00:07 {
filename "/ltsp/amd64/grub/x86_64-efi/core.efi";
} else {
filename "/ltsp/amd64/grub/i386-pc/core.0";
}
range 10.9.200.0 10.9.250.254;
}
You can start from this, but what about me, I have multiple LTSP-servers and I configure leases statically for each node via the Ansible playbook.
Try to run your first node. If everything was right, you will have a running system there. The node also will be added to your Kubernetes cluster.
Now you can try to make your own changes.
If you need something more, note that LTSP can be easily changed to meet your needs. Feel free to look into the source code and you can find many answers there.
UPD: Many people asking me: Why not simple use CoreOS and Ignition?
I can answer. The main feature here is image preparation process, not configuration. In case with LTSP you have classic Ubuntu system, and everything that can be installed on Ubuntu it can also be written here in the Dockerfile. In case CoreOS you have no so many freedom and you can’t easily add custom kernel modules and packages at the build stage of the boot image.
Health checking gRPC servers on Kubernetes
Author: Ahmet Alp Balkan (Google)
Update (December 2021): Kubernetes now has built-in gRPC health probes starting in v1.23. To learn more, see Configure Liveness, Readiness and Startup Probes. This article was originally written about an external tool to achieve the same task.
gRPC is on its way to becoming the lingua franca for communication between cloud-native microservices. If you are deploying gRPC applications to Kubernetes today, you may be wondering about the best way to configure health checks. In this article, we will talk about grpc-health-probe, a Kubernetes-native way to health check gRPC apps.
If you're unfamiliar, Kubernetes health checks (liveness and readiness probes) is what's keeping your applications available while you're sleeping. They detect unresponsive pods, mark them unhealthy, and cause these pods to be restarted or rescheduled.
Kubernetes does not support gRPC health checks natively. This leaves the gRPC developers with the following three approaches when they deploy to Kubernetes:
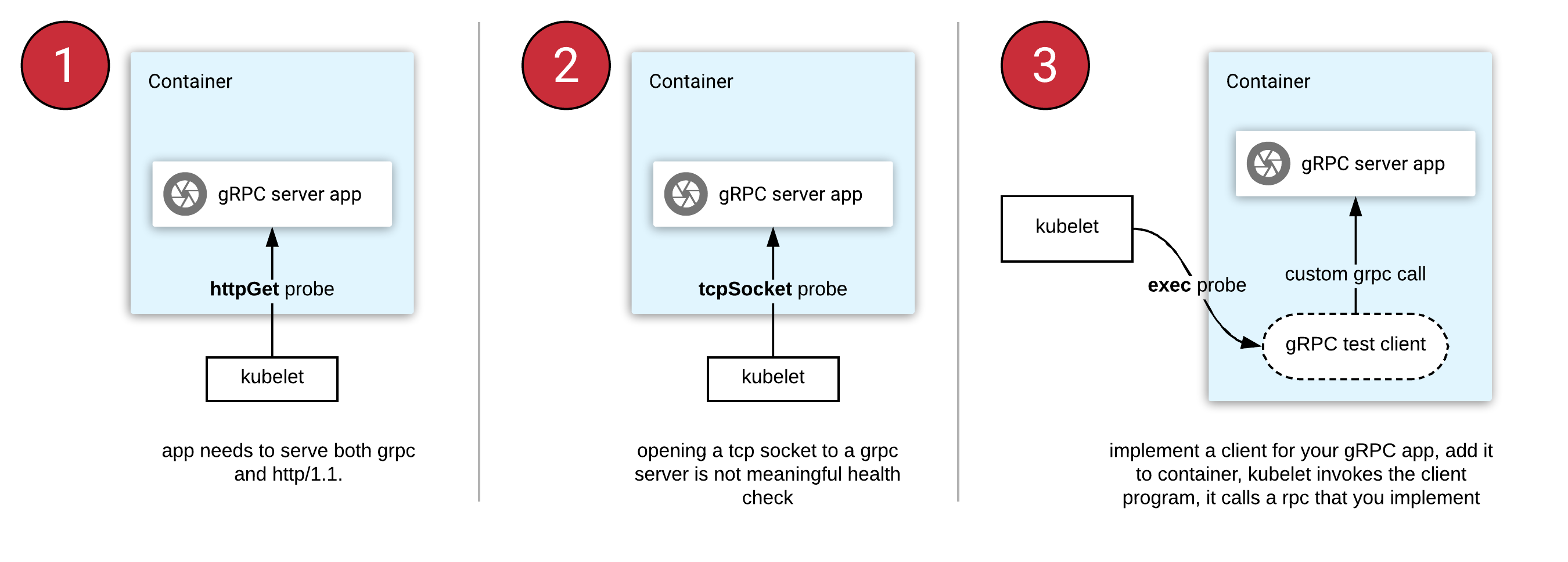
- httpGet probe: Cannot be natively used with gRPC. You need to refactor your app to serve both gRPC and HTTP/1.1 protocols (on different port numbers).
- tcpSocket probe: Opening a socket to gRPC server is not meaningful, since it cannot read the response body.
- exec probe: This invokes a program in a container's ecosystem periodically. In the case of gRPC, this means you implement a health RPC yourself, then write and ship a client tool with your container.
Can we do better? Absolutely.
Introducing “grpc-health-probe”
To standardize the "exec probe" approach mentioned above, we need:
- a standard health check "protocol" that can be implemented in any gRPC server easily.
- a standard health check "tool" that can query the health protocol easily.
Thankfully, gRPC has a standard health checking protocol. It can be used easily from any language. Generated code and the utilities for setting the health status are shipped in nearly all language implementations of gRPC.
If you
implement
this health check protocol in your gRPC apps, you can then use a standard/common
tool to invoke this Check() method to determine server status.
The next thing you need is the "standard tool", and it's the grpc-health-probe.

With this tool, you can use the same health check configuration in all your gRPC applications. This approach requires you to:
- Find the gRPC "health" module in your favorite language and start using it (example Go library).
- Ship the grpc_health_probe binary in your container.
- Configure Kubernetes "exec" probe to invoke the "grpc_health_probe" tool in the container.
In this case, executing "grpc_health_probe" will call your gRPC server over
localhost, since they are in the same pod.
What's next
grpc-health-probe project is still in its early days and it needs your feedback. It supports a variety of features like communicating with TLS servers and configurable connection/RPC timeouts.
If you are running a gRPC server on Kubernetes today, try using the gRPC Health Protocol and try the grpc-health-probe in your deployments, and give feedback.
Further reading
- Protocol: GRPC Health Checking Protocol (health.proto)
- Documentation: Kubernetes liveness and readiness probes
- Article: Advanced Kubernetes Health Check Patterns
Kubernetes 1.12: Kubelet TLS Bootstrap and Azure Virtual Machine Scale Sets (VMSS) Move to General Availability
Author: The 1.12 Release Team
We’re pleased to announce the delivery of Kubernetes 1.12, our third release of 2018!
Today’s release continues to focus on internal improvements and graduating features to stable in Kubernetes. This newest version graduates key features such as security and Azure. Notable additions in this release include two highly-anticipated features graduating to general availability: Kubelet TLS Bootstrap and Support for Azure Virtual Machine Scale Sets (VMSS).
These new features mean increased security, availability, resiliency, and ease of use to get production applications to market faster. The release also signifies the increasing maturation and sophistication of Kubernetes on the developer side.
Let’s dive into the key features of this release:
Introducing General Availability of Kubelet TLS Bootstrap
We’re excited to announce General Availability (GA) of Kubelet TLS Bootstrap. In Kubernetes 1.4, we introduced an API for requesting certificates from a cluster-level Certificate Authority (CA). The original intent of this API is to enable provisioning of TLS client certificates for kubelets. This feature allows for a kubelet to bootstrap itself into a TLS-secured cluster. Most importantly, it automates the provision and distribution of signed certificates.
Before, when a kubelet ran for the first time, it had to be given client credentials in an out-of-band process during cluster startup. The burden was on the operator to provision these credentials. Because this task was so onerous to manually execute and complex to automate, many operators deployed clusters with a single credential and single identity for all kubelets. These setups prevented deployment of node lockdown features like the Node authorizer and the NodeRestriction admission controller.
To alleviate this, SIG Auth introduced a way for kubelet to generate a private key and a CSR for submission to a cluster-level certificate signing process. The v1 (GA) designation indicates production hardening and readiness, and comes with the guarantee of long-term backwards compatibility.
Alongside this, Kubelet server certificate bootstrap and rotation is moving to beta. Currently, when a kubelet first starts, it generates a self-signed certificate/key pair that is used for accepting incoming TLS connections. This feature introduces a process for generating a key locally and then issuing a Certificate Signing Request to the cluster API server to get an associated certificate signed by the cluster’s root certificate authority. Also, as certificates approach expiration, the same mechanism will be used to request an updated certificate.
Support for Azure Virtual Machine Scale Sets (VMSS) and Cluster-Autoscaler is Now Stable
Azure Virtual Machine Scale Sets (VMSS) allow you to create and manage a homogenous VM pool that can automatically increase or decrease based on demand or a set schedule. This enables you to easily manage, scale, and load balance multiple VMs to provide high availability and application resiliency, ideal for large-scale applications that can run as Kubernetes workloads.
With this new stable feature, Kubernetes supports the scaling of containerized applications with Azure VMSS, including the ability to integrate it with cluster-autoscaler to automatically adjust the size of the Kubernetes clusters based on the same conditions.
Additional Notable Feature Updates
RuntimeClass is a new cluster-scoped resource that surfaces container runtime properties to the control plane being released as an alpha feature.
Snapshot / restore functionality for Kubernetes and CSI is being introduced as an alpha feature. This provides standardized APIs design (CRDs) and adds PV snapshot/restore support for CSI volume drivers.
Topology aware dynamic provisioning is now in beta, meaning storage resources can now understand where they live. This also includes beta support to AWS EBS and GCE PD.
Configurable pod process namespace sharing is moving to beta, meaning users can configure containers within a pod to share a common PID namespace by setting an option in the PodSpec.
Taint node by condition is now in beta, meaning users have the ability to represent node conditions that block scheduling by using taints.
Arbitrary / Custom Metrics in the Horizontal Pod Autoscaler is moving to a second beta to test some additional feature enhancements. This reworked Horizontal Pod Autoscaler functionality includes support for custom metrics and status conditions.
Improvements that will allow the Horizontal Pod Autoscaler to reach proper size faster are moving to beta.
Vertical Scaling of Pods is now in beta, which makes it possible to vary the resource limits on a pod over its lifetime. In particular, this is valuable for pets (i.e., pods that are very costly to destroy and re-create).
Encryption at rest via KMS is now in beta. This adds multiple encryption providers, including Google Cloud KMS, Azure Key Vault, AWS KMS, and Hashicorp Vault, that will encrypt data as it is stored to etcd.
Availability
Kubernetes 1.12 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials. You can also install 1.12 using Kubeadm.
5 Day Features Blog Series
If you’re interested in exploring these features more in depth, check back next week for our 5 Days of Kubernetes series where we’ll highlight detailed walkthroughs of the following features:
- Day 1 - Kubelet TLS Bootstrap
- Day 2 - Support for Azure Virtual Machine Scale Sets (VMSS) and Cluster-Autoscaler
- Day 3 - Snapshots Functionality
- Day 4 - RuntimeClass
- Day 5 - Topology Resources
Release team
This release is made possible through the effort of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Tim Pepper, Orchestration & Containers Lead, at VMware Open Source Technology Center. The 36 individuals on the release team coordinate many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has over 22,000 individual contributors to date and an active community of more than 45,000 people.
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. On average, 259 different companies and over 1,400 individuals contribute to Kubernetes each month. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
User Highlights
Established, global organizations are using Kubernetes in production at massive scale. Recently published user stories from the community include:
- Ygrene, a PACE (Property Assessed Clean Energy) financing company, is using cloud native to bring security and scalability to the finance industry, cutting deployment times down to five minutes with Kubernetes.
- Sling TV, a live TV streaming service, uses Kubernetes to enable their hybrid cloud strategy and deliver a high-quality service for their customers.
- ING, a Dutch multinational banking and financial services corporation, moved to Kubernetes with the intent to eventually be able to go from idea to production within 48 hours.
- Pinterest, a web and mobile application company that is running on 1,000 microservices and hundreds of thousands of data jobs, moved to Kubernetes to build on-demand scaling and simply the deployment process.
- Pearson, a global education company serving 75 million learners, is using Kubernetes to transform the way that educational content is delivered online and has saved 15-20% in developer productivity.
Is Kubernetes helping your team? Share your story with the community.
Ecosystem Updates
- CNCF recently released the findings of their bi-annual CNCF survey, finding that the use of cloud native technologies in production has grown over 200% within the last six months.
- CNCF expanded its certification offerings to include a Certified Kubernetes Application Developer exam. The CKAD exam certifies an individual's ability to design, build, configure, and expose cloud native applications for Kubernetes. More information can be found here.
- CNCF added a new partner category, Kubernetes Training Partners (KTP). KTPs are a tier of vetted training providers who have deep experience in cloud native technology training. View partners and learn more here.
- CNCF also offers online training that teaches the skills needed to create and configure a real-world Kubernetes cluster.
- Kubernetes documentation now features user journeys: specific pathways for learning based on who readers are and what readers want to do. Learning Kubernetes is easier than ever for beginners, and more experienced users can find task journeys specific to cluster admins and application developers.
KubeCon
The world’s largest Kubernetes gathering, KubeCon + CloudNativeCon is coming to Shanghai from November 13-15, 2018 and Seattle from December 10-13, 2018. This conference will feature technical sessions, case studies, developer deep dives, salons and more! Register today!
Webinar
Join members of the Kubernetes 1.12 release team on November 6th at 10am PDT to learn about the major features in this release. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
Thank you for your continued feedback and support.
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Chat with the community on Slack
- Share your Kubernetes story
Hands On With Linkerd 2.0
Author: Thomas Rampelberg (Buoyant)
Linkerd 2.0 was recently announced as generally available (GA), signaling its readiness for production use. In this tutorial, we’ll walk you through how to get Linkerd 2.0 up and running on your Kubernetes cluster in a matter seconds.
But first, what is Linkerd and why should you care? Linkerd is a service sidecar that augments a Kubernetes service, providing zero-config dashboards and UNIX-style CLI tools for runtime debugging, diagnostics, and reliability. Linkerd is also a service mesh, applied to multiple (or all) services in a cluster to provide a uniform layer of telemetry, security, and control across them.
Linkerd works by installing ultralight proxies into each pod of a service. These proxies report telemetry data to, and receive signals from, a control plane. This means that using Linkerd doesn’t require any code changes, and can even be installed live on a running service. Linkerd is fully open source, Apache v2 licensed, and is hosted by the Cloud Native Computing Foundation (just like Kubernetes itself!)
Without further ado, let’s see just how quickly you can get Linkerd running on your Kubernetes cluster. In this tutorial, we’ll walk you through how to deploy Linkerd on any Kubernetes 1.9+ cluster and how to use it to debug failures in a sample gRPC application.
Step 1: Install the demo app 🚀
Before we install Linkerd, let’s start by installing a basic gRPC demo application called Emojivoto onto your Kubernetes cluster. To install Emojivoto, run:
curl https://run.linkerd.io/emojivoto.yml | kubectl apply -f -
This command downloads the Kubernetes manifest for Emojivoto, and uses kubectl to apply it to your Kubernetes cluster. Emojivoto is comprised of several services that run in the “emojivoto” namespace. You can see the services by running:
kubectl get -n emojivoto deployments
You can also see the app live by running
minikube -n emojivoto service web-svc --url # if you’re on minikube
… or:
kubectl get svc web-svc -n emojivoto -o jsonpath="{.status.loadBalancer.ingress[0].*}" #
… if you’re somewhere else
Click around. You might notice that some parts of the application are broken! If you were to inspect your handly local Kubernetes dashboard, you wouldn’t see very much interesting---as far as Kubernetes is concerned, the app is running just fine. This is a very common situation! Kubernetes understands whether your pods are running, but not whether they are responding properly.
In the next few steps, we’ll walk you through how to use Linkerd to diagnose the problem.
Step 2: Install Linkerd’s CLI
We’ll start by installing Linkerd’s command-line interface (CLI) onto your local machine. Visit the Linkerd releases page, or simply run:
curl -sL https://run.linkerd.io/install | sh
Once installed, add the linkerd command to your path with:
export PATH=$PATH:$HOME/.linkerd2/bin
You should now be able to run the command linkerd version, which should display:
Client version: v2.0
Server version: unavailable
“Server version: unavailable” means that we need to add Linkerd’s control plane to the cluster, which we’ll do next. But first, let’s validate that your cluster is prepared for Linkerd by running:
linkerd check --pre
This handy command will report any problems that will interfere with your ability to install Linkerd. Hopefully everything looks OK and you’re ready to move on to the next step.
Step 3: Install Linkerd’s control plane onto the cluster
In this step, we’ll install Linkerd’s lightweight control plane into its own namespace (“linkerd”) on your cluster. To do this, run:
linkerd install | kubectl apply -f -
This command generates a Kubernetes manifest and uses kubectl command to apply it to your Kubernetes cluster. (Feel free to inspect the manifest before you apply it.)
(Note: if your Kubernetes cluster is on GKE with RBAC enabled, you’ll need an extra step: you must grant a ClusterRole of cluster-admin to your Google Cloud account first, in order to install certain telemetry features in the control plane. To do that, run: kubectl create clusterrolebinding cluster-admin-binding-$USER --clusterrole=cluster-admin --user=$(gcloud config get-value account).)
Depending on the speed of your internet connection, it may take a minute or two for your Kubernetes cluster to pull the Linkerd images. While that’s happening, we can validate that everything’s happening correctly by running:
linkerd check
This command will patiently wait until Linkerd has been installed and is running.
Finally, we’re ready to view Linkerd’s dashboard! Just run:
linkerd dashboard
If you see something like below, Linkerd is now running on your cluster. 🎉
Step 4: Add Linkerd to the web service
At this point we have the Linkerd control plane installed in the “linkerd” namespace, and we have our emojivoto demo app installed in the “emojivoto” namespace. But we haven’t actually added Linkerd to our service yet. So let’s do that.
In this example, let’s pretend we are the owners of the “web” service. Other services, like “emoji” and “voting”, are owned by other teams--so we don’t want to touch them.
There are a couple ways to add Linkerd to our service. For demo purposes, the easiest is to do something like this:
kubectl get -n emojivoto deploy/web -o yaml | linkerd inject - | kubectl apply -f -
This command retrieves the manifest of the “web” service from Kubernetes, runs this manifest through linkerd inject, and finally reapplies it to the Kubernetes cluster. The linkerd inject command augments the manifest to include Linkerd’s data plane proxies. As with linkerd install, linkerd inject is a pure text operation, meaning that you can inspect the input and output before you use it. Since “web” is a Deployment, Kubernetes is kind enough to slowly roll the service one pod at a time--meaning that “web” can be serving traffic live while we add Linkerd to it!
We now have a service sidecar running on the “web” service!
Step 5: Debugging for Fun and for Profit
Congratulations! You now have a full gRPC application running on your Kubernetes cluster with Linkerd installed on the “web” service. Of course, that application is failing when you use it--so now let’s use Linkerd to track down those errors.
If you glance at the Linkerd dashboard (the linkerd dashboard command), you should see all services in the “emojivoto” namespace show up. Since “web” has the Linkerd service sidecar installed on it, you’ll also see success rate, requests per second, and latency percentiles show up.
That’s pretty neat, but the first thing you might notice is that success rate is well below 100%! Click on “web” and let’s dig in.
You should now be looking at the Deployment page for the web service. The first thing you’ll see here is that web is taking traffic from vote-bot (a service included in the Emojivoto manifest to continually generate a low level of live traffic), and has two outgoing dependencies, emoji and voting.

The emoji service is operating at 100%, but the voting service is failing! A failure in a dependent service may be exactly what’s causing the errors that web is returning.
Let’s scroll a little further down the page, we’ll see a live list of all traffic endpoints that “web” is receiving. This is interesting:
There are two calls that are not at 100%: the first is vote-bot’s call the “/api/vote” endpoint. The second is the “VotePoop” call from the web service to the voting service. Very interesting! Since /api/vote is an incoming call, and “/VotePoop” is an outgoing call, this is a good clue that the failure of the vote service’s VotePoop endpoint is what’s causing the problem!
Finally, if we click on the “tap” icon for that row in the far right column, we’ll be taken to live list of requests that match this endpoint. This allows us to confirm that the requests are failing (they all have gRPC status code 2, indicating an error).
At this point we have the ammunition we need to talk to the owners of the vote “voting” service. We’ve identified an endpoint on their service that consistently returns an error, and have found no other obvious sources of failures in the system.
We hope you’ve enjoyed this journey through Linkerd 2.0. There is much more for you to explore. For example, everything we did above using the web UI can also be accomplished via pure CLI commands, e.g. linkerd top, linkerd stat, and linkerd tap.
Also, did you notice the little Grafana icon on the very first page we looked at? Linkerd ships with automatic Grafana dashboards for all those metrics, allowing you to view everything you’re seeing in the Linkerd dashboard in a time series format. Check it out!
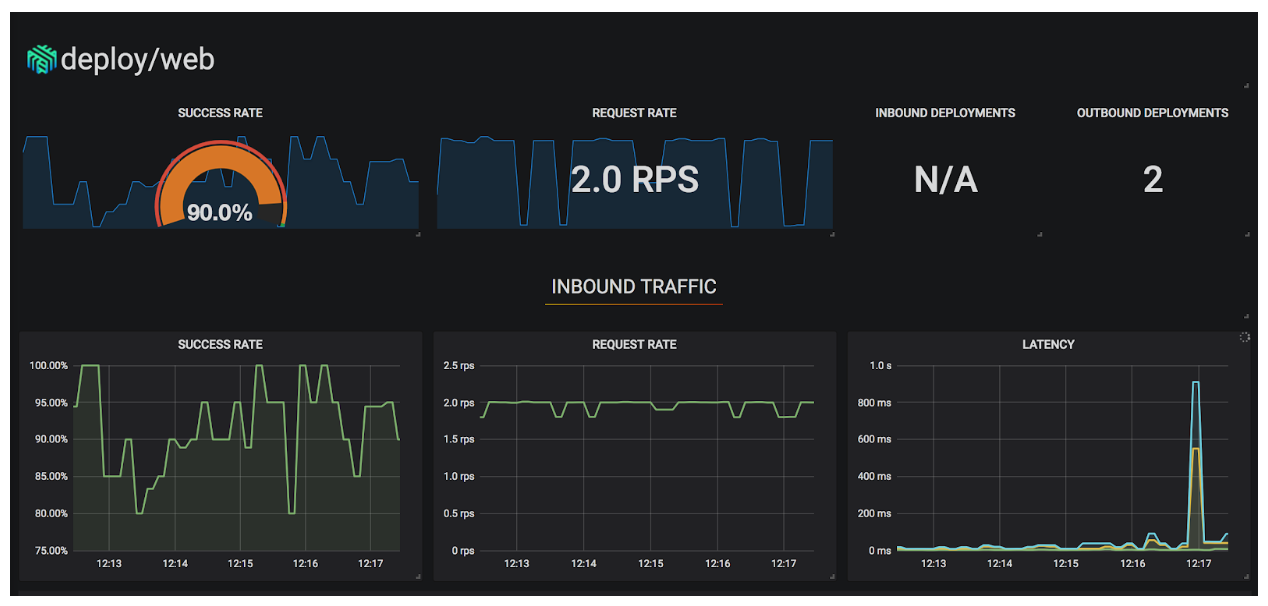
Want more?
In this tutorial, we’ve shown you how to install Linkerd on a cluster, add it as a service sidecar to just one service--while the service is receiving live traffic!---and use it to debug a runtime issue. But this is just the tip of the iceberg. We haven’t even touched any of Linkerd’s reliability or security features!
Linkerd has a thriving community of adopters and contributors, and we’d love for YOU to be a part of it. For more, check out the docs and GitHub repo, join the Linkerd Slack and mailing lists (users, developers, announce), and, of course, follow @linkerd on Twitter! We can’t wait to have you aboard!
2018 Steering Committee Election Cycle Kicks Off
Author: Paris Pittman (Google), Jorge Castro (Heptio), Ihor Dvoretskyi (CNCF)
Having a clear, definable governance model is crucial for the health of open source projects. For one of the highest velocity projects in the open source world, governance is critical especially for one as large and active as Kubernetes, which is one of the most high-velocity projects in the open source world. A clear structure helps users trust that the project will be nurtured and progress forward. Initially, this structure was laid by the former 7 member bootstrap committee composed of founders and senior contributors with a goal to create the foundational governance building blocks.
The initial charter and establishment of an election process to seat a full Steering Committee was a part of those first building blocks. Last year, the bootstrap committee kicked off the first Kubernetes Steering Committee election which brought forth 6 new members from the community as voted on by contributors. These new members plus the bootstrap committee formed the Steering Committee that we know today. This yearly election cycle will continue to ensure that new representatives get cycled through to add different voices and thoughts on the Kubernetes project strategy.
The committee has worked hard on topics that will streamline the project and how we operate. SIG (Special Interest Group) governance was an overarching recurring theme this year: Kubernetes community is not a monolithic organization, but a huge, distributed community, where Special Interest Groups (SIGs) and Working Groups (WGs) are the atomic community units, that are making Kubernetes so successful from the ground.
Contributors - this is where you come in.
There are three seats up for election this year. The voters guide will get you up to speed on the specifics of this years election including candidate bios as they are updated in real time. The elections process doc will steer you towards eligibility, operations, and the fine print.
- Nominate yourself, someone else, and/or put your support to others.
Want to help chart our course? Interested in governance and community topics? Add your name! The nomination process is optional.
- Vote.
On September 19th, eligible voters will receive an email poll invite conducted by CIVS. The newly elected will be announced at the weekly community meeting on Thursday, October 4th at 5pm UTC.
To those who are running:

Helpful resources
- Steering Committee - who sits on the committee and terms, their projects and meetings info
- Steering Committee Charter - this is a great read if you’re interested in running (or assessing for the best candidates!)
- Election Process
- Voters Guide! - Updated on a rolling basis. This guide will always have the latest information throughout the election cycle. The complete schedule of events and candidate bios will be housed here.
The Machines Can Do the Work, a Story of Kubernetes Testing, CI, and Automating the Contributor Experience
Author: Aaron Crickenberger (Google) and Benjamin Elder (Google)
“Large projects have a lot of less exciting, yet, hard work. We value time spent automating repetitive work more highly than toil. Where that work cannot be automated, it is our culture to recognize and reward all types of contributions. However, heroism is not sustainable.” - Kubernetes Community Values
Like many open source projects, Kubernetes is hosted on GitHub. We felt the barrier to participation would be lowest if the project lived where developers already worked, using tools and processes developers already knew. Thus the project embraced the service fully: it was the basis of our workflow, our issue tracker, our documentation, our blog platform, our team structure, and more.
This strategy worked. It worked so well that the project quickly scaled past its contributors’ capacity as humans. What followed was an incredible journey of automation and innovation. We didn’t just need to rebuild our airplane mid-flight without crashing, we needed to convert it into a rocketship and launch into orbit. We needed machines to do the work.
The Work
Initially, we focused on the fact that we needed to support the sheer volume of tests mandated by a complex distributed system such as Kubernetes. Real world failure scenarios had to be exercised via end-to-end (e2e) tests to ensure proper functionality. Unfortunately, e2e tests were susceptible to flakes (random failures) and took anywhere from an hour to a day to complete.
Further experience revealed other areas where machines could do the work for us:
- PR Workflow
- Did the contributor sign our CLA?
- Did the PR pass tests?
- Is the PR mergeable?
- Did the merge commit pass tests?
- Triage
- Who should be reviewing PRs?
- Is there enough information to route an issue to the right people?
- Is an issue still relevant?
- Project Health
- What is happening in the project?
- What should we be paying attention to?
As we developed automation to improve our situation, we followed a few guiding principles:
- Follow the push/poll control loop patterns that worked well for Kubernetes
- Prefer stateless loosely coupled services that do one thing well
- Prefer empowering the entire community over empowering a few core contributors
- Eat our own dogfood and avoid reinventing wheels
Enter Prow
This led us to create Prow as the central component for our automation. Prow is sort of like an If This, Then That for GitHub events, with a built-in library of commands, plugins, and utilities. We built Prow on top of Kubernetes to free ourselves from worrying about resource management and scheduling, and ensure a more pleasant operational experience.
Prow lets us do things like:
- Allow our community to triage issues/PRs by commenting commands such as “/priority critical-urgent”, “/assign mary” or “/close”
- Auto-label PRs based on how much code they change, or which files they touch
- Age out issues/PRs that have remained inactive for too long
- Auto-merge PRs that meet our PR workflow requirements
- Run CI jobs defined as Knative Builds, Kubernetes Pods, or Jenkins jobs
- Enforce org-wide and per-repo GitHub policies like branch protection and GitHub labels
Prow was initially developed by the engineering productivity team building Google Kubernetes Engine, and is actively contributed to by multiple members of Kubernetes SIG Testing. Prow has been adopted by several other open source projects, including Istio, JetStack, Knative and OpenShift. Getting started with Prow takes a Kubernetes cluster and kubectl apply starter.yaml (running pods on a Kubernetes cluster).
Once we had Prow in place, we began to hit other scaling bottlenecks, and so produced additional tooling to support testing at the scale required by Kubernetes, including:
- Boskos: manages job resources (such as GCP projects) in pools, checking them out for jobs and cleaning them up automatically (with monitoring)
- ghProxy: a reverse proxy HTTP cache optimized for use with the GitHub API, to ensure our token usage doesn’t hit API limits (with monitoring)
- Greenhouse: allows us to use a remote bazel cache to provide faster build and test results for PRs (with monitoring)
- Splice: allows us to test and merge PRs in a batch, ensuring our merge velocity is not limited to our test velocity
- Tide: allows us to merge PRs selected via GitHub queries rather than ordered in a queue, allowing for significantly higher merge velocity in tandem with splice
Scaling Project Health
With workflow automation addressed, we turned our attention to project health. We chose to use Google Cloud Storage (GCS) as our source of truth for all test data, allowing us to lean on established infrastructure, and allowed the community to contribute results. We then built a variety of tools to help individuals and the project as a whole make sense of this data, including:
- Gubernator: display the results and test history for a given PR
- Kettle: transfer data from GCS to a publicly accessible bigquery dataset
- PR dashboard: a workflow-aware dashboard that allows contributors to understand which PRs require attention and why
- Triage: identify common failures that happen across all jobs and tests
- Testgrid: display test results for a given job across all runs, summarize test results across groups of jobs
We approached the Cloud Native Computing Foundation (CNCF) to develop DevStats to glean insights from our GitHub events such as:
- Which prow commands are people most actively using
- PR reviews by contributor over time
- Time spent in each phase of our PR workflow
Into the Beyond
Today, the Kubernetes project spans over 125 repos across five orgs. There are 31 Special Interests Groups and 10 Working Groups coordinating development within the project. In the last year the project has had participation from over 13,800 unique developers on GitHub.
On any given weekday our Prow instance runs over 10,000 CI jobs; from March 2017 to March 2018 it ran 4.3 million jobs. Most of these jobs involve standing up an entire Kubernetes cluster, and exercising it using real world scenarios. They allow us to ensure all supported releases of Kubernetes work across cloud providers, container engines, and networking plugins. They make sure the latest releases of Kubernetes work with various optional features enabled, upgrade safely, meet performance requirements, and work across architectures.
With today’s announcement from CNCF – noting that Google Cloud has begun transferring ownership and management of the Kubernetes project’s cloud resources to CNCF community contributors, we are excited to embark on another journey. One that allows the project infrastructure to be owned and operated by the community of contributors, following the same open governance model that has worked for the rest of the project. Sound exciting to you? Come talk to us at #sig-testing on kubernetes.slack.com.
Want to find out more? Come check out these resources:
Introducing Kubebuilder: an SDK for building Kubernetes APIs using CRDs
Author: Phillip Wittrock (Google), Sunil Arora (Google)
How can we enable applications such as MySQL, Spark and Cassandra to manage themselves just like Kubernetes Deployments and Pods do? How do we configure these applications as their own first class APIs instead of a collection of StatefulSets, Services, and ConfigMaps?
We have been working on a solution and are happy to introduce kubebuilder, a comprehensive development kit for rapidly building and publishing Kubernetes APIs and Controllers using CRDs. Kubebuilder scaffolds projects and API definitions and is built on top of the controller-runtime libraries.
Why Kubebuilder and Kubernetes APIs?
Applications and cluster resources typically require some operational work - whether it is replacing failed replicas with new ones, or scaling replica counts while resharding data. Running the MySQL application may require scheduling backups, reconfiguring replicas after scaling, setting up failure detection and remediation, etc.
With the Kubernetes API model, management logic is embedded directly into an application specific Kubernetes API, e.g. a “MySQL” API. Users then declaratively manage the application through YAML configuration using tools such as kubectl, just like they do for Kubernetes objects. This approach is referred to as an Application Controller, also known as an Operator. Controllers are a powerful technique backing the core Kubernetes APIs that may be used to build many kinds of solutions in addition to Applications; such as Autoscalers, Workload APIs, Configuration APIs, CI/CD systems, and more.
However, while it has been possible for trailblazers to build new Controllers on top of the raw API machinery, doing so has been a DIY “from scratch” experience, requiring developers to learn low level details about how Kubernetes libraries are implemented, handwrite boilerplate code, and wrap their own solutions for integration testing, RBAC configuration, documentation, etc. Kubebuilder makes this experience simple and easy by applying the lessons learned from building the core Kubernetes APIs.
Getting Started Building Application Controllers and Kubernetes APIs
By providing an opinionated and structured solution for creating Controllers and Kubernetes APIs, developers have a working “out of the box” experience that uses the lessons and best practices learned from developing the core Kubernetes APIs. Creating a new "Hello World" Controller with kubebuilder is as simple as:
- Create a project with
kubebuilder init - Define a new API with
kubebuilder create api - Build and run the provided main function with
make install & make run
This will scaffold the API and Controller for users to modify, as well as scaffold integration tests, RBAC rules, Dockerfiles, Makefiles, etc. After adding their implementation to the project, users create the artifacts to publish their API through:
- Build and push the container image from the provided Dockerfile using
make docker-buildandmake docker-pushcommands - Deploy the API using
make deploycommand
Whether you are already a Controller aficionado or just want to learn what the buzz is about, check out the kubebuilder repo or take a look at an example in the kubebuilder book to learn about how simple and easy it is to build Controllers.
Get Involved
Kubebuilder is a project under SIG API Machinery and is being actively developed by contributors from many companies such as Google, Red Hat, VMware, Huawei and others. Get involved by giving us feedback through these channels:
- Kubebuilder chat room on Slack
- SIG mailing list
- GitHub issues
- Send a pull request in the kubebuilder repo
Out of the Clouds onto the Ground: How to Make Kubernetes Production Grade Anywhere
Authors: Steven Wong (VMware), Michael Gasch (VMware)
This blog offers some guidelines for running a production grade Kubernetes cluster in an environment like an on-premise data center or edge location.
What does it mean to be “production grade”?
- The installation is secure
- The deployment is managed with a repeatable and recorded process
- Performance is predictable and consistent
- Updates and configuration changes can be safely applied
- Logging and monitoring is in place to detect and diagnose failures and resource shortages
- Service is “highly available enough” considering available resources, including constraints on money, physical space, power, etc.
- A recovery process is available, documented, and tested for use in the event of failures
In short, production grade means anticipating accidents and preparing for recovery with minimal pain and delay.
This article is directed at on-premise Kubernetes deployments on a hypervisor or bare-metal platform, facing finite backing resources compared to the expansibility of the major public clouds. However, some of these recommendations may also be useful in a public cloud if budget constraints limit the resources you choose to consume.
A single node bare-metal Minikube deployment may be cheap and easy, but is not production grade. Conversely, you’re not likely to achieve Google’s Borg experience in a retail store, branch office, or edge location, nor are you likely to need it.
This blog offers some guidance on achieving a production worthy Kubernetes deployment, even when dealing with some resource constraints.

Critical components in a Kubernetes cluster
Before we dive into the details, it is critical to understand the overall Kubernetes architecture.
A Kubernetes cluster is a highly distributed system based on a control plane and clustered worker node architecture as depicted below.
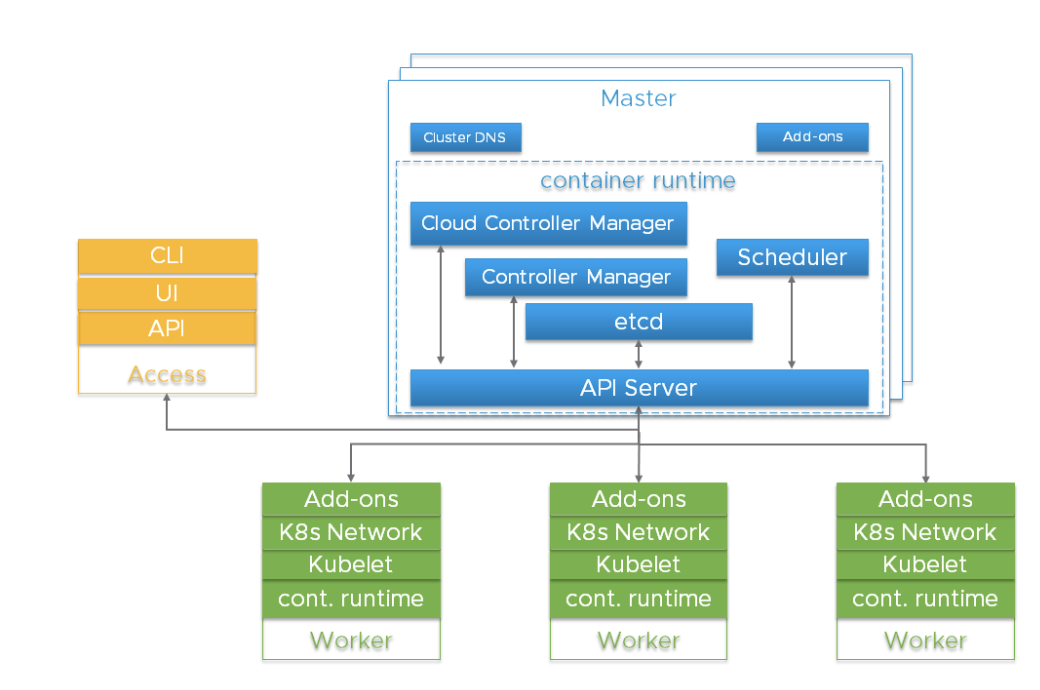
Typically the API server, Controller Manager and Scheduler components are co-located within multiple instances of control plane (aka Master) nodes. Master nodes usually include etcd too, although there are high availability and large cluster scenarios that call for running etcd on independent hosts. The components can be run as containers, and optionally be supervised by Kubernetes, i.e. running as statics pods.
For high availability, redundant instances of these components are used. The importance and required degree of redundancy varies.
Kubernetes components from an HA perspective
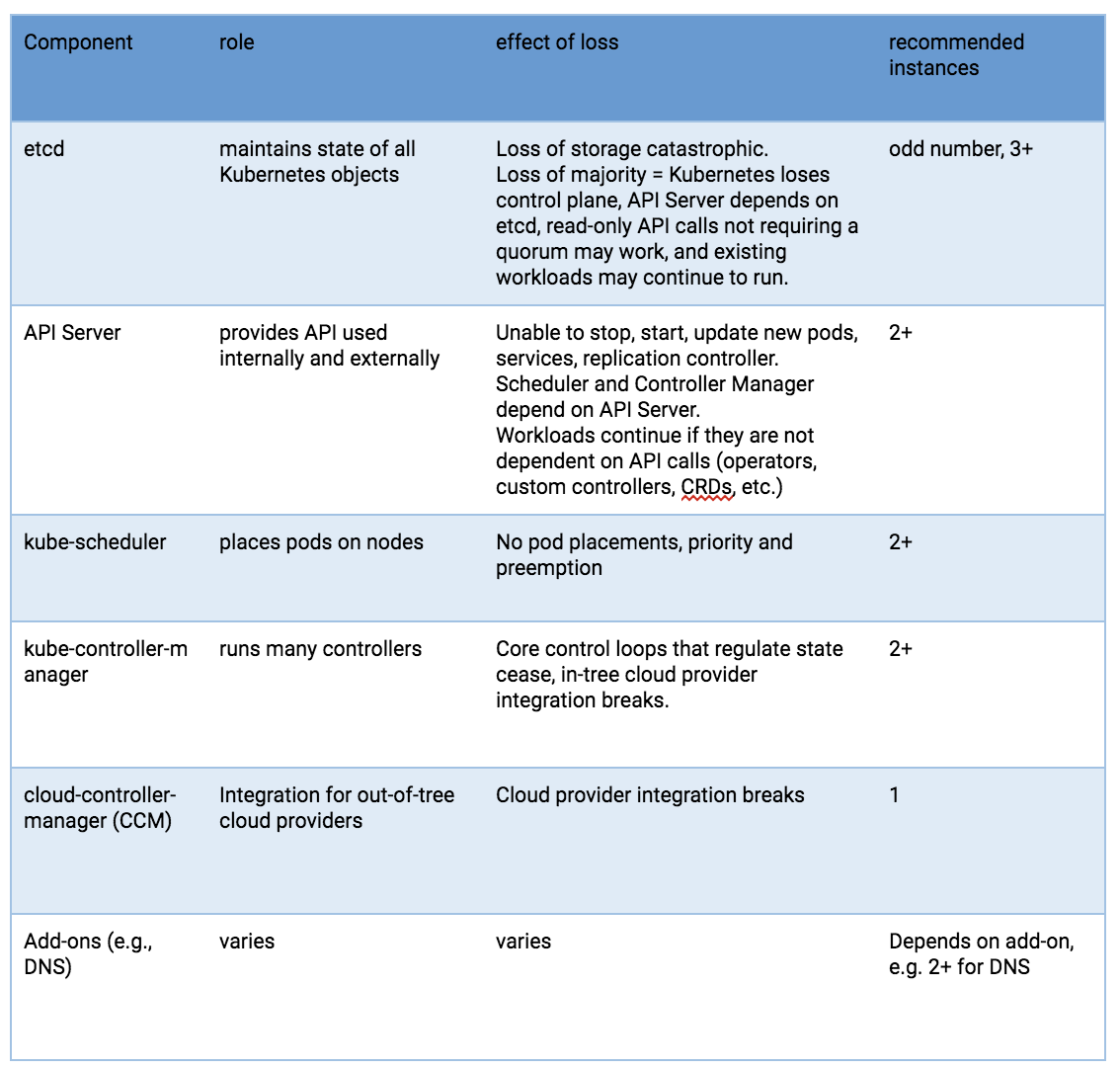
Risks to these components include hardware failures, software bugs, bad updates, human errors, network outages, and overloaded systems resulting in resource exhaustion. Redundancy can mitigate the impact of many of these hazards. In addition, the resource scheduling and high availability features of a hypervisor platform can be useful to surpass what can be achieved using the Linux operating system, Kubernetes, and a container runtime alone.
The API Server uses multiple instances behind a load balancer to achieve scale and availability. The load balancer is a critical component for purposes of high availability. Multiple DNS API Server ‘A’ records might be an alternative if you don’t have a load balancer.
The kube-scheduler and kube-controller-manager engage in a leader election process, rather than utilizing a load balancer. Since a cloud-controller-manager is used for selected types of hosting infrastructure, and these have implementation variations, they will not be discussed, beyond indicating that they are a control plane component.
Pods running on Kubernetes worker nodes are managed by the kubelet agent. Each worker instance runs the kubelet agent and a CRI-compatible container runtime. Kubernetes itself is designed to monitor and recover from worker node outages. But for critical workloads, hypervisor resource management, workload isolation and availability features can be used to enhance availability and make performance more predictable.
etcd
etcd is the persistent store for all Kubernetes objects. The availability and recoverability of the etcd cluster should be the first consideration in a production-grade Kubernetes deployment.
A five-node etcd cluster is a best practice if you can afford it. Why? Because you could engage in maintenance on one and still tolerate a failure. A three-node cluster is the minimum recommendation for production-grade service, even if only a single hypervisor host is available. More than seven nodes is not recommended except for very large installations straddling multiple availability zones.
The minimum recommendation for hosting an etcd cluster node is 2GB of RAM with 8GB of SSD-backed disk. Usually, 8GB RAM and a 20GB disk will be enough. Disk performance affects failed node recovery time. See https://coreos.com/etcd/docs/latest/op-guide/hardware.html for more on this.
Consider multiple etcd clusters in special situations
For very large Kubernetes clusters, consider using a separate etcd cluster for Kubernetes events so that event storms do not impact the main Kubernetes API service. If you use flannel networking, it retains configuration in etcd and may have differing version requirements than Kubernetes, which can complicate etcd backup -- consider using a dedicated etcd cluster for flannel.
Single host deployments
The availability risk list includes hardware, software and people. If you are limited to a single host, the use of redundant storage, error-correcting memory and dual power supplies can reduce hardware failure exposure. Running a hypervisor on the physical host will allow operation of redundant software components and add operational advantages related to deployment, upgrade, and resource consumption governance, with predictable and repeatable performance under stress. For example, even if you can only afford to run singletons of the master services, they need to be protected from overload and resource exhaustion while competing with your application workload. A hypervisor can be more effective and easier to manage than configuring Linux scheduler priorities, cgroups, Kubernetes flags, etc.
If resources on the host permit, you can deploy three etcd VMs. Each of the etcd VMs should be backed by a different physical storage device, or they should use separate partitions of a backing store using redundancy (mirroring, RAID, etc).
Dual redundant instances of the API server, scheduler and controller manager would be the next upgrade, if your single host has the resources.
Single host deployment options, least production worthy to better
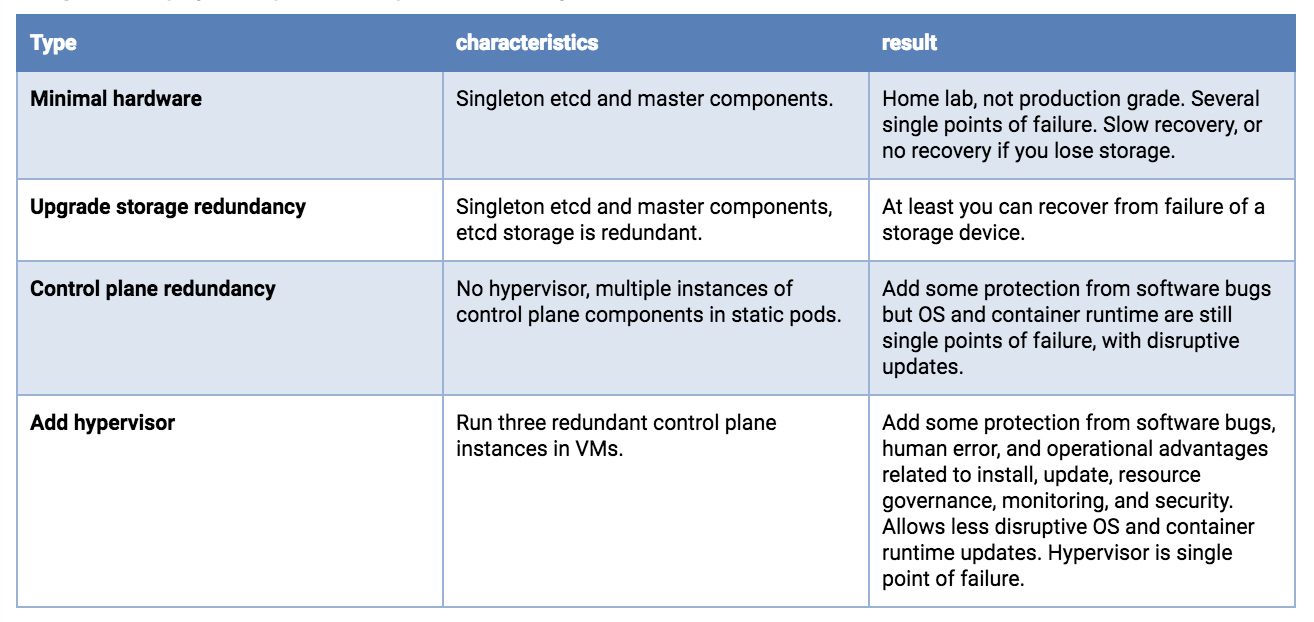
Dual host deployments
With two hosts, storage concerns for etcd are the same as a single host, you want redundancy. And you would preferably run 3 etcd instances. Although possibly counter-intuitive, it is better to concentrate all etcd nodes on a single host. You do not gain reliability by doing a 2+1 split across two hosts - because loss of the node holding the majority of etcd instances results in an outage, whether that majority is 2 or 3. If the hosts are not identical, put the whole etcd cluster on the most reliable host.
Running redundant API Servers, kube-schedulers, and kube-controller-managers is recommended. These should be split across hosts to minimize risk due to container runtime, OS and hardware failures.
Running a hypervisor layer on the physical hosts will allow operation of redundant software components with resource consumption governance, and can have planned maintenance operational advantages.
Dual host deployment options, least production worthy to better
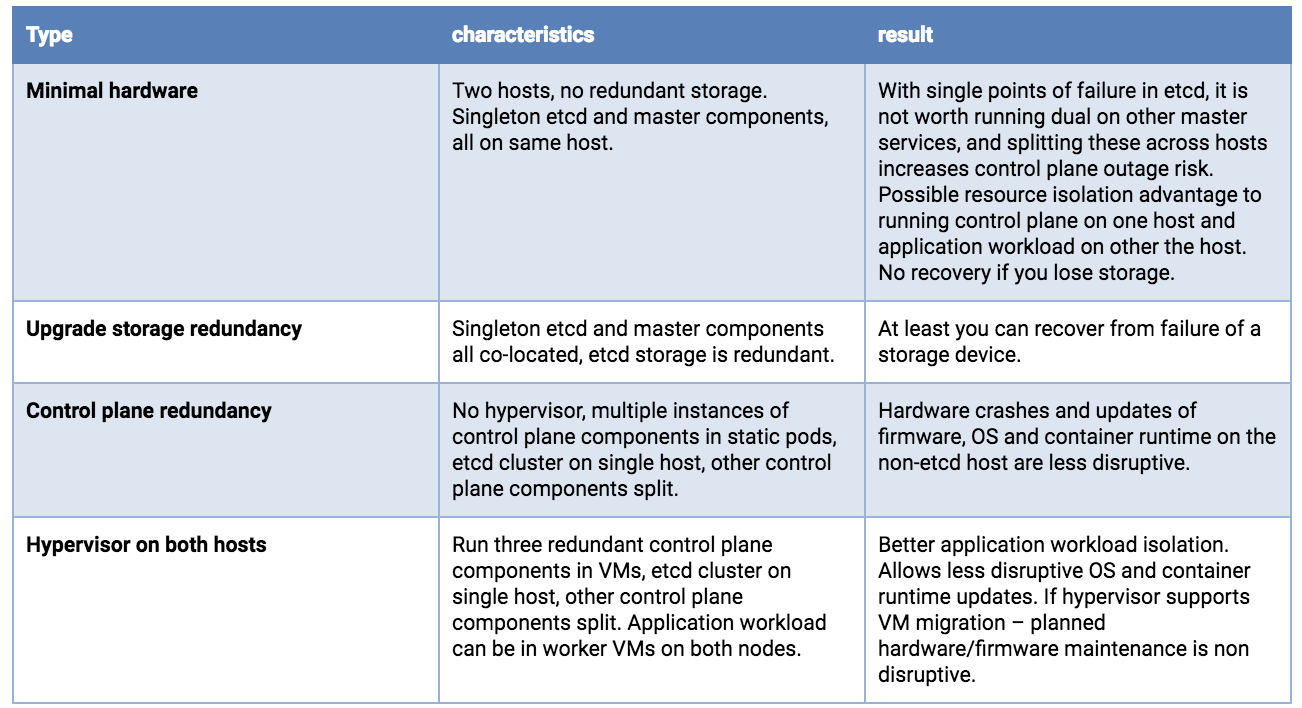
Triple (or larger) host deployments -- Moving into uncompromised production-grade service Splitting etcd across three hosts is recommended. A single hardware failure will reduce application workload capacity, but should not result in a complete service outage.
With very large clusters, more etcd instances will be required.
Running a hypervisor layer offers operational advantages and better workload isolation. It is beyond the scope of this article, but at the three-or-more host level, advanced features may be available (clustered redundant shared storage, resource governance with dynamic load balancing, automated health monitoring with live migration or failover).
Triple (or more) host options, least production worthy to better

Kubernetes configuration settings
Master and Worker nodes should be protected from overload and resource exhaustion. Hypervisor features can be used to isolate critical components and reserve resources. There are also Kubernetes configuration settings that can throttle things like API call rates and pods per node. Some install suites and commercial distributions take care of this, but if you are performing a custom Kubernetes deployment, you may find that the defaults are not appropriate, particularly if your resources are small or your cluster is large.
Resource consumption by the control plane will correlate with the number of pods and the pod churn rate. Very large and very small clusters will benefit from non-default settings of kube-apiserver request throttling and memory. Having these too high can lead to request limit exceeded and out of memory errors.
On worker nodes, Node Allocatable should be configured based on a reasonable supportable workload density at each node. Namespaces can be created to subdivide the worker node cluster into multiple virtual clusters with resource CPU and memory quotas. Kubelet handling of out of resource conditions can be configured.
Security
Every Kubernetes cluster has a cluster root Certificate Authority (CA). The Controller Manager, API Server, Scheduler, kubelet client, kube-proxy and administrator certificates need to be generated and installed. If you use an install tool or a distribution this may be handled for you. A manual process is described here. You should be prepared to reinstall certificates in the event of node replacements or expansions.
As Kubernetes is entirely API driven, controlling and limiting who can access the cluster and what actions they are allowed to perform is essential. Encryption and authentication options are addressed in this documentation.
Kubernetes application workloads are based on container images. You want the source and content of these images to be trustworthy. This will almost always mean that you will host a local container image repository. Pulling images from the public Internet can present both reliability and security issues. You should choose a repository that supports image signing, security scanning, access controls on pushing and pulling images, and logging of activity.
Processes must be in place to support applying updates for host firmware, hypervisor, OS, Kubernetes, and other dependencies. Version monitoring should be in place to support audits.
Recommendations:
- Tighten security settings on the control plane components beyond defaults (e.g., locking down worker nodes)
- Utilize Pod Security Policies
- Consider the NetworkPolicy integration available with your networking solution, including how you will accomplish tracing, monitoring and troubleshooting.
- Use RBAC to drive authorization decisions and enforcement.
- Consider physical security, especially when deploying to edge or remote office locations that may be unattended. Include storage encryption to limit exposure from stolen devices and protection from attachment of malicious devices like USB keys.
- Protect Kubernetes plain-text cloud provider credentials (access keys, tokens, passwords, etc.)
Kubernetes secret objects are appropriate for holding small amounts of sensitive data. These are retained within etcd. These can be readily used to hold credentials for the Kubernetes API but there are times when a workload or an extension of the cluster itself needs a more full-featured solution. The HashiCorp Vault project is a popular solution if you need more than the built-in secret objects can provide.
Disaster Recovery and Backup

Utilizing redundancy through the use of multiple hosts and VMs helps reduce some classes of outages, but scenarios such as a sitewide natural disaster, a bad update, getting hacked, software bugs, or human error could still result in an outage.
A critical part of a production deployment is anticipating a possible future recovery.
It’s also worth noting that some of your investments in designing, documenting, and automating a recovery process might also be re-usable if you need to do large-scale replicated deployments at multiple sites.
Elements of a DR plan include backups (and possibly replicas), replacements, a planned process, people who can carry out the process, and recurring training. Regular test exercises and chaos engineering principles can be used to audit your readiness.
Your availability requirements might demand that you retain local copies of the OS, Kubernetes components, and container images to allow recovery even during an Internet outage. The ability to deploy replacement hosts and nodes in an “air-gapped” scenario can also offer security and speed of deployment advantages.
All Kubernetes objects are stored on etcd. Periodically backing up the etcd cluster data is important to recover Kubernetes clusters under disaster scenarios, such as losing all master nodes.
Backing up an etcd cluster can be accomplished with etcd’s built-in snapshot mechanism, and copying the resulting file to storage in a different failure domain. The snapshot file contains all the Kubernetes states and critical information. In order to keep the sensitive Kubernetes data safe, encrypt the snapshot files.
Using disk volume based snapshot recovery of etcd can have issues; see #40027. API-based backup solutions (e.g., Ark) can offer more granular recovery than a etcd snapshot, but also can be slower. You could utilize both snapshot and API-based backups, but you should do one form of etcd backup as a minimum.
Be aware that some Kubernetes extensions may maintain state in independent etcd clusters, on persistent volumes, or through other mechanisms. If this state is critical, it should have a backup and recovery plan.
Some critical state is held outside etcd. Certificates, container images, and other configuration- and operation-related state may be managed by your automated install/update tooling. Even if these items can be regenerated, backup or replication might allow for faster recovery after a failure. Consider backups with a recovery plan for these items:
- Certificate and key pairs
- CA
- API Server
- Apiserver-kubelet-client
- ServiceAccount signing
- “Front proxy”
- Front proxy client
- Critical DNS records
- IP/subnet assignments and reservations
- External load-balancers
- kubeconfig files
- LDAP or other authentication details
- Cloud provider specific account and configuration data
Considerations for your production workloads
Anti-affinity specifications can be used to split clustered services across backing hosts, but at this time the settings are used only when the pod is scheduled. This means that Kubernetes can restart a failed node of your clustered application, but does not have a native mechanism to rebalance after a fail back. This is a topic worthy of a separate blog, but supplemental logic might be useful to achieve optimal workload placements after host or worker node recoveries or expansions. The Pod Priority and Preemption feature can be used to specify a preferred triage in the event of resource shortages caused by failures or bursting workloads.
For stateful services, external attached volume mounts are the standard Kubernetes recommendation for a non-clustered service (e.g., a typical SQL database). At this time Kubernetes managed snapshots of these external volumes is in the category of a roadmap feature request, likely to align with the Container Storage Interface (CSI) integration. Thus performing backups of such a service would involve application specific, in-pod activity that is beyond the scope of this document. While awaiting better Kubernetes support for a snapshot and backup workflow, running your database service in a VM rather than a container, and exposing it to your Kubernetes workload may be worth considering.
Cluster-distributed stateful services (e.g., Cassandra) can benefit from splitting across hosts, using local persistent volumes if resources allow. This would require deploying multiple Kubernetes worker nodes (could be VMs on hypervisor hosts) to preserve a quorum under single point failures.
Other considerations
Logs and metrics (if collected and persistently retained) are valuable to diagnose outages, but given the variety of technologies available it will not be addressed in this blog. If Internet connectivity is available, it may be desirable to retain logs and metrics externally at a central location.
Your production deployment should utilize an automated installation, configuration and update tool (e.g., Ansible, BOSH, Chef, Juju, kubeadm, Puppet, etc.). A manual process will have repeatability issues, be labor intensive, error prone, and difficult to scale. Certified distributions are likely to include a facility for retaining configuration settings across updates, but if you implement your own install and config toolchain, then retention, backup and recovery of the configuration artifacts is essential. Consider keeping your deployment components and settings under a version control system such as Git.
Outage recovery
Runbooks documenting recovery procedures should be tested and retained offline -- perhaps even printed. When an on-call staff member is called up at 2 am on a Friday night, it may not be a great time to improvise. Better to execute from a pre-planned, tested checklist -- with shared access by remote and onsite personnel.
Final thoughts

Buying a ticket on a commercial airline is convenient and safe. But when you travel to a remote location with a short runway, that commercial Airbus A320 flight isn’t an option. This doesn’t mean that air travel is off the table. It does mean that some compromises are necessary.
The adage in aviation is that on a single engine aircraft, an engine failure means you crash. With twin engines, at the very least, you get more choices of where you crash. Kubernetes on a small number of hosts is similar, and if your business case justifies it, you might scale up to a larger fleet of mixed large and small vehicles (e.g., FedEx, Amazon).
Those designing a production-grade Kubernetes solution have a lot of options and decisions. A blog-length article can’t provide all the answers, and can’t know your specific priorities. We do hope this offers a checklist of things to consider, along with some useful guidance. Some options were left “on the cutting room floor” (e.g., running Kubernetes components using self-hosting instead of static pods). These might be covered in a follow up if there is interest. Also, Kubernetes’ high enhancement rate means that if your search engine found this article after 2019, some content might be past the “sell by” date.
Dynamically Expand Volume with CSI and Kubernetes
Author: Orain Xiong (Co-Founder, WoquTech)
There is a very powerful storage subsystem within Kubernetes itself, covering a fairly broad spectrum of use cases. Whereas, when planning to build a product-grade relational database platform with Kubernetes, we face a big challenge: coming up with storage. This article describes how to extend latest Container Storage Interface 0.2.0 and integrate with Kubernetes, and demonstrates the essential facet of dynamically expanding volume capacity.
Introduction
As we focalize our customers, especially in financial space, there is a huge upswell in the adoption of container orchestration technology.
They are looking forward to open source solutions to redesign already existing monolithic applications, which have been running for several years on virtualization infrastructure or bare metal.
Considering extensibility and the extent of technical maturity, Kubernetes and Docker are at the very top of the list. But migrating monolithic applications to a distributed orchestration like Kubernetes is challenging, the relational database is critical for the migration.
With respect to the relational database, we should pay attention to storage. There is a very powerful storage subsystem within Kubernetes itself. It is very useful and covers a fairly broad spectrum of use cases. When planning to run a relational database with Kubernetes in production, we face a big challenge: coming up with storage. There are still some fundamental functionalities which are left unimplemented. Specifically, dynamically expanding volume. It sounds boring but is highly required, except for actions like create and delete and mount and unmount.
Currently, expanding volume is only available with those storage provisioners:
- gcePersistentDisk
- awsElasticBlockStore
- OpenStack Cinder
- glusterfs
- rbd
In order to enable this feature, we should set feature gate ExpandPersistentVolumes true and turn on the PersistentVolumeClaimResize admission plugin. Once PersistentVolumeClaimResize has been enabled, resizing will be allowed by a Storage Class whose allowVolumeExpansion field is set to true.
Unfortunately, dynamically expanding volume through the Container Storage Interface (CSI) and Kubernetes is unavailable, even though the underlying storage providers have this feature.
This article will give a simplified view of CSI, followed by a walkthrough of how to introduce a new expanding volume feature on the existing CSI and Kubernetes. Finally, the article will demonstrate how to dynamically expand volume capacity.
Container Storage Interface (CSI)
To have a better understanding of what we're going to do, the first thing we need to know is what the Container Storage Interface is. Currently, there are still some problems for already existing storage subsystem within Kubernetes. Storage driver code is maintained in the Kubernetes core repository which is difficult to test. But beyond that, Kubernetes needs to give permissions to storage vendors to check code into the Kubernetes core repository. Ideally, that should be implemented externally.
CSI is designed to define an industry standard that will enable storage providers who enable CSI to be available across container orchestration systems that support CSI.
This diagram depicts a kind of high-level Kubernetes archetypes integrated with CSI:
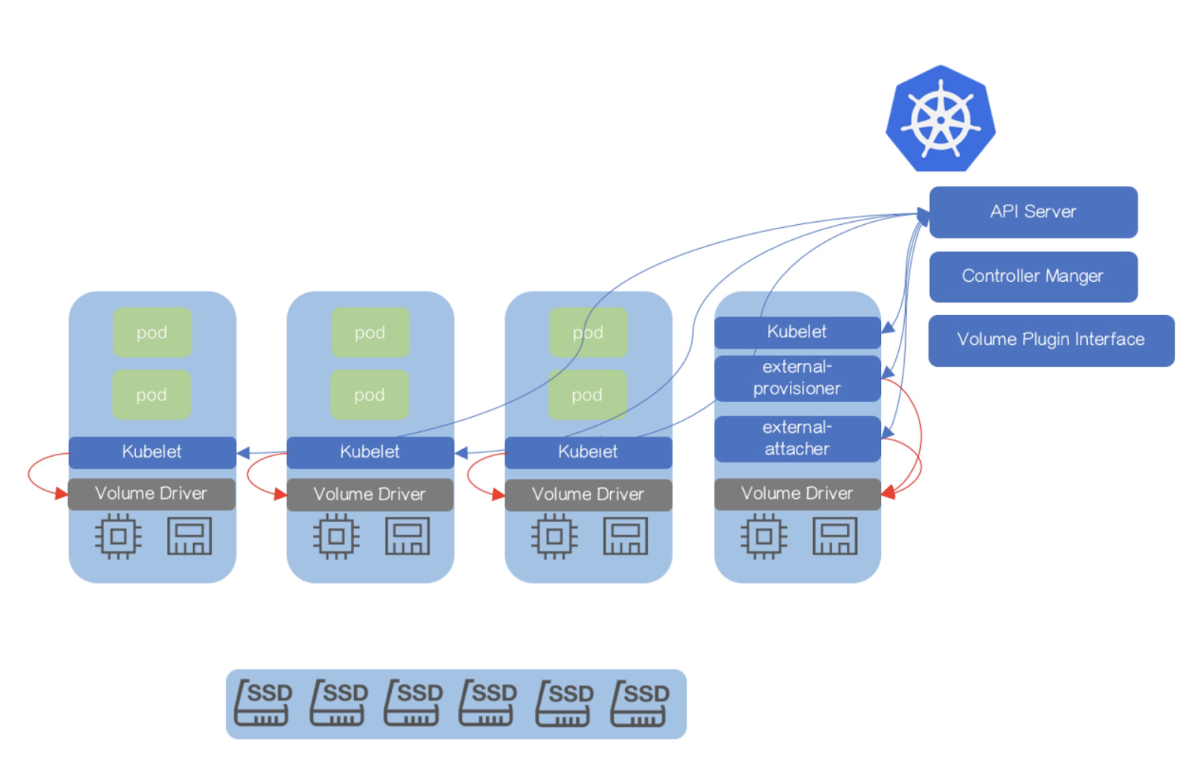
- Three new external components are introduced to decouple Kubernetes and Storage Provider logic
- Blue arrows present the conventional way to call against API Server
- Red arrows present gRPC to call against Volume Driver
For more details, please visit: https://github.com/container-storage-interface/spec/blob/master/spec.md
Extend CSI and Kubernetes
In order to enable the feature of expanding volume atop Kubernetes, we should extend several components including CSI specification, “in-tree” volume plugin, external-provisioner and external-attacher.
Extend CSI spec
The feature of expanding volume is still undefined in latest CSI 0.2.0. The new 3 RPCs, including RequiresFSResize and ControllerResizeVolume and NodeResizeVolume, should be introduced.
service Controller {
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
……
rpc RequiresFSResize (RequiresFSResizeRequest)
returns (RequiresFSResizeResponse) {}
rpc ControllerResizeVolume (ControllerResizeVolumeRequest)
returns (ControllerResizeVolumeResponse) {}
}
service Node {
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
……
rpc NodeResizeVolume (NodeResizeVolumeRequest)
returns (NodeResizeVolumeResponse) {}
}
Extend “In-Tree” Volume Plugin
In addition to the extend CSI specification, the csiPlugin interface within Kubernetes should also implement expandablePlugin. The csiPlugin interface will expand PersistentVolumeClaim representing for ExpanderController.
type ExpandableVolumePlugin interface {
VolumePlugin
ExpandVolumeDevice(spec Spec, newSize resource.Quantity, oldSize resource.Quantity) (resource.Quantity, error)
RequiresFSResize() bool
}
Implement Volume Driver
Finally, to abstract complexity of the implementation, we should hard code the separate storage provider management logic into the following functions which is well-defined in the CSI specification:
- CreateVolume
- DeleteVolume
- ControllerPublishVolume
- ControllerUnpublishVolume
- ValidateVolumeCapabilities
- ListVolumes
- GetCapacity
- ControllerGetCapabilities
- RequiresFSResize
- ControllerResizeVolume
Demonstration
Let’s demonstrate this feature with a concrete user case.
- Create storage class for CSI storage provisioner
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-qcfs
parameters:
csiProvisionerSecretName: orain-test
csiProvisionerSecretNamespace: default
provisioner: csi-qcfsplugin
reclaimPolicy: Delete
volumeBindingMode: Immediate
-
Deploy CSI Volume Driver including storage provisioner
csi-qcfspluginacross Kubernetes cluster -
Create PVC
qcfs-pvcwhich will be dynamically provisioned by storage classcsi-qcfs
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: qcfs-pvc
namespace: default
....
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: csi-qcfs
- Create MySQL 5.7 instance to use PVC
qcfs-pvc - In order to mirror the exact same production-level scenario, there are actually two different types of workloads including:
- Batch insert to make MySQL consuming more file system capacity
- Surge query request
- Dynamically expand volume capacity through edit pvc
qcfs-pvcconfiguration
The Prometheus and Grafana integration allows us to visualize corresponding critical metrics.
We notice that the middle reading shows MySQL datafile size increasing slowly during bulk inserting. At the same time, the bottom reading shows file system expanding twice in about 20 minutes, from 300 GiB to 400 GiB and then 500 GiB. Meanwhile, the upper reading shows the whole process of expanding volume immediately completes and hardly impacts MySQL QPS.
Conclusion
Regardless of whatever infrastructure applications have been running on, the database is always a critical resource. It is essential to have a more advanced storage subsystem out there to fully support database requirements. This will help drive the more broad adoption of cloud native technology.
KubeVirt: Extending Kubernetes with CRDs for Virtualized Workloads
Author: David Vossel (Red Hat)
What is KubeVirt?
KubeVirt is a Kubernetes addon that provides users the ability to schedule traditional virtual machine workloads side by side with container workloads. Through the use of Custom Resource Definitions (CRDs) and other Kubernetes features, KubeVirt seamlessly extends existing Kubernetes clusters to provide a set of virtualization APIs that can be used to manage virtual machines.
Why Use CRDs Over an Aggregated API Server?
Back in the middle of 2017, those of us working on KubeVirt were at a crossroads. We had to make a decision whether or not to extend Kubernetes using an aggregated API server or to make use of the new Custom Resource Definitions (CRDs) feature.
At the time, CRDs lacked much of the functionality we needed to deliver our feature set. The ability to create our own aggregated API server gave us all the flexibility we needed, but it had one major flaw. An aggregated API server significantly increased the complexity involved with installing and operating KubeVirt.
The crux of the issue for us was that aggregated API servers required access to etcd for object persistence. This meant that cluster admins would have to either accept that KubeVirt needs a separate etcd deployment which increases complexity, or provide KubeVirt with shared access to the Kubernetes etcd store which introduces risk.
We weren’t okay with this tradeoff. Our goal wasn’t to just extend Kubernetes to run virtualization workloads, it was to do it in the most seamless and effortless way possible. We felt that the added complexity involved with an aggregated API server sacrificed the part of the user experience involved with installing and operating KubeVirt.
Ultimately we chose to go with CRDs and trust that the Kubernetes ecosystem would grow with us to meet the needs of our use case. Our bets were well placed. At this point there are either solutions in place or solutions under discussion that solve every feature gap we encountered back in 2017 when were evaluating CRDs vs an aggregated API server.
Building Layered “Kubernetes like” APIs with CRDs
We designed KubeVirt’s API to follow the same patterns users are already familiar with in the Kubernetes core API.
For example, in Kubernetes the lowest level unit that users create to perform work is a Pod. Yes, Pods do have multiple containers but logically the Pod is the unit at the bottom of the stack. A Pod represents a mortal workload. The Pod gets scheduled, eventually the Pod’s workload terminates, and that’s the end of the Pod’s lifecycle.
Workload controllers such as the ReplicaSet and StatefulSet are layered on top of the Pod abstraction to help manage scale out and stateful applications. From there we have an even higher level controller called a Deployment which is layered on top of ReplicaSets help manage things like rolling updates.
In KubeVirt, this concept of layering controllers is at the very center of our design. The KubeVirt VirtualMachineInstance (VMI) object is the lowest level unit at the very bottom of the KubeVirt stack. Similar in concept to a Pod, a VMI represents a single mortal virtualized workload that executes once until completion (powered off).
Layered on top of VMIs we have a workload controller called a VirtualMachine (VM). The VM controller is where we really begin to see the differences between how users manage virtualized workloads vs containerized workloads. Within the context of existing Kubernetes functionality, the best way to describe the VM controller’s behavior is to compare it to a StatefulSet of size one. This is because the VM controller represents a single stateful (immortal) virtual machine capable of persisting state across both node failures and multiple restarts of its underlying VMI. This object behaves in the way that is familiar to users who have managed virtual machines in AWS, GCE, OpenStack or any other similar IaaS cloud platform. The user can shutdown a VM, then choose to start that exact same VM up again at a later time.
In addition to VMs, we also have a VirtualMachineInstanceReplicaSet (VMIRS) workload controller which manages scale out of identical VMI objects. This controller behaves nearly identically to the Kubernetes ReplicSet controller. The primary difference being that the VMIRS manages VMI objects and the ReplicaSet manages Pods. Wouldn’t it be nice if we could come up with a way to use the Kubernetes ReplicaSet controller to scale out CRDs?
Each one of these KubeVirt objects (VMI, VM, VMIRS) are registered with Kubernetes as a CRD when the KubeVirt install manifest is posted to the cluster. By registering our APIs as CRDs with Kubernetes, all the tooling involved with managing Kubernetes clusters (like kubectl) have access to the KubeVirt APIs just as if they are native Kubernetes objects.
Dynamic Webhooks for API Validation
One of the responsibilities of the Kubernetes API server is to intercept and validate requests prior to allowing objects to be persisted into etcd. For example, if someone tries to create a Pod using a malformed Pod specification, the Kubernetes API server immediately catches the error and rejects the POST request. This all occurs before the object is persistent into etcd preventing the malformed Pod specification from making its way into the cluster.
This validation occurs during a process called admission control. Until recently, it was not possible to extend the default Kubernetes admission controllers without altering code and compiling/deploying an entirely new Kubernetes API server. This meant that if we wanted to perform admission control on KubeVirt’s CRD objects while they are posted to the cluster, we’d have to build our own version of the Kubernetes API server and convince our users to use that instead. That was not a viable solution for us.
Using the new Dynamic Admission Control feature that first landed in Kubernetes 1.9, we now have a path for performing custom validation on KubeVirt API through the use of a ValidatingAdmissionWebhook. This feature allows KubeVirt to dynamically register an HTTPS webhook with Kubernetes at KubeVirt install time. After registering the custom webhook, all requests related to KubeVirt API objects are forwarded from the Kubernetes API server to our HTTPS endpoint for validation. If our endpoint rejects a request for any reason, the object will not be persisted into etcd and the client receives our response outlining the reason for the rejection.
For example, if someone posts a malformed VirtualMachine object, they’ll receive an error indicating what the problem is.
$ kubectl create -f my-vm.yaml
Error from server: error when creating "my-vm.yaml": admission webhook "virtualmachine-validator.kubevirt.io" denied the request: spec.template.spec.domain.devices.disks[0].volumeName 'registryvolume' not found.
In the example output above, that error response is coming directly from KubeVirt’s admission control webhook.
CRD OpenAPIv3 Validation
In addition to the validating webhook, KubeVirt also uses the ability to provide an OpenAPIv3 validation schema when registering a CRD with the cluster. While the OpenAPIv3 schema does not let us express some of the more advanced validation checks that the validation webhook provides, it does offer the ability to enforce simple validation checks involving things like required fields, max/min value lengths, and verifying that values are formatted in a way that matches a regular expression string.
Dynamic Webhooks for “PodPreset Like” Behavior
The Kubernetes Dynamic Admission Control feature is not only limited to validation logic, it also provides the ability for applications like KubeVirt to both intercept and mutate requests as they enter the cluster. This is achieved through the use of a MutatingAdmissionWebhook object. In KubeVirt, we are looking to use a mutating webhook to support our VirtualMachinePreset (VMPreset) feature.
A VMPreset acts in a similar way to a PodPreset. Just like a PodPreset allows users to define values that should automatically be injected into pods at creation time, a VMPreset allows users to define values that should be injected into VMs at creation time. Through the use of a mutating webhook, KubeVirt can intercept a request to create a VM, apply VMPresets to the VM spec, and then validate that the resulting VM object. This all occurs before the VM object is persisted into etcd which allows KubeVirt to immediately notify the user of any conflicts at the time the request is made.
Subresources for CRDs
When comparing the use of CRDs to an aggregated API server, one of the features CRDs lack is the ability to support subresources. Subresources are used to provide additional resource functionality. For example, the pod/logs and pod/exec subresource endpoints are used behind the scenes to provide the kubectl logs and kubectl exec command functionality.
Just like Kubernetes uses the pod/exec subresource to provide access to a pod’s environment, in KubeVirt we want subresources to provide serial-console, VNC, and SPICE access to a virtual machine. By adding virtual machine guest access through subresources, we can leverage RBAC to provide access control for these features.
So, given that the KubeVirt team decided to use CRD’s instead of an aggregated API server for custom resource support, how can we have subresources for CRDs when the CRD feature expiclity does not support subresources?
We created a workaround for this limitation by implementing a stateless aggregated API server that exists only to serve subresource requests. With no state, we don’t have to worry about any of the issues we identified earlier with regards to access to etcd. This means the KubeVirt API is actually supported through a combination of both CRDs for resources and an aggregated API server for stateless subresources.
This isn’t a perfect solution for us. Both aggregated API servers and CRDs require us to register an API GroupName with Kubernetes. This API GroupName field essentially namespaces the API’s REST path in a way that prevents API naming conflicts between other third party applications. Because CRDs and aggregated API servers can’t share the same GroupName, we have to register two separate GroupNames. One is used by our CRDs and the other is used by the aggregated API server for subresource requests.
Having two GroupNames in our API is slightly inconvenient because it means the REST path for the endpoints that serve the KubeVirt subresource requests have a slightly different base path than the resources.
For example, the endpoint to create a VMI object is as follows.
/apis/kubevirt.io/v1alpha2/namespaces/my-namespace/virtualmachineinstances/my-vm
However, the subresource endpoint to access graphical VNC looks like this.
/apis/subresources.kubevirt.io/v1alpha2/namespaces/my-namespace/virtualmachineinstances/my-vm/vnc
Notice that the first request uses kubevirt.io and the second request uses subresource.kubevirt.io. We don’t like that, but that’s how we’ve managed to combine CRDs with a stateless aggregated API server for subresources.
One thing worth noting is that in Kubernetes 1.10 a very basic form of CRD subresource support was added in the form of the /status and /scale subresources. This support does not help us deliver the virtualization features we want subresources for. However, there have been discussions about exposing custom CRD subresources as webhooks in a future Kubernetes version. If this functionality lands, we will gladly transition away from our stateless aggregated API server workaround to use a subresource webhook feature.
CRD Finalizers
A CRD finalizer is a feature that lets us provide a pre-delete hook in order to perform actions before allowing a CRD object to be removed from persistent storage. In KubeVirt, we use finalizers to guarantee a virtual machine has completely terminated before we allow the corresponding VMI object to be removed from etcd.
API Versioning for CRDs
The Kubernetes core APIs have the ability to support multiple versions for a single object type and perform conversions between those versions. This gives the Kubernetes core APIs a path for advancing the v1alpha1 version of an object to a v1beta1 version and so forth.
Prior to Kubernetes 1.11, CRDs did not have support for multiple versions. This meant when we wanted to progress a CRD from kubevirt.io/v1alpha1 to kubevirt.io/v1beta1, the only path available to was to backup our CRD objects, delete the registered CRD from Kubernetes, register a new CRD with the updated version, convert the backed up CRD objects to the new version, and finally post the migrated CRD objects back to the cluster.
That strategy was not exactly a viable option for us.
Fortunately thanks to some recent work to rectify this issue in Kubernetes, the latest Kubernetes v1.11 now supports CRDs with multiple versions. Note however that this initial multi version support is limited. While a CRD can now have multiple versions, the feature does not currently contain a path for performing conversions between versions. In KubeVirt, the lack of conversion makes it difficult us to evolve our API as we progress versions. Luckily, support for conversions between versions is underway and we look forward to taking advantage of that feature once it lands in a future Kubernetes release.
Feature Highlight: CPU Manager
Authors: Balaji Subramaniam (Intel), Connor Doyle (Intel)
This blog post describes the CPU Manager, a beta feature in Kubernetes. The CPU manager feature enables better placement of workloads in the Kubelet, the Kubernetes node agent, by allocating exclusive CPUs to certain pod containers.
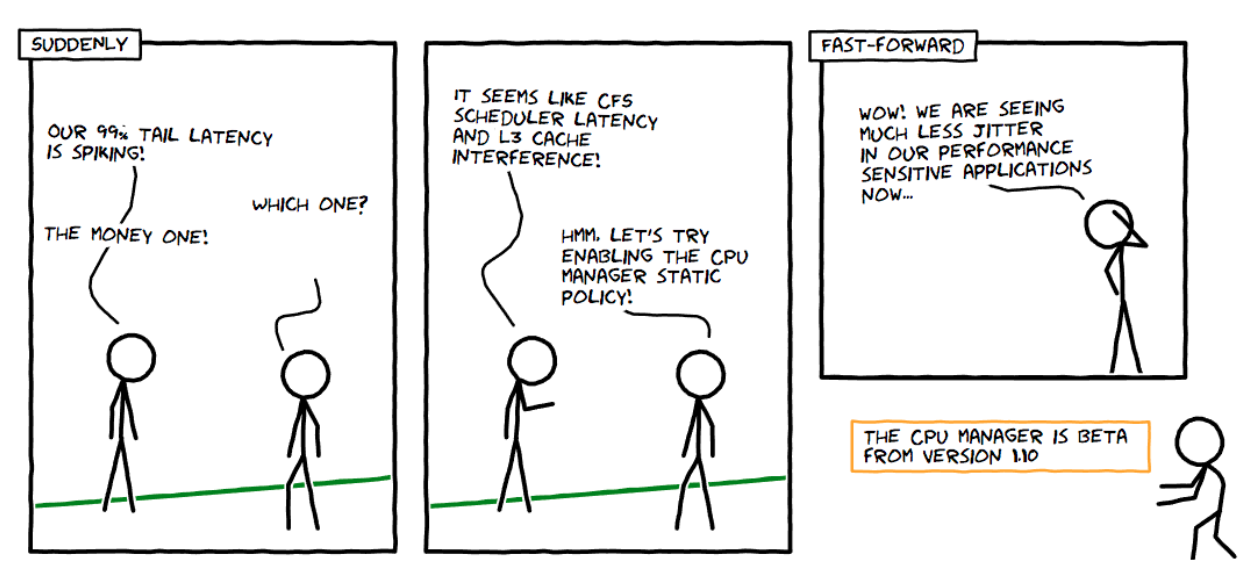
Sounds Good! But Does the CPU Manager Help Me?
It depends on your workload. A single compute node in a Kubernetes cluster can run many pods and some of these pods could be running CPU-intensive workloads. In such a scenario, the pods might contend for the CPU resources available in that compute node. When this contention intensifies, the workload can move to different CPUs depending on whether the pod is throttled and the availability of CPUs at scheduling time. There might also be cases where the workload could be sensitive to context switches. In all the above scenarios, the performance of the workload might be affected.
If your workload is sensitive to such scenarios, then CPU Manager can be enabled to provide better performance isolation by allocating exclusive CPUs for your workload.
CPU manager might help workloads with the following characteristics:
- Sensitive to CPU throttling effects.
- Sensitive to context switches.
- Sensitive to processor cache misses.
- Benefits from sharing a processor resources (e.g., data and instruction caches).
- Sensitive to cross-socket memory traffic.
- Sensitive or requires hyperthreads from the same physical CPU core.
Ok! How Do I use it?
Using the CPU manager is simple. First, enable CPU manager with the Static policy in the Kubelet running on the compute nodes of your cluster. Then configure your pod to be in the Guaranteed Quality of Service (QoS) class. Request whole numbers of CPU cores (e.g., 1000m, 4000m) for containers that need exclusive cores. Create your pod in the same way as before (e.g., kubectl create -f pod.yaml). And voilà, the CPU manager will assign exclusive CPUs to each of container in the pod according to their CPU requests.
apiVersion: v1
kind: Pod
metadata:
name: exclusive-2
spec:
containers:
- image: quay.io/connordoyle/cpuset-visualizer
name: exclusive-2
resources:
# Pod is in the Guaranteed QoS class because requests == limits
requests:
# CPU request is an integer
cpu: 2
memory: "256M"
limits:
cpu: 2
memory: "256M"
Pod specification requesting two exclusive CPUs.
Hmm … How Does the CPU Manager Work?
For Kubernetes, and the purposes of this blog post, we will discuss three kinds of CPU resource controls available in most Linux distributions. The first two are CFS shares (what's my weighted fair share of CPU time on this system) and CFS quota (what's my hard cap of CPU time over a period). The CPU manager uses a third control called CPU affinity (on what logical CPUs am I allowed to execute).
By default, all the pods and the containers running on a compute node of your Kubernetes cluster can execute on any available cores in the system. The total amount of allocatable shares and quota are limited by the CPU resources explicitly reserved for kubernetes and system daemons. However, limits on the CPU time being used can be specified using CPU limits in the pod spec. Kubernetes uses CFS quota to enforce CPU limits on pod containers.
When CPU manager is enabled with the "static" policy, it manages a shared pool of CPUs. Initially this shared pool contains all the CPUs in the compute node. When a container with integer CPU request in a Guaranteed pod is created by the Kubelet, CPUs for that container are removed from the shared pool and assigned exclusively for the lifetime of the container. Other containers are migrated off these exclusively allocated CPUs.
All non-exclusive-CPU containers (Burstable, BestEffort and Guaranteed with non-integer CPU) run on the CPUs remaining in the shared pool. When a container with exclusive CPUs terminates, its CPUs are added back to the shared CPU pool.
More Details Please ...
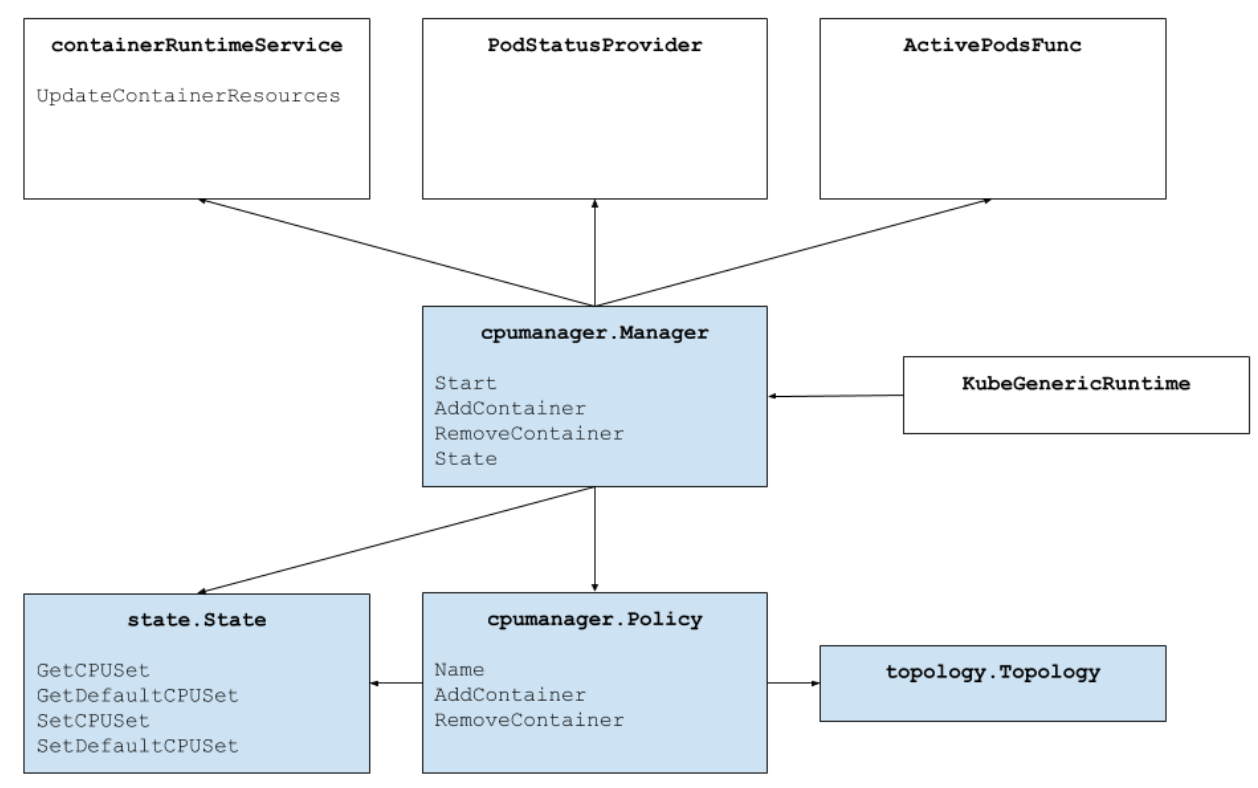
The figure above shows the anatomy of the CPU manager. The CPU Manager uses the Container Runtime Interface's UpdateContainerResources method to modify the CPUs on which containers can run. The Manager periodically reconciles the current State of the CPU resources of each running container with cgroupfs.
The CPU Manager uses Policies to decide the allocation of CPUs. There are two policies implemented: None and Static. By default, the CPU manager is enabled with the None policy from Kubernetes version 1.10.
The Static policy allocates exclusive CPUs to pod containers in the Guaranteed QoS class which request integer CPUs. On a best-effort basis, the Static policy tries to allocate CPUs topologically in the following order:
- Allocate all the CPUs in the same processor socket if available and the container requests at least an entire socket worth of CPUs.
- Allocate all the logical CPUs (hyperthreads) from the same physical CPU core if available and the container requests an entire core worth of CPUs.
- Allocate any available logical CPU, preferring to acquire CPUs from the same socket.
How is Performance Isolation Improved by CPU Manager?
With CPU manager static policy enabled, the workloads might perform better due to one of the following reasons:
- Exclusive CPUs can be allocated for the workload container but not the other containers. These containers do not share the CPU resources. As a result, we expect better performance due to isolation when an aggressor or a co-located workload is involved.
- There is a reduction in interference between the resources used by the workload since we can partition the CPUs among workloads. These resources might also include the cache hierarchies and memory bandwidth and not just the CPUs. This helps improve the performance of workloads in general.
- CPU Manager allocates CPUs in a topological order on a best-effort basis. If a whole socket is free, the CPU Manager will exclusively allocate the CPUs from the free socket to the workload. This boosts the performance of the workload by avoiding any cross-socket traffic.
- Containers in Guaranteed QoS pods are subject to CFS quota. Very bursty workloads may get scheduled, burn through their quota before the end of the period, and get throttled. During this time, there may or may not be meaningful work to do with those CPUs. Because of how the resource math lines up between CPU quota and number of exclusive CPUs allocated by the static policy, these containers are not subject to CFS throttling (quota is equal to the maximum possible cpu-time over the quota period).
Ok! Ok! Do You Have Any Results?
Glad you asked! To understand the performance improvement and isolation provided by enabling the CPU Manager feature in the Kubelet, we ran experiments on a dual-socket compute node (Intel Xeon CPU E5-2680 v3) with hyperthreading enabled. The node consists of 48 logical CPUs (24 physical cores each with 2-way hyperthreading). Here we demonstrate the performance benefits and isolation provided by the CPU Manager feature using benchmarks and real-world workloads for three different scenarios.
How Do I Interpret the Plots?
For each scenario, we show box plots that illustrates the normalized execution time and its variability of running a benchmark or real-world workload with and without CPU Manager enabled. The execution time of the runs are normalized to the best-performing run (1.00 on y-axis represents the best performing run and lower is better). The height of the box plot shows the variation in performance. For example if the box plot is a line, then there is no variation in performance across runs. In the box, middle line is the median, upper line is 75th percentile and lower line is 25th percentile. The height of the box (i.e., difference between 75th and 25th percentile) is defined as the interquartile range (IQR). Whiskers shows data outside that range and the points show outliers. The outliers are defined as any data 1.5x IQR below or above the lower or upper quartile respectively. Every experiment is run ten times.
Protection from Aggressor Workloads
We ran six benchmarks from the PARSEC benchmark suite (the victim workloads) co-located with a CPU stress container (the aggressor workload) with and without the CPU Manager feature enabled. The CPU stress container is run as a pod in the Burstable QoS class requesting 23 CPUs with --cpus 48 flag. The benchmarks are run as pods in the Guaranteed QoS class requesting a full socket worth of CPUs (24 CPUs on this system). The figure below plots the normalized execution time of running a benchmark pod co-located with the stress pod, with and without the CPU Manager static policy enabled. We see improved performance and reduced performance variability when static policy is enabled for all test cases.
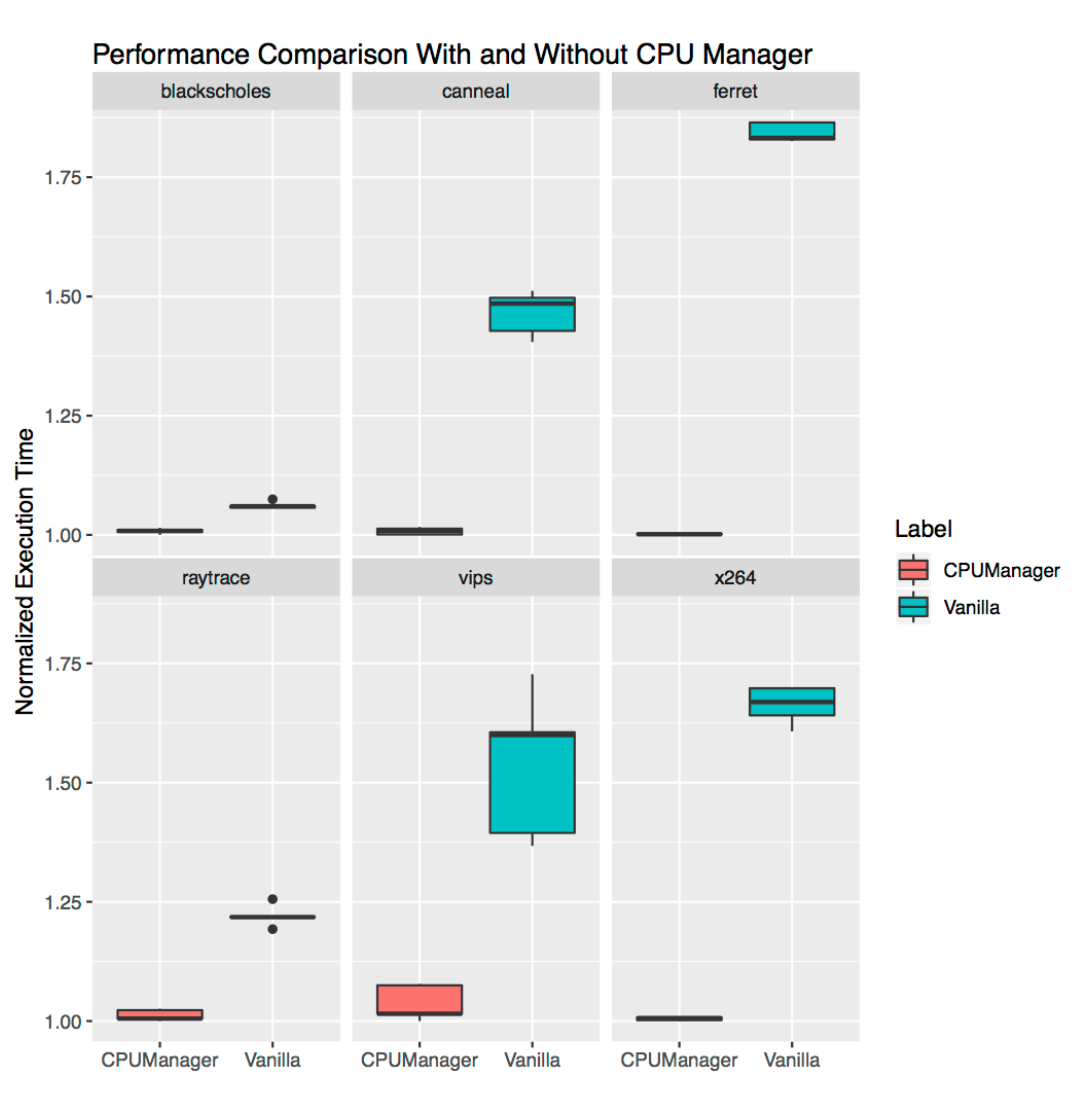
Performance Isolation for Co-located Workloads
In this section, we demonstrate how CPU manager can be beneficial to multiple workloads in a co-located workload scenario. In the box plots below we show the performance of two benchmarks (Blackscholes and Canneal) from the PARSEC benchmark suite run in the Guaranteed (Gu) and Burstable (Bu) QoS classes co-located with each other, with and without the CPU manager static policy enabled.
Starting from the top left and proceeding clockwise, we show the performance of Blackscholes in the Bu QoS class (top left), Canneal in the Bu QoS class (top right), Canneal in Gu QoS class (bottom right) and Blackscholes in the Gu QoS class (bottom left, respectively. In each case, they are co-located with Canneal in the Gu QoS class (top left), Blackscholes in the Gu QoS class (top right), Blackscholes in the Bu QoS class (bottom right) and Canneal in the Bu QoS class (bottom left) going clockwise from top left, respectively. For example, Bu-blackscholes-Gu-canneal plot (top left) is showing the performance of Blackscholes running in the Bu QoS class when co-located with Canneal running in the Gu QoS class. In each case, the pod in Gu QoS class requests cores worth a whole socket (i.e., 24 CPUs) and the pod in Bu QoS class request 23 CPUs.
There is better performance and less performance variation for both the co-located workloads in all the tests. For example, consider the case of Bu-blackscholes-Gu-canneal (top left) and Gu-canneal-Bu-blackscholes (bottom right). They show the performance of Blackscholes and Canneal run simultaneously with and without the CPU manager enabled. In this particular case, Canneal gets exclusive cores due to CPU manager since it is in the Gu QoS class and requesting integer number of CPU cores. But Blackscholes also gets exclusive set of CPUs as it is the only workload in the shared pool. As a result, both Blackscholes and Canneal get some performance isolation benefits due to the CPU manager.
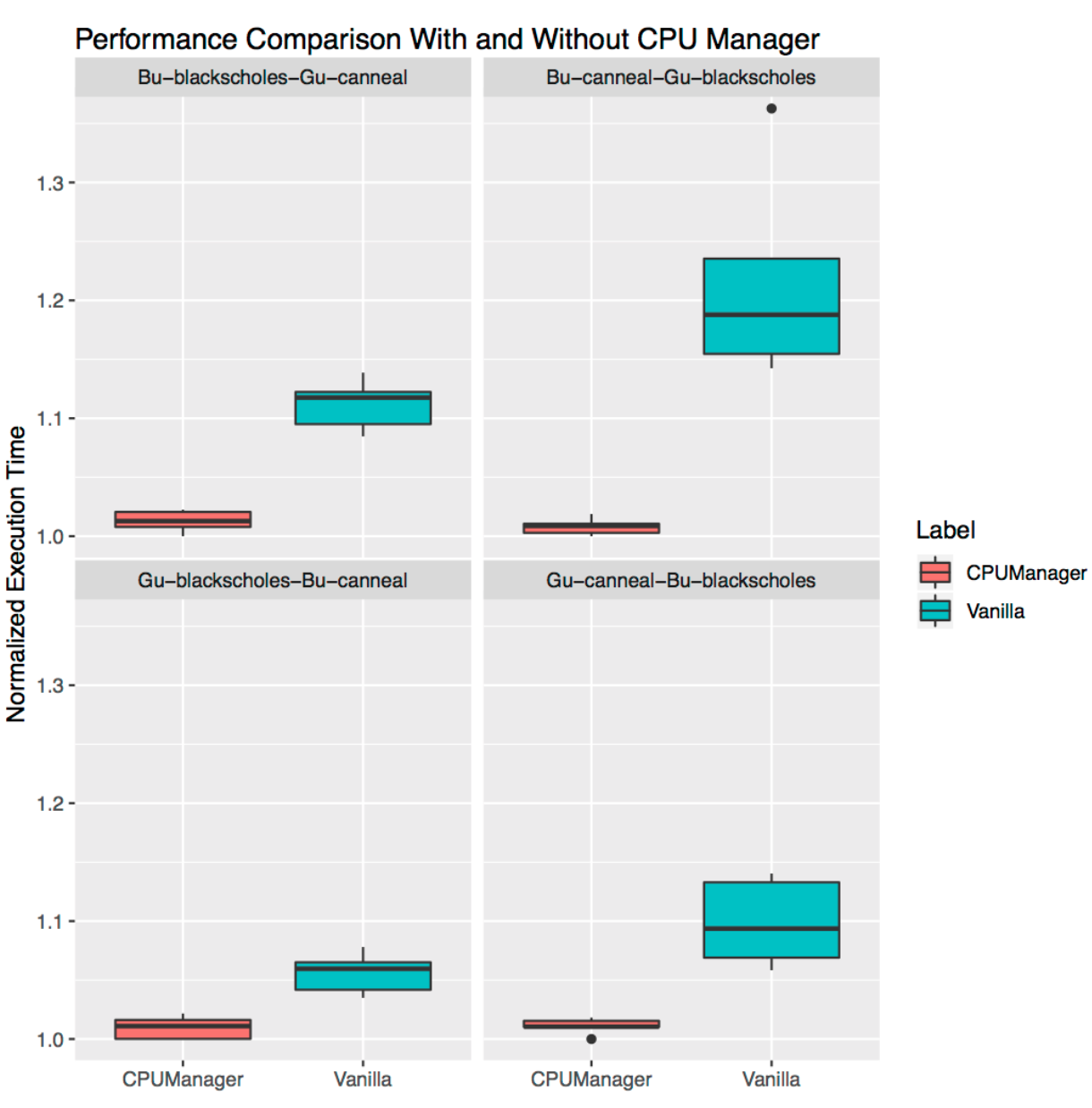
Performance Isolation for Stand-Alone Workloads
This section shows the performance improvement and isolation provided by the CPU manager for stand-alone real-world workloads. We use two workloads from the TensorFlow official models: wide and deep and ResNet. We use the census and CIFAR10 dataset for the wide and deep and ResNet models respectively. In each case the pods (wide and deep, ResNet request 24 CPUs which corresponds to a whole socket worth of cores. As shown in the plots, CPU manager enables better performance isolation in both cases.
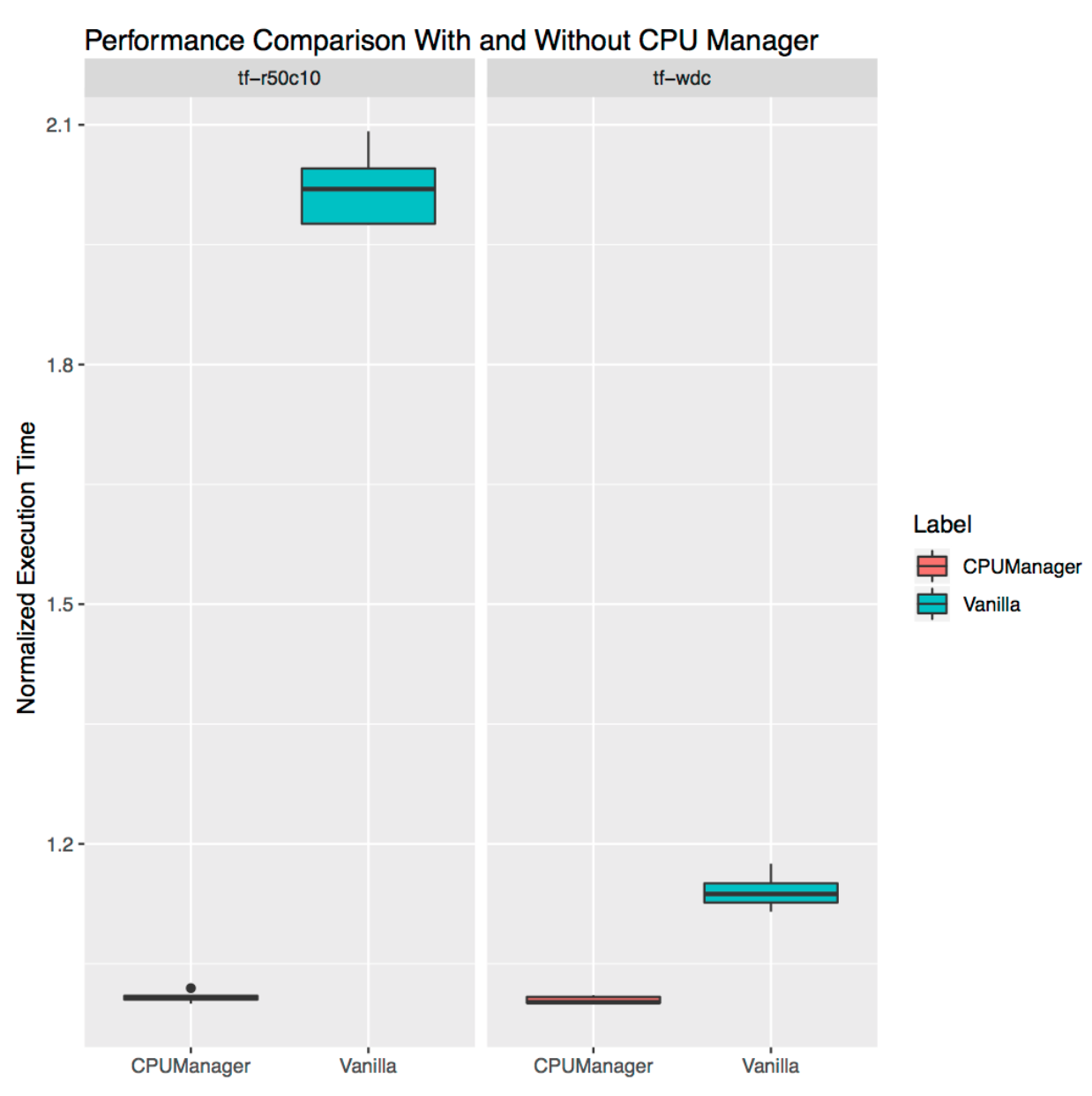
Limitations
Users might want to get CPUs allocated on the socket near to the bus which connects to an external device, such as an accelerator or high-performance network card, in order to avoid cross-socket traffic. This type of alignment is not yet supported by CPU manager. Since the CPU manager provides a best-effort allocation of CPUs belonging to a socket and physical core, it is susceptible to corner cases and might lead to fragmentation. The CPU manager does not take the isolcpus Linux kernel boot parameter into account, although this is reportedly common practice for some low-jitter use cases.
Acknowledgements
We thank the members of the community who have contributed to this feature or given feedback including members of WG-Resource-Management and SIG-Node. cmx.io (for the fun drawing tool).
Notices and Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to www.intel.com/benchmarks.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com.
Workload Configuration: https://gist.github.com/balajismaniam/fac7923f6ee44f1f36969c29354e3902 https://gist.github.com/balajismaniam/7c2d57b2f526a56bb79cf870c122a34c https://gist.github.com/balajismaniam/941db0d0ec14e2bc93b7dfe04d1f6c58 https://gist.github.com/balajismaniam/a1919010fe9081ca37a6e1e7b01f02e3 https://gist.github.com/balajismaniam/9953b54dd240ecf085b35ab1bc283f3c
System Configuration: CPU Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 2 Core(s) per socket: 12 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel Model name: Intel(R) Xeon(R) CPU E5-2680 v3 Memory 256 GB OS/Kernel Linux 3.10.0-693.21.1.el7.x86_64
Intel, the Intel logo, Xeon are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries.
*Other names and brands may be claimed as the property of others.
© Intel Corporation.
The History of Kubernetes & the Community Behind It
Authors: Brendan Burns (Distinguished Engineer, Microsoft)

It is remarkable to me to return to Portland and OSCON to stand on stage with members of the Kubernetes community and accept this award for Most Impactful Open Source Project. It was scarcely three years ago, that on this very same stage we declared Kubernetes 1.0 and the project was added to the newly formed Cloud Native Computing Foundation.
To think about how far we have come in that short period of time and to see the ways in which this project has shaped the cloud computing landscape is nothing short of amazing. The success is a testament to the power and contributions of this amazing open source community. And the daily passion and quality contributions of our endlessly engaged, world-wide community is nothing short of humbling.
Congratulations @kubernetesio for winning the "most impact" award at #OSCON I'm so proud to be a part of this amazing community! @CloudNativeFdn pic.twitter.com/5sRUYyefAK
— Jaice Singer DuMars (@jaydumars) July 19, 2018
👏 congrats @kubernetesio community on winning the #oscon Most Impact Award, we are proud of you! pic.twitter.com/5ezDphi6J6
— CNCF (@CloudNativeFdn) July 19, 2018
At a meetup in Portland this week, I had a chance to tell the story of Kubernetes’ past, its present and some thoughts about its future, so I thought I would write down some pieces of what I said for those of you who couldn’t be there in person.
It all began in the fall of 2013, with three of us: Craig McLuckie, Joe Beda and I were working on public cloud infrastructure. If you cast your mind back to the world of cloud in 2013, it was a vastly different place than it is today. Imperative bash scripts were only just starting to give way to declarative configuration of IaaS with systems. Netflix was popularizing the idea of immutable infrastructure but doing it with heavy-weight full VM images. The notion of orchestration, and certainly container orchestration existed in a few internet scale companies, but not in cloud and certainly not in the enterprise.
Docker changed all of that. By popularizing a lightweight container runtime and providing a simple way to package, distributed and deploy applications onto a machine, the Docker tooling and experience popularized a brand-new cloud native approach to application packaging and maintenance. Were it not for Docker’s shifting of the cloud developer’s perspective, Kubernetes simply would not exist.
I think that it was Joe who first suggested that we look at Docker in the summer of 2013, when Craig, Joe and I were all thinking about how we could bring a cloud native application experience to a broader audience. And for all three of us, the implications of this new tool were immediately obvious. We knew it was a critical component in the development of cloud native infrastructure.
But as we thought about it, it was equally obvious that Docker, with its focus on a single machine, was not the complete solution. While Docker was great at building and packaging individual containers and running them on individual machines, there was a clear need for an orchestrator that could deploy and manage large numbers of containers across a fleet of machines.
As we thought about it some more, it became increasingly obvious to Joe, Craig and I, that not only was such an orchestrator necessary, it was also inevitable, and it was equally inevitable that this orchestrator would be open source. This realization crystallized for us in the late fall of 2013, and thus began the rapid development of first a prototype, and then the system that would eventually become known as Kubernetes. As 2013 turned into 2014 we were lucky to be joined by some incredibly talented developers including Ville Aikas, Tim Hockin, Dawn Chen, Brian Grant and Daniel Smith.
Happy to see k8s team members winning the “most impact” award. #oscon pic.twitter.com/D6mSIiDvsU
— Bridget Kromhout (@bridgetkromhout) July 19, 2018
Kubernetes won the O'Reilly Most Impact Award. Thanks to our contributors and users! pic.twitter.com/T6Co1wpsAh
— Brian Grant (@bgrant0607) July 19, 2018
The initial goal of this small team was to develop a “minimally viable orchestrator.” From experience we knew that the basic feature set for such an orchestrator was:
- Replication to deploy multiple instances of an application
- Load balancing and service discovery to route traffic to these replicated containers
- Basic health checking and repair to ensure a self-healing system
- Scheduling to group many machines into a single pool and distribute work to them
Along the way, we also spent a significant chunk of our time convincing executive leadership that open sourcing this project was a good idea. I’m endlessly grateful to Craig for writing numerous whitepapers and to Eric Brewer, for the early and vocal support that he lent us to ensure that Kubernetes could see the light of day.
In June of 2014 when Kubernetes was released to the world, the list above was the sum total of its basic feature set. As an early stage open source community, we then spent a year building, expanding, polishing and fixing this initial minimally viable orchestrator into the product that we released as a 1.0 in OSCON in 2015. We were very lucky to be joined early on by the very capable OpenShift team which lent significant engineering and real world enterprise expertise to the project. Without their perspective and contributions, I don’t think we would be standing here today.
Three years later, the Kubernetes community has grown exponentially, and Kubernetes has become synonymous with cloud native container orchestration. There are more than 1700 people who have contributed to Kubernetes, there are more than 500 Kubernetes meetups worldwide and more than 42000 users have joined the #kubernetes-dev channel. What’s more, the community that we have built works successfully across geographic, language and corporate boundaries. It is a truly open, engaged and collaborative community, and in-and-of-itself and amazing achievement. Many thanks to everyone who has helped make it what it is today. Kubernetes is a commodity in the public cloud because of you.
But if Kubernetes is a commodity, then what is the future? Certainly, there are an endless array of tweaks, adjustments and improvements to the core codebase that will occupy us for years to come, but the true future of Kubernetes are the applications and experiences that are being built on top of this new, ubiquitous platform.
Kubernetes has dramatically reduced the complexity to build new developer experiences, and a myriad of new experiences have been developed or are in the works that provide simplified or targeted developer experiences like Functions-as-a-Service, on top of core Kubernetes-as-a-Service.
The Kubernetes cluster itself is being extended with custom resource definitions (which I first described to Kelsey Hightower on a walk from OSCON to a nearby restaurant in 2015), these new resources allow cluster operators to enable new plugin functionality that extend and enhance the APIs that their users have access to.
By embedding core functionality like logging and monitoring in the cluster itself and enabling developers to take advantage of such services simply by deploying their application into the cluster, Kubernetes has reduced the learning necessary for developers to build scalable reliable applications.
Finally, Kubernetes has provided a new, common vocabulary for expressing the patterns and paradigms of distributed system development. This common vocabulary means that we can more easily describe and discuss the common ways in which our distributed systems are built, and furthermore we can build standardized, re-usable implementations of such systems. The net effect of this is the development of higher quality, reliable distributed systems, more quickly.
It’s truly amazing to see how far Kubernetes has come, from a rough idea in the minds of three people in Seattle to a phenomenon that has redirected the way we think about cloud native development across the world. It has been an amazing journey, but what’s truly amazing to me, is that I think we’re only just now scratching the surface of the impact that Kubernetes will have. Thank you to everyone who has enabled us to get this far, and thanks to everyone who will take us further.
Brendan
Kubernetes Wins the 2018 OSCON Most Impact Award
Authors: Brian Grant (Principal Engineer, Google) and Tim Hockin (Principal Engineer, Google)
We are humbled to be recognized by the community with this award.
We had high hopes when we created Kubernetes. We wanted to change the way cloud applications were deployed and managed. Whether we’d succeed or not was very uncertain. And look how far we’ve come in such a short time.
The core technology behind Kubernetes was informed by lessons learned from Google’s internal infrastructure, but nobody can deny the enormous role of the Kubernetes community in the success of the project. The community, of which Google is a part, now drives every aspect of the project: the design, development, testing, documentation, releases, and more. That is what makes Kubernetes fly.
While we actively sought partnerships and community engagement, none of us anticipated just how important the open-source community would be, how fast it would grow, or how large it would become. Honestly, we really didn’t have much of a plan.
We looked to other open-source projects for inspiration and advice: Docker (now Moby), other open-source projects at Google such as Angular and Go, the Apache Software Foundation, OpenStack, Node.js, Linux, and others. But it became clear that there was no clear-cut recipe we could follow. So we winged it.
Rather than rehashing history, we thought we’d share two high-level lessons we learned along the way.
First, in order to succeed, community health and growth needs to be treated as a top priority. It’s hard, and it is time-consuming. It requires attention to both internal project dynamics and outreach, as well as constant vigilance to build and sustain relationships, be inclusive, maintain open communication, and remain responsive to contributors and users. Growing existing contributors and onboarding new ones is critical to sustaining project growth, but that takes time and energy that might otherwise be spent on development. These things have to become core values in order for contributors to keep them going.
Second, start simple with how the project is organized and operated, but be ready to adopt to more scalable approaches as it grows. Over time, Kubernetes has transitioned from what was effectively a single team and git repository to many subgroups (Special Interest Groups and Working Groups), sub-projects, and repositories. From manual processes to fully automated ones. From informal policies to formal governance.
We certainly didn’t get everything right or always adapt quickly enough, and we constantly struggle with scale. At this point, Kubernetes has more than 20,000 contributors and is approaching one million comments on its issues and pull requests, making it one of the fastest moving projects in the history of open source.
Thank you to all our contributors and to all the users who’ve stuck with us on the sometimes bumpy journey. This project would not be what it is today without the community.
11 Ways (Not) to Get Hacked
Author: Andrew Martin (ControlPlane)
Kubernetes security has come a long way since the project's inception, but still contains some gotchas. Starting with the control plane, building up through workload and network security, and finishing with a projection into the future of security, here is a list of handy tips to help harden your clusters and increase their resilience if compromised.
Part One: The Control Plane
The control plane is Kubernetes' brain. It has an overall view of every container and pod running on the cluster, can schedule new pods (which can include containers with root access to their parent node), and can read all the secrets stored in the cluster. This valuable cargo needs protecting from accidental leakage and malicious intent: when it's accessed, when it's at rest, and when it's being transported across the network.
1. TLS Everywhere
TLS should be enabled for every component that supports it to prevent traffic sniffing, verify the identity of the server, and (for mutual TLS) verify the identity of the client.
Note that some components and installation methods may enable local ports over HTTP and administrators should familiarize themselves with the settings of each component to identify potentially unsecured traffic.
This network diagram by Lucas Käldström demonstrates some of the places TLS should ideally be applied: between every component on the master, and between the Kubelet and API server. Kelsey Hightower's canonical Kubernetes The Hard Way provides detailed manual instructions, as does etcd's security model documentation.
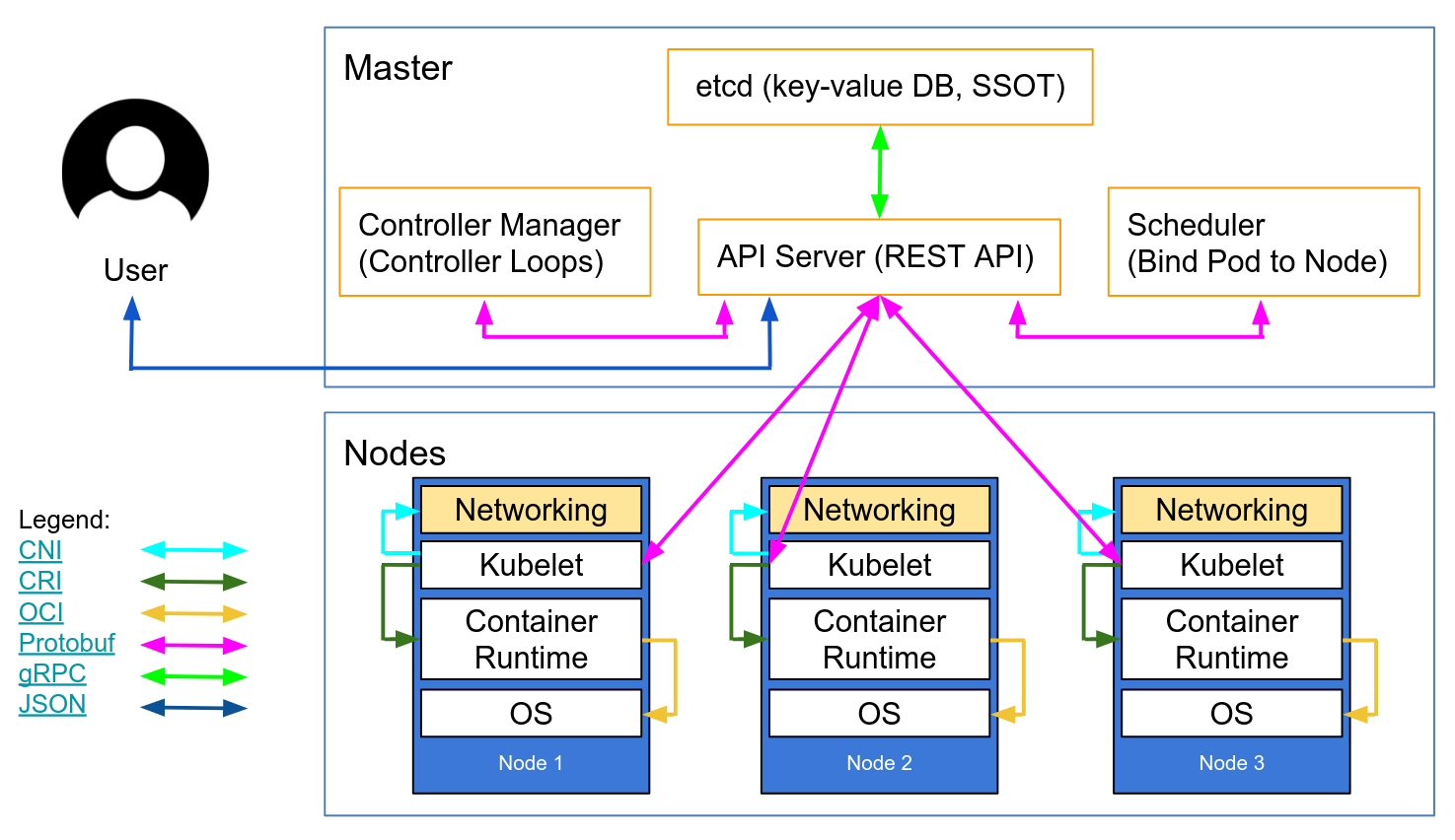
Autoscaling Kubernetes nodes was historically difficult, as each node requires a TLS key to connect to the master, and baking secrets into base images is not good practice. Kubelet TLS bootstrapping provides the ability for a new kubelet to create a certificate signing request so that certificates are generated at boot time.
2. Enable RBAC with Least Privilege, Disable ABAC, and Monitor Logs
Role-based access control provides fine-grained policy management for user access to resources, such as access to namespaces.
Kubernetes' ABAC (Attribute Based Access Control) has been superseded by RBAC since release 1.6, and should not be enabled on the API server. Use RBAC instead:
--authorization-mode=RBAC
Or use this flag to disable it in GKE:
--no-enable-legacy-authorization
There are plenty of good examples of RBAC policies for cluster services, as well as the docs. And it doesn't have to stop there - fine-grained RBAC policies can be extracted from audit logs with audit2rbac.
Incorrect or excessively permissive RBAC policies are a security threat in case of a compromised pod. Maintaining least privilege, and continuously reviewing and improving RBAC rules, should be considered part of the "technical debt hygiene" that teams build into their development lifecycle.
Audit Logging (beta in 1.10) provides customisable API logging at the payload (e.g. request and response), and also metadata levels. Log levels can be tuned to your organisation's security policy - GKE provides sane defaults to get you started.
For read requests such as get, list, and watch, only the request object is saved in the audit logs; the response object is not. For requests involving sensitive data such as Secret and ConfigMap, only the metadata is exported. For all other requests, both request and response objects are saved in audit logs.
Don't forget: keeping these logs inside the cluster is a security threat in case of compromise. These, like all other security-sensitive logs, should be transported outside the cluster to prevent tampering in the event of a breach.
3. Use Third Party Auth for API Server
Centralising authentication and authorisation across an organisation (aka Single Sign On) helps onboarding, offboarding, and consistent permissions for users.
Integrating Kubernetes with third party auth providers (like Google or GitHub) uses the remote platform's identity guarantees (backed up by things like 2FA) and prevents administrators having to reconfigure the Kubernetes API server to add or remove users.
Dex is an OpenID Connect Identity (OIDC) and OAuth 2.0 provider with pluggable connectors. Pusher takes this a stage further with some custom tooling, and there are some other helpers available with slightly different use cases.
4. Separate and Firewall your etcd Cluster
etcd stores information on state and secrets, and is a critical Kubernetes component - it should be protected differently from the rest of your cluster.
Write access to the API server's etcd is equivalent to gaining root on the entire cluster, and even read access can be used to escalate privileges fairly easily.
The Kubernetes scheduler will search etcd for pod definitions that do not have a node. It then sends the pods it finds to an available kubelet for scheduling. Validation for submitted pods is performed by the API server before it writes them to etcd, so malicious users writing directly to etcd can bypass many security mechanisms - e.g. PodSecurityPolicies.
etcd should be configured with peer and client TLS certificates, and deployed on dedicated nodes. To mitigate against private keys being stolen and used from worker nodes, the cluster can also be firewalled to the API server.
5. Rotate Encryption Keys
A security best practice is to regularly rotate encryption keys and certificates, in order to limit the "blast radius" of a key compromise.
Kubernetes will rotate some certificates automatically (notably, the kubelet client and server certs) by creating new CSRs as its existing credentials expire.
However, the symmetric encryption keys that the API server uses to encrypt etcd values are not automatically rotated - they must be rotated manually. Master access is required to do this, so managed services (such as GKE or AKS) abstract this problem from an operator.
Part Two: Workloads
With minimum viable security on the control plane the cluster is able to operate securely. But, like a ship carrying potentially dangerous cargo, the ship's containers must be protected to contain that cargo in the event of an unexpected accident or breach. The same is true for Kubernetes workloads (pods, deployments, jobs, sets, etc.) - they may be trusted at deployment time, but if they're internet-facing there's always a risk of later exploitation. Running workloads with minimal privileges and hardening their runtime configuration can help to mitigate this risk.
6. Use Linux Security Features and PodSecurityPolicies
The Linux kernel has a number of overlapping security extensions (capabilities, SELinux, AppArmor, seccomp-bpf) that can be configured to provide least privilege to applications.
Tools like bane can help to generate AppArmor profiles, and docker-slim for seccomp profiles, but beware - a comprehensive test suite it required to exercise all code paths in your application when verifying the side effects of applying these policies.
PodSecurityPolicies can be used to mandate the use of security extensions and other Kubernetes security directives. They provide a minimum contract that a pod must fulfil to be submitted to the API server - including security profiles, the privileged flag, and the sharing of host network, process, or IPC namespaces.
These directives are important, as they help to prevent containerised processes from escaping their isolation boundaries, and Tim Allclair's example PodSecurityPolicy is a comprehensive resource that you can customise to your use case.
7. Statically Analyse YAML
Where PodSecurityPolicies deny access to the API server, static analysis can also be used in the development workflow to model an organisation's compliance requirements or risk appetite.
Sensitive information should not be stored in pod-type YAML resource (deployments, pods, sets, etc.), and sensitive configmaps and secrets should be encrypted with tools such as vault (with CoreOS's operator), git-crypt, sealed secrets, or cloud provider KMS.
Static analysis of YAML configuration can be used to establish a baseline for runtime security. kubesec generates risk scores for resources:
{
"score": -30,
"scoring": {
"critical": [{
"selector": "containers[] .securityContext .privileged == true",
"reason": "Privileged containers can allow almost completely unrestricted host access"
}],
"advise": [{
"selector": "containers[] .securityContext .runAsNonRoot == true",
"reason": "Force the running image to run as a non-root user to ensure least privilege"
}, {
"selector": "containers[] .securityContext .capabilities .drop",
"reason": "Reducing kernel capabilities available to a container limits its attack surface",
"href": "/docs/tasks/configure-pod-container/security-context/"
}]
}
}
And kubetest is a unit test framework for Kubernetes configurations:
#// vim: set ft=python:
def test_for_team_label():
if spec["kind"] == "Deployment":
labels = spec["spec"]["template"]["metadata"]["labels"]
assert_contains(labels, "team", "should indicate which team owns the deployment")
test_for_team_label()
These tools "shift left" (moving checks and verification earlier in the development cycle). Security testing in the development phase gives users fast feedback about code and configuration that may be rejected by a later manual or automated check, and can reduce the friction of introducing more secure practices.
8. Run Containers as a Non-Root User
Containers that run as root frequently have far more permissions than their workload requires which, in case of compromise, could help an attacker further their attack.
Containers still rely on the traditional Unix security model (called discretionary access control or DAC) - everything is a file, and permissions are granted to users and groups.
User namespaces are not enabled in Kubernetes. This means that a container's user ID table maps to the host's user table, and running a process as the root user inside a container runs it as root on the host. Although we have layered security mechanisms to prevent container breakouts, running as root inside the container is still not recommended.
Many container images use the root user to run PID 1 - if that process is compromised, the attacker has root in the container, and any mis-configurations become much easier to exploit.
Bitnami has done a lot of work moving their container images to non-root users (especially as OpenShift requires this by default), which may ease a migration to non-root container images.
This PodSecurityPolicy snippet prevents running processes as root inside a container, and also escalation to root:
# Required to prevent escalations to root.
allowPrivilegeEscalation: false
runAsUser:
# Require the container to run without root privileges.
rule: 'MustRunAsNonRoot'
Non-root containers cannot bind to the privileged ports under 1024 (this is gated by the CAP_NET_BIND_SERVICE kernel capability), but services can be used to disguise this fact. In this example the fictional MyApp application is bound to port 8443 in its container, but the service exposes it on 443 by proxying the request to the targetPort:
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 443
targetPort: 8443
Having to run workloads as a non-root user is not going to change until user namespaces are usable, or the ongoing work to run containers without root lands in container runtimes.
9. Use Network Policies
By default, Kubernetes networking allows all pod to pod traffic; this can be restricted using a Network Policy .
Traditional services are restricted with firewalls, which use static IP and port ranges for each service. As these IPs very rarely change they have historically been used as a form of identity. Containers rarely have static IPs - they are built to fail fast, be rescheduled quickly, and use service discovery instead of static IP addresses. These properties mean that firewalls become much more difficult to configure and review.
As Kubernetes stores all its system state in etcd it can configure dynamic firewalling - if it is supported by the CNI networking plugin. Calico, Cilium, kube-router, Romana, and Weave Net all support network policy.
It should be noted that these policies fail-closed, so the absence of a podSelector here defaults to a wildcard:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector:
Here's an example NetworkPolicy that denies all egress except UDP 53 (DNS), which also prevents inbound connections to your application. NetworkPolicies are stateful, so the replies to outbound requests still reach the application.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: myapp-deny-external-egress
spec:
podSelector:
matchLabels:
app: myapp
policyTypes:
- Egress
egress:
- ports:
- port: 53
protocol: UDP
- to:
- namespaceSelector: {}
Kubernetes network policies can not be applied to DNS names. This is because DNS can resolve round-robin to many IPs, or dynamically based on the calling IP, so network policies can be applied to a fixed IP or podSelector (for dynamic Kubernetes IPs) only.
Best practice is to start by denying all traffic for a namespace and incrementally add routes to allow an application to pass its acceptance test suite. This can become complex, so ControlPlane hacked together netassert - network security testing for DevSecOps workflows with highly parallelised nmap:
k8s: # used for Kubernetes pods
deployment: # only deployments currently supported
test-frontend: # pod name, defaults to `default` namespace
test-microservice: 80 # `test-microservice` is the DNS name of the target service
test-database: -80 # `test-frontend` should not be able to access test-database’s port 80
169.254.169.254: -80, -443 # AWS metadata API
metadata.google.internal: -80, -443 # GCP metadata API
new-namespace:test-microservice: # `new-namespace` is the namespace name
test-database.new-namespace: 80 # longer DNS names can be used for other namespaces
test-frontend.default: 80
169.254.169.254: -80, -443 # AWS metadata API
metadata.google.internal: -80, -443 # GCP metadata API
Cloud provider metadata APIs are a constant source of escalation (as the recent Shopify bug bounty demonstrates), so specific tests to confirm that the APIs are blocked on the container network helps to guard against accidental misconfiguration.
10. Scan Images and Run IDS
Web servers present an attack surface to the network they're attached to: scanning an image's installed files ensures the absence of known vulnerabilities that an attacker could exploit to gain remote access to the container. An IDS (Intrusion Detection System) detects them if they do.
Kubernetes permits pods into the cluster through a series of admission controller gates, which are applied to pods and other resources like deployments. These gates can validate each pod for admission or change its contents, and they now support backend webhooks.
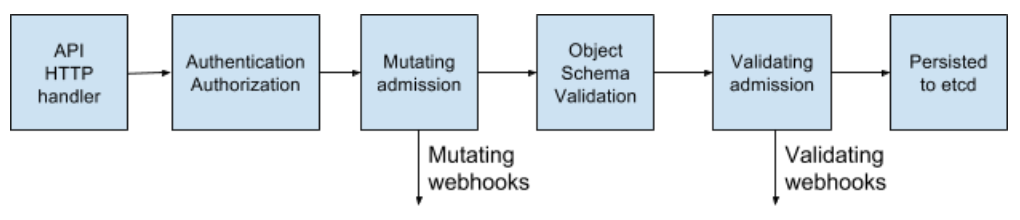
These webhooks can be used by container image scanning tools to validate images before they are deployed to the cluster. Images that have failed checks can be refused admission.
Scanning container images for known vulnerabilities can reduce the window of time that an attacker can exploit a disclosed CVE. Free tools such as CoreOS's Clair and Aqua's Micro Scanner should be used in a deployment pipeline to prevent the deployment of images with critical, exploitable vulnerabilities.
Tools such as Grafeas can store image metadata for constant compliance and vulnerability checks against a container's unique signature (a content addressable hash). This means that scanning a container image with that hash is the same as scanning the images deployed in production, and can be done continually without requiring access to production environments.
Unknown Zero Day vulnerabilities will always exist, and so intrusion detection tools such as Twistlock, Aqua, and Sysdig Secure should be deployed in Kubernetes. IDS detects unusual behaviours in a container and pauses or kills it - Sysdig's Falco is a an Open Source rules engine, and an entrypoint to this ecosystem.
Part Three: The Future
The next stage of security's "cloud native evolution" looks to be the service mesh, although adoption may take time - migration involves shifting complexity from applications to the mesh infrastructure, and organisations will be keen to understand best-practice.

11. Run a Service Mesh
A service mesh is a web of encrypted persistent connections, made between high performance "sidecar" proxy servers like Envoy and Linkerd. It adds traffic management, monitoring, and policy - all without microservice changes.
Offloading microservice security and networking code to a shared, battle tested set of libraries was already possible with Linkerd, and the introduction of Istio by Google, IBM, and Lyft, has added an alternative in this space. With the addition of SPIFFE for per-pod cryptographic identity and a plethora of other features, Istio could simplify the deployment of the next generation of network security.
In "Zero Trust" networks there may be no need for traditional firewalling or Kubernetes network policy, as every interaction occurs over mTLS (mutual TLS), ensuring that both parties are not only communicating securely, but that the identity of both services is known.
This shift from traditional networking to Cloud Native security principles is not one we expect to be easy for those with a traditional security mindset, and the Zero Trust Networking book from SPIFFE's Evan Gilman is a highly recommended introduction to this brave new world.
Istio 0.8 LTS is out, and the project is rapidly approaching a 1.0 release. Its stability versioning is the same as the Kubernetes model: a stable core, with individual APIs identifying themselves under their own alpha/beta stability namespace. Expect to see an uptick in Istio adoption over the coming months.
Conclusion
Cloud Native applications have a more fine-grained set of lightweight security primitives to lock down workloads and infrastructure. The power and flexibility of these tools is both a blessing and curse - with insufficient automation it has become easier to expose insecure workloads which permit breakouts from the container or its isolation model.
There are more defensive tools available than ever, but caution must be taken to reduce attack surfaces and the potential for misconfiguration.
However if security slows down an organisation's pace of feature delivery it will never be a first-class citizen. Applying Continuous Delivery principles to the software supply chain allows an organisation to achieve compliance, continuous audit, and enforced governance without impacting the business's bottom line.
Iteratating quickly on security is easiest when supported by a comprehensive test suite. This is achieved with Continuous Security - an alternative to point-in-time penetration tests, with constant pipeline validation ensuring an organisation's attack surface is known, and the risk constantly understood and managed.
This is ControlPlane's modus operandi: if we can help kickstart a Continuous Security discipline, deliver Kubernetes security and operations training, or co-implement a secure cloud native evolution for you, please get in touch.
Andrew Martin is a co-founder at @controlplaneio and tweets about cloud native security at @sublimino
How the sausage is made: the Kubernetes 1.11 release interview, from the Kubernetes Podcast
Author: Craig Box (Google)
At KubeCon EU, my colleague Adam Glick and I were pleased to announce the Kubernetes Podcast from Google. In this weekly conversation, we focus on all the great things that are happening in the world of Kubernetes and Cloud Native. From the news of the week, to interviews with people in the community, we help you stay up to date on everything Kubernetes.
We recently had the pleasure of speaking to the release manager for Kubernetes 1.11, Josh Berkus from Red Hat, and the release manager for the upcoming 1.12, Tim Pepper from VMware.
In this conversation we learned about the release process, the impact of quarterly releases on end users, and how Kubernetes is like baking.
I encourage you to listen to the podcast version if you have a commute, or a dog to walk. If you like what you hear, we encourage you to subscribe! In case you're short on time, or just want to browse quickly, we are delighted to share the transcript with you.
CRAIG BOX: First of all, congratulations both, and thank you.
JOSH BERKUS: Well, thank you. Congratulations for me, because my job is done.
[LAUGHTER]
Congratulations and sympathy for Tim.
[LAUGH]
TIM PEPPER: Thank you, and I guess thank you?
[LAUGH]
ADAM GLICK: For those that don't know a lot about the process, why don't you help people understand — what is it like to be the release manager? What's the process that a release goes through to get to the point when everyone just sees, OK, it's released — 1.11 is available? What does it take to get up to that?
JOSH BERKUS: We have a quarterly release cycle. So every three months, we're releasing. And ideally and fortunately, this is actually now how we are doing things. Somewhere around two, three weeks before the previous release, somebody volunteers to be the release lead. That person is confirmed by SIG Release. So far, we've never had more than one volunteer, so there hasn't been really a fight about it.
And then that person starts working with others to put together a team called the release team. Tim's just gone through this with Stephen Augustus and picking out a whole bunch of people. And then after or a little before— probably after, because we want to wait for the retrospective from the previous release— the release lead then sets a schedule for the upcoming release, as in when all the deadlines will be.
And this is a thing, because we're still tinkering with relative deadlines, and how long should code freeze be, and how should we track features? Because we don't feel that we've gotten down that sort of cadence perfectly yet. I mean, like, we've done pretty well, but we don't feel like we want to actually set [in stone], this is the schedule for each and every release.
Also, we have to adjust the schedule because of holidays, right? Because you can't have the code freeze deadline starting on July 4 or in the middle of design or sometime else when we're going to have a large group of contributors who are out on vacation.
TIM PEPPER: This is something I've had to spend some time looking at, thinking about 1.12. Going back to early June as we were tinkering with the code freeze date, starting to think about, well, what are the implications going to be on 1.12? When would these things start falling on the calendar? And then also for 1.11, we had one complexity. If we slipped the release past this week, we start running into the US 4th of July holiday, and we're not likely to get a lot done.
So much of a slip would mean slipping into the middle of July before we'd really know that we were successfully triaging things. And worst case maybe, we're quite a bit later into July.
So instead of quarterly with a three-month sort of cadence, well, maybe we've accidentally ended up chopping out one month out of the next release or pushing it quite a bit into the end of the year. And that made the deliberation around things quite complex, but thankfully this week, everything's gone smoothly in the end.
CRAIG BOX: All the releases so far have been one quarter — they've been a 12-week release cycle, give or take. Is that something that you think will continue going forward, or is the release team thinking about different ways they could run releases?
TIM PEPPER: The whole community is thinking about this. There are voices who'd like the cadence to be faster, and there are voices who'd like it to be shorter. And there's good arguments for both.
ADAM GLICK: Because it's interesting. It sounds like it is a date-driven release cycle versus a feature-driven release cycle.
JOSH BERKUS: Yeah, certainly. I really honestly think everybody in the world of software recognizes that feature-driven release cycles just don't work. And a big part of the duties of the release team collectively— several members of the team do this— is yanking things out of the release that are not ready. And the hard part of that is figuring out which things aren't ready, right? Because the person who's working on it tends to be super optimistic about what they can get done and what they can get fixed before the deadline.
ADAM GLICK: Of course.
TIM PEPPER: And this is one of the things I think that's useful about the process we have in place on the release team for having shadows who spend some time on the release team, working their way up into more of a lead position and gaining some experience, starting to get some exposure to see that optimism and see the processes for vetting.
And it's even an overstatement to say the process. Just see the way that we build the intuition for how to vet and understand and manage the risk, and really go after and chase things down proactively and early to get resolution in a timely way versus continuing to just all be optimistic and letting things maybe languish and put a release at risk.
CRAIG BOX: I've been reading this week about the introduction of feature branches to Kubernetes. The new server-side apply feature, for example, is being built in a branch so that it didn't have to be half-built in master and then ripped out again as the release approached, if the feature wasn't ready. That seems to me like something that's a normal part of software development? Is there a reason it's taken so long to bring that to core Kubernetes?
JOSH BERKUS: I don't actually know the history of why we're not using feature branches. I mean, the reason why we're not using feature branches pervasively now is that we have to transition from a different system. And I'm not really clear on how we adopted that linear development system. But it's certainly something we discussed on the release team, because there were issues of features that we thought were going to be ready, and then developed major problems. And we're like, if we have to back this out, that's going to be painful. And we did actually have to back one feature out, which involved not pulling out a Git commit, but literally reversing the line changes, which is really not how you want to be doing things.
CRAIG BOX: No.
TIM PEPPER: The other big benefit, I think, to the release branches if they are well integrated with the CI system for continuous integration and testing, you really get the feedback, and you can demonstrate, this set of stuff is ready. And then you can do deferred commitment on the master branch. And what comes in to a particular release on the timely cadence that users are expecting is stuff that's ready. You don't have potentially destabilizing things, because you can get a lot more proof and evidence of readiness.
ADAM GLICK: What are you looking at in terms of the tool chain that you're using to do this? You mentioned a couple of things, and I know it's obviously run through GitHub. But I imagine you have a number of other tools that you're using in order to manage the release, to make sure that you understand what's ready, what's not. You mentioned balancing between people who are very optimistic about the feature they're working on making it in versus the time-driven deadline, and balancing those two. Is that just a manual process, or do you have a set of tools that help you do that?
JOSH BERKUS: Well, there's code review, obviously. So just first of all, process was somebody wants to actually put in a feature, commit, or any kind of merge really, right? So that has to be assigned to one of the SIGs, one of these Special Interest Groups. Possibly more than one, depending on what areas it touches.
And then two generally overlapping groups of people have to approve that. One would be the SIG that it's assigned to, and the second would be anybody represented in the OWNERS files in the code tree of the directories which get touched.
Now sometimes those are the same group of people. I'd say often, actually. But sometimes they're not completely the same group of people, because sometimes you're making a change to the network, but that also happens to touch GCP support and OpenStack support, and so they need to review it as well.
So the first part is the human part, which is a bunch of other people need to look at this. And possibly they're going to comment "Hey. This is a really weird way to do this. Do you have a reason for it?"
Then the second part of it is the automated testing that happens, the automated acceptance testing that happens via webhook on there. And actually, one of the things that we did that was a significant advancement in this release cycle— and by we, I actually mean not me, but the great folks at SIG Scalability did— was add an additional acceptance test that does a mini performance test.
Because one of the problems we've had historically is our major performance tests are large and take a long time to run, and so by the time we find out that we're failing the performance tests, we've already accumulated, you know, 40, 50 commits. And so now we're having to do git bisect to find out which of those commits actually caused the performance regression, which can make them very slow to address.
And so adding that performance pre-submit, the performance acceptance test really has helped stabilize performance in terms of new commits. So then we have that level of testing that you have to get past.
And then when we're done with that level of testing, we run a whole large battery of larger tests— end-to-end tests, performance tests, upgrade and downgrade tests. And one of the things that we've added recently and we're integrating to the process something called conformance tests. And the conformance test is we're testing whether or not you broke backwards compatibility, because it's obviously a big deal for Kubernetes users if you do that when you weren't intending to.
One of the busiest roles in the release team is a role called CI Signal. And it's that person's job just to watch all of the tests for new things going red and then to try to figure out why they went red and bring it to people's attention.
ADAM GLICK: I've often heard what you're referring to kind of called a breaking change, because it breaks the existing systems that are running. How do you identify those to people so when they see, hey, there's a new version of Kubernetes out there, I want to try it out, is that just going to release notes? Or is there a special way that you identify breaking changes as opposed to new features?
JOSH BERKUS: That goes into release notes. I mean, keep in mind that one of the things that happens with Kubernetes' features is we go through this alpha, beta, general availability phase, right? So a feature's alpha for a couple of releases and then becomes beta for a release or two, and then it becomes generally available. And part of the idea of having this that may require a feature to go through that cycle for a year or more before its general availability is by the time it's general availability, we really want it to be, we are not going to change the API for this.
However, stuff happens, and we do occasionally have to do those. And so far, our main way to identify that to people actually is in the release notes. If you look at the current release notes, there are actually two things in there right now that are sort of breaking changes.
One of them is the bit with priority and preemption in that preemption being on by default now allows badly behaved users of the system to cause trouble in new ways. I'd actually have to look at the release notes to see what the second one was...
TIM PEPPER: The JSON capitalization case sensitivity.
JOSH BERKUS: Right. Yeah. And that was one of those cases where you have to break backwards compatibility, because due to a library switch, we accidentally enabled people using JSON in a case-insensitive way in certain APIs, which was never supposed to be the case. But because we didn't have a specific test for that, we didn't notice that we'd done it.
And so for three releases, people could actually shove in malformed JSON, and Kubernetes would accept it. Well, we have to fix that now. But that does mean that there are going to be users out in the field who have malformed JSON in their configuration management that is now going to break.
CRAIG BOX: But at least the good news is Kubernetes was always outputting correct formatted JSON during this period, I understand.
JOSH BERKUS: Mm-hmm.
TIM PEPPER: I think that also kind of reminds of one of the other areas— so kind of going back to the question of, well, how do you share word of breaking changes? Well, one of the ways you do that is to have as much quality CI that you can to catch these things that are important. Give the feedback to the developer who's making the breaking change, such that they don't make the breaking change. And then you don't actually have to communicate it out to users.
So some of this is bound to happen, because you always have test escapes. But it's also a reminder of the need to ensure that you're also really building and maintaining your test cases and the quality and coverage of your CI system over time.
ADAM GLICK: What do you mean when you say test escapes?
TIM PEPPER: So I guess it's a term in the art, but for those who aren't familiar with it, you have intended behavior that wasn't covered by test, and as a result, an unintended change happens to that. And instead of your intended behavior being shipped, you're shipping something else.
JOSH BERKUS: The JSON change is a textbook example of this, which is we were testing that the API would continue to accept correct JSON. We were not testing adequately that it wouldn't accept incorrect JSON.
TIM PEPPER: A test escape, another way to think of it as you shipped a bug because there was not a test case highlighting the possibility of the bug.
ADAM GLICK: It's the classic, we tested to make sure the feature worked. We didn't test to make sure that breaking things didn't work.
TIM PEPPER: It's common for us to focus on "I've created this feature and I'm testing the positive cases". And this also comes to thinking about things like secure by default and having a really robust system. A harder piece of engineering often is to think about the failure cases and really actively manage those well.
JOSH BERKUS: I had a conversation with a contributor recently where it became apparent that contributor had never worked on a support team, because their conception of a badly behaved user was, like, a hacker, right? An attacker who comes from outside.
And I'm like, no, no, no. You're stable of badly behaved users is your own staff. You know, they will do bad things, not necessarily intending to do bad things, but because they're trying to take a shortcut. And that is actually your primary concern in terms of preventing breaking the system.
CRAIG BOX: Josh, what was your preparation to be release manager for 1.11?
JOSH BERKUS: I was on the release team for two cycles, plus I was kind of auditing the release team for half a cycle before that. So in 1.9, I originally joined to be the shadow for bug triage, except I ended up not being the shadow, because the person who was supposed to be the lead for bug triage then dropped out. Then I ended up being the bug triage lead, and had to kind of improvise it because there wasn't documentation on what was involved in the role at the time.
And then I was bug triage lead for a second cycle, for the 1.10 cycle, and then took over as release lead for the cycle. And one of the things on my to-do list is to update the requirements to be release lead, because we actually do have written requirements, and to say that the expectation now is that you spend at least two cycles on the release team, one of them either as a lead or as a shadow to the release lead.
CRAIG BOX: And is bug triage lead just what it sounds like?
JOSH BERKUS: Yeah. Pretty much. There's more tracking involved than triage. Part of it is just deficiencies in tooling, something we're looking to address. But things like GitHub API limitations make it challenging to build automated tools that help us intelligently track issues. And we are actually working with GitHub on that. Like, they've been helpful. It's just, they have their own scaling problems.
But then beyond that, you know, a lot of that, it's what you would expect it to be in terms of what triage says, right? Which is looking at every issue and saying, first of all, is this a real issue? Second, is it a serious issue? Third, who needs to address this?
And that's a lot of the work, because for anybody who is a regular contributor to Kubernetes, the number of GitHub notifications that they receive per day means that most of us turn our GitHub notifications off.
CRAIG BOX: Indeed.
JOSH BERKUS: Because it's just this fire hose. And as a result, when somebody really needs to pay attention to something right now, that generally requires a human to go and track them down by email or Slack or whatever they prefer. Twitter in some cases. I've done that. And say, hey. We really need you to look at this issue, because it's about to hold up the beta release.
ADAM GLICK: When you look at the process that you're doing now, what are the changes that are coming in the future that will make the release process even better and easier?
JOSH BERKUS: Well, we just went through this whole retro, and I put in some recommendations for things. Obviously, some additional automation, which I'm going to be looking at doing now that I'm cycling off of the release team for a quarter and can actually look at more longer term goals, will help, particularly now that we've addressed actually some of our GitHub data flow issues.
Beyond that, I put in a whole bunch of recommendations in the retro, but it's actually up to Tim which recommendations he's going to try to implement. So I'll let him [comment].
TIM PEPPER: I think one of the biggest changes that happened in the 1.11 cycle is this emphasis on trying to keep our continuous integration test status always green. That is huge for software development and keeping velocity. If you have this more, I guess at this point antiquated notion of waterfall development, where you do feature development for a while and are accepting of destabilization, and somehow later you're going to come back and spend a period on stabilization and fixing, that really elongates the feedback loop for developers.
And they don't realize what was broken, and the problems become much more complex to sort out as time goes by. One, developers aren't thinking about what it was that they'd been working on anymore. They've lost the context to be able to efficiently solve the problem.
But then you start also getting interactions. Maybe a bug was introduced, and other people started working around it or depending on it, and you get complex dependencies then that are harder to fix. And when you're trying to do that type of complex resolution late in the cycle, it becomes untenable over time. So I think continuing on that and building on it, I'm seeing a little bit more focus on test cases and meaningful test coverage. I think that's a great cultural change to have happening.
And maybe because I'm following Josh into this role from a bug triage position and in his mentions earlier of just the communications and tracking involved with that versus triage, I do have a bit of a concern that at times, email and Slack are relatively quiet. Some of the SIG meeting notes are a bit sparse or YouTube videos slow to upload. So the general artifacts around choice making I think is an area where we need a little more rigor. So I'm hoping to see some of that.
And that can be just as subtle as commenting on issues like, hey, this commit doesn't say what it's doing. And for that reason on the release team, we can't assess its risk versus value. So could you give a little more information here? Things like that give more information both to the release team and the development community as well, because this is open source. And to collaborate, you really do need to communicate in depth.
CRAIG BOX: Speaking of cultural changes, professional baker to Kubernetes' release lead sounds like quite a journey.
JOSH BERKUS: There was a lot of stuff in between.
CRAIG BOX: Would you say there are a lot of similarities?
JOSH BERKUS: You know, believe it or not, there actually are similarities. And here's where it's similar, because I was actually thinking about this earlier. So when I was a professional baker, one of the things that I had to do was morning pastry. Like, I was actually in charge of doing several other things for custom orders, but since I had to come to work at 3:00 AM anyway— which also distressingly has similarities with some of this process. Because I had to come to work at 3:00 AM anyway, one of my secondary responsibilities was traying the morning pastry.
And one of the parts of that is you have this great big gas-fired oven with 10 rotating racks in it that are constantly rotating. Like, you get things in and out in the oven by popping them in and out while the racks are moving. That takes a certain amount of skill. You get burn marks on your wrists for your first couple of weeks of work. And then different pastries require a certain number of rotations to be done.
And there's a lot of similarities to the release cadence, because what you're doing is you're popping something in the oven or you're seeing something get kicked off, and then you have a certain amount of time before you need to check on it or you need to pull it out. And you're doing that in parallel with a whole bunch of other things. You know, with 40 other trays.
CRAIG BOX: And with presumably a bunch of colleagues who are all there at the same time.
JOSH BERKUS: Yeah. And the other thing is that these deadlines are kind of absolute, right? You can't say, oh, well, I was reading a magazine article, and I didn't have time to pull that tray out. It's too late. The pastry is burned, and you're going to have to throw it away, and they're not going to have enough pastry in the front case for the morning rush. And the customers are not interested in your excuses for that.
So from that perspective, from the perspective of saying, hey, we have a bunch of things that need to happen in parallel, they have deadlines and those deadlines are hard deadlines, there it's actually fairly similar.
CRAIG BOX: Tim, do you have any other history that helped get you to where you are today?
TIM PEPPER: I think in some ways I'm more of a traditional journey. I've got a computer engineering bachelor's degree. But I'm also maybe a bit of an outlier. In the late '90s, I found a passion for open source and Linux. Maybe kind of an early adopter, early believer in that.
And was working in the industry in the Bay Area for a while. Got involved in the Silicon Valley and Bay Area Linux users groups a bit, and managed to find work as a Linux sysadmin, and then doing device driver and kernel work and on up into distro. So that was all kind of standard in a way. And then I also did some other work around hardware enablement, high-performance computing, non-uniform memory access. Things that are really, really systems work.
And then about three years ago, my boss was really bending my ear and trying to get me to work on this cloud-related project. And that just felt so abstract and different from the low-level bits type of stuff that I'd been doing.
But kind of grudgingly, I eventually came around to the realization that the cloud is interesting, and it's so much more complex than local machine-only systems work, the type of things that I'd been doing before. It's massively distributed and you have a high-latency, low-reliability interconnect on all the nodes in the distributed network. So it's wildly complex engineering problems that need solved.
And so that got me interested. Started working then on this open source orchestrator for virtual machines and containers. It was written in Go and was having a lot of fun. But it wasn't Kubernetes, and it was becoming clear that Kubernetes was taking off. So about a year ago, I made the deliberate choice to move over to Kubernetes work.
ADAM GLICK: Previously, Josh, you spoke a little bit about your preparation for becoming a release manager. For other folks that are interested in getting involved in the community and maybe getting involved in release management, should they follow the same path that you did? Or what are ways that would be good for them to get involved? And for you, Tim, how you've approached the preparation for taking on the next release.
JOSH BERKUS: The great thing with the release team is that we have this formal mentorship path. And it's fast, right? That's the advantage of releasing quarterly, right? Is that within six months, you can go from joining the team as a shadow to being the release lead if you have the time. And you know, by the time you work your way up to release time, you better have support from your boss about this, because you're going to end up spending a majority of your work time towards the end of the release on release management.
So the answer is to sign up to look when we're getting into the latter half of release cycle, to sign up as a shadow. Or at the beginning of a release cycle, to sign up as a shadow. Some positions actually can reasonably use more than one shadow. There's some position that just require a whole ton of legwork like release notes. And as a result, could actually use more than one shadow meaningfully. So there's probably still places where people could sign up for 1.12. Is that true, Tim?
TIM PEPPER: Definitely. I think— gosh, right now we have 34 volunteers on the release team, which is—
ADAM GLICK: Wow.
JOSH BERKUS: OK. OK. Maybe not then.
[LAUGH]
TIM PEPPER: It's potentially becoming a lot of cats to herd. But I think even outside of that formal volunteering to be a named shadow, anybody is welcome to show up to the release team meetings, follow the release team activities on Slack, start understanding how the process works. And really, this is the case all across open source. It doesn't even have to be the release team. If you're passionate about networking, start following what SIG Network is doing. It's the same sort of path, I think, into any area on the project.
Each of the SIGs [has] a channel. So it would be #SIG-whatever the name is. [In our] case, #SIG-Release.
I'd also maybe give a plug for a talk I did at KubeCon in Copenhagen this spring, talking about how the release team specifically can be a path for new contributors coming in. And had some ideas and suggestions there for newcomers.
CRAIG BOX: There's three questions in the Google SRE postmortem template that I really like. And I'm sure you will have gone through these in the retrospective process as you released 1.11, so I'd like to ask them now one at a time.
First of all, what went well?
JOSH BERKUS: Two things, I think, really improved things, both for contributors and for the release team. Thing number one was putting a strong emphasis on getting the test grid green well ahead of code freeze.
TIM PEPPER: Definitely.
JOSH BERKUS: Now partly that went well because we had a spectacular CI lead, Aish Sundar, who's now in training to become the release lead.
TIM PEPPER: And I'd count that partly as one of the "Where were you lucky?" areas. We happened upon a wonderful person who just popped up and volunteered.
JOSH BERKUS: Yes. And then but part of that was also that we said, hey. You know, we're not going to do what we've done before which is not really care about these tests until code slush. We're going to care about these tests now.
And importantly— this is really important to the Kubernetes community— when we went to the various SIGs, the SIG Cluster Lifecycle and SIG Scalability and SIG Node and the other ones who were having test failures, and we said this to them. They didn't say, get lost. I'm busy. They said, what's failing?
CRAIG BOX: Great.
JOSH BERKUS: And so that made a big difference. And the second thing that was pretty much allowed by the first thing was to shorten the code freeze period. Because the code freeze period is frustrating for developers, because if they don't happen to be working on a 1.11 feature, even if they worked on one before, and they delivered it early in the cycle, and it's completely done, they're kind of paralyzed, and they can't do anything during code freeze. And so it's very frustrating for them, and we want to make that period as short as possible. And we did that this time, and I think it helped everybody.
CRAIG BOX: What went poorly?
JOSH BERKUS: We had a lot of problems with flaky tests. We have a lot of old tests that are not all that well maintained, and they're testing very complicated things like upgrading a cluster that has 40 nodes. And as a result, these tests have high failure rates that have very little to do with any change in the code.
And so one of the things that happened, and the reason we had a one-day delay in the release is, you know, we're a week out from release, and just by random luck of the draw, a bunch of these tests all at once got a run of failures. And it turned out that run of failures didn't actually mean anything, having anything to do with Kubernetes. But there was no way for us to tell that without a lot of research, and we were not going to have enough time for that research without delaying the release.
So one of the things we're looking to address in the 1.12 cycle is to actually move some of those flaky tests out. Either fix them or move them out of the release blocking category.
TIM PEPPER: In a way, I think this also highlights one of the things that Josh mentioned that went well, the emphasis early on getting the test results green, it allows us to see the extent to which these flakes are such a problem. And then the unlucky occurrence of them all happening to overlap on a failure, again, highlights that these flakes have been called out in the community for quite some time. I mean, at least a year. I know one contributor who was really concerned about them.
But they became a second order concern versus just getting things done in the short term, getting features and proving that the features worked, and kind of accepting in a risk management way on the release team that, yes, those are flakes. We don't have time to do something about them, and it's OK. But because of the emphasis on keeping the test always green now, we have the luxury maybe to focus on improving these flakes, and really get to where we have truly high quality CI signal, and can really believe in the results that we have on an ongoing basis.
JOSH BERKUS: And having solved some of the more basic problems, we're now seeing some of the other problems like coordination between related features. Like we right now have a feature where— and this is one of the sort of backwards compatibility release notes— where the feature went into beta, and is on by default.
And the second feature that was supposed to provide access control for the first feature did not go in as beta, and is not on by default. And the team for the first feature did not realize the second feature was being held up until two days before the release. So it's going to result in us actually patching something in 11.1.
And so like, we put that into something that didn't go well. But on the other hand, as Tim points out, a few release cycles ago, we wouldn't even have identified that as a problem, because we were still struggling with just individual features having a clear idea well ahead of the release of what was going in and what wasn't going in.
TIM PEPPER: I think something like this also is a case that maybe advocates for the use of feature branches. If these things are related, we might have seen it and done more pre-testing within that branch and pre-integration, and decide maybe to merge a couple of what initially had been disjoint features into a single feature branch, and really convince ourselves that together they were good. And cross all the Ts, dot all the Is on them, and not have something that's gated on an alpha feature that's possibly falling away.
CRAIG BOX: And then the final question, which I think you've both touched on a little. Where did you get lucky, or unlucky perhaps?
JOSH BERKUS: I would say number one where I got lucky is truly having a fantastic team. I mean, we just had a lot of terrific people who were very good and very energetic and very enthusiastic about taking on their release responsibilities including Aish and Tim and Ben and Nick and Misty who took over Docs four weeks into the release. And then went crazy with it and said, well, I'm new here, so I'm going to actually change a bunch of things we've been doing that didn't work in the first place. So that was number one. I mean, that really made honestly all the difference.
And then the second thing, like I said, is that we didn't have sort of major, unexpected monkey wrenches thrown at us. So in the 1.10 cycle, we actually had two of those, which is why I still count Jace as heroic for pulling off a release that was only a week late.
You know, number one was having the scalability tests start failing for unrelated reasons for a long period, which then masked the fact that they were actually failing for real reasons when we actually got them working again. And as a result, ending up debugging a major and super complicated scalability issue within days of what was supposed to be the original release date. So that was monkey wrench number one for the 1.10 cycle.
Monkey wrench number two for the 1.10 cycle was we got a security hole that needed to be patched. And so again, a week out from what was supposed to be the original release date, we were releasing a security update, and that security update required patching the release branch. And it turns out that patch against the release branch broke a bunch of incoming features. And we didn't get anything of that magnitude in the 1.11 release, and I'm thankful for that.
TIM PEPPER: Also, I would maybe argue in a way that a portion of that wasn't just luck. The extent to which this community has a good team, not just the release team but beyond, some of this goes to active work that folks all across the project, but especially in the contributor experience SIG are doing to cultivate a positive and inclusive culture here. And you really see that. When problems crop up, you're seeing people jump on and really try to constructively tackle them. And it's really fun to be a part of that.
Thanks to Josh Berkus and Tim Pepper for talking to the Kubernetes Podcast from Google.
Josh Berkus hangs out in #sig-release on the Kubernetes Slack. He maintains a newsletter called "Last Week in Kubernetes Development", with Noah Kantrowitz. You can read him on Twitter at @fuzzychef, but he does warn you that there's a lot of politics there as well.
Tim Pepper is also on Slack - he's always open to folks reaching out with a question, looking for help or advice. On Twitter you'll find him at @pythomit, which is "Timothy P" backwards. Tim is an avid soccer fan and season ticket holder for the Portland Timbers and the Portland Thorns, so you'll get all sorts of opinions on soccer in addition to technology!
You can find the Kubernetes Podcast from Google at @kubernetespod on Twitter, and you can subscribe so you never miss an episode.
Resizing Persistent Volumes using Kubernetes
Author: Hemant Kumar (Red Hat)
Editor’s note: this post is part of a series of in-depth articles on what’s new in Kubernetes 1.11
In Kubernetes v1.11 the persistent volume expansion feature is being promoted to beta. This feature allows users to easily resize an existing volume by editing the PersistentVolumeClaim (PVC) object. Users no longer have to manually interact with the storage backend or delete and recreate PV and PVC objects to increase the size of a volume. Shrinking persistent volumes is not supported.
Volume expansion was introduced in v1.8 as an Alpha feature, and versions prior to v1.11 required enabling the feature gate, ExpandPersistentVolumes, as well as the admission controller, PersistentVolumeClaimResize (which prevents expansion of PVCs whose underlying storage provider does not support resizing). In Kubernetes v1.11+, both the feature gate and admission controller are enabled by default.
Although the feature is enabled by default, a cluster admin must opt-in to allow users to resize their volumes. Kubernetes v1.11 ships with volume expansion support for the following in-tree volume plugins: AWS-EBS, GCE-PD, Azure Disk, Azure File, Glusterfs, Cinder, Portworx, and Ceph RBD. Once the admin has determined that volume expansion is supported for the underlying provider, they can make the feature available to users by setting the allowVolumeExpansion field to true in their StorageClass object(s). Only PVCs created from that StorageClass will be allowed to trigger volume expansion.
~> cat standard.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
parameters:
type: pd-standard
provisioner: kubernetes.io/gce-pd
allowVolumeExpansion: true
reclaimPolicy: Delete
Any PVC created from this StorageClass can be edited (as illustrated below) to request more space. Kubernetes will interpret a change to the storage field as a request for more space, and will trigger automatic volume resizing.

File System Expansion
Block storage volume types such as GCE-PD, AWS-EBS, Azure Disk, Cinder, and Ceph RBD typically require a file system expansion before the additional space of an expanded volume is usable by pods. Kubernetes takes care of this automatically whenever the pod(s) referencing your volume are restarted.
Network attached file systems (like Glusterfs and Azure File) can be expanded without having to restart the referencing Pod, because these systems do not require special file system expansion.
File system expansion must be triggered by terminating the pod using the volume. More specifically:
- Edit the PVC to request more space.
- Once underlying volume has been expanded by the storage provider, then the PersistentVolume object will reflect the updated size and the PVC will have the
FileSystemResizePendingcondition.
You can verify this by running kubectl get pvc <pvc_name> -o yaml
~> kubectl get pvc myclaim -o yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
namespace: default
uid: 02d4aa83-83cd-11e8-909d-42010af00004
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 14Gi
storageClassName: standard
volumeName: pvc-xxx
status:
capacity:
storage: 9G
conditions:
- lastProbeTime: null
lastTransitionTime: 2018-07-11T14:51:10Z
message: Waiting for user to (re-)start a pod to finish file system resize of
volume on node.
status: "True"
type: FileSystemResizePending
phase: Bound
- Once the PVC has the condition
FileSystemResizePendingthen pod that uses the PVC can be restarted to finish file system resizing on the node. Restart can be achieved by deleting and recreating the pod or by scaling down the deployment and then scaling it up again. - Once file system resizing is done, the PVC will automatically be updated to reflect new size.
Any errors encountered while expanding file system should be available as events on pod.
Online File System Expansion
Kubernetes v1.11 also introduces an alpha feature called online file system expansion. This feature enables file system expansion while a volume is still in-use by a pod. Because this feature is alpha, it requires enabling the feature gate, ExpandInUsePersistentVolumes. It is supported by the in-tree volume plugins GCE-PD, AWS-EBS, Cinder, and Ceph RBD. When this feature is enabled, pod referencing the resized volume do not need to be restarted. Instead, the file system will automatically be resized while in use as part of volume expansion. File system expansion does not happen until a pod references the resized volume, so if no pods referencing the volume are running file system expansion will not happen.
How can I learn more?
Check out additional documentation on this feature here: http://k8s.io/docs/concepts/storage/persistent-volumes.
Dynamic Kubelet Configuration
Author: Michael Taufen (Google)
Editor’s note: this post is part of a series of in-depth articles on what’s new in Kubernetes 1.11
Why Dynamic Kubelet Configuration?
Kubernetes provides API-centric tooling that significantly improves workflows for managing applications and infrastructure. Most Kubernetes installations, however, run the Kubelet as a native process on each host, outside the scope of standard Kubernetes APIs.
In the past, this meant that cluster administrators and service providers could not rely on Kubernetes APIs to reconfigure Kubelets in a live cluster. In practice, this required operators to either ssh into machines to perform manual reconfigurations, use third-party configuration management automation tools, or create new VMs with the desired configuration already installed, then migrate work to the new machines. These approaches are environment-specific and can be expensive.
Dynamic Kubelet configuration gives cluster administrators and service providers the ability to reconfigure Kubelets in a live cluster via Kubernetes APIs.
What is Dynamic Kubelet Configuration?
Kubernetes v1.10 made it possible to configure the Kubelet via a beta config file API. Kubernetes already provides the ConfigMap abstraction for storing arbitrary file data in the API server.
Dynamic Kubelet configuration extends the Node object so that a Node can refer to a ConfigMap that contains the same type of config file. When a Node is updated to refer to a new ConfigMap, the associated Kubelet will attempt to use the new configuration.
How does it work?
Dynamic Kubelet configuration provides the following core features:
- Kubelet attempts to use the dynamically assigned configuration.
- Kubelet "checkpoints" configuration to local disk, enabling restarts without API server access.
- Kubelet reports assigned, active, and last-known-good configuration sources in the Node status.
- When invalid configuration is dynamically assigned, Kubelet automatically falls back to a last-known-good configuration and reports errors in the Node status.
To use the dynamic Kubelet configuration feature, a cluster administrator or service provider will first post a ConfigMap containing the desired configuration, then set each Node.Spec.ConfigSource.ConfigMap reference to refer to the new ConfigMap. Operators can update these references at their preferred rate, giving them the ability to perform controlled rollouts of new configurations.
Each Kubelet watches its associated Node object for changes. When the Node.Spec.ConfigSource.ConfigMap reference is updated, the Kubelet will "checkpoint" the new ConfigMap by writing the files it contains to local disk. The Kubelet will then exit, and the OS-level process manager will restart it. Note that if the Node.Spec.ConfigSource.ConfigMap reference is not set, the Kubelet uses the set of flags and config files local to the machine it is running on.
Once restarted, the Kubelet will attempt to use the configuration from the new checkpoint. If the new configuration passes the Kubelet's internal validation, the Kubelet will update Node.Status.Config to reflect that it is using the new configuration. If the new configuration is invalid, the Kubelet will fall back to its last-known-good configuration and report an error in Node.Status.Config.
Note that the default last-known-good configuration is the combination of Kubelet command-line flags with the Kubelet's local configuration file. Command-line flags that overlap with the config file always take precedence over both the local configuration file and dynamic configurations, for backwards-compatibility.
See the following diagram for a high-level overview of a configuration update for a single Node:
How can I learn more?
Please see the official tutorial at /docs/tasks/administer-cluster/reconfigure-kubelet/, which contains more in-depth details on user workflow, how a configuration becomes "last-known-good," how the Kubelet "checkpoints" config, and possible failure modes.
CoreDNS GA for Kubernetes Cluster DNS
Author: John Belamaric (Infoblox)
Editor’s note: this post is part of a series of in-depth articles on what’s new in Kubernetes 1.11
Introduction
In Kubernetes 1.11, CoreDNS has reached General Availability (GA) for DNS-based service discovery, as an alternative to the kube-dns addon. This means that CoreDNS will be offered as an option in upcoming versions of the various installation tools. In fact, the kubeadm team chose to make it the default option starting with Kubernetes 1.11.
DNS-based service discovery has been part of Kubernetes for a long time with the kube-dns cluster addon. This has generally worked pretty well, but there have been some concerns around the reliability, flexibility and security of the implementation.
CoreDNS is a general-purpose, authoritative DNS server that provides a backwards-compatible, but extensible, integration with Kubernetes. It resolves the issues seen with kube-dns, and offers a number of unique features that solve a wider variety of use cases.
In this article, you will learn about the differences in the implementations of kube-dns and CoreDNS, and some of the helpful extensions offered by CoreDNS.
Implementation differences
In kube-dns, several containers are used within a single pod: kubedns, dnsmasq, and sidecar. The kubedns
container watches the Kubernetes API and serves DNS records based on the Kubernetes DNS specification, dnsmasq provides caching and stub domain support, and sidecar provides metrics and health checks.
This setup leads to a few issues that have been seen over time. For one, security vulnerabilities in dnsmasq have led to the need
for a security-patch release of Kubernetes in the past. Additionally, because dnsmasq handles the stub domains,
but kubedns handles the External Services, you cannot use a stub domain in an external service, which is very
limiting to that functionality (see dns#131).
All of these functions are done in a single container in CoreDNS, which is running a process written in Go. The different plugins that are enabled replicate (and enhance) the functionality found in kube-dns.
Configuring CoreDNS
In kube-dns, you can modify a ConfigMap to change the behavior of your service discovery. This allows the addition of features such as serving stub domains, modifying upstream nameservers, and enabling federation.
In CoreDNS, you similarly can modify the ConfigMap for the CoreDNS Corefile to change how service discovery works. This Corefile configuration offers many more options than you will find in kube-dns, since it is the primary configuration file that CoreDNS uses for configuration of all of its features, even those that are not Kubernetes related.
When upgrading from kube-dns to CoreDNS using kubeadm, your existing ConfigMap will be used to generate the
customized Corefile for you, including all of the configuration for stub domains, federation, and upstream nameservers. See Using CoreDNS for Service Discovery for more details.
Bug fixes and enhancements
There are several open issues with kube-dns that are resolved in CoreDNS, either in default configuration or with some customized configurations.
-
dns#55 - Custom DNS entries for kube-dns may be handled using the "fallthrough" mechanism in the kubernetes plugin, using the rewrite plugin, or simply serving a subzone with a different plugin such as the file plugin.
-
dns#116 - Only one A record set for headless service with pods having single hostname. This issue is fixed without any additional configuration.
-
dns#131 - externalName not using stubDomains settings. This issue is fixed without any additional configuration.
-
dns#167 - enable skyDNS round robin A/AAAA records. The equivalent functionality can be configured using the load balance plugin.
-
dns#190 - kube-dns cannot run as non-root user. This issue is solved today by using a non-default image, but it will be made the default CoreDNS behavior in a future release.
-
dns#232 - fix pod hostname to be podname for dns srv records is an enhancement that is supported through the "endpoint_pod_names" feature described below.
Metrics
The functional behavior of the default CoreDNS configuration is the same as kube-dns. However,
one difference you need to be aware of is that the published metrics are not the same. In kube-dns,
you get separate metrics for dnsmasq and kubedns (skydns). In CoreDNS there is a completely
different set of metrics, since it is all a single process. You can find more details on these
metrics on the CoreDNS Prometheus plugin page.
Some special features
The standard CoreDNS Kubernetes configuration is designed to be backwards compatible with the prior kube-dns behavior. But with some configuration changes, CoreDNS can allow you to modify how the DNS service discovery works in your cluster. A number of these features are intended to still be compliant with the Kubernetes DNS specification; they enhance functionality but remain backward compatible. Since CoreDNS is not only made for Kubernetes, but is instead a general-purpose DNS server, there are many things you can do beyond that specification.
Pods verified mode
In kube-dns, pod name records are "fake". That is, any "a-b-c-d.namespace.pod.cluster.local" query will return the IP address "a.b.c.d". In some cases, this can weaken the identity guarantees offered by TLS. So, CoreDNS offers a "pods verified" mode, which will only return the IP address if there is a pod in the specified namespace with that IP address.
Endpoint names based on pod names
In kube-dns, when using a headless service, you can use an SRV request to get a list of all endpoints for the service:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 10 33 0 6234396237313665.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 10 33 0 6662363165353239.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 10 33 0 6338633437303230.headless.default.svc.cluster.local.
dnstools#
However, the endpoint DNS names are (for practical purposes) random. In CoreDNS, by default, you get endpoint DNS names based upon the endpoint IP address:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-14.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-18.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-4.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-9.headless.default.svc.cluster.local.
For some applications, it is desirable to have the pod name for this, rather than the pod IP address (see for example kubernetes#47992 and coredns#1190). To enable this in CoreDNS, you specify the "endpoint_pod_names" option in your Corefile, which results in this:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-qv84p.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-zc8lx.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-q7lf2.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-566rt.headless.default.svc.cluster.local.
Autopath
CoreDNS also has a special feature to improve latency in DNS requests for external names. In Kubernetes, the
DNS search path for pods specifies a long list of suffixes. This enables the use of short names when requesting
services in the cluster - for example, "headless" above, rather than "headless.default.svc.cluster.local". However,
when requesting an external name - "infoblox.com", for example - several invalid DNS queries are made by the client,
requiring a roundtrip from the client to kube-dns each time (actually to dnsmasq and then to kubedns, since negative caching is disabled):
- infoblox.com.default.svc.cluster.local -> NXDOMAIN
- infoblox.com.svc.cluster.local -> NXDOMAIN
- infoblox.com.cluster.local -> NXDOMAIN
- infoblox.com.your-internal-domain.com -> NXDOMAIN
- infoblox.com -> returns a valid record
In CoreDNS, an optional feature called autopath can be enabled that will cause this search path to be followed in the server. That is, CoreDNS will figure out from the source IP address which namespace the client pod is in, and it will walk this search list until it gets a valid answer. Since the first 3 of these are resolved internally within CoreDNS itself, it cuts out all of the back and forth between the client and server, reducing latency.
A few other Kubernetes specific features
In CoreDNS, you can use standard DNS zone transfer to export the entire DNS record set. This is useful for debugging your services as well as importing the cluster zone into other DNS servers.
You can also filter by namespaces or a label selector. This can allow you to run specific CoreDNS instances that will only server records that match the filters, exposing only a limited set of your services via DNS.
Extensibility
In addition to the features described above, CoreDNS is easily extended. It is possible to build custom versions of CoreDNS that include your own features. For example, this ability has been used to extend CoreDNS to do recursive resolution with the unbound plugin, to server records directly from a database with the pdsql plugin, and to allow multiple CoreDNS instances to share a common level 2 cache with the redisc plugin.
Many other interesting extensions have been added, which you will find on the External Plugins page of the CoreDNS site. One that is really interesting for Kubernetes and Istio users is the kubernetai plugin, which allows a single CoreDNS instance to connect to multiple Kubernetes clusters and provide service discovery across all of them.
What's Next?
CoreDNS is an independent project, and as such is developing many features that are not directly related to Kubernetes. However, a number of these will have applications within Kubernetes. For example, the upcoming integration with policy engines will allow CoreDNS to make intelligent choices about which endpoint to return when a headless service is requested. This could be used to route traffic to a local pod, or to a more responsive pod. Many other features are in development, and of course as an open source project, we welcome you to suggest and contribute your own features!
The features and differences described above are a few examples. There is much more you can do with CoreDNS. You can find out more on the CoreDNS Blog.
Get involved with CoreDNS
CoreDNS is an incubated CNCF project.
We're most active on Slack (and GitHub):
- Slack: #coredns on https://slack.cncf.io
- GitHub: https://github.com/coredns/coredns
More resources can be found:
- Website: https://coredns.io
- Blog: https://blog.coredns.io
- Twitter: @corednsio
- Mailing list/group: coredns-discuss@googlegroups.com
Meet Our Contributors - Monthly Streaming YouTube Mentoring Series
Author: Paris Pittman (Google)

July 11th at 2:30pm and 8pm UTC kicks off our next installment of Meet Our Contributors YouTube series. This month is special: members of the steering committee will be on to answer any and all questions from the community on the first 30 minutes of the 8pm UTC session. More on submitting questions below.
Meet Our Contributors was created to give an opportunity to new and current contributors alike to get time in front of our upstream community to ask questions that you would typically ask a mentor. We have 3-6 contributors on each session (an AM and PM session depending on where you are in the world!) answer questions live on a YouTube stream. If you miss it, don’t stress, the recording is up after it’s over. Check out a past episode here.
As you can imagine, the questions span broadly from introductory - “what’s a SIG?” to more advanced - “why’s my test flaking?” You’ll also hear growth related advice questions such as “what’s my best path to becoming an approver?” We’re happy to do a live code/docs review or explain part of the codebase as long as we have a few days notice.
We answer at least 10 questions per session and have helped 500+ people to date. This is a scalable mentoring initiative that makes it easy for all parties to share information, get advice, and get going with what they are trying to accomplish. We encourage you to submit questions for our next session:
- Join the Kubernetes Slack channel - #meet-our-contributors - to ask your question or for more detailed information. DM paris@ if you would like to remain anonymous.
- Twitter works, too, with the hashtag #k8smoc
If you are contributor reading this that has wanted to mentor but just can’t find the time - this is for you! Reach out to us.
You can join us live on June 6th at 2:30pm and 8pm UTC, and every first Wednesday of the month, on the Kubernetes Community live stream. We look forward to seeing you there!
IPVS-Based In-Cluster Load Balancing Deep Dive
Author: Jun Du(Huawei), Haibin Xie(Huawei), Wei Liang(Huawei)
Editor’s note: this post is part of a series of in-depth articles on what’s new in Kubernetes 1.11
Introduction
Per the Kubernetes 1.11 release blog post , we announced that IPVS-Based In-Cluster Service Load Balancing graduates to General Availability. In this blog, we will take you through a deep dive of the feature.
What Is IPVS?
IPVS (IP Virtual Server) is built on top of the Netfilter and implements transport-layer load balancing as part of the Linux kernel.
IPVS is incorporated into the LVS (Linux Virtual Server), where it runs on a host and acts as a load balancer in front of a cluster of real servers. IPVS can direct requests for TCP- and UDP-based services to the real servers, and make services of the real servers appear as virtual services on a single IP address. Therefore, IPVS naturally supports Kubernetes Service.
Why IPVS for Kubernetes?
As Kubernetes grows in usage, the scalability of its resources becomes more and more important. In particular, the scalability of services is paramount to the adoption of Kubernetes by developers/companies running large workloads.
Kube-proxy, the building block of service routing has relied on the battle-hardened iptables to implement the core supported Service types such as ClusterIP and NodePort. However, iptables struggles to scale to tens of thousands of Services because it is designed purely for firewalling purposes and is based on in-kernel rule lists.
Even though Kubernetes already support 5000 nodes in release v1.6, the kube-proxy with iptables is actually a bottleneck to scale the cluster to 5000 nodes. One example is that with NodePort Service in a 5000-node cluster, if we have 2000 services and each services have 10 pods, this will cause at least 20000 iptable records on each worker node, and this can make the kernel pretty busy.
On the other hand, using IPVS-based in-cluster service load balancing can help a lot for such cases. IPVS is specifically designed for load balancing and uses more efficient data structures (hash tables) allowing for almost unlimited scale under the hood.
IPVS-based Kube-proxy
Parameter Changes
Parameter: --proxy-mode In addition to existing userspace and iptables modes, IPVS mode is configured via --proxy-mode=ipvs. It implicitly uses IPVS NAT mode for service port mapping.
Parameter: --ipvs-scheduler
A new kube-proxy parameter has been added to specify the IPVS load balancing algorithm, with the parameter being --ipvs-scheduler. If it’s not configured, then round-robin (rr) is the default value.
- rr: round-robin
- lc: least connection
- dh: destination hashing
- sh: source hashing
- sed: shortest expected delay
- nq: never queue
In the future, we can implement Service specific scheduler (potentially via annotation), which has higher priority and overwrites the value.
Parameter: --cleanup-ipvs Similar to the --cleanup-iptables parameter, if true, cleanup IPVS configuration and IPTables rules that are created in IPVS mode.
Parameter: --ipvs-sync-period Maximum interval of how often IPVS rules are refreshed (e.g. '5s', '1m'). Must be greater than 0.
Parameter: --ipvs-min-sync-period Minimum interval of how often the IPVS rules are refreshed (e.g. '5s', '1m'). Must be greater than 0.
Parameter: --ipvs-exclude-cidrs A comma-separated list of CIDR's which the IPVS proxier should not touch when cleaning up IPVS rules because IPVS proxier can't distinguish kube-proxy created IPVS rules from user original IPVS rules. If you are using IPVS proxier with your own IPVS rules in the environment, this parameter should be specified, otherwise your original rule will be cleaned.
Design Considerations
IPVS Service Network Topology
When creating a ClusterIP type Service, IPVS proxier will do the following three things:
- Make sure a dummy interface exists in the node, defaults to kube-ipvs0
- Bind Service IP addresses to the dummy interface
- Create IPVS virtual servers for each Service IP address respectively
Here comes an example:
# kubectl describe svc nginx-service
Name: nginx-service
...
Type: ClusterIP
IP: 10.102.128.4
Port: http 3080/TCP
Endpoints: 10.244.0.235:8080,10.244.1.237:8080
Session Affinity: None
# ip addr
...
73: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ff
inet 10.102.128.4/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:3080 rr
-> 10.244.0.235:8080 Masq 1 0 0
-> 10.244.1.237:8080 Masq 1 0 0
Please note that the relationship between a Kubernetes Service and IPVS virtual servers is 1:N. For example, consider a Kubernetes Service that has more than one IP address. An External IP type Service has two IP addresses - ClusterIP and External IP. Then the IPVS proxier will create 2 IPVS virtual servers - one for Cluster IP and another one for External IP. The relationship between a Kubernetes Endpoint (each IP+Port pair) and an IPVS virtual server is 1:1.
Deleting of a Kubernetes service will trigger deletion of the corresponding IPVS virtual server, IPVS real servers and its IP addresses bound to the dummy interface.
Port Mapping
There are three proxy modes in IPVS: NAT (masq), IPIP and DR. Only NAT mode supports port mapping. Kube-proxy leverages NAT mode for port mapping. The following example shows IPVS mapping Service port 3080 to Pod port 8080.
TCP 10.102.128.4:3080 rr
-> 10.244.0.235:8080 Masq 1 0 0
-> 10.244.1.237:8080 Masq 1 0
Session Affinity
IPVS supports client IP session affinity (persistent connection). When a Service specifies session affinity, the IPVS proxier will set a timeout value (180min=10800s by default) in the IPVS virtual server. For example:
# kubectl describe svc nginx-service
Name: nginx-service
...
IP: 10.102.128.4
Port: http 3080/TCP
Session Affinity: ClientIP
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:3080 rr persistent 10800
Iptables & Ipset in IPVS Proxier
IPVS is for load balancing and it can't handle other workarounds in kube-proxy, e.g. packet filtering, hairpin-masquerade tricks, SNAT, etc.
IPVS proxier leverages iptables in the above scenarios. Specifically, ipvs proxier will fall back on iptables in the following 4 scenarios:
- kube-proxy start with --masquerade-all=true
- Specify cluster CIDR in kube-proxy startup
- Support Loadbalancer type service
- Support NodePort type service
However, we don't want to create too many iptables rules. So we adopt ipset for the sake of decreasing iptables rules. The following is the table of ipset sets that IPVS proxier maintains:
| set name | members | usage |
|---|---|---|
| KUBE-CLUSTER-IP | All Service IP + port | masquerade for cases that masquerade-all=true or clusterCIDR specified |
| KUBE-LOOP-BACK | All Service IP + port + IP | masquerade for resolving hairpin issue |
| KUBE-EXTERNAL-IP | Service External IP + port | masquerade for packets to external IPs |
| KUBE-LOAD-BALANCER | Load Balancer ingress IP + port | masquerade for packets to Load Balancer type service |
| KUBE-LOAD-BALANCER-LOCAL | Load Balancer ingress IP + port with externalTrafficPolicy=local |
accept packets to Load Balancer with externalTrafficPolicy=local |
| KUBE-LOAD-BALANCER-FW | Load Balancer ingress IP + port with loadBalancerSourceRanges |
Drop packets for Load Balancer type Service with loadBalancerSourceRanges specified |
| KUBE-LOAD-BALANCER-SOURCE-CIDR | Load Balancer ingress IP + port + source CIDR | accept packets for Load Balancer type Service with loadBalancerSourceRanges specified |
| KUBE-NODE-PORT-TCP | NodePort type Service TCP port | masquerade for packets to NodePort(TCP) |
| KUBE-NODE-PORT-LOCAL-TCP | NodePort type Service TCP port with externalTrafficPolicy=local |
accept packets to NodePort Service with externalTrafficPolicy=local |
| KUBE-NODE-PORT-UDP | NodePort type Service UDP port | masquerade for packets to NodePort(UDP) |
| KUBE-NODE-PORT-LOCAL-UDP | NodePort type service UDP port with externalTrafficPolicy=local |
accept packets to NodePort Service with externalTrafficPolicy=local |
In general, for IPVS proxier, the number of iptables rules is static, no matter how many Services/Pods we have.
Run kube-proxy in IPVS Mode
Currently, local-up scripts, GCE scripts, and kubeadm support switching IPVS proxy mode via exporting environment variables (KUBE_PROXY_MODE=ipvs) or specifying flag (--proxy-mode=ipvs). Before running IPVS proxier, please ensure IPVS required kernel modules are already installed.
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
Finally, for Kubernetes v1.10, feature gate SupportIPVSProxyMode is set to true by default. For Kubernetes v1.11, the feature gate is entirely removed. However, you need to enable --feature-gates=SupportIPVSProxyMode=true explicitly for Kubernetes before v1.10.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
Thank you for your continued feedback and support. Post questions (or answer questions) on Stack Overflow Join the community portal for advocates on K8sPort Follow us on Twitter @Kubernetesio for latest updates Chat with the community on Slack Share your Kubernetes story
Airflow on Kubernetes (Part 1): A Different Kind of Operator
Author: Daniel Imberman (Bloomberg LP)
Introduction
As part of Bloomberg's continued commitment to developing the Kubernetes ecosystem, we are excited to announce the Kubernetes Airflow Operator; a mechanism for Apache Airflow, a popular workflow orchestration framework to natively launch arbitrary Kubernetes Pods using the Kubernetes API.
What Is Airflow?
Apache Airflow is one realization of the DevOps philosophy of "Configuration As Code." Airflow allows users to launch multi-step pipelines using a simple Python object DAG (Directed Acyclic Graph). You can define dependencies, programmatically construct complex workflows, and monitor scheduled jobs in an easy to read UI.
Why Airflow on Kubernetes?
Since its inception, Airflow's greatest strength has been its flexibility. Airflow offers a wide range of integrations for services ranging from Spark and HBase, to services on various cloud providers. Airflow also offers easy extensibility through its plug-in framework. However, one limitation of the project is that Airflow users are confined to the frameworks and clients that exist on the Airflow worker at the moment of execution. A single organization can have varied Airflow workflows ranging from data science pipelines to application deployments. This difference in use-case creates issues in dependency management as both teams might use vastly different libraries for their workflows.
To address this issue, we've utilized Kubernetes to allow users to launch arbitrary Kubernetes pods and configurations. Airflow users can now have full power over their run-time environments, resources, and secrets, basically turning Airflow into an "any job you want" workflow orchestrator.
The Kubernetes Operator
Before we move any further, we should clarify that an Operator in Airflow is a task definition. When a user creates a DAG, they would use an operator like the "SparkSubmitOperator" or the "PythonOperator" to submit/monitor a Spark job or a Python function respectively. Airflow comes with built-in operators for frameworks like Apache Spark, BigQuery, Hive, and EMR. It also offers a Plugins entrypoint that allows DevOps engineers to develop their own connectors.
Airflow users are always looking for ways to make deployments and ETL pipelines simpler to manage. Any opportunity to decouple pipeline steps, while increasing monitoring, can reduce future outages and fire-fights. The following is a list of benefits provided by the Airflow Kubernetes Operator:
-
Increased flexibility for deployments:
Airflow's plugin API has always offered a significant boon to engineers wishing to test new functionalities within their DAGs. On the downside, whenever a developer wanted to create a new operator, they had to develop an entirely new plugin. Now, any task that can be run within a Docker container is accessible through the exact same operator, with no extra Airflow code to maintain. -
Flexibility of configurations and dependencies: For operators that are run within static Airflow workers, dependency management can become quite difficult. If a developer wants to run one task that requires SciPy and another that requires NumPy, the developer would have to either maintain both dependencies within all Airflow workers or offload the task to an external machine (which can cause bugs if that external machine changes in an untracked manner). Custom Docker images allow users to ensure that the tasks environment, configuration, and dependencies are completely idempotent.
-
Usage of kubernetes secrets for added security: Handling sensitive data is a core responsibility of any DevOps engineer. At every opportunity, Airflow users want to isolate any API keys, database passwords, and login credentials on a strict need-to-know basis. With the Kubernetes operator, users can utilize the Kubernetes Vault technology to store all sensitive data. This means that the Airflow workers will never have access to this information, and can simply request that pods be built with only the secrets they need.
Architecture
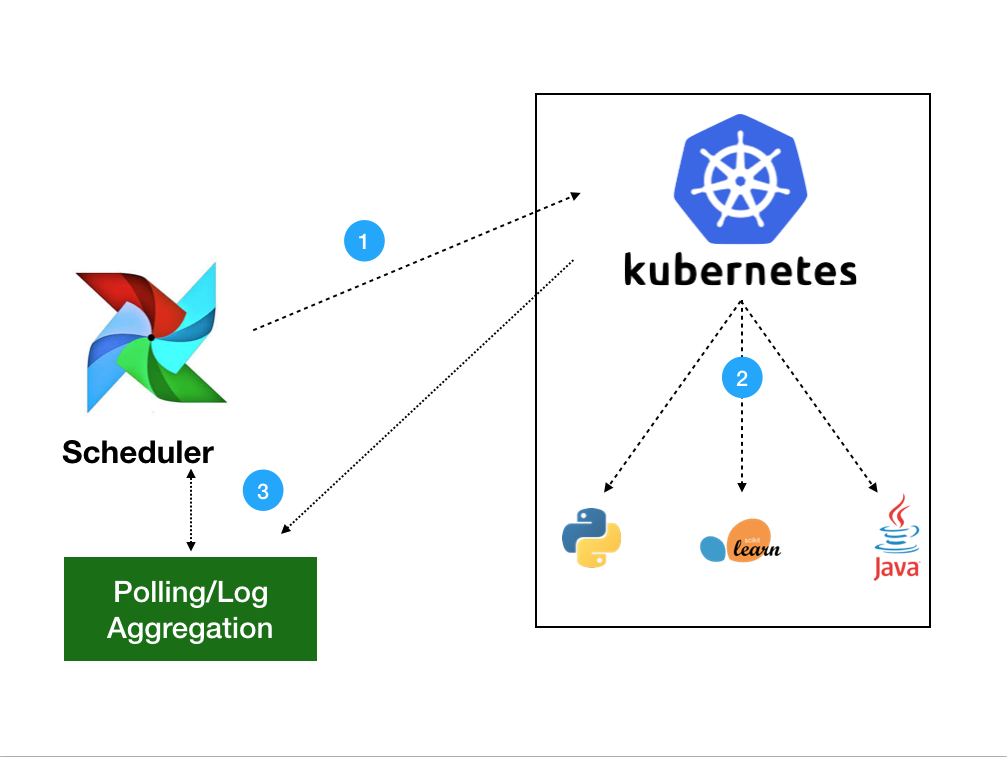
The Kubernetes Operator uses the Kubernetes Python Client to generate a request that is processed by the APIServer (1). Kubernetes will then launch your pod with whatever specs you've defined (2). Images will be loaded with all the necessary environment variables, secrets and dependencies, enacting a single command. Once the job is launched, the operator only needs to monitor the health of track logs (3). Users will have the choice of gathering logs locally to the scheduler or to any distributed logging service currently in their Kubernetes cluster.
Using the Kubernetes Operator
A Basic Example
The following DAG is probably the simplest example we could write to show how the Kubernetes Operator works. This DAG creates two pods on Kubernetes: a Linux distro with Python and a base Ubuntu distro without it. The Python pod will run the Python request correctly, while the one without Python will report a failure to the user. If the Operator is working correctly, the passing-task pod should complete, while the failing-task pod returns a failure to the Airflow webserver.
from airflow import DAG
from datetime import datetime, timedelta
from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
from airflow.operators.dummy_operator import DummyOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime.utcnow(),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(
'kubernetes_sample', default_args=default_args, schedule_interval=timedelta(minutes=10))
start = DummyOperator(task_id='run_this_first', dag=dag)
passing = KubernetesPodOperator(namespace='default',
image="Python:3.6",
cmds=["Python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="passing-test",
task_id="passing-task",
get_logs=True,
dag=dag
)
failing = KubernetesPodOperator(namespace='default',
image="ubuntu:1604",
cmds=["Python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="fail",
task_id="failing-task",
get_logs=True,
dag=dag
)
passing.set_upstream(start)
failing.set_upstream(start)
But how does this relate to my workflow?
While this example only uses basic images, the magic of Docker is that this same DAG will work for any image/command pairing you want. The following is a recommended CI/CD pipeline to run production-ready code on an Airflow DAG.
1: PR in github
Use Travis or Jenkins to run unit and integration tests, bribe your favorite team-mate into PR'ing your code, and merge to the master branch to trigger an automated CI build.
2: CI/CD via Jenkins -> Docker Image
Generate your Docker images and bump release version within your Jenkins build.
3: Airflow launches task
Finally, update your DAGs to reflect the new release version and you should be ready to go!
production_task = KubernetesPodOperator(namespace='default',
# image="my-production-job:release-1.0.1", <-- old release
image="my-production-job:release-1.0.2",
cmds=["Python","-c"],
arguments=["print('hello world')"],
name="fail",
task_id="failing-task",
get_logs=True,
dag=dag
)
Launching a test deployment
Since the Kubernetes Operator is not yet released, we haven't released an official helm chart or operator (however both are currently in progress). However, we are including instructions for a basic deployment below and are actively looking for foolhardy beta testers to try this new feature. To try this system out please follow these steps:
Step 1: Set your kubeconfig to point to a kubernetes cluster
Step 2: Clone the Airflow Repo:
Run git clone https://github.com/apache/incubator-airflow.git to clone the official Airflow repo.
Step 3: Run
To run this basic deployment, we are co-opting the integration testing script that we currently use for the Kubernetes Executor (which will be explained in the next article of this series). To launch this deployment, run these three commands:
sed -ie "s/KubernetesExecutor/LocalExecutor/g" scripts/ci/kubernetes/kube/configmaps.yaml
./scripts/ci/kubernetes/Docker/build.sh
./scripts/ci/kubernetes/kube/deploy.sh
Before we move on, let's discuss what these commands are doing:
sed -ie "s/KubernetesExecutor/LocalExecutor/g" scripts/ci/kubernetes/kube/configmaps.yaml
The Kubernetes Executor is another Airflow feature that allows for dynamic allocation of tasks as idempotent pods. The reason we are switching this to the LocalExecutor is simply to introduce one feature at a time. You are more then welcome to skip this step if you would like to try the Kubernetes Executor, however we will go into more detail in a future article.
./scripts/ci/kubernetes/Docker/build.sh
This script will tar the Airflow master source code build a Docker container based on the Airflow distribution
./scripts/ci/kubernetes/kube/deploy.sh
Finally, we create a full Airflow deployment on your cluster. This includes Airflow configs, a postgres backend, the webserver + scheduler, and all necessary services between. One thing to note is that the role binding supplied is a cluster-admin, so if you do not have that level of permission on the cluster, you can modify this at scripts/ci/kubernetes/kube/airflow.yaml
Step 4: Log into your webserver
Now that your Airflow instance is running let's take a look at the UI! The UI lives in port 8080 of the Airflow pod, so simply run
WEB=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}' | grep "airflow" | head -1)
kubectl port-forward $WEB 8080:8080
Now the Airflow UI will exist on http://localhost:8080. To log in simply enter airflow/airflow and you should have full access to the Airflow web UI.
Step 5: Upload a test document
To modify/add your own DAGs, you can use kubectl cp to upload local files into the DAG folder of the Airflow scheduler. Airflow will then read the new DAG and automatically upload it to its system. The following command will upload any local file into the correct directory:
kubectl cp <local file> <namespace>/<pod>:/root/airflow/dags -c scheduler
Step 6: Enjoy!
So when will I be able to use this?
While this feature is still in the early stages, we hope to see it released for wide release in the next few months.
Get Involved
This feature is just the beginning of multiple major efforts to improves Apache Airflow integration into Kubernetes. The Kubernetes Operator has been merged into the 1.10 release branch of Airflow (the executor in experimental mode), along with a fully k8s native scheduler called the Kubernetes Executor (article to come). These features are still in a stage where early adopters/contributers can have a huge influence on the future of these features.
For those interested in joining these efforts, I'd recommend checkint out these steps:
- Join the airflow-dev mailing list at dev@airflow.apache.org.
- File an issue in Apache Airflow JIRA
- Join our SIG-BigData meetings on Wednesdays at 10am PST.
- Reach us on slack at #sig-big-data on kubernetes.slack.com
Special thanks to the Apache Airflow and Kubernetes communities, particularly Grant Nicholas, Ben Goldberg, Anirudh Ramanathan, Fokko Dreisprong, and Bolke de Bruin, for your awesome help on these features as well as our future efforts.
Kubernetes 1.11: In-Cluster Load Balancing and CoreDNS Plugin Graduate to General Availability
Author: Kubernetes 1.11 Release Team
We’re pleased to announce the delivery of Kubernetes 1.11, our second release of 2018!
Today’s release continues to advance maturity, scalability, and flexibility of Kubernetes, marking significant progress on features that the team has been hard at work on over the last year. This newest version graduates key features in networking, opens up two major features from SIG-API Machinery and SIG-Node for beta testing, and continues to enhance storage features that have been a focal point of the past two releases. The features in this release make it increasingly possible to plug any infrastructure, cloud or on-premise, into the Kubernetes system.
Notable additions in this release include two highly-anticipated features graduating to general availability: IPVS-based In-Cluster Load Balancing and CoreDNS as a cluster DNS add-on option, which means increased scalability and flexibility for production applications.
Let’s dive into the key features of this release:
IPVS-Based In-Cluster Service Load Balancing Graduates to General Availability
In this release, IPVS-based in-cluster service load balancing has moved to stable. IPVS (IP Virtual Server) provides high-performance in-kernel load balancing, with a simpler programming interface than iptables. This change delivers better network throughput, better programming latency, and higher scalability limits for the cluster-wide distributed load-balancer that comprises the Kubernetes Service model. IPVS is not yet the default but clusters can begin to use it for production traffic.
CoreDNS Promoted to General Availability
CoreDNS is now available as a cluster DNS add-on option, and is the default when using kubeadm. CoreDNS is a flexible, extensible authoritative DNS server and directly integrates with the Kubernetes API. CoreDNS has fewer moving parts than the previous DNS server, since it’s a single executable and a single process, and supports flexible use cases by creating custom DNS entries. It’s also written in Go making it memory-safe. You can learn more about CoreDNS here.
Dynamic Kubelet Configuration Moves to Beta
This feature makes it possible for new Kubelet configurations to be rolled out in a live cluster. Currently, Kubelets are configured via command-line flags, which makes it difficult to update Kubelet configurations in a running cluster. With this beta feature, users can configure Kubelets in a live cluster via the API server.
Custom Resource Definitions Can Now Define Multiple Versions
Custom Resource Definitions are no longer restricted to defining a single version of the custom resource, a restriction that was difficult to work around. Now, with this beta feature, multiple versions of the resource can be defined. In the future, this will be expanded to support some automatic conversions; for now, this feature allows custom resource authors to “promote with safe changes, e.g. v1beta1 to v1,” and to create a migration path for resources which do have changes.
Custom Resource Definitions now also support "status" and "scale" subresources, which integrate with monitoring and high-availability frameworks. These two changes advance the ability to run cloud-native applications in production using Custom Resource Definitions.
Enhancements to CSI
Container Storage Interface (CSI) has been a major topic over the last few releases. After moving to beta in 1.10, the 1.11 release continues enhancing CSI with a number of features. The 1.11 release adds alpha support for raw block volumes to CSI, integrates CSI with the new kubelet plugin registration mechanism, and makes it easier to pass secrets to CSI plugins.
New Storage Features
Support for online resizing of Persistent Volumes has been introduced as an alpha feature. This enables users to increase the size of PVs without having to terminate pods and unmount volume first. The user will update the PVC to request a new size and kubelet will resize the file system for the PVC.
Support for dynamic maximum volume count has been introduced as an alpha feature. This new feature enables in-tree volume plugins to specify the maximum number of volumes that can be attached to a node and allows the limit to vary depending on the type of node. Previously, these limits were hard coded or configured via an environment variable.
The StorageObjectInUseProtection feature is now stable and prevents the removal of both Persistent Volumes that are bound to a Persistent Volume Claim, and Persistent Volume Claims that are being used by a pod. This safeguard will help prevent issues from deleting a PV or a PVC that is currently tied to an active pod.
Each Special Interest Group (SIG) within the community continues to deliver the most-requested enhancements, fixes, and functionality for their respective specialty areas. For a complete list of inclusions by SIG, please visit the release notes.
Availability
Kubernetes 1.11 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials.
You can also install 1.11 using Kubeadm. Version 1.11.0 will be available as Deb and RPM packages, installable using the Kubeadm cluster installer sometime on June 28th.
4 Day Features Blog Series
If you’re interested in exploring these features more in depth, check back in two weeks for our 4 Days of Kubernetes series where we’ll highlight detailed walkthroughs of the following features:
- Day 1: IPVS-Based In-Cluster Service Load Balancing Graduates to General Availability
- Day 2: CoreDNS Promoted to General Availability
- Day 3: Dynamic Kubelet Configuration Moves to Beta
- Day 4: Resizing Persistent Volumes using Kubernetes
Release team
This release is made possible through the effort of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Josh Berkus, Kubernetes Community Manager at Red Hat. The 20 individuals on the release team coordinate many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has over 20,000 individual contributors to date and an active community of more than 40,000 people.
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. On average, 250 different companies and over 1,300 individuals contribute to Kubernetes each month. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
User Highlights
Established, global organizations are using Kubernetes in production at massive scale. Recently published user stories from the community include:
- The New York Times, known as the newspaper of record, moved out of its data centers and into the public cloud with the help of Google Cloud Platform and Kubernetes. This move meant a significant increase in speed of delivery, from 45 minutes to just a few seconds with Kubernetes.
- Nordstrom, a leading fashion retailer based in the U.S., began their cloud native journey by adopting Docker containers orchestrated with Kubernetes. The results included a major increase in Ops efficiency, improving CPU utilization from 5x to 12x depending on the workload.
- Squarespace, a SaaS solution for easily building and hosting websites, moved their monolithic application to microservices with the help of Kubernetes. This resulted in a deployment time reduction of almost 85%.
- Crowdfire, a leading social media management platform, moved from a monolithic application to a custom Kubernetes-based setup. This move reduced deployment time from 15 minutes to less than a minute.
Is Kubernetes helping your team? Share your story with the community.
Ecosystem Updates
- The CNCF recently expanded its certification offerings to include a Certified Kubernetes Application Developer exam. The CKAD exam certifies an individual's ability to design, build, configure, and expose cloud native applications for Kubernetes. More information can be found here.
- The CNCF recently added a new partner category, Kubernetes Training Partners (KTP). KTPs are a tier of vetted training providers who have deep experience in cloud native technology training. View partners and learn more here.
- CNCF also offers online training that teaches the skills needed to create and configure a real-world Kubernetes cluster.
- Kubernetes documentation now features user journeys: specific pathways for learning based on who readers are and what readers want to do. Learning Kubernetes is easier than ever for beginners, and more experienced users can find task journeys specific to cluster admins and application developers.
KubeCon
The world’s largest Kubernetes gathering, KubeCon + CloudNativeCon is coming to [Shanghai](https://events.linuxfoundation.cn/events/kubecon-cloudnativecon-china-2018/ from November 14-15, 2018 and Seattle from December 11-13, 2018. This conference will feature technical sessions, case studies, developer deep dives, salons and more! The CFP for both event is currently open. Submit your talk and register today!
Webinar
Join members of the Kubernetes 1.11 release team on July 31st at 10am PDT to learn about the major features in this release including In-Cluster Load Balancing and the CoreDNS Plugin. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
Thank you for your continued feedback and support.
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Chat with the community on Slack
- Share your Kubernetes story
Dynamic Ingress in Kubernetes
Author: Richard Li (Datawire)
Kubernetes makes it easy to deploy applications that consist of many microservices, but one of the key challenges with this type of architecture is dynamically routing ingress traffic to each of these services. One approach is Ambassador, a Kubernetes-native open source API Gateway built on the Envoy Proxy. Ambassador is designed for dynamic environment where services may come and go frequently.
Ambassador is configured using Kubernetes annotations. Annotations are used to configure specific mappings from a given Kubernetes service to a particular URL. A mapping can include a number of annotations for configuring a route. Examples include rate limiting, protocol, cross-origin request sharing, traffic shadowing, and routing rules.
A Basic Ambassador Example
Ambassador is typically installed as a Kubernetes deployment, and is also available as a Helm chart. To configure Ambassador, create a Kubernetes service with the Ambassador annotations. Here is an example that configures Ambassador to route requests to /httpbin/ to the public httpbin.org service:
apiVersion: v1
kind: Service
metadata:
name: httpbin
annotations:
getambassador.io/config: |
---
apiVersion: ambassador/v0
kind: Mapping
name: httpbin_mapping
prefix: /httpbin/
service: httpbin.org:80
host_rewrite: httpbin.org
spec:
type: ClusterIP
ports:
- port: 80
A mapping object is created with a prefix of /httpbin/ and a service name of httpbin.org. The host_rewrite annotation specifies that the HTTP host header should be set to httpbin.org.
Kubeflow
Kubeflow provides a simple way to easily deploy machine learning infrastructure on Kubernetes. The Kubeflow team needed a proxy that provided a central point of authentication and routing to the wide range of services used in Kubeflow, many of which are ephemeral in nature.
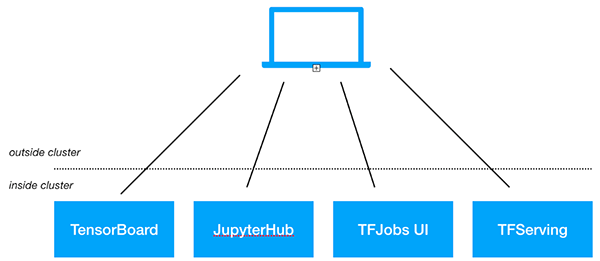
Service configuration
With Ambassador, Kubeflow can use a distributed model for configuration. Instead of a central configuration file, Ambassador allows each service to configure its route in Ambassador via Kubernetes annotations. Here is a simplified example configuration:
---
apiVersion: ambassador/v0
kind: Mapping
name: tfserving-mapping-test-post
prefix: /models/test/
rewrite: /model/test/:predict
method: POST
service: test.kubeflow:8000
In this example, the “test” service uses Ambassador annotations to dynamically configure a route to the service, triggered only when the HTTP method is a POST, and the annotation also specifies a rewrite rule.
Kubeflow and Ambassador
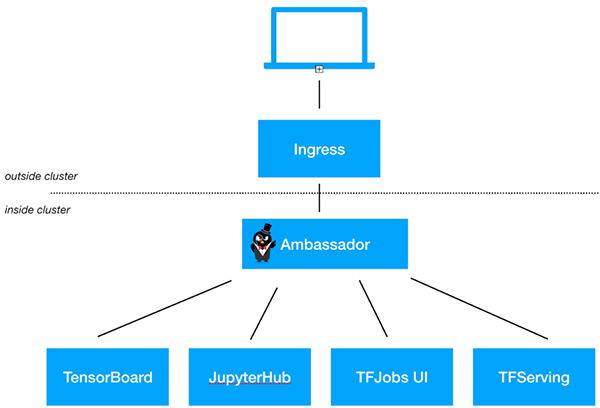
With Ambassador, Kubeflow manages routing easily with Kubernetes annotations. Kubeflow configures a single ingress object that directs traffic to Ambassador, then creates services with Ambassador annotations as needed to direct traffic to specific backends. For example, when deploying TensorFlow services, Kubeflow creates and annotates a K8s service so that the model will be served at https://
If you’re interested in using Ambassador with Kubeflow, the standard Kubeflow install automatically installs and configures Ambassador.
If you’re interested in using Ambassador as an API Gateway or Kubernetes ingress solution for your non-Kubeflow services, check out the Getting Started with Ambassador guide.
4 Years of K8s
Author: Joe Beda (CTO and Founder, Heptio)
On June 6, 2014 I checked in the first commit of what would become the public repository for Kubernetes. Many would assume that is where the story starts. It is the beginning of history, right? But that really doesn’t tell the whole story.

The cast leading up to that commit was large and the success for Kubernetes since then is owed to an ever larger cast.
Kubernetes was built on ideas that had been proven out at Google over the previous ten years with Borg. And Borg, itself, owed its existence to even earlier efforts at Google and beyond.
Concretely, Kubernetes started as some prototypes from Brendan Burns combined with ongoing work from me and Craig McLuckie to better align the internal Google experience with the Google Cloud experience. Brendan, Craig, and I really wanted people to use this, so we made the case to build out this prototype as an open source project that would bring the best ideas from Borg out into the open.
After we got the nod, it was time to actually build the system. We took Brendan’s prototype (in Java), rewrote it in Go, and built just enough to get the core ideas across. By this time the team had grown to include Ville Aikas, Tim Hockin, Brian Grant, Dawn Chen and Daniel Smith. Once we had something working, someone had to sign up to clean things up to get it ready for public launch. That ended up being me. Not knowing the significance at the time, I created a new repo, moved things over, and checked it in. So while I have the first public commit to the repo, there was work underway well before that.
The version of Kubernetes at that point was really just a shadow of what it was to become. The core concepts were there but it was very raw. For example, Pods were called Tasks. That was changed a day before we went public. All of this led up to the public announcement of Kubernetes on June 10th, 2014 in a keynote from Eric Brewer at the first DockerCon. You can watch that video here:
But, however raw, that modest start was enough to pique the interest of a community that started strong and has only gotten stronger. Over the past four years Kubernetes has exceeded the expectations of all of us that were there early on. We owe the Kubernetes community a huge debt. The success the project has seen is based not just on code and technology but also the way that an amazing group of people have come together to create something special. The best expression of this is the set of Kubernetes values that Sarah Novotny helped curate.
Here is to another 4 years and beyond! 🎉🎉🎉
Say Hello to Discuss Kubernetes
Author: Jorge Castro (Heptio)
Communication is key when it comes to engaging a community of over 35,000 people in a global and remote environment. Keeping track of everything in the Kubernetes community can be an overwhelming task. On one hand we have our official resources, like Stack Overflow, GitHub, and the mailing lists, and on the other we have more ephemeral resources like Slack, where you can hop in, chat with someone, and then go on your merry way.
Slack is great for casual and timely conversations and keeping up with other community members, but communication can't be easily referenced in the future. Plus it can be hard to raise your hand in a room filled with 35,000 participants and find a voice. Mailing lists are useful when trying to reach a specific group of people with a particular ask and want to keep track of responses on the thread, but can be daunting with a large amount of people. Stack Overflow and GitHub are ideal for collaborating on projects or questions that involve code and need to be searchable in the future, but certain topics like "What's your favorite CI/CD tool" or "Kubectl tips and tricks" are offtopic there.
While our current assortment of communication channels are valuable in their own rights, we found that there was still a gap between email and real time chat. Across the rest of the web, many other open source projects like Docker, Mozilla, Swift, Ghost, and Chef have had success building communities on top of Discourse, an open source discussion platform. So what if we could use this tool to bring our discussions together under a modern roof, with an open API, and perhaps not let so much of our information fade into the ether? There's only one way to find out: Welcome to discuss.kubernetes.io
Right off the bat we have categories that users can browse. Checking and posting in these categories allow users to participate in things they might be interested in without having to commit to subscribing to a list. Granular notification controls allow the users to subscribe to just the category or tag they want, and allow for responding to topics via email.
Ecosystem partners and developers now have a place where they can announce projects that they're working on to users without wondering if it would be offtopic on an official list. We can make this place be not just about core Kubernetes, but about the hundreds of wonderful tools our community is building.
This new community forum gives people a place to go where they can discuss Kubernetes, and a sounding board for developers to make announcements of things happening around Kubernetes, all while being searchable and easily accessible to a wider audience.
Hop in and take a look. We're just getting started, so you might want to begin by introducing yourself and then browsing around. Apps are also available for Android and iOS.
Introducing kustomize; Template-free Configuration Customization for Kubernetes
Authors: Jeff Regan (Google), Phil Wittrock (Google)
If you run a Kubernetes environment, chances are you’ve customized a Kubernetes configuration — you've copied some API object YAML files and edited them to suit your needs.
But there are drawbacks to this approach — it can be hard to go back to the source material and incorporate any improvements that were made to it. Today Google is announcing kustomize, a command-line tool contributed as a subproject of SIG-CLI. The tool provides a new, purely declarative approach to configuration customization that adheres to and leverages the familiar and carefully designed Kubernetes API.
Here’s a common scenario. Somewhere on the internet you find someone’s Kubernetes configuration for a content management system. It's a set of files containing YAML specifications of Kubernetes API objects. Then, in some corner of your own company you find a configuration for a database to back that CMS — a database you prefer because you know it well.
You want to use these together, somehow. Further, you want to customize the files so that your resource instances appear in the cluster with a label that distinguishes them from a colleague’s resources who’s doing the same thing in the same cluster. You also want to set appropriate values for CPU, memory and replica count.
Additionally, you’ll want multiple variants of the entire configuration: a small variant (in terms of computing resources used) devoted to testing and experimentation, and a much larger variant devoted to serving outside users in production. Likewise, other teams will want their own variants.
This raises all sorts of questions. Do you copy your configuration to multiple locations and edit them independently? What if you have dozens of development teams who need slightly different variations of the stack? How do you maintain and upgrade the aspects of configuration that they share in common? Workflows using kustomize provide answers to these questions.
Customization is reuse
Kubernetes configurations aren't code (being YAML specifications of API objects, they are more strictly viewed as data), but configuration lifecycle has many similarities to code lifecycle.
You should keep configurations in version control. Configuration owners aren’t necessarily the same set of people as configuration users. Configurations may be used as parts of a larger whole. Users will want to reuse configurations for different purposes.
One approach to configuration reuse, as with code reuse, is to simply copy it all and customize the copy. As with code, severing the connection to the source material makes it difficult to benefit from ongoing improvements to the source material. Taking this approach with many teams or environments, each with their own variants of a configuration, makes a simple upgrade intractable.
Another approach to reuse is to express the source material as a parameterized template. A tool processes the template—executing any embedded scripting and replacing parameters with desired values—to generate the configuration. Reuse comes from using different sets of values with the same template. The challenge here is that the templates and value files are not specifications of Kubernetes API resources. They are, necessarily, a new thing, a new language, that wraps the Kubernetes API. And yes, they can be powerful, but bring with them learning and tooling costs. Different teams want different changes—so almost every specification that you can include in a YAML file becomes a parameter that needs a value. As a result, the value sets get large, since all parameters (that don't have trusted defaults) must be specified for replacement. This defeats one of the goals of reuse—keeping the differences between the variants small in size and easy to understand in the absence of a full resource declaration.
A new option for configuration customization
Compare that to kustomize, where the tool’s
behavior is determined by declarative specifications
expressed in a file called kustomization.yaml.
The kustomize program reads the file and the Kubernetes API resource files it references, then emits complete resources to standard output. This text output can be further processed by other tools, or streamed directly to kubectl for application to a cluster.
For example, if a file called kustomization.yaml
containing
commonLabels:
app: hello
resources:
- deployment.yaml
- configMap.yaml
- service.yaml
is in the current working directory, along with the three resource files it mentions, then running
kustomize build
emits a YAML stream that includes the three given
resources, and adds a common label app: hello to
each resource.
Similarly, you can use a commonAnnotations field to add an annotation to all resources, and a namePrefix field to add a common prefix to all resource names. This trivial yet common customization is just the beginning.
A more common use case is that you’ll need multiple variants of a common set of resources, e.g., a development, staging and production variant.
For this purpose, kustomize supports the idea of an overlay and a base. Both are represented by a kustomization file. The base declares things that the variants share in common (both resources and a common customization of those resources), and the overlays declare the differences.
Here’s a file system layout to manage a staging and production variant of a given cluster app:
someapp/
├── base/
│ ├── kustomization.yaml
│ ├── deployment.yaml
│ ├── configMap.yaml
│ └── service.yaml
└── overlays/
├── production/
│ └── kustomization.yaml
│ ├── replica_count.yaml
└── staging/
├── kustomization.yaml
└── cpu_count.yaml
The file someapp/base/kustomization.yaml specifies the
common resources and common customizations to those
resources (e.g., they all get some label, name prefix
and annotation).
The contents of
someapp/overlays/production/kustomization.yaml could
be
commonLabels:
env: production
bases:
- ../../base
patches:
- replica_count.yaml
This kustomization specifies a patch file
replica_count.yaml, which could be:
apiVersion: apps/v1
kind: Deployment
metadata:
name: the-deployment
spec:
replicas: 100
A patch is a partial resource declaration, in this case
a patch of the deployment in
someapp/base/deployment.yaml, modifying only the
replicas count to handle production traffic.
The patch, being a partial deployment spec, has a clear context and purpose and can be validated even if it’s read in isolation from the remaining configuration. It’s not just a context free {parameter name, value} tuple.
To create the resources for the production variant, run
kustomize build someapp/overlays/production
The result is printed to stdout as a set of complete resources, ready to be applied to a cluster. A similar command defines the staging environment.
In summary
With kustomize, you can manage an arbitrary number of distinctly customized Kubernetes configurations using only Kubernetes API resource files. Every artifact that kustomize uses is plain YAML and can be validated and processed as such. kustomize encourages a fork/modify/rebase workflow.
To get started, try the hello world example. For discussion and feedback, join the mailing list or open an issue. Pull requests are welcome.
Kubernetes Containerd Integration Goes GA
Kubernetes Containerd Integration Goes GA
Authors: Lantao Liu, Software Engineer, Google and Mike Brown, Open Source Developer Advocate, IBM
In a previous blog - Containerd Brings More Container Runtime Options for Kubernetes, we introduced the alpha version of the Kubernetes containerd integration. With another 6 months of development, the integration with containerd is now generally available! You can now use containerd 1.1 as the container runtime for production Kubernetes clusters!
Containerd 1.1 works with Kubernetes 1.10 and above, and supports all Kubernetes features. The test coverage of containerd integration on Google Cloud Platform in Kubernetes test infrastructure is now equivalent to the Docker integration (See: test dashboard).
We're very glad to see containerd rapidly grow to this big milestone. Alibaba Cloud started to use containerd actively since its first day, and thanks to the simplicity and robustness emphasise, make it a perfect container engine running in our Serverless Kubernetes product, which has high qualification on performance and stability. No doubt, containerd will be a core engine of container era, and continue to driving innovation forward.
— Xinwei, Staff Engineer in Alibaba Cloud
Architecture Improvements
The Kubernetes containerd integration architecture has evolved twice. Each evolution has made the stack more stable and efficient.
Containerd 1.0 - CRI-Containerd (end of life)
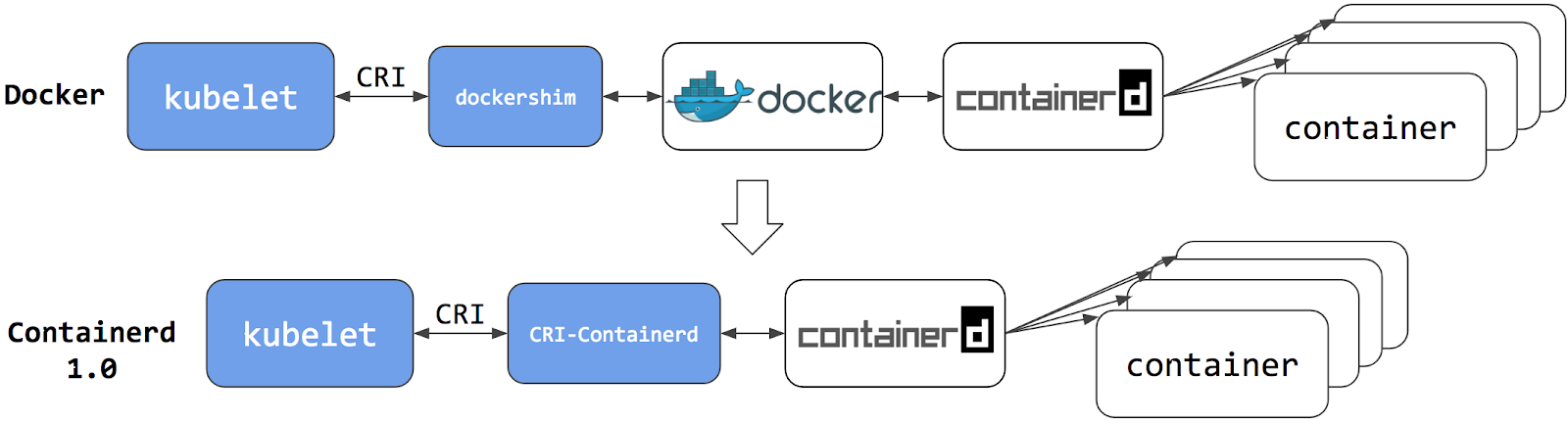
For containerd 1.0, a daemon called cri-containerd was required to operate between Kubelet and containerd. Cri-containerd handled the Container Runtime Interface (CRI) service requests from Kubelet and used containerd to manage containers and container images correspondingly. Compared to the Docker CRI implementation (dockershim), this eliminated one extra hop in the stack.
However, cri-containerd and containerd 1.0 were still 2 different daemons which interacted via grpc. The extra daemon in the loop made it more complex for users to understand and deploy, and introduced unnecessary communication overhead.
Containerd 1.1 - CRI Plugin (current)
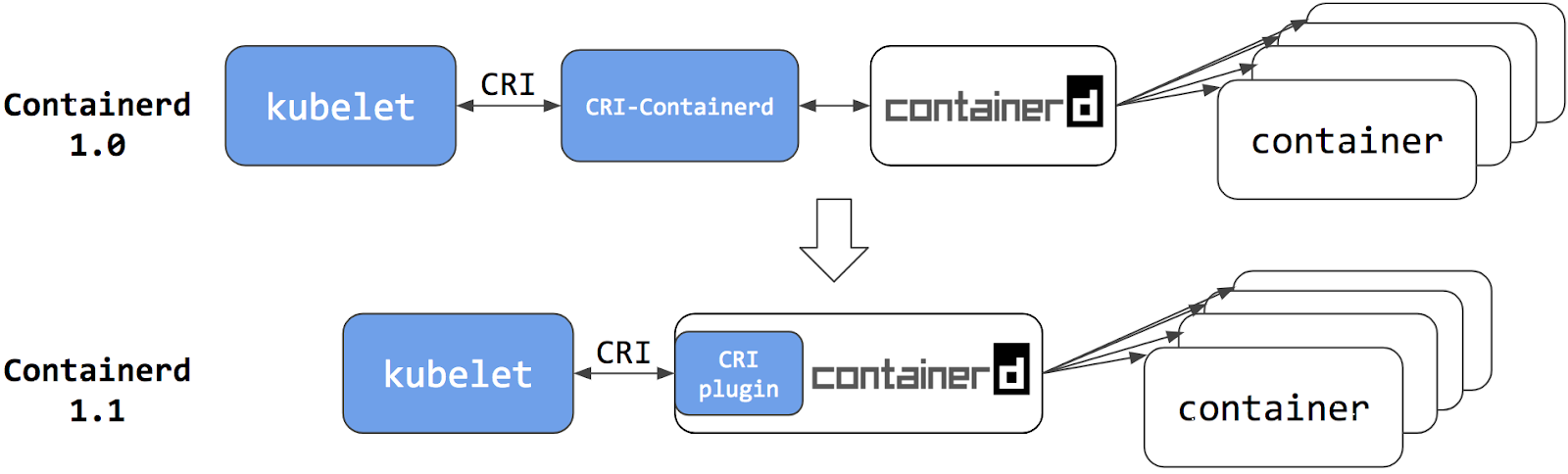
In containerd 1.1, the cri-containerd daemon is now refactored to be a containerd CRI plugin. The CRI plugin is built into containerd 1.1, and enabled by default. Unlike cri-containerd, the CRI plugin interacts with containerd through direct function calls. This new architecture makes the integration more stable and efficient, and eliminates another grpc hop in the stack. Users can now use Kubernetes with containerd 1.1 directly. The cri-containerd daemon is no longer needed.
Performance
Improving performance was one of the major focus items for the containerd 1.1 release. Performance was optimized in terms of pod startup latency and daemon resource usage.
The following results are a comparison between containerd 1.1 and Docker 18.03 CE. The containerd 1.1 integration uses the CRI plugin built into containerd; and the Docker 18.03 CE integration uses the dockershim.
The results were generated using the Kubernetes node performance benchmark, which is part of Kubernetes node e2e test. Most of the containerd benchmark data is publicly accessible on the node performance dashboard.
Pod Startup Latency
The "105 pod batch startup benchmark" results show that the containerd 1.1 integration has lower pod startup latency than Docker 18.03 CE integration with dockershim (lower is better).
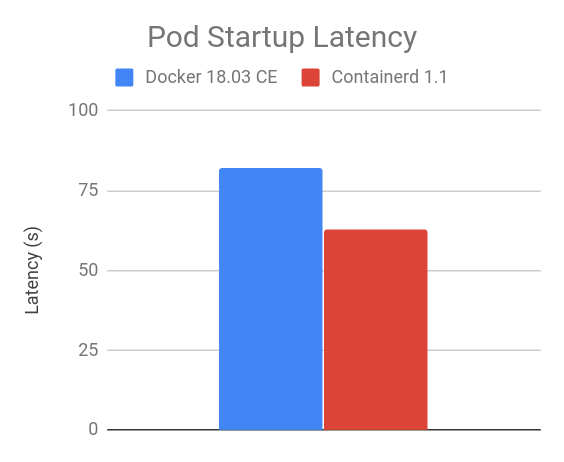
CPU and Memory
At the steady state, with 105 pods, the containerd 1.1 integration consumes less CPU and memory overall compared to Docker 18.03 CE integration with dockershim. The results vary with the number of pods running on the node, 105 is chosen because it is the current default for the maximum number of user pods per node.
As shown in the figures below, compared to Docker 18.03 CE integration with dockershim, the containerd 1.1 integration has 30.89% lower kubelet cpu usage, 68.13% lower container runtime cpu usage, 11.30% lower kubelet resident set size (RSS) memory usage, 12.78% lower container runtime RSS memory usage.
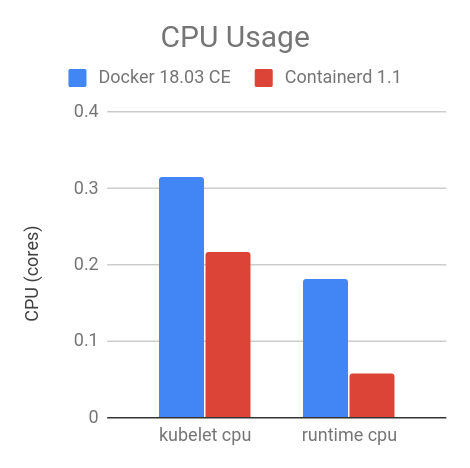
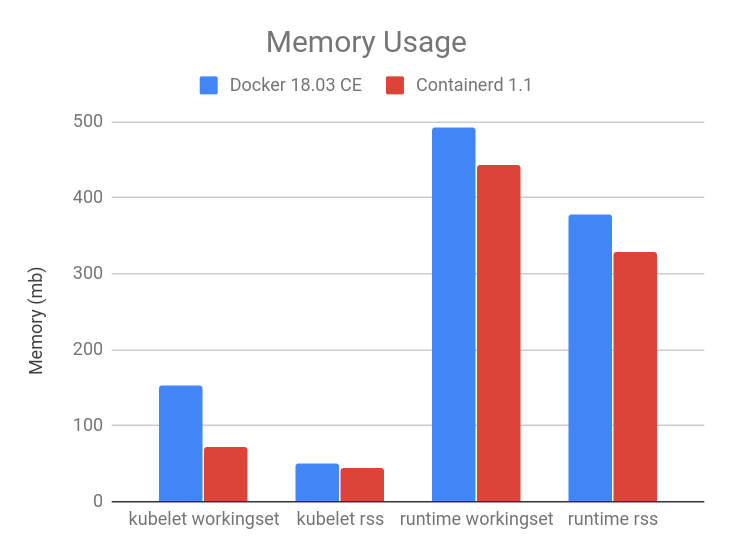
crictl
Container runtime command-line interface (CLI) is a useful tool for system and application troubleshooting. When using Docker as the container runtime for Kubernetes, system administrators sometimes login to the Kubernetes node to run Docker commands for collecting system and/or application information. For example, one may use docker ps and docker inspect to check application process status, docker images to list images on the node, and docker info to identify container runtime configuration, etc.
For containerd and all other CRI-compatible container runtimes, e.g. dockershim, we recommend using crictl as a replacement CLI over the Docker CLI for troubleshooting pods, containers, and container images on Kubernetes nodes.
crictl is a tool providing a similar experience to the Docker CLI for Kubernetes node troubleshooting and crictl works consistently across all CRI-compatible container runtimes. It is hosted in the kubernetes-incubator/cri-tools repository and the current version is v1.0.0-beta.1. crictl is designed to resemble the Docker CLI to offer a better transition experience for users, but it is not exactly the same. There are a few important differences, explained below.
Limited Scope - crictl is a Troubleshooting Tool
The scope of crictl is limited to troubleshooting, it is not a replacement to docker or kubectl. Docker's CLI provides a rich set of commands, making it a very useful development tool. But it is not the best fit for troubleshooting on Kubernetes nodes. Some Docker commands are not useful to Kubernetes, such as docker network and docker build; and some may even break the system, such as docker rename. crictl provides just enough commands for node troubleshooting, which is arguably safer to use on production nodes.
Kubernetes Oriented
crictl offers a more kubernetes-friendly view of containers. Docker CLI lacks core Kubernetes concepts, e.g. pod and namespace, so it can't provide a clear view of containers and pods. One example is that docker ps shows somewhat obscure, long Docker container names, and shows pause containers and application containers together:

However, pause containers are a pod implementation detail, where one pause container is used for each pod, and thus should not be shown when listing containers that are members of pods.
crictl, by contrast, is designed for Kubernetes. It has different sets of commands for pods and containers. For example, crictl pods lists pod information, and crictl ps only lists application container information. All information is well formatted into table columns.


As another example, crictl pods includes a --namespace option for filtering pods by the namespaces specified in Kubernetes.

For more details about how to use crictl with containerd:
What about Docker Engine?
"Does switching to containerd mean I can't use Docker Engine anymore?" We hear this question a lot, the short answer is NO.
Docker Engine is built on top of containerd. The next release of Docker Community Edition (Docker CE) will use containerd version 1.1. Of course, it will have the CRI plugin built-in and enabled by default. This means users will have the option to continue using Docker Engine for other purposes typical for Docker users, while also being able to configure Kubernetes to use the underlying containerd that came with and is simultaneously being used by Docker Engine on the same node. See the architecture figure below showing the same containerd being used by Docker Engine and Kubelet:
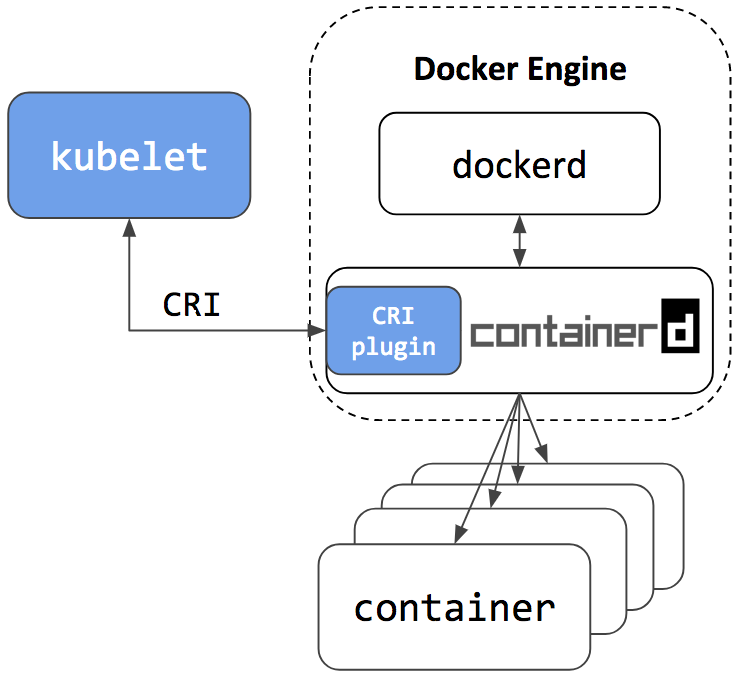
Since containerd is being used by both Kubelet and Docker Engine, this means users who choose the containerd integration will not just get new Kubernetes features, performance, and stability improvements, they will also have the option of keeping Docker Engine around for other use cases.
A containerd namespace mechanism is employed to guarantee that Kubelet and Docker Engine won't see or have access to containers and images created by each other. This makes sure they won't interfere with each other. This also means that:
- Users won't see Kubernetes created containers with the docker ps command. Please use crictl ps instead. And vice versa, users won't see Docker CLI created containers in Kubernetes or with crictl ps command. The crictl create and crictl runp commands are only for troubleshooting. Manually starting pod or container with crictl on production nodes is not recommended.
- Users won't see Kubernetes pulled images with the docker images command. Please use the crictl images command instead. And vice versa, Kubernetes won't see images created by docker pull, docker load or docker build commands. Please use the crictl pull command instead, and ctr cri load if you have to load an image.
Summary
- Containerd 1.1 natively supports CRI. It can be used directly by Kubernetes.
- Containerd 1.1 is production ready.
- Containerd 1.1 has good performance in terms of pod startup latency and system resource utilization.
- crictl is the CLI tool to talk with containerd 1.1 and other CRI-conformant container runtimes for node troubleshooting.
- The next stable release of Docker CE will include containerd 1.1. Users have the option to continue using Docker for use cases not specific to Kubernetes, and configure Kubernetes to use the same underlying containerd that comes with Docker.
We'd like to thank all the contributors from Google, IBM, Docker, ZTE, ZJU and many other individuals who made this happen!
For a detailed list of changes in the containerd 1.1 release, please see the release notes here: https://github.com/containerd/containerd/releases/tag/v1.1.0
Try it out
To setup a Kubernetes cluster using containerd as the container runtime:
- For a production quality cluster on GCE brought up with kube-up.sh, see here.
- For a multi-node cluster installer and bring up steps using Ansible and kubeadm, see here.
- For creating a cluster from scratch on Google Cloud, see Kubernetes the Hard Way.
- For a custom installation from release tarball, see here.
- To install using LinuxKit on a local VM, see here.
Contribute
The containerd CRI plugin is an open source github project within containerd https://github.com/containerd/cri. Any contributions in terms of ideas, issues, and/or fixes are welcome. The getting started guide for developers is a good place to start for contributors.
Community
The project is developed and maintained jointly by members of the Kubernetes SIG-Node community and the containerd community. We'd love to hear feedback from you. To join the communities:
- sig-node community site
- Slack:
- #sig-node channel in kubernetes.slack.com
- #containerd channel in https://dockr.ly/community
- Mailing List: https://groups.google.com/forum/#!forum/kubernetes-sig-node
Getting to Know Kubevirt
Author: Jason Brooks (Red Hat)
Once you've become accustomed to running Linux container workloads on Kubernetes, you may find yourself wishing that you could run other sorts of workloads on your Kubernetes cluster. Maybe you need to run an application that isn't architected for containers, or that requires a different version of the Linux kernel -- or an all together different operating system -- than what's available on your container host.
These sorts of workloads are often well-suited to running in virtual machines (VMs), and KubeVirt, a virtual machine management add-on for Kubernetes, is aimed at allowing users to run VMs right alongside containers in the their Kubernetes or OpenShift clusters.
KubeVirt extends Kubernetes by adding resource types for VMs and sets of VMs through Kubernetes' Custom Resource Definitions API (CRD). KubeVirt VMs run within regular Kubernetes pods, where they have access to standard pod networking and storage, and can be managed using standard Kubernetes tools such as kubectl.
Running VMs with Kubernetes involves a bit of an adjustment compared to using something like oVirt or OpenStack, and understanding the basic architecture of KubeVirt is a good place to begin.
In this post, we’ll talk about some of the components that are involved in KubeVirt at a high level. The components we’ll check out are CRDs, the KubeVirt virt-controller, virt-handler and virt-launcher components, libvirt, storage, and networking.
KubeVirt Components
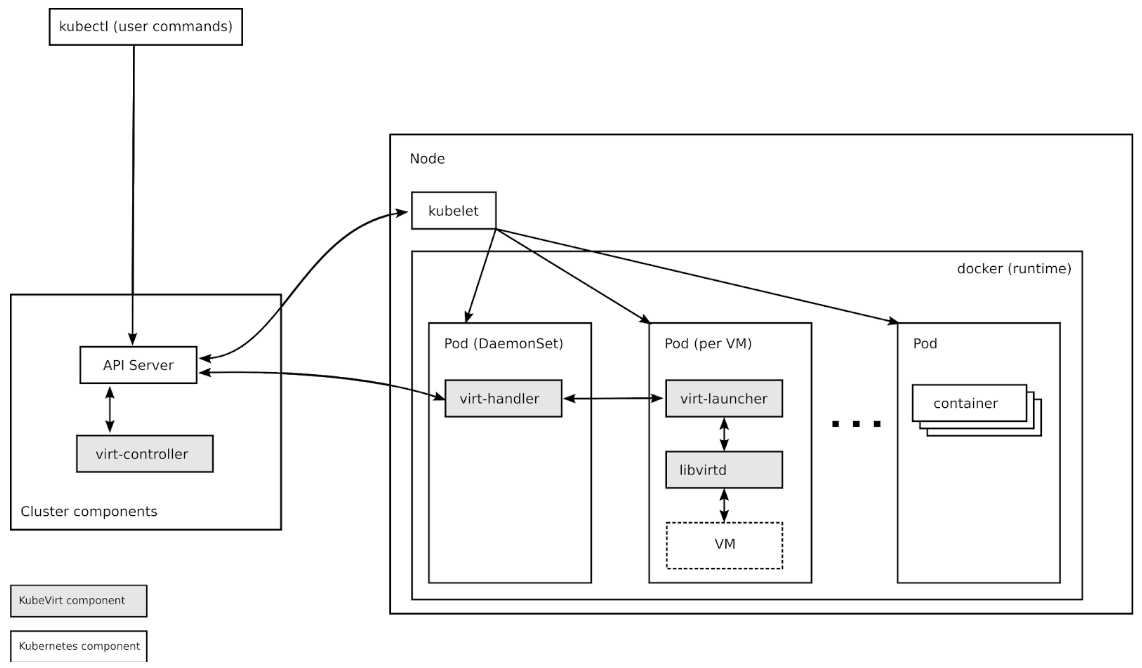
Custom Resource Definitions
Kubernetes resources are endpoints in the Kubernetes API that store collections of related API objects. For instance, the built-in pods resource contains a collection of Pod objects. The Kubernetes Custom Resource Definition API allows users to extend Kubernetes with additional resources by defining new objects with a given name and schema. Once you've applied a custom resource to your cluster, the Kubernetes API server serves and handles the storage of your custom resource.
KubeVirt's primary CRD is the VirtualMachine (VM) resource, which contains a collection of VM objects inside the Kubernetes API server. The VM resource defines all the properties of the Virtual machine itself, such as the machine and CPU type, the amount of RAM and vCPUs, and the number and type of NICs available in the VM.
virt-controller
The virt-controller is a Kubernetes Operator that’s responsible for cluster-wide virtualization functionality. When new VM objects are posted to the Kubernetes API server, the virt-controller takes notice and creates the pod in which the VM will run. When the pod is scheduled on a particular node, the virt-controller updates the VM object with the node name, and hands off further responsibilities to a node-specific KubeVirt component, the virt-handler, an instance of which runs on every node in the cluster.
virt-handler
Like the virt-controller, the virt-handler is also reactive, watching for changes to the VM object, and performing all necessary operations to change a VM to meet the required state. The virt-handler references the VM specification and signals the creation of a corresponding domain using a libvirtd instance in the VM's pod. When a VM object is deleted, the virt-handler observes the deletion and turns off the domain.
virt-launcher
For every VM object one pod is created. This pod's primary container runs the virt-launcher KubeVirt component. The main purpose of the virt-launcher Pod is to provide the cgroups and namespaces which will be used to host the VM process.
virt-handler signals virt-launcher to start a VM by passing the VM's CRD object to virt-launcher. virt-launcher then uses a local libvirtd instance within its container to start the VM. From there virt-launcher monitors the VM process and terminates once the VM has exited.
If the Kubernetes runtime attempts to shutdown the virt-launcher pod before the VM has exited, virt-launcher forwards signals from Kubernetes to the VM process and attempts to hold off the termination of the pod until the VM has shutdown successfully.
# kubectl get pods
NAME READY STATUS RESTARTS AGE
virt-controller-7888c64d66-dzc9p 1/1 Running 0 2h
virt-controller-7888c64d66-wm66x 0/1 Running 0 2h
virt-handler-l2xkt 1/1 Running 0 2h
virt-handler-sztsw 1/1 Running 0 2h
virt-launcher-testvm-ephemeral-dph94 2/2 Running 0 2h
libvirtd
An instance of libvirtd is present in every VM pod. virt-launcher uses libvirtd to manage the life-cycle of the VM process.
Storage and Networking
KubeVirt VMs may be configured with disks, backed by volumes.
Persistent Volume Claim volumes make Kubernetes persistent volume available as disks directly attached to the VM. This is the primary way to provide KubeVirt VMs with persistent storage. Currently, persistent volumes must be iscsi block devices, although work is underway to enable file-based pv disks.
Ephemeral Volumes are a local copy on write images that use a network volume as a read-only backing store. KubeVirt dynamically generates the ephemeral images associated with a VM when the VM starts, and discards the ephemeral images when the VM stops. Currently, ephemeral volumes must be backed by pvc volumes.
Registry Disk volumes reference docker image that embed a qcow or raw disk. As the name suggests, these volumes are pulled from a container registry. Like regular ephemeral container images, data in these volumes persists only while the pod lives.
CloudInit NoCloud volumes provide VMs with a cloud-init NoCloud user-data source, which is added as a disk to the VM, where it's available to provide configuration details to guests with cloud-init installed. Cloud-init details can be provided in clear text, as base64 encoded UserData files, or via Kubernetes secrets.
In the example below, a Registry Disk is configured to provide the image from which to boot the VM. A cloudInit NoCloud volume, paired with an ssh-key stored as clear text in the userData field, is provided for authentication with the VM:
apiVersion: kubevirt.io/v1alpha1
kind: VirtualMachine
metadata:
name: myvm
spec:
terminationGracePeriodSeconds: 5
domain:
resources:
requests:
memory: 64M
devices:
disks:
- name: registrydisk
volumeName: registryvolume
disk:
bus: virtio
- name: cloudinitdisk
volumeName: cloudinitvolume
disk:
bus: virtio
volumes:
- name: registryvolume
registryDisk:
image: kubevirt/cirros-registry-disk-demo:devel
- name: cloudinitvolume
cloudInitNoCloud:
userData: |
ssh-authorized-keys:
- ssh-rsa AAAAB3NzaK8L93bWxnyp test@test.com
Just as with regular Kubernetes pods, basic networking functionality is made available automatically to each KubeVirt VM, and particular TCP or UDP ports can be exposed to the outside world using regular Kubernetes services. No special network configuration is required.
Getting Involved
KubeVirt development is accelerating, and the project is eager for new contributors. If you're interested in getting involved, check out the project's open issues and check out the project calendar.
If you need some help or want to chat you can connect to the team via freenode IRC in #kubevirt, or on the KubeVirt mailing list. User documentation is available at https://kubevirt.gitbooks.io/user-guide/.
Gardener - The Kubernetes Botanist
Authors: Rafael Franzke (SAP), Vasu Chandrasekhara (SAP)
Today, Kubernetes is the natural choice for running software in the Cloud. More and more developers and corporations are in the process of containerizing their applications, and many of them are adopting Kubernetes for automated deployments of their Cloud Native workloads.
There are many Open Source tools which help in creating and updating single Kubernetes clusters. However, the more clusters you need the harder it becomes to operate, monitor, manage, and keep all of them alive and up-to-date.
And that is exactly what project "Gardener" focuses on. It is not just another provisioning tool, but it is rather designed to manage Kubernetes clusters as a service. It provides Kubernetes-conformant clusters on various cloud providers and the ability to maintain hundreds or thousands of them at scale. At SAP, we face this heterogeneous multi-cloud & on-premise challenge not only in our own platform, but also encounter the same demand at all our larger and smaller customers implementing Kubernetes & Cloud Native.
Inspired by the possibilities of Kubernetes and the ability to self-host, the foundation of Gardener is Kubernetes itself. While self-hosting, as in, to run Kubernetes components inside Kubernetes is a popular topic in the community, we apply a special pattern catering to the needs of operating a huge number of clusters with minimal total cost of ownership. We take an initial Kubernetes cluster (called "seed" cluster) and seed the control plane components (such as the API server, scheduler, controller-manager, etcd and others) of an end-user cluster as simple Kubernetes pods. In essence, the focus of the seed cluster is to deliver a robust Control-Plane-as-a-Service at scale. Following our botanical terminology, the end-user clusters when ready to sprout are called "shoot" clusters. Considering network latency and other fault scenarios, we recommend a seed cluster per cloud provider and region to host the control planes of the many shoot clusters.
Overall, this concept of reusing Kubernetes primitives already simplifies deployment, management, scaling & patching/updating of the control plane. Since it builds upon highly available initial seed clusters, we can evade multiple quorum number of master node requirements for shoot cluster control planes and reduce waste/costs. Furthermore, the actual shoot cluster consists only of worker nodes for which full administrative access to the respective owners could be granted, thereby structuring a necessary separation of concerns to deliver a higher level of SLO. The architectural role & operational ownerships are thus defined as following (cf. Figure 1):
- Kubernetes as a Service provider owns, operates, and manages the garden and the seed clusters. They represent parts of the required landscape/infrastructure.
- The control planes of the shoot clusters are run in the seed and, consequently, within the separate security domain of the service provider.
- The shoot clusters' machines are run under the ownership of and in the cloud provider account and the environment of the customer, but still managed by the Gardener.
- For on-premise or private cloud scenarios the delegation of ownership & management of the seed clusters (and the IaaS) is feasible.
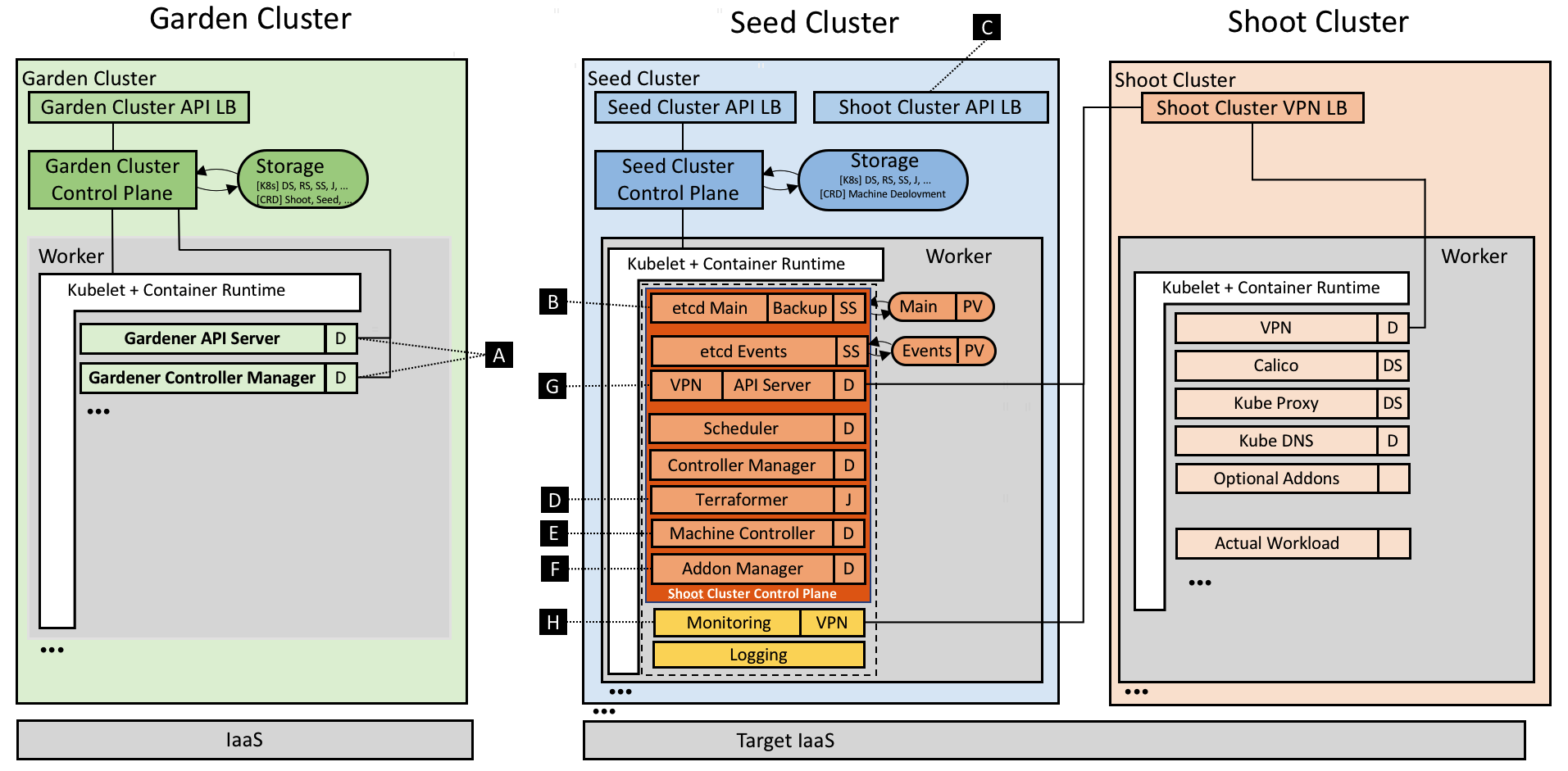
Figure 1 Technical Gardener landscape with components.
The Gardener is developed as an aggregated API server and comes with a bundled set of controllers. It runs inside another dedicated Kubernetes cluster (called "garden" cluster) and it extends the Kubernetes API with custom resources. Most prominently, the Shoot resource allows a description of the entire configuration of a user's Kubernetes cluster in a declarative way. Corresponding controllers will, just like native Kubernetes controllers, watch these resources and bring the world's actual state to the desired state (resulting in create, reconcile, update, upgrade, or delete operations.) The following example manifest shows what needs to be specified:
apiVersion: garden.sapcloud.io/v1beta1
kind: Shoot
metadata:
name: dev-eu1
namespace: team-a
spec:
cloud:
profile: aws
region: us-east-1
secretBindingRef:
name: team-a-aws-account-credentials
aws:
machineImage:
ami: ami-34237c4d
name: CoreOS
networks:
vpc:
cidr: 10.250.0.0/16
...
workers:
- name: cpu-pool
machineType: m4.xlarge
volumeType: gp2
volumeSize: 20Gi
autoScalerMin: 2
autoScalerMax: 5
dns:
provider: aws-route53
domain: dev-eu1.team-a.example.com
kubernetes:
version: 1.10.2
backup:
...
maintenance:
...
addons:
cluster-autoscaler:
enabled: true
...
Once sent to the garden cluster, Gardener will pick it up and provision the actual shoot. What is not shown above is that each action will enrich the Shoot's status field indicating whether an operation is currently running and recording the last error (if there was any) and the health of the involved components. Users are able to configure and monitor their cluster's state in true Kubernetes style. Our users have even written their own custom controllers watching & mutating these Shoot resources.
Technical deep dive
The Gardener implements a Kubernetes inception approach; thus, it leverages Kubernetes capabilities to perform its operations. It provides a couple of controllers (cf. [A]) watching Shoot resources whereas the main controller is responsible for the standard operations like create, update, and delete. Another controller named "shoot care" is performing regular health checks and garbage collections, while a third's ("shoot maintenance") tasks are to cover actions like updating the shoot's machine image to the latest available version.
For every shoot, Gardener creates a dedicated Namespace in the seed with appropriate security policies and within it pre-creates the later required certificates managed as Secrets.
etcd
The backing data store etcd (cf. [B]) of a Kubernetes cluster is deployed as a StatefulSet with one replica and a PersistentVolume(Claim). Embracing best practices, we run another etcd shard-instance to store Events of a shoot. Anyway, the main etcd pod is enhanced with a sidecar validating the data at rest and taking regular snapshots which are then efficiently backed up to an object store. In case etcd's data is lost or corrupt, the sidecar restores it from the latest available snapshot. We plan to develop incremental/continuous backups to avoid discrepancies (in case of a recovery) between a restored etcd state and the actual state [1].
Kubernetes control plane
As already mentioned above, we have put the other Kubernetes control plane components into native Deployments and run them with the rolling update strategy. By doing so, we can not only leverage the existing deployment and update capabilities of Kubernetes, but also its monitoring and liveliness proficiencies. While the control plane itself uses in-cluster communication, the API Servers' Service is exposed via a load balancer for external communication (cf. [C]). In order to uniformly generate the deployment manifests (mainly depending on both the Kubernetes version and cloud provider), we decided to utilize Helm charts whereas Gardener leverages only Tillers rendering capabilities, but deploys the resulting manifests directly without running Tiller at all [2].
Infrastructure preparation
One of the first requirements when creating a cluster is a well-prepared infrastructure on the cloud provider side including networks and security groups. In our current provider specific in-tree implementation of Gardener (called the "Botanist"), we employ Terraform to accomplish this task. Terraform provides nice abstractions for the major cloud providers and implements capabilities like parallelism, retry mechanisms, dependency graphs, idempotency, and more. However, we found that Terraform is challenging when it comes to error handling and it does not provide a technical interface to extract the root cause of an error. Currently, Gardener generates a Terraform script based on the shoot specification and stores it inside a ConfigMap in the respective namespace of the seed cluster. The Terraformer component then runs as a Job (cf. [D]), executes the mounted Terraform configuration, and writes the produced state back into another ConfigMap. Using the Job primitive in this manner helps to inherit its retry logic and achieve fault tolerance against temporary connectivity issues or resource constraints. Moreover, Gardener only needs to access the Kubernetes API of the seed cluster to submit the Job for the underlying IaaS. This design is important for private cloud scenarios in which typically the IaaS API is not exposed publicly.
Machine controller manager
What is required next are the nodes to which the actual workload of a cluster is to be scheduled. However, Kubernetes offers no primitives to request nodes forcing a cluster administrator to use external mechanisms. The considerations include the full lifecycle, beginning with initial provisioning and continuing with providing security fixes, and performing health checks and rolling updates. While we started with instantiating static machines or utilizing instance templates of the cloud providers to create the worker nodes, we concluded (also from our previous production experience with running a cloud platform) that this approach requires extensive effort. During discussions at KubeCon 2017, we recognized that the best way, of course, to manage cluster nodes is to again apply core Kubernetes concepts and to teach the system to self-manage the nodes/machines it runs. For that purpose, we developed the machine controller manager (cf. [E]) which extends Kubernetes with MachineDeployment, MachineClass, MachineSet & Machine resources and enables declarative management of (virtual) machines from within the Kubernetes context just like Deployments, ReplicaSets & Pods. We reused code from existing Kubernetes controllers and just needed to abstract a few IaaS/cloud provider specific methods for creating, deleting, and listing machines in dedicated drivers. When comparing Pods and Machines a subtle difference becomes evident: creating virtual machines directly results in costs, and if something unforeseen happens, these costs can increase very quickly. To safeguard against such rampage, the machine controller manager comes with a safety controller that terminates orphaned machines and freezes the rollout of MachineDeployments and MachineSets beyond certain thresholds and time-outs. Furthermore, we leverage the existing official cluster-autoscaler already including the complex logic of determining which node pool to scale out or down. Since its cloud provider interface is well-designed, we enabled the autoscaler to directly modify the number of replicas in the respective MachineDeployment resource when triggering to scale out or down.
Addons
Besides providing a properly setup control plane, every Kubernetes cluster requires a few system components to work. Usually, that's the kube-proxy, an overlay network, a cluster DNS, and an ingress controller. Apart from that, Gardener allows to order optional add-ons configurable by the user (in the shoot resource definition), e.g. Heapster, the Kubernetes Dashboard, or Cert-Manager. Again, the Gardener renders the manifests for all these components via Helm charts (partly adapted and curated from the upstream charts repository). However, these resources are managed in the shoot cluster and can thus be tweaked by users with full administrative access. Hence, Gardener ensures that these deployed resources always match the computed/desired configuration by utilizing an existing watch dog, the kube-addon-manager (cf. [F]).
Network air gap
While the control plane of a shoot cluster runs in a seed managed & supplied by your friendly platform-provider, the worker nodes are typically provisioned in a separate cloud provider (billing) account of the user. Typically, these worker nodes are placed into private networks [3] to which the API Server in the seed control plane establishes direct communication, using a simple VPN solution based on ssh (cf. [G]). We have recently migrated the SSH-based implementation to an OpenVPN-based implementation which significantly increased the network bandwidth.
Monitoring & Logging
Monitoring, alerting, and logging are crucial to supervise clusters and keep them healthy so as to avoid outages and other issues. Prometheus has become the most used monitoring system in the Kubernetes domain. Therefore, we deploy a central Prometheus instance into the garden namespace of every seed. It collects metrics from all the seed's kubelets including those for all pods running in the seed cluster. In addition, next to every control plane a dedicated tenant Prometheus instance is provisioned for the shoot itself (cf. [H]). It gathers metrics for its own control plane as well as for the pods running on the shoot's worker nodes. The former is done by fetching data from the central Prometheus' federation endpoint and filtering for relevant control plane pods of the particular shoot. Other than that, Gardener deploys two kube-state-metrics instances, one responsible for the control plane and one for the workload, exposing cluster-level metrics to enrich the data. The node exporter provides more detailed node statistics. A dedicated tenant Grafana dashboard displays the analytics and insights via lucid dashboards. We also defined alerting rules for critical events and employed the AlertManager to send emails to operators and support teams in case any alert is fired.
[1] This is also the reason for not supporting point-in-time recovery. There is no reliable infrastructure reconciliation implemented in Kubernetes so far. Thus, restoring from an old backup without refreshing the actual workload and state of the concerned cluster would generally not be of much help.
[2] The most relevant criteria for this decision was that Tiller requires a port-forward connection for communication which we experienced to be too unstable and error-prone for our automated use case. Nevertheless, we are looking forward to Helm v3 hopefully interacting with Tiller using CustomResourceDefinitions.
[3] Gardener offers to either create & prepare these networks with the Terraformer or it can be instructed to reuse pre-existing networks.
Usability and Interaction
Despite requiring only the familiar kubectl command line tool for managing all of Gardener, we provide a central dashboard for comfortable interaction. It enables users to easily keep track of their clusters' health, and operators to monitor, debug, and analyze the clusters they are responsible for. Shoots are grouped into logical projects in which teams managing a set of clusters can collaborate and even track issues via an integrated ticket system (e.g. GitHub Issues). Moreover, the dashboard helps users to add & manage their infrastructure account secrets and to view the most relevant data of all their shoot clusters in one place while being independent from the cloud provider they are deployed to.
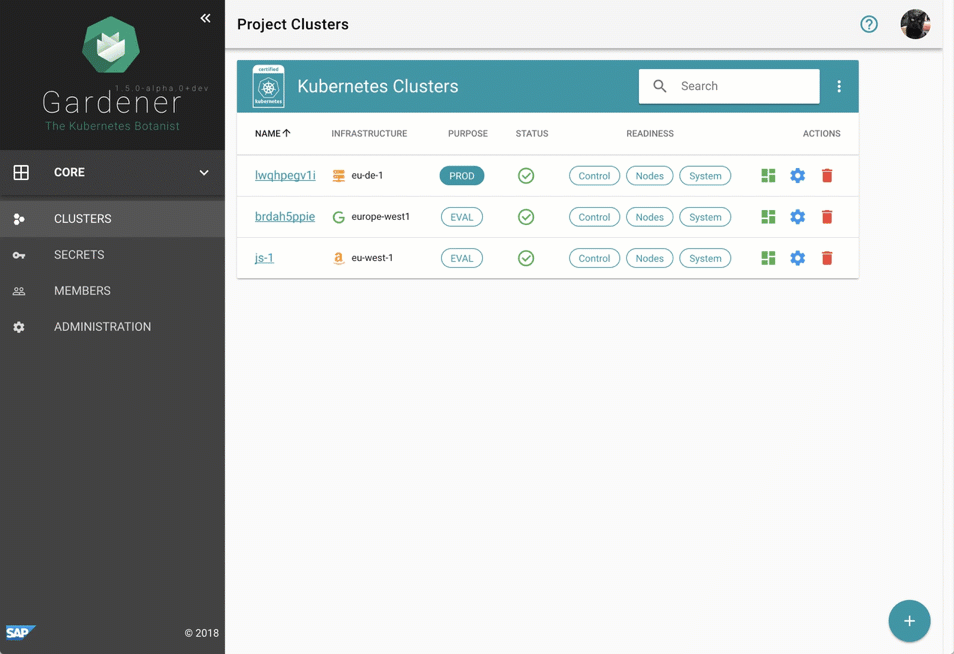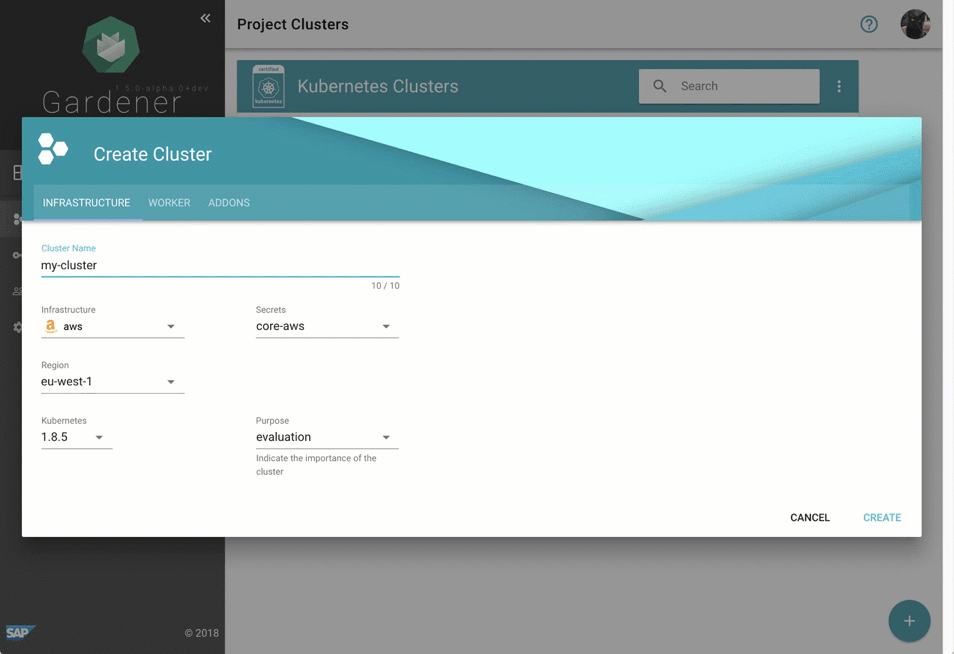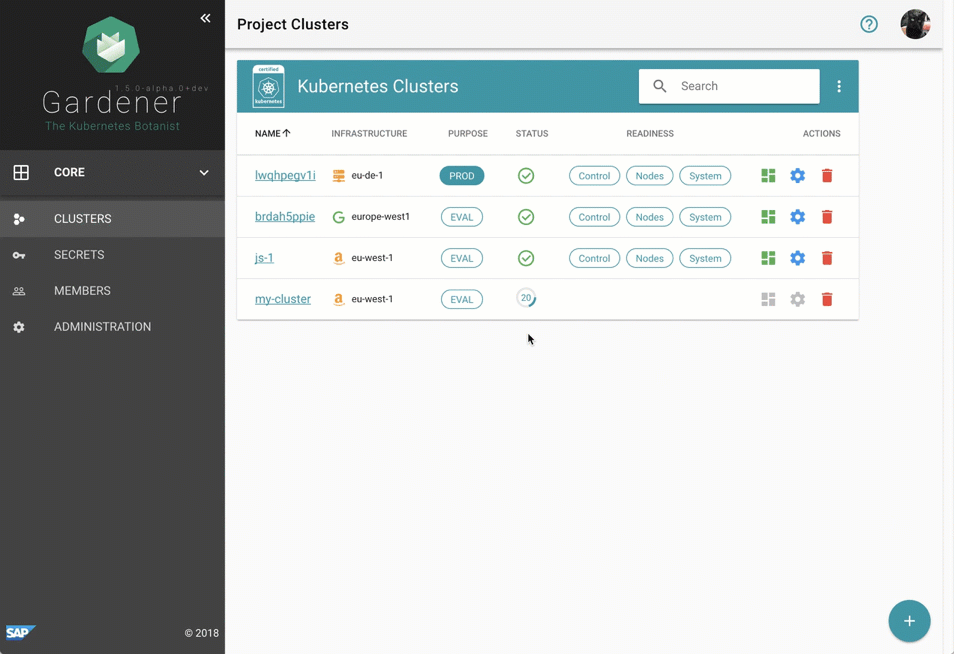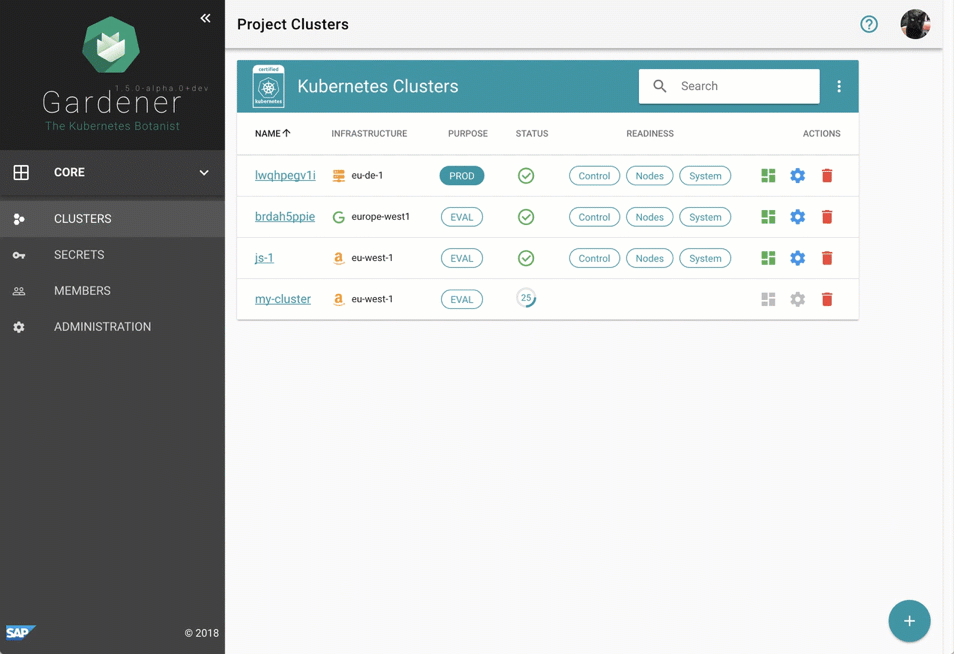
Figure 2 Animated Gardener dashboard.
More focused on the duties of developers and operators, the Gardener command line client gardenctl simplifies administrative tasks by introducing easy higher-level abstractions with simple commands that help condense and multiplex information & actions from/to large amounts of seed and shoot clusters.
$ gardenctl ls shoots
projects:
- project: team-a
shoots:
- dev-eu1
- prod-eu1
$ gardenctl target shoot prod-eu1
[prod-eu1]
$ gardenctl show prometheus
NAME READY STATUS RESTARTS AGE IP NODE
prometheus-0 3/3 Running 0 106d 10.241.241.42 ip-10-240-7-72.eu-central-1.compute.internal
URL: https://user:password@p.prod-eu1.team-a.seed.aws-eu1.example.com
Outlook and future plans
The Gardener is already capable of managing Kubernetes clusters on AWS, Azure, GCP, OpenStack [4]. Actually, due to the fact that it relies only on Kubernetes primitives, it nicely connects to private cloud or on-premise requirements. The only difference from Gardener's point of view would be the quality and scalability of the underlying infrastructure - the lingua franca of Kubernetes ensures strong portability guarantees for our approach.
Nevertheless, there are still challenges ahead. We are probing a possibility to include an option to create a federation control plane delegating to multiple shoot clusters in this Open Source project. In the previous sections we have not explained how to bootstrap the garden and the seed clusters themselves. You could indeed use any production ready cluster provisioning tool or the cloud providers' Kubernetes as a Service offering. We have built an uniform tool called Kubify based on Terraform and reused many of the mentioned Gardener components. We envision the required Kubernetes infrastructure to be able to be spawned in its entirety by an initial bootstrap Gardener and are already discussing how we could achieve that.
Another important topic we are focusing on is disaster recovery. When a seed cluster fails, the user's static workload will continue to operate. However, administrating the cluster won't be possible anymore. We are considering to move control planes of the shoots hit by a disaster to another seed. Conceptually, this approach is feasible and we already have the required components in place to implement that, e.g. automated etcd backup and restore. The contributors for this project not only have a mandate for developing Gardener for production, but most of us even run it in true DevOps mode as well. We completely trust the Kubernetes concepts and are committed to follow the "eat your own dog food" approach.
In order to enable a more independent evolution of the Botanists, which contain the infrastructure provider specific parts of the implementation, we plan to describe well-defined interfaces and factor out the Botanists into their own components. This is similar to what Kubernetes is currently doing with the cloud-controller-manager. Currently, all the cloud specifics are part of the core Gardener repository presenting a soft barrier to extending or supporting new cloud providers.
When taking a look at how the shoots are actually provisioned, we need to gain more experience on how really large clusters with thousands of nodes and pods (or more) behave. Potentially, we will have to deploy e.g. the API server and other components in a scaled-out fashion for large clusters to spread the load. Fortunately, horizontal pod autoscaling based on custom metrics from Prometheus will make this relatively easy with our setup. Additionally, the feedback from teams who run production workloads on our clusters, is that Gardener should support with prearranged Kubernetes QoS. Needless to say, our aspiration is going to be the integration and contribution to the vision of Kubernetes Autopilot.
[4] Prototypes already validated CTyun & Aliyun.
Gardener is open source
The Gardener project is developed as Open Source and hosted on GitHub: https://github.com/gardener
SAP is working on Gardener since mid 2017 and is focused on building up a project that can easily be evolved and extended. Consequently, we are now looking for further partners and contributors to the project. As outlined above, we completely rely on Kubernetes primitives, add-ons, and specifications and adapt its innovative Cloud Native approach. We are looking forward to aligning with and contributing to the Kubernetes community. In fact, we envision contributing the complete project to the CNCF.
At the moment, an important focus on collaboration with the community is the Cluster API working group within the SIG Cluster Lifecycle founded a few months ago. Its primary goal is the definition of a portable API representing a Kubernetes cluster. That includes the configuration of control planes and the underlying infrastructure. The overlap of what we have already in place with Shoot and Machine resources compared to what the community is working on is striking. Hence, we joined this working group and are actively participating in their regular meetings, trying to contribute back our learnings from production. Selfishly, it is also in our interest to shape a robust API.
If you see the potential of the Gardener project then please learn more about it on GitHub and help us make Gardener even better by asking questions, engaging in discussions, and by contributing code. Also, try out our quick start setup.
We are looking forward to seeing you there!
Docs are Migrating from Jekyll to Hugo
Author: Zach Corleissen (CNCF)
Changing the site framework
After nearly a year of investigating how to enable multilingual support for Kubernetes docs, we've decided to migrate the site's static generator from Jekyll to Hugo.
What does the Hugo migration mean for users and contributors?
Things will break
Hugo's Markdown parser is differently strict than Jekyll's. As a consequence, some Markdown formatting that rendered fine in Jekyll now produces some unexpected results: strange left nav ordering, vanishing tutorials, and broken links, among others.
If you encounter any site weirdness or broken formatting, please open an issue. You can see the list of issues that are specific to Hugo migration.
Multilingual support is coming
Our initial search focused on finding a language selector that would play well with Jekyll. The projects we found weren't well-supported, and a prototype of one plugin made it clear that a Jekyll implementation would create technical debt that drained resources away from the quality of the docs.
We chose Hugo after months of research and conversations with other open source translation projects. (Special thanks to Andreas Jaeger and his experience at OpenStack). Hugo's multilingual support is built in and easy.
Pain now, relief later
Another advantage of Hugo is that build performance scales well at size. At 250+ pages, the Kubernetes site's build times suffered significantly with Jekyll. We're excited about removing the barrier to contribution created by slow site build times.
Again, if you encounter any broken, missing, or unexpected content, please open an issue and let us know.
Announcing Kubeflow 0.1
Since Last We Met
Since the initial announcement of Kubeflow at the last KubeCon+CloudNativeCon, we have been both surprised and delighted by the excitement for building great ML stacks for Kubernetes. In just over five months, the Kubeflow project now has:
- 70+ contributors
- 20+ contributing organizations
- 15 repositories
- 3100+ GitHub stars
- 700+ commits
and already is among the top 2% of GitHub projects ever.
People are excited to chat about Kubeflow as well! The Kubeflow community has also held meetups, talks and public sessions all around the world with thousands of attendees. With all this help, we’ve started to make substantial in every step of ML, from building your first model all the way to building a production-ready, high-scale deployments. At the end of the day, our mission remains the same: we want to let data scientists and software engineers focus on the things they do well by giving them an easy-to-use, portable and scalable ML stack.
Introducing Kubeflow 0.1
Today, we’re proud to announce the availability of Kubeflow 0.1, which provides a minimal set of packages to begin developing, training and deploying ML. In just a few commands, you can get:
- Jupyter Hub - for collaborative & interactive training
- A TensorFlow Training Controller with native distributed training
- A TensorFlow Serving for hosting
- Argo for workflows
- SeldonCore for complex inference and non TF models
- Ambassador for Reverse Proxy
- Wiring to make it work on any Kubernetes anywhere
To get started, it’s just as easy as it always has been:
# Create a namespace for kubeflow deployment
NAMESPACE=kubeflow
kubectl create namespace ${NAMESPACE}
VERSION=v0.1.3
# Initialize a ksonnet app. Set the namespace for it's default environment.
APP_NAME=my-kubeflow
ks init ${APP_NAME}
cd ${APP_NAME}
ks env set default --namespace ${NAMESPACE}
# Install Kubeflow components
ks registry add kubeflow github.com/kubeflow/kubeflow/tree/${VERSION}/kubeflow
ks pkg install kubeflow/core@${VERSION}
ks pkg install kubeflow/tf-serving@${VERSION}
ks pkg install kubeflow/tf-job@${VERSION}
# Create templates for core components
ks generate kubeflow-core kubeflow-core
# Deploy Kubeflow
ks apply default -c kubeflow-core
And thats it! JupyterHub is deployed so we can now use Jupyter to begin developing models. Once we have python code to build our model we can build a docker image and train our model using our TFJob operator by running commands like the following:
ks generate tf-job my-tf-job --name=my-tf-job --image=gcr.io/my/image:latest
ks apply default -c my-tf-job
We could then deploy the model by doing
ks generate tf-serving ${MODEL_COMPONENT} --name=${MODEL_NAME}
ks param set ${MODEL_COMPONENT} modelPath ${MODEL_PATH}
ks apply ${ENV} -c ${MODEL_COMPONENT}
Within just a few commands, data scientists and software engineers can now create even complicated ML solutions and focus on what they do best: answering business critical questions.
Community Contributions
It’d be impossible to have gotten where we are without enormous help from everyone in the community. Some specific contributions that we want to highlight include:
- Argo for managing ML workflows
- Caffe2 Operator for running Caffe2 jobs
- Horovod & OpenMPI for improved distributed training performance of TensorFlow
- Identity Aware Proxy, which enables using security your services with identities, rather than VPNs and Firewalls
- Katib for hyperparameter tuning
- Kubernetes volume controller which provides basic volume and data management using volumes and volume sources in a Kubernetes cluster.
- Kubebench for benchmarking of HW and ML stacks
- Pachyderm for managing complex data pipelines
- PyTorch operator for running PyTorch jobs
- Seldon Core for running complex model deployments and non-TensorFlow serving
It’s difficult to overstate how much the community has helped bring all these projects (and more) to fruition. Just a few of the contributing companies include: Alibaba Cloud, Ant Financial, Caicloud, Canonical, Cisco, Datawire, Dell, GitHub, Google, Heptio, Huawei, Intel, Microsoft, Momenta, One Convergence, Pachyderm, Project Jupyter, Red Hat, Seldon, Uber and Weaveworks.
Learning More
If you’d like to try out Kubeflow, we have a number of options for you:
- You can use sample walkthroughs hosted on Katacoda
- You can follow a guided tutorial with existing models from the examples repository. These include the GitHub Issue Summarization, MNIST and Reinforcement Learning with Agents.
- You can start a cluster on your own and try your own model. Any Kubernetes conformant cluster will support Kubeflow including those from contributors Caicloud, Canonical, Google, Heptio, Mesosphere, Microsoft, IBM, Red Hat/Openshift and Weaveworks.
There were also a number of sessions at KubeCon + CloudNativeCon EU 2018 covering Kubeflow. The links to the talks are here; the associated videos will be posted in the coming days.
-
Wednesday, May 2:
-
Thursday, May 3:
- Kubeflow Deep Dive - Jeremy Lewi, Google
- Write Once, Train & Predict Everywhere: Portable ML Stacks with Kubeflow - Jeremy Lewi, Google & Stephan Fabel, Canonical
- Compliant Data Management and Machine Learning on Kubernetes - Daniel Whitenack, Pachyderm
- Bringing Your Data Pipeline into The Machine Learning Era - Chris Gaun & Jörg Schad, Mesosphere
-
Friday, May 4:
What’s Next?
Our next major release will be 0.2 coming this summer. In it, we expect to land the following new features:
- Simplified setup via a bootstrap container
- Improved accelerator integration
- Support for more ML frameworks, e.g., Spark ML, XGBoost, sklearn
- Autoscaled TF Serving
- Programmatic data transforms, e.g., tf.transform
But the most important feature is the one we haven’t heard yet. Please tell us! Some options for making your voice heard include:
- The Kubeflow Slack channel
- The Kubeflow-discuss email list
- The Kubeflow twitter account
- Our weekly community meeting
- Please download and run kubeflow, and submit bugs!
Thank you for all your support so far! Jeremy Lewi & David Aronchick Google
Current State of Policy in Kubernetes
Kubernetes has grown dramatically in its impact to the industry; and with rapid growth, we are beginning to see variations across components in how they define and apply policies.
Currently, policy related components could be found in identity services, networking services, storage services, multi-cluster federation, RBAC and many other areas, with different degree of maturity and also different motivations for specific problems. Within each component, some policies are extensible while others are not. The languages used by each project to express intent vary based on the original authors and experience. Driving consistent views of policies across the entire domain is a daunting task.
Adoption of Kubernetes in regulated industries will also drive the need to ensure that a deployed cluster confirms with various legal requirements, such as PCI, HIPPA, or GDPR. Each of these compliance standards enforces a certain level of privacy around user information, data, and isolation.
The core issues with the current Kubernetes policy implementations are identified as follows:
- Lack of big picture across the platform
- Lack of coordination and common language among different policy components
- Lack of consistency for extensible policy creation across the platform.
- There are areas where policy components are extensible, and there are also areas where strict end-to-end solutions are enforced. No consensus is established on the preference to a extensible and pluggable architecture.
- Lack of consistent auditability across the Kubernetes architecture of policies which are created, modified, or disabled as well as the actions performed on behalf of the policies which are applied.
Forming Kubernetes Policy WG
We have established a new WG to directly address these issues. We intend to provide an overall architecture that describes both the current policy related implementations as well as future policy related proposals in Kubernetes. Through a collaborative method, we want to present both dev and end user a universal view of policy in Kubernetes.
We are not seeking to redefine and replace existing implementations which have been reached by thorough discussion and consensus. Rather to establish a summarized review of current implementation and addressing gaps to address broad end to end scenarios as defined in our initial design proposal.
Kubernetes Policy WG has been focusing on the design proposal document and using the weekly meeting for discussions among WG members. The design proposal outlines the background and motivation of why we establish the WG, the concrete use cases from which the gaps/requirement analysis is deduced, the overall architecture and the container policy interface proposal.
Key Policy Scenarios in Kubernetes
Among several use cases the workgroup has brainstormed, eventually three major scenario stands out.
The first one is about legislation/regulation compliance which requires the Kubernetes clusters conform to. The compliance scenario takes GDPR as an legislation example and the suggested policy architecture out of the discussion is to have a datapolicy controller responsible for the auditing.
The second scenario is about capacity leasing, or multi-tenant quota in traditional IaaS concept, which deals with when a large enterprise want to delegate the resource control to various Lines Of Business it has, how the Kubernetes cluster should be configured to have a policy driven mechanism to enforce the quota system. The ongoing multi-tenant controller design proposed in the multi-tenancy working group could be an ideal enforcement point for the quota policy controller, which in turn might take a look at kube-arbitrator for inspiration.
The last scenario is about cluster policy which refers to the general security and resource oriented policy control. Luster policy will involve both cluster level and namespace level policy control as well as enforcement, and there is a proposal called Kubernetes Security Profile that is under development by the Policy WG member to provide a PoC for this use case.
Kubernetes Policy Architecture
Building upon the three scenarios, the WG is now working on three concrete proposals together with sig-arch, sig-auth and other related projects. Besides the Kubernetes security profile proposal aiming at the cluster policy use case, we also have the scheduling policy proposal which partially targets the capacity leasing use case and the topology service policy proposal which deals with affinity based upon service requirement and enforcement on routing level.
When these concrete proposals got clearer the WG will be able to provide a high level Kubernetes policy architecture as part of the motivation of the establishment of the Policy WG.
Towards Cloud Native Policy Driven Architecture
Policy is definitely something goes beyond Kubernetes and applied to a broader cloud native context. Our work in the Kubernetes Policy WG will provide the foundation of building a CNCF wide policy architecture, with the integration of Kubernetes and various other cloud native components such as open policy agent, Istio, Envoy, SPIFEE/SPIRE and so forth. The Policy WG has already collaboration with the CNCF SAFE WG (in-forming) team, and will work on more alignments to make sure a community driven cloud native policy architecture design.
Authors: Zhipeng Huang, Torin Sandall, Michael Elder, Erica Von Buelow, Khalid Ahmed, Yisui Hu
Developing on Kubernetes
Authors: Michael Hausenblas (Red Hat), Ilya Dmitrichenko (Weaveworks)
How do you develop a Kubernetes app? That is, how do you write and test an app that is supposed to run on Kubernetes? This article focuses on the challenges, tools and methods you might want to be aware of to successfully write Kubernetes apps alone or in a team setting.
We’re assuming you are a developer, you have a favorite programming language, editor/IDE, and a testing framework available. The overarching goal is to introduce minimal changes to your current workflow when developing the app for Kubernetes. For example, if you’re a Node.js developer and are used to a hot-reload setup—that is, on save in your editor the running app gets automagically updated—then dealing with containers and container images, with container registries, Kubernetes deployments, triggers, and more can not only be overwhelming but really take all the fun out if it.
In the following, we’ll first discuss the overall development setup, then review tools of the trade, and last but not least do a hands-on walkthrough of three exemplary tools that allow for iterative, local app development against Kubernetes.
Where to run your cluster?
As a developer you want to think about where the Kubernetes cluster you’re developing against runs as well as where the development environment sits. Conceptually there are four development modes:
A number of tools support pure offline development including Minikube, Docker for Mac/Windows, Minishift, and the ones we discuss in detail below. Sometimes, for example, in a microservices setup where certain microservices already run in the cluster, a proxied setup (forwarding traffic into and from the cluster) is preferable and Telepresence is an example tool in this category. The live mode essentially means you’re building and/or deploying against a remote cluster and, finally, the pure online mode means both your development environment and the cluster are remote, as this is the case with, for example, Eclipse Che or Cloud 9. Let’s now have a closer look at the basics of offline development: running Kubernetes locally.
Minikube is a popular choice for those who prefer to run Kubernetes in a local VM. More recently Docker for Mac and Windows started shipping Kubernetes as an experimental package (in the “edge” channel). Some reasons why you may want to prefer using Minikube over the Docker desktop option are:
- You already have Minikube installed and running
- You prefer to wait until Docker ships a stable package
- You’re a Linux desktop user
- You are a Windows user who doesn’t have Windows 10 Pro with Hyper-V
Running a local cluster allows folks to work offline and that you don’t have to pay for using cloud resources. Cloud provider costs are often rather affordable and free tiers exists, however some folks prefer to avoid having to approve those costs with their manager as well as potentially incur unexpected costs, for example, when leaving cluster running over the weekend.
Some developers prefer to use a remote Kubernetes cluster, and this is usually to allow for larger compute and storage capacity and also enable collaborative workflows more easily. This means it’s easier for you to pull in a colleague to help with debugging or share access to an app in the team. Additionally, for some developers it can be critical to mirror production environment as closely as possible, especially when it comes down to external cloud services, say, proprietary databases, object stores, message queues, external load balancer, or mail delivery systems.
In summary, there are good reasons for you to develop against a local cluster as well as a remote one. It very much depends on in which phase you are: from early prototyping and/or developing alone to integrating a set of more stable microservices.
Now that you have a basic idea of the options around the runtime environment, let’s move on to how to iteratively develop and deploy your app.
The tools of the trade
We are now going to review tooling allowing you to develop apps on Kubernetes with the focus on having minimal impact on your existing workflow. We strive to provide an unbiased description including implications of using each of the tools in general terms.
Note that this is a tricky area since even for established technologies such as, for example, JSON vs YAML vs XML or REST vs gRPC vs SOAP a lot depends on your background, your preferences and organizational settings. It’s even harder to compare tooling in the Kubernetes ecosystem as things evolve very rapidly and new tools are announced almost on a weekly basis; during the preparation of this post alone, for example, Gitkube and Watchpod came out. To cover these new tools as well as related, existing tooling such as Weave Flux and OpenShift’s S2I we are planning a follow-up blog post to the one you’re reading.
Draft
Draft aims to help you get started deploying any app to Kubernetes. It is capable of applying heuristics as to what programming language your app is written in and generates a Dockerfile along with a Helm chart. It then runs the build for you and deploys resulting image to the target cluster via the Helm chart. It also allows user to setup port forwarding to localhost very easily.
Implications:
- User can customise the chart and Dockerfile templates however they like, or even create a custom pack (with Dockerfile, the chart and more) for future use
- It’s not very simple to guess how just any app is supposed to be built, in some cases user may need to tweak Dockerfile and the Helm chart that Draft generates
- With Draft version 0.12.0 or older, every time user wants to test a change, they need to wait for Draft to copy the code to the cluster, then run the build, push the image and release updated chart; this can timely, but it results in an image being for every single change made by the user (whether it was committed to git or not)
- As of Draft version 0.12.0, builds are executed locally
- User doesn’t have an option to choose something other than Helm for deployment
- It can watch local changes and trigger deployments, but this feature is not enabled by default
- It allows developer to use either local or remote Kubernetes cluster
- Deploying to production is up to the user, Draft authors recommend their other project – Brigade
- Can be used instead of Skaffold, and along the side of Squash
More info:
Skaffold
Skaffold is a tool that aims to provide portability for CI integrations with different build system, image registry and deployment tools. It is different from Draft, yet somewhat comparable. It has a basic capability for generating manifests, but it’s not a prominent feature. Skaffold is extendible and lets user pick tools for use in each of the steps in building and deploying their app.
Implications:
- Modular by design
- Works independently of CI vendor, user doesn’t need Docker or Kubernetes plugin
- Works without CI as such, i.e. from the developer’s laptop
- It can watch local changes and trigger deployments
- It allows developer to use either local or remote Kubernetes cluster
- It can be used to deploy to production, user can configure how exactly they prefer to do it and provide different kind of pipeline for each target environment
- Can be used instead of Draft, and along the side with most other tools
More info:
Squash
Squash consists of a debug server that is fully integrated with Kubernetes, and a IDE plugin. It allows you to insert breakpoints and do all the fun stuff you are used to doing when debugging an application using an IDE. It bridges IDE debugging experience with your Kubernetes cluster by allowing you to attach the debugger to a pod running in your Kubernetes cluster.
Implications:
- Can be used independently of other tools you chose
- Requires a privileged DaemonSet
- Integrates with popular IDEs
- Supports Go, Python, Node.js, Java and gdb
- User must ensure application binaries inside the container image are compiled with debug symbols
- Can be used in combination with any other tools described here
- It can be used with either local or remote Kubernetes cluster
More info:
Telepresence
Telepresence connects containers running on developer’s workstation with a remote Kubernetes cluster using a two-way proxy and emulates in-cluster environment as well as provides access to config maps and secrets. It aims to improve iteration time for container app development by eliminating the need for deploying app to the cluster and leverages local container to abstract network and filesystem interface in order to make it appear as if the app was running in the cluster.
Implications:
- It can be used independently of other tools you chose
- Using together with Squash is possible, although Squash would have to be used for pods in the cluster, while conventional/local debugger would need to be used for debugging local container that’s connected to the cluster via Telepresence
- Telepresence imposes some network latency
- It provides connectivity via a side-car process - sshuttle, which is based on SSH
- More intrusive dependency injection mode with LD_PRELOAD/DYLD_INSERT_LIBRARIES is also available
- It is most commonly used with a remote Kubernetes cluster, but can be used with a local one also
More info:
- Telepresence: fast, realistic local development for Kubernetes microservices
- Getting Started Guide
- How It Works
Ksync
Ksync synchronizes application code (and configuration) between your local machine and the container running in Kubernetes, akin to what oc rsync does in OpenShift. It aims to improve iteration time for app development by eliminating build and deployment steps.
Implications:
- It bypasses container image build and revision control
- Compiled language users have to run builds inside the pod (TBC)
- Two-way sync – remote files are copied to local directory
- Container is restarted each time remote filesystem is updated
- No security features – development only
- Utilizes Syncthing, a Go library for peer-to-peer sync
- Requires a privileged DaemonSet running in the cluster
- Node has to use Docker with overlayfs2 – no other CRI implementations are supported at the time of writing
More info:
- Getting Started Guide
- How It Works
- Katacoda scenario to try out ksync in your browser
- Syncthing Specification
Hands-on walkthroughs
The app we will be using for the hands-on walkthroughs of the tools in the following is a simple stock market simulator, consisting of two microservices:
- The
stock-genmicroservice is written in Go and generates stock data randomly and exposes it via HTTP endpoint/stockdata. * A second microservice,stock-conis a Node.js app that consumes the stream of stock data fromstock-genand provides an aggregation in form of a moving average via the HTTP endpoint/average/$SYMBOLas well as a health-check endpoint at/healthz.
Overall, the default setup of the app looks as follows:
In the following we’ll do a hands-on walkthrough for a representative selection of tools discussed above: ksync, Minikube with local build, as well as Skaffold. For each of the tools we do the following:
- Set up the respective tool incl. preparations for the deployment and local consumption of the
stock-conmicroservice. - Perform a code update, that is, change the source code of the
/healthzendpoint in thestock-conmicroservice and observe the updates.
Note that for the target Kubernetes cluster we’ve been using Minikube locally, but you can also a remote cluster for ksync and Skaffold if you want to follow along.
Walkthrough: ksync
As a preparation, install ksync and then carry out the following steps to prepare the development setup:
$ mkdir -p $(pwd)/ksync
$ kubectl create namespace dok
$ ksync init -n dok
With the basic setup completed we're ready to tell ksync’s local client to watch a certain Kubernetes namespace and then we create a spec to define what we want to sync (the directory $(pwd)/ksync locally with /app in the container). Note that target pod is specified via the selector parameter:
$ ksync watch -n dok
$ ksync create -n dok --selector=app=stock-con $(pwd)/ksync /app
$ ksync get -n dok
Now we deploy the stock generator and the stock consumer microservice:
$ kubectl -n=dok apply \
-f https://raw.githubusercontent.com/kubernauts/dok-example-us/master/stock-gen/app.yaml
$ kubectl -n=dok apply \
-f https://raw.githubusercontent.com/kubernauts/dok-example-us/master/stock-con/app.yaml
Once both deployments are created and the pods are running, we forward the stock-con service for local consumption (in a separate terminal session):
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898
With that we should be able to consume the stock-con service from our local machine; we do this by regularly checking the response of the healthz endpoint like so (in a separate terminal session):
$ watch curl localhost:9898/healthz
Now change the code in the ksync/stock-condirectory, for example update the /healthz endpoint code in service.js by adding a field to the JSON response and observe how the pod gets updated and the response of the curl localhost:9898/healthz command changes. Overall you should have something like the following in the end:
Walkthrough: Minikube with local build
For the following you will need to have Minikube up and running and we will leverage the Minikube-internal Docker daemon for building images, locally. As a preparation, do the following
$ git clone https://github.com/kubernauts/dok-example-us.git && cd dok-example-us
$ eval $(minikube docker-env)
$ kubectl create namespace dok
Now we deploy the stock generator and the stock consumer microservice:
$ kubectl -n=dok apply -f stock-gen/app.yaml
$ kubectl -n=dok apply -f stock-con/app.yaml
Once both deployments are created and the pods are running, we forward the stock-con service for local consumption (in a separate terminal session) and check the response of the healthz endpoint:
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898 &
$ watch curl localhost:9898/healthz
Now change the code in the stock-condirectory, for example, update the /healthz endpoint code in service.js by adding a field to the JSON response. Once you’re done with your code update, the last step is to build a new container image and kick off a new deployment like shown below:
$ docker build -t stock-con:dev -f Dockerfile .
$ kubectl -n dok set image deployment/stock-con *=stock-con:dev
Overall you should have something like the following in the end:
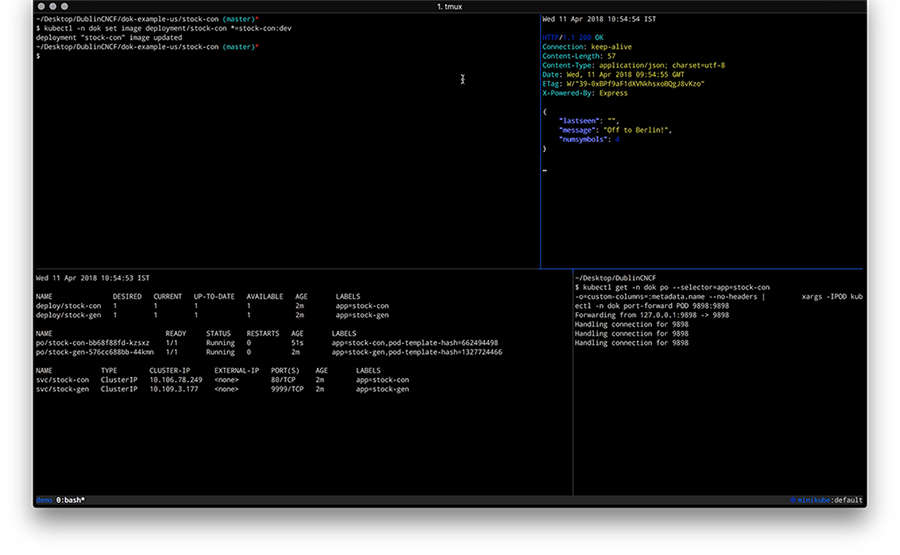
Walkthrough: Skaffold
To perform this walkthrough you first need to install Skaffold. Once that is done, you can do the following steps to prepare the development setup:
$ git clone https://github.com/kubernauts/dok-example-us.git && cd dok-example-us
$ kubectl create namespace dok
Now we deploy the stock generator (but not the stock consumer microservice, that is done via Skaffold):
$ kubectl -n=dok apply -f stock-gen/app.yaml
Note that initially we experienced an authentication error when doing skaffold dev and needed to apply a fix as described in Issue 322. Essentially it means changing the content of ~/.docker/config.json to:
{
"auths": {}
}
Next, we had to patch stock-con/app.yaml slightly to make it work with Skaffold:
Add a namespace field to both the stock-con deployment and the service with the value of dok.
Change the image field of the container spec to quay.io/mhausenblas/stock-con since Skaffold manages the container image tag on the fly.
The resulting app.yaml file stock-con looks as follows:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
labels:
app: stock-con
name: stock-con
namespace: dok
spec:
replicas: 1
template:
metadata:
labels:
app: stock-con
spec:
containers:
- name: stock-con
image: quay.io/mhausenblas/stock-con
env:
- name: DOK_STOCKGEN_HOSTNAME
value: stock-gen
- name: DOK_STOCKGEN_PORT
value: "9999"
ports:
- containerPort: 9898
protocol: TCP
livenessProbe:
initialDelaySeconds: 2
periodSeconds: 5
httpGet:
path: /healthz
port: 9898
readinessProbe:
initialDelaySeconds: 2
periodSeconds: 5
httpGet:
path: /healthz
port: 9898
---
apiVersion: v1
kind: Service
metadata:
labels:
app: stock-con
name: stock-con
namespace: dok
spec:
type: ClusterIP
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9898
selector:
app: stock-con
The final step before we can start development is to configure Skaffold. So, create a file skaffold.yaml in the stock-con/ directory with the following content:
apiVersion: skaffold/v1alpha2
kind: Config
build:
artifacts:
- imageName: quay.io/mhausenblas/stock-con
workspace: .
docker: {}
local: {}
deploy:
kubectl:
manifests:
- app.yaml
Now we’re ready to kick off the development. For that execute the following in the stock-con/ directory:
$ skaffold dev
Above command triggers a build of the stock-con image and then a deployment. Once the pod of the stock-con deployment is running, we again forward the stock-con service for local consumption (in a separate terminal session) and check the response of the healthz endpoint:
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898 &
$ watch curl localhost:9898/healthz
If you now change the code in the stock-condirectory, for example, by updating the /healthz endpoint code in service.js by adding a field to the JSON response, you should see Skaffold noticing the change and create a new image as well as deploy it. The resulting screen would look something like this:
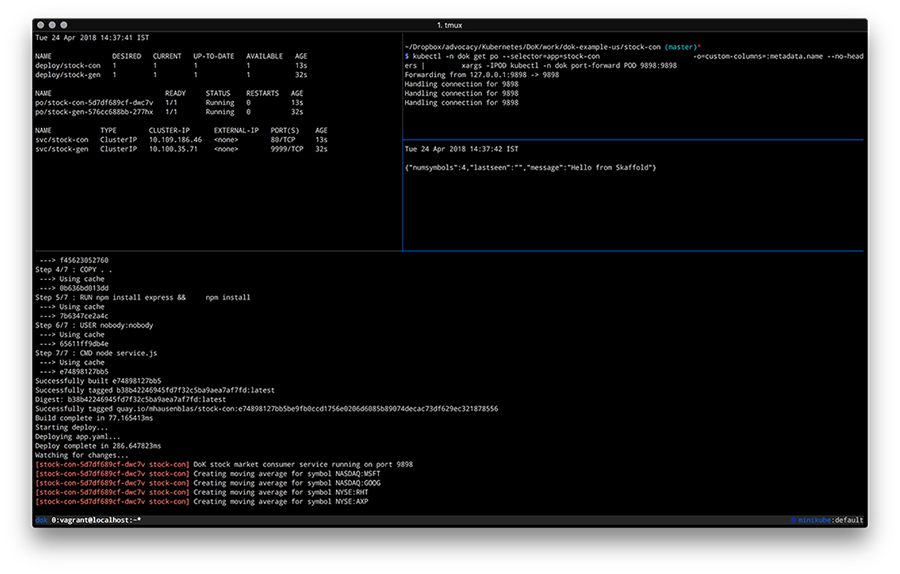
By now you should have a feeling how different tools enable you to develop apps on Kubernetes and if you’re interested to learn more about tools and or methods, check out the following resources:
- Blog post by Shahidh K Muhammed on Draft vs Gitkube vs Helm vs Ksonnet vs Metaparticle vs Skaffold (03/2018)
- Blog post by Gergely Nemeth on Using Kubernetes for Local Development, with a focus on Skaffold (03/2018)
- Blog post by Richard Li on Locally developing Kubernetes services (without waiting for a deploy), with a focus on Telepresence
- Blog post by Abhishek Tiwari on Local Development Environment for Kubernetes using Minikube (09/2017)
- Blog post by Aymen El Amri on Using Kubernetes for Local Development — Minikube (08/2017)
- Blog post by Alexis Richardson on GitOps - Operations by Pull Request (08/2017)
- Slide deck GitOps: Drive operations through git, with a focus on Gitkube by Tirumarai Selvan (03/2018)
- Slide deck Developing apps on Kubernetes, a talk Michael Hausenblas gave at a CNCF Paris meetup (04/2018)
- YouTube videos:
- Raw responses to the Kubernetes Application Survey 2018 by SIG Apps
With that we wrap up this post on how to go about developing apps on Kubernetes, we hope you learned something and if you have feedback and/or want to point out a tool that you found useful, please let us know via Twitter: Ilya and Michael.
Zero-downtime Deployment in Kubernetes with Jenkins
Ever since we added the Kubernetes Continuous Deploy and Azure Container Service plugins to the Jenkins update center, "How do I create zero-downtime deployments" is one of our most frequently-asked questions. We created a quickstart template on Azure to demonstrate what zero-downtime deployments can look like. Although our example uses Azure, the concept easily applies to all Kubernetes installations.
Rolling Update
Kubernetes supports the RollingUpdate strategy to replace old pods with new ones gradually, while continuing to serve clients without incurring downtime. To perform a RollingUpdate deployment:
- Set
.spec.strategy.typetoRollingUpdate(the default value). - Set
.spec.strategy.rollingUpdate.maxUnavailableand.spec.strategy.rollingUpdate.maxSurgeto some reasonable value.maxUnavailable: the maximum number of pods that can be unavailable during the update process. This can be an absolute number or percentage of the replicas count; the default is 25%.maxSurge: the maximum number of pods that can be created over the desired number of pods. Again this can be an absolute number or a percentage of the replicas count; the default is 25%.
- Configure the
readinessProbefor your service container to help Kubernetes determine the state of the pods. Kubernetes will only route the client traffic to the pods with a healthy liveness probe.
We'll use deployment of the official Tomcat image to demonstrate this:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: tomcat-deployment-rolling-update
spec:
replicas: 2
template:
metadata:
labels:
app: tomcat
role: rolling-update
spec:
containers:
- name: tomcat-container
image: tomcat:${TOMCAT_VERSION}
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /
port: 8080
strategy:
type: RollingUpdate
rollingUp maxSurge: 50%
If the Tomcat running in the current deployments is version 7, we can replace ${TOMCAT_VERSION} with 8 and apply this to the Kubernetes cluster. With the Kubernetes Continuous Deploy or the Azure Container Service plugin, the value can be fetched from an environment variable which eases the deployment process.
Behind the scenes, Kubernetes manages the update like so:
- Initially, all pods are running Tomcat 7 and the frontend Service routes the traffic to these pods.
- During the rolling update, Kubernetes takes down some Tomcat 7 pods and creates corresponding new Tomcat 8 pods. It ensures:
- at most
maxUnavailablepods in the desired Pods can be unavailable, that is, at least (replicas-maxUnavailable) pods should be serving the client traffic, which is 2-1=1 in our case. - at most maxSurge more pods can be created during the update process, that is 2*50%=1 in our case.
- at most
- One Tomcat 7 pod is taken down, and one Tomcat 8 pod is created. Kubernetes will not route the traffic to any of them because their readiness probe is not yet successful.
- When the new Tomcat 8 pod is ready as determined by the readiness probe, Kubernetes will start routing the traffic to it. This means during the update process, users may see both the old service and the new service.
- The rolling update continues by taking down Tomcat 7 pods and creating Tomcat 8 pods, and then routing the traffic to the ready pods.
- Finally, all pods are on Tomcat 8.
The Rolling Update strategy ensures we always have some Ready backend pods serving client requests, so there's no service downtime. However, some extra care is required:
- During the update, both the old pods and new pods may serve the requests. Without well defined session affinity in the Service layer, a user may be routed to the new pods and later back to the old pods.
- This also requires you to maintain well-defined forward and backward compatibility for both data and the API, which can be challenging.
- It may take a long time before a pod is ready for traffic after it is started. There may be a long window of time where the traffic is served with less backend pods than usual. Generally, this should not be a problem as we tend to do production upgrades when the service is less busy. But this will also extend the time window for issue 1.
- We cannot do comprehensive tests for the new pods being created. Moving application changes from dev / QA environments to production can represent a persistent risk of breaking existing functionality. The readiness probe can do some work to check readiness, however, it should be a lightweight task that can be run periodically, and not suitable to be used as an entry point to start the complete tests.
Blue/green Deployment
Blue/green deployment quoted from TechTarget
A blue/green deployment is a change management strategy for releasing software code. Blue/green deployments, which may also be referred to as A/B deployments require two identical hardware environments that are configured exactly the same way. While one environment is active and serving end users, the other environment remains idle.
Container technology offers a stand-alone environment to run the desired service, which makes it super easy to create identical environments as required in the blue/green deployment. The loosely coupled Services - ReplicaSets, and the label/selector-based service routing in Kubernetes make it easy to switch between different backend environments. With these techniques, the blue/green deployments in Kubernetes can be done as follows:
- Before the deployment, the infrastructure is prepared like so:
- Prepare the blue deployment and green deployment with
TOMCAT_VERSION=7andTARGET_ROLEset to blue or green respectively.
- Prepare the blue deployment and green deployment with
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: tomcat-deployment-${TARGET_ROLE}
spec:
replicas: 2
template:
metadata:
labels:
app: tomcat
role: ${TARGET_ROLE}
spec:
containers:
- name: tomcat-container
image: tomcat:${TOMCAT_VERSION}
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /
port: 8080
- Prepare the public service endpoint, which initially routes to one of the backend environments, say
TARGET_ROLE=blue.
kind: Service
apiVersion: v1
metadata:
name: tomcat-service
labels:
app: tomcat
role: ${TARGET_ROLE}
env: prod
spec:
type: LoadBalancer
selector:
app: tomcat
role: ${TARGET_ROLE}
ports:
- port: 80
targetPort: 8080
- Optionally, prepare a test endpoint so that we can visit the backend environments for testing. They are similar to the public service endpoint, but they are intended to be accessed internally by the dev/ops team only.
kind: Service
apiVersion: v1
metadata:
name: tomcat-test-${TARGET_ROLE}
labels:
app: tomcat
role: test-${TARGET_ROLE}
spec:
type: LoadBalancer
selector:
app: tomcat
role: ${TARGET_ROLE}
ports:
- port: 80
targetPort: 8080
- Update the application in the inactive environment, say green environment. Set
TARGET_ROLE=greenandTOMCAT_VERSION=8in the deployment config to update the green environment. - Test the deployment via the
tomcat-test-greentest endpoint to ensure the green environment is ready to serve client traffic. - Switch the frontend Service routing to the green environment by updating the Service config with
TARGET_ROLE=green. - Run additional tests on the public endpoint to ensure it is working properly.
- Now the blue environment is idle and we can:
- leave it with the old application so that we can roll back if there's issue with the new application
- update it to make it a hot backup of the active environment
- reduce its replica count to save the occupied resources
As compared to Rolling Update, the blue/green up* The public service is either routed to the old applications, or new applications, but never both at the same time.
- The time it takes for the new pods to be ready does not affect the public service quality, as the traffic will only be routed to the new pods when all of them are tested to be ready.
- We can do comprehensive tests on the new environment before it serves any public traffic. Just keep in mind this is in production, and the tests should not pollute live application data.
Jenkins Automation
Jenkins provides easy-to-setup workflow to automate your deployments. With Pipeline support, it is flexible to build the zero-downtime deployment workflow, and visualize the deployment steps. To facilitate the deployment process for Kubernetes resources, we published the Kubernetes Continuous Deploy and the Azure Container Service plugins built based on the kubernetes-client. You can deploy the resource to Azure Kubernetes Service (AKS) or the general Kubernetes clusters without the need of kubectl, and it supports variable substitution in the resource configuration so you can deploy environment-specific resources to the clusters without updating the resource config. We created a Jenkins Pipeline to demonstrate the blue/green deployment to AKS. The flow is like the following:

- Pre-clean: clean workspace.
- SCM: pulling code from the source control management system.
- Prepare Image: prepare the application docker images and upload them to some Docker repository.
- Check Env: determine the active and inactive environment, which drives the following deployment.
- Deploy: deploy the new application resource configuration to the inactive environment. With the Azure Container Service plugin, this can be done with:
acsDeploy azureCredentialsId: 'stored-azure-credentials-id',
configFilePaths: "glob/path/to/*/resource-config-*.yml",
containerService: "aks-name | AKS",
resourceGroupName: "resource-group-name",
enableConfigSubstitution: true
- Verify Staged: verify the deployment to the inactive environment to ensure it is working properly. Again, note this is in the production environment, so be careful not to pollute live application data during tests.
- Confirm: Optionally, send email notifications for manual user approval to proceed with the actual environment switch.
- Switch: Switch the frontend service endpoint routing to the inactive environment. This is just another service deployment to the AKS Kubernetes cluster.
- Verify Prod: verify the frontend service endpoint is working properly with the new environment.
- Post-clean: do some post clean on the temporary files.
For the Rolling Update strategy, simply deploy the deployment configuration to the Kubernetes cluster, which is a simple, single step.
Put It All Together
We built a quickstart template on Azure to demonstrate how we can do the zero-downtime deployment to AKS (Kubernetes) with Jenkins. Go to Jenkins Blue-Green Deployment on Kubernetes and click the button Deploy to Azure to get the working demo. This template will provision:
- An AKS cluster, with the following resources:
- Two similar deployments representing the environments "blue" and "green". Both are initially set up with the
tomcat:7 image. - Two test endpoint services (
tomcat-test-blueandtomcat-test-green), which are connected to the corresponding deployments, and can be used to test if the deployments are ready for production use. - A production service endpoint (
tomcat-service) which represents the public endpoint that the users will access. Initially it is routing to the "blue" environment.
- Two similar deployments representing the environments "blue" and "green". Both are initially set up with the
- A Jenkins master running on an Ubuntu 16.04 VM, with the Azure service principal credentials configured. The Jenkins instance has two sample jobs:
- AKS Kubernetes Rolling Update Deployment pipeline to demonstrate the Rolling Update deployment to AKS.
- AKS Kubernetes Blue/green Deployment pipeline to demonstrate the blue/green deployment to AKS.
- We didn't include the email confirmation step in the quickstart template. To add that, you need to configure the email SMTP server details in the Jenkins system configuration, and then add a Pipeline stage before Switch:
stage('Confirm') {
mail (to: 'to@example.com',
subject: "Job '${env.JOB_NAME}' (${env.BUILD_NUMBER}) is waiting for input",
body: "Please go to ${env.BUILD_URL}.")
input 'Ready to go?'
}
Follow the Steps to setup the resources and you can try it out by start the Jenkins build jobs.
Kubernetes Community - Top of the Open Source Charts in 2017
2017 was a huge year for Kubernetes, and GitHub’s latest Octoverse report illustrates just how much attention this project has been getting.
Kubernetes, an open source platform for running application containers, provides a consistent interface that enables developers and ops teams to automate the deployment, management, and scaling of a wide variety of applications on just about any infrastructure.
Solving these shared challenges by leveraging a wide community of expertise and industrial experience, as Kubernetes does, helps engineers focus on building their own products at the top of the stack, rather than needlessly duplicating work that now exists as a standard part of the “cloud native” toolkit.
However, achieving these gains via ad-hoc collective organizing is its own unique challenge, one which makes it increasingly difficult to support open source, community-driven efforts through periods of rapid growth.
Read on to find out how the Kubernetes Community has addressed these scaling challenges to reach the top of the charts in GitHub’s 2017 Octoverse report.
Most-Discussed on GitHub
The top two most-discussed repos of 2017 are both based on Kubernetes:

Of all the open source repositories on GitHub, none received more issue comments than kubernetes/kubernetes. OpenShift, a CNCF certified distribution of Kubernetes, took second place.
Open discussion with ample time for community feedback and review helps build shared infrastructure and establish new standards for cloud native computing.
Most Reviewed on GitHub
Successfully scaling an open source effort’s communications often leads to better coordination and higher-quality feature delivery. The Kubernetes project’s Special Interest Group (SIG) structure has helped it become GitHub’s second most reviewed project:

Using SIGs to segment and standardize mechanisms for community participation helps channel more frequent reviews from better-qualified community members.
When managed effectively, active community discussions indicate more than just a highly contentious codebase, or a project with an extensive list of unmet needs.
Scaling a project’s capacity to handle issues and community interactions helps to expand the conversation. Meanwhile, large communities come with more diverse use cases and a larger array of support problems to manage. The Kubernetes SIG organization structure helps to address the challenges of complex communication at scale.
SIG meetings provide focused opportunities for users, maintainers, and specialists from various disciplines to collaborate together in support of this community effort. These investments in organizing help create an environment where it’s easier to prioritize architecture discussion and planning over commit velocity; enabling the project to sustain this kind of scale.
Join the party!
You may already be using solutions that are successfully managed and scaled on Kubernetes. For example, GitHub.com, which hosts Kubernetes’ upstream source code, now runs on Kubernetes as well!
Check out the Kubernetes Contributors’ guide for more information on how to get started as a contributor.
You can also join the weekly Kubernetes Community meeting and consider joining a SIG or two.
Kubernetes Application Survey 2018 Results
Understanding how people use or want to use Kubernetes can help us shape everything from what we build to how we do it. To help us understand how application developers, application operators, and ecosystem tool developers are using and want to use Kubernetes, the Application Definition Working Group recently performed a survey. The survey focused in on these types of user roles and the features and sub-projects owned by the Kubernetes organization. That included kubectl, Dashboard, Minikube, Helm, the Workloads API, etc.
The results are in and the raw data is now available for everyone.
There is too much data to summarize in a single blog post and we hope people will be able to find useful information by pouring over the data. Here are some of the highlights that caught our attention.
Participation
First, I would like to thank the 380 people who took the survey and provided feedback. We appreciate the time put into to share so much detail.
6.8x Response Increase
In the summer of 2016 we ran a survey on application usage. Kubernetes was much newer and the number of people talking about operating applications was much smaller.
The number of respondents in the past year and 10 months increased at a rate of 6.8 times.
Where Are We In Innovation Lifecycle?
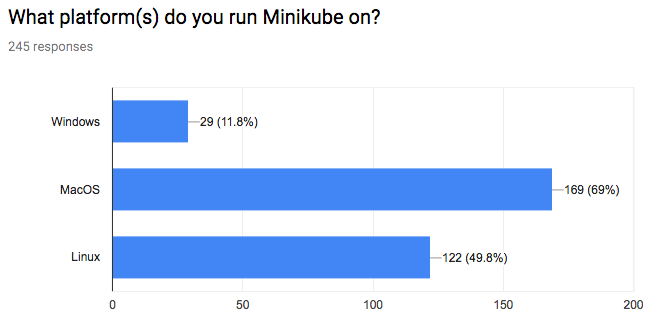
Minikube is used primarily by people on macOS and Linux. Yet, according to the 2018 Stack Overflow survey, almost half of developers use Windows as their primary operating system. This is where Minikube would run.
Seeing differences from other data sets is worth looking more deeply at to better understand our audience, where Kubernetes is at, and where it is on the journey it's headed.
Plenty of Custom Tooling
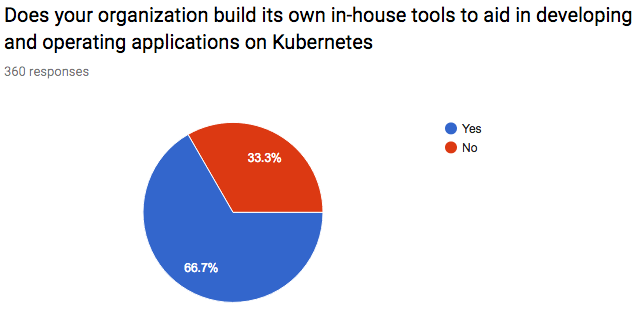
Two thirds of respondents work for organizations developing their own tooling to help with application development and operation. We wondered why this might happen so we asked why as a follow-up question. 44% of people who took the survey told us why they do it.
App Management Tools
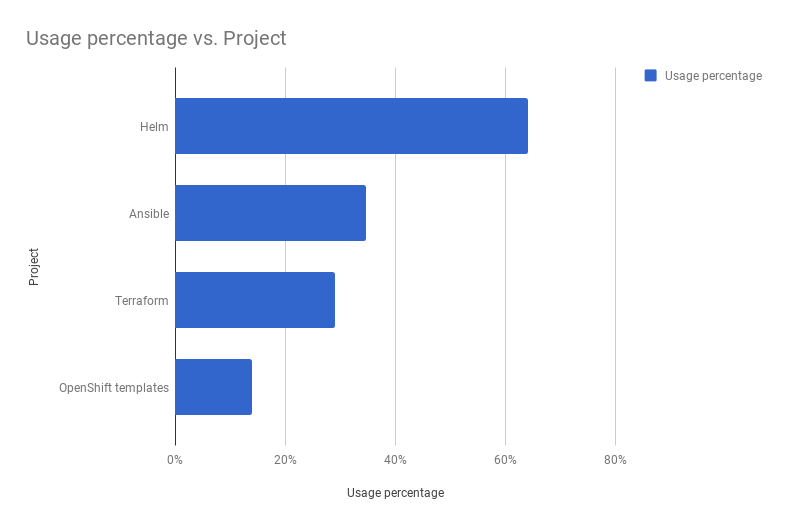
Only 4 tools were in use by more than 10% of those who took the survey with Helm being in use by 64% of them. Many more tools were used by more than 1% of people including those we directly asked about and the space for people to fill in those we didn't ask about. The long tail, captured in the survey, contained more than 80 tools in use.
Want To See More?
As the Application Definition Working Group is working through the data we're putting observations into a Google Slides Document. This is a living document that will continue to grow while we look over and discuss the data.
There is a session at KubeCon where the Application Definition Working Group will be meeting and discussing the survey. This is a session open to anyone in attendance, if you would like to attend.
While this working group is doing analysis and sharing it, we want to encourage others to look at the data and share any insights that might be gained.
Note, the survey questions were generated by the application definition working group with the help of people working on various sub-projects included in the survey. This is the reason some sub-projects have more and varied questions compared to some others. The survey was shared on social media, on mailing lists, in blog posts, in various meetings, and beyond while collecting information for two weeks.
Local Persistent Volumes for Kubernetes Goes Beta
The Local Persistent Volumes beta feature in Kubernetes 1.10 makes it possible to leverage local disks in your StatefulSets. You can specify directly-attached local disks as PersistentVolumes, and use them in StatefulSets with the same PersistentVolumeClaim objects that previously only supported remote volume types.
Persistent storage is important for running stateful applications, and Kubernetes has supported these workloads with StatefulSets, PersistentVolumeClaims and PersistentVolumes. These primitives have supported remote volume types well, where the volumes can be accessed from any node in the cluster, but did not support local volumes, where the volumes can only be accessed from a specific node. The demand for using local, fast SSDs in replicated, stateful workloads has increased with demand to run more workloads in Kubernetes.
Addressing hostPath challenges
The prior mechanism of accessing local storage through hostPath volumes had many challenges. hostPath volumes were difficult to use in production at scale: operators needed to care for local disk management, topology, and scheduling of individual pods when using hostPath volumes, and could not use many Kubernetes features (like StatefulSets). Existing Helm charts that used remote volumes could not be easily ported to use hostPath volumes. The Local Persistent Volumes feature aims to address hostPath volumes’ portability, disk accounting, and scheduling challenges.
Disclaimer
Before going into details about how to use Local Persistent Volumes, note that local volumes are not suitable for most applications. Using local storage ties your application to that specific node, making your application harder to schedule. If that node or local volume encounters a failure and becomes inaccessible, then that pod also becomes inaccessible. In addition, many cloud providers do not provide extensive data durability guarantees for local storage, so you could lose all your data in certain scenarios.
For those reasons, most applications should continue to use highly available, remotely accessible, durable storage.
Suitable workloads
Some use cases that are suitable for local storage include:
- Caching of datasets that can leverage data gravity for fast processing
- Distributed storage systems that shard or replicate data across multiple nodes. Examples include distributed datastores like Cassandra, or distributed file systems like Gluster or Ceph.
Suitable workloads are tolerant of node failures, data unavailability, and data loss. They provide critical, latency-sensitive infrastructure services to the rest of the cluster, and should run with high priority compared to other workloads.
Enabling smarter scheduling and volume binding
An administrator must enable smarter scheduling for local persistent volumes. Before any PersistentVolumeClaims for your local PersistentVolumes are created, a StorageClass must be created with the volumeBindingMode set to “WaitForFirstConsumer”:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
This setting tells the PersistentVolume controller to not immediately bind a PersistentVolumeClaim. Instead, the system waits until a Pod that needs to use a volume is scheduled. The scheduler then chooses an appropriate local PersistentVolume to bind to, taking into account the Pod’s other scheduling constraints and policies. This ensures that the initial volume binding is compatible with any Pod resource requirements, selectors, affinity and anti-affinity policies, and more.
Note that dynamic provisioning is not supported in beta. All local PersistentVolumes must be statically created.
Creating a local persistent volume
For this initial beta offering, local disks must first be pre-partitioned, formatted, and mounted on the local node by an administrator. Directories on a shared file system are also supported, but must also be created before use.
Once you set up the local volume, you can create a PersistentVolume for it. In this example, the local volume is mounted at “/mnt/disks/vol1” on node “my-node”:
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-local-pv
spec:
capacity:
storage: 500Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/disks/vol1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- my-node
Note that there’s a new nodeAffinity field in the PersistentVolume object: this is how the Kubernetes scheduler understands that this PersistentVolume is tied to a specific node. nodeAffinity is a required field for local PersistentVolumes.
When local volumes are manually created like this, the only supported persistentVolumeReclaimPolicy is “Retain”. When the PersistentVolume is released from the PersistentVolumeClaim, an administrator must manually clean up and set up the local volume again for reuse.
Automating local volume creation and deletion
Manually creating and cleaning up local volumes is a big administrative burden, so we’ve written a simple local volume manager to automate some of these pieces. It’s available in the external-storage repo as an optional program that you can deploy in your cluster, including instructions and example deployment specs for how to run it.
To use this, the local volumes must still first be set up and mounted on the local node by an administrator. The administrator needs to mount the local volume into a configurable “discovery directory” that the local volume manager recognizes. Directories on a shared file system are supported, but they must be bind-mounted into the discovery directory.
This local volume manager monitors the discovery directory, looking for any new mount points. The manager creates a PersistentVolume object with the appropriate storageClassName, path, nodeAffinity, and capacity for any new mount point that it detects. These PersistentVolume objects can eventually be claimed by PersistentVolumeClaims, and then mounted in Pods.
After a Pod is done using the volume and deletes the PersistentVolumeClaim for it, the local volume manager cleans up the local mount by deleting all files from it, then deleting the PersistentVolume object. This triggers the discovery cycle: a new PersistentVolume is created for the volume and can be reused by a new PersistentVolumeClaim.
Once the administrator initially sets up the local volume mount, this local volume manager takes over the rest of the PersistentVolume lifecycle without any further administrator intervention required.
Using local volumes in a pod
After all that administrator work, how does a user actually mount a local volume into their Pod? Luckily from the user’s perspective, a local volume can be requested in exactly the same way as any other PersistentVolume type: through a PersistentVolumeClaim. Just specify the appropriate StorageClassName for local volumes in the PersistentVolumeClaim object, and the system takes care of the rest!
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: example-local-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-storage
resources:
requests:
storage: 500Gi
Or in a StatefulSet as a volumeClaimTemplate:
kind: StatefulSet
...
volumeClaimTemplates:
- metadata:
name: example-local-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-storage
resources:
requests:
storage: 500Gi
Documentation
The Kubernetes website provides full documentation for local persistent volumes.
Future enhancements
The local persistent volume beta feature is not complete by far. Some notable enhancements under development:
- Starting in 1.10, local raw block volumes is available as an alpha feature. This is useful for workloads that need to directly access block devices and manage their own data format.
- Dynamic provisioning of local volumes using LVM is under design and an alpha implementation will follow in a future release. This will eliminate the current need for an administrator to pre-partition, format and mount local volumes, as long as the workload’s performance requirements can tolerate sharing disks.
Complementary features
Pod priority and preemption is another Kubernetes feature that is complementary to local persistent volumes. When your application uses local storage, it must be scheduled to the specific node where the local volume resides. You can give your local storage workload high priority so if that node ran out of room to run your workload, Kubernetes can preempt lower priority workloads to make room for it.
Pod disruption budget is also very important for those workloads that must maintain quorum. Setting a disruption budget for your workload ensures that it does not drop below quorum due to voluntary disruption events, such as node drains during upgrade.
Pod affinity and anti-affinity ensures that your workloads stay either co-located or spread out across failure domains. If you have multiple local persistent volumes available on a single node, it may be preferable to specify an pod anti-affinity policy to spread your workload across nodes. Note that if you want multiple pods to share the same local persistent volume, you do not need to specify a pod affinity policy. The scheduler understands the locality constraints of the local persistent volume and schedules your pod to the correct node.
Getting involved
If you have feedback for this feature or are interested in getting involved with the design and development, join the Kubernetes Storage Special-Interest-Group (SIG). We’re rapidly growing and always welcome new contributors.
Special thanks to all the contributors from multiple companies that helped bring this feature to beta, including Cheng Xing (verult), David Zhu (davidz627), Deyuan Deng (ddysher), Dhiraj Hedge (dhirajh), Ian Chakeres (ianchakeres), Jan Šafránek (jsafrane), Matthew Wong (wongma7), Michelle Au (msau42), Serguei Bezverkhi (sbezverk), and Yuquan Ren (nickrenren).
Migrating the Kubernetes Blog
We recently migrated the Kubernetes Blog from the Blogger platform to GitHub. With the change in platform comes a change in URL: formerly at http://blog.kubernetes.io, the blog now resides at https://kubernetes.io/blog.
All existing posts redirect from their former URLs with <rel=canonical> tags, preserving SEO values.
Why and how we migrated the blog
Our primary reasons for migrating were to streamline blog submissions and reviews, and to make the overall blog process faster and more transparent. Blogger's web interface made it difficult to provide drafts to multiple reviewers without also granting unnecessary access permissions and compromising security. GitHub's review process offered clear improvements.
We learned from Jim Brikman's experience during his own site migration away from Blogger.
Our migration was broken into several pull requests, but you can see the work that went into the primary migration PR.
We hope that making blog submissions more accessible will encourage greater community involvement in creating and reviewing blog content.
How to Submit a Blog Post
You can submit a blog post for consideration one of two ways:
- Submit a Google Doc through the blog submission form
- Open a pull request against the website repository as described here
If you have a post that you want to remain confidential until your publish date, please submit your post via the Google form. Otherwise, you can choose your submission process based on your comfort level and preferred workflow.
Call for reviewers
The Kubernetes Blog needs more reviewers! If you're interested in contributing to the Kubernetes project and can participate on a regular, weekly basis, send an introductory email to k8sblog@linuxfoundation.org.
Container Storage Interface (CSI) for Kubernetes Goes Beta
![]()
The Kubernetes implementation of the Container Storage Interface (CSI) is now beta in Kubernetes v1.10. CSI was introduced as alpha in Kubernetes v1.9.
Kubernetes features are generally introduced as alpha and moved to beta (and eventually to stable/GA) over subsequent Kubernetes releases. This process allows Kubernetes developers to get feedback, discover and fix issues, iterate on the designs, and deliver high quality, production grade features.
Why introduce Container Storage Interface in Kubernetes?
Although Kubernetes already provides a powerful volume plugin system that makes it easy to consume different types of block and file storage, adding support for new volume plugins has been challenging. Because volume plugins are currently “in-tree”—volume plugins are part of the core Kubernetes code and shipped with the core Kubernetes binaries—vendors wanting to add support for their storage system to Kubernetes (or even fix a bug in an existing volume plugin) must align themselves with the Kubernetes release process.
With the adoption of the Container Storage Interface, the Kubernetes volume layer becomes truly extensible. Third party storage developers can now write and deploy volume plugins exposing new storage systems in Kubernetes without ever having to touch the core Kubernetes code. This will result in even more options for the storage that backs Kubernetes users’ stateful containerized workloads.
What’s new in Beta?
With the promotion to beta CSI is now enabled by default on standard Kubernetes deployments instead of being opt-in.
The move of the Kubernetes implementation of CSI to beta also means:
- Kubernetes is compatible with v0.2 of the CSI spec (instead of v0.1)
- There were breaking changes between the CSI spec v0.1 and v0.2, so existing CSI drivers must be updated to be 0.2 compatible before use with Kubernetes 1.10.0+.
- Mount propagation, a feature that allows bidirectional mounts between containers and host (a requirement for containerized CSI drivers), has also moved to beta.
- The Kubernetes
VolumeAttachmentobject, introduced in v1.9 in the storage v1alpha1 group, has been added to the storage v1beta1 group. - The Kubernetes
CSIPersistentVolumeSourceobject has been promoted to beta. AVolumeAttributesfield was added to KubernetesCSIPersistentVolumeSourceobject (in alpha this was passed around via annotations). - Node authorizer has been updated to limit access to
VolumeAttachmentobjects from kubelet. - The Kubernetes
CSIPersistentVolumeSourceobject and the CSI external-provisioner have been modified to allow passing of secrets to the CSI volume plugin. - The Kubernetes
CSIPersistentVolumeSourcehas been modified to allow passing in filesystem type (previously always assumed to beext4). - A new optional call,
NodeStageVolume, has been added to the CSI spec, and the Kubernetes CSI volume plugin has been modified to callNodeStageVolumeduringMountDevice(in alpha this step was a no-op).
How do I deploy a CSI driver on a Kubernetes Cluster?
CSI plugin authors must provide their own instructions for deploying their plugin on Kubernetes.
The Kubernetes-CSI implementation team created a sample hostpath CSI driver. The sample provides a rough idea of what the deployment process for a CSI driver looks like. Production drivers, however, would deploy node components via a DaemonSet and controller components via a StatefulSet rather than a single pod (for example, see the deployment files for the GCE PD driver).
How do I use a CSI Volume in my Kubernetes pod?
Assuming a CSI storage plugin is already deployed on your cluster, you can use it through the familiar Kubernetes storage primitives: PersistentVolumeClaims, PersistentVolumes, and StorageClasses.
CSI is a beta feature in Kubernetes v1.10. Although it is enabled by default, it may require the following flag:
- API server binary and kubelet binaries:
--allow-privileged=true- Most CSI plugins will require bidirectional mount propagation, which can only be enabled for privileged pods. Privileged pods are only permitted on clusters where this flag has been set to true (this is the default in some environments like GCE, GKE, and kubeadm).
Dynamic Provisioning
You can enable automatic creation/deletion of volumes for CSI Storage plugins that support dynamic provisioning by creating a StorageClass pointing to the CSI plugin.
The following StorageClass, for example, enables dynamic creation of “fast-storage” volumes by a CSI volume plugin called “com.example.csi-driver”.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast-storage
provisioner: com.example.csi-driver
parameters:
type: pd-ssd
csiProvisionerSecretName: mysecret
csiProvisionerSecretNamespace: mynamespace
New for beta, the default CSI external-provisioner reserves the parameter keys csiProvisionerSecretName and csiProvisionerSecretNamespace. If specified, it fetches the secret and passes it to the CSI driver during provisioning.
Dynamic provisioning is triggered by the creation of a PersistentVolumeClaim object. The following PersistentVolumeClaim, for example, triggers dynamic provisioning using the StorageClass above.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-request-for-storage
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: fast-storage
When volume provisioning is invoked, the parameter type: pd-ssd and the secret any referenced secret(s) are passed to the CSI plugin com.example.csi-driver via a CreateVolume call. In response, the external volume plugin provisions a new volume and then automatically create a PersistentVolume object to represent the new volume. Kubernetes then binds the new PersistentVolume object to the PersistentVolumeClaim, making it ready to use.
If the fast-storage StorageClass is marked as “default”, there is no need to include the storageClassName in the PersistentVolumeClaim, it will be used by default.
Pre-Provisioned Volumes
You can always expose a pre-existing volume in Kubernetes by manually creating a PersistentVolume object to represent the existing volume. The following PersistentVolume, for example, exposes a volume with the name “existingVolumeName” belonging to a CSI storage plugin called “com.example.csi-driver”.
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-manually-created-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
csi:
driver: com.example.csi-driver
volumeHandle: existingVolumeName
readOnly: false
fsType: ext4
volumeAttributes:
foo: bar
controllerPublishSecretRef:
name: mysecret1
namespace: mynamespace
nodeStageSecretRef:
name: mysecret2
namespace: mynamespace
nodePublishSecretRef
name: mysecret3
namespace: mynamespace
Attaching and Mounting
You can reference a PersistentVolumeClaim that is bound to a CSI volume in any pod or pod template.
kind: Pod
apiVersion: v1
metadata:
name: my-pod
spec:
containers:
- name: my-frontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: my-csi-volume
volumes:
- name: my-csi-volume
persistentVolumeClaim:
claimName: my-request-for-storage
When the pod referencing a CSI volume is scheduled, Kubernetes will trigger the appropriate operations against the external CSI plugin (ControllerPublishVolume, NodeStageVolume, NodePublishVolume, etc.) to ensure the specified volume is attached, mounted, and ready to use by the containers in the pod.
For more details please see the CSI implementation design doc and documentation.
How do I write a CSI driver?
CSI Volume Driver deployments on Kubernetes must meet some minimum requirements.
The minimum requirements document also outlines the suggested mechanism for deploying an arbitrary containerized CSI driver on Kubernetes. This mechanism can be used by a Storage Provider to simplify deployment of containerized CSI compatible volume drivers on Kubernetes.
As part of the suggested deployment process, the Kubernetes team provides the following sidecar (helper) containers:
- external-attacher
- watches Kubernetes
VolumeAttachmentobjects and triggersControllerPublishandControllerUnpublishoperations against a CSI endpoint
- watches Kubernetes
- external-provisioner
- watches Kubernetes
PersistentVolumeClaimobjects and triggersCreateVolumeandDeleteVolumeoperations against a CSI endpoint
- watches Kubernetes
- driver-registrar
- registers the CSI driver with kubelet (in the future) and adds the drivers custom
NodeId(retrieved viaGetNodeIDcall against the CSI endpoint) to an annotation on the Kubernetes Node API Object
- registers the CSI driver with kubelet (in the future) and adds the drivers custom
- livenessprobe
- can be included in a CSI plugin pod to enable the Kubernetes Liveness Probe mechanism
Storage vendors can build Kubernetes deployments for their plugins using these components, while leaving their CSI driver completely unaware of Kubernetes.
Where can I find CSI drivers?
CSI drivers are developed and maintained by third parties. You can find a non-definitive list of some sample and production CSI drivers.
What about FlexVolumes?
As mentioned in the alpha release blog post, FlexVolume plugin was an earlier attempt to make the Kubernetes volume plugin system extensible. Although it enables third party storage vendors to write drivers “out-of-tree”, because it is an exec based API, FlexVolumes requires files for third party driver binaries (or scripts) to be copied to a special plugin directory on the root filesystem of every node (and, in some cases, master) machine. This requires a cluster admin to have write access to the host filesystem for each node and some external mechanism to ensure that the driver file is recreated if deleted, just to deploy a volume plugin.
In addition to being difficult to deploy, Flex did not address the pain of plugin dependencies: Volume plugins tend to have many external requirements (on mount and filesystem tools, for example). These dependencies are assumed to be available on the underlying host OS, which is often not the case.
CSI addresses these issues by not only enabling storage plugins to be developed out-of-tree, but also containerized and deployed via standard Kubernetes primitives.
If you still have questions about in-tree volumes vs CSI vs Flex, please see the Volume Plugin FAQ.
What will happen to the in-tree volume plugins?
Once CSI reaches stability, we plan to migrate most of the in-tree volume plugins to CSI. Stay tuned for more details as the Kubernetes CSI implementation approaches stable.
What are the limitations of beta?
The beta implementation of CSI has the following limitations:
- Block volumes are not supported; only file.
- CSI drivers must be deployed with the provided external-attacher sidecar plugin, even if they don’t implement
ControllerPublishVolume. - Topology awareness is not supported for CSI volumes, including the ability to share information about where a volume is provisioned (zone, regions, etc.) with the Kubernetes scheduler to allow it to make smarter scheduling decisions, and the ability for the Kubernetes scheduler or a cluster administrator or an application developer to specify where a volume should be provisioned.
driver-registrarrequires permissions to modify all Kubernetes node API objects which could result in a compromised node gaining the ability to do the same.
What’s next?
Depending on feedback and adoption, the Kubernetes team plans to push the CSI implementation to GA in 1.12.
The team would like to encourage storage vendors to start developing CSI drivers, deploying them on Kubernetes, and sharing feedback with the team via the Kubernetes Slack channel wg-csi, the Google group kubernetes-sig-storage-wg-csi, or any of the standard SIG storage communication channels.
How do I get involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together.
In addition to the contributors who have been working on the Kubernetes implementation of CSI since alpha:
- Bradley Childs (childsb)
- Chakravarthy Nelluri (chakri-nelluri)
- Jan Šafránek (jsafrane)
- Luis Pabón (lpabon)
- Saad Ali (saad-ali)
- Vladimir Vivien (vladimirvivien)
We offer a huge thank you to the new contributors who stepped up this quarter to help the project reach beta:
- David Zhu (davidz627)
- Edison Xiang (edisonxiang)
- Felipe Musse (musse)
- Lin Ml (mlmhl)
- Lin Youchong (linyouchong)
- Pietro Menna (pietromenna)
- Serguei Bezverkhi (sbezverk)
- Xing Yang (xing-yang)
- Yuquan Ren (NickrenREN)
If you’re interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special Interest Group (SIG). We’re rapidly growing and always welcome new contributors.
Fixing the Subpath Volume Vulnerability in Kubernetes
On March 12, 2018, the Kubernetes Product Security team disclosed CVE-2017-1002101, which allowed containers using subpath volume mounts to access files outside of the volume. This means that a container could access any file available on the host, including volumes for other containers that it should not have access to.
The vulnerability has been fixed and released in the latest Kubernetes patch releases. We recommend that all users upgrade to get the fix. For more details on the impact and how to get the fix, please see the announcement. (Note, some functional regressions were found after the initial fix and are being tracked in issue #61563).
This post presents a technical deep dive on the vulnerability and the solution.
Kubernetes Background
To understand the vulnerability, one must first understand how volume and subpath mounting works in Kubernetes.
Before a container is started on a node, the kubelet volume manager locally mounts all the volumes specified in the PodSpec under a directory for that Pod on the host system. Once all the volumes are successfully mounted, it constructs the list of volume mounts to pass to the container runtime. Each volume mount contains information that the container runtime needs, the most relevant being:
- Path of the volume in the container
- Path of the volume on the host (
/var/lib/kubelet/pods/<pod uid>/volumes/<volume type>/<volume name>)
When starting the container, the container runtime creates the path in the container root filesystem, if necessary, and then bind mounts it to the provided host path.
Subpath mounts are passed to the container runtime just like any other volume. The container runtime does not distinguish between a base volume and a subpath volume, and handles them the same way. Instead of passing the host path to the root of the volume, Kubernetes constructs the host path by appending the Pod-specified subpath (a relative path) to the base volume’s host path.
For example, here is a spec for a subpath volume mount:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
<snip>
volumeMounts:
- mountPath: /mnt/data
name: my-volume
subPath: dataset1
volumes:
- name: my-volume
emptyDir: {}
In this example, when the Pod gets scheduled to a node, the system will:
- Set up an EmptyDir volume at
/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volume - Construct the host path for the subpath mount:
/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volume/ + dataset1 - Pass the following mount information to the container runtime:
- Container path:
/mnt/data - Host path:
/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volume/dataset1
- Container path:
- The container runtime bind mounts
/mnt/datain the container root filesystem to/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volume/dataset1on the host. - The container runtime starts the container.
The Vulnerability
The vulnerability with subpath volumes was discovered by Maxim Ivanov, by making a few observations:
- Subpath references files or directories that are controlled by the user, not the system.
- Volumes can be shared by containers that are brought up at different times in the Pod lifecycle, including by different Pods.
- Kubernetes passes host paths to the container runtime to bind mount into the container.
The basic example below demonstrates the vulnerability. It takes advantage of the observations outlined above by:
- Using an init container to setup the volume with a symlink.
- Using a regular container to mount that symlink as a subpath later.
- Causing kubelet to evaluate the symlink on the host before passing it into the container runtime.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
initContainers:
- name: prep-symlink
image: "busybox"
command: ["bin/sh", "-ec", "ln -s / /mnt/data/symlink-door"]
volumeMounts:
- name: my-volume
mountPath: /mnt/data
containers:
- name: my-container
image: "busybox"
command: ["/bin/sh", "-ec", "ls /mnt/data; sleep 999999"]
volumeMounts:
- mountPath: /mnt/data
name: my-volume
subPath: symlink-door
volumes:
- name: my-volume
emptyDir: {}
For this example, the system will:
- Setup an EmptyDir volume at
/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volume - Pass the following mount information for the init container to the container runtime:
- Container path:
/mnt/data - Host path:
/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volume
- Container path:
- The container runtime bind mounts
/mnt/datain the container root filesystem to/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volumeon the host. - The container runtime starts the init container.
- The init container creates a symlink inside the container:
/mnt/data/symlink-door->/, and then exits. - Kubelet starts to prepare the volume mounts for the normal containers.
- It constructs the host path for the subpath volume mount:
/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volume/ + symlink-door. - And passes the following mount information to the container runtime:
- Container path:
/mnt/data - Host path:
/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty-dir/my-volume/symlink-door
- Container path:
- The container runtime bind mounts
/mnt/datain the container root filesystem to/var/lib/kubelet/pods/1234/volumes/kubernetes.io~empty~dir/my-volume/symlink-door - However, the bind mount resolves symlinks, which in this case, resolves to
/on the host! Now the container can see all of the host’s filesystem through its mount point/mnt/data.
This is a manifestation of a symlink race, where a malicious user program can gain access to sensitive data by causing a privileged program (in this case, kubelet) to follow a user-created symlink.
It should be noted that init containers are not always required for this exploit, depending on the volume type. It is used in the EmptyDir example because EmptyDir volumes cannot be shared with other Pods, and only created when a Pod is created, and destroyed when the Pod is destroyed. For persistent volume types, this exploit can also be done across two different Pods sharing the same volume.
The Fix
The underlying issue is that the host path for subpaths are untrusted and can point anywhere in the system. The fix needs to ensure that this host path is both:
- Resolved and validated to point inside the base volume.
- Not changeable by the user in between the time of validation and when the container runtime bind mounts it.
The Kubernetes product security team went through many iterations of possible solutions before finally agreeing on a design.
Idea 1
Our first design was relatively simple. For each subpath mount in each container:
- Resolve all the symlinks for the subpath.
- Validate that the resolved path is within the volume.
- Pass the resolved path to the container runtime.
However, this design is prone to the classic time-of-check-to-time-of-use (TOCTTOU) problem. In between steps 2) and 3), the user could change the path back to a symlink. The proper solution needs some way to “lock” the path so that it cannot be changed in between validation and bind mounting by the container runtime. All the subsequent ideas use an intermediate bind mount by kubelet to achieve this “lock” step before handing it off to the container runtime. Once a bind mount is performed, the mount source is fixed and cannot be changed.
Idea 2
We went a bit wild with this idea:
- Create a working directory under the kubelet’s pod directory. Let’s call it
dir1. - Bind mount the base volume to under the working directory,
dir1/volume. - Chroot to the working directory
dir1. - Inside the chroot, bind mount
volume/subpathtosubpath. This ensures that any symlinks get resolved to inside the chroot environment. - Exit the chroot.
- On the host again, pass the bind mounted
dir1/subpathto the container runtime.
While this design does ensure that the symlinks cannot point outside of the volume, it was ultimately rejected due to difficulties of implementing the chroot mechanism in 4) across all the various distros and environments that Kubernetes has to support, including containerized kubelets.
Idea 3
Coming back to earth a little bit, our next idea was to:
- Bind mount the subpath to a working directory under the kubelet’s pod directory.
- Get the source of the bind mount, and validate that it is within the base volume.
- Pass the bind mount to the container runtime.
In theory, this sounded pretty simple, but in reality, 2) was quite difficult to implement correctly. Many scenarios had to be handled where volumes (like EmptyDir) could be on a shared filesystem, on a separate filesystem, on the root filesystem, or not on the root filesystem. NFS volumes ended up handling all bind mounts as a separate mount, instead of as a child to the base volume. There was additional uncertainty about how out-of-tree volume types (that we couldn’t test) would behave.
The Solution
Given the amount of scenarios and corner cases that had to be handled with the previous design, we really wanted to find a solution that was more generic across all volume types. The final design that we ultimately went with was to:
- Resolve all the symlinks in the subpath.
- Starting with the base volume, open each path segment one by one, using the
openat()syscall, and disallow symlinks. With each path segment, validate that the current path is within the base volume. - Bind mount
/proc/<kubelet pid>/fd/<final fd>to a working directory under the kubelet’s pod directory. The proc file is a link to the opened file. If that file gets replaced while kubelet still has it open, then the link will still point to the original file. - Close the fd and pass the bind mount to the container runtime.
Note that this solution is different for Windows hosts, where the mounting semantics are different than Linux. In Windows, the design is to:
- Resolve all the symlinks in the subpath.
- Starting with the base volume, open each path segment one by one with a file lock, and disallow symlinks. With each path segment, validate that the current path is within the base volume.
- Pass the resolved subpath to the container runtime, and start the container.
- After the container has started, unlock and close all the files.
Both solutions are able to address all the requirements of:
- Resolving the subpath and validating that it points to a path inside the base volume.
- Ensuring that the subpath host path cannot be changed in between the time of validation and when the container runtime bind mounts it.
- Being generic enough to support all volume types.
Acknowledgements
Special thanks to many folks involved with handling this vulnerability:
- Maxim Ivanov, who responsibly disclosed the vulnerability to the Kubernetes Product Security team.
- Kubernetes storage and security engineers from Google, Microsoft, and RedHat, who developed, tested, and reviewed the fixes.
- Kubernetes test-infra team, for setting up the private build infrastructure
- Kubernetes patch release managers, for coordinating and handling all the releases.
- All the production release teams that worked to deploy the fix quickly after release.
If you find a vulnerability in Kubernetes, please follow our responsible disclosure process and let us know; we want to do our best to make Kubernetes secure for all users.
-- Michelle Au, Software Engineer, Google; and Jan Šafránek, Software Engineer, Red Hat
Kubernetes 1.10: Stabilizing Storage, Security, and Networking
Editor's note: today's post is by the 1.10 Release Team
We’re pleased to announce the delivery of Kubernetes 1.10, our first release of 2018!
Today’s release continues to advance maturity, extensibility, and pluggability of Kubernetes. This newest version stabilizes features in 3 key areas, including storage, security, and networking. Notable additions in this release include the introduction of external kubectl credential providers (alpha), the ability to switch DNS service to CoreDNS at install time (beta), and the move of Container Storage Interface (CSI) and persistent local volumes to beta.
Let’s dive into the key features of this release:
Storage - CSI and Local Storage move to beta
This is an impactful release for the Storage Special Interest Group (SIG), marking the culmination of their work on multiple features. The Kubernetes implementation of the Container Storage Interface (CSI) moves to beta in this release: installing new volume plugins is now as easy as deploying a pod. This in turn enables third-party storage providers to develop their solutions independently outside of the core Kubernetes codebase. This continues the thread of extensibility within the Kubernetes ecosystem.
Durable (non-shared) local storage management progressed to beta in this release, making locally attached (non-network attached) storage available as a persistent volume source. This means higher performance and lower cost for distributed file systems and databases.
This release also includes many updates to Persistent Volumes. Kubernetes can automatically prevent deletion of Persistent Volume Claims that are in use by a pod (beta) and prevent deletion of a Persistent Volume that is bound to a Persistent Volume Claim (beta). This helps ensure that storage API objects are deleted in the correct order.
Security - External credential providers (alpha)
Kubernetes, which is already highly extensible, gains another extension point in 1.10 with external kubectl credential providers (alpha). Cloud providers, vendors, and other platform developers can now release binary plugins to handle authentication for specific cloud-provider IAM services, or that integrate with in-house authentication systems that aren’t supported in-tree, such as Active Directory. This complements the Cloud Controller Manager feature added in 1.9.
Networking - CoreDNS as a DNS provider (beta)
The ability to switch the DNS service to CoreDNS at install time is now in beta. CoreDNS has fewer moving parts: it’s a single executable and a single process, and supports additional use cases.
Each Special Interest Group (SIG) within the community continues to deliver the most-requested enhancements, fixes, and functionality for their respective specialty areas. For a complete list of inclusions by SIG, please visit the release notes.
Availability
Kubernetes 1.10 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials.
2 Day Features Blog Series
If you’re interested in exploring these features more in depth, check back next week for our 2 Days of Kubernetes series where we’ll highlight detailed walkthroughs of the following features:
Day 1 - Container Storage Interface (CSI) for Kubernetes going Beta Day 2 - Local Persistent Volumes for Kubernetes going Beta
Release team
This release is made possible through the effort of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Jaice Singer DuMars, Kubernetes Ambassador for Microsoft. The 10 individuals on the release team coordinate many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem.
Project Velocity
The CNCF has continued refining an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. Thanks to increased automation, issue count at the end of the release was only slightly higher than it was at the beginning. This marks a major shift toward issue manageability. With 75,000+ comments, Kubernetes remains one of the most actively discussed projects on GitHub.
User Highlights
According to a recent CNCF survey, more than 49% of Asia-based respondents use Kubernetes in production, with another 49% evaluating it for use in production. Established, global organizations are using Kubernetes in production at massive scale. Recently published user stories from the community include:
- Huawei, the largest telecommunications equipment manufacturer in the world, moved its internal IT department’s applications to run on Kubernetes. This resulted in the global deployment cycles decreasing from a week to minutes, and the efficiency of application delivery improved by tenfold.
- Jinjiang Travel International, one of the top 5 largest OTA and hotel companies, use Kubernetes to speed up their software release velocity from hours to just minutes. Additionally, they leverage Kubernetes to increase the scalability and availability of their online workloads.
- Haufe Group, the Germany-based media and software company, utilized Kubernetes to deliver a new release in half an hour instead of days. The company is also able to scale down to around half the capacity at night, saving 30 percent on hardware costs.
- BlackRock, the world’s largest asset manager, was able to move quickly using Kubernetes and built an investor research web app from inception to delivery in under 100 days. Is Kubernetes helping your team? Share your story with the community.
Ecosystem Updates
- The CNCF is expanding its certification offerings to include a Certified Kubernetes Application Developer exam. The CKAD exam certifies an individual's ability to design, build, configure, and expose cloud native applications for Kubernetes. The CNCF is looking for beta testers for this new program. More information can be found here.
- Kubernetes documentation now features user journeys: specific pathways for learning based on who readers are and what readers want to do. Learning Kubernetes is easier than ever for beginners, and more experienced users can find task journeys specific to cluster admins and application developers.
- CNCF also offers online training that teaches the skills needed to create and configure a real-world Kubernetes cluster.
KubeCon
The world’s largest Kubernetes gathering, KubeCon + CloudNativeCon is coming to Copenhagen from May 2-4, 2018 and will feature technical sessions, case studies, developer deep dives, salons and more! Check out the schedule of speakers and register today!
Webinar
Join members of the Kubernetes 1.10 release team on April 10th at 10am PDT to learn about the major features in this release including Local Persistent Volumes and the Container Storage Interface (CSI). Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
Thank you for your continued feedback and support.
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Chat with the community on Slack
- Share your Kubernetes story.
Principles of Container-based Application Design
It's possible nowadays to put almost any application in a container and run it. Creating cloud-native applications, however—containerized applications that are automated and orchestrated effectively by a cloud-native platform such as Kubernetes—requires additional effort. Cloud-native applications anticipate failure; they run and scale reliably even when their infrastructure experiences outages. To offer such capabilities, cloud-native platforms like Kubernetes impose a set of contracts and constraints on applications. These contracts ensure that applications they run conform to certain constraints and allow the platform to automate application management.
I've outlined seven principlesfor containerized applications to follow in order to be fully cloud-native.
| ----- |
| 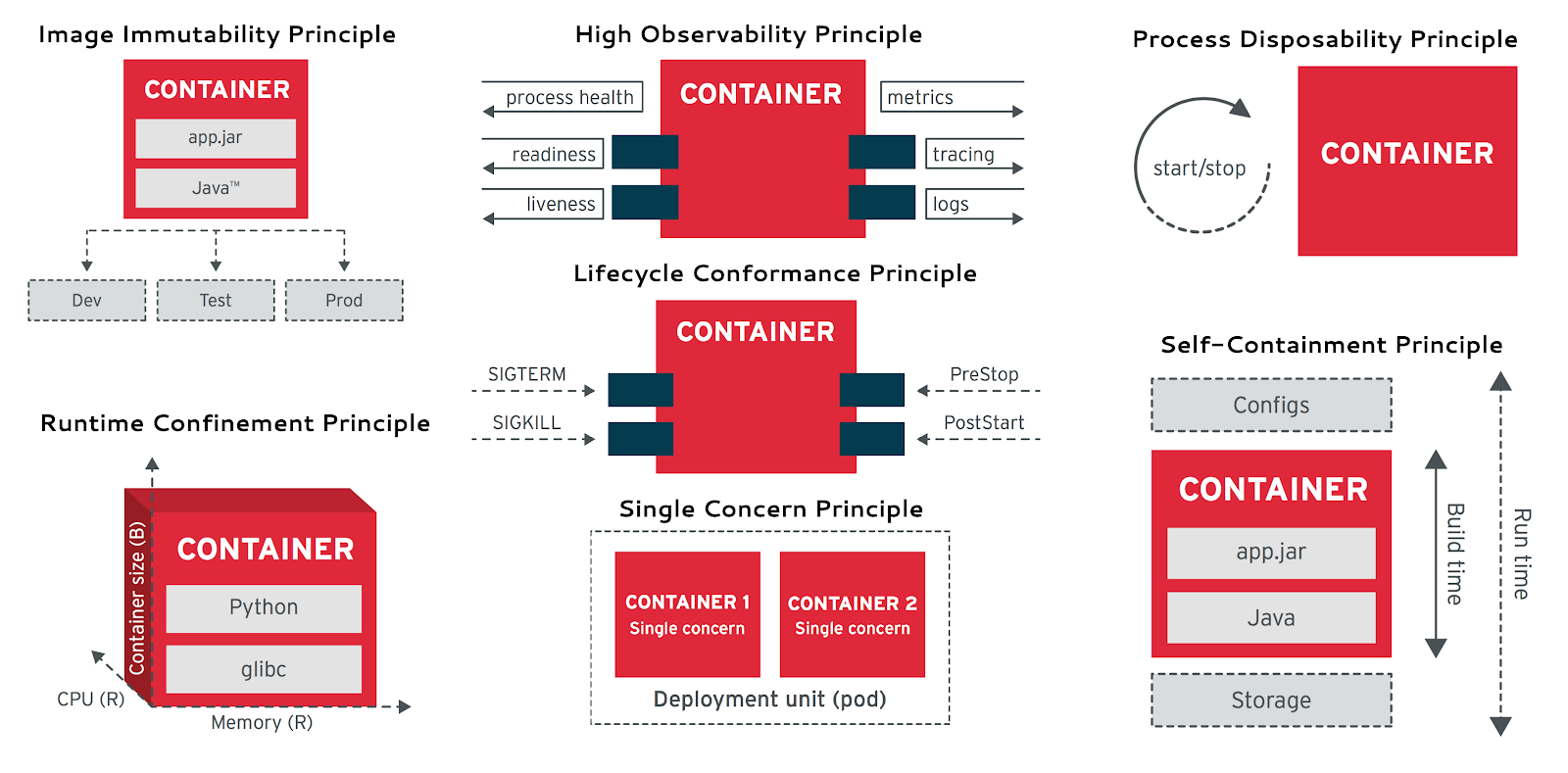
These seven principles cover both build time and runtime concerns.
Build time
- Single Concern: Each container addresses a single concern and does it well.
- Self-Containment: A container relies only on the presence of the Linux kernel. Additional libraries are added when the container is built.
- Image Immutability: Containerized applications are meant to be immutable, and once built are not expected to change between different environments.
Runtime
- High Observability: Every container must implement all necessary APIs to help the platform observe and manage the application in the best way possible.
- Lifecycle Conformance: A container must have a way to read events coming from the platform and conform by reacting to those events.
- Process Disposability: Containerized applications must be as ephemeral as possible and ready to be replaced by another container instance at any point in time.
- Runtime Confinement: Every container must declare its resource requirements and restrict resource use to the requirements indicated. The build time principles ensure that containers have the right granularity, consistency, and structure in place. The runtime principles dictate what functionalities must be implemented in order for containerized applications to possess cloud-native function. Adhering to these principles helps ensure that your applications are suitable for automation in Kubernetes.
The white paper is freely available for download:
To read more about designing cloud-native applications for Kubernetes, check out my Kubernetes Patterns book.
— Bilgin Ibryam, Principal Architect, Red Hat
Twitter:
Blog: http://www.ofbizian.com
Linkedin:
Bilgin Ibryam (@bibryam) is a principal architect at Red Hat, open source committer at ASF, blogger, author, and speaker. He is the author of Camel Design Patterns and Kubernetes Patterns books. In his day-to-day job, Bilgin enjoys mentoring, training and leading teams to be successful with distributed systems, microservices, containers, and cloud-native applications in general.
Expanding User Support with Office Hours
Today's post is by Jorge Castro and Ilya Dmitichenko on Kubernetes office hours.
Today's developer has an almost overwhelming amount of resources available for learning. Kubernetes development teams use StackOverflow, user documentation, Slack, and the mailing lists. Additionally, the community itself continues to amass an awesome list of resources.
One of the challenges of large projects is keeping user resources relevant and useful. While documentation can be useful, great learning also happens in Q&A sessions at conferences, or by learning with someone whose explanation matches your learning style. Consider that learning Kung Fu from Morpheus would be a lot more fun than reading a book about Kung Fu!

We as Kubernetes developers want to create an interactive experience: where Kubernetes users can get their questions answered by experts in real time, or at least referred to the best known documentation or code example.
Having discussed a few broad ideas, we eventually decided to make Kubernetes Office Hours a live stream where we take user questions from the audience and present them to our panel of contributors and expert users. We run two sessions: one for European time zones, and one for the Americas. These streaming setup guidelines make office hours extensible—for example, if someone wants to run office hours for Asia/Pacific timezones, or for another CNCF project.
To give you an idea of what Kubernetes office hours are like, here's Josh Berkus answering a question on running databases on Kubernetes. Despite the popularity of this topic, it's still difficult for a new user to get a constructive answer. Here's an excellent response from Josh:
It's often easier to field this kind of question in office hours than it is to ask a developer to write a full-length blog post. [Editor's note: That's legit!] Because we don't have infinite developers with infinite time, this kind of focused communication creates high-bandwidth help while limiting developer commitments to 1 hour per month. This allows a rotating set of experts to share the load without overwhelming any one person.
We hold office hours the third Wednesday of every month on the Kubernetes YouTube Channel. You can post questions on the #office-hours channel on Slack, or you can submit your question to Stack Overflow and post a link on Slack. If you post a question in advance, you might get better answers, as volunteers have more time to research and prepare. If a question can't be fully solved during the call, the team will try their best to point you in the right direction and/or ping other people in the community to take a look. Check out this page for more details on what's off- and on topic as well as meeting information for your time zone. We hope to hear your questions soon!
Special thanks to Amazon, Bitnami, Giant Swarm, Heptio, Liquidweb, Northwestern Mutual, Packet.net, Pivotal, Red Hat, Weaveworks, and VMWare for donating engineering time to office hours.
And thanks to Alan Pope, Joe Beda, and Charles Butler for technical support in making our livestream better.
How to Integrate RollingUpdate Strategy for TPR in Kubernetes
With Kubernetes, it's easy to manage and scale stateless applications like web apps and API services right out of the box. To date, almost all of the talks about Kubernetes has been about microservices and stateless applications.
With the popularity of container-based microservice architectures, there is a strong need to deploy and manage RDBMS(Relational Database Management Systems). RDBMS requires experienced database-specific knowledge to correctly scale, upgrade, and re-configure while protecting against data loss or unavailability.
For example, MySQL (the most popular open source RDBMS) needs to store data in files that are persistent and exclusive to each MySQL database's storage. Each MySQL database needs to be individually distinct, another, more complex is in cluster that need to distinguish one MySQL database from a cluster as a different role, such as master, slave, or shard. High availability and zero data loss are also hard to accomplish when replacing database nodes on failed machines.
Using powerful Kubernetes API extension mechanisms, we can encode RDBMS domain knowledge into software, named WQ-RDS, running atop Kubernetes like built-in resources.
WQ-RDS leverages Kubernetes primitive resources and controllers, it deliveries a number of enterprise-grade features and brings a significantly reliable way to automate time-consuming operational tasks like database setup, patching backups, and setting up high availability clusters. WQ-RDS supports mainstream versions of Oracle and MySQL (both compatible with MariaDB).
Let's demonstrate how to manage a MySQL sharding cluster.
MySQL Sharding Cluster
MySQL Sharding Cluster is a scale-out database architecture. Based on the hash algorithm, the architecture distributes data across all the shards of the cluster. Sharding is entirely transparent to clients: Proxy is able to connect to any Shards in the cluster and issue queries to the correct shards directly.
| ----- |
| 
Note: Each shard corresponds to a single MySQL instance. Currently, WQ-RDS supports a maximum of 64 shards.
|
All of the shards are built with Kubernetes Statefulset, Services, Storage Class, configmap, secrets and MySQL. WQ-RDS manages the entire lifecycle of the sharding cluster. Advantages of the sharding cluster are obvious:
- Scale out queries per second (QPS) and transactions per second (TPS)
- Scale out storage capacity: gain more storage by distributing data to multiple nodes
Create a MySQL Sharding Cluster
Let's create a Kubernetes cluster with 8 shards.
kubectl create -f mysqlshardingcluster.yaml
Next, create a MySQL Sharding Cluster including 8 shards.
- TPR : MysqlCluster and MysqlDatabase
[root@k8s-master ~]# kubectl get mysqlcluster
NAME KIND
clustershard-c MysqlCluster.v1.mysql.orain.com
MysqlDatabase from clustershard-c0 to clustershard-c7 belongs to MysqlCluster clustershard-c.
[root@k8s-master ~]# kubectl get mysqldatabase
NAME KIND
clustershard-c0 MysqlDatabase.v1.mysql.orain.com
clustershard-c1 MysqlDatabase.v1.mysql.orain.com
clustershard-c2 MysqlDatabase.v1.mysql.orain.com
clustershard-c3 MysqlDatabase.v1.mysql.orain.com
clustershard-c4 MysqlDatabase.v1.mysql.orain.com
clustershard-c5 MysqlDatabase.v1.mysql.orain.com
clustershard-c6 MysqlDatabase.v1.mysql.orain.com
clustershard-c7 MysqlDatabase.v1.mysql.orain.com
Next, let's look at two main features: high availability and RollingUpdate strategy.
To demonstrate, we'll start by running sysbench to generate some load on the cluster. In this example, QPS metrics are generated by MySQL export, collected by Prometheus, and visualized in Grafana.
Feature: high availability
WQ-RDS handles MySQL instance crashes while protecting against data loss.
When killing clustershard-c0, WQ-RDS will detect that clustershard-c0 is unavailable and replace clustershard-c0 on failed machine, taking about 35 seconds on average.

zero data loss at same time.

Feature : RollingUpdate Strategy
MySQL Sharding Cluster brings us not only strong scalability but also some level of maintenance complexity. For example, when updating a MySQL configuration like innodb_buffer_pool_size, a DBA has to perform a number of steps:
1. Apply change time.
2. Disable client access to database proxies.
3. Start a rolling upgrade.
Rolling upgrades need to proceed in order and are the most demanding step of the process. One cannot continue a rolling upgrade until and unless previous updates to MySQL instances are running and ready.
4 Verify the cluster.
5. Enable client access to database proxies.
Possible problems with a rolling upgrade include:
- node reboot
- MySQL instances restart
- human error Instead, WQ-RDS enables a DBA to perform rolling upgrades automatically.
StatefulSet RollingUpdate in Kubernetes
Kubernetes 1.7 includes a major feature that adds automated updates to StatefulSets and supports a range of update strategies including rolling updates.
Note: For more information about StatefulSet RollingUpdate, see the Kubernetes docs.
Because TPR (currently CRD) does not support the rolling upgrade strategy, we needed to integrate the RollingUpdate strategy into WQ-RDS. Fortunately, the Kubernetes repo is a treasure for learning. In the process of implementation, there are some points to share:
-
**MySQL Sharding Cluster has **changed: Each StatefulSet has its corresponding ControllerRevision, which records all the revision data and order (like git). Whenever StatefulSet is syncing, StatefulSet Controller will firstly compare it's spec to the latest corresponding ControllerRevision data (similar to git diff). If changed, a new ControllerrRevision will be generated, and the revision number will be incremented by 1. WQ-RDS borrows the process, MySQL Sharding Cluster object will record all the revision and order in ControllerRevision.
-
**How to initialize MySQL Sharding Cluster to meet request **replicas: Statefulset supports two Pod management policies: Parallel and OrderedReady. Because MySQL Sharding Cluster doesn't require ordered creation for its initial processes, we use the Parallel policy to accelerate the initialization of the cluster.
-
**How to perform a Rolling **Upgrade: Statefulset recreates pods in strictly decreasing order. The difference is that WQ-RDS updates shards instead of recreating them, as shown below:
-
When RollingUpdate ends: Kubernetes signals termination clearly. A rolling update completes when all of a set's Pods have been updated to the updateRevision. The status's currentRevision is set to updateRevision and its updateRevision is set to the empty string. The status's currentReplicas is set to updateReplicas and its updateReplicas are set to 0.

Controller revision in WQ-RDS
Revision information is stored in MysqlCluster.Status and is no different than Statefulset.Status.
root@k8s-master ~]# kubectl get mysqlcluster -o yaml clustershard-c
apiVersion: v1
items:
\- apiVersion: mysql.orain.com/v1
kind: MysqlCluster
metadata:
creationTimestamp: 2017-10-20T08:19:41Z
labels:
AppName: clustershard-crm
Createdby: orain.com
DBType: MySQL
name: clustershard-c
namespace: default
resourceVersion: "415852"
uid: 6bb089bb-b56f-11e7-ae02-525400e717a6
spec:
dbresourcespec:
limitedcpu: 1200m
limitedmemory: 400Mi
requestcpu: 1000m
requestmemory: 400Mi
status:
currentReplicas: 8
currentRevision: clustershard-c-648d878965
replicas: 8
updateRevision: clustershard-c-648d878965
kind: List
Example: Perform a rolling upgrade
Finally, We can now update "clustershard-c" to update configuration "innodb_buffer_pool_size" from 6GB to 7GB and reboot.
The process takes 480 seconds.

The upgrade is in monotonically decreasing manner:








Conclusion
RollingUpgrade is meaningful to database administrators. It provides a more effective way to operator database.
--Orain Xiong, co-founder, Woqutech
Apache Spark 2.3 with Native Kubernetes Support
Kubernetes and Big Data
The open source community has been working over the past year to enable first-class support for data processing, data analytics and machine learning workloads in Kubernetes. New extensibility features in Kubernetes, such as custom resources and custom controllers, can be used to create deep integrations with individual applications and frameworks.
Traditionally, data processing workloads have been run in dedicated setups like the YARN/Hadoop stack. However, unifying the control plane for all workloads on Kubernetes simplifies cluster management and can improve resource utilization.
"Bloomberg has invested heavily in machine learning and NLP to give our clients a competitive edge when it comes to the news and financial information that powers their investment decisions. By building our Data Science Platform on top of Kubernetes, we're making state-of-the-art data science tools like Spark, TensorFlow, and our sizable GPU footprint accessible to the company's 5,000+ software engineers in a consistent, easy-to-use way." - Steven Bower, Team Lead, Search and Data Science Infrastructure at Bloomberg
Introducing Apache Spark + Kubernetes
Apache Spark 2.3 with native Kubernetes support combines the best of the two prominent open source projects — Apache Spark, a framework for large-scale data processing; and Kubernetes.
Apache Spark is an essential tool for data scientists, offering a robust platform for a variety of applications ranging from large scale data transformation to analytics to machine learning. Data scientists are adopting containers en masse to improve their workflows by realizing benefits such as packaging of dependencies and creating reproducible artifacts. Given that Kubernetes is the de facto standard for managing containerized environments, it is a natural fit to have support for Kubernetes APIs within Spark.
Starting with Spark 2.3, users can run Spark workloads in an existing Kubernetes 1.7+ cluster and take advantage of Apache Spark's ability to manage distributed data processing tasks. Apache Spark workloads can make direct use of Kubernetes clusters for multi-tenancy and sharing through Namespaces and Quotas, as well as administrative features such as Pluggable Authorization and Logging. Best of all, it requires no changes or new installations on your Kubernetes cluster; simply create a container image and set up the right RBAC roles for your Spark Application and you're all set.
Concretely, a native Spark Application in Kubernetes acts as a custom controller, which creates Kubernetes resources in response to requests made by the Spark scheduler. In contrast with deploying Apache Spark in Standalone Mode in Kubernetes, the native approach offers fine-grained management of Spark Applications, improved elasticity, and seamless integration with logging and monitoring solutions. The community is also exploring advanced use cases such as managing streaming workloads and leveraging service meshes like Istio.

To try this yourself on a Kubernetes cluster, simply download the binaries for the official Apache Spark 2.3 release. For example, below, we describe running a simple Spark application to compute the mathematical constant Pi across three Spark executors, each running in a separate pod. Please note that this requires a cluster running Kubernetes 1.7 or above, a kubectl client that is configured to access it, and the necessary RBAC rules for the default namespace and service account.
$ kubectl cluster-info
Kubernetes master is running at https://xx.yy.zz.ww
$ bin/spark-submit
--master k8s://https://xx.yy.zz.ww
--deploy-mode cluster
--name spark-pi
--class org.apache.spark.examples.SparkPi
--conf spark.executor.instances=5
--conf spark.kubernetes.container.image=
--conf spark.kubernetes.driver.pod.name=spark-pi-driver
local:///opt/spark/examples/jars/spark-examples_2.11-2.3.0.jar
To watch Spark resources that are created on the cluster, you can use the following kubectl command in a separate terminal window.
$ kubectl get pods -l 'spark-role in (driver, executor)' -w
NAME READY STATUS RESTARTS AGE
spark-pi-driver 1/1 Running 0 14s
spark-pi-da1968a859653d6bab93f8e6503935f2-exec-1 0/1 Pending 0 0s
The results can be streamed during job execution by running:
$ kubectl logs -f spark-pi-driver
When the application completes, you should see the computed value of Pi in the driver logs.
In Spark 2.3, we're starting with support for Spark applications written in Java and Scala with support for resource localization from a variety of data sources including HTTP, GCS, HDFS, and more. We have also paid close attention to failure and recovery semantics for Spark executors to provide a strong foundation to build upon in the future. Get started with the open-source documentation today.
Get Involved
There's lots of exciting work to be done in the near future. We're actively working on features such as dynamic resource allocation, in-cluster staging of dependencies, support for PySpark & SparkR, support for Kerberized HDFS clusters, as well as client-mode and popular notebooks' interactive execution environments. For people who fell in love with the Kubernetes way of managing applications declaratively, we've also been working on a Kubernetes Operator for spark-submit, which allows users to declaratively specify and submit Spark Applications.
And we're just getting started! We would love for you to get involved and help us evolve the project further.
Huge thanks to the Apache Spark and Kubernetes contributors spread across multiple organizations who spent many hundreds of hours working on this effort. We look forward to seeing more of you contribute to the project and help it evolve further.
Anirudh Ramanathan and Palak Bhatia
Google
Kubernetes: First Beta Version of Kubernetes 1.10 is Here
Editor's note: Today's post is by Nick Chase. Nick is Head of Content at Mirantis. The Kubernetes community has released the first beta version of Kubernetes 1.10, which means you can now try out some of the new features and give your feedback to the release team ahead of the official release. The release, currently scheduled for March 21, 2018, is targeting the inclusion of more than a dozen brand new alpha features and more mature versions of more than two dozen more.
Specifically, Kubernetes 1.10 will include production-ready versions of Kubelet TLS Bootstrapping, API aggregation, and more detailed storage metrics.
Some of these features will look familiar because they emerged at earlier stages in previous releases. Each stage has specific meanings:
- stable: The same as "generally available", features in this stage have been thoroughly tested and can be used in production environments.
- beta: The feature has been around long enough that the team is confident that the feature itself is on track to be included as a stable feature, and any API calls aren't going to change. You can use and test these features, but including them in mission-critical production environments is not advised because they are not completely hardened.
- alpha: New features generally come in at this stage. These features are still being explored. APIs and options may change in future versions, or the feature itself may disappear. Definitely not for production environments. You can download the latest release of Kubernetes 1.10 from . To give feedback to the development community, create an issue in the Kubernetes 1.10 milestone and tag the appropriate SIG before March 9.
Here's what to look for, though you should remember that while this is the current plan as of this writing, there's always a possibility that one or more features may be held for a future release. We'll start with authentication.
Authentication (SIG-Auth)
- Kubelet TLS Bootstrap (stable): Kubelet TLS bootstrapping is probably the "headliner" of the Kubernetes 1.10 release as it becomes available for production environments. It provides the ability for a new kubelet to create a certificate signing request, which enables you to add new nodes to your cluster without having to either manually add security certificates or use self-signed certificates that eliminate many of the benefits of having certificates in the first place.
- Pod Security Policy moves to its own API group (beta): The beta release of the Pod Security Policy lets administrators decide what contexts pods can run in. In other words, you have the ability to prevent unprivileged users from creating privileged pods -- that is, pods that can perform actions such as writing files or accessing Secrets -- in particular namespaces.
- Limit node access to API (beta): Also in beta, you now have the ability to limit calls to the API on a node to just that specific node, and to ensure that a node is only calling its own API, and not those on other nodes.
- External client-go credential providers (alpha): client-go is the Go language client for accessing the Kubernetes API. This feature adds the ability to add external credential providers. For example, Amazon might want to create its own authenticator to validate interaction with EKS clusters; this feature enables them to do that without having to include their authenticator in the Kubernetes codebase.
- TokenRequest API (alpha): The TokenRequest API provides the groundwork for much needed improvements to service account tokens; this feature enables creation of tokens that aren't persisted in the Secrets API, that are targeted for specific audiences (such as external secret stores), have configurable expiries, and are bindable to specific pods.
Networking (SIG-Network)
- Support configurable pod resolv.conf (beta): You now have the ability to specifically control DNS for a single pod, rather than relying on the overall cluster DNS.
- Although the feature is called Switch default DNS plugin to CoreDNS (beta), that's not actually what will happen in this cycle. The community has been working on the switch from kube-dns, which includes dnsmasq, to CoreDNS, another CNCF project with fewer moving parts, for several releases. In Kubernetes 1.10, the default will still be kube-dns, but when CoreDNS reaches feature parity with kube-dns, the team will look at making it the default.
- Topology aware routing of services (alpha): The ability to distribute workloads is one of the advantages of Kubernetes, but one thing that has been missing until now is the ability to keep workloads and services geographically close together for latency purposes. Topology aware routing will help with this problem. (This functionality may be delayed until Kubernetes 1.11.)
- Make NodePort IP address configurable (alpha): Not having to specify IP addresses in a Kubernetes cluster is great -- until you actually need to know what one of those addresses is ahead of time, such as for setting up database replication or other tasks. You will now have the ability to specifically configure NodePort IP addresses to solve this problem. (This functionality may be delayed until Kubernetes 1.11.)
Kubernetes APIs (SIG-API-machinery)
- API Aggregation (stable): Kubernetes makes it possible to extend its API by creating your own functionality and registering your functions so that they can be served alongside the core K8s functionality. This capability will be upgraded to "stable" in Kubernetes 1.10, so you can use it in production. Additionally, SIG-CLI is adding a feature called kubectl get and describe should work well with extensions (alpha) to make the server, rather than the client, return this information for a smoother user experience.
- Support for self-hosting authorizer webhook (alpha): Earlier versions of Kubernetes brought us the authorizer webhooks, which make it possible to customize the enforcement of permissions before commands are executed. Those webhooks, however, have to live somewhere, and this new feature makes it possible to host them in the cluster itself.
Storage (SIG-Storage)
- Detailed storage metrics of internal state (stable): With a distributed system such as Kubernetes, it's particularly important to know what's going on inside the system at any given time, either for troubleshooting purposes or simply for automation. This release brings to general availability detailed metrics of what's going in inside the storage systems, including metrics such as mount and unmount time, number of volumes in a particular state, and number of orphaned pod directories. You can find a full list in this design document.
- Mount namespace propagation (beta): This feature allows a container to mount a volume as rslave so that host mounts can be seen inside the container, or as rshared so that any mounts from inside the container are reflected in the host's mount namespace. The default for this feature is rslave.
- Local Ephemeral Storage Capacity Isolation (beta): Without this feature in place, every pod on a node that is using ephemeral storage is pulling from the same pool, and allocating storage is on a "best-effort" basis; in other words, a pod never knows for sure how much space it has available. This function provides the ability for a pod to reserve its own storage.
- Out-of-tree CSI Volume Plugins (beta): Kubernetes 1.9 announced the release of the Container Storage Interface, which provides a standard way for vendors to provide storage to Kubernetes. This function makes it possible for them to create drivers that live "out-of-tree", or out of the normal Kubernetes core. This means that vendors can control their own plugins and don't have to rely on the community for code reviews and approvals.
- Local Persistent Storage (beta): This feature enables PersistentVolumes to be created with locally attached disks, and not just network volumes.
- Prevent deletion of Persistent Volume Claims that are used by a pod (beta) and 7. Prevent deletion of Persistent Volume that is bound to a Persistent Volume Claim (beta): In previous versions of Kubernetes it was possible to delete storage that is in use by a pod, causing massive problems for the pod. These features provide validation that prevents that from happening.
- Running out of storage space on your Persistent Volume? If you are, you can use Add support for online resizing of PVs (alpha) to enlarge the underlying volume it without disrupting existing data. This also works in conjunction with the new Add resize support for FlexVolume (alpha); FlexVolumes are vendor-supported volumes implemented through FlexVolume plugins.
- Topology Aware Volume Scheduling (beta): This feature enables you to specify topology constraints on PersistentVolumes and have those constraints evaluated by the scheduler. It also delays the initial PersistentVolumeClaim binding until the Pod has been scheduled so that the volume binding decision is smarter and considers all Pod scheduling constraints as well. At the moment, this feature is most useful for local persistent volumes, but support for dynamic provisioning is under development.
Node management (SIG-Node)
- Dynamic Kubelet Configuration (beta): Kubernetes makes it easy to make changes to existing clusters, such as increasing the number of replicas or making a service available over the network. This feature makes it possible to change Kubernetes itself (or rather, the Kubelet that runs Kubernetes behind the scenes) without bringing down the node on which Kubelet is running.
- CRI validation test suite (beta): The Container Runtime Interface (CRI) makes it possible to run containers other than Docker (such as Rkt containers or even virtual machines using Virtlet) on Kubernetes. This features provides a suite of validation tests to make certain that these CRI implementations are compliant, enabling developers to more easily find problems.
- Configurable Pod Process Namespace Sharing (alpha): Although pods can easily share the Kubernetes namespace, the process, or PID namespace has been a more difficult issue due to lack of support in Docker. This feature enables you to set a parameter on the pod to determine whether containers get their own operating system processes or share a single process.
- Add support for Windows Container Configuration in CRI (alpha): The Container Runtime Interface was originally designed with Linux-based containers in mind, and it was impossible to implement support for Windows-based containers using CRI. This feature solves that problem, making it possible to specify a WindowsContainerConfig.
- Debug Containers (alpha): It's easy to debug a container if you have the appropriate utilities. But what if you don't? This feature makes it possible to run debugging tools on a container even if those tools weren't included in the original container image.
Other changes:
- Deployment (SIG-Cluster Lifecycle): Support out-of-process and out-of-tree cloud providers (beta): As Kubernetes gains acceptance, more and more cloud providers will want to make it available. To do that more easily, the community is working on extracting provider-specific binaries so that they can be more easily replaced.
- Kubernetes on Azure (SIG-Azure): Kubernetes has a cluster-autoscaler that automatically adds nodes to your cluster if you're running too many workloads, but until now it wasn't available on Azure. The Add Azure support to cluster-autoscaler (alpha) feature aims to fix that. Closely related, the Add support for Azure Virtual Machine Scale Sets (alpha) feature makes use of Azure's own autoscaling capabilities to make resources available.
You can download the Kubernetes 1.10 beta from . Again, if you've got feedback (and the community hopes you do) please add an issue to the 1.10 milestone and tag the relevant SIG before March 9.
_
(Many thanks to community members Michelle Au, Jan Šafránek, Eric Chiang, Michał Nasiadka, Radosław Pieczonka, Xing Yang, Daniel Smith, sylvain boily, Leo Sunmo, Michal Masłowski, Fernando Ripoll, ayodele abejide, Brett Kochendorfer, Andrew Randall, Casey Davenport, Duffie Cooley, Bryan Venteicher, Mark Ayers, Christopher Luciano, and Sandor Szuecs for their invaluable help in reviewing this article for accuracy.)_
Reporting Errors from Control Plane to Applications Using Kubernetes Events
At Box, we manage several large scale Kubernetes clusters that serve as an internal platform as a service (PaaS) for hundreds of deployed microservices. The majority of those microservices are applications that power box.com for over 80,000 customers. The PaaS team also deploys several services affiliated with the platform infrastructure as the control plane.
One use case of Box’s control plane is public key infrastructure (PKI) processing. In our infrastructure, applications needing a new SSL certificate also need to trigger some processing in the control plane. The majority of our applications are not allowed to generate new SSL certificates due to security reasons. The control plane has a different security boundary and network access, and is therefore allowed to generate certificates.
| |
| Figure1: Block Diagram of the PKI flow |
If an application needs a new certificate, the application owner explicitly adds a Custom Resource Definition (CRD) to the application’s Kubernetes config [1]. This CRD specifies parameters for the SSL certificate: name, common name, and others. A microservice in the control plane watches CRDs and triggers some processing for SSL certificate generation [2]. Once the certificate is ready, the same control plane service sends it to the API server in a Kubernetes Secret [3]. After that, the application containers access their certificates using Kubernetes Secret VolumeMounts [4]. You can see a working demo of this system in our example application on GitHub.
The rest of this post covers the error scenarios in this “triggered” processing in the control plane. In particular, we are especially concerned with user input errors. Because the SSL certificate parameters come from the application’s config file in a CRD format, what should happen if there is an error in that CRD specification? Even a typo results in a failure of the SSL certificate creation. The error information is available in the control plane even though the root cause is most probably inside the application’s config file. The application owner does not have access to the control plane’s state or logs.
Providing the right diagnosis to the application owner so she can fix the mistake becomes a serious productivity problem at scale. Box’s rapid migration to microservices results in several new deployments every week. Numerous first time users, who do not know every detail of the infrastructure, need to succeed in deploying their services and troubleshooting problems easily. As the owners of the infrastructure, we do not want to be the bottleneck while reading the errors from the control plane logs and passing them on to application owners. If something in an owner’s configuration causes an error somewhere else, owners need a fully empowering diagnosis. This error data must flow automatically without any human involvement.
After considerable thought and experimentation, we found that Kubernetes Events work great to automatically communicate these kind of errors. If the error information is placed in a pod’s event stream, it shows up in kubectl describe output. Even beginner users can execute kubectl describe pod and obtain an error diagnosis.
We experimented with a status web page for the control plane service as an alternative to Kubernetes Events. We determined that the status page could update every time after processing an SSL certificate, and that application owners could probe the status page and get the diagnosis from there. After experimenting with a status page initially, we have seen that this does not work as effectively as the Kubernetes Events solution. The status page becomes a new interface to learn for the application owner, a new web address to remember, and one more context switch to a distinct tool during troubleshooting efforts. On the other hand, Kubernetes Events show up cleanly at the kubectl describe output, which is easily recognized by the developers.
Here is a simplified example showing how we used Kubernetes Events for error reporting across distinct services. We have open sourced a sample golang application representative of the previously mentioned control plane service. It watches changes on CRDs and does input parameter checking. If an error is discovered, a Kubernetes Event is generated and the relevant pod’s event stream is updated.
The sample application executes this code to setup the Kubernetes Event generation:
// eventRecorder returns an EventRecorder type that can be
// used to post Events to different object's lifecycles.
func eventRecorder(
kubeClient \*kubernetes.Clientset) (record.EventRecorder, error) {
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(glog.Infof)
eventBroadcaster.StartRecordingToSink(
&typedcorev1.EventSinkImpl{
Interface: kubeClient.CoreV1().Events("")})
recorder := eventBroadcaster.NewRecorder(
scheme.Scheme,
v1.EventSource{Component: "controlplane"})
return recorder, nil
}
After the one-time setup, the following code generates events affiliated with pods:
ref, err := reference.GetReference(scheme.Scheme, &pod)
if err != nil {
glog.Fatalf("Could not get reference for pod %v: %v\n",
pod.Name, err)
}
recorder.Event(ref, v1.EventTypeWarning, "pki ServiceName error",
fmt.Sprintf("ServiceName: %s in pki: %s is not found in"+
" allowedNames: %s", pki.Spec.ServiceName, pki.Name,
allowedNames))
Further implementation details can be understood by running the sample application.
As mentioned previously, here is the relevant kubectl describe output for the application owner.
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------
....
1d 1m 24 controlplane Warning pki ServiceName error ServiceName: appp1 in pki: app1-pki is not found in allowedNames: [app1 app2]
....
We have demonstrated a practical use case with Kubernetes Events. The automated feedback to programmers in the case of configuration errors has significantly improved our troubleshooting efforts. In the future, we plan to use Kubernetes Events in various other applications under similar use cases. The recently created sample-controller example also utilizes Kubernetes Events in a similar scenario. It is great to see there are more sample applications to guide the community. We are excited to continue exploring other use cases for Events and the rest of the Kubernetes API to make development easier for our engineers.
If you have a Kubernetes experience you’d like to share, submit your story. If you use Kubernetes in your organization and want to voice your experience more directly, consider joining the CNCF End User Community that Box and dozens of like-minded companies are part of.
Special thanks for Greg Lyons and Mohit Soni for their contributions.
Hakan Baba, Sr. Software Engineer, Box
Core Workloads API GA
DaemonSet, Deployment, ReplicaSet, and StatefulSet are GA
Editor’s Note: We’re happy to announce that the Core Workloads API is GA in Kubernetes 1.9! This blog post from Kenneth Owens reviews how Core Workloads got to GA from its origins, reveals changes in 1.9, and talks about what you can expect going forward.
In the Beginning …
There were Pods, tightly coupled containers that share resource requirements, networking, storage, and a lifecycle. Pods were useful, but, as it turns out, users wanted to seamlessly, reproducibly, and automatically create many identical replicas of the same Pod, so we created ReplicationController.
Replication was a step forward, but what users really needed was higher level orchestration of their replicated Pods. They wanted rolling updates, roll backs, and roll overs. So the OpenShift team created DeploymentConfig. DeploymentConfigs were also useful, and OpenShift users were happy. In order to allow all OSS Kubernetes uses to share in the elation, and to take advantage of set-based label selectors, ReplicaSet and Deployment were added to the extensions/v1beta1 group version providing rolling updates, roll backs, and roll overs for all Kubernetes users.
That mostly solved the problem of orchestrating containerized 12 factor apps on Kubernetes, so the community turned its attention to a different problem. Replicating a Pod <n> times isn’t the right hammer for every nail in your cluster. Sometimes, you need to run a Pod on every Node, or on a subset of Nodes (for example, shared side cars like log shippers and metrics collectors, Kubernetes add-ons, and Distributed File Systems). The state of the art was Pods combined with NodeSelectors, or static Pods, but this is unwieldy. After having grown used to the ease of automation provided by Deployments, users demanded the same features for this category of application, so DaemonSet was added to extension/v1beta1 as well.
For a time, users were content, until they decided that Kubernetes needed to be able to orchestrate more than just 12 factor apps and cluster infrastructure. Whether your architecture is N-tier, service oriented, or micro-service oriented, your 12 factor apps depend on stateful workloads (for example, RDBMSs, distributed key value stores, and messaging queues) to provide services to end users and other applications. These stateful workloads can have availability and durability requirements that can only be achieved by distributed systems, and users were ready to use Kubernetes to orchestrate the entire stack.
While Deployments are great for stateless workloads, they don’t provide the right guarantees for the orchestration of distributed systems. These applications can require stable network identities, ordered, sequential deployment, updates, and deletion, and stable, durable storage. PetSet was added to the apps/v1beta1 group version to address this category of application. Unfortunately, we were less than thoughtful with its naming, and, as we always strive to be an inclusive community, we renamed the kind to StatefulSet.
Finally, we were done.

...Or were we?
Kubernetes 1.8 and apps/v1beta2
Pod, ReplicationController, ReplicaSet, Deployment, DaemonSet, and StatefulSet came to collectively be known as the core workloads API. We could finally orchestrate all of the things, but the API surface was spread across three groups, had many inconsistencies, and left users wondering about the stability of each of the core workloads kinds. It was time to stop adding new features and focus on consistency and stability.
Pod and ReplicationController were at GA stability, and even though you can run a workload in a Pod, it’s a nucleus primitive that belongs in core. As Deployments are the recommended way to manage your stateless apps, moving ReplicationController would serve no purpose. In Kubernetes 1.8, we moved all the other core workloads API kinds (Deployment, DaemonSet, ReplicaSet, and StatefulSet) to the apps/v1beta2 group version. This had the benefit of providing a better aggregation across the API surface, and allowing us to break backward compatibility to fix inconsistencies. Our plan was to promote this new surface to GA, wholesale and as is, when we were satisfied with its completeness. The modifications in this release, which are also implemented in apps/v1, are described below.
Selector Defaulting Deprecated
In prior versions of the apps and extensions groups, label selectors of the core workloads API kinds were, when left unspecified, defaulted to a label selector generated from the kind’s template’s labels.
This was completely incompatible with strategic merge patch and kubectl apply. Moreover, we’ve found that defaulting the value of a field from the value of another field of the same object is an anti-pattern, in general, and particularly dangerous for the API objects used to orchestrate workloads.
Immutable Selectors
Selector mutation, while allowing for some use cases like promotable Deployment canaries, is not handled gracefully by our workload controllers, and we have always strongly cautioned users against it. To provide a consistent, usable, and stable API, selectors were made immutable for all kinds in the workloads API.
We believe that there are better ways to support features like promotable canaries and orchestrated Pod relabeling, but, if restricted selector mutation is a necessary feature for our users, we can relax immutability in the future without breaking backward compatibility.
The development of features like promotable canaries, orchestrated Pod relabeling, and restricted selector mutability is driven by demand signals from our users. If you are currently modifying the selectors of your core workload API objects, please tell us about your use case via a GitHub issue, or by participating in SIG apps.
Default Rolling Updates
Prior to apps/v1beta2, some kinds defaulted their update strategy to something other than RollingUpdate (e.g. app/v1beta1/StatefulSet uses OnDelete by default). We wanted to be confident that RollingUpdate worked well prior to making it the default update strategy, and we couldn’t change the default behavior in released versions without breaking our promise with respect to backward compatibility. In apps/v1beta2 we enabled RollingUpdate for all core workloads kinds by default.
CreatedBy Annotation Deprecated
The "kubernetes.io/created-by" was a legacy hold over from the days before garbage collection. Users should use an object’s ControllerRef from its ownerReferences to determine object ownership. We deprecated this feature in 1.8 and removed it in 1.9.
Scale Subresources
A scale subresource was added to all of the applicable kinds in apps/v1beta2 (DaemonSet scales based on its node selector).
Kubernetes 1.9 and apps/v1
In Kubernetes 1.9, as planned, we promoted the entire core workloads API surface to GA in the apps/v1 group version. We made a few more changes to make the API consistent, but apps/v1 is mostly identical to apps/v1beta2. The reality is that most users have been treating the beta versions of the core workloads API as GA for some time now. Anyone who is still using ReplicationControllers and shying away from DaemonSets, Deployments, and StatefulSets, due to a perceived lack of stability, should plan migrate their workloads (where applicable) to apps/v1. The minor changes that were made during promotion are described below.
Garbage Collection Defaults to Delete
Prior to apps/v1 the default garbage collection policy for Pods in a DaemonSet, Deployment, ReplicaSet, or StatefulSet, was to orphan the Pods. That is, if you deleted one of these kinds, the Pods that they owned would not be deleted automatically unless cascading deletion was explicitly specified. If you use kubectl, you probably didn’t notice this, as these kinds are scaled to zero prior to deletion. In apps/v1 all core worloads API objects will now, by default, be deleted when their owner is deleted. For most users, this change is transparent.
Status Conditions
Prior to apps/v1 only Deployment and ReplicaSet had Conditions in their Status objects. For consistency's sake, either all of the objects or none of them should have conditions. After some debate, we decided that Conditions are useful, and we added Conditions to StatefulSetStatus and DaemonSetStatus. The StatefulSet and DaemonSet controllers currently don’t populate them, but we may choose communicate conditions to clients, via this mechanism, in the future.
Scale Subresource Migrated to autoscale/v1
We originally added a scale subresource to the apps group. This was the wrong direction for integration with the autoscaling, and, at some point, we would like to use custom metrics to autoscale StatefulSets. So the apps/v1 group version uses the autoscaling/v1 scale subresource.
Migration and Deprecation
The question most you’re probably asking now is, “What’s my migration path onto apps/v1 and how soon should I plan on migrating?” All of the group versions prior to apps/v1 are deprecated as of Kubernetes 1.9, and all new code should be developed against apps/v1, but, as discussed above, many of our users treat extensions/v1beta1 as if it were GA. We realize this, and the minimum support timelines in our deprecation policy are just that, minimums.
In future releases, before completely removing any of the group versions, we will disable them by default in the API Server. At this point, you will still be able to use the group version, but you will have to explicitly enable it. We will also provide utilities to upgrade the storage version of the API objects to apps/v1. Remember, all of the versions of the core workloads kinds are bidirectionally convertible. If you want to manually update your core workloads API objects now, you can use kubectl convert to convert manifests between group versions.
What’s Next?
The core workloads API surface is stable, but it’s still software, and software is never complete. We often add features to stable APIs to support new use cases, and we will likely do so for the core workloads API as well. GA stability means that any new features that we do add will be strictly backward compatible with the existing API surface. From this point forward, nothing we do will break our backwards compatibility guarantees. If you’re looking to participate in the evolution of this portion of the API, please feel free to get involved in GitHub or to participate in SIG Apps.
--Kenneth Owens, Software Engineer, Google
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Introducing client-go version 6
The Kubernetes API server exposes a REST interface consumable by any client. client-go is the official client library for the Go programming language. It is used both internally by Kubernetes itself (for example, inside kubectl) as well as by numerous external consumers:operators like the etcd-operator or prometheus-operator;higher level frameworks like KubeLess and OpenShift; and many more.
The version 6 update to client-go adds support for Kubernetes 1.9, allowing access to the latest Kubernetes features. While the changelog contains all the gory details, this blog post highlights the most prominent changes and intends to guide on how to upgrade from version 5.
This blog post is one of a number of efforts to make client-go more accessible to third party consumers. Easier access is a joint effort by a number of people from numerous companies, all meeting in the #client-go-docs channel of the Kubernetes Slack. We are happy to hear feedback and ideas for further improvement, and of course appreciate anybody who wants to contribute.
API group changes
The following API group promotions are part of Kubernetes 1.9:
- Workload objects (Deployments, DaemonSets, ReplicaSets, and StatefulSets) have been promoted to the apps/v1 API group in Kubernetes 1.9. client-go follows this transition and allows developers to use the latest version by importing the k8s.io/api/apps/v1 package instead of k8s.io/api/apps/v1beta1 and by using Clientset.AppsV1().
- Admission Webhook Registration has been promoted to the admissionregistration.k8s.io/v1beta1 API group in Kubernetes 1.9. The former ExternalAdmissionHookConfiguration type has been replaced by the incompatible ValidatingWebhookConfiguration and MutatingWebhookConfiguration types. Moreover, the webhook admission payload type AdmissionReview in admission.k8s.io has been promoted to v1beta1. Note that versioned objects are now passed to webhooks. Refer to the admission webhook documentation for details.
Validation for CustomResources
In Kubernetes 1.8 we introduced CustomResourceDefinitions (CRD) pre-persistence schema validation as an alpha feature. With 1.9, the feature got promoted to beta and will be enabled by default. As a client-go user, you will find the API types at k8s.io/apiextensions-apiserver/pkg/apis/apiextensions/v1beta1.
The OpenAPI v3 schema can be defined in the CRD spec as:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata: ...
spec:
...
validation:
openAPIV3Schema:
properties:
spec:
properties:
version:
type: string
enum:
- "v1.0.0"
- "v1.0.1"
replicas:
type: integer
minimum: 1
maximum: 10
The schema in the above CRD applies following validations for the instance:
- spec.version must be a string and must be either “v1.0.0” or “v1.0.1”.
- spec.replicas must be an integer and must have a minimum value of 1 and a maximum value of 10. A CustomResource with invalid values for spec.version (v1.0.2) and spec.replicas (15) will be rejected:
apiVersion: mygroup.example.com/v1
kind: App
metadata:
name: example-app
spec:
version: "v1.0.2"
replicas: 15
$ kubectl create -f app.yaml
The App "example-app" is invalid: []: Invalid value: map[string]interface {}{"apiVersion":"mygroup.example.com/v1", "kind":"App", "metadata":map[string]interface {}{"creationTimestamp":"2017-08-31T20:52:54Z", "uid":"5c674651-8e8e-11e7-86ad-f0761cb232d1", "clusterName":"", "name":"example-app", "namespace":"default", "deletionTimestamp":interface {}(nil), "deletionGracePeriodSeconds":(\*int64)(nil)}, "spec":map[string]interface {}{"replicas":15, "version":"v1.0.2"}}:
validation failure list:
spec.replicas in body should be less than or equal to 10
spec.version in body should be one of [v1.0.0 v1.0.1]
Note that with Admission Webhooks, Kubernetes 1.9 provides another beta feature to validate objects before they are created or updated. Starting with 1.9, these webhooks also allow mutation of objects (for example, to set defaults or to inject values). Of course, webhooks work with CRDs as well. Moreover, webhooks can be used to implement validations that are not easily expressible with CRD validation. Note that webhooks are harder to implement than CRD validation, so for many purposes, CRD validation is the right tool.
Creating namespaced informers
Often objects in one namespace or only with certain labels are to be processed in a controller. Informers now allow you to tweak the ListOptions used to query the API server to list and watch objects. Uninitialized objects (for consumption by initializers) can be made visible by setting IncludeUnitialized to true. All this can be done using the new NewFilteredSharedInformerFactory constructor for shared informers:
import “k8s.io/client-go/informers”
...
sharedInformers := informers.NewFilteredSharedInformerFactory(
client,
30\*time.Minute,
“some-namespace”,
func(opt \*metav1.ListOptions) {
opt.LabelSelector = “foo=bar”
},
)
Note that the corresponding lister will only know about the objects matching the namespace and the given ListOptions. Note that the same restrictions apply for a List or Watch call on a client.
This production code example of a cert-manager demonstrates how namespace informers can be used in real code.
Polymorphic scale client
Historically, only types in the extensions API group would work with autogenerated Scale clients. Furthermore, different API groups use different Scale types for their /scale subresources. To remedy these issues, k8s.io/client-go/scale provides a polymorphic scale client to scale different resources in different API groups in a coherent way:
import (
apimeta "k8s.io/apimachinery/pkg/api/meta"
discocache "k8s.io/client-go/discovery/cached"
"k8s.io/client-go/discovery"
"k8s.io/client-go/dynamic"
“k8s.io/client-go/scale”
)
...
cachedDiscovery := discocache.NewMemCacheClient(client.Discovery())
restMapper := discovery.NewDeferredDiscoveryRESTMapper(
cachedDiscovery,
apimeta.InterfacesForUnstructured,
)
scaleKindResolver := scale.NewDiscoveryScaleKindResolver(
client.Discovery(),
)
scaleClient, err := scale.NewForConfig(
client, restMapper,
dynamic.LegacyAPIPathResolverFunc,
scaleKindResolver,
)
scale, err := scaleClient.Scales("default").Get(groupResource, "foo")
The returned scale object is generic and is exposed as the autoscaling/v1.Scale object. It is backed by an internal Scale type, with conversions defined to and from all the special Scale types in the API groups supporting scaling. We planto extend this to CustomResources in 1.10.
If you’re implementing support for the scale subresource, we recommend that you expose the autoscaling/v1.Scale object.
Type-safe DeepCopy
Deeply copying an object formerly required a call to Scheme.Copy(Object) with the notable disadvantage of losing type safety. A typical piece of code from client-go version 5 required type casting:
newObj, err := runtime.NewScheme().Copy(node)
if err != nil {
return fmt.Errorf("failed to copy node %v: %s”, node, err)
}
newNode, ok := newObj.(\*v1.Node)
if !ok {
return fmt.Errorf("failed to type-assert node %v", newObj)
}
Thanks to k8s.io/code-generator, Copy has now been replaced by a type-safe DeepCopy method living on each object, allowing you to simplify code significantly both in terms of volume and API error surface:
newNode := node.DeepCopy()
No error handling is necessary: this call never fails. If and only if the node is nil does DeepCopy() return nil.
To copy runtime.Objects there is an additional DeepCopyObject() method in the runtime.Object interface.
With the old method gone for good, clients need to update their copy invocations accordingly.
Code generation and CustomResources
Using client-go’s dynamic client to access CustomResources is discouraged and superseded by type-safe code using the generators in k8s.io/code-generator. Check out the Deep Dive on the Open Shift blog to learn about using code generation with client-go.
Comment Blocks
You can now place tags in the comment block just above a type or function, or in the second block above. There is no distinction anymore between these two comment blocks. This used to a be a source of subtle errors when using the generators:
// second block above
// +k8s:some-tag
// first block above
// +k8s:another-tag
type Foo struct {}
Custom Client Methods
You can now use extended tag definitions to create custom verbs . This lets you expand beyond the verbs defined by HTTP. This opens the door to higher levels of customization.
For example, this block leads to the generation of the method UpdateScale(s *autoscaling.Scale) (*autoscaling.Scale, error):
// genclient:method=UpdateScale,verb=update,subresource=scale,input=k8s.io/kubernetes/pkg/apis/autoscaling.Scale,result=k8s.io/kubernetes/pkg/apis/autoscaling.Scale
Resolving Golang Naming Conflicts
In more complex API groups it’s possible for Kinds, the group name, the Go package name, and the Go group alias name to conflict. This was not handled correctly prior to 1.9. The following tags resolve naming conflicts and make the generated code prettier:
// +groupName=example2.example.com
// +groupGoName=SecondExample
These are usually in the doc.go file of an API package. The first is used as the CustomResource group name when RESTfully speaking to the API server using HTTP. The second is used in the generated Golang code (for example, in the clientset) to access the group version:
clientset.SecondExampleV1()
It’s finally possible to have dots in Go package names. In this section’s example, you would put the groupName snippet into the pkg/apis/example2.example.com directory of your project.
Example projects
Kubernetes 1.9 includes a number of example projects which can serve as a blueprint for your own projects:
- k8s.io/sample-apiserver is a simple user-provided API server that is integrated into a cluster via API aggregation.
- k8s.io/sample-controller is a full-featured controller (also called an operator) with shared informers and a workqueue to process created, changed or deleted objects. It is based on CustomResourceDefinitions and uses k8s.io/code-generator to generate deepcopy functions, typed clientsets, informers, and listers.
Vendoring
In order to update from the previous version 5 to version 6 of client-go, the library itself as well as certain third-party dependencies must be updated. Previously, this process had been tedious due to the fact that a lot of code got refactored or relocated within the existing package layout across releases. Fortunately, far less code had to move in the latest version, which should ease the upgrade procedure for most users.
State of the published repositories
In the past k8s.io/client-go, k8s.io/api, and k8s.io/apimachinery were updated infrequently. Tags (for example, v4.0.0) were created quite some time after the Kubernetes releases. With the 1.9 release we resumed running a nightly bot that updates all the repositories for public consumption, even before manual tagging. This includes the branches:
- master
- release-1.8 / release-5.0
- release-1.9 / release-6.0 Kubernetes tags (for example, v1.9.1-beta1) are also applied automatically to the published repositories, prefixed with kubernetes- (for example, kubernetes-1.9.1-beta1).
These tags have limited test coverage, but can be used by early adopters of client-go and the other libraries. Moreover, they help to vendor the correct version of k8s.io/api and k8s.io/apimachinery. Note that we only create a v6.0.3-like semantic versioning tag on k8s.io/client-go. The corresponding tag for k8s.io/api and k8s.io/apimachinery is kubernetes-1.9.3.
Also note that only these tags correspond to tested releases of Kubernetes. If you depend on the release branch, e.g., release-1.9, your client is running on unreleased Kubernetes code.
State of vendoring of client-go
In general, the list of which dependencies to vendor is automatically generated and written to the file Godeps/Godeps.json. Only the revisions listed there are tested. This means especially that we do not and cannot test the code-base against master branches of our dependencies. This puts us in the following situation depending on the used vendoring tool:
- godep reads Godeps/Godeps.json by running godep restore from k8s.io/client-go in your GOPATH. Then use godep save to vendor in your project. godep will choose the correct versions from your GOPATH.
- glide reads Godeps/Godeps.json automatically from its dependencies including from k8s.io/client-go, both on init and on update. Hence, glide should be mostly automatic as long as there are no conflicts.
- dep does not currently respect Godeps/Godeps.json in a consistent way, especially not on updates. It is crucial to specify client-go dependencies manually as constraints or overrides, also for non k8s.io/* dependencies. Without those, dep simply chooses the dependency master branches, which can cause problems as they are updated frequently.
- The Kubernetes and golang/dep community are aware of the problems [issue #1124, issue #1236] and are working together on solutions. Until then special care must be taken. Please see client-go’s INSTALL.md for more details.
Updating dependencies – golang/dep
Even with the deficiencies of golang/dep today, dep is slowly becoming the de-facto standard in the Go ecosystem. With the necessary care and the awareness of the missing features, dep can be (and is!) used successfully. Here’s a demonstration of how to update a project with client-go 5 to the latest version 6 using dep:
(If you are still running client-go version 4 and want to play it safe by not skipping a release, now is a good time to check out this excellent blog post describing how to upgrade to version 5, put together by our friends at Heptio.)
Before starting, it is important to understand that client-go depends on two other Kubernetes projects: k8s.io/apimachinery and k8s.io/api. In addition, if you are using CRDs, you probably also depend on k8s.io/apiextensions-apiserver for the CRD client. The first exposes lower-level API mechanics (such as schemes, serialization, and type conversion), the second holds API definitions, and the third provides APIs related to CustomResourceDefinitions. In order for client-go to operate correctly, it needs to have its companion libraries vendored in correspondingly matching versions. Each library repository provides a branch named release-<version> where <version> refers to a particular Kubernetes version; for client-go version 6, it is imperative to refer to the release-1.9 branch on each repository.
Assuming the latest version 5 patch release of client-go being vendored through dep, the Gopkg.toml manifest file should look something like this (possibly using branches instead of versions):
[[constraint]]
name = "k8s.io/api"
version = "kubernetes-1.8.1"
[[constraint]]
name = "k8s.io/apimachinery"
version = "kubernetes-1.8.1"
[[constraint]]
name = "k8s.io/apiextensions-apiserver"
version = "kubernetes-1.8.1"
[[constraint]]
name = "k8s.io/client-go"
version = "5.0.1"
Note that some of the libraries could be missing if they are not actually needed by the client.
Upgrading to client-go version 6 means bumping the version and tag identifiers as following ( emphasis given):
[constraint]]
name = "k8s.io/api"
version = "kubernetes-1.9.0"
[[constraint]]
name = "k8s.io/apimachinery"
version = "kubernetes-1.9.0"
[[constraint]]
name = "k8s.io/apiextensions-apiserver"
version = "kubernetes-1.9.0"
[[constraint]]
name = "k8s.io/client-go"
version = "6.0.0"
The result of the upgrade can be found here.
A note of caution: dep cannot capture the complete set of dependencies in a reliable and reproducible fashion as described above. This means that for a 100% future-proof project you have to add constraints (or even overrides) to many other packages listed in client-go’s Godeps/Godeps.json. Be prepared to add them if something breaks. We are working with the golang/dep community to make this an easier and more smooth experience.
Finally, we need to tell dep to upgrade to the specified versions by executing dep ensure. If everything goes well, the output of the command invocation should be empty, with the only indication that it was successful being a number of updated files inside the vendor folder.
If you are using CRDs, you probably also use code-generation. The following block for Gopkg.toml will add the required code-generation packages to your project:
required = [
"k8s.io/code-generator/cmd/client-gen",
"k8s.io/code-generator/cmd/conversion-gen",
"k8s.io/code-generator/cmd/deepcopy-gen",
"k8s.io/code-generator/cmd/defaulter-gen",
"k8s.io/code-generator/cmd/informer-gen",
"k8s.io/code-generator/cmd/lister-gen",
]
[[constraint]]
branch = "kubernetes-1.9.0"
name = "k8s.io/code-generator"
Whether you would also like to prune unneeded packages (such as test files) through dep or commit the changes into the VCS at this point is up to you -- but from an upgrade perspective, you should now be ready to harness all the fancy new features that Kubernetes 1.9 brings through client-go.
Extensible Admission is Beta
In this post we review a feature, available in the Kubernetes API server, that allows you to implement arbitrary control decisions and which has matured considerably in Kubernetes 1.9.
The admission stage of API server processing is one of the most powerful tools for securing a Kubernetes cluster by restricting the objects that can be created, but it has always been limited to compiled code. In 1.9, we promoted webhooks for admission to beta, allowing you to leverage admission from outside the API server process.
What is Admission?
Admission is the phase of handling an API server request that happens before a resource is persisted, but after authorization. Admission gets access to the same information as authorization (user, URL, etc) and the complete body of an API request (for most requests).

The admission phase is composed of individual plugins, each of which are narrowly focused and have semantic knowledge of what they are inspecting. Examples include: PodNodeSelector (influences scheduling decisions), PodSecurityPolicy (prevents escalating containers), and ResourceQuota (enforces resource allocation per namespace).
Admission is split into two phases:
- Mutation, which allows modification of the body content itself as well as rejection of an API request.
- Validation, which allows introspection queries and rejection of an API request. An admission plugin can be in both phases, but all mutation happens before validation.
Mutation
The mutation phase of admission allows modification of the resource content before it is persisted. Because the same field can be mutated multiple times while in the admission chain, the order of the admission plugins in the mutation matters.
One example of a mutating admission plugin is the PodNodeSelector plugin, which uses an annotation on a namespace namespace.annotations[“scheduler.alpha.kubernetes.io/node-selector”] to find a label selector and add it to the pod.spec.nodeselector field. This positively restricts which nodes the pods in a particular namespace can land on, as opposed to taints, which provide negative restriction (also with an admission plugin).
Validation
The validation phase of admission allows the enforcement of invariants on particular API resources. The validation phase runs after all mutators finish to ensure that the resource isn’t going to change again.
One example of a validation admission plugin is also the PodNodeSelector plugin, which ensures that all pods’ spec.nodeSelector fields are constrained by the node selector restrictions on the namespace. Even if a mutating admission plugin tries to change the spec.nodeSelector field after the PodNodeSelector runs in the mutating chain, the PodNodeSelector in the validating chain prevents the API resource from being created because it fails validation.
What are admission webhooks?
Admission webhooks allow a Kubernetes installer or a cluster-admin to add mutating and validating admission plugins to the admission chain of kube-apiserver as well as any extensions apiserver based on k8s.io/apiserver 1.9, like metrics, service-catalog, or kube-projects, without recompiling them. Both kinds of admission webhooks run at the end of their respective chains and have the same powers and limitations as compiled admission plugins.
What are they good for?
Webhook admission plugins allow for mutation and validation of any resource on any API server, so the possible applications are vast. Some common use-cases include:
- Mutation of resources like pods. Istio has talked about doing this to inject side-car containers into pods. You could also write a plugin which forcefully resolves image tags into image SHAs.
- Name restrictions. On multi-tenant systems, reserving namespaces has emerged as a use-case.
- Complex CustomResource validation. Because the entire object is visible, a clever admission plugin can perform complex validation on dependent fields (A requires B) and even external resources (compare to LimitRanges).
- Security response. If you forced image tags into image SHAs, you could write an admission plugin that prevents certain SHAs from running.
Registration
Webhook admission plugins of both types are registered in the API, and all API servers (kube-apiserver and all extension API servers) share a common config for them. During the registration process, a webhook admission plugin describes:
- How to connect to the webhook admission server
- How to verify the webhook admission server (Is it really the server I expect?)
- Where to send the data at that server (which URL path)
- Which resources and which HTTP verbs it will handle
- What an API server should do on connection failures (for example, if the admission webhook server goes down)
1 apiVersion: admissionregistration.k8s.io/v1beta1
2 kind: ValidatingWebhookConfiguration
3 metadata:
4 name: namespacereservations.admission.online.openshift.io
5 webhooks:
6 - name: namespacereservations.admission.online.openshift.io
7 clientConfig:
8 service:
9 namespace: default
10 name: kubernetes
11 path: /apis/admission.online.openshift.io/v1alpha1/namespacereservations
12 caBundle: KUBE\_CA\_HERE
13 rules:
14 - operations:
15 - CREATE
16 apiGroups:
17 - ""
18 apiVersions:
19 - "\*"
20 resources:
21 - namespaces
22 failurePolicy: Fail
Line 6: name - the name for the webhook itself. For mutating webhooks, these are sorted to provide ordering.
Line 7: clientConfig - provides information about how to connect to, trust, and send data to the webhook admission server.
Line 13: rules - describe when an API server should call this admission plugin. In this case, only for creates of namespaces. You can specify any resource here so specifying creates of serviceinstances.servicecatalog.k8s.io is also legal.
Line 22: failurePolicy - says what to do if the webhook admission server is unavailable. Choices are “Ignore” (fail open) or “Fail” (fail closed). Failing open makes for unpredictable behavior for all clients.
Authentication and trust
Because webhook admission plugins have a lot of power (remember, they get to see the API resource content of any request sent to them and might modify them for mutating plugins), it is important to consider:
- How individual API servers verify their connection to the webhook admission server
- How the webhook admission server authenticates precisely which API server is contacting it
- Whether that particular API server has authorization to make the request There are three major categories of connection:
- From kube-apiserver or extension-apiservers to externally hosted admission webhooks (webhooks not hosted in the cluster)
- From kube-apiserver to self-hosted admission webhooks
- From extension-apiservers to self-hosted admission webhooks To support these categories, the webhook admission plugins accept a kubeconfig file which describes how to connect to individual servers. For interacting with externally hosted admission webhooks, there is really no alternative to configuring that file manually since the authentication/authorization and access paths are owned by the server you’re hooking to.
For the self-hosted category, a cleverly built webhook admission server and topology can take advantage of the safe defaulting built into the admission plugin and have a secure, portable, zero-config topology that works from any API server.
Simple, secure, portable, zero-config topology
If you build your webhook admission server to also be an extension API server, it becomes possible to aggregate it as a normal API server. This has a number of advantages:
- Your webhook becomes available like any other API under default kube-apiserver service
kubernetes.default.svc(e.g. https://kubernetes.default.svc/apis/admission.example.com/v1/mymutatingadmissionreviews). Among other benefits, you can test usingkubectl. - Your webhook automatically (without any config) makes use of the in-cluster authentication and authorization provided by kube-apiserver. You can restrict access to your webhook with normal RBAC rules.
- Your extension API servers and kube-apiserver automatically (without any config) make use of their in-cluster credentials to communicate with the webhook.
- Extension API servers do not leak their service account token to your webhook because they go through kube-apiserver, which is a secure front proxy.
Source: https://drive.google.com/a/redhat.com/file/d/12nC9S2fWCbeX_P8nrmL6NgOSIha4HDNp

In short: a secure topology makes use of all security mechanisms of API server aggregation and additionally requires no additional configuration.
Other topologies are possible but require additional manual configuration as well as a lot of effort to create a secure setup, especially when extension API servers like service catalog come into play. The topology above is zero-config and portable to every Kubernetes cluster.
How do I write a webhook admission server?
Writing a full server complete with authentication and authorization can be intimidating. To make it easier, there are projects based on Kubernetes 1.9 that provide a library for building your webhook admission server in 200 lines or less. Take a look at the generic-admission-apiserver and the kubernetes-namespace-reservation projects for the library and an example of how to build your own secure and portable webhook admission server.
With the admission webhooks introduced in 1.9 we’ve made Kubernetes even more adaptable to your needs. We hope this work, driven by both Red Hat and Google, will enable many more workloads and support ecosystem components. (Istio is one example.) Now is a good time to give it a try!
If you’re interested in giving feedback or contributing to this area, join us in the SIG API machinery.
Introducing Container Storage Interface (CSI) Alpha for Kubernetes
One of the key differentiators for Kubernetes has been a powerful volume plugin system that enables many different types of storage systems to:
- Automatically create storage when required.
- Make storage available to containers wherever they’re scheduled.
- Automatically delete the storage when no longer needed. Adding support for new storage systems to Kubernetes, however, has been challenging.
Kubernetes 1.9 introduces an alpha implementation of the Container Storage Interface (CSI) which makes installing new volume plugins as easy as deploying a pod. It also enables third-party storage providers to develop solutions without the need to add to the core Kubernetes codebase.
Because the feature is alpha in 1.9, it must be explicitly enabled. Alpha features are not recommended for production usage, but are a good indication of the direction the project is headed (in this case, towards a more extensible and standards based Kubernetes storage ecosystem).
Why Kubernetes CSI?
Kubernetes volume plugins are currently “in-tree”, meaning they’re linked, compiled, built, and shipped with the core kubernetes binaries. Adding support for a new storage system to Kubernetes (a volume plugin) requires checking code into the core Kubernetes repository. But aligning with the Kubernetes release process is painful for many plugin developers.
The existing Flex Volume plugin attempted to address this pain by exposing an exec based API for external volume plugins. Although it enables third party storage vendors to write drivers out-of-tree, in order to deploy the third party driver files it requires access to the root filesystem of node and master machines.
In addition to being difficult to deploy, Flex did not address the pain of plugin dependencies: Volume plugins tend to have many external requirements (on mount and filesystem tools, for example). These dependencies are assumed to be available on the underlying host OS which is often not the case (and installing them requires access to the root filesystem of node machine).
CSI addresses all of these issues by enabling storage plugins to be developed out-of-tree, containerized, deployed via standard Kubernetes primitives, and consumed through the Kubernetes storage primitives users know and love (PersistentVolumeClaims, PersistentVolumes, StorageClasses).
What is CSI?
The goal of CSI is to establish a standardized mechanism for Container Orchestration Systems (COs) to expose arbitrary storage systems to their containerized workloads. The CSI specification emerged from cooperation between community members from various Container Orchestration Systems (COs)--including Kubernetes, Mesos, Docker, and Cloud Foundry. The specification is developed, independent of Kubernetes, and maintained at https://github.com/container-storage-interface/spec/blob/master/spec.md.
Kubernetes v1.9 exposes an alpha implementation of the CSI specification enabling CSI compatible volume drivers to be deployed on Kubernetes and consumed by Kubernetes workloads.
How do I deploy a CSI driver on a Kubernetes Cluster?
CSI plugin authors will provide their own instructions for deploying their plugin on Kubernetes.
How do I use a CSI Volume?
Assuming a CSI storage plugin is already deployed on your cluster, you can use it through the familiar Kubernetes storage primitives: PersistentVolumeClaims, PersistentVolumes, and StorageClasses.
CSI is an alpha feature in Kubernetes v1.9. To enable it, set the following flags:
CSI is an alpha feature in Kubernetes v1.9. To enable it, set the following flags:
API server binary:
--feature-gates=CSIPersistentVolume=true
--runtime-config=storage.k8s.io/v1alpha1=true
API server binary and kubelet binaries:
--feature-gates=MountPropagation=true
--allow-privileged=true
Dynamic Provisioning
You can enable automatic creation/deletion of volumes for CSI Storage plugins that support dynamic provisioning by creating a StorageClass pointing to the CSI plugin.
The following StorageClass, for example, enables dynamic creation of “fast-storage” volumes by a CSI volume plugin called “com.example.team/csi-driver”.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast-storage
provisioner: com.example.team/csi-driver
parameters:
type: pd-ssd
To trigger dynamic provisioning, create a PersistentVolumeClaim object. The following PersistentVolumeClaim, for example, triggers dynamic provisioning using the StorageClass above.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-request-for-storage
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: fast-storage
When volume provisioning is invoked, the parameter “type: pd-ssd” is passed to the CSI plugin “com.example.team/csi-driver” via a “CreateVolume” call. In response, the external volume plugin provisions a new volume and then automatically create a PersistentVolume object to represent the new volume. Kubernetes then binds the new PersistentVolume object to the PersistentVolumeClaim, making it ready to use.
If the “fast-storage” StorageClass is marked default, there is no need to include the storageClassName in the PersistentVolumeClaim, it will be used by default.
Pre-Provisioned Volumes
You can always expose a pre-existing volume in Kubernetes by manually creating a PersistentVolume object to represent the existing volume. The following PersistentVolume, for example, exposes a volume with the name “existingVolumeName” belonging to a CSI storage plugin called “com.example.team/csi-driver”.
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-manually-created-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
csi:
driver: com.example.team/csi-driver
volumeHandle: existingVolumeName
readOnly: false
Attaching and Mounting
You can reference a PersistentVolumeClaim that is bound to a CSI volume in any pod or pod template.
kind: Pod
apiVersion: v1
metadata:
name: my-pod
spec:
containers:
- name: my-frontend
image: dockerfile/nginx
volumeMounts:
- mountPath: "/var/www/html"
name: my-csi-volume
volumes:
- name: my-csi-volume
persistentVolumeClaim:
claimName: my-request-for-storage
When the pod referencing a CSI volume is scheduled, Kubernetes will trigger the appropriate operations against the external CSI plugin (ControllerPublishVolume, NodePublishVolume, etc.) to ensure the specified volume is attached, mounted, and ready to use by the containers in the pod.
For more details please see the CSI implementation design doc and documentation.
How do I create a CSI driver?
Kubernetes is as minimally prescriptive on the packaging and deployment of a CSI Volume Driver as possible. The minimum requirements for deploying a CSI Volume Driver on Kubernetes are documented here.
The minimum requirements document also contains a section outlining the suggested mechanism for deploying an arbitrary containerized CSI driver on Kubernetes. This mechanism can be used by a Storage Provider to simplify deployment of containerized CSI compatible volume drivers on Kubernetes.
As part of this recommended deployment process, the Kubernetes team provides the following sidecar (helper) containers:
-
- Sidecar container that watches Kubernetes VolumeAttachment objects and triggers ControllerPublish and ControllerUnpublish operations against a CSI endpoint.
-
- Sidecar container that watches Kubernetes PersistentVolumeClaim objects and triggers CreateVolume and DeleteVolume operations against a CSI endpoint.
-
- Sidecar container that registers the CSI driver with kubelet (in the future), and adds the drivers custom NodeId (retrieved via GetNodeID call against the CSI endpoint) to an annotation on the Kubernetes Node API Object
Storage vendors can build Kubernetes deployments for their plugins using these components, while leaving their CSI driver completely unaware of Kubernetes.
Where can I find CSI drivers?
CSI drivers are developed and maintained by third-parties. You can find example CSI drivers here, but these are provided purely for illustrative purposes, and are not intended to be used for production workloads.
What about Flex?
The Flex Volume plugin exists as an exec based mechanism to create “out-of-tree” volume plugins. Although it has some drawbacks (mentioned above), the Flex volume plugin coexists with the new CSI Volume plugin. SIG Storage will continue to maintain the Flex API so that existing third-party Flex drivers (already deployed in production clusters) continue to work. In the future, new volume features will only be added to CSI, not Flex.
What will happen to the in-tree volume plugins?
Once CSI reaches stability, we plan to migrate most of the in-tree volume plugins to CSI. Stay tuned for more details as the Kubernetes CSI implementation approaches stable.
What are the limitations of alpha?
The alpha implementation of CSI has the following limitations:
- The credential fields in CreateVolume, NodePublishVolume, and ControllerPublishVolume calls are not supported.
- Block volumes are not supported; only file.
- Specifying filesystems is not supported, and defaults to ext4.
- CSI drivers must be deployed with the provided “external-attacher,” even if they don’t implement “ControllerPublishVolume”.
- Kubernetes scheduler topology awareness is not supported for CSI volumes: in short, sharing information about where a volume is provisioned (zone, regions, etc.) to allow k8s scheduler to make smarter scheduling decisions.
What’s next?
Depending on feedback and adoption, the Kubernetes team plans to push the CSI implementation to beta in either 1.10 or 1.11.
How Do I Get Involved?
This project, like all of Kubernetes, is the result of hard work by many contributors from diverse backgrounds working together. A huge thank you to Vladimir Vivien (vladimirvivien), Jan Šafránek (jsafrane), Chakravarthy Nelluri (chakri-nelluri), Bradley Childs (childsb), Luis Pabón (lpabon), and Saad Ali (saad-ali) for their tireless efforts in bringing CSI to life in Kubernetes.
If you’re interested in getting involved with the design and development of CSI or any part of the Kubernetes Storage system, join the Kubernetes Storage Special-Interest-Group (SIG). We’re rapidly growing and always welcome new contributors.
Kubernetes v1.9 releases beta support for Windows Server Containers
With the release of Kubernetes v1.9, our mission of ensuring Kubernetes works well everywhere and for everyone takes a great step forward. We’ve advanced support for Windows Server to beta along with continued feature and functional advancements on both the Kubernetes and Windows platforms. SIG-Windows has been working since March of 2016 to open the door for many Windows-specific applications and workloads to run on Kubernetes, significantly expanding the implementation scenarios and the enterprise reach of Kubernetes.
Enterprises of all sizes have made significant investments in .NET and Windows based applications. Many enterprise portfolios today contain .NET and Windows, with Gartner claiming that 80% of enterprise apps run on Windows. According to StackOverflow Insights, 40% of professional developers use the .NET programming languages (including .NET Core).
But why is all this information important? It means that enterprises have both legacy and new born-in-the-cloud (microservice) applications that utilize a wide array of programming frameworks. There is a big push in the industry to modernize existing/legacy applications to containers, using an approach similar to “lift and shift”. Modernizing existing applications into containers also provides added flexibility for new functionality to be introduced in additional Windows or Linux containers. Containers are becoming the de facto standard for packaging, deploying, and managing both existing and microservice applications. IT organizations are looking for an easier and homogenous way to orchestrate and manage containers across their Linux and Windows environments. Kubernetes v1.9 now offers beta support for Windows Server containers, making it the clear choice for orchestrating containers of any kind.
Features
Alpha support for Windows Server containers in Kubernetes was great for proof-of-concept projects and visualizing the road map for support of Windows in Kubernetes. The alpha release had significant drawbacks, however, and lacked many features, especially in networking. SIG-Windows, Microsoft, Cloudbase Solutions, Apprenda, and other community members banded together to create a comprehensive beta release, enabling Kubernetes users to start evaluating and using Windows.
Some key feature improvements for Windows Server containers on Kubernetes include:
- Improved support for pods! Multiple Windows Server containers in a pod can now share the network namespace using network compartments in Windows Server. This feature brings the concept of a pod to parity with Linux-based containers
- Reduced network complexity by using a single network endpoint per pod
- Kernel-Based load-balancing using the Virtual Filtering Platform (VFP) Hyper-v Switch Extension (analogous to Linux iptables)
- Container Runtime Interface (CRI) pod and node level statistics. Windows Server containers can now be profiled for Horizontal Pod Autoscaling using performance metrics gathered from the pod and the node
- Support for kubeadm commands to add Windows Server nodes to a Kubernetes environment. Kubeadm simplifies the provisioning of a Kubernetes cluster, and with the support for Windows Server, you can use a single tool to deploy Kubernetes in your infrastructure
- Support for ConfigMaps, Secrets, and Volumes. These are key features that allow you to separate, and in some cases secure, the configuration of the containers from the implementation The crown jewels of Kubernetes 1.9 Windows support, however, are the networking enhancements. With the release of Windows Server 1709, Microsoft has enabled key networking capabilities in the operating system and the Windows Host Networking Service (HNS) that paved the way to produce a number of CNI plugins that work with Windows Server containers in Kubernetes. The Layer-3 routed and network overlay plugins that are supported with Kubernetes 1.9 are listed below:
- Upstream L3 Routing - IP routes configured in upstream ToR
- Host-Gateway - IP routes configured on each host
- Open vSwitch (OVS) & Open Virtual Network (OVN) with Overlay - Supports STT and Geneve tunneling types You can read more about each of their configuration, setup, and runtime capabilities to make an informed selection for your networking stack in Kubernetes.
Even though you have to continue running the Kubernetes Control Plane and Master Components in Linux, you are now able to introduce Windows Server as a Node in Kubernetes. As a community, this is a huge milestone and achievement. We will now start seeing .NET, .NET Core, ASP.NET, IIS, Windows Services, Windows executables and many more windows-based applications in Kubernetes.
What’s coming next
A lot of work went into this beta release, but the community realizes there are more areas of investment needed before we can release Windows support as GA (General Availability) for production workloads. Some keys areas of focus for the first two quarters of 2018 include:
- Continue to make progress in the area of networking. Additional CNI plugins are under development and nearing completion
- Overlay - win-overlay (vxlan or IP-in-IP encapsulation using Flannel)
- Win-l2bridge (host-gateway)
- OVN using cloud networking - without overlays
- Support for Kubernetes network policies in ovn-kubernetes
- Support for Hyper-V Isolation
- Support for StatefulSet functionality for stateful applications
- Produce installation artifacts and documentation that work on any infrastructure and across many public cloud providers like Microsoft Azure, Google Cloud, and Amazon AWS
- Continuous Integration/Continuous Delivery (CI/CD) infrastructure for SIG-Windows
- Scalability and Performance testing Even though we have not committed to a timeline for GA, SIG-Windows estimates a GA release in the first half of 2018.
Get Involved
As we continue to make progress towards General Availability of this feature in Kubernetes, we welcome you to get involved, contribute code, provide feedback, deploy Windows Server containers to your Kubernetes cluster, or simply join our community.
- If you want to get started on deploying Windows Server containers in Kubernetes, read our getting started guide at /docs/getting-started-guides/windows/
- We meet every other Tuesday at 12:30 Eastern Standard Time (EST) at https://zoom.us/my/sigwindows. All our meetings are recorded on youtube and referenced at https://www.youtube.com/playlist?list=PL69nYSiGNLP2OH9InCcNkWNu2bl-gmIU4
- Chat with us on Slack at https://kubernetes.slack.com/messages/sig-windows
- Find us on GitHub at https://github.com/kubernetes/community/tree/master/sig-windows
Thank you,
Michael Michael (@michmike77)
SIG-Windows Lead
Senior Director of Product Management, Apprenda
Five Days of Kubernetes 1.9
Kubernetes 1.9 is live, made possible by hundreds of contributors pushing thousands of commits in this latest releases.
The community has tallied around 32,300 commits in the main repo and continues rapid growth outside of the main repo, which signals growing maturity and stability for the project. The community has logged more than 90,700 commits across all repos and 7,800 commits across all repos for v1.8.0 to v1.9.0 alone.
With the help of our growing community of 1,400 plus contributors, we issued more than 4,490 PRs and pushed more than 7,800 commits to deliver Kubernetes 1.9 with many notable updates, including enhancements for the workloads and stateful application support areas. This all points to increased extensibility and standards-based Kubernetes ecosystem.
While many improvements have been contributed, we highlight key features in this series of in-depth posts listed below. Follow along and see what’s new and improved with workloads, Windows support and more.
Day 1: 5 Days of Kubernetes 1.9
Day 2: Windows and Docker support for Kubernetes (beta)
Day 3: Storage, CSI framework (alpha)
Day 4: Web Hook and Mission Critical, Dynamic Admission Control
Day 5: Introducing client-go version 6
Day 6: Workloads API
Connect
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Get involved with the Kubernetes project on GitHub
Introducing Kubeflow - A Composable, Portable, Scalable ML Stack Built for Kubernetes
Today’s post is by David Aronchick and Jeremy Lewi, a PM and Engineer on the Kubeflow project, a new open source GitHub repo dedicated to making using machine learning (ML) stacks on Kubernetes easy, fast and extensible.
Kubernetes and Machine Learning
Kubernetes has quickly become the hybrid solution for deploying complicated workloads anywhere. While it started with just stateless services, customers have begun to move complex workloads to the platform, taking advantage of rich APIs, reliability and performance provided by Kubernetes. One of the fastest growing use cases is to use Kubernetes as the deployment platform of choice for machine learning.
Building any production-ready machine learning system involves various components, often mixing vendors and hand-rolled solutions. Connecting and managing these services for even moderately sophisticated setups introduces huge barriers of complexity in adopting machine learning. Infrastructure engineers will often spend a significant amount of time manually tweaking deployments and hand rolling solutions before a single model can be tested.
Worse, these deployments are so tied to the clusters they have been deployed to that these stacks are immobile, meaning that moving a model from a laptop to a highly scalable cloud cluster is effectively impossible without significant re-architecture. All these differences add up to wasted effort and create opportunities to introduce bugs at each transition.
Introducing Kubeflow
To address these concerns, we’re announcing the creation of the Kubeflow project, a new open source GitHub repo dedicated to making using ML stacks on Kubernetes easy, fast and extensible. This repository contains:
- JupyterHub to create & manage interactive Jupyter notebooks
- A Tensorflow Custom Resource (CRD) that can be configured to use CPUs or GPUs, and adjusted to the size of a cluster with a single setting
- A TF Serving container Because this solution relies on Kubernetes, it runs wherever Kubernetes runs. Just spin up a cluster and go!
Using Kubeflow
Let's suppose you are working with two different Kubernetes clusters: a local minikube cluster; and a GKE cluster with GPUs; and that you have two kubectl contexts defined named minikube and gke.
First we need to initialize our ksonnet application and install the Kubeflow packages. (To use ksonnet, you must first install it on your operating system - the instructions for doing so are here)
ks init my-kubeflow
cd my-kubeflow
ks registry add kubeflow \
github.com/google/kubeflow/tree/master/kubeflow
ks pkg install kubeflow/core
ks pkg install kubeflow/tf-serving
ks pkg install kubeflow/tf-job
ks generate core kubeflow-core --name=kubeflow-core
We can now define environments corresponding to our two clusters.
kubectl config use-context minikube
ks env add minikube
kubectl config use-context gke
ks env add gke
And we’re done! Now just create the environments on your cluster. First, on minikube:
ks apply minikube -c kubeflow-core
And to create it on our multi-node GKE cluster for quicker training:
ks apply gke -c kubeflow-core
By making it easy to deploy the same rich ML stack everywhere, the drift and rewriting between these environments is kept to a minimum.
To access either deployments, you can execute the following command:
kubectl port-forward tf-hub-0 8100:8000
and then open up http://127.0.0.1:8100 to access JupyterHub. To change the environment used by kubectl, use either of these commands:
# To access minikube
kubectl config use-context minikube
# To access GKE
kubectl config use-context gke
When you execute apply you are launching on K8s
- JupyterHub for launching and managing Jupyter notebooks on K8s
- A TF CRD
Let's suppose you want to submit a training job. Kubeflow provides ksonnet prototypes that make it easy to define components. The tf-job prototype makes it easy to create a job for your code but for this example, we'll use the tf-cnn prototype which runs TensorFlow's CNN benchmark.
To submit a training job, you first generate a new job from a prototype:
ks generate tf-cnn cnn --name=cnn
By default the tf-cnn prototype uses 1 worker and no GPUs which is perfect for our minikube cluster so we can just submit it.
ks apply minikube -c cnn
On GKE, we’ll want to tweak the prototype to take advantage of the multiple nodes and GPUs. First, let’s list all the parameters available:
# To see a list of parameters
ks prototype list tf-job
Now let’s adjust the parameters to take advantage of GPUs and access to multiple nodes.
ks param set --env=gke cnn num\_gpus 1
ks param set --env=gke cnn num\_workers 1
ks apply gke -c cnn
Note how we set those parameters so they are used only when you deploy to GKE. Your minikube parameters are unchanged!
After training, you export your model to a serving location.
Kubeflow also includes a serving package as well. In a separate example, we trained a standard Inception model, and stored the trained model in a bucket we’ve created called ‘gs://kubeflow-models’ with the path ‘/inception’.
To deploy a the trained model for serving, execute the following:
ks generate tf-serving inception --name=inception
---namespace=default --model\_path=gs://kubeflow-models/inception
ks apply gke -c inception
This highlights one more option in Kubeflow - the ability to pass in inputs based on your deployment. This command creates a tf-serving service on the GKE cluster, and makes it available to your application.
For more information about of deploying and monitoring TensorFlow training jobs and TensorFlow models please refer to the user guide.
Kubeflow + ksonnet
One choice we want to call out is the use of the ksonnet project. We think working with multiple environments (dev, test, prod) will be the norm for most Kubeflow users. By making environments a first class concept, ksonnet makes it easy for Kubeflow users to easily move their workloads between their different environments.
Particularly now that Helm is integrating ksonnet with the next version of their platform, we felt like it was the perfect choice for us. More information about ksonnet can be found in the ksonnet docs.
We also want to thank the team at Heptio for expediting features critical to Kubeflow's use of ksonnet.
What’s Next?
We are in the midst of building out a community effort right now, and we would love your help! We’ve already been collaborating with many teams - CaiCloud, Red Hat & OpenShift, Canonical, Weaveworks, Container Solutions and many others. CoreOS, for example, is already seeing the promise of Kubeflow:
“The Kubeflow project was a needed advancement to make it significantly easier to set up and productionize machine learning workloads on Kubernetes, and we anticipate that it will greatly expand the opportunity for even more enterprises to embrace the platform. We look forward to working with the project members in providing tight integration of Kubeflow with Tectonic, the enterprise Kubernetes platform.” -- Reza Shafii, VP of product, CoreOS
If you’d like to try out Kubeflow right now right in your browser, we’ve partnered with Katacoda to make it super easy. You can try it here!
And we’re just getting started! We would love for you to help. How you might ask? Well…
- Please join theslack channel
- Please join thekubeflow-discuss email list
- Please subscribe to theKubeflow twitter account
- Please download and run kubeflow, and submit bugs! Thank you for your support so far, we could not be more excited!
Jeremy Lewi & David Aronchick Google
Kubernetes 1.9: Apps Workloads GA and Expanded Ecosystem
We’re pleased to announce the delivery of Kubernetes 1.9, our fourth and final release this year.
Today’s release continues the evolution of an increasingly rich feature set, more robust stability, and even greater community contributions. As the fourth release of the year, it gives us an opportunity to look back at the progress made in key areas. Particularly notable is the advancement of the Apps Workloads API to stable. This removes any reservations potential adopters might have had about the functional stability required to run mission-critical workloads. Another big milestone is the beta release of Windows support, which opens the door for many Windows-specific applications and workloads to run in Kubernetes, significantly expanding the implementation scenarios and enterprise readiness of Kubernetes.
Workloads API GA
We’re excited to announce General Availability (GA) of the apps/v1 Workloads API, which is now enabled by default. The Apps Workloads API groups the DaemonSet, Deployment, ReplicaSet, and StatefulSet APIs together to form the foundation for long-running stateless and stateful workloads in Kubernetes. Note that the Batch Workloads API (Job and CronJob) is not part of this effort and will have a separate path to GA stability.
Deployment and ReplicaSet, two of the most commonly used objects in Kubernetes, are now stabilized after more than a year of real-world use and feedback. SIG Apps has applied the lessons from this process to all four resource kinds over the last several release cycles, enabling DaemonSet and StatefulSet to join this graduation. The v1 (GA) designation indicates production hardening and readiness, and comes with the guarantee of long-term backwards compatibility.
Windows Support (beta)
Kubernetes was originally developed for Linux systems, but as our users are realizing the benefits of container orchestration at scale, we are seeing demand for Kubernetes to run Windows workloads. Work to support Windows Server in Kubernetes began in earnest about 12 months ago. SIG-Windowshas now promoted this feature to beta status, which means that we can evaluate it for usage.
Storage Enhancements
From the first release, Kubernetes has supported multiple options for persistent data storage, including commonly-used NFS or iSCSI, along with native support for storage solutions from the major public and private cloud providers. As the project and ecosystem grow, more and more storage options have become available for Kubernetes. Adding volume plugins for new storage systems, however, has been a challenge.
Container Storage Interface (CSI) is a cross-industry standards initiative that aims to lower the barrier for cloud native storage development and ensure compatibility. SIG-Storage and the CSI Community are collaborating to deliver a single interface for provisioning, attaching, and mounting storage compatible with Kubernetes.
Kubernetes 1.9 introduces an alpha implementation of the Container Storage Interface (CSI), which will make installing new volume plugins as easy as deploying a pod, and enable third-party storage providers to develop their solutions without the need to add to the core Kubernetes codebase.
Because the feature is alpha in 1.9, it must be explicitly enabled and is not recommended for production usage, but it indicates the roadmap working toward a more extensible and standards-based Kubernetes storage ecosystem.
Additional Features
Custom Resource Definition (CRD) Validation, now graduating to beta and enabled by default, helps CRD authors give clear and immediate feedback for invalid objects
SIG Node hardware accelerator moves to alpha, enabling GPUs and consequently machine learning and other high performance workloads
CoreDNS alpha makes it possible to install CoreDNS with standard tools
IPVS mode for kube-proxy goes beta, providing better scalability and performance for large clusters
Each Special Interest Group (SIG) in the community continues to deliver the most requested user features for their area. For a complete list, please visit the release notes.
Availability
Kubernetes 1.9 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials.
Release team
This release is made possible through the effort of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Anthony Yeh, Software Engineer at Google. The 14 individuals on the release team coordinate many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process has become an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem.
Project Velocity
The CNCF has embarked on an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors. Open issues remained relatively stable over the course of the release, while forks rose approximately 20%, as did individuals starring the various project repositories. Approver volume has risen slightly since the last release, but a lull is commonplace during the last quarter of the year. With 75,000+ comments, Kubernetes remains one of the most actively discussed projects on GitHub.
User highlights
According to the latest survey conducted by CNCF, 61 percent of organizations are evaluating and 83 percent are using Kubernetes in production. Example of user stories from the community include:
BlaBlaCar, the world’s largest long distance carpooling community connects 40 million members across 22 countries. The company has about 3,000 pods, with 1,200 of them running on Kubernetes, leading to improved website availability for customers.
Pokémon GO, the popular free-to-play, location-based augmented reality game developed by Niantic for iOS and Android devices, has its application logic running on Google Container Engine powered by Kubernetes. This was the largest Kubernetes deployment ever on Google Container Engine.
Is Kubernetes helping your team? Share your story with the community.
Ecosystem updates
Announced on November 13, the Certified Kubernetes Conformance Program ensures that Certified Kubernetes™ products deliver consistency and portability. Thirty-two Certified Kubernetes Distributions and Platforms are now available. Development of the certification program involved close collaboration between CNCF and the rest of the Kubernetes community, especially the Testing and Architecture Special Interest Groups (SIGs). The Kubernetes Architecture SIG is the final arbiter of the definition of API conformance for the program. The program also includes strong guarantees that commercial providers of Kubernetes will continue to release new versions to ensure that customers can take advantage of the rapid pace of ongoing development.
CNCF also offers online training that teaches the skills needed to create and configure a real-world Kubernetes cluster.
KubeCon
For recorded sessions from the largest Kubernetes gathering, KubeCon + CloudNativeCon in Austin from December 6-8, 2017, visit YouTube/CNCF. The premiere Kubernetes event will be back May 2-4, 2018 in Copenhagen and will feature technical sessions, case studies, developer deep dives, salons and more! CFP closes January 12, 2018.
Webinar
Join members of the Kubernetes 1.9 release team on January 9th from 10am-11am PT to learn about the major features in this release as they demo some of the highlights in the areas of Windows and Docker support, storage, admission control, and the workloads API. Register here.
Get involved:
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
Thank you for your continued feedback and support.
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Chat with the community on Slack
- Share your Kubernetes story.
Using eBPF in Kubernetes
Introduction
Kubernetes provides a high-level API and a set of components that hides almost all of the intricate and—to some of us—interesting details of what happens at the systems level. Application developers are not required to have knowledge of the machines' IP tables, cgroups, namespaces, seccomp, or, nowadays, even the container runtime that their application runs on top of. But underneath, Kubernetes and the technologies upon which it relies (for example, the container runtime) heavily leverage core Linux functionalities.
This article focuses on a core Linux functionality increasingly used in networking, security and auditing, and tracing and monitoring tools. This functionality is called extended Berkeley Packet Filter (eBPF)
Note: In this article we use both acronyms: eBPF and BPF. The former is used for the extended BPF functionality, and the latter for "classic" BPF functionality.
What is BPF?
BPF is a mini-VM residing in the Linux kernel that runs BPF programs. Before running, BPF programs are loaded with the bpf() syscall and are validated for safety: checking for loops, code size, etc. BPF programs are attached to kernel objects and executed when events happen on those objects—for example, when a network interface emits a packet.
BPF Superpowers
BPF programs are event-driven by definition, an incredibly powerful concept, and executes code in the kernel when an event occurs. Netflix's Brendan Gregg refers to BPF as a Linux superpower.
The 'e' in eBPF
Traditionally, BPF could only be attached to sockets for socket filtering. BPF’s first use case was in tcpdump. When you run tcpdump the filter is compiled into a BPF program and attached to a raw AF_PACKET socket in order to print out filtered packets.
But over the years, eBPF added the ability to attach to other kernel objects. In addition to socket filtering, some supported attach points are:
- Kprobes (and userspace equivalents uprobes)
- Tracepoints
- Network schedulers or qdiscs for classification or action (tc)
- XDP (eXpress Data Path) This and other, newer features like in-kernel helper functions and shared data-structures (maps) that can be used to communicate with user space, extend BPF’s capabilities.
Existing Use Cases of eBPF with Kubernetes
Several open-source Kubernetes tools already use eBPF and many use cases warrant a closer look, especially in areas such as networking, monitoring and security tools.
Dynamic Network Control and Visibility with Cilium
Cilium is a networking project that makes heavy use of eBPF superpowers to route and filter network traffic for container-based systems. By using eBPF, Cilium can dynamically generate and apply rules—even at the device level with XDP—without making changes to the Linux kernel itself.
The Cilium Agent runs on each host. Instead of managing IP tables, it translates network policy definitions to BPF programs that are loaded into the kernel and attached to a container's virtual ethernet device. These programs are executed—rules applied—on each packet that is sent or received.
This diagram shows how the Cilium project works:

Depending on what network rules are applied, BPF programs may be attached with tc or XDP. By using XDP, Cilium can attach the BPF programs at the lowest possible point, which is also the most performant point in the networking software stack.
If you'd like to learn more about how Cilium uses eBPF, take a look at the project's BPF and XDP reference guide.
Tracking TCP Connections in Weave Scope
Weave Scope is a tool for monitoring, visualizing and interacting with container-based systems. For our purposes, we'll focus on how Weave Scope gets the TCP connections.

Weave Scope employs an agent that runs on each node of a cluster. The agent monitors the system, generates a report and sends it to the app server. The app server compiles the reports it receives and presents the results in the Weave Scope UI.
To accurately draw connections between containers, the agent attaches a BPF program to kprobes that track socket events: opening and closing connections. The BPF program, tcptracer-bpf, is compiled into an ELF object file and loaded using gobpf.
(As a side note, Weave Scope also has a plugin that make use of eBPF: HTTP statistics.)
To learn more about how this works and why it's done this way, read this extensive post that the Kinvolk team wrote for the Weaveworks Blog. You can also watch a recent talk about the topic.
Limiting syscalls with seccomp-bpf
Linux has more than 300 system calls (read, write, open, close, etc.) available for use—or misuse. Most applications only need a small subset of syscalls to function properly. seccomp is a Linux security facility used to limit the set of syscalls that an application can use, thereby limiting potential misuse.
The original implementation of seccomp was highly restrictive. Once applied, if an application attempted to do anything beyond reading and writing to files it had already opened, seccomp sent a SIGKILL signal.
seccomp-bpf enables more complex filters and a wider range of actions. Seccomp-bpf, also known as seccomp mode 2, allows for applying custom filters in the form of BPF programs. When the BPF program is loaded, the filter is applied to each syscall and the appropriate action is taken (Allow, Kill, Trap, etc.).
seccomp-bpf is widely used in Kubernetes tools and exposed in Kubernetes itself. For example, seccomp-bpf is used in Docker to apply custom seccomp security profiles, in rkt to apply seccomp isolators, and in Kubernetes itself in its Security Context.
But in all of these cases the use of BPF is hidden behind libseccomp. Behind the scenes, libseccomp generates BPF code from rules provided to it. Once generated, the BPF program is loaded and the rules applied.
Potential Use Cases for eBPF with Kubernetes
eBPF is a relatively new Linux technology. As such, there are many uses that remain unexplored. eBPF itself is also evolving: new features are being added in eBPF that will enable new use cases that aren’t currently possible. In the following sections, we're going to look at some of these that have only recently become possible and ones on the horizon. Our hope is that these features will be leveraged by open source tooling.
Pod and container level network statistics
BPF socket filtering is nothing new, but BPF socket filtering per cgroup is. Introduced in Linux 4.10, cgroup-bpf allows attaching eBPF programs to cgroups. Once attached, the program is executed for all packets entering or exiting any process in the cgroup.
A cgroup is, amongst other things, a hierarchical grouping of processes. In Kubernetes, this grouping is found at the container level. One idea for making use of cgroup-bpf, is to install BPF programs that collect detailed per-pod and/or per-container network statistics.
Generally, such statistics are collected by periodically checking the relevant file in Linux's /sys directory or using Netlink. By using BPF programs attached to cgroups for this, we can get much more detailed statistics: for example, how many packets/bytes on tcp port 443, or how many packets/bytes from IP 10.2.3.4. In general, because BPF programs have a kernel context, they can safely and efficiently deliver more detailed information to user space.
To explore the idea, the Kinvolk team implemented a proof-of-concept: https://github.com/kinvolk/cgnet. This project attaches a BPF program to each cgroup and exports the information to Prometheus.
There are of course other interesting possibilities, like doing actual packet filtering. But the obstacle currently standing in the way of this is having cgroup v2 support—required by cgroup-bpf—in Docker and Kubernetes.
Application-applied LSM
Linux Security Modules (LSM) implements a generic framework for security policies in the Linux kernel. SELinux and AppArmor are examples of these. Both of these implement rules at a system-global scope, placing the onus on the administrator to configure the security policies.
Landlock is another LSM under development that would co-exist with SELinux and AppArmor. An initial patchset has been submitted to the Linux kernel and is in an early stage of development. The main difference with other LSMs is that Landlock is designed to allow unprivileged applications to build their own sandbox, effectively restricting themselves instead of using a global configuration. With Landlock, an application can load a BPF program and have it executed when the process performs a specific action. For example, when the application opens a file with the open() system call, the kernel will execute the BPF program, and, depending on what the BPF program returns, the action will be accepted or denied.
In some ways, it is similar to seccomp-bpf: using a BPF program, seccomp-bpf allows unprivileged processes to restrict what system calls they can perform. Landlock will be more powerful and provide more flexibility. Consider the following system call:
C
fd = open(“myfile.txt”, O\_RDWR);
The first argument is a “char *”, a pointer to a memory address, such as 0xab004718.
With seccomp, a BPF program only has access to the parameters of the syscall but cannot dereference the pointers, making it impossible to make security decisions based on a file. seccomp also uses classic BPF, meaning it cannot make use of eBPF maps, the mechanism for interfacing with user space. This restriction means security policies cannot be changed in seccomp-bpf based on a configuration in an eBPF map.
BPF programs with Landlock don’t receive the arguments of the syscalls but a reference to a kernel object. In the example above, this means it will have a reference to the file, so it does not need to dereference a pointer, consider relative paths, or perform chroots.
Use Case: Landlock in Kubernetes-based serverless frameworks
In Kubernetes, the unit of deployment is a pod. Pods and containers are the main unit of isolation. In serverless frameworks, however, the main unit of deployment is a function. Ideally, the unit of deployment equals the unit of isolation. This puts serverless frameworks like Kubeless or OpenFaaS into a predicament: optimize for unit of isolation or deployment?
To achieve the best possible isolation, each function call would have to happen in its own container—ut what's good for isolation is not always good for performance. Inversely, if we run function calls within the same container, we increase the likelihood of collisions.
By using Landlock, we could isolate function calls from each other within the same container, making a temporary file created by one function call inaccessible to the next function call, for example. Integration between Landlock and technologies like Kubernetes-based serverless frameworks would be a ripe area for further exploration.
Auditing kubectl-exec with eBPF
In Kubernetes 1.7 the audit proposal started making its way in. It's currently pre-stable with plans to be stable in the 1.10 release. As the name implies, it allows administrators to log and audit events that take place in a Kubernetes cluster.
While these events log Kubernetes events, they don't currently provide the level of visibility that some may require. For example, while we can see that someone has used kubectl exec to enter a container, we are not able to see what commands were executed in that session. With eBPF one can attach a BPF program that would record any commands executed in the kubectl exec session and pass those commands to a user-space program that logs those events. We could then play that session back and know the exact sequence of events that took place.
Learn more about eBPF
If you're interested in learning more about eBPF, here are some resources:
-
A comprehensive reading list about eBPF for doing just that
-
BCC (BPF Compiler Collection) provides tools for working with eBPF as well as many example tools making use of BCC.
-
Some videos
- BPF: Tracing and More by Brendan Gregg
- Cilium - Container Security and Networking Using BPF and XDP by Thomas Graf
- Using BPF in Kubernetes by Alban Crequy
Conclusion
We are just starting to see the Linux superpowers of eBPF being put to use in Kubernetes tools and technologies. We will undoubtedly see increased use of eBPF. What we have highlighted here is just a taste of what you might expect in the future. What will be really exciting is seeing how these technologies will be used in ways that we have not yet thought about. Stay tuned!
The Kinvolk team will be hanging out at the Kinvolk booth at KubeCon in Austin. Come by to talk to us about all things, Kubernetes, Linux, container runtimes and yeah, eBPF.
PaddlePaddle Fluid: Elastic Deep Learning on Kubernetes
Editor's note: Today's post is a joint post from the deep learning team at Baidu and the etcd team at CoreOS.
PaddlePaddle Fluid: Elastic Deep Learning on Kubernetes
Two open source communities—PaddlePaddle, the deep learning framework originated in Baidu, and Kubernetes®, the most famous containerized application scheduler—are announcing the Elastic Deep Learning (EDL) feature in PaddlePaddle’s new release codenamed Fluid.
Fluid EDL includes a Kubernetes controller, PaddlePaddle auto-scaler, which changes the number of processes of distributed jobs according to the idle hardware resource in the cluster, and a new fault-tolerable architecture as described in the PaddlePaddle design doc.
Industrial deep learning requires significant computation power. Research labs and companies often build GPU clusters managed by SLURM, MPI, or SGE. These clusters either run a submitted job if it requires less than the idle resource, or pend the job for an unpredictably long time. This approach has its drawbacks: in an example with 99 available nodes and a submitted job that requires 100, the job has to wait without using any of the available nodes. Fluid works with Kubernetes to power elastic deep learning jobs, which often lack optimal resources, by helping to expose potential algorithmic problems as early as possible.
Another challenge is that industrial users tend to run deep learning jobs as a subset stage of the complete data pipeline, including the web server and log collector. Such general-purpose clusters require priority-based elastic scheduling. This makes it possible to run more processes in the web server job and less in deep learning during periods of high web traffic, then prioritize deep learning when web traffic is low. Fluid talks to Kubernetes' API server to understand the global picture and orchestrate the number of processes affiliated with various jobs.
In both scenarios, PaddlePaddle jobs are tolerant to a process spikes and decreases. We achieved this by implementing the new design, which introduces a master process in addition to the old PaddlePaddle architecture as described in a previous blog post. In the new design, as long as there are three processes left in a job, it continues. In extreme cases where all processes are killed, the job can be restored and resume.
We tested Fluid EDL for two use cases: 1) the Kubernetes cluster runs only PaddlePaddle jobs; and 2) the cluster runs PaddlePaddle and Nginx jobs.
In the first test, we started up to 20 PaddlePaddle jobs one by one with a 10-second interval. Each job has 60 trainers and 10 parameter server processes, and will last for hours. We repeated the experiment 20 times: 10 with FluidEDL turned off and 10 with FluidEDL turned on. In Figure one, solid lines correspond to the first 10 experiments and dotted lines the rest. In the upper part of the figure, we see that the number of pending jobs increments monotonically without EDL. However, when EDL is turned on, resources are evenly distributed to all jobs. Fluid EDL kills some existing processes to make room for new jobs and jobs coming in at a later point in time. In both cases, the cluster is equally utilized (see lower part of figure).
|  |
| Figure 1. Fluid EDL evenly distributes resource among jobs.
|
| Figure 1. Fluid EDL evenly distributes resource among jobs.
|
In the second test, each experiment ran 400 Nginx pods, which has higher priority than the six PaddlePaddle jobs. Initially, each PaddlePaddle job had 15 trainers and 10 parameter servers. We killed 100 Nginx pods every 90 seconds until 100 left, and then we started to increase the number of Nginx jobs by 100 every 90 seconds. The upper part of Figure 2 shows this process. The middle of the diagram shows that Fluid EDL automatically started some PaddlePaddle processes by decreasing Nginx pods, and killed PaddlePaddle processes by increasing Nginx pods later on. As a result, the cluster maintains around 90% utilization as shown in the bottom of the figure. When Fluid EDL was turned off, there were no PaddlePaddle processes autoincrement, and the utilization fluctuated with the varying number of Nginx pods.
|  |
| Figure 2. Fluid changes PaddlePaddle processes with the change of Nginx processes. |
|
| Figure 2. Fluid changes PaddlePaddle processes with the change of Nginx processes. |
We continue to work on FluidEDL and welcome comments and contributions. Visit the PaddlePaddle repo, where you can find the design doc, a simple tutorial, and experiment details.
-
Xu Yan (Baidu Research)
-
Helin Wang (Baidu Research)
-
Yi Wu (Baidu Research)
-
Xi Chen (Baidu Research)
-
Weibao Gong (Baidu Research)
-
Xiang Li (CoreOS)
-
Yi Wang (Baidu Research)
Autoscaling in Kubernetes
Kubernetes allows developers to automatically adjust cluster sizes and the number of pod replicas based on current traffic and load. These adjustments reduce the amount of unused nodes, saving money and resources. In this talk, Marcin Wielgus of Google walks you through the current state of pod and node autoscaling in Kubernetes: .how it works, and how to use it, including best practices for deployments in production applications.
Enjoyed this talk? Join us for more exciting sessions on scaling and automating your Kubernetes clusters at KubeCon in Austin on December 6-8. Register Now
Be sure to check out Automating and Testing Production Ready Kubernetes Clusters in the Public Cloud by Ron Lipke, Senior Developer, Platform as a Service, Gannet/USA Today Network.
Certified Kubernetes Conformance Program: Launch Celebration Round Up
 This week the CNCFⓇ certified the first group of KubernetesⓇ offerings under the Certified Kubernetes Conformance Program. These first certifications follow a beta phase during which we invited participants to submit conformance results. The community response was overwhelming: CNCF certified offerings from 32 vendors!
This week the CNCFⓇ certified the first group of KubernetesⓇ offerings under the Certified Kubernetes Conformance Program. These first certifications follow a beta phase during which we invited participants to submit conformance results. The community response was overwhelming: CNCF certified offerings from 32 vendors!
The new Certified Kubernetes Conformance Program gives enterprise organizations the confidence that workloads running on any Certified Kubernetes distribution or platform will work correctly on other Certified Kubernetes distributions or platforms. A Certified Kubernetes product guarantees that the complete Kubernetes API functions as specified, so users can rely on a seamless, stable experience.
Here’s what the world had to say about the Certified Kubernetes Conformance Program.
Press coverage:
-
IBM, Google, Microsoft, and 33 more partner to ensure Kubernetes workload portability, VentureBeat.
-
The CNCF just got 36 companies to agree to a Kubernetes certification standard, TechCrunch
-
CNCF Ensures Kubernetes Interoperability with a New Cert Program, The New Stack
-
Cloud Native launches Certified Kubernetes program, SD Times
-
CNCF offers Kubernetes Software Conformance Certification program RCR Wireless
-
New Kubernetes Certification Program Announced Virtualization Review
-
Key Cloud Computing Group Launches Interoperability Certification for Kubernetes GeekWire
-
New Kubernetes Certification Program Helps Deliver Consistency in the Cloud BetaNews
-
CNCF Launches Kubernetes Conformance Certification Program, sdxcentral Community blog round-up:
-
Introducing Certified Kubernetes (and Google Kubernetes Engine!), Google
-
Certified Kubernetes: A key step forward for the open source ecosystem, Heptio
-
VMware Pivotal Container Service Achieves Kubernetes Certification, VMWare Pivotal
-
Huawei Cloud Container Engine gained first wave of Certificated Kubernetes Qualification, Huawei
-
Cloud Foundry Container Runtime Gets Kubernetes-Certified, Cloud Foundry
-
SUSE CaaS Platform 2 certified under Kubernetes Conformance Software Certification, SUSE
-
Kubernetes on Mesosphere DC/OS now certified by CNCF, Mesosphere
-
Rancher joins the CNCF Kubernetes Software Conformance Certification program, Rancher
-
StackPointCloud Becomes First Multi-Cloud CNCF Certified Kubernetes Offering, StackPointCloud Visit https://www.cncf.io/certification/software-conformance for more information about the Certified Kubernetes Conformance Program, and learn how you can join a growing list of Certified Kubernetes providers.
“Cloud Native Computing Foundation”, “CNCF” and “Kubernetes” are registered trademarks of The Linux Foundation in the United States and other countries. “Certified Kubernetes” and the Certified Kubernetes design are trademarks of The Linux Foundation in the United States and other countries.
Kubernetes is Still Hard (for Developers)
Kubernetes has made the Ops experience much easier, but how does the developer experience compare? Ops teams can deploy a Kubernetes cluster in a matter of minutes. But developers need to understand a host of new concepts before beginning to work with Kubernetes. This can be a tedious and manual process, but it doesn’t have to be. In this talk, Michelle Noorali, co-lead of SIG-Apps, reimagines the Kubernetes developer experience. She shares her top 3 tips for building a successful developer experience including:
- A framework for thinking about cloud native applications
- An integrated experience for debugging and fine-tuning cloud native applicationsA way to get a cloud native application out the door quickly Interested in learning how far the Kubernetes developer experience has come? Join us at KubeCon in Austin on December 6-8. Register Now >>
Check out Michelle’s keynote to learn about exciting new updates from CNCF projects.
Securing Software Supply Chain with Grafeas
Editor's note: This post is written by Kelsey Hightower, Staff Developer Advocate at Google, and Sandra Guo, Product Manager at Google.
Kubernetes has evolved to support increasingly complex classes of applications, enabling the development of two major industry trends: hybrid cloud and microservices. With increasing complexity in production environments, customers—especially enterprises—are demanding better ways to manage their software supply chain with more centralized visibility and control over production deployments.
On October 12th, Google and partners announced Grafeas, an open source initiative to define a best practice for auditing and governing the modern software supply chain. With Grafeas (“scribe” in Greek), developers can plug in components of the CI/CD pipeline into a central source of truth for tracking and enforcing policies. Google is also working on Kritis (“judge” in Greek), allowing devOps teams to enforce deploy-time image policy using metadata and attestations stored in Grafeas.
Grafeas allows build, auditing and compliance tools to exchange comprehensive metadata on container images using a central API. This allows enforcing policies that provide central control over the software supply process.

Example application: PaymentProcessor
Let’s consider a simple application, PaymentProcessor, that retrieves, processes and updates payment info stored in a database. This application is made up of two containers: a standard ruby container and custom logic.
Due to the sensitive nature of the payment data, the developers and DevOps team really want to make sure that the code meets certain security and compliance requirements, with detailed records on the provenance of this code. There are CI/CD stages that validate the quality of the PaymentProcessor release, but there is no easy way to centrally view/manage this information:

Visibility and governance over the PaymentProcessor Code
Grafeas provides an API for customers to centrally manage metadata created by various CI/CD components and enables deploy time policy enforcement through a Kritis implementation.

Let’s consider a basic example of how Grafeas can provide deploy time control for the PaymentProcessor app using a demo verification pipeline.
Assume that a PaymentProcessor container image has been created and pushed to Google Container Registry. This example uses the gcr.io/exampleApp/PaymentProcessor container for testing. You as the QA engineer want to create an attestation certifying this image for production usage. Instead of trusting an image tag like 0.0.1, which can be reused and point to a different container image later, we can trust the image digest to ensure the attestation links to the full image contents.
1. Set up the environment
Generate a signing key:
gpg --quick-generate-key --yes qa\_bob@example.com
Export the image signer's public key:
gpg --armor --export image.signer@example.com \> ${GPG\_KEY\_ID}.pub
Create the ‘qa’ AttestationAuthority note via the Grafeas API:
curl -X POST \
"http://127.0.0.1:8080/v1alpha1/projects/image-signing/notes?noteId=qa" \
-d @note.json
Create the Kubernetes ConfigMap for admissions control and store the QA signer's public key:
kubectl create configmap image-signature-webhook \
--from-file ${GPG\_KEY\_ID}.pub
kubectl get configmap image-signature-webhook -o yaml
Set up an admissions control webhook to require QA signature during deployment.
kubectl apply -f kubernetes/image-signature-webhook.yaml
2. Attempt to deploy an image without QA attestation
Attempt to run the image in paymentProcessor.ymal before it is QA attested:
kubectl apply -f pods/nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: payment
spec:
containers:
- name: payment
image: "gcr.io/hightowerlabs/payment@sha256:aba48d60ba4410ec921f9d2e8169236c57660d121f9430dc9758d754eec8f887"
Create the paymentProcessor pod:
kubectl apply -f pods/paymentProcessor.yaml
Notice the paymentProcessor pod was not created and the following error was returned:
The "" is invalid: : No matched signatures for container image: gcr.io/hightowerlabs/payment@sha256:aba48d60ba4410ec921f9d2e8169236c57660d121f9430dc9758d754eec8f887
3. Create an image signature
Assume the image digest is stored in Image-digest.txt, sign the image digest:
gpg -u qa\_bob@example.com \
--armor \
--clearsign \
--output=signature.gpg \
Image-digest.txt
4. Upload the signature to the Grafeas API
Generate a pgpSignedAttestation occurrence from the signature :
cat \> occurrence.json \<\<EOF
{
"resourceUrl": "$(cat image-digest.txt)",
"noteName": "projects/image-signing/notes/qa",
"attestation": {
"pgpSignedAttestation": {
"signature": "$(cat signature.gpg)",
"contentType": "application/vnd.gcr.image.url.v1",
"pgpKeyId": "${GPG\_KEY\_ID}"
}
}
}
EOF
Upload the attestation through the Grafeas API:
curl -X POST \
'http://127.0.0.1:8080/v1alpha1/projects/image-signing/occurrences' \
-d @occurrence.json
5. Verify QA attestation during a production deployment
Attempt to run the image in paymentProcessor.ymal now that it has the correct attestation in the Grafeas API:
kubectl apply -f pods/paymentProcessor.yaml
pod "PaymentProcessor" created
With the attestation added the pod will be created as the execution criteria are met.
For more detailed information, see this Grafeas tutorial.
Summary
The demo above showed how you can integrate your software supply chain with Grafeas and gain visibility and control over your production deployments. However, the demo verification pipeline by itself is not a full Kritis implementation. In addition to basic admission control, Kritis provides additional support for workflow enforcement, multi-authority signing, breakglass deployment and more. You can read the Kritis whitepaper for more details. The team is actively working on a full open-source implementation. We’d love your feedback!
In addition, a hosted alpha implementation of Kritis, called Binary Authorization, is available on Google Container Engine and will be available for broader consumption soon.
Google, JFrog, and other partners joined forces to create Grafeas based on our common experiences building secure, large, and complex microservice deployments for internal and enterprise customers. Grafeas is an industry-wide community effort.
To learn more about Grafeas and contribute to the project:
- Register for the JFrog-Google webinar [here]
- Try Grafeas now and join the GitHub project: https://github.com/grafeas
- Try out the Grafeas demo and tutorial: https://github.com/kelseyhightower/grafeas-tutorial
- Attend Shopify’s talks at KubeCon in December
- Fill out [this form] if you’re interested in learning more about our upcoming releases or talking to us about integrations
- See grafeas.io for documentation and examples
We hope you join us!
The Grafeas Team
Containerd Brings More Container Runtime Options for Kubernetes
Editor's note: Today's post is by Lantao Liu, Software Engineer at Google, and Mike Brown, Open Source Developer Advocate at IBM.
A container runtime is software that executes containers and manages container images on a node. Today, the most widely known container runtime is Docker, but there are other container runtimes in the ecosystem, such as rkt, containerd, and lxd. Docker is by far the most common container runtime used in production Kubernetes environments, but Docker’s smaller offspring, containerd, may prove to be a better option. This post describes using containerd with Kubernetes.
Kubernetes 1.5 introduced an internal plugin API named Container Runtime Interface (CRI) to provide easy access to different container runtimes. CRI enables Kubernetes to use a variety of container runtimes without the need to recompile. In theory, Kubernetes could use any container runtime that implements CRI to manage pods, containers and container images.
Over the past 6 months, engineers from Google, Docker, IBM, ZTE, and ZJU have worked to implement CRI for containerd. The project is called cri-containerd, which had its feature complete v1.0.0-alpha.0 release on September 25, 2017. With cri-containerd, users can run Kubernetes clusters using containerd as the underlying runtime without Docker installed.
containerd
Containerd is an OCI compliant core container runtime designed to be embedded into larger systems. It provides the minimum set of functionality to execute containers and manages images on a node. It was initiated by Docker Inc. and donated to CNCF in March of 2017. The Docker engine itself is built on top of earlier versions of containerd, and will soon be updated to the newest version. Containerd is close to a feature complete stable release, with 1.0.0-beta.1 available right now.
Containerd has a much smaller scope than Docker, provides a golang client API, and is more focused on being embeddable.The smaller scope results in a smaller codebase that’s easier to maintain and support over time, matching Kubernetes requirements as shown in the following table:
| Containerd Scope (In/Out) | Kubernetes Requirement | |
|---|---|---|
| Container Lifecycle Management | In | Container Create/Start/Stop/Delete/List/Inspect (✔️) |
| Image Management | In | Pull/List/Inspect (✔️) |
| Networking | Out No concrete network solution. User can setup network namespace and put containers into it. | Kubernetes networking deals with pods, rather than containers, so container runtimes should not provide complex networking solutions that don't satisfy requirements. (✔️) |
| Volumes | Out, No volume management. User can setup host path, and mount it into container. | Kubernetes manages volumes. Container runtimes should not provide internal volume management that may conflict with Kubernetes. (✔️) |
| Persistent Container Logging | Out, No persistent container log. Container STDIO is provided as FIFOs, which can be redirected/decorated as is required. | Kubernetes has specific requirements for persistent container logs, such as format and path etc. Container runtimes should not persist an unmanageable container log. (✔️) |
| Metrics | In Containerd provides container and snapshot metrics as part of the API. | Kubernetes expects container runtime to provide container metrics (CPU, Memory, writable layer size, etc.) and image filesystem usage (disk, inode usage, etc.). (✔️) |
| Overall, from a technical perspective, containerd is a very good alternative container runtime for Kubernetes. |
cri-containerd
Cri-containerd is exactly that: an implementation of CRI for containerd. It operates on the same node as the Kubelet and containerd. Layered between Kubernetes and containerd, cri-containerd handles all CRI service requests from the Kubelet and uses containerd to manage containers and container images. Cri-containerd manages these service requests in part by forming containerd service requests while adding sufficient additional function to support the CRI requirements.
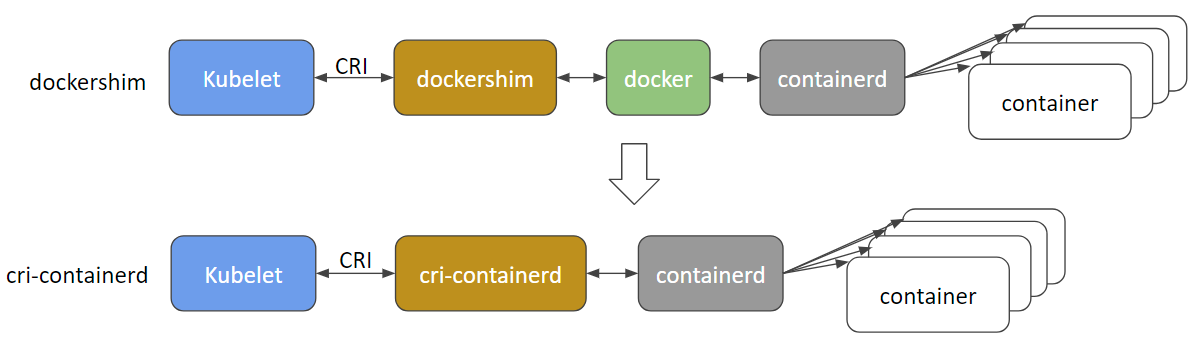
Compared with the current Docker CRI implementation (dockershim), cri-containerd eliminates an extra hop in the stack, making the stack more stable and efficient.
Architecture
Cri-containerd uses containerd to manage the full container lifecycle and all container images. As also shown below, cri-containerd manages pod networking via CNI (another CNCF project).
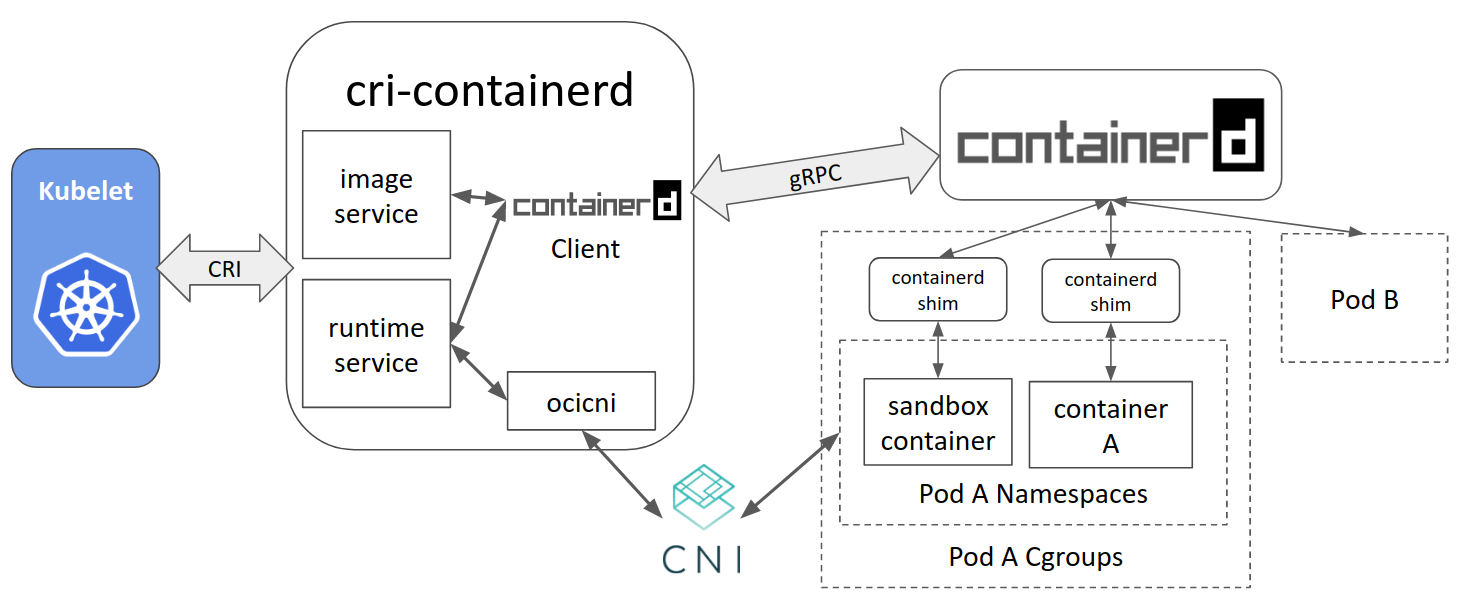
Let’s use an example to demonstrate how cri-containerd works for the case when Kubelet creates a single-container pod:
- Kubelet calls cri-containerd, via the CRI runtime service API, to create a pod;
- cri-containerd uses containerd to create and start a special pause container (the sandbox container) and put that container inside the pod’s cgroups and namespace (steps omitted for brevity);
- cri-containerd configures the pod’s network namespace using CNI;
- Kubelet subsequently calls cri-containerd, via the CRI image service API, to pull the application container image;
- cri-containerd further uses containerd to pull the image if the image is not present on the node;
- Kubelet then calls cri-containerd, via the CRI runtime service API, to create and start the application container inside the pod using the pulled container image;
- cri-containerd finally calls containerd to create the application container, put it inside the pod’s cgroups and namespace, then to start the pod’s new application container. After these steps, a pod and its corresponding application container is created and running.
Status
Cri-containerd v1.0.0-alpha.0 was released on Sep. 25, 2017.
It is feature complete. All Kubernetes features are supported.
All CRI validation tests have passed. (A CRI validation is a test framework for validating whether a CRI implementation meets all the requirements expected by Kubernetes.)
All regular node e2e tests have passed. (The Kubernetes test framework for testing Kubernetes node level functionalities such as managing pods, mounting volumes etc.)
To learn more about the v1.0.0-alpha.0 release, see the project repository.
Try it Out
For a multi-node cluster installer and bring up steps using ansible and kubeadm, see this repo link.
For creating a cluster from scratch on Google Cloud, see Kubernetes the Hard Way.
For a custom installation from release tarball, see this repo link.
For a installation with LinuxKit on a local VM, see this repo link.
Next Steps
We are focused on stability and usability improvements as our next steps.
-
Stability:
- Set up a full set of Kubernetes integration test in the Kubernetes test infrastructure on various OS distros such as Ubuntu, COS (Container-Optimized OS) etc.
- Actively fix any test failures and other issues reported by users.
-
Usability:
- Improve the user experience of crictl. Crictl is a portable command line tool for all CRI container runtimes. The goal here is to make it easy to use for debug and development scenarios.
- Integrate cri-containerd with kube-up.sh, to help users bring up a production quality Kubernetes cluster using cri-containerd and containerd.
- Improve our documentation for users and admins alike.
We plan to release our v1.0.0-beta.0 by the end of 2017.
Contribute
Cri-containerd is a Kubernetes incubator project located at https://github.com/kubernetes-incubator/cri-containerd. Any contributions in terms of ideas, issues, and/or fixes are welcome. The getting started guide for developers is a good place to start for contributors.
Community
Cri-containerd is developed and maintained by the Kubernetes SIG-Node community. We’d love to hear feedback from you. To join the community:
- sig-node community site
- Slack: #sig-node channel in Kubernetes (kubernetes.slack.com)
- Mailing List: https://groups.google.com/forum/#!forum/kubernetes-sig-node
Kubernetes the Easy Way
Editor's note: Today's post is by Dan Garfield, VP of Marketing at Codefresh, on how to set up and easily deploy a Kubernetes cluster.
Kelsey Hightower wrote an invaluable guide for Kubernetes called Kubernetes the Hard Way. It’s an awesome resource for those looking to understand the ins and outs of Kubernetes—but what if you want to put Kubernetes on easy mode? That’s something we’ve been working on together with Google Cloud. In this guide, we’ll show you how to get a cluster up and running, as well as how to actually deploy your code to that cluster and run it.
This is Kubernetes the easy way.
What We’ll Accomplish
- 1.Set up a cluster
- 2.Deploy an application to the cluster
- 3.Automate deployment with rolling updates
Prerequisites
- A containerized application
- You can also use a demo app.
- A Google Cloud Account or a Kubernetes cluster on another provider
- Everything after Cluster creation is identical with all providers.
- A free account on Codefresh
- Codefresh is a service that handles Kubernetes deployment configuration and automation.
We made Codefresh free for open-source projects and offer 200 builds/mo free for private projects, to make adopting Kubernetes as easy as possible. Deploy as much as you like on as many clusters as you like.
Set Up a Cluster
- Create an account at cloud.google.com and log in.
Note: If you’re using a Cluster outside of Google Cloud, you can skip this step.
Google Container Engine is Google Cloud’s managed Kubernetes service. In our testing, it’s both powerful and easy to use.
If you’re new to the platform, you can get a $500 credit at the end of this process.
- Open the menu and scroll down to Container Engine. Then select Container Clusters.

- Click Create cluster.
We’re done with step 1. In my experience it usually takes less than 5 minutes for a cluster to be created.
Deploy an Application to Kubernetes
First go to Codefresh and create an account using GitHub, Bitbucket, or Gitlab. As mentioned previously, Codefresh is free for both open source and smaller private projects. We’ll use it to create the configuration Yaml necessary to deploy our application to Kubernetes. Then we'll deploy our application and automate the process to happen every time we commit code changes. Here are the steps:
- 1.Create a Codefresh account
- 2.Connect to Google Cloud (or other cluster)
- 3.Add Cluster
- 4.Deploy static image
- 5.Build and deploy an image
- 6.Automate the process
Connect to Google Cloud
To connect your Clusters in Google Container Engine, go to Account Settings > Integrations > Kubernetes and click Authenticate. This prompts you to login with your Google credentials.
Once you log in, all of your clusters are available within Codefresh.

Add Cluster
To add your cluster, click the down arrow, and then click add cluster, select the project and cluster name. You can now deploy images!
Optional: Use an Alternative Cluster
To connect a non-GKE cluster we’ll need to add a token and certificate to Codefresh. Go to Account Settings (bottom left) > Integrations > Kubernetes > Configure > Add Provider > Custom Providers. Expand the dropdown and click Add Cluster.

Follow the instructions on how to generate the needed information and click Save. Your cluster now appears under the Kubernetes tab.
Deploy Static Image to Kubernetes
Now for the fun part! Codefresh provides an easily modifiable boilerplate that takes care of the heavy lifting of configuring Kubernetes for your application.
- Click on the Kubernetes tab: this shows a list of namespaces.
Think of namespaces as acting a bit like VLANs on a Kubernetes cluster. Each namespace can contain all the services that need to talk to each other on a Kubernetes cluster. For now, we’ll just work off the default namespace (the easy way!).
- Click Add Service and fill in the details.
You can use the demo application I mentioned earlier that has a Node.js frontend with a MongoDB.

Here’s the info we need to pass:
Cluster - This is the cluster we added earlier, our application will be deployed there.
Namespace - We’ll use default for our namespace but you can create and use a new one if you’d prefer. Namespaces are discrete units for grouping all the services associated with an application.
Service name - You can name the service whatever you like. Since we’re deploying Mongo, I’ll just name it mongo!
Expose port - We don’t need to expose the port outside of our cluster so we won’t check the box for now but we will specify a port where other containers can talk to this service. Mongo’s default port is ‘27017’.
Image - Mongo is a public image on Dockerhub, so I can reference it by name and tag, ‘mongo:latest’.
Internal Ports - This is the port the mongo application listens on, in this case it’s ‘27017’ again.
We can ignore the other options for now.
- Scroll down and click Deploy.

Boom! You’ve just deployed this image to Kubernetes. You can see by clicking on the status that the service, deployment, replicas, and pods are all configured and running. If you click Edit > Advanced, you can see and edit all the raw YAML files associated with this application, or copy them and put them into your repository for use on any cluster.
Build and Deploy an Image
To get the rest of our demo application up and running we need to build and deploy the Node.js portion of the application. To do that we’ll need to add our repository to Codefresh.
- Click on Repositories > Add Repository, then copy and paste the demochat repo url (or use your own repo).

We have the option to use a dockerfile, or to use a template if we need help creating a dockerfile. In this case, the demochat repo already has a dockerfile so we’ll select that. Click through the next few screens until the image builds.
Once the build is finished the image is automatically saved inside of the Codefresh docker registry. You can also add any other registry to your account and use that instead.
To deploy the image we’ll need
- a pull secret
- the image name and registry
- the ports that will be used
Creating the Pull Secret
The pull secret is a token that the Kubernetes cluster can use to access a private Docker registry. To create one, we’ll need to generate the token and save it to Codefresh.
-
Click on User Settings (bottom left) and generate a new token.
-
Copy the token to your clipboard.

-
Go to Account Settings > Integrations > Docker Registry > Add Registry and select Codefresh Registry. Paste in your token and enter your username (entry is case sensitive). Your username must match your name displayed at the bottom left of the screen.
-
Test and save it.
We’ll now be able to create our secret later on when we deploy our image.
Get the image name
- Click on Images and open the image you just built. Under Comment you’ll see the image name starting with r.cfcr.io.

- Copy the image name; we’ll need to paste it in later.
Deploy the private image to Kubernetes
We’re now ready to deploy the image we built.
- Go to the Kubernetes page and, like we did with mongo, click Add Service and fill out the page. Make sure to select the same namespace you used to deploy mongo earlier.

Now let’s expose the port so we can access this application. This provisions an IP address and automatically configures ingress.
- Click Deploy : your application will be up and running within a few seconds! The IP address may take longer to provision depending on your cluster location.

From this view you can scale the replicas, see application status, and similar tasks.
- Click on the IP address to view the running application.

At this point you should have your entire application up and running! Not so bad huh? Now to automate deployment!
Automate Deployment to Kubernetes
Every time we make a change to our application, we want to build a new image and deploy it to our cluster. We’ve already set up automated builds, but to automate deployment:
-
Click on Repositories (top left).
-
Click on the pipeline for the demochat repo (the gear icon).

-
It’s a good idea to run some tests before deploying. Under Build and Unit Test, add npm test for the unit test script.
-
Click Deploy Script and select Kubernetes (Beta). Enter the information for the service you’ve already deployed.

You can see the option to use a deployment file from your repo, or to use the deployment file that you just generated.
- Click Save.
You’re done with deployment automation! Now whenever a change is made, the image will build, test, and deploy.
Conclusions
We want to make it easy for every team, not just big enterprise teams, to adopt Kubernetes while preserving all of Kubernetes’ power and flexibility. At any point on the Kubernetes service screen you can switch to YAML to view all of the YAMLfiles generated by the configuration you performed in this walkthrough. You can tweak the file content, copy and paste them into local files, etc.
This walkthrough gives everyone a solid base to start with. When you’re ready, you can tweak the entities directly to specify the exact configuration you’d like.
We’d love your feedback! Please share with us on Twitter, or reach out directly.
Addendums
Do you have a video to walk me through this? You bet.
Does this work with Helm Charts? Yes! We’re currently piloting Helm Charts with a limited set of users. Ping us if you’d like to try it early.
Does this work with any Kubernetes cluster? It should work with any Kubernetes cluster and is tested for Kubernetes 1.5 forward.
Can I deploy Codefresh in my own data center? Sure, Codefresh is built on top of Kubernetes using Helm Charts. Codefresh cloud is free for open source, and 200 builds/mo. Codefresh on prem is currently for enterprise users only.
Won’t the database be wiped every time we update? Yes, in this case we skipped creating a persistent volume. It’s a bit more work to get the persistent volume configured, if you’d like, feel free to reach out and we’re happy to help!
Enforcing Network Policies in Kubernetes
Editor's note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.8. Today’s post comes from Ahmet Alp Balkan, Software Engineer, Google.
Kubernetes now offers functionality to enforce rules about which pods can communicate with each other using network policies. This feature is has become stable Kubernetes 1.7 and is ready to use with supported networking plugins. The Kubernetes 1.8 release has added better capabilities to this feature.
Network policy: What does it mean?
In a Kubernetes cluster configured with default settings, all pods can discover and communicate with each other without any restrictions. The new Kubernetes object type NetworkPolicy lets you allow and block traffic to pods.
If you’re running multiple applications in a Kubernetes cluster or sharing a cluster among multiple teams, it’s a security best practice to create firewalls that permit pods to talk to each other while blocking other network traffic. Networking policy corresponds to the Security Groups concepts in the Virtual Machines world.
How do I add Network Policy to my cluster?
Networking Policies are implemented by networking plugins. These plugins typically install an overlay network in your cluster to enforce the Network Policies configured. A number of networking plugins, including Calico, Romana and Weave Net, support using Network Policies.
Google Container Engine (GKE) also provides beta support for Network Policies using the Calico networking plugin when you create clusters with the following command:
gcloud beta container clusters create --enable-network-policy
How do I configure a Network Policy?
Once you install a networking plugin that implements Network Policies, you need to create a Kubernetes resource of type NetworkPolicy. This object describes two set of label-based pod selector fields, matching:
- a set of pods the network policy applies to (required)
- a set of pods allowed access to each other (optional). If you omit this field, it matches to no pods; therefore, no pods are allowed. If you specify an empty pod selector, it matches to all pods; therefore, all pods are allowed.
Example: restricting traffic to a pod
The following example of a network policy blocks all in-cluster traffic to a set of web server pods, except the pods allowed by the policy configuration.

To achieve this setup, create a NetworkPolicy with the following manifest:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
app: foo
Once you apply this configuration, only pods with label app: foo can talk to the pods with the label app: nginx. For a more detailed tutorial, see the Kubernetes documentation.
Example: restricting traffic between all pods by default
If you specify the spec.podSelector field as empty, the set of pods the network policy matches to all pods in the namespace, blocking all traffic between pods by default. In this case, you must explicitly create network policies whitelisting all communication between the pods.

You can enable a policy like this by applying the following manifest in your Kubernetes cluster:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector:
Other Network Policy features
In addition to the previous examples, you can make the Network Policy API enforce more complicated rules:
- Egress network policies: Introduced in Kubernetes 1.8, you can restrict your workloads from establishing connections to resources outside specified IP ranges.
- IP blocks support: In addition to using podSelector/namespaceSelector, you can specify IP ranges with CIDR blocks to allow/deny traffic in ingress or egress rules.
- Cross-namespace policies: Using the ingress.namespaceSelector field, you can enforce Network Policies for particular or for all namespaces in the cluster. For example, you can create privileged/system namespaces that can communicate with pods even though the default policy is to block traffic.
- Restricting traffic to port numbers: Using the ingress.ports field, you can specify port numbers for the policy to enforce. If you omit this field, the policy matches all ports by default. For example, you can use this to allow a monitoring pod to query only the monitoring port number of an application.
- Multiple ingress rules on a single policy: Because spec.ingress field is an array, you can use the same NetworkPolicy object to give access to different ports using different pod selectors. For example, a NetworkPolicy can have one ingress rule giving pods with the kind: monitoring label access to port 9000, and another ingress rule for the label app: foo giving access to port 80, without creating an additional NetworkPolicy resource.
Learn more
- Read more: Networking Policy documentation
- Read more: Unofficial Network Policy Guide
- Hands-on: Declare a Network Policy
- Try: Network Policy Recipes
Using RBAC, Generally Available in Kubernetes v1.8
Editor's note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.8. Today’s post comes from Eric Chiang, software engineer, CoreOS, and SIG-Auth co-lead.
Kubernetes 1.8 represents a significant milestone for the role-based access control (RBAC) authorizer, which was promoted to GA in this release. RBAC is a mechanism for controlling access to the Kubernetes API, and since its beta in 1.6, many Kubernetes clusters and provisioning strategies have enabled it by default.
Going forward, we expect to see RBAC become a fundamental building block for securing Kubernetes clusters. This post explores using RBAC to manage user and application access to the Kubernetes API.
Granting access to users
RBAC is configured using standard Kubernetes resources. Users can be bound to a set of roles (ClusterRoles and Roles) through bindings (ClusterRoleBindings and RoleBindings). Users start with no permissions and must explicitly be granted access by an administrator.
All Kubernetes clusters install a default set of ClusterRoles, representing common buckets users can be placed in. The “edit” role lets users perform basic actions like deploying pods; “view” lets a user observe non-sensitive resources; “admin” allows a user to administer a namespace; and “cluster-admin” grants access to administer a cluster.
$ kubectl get clusterroles
NAME AGE
admin 40m
cluster-admin 40m
edit 40m
# ...
view 40m
ClusterRoleBindings grant a user, group, or service account a ClusterRole’s power across the entire cluster. Using kubectl, we can let a sample user “jane” perform basic actions in all namespaces by binding her to the “edit” ClusterRole:
$ kubectl create clusterrolebinding jane --clusterrole=edit --user=jane
$ kubectl get namespaces --as=jane
NAME STATUS AGE
default Active 43m
kube-public Active 43m
kube-system Active 43m
$ kubectl auth can-i create deployments --namespace=dev --as=jane
yes
RoleBindings grant a ClusterRole’s power within a namespace, allowing administrators to manage a central list of ClusterRoles that are reused throughout the cluster. For example, as new resources are added to Kubernetes, the default ClusterRoles are updated to automatically grant the correct permissions to RoleBinding subjects within their namespace.
Next we’ll let the group “infra” modify resources in the “dev” namespace:
$ kubectl create rolebinding infra --clusterrole=edit --group=infra --namespace=dev
rolebinding "infra" created
Because we used a RoleBinding, these powers only apply within the RoleBinding’s namespace. In our case, a user in the “infra” group can view resources in the “dev” namespace but not in “prod”:
$ kubectl get deployments --as=dave --as-group=infra --namespace dev
No resources found.
$ kubectl get deployments --as=dave --as-group=infra --namespace prod
Error from server (Forbidden): deployments.extensions is forbidden: User "dave" cannot list deployments.extensions in the namespace "prod".
Creating custom roles
When the default ClusterRoles aren’t enough, it’s possible to create new roles that define a custom set of permissions. Since ClusterRoles are just regular API resources, they can be expressed as YAML or JSON manifests and applied using kubectl.
Each ClusterRole holds a list of permissions specifying “rules.” Rules are purely additive and allow specific HTTP verb to be performed on a set of resource. For example, the following ClusterRole holds the permissions to perform any action on "deployments”, “configmaps,” or “secrets”, and to view any “pod”:
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: deployer
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "watch", "create", "delete", "update", "patch"]
- apiGroups: [""] # "" indicates the core API group
resources: ["configmaps", "secrets"]
verbs: ["get", "list", "watch", "create", "delete", "update", "patch"]
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "list", "watch"]
Verbs correspond to the HTTP verb of the request, while the resource and API groups refer to the resource being referenced. Consider the following Ingress resource:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
backend:
serviceName: testsvc
servicePort: 80
To POST the resource, the user would need the following permissions:
rules:
- apiGroups: ["extensions"] # "apiVersion" without version
resources: ["ingresses"] # Plural of "kind"
verbs: ["create"] # "POST" maps to "create"
Roles for applications
When deploying containers that require access to the Kubernetes API, it’s good practice to ship an RBAC Role with your application manifests. Besides ensuring your app works on RBAC enabled clusters, this helps users audit what actions your app will perform on the cluster and consider their security implications.
A namespaced Role is usually more appropriate for an application, since apps are traditionally run inside a single namespace and the namespace's resources should be tied to the lifecycle of the app. However, Roles cannot grant access to non-namespaced resources (such as nodes) or across namespaces, so some apps may still require ClusterRoles.
The following Role allows a Prometheus instance to monitor and discover services, endpoints, and pods in the “dev” namespace:
kind: Role
metadata:
name: prometheus-role
namespace: dev
rules:
- apiGroups: [""] # "" refers to the core API group
Resources: ["services", "endpoints", "pods"]
verbs: ["get", "list", "watch"]
Containers running in a Kubernetes cluster receive service account credentials to talk to the Kubernetes API, and service accounts can be targeted by a RoleBinding. Pods normally run with the “default” service account, but it’s good practice to run each app with a unique service account so RoleBindings don’t unintentionally grant permissions to other apps.
To run a pod with a custom service account, create a ServiceAccount resource in the same namespace and specify the serviceAccountName field of the manifest.
apiVersion: apps/v1beta2 # Abbreviated, not a full manifest
kind: Deployment
metadata:
name: prometheus-deployment
namespace: dev
spec:
replicas: 1
template:
spec:
containers:
- name: prometheus
image: prom/prometheus:v1.8.0
command: ["prometheus", "-config.file=/etc/prom/config.yml"]
# Run this pod using the "prometheus-sa" service account.
serviceAccountName: prometheus-sa
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus-sa
namespace: dev
Get involved
Development of RBAC is a community effort organized through the Auth Special Interest Group, one of the many SIGs responsible for maintaining Kubernetes. A great way to get involved in the Kubernetes community is to join a SIG that aligns with your interests, provide feedback, and help with the roadmap.
About the author
Eric Chiang is a software engineer and technical lead of Kubernetes development at CoreOS, the creator of Tectonic, the enterprise-ready Kubernetes platform. Eric co-leads Kubernetes SIG Auth and maintains several open source projects and libraries on behalf of CoreOS.
It Takes a Village to Raise a Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.8, written by Jaice Singer DuMars from Microsoft.
Each time we release a new version of Kubernetes, it’s enthralling to see how the community responds to all of the hard work that went into it. Blogs on new or enhanced capabilities crop up all over the web like wildflowers in the spring. Talks, videos, webinars, and demos are not far behind. As soon as the community seems to take this all in, we turn around and add more to the mix. It’s a thrilling time to be a part of this project, and even more so, the movement. It’s not just software anymore.
When circumstances opened the door for me to lead the 1.8 release, I signed on despite a minor case of the butterflies. In a private conversation with another community member, they assured me that “being organized, following up, and knowing when to ask for help” were the keys to being a successful lead. That’s when I knew I could do it — and so I did.
From that point forward, I was wrapped in a patchwork quilt of community that magically appeared at just the right moments. The community’s commitment and earnest passion for quality, consistency, and accountability formed a bedrock from which the release itself was chiseled.
The 1.8 release team proved incredibly cohesive despite a late start. We approached even the most difficult situations with humor, diligence, and sincere curiosity. My experience leading large teams served me well, and underscored another difference about this release: it was more valuable for me to focus on leadership than diving into the technical weeds to solve every problem.
Also, the uplifting power of emoji in Slack cannot be overestimated.
An important inflection point is underway in the Kubernetes project. If you’ve taken a ride on a “startup rollercoaster,” this is a familiar story. You come up with an idea so crazy that it might work. You build it, get traction, and slowly clickity-clack up that first big hill. The view from the top is dizzying, as you’ve poured countless hours of life into something completely unknown. Once you go over the top of that hill, everything changes. Breakneck acceleration defines or destroys what has been built.
In my experience, that zero gravity point is where everyone in the company (or in this case, project) has to get serious about not only building something, but also maintaining it. Without a commitment to maintenance, things go awry really quickly. From codebases that resemble the Winchester Mystery House to epidemics of crashing production implementations, a fiery descent into chaos can happen quickly despite the outward appearance of success. Thankfully, the Kubernetes community seems to be riding our growth rollercoaster with increasing success at each release.
As software startups mature, there is a natural evolution reflected in the increasing distribution of labor. Explosive adoption means that full-time security, operations, quality, documentation, and project management staff become necessary to deliver stability, reliability, and extensibility. Also, you know things are getting serious when intentional architecture becomes necessary to ensure consistency over time.
Kubernetes has followed a similar path. In the absence of company departments or skill-specific teams, Special Interest Groups (SIGs) have organically formed around core project needs like storage, networking, API machinery, applications, and the operational lifecycle. As SIGs have proliferated, the Kubernetes governance model has crystallized around them, providing a framework for code ownership and shared responsibility. SIGs also help ensure the community is sustainable because success is often more about people than code.
At the Kubernetes leadership summit in June, a proposed SIG architecture was ratified with a unanimous vote, underscoring a stability theme that seemed to permeate every conversation in one way or another. The days of filling in major functionality gaps appear to be over, and a new era of feature depth has emerged in its place.
Another change is the move away from project-level release “feature themes” to SIG-level initiatives delivered in increments over the course of several releases. That’s an important shift: SIGs have a mission, and everything they deliver should ultimately serve that. As a community, we need to provide facilitation and support so SIGs are empowered to do their best work with minimal overhead and maximum transparency.
Wisely, the community also spotted the opportunity to provide safe mechanisms for innovation that are increasingly less dependent on the code in kubernetes/kubernetes. This in turn creates a flourishing habitat for experimentation without hampering overall velocity. The project can also address technical debt created during the initial ride up the rollercoaster. However, new mechanisms for innovation present an architectural challenge in defining what is and is not Kubernetes. SIG Architecture addresses the challenge of defining Kubernetes’ boundaries. It’s a work in progress that trends toward continuous improvement.
This can be a little overwhelming at the individual level. In reality, it’s not that much different from any other successful startup, save for the fact that authority does not come from a traditional org chart. It comes from SIGs, community technical leaders, the newly-formed steering committee, and ultimately you.
The Kubernetes release process provides a special opportunity to see everything that makes this project tick. I’ll tell you what I saw: people, working together, to do the best they can, in service to everyone who sets out on the cloud native journey.
kubeadm v1.8 Released: Introducing Easy Upgrades for Kubernetes Clusters
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.8
Since its debut in September 2016, the Cluster Lifecycle Special Interest Group (SIG) has established kubeadm as the easiest Kubernetes bootstrap method. Now, we’re releasing kubeadm v1.8.0 in tandem with the release of Kubernetes v1.8.0. In this blog post, I’ll walk you through the changes we’ve made to kubeadm since the last update, the scope of kubeadm, and how you can contribute to this effort.
Security first: kubeadm v1.6 & v1.7
Previously, we discussed planned updates for kubeadm v1.6. Our primary focus for v1.6 was security. We started enforcing role based access control (RBAC) as it graduated to beta, gave unique identities and locked-down privileges for different system components in the cluster, disabled the insecure localhost:8080 API server port, started authorizing all API calls to the kubelets, and improved the token discovery method used formerly in v1.5. Token discovery (aka Bootstrap Tokens) graduated to beta in v1.8.
In number of features, kubeadm v1.7.0 was a much smaller release compared to v1.6.0 and v1.8.0. The main additions were enforcing the Node Authorizer, which significantly reduces the attack surface for a Kubernetes cluster, and initial, limited upgrading support from v1.6 clusters.
Easier upgrades, extensibility, and stabilization in v1.8
We had eight weeks between Kubernetes v1.7.0 and our stabilization period (code freeze) to implement new features and to stabilize the upcoming v1.8.0 release. Our goal for kubeadm v1.8.0 was to make it more extensible. We wanted to add a lot of new features and improvements in this cycle, and we succeeded.Upgrades along with better introspectability. The most important update in kubeadm v1.8.0 (and my favorite new feature) is one-command upgrades of the control plane. While v1.7.0 had the ability to upgrade clusters, the user experience was far from optimal, and the process was risky.
Now, you can easily check to see if your system can handle an upgrade by entering:
$ kubeadm upgrade plan
This gives you information about which versions you can upgrade to, as well as the health of your cluster.
You can examine the effects an upgrade will have on your system by specifying the --dry-run flag. In previous versions of kubeadm, upgrades were essentially blind in that you could only make assumptions about how an upgrade would impact your cluster. With the new dry run feature, there is no more mystery. You can see exactly what applying an upgrade would do before applying it.
After checking to see how an upgrade will affect your cluster, you can apply the upgrade by typing:
$ kubeadm upgrade apply v1.8.0
This is a much cleaner and safer way of performing an upgrade than the previous version. As with any type of upgrade or downgrade, it’s a good idea to backup your cluster first using your preferred solution.
Self-hosting
Self-hosting in this context refers to a specific way of setting up the control plane. The self-hosting concept was initially developed by CoreOS in their bootkube project. The long-term goal is to move this functionality (currently in an alpha stage) to the generic kubeadm toolbox. Self-hosting means that the control plane components, the API Server, Controller Manager and Scheduler are workloads themselves in the cluster they run. This means the control plane components can be managed using Kubernetes primitives, which has numerous advantages. For instance, leader-elected components like the scheduler and controller-manager will automatically be run on all masters when HA is implemented if they are run in a DaemonSet. Rolling upgrades in Kubernetes can be used for upgrades of the control plane components, and next to no extra code has to be written for that to work; it’s one of Kubernetes’ built-in primitives!
Self-hosting won’t be the default until v1.9.0, but users can easily test the feature in experimental clusters. If you test this feature, we’d love your feedback!
You can test out self-hosting by enabling its feature gate:
$ kubeadm init --feature-gates=SelfHosting=true
Extensibility
We’ve added some new extensibility features. You can delegate some tasks, like generating certificates or writing control plane arguments to kubeadm, but still drive the control plane bootstrap process yourself. Basically, you can let kubeadm do some parts and fill in yourself where you need customizations. Previously, you could only use kubeadm init to perform “the full meal deal.” The inclusion of the kubeadm alpha phase command supports our aim to make kubeadm more modular, letting you invoke atomic sub-steps of the bootstrap process.
In v1.8.0, kubeadm alpha phase is just that: an alpha preview. We hope that we can graduate the command to beta as kubeadm phase in v1.9.0. We can’t wait for feedback from the community on how to better improve this feature!
Improvements
Along with our new kubeadm features, we’ve also made improvements to existing ones. The Bootstrap Token feature that makes kubeadm join so short and sweet has graduated from alpha to beta and gained even more security features.
If you made customizations to your system in v1.6 or v1.7, you had to remember what those customizations were when you upgraded your cluster. No longer: beginning with v1.8.0, kubeadm uploads your configuration to a ConfigMap inside of the cluster, and later reads that configuration when upgrading for a seamless user experience.
The first certificate rotation feature has graduated to beta in v1.8, which is great to see. Thanks to the Auth Special Interest Group, the Kubernetes node component kubelet can now rotate its client certificate automatically. We expect this area to improve continuously, and will continue to be a part of this cross-SIG effort to easily rotate all certificates in any cluster.
Last but not least, kubeadm is more resilient now. kubeadm init will detect even more faulty environments earlier, and time out instead of waiting forever for the expected condition.
The scope of kubeadm
As there are so many different end-to-end installers for Kubernetes, there is some fragmentation in the ecosystem. With each new release of Kubernetes, these installers naturally become more divergent. This can create problems down the line if users rely on installer-specific variations and hooks that aren’t standardized in any way. Our goal from the beginning has been to make kubeadm a building block for deploying Kubernetes clusters and to provide kubeadm init and kubeadm join as best-practice “fast paths” for new Kubernetes users. Ideally, using kubeadm as the basis of all deployments will make it easier to create conformant clusters.
kubeadm performs the actions necessary to get a minimum viable cluster up and running. It only cares about bootstrapping, not about provisioning machines, by design. Likewise, installing various nice-to-have addons by default like the Kubernetes Dashboard, some monitoring solution, cloud provider-specific addons, etc. is not in scope. Instead, we expect higher-level and more tailored tooling to be built on top of kubeadm, that installs the software the end user needs.
v1.9.0 and beyond
What’s in store for the future of kubeadm?
Planned features
We plan to address high availability (replicated etcd and multiple, redundant API servers and other control plane components) as an alpha feature in v1.9.0. This has been a regular request from our user base.
Also, we want to make self-hosting the default way to deploy your control plane: Kubernetes becomes much easier to manage if we can rely on Kubernetes' own tools to manage the cluster components.
Promoting kubeadm adoption and getting involved
The kubeadm adoption working group is an ongoing effort between SIG Cluster Lifecycle and other parties in the Kubernetes ecosystem. This working group focuses on making kubeadm more extensible in order to promote adoption of it for other end-to-end installers in the community. Everyone is welcome to join. So far, we’re glad to announce that kubespray started using kubeadm under the hood, and gained new features at the same time! We’re excited to see others follow and make the ecosystem stronger.
kubeadm is a great way to learn about Kubernetes: it binds all of Kubernetes’ components together in a single package. To learn more about what kubeadm really does under the hood, this document describes kubeadm functions in v1.8.0.
If you want to get involved in these efforts, join SIG Cluster Lifecycle. We meet on Zoom once a week on Tuesdays at 16:00 UTC. For more information about what we talk about in our weekly meetings, check out our meeting notes. Meetings are a great educational opportunity, even if you don’t want to jump in and present your own ideas right away. You can also sign up for our mailing list, join our Slack channel, or check out the video archive of our past meetings. Even if you’re only interested in watching the video calls initially, we’re excited to welcome you as a new member to SIG Cluster Lifecycle!
If you want to know what a kubeadm developer does at a given time in the Kubernetes release cycle, check out this doc. Finally, don’t hesitate to join if any of our upcoming projects are of interest to you!
Thank you,
Lucas Käldström
Kubernetes maintainer & SIG Cluster Lifecycle co-lead
Weaveworks contractor
Five Days of Kubernetes 1.8
Kubernetes 1.8 is live, made possible by hundreds of contributors pushing thousands of commits in this latest releases.
The community has tallied more than 66,000 commits in the main repo and continues rapid growth outside of the main repo, which signals growing maturity and stability for the project. The community has logged more than 120,000 commits across all repos and 17,839 commits across all repos for v1.7.0 to v1.8.0 alone.
With the help of our growing community of 1,400 plus contributors, we issued more than 3,000 PRs and pushed more than 5,000 commits to deliver Kubernetes 1.8 with significant security and workload support updates. This all points to increased stability, a result of our project-wide focus on maturing process, formalizing architecture, and strengthening Kubernetes’ governance model.
While many improvements have been contributed, we highlight key features in this series of in-depth posts listed below. Follow along and see what’s new and improved with storage, security and more.
Day 1: 5 Days of Kubernetes 1.8
Day 2: kubeadm v1.8 Introduces Easy Upgrades for Kubernetes Clusters
Day 3: Kubernetes v.1.8 Retrospective: It Takes a Village to Raise a Kubernetes
Day 4: Using RBAC, Generally Available in Kubernetes v1.8
Day 5: Enforcing Network Policies in Kubernetes
Connect
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Get involved with the Kubernetes project on GitHub
Introducing Software Certification for Kubernetes
Editor's Note: Today's post is by William Denniss, Product Manager, Google Cloud on the new Certified Kubernetes Conformance Program.
Over the last three years, Kubernetes® has seen wide-scale adoption by a vibrant and diverse community of providers. In fact, there are now more than 60 known Kubernetes platforms and distributions. From the start, one goal of Kubernetes has been consistency and portability.
In order to better serve this goal, today the Kubernetes community and the Cloud Native Computing Foundation® (CNCF®) announce the availability of the beta Certified Kubernetes Conformance Program. The Kubernetes conformance certification program gives users the confidence that when they use a Certified Kubernetes™ product, they can rely on a high level of common functionality. Certification provides Independent Software Vendors (ISVs) confidence that if their customer is using a Certified Kubernetes product, their software will behave as expected.
CNCF and the Kubernetes Community invites all vendors to run the conformance test suite, and submit conformance testing results for review and certification by the CNCF. When the program graduates to GA (generally available) later this year, all vendors receiving certification during the beta period will be listed in the launch announcement.
Just like Kubernetes itself, conformance certification is an evolving program managed by contributors in our community. Certification is versioned alongside Kubernetes, and certification requirements receive updates with each version of Kubernetes as features are added and the architecture changes. The Kubernetes community, through SIG Architecture, controls changes and overseers what it means to be Certified Kubernetes. The Testing SIG works on the mechanics of conformance tests, while the Conformance Working Group develops process and policy for the certification program.

Once the program moves to GA, certified products can proudly display the new Certified Kubernetes logo mark with stylized version information on their marketing materials. Certified products can also take advantage of a new combination trademark rule the CNCF adopted for Certified Kubernetes providers that keep their certification up to date.
Products must complete a recertification each year for the current or previous version of Kubernetes to remain certified. This ensures that when you see the Certified Kubernetes™ mark on a product, you’re not only getting something that’s proven conformant, but also contains the latest features and improvements from the community.
Visit https://github.com/cncf/k8s-conformance for more information about the Certified Kubernetes Conformance Program, and learn how you can include your product in a growing list of Certified Kubernetes providers.
“Cloud Native Computing Foundation”, “CNCF” and “Kubernetes” are registered trademarks of The Linux Foundation in the United States and other countries. “Certified Kubernetes” and the Certified Kubernetes design are trademarks of The Linux Foundation in the United States and other countries.
Request Routing and Policy Management with the Istio Service Mesh
Editor's note: Today’s post by Frank Budinsky, Software Engineer, IBM, Andra Cismaru, Software Engineer, Google, and Israel Shalom, Product Manager, Google, is the second post in a three-part series on Istio. It offers a closer look at request routing and policy management.
In a previous article, we looked at a simple application (Bookinfo) that is composed of four separate microservices. The article showed how to deploy an application with Kubernetes and an Istio-enabled cluster without changing any application code. The article also outlined how to view Istio provided L7 metrics on the running services.
This article follows up by taking a deeper look at Istio using Bookinfo. Specifically, we’ll look at two more features of Istio: request routing and policy management.
Running the Bookinfo Application
As before, we run the v1 version of the Bookinfo application. After installing Istio in our cluster, we start the app defined in bookinfo-v1.yaml using the following command:
kubectl apply -f \<(istioctl kube-inject -f bookinfo-v1.yaml)
We created an Ingress resource for the app:
cat \<\<EOF | kubectl create -f -
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: bookinfo
annotations:
kubernetes.io/ingress.class: "istio"
spec:
rules:
- http:
paths:
- path: /productpage
backend:
serviceName: productpage
servicePort: 9080
- path: /login
backend:
serviceName: productpage
servicePort: 9080
- path: /logout
backend:
serviceName: productpage
servicePort: 9080
EOF
Then we retrieved the NodePort address of the Istio Ingress controller:
export BOOKINFO\_URL=$(kubectl get po -n istio-system -l istio=ingress -o jsonpath={.items[0].status.hostIP}):$(kubectl get svc -n istio-system istio-ingress -o jsonpath={.spec.ports[0].nodePort})
Finally, we pointed our browser to http://$BOOKINFO_URL/productpage, to see the running v1 application:

HTTP request routing
Existing container orchestration platforms like Kubernetes, Mesos, and other microservice frameworks allow operators to control when a particular set of pods/VMs should receive traffic (e.g., by adding/removing specific labels). Unlike existing techniques, Istio decouples traffic flow and infrastructure scaling. This allows Istio to provide a variety of traffic management features that reside outside the application code, including dynamic HTTP request routing for A/B testing, canary releases, gradual rollouts, failure recovery using timeouts, retries, circuit breakers, and fault injection to test compatibility of failure recovery policies across services.
To demonstrate, we’ll deploy v2 of the reviews service and use Istio to make it visible only for a specific test user. We can create a Kubernetes deployment, reviews-v2, with this YAML file:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: reviews-v2
spec:
replicas: 1
template:
metadata:
labels:
app: reviews
version: v2
spec:
containers:
- name: reviews
image: istio/examples-bookinfo-reviews-v2:0.2.3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9080
From a Kubernetes perspective, the v2 deployment adds additional pods that the reviews service selector includes in the round-robin load balancing algorithm. This is also the default behavior for Istio.
Before we start reviews:v2, we’ll start the last of the four Bookinfo services, ratings, which is used by the v2 version to provide ratings stars corresponding to each review:
kubectl apply -f \<(istioctl kube-inject -f bookinfo-ratings.yaml)
If we were to start reviews:v2 now, we would see browser responses alternating between v1 (reviews with no corresponding ratings) and v2 (review with black rating stars). This will not happen, however, because we’ll use Istio’s traffic management feature to control traffic.
With Istio, new versions don’t need to become visible based on the number of running pods. Version visibility is controlled instead by rules that specify the exact criteria. To demonstrate, we start by using Istio to specify that we want to send 100% of reviews traffic to v1 pods only.
Immediately setting a default rule for every service in the mesh is an Istio best practice. Doing so avoids accidental visibility of newer, potentially unstable versions. For the purpose of this demonstration, however, we’ll only do it for the reviews service:
cat \<\<EOF | istioctl create -f -
apiVersion: config.istio.io/v1alpha2
kind: RouteRule
metadata:
name: reviews-default
spec:
destination:
name: reviews
route:
- labels:
version: v1
weight: 100
EOF
This command directs the service mesh to send 100% of traffic for the reviews service to pods with the label “version: v1”. With this rule in place, we can safely deploy the v2 version without exposing it.
kubectl apply -f \<(istioctl kube-inject -f bookinfo-reviews-v2.yaml)
Refreshing the Bookinfo web page confirms that nothing has changed.
At this point we have all kinds of options for how we might want to expose reviews:v2. If for example we wanted to do a simple canary test, we could send 10% of the traffic to v2 using a rule like this:
apiVersion: config.istio.io/v1alpha2
kind: RouteRule
metadata:
name: reviews-default
spec:
destination:
name: reviews
route:
- labels:
version: v2
weight: 10
- labels:
version: v1
weight: 90
A better approach for early testing of a service version is to instead restrict access to it much more specifically. To demonstrate, we’ll set a rule to only make reviews:v2 visible to a specific test user. We do this by setting a second, higher priority rule that will only be applied if the request matches a specific condition:
cat \<\<EOF | istioctl create -f -
apiVersion: config.istio.io/v1alpha2
kind: RouteRule
metadata:
name: reviews-test-v2
spec:
destination:
name: reviews
precedence: 2
match:
request:
headers:
cookie:
regex: "^(.\*?;)?(user=jason)(;.\*)?$"
route:
- labels:
version: v2
weight: 100
EOF
Here we’re specifying that the request headers need to include a user cookie with value “tester” as the condition. If this rule is not matched, we fall back to the default routing rule for v1.
If we login to the Bookinfo UI with the user name “tester” (no password needed), we will now see version v2 of the application (each review includes 1-5 black rating stars). Every other user is unaffected by this change.

Once the v2 version has been thoroughly tested, we can use Istio to proceed with a canary test using the rule shown previously, or we can simply migrate all of the traffic from v1 to v2, optionally in a gradual fashion by using a sequence of rules with weights less than 100 (for example: 10, 20, 30, ... 100). This traffic control is independent of the number of pods implementing each version. If, for example, we had auto scaling in place, and high traffic volumes, we would likely see a corresponding scale up of v2 and scale down of v1 pods happening independently at the same time. For more about version routing with autoscaling, check out "Canary Deployments using Istio".
In our case, we’ll send all of the traffic to v2 with one command:
cat \<\<EOF | istioctl replace -f -
apiVersion: config.istio.io/v1alpha2
kind: RouteRule
metadata:
name: reviews-default
spec:
destination:
name: reviews
route:
- labels:
version: v2
weight: 100
EOF
We should also remove the special rule we created for the tester so that it doesn’t override any future rollouts we decide to do:
istioctl delete routerule reviews-test-v2
In the Bookinfo UI, we’ll see that we are now exposing the v2 version of reviews to all users.
Policy enforcement
Istio provides policy enforcement functions, such as quotas, precondition checking, and access control. We can demonstrate Istio’s open and extensible framework for policies with an example: rate limiting.
Let’s pretend that the Bookinfo ratings service is an external paid service--for example, Rotten Tomatoes®--with a free quota of 1 request per second (req/sec). To make sure the application doesn’t exceed this limit, we’ll specify an Istio policy to cut off requests once the limit is reached. We’ll use one of Istio’s built-in policies for this purpose.
To set a 1 req/sec quota, we first configure a memquota handler with rate limits:
cat \<\<EOF | istioctl create -f -
apiVersion: "config.istio.io/v1alpha2"
kind: memquota
metadata:
name: handler
namespace: default
spec:
quotas:
- name: requestcount.quota.default
maxAmount: 5000
validDuration: 1s
overrides:
- dimensions:
destination: ratings
maxAmount: 1
validDuration: 1s
EOF
Then we create a quota instance that maps incoming attributes to quota dimensions, and create a rule that uses it with the memquota handler:
cat \<\<EOF | istioctl create -f -
apiVersion: "config.istio.io/v1alpha2"
kind: quota
metadata:
name: requestcount
namespace: default
spec:
dimensions:
source: source.labels["app"] | source.service | "unknown"
sourceVersion: source.labels["version"] | "unknown"
destination: destination.labels["app"] | destination.service | "unknown"
destinationVersion: destination.labels["version"] | "unknown"
---
apiVersion: "config.istio.io/v1alpha2"
kind: rule
metadata:
name: quota
namespace: default
spec:
actions:
- handler: handler.memquota
instances:
- requestcount.quota
EOF
To see the rate limiting in action, we’ll generate some load on the application:
wrk -t1 -c1 -d20s http://$BOOKINFO\_URL/productpage
In the web browser, we’ll notice that while the load generator is running (i.e., generating more than 1 req/sec), browser traffic is cut off. Instead of the black stars next to each review, the page now displays a message indicating that ratings are not currently available.
Stopping the load generator means the limit will no longer be exceeded: the black stars return when we refresh the page.
Summary
We’ve shown you how to introduce advanced features like HTTP request routing and policy injection into a service mesh configured with Istio without restarting any of the services. This lets you develop and deploy without worrying about the ongoing management of the service mesh; service-wide policies can always be added later.
In the next and last installment of this series, we’ll focus on Istio’s security and authentication capabilities. We’ll discuss how to secure all interservice communications in a mesh, even against insiders with access to the network, without any changes to the application code or the deployment.
Kubernetes Community Steering Committee Election Results
Beginning with the announcement of Kubernetes 1.0 at OSCON in 2015, there has been a concerted effort to share the power and burden of leadership across the Kubernetes community.
With the work of the Bootstrap Governance Committee, consisting of Brandon Philips, Brendan Burns, Brian Grant, Clayton Coleman, Joe Beda, Sarah Novotny and Tim Hockin - a cross section of long-time leaders representing 5 different companies with major investments of talent and effort in the Kubernetes Ecosystem - we wrote an initial Steering Committee Charter and launched a community wide election to seat a Kubernetes Steering Committee.
To quote from the Charter -
The initial role of the steering committee is to instantiate the formal process for Kubernetes governance. In addition to defining the initial governance process, the bootstrap committee strongly believes that it is important to provide a means for iterating the processes defined by the steering committee. We do not believe that we will get it right the first time, or possibly ever, and won’t even complete the governance development in a single shot. The role of the steering committee is to be a live, responsive body that can refactor and reform as necessary to adapt to a changing project and community.
This is our largest step yet toward making an implicit governance structure explicit. Kubernetes vision has been one of an inclusive and broad community seeking to build software which empowers our users with the portability of containers. The Steering Committee will be a strong leadership voice guiding the project toward success.
The Kubernetes Community is pleased to announce the results of the 2017 Steering Committee Elections. Please congratulate Aaron Crickenberger, Derek Carr, Michelle Noorali, Phillip Wittrock, Quinton Hoole and Timothy St. Clair , who will be joining the members of the Bootstrap Governance committee on the newly formed Kubernetes Steering Committee. Derek, Michelle, and Phillip will serve for 2 years. Aaron, Quinton, and Timothy will serve for 1 year.
This group will meet regularly in order to clarify and streamline the structure and operation of the project. Early work will include electing a representative to the CNCF Governing Board, evolving project processes, refining and documenting the vision and scope of the project, and chartering and delegating to more topical community groups.
Please see the full Steering Committee backlog for more details.
Kubernetes 1.8: Security, Workloads and Feature Depth
Editor's note: today's post is by Aparna Sinha, Group Product Manager, Kubernetes, Google; Ihor Dvoretskyi, Developer Advocate, CNCF; Jaice Singer DuMars, Kubernetes Ambassador, Microsoft; and Caleb Miles, Technical Program Manager, CoreOS on the latest release of Kubernetes 1.8.
We’re pleased to announce the delivery of Kubernetes 1.8, our third release this year. Kubernetes 1.8 represents a snapshot of many exciting enhancements and refinements underway. In addition to functional improvements, we’re increasing project-wide focus on maturing process, formalizing architecture, and strengthening Kubernetes’ governance model. The evolution of mature processes clearly signals that sustainability is a driving concern, and helps to ensure that Kubernetes is a viable and thriving project far into the future.
Spotlight on security
Kubernetes 1.8 graduates support for role based access control (RBAC) to stable. RBAC allows cluster administrators to dynamically define roles to enforce access policies through the Kubernetes API. Beta support for filtering outbound traffic through network policies augments existing support for filtering inbound traffic to a pod. RBAC and Network Policies are two powerful tools for enforcing organizational and regulatory security requirements within Kubernetes.
Transport Layer Security (TLS) certificate rotation for the Kubelet graduates to beta. Automatic certificate rotation eases secure cluster operation.
Spotlight on workload support
Kubernetes 1.8 promotes the core Workload APIs to beta with the apps/v1beta2 group and version. The beta contains the current version of Deployment, DaemonSet, ReplicaSet, and StatefulSet. The Workloads APIs provide a stable foundation for migrating existing workloads to Kubernetes as well as developing cloud native applications that target Kubernetes natively.
For those considering running Big Data workloads on Kubernetes, the Workloads API now enables native Kubernetes support in Apache Spark.
Batch workloads, such as nightly ETL jobs, will benefit from the graduation of CronJobs to beta.
Custom Resource Definitions (CRDs) remain in beta for Kubernetes 1.8. A CRD provides a powerful mechanism to extend Kubernetes with user-defined API objects. One use case for CRDs is the automation of complex stateful applications such as key-value stores, databases and storage engines through the Operator Pattern. Expect continued enhancements to CRDs such as validation as stabilization continues.
Spoilers ahead
Volume snapshots, PV resizing, automatic taints, priority pods, kubectl plugins, oh my!
In addition to stabilizing existing functionality, Kubernetes 1.8 offers a number of alpha features that preview new functionality.
Each Special Interest Group (SIG) in the community continues to deliver the most requested user features for their area. For a complete list, please visit the release notes.
Availability
Kubernetes 1.8 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials.
Release team
The Release team for 1.8 was led by Jaice Singer DuMars, Kubernetes Ambassador at Microsoft, and was comprised of 14 individuals responsible for managing all aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process has become an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid clip. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem.
User Highlights
According to Redmonk, 54 percent of Fortune 100 companies are running Kubernetes in some form with adoption coming from every sector across the world. Recent user stories from the community include:
- Ancestry.com currently holds 20 billion historical records and 90 million family trees, making it the largest consumer genomics DNA network in the world. With the move to Kubernetes, its deployment time for its Shaky Leaf icon service was cut down from 50 minutes to 2 or 5 minutes.
- Wink, provider of smart home devices and apps, runs 80 percent of its workloads on a unified stack of Kubernetes-Docker-CoreOS, allowing them to continually innovate and improve its products and services.
- Pear Deck, a teacher communication app for students, ported their Heroku apps into Kubernetes, allowing them to deploy the exact same configuration in lots of different clusters in 30 seconds.
- Buffer, social media management for agencies and marketers, has a remote team of 80 spread across a dozen different time zones. Kubernetes has provided the kind of liquid infrastructure where a developer could create an app and deploy it and scale it horizontally as necessary.
Is Kubernetes helping your team? Share your story with the community.
Ecosystem updates
Announced on September 11, Kubernetes Certified Service Providers (KCSPs) are pre-qualified organizations with deep experience helping enterprises successfully adopt Kubernetes. Individual professionals can now register for the new Certified Kubernetes Administrator (CKA) program and exam, which requires passing an online, proctored, performance-based exam that tests one’s ability to solve multiple issues in a hands-on, command-line environment.
CNCF also offers online training that teaches the skills needed to create and configure a real-world Kubernetes cluster.
KubeCon
Join the community at KubeCon + CloudNativeCon in Austin, December 6-8 for the largest Kubernetes gathering ever. The premiere Kubernetes event will feature technical sessions, case studies, developer deep dives, salons and more! A full schedule of events and speakers will be available here on September 28. Discounted registration ends October 6.
Open Source Summit EU
Ihor Dvoretskyi, Kubernetes 1.8 features release lead, will present new features and enhancements at Open Source Summit EU in Prague, October 23. Registration is still open.
Get involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below.
- Thank you for your continued feedback and support.
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Chat with the community on Slack.
- Share your Kubernetes story.
Kubernetes StatefulSets & DaemonSets Updates
Editor's note: today's post is by Janet Kuo and Kenneth Owens, Software Engineers at Google.
This post talks about recent updates to the DaemonSet and StatefulSet API objects for Kubernetes. We explore these features using Apache ZooKeeper and Apache Kafka StatefulSets and a Prometheus node exporter DaemonSet.
In Kubernetes 1.6, we added the RollingUpdate update strategy to the DaemonSet API Object. Configuring your DaemonSets with the RollingUpdate strategy causes the DaemonSet controller to perform automated rolling updates to the Pods in your DaemonSets when their spec.template are updated.
In Kubernetes 1.7, we enhanced the DaemonSet controller to track a history of revisions to the PodTemplateSpecs of DaemonSets. This allows the DaemonSet controller to roll back an update. We also added the RollingUpdate strategy to the StatefulSet API Object, and implemented revision history tracking for the StatefulSet controller. Additionally, we added the Parallel pod management policy to support stateful applications that require Pods with unique identities but not ordered Pod creation and termination.
StatefulSet rolling update and Pod management policy
First, we’re going to demonstrate how to use StatefulSet rolling updates and Pod management policies by deploying a ZooKeeper ensemble and a Kafka cluster.
Prerequisites
To follow along, you’ll need to set up a Kubernetes 1.7 cluster with at least 3 schedulable nodes. Each node needs 1 CPU and 2 GiB of memory available. You will also need either a dynamic provisioner to allow the StatefulSet controller to provision 6 persistent volumes (PVs) with 10 GiB each, or you will need to manually provision the PVs prior to deploying the ZooKeeper ensemble or deploying the Kafka cluster.
Deploying a ZooKeeper ensemble
Apache ZooKeeper is a strongly consistent, distributed system used by other distributed systems for cluster coordination and configuration management.
Note: You can create a ZooKeeper ensemble using this zookeeper_mini.yaml manifest. You can learn more about running a ZooKeeper ensemble on Kubernetes here, as well as a more in-depth explanation of the manifest and its contents.
When you apply the manifest, you will see output like the following.
$ kubectl apply -f zookeeper\_mini.yaml
service "zk-hs" created
service "zk-cs" created
poddisruptionbudget "zk-pdb" created
statefulset "zk" created
The manifest creates an ensemble of three ZooKeeper servers using a StatefulSet, zk; a Headless Service, zk-hs, to control the domain of the ensemble; a Service, zk-cs, that clients can use to connect to the ready ZooKeeper instances; and a PodDisruptionBugdet, zk-pdb, that allows for one planned disruption. (Note that while this ensemble is suitable for demonstration purposes, it isn’t sized correctly for production use.)
If you use kubectl get to watch Pod creation in another terminal you will see that, in contrast to the OrderedReady strategy (the default policy that implements the full version of the StatefulSet guarantees), all of the Pods in the zk StatefulSet are created in parallel.
$ kubectl get po -lapp=zk -w
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-2 0/1 Pending 0 0s
zk-1 0/1 ContainerCreating 0 0s
zk-2 0/1 Pending 0 0s
zk-2 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 10s
zk-2 0/1 Running 0 11s
zk-1 0/1 Running 0 19s
zk-0 1/1 Running 0 20s
zk-1 1/1 Running 0 30s
zk-2 1/1 Running 0 30s
This is because the zookeeper_mini.yaml manifest sets the podManagementPolicy of the StatefulSet to Parallel.
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: zk
spec:
serviceName: zk-hs
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: Parallel
...
Many distributed systems, like ZooKeeper, do not require ordered creation and termination for their processes. You can use the Parallel Pod management policy to accelerate the creation and deletion of StatefulSets that manage these systems. Note that, when Parallel Pod management is used, the StatefulSet controller will not block when it fails to create a Pod. Ordered, sequential Pod creation and termination is performed when a StatefulSet’s podManagementPolicy is set to OrderedReady.
Deploying a Kafka Cluster
Apache Kafka is a popular distributed streaming platform. Kafka producers write data to partitioned topics which are stored, with a configurable replication factor, on a cluster of brokers. Consumers consume the produced data from the partitions stored on the brokers.
Note: Details of the manifests contents can be found here. You can learn more about running a Kafka cluster on Kubernetes here.
To create a cluster, you only need to download and apply the kafka_mini.yaml manifest. When you apply the manifest, you will see output like the following:
$ kubectl apply -f kafka\_mini.yaml
service "kafka-hs" created
poddisruptionbudget "kafka-pdb" created
statefulset "kafka" created
The manifest creates a three broker cluster using the kafka StatefulSet, a Headless Service, kafka-hs, to control the domain of the brokers; and a PodDisruptionBudget, kafka-pdb, that allows for one planned disruption. The brokers are configured to use the ZooKeeper ensemble we created above by connecting through the zk-cs Service. As with the ZooKeeper ensemble deployed above, this Kafka cluster is fine for demonstration purposes, but it’s probably not sized correctly for production use.
If you watch Pod creation, you will notice that, like the ZooKeeper ensemble created above, the Kafka cluster uses the Parallel podManagementPolicy.
$ kubectl get po -lapp=kafka -w
NAME READY STATUS RESTARTS AGE
kafka-0 0/1 Pending 0 0s
kafka-0 0/1 Pending 0 0s
kafka-1 0/1 Pending 0 0s
kafka-1 0/1 Pending 0 0s
kafka-2 0/1 Pending 0 0s
kafka-0 0/1 ContainerCreating 0 0s
kafka-2 0/1 Pending 0 0s
kafka-1 0/1 ContainerCreating 0 0s
kafka-1 0/1 Running 0 11s
kafka-0 0/1 Running 0 19s
kafka-1 1/1 Running 0 23s
kafka-0 1/1 Running 0 32s
Producing and consuming data
You can use kubectl run to execute the kafka-topics.sh script to create a topic named test.
$ kubectl run -ti --image=gcr.io/google\_containers/kubernetes-kafka:1.0-10.2.1 createtopic --restart=Never --rm -- kafka-topics.sh --create \
\> --topic test \
\> --zookeeper zk-cs.default.svc.cluster.local:2181 \
\> --partitions 1 \
\> --replication-factor 3
Now you can use kubectl run to execute the kafka-console-consumer.sh command to listen for messages.
$ kubectl run -ti --image=gcr.io/google\_containers/kubnetes-kafka:1.0-10.2.1 consume --restart=Never --rm -- kafka-console-consumer.sh --topic test --bootstrap-server kafka-0.kafka-hs.default.svc.cluster.local:9093
In another terminal, you can run the kafka-console-producer.sh command.
$kubectl run -ti --image=gcr.io/google\_containers/kubernetes-kafka:1.0-10.2.1 produce --restart=Never --rm \
\> -- kafka-console-producer.sh --topic test --broker-list kafka-0.kafka-hs.default.svc.cluster.local:9093,kafka-1.kafka-hs.default.svc.cluster.local:9093,kafka-2.kafka-hs.default.svc.cluster.local:9093
Output from the second terminal appears in the first terminal. If you continue to produce and consume messages while updating the cluster, you will notice that no messages are lost. You may see error messages as the leader for the partition changes when individual brokers are updated, but the client retries until the message is committed. This is due to the ordered, sequential nature of StatefulSet rolling updates which we will explore further in the next section.
Updating the Kafka cluster
StatefulSet updates are like DaemonSet updates in that they are both configured by setting the spec.updateStrategy of the corresponding API object. When the update strategy is set to OnDelete, the respective controllers will only create new Pods when a Pod in the StatefulSet or DaemonSet has been deleted. When the update strategy is set to RollingUpdate, the controllers will delete and recreate Pods when a modification is made to the spec.template field of a DaemonSet or StatefulSet. You can use rolling updates to change the configuration (via environment variables or command line parameters), resource requests, resource limits, container images, labels, and/or annotations of the Pods in a StatefulSet or DaemonSet. Note that all updates are destructive, always requiring that each Pod in the DaemonSet or StatefulSet be destroyed and recreated. StatefulSet rolling updates differ from DaemonSet rolling updates in that Pod termination and creation is ordered and sequential.
You can patch the kafka StatefulSet to reduce the CPU resource request to 250m.
$ kubectl patch sts kafka --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/resources/requests/cpu", "value":"250m"}]'
statefulset "kafka" patched
If you watch the status of the Pods in the StatefulSet, you will see that each Pod is deleted and recreated in reverse ordinal order (starting with the Pod with the largest ordinal and progressing to the smallest). The controller waits for each updated Pod to be running and ready before updating the subsequent Pod.
$kubectl get po -lapp=kafka -w
NAME READY STATUS RESTARTS AGE
kafka-0 1/1 Running 0 13m
kafka-1 1/1 Running 0 13m
kafka-2 1/1 Running 0 13m
kafka-2 1/1 Terminating 0 14m
kafka-2 0/1 Terminating 0 14m
kafka-2 0/1 Terminating 0 14m
kafka-2 0/1 Terminating 0 14m
kafka-2 0/1 Pending 0 0s
kafka-2 0/1 Pending 0 0s
kafka-2 0/1 ContainerCreating 0 0s
kafka-2 0/1 Running 0 10s
kafka-2 1/1 Running 0 21s
kafka-1 1/1 Terminating 0 14m
kafka-1 0/1 Terminating 0 14m
kafka-1 0/1 Terminating 0 14m
kafka-1 0/1 Terminating 0 14m
kafka-1 0/1 Pending 0 0s
kafka-1 0/1 Pending 0 0s
kafka-1 0/1 ContainerCreating 0 0s
kafka-1 0/1 Running 0 11s
kafka-1 1/1 Running 0 21s
kafka-0 1/1 Terminating 0 14m
kafka-0 0/1 Terminating 0 14m
kafka-0 0/1 Terminating 0 14m
kafka-0 0/1 Terminating 0 14m
kafka-0 0/1 Pending 0 0s
kafka-0 0/1 Pending 0 0s
kafka-0 0/1 ContainerCreating 0 0s
kafka-0 0/1 Running 0 10s
kafka-0 1/1 Running 0 22s
Note that unplanned disruptions will not lead to unintentional updates during the update process. That is, the StatefulSet controller will always recreate the Pod at the correct version to ensure the ordering of the update is preserved. If a Pod is deleted, and if it has already been updated, it will be created from the updated version of the StatefulSet’s spec.template. If the Pod has not already been updated, it will be created from the previous version of the StatefulSet’s spec.template. We will explore this further in the following sections.
Staging an update
Depending on how your organization handles deployments and configuration modifications, you may want or need to stage updates to a StatefulSet prior to allowing the roll out to progress. You can accomplish this by setting a partition for the RollingUpdate. When the StatefulSet controller detects a partition in the updateStrategy of a StatefulSet, it will only apply the updated version of the StatefulSet’s spec.template to Pods whose ordinal is greater than or equal to the value of the partition.
You can patch the kafka StatefulSet to add a partition to the RollingUpdate update strategy. If you set the partition to a number greater than or equal to the StatefulSet’s spec.replicas (as below), any subsequent updates you perform to the StatefulSet’s spec.template will be staged for roll out, but the StatefulSet controller will not start a rolling update.
$ kubectl patch sts kafka -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":3}}}}'
statefulset "kafka" patched
If you patch the StatefulSet to set the requested CPU to 0.3, you will notice that none of the Pods are updated.
$ kubectl patch sts kafka --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/resources/requests/cpu", "value":"0.3"}]'
statefulset "kafka" patched
Even if you delete a Pod and wait for the StatefulSet controller to recreate it, you will notice that the Pod is recreated with current CPU request.
$ kubectl delete po kafka-1
pod "kafka-1" deleted
$ kubectl get po kafka-1 -w
NAME READY STATUS RESTARTS AGE
kafka-1 0/1 ContainerCreating 0 10s
kafka-1 0/1 Running 0 19s
kafka-1 1/1 Running 0 21s
$ kubectl get po kafka-1 -o yaml
apiVersion: v1
kind: Pod
metadata:
...
resources:
requests:
cpu: 250m
memory: 1Gi
Rolling out a canary
Often, we want to verify an image update or configuration change on a single instance of an application before rolling it out globally. If you modify the partition created above to be 2, the StatefulSet controller will roll out a canary that can be used to verify that the update is working as intended.
$ kubectl patch sts kafka -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":2}}}}'
statefulset "kafka" patched
You can watch the StatefulSet controller update the kafka-2 Pod and pause after the update is complete.
$ kubectl get po -lapp=kafka -w
NAME READY STATUS RESTARTS AGE
kafka-0 1/1 Running 0 50m
kafka-1 1/1 Running 0 10m
kafka-2 1/1 Running 0 29s
kafka-2 1/1 Terminating 0 34s
kafka-2 0/1 Terminating 0 38s
kafka-2 0/1 Terminating 0 39s
kafka-2 0/1 Terminating 0 39s
kafka-2 0/1 Pending 0 0s
kafka-2 0/1 Pending 0 0s
kafka-2 0/1 Terminating 0 20s
kafka-2 0/1 Terminating 0 20s
kafka-2 0/1 Pending 0 0s
kafka-2 0/1 Pending 0 0s
kafka-2 0/1 ContainerCreating 0 0s
kafka-2 0/1 Running 0 19s
kafka-2 1/1 Running 0 22s
Phased roll outs
Similar to rolling out a canary, you can roll out updates based on a phased progression (e.g. linear, geometric, or exponential roll outs).
If you patch the kafka StatefulSet to set the partition to 1, the StatefulSet controller updates one more broker.
$ kubectl patch sts kafka -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":1}}}}'
statefulset "kafka" patched
If you set it to 0, the StatefulSet controller updates the final broker and completes the update.
$ kubectl patch sts kafka -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":0}}}}'
statefulset "kafka" patched
Note that you don’t have to decrement the partition by one. For a larger StatefulSet--for example, one with 100 replicas--you might use a progression more like 100, 99, 90, 50, 0. In this case, you would stage your update, deploy a canary, roll out to 10 instances, update fifty percent of the Pods, and then complete the update.
Cleaning up
To delete the API Objects created above, you can use kubectl delete on the two manifests you used to create the ZooKeeper ensemble and the Kafka cluster.
$ kubectl delete -f kafka\_mini.yaml
service "kafka-hs" deleted
poddisruptionbudget "kafka-pdb" deleted
Statefulset “kafka” deleted
$ kubectl delete -f zookeeper\_mini.yaml
service "zk-hs" deleted
service "zk-cs" deleted
poddisruptionbudget "zk-pdb" deleted
statefulset "zk" deleted
By design, the StatefulSet controller does not delete any persistent volume claims (PVCs): the PVCs created for the ZooKeeper ensemble and the Kafka cluster must be manually deleted. Depending on the storage reclamation policy of your cluster, you many also need to manually delete the backing PVs.
DaemonSet rolling update, history, and rollback
In this section, we’re going to show you how to perform a rolling update on a DaemonSet, look at its history, and then perform a rollback after a bad rollout. We will use a DaemonSet to deploy a Prometheus node exporter on each Kubernetes node in the cluster. These node exporters export node metrics to the Prometheus monitoring system. For the sake of simplicity, we’ve omitted the installation of the Prometheus server and the service for communication with DaemonSet pods from this blogpost.
Prerequisites
To follow along with this section of the blog, you need a working Kubernetes 1.7 cluster and kubectl version 1.7 or later. If you followed along with the first section, you can use the same cluster.
DaemonSet rolling upFirst, prepare the node exporter DaemonSet manifest to run a v0.13 Prometheus node exporter on every node in the cluster:
$ cat \>\> node-exporter-v0.13.yaml \<\<EOF
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-exporter
spec:
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: node-exporter
name: node-exporter
spec:
containers:
- image: prom/node-exporter:v0.13.0
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
hostNetwork: true
hostPID: true
EOF
Note that you need to enable the DaemonSet rolling update feature by explicitly setting DaemonSet .spec.updateStrategy.type to RollingUpdate.
Apply the manifest to create the node exporter DaemonSet:
$ kubectl apply -f node-exporter-v0.13.yaml --record
daemonset "node-exporter" created
Wait for the first DaemonSet rollout to complete:
$ kubectl rollout status ds node-exporter
daemon set "node-exporter" successfully rolled out
You should see each of your node runs one copy of the node exporter pod:
$ kubectl get pods -l app=node-exporter -o wide
To perform a rolling update on the node exporter DaemonSet, prepare a manifest that includes the v0.14 Prometheus node exporter:
$ cat node-exporter-v0.13.yaml ``` sed "s/v0.13.0/v0.14.0/g" \> node-exporter-v0.14.yaml
Then apply the v0.14 node exporter DaemonSet:
$ kubectl apply -f node-exporter-v0.14.yaml --record
daemonset "node-exporter" configured
Wait for the DaemonSet rolling update to complete:
$ kubectl rollout status ds node-exporter
...
Waiting for rollout to finish: 3 out of 4 new pods have been updated...
Waiting for rollout to finish: 3 of 4 updated pods are available...
daemon set "node-exporter" successfully rolled out
We just triggered a DaemonSet rolling update by updating the DaemonSet template. By default, one old DaemonSet pod will be killed and one new DaemonSet pod will be created at a time.
Now we’ll cause a rollout to fail by updating the image to an invalid value:
$ cat node-exporter-v0.13.yaml | sed "s/v0.13.0/bad/g" \> node-exporter-bad.yaml
$ kubectl apply -f node-exporter-bad.yaml --record
daemonset "node-exporter" configured
Notice that the rollout never finishes:
$ kubectl rollout status ds node-exporter
Waiting for rollout to finish: 0 out of 4 new pods have been updated...
Waiting for rollout to finish: 1 out of 4 new pods have been updated…
# Use ^C to exit
This behavior is expected. We mentioned earlier that a DaemonSet rolling update kills and creates one pod at a time. Because the new pod never becomes available, the rollout is halted, preventing the invalid specification from propagating to more than one node. StatefulSet rolling updates implement the same behavior with respect to failed deployments. Unsuccessful updates are blocked until it corrected via roll back or by rolling forward with a specification.
$ kubectl get pods -l app=node-exporter
NAME READY STATUS RESTARTS AGE
node-exporter-f2n14 0/1 ErrImagePull 0 3m
...
# N = number of nodes
$ kubectl get ds node-exporter
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
node-exporter N N N-1 1 N \<none\> 46m
DaemonSet history, rollbacks, and rolling forward
Next, perform a rollback. Take a look at the node exporter DaemonSet rollout history:
$ kubectl rollout history ds node-exporter
daemonsets "node-exporter"
REVISION CHANGE-CAUSE
1 kubectl apply --filename=node-exporter-v0.13.yaml --record=true
2 kubectl apply --filename=node-exporter-v0.14.yaml --record=true
3 kubectl apply --filename=node-exporter-bad.yaml --record=true
Check the details of the revision you want to roll back to:
$ kubectl rollout history ds node-exporter --revision=2
daemonsets "node-exporter" with revision #2
Pod Template:
Labels: app=node-exporter
Containers:
node-exporter:
Image: prom/node-exporter:v0.14.0
Port: 9100/TCP
Environment: \<none\>
Mounts: \<none\>
Volumes: \<none\>
You can quickly roll back to any DaemonSet revision you found through kubectl rollout history:
# Roll back to the last revision
$ kubectl rollout undo ds node-exporter
daemonset "node-exporter" rolled back
# Or use --to-revision to roll back to a specific revision
$ kubectl rollout undo ds node-exporter --to-revision=2
daemonset "node-exporter" rolled back
A DaemonSet rollback is done by rolling forward. Therefore, after the rollback, DaemonSet revision 2 becomes revision 4 (current revision):
$ kubectl rollout history ds node-exporter
daemonsets "node-exporter"
REVISION CHANGE-CAUSE
1 kubectl apply --filename=node-exporter-v0.13.yaml --record=true
3 kubectl apply --filename=node-exporter-bad.yaml --record=true
4 kubectl apply --filename=node-exporter-v0.14.yaml --record=true
The node exporter DaemonSet is now healthy again:
$ kubectl rollout status ds node-exporter
daemon set "node-exporter" successfully rolled out
# N = number of nodes
$ kubectl get ds node-exporter
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
node-exporter N N N N N \<none\> 46m
If current DaemonSet revision is specified while performing a rollback, the rollback is skipped:
$ kubectl rollout undo ds node-exporter --to-revision=4
daemonset "node-exporter" skipped rollback (current template already matches revision 4)
You will see this complaint from kubectl if the DaemonSet revision is not found:
$ kubectl rollout undo ds node-exporter --to-revision=10
error: unable to find specified revision 10 in history
Note that kubectl rollout history and kubectl rollout status support StatefulSets, too!
Cleaning up
$ kubectl delete ds node-exporter
What’s next for DaemonSet and StatefulSet
Rolling updates and roll backs close an important feature gap for DaemonSets and StatefulSets. As we plan for Kubernetes 1.8, we want to continue to focus on advancing the core controllers to GA. This likely means that some advanced feature requests (e.g. automatic roll back, infant mortality detection) will be deferred in favor of ensuring the consistency, usability, and stability of the core controllers. We welcome feedback and contributions, so please feel free to reach out on Slack, to ask questions on Stack Overflow, or open issues or pull requests on GitHub.
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Get involved with the Kubernetes project on GitHub
Introducing the Resource Management Working Group
Editor's note: today's post is by Jeremy Eder, Senior Principal Software Engineer at Red Hat, on the formation of the Resource Management Working Group
Why are we here?
Kubernetes has evolved to support diverse and increasingly complex classes of applications. We can onboard and scale out modern, cloud-native web applications based on microservices, batch jobs, and stateful applications with persistent storage requirements.
However, there are still opportunities to improve Kubernetes; for example, the ability to run workloads that require specialized hardware or those that perform measurably better when hardware topology is taken into account. These conflicts can make it difficult for application classes (particularly in established verticals) to adopt Kubernetes.
We see an unprecedented opportunity here, with a high cost if it’s missed. The Kubernetes ecosystem must create a consumable path forward to the next generation of system architectures by catering to needs of as-yet unserviced workloads in meaningful ways. The Resource Management Working Group, along with other SIGs, must demonstrate the vision customers want to see, while enabling solutions to run well in a fully integrated, thoughtfully planned end-to-end stack.
Kubernetes Working Groups are created when a particular challenge requires cross-SIG collaboration. The Resource Management Working Group, for example, works primarily with sig-node and sig-scheduling to drive support for additional resource management capabilities in Kubernetes. We make sure that key contributors from across SIGs are frequently consulted because working groups are not meant to make system-level decisions on behalf of any SIG.
An example and key benefit of this is the working group’s relationship with sig-node. We were able to ensure completion of several releases of node reliability work (complete in 1.6) before contemplating feature design on top. Those designs are use-case driven: research into technical requirements for a variety of workloads, then sorting based on measurable impact to the largest cross-section.
Target Workloads and Use-cases
One of the working group’s key design tenets is that user experience must remain clean and portable, while still surfacing infrastructure capabilities that are required by businesses and applications.
While not representing any commitment, we hope in the fullness of time that Kubernetes can optimally run financial services workloads, machine learning/training, grid schedulers, map-reduce, animation workloads, and more. As a use-case driven group, we account for potential application integration that can also facilitate an ecosystem of complementary independent software vendors to flourish on top of Kubernetes.
Why do this?
Kubernetes covers generic web hosting capabilities very well, so why go through the effort of expanding workload coverage for Kubernetes at all? The fact is that workloads elegantly covered by Kubernetes today, only represent a fraction of the world’s compute usage. We have a tremendous opportunity to safely and methodically expand upon the set of workloads that can run optimally on Kubernetes.
To date, there’s demonstrable progress in the areas of expanded workload coverage:
- Stateful applications such as Zookeeper, etcd, MySQL, Cassandra, ElasticSearch
- Jobs, such as timed events to process the day’s logs or any other batch processing
- Machine Learning and compute-bound workload acceleration through Alpha GPU support Collectively, the folks working on Kubernetes are hearing from their customers that we need to go further. Following the tremendous popularity of containers in 2014, industry rhetoric circled around a more modern, container-based, datacenter-level workload orchestrator as folks looked to plan their next architectures.
As a consequence, we began advocating for increasing the scope of workloads covered by Kubernetes, from overall concepts to specific features. Our aim is to put control and choice in users hands, helping them move with confidence towards whatever infrastructure strategy they choose. In this advocacy, we quickly found a large group of like-minded companies interested in broadening the types of workloads that Kubernetes can orchestrate. And thus the working group was born.
Genesis of the Resource Management Working Group
After extensive development/feature discussions during the Kubernetes Developer Summit 2016 after CloudNativeCon | KubeCon Seattle, we decided to formalize our loosely organized group. In January 2017, the Kubernetes Resource Management Working Group was formed. This group (led by Derek Carr from Red Hat and Vishnu Kannan from Google) was originally cast as a temporary initiative to provide guidance back to sig-node and sig-scheduling (primarily). However, due to the cross-cutting nature of the goals within the working group, and the depth of roadmap quickly uncovered, the Resource Management Working Group became its own entity within the first few months.
Recently, Brian Grant from Google (@bgrant0607) posted the following image on his Twitter feed. This image helps to explain the role of each SIG, and shows where the Resource Management Working Group fits into the overall project organization.
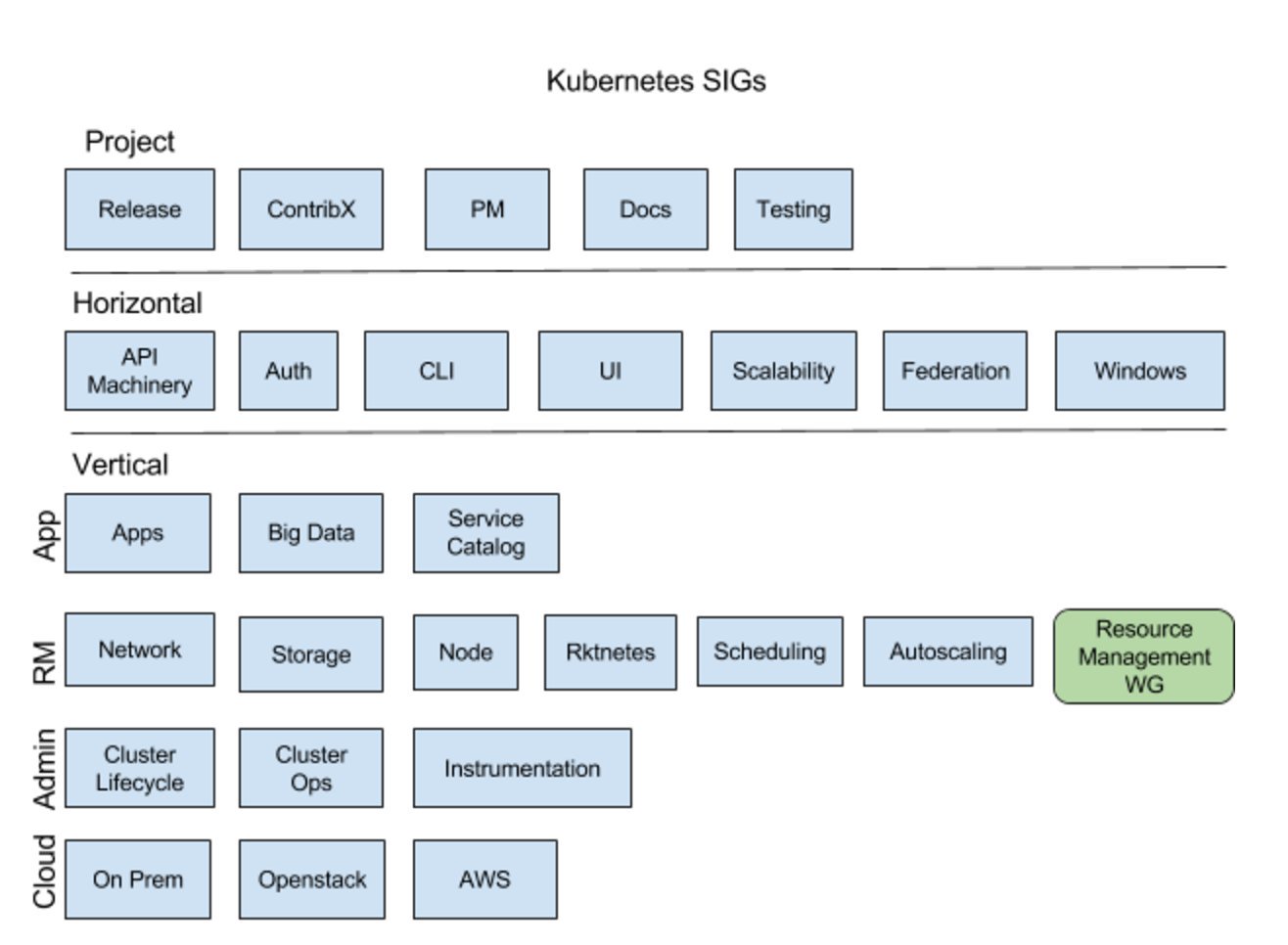
To help bootstrap this effort, the Resource Management Working Group had its first face-to-face kickoff meeting in May 2017. Thanks to Google for hosting!

Folks from Intel, NVIDIA, Google, IBM, Red Hat. and Microsoft (among others) participated.
You can read the outcomes of that 3-day meeting here.
The group’s prioritized list of features for increasing workload coverage on Kubernetes enumerated in the charter of the Resource Management Working group includes:
- Support for performance sensitive workloads (exclusive cores, cpu pinning strategies, NUMA)
- Integrating new hardware devices (GPUs, FPGAs, Infiniband, etc.)
- Improving resource isolation (local storage, hugepages, caches, etc.)
- Improving Quality of Service (performance SLOs)
- Performance benchmarking
- APIs and extensions related to the features mentioned above The discussions made it clear that there was tremendous overlap between needs for various workloads, and that we ought to de-duplicate requirements, and plumb generically.
Workload Characteristics
The set of initially targeted use-cases share one or more of the following characteristics:
- Deterministic performance (address long tail latencies)
- Isolation within a single node, as well as within groups of nodes sharing a control plane
- Requirements on advanced hardware and/or software capabilities
- Predictable, reproducible placement: applications need granular guarantees around placement The Resource Management Working Group is spearheading the feature design and development in support of these workload requirements. Our goal is to provide best practices and patterns for these scenarios.
Initial Scope
In the months leading up to our recent face-to-face, we had discussed how to safely abstract resources in a way that retains portability and clean user experience, while still meeting application requirements. The working group came away with a multi-release roadmap that included 4 short- to mid-term targets with great overlap between target workloads:
-
Device Manager (Plugin) Proposal
- Kubernetes should provide access to hardware devices such as NICs, GPUs, FPGA, Infiniband and so on.
-
- Kubernetes should provide a way for users to request static CPU assignment via the Guaranteed QoS tier. No support for NUMA in this phase.
-
HugePages support in Kubernetes
- Kubernetes should provide a way for users to consume huge pages of any size.
-
- Kubernetes should implement an abstraction layer (analogous to StorageClasses) for devices other than CPU and memory that allows a user to consume a resource in a portable way. For example, how can a pod request a GPU that has a minimum amount of memory?
Getting Involved & Summary
Our charter document includes a Contact Us section with links to our mailing list, Slack channel, and Zoom meetings. Recordings of previous meetings are uploaded to Youtube. We plan to discuss these topics and more at the 2017 Kubernetes Developer Summit at CloudNativeCon | KubeCon in Austin. Please come and join one of our meetings (users, customers, software and hardware vendors are all welcome) and contribute to the working group!
Windows Networking at Parity with Linux for Kubernetes
Editor's note: today's post is by Jason Messer, Principal PM Manager at Microsoft, on improvements to the Windows network stack to support the Kubernetes CNI model.
Since I last blogged about Kubernetes Networking for Windows four months ago, the Windows Core Networking team has made tremendous progress in both the platform and open source Kubernetes projects. With the updates, Windows is now on par with Linux in terms of networking. Customers can now deploy mixed-OS, Kubernetes clusters in any environment including Azure, on-premises, and on 3rd-party cloud stacks with the same network primitives and topologies supported on Linux without any workarounds, “hacks”, or 3rd-party switch extensions.
"So what?", you may ask. There are multiple application and infrastructure-related reasons why these platform improvements make a substantial difference in the lives of developers and operations teams wanting to run Kubernetes. Read on to learn more!
Tightly-Coupled Communication
These improvements enable tightly-coupled communication between multiple Windows Server containers (without Hyper-V isolation) within a single "Pod". Think of Pods as the scheduling unit for the Kubernetes cluster, inside of which, one or more application containers are co-located and able to share storage and networking resources. All containers within a Pod shared the same IP address and port range and are able to communicate with each other using localhost. This enables applications to easily leverage "helper" programs for tasks such as monitoring, configuration updates, log management, and proxies. Another way to think of a Pod is as a compute host with the app containers representing processes.
Simplified Network Topology
We also simplified the network topology on Windows nodes in a Kubernetes cluster by reducing the number of endpoints required per container (or more generally, per pod) to one. Previously, Windows containers (pods) running in a Kubernetes cluster required two endpoints - one for external (internet) communication and a second for intra-cluster communication between between other nodes or pods in the cluster. This was due to the fact that external communication from containers attached to a host network with local scope (i.e. not publicly routable) required a NAT operation which could only be provided through the Windows NAT (WinNAT) component on the host. Intra-cluster communication required containers to be attached to a separate network with "global" (cluster-level) scope through a second endpoint. Recent platform improvements now enable NAT''ing to occur directly on a container endpoint which is implemented with the Microsoft Virtual Filtering Platform (VFP) Hyper-V switch extension. Now, both external and intra-cluster traffic can flow through a single endpoint.
Load-Balancing using VFP in Windows kernel
Kubernetes worker nodes rely on the kube-proxy to load-balance ingress network traffic to Service IPs between pods in a cluster. Previous versions of Windows implemented the Kube-proxy's load-balancing through a user-space proxy. We recently added support for "Proxy mode: iptables" which is implemented using VFP in the Windows kernel so that any IP traffic can be load-balanced more efficiently by the Windows OS kernel. Users can also configure an external load balancer by specifying the externalIP parameter in a service definition. In addition to the aforementioned improvements, we have also added platform support for the following:
- Support for DNS search suffixes per container / Pod (Docker improvement - removes additional work previously done by kube-proxy to append DNS suffixes)
- [Platform Support] 5-tuple rules for creating ACLs (Looking for help from community to integrate this with support for K8s Network Policy)
Now that Windows Server has joined the Windows Insider Program, customers and partners can take advantage of these new platform features today which accrue value to eagerly anticipated, new feature release later this year and new build after six months. The latest Windows Server insider build now includes support for all of these platform improvements.
In addition to the platform improvements for Windows, the team submitted code (PRs) for CNI, kubelet, and kube-proxy with the goal of mainlining Windows support into the Kubernetes v1.8 release. These PRs remove previous work-arounds required on Windows for items such as user-mode proxy for internal load balancing, appending additional DNS suffixes to each Kube-DNS request, and a separate container endpoint for external (internet) connectivity.
- https://github.com/kubernetes/kubernetes/pull/51063
- https://github.com/kubernetes/kubernetes/pull/51064
These new platform features and work on kubelet and kube-proxy align with the CNI network model used by Kubernetes on Linux and simplify the deployment of a K8s cluster without additional configuration or custom (Azure) resource templates. To this end, we completed work on CNI network and IPAM plugins to create/remove endpoints and manage IP addresses. The CNI plugin works through kubelet to target the Windows Host Networking Service (HNS) APIs to create an 'l2bridge' network (analogous to macvlan on Linux) which is enforced by the VFP switch extension.
The 'l2bridge' network driver re-writes the MAC address of container network traffic on ingress and egress to use the container host's MAC address. This obviates the need for multiple MAC addresses (one per container running on the host) to be "learned" by the upstream network switch port to which the container host is connected. This preserves memory space in physical switch TCAM tables and relies on the Hyper-V virtual switch to do MAC address translation in the host to forward traffic to the correct container. IP addresses are managed by a default, Windows IPAM plug-in which requires that POD CIDR IPs be taken from the container host's network IP space.
The team demoed (link to video) these new platform features and open-source updates to the SIG-Windows group on 8/8. We are working with the community to merge the kubelet and kube-proxy PRs to mainline these changes in time for the Kubernetes v1.8 release due out this September. These capabilities can then be used on current Windows Server insider builds and the Windows Server, version 1709.
Soon after RTM, we will also introduce these improvements into the Azure Container Service (ACS) so that Windows worker nodes and the containers hosted are first-class, Azure VNet citizens. An Azure IPAM plugin for Windows CNI will enable these endpoints to directly attach to Azure VNets with network policies for Windows containers enforced the same way as VMs.
| Feature | Windows Server 2016 (In-Market) | Next Windows Server Feature Release, Semi-Annual Channel | Linux | | Multiple Containers per Pod with shared network namespace (Compartment) | One Container per Pod | ✔ | ✔ | | Single (Shared) Endpoint per Pod | Two endpoints: WinNAT (External) + Transparent (Intra-Cluster) | ✔ | ✔ | | User-Mode, Load Balancing | ✔ | ✔ | ✔ | | Kernel-Mode, Load Balancing | Not Supported | ✔ | ✔ | | Support for DNS search suffixes per Pod (Docker update) | Kube-Proxy added multiple DNS suffixes to each request | ✔ | ✔ | | CNI Plugin Support | Not Supported | ✔ | ✔ |
The Kubernetes SIG Windows group meets bi-weekly on Tuesdays at 12:30 PM ET. To join or view notes from previous meetings, check out this document.
Kubernetes Meets High-Performance Computing
Editor's note: today's post is by Robert Lalonde, general manager at Univa, on supporting mixed HPC and containerized applications
Anyone who has worked with Docker can appreciate the enormous gains in efficiency achievable with containers. While Kubernetes excels at orchestrating containers, high-performance computing (HPC) applications can be tricky to deploy on Kubernetes.
In this post, I discuss some of the challenges of running HPC workloads with Kubernetes, explain how organizations approach these challenges today, and suggest an approach for supporting mixed workloads on a shared Kubernetes cluster. We will also provide information and links to a case study on a customer, IHME, showing how Kubernetes is extended to service their HPC workloads seamlessly while retaining scalability and interfaces familiar to HPC users.
HPC workloads unique challenges
In Kubernetes, the base unit of scheduling is a Pod: one or more Docker containers scheduled to a cluster host. Kubernetes assumes that workloads are containers. While Kubernetes has the notion of Cron Jobs and Jobs that run to completion, applications deployed on Kubernetes are typically long-running services, like web servers, load balancers or data stores and while they are highly dynamic with pods coming and going, they differ greatly from HPC application patterns.
Traditional HPC applications often exhibit different characteristics:
- In financial or engineering simulations, a job may be comprised of tens of thousands of short-running tasks, demanding low-latency and high-throughput scheduling to complete a simulation in an acceptable amount of time.
- A computational fluid dynamics (CFD) problem may execute in parallel across many hundred or even thousands of nodes using a message passing library to synchronize state. This requires specialized scheduling and job management features to allocate and launch such jobs and then to checkpoint, suspend/resume or backfill them.
- Other HPC workloads may require specialized resources like GPUs or require access to limited software licenses. Organizations may enforce policies around what types of resources can be used by whom to ensure projects are adequately resourced and deadlines are met.
HPC workload schedulers have evolved to support exactly these kinds of workloads. Examples include Univa Grid Engine, IBM Spectrum LSF and Altair’s PBS Professional. Sites managing HPC workloads have come to rely on capabilities like array jobs, configurable pre-emption, user, group or project based quotas and a variety of other features.
Blurring the lines between containers and HPC
HPC users believe containers are valuable for the same reasons as other organizations. Packaging logic in a container to make it portable, insulated from environmental dependencies, and easily exchanged with other containers clearly has value. However, making the switch to containers can be difficult.
HPC workloads are often integrated at the command line level. Rather than requiring coding, jobs are submitted to queues via the command line as binaries or simple shell scripts that act as wrappers. There are literally hundreds of engineering, scientific and analytic applications used by HPC sites that take this approach and have mature and certified integrations with popular workload schedulers.
While the notion of packaging a workload into a Docker container, publishing it to a registry, and submitting a YAML description of the workload is second nature to users of Kubernetes, this is foreign to most HPC users. An analyst running models in R, MATLAB or Stata simply wants to submit their simulation quickly, monitor their execution, and get a result as quickly as possible.
Existing approaches
To deal with the challenges of migrating to containers, organizations running container and HPC workloads have several options:
- Maintain separate infrastructures
For sites with sunk investments in HPC, this may be a preferred approach. Rather than disrupt existing environments, it may be easier to deploy new containerized applications on a separate cluster and leave the HPC environment alone. The challenge is that this comes at the cost of siloed clusters, increasing infrastructure and management cost.
- Run containerized workloads under an existing HPC workload manager
For sites running traditional HPC workloads, another approach is to use existing job submission mechanisms to launch jobs that in turn instantiate Docker containers on one or more target hosts. Sites using this approach can introduce containerized workloads with minimal disruption to their environment. Leading HPC workload managers such as Univa Grid Engine Container Edition and IBM Spectrum LSF are adding native support for Docker containers. Shifter and Singularity are important open source tools supporting this type of deployment also. While this is a good solution for sites with simple requirements that want to stick with their HPC scheduler, they will not have access to native Kubernetes features, and this may constrain flexibility in managing long-running services where Kubernetes excels.
- Use native job scheduling features in Kubernetes
Sites less invested in existing HPC applications can use existing scheduling facilities in Kubernetes for jobs that run to completion. While this is an option, it may be impractical for many HPC users. HPC applications are often either optimized towards massive throughput or large scale parallelism. In both cases startup and teardown latencies have a discriminating impact. Latencies that appear to be acceptable for containerized microservices today would render such applications unable to scale to the required levels.
All of these solutions involve tradeoffs. The first option doesn’t allow resources to be shared (increasing costs) and the second and third options require customers to pick a single scheduler, constraining future flexibility.
Mixed workloads on Kubernetes
A better approach is to support HPC and container workloads natively in the same shared environment. Ideally, users should see the environment appropriate to their workload or workflow type.
One approach to supporting mixed workloads is to allow Kubernetes and the HPC workload manager to co-exist on the same cluster, throttling resources to avoid conflicts. While simple, this means that neither workload manager can fully utilize the cluster.
Another approach is to use a peer scheduler that coordinates with the Kubernetes scheduler. Navops Command by Univa is a solution that takes this third approach, augmenting the functionality of the Kubernetes scheduler. Navops Command provides its own web interface and CLI and allows additional scheduling policies to be enabled on Kubernetes without impacting the operation of the Kubernetes scheduler and existing containerized applications. Navops Command plugs into the Kubernetes architecture via the 'schedulerName' attribute in the pod spec as a peer scheduler that workloads can choose to use instead of the Kubernetes stock scheduler as shown below.

With this approach, Kubernetes acts as a resource manager, making resources available to a separate HPC scheduler. Cluster administrators can use a visual interface to allocate resources based on policy or simply drag sliders via a web UI to allocate different proportions of the Kubernetes environment to non-container (HPC) workloads, and native Kubernetes applications and services.

From a client perspective, the HPC scheduler runs as a service deployed in Kubernetes pods, operating just as it would on a bare metal cluster. Navops Command provides additional scheduling features including things like resource reservation, run-time quotas, workload preemption and more. This environment works equally well for on-premise, cloud-based or hybrid deployments.
Deploying mixed workloads at IHME
One client having success with mixed workloads is the Institute for Health Metrics & Evaluation (IHME), an independent health research center at the University of Washington. In support of their globally recognized Global Health Data Exchange (GHDx), IHME operates a significantly sized environment comprised of 500 nodes and 20,000 cores running a mix of analytic, HPC, and container-based applications on Kubernetes. This case study describes IHME’s success hosting existing HPC workloads on a shared Kubernetes cluster using Navops Command.

For sites deploying new clusters that want access to the rich capabilities in Kubernetes but need the flexibility to run non-containerized workloads, this approach is worth a look. It offers the opportunity for sites to share infrastructure between Kubernetes and HPC workloads without disrupting existing applications and businesses processes. It also allows them to migrate their HPC workloads to use Docker containers at their own pace.
High Performance Networking with EC2 Virtual Private Clouds
One of the most popular platforms for running Kubernetes is Amazon Web Services’ Elastic Compute Cloud (AWS EC2). With more than a decade of experience delivering IaaS, and expanding over time to include a rich set of services with easy to consume APIs, EC2 has captured developer mindshare and loyalty worldwide.
When it comes to networking, however, EC2 has some limits that hinder performance and make deploying Kubernetes clusters to production unnecessarily complex. The preview release of Romana v2.0, a network and security automation solution for Cloud Native applications, includes features that address some well known network issues when running Kubernetes in EC2.
Traditional VPC Networking Performance Roadblocks
A Kubernetes pod network is separate from an Amazon Virtual Private Cloud (VPC) instance network; consequently, off-instance pod traffic needs a route to the destination pods. Fortunately, VPCs support setting these routes. When building a cluster network with the kubenet plugin, whenever new nodes are added, the AWS cloud provider will automatically add a VPC route to the pods running on that node.
Using kubenet to set routes provides native VPC network performance and visibility. However, since kubenet does not support more advanced network functions like network policy for pod traffic isolation, many users choose to run a Container Network Interface (CNI) provider on the back end.
Before Romana v2.0, all CNI network providers required an overlay when used across Availability Zones (AZs), leaving CNI users who want to deploy HA clusters unable to get the performance of native VPC networking.
Even users who don’t need advanced networking encounter restriction, since the VPC route tables support a maximum of 50 entries, which limits the size of a cluster to 50 nodes (or less, if some VPC routes are needed for other purposes). Until Romana v2.0, users also needed to run an overlay network to get around this limit.
Whether you were interested in advanced networking for traffic isolation or running large production HA clusters (or both), you were unable to get the performance and visibility of native VPC networking.
Kubernetes on Multi-Segment Networks
The way to avoid running out of VPC routes is to use them sparingly by making them forward pod traffic for multiple instances. From a networking perspective, what that means is that the VPC route needs to forward to a router, which can then forward traffic on to the final destination instance.
Romana is a CNI network provider that configures routes on the host to forward pod network traffic without an overlay. Since inter-node routes are installed on hosts, no VPC routes are necessary at all. However, when the VPC is split into subnets for an HA deployment across zones, VPC routes are necessary.
Fortunately, inter-node routes on hosts allows them to act as a network router and forward traffic inbound from another zone just as it would for traffic from local pods. This makes any Kubernetes node configured by Romana able to accept inbound pod traffic from other zones and forward it to the proper destination node on the subnet.
Because of this local routing function, top-level routes to pods on other instances on the subnet can be aggregated, collapsing the total number of routes necessary to as few as one per subnet. To avoid using a single instance to forward all traffic, more routes can be used to spread traffic across multiple instances, up to the maximum number of available routes (i.e. equivalent to kubenet).
The net result is that you can now build clusters of any size across AZs without an overlay. Romana clusters also support network policies for better security through network isolation.
Making it All Work
While the combination of aggregated routes and node forwarding on a subnet eliminates overlays and avoids the VPC 50 route limitation, it imposes certain requirements on the CNI provider. For example, hosts should be configured with inter-node routes only to other nodes in the same zone on the local subnet. Traffic to all other hosts must use the default route off host, then use the (aggregated) VPC route to forward traffic out of the zone. Also: when adding a new host, in order to maintain aggregated VPC routes, the CNI plugin needs to use IP addresses for pods that are reachable on the new host.
The latest release of Romana also addresses questions about how VPC routes are installed; what happens when a node that is forwarding traffic fails; how forwarding node failures are detected; and how routes get updated and the cluster recovers.
Romana v2.0 includes a new AWS route configuration function to set VPC routes. This is part of a new set of network advertising features that automate route configuration in L3 networks. Romana v2.0 includes topology-aware IP address management (IPAM) that enables VPC route aggregation to stay within the 50 route limit as described here, as well as new health checks to update VPC routes when a routing instance fails. For smaller clusters, Romana configures VPC routes as kubenet does, with a route to each instance, taking advantage of every available VPC route.
Native VPC Networking Everywhere
When using Romana v2.0, native VPC networking is now available for clusters of any size, with or without network policies and for HA production deployment split across multiple zones.

The preview release of Romana v2.0 is available here. We welcome comments and feedback so we can make EC2 deployments of Kubernetes as fast and reliable as possible.
-- Juergen Brendel and Chris Marino, co-founders of Pani Networks, sponsor of the Romana project
Kompose Helps Developers Move Docker Compose Files to Kubernetes
Editor's note: today's post is by Charlie Drage, Software Engineer at Red Hat giving an update about the Kubernetes project Kompose.
I'm pleased to announce that Kompose, a conversion tool for developers to transition Docker Compose applications to Kubernetes, has graduated from the Kubernetes Incubator to become an official part of the project.
Since our first commit on June 27, 2016, Kompose has achieved 13 releases over 851 commits, gaining 21 contributors since the inception of the project. Our work started at Skippbox (now part of Bitnami) and grew through contributions from Google and Red Hat.
The Kubernetes Incubator allowed contributors to get to know each other across companies, as well as collaborate effectively under guidance from Kubernetes contributors and maintainers. Our incubation led to the development and release of a new and useful tool for the Kubernetes ecosystem.
We’ve created a reliable, scalable Kubernetes environment from an initial Docker Compose file. We worked hard to convert as many keys as possible to their Kubernetes equivalent. Running a single command gets you up and running on Kubernetes: kompose up.
We couldn’t have done it without feedback and contributions from the community!
If you haven’t yet tried Kompose on GitHub check it out!
Kubernetes guestbook
The go-to example for Kubernetes is the famous guestbook, which we use as a base for conversion.
Here is an example from the official kompose.io site, starting with a simple Docker Compose file).
First, we’ll retrieve the file:
$ wget https://raw.githubusercontent.com/kubernetes/kompose/master/examples/docker-compose.yaml
You can test it out by first deploying to Docker Compose:
$ docker-compose up -d
Creating network "examples\_default" with the default driver
Creating examples\_redis-slave\_1
Creating examples\_frontend\_1
Creating examples\_redis-master\_1
And when you’re ready to deploy to Kubernetes:
$ kompose up
We are going to create Kubernetes Deployments, Services and PersistentVolumeClaims for your Dockerized application.
If you need different kind of resources, use the kompose convert and kubectl create -f commands instead.
INFO Successfully created Service: redis
INFO Successfully created Service: web
INFO Successfully created Deployment: redis
INFO Successfully created Deployment: web
Your application has been deployed to Kubernetes. You can run kubectl get deployment,svc,pods,pvc for details
Check out other examples of what Kompose can do.
Converting to alternative Kubernetes controllers
Kompose can also convert to specific Kubernetes controllers with the use of flags:
$ kompose convert --help
Usage:
kompose convert [file] [flags]
Kubernetes Flags:
--daemon-set Generate a Kubernetes daemonset object
-d, --deployment Generate a Kubernetes deployment object
-c, --chart Create a Helm chart for converted objects
--replication-controller Generate a Kubernetes replication controller object
…
For example, let’s convert our guestbook example to a DaemonSet:
$ kompose convert --daemon-set
INFO Kubernetes file "frontend-service.yaml" created
INFO Kubernetes file "redis-master-service.yaml" created
INFO Kubernetes file "redis-slave-service.yaml" created
INFO Kubernetes file "frontend-daemonset.yaml" created
INFO Kubernetes file "redis-master-daemonset.yaml" created
INFO Kubernetes file "redis-slave-daemonset.yaml" created
Key Kompose 1.0 features
With our graduation, comes the release of Kompose 1.0.0, here’s what’s new:
- Docker Compose Version 3: Kompose now supports Docker Compose Version 3. New keys such as ‘deploy’ now convert to their Kubernetes equivalent.
- Docker Push and Build Support: When you supply a ‘build’ key within your
docker-compose.yamlfile, Kompose will automatically build and push the image to the respective Docker repository for Kubernetes to consume. - New Keys: With the addition of version 3 support, new keys such as pid and deploy are supported. For full details on what Kompose supports, view our conversion document.
- Bug Fixes: In every release we fix any bugs related to edge-cases when converting. This release fixes issues relating to converting volumes with ‘./’ in the target name.
What’s ahead?
As we continue development, we will strive to convert as many Docker Compose keys as possible for all future and current Docker Compose releases, converting each one to their Kubernetes equivalent. All future releases will be backwards-compatible.
--Charlie Drage, Software Engineer, Red Hat
- Post questions (or answer questions) onStack Overflow
- Join the community portal for advocates onK8sPort
- Follow us on Twitter@Kubernetesio for latest updates
- Connect with the community onSlack
- Get involved with the Kubernetes project onGitHub
Happy Second Birthday: A Kubernetes Retrospective
As we do every July, we’re excited to celebrate Kubernetes 2nd birthday! In the two years since GA 1.0 launched as an open source project, Kubernetes (abbreviated as K8s) has grown to become the highest velocity cloud-related project. With more than 2,611 diverse contributors, from independents to leading global companies, the project has had 50,685 commits in the last 12 months. Of the 54 million projects on GitHub, Kubernetes is in the top 5 for number of unique developers contributing code. It also has more pull requests and issue comments than any other project on GitHub.

Figure 1: Kubernetes Rankings
At the center of the community are Special Interest Groups with members from different companies and organizations, all with a common interest in a specific topic. Given how fast Kubernetes is growing, SIGs help nurture and distribute leadership, while advancing new proposals, designs and release updates. Here's a look at the SIG building blocks supporting Kubernetes:

Kubernetes has also earned the trust of many Fortune 500 companies with deployments at Box, Comcast, Pearson, GolfNow, eBay, Ancestry.com and contributions from CoreOS, Fujitsu, Google, Huawei, Mirantis, Red Hat, Weaveworks and ZTE Company and others. Today, on the second anniversary of the Kubernetes 1.0 launch, we take a look back at some of the major accomplishments of the last year:
July 2016
- Kubernauts celebrated its first anniversary of the Kubernetes 1.0 launch with 20 #k8sbday parties hosted worldwide
- Kubernetes v1.3 release
September 2016
- Kubernetes v1.4 release
- Launch of kubeadm, a tool that makes Kubernetes dramatically easier to install
- Pokemon Go - one of the largest installs of Kubernetes ever
October 2016
- Introduced Kubernetes service partners program and a redesigned partners page
November 2016
- CloudNativeCon/KubeCon Seattle
- Cloud Native Computing Foundation partners with The Linux Foundation to launch a new Kubernetes certification, training and managed service provider program
December 2016
- Kubernetes v1.5 release
January 2017
- Survey from CloudNativeCon + KubeCon Seattle showcases the maturation of Kubernetes deployment
March 2017
- CloudNativeCon/KubeCon Europe
- Kubernetesv1.6 release
April 2017
- The Battery Open Source Software (BOSS) Index lists Kubernetes as #33 in the top 100 popular open-source software projects
May 2017
- Four Kubernetes projects accepted to The Google Summer of Code (GSOC) 2017 program
- Stutterstock and Kubernetes appear in The Wall Street Journal: “On average we [Shutterstock] deploy 45 different releases into production a day using that framework. We use Docker, Kubernetes and Jenkins [to build and run containers and automate development,” said CTO Marty Brodbeck on the company’s IT overhaul and adoption of containerization.
June 2017
- Kubernetes v1.7 release
- Survey from CloudNativeCon + KubeCon Europe shows Kubernetes leading as the orchestration platform of choice
- Kubernetes ranked #4 in the 30 highest velocity open source projects

Figure 2: The 30 highest velocity open source projects. Source: https://github.com/cncf/velocity
July 2017
- Kubernauts celebrate the second anniversary of the Kubernetes 1.0 launch with #k8sbday parties worldwide!
At the one year anniversary of the Kubernetes 1.0 launch, there were 130 Kubernetes-related Meetup groups. Today, there are more than 322 Meetup groups with 104,195 members. Local Meetups around the world joined the #k8sbday celebration! Take a look at some of the pictures from their celebrations. We hope you’ll join us at CloudNativeCon + KubeCon, December 6- 8 in Austin, TX.

Celebrating at the K8s birthday party in San Francisco

Celebrating in RTP, NC with a presentation from Jason McGee, VP and CTO, IBM Cloud Platform. Photo courtesy of @FranklyBriana

The Kubernetes Singapore meetup celebrating with an intro to GKE. Photo courtesy of @hunternield


New York celebrated with mini k8s cupcakes and a presentation on the history of cloud native from CNCF Executive Director, Dan Kohn. Photo courtesy of @arieljatib and @coreos


Quebec City had custom k8s cupcakes too! Photo courtesy of @zig_max

Beijing celebrated with custom k8s lollipops. Photo courtesy of @maxwell9215
-- Sarah Novotny, Program Manager, Kubernetes Community
How Watson Health Cloud Deploys Applications with Kubernetes
Today’s post is by Sandhya Kapoor, Senior Technologist, Watson Platform for Health, IBM
For more than a year, Watson Platform for Health at IBM deployed healthcare applications in virtual machines on our cloud platform. Because virtual machines had been a costly, heavyweight solution for us, we were interested to evaluate Kubernetes for our deployments.
Our design was to set up the application and data containers in the same namespace, along with the required agents using sidecars, to meet security and compliance requirements in the healthcare industry.
I was able to run more processes on a single physical server than I could using a virtual machine. Also, running our applications in containers ensured optimal usage of system resources.
To orchestrate container deployment, we are using IBM Cloud Kubernetes Service infrastructure, a Kubernetes implementation by IBM for automating deployment, scaling, and operations of application containers across clusters of hosts, providing container-centric infrastructure.
With Kubernetes, our developers can rapidly develop highly available applications by leveraging the power and flexibility of containers, and with integrated and secure volume service, we can store persistent data, share data between Kubernetes pods, and restore data when needed.
Here is a snapshot of Watson Care Manager, running inside a Kubernetes cluster:


Before deploying an app, a user must create a worker node cluster. I can create a cluster using the kubectl cli commands or create it from the IBM Cloud dashboard.
Our clusters consist of one or more physical or virtual machines, also known as worker nodes, that are loosely coupled, extensible, and centrally monitored and managed by the Kubernetes master. When we deploy a containerized app, the Kubernetes master decides where to deploy the app, taking into consideration the deployment requirements and available capacity in the cluster.
A user makes a request to Kubernetes to deploy the containers, specifying the number of replicas required for high availability. The Kubernetes scheduler decides where the pods (groups of one or more containers) will be scheduled and which worker nodes they will be deployed on, storing this information internally in Kubernetes and etcd. The deployment of pods in worker nodes is updated based on load at runtime, optimizing the placement of pods in the cluster.
Kubelet running in each worker node regularly polls the kube API server. If there is new work to do, kubelet pulls the configuration information and takes action, for example, spinning off a new pod.
Process Flow:
| 
Usage of GitLab in the Process Flow:
We stored all our artifacts in GitLab, which includes the Docker files that are required for creating the image, YAML files needed to create a pod, and the configuration files to make the Healthcare application run.
GitLab and Jenkins interaction in the Process Flow:
We use Jenkins for continuous integration and build automation to create/pull/retag the Docker image and push the image to a Docker registry in the cloud.
Basically, we have a Jenkins job configured to interact with GitLab project to get the latest artifacts and, based on requirements, it will either create a new Docker image from scratch by pulling the needed intermediate images from Docker/Bluemix repository or update the Docker image.
After the image is created/updated the Jenkins job pushes the image to a Bluemix repository to save the latest image to be pulled by UrbanCode Deploy (UCD) component.
Jenkins and UCD interaction in the Process Flow:
The Jenkins job is configured to use the UCD component and its respective application, application process, and the UCD environment to deploy the application. The Docker image version files that will be used by the UCD component are also passed via Jenkins job to the UCD component.
Usage of UCD in the Process Flow:
UCD is used for deployment and the end-to end deployment process is automated here. UCD component process involves the following steps:
- Download the required artifacts for deployment from the Gitlab.
- Login to Bluemix and set the KUBECONFIG based on the Kubernetes cluster used for creating the pods.
- Create the application pod in the cluster using kubectl create command.
- If needed, run a rolling update to update the existing pod.

Deploying the application in IBM Cloud Kubernetes Service:
Provision a cluster in IBM Cloud Kubernetes Service with <x> worker nodes. Create Kubernetes controllers for deploying the containers in worker nodes, the IBM Cloud Kubernetes Service infrastructure pulls the Docker images from IBM Cloud Container Registry to create containers. We tried deploying an application container and running a logmet agent (see Reading and displaying logs using logmet container, below) inside the containers that forwards the application logs to an IBM Cloud logging service. As part of the process, YAML files are used to create a controller resource for the UrbanCode Deploy (UCD). UCD agent is deployed as a DaemonSet controller, which is used to connect to the UCD server. The whole process of deployment of application happens in UCD. To support the application for public access, we created a service resource to interact between pods and access container services. For storage support, we created persistent volume claims and mounted the volume for the containers.
| 
Reading and displaying logs using logmet container:
Logmet is a cloud logging service that helps to collect, store, and analyze an application’s log data. It also aggregates application and environment logs for consolidated application or environment insights and forwards them. Metrics are transmitted with collectd. We chose a model that runs a logmet agent process inside the container. The agent takes care of forwarding the logs to the cloud logging service configured in containers.
The application pod mounts the application logging directory to the storage space, which is created by persistent volume claim, and stores the logs, which are not lost even when the pod dies. Kibana is an open source data visualization plugin for Elasticsearch. It provides visualization capabilities on top of the content indexed on an Elasticsearch cluster.

Exposing services with Ingress:
Ingress controllers are reverse proxies that expose services outside cluster through URLs. They act as an external HTTP load balancer that uses a unique public entry point to route requests to the application.
To expose our services to outside the cluster, we used Ingress. In IBM Cloud Kubernetes Service, if we create a paid cluster, an Ingress controller is automatically installed for us to use. We were able to access services through Ingress by creating a YAML resource file that specifies the service path.
–Sandhya Kapoor, Senior Technologist, Watson Platform for Health, IBM
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Get involved with the Kubernetes project on GitHub
Kubernetes 1.7: Security Hardening, Stateful Application Updates and Extensibility
Today we’re announcing Kubernetes 1.7, a milestone release that adds security, storage and extensibility features motivated by widespread production use of Kubernetes in the most demanding enterprise environments.
At-a-glance, security enhancements in this release include encrypted secrets, network policy for pod-to-pod communication, node authorizer to limit kubelet access and client / server TLS certificate rotation.
For those of you running scale-out databases on Kubernetes, this release has a major feature that adds automated updates to StatefulSets and enhances updates for DaemonSets. We are also announcing alpha support for local storage and a burst mode for scaling StatefulSets faster.
Also, for power users, API aggregation in this release allows user-provided apiservers to be served along with the rest of the Kubernetes API at runtime. Additional highlights include support for extensible admission controllers, pluggable cloud providers, and container runtime interface (CRI) enhancements.
What’s New
Security:
- The Network Policy API is promoted to stable. Network policy, implemented through a network plug-in, allows users to set and enforce rules governing which pods can communicate with each other.
- Node authorizer and admission control plugin are new additions that restrict kubelet’s access to secrets, pods and other objects based on its node.
- Encryption for Secrets, and other resources in etcd, is now available as alpha.
- Kubelet TLS bootstrapping now supports client and server certificate rotation.
- Audit logs stored by the API server are now more customizable and extensible with support for event filtering and webhooks. They also provide richer data for system audit.
Stateful workloads:
- StatefulSet Updates is a new beta feature in 1.7, allowing automated updates of stateful applications such as Kafka, Zookeeper and etcd, using a range of update strategies including rolling updates.
- StatefulSets also now support faster scaling and startup for applications that do not require ordering through Pod Management Policy. This can be a major performance improvement.
- Local Storage (alpha) was one of most frequently requested features for stateful applications. Users can now access local storage volumes through the standard PVC/PV interface and via StorageClasses in StatefulSets.
- DaemonSets, which create one pod per node already have an update feature, and in 1.7 have added smart rollback and history capability.
- A new StorageOS Volume plugin provides highly-available cluster-wide persistent volumes from local or attached node storage.
Extensibility:
-
API aggregation at runtime is the most powerful extensibility features in this release, allowing power users to add Kubernetes-style pre-built, 3rd party or user-created APIs to their cluster.
-
Container Runtime Interface (CRI) has been enhanced with New RPC calls to retrieve container metrics from the runtime. Validation tests for the CRI have been published and Alpha integration with containerd, which supports basic pod lifecycle and image management is now available. Read our previous in-depth post introducing CRI.
Additional Features:
- Alpha support for external admission controllers is introduced, providing two options for adding custom business logic to the API server for modifying objects as they are created and validating policy.
- Policy-based Federated Resource Placement is introduced as Alpha providing placement policies for the federated clusters, based on custom requirements such as regulation, pricing or performance.
Deprecation:
- Third Party Resource (TPR) has been replaced with Custom Resource Definitions (CRD) which provides a cleaner API, and resolves issues and corner cases that were raised during the beta period of TPR. If you use the TPR beta feature, you are encouraged to migrate, as it is slated for removal by the community in Kubernetes 1.8.
The above are a subset of the feature highlights in Kubernetes 1.7. For a complete list please visit the release notes.
Adoption
This release is possible thanks to our vast and open community. Together, we’ve already pushed more than 50,000 commits in just three years, and that’s only in the main Kubernetes repo. Additional extensions to Kubernetes are contributed in associated repos bringing overall stability to the project. This velocity makes Kubernetes one of the fastest growing open source projects -- ever.
Kubernetes adoption has been coming from every sector across the world. Recent user stories from the community include:
- GolfNow, a member of the NBC Sports Group, migrated their application to Kubernetes giving them better resource utilization andslashing their infrastructure costs in half.
- Bitmovin, provider of video infrastructure solutions, showed us how they’re using Kubernetes to do multi-stage canary deployments in the cloud and on-prem.
- Ocado, world’s largest online supermarket, uses Kubernetes to create a distributed data center for their smart warehouses. Read about their full setup here.
- Is Kubernetes helping your team? Share your story with the community. See our growing resource of user case studies and learn from great companies like Box that have adopted Kubernetes in their organization.
Huge kudos and thanks go out to the Kubernetes 1.7 release team, led by Dawn Chen of Google.
Availability
Kubernetes 1.7 is available for download on GitHub. To get started with Kubernetes, try one of the these interactive tutorials.
Get Involved
Join the community at CloudNativeCon + KubeCon in Austin Dec. 6-8 for the largest Kubernetes gathering ever. Speaking submissions are open till August 21 and discounted registration ends October 6.
The simplest way to get involved is joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and these channels:
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Share your Kubernetes story.
Many thanks to our vast community of contributors and supporters in making this and all releases possible.
-- Aparna Sinha, Group Product Manager, Kubernetes Google and Ihor Dvoretskyi, Program Manager, Kubernetes Mirantis
Managing microservices with the Istio service mesh
Today’s post is by the Istio team showing how you can get visibility, resiliency, security and control for your microservices in Kubernetes.
Services are at the core of modern software architecture. Deploying a series of modular, small (micro-)services rather than big monoliths gives developers the flexibility to work in different languages, technologies and release cadence across the system; resulting in higher productivity and velocity, especially for larger teams.
With the adoption of microservices, however, new problems emerge due to the sheer number of services that exist in a larger system. Problems that had to be solved once for a monolith, like security, load balancing, monitoring, and rate limiting need to be handled for each service.
Kubernetes and Services
Kubernetes supports a microservices architecture through the Service construct. It allows developers to abstract away the functionality of a set of Pods, and expose it to other developers through a well-defined API. It allows adding a name to this level of abstraction and perform rudimentary L4 load balancing. But it doesn’t help with higher-level problems, such as L7 metrics, traffic splitting, rate limiting, circuit breaking, etc.
Istio, announced last week at GlueCon 2017, addresses these problems in a fundamental way through a service mesh framework. With Istio, developers can implement the core logic for the microservices, and let the framework take care of the rest – traffic management, discovery, service identity and security, and policy enforcement. Better yet, this can be also done for existing microservices without rewriting or recompiling any of their parts. Istio uses Envoy as its runtime proxy component and provides an extensible intermediation layer which allows global cross-cutting policy enforcement and telemetry collection.
The current release of Istio is targeted to Kubernetes users and is packaged in a way that you can install in a few lines and get visibility, resiliency, security and control for your microservices in Kubernetes out of the box.
In a series of blog posts, we'll look at a simple application that is composed of 4 separate microservices. We'll start by looking at how the application can be deployed using plain Kubernetes. We'll then deploy the exact same services into an Istio-enabled cluster without changing any of the application code -- and see how we can observe metrics.
In subsequent posts, we’ll focus on more advanced capabilities such as HTTP request routing, policy, identity and security management.
Example Application: BookInfo
We will use a simple application called BookInfo, that displays information, reviews and ratings for books in a store. The application is composed of four microservices written in different languages:

It’s worth noting that these services have no dependencies on Kubernetes and Istio, but make an interesting case study. Particularly, the multitude of services, languages and versions for the reviews service make it an interesting service mesh example. More information about this example can be found here.
Running the Bookinfo Application in Kubernetes
In this post we’ll focus on the v1 version of the app:

Deploying it with Kubernetes is straightforward, no different than deploying any other services. Service and Deployment resources for the productpage microservice looks like this:
apiVersion: v1
kind: Service
metadata:
name: productpage
labels:
app: productpage
spec:
type: NodePort
ports:
- port: 9080
name: http
selector:
app: productpage
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: productpage-v1
spec:
replicas: 1
template:
metadata:
labels:
app: productpage
track: stable
spec:
containers:
- name: productpage
image: istio/examples-bookinfo-productpage-v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9080
The other two services that we will need to deploy if we want to run the app are details and reviews-v1. We don’t need to deploy the ratings service at this time because v1 of the reviews service doesn’t use it. The remaining services follow essentially the same pattern as productpage. The yaml files for all services can be found here.
To run the services as an ordinary Kubernetes app:
kubectl apply -f bookinfo-v1.yaml
To access the application from outside the cluster we’ll need the NodePort address of the productpage service:
export BOOKINFO\_URL=$(kubectl get po -l app=productpage -o jsonpath={.items[0].status.hostIP}):$(kubectl get svc productpage -o jsonpath={.spec.ports[0].nodePort})
We can now point the browser to http://$BOOKINFO_URL/productpage, and see:

Running the Bookinfo Application with Istio
Now that we’ve seen the app, we’ll adjust our deployment slightly to make it work with Istio. We first need to install Istio in our cluster. To see all of the metrics and tracing features in action, we also install the optional Prometheus, Grafana, and Zipkin addons. We can now delete the previous app and start the Bookinfo app again using the exact same yaml file, this time with Istio:
kubectl delete -f bookinfo-v1.yaml
kubectl apply -f \<(istioctl kube-inject -f bookinfo-v1.yaml)
Notice that this time we use the istioctl kube-inject command to modify bookinfo-v1.yaml before creating the deployments. It injects the Envoy sidecar into the Kubernetes pods as documented here. Consequently, all of the microservices are packaged with an Envoy sidecar that manages incoming and outgoing traffic for the service.
In the Istio service mesh we will not want to access the application productpage directly, as we did in plain Kubernetes. Instead, we want an Envoy sidecar in the request path so that we can use Istio’s management features (version routing, circuit breakers, policies, etc.) to control external calls to productpage , just like we can for internal requests. Istio’s Ingress controller is used for this purpose.
To use the Istio Ingress controller, we need to create a Kubernetes Ingress resource for the app, annotated with kubernetes.io/ingress.class: "istio", like this:
cat \<\<EOF ``` kubectl create -f -
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: bookinfo
annotations:
kubernetes.io/ingress.class: "istio"
spec:
rules:
- http:
paths:
- path: /productpage
backend:
serviceName: productpage
servicePort: 9080
- path: /login
backend:
serviceName: productpage
servicePort: 9080
- path: /logout
backend:
serviceName: productpage
servicePort: 9080
EOF
The resulting deployment with Istio and v1 version of the bookinfo app looks like this:

This time we will access the app using the NodePort address of the Istio Ingress controller:
export BOOKINFO\_URL=$(kubectl get po -l istio=ingress -o jsonpath={.items[0].status.hostIP}):$(kubectl get svc istio-ingress -o jsonpath={.spec.ports[0].nodePort})
We can now load the page at http://$BOOKINFO_URL/productpage and once again see the running app -- there should be no difference from the previous deployment without Istio for the user.
However, now that the application is running in the Istio service mesh, we can immediately start to see some benefits.
Metrics collection
The first thing we get from Istio out-of-the-box is the collection of metrics in Prometheus. These metrics are generated by the Istio filter in Envoy, collected according to default rules (which can be customized), and then sent to Prometheus. The metrics can be visualized in the Istio dashboard in Grafana. Note that while Prometheus is the out-of-the-box default metrics backend, Istio allows you to plug in to others, as we’ll demonstrate in future blog posts.
To demonstrate, we'll start by running the following command to generate some load on the application:
wrk -t1 -c1 -d20s http://$BOOKINFO\_URL/productpage
We obtain Grafana’s NodePort URL:
export GRAFANA\_URL=$(kubectl get po -l app=grafana -o jsonpath={.items[0].status.hostIP}):$(kubectl get svc grafana -o jsonpath={.spec.ports[0].nodePort})
We can now open a browser at http://$GRAFANA_URL/dashboard/db/istio-dashboard and examine the various performance metrics for each of the Bookinfo services:

Distributed tracing The next thing we get from Istio is call tracing with Zipkin. We obtain its NodePort URL:
export ZIPKIN\_URL=$(kubectl get po -l app=zipkin -o jsonpath={.items[0].status.hostIP}):$(kubectl get svc zipkin -o jsonpath={.spec.ports[0].nodePort})
We can now point a browser at http://$ZIPKIN_URL/ to see request trace spans through the Bookinfo services.

Although the Envoy proxies send trace spans to Zipkin out-of-the-box, to leverage its full potential, applications need to be Zipkin aware and forward some headers to tie the individual spans together. See zipkin-tracing for details.
Holistic view of the entire fleet The metrics that Istio provides are much more than just a convenience. They provide a consistent view of the service mesh, by generating uniform metrics throughout. We don’t have to worry about reconciling different types of metrics emitted by various runtime agents, or add arbitrary agents to gather metrics for legacy uninstrumented apps. We also no longer have to rely on the development process to properly instrument the application to generate metrics. The service mesh sees all the traffic, even into and out of legacy "black box" services, and generates metrics for all of it. Summary The demo above showed how in a few steps, we can launch Istio-backed services and observe L7 metrics on them. Over the next weeks we’ll follow on with demonstration of more Istio capabilities like policy management and HTTP request routing. Google, IBM and Lyft joined forces to create Istio based on our common experiences building and operating large and complex microservice deployments for internal and enterprise customers. Istio is an industry-wide community effort. We’ve been thrilled to see the enthusiasm from the industry partners and the insights they brought. As we take the next step and release Istio to the wild, we cannot wait to see what the broader community of contributors will bring to it. If you’re using or considering to use a microservices architecture on Kubernetes, we encourage you to give Istio a try, learn about it more at istio.io, let us know what you think, or better yet, join the developer community to help shape its future!
--On behalf of the Istio team. Frank Budinsky, Software Engineer at IBM, Andra Cismaru, Software Engineer and Israel Shalom, Product Manager at Google.
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Draft: Kubernetes container development made easy
_Today's post is by _Brendan Burns, Director of Engineering at Microsoft Azure and Kubernetes co-founder.
About a month ago Microsoft announced the acquisition of Deis to expand our expertise in containers and Kubernetes. Today, I’m excited to announce a new open source project derived from this newly expanded Azure team: Draft.
While by now the strengths of Kubernetes for deploying and managing applications at scale are well understood. The process of developing a new application for Kubernetes is still too hard. It’s harder still if you are new to containers, Kubernetes, or developing cloud applications.
Draft fills this role. As its name implies it is a tool that helps you begin that first draft of a containerized application running in Kubernetes. When you first run the draft tool, it automatically discovers the code that you are working on and builds out the scaffolding to support containerizing your application. Using heuristics and a variety of pre-defined project templates draft will create an initial Dockerfile to containerize your application, as well as a Helm Chart to enable your application to be deployed and maintained in a Kubernetes cluster. Teams can even bring their own draft project templates to customize the scaffolding that is built by the tool.
But the value of draft extends beyond simply scaffolding in some files to help you create your application. Draft also deploys a server into your existing Kubernetes cluster that is automatically kept in sync with the code on your laptop. Whenever you make changes to your application, the draft daemon on your laptop synchronizes that code with the draft server in Kubernetes and a new container is built and deployed automatically without any user action required. Draft enables the “inner loop” development experience for the cloud.
Of course, as is the expectation with all infrastructure software today, Draft is available as an open source project, and it itself is in “draft” form :) We eagerly invite the community to come and play around with draft today, we think it’s pretty awesome, even in this early form. But we’re especially excited to see how we can develop a community around draft to make it even more powerful for all developers of containerized applications on Kubernetes.
To give you a sense for what Draft can do, here is an example drawn from the Getting Started page in the GitHub repository.
There are multiple example applications included within the examples directory. For this walkthrough, we'll be using the python example application which uses Flask to provide a very simple Hello World webserver.
$ cd examples/python
Draft Create
We need some "scaffolding" to deploy our app into a Kubernetes cluster. Draft can create a Helm chart, a Dockerfile and a draft.toml with draft create:
$ draft create
--\> Python app detected
--\> Ready to sail
$ ls
Dockerfile app.py chart/ draft.toml requirements.txt
The chart/ and Dockerfile assets created by Draft default to a basic Python configuration. This Dockerfile harnesses the python:onbuild image, which will install the dependencies in requirements.txt and copy the current directory into /usr/src/app. And to align with the service values in chart/values.yaml, this Dockerfile exposes port 80 from the container.
The draft.toml file contains basic configuration about the application like the name, which namespace it will be deployed to, and whether to deploy the app automatically when local files change.
$ cat draft.toml
[environments]
[environments.development]
name = "tufted-lamb"
namespace = "default"
watch = true
watch\_delay = 2
Draft Up
Now we're ready to deploy app.py to a Kubernetes cluster.
Draft handles these tasks with one draft up command:
- reads configuration from draft.toml
- compresses the chart/ directory and the application directory as two separate tarballs
- uploads the tarballs to draftd, the server-side component
- draftd then builds the docker image and pushes the image to a registry
- draftd instructs helm to install the Helm chart, referencing the Docker registry image just built
With the watch option set to true, we can let this run in the background while we make changes later on…
$ draft up
--\> Building Dockerfile
Step 1 : FROM python:onbuild
onbuild: Pulling from library/python
...
Successfully built 38f35b50162c
--\> Pushing docker.io/microsoft/tufted-lamb:5a3c633ae76c9bdb81b55f5d4a783398bf00658e
The push refers to a repository [docker.io/microsoft/tufted-lamb]
...
5a3c633ae76c9bdb81b55f5d4a783398bf00658e: digest: sha256:9d9e9fdb8ee3139dd77a110fa2d2b87573c3ff5ec9c045db6009009d1c9ebf5b size: 16384
--\> Deploying to Kubernetes
Release "tufted-lamb" does not exist. Installing it now.
--\> Status: DEPLOYED
--\> Notes:
1. Get the application URL by running these commands:
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
You can watch the status of by running 'kubectl get svc -w tufted-lamb-tufted-lamb'
export SERVICE\_IP=$(kubectl get svc --namespace default tufted-lamb-tufted-lamb -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
echo http://$SERVICE\_IP:80
Watching local files for changes...
Interact with the Deployed App
Using the handy output that follows successful deployment, we can now contact our app. Note that it may take a few minutes before the load balancer is provisioned by Kubernetes. Be patient!
$ export SERVICE\_IP=$(kubectl get svc --namespace default tufted-lamb-tufted-lamb -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
$ curl [http://$SERVICE\_IP](http://%24service_ip/)
When we curl our app, we see our app in action! A beautiful "Hello World!" greets us.
Update the App
Now, let's change the "Hello, World!" output in app.py to output "Hello, Draft!" instead:
$ cat \<\<EOF \> app.py
from flask import Flask
app = Flask(\_\_name\_\_)
@app.route("/")
def hello():
return "Hello, Draft!\n"
if \_\_name\_\_ == "\_\_main\_\_":
app.run(host='0.0.0.0', port=8080)
EOF
Draft Up(grade)
Now if we watch the terminal that we initially called draft up with, Draft will notice that there were changes made locally and call draft up again. Draft then determines that the Helm release already exists and will perform a helm upgrade rather than attempting another helm install:
--\> Building Dockerfile
Step 1 : FROM python:onbuild
...
Successfully built 9c90b0445146
--\> Pushing docker.io/microsoft/tufted-lamb:f031eb675112e2c942369a10815850a0b8bf190e
The push refers to a repository [docker.io/microsoft/tufted-lamb]
...
--\> Deploying to Kubernetes
--\> Status: DEPLOYED
--\> Notes:
1. Get the application URL by running these commands:
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
You can watch the status of by running 'kubectl get svc -w tufted-lamb-tufted-lamb'
export SERVICE\_IP=$(kubectl get svc --namespace default tufted-lamb-tufted-lamb -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
echo [http://$SERVICE\_IP:80](http://%24service_ip/)
Now when we run curl http://$SERVICE_IP, our first app has been deployed and updated to our Kubernetes cluster via Draft!
We hope this gives you a sense for everything that Draft can do to streamline development for Kubernetes. Happy drafting!
--Brendan Burns, Director of Engineering, Microsoft Azure
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Get involved with the Kubernetes project on GitHub
Kubernetes: a monitoring guide
Today’s post is by Jean-Mathieu Saponaro, Research & Analytics Engineer at Datadog, discussing what Kubernetes changes for monitoring, and how you can prepare to properly monitor a containerized infrastructure orchestrated by Kubernetes.
Container technologies are taking the infrastructure world by storm. While containers solve or simplify infrastructure management processes, they also introduce significant complexity in terms of orchestration. That’s where Kubernetes comes to our rescue. Just like a conductor directs an orchestra, Kubernetes oversees our ensemble of containers—starting, stopping, creating, and destroying them automatically to keep our applications humming along.
Kubernetes makes managing a containerized infrastructure much easier by creating levels of abstractions such as pods and services. We no longer have to worry about where applications are running or if they have enough resources to work properly. But that doesn’t change the fact that, in order to ensure good performance, we need to monitor our applications, the containers running them, and Kubernetes itself.
Rethinking monitoring for the Kubernetes era
Just as containers have completely transformed how we think about running services on virtual machines, Kubernetes has changed the way we interact with containers. The good news is that with proper monitoring, the abstraction levels inherent to Kubernetes provide a comprehensive view of your infrastructure, even if the containers and applications are constantly moving. But Kubernetes monitoring requires us to rethink and reorient our strategies, since it differs from monitoring traditional hosts such as VMs or physical machines in several ways.
Tags and labels become essential
With containers and their orchestration completely managed by Kubernetes, labels are now the only way we have to interact with pods and containers. That’s why they are absolutely crucial for monitoring since all metrics and events will be sliced and diced using labels across the different layers of your infrastructure. Defining your labels with a logical and easy-to-understand schema is essential so your metrics will be as useful as possible.
There are now more components to monitor

Applications are constantly moving
Kubernetes schedules applications dynamically based on scheduling policy, so you don’t always know where applications are running. But they still need to be monitored. That’s why using a monitoring system or tool with service discovery is a must. It will automatically adapt metric collection to moving containers so applications can be continuously monitored without interruption.
Be prepared for distributed clusters
Kubernetes has the ability to distribute containerized applications across multiple data centers and potentially different cloud providers. That means metrics must be collected and aggregated among all these different sources.
For more details about all these new monitoring challenges inherent to Kubernetes and how to overcome them, we recently published an in-depth Kubernetes monitoring guide. Part 1 of the series covers how to adapt your monitoring strategies to the Kubernetes era.
Metrics to monitor
Whether you use Heapster data or a monitoring tool integrating with Kubernetes and its different APIs, there are several key types of metrics that need to be closely tracked:
- Running pods and their deployments
- Usual resource metrics such as CPU, memory usage, and disk I/O
- Container-native metrics
- Application metrics for which a service discovery feature in your monitoring tool is essential
All these metrics should be aggregated using Kubernetes labels and correlated with events from Kubernetes and container technologies.
Part 2 of our series on Kubernetes monitoring guides you through all the data that needs to be collected and tracked.
Collecting these metrics
Whether you want to track these key performance metrics by combining Heapster, a storage backend, and a graphing tool, or by integrating a monitoring tool with the different components of your infrastructure, Part 3, about Kubernetes metric collection, has you covered.
Anchors aweigh!
Using Kubernetes drastically simplifies container management. But it requires us to rethink our monitoring strategies on several fronts, and to make sure all the key metrics from the different components are properly collected, aggregated, and tracked. We hope our monitoring guide will help you to effectively monitor your Kubernetes clusters. Feedback and suggestions are more than welcome.
--Jean-Mathieu Saponaro, Research & Analytics Engineer, Datadog
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Kubespray Ansible Playbooks foster Collaborative Kubernetes Ops
Today’s guest post is by Rob Hirschfeld, co-founder of open infrastructure automation project, Digital Rebar and co-chair of the SIG Cluster Ops.
Why Kubespray?
Making Kubernetes operationally strong is a widely held priority and I track many deployment efforts around the project. The incubated Kubespray project is of particular interest for me because it uses the popular Ansible toolset to build robust, upgradable clusters on both cloud and physical targets. I believe using tools familiar to operators grows our community.
We’re excited to see the breadth of platforms enabled by Kubespray and how well it handles a wide range of options like integrating Ceph for StatefulSet persistence and Helm for easier application uploads. Those additions have allowed us to fully integrate the OpenStack Helm charts (demo video).
By working with the upstream source instead of creating different install scripts, we get the benefits of a larger community. This requires some extra development effort; however, we believe helping share operational practices makes the whole community stronger. That was also the motivation behind the SIG-Cluster Ops.
With Kubespray delivering robust installs, we can focus on broader operational concerns.
For example, we can now drive parallel deployments, so it’s possible to fully exercise the options enabled by Kubespray simultaneously for development and testing.
That’s helpful to built-test-destroy coordinated Kubernetes installs on CentOS, Red Hat and Ubuntu as part of an automation pipeline. We can also set up a full classroom environment from a single command using Digital Rebar’s providers, tenants and cluster definition JSON.
Let’s explore the classroom example:
First, we define a student cluster in JSON like the snippet below
| {
"attribs": {
"k8s-version": "v1.6.0",
"k8s-kube_network_plugin": "calico",
"k8s-docker_version": "1.12"
},
"name": "cluster01",
"tenant": "cluster01",
"public_keys": {
"cluster01": "ssh-rsa AAAAB..... user@example.com"
},
"provider": {
"name": "google-provider"
},
"nodes": [
{
"roles": ["etcd","k8s-addons", "k8s-master"],
"count": 1
},
{
"roles": ["k8s-worker"],
"count": 3
}
]
} |
Then we run the Digital Rebar workloads Multideploy.sh reference script which inspects the deployment files to pull out key information. Basically, it automates the following steps:
| rebar provider create {“name”:“google-provider”, [secret stuff]}
rebar tenants create {“name”:“cluster01”}
rebar deployments create [contents from cluster01 file] |
The deployments create command will automatically request nodes from the provider. Since we’re using tenants and SSH key additions, each student only gets access to their own cluster. When we’re done, adding the --destroy flag will reverse the process for the nodes and deployments but leave the providers and tenants.
We are invested in operational scripts like this example using Kubespray and Digital Rebar because if we cannot manage variation in a consistent way then we’re doomed to operational fragmentation.
I am excited to see and be part of the community progress towards enterprise-ready Kubernetes operations on both cloud and on-premises. That means I am seeing reasonable patterns emerge with sharable/reusable automation. I strongly recommend watching (or better, collaborating in) these efforts if you are deploying Kubernetes even at experimental scale. Being part of the community requires more upfront effort but returns dividends as you get the benefits of shared experience and improvement.
When deploying at scale, how do you set up a system to be both repeatable and multi-platform without compromising scale or security?
With Kubespray and Digital Rebar as a repeatable base, extensions get much faster and easier. Even better, using upstream directly allows improvements to be quickly cycled back into upstream. That means we’re closer to building a community focused on the operational side of Kubernetes with an SRE mindset.
If this is interesting, please engage with us in the Cluster Ops SIG, Kubespray or Digital Rebar communities.
-- Rob Hirschfeld, co-founder of RackN and co-chair of the Cluster Ops SIG
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Dancing at the Lip of a Volcano: The Kubernetes Security Process - Explained
Editor's note: Today’s post is by Jess Frazelle of Google and Brandon Philips of CoreOS about the Kubernetes security disclosures and response policy.
Software running on servers underpins ever growing amounts of the world's commerce, communications, and physical infrastructure. And nearly all of these systems are connected to the internet; which means vital security updates must be applied rapidly. As software developers and IT professionals, we often find ourselves dancing on the edge of a volcano: we may either fall into magma induced oblivion from a security vulnerability exploited before we can fix it, or we may slide off the side of the mountain because of an inadequate process to address security vulnerabilities.
The Kubernetes community believes that we can help teams restore their footing on this volcano with a foundation built on Kubernetes. And the bedrock of this foundation requires a process for quickly acknowledging, patching, and releasing security updates to an ever growing community of Kubernetes users.
With over 1,200 contributors and over a million lines of code, each release of Kubernetes is a massive undertaking staffed by brave volunteer release managers. These normal releases are fully transparent and the process happens in public. However, security releases must be handled differently to keep potential attackers in the dark until a fix is made available to users.
We drew inspiration from other open source projects in order to create the Kubernetes security release process. Unlike a regularly scheduled release, a security release must be delivered on an accelerated schedule, and we created the Product Security Team to handle this process.
This team quickly selects a lead to coordinate work and manage communication with the persons that disclosed the vulnerability and the Kubernetes community. The security release process also documents ways to measure vulnerability severity using the Common Vulnerability Scoring System (CVSS) Version 3.0 Calculator. This calculation helps inform decisions on release cadence in the face of holidays or limited developer bandwidth. By making severity criteria transparent we are able to better set expectations and hit critical timelines during an incident where we strive to:
- Respond to the person or team who reported the vulnerability and staff a development team responsible for a fix within 24 hours
- Disclose a forthcoming fix to users within 7 days of disclosure
- Provide advance notice to vendors within 14 days of disclosure
- Release a fix within 21 days of disclosure
As we continue to harden Kubernetes, the security release process will help ensure that Kubernetes remains a secure platform for internet scale computing. If you are interested in learning more about the security release process please watch the presentation from KubeCon Europe 2017 on YouTube and follow along with the slides. If you are interested in learning more about authentication and authorization in Kubernetes, along with the Kubernetes cluster security model, consider joining Kubernetes SIG Auth. We also hope to see you at security related presentations and panels at the next Kubernetes community event: CoreOS Fest 2017 in San Francisco on May 31 and June 1.
As a thank you to the Kubernetes community, a special 25 percent discount to CoreOS Fest is available using k8s25code or via this special 25 percent off link to register today for CoreOS Fest 2017.
--Brandon Philips of CoreOS and Jess Frazelle of Google
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Get involved with the Kubernetes project on GitHub
How Bitmovin is Doing Multi-Stage Canary Deployments with Kubernetes in the Cloud and On-Prem
Editor's Note: Today’s post is by Daniel Hoelbling-Inzko, Infrastructure Architect at Bitmovin, a company that provides services that transcode digital video and audio to streaming formats, sharing insights about their use of Kubernetes.
Running a large scale video encoding infrastructure on multiple public clouds is tough. At Bitmovin, we have been doing it successfully for the last few years, but from an engineering perspective, it’s neither been enjoyable nor particularly fun.
So obviously, one of the main things that really sold us on using Kubernetes, was it’s common abstraction from the different supported cloud providers and the well thought out programming interface it provides. More importantly, the Kubernetes project did not settle for the lowest common denominator approach. Instead, they added the necessary abstract concepts that are required and useful to run containerized workloads in a cloud and then did all the hard work to map these concepts to the different cloud providers and their offerings.
The great stability, speed and operational reliability we saw in our early tests in mid-2016 made the migration to Kubernetes a no-brainer.
And, it didn’t hurt that the vision for scale the Kubernetes project has been pursuing is closely aligned with our own goals as a company. Aiming for >1,000 node clusters might be a lofty goal, but for a fast growing video company like ours, having your infrastructure aim to support future growth is essential. Also, after initial brainstorming for our new infrastructure, we immediately knew that we would be running a huge number of containers and having a system, with the expressed goal of working at global scale, was the perfect fit for us. Now with the recent Kubernetes 1.6 release and its support for 5,000 node clusters, we feel even more validated in our choice of a container orchestration system.
During the testing and migration phase of getting our infrastructure running on Kubernetes, we got quite familiar with the Kubernetes API and the whole ecosystem around it. So when we were looking at expanding our cloud video encoding offering for customers to use in their own datacenters or cloud environments, we quickly decided to leverage Kubernetes as our ubiquitous cloud operating system to base the solution on.
Just a few months later this effort has become our newest service offering: Bitmovin Managed On-Premise encoding. Since all Kubernetes clusters share the same API, adapting our cloud encoding service to also run on Kubernetes enabled us to deploy into our customer’s datacenter, regardless of the hardware infrastructure running underneath. With great tools from the community, like kube-up and turnkey solutions, like Google Container Engine, anyone can easily provision a new Kubernetes cluster, either within their own infrastructure or in their own cloud accounts.
To give us the maximum flexibility for customers that deploy to bare metal and might not have any custom cloud integrations for Kubernetes yet, we decided to base our solution solely on facilities that are available in any Kubernetes install and don’t require any integration into the surrounding infrastructure (it will even run inside Minikube!). We don’t rely on Services of type LoadBalancer, primarily because enterprise IT is usually reluctant to open up ports to the open internet - and not every bare metal Kubernetes install supports externally provisioned load balancers out of the box. To avoid these issues, we deploy a BitmovinAgent that runs inside the Cluster and polls our API for new encoding jobs without requiring any network setup. This agent then uses the locally available Kubernetes credentials to start up new deployments that run the encoders on the available hardware through the Kubernetes API.
Even without having a full cloud integration available, the consistent scheduling, health checking and monitoring we get from using the Kubernetes API really enabled us to focus on making the encoder work inside a container rather than spending precious engineering resources on integrating a bunch of different hypervisors, machine provisioners and monitoring systems.

Our first encounters with the Kubernetes API were not for the On-Premise encoding product. Building our containerized encoding workflow on Kubernetes was rather a decision we made after seeing how incredibly easy and powerful the Kubernetes platform proved during development and rollout of our Bitmovin API infrastructure. We migrated to Kubernetes around four months ago and it has enabled us to provide rapid development iterations to our service while meeting our requirements of downtime-free deployments and a stable development to production pipeline. To achieve this we came up with an architecture that runs almost a thousand containers and meets the following requirements we had laid out on day one:
- 1.Zero downtime deployments for our customers
- 2.Continuous deployment to production on each git mainline push
- 3.High stability of deployed services for customers
Obviously #2 and #3 are at odds with each other, if each merged feature gets deployed to production right away - how can we ensure these releases are bug-free and don’t have adverse side effects for our customers?
To overcome this oxymoron, we came up with a four-stage canary pipeline for each microservice where we simultaneously deploy to production and keep changes away from customers until the new build has proven to work reliably and correctly in the production environment.
Once a new build is pushed, we deploy it to an internal stage that’s only accessible for our internal tests and the integration test suite. Once the internal test suite passes, QA reports no issues, and we don’t detect any abnormal behavior, we push the new build to our free stage. This means that 5% of our free users would get randomly assigned to this new build. After some time in this stage the build gets promoted to the next stage that gets 5% of our paid users routed to it. Only once the build has successfully passed all 3 of these hurdles, does it get deployed to the production tier, where it will receive all traffic from our remaining users as well as our enterprise customers, which are not part of the paid bucket and never see their traffic routed to a canary track.

This setup makes us a pretty big Kubernetes installation by default, since all of our canary tiers are available at a minimum replication of 2. Since we are currently deploying around 30 microservices (and growing) to our clusters, it adds up to a minimum of 10 pods per service (8 application pods + minimum 2 HAProxy pods that do the canary routing). Although, in reality our preferred standard configuration is usually running 2 internal, 4 free, 4 others and 10 production pods alongside 4 HAProxy pods - totalling around 700 pods in total. This also means that we are running at least 150 services that provide a static ClusterIP to their underlying microservice canary tier.
A typical deployment looks like this:
| Services (ClusterIP) | Deployments | #Pods | | account-service | account-service-haproxy | 4 | | account-service-internal | account-service-internal-v1.18.0 | 2 | | account-service-canary | account-service-canary-v1.17.0 | 4 | | account-service-paid | account-service-paid-v1.15.0 | 4 | | account-service-production | account-service-production-v1.15.0 | 10 |
An example service definition the production track will have the following label selectors:
apiVersion: v1
kind: Service
metadata:
name: account-service-production
labels:
app: account-service-production
tier: service
lb: private
spec:
ports:
- port: 8080
name: http
targetPort: 8080
protocol: TCP
selector:
app: account-service
tier: service
track: production
In front of the Kubernetes services, load balancing the different canary versions of the service, lives a small cluster of HAProxy pods that get their haproxy.conf from the Kubernetes ConfigMaps that looks something like this:
frontend http-in
bind \*:80
log 127.0.0.1 local2 debug
acl traffic\_internal hdr(X-Traffic-Group) -m str -i INTERNAL
acl traffic\_free hdr(X-Traffic-Group) -m str -i FREE
acl traffic\_enterprise hdr(X-Traffic-Group) -m str -i ENTERPRISE
use\_backend internal if traffic\_internal
use\_backend canary if traffic\_free
use\_backend enterprise if traffic\_enterprise
default\_backend paid
backend internal
balance roundrobin
server internal-lb user-resource-service-internal:8080 resolvers dns check inter 2000
backend canary
balance roundrobin
server canary-lb user-resource-service-canary:8080 resolvers dns check inter 2000 weight 5
server production-lb user-resource-service-production:8080 resolvers dns check inter 2000 weight 95
backend paid
balance roundrobin
server canary-paid-lb user-resource-service-paid:8080 resolvers dns check inter 2000 weight 5
server production-lb user-resource-service-production:8080 resolvers dns check inter 2000 weight 95
backend enterprise
balance roundrobin
server production-lb user-resource-service-production:8080 resolvers dns check inter 2000 weight 100
Each HAProxy will inspect a header that gets assigned by our API-Gateway called X-Traffic-Group that determines which bucket of customers this request belongs to. Based on that, a decision is made to hit either a canary deployment or the production deployment.
Obviously, at this scale, kubectl (while still our main day-to-day tool to work on the cluster) doesn’t really give us a good overview of whether everything is actually running as it’s supposed to and what is maybe over or under replicated.
Since we do blue/green deployments, we sometimes forget to shut down the old version after the new one comes up, so some services might be running over replicated and finding these issues in a soup of 25 deployments listed in kubectl is not trivial, to say the least.
So, having a container orchestrator like Kubernetes, that’s very API driven, was really a godsend for us, as it allowed us to write tools that take care of that.
We built tools that either run directly off kubectl (eg bash-scripts) or interact directly with the API and understand our special architecture to give us a quick overview of the system. These tools were mostly built in Go using the client-go library.
One of these tools is worth highlighting, as it’s basically our only way to really see service health at a glance. It goes through all our Kubernetes services that have the tier: service selector and checks if the accompanying HAProxy deployment is available and all pods are running with 4 replicas. It also checks if the 4 services behind the HAProxys (internal, free, others and production) have at least 2 endpoints running. If any of these conditions are not met, we immediately get a notification in Slack and by email.
Managing this many pods with our previous orchestrator proved very unreliable and the overlay network frequently caused issues. Not so with Kubernetes - even doubling our current workload for test purposes worked flawlessly and in general, the cluster has been working like clockwork ever since we installed it.
Another advantage of switching over to Kubernetes was the availability of the kubernetes resource specifications, in addition to the API (which we used to write some internal tools for deployment). This enabled us to have a Git repo with all our Kubernetes specifications, where each track is generated off a common template and only contains placeholders for variable things like the canary track and the names.
All changes to the cluster have to go through tools that modify these resource specifications and get checked into git automatically so, whenever we see issues, we can debug what changes the infrastructure went through over time!
To summarize this post - by migrating our infrastructure to Kubernetes, Bitmovin is able to have:
- Zero downtime deployments, allowing our customers to encode 24/7 without interruption
- Fast development to production cycles, enabling us to ship new features faster
- Multiple levels of quality assurance and high confidence in production deployments
- Ubiquitous abstractions across cloud architectures and on-premise deployments
- Stable and reliable health-checking and scheduling of services
- Custom tooling around our infrastructure to check and validate the system
- History of deployments (resource specifications in git + custom tooling)
We want to thank the Kubernetes community for the incredible job they have done with the project. The velocity at which the project moves is just breathtaking! Maintaining such a high level of quality and robustness in such a diverse environment is really astonishing.
--Daniel Hoelbling-Inzko, Infrastructure Architect, Bitmovin
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Get involved with the Kubernetes project on GitHub
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Download Kubernetes
RBAC Support in Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.6
One of the highlights of the Kubernetes 1.6 release is the RBAC authorizer feature moving to beta. RBAC, Role-based access control, is an authorization mechanism for managing permissions around Kubernetes resources. RBAC allows configuration of flexible authorization policies that can be updated without cluster restarts.
The focus of this post is to highlight some of the interesting new capabilities and best practices.
RBAC vs ABAC
Currently there are several authorization mechanisms available for use with Kubernetes. Authorizers are the mechanisms that decide who is permitted to make what changes to the cluster using the Kubernetes API. This affects things like kubectl, system components, and also certain applications that run in the cluster and manipulate the state of the cluster, like Jenkins with the Kubernetes plugin, or Helm that runs in the cluster and uses the Kubernetes API to install applications in the cluster. Out of the available authorization mechanisms, ABAC and RBAC are the mechanisms local to a Kubernetes cluster that allow configurable permissions policies.
ABAC, Attribute Based Access Control, is a powerful concept. However, as implemented in Kubernetes, ABAC is difficult to manage and understand. It requires ssh and root filesystem access on the master VM of the cluster to make authorization policy changes. For permission changes to take effect the cluster API server must be restarted.
RBAC permission policies are configured using kubectl or the Kubernetes API directly. Users can be authorized to make authorization policy changes using RBAC itself, making it possible to delegate resource management without giving away ssh access to the cluster master. RBAC policies map easily to the resources and operations used in the Kubernetes API.
Based on where the Kubernetes community is focusing their development efforts, going forward RBAC should be preferred over ABAC.
Basic Concepts
There are a few basic ideas behind RBAC that are foundational in understanding it. At its core, RBAC is a way of granting users granular access to Kubernetes API resources.

The connection between user and resources is defined in RBAC using two objects.
Roles
A Role is a collection of permissions. For example, a role could be defined to include read permission on pods and list permission for pods. A ClusterRole is just like a Role, but can be used anywhere in the cluster.
Role Bindings
A RoleBinding maps a Role to a user or set of users, granting that Role's permissions to those users for resources in that namespace. A ClusterRoleBinding allows users to be granted a ClusterRole for authorization across the entire cluster.

Additionally there are cluster roles and cluster role bindings to consider. Cluster roles and cluster role bindings function like roles and role bindings except they have wider scope. The exact differences and how cluster roles and cluster role bindings interact with roles and role bindings are covered in the Kubernetes documentation.
RBAC in Kubernetes
RBAC is now deeply integrated into Kubernetes and used by the system components to grant the permissions necessary for them to function. System roles are typically prefixed with system: so they can be easily recognized.
➜ kubectl get clusterroles --namespace=kube-system
NAME KIND
admin ClusterRole.v1beta1.rbac.authorization.k8s.io
cluster-admin ClusterRole.v1beta1.rbac.authorization.k8s.io
edit ClusterRole.v1beta1.rbac.authorization.k8s.io
kubelet-api-admin ClusterRole.v1beta1.rbac.authorization.k8s.io
system:auth-delegator ClusterRole.v1beta1.rbac.authorization.k8s.io
system:basic-user ClusterRole.v1beta1.rbac.authorization.k8s.io
system:controller:attachdetach-controller ClusterRole.v1beta1.rbac.authorization.k8s.io
system:controller:certificate-controller ClusterRole.v1beta1.rbac.authorization.k8s.io
...
The RBAC system roles have been expanded to cover the necessary permissions for running a Kubernetes cluster with RBAC only.
During the permission translation from ABAC to RBAC, some of the permissions that were enabled by default in many deployments of ABAC authorized clusters were identified as unnecessarily broad and were scoped down in RBAC. The area most likely to impact workloads on a cluster is the permissions available to service accounts. With the permissive ABAC configuration, requests from a pod using the pod mounted token to authenticate to the API server have broad authorization. As a concrete example, the curl command at the end of this sequence will return a JSON formatted result when ABAC is enabled and an error when only RBAC is enabled.
➜ kubectl run nginx --image=nginx:latest
➜ kubectl exec -it $(kubectl get pods -o jsonpath='{.items[0].metadata.name}') bash
➜ apt-get update && apt-get install -y curl
➜ curl -ik \
-H "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" \
https://kubernetes/api/v1/namespaces/default/pods
Any applications you run in your Kubernetes cluster that interact with the Kubernetes API have the potential to be affected by the permissions changes when transitioning from ABAC to RBAC.
To smooth the transition from ABAC to RBAC, you can create Kubernetes 1.6 clusters with both ABAC and RBAC authorizers enabled. When both ABAC and RBAC are enabled, authorization for a resource is granted if either authorization policy grants access. However, under that configuration the most permissive authorizer is used and it will not be possible to use RBAC to fully control permissions.
At this point, RBAC is complete enough that ABAC support should be considered deprecated going forward. It will still remain in Kubernetes for the foreseeable future but development attention is focused on RBAC.
Two different talks at the at the Google Cloud Next conference touched on RBAC related changes in Kubernetes 1.6, jump to the relevant parts here and here. For more detailed information about using RBAC in Kubernetes 1.6 read the full RBAC documentation.
Get Involved
If you’d like to contribute or simply help provide feedback and drive the roadmap, join our community. Specifically interested in security and RBAC related conversation, participate through one of these channels:
- Chat with us on the Kubernetes Slack sig-auth channel
- Join the biweekly SIG-Auth meetings on Wednesday at 11:00 AM PT
Thanks for your support and contributions. Read more in-depth posts on what's new in Kubernetes 1.6 here.
-- Jacob Simpson, Greg Castle & CJ Cullen, Software Engineers at Google
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Get involved with the Kubernetes project on GitHub
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Download Kubernetes
Configuring Private DNS Zones and Upstream Nameservers in Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.6
Many users have existing domain name zones that they would like to integrate into their Kubernetes DNS namespace. For example, hybrid-cloud users may want to resolve their internal “.corp” domain addresses within the cluster. Other users may have a zone populated by a non-Kubernetes service discovery system (like Consul). We’re pleased to announce that, in Kubernetes 1.6, kube-dns adds support for configurable private DNS zones (often called “stub domains”) and external upstream DNS nameservers. In this blog post, we describe how to configure and use this feature.
Default lookup flow

Kubernetes currently supports two DNS policies specified on a per-pod basis using the dnsPolicy flag: “Default” and “ClusterFirst”. If dnsPolicy is not explicitly specified, then “ClusterFirst” is used:
- If dnsPolicy is set to “Default”, then the name resolution configuration is inherited from the node the pods run on. Note: this feature cannot be used in conjunction with dnsPolicy: “Default”.
- If dnsPolicy is set to “ClusterFirst”, then DNS queries will be sent to the kube-dns service. Queries for domains rooted in the configured cluster domain suffix (any address ending in “.cluster.local” in the example above) will be answered by the kube-dns service. All other queries (for example, www.kubernetes.io) will be forwarded to the upstream nameserver inherited from the node. Before this feature, it was common to introduce stub domains by replacing the upstream DNS with a custom resolver. However, this caused the custom resolver itself to become a critical path for DNS resolution, where issues with scalability and availability may cause the cluster to lose DNS functionality. This feature allows the user to introduce custom resolution without taking over the entire resolution path.
Customizing the DNS Flow
Beginning in Kubernetes 1.6, cluster administrators can specify custom stub domains and upstream nameservers by providing a ConfigMap for kube-dns. For example, the configuration below inserts a single stub domain and two upstream nameservers. As specified, DNS requests with the “.acme.local” suffix will be forwarded to a DNS listening at 1.2.3.4. Additionally, Google Public DNS will serve upstream queries. See ConfigMap Configuration Notes at the end of this section for a few notes about the data format.
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-dns
namespace: kube-system
data:
stubDomains: |
{“acme.local”: [“1.2.3.4”]}
upstreamNameservers: |
[“8.8.8.8”, “8.8.4.4”]
The diagram below shows the flow of DNS queries specified in the configuration above. With the dnsPolicy set to “ClusterFirst” a DNS query is first sent to the DNS caching layer in kube-dns. From here, the suffix of the request is examined and then forwarded to the appropriate DNS. In this case, names with the cluster suffix (e.g.; “.cluster.local”) are sent to kube-dns. Names with the stub domain suffix (e.g.; “.acme.local”) will be sent to the configured custom resolver. Finally, requests that do not match any of those suffixes will be forwarded to the upstream DNS.

Below is a table of example domain names and the destination of the queries for those domain names:
| Domain name | Server answering the query |
| kubernetes.default.svc.cluster.local | kube-dns |
| foo.acme.local | custom DNS (1.2.3.4) |
| widget.com | upstream DNS (one of 8.8.8.8, 8.8.4.4) |
ConfigMap Configuration Notes
-
stubDomains (optional)
- Format: a JSON map using a DNS suffix key (e.g.; “acme.local”) and a value consisting of a JSON array of DNS IPs.
- Note: The target nameserver may itself be a Kubernetes service. For instance, you can run your own copy of dnsmasq to export custom DNS names into the ClusterDNS namespace.
-
upstreamNameservers (optional)
- Format: a JSON array of DNS IPs.
- Note: If specified, then the values specified replace the nameservers taken by default from the node’s /etc/resolv.conf
- Limits: a maximum of three upstream nameservers can be specified
Example #1: Adding a Consul DNS Stub Domain
In this example, the user has Consul DNS service discovery system they wish to integrate with kube-dns. The consul domain server is located at 10.150.0.1, and all consul names have the suffix “.consul.local”. To configure Kubernetes, the cluster administrator simply creates a ConfigMap object as shown below. Note: in this example, the cluster administrator did not wish to override the node’s upstream nameservers, so they didn’t need to specify the optional upstreamNameservers field.
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-dns
namespace: kube-system
data:
stubDomains: |
{“consul.local”: [“10.150.0.1”]}
Example #2: Replacing the Upstream Nameservers
In this example the cluster administrator wants to explicitly force all non-cluster DNS lookups to go through their own nameserver at 172.16.0.1. Again, this is easy to accomplish; they just need to create a ConfigMap with the upstreamNameservers field specifying the desired nameserver.
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-dns
namespace: kube-system
data:
upstreamNameservers: |
[“172.16.0.1”]
**Get involved**
If you’d like to contribute or simply help provide feedback and drive the roadmap, [join our community](https://github.com/kubernetes/community#kubernetes-community). Specifically for network related conversations participate though one of these channels:
- Chat with us on the Kubernetes [Slack network channel](https://kubernetes.slack.com/messages/sig-network/)
- Join our Special Interest Group, [SIG-Network](https://github.com/kubernetes/community/wiki/SIG-Network), which meets on Tuesdays at 14:00 PT
Thanks for your support and contributions. Read more in-depth posts on what's new in Kubernetes 1.6 [here](https://kubernetes.io/blog/2017/03/five-days-of-kubernetes-1-6).
_--Bowei Du, Software Engineer and Matthew DeLio, Product Manager, Google_
- Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
- Join the community portal for advocates on [K8sPort](http://k8sport.org/)
- Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
- Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
- Connect with the community on [Slack](http://slack.k8s.io/)
- [Download](http://get.k8s.io/) Kubernetes
Advanced Scheduling in Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.6
The Kubernetes scheduler’s default behavior works well for most cases -- for example, it ensures that pods are only placed on nodes that have sufficient free resources, it ties to spread pods from the same set (ReplicaSet, StatefulSet, etc.) across nodes, it tries to balance out the resource utilization of nodes, etc.
But sometimes you want to control how your pods are scheduled. For example, perhaps you want to ensure that certain pods only schedule on nodes with specialized hardware, or you want to co-locate services that communicate frequently, or you want to dedicate a set of nodes to a particular set of users. Ultimately, you know much more about how your applications should be scheduled and deployed than Kubernetes ever will. So Kubernetes 1.6 offers four advanced scheduling features: node affinity/anti-affinity, taints and tolerations, pod affinity/anti-affinity, and custom schedulers. Each of these features are now in beta in Kubernetes 1.6.
Node Affinity/Anti-Affinity
Node Affinity/Anti-Affinity is one way to set rules on which nodes are selected by the scheduler. This feature is a generalization of the nodeSelector feature which has been in Kubernetes since version 1.0. The rules are defined using the familiar concepts of custom labels on nodes and selectors specified in pods, and they can be either required or preferred, depending on how strictly you want the scheduler to enforce them.
Required rules must be met for a pod to schedule on a particular node. If no node matches the criteria (plus all of the other normal criteria, such as having enough free resources for the pod’s resource request), then the pod won’t be scheduled. Required rules are specified in the requiredDuringSchedulingIgnoredDuringExecution field of nodeAffinity.
For example, if we want to require scheduling on a node that is in the us-central1-a GCE zone of a multi-zone Kubernetes cluster, we can specify the following affinity rule as part of the Pod spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "failure-domain.beta.kubernetes.io/zone"
operator: In
values: ["us-central1-a"]
“IgnoredDuringExecution” means that the pod will still run if labels on a node change and affinity rules are no longer met. There are future plans to offer requiredDuringSchedulingRequiredDuringExecution which will evict pods from nodes as soon as they don’t satisfy the node affinity rule(s).
Preferred rules mean that if nodes match the rules, they will be chosen first, and only if no preferred nodes are available will non-preferred nodes be chosen. You can prefer instead of require that pods are deployed to us-central1-a by slightly changing the pod spec to use preferredDuringSchedulingIgnoredDuringExecution:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "failure-domain.beta.kubernetes.io/zone"
operator: In
values: ["us-central1-a"]
Node anti-affinity can be achieved by using negative operators. So for instance if we want our pods to avoid us-central1-a we can do this:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "failure-domain.beta.kubernetes.io/zone"
operator: NotIn
values: ["us-central1-a"]
Valid operators you can use are In, NotIn, Exists, DoesNotExist. Gt, and Lt.
Additional use cases for this feature are to restrict scheduling based on nodes’ hardware architecture, operating system version, or specialized hardware. Node affinity/anti-affinity is beta in Kubernetes 1.6.
Taints and Tolerations
A related feature is “taints and tolerations,” which allows you to mark (“taint”) a node so that no pods can schedule onto it unless a pod explicitly “tolerates” the taint. Marking nodes instead of pods (as in node affinity/anti-affinity) is particularly useful for situations where most pods in the cluster should avoid scheduling onto the node. For example, you might want to mark your master node as schedulable only by Kubernetes system components, or dedicate a set of nodes to a particular group of users, or keep regular pods away from nodes that have special hardware so as to leave room for pods that need the special hardware.
The kubectl command allows you to set taints on nodes, for example:
kubectl taint nodes node1 key=value:NoSchedule
creates a taint that marks the node as unschedulable by any pods that do not have a toleration for taint with key key, value value, and effect NoSchedule. (The other taint effects are PreferNoSchedule, which is the preferred version of NoSchedule, and NoExecute, which means any pods that are running on the node when the taint is applied will be evicted unless they tolerate the taint.) The toleration you would add to a PodSpec to have the corresponding pod tolerate this taint would look like this
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
In addition to moving taints and tolerations to beta in Kubernetes 1.6, we have introduced an alpha feature that uses taints and tolerations to allow you to customize how long a pod stays bound to a node when the node experiences a problem like a network partition instead of using the default five minutes. See this section of the documentation for more details.
Pod Affinity/Anti-Affinity
Node affinity/anti-affinity allows you to constrain which nodes a pod can run on based on the nodes’ labels. But what if you want to specify rules about how pods should be placed relative to one another, for example to spread or pack pods within a service or relative to pods in other services? For that you can use pod affinity/anti-affinity, which is also beta in Kubernetes 1.6.
Let’s look at an example. Say you have front-ends in service S1, and they communicate frequently with back-ends that are in service S2 (a “north-south” communication pattern). So you want these two services to be co-located in the same cloud provider zone, but you don’t want to have to choose the zone manually--if the zone fails, you want the pods to be rescheduled to another (single) zone. You can specify this with a pod affinity rule that looks like this (assuming you give the pods of this service a label “service=S2” and the pods of the other service a label “service=S1”):
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: service
operator: In
values: [“S1”]
topologyKey: failure-domain.beta.kubernetes.io/zone
As with node affinity/anti-affinity, there is also a preferredDuringSchedulingIgnoredDuringExecution variant.
Pod affinity/anti-affinity is very flexible. Imagine you have profiled the performance of your services and found that containers from service S1 interfere with containers from service S2 when they share the same node, perhaps due to cache interference effects or saturating the network link. Or maybe due to security concerns you never want containers of S1 and S2 to share a node. To implement these rules, just make two changes to the snippet above -- change podAffinity to podAntiAffinity and change topologyKey to kubernetes.io/hostname.
Custom Schedulers
If the Kubernetes scheduler’s various features don’t give you enough control over the scheduling of your workloads, you can delegate responsibility for scheduling arbitrary subsets of pods to your own custom scheduler(s) that run(s) alongside, or instead of, the default Kubernetes scheduler. Multiple schedulers is beta in Kubernetes 1.6.
Each new pod is normally scheduled by the default scheduler. But if you provide the name of your own custom scheduler, the default scheduler will ignore that Pod and allow your scheduler to schedule the Pod to a node. Let’s look at an example.
Here we have a Pod where we specify the schedulerName field:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
schedulerName: my-scheduler
containers:
- name: nginx
image: nginx:1.10
If we create this Pod without deploying a custom scheduler, the default scheduler will ignore it and it will remain in a Pending state. So we need a custom scheduler that looks for, and schedules, pods whose schedulerName field is my-scheduler.
A custom scheduler can be written in any language and can be as simple or complex as you need. Here is a very simple example of a custom scheduler written in Bash that assigns a node randomly. Note that you need to run this along with kubectl proxy for it to work.
#!/bin/bash
SERVER='localhost:8001'
while true;
do
for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName == "my-scheduler") | select(.spec.nodeName == null) | .metadata.name' | tr -d '"')
;
do
NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"'))
NUMNODES=${#NODES[@]}
CHOSEN=${NODES[$[$RANDOM % $NUMNODES]]}
curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind": "Binding", "metadata": {"name": "'$PODNAME'"}, "target": {"apiVersion": "v1", "kind"
: "Node", "name": "'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
echo "Assigned $PODNAME to $CHOSEN"
done
sleep 1
done
Learn more
The Kubernetes 1.6 release notes have more information about these features, including details about how to change your configurations if you are already using the alpha version of one or more of these features (this is required, as the move from alpha to beta is a breaking change for these features).
Acknowledgements
The features described here, both in their alpha and beta forms, were a true community effort, involving engineers from Google, Huawei, IBM, Red Hat and more.
Get Involved
Share your voice at our weekly community meeting:
- Post questions (or answer questions) on Stack Overflow
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack (room #sig-scheduling)
Many thanks for your contributions.
--Ian Lewis, Developer Advocate, and David Oppenheimer, Software Engineer, Google
Scalability updates in Kubernetes 1.6: 5,000 node and 150,000 pod clusters
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.6
Last summer we shared updates on Kubernetes scalability, since then we’ve been working hard and are proud to announce that Kubernetes 1.6 can handle 5,000-node clusters with up to 150,000 pods. Moreover, those cluster have even better end-to-end pod startup time than the previous 2,000-node clusters in the 1.3 release; and latency of the API calls are within the one-second SLO.
In this blog post we review what metrics we monitor in our tests and describe our performance results from Kubernetes 1.6. We also discuss what changes we made to achieve the improvements, and our plans for upcoming releases in the area of system scalability.
X-node clusters - what does it mean?
Now that Kubernetes 1.6 is released, it is a good time to review what it means when we say we “support” X-node clusters. As described in detail in a previous blog post, we currently have two performance-related Service Level Objectives (SLO):
- API-responsiveness : 99% of all API calls return in less than 1s
- Pod startup time : 99% of pods and their containers (with pre-pulled images) start within 5s. As before, it is possible to run larger deployments than the stated supported 5,000-node cluster (and users have), but performance may be degraded and it may not meet our strict SLO defined above.
We are aware of the limited scope of these SLOs. There are many aspects of the system that they do not exercise. For example, we do not measure how soon a new pod that is part of a service will be reachable through the service IP address after the pod is started. If you are considering using large Kubernetes clusters and have performance requirements not covered by our SLOs, please contact the Kubernetes Scalability SIG so we can help you understand whether Kubernetes is ready to handle your workload now.
The top scalability-related priority for upcoming Kubernetes releases is to enhance our definition of what it means to support X-node clusters by:
- refining currently existing SLOs
- adding more SLOs (that will cover various areas of Kubernetes, including networking)
Kubernetes 1.6 performance metrics at scale
So how does performance in large clusters look in Kubernetes 1.6? The following graph shows the end-to-end pod startup latency with 2000- and 5000-node clusters. For comparison, we also show the same metric from Kubernetes 1.3, which we published in our previous scalability blog post that described support for 2000-node clusters. As you can see, Kubernetes 1.6 has better pod startup latency with both 2000 and 5000 nodes compared to Kubernetes 1.3 with 2000 nodes [1].

The next graph shows API response latency for a 5000-node Kubernetes 1.6 cluster. The latencies at all percentiles are less than 500ms, and even 90th percentile is less than about 100ms.

How did we get here?
Over the past nine months (since the last scalability blog post), there have been a huge number of performance and scalability related changes in Kubernetes. In this post we will focus on the two biggest ones and will briefly enumerate a few others.
etcd v3
In Kubernetes 1.6 we switched the default storage backend (key-value store where the whole cluster state is stored) from etcd v2 to etcd v3. The initial works towards this transition has been started during the 1.3 release cycle. You might wonder why it took us so long, given that:
-
the first stable version of etcd supporting the v3 API was announced on June 30, 2016
-
the new API was designed together with the Kubernetes team to support our needs (from both a feature and scalability perspective)
-
the integration of etcd v3 with Kubernetes had already mostly been finished when etcd v3 was announced (indeed CoreOS used Kubernetes as a proof-of-concept for the new etcd v3 API) As it turns out, there were a lot of reasons. We will describe the most important ones below.
-
Changing storage in a backward incompatible way, as is in the case for the etcd v2 to v3 migration, is a big change, and thus one for which we needed a strong justification. We found this justification in September when we determined that we would not be able to scale to 5000-node clusters if we continued to use etcd v2 (kubernetes/32361 contains some discussion about it). In particular, what didn’t scale was the watch implementation in etcd v2. In a 5000-node cluster, we need to be able to send at least 500 watch events per second to a single watcher, which wasn’t possible in etcd v2.
-
Once we had the strong incentive to actually update to etcd v3, we started thoroughly testing it. As you might expect, we found some issues. There were some minor bugs in Kubernetes, and in addition we requested a performance improvement in etcd v3’s watch implementation (watch was the main bottleneck in etcd v2 for us). This led to the 3.0.10 etcd patch release.
-
Once those changes had been made, we were convinced that new Kubernetes clusters would work with etcd v3. But the large challenge of migrating existing clusters remained. For this we needed to automate the migration process, thoroughly test the underlying CoreOS etcd upgrade tool, and figure out a contingency plan for rolling back from v3 to v2. But finally, we are confident that it should work.
Switching storage data format to protobuf
In the Kubernetes 1.3 release, we enabled protobufs as the data format for Kubernetes components to communicate with the API server (in addition to maintaining support for JSON). This gave us a huge performance improvement.
However, we were still using JSON as a format in which data was stored in etcd, even though technically we were ready to change that. The reason for delaying this migration was related to our plans to migrate to etcd v3. Now you are probably wondering how this change was depending on migration to etcd v3. The reason for it was that with etcd v2 we couldn’t really store data in binary format (to workaround it we were additionally base64-encoding the data), whereas with etcd v3 it just worked. So to simplify the transition to etcd v3 and avoid some non-trivial transformation of data stored in etcd during it, we decided to wait with switching storage data format to protobufs until migration to etcd v3 storage backend is done.
Other optimizations
We made tens of optimizations throughout the Kubernetes codebase during the last three releases, including:
- optimizing the scheduler (which resulted in 5-10x higher scheduling throughput)
- switching all controllers to a new recommended design using shared informers, which reduced resource consumption of controller-manager - for reference see this document
- optimizing individual operations in the API server (conversions, deep-copies, patch)
- reducing memory allocation in the API server (which significantly impacts the latency of API calls) We want to emphasize that the optimization work we have done during the last few releases, and indeed throughout the history of the project, is a joint effort by many different companies and individuals from the whole Kubernetes community.
What’s next?
People frequently ask how far we are going to go in improving Kubernetes scalability. Currently we do not have plans to increase scalability beyond 5000-node clusters (within our SLOs) in the next few releases. If you need clusters larger than 5000 nodes, we recommend to use federation to aggregate multiple Kubernetes clusters.
However, that doesn’t mean we are going to stop working on scalability and performance. As we mentioned at the beginning of this post, our top priority is to refine our two existing SLOs and introduce new ones that will cover more parts of the system, e.g. networking. This effort has already started within the Scalability SIG. We have made significant progress on how we would like to define performance SLOs, and this work should be finished in the coming month.
Join the effort
If you are interested in scalability and performance, please join our community and help us shape Kubernetes. There are many ways to participate, including:
- Chat with us in the Kubernetes Slack scalability channel:
- Join our Special Interest Group, SIG-Scalability, which meets every Thursday at 9:00 AM PST Thanks for the support and contributions! Read more in-depth posts on what's new in Kubernetes 1.6 here.
-- Wojciech Tyczynski, Software Engineer, Google
[1] We are investigating why 5000-node clusters have better startup time than 2000-node clusters. The current theory is that it is related to running 5000-node experiments using 64-core master and 2000-node experiments using 32-core master.
Dynamic Provisioning and Storage Classes in Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.6
Storage is a critical part of running stateful containers, and Kubernetes offers powerful primitives for managing it. Dynamic volume provisioning, a feature unique to Kubernetes, allows storage volumes to be created on-demand. Before dynamic provisioning, cluster administrators had to manually make calls to their cloud or storage provider to provision new storage volumes, and then create PersistentVolume objects to represent them in Kubernetes. With dynamic provisioning, these two steps are automated, eliminating the need for cluster administrators to pre-provision storage. Instead, the storage resources can be dynamically provisioned using the provisioner specified by the StorageClass object (see user-guide). StorageClasses are essentially blueprints that abstract away the underlying storage provider, as well as other parameters, like disk-type (e.g.; solid-state vs standard disks).
StorageClasses use provisioners that are specific to the storage platform or cloud provider to give Kubernetes access to the physical media being used. Several storage provisioners are provided in-tree (see user-guide), but additionally out-of-tree provisioners are now supported (see kubernetes-incubator).
In the Kubernetes 1.6 release, dynamic provisioning has been promoted to stable (having entered beta in 1.4). This is a big step forward in completing the Kubernetes storage automation vision, allowing cluster administrators to control how resources are provisioned and giving users the ability to focus more on their application. With all of these benefits, there are a few important user-facing changes (discussed below) that are important to understand before using Kubernetes 1.6.
Storage Classes and How to Use them
StorageClasses are the foundation of dynamic provisioning, allowing cluster administrators to define abstractions for the underlying storage platform. Users simply refer to a StorageClass by name in the PersistentVolumeClaim (PVC) using the “storageClassName” parameter.
In the following example, a PVC refers to a specific storage class named “gold”.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
namespace: testns
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
storageClassName: gold
In order to promote the usage of dynamic provisioning this feature permits the cluster administrator to specify a default StorageClass. When present, the user can create a PVC without having specifying a storageClassName, further reducing the user’s responsibility to be aware of the underlying storage provider. When using default StorageClasses, there are some operational subtleties to be aware of when creating PersistentVolumeClaims (PVCs). This is particularly important if you already have existing PersistentVolumes (PVs) that you want to re-use:
-
PVs that are already “Bound” to PVCs will remain bound with the move to 1.6
- They will not have a StorageClass associated with them unless the user manually adds it
- If PVs become “Available” (i.e.; if you delete a PVC and the corresponding PV is recycled), then they are subject to the following
-
If storageClassName is not specified in the PVC, the default storage class will be used for provisioning.
- Existing, “Available”, PVs that do not have the default storage class label will not be considered for binding to the PVC
-
If storageClassName is set to an empty string (‘’) in the PVC, no storage class will be used (i.e.; dynamic provisioning is disabled for this PVC)
- Existing, “Available”, PVs (that do not have a specified storageClassName) will be considered for binding to the PVC
-
If storageClassName is set to a specific value, then the matching storage class will be used
- Existing, “Available”, PVs that have a matching storageClassName will be considered for binding to the PVC
- If no corresponding storage class exists, the PVC will fail. To reduce the burden of setting up default StorageClasses in a cluster, beginning with 1.6, Kubernetes installs (via the add-on manager) default storage classes for several cloud providers. To use these default StorageClasses, users do not need refer to them by name – that is, storageClassName need not be specified in the PVC.
The following table provides more detail on default storage classes pre-installed by cloud provider as well as the specific parameters used by these defaults.
| Cloud Provider | Default StorageClass Name | Default Provisioner |
|---|---|---|
| Amazon Web Services | gp2 | aws-ebs |
| Microsoft Azure | standard | azure-disk |
| Google Cloud Platform | standard | gce-pd |
| OpenStack | standard | cinder |
| VMware vSphere | thin | vsphere-volume |
While these pre-installed default storage classes are chosen to be “reasonable” for most storage users, this guide provides instructions on how to specify your own default.
Dynamically Provisioned Volumes and the Reclaim Policy
All PVs have a reclaim policy associated with them that dictates what happens to a PV once it becomes released from a claim (see user-guide). Since the goal of dynamic provisioning is to completely automate the lifecycle of storage resources, the default reclaim policy for dynamically provisioned volumes is “delete”. This means that when a PersistentVolumeClaim (PVC) is released, the dynamically provisioned volume is de-provisioned (deleted) on the storage provider and the data is likely irretrievable. If this is not the desired behavior, the user must change the reclaim policy on the corresponding PersistentVolume (PV) object after the volume is provisioned.
How do I change the reclaim policy on a dynamically provisioned volume?
You can change the reclaim policy by editing the PV object and changing the “persistentVolumeReclaimPolicy” field to the desired value. For more information on various reclaim policies see user-guide.
FAQs
How do I use a default StorageClass?
If your cluster has a default StorageClass that meets your needs, then all you need to do is create a PersistentVolumeClaim (PVC) and the default provisioner will take care of the rest – there is no need to specify the storageClassName:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
namespace: testns
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
Can I add my own storage classes?
Yes. To add your own storage class, first determine which provisioners will work in your cluster. Then, create a StorageClass object with parameters customized to meet your needs (see user-guide for more detail). For many users, the easiest way to create the object is to write a yaml file and apply it with “kubectl create -f”. The following is an example of a StorageClass for Google Cloud Platform named “gold” that creates a “pd-ssd”. Since multiple classes can exist within a cluster, the administrator may leave the default enabled for most workloads (since it uses a “pd-standard”), with the “gold” class reserved for workloads that need extra performance.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gold
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
How do I check if I have a default StorageClass Installed?
You can use kubectl to check for StorageClass objects. In the example below there are two storage classes: “gold” and “standard”. The “gold” class is user-defined, and the “standard” class is installed by Kubernetes and is the default.
$ kubectl get sc
NAME TYPE
gold kubernetes.io/gce-pd
standard (default) kubernetes.io/gce-pd
$ kubectl describe storageclass standard
Name: standard
IsDefaultClass: Yes
Annotations: storageclass.beta.kubernetes.io/is-default-class=true
Provisioner: kubernetes.io/gce-pd
Parameters: type=pd-standard
Events: \<none\>
Can I delete/turn off the default StorageClasses?
You cannot delete the default storage class objects provided. Since they are installed as cluster addons, they will be recreated if they are deleted.
You can, however, disable the defaulting behavior by removing (or setting to false) the following annotation: storageclass.beta.kubernetes.io/is-default-class.
If there are no StorageClass objects marked with the default annotation, then PersistentVolumeClaim objects (without a StorageClass specified) will not trigger dynamic provisioning. They will, instead, fall back to the legacy behavior of binding to an available PersistentVolume object.
Can I assign my existing PVs to a particular StorageClass?
Yes, you can assign a StorageClass to an existing PV by editing the appropriate PV object and adding (or setting) the desired storageClassName field to it.
What happens if I delete a PersistentVolumeClaim (PVC)?
If the volume was dynamically provisioned, then the default reclaim policy is set to “delete”. This means that, by default, when the PVC is deleted, the underlying PV and storage asset will also be deleted. If you want to retain the data stored on the volume, then you must change the reclaim policy from “delete” to “retain” after the PV is provisioned.
--Saad Ali & Michelle Au, Software Engineers, and Matthew De Lio, Product Manager, Google
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Get involved with the Kubernetes project on GitHub
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
- Download Kubernetes
Five Days of Kubernetes 1.6
With the help of our growing community of 1,110 plus contributors, we pushed around 5,000 commits to deliver Kubernetes 1.6, bringing focus on multi-user, multi-workloads at scale. While many improvements have been contributed, we selected few features to highlight in a series of in-depths posts listed below.
Follow along and read what’s new:
Connect
- Follow us on Twitter @Kubernetesio for latest updates
- Post questions (or answer questions) on Stack Overflow
- Join the community portal for advocates on K8sPort
- Get involved with the Kubernetes project on GitHub
- Connect with the community on Slack
- Download Kubernetes
Kubernetes 1.6: Multi-user, Multi-workloads at Scale
Today we’re announcing the release of Kubernetes 1.6.
In this release the community’s focus is on scale and automation, to help you deploy multiple workloads to multiple users on a cluster. We are announcing that 5,000 node clusters are supported. We moved dynamic storage provisioning to stable. Role-based access control (RBAC), kubefed, kubeadm, and several scheduling features are moving to beta. We have also added intelligent defaults throughout to enable greater automation out of the box.
What’s New
Scale and Federation : Large enterprise users looking for proof of at-scale performance will be pleased to know that Kubernetes’ stringent scalability SLO now supports 5,000 node (150,000 pod) clusters. This 150% increase in total cluster size, powered by a new version of etcd v3 by CoreOS, is great news if you are deploying applications such as search or games which can grow to consume larger clusters.
For users who want to scale beyond 5,000 nodes or spread across multiple regions or clouds, federation lets you combine multiple Kubernetes clusters and address them through a single API endpoint. In this release, the kubefed command line utility graduated to beta - with improved support for on-premise clusters. kubefed now automatically configures kube-dns on joining clusters and can pass arguments to federated components.
Security and Setup : Users concerned with security will find that RBAC, now beta adds a significant security benefit through more tightly scoped default roles for system components. The default RBAC policies in 1.6 grant scoped permissions to control-plane components, nodes, and controllers. RBAC allows cluster administrators to selectively grant particular users or service accounts fine-grained access to specific resources on a per-namespace basis. RBAC users upgrading from 1.5 to 1.6 should view the guidance here.
Users looking for an easy way to provision a secure cluster on physical or cloud servers can use kubeadm, which is now beta. kubeadm has been enhanced with a set of command line flags and a base feature set that includes RBAC setup, use of the Bootstrap Token system and an enhanced Certificates API.
Advanced Scheduling : This release adds a set of powerful and versatile scheduling constructs to give you greater control over how pods are scheduled, including rules to restrict pods to particular nodes in heterogeneous clusters, and rules to spread or pack pods across failure domains such as nodes, racks, and zones.
Node affinity/anti-affinity, now in beta, allows you to restrict pods to schedule only on certain nodes based on node labels. Use built-in or custom node labels to select specific zones, hostnames, hardware architecture, operating system version, specialized hardware, etc. The scheduling rules can be required or preferred, depending on how strictly you want the scheduler to enforce them.
A related feature, called taints and tolerations, makes it possible to compactly represent rules for excluding pods from particular nodes. The feature, also now in beta, makes it easy, for example, to dedicate sets of nodes to particular sets of users, or to keep nodes that have special hardware available for pods that need the special hardware by excluding pods that don’t need it.
Sometimes you want to co-schedule services, or pods within a service, near each other topologically, for example to optimize North-South or East-West communication. Or you want to spread pods of a service for failure tolerance, or keep antagonistic pods separated, or ensure sole tenancy of nodes. Pod affinity and anti-affinity, now in beta, enables such use cases by letting you set hard or soft requirements for spreading and packing pods relative to one another within arbitrary topologies (node, zone, etc.).
Lastly, for the ultimate in scheduling flexibility, you can run your own custom scheduler(s) alongside, or instead of, the default Kubernetes scheduler. Each scheduler is responsible for different sets of pods. Multiple schedulers is beta in this release.
Dynamic Storage Provisioning : Users deploying stateful applications will benefit from the extensive storage automation capabilities in this release of Kubernetes.
Since its early days, Kubernetes has been able to automatically attach and detach storage, format disk, mount and unmount volumes per the pod spec, and do so seamlessly as pods move between nodes. In addition, the PersistentVolumeClaim (PVC) and PersistentVolume (PV) objects decouple the request for storage from the specific storage implementation, making the pod spec portable across a range of cloud and on-premise environments. In this release StorageClass and dynamic volume provisioning are promoted to stable, completing the automation story by creating and deleting storage on demand, eliminating the need to pre-provision.
The design allows cluster administrators to define and expose multiple flavors of storage within a cluster, each with a custom set of parameters. End users can stop worrying about the complexity and nuances of how storage is provisioned, while still selecting from multiple storage options.
In 1.6 Kubernetes comes with a set of built-in defaults to completely automate the storage provisioning lifecycle, freeing you to work on your applications. Specifically, Kubernetes now pre-installs system-defined StorageClass objects for AWS, Azure, GCP, OpenStack and VMware vSphere by default. This gives Kubernetes users on these providers the benefits of dynamic storage provisioning without having to manually setup StorageClass objects. This is a change in the default behavior of PVC objects on these clouds. Note that default behavior is that dynamically provisioned volumes are created with the “delete” reclaim policy. That means once the PVC is deleted, the dynamically provisioned volume is automatically deleted so users do not have the extra step of ‘cleaning up’.
In addition, we have expanded the range of storage supported overall including:
- ScaleIO Kubernetes Volume Plugin enabling pods to seamlessly access and use data stored on ScaleIO volumes.
- Portworx Kubernetes Volume Plugin adding the capability to use Portworx as a storage provider for Kubernetes clusters. Portworx pools your server capacity and turns your servers or cloud instances into converged, highly available compute and storage nodes.
- Support for NFSv3, NFSv4, and GlusterFS on clusters using the COS node image
- Support for user-written/run dynamic PV provisioners. A golang library and examples can be found here.
- Beta support for mount options in persistent volumes
Container Runtime Interface, etcd v3 and Daemon set updates : while users may not directly interact with the container runtime or the API server datastore, they are foundational components for user facing functionality in Kubernetes’. As such the community invests in expanding the capabilities of these and other system components.
- The Docker-CRI implementation is beta and is enabled by default in kubelet. Alpha support for other runtimes, cri-o, frakti, rkt, has also been implemented.
- The default backend storage for the API server has been upgraded to use etcd v3 by default for new clusters. If you are upgrading from a 1.5 cluster, care should be taken to ensure continuity by planning a data migration window.
- Node reliability is improved as Kubelet exposes an admin configurable Node Allocatable feature to reserve compute resources for system daemons.
- Daemon set updates lets you perform rolling updates on a daemon set
Alpha features : this release was mostly focused on maturing functionality, however, a few alpha features were added to support the roadmap
- Out-of-tree cloud provider support adds a new cloud-controller-manager binary that may be used for testing the new out-of-core cloud provider flow
- Per-pod-eviction in case of node problems combined with tolerationSeconds, lets users tune the duration a pod stays bound to a node that is experiencing problems
- Pod Injection Policy adds a new API resource PodPreset to inject information such as secrets, volumes, volume mounts, and environment variables into pods at creation time.
- Custom metrics support in the Horizontal Pod Autoscaler changed to use
- Multiple Nvidia GPU support is introduced with the Docker runtime only
These are just some of the highlights in our first release for the year. For a complete list please visit the release notes.
Community
This release is possible thanks to our vast and open community. Together, we’ve pushed nearly 5,000 commits by some 275 authors. To bring our many advocates together, the community has launched a new program called K8sPort, an online hub where the community can participate in gamified challenges and get credit for their contributions. Read more about the program here.
Release Process
A big thanks goes out to the release team for 1.6 (lead by Dan Gillespie of CoreOS) for their work bringing the 1.6 release to light. This release team is an exemplar of the Kubernetes community’s commitment to community governance. Dan is the first non-Google release manager and he, along with the rest of the team, worked throughout the release (building on the 1.5 release manager, Saad Ali’s, great work) to uncover and document tribal knowledge, shine light on tools and processes that still require special permissions, and prioritize work to improve the Kubernetes release process. Many thanks to the team.
User Adoption
We’re continuing to see rapid adoption of Kubernetes in all sectors and sizes of businesses. Furthermore, adoption is coming from across the globe, from a startup in Tennessee, USA to a Fortune 500 company in China.
- JD.com, one of China's largest internet companies, uses Kubernetes in conjunction with their OpenStack deployment. They’ve move 20% of their applications thus far on Kubernetes and are already running 20,000 pods daily. Read more about their setup here.
- Spire, a startup based in Tennessee, witnessed their public cloud provider experience an outage, but suffered zero downtime because Kubernetes was able to move their workloads to different zones. Read their full experience here.
“With Kubernetes, there was never a moment of panic, just a sense of awe watching the automatic mitigation as it happened.”
- Share your Kubernetes use case story with the community here.
Availability
Kubernetes 1.6 is available for download here on GitHub and via get.k8s.io. To get started with Kubernetes, try one of the these interactive tutorials.
Get Involved
CloudNativeCon + KubeCon in Berlin is this week March 29-30, 2017. We hope to get together with much of the community and share more there!
Share your voice at our weekly community meeting:
- Post questions (or answer questions) on Stack Overflow
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
Many thanks for your contributions and advocacy!
-- Aparna Sinha, Senior Product Manager, Kubernetes, Google
PS: read this series of in-depth articles on what's new in Kubernetes 1.6
The K8sPort: Engaging Kubernetes Community One Activity at a Time
Editor's note: Today’s post is by Ryan Quackenbush, Advocacy Programs Manager at Apprenda, showing a new community portal for Kubernetes advocates: the K8sPort.
The K8sPort is a hub designed to help you, the Kubernetes community, earn credit for the hard work you’re putting forth in making this one of the most successful open source projects ever. Back at KubeCon Seattle in November, I presented a lightning talk of a preview of K8sPort.
This hub, and our intentions in helping to drive this initiative in the community, grew out of a desire to help cultivate an engaged community of Kubernetes advocates. This is done through gamification in a community hub full of different activities called “challenges,” which are activities meant to help direct members of the community to attend various events and meetings, share and provide feedback on important content, answer questions posed on sites like Stack Overflow, and more.
By completing these challenges, you collect points and can redeem them for different types of rewards and experiences, examples of which include charitable donations, gift certificates, conference tickets and more. As advocates complete challenges and gain points, they’ll earn performance-related badges, move up in community tiers and participate in a fun community leaderboard.
My presentation at KubeCon, simply put, was a call for early signups. Those who’ve been piloting the program have, for the most part, had positive things to say about their experiences.
I know I'm the only one playing with @K8sPort but it may be the most important thing the #Kubernetes community has.
— Justin Garrison (@rothgar) November 22, 2016
- “Great way of improving the community and documentation. The gamification of Kubernetes gave me more insight into the stack as well.”
- Jonas Kint, Devops Engineer at Showpad
- _“A great way to engage with the kubernetes project and also help the community. Fun stuff.” _
- Kevin Duane, Systems Engineer at The Walt Disney Company
- “K8sPort seems like an awesome idea for incentivising giving back to the community in a way that will hopefully cause more valuable help from more people than might usually be helping.”
- William Stewart, Site Reliability Engineer at Superbalist
Today I am pleased to announce that the Cloud Native Computing Foundation (CNCF) is making the K8sPort generally available to the entire contributing community! We’ve simplified the signup process by allowing would-be advocates to authenticate and register through the use of their existing GitHub accounts.

If you’re a contributing member of the Kubernetes community and you have an active GitHub account tied to the Kubernetes repository at GitHub, you can authenticate using your GitHub credentials and gain access to the K8sPort.

If you’re interested in joining the advocacy hub, please join us at k8sport.org! We hope you’re as excited about what you see as we are to continue to build it and present it to you.
For a quick walkthrough on K8sPort authentication and the hub itself, see this quick demo, below.
--Ryan Quackenbush, Advocacy Programs Manager, Apprenda
Deploying PostgreSQL Clusters using StatefulSets
Editor’s note: Today’s guest post is by Jeff McCormick, a developer at Crunchy Data, showing how to build a PostgreSQL cluster using the new Kubernetes StatefulSet feature.
In an earlier post, I described how to deploy a PostgreSQL cluster using Helm, a Kubernetes package manager. The following example provides the steps for building a PostgreSQL cluster using the new Kubernetes StatefulSets feature.
StatefulSets Example
Step 1 - Create Kubernetes Environment
StatefulSets is a new feature implemented in Kubernetes 1.5 (prior versions it was known as PetSets). As a result, running this example will require an environment based on Kubernetes 1.5.0 or above.
The example in this blog deploys on Centos7 using kubeadm. Some instructions on what kubeadm provides and how to deploy a Kubernetes cluster is located here.
Step 2 - Install NFS
The example in this blog uses NFS for the Persistent Volumes, but any shared file system would also work (ex: ceph, gluster).
The example script assumes your NFS server is running locally and your hostname resolves to a known IP address.
In summary, the steps used to get NFS working on a Centos 7 host are as follows:
sudo setsebool -P virt\_use\_nfs 1
sudo yum -y install nfs-utils libnfsidmap
sudo systemctl enable rpcbind nfs-server
sudo systemctl start rpcbind nfs-server rpc-statd nfs-idmapd
sudo mkdir /nfsfileshare
sudo chmod 777 /nfsfileshare/
sudo vi /etc/exports
sudo exportfs -r
The /etc/exports file should contain a line similar to this one except with the applicable IP address specified:
/nfsfileshare 192.168.122.9(rw,sync)
After these steps NFS should be running in the test environment.
Step 3 - Clone the Crunchy PostgreSQL Container Suite
The example used in this blog is found at in the Crunchy Containers GitHub repo here. Clone the Crunchy Containers repository to your test Kubernertes host and go to the example:
cd $HOME
git clone https://github.com/CrunchyData/crunchy-containers.git
cd crunchy-containers/examples/kube/statefulset
Next, pull down the Crunchy PostgreSQL container image:
docker pull crunchydata/crunchy-postgres:centos7-9.5-1.2.6
Step 4 - Run the Example
To begin, it is necessary to set a few of the environment variables used in the example:
export BUILDBASE=$HOME/crunchy-containers
export CCP\_IMAGE\_TAG=centos7-9.5-1.2.6
BUILDBASE is where you cloned the repository and CCP_IMAGE_TAG is the container image version we want to use.
Next, run the example:
./run.sh
That script will create several Kubernetes objects including:
- Persistent Volumes (pv1, pv2, pv3)
- Persistent Volume Claim (pgset-pvc)
- Service Account (pgset-sa)
- Services (pgset, pgset-master, pgset-replica)
- StatefulSet (pgset)
- Pods (pgset-0, pgset-1)
At this point, two pods will be running in the Kubernetes environment:
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
pgset-0 1/1 Running 0 2m
pgset-1 1/1 Running 1 2m
Immediately after the pods are created, the deployment will be as depicted below:

Step 5 - What Just Happened?
This example will deploy a StatefulSet, which in turn creates two pods.
The containers in those two pods run the PostgreSQL database. For a PostgreSQL cluster, we need one of the containers to assume the master role and the other containers to assume the replica role.
So, how do the containers determine who will be the master, and who will be the replica?
This is where the new StateSet mechanics come into play. The StateSet mechanics assign a unique ordinal value to each pod in the set.
The StatefulSets provided unique ordinal value always start with 0. During the initialization of the container, each container examines its assigned ordinal value. An ordinal value of 0 causes the container to assume the master role within the PostgreSQL cluster. For all other ordinal values, the container assumes a replica role. This is a very simple form of discovery made possible by the StatefulSet mechanics.
PostgreSQL replicas are configured to connect to the master database via a Service dedicated to the master database. In order to support this replication, the example creates a separate Service for each of the master role and the replica role. Once the replica has connected, the replica will begin replicating state from the master.
During the container initialization, a master container will use a Service Account (pgset-sa) to change it’s container label value to match the master Service selector. Changing the label is important to enable traffic destined to the master database to reach the correct container within the Stateful Set. All other pods in the set assume the replica Service label by default.
Step 6 - Deployment Diagram
The example results in a deployment depicted below:

In this deployment, there is a Service for the master and a separate Service for the replica. The replica is connected to the master and replication of state has started.
The Crunchy PostgreSQL container supports other forms of cluster deployment, the style of deployment is dictated by setting the PG_MODE environment variable for the container. In the case of a StatefulSet deployment, that value is set to: PG_MODE=set
This environment variable is a hint to the container initialization logic as to the style of deployment we intend.
Step 7 - Testing the Example
The tests below assume that the psql client has been installed on the test system. If not, the psql client has been previously installed, it can be installed as follows:
sudo yum -y install postgresql
In addition, the tests below assume that the tested environment DNS resolves to the Kube DNS and that the tested environment DNS search path is specified to match the applicable Kube namespace and domain. The master service is named pgset-master and the replica service is named pgset-replica.
Test the master as follows (the password is password):
psql -h pgset-master -U postgres postgres -c 'table pg\_stat\_replication'
If things are working, the command above will return output indicating that a single replica is connecting to the master.
Next, test the replica as follows:
psql -h pgset-replica -U postgres postgres -c 'create table foo (id int)'
The command above should fail as the replica is read-only within a PostgreSQL cluster.
Next, scale up the set as follows:
kubectl scale statefulset pgset --replicas=3
The command above should successfully create a new replica pod called pgset-2 as depicted below:

Step 8 - Persistence Explained
Take a look at the persisted PostgreSQL data files on the resulting NFS mount path:
$ ls -l /nfsfileshare/
total 12
drwx------ 20 26 26 4096 Jan 17 16:35 pgset-0
drwx------ 20 26 26 4096 Jan 17 16:35 pgset-1
drwx------ 20 26 26 4096 Jan 17 16:48 pgset-2
Each container in the stateful set binds to the single NFS Persistent Volume Claim (pgset-pvc) created in the example script.
Since NFS and the PVC can be shared, each pod can write to this NFS path.
The container is designed to create a subdirectory on that path using the pod host name for uniqueness.
Conclusion
StatefulSets is an exciting feature added to Kubernetes for container builders that are implementing clustering. The ordinal values assigned to the set provide a very simple mechanism to make clustering decisions when deploying a PostgreSQL cluster.
--Jeff McCormick, Developer, Crunchy Data
Containers as a Service, the foundation for next generation PaaS
Today’s post is by Brendan Burns, Partner Architect, at Microsoft & Kubernetes co-founder.
Containers are revolutionizing the way that people build, package and deploy software. But what is often overlooked is how they are revolutionizing the way that people build the software that builds, packages and deploys software. (it’s ok if you have to read that sentence twice…) Today, and in a talk at Container World tomorrow, I’m taking a look at how container orchestrators like Kubernetes form the foundation for next generation platform as a service (PaaS). In particular, I’m interested in how cloud container as a service (CaaS) platforms like Azure Container Service, Google Container Engine and others are becoming the new infrastructure layer that PaaS is built upon.
To see this, it’s important to consider the set of services that have traditionally been provided by PaaS platforms:
- Source code and executable packaging and distribution
- Reliable, zero-downtime rollout of software versions
- Healing, auto-scaling, load balancing
When you look at this list, it’s clear that most of these traditional “PaaS” roles have now been taken over by containers. The container image and container image build tooling has become the way to package up your application. Container registries have become the way to distribute your application across the world. Reliable software rollout is achieved using orchestrator concepts like Deployment in Kubernetes, and service healing, auto-scaling and load-balancing are all properties of an application deployed in Kubernetes using ReplicaSets and Services.
What then is left for PaaS? Is PaaS going to be replaced by container as a service? I think the answer is “no.” The piece that is left for PaaS is the part that was always the most important part of PaaS in the first place, and that’s the opinionated developer experience. In addition to all of the generic parts of PaaS that I listed above, the most important part of a PaaS has always been the way in which the developer experience and application framework made developers more productive within the boundaries of the platform. PaaS enables developers to go from source code on their laptop to a world-wide scalable service in less than an hour. That’s hugely powerful.
However, in the world of traditional PaaS, the skills needed to build PaaS infrastructure itself, the software on which the user’s software ran, required very strong skills and experience with distributed systems. Consequently, PaaS tended to be built by distributed system engineers rather than experts in a particular vertical developer experience. This means that PaaS platforms tended towards general purpose infrastructure rather than targeting specific verticals. Recently, we have seen this start to change, first with PaaS targeted at mobile API backends, and later with PaaS targeting “function as a service”. However, these products were still built from the ground up on top of raw infrastructure.
More recently, we are starting to see these platforms build on top of container infrastructure. Taking for example “function as a service” there are at least two (and likely more) open source implementations of functions as a service that run on top of Kubernetes (fission and funktion). This trend will only continue. Building a platform as a service, on top of container as a service is easy enough that you could imagine giving it out as an undergraduate computer science assignment. This ease of development means that individual developers with specific expertise in a vertical (say software for running three-dimensional simulations) can and will build PaaS platforms targeted at that specific vertical experience. In turn, by targeting such a narrow experience, they will build an experience that fits that narrow vertical perfectly, making their solution a compelling one in that target market.
This then points to the other benefit of next generation PaaS being built on top of container as a service. It frees the developer from having to make an “all-in” choice on a particular PaaS platform. When layered on top of container as a service, the basic functionality (naming, discovery, packaging, etc) are all provided by the CaaS and thus common across multiple PaaS that happened to be deployed on top of that CaaS. This means that developers can mix and match, deploying multiple PaaS to the same container infrastructure, and choosing for each application the PaaS platform that best suits that particular platform. Also, importantly, they can choose to “drop down” to raw CaaS infrastructure if that is a better fit for their application. Freeing PaaS from providing the infrastructure layer, enables PaaS to diversify and target specific experiences without fear of being too narrow. The experiences become more targeted, more powerful, and yet by building on top of container as a service, more flexible as well.
Kubernetes is infrastructure for next generation applications, PaaS and more. Given this, I’m really excited by our announcement today that Kubernetes on Azure Container Service has reached general availability. When you deploy your next generation application to Azure, whether on a PaaS or deployed directly onto Kubernetes itself (or both) you can deploy it onto a managed, supported Kubernetes cluster.
Furthermore, because we know that the world of PaaS and software development in general is a hybrid one, we’re excited to announce the preview availability of Windows clusters in Azure Container Service. We’re also working on hybrid clusters in ACS-Engine and expect to roll those out to general availability in the coming months.
I’m thrilled to see how containers and container as a service is changing the world of compute, I’m confident that we’re only scratching the surface of the transformation we’ll see in the coming months and years.
--Brendan Burns, Partner Architect, at Microsoft and co-founder of Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Download Kubernetes
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Inside JD.com's Shift to Kubernetes from OpenStack
Editor's note: Today’s post is by the Infrastructure Platform Department team at JD.com about their transition from OpenStack to Kubernetes. JD.com is one of China’s largest companies and the first Chinese Internet company to make the Global Fortune 500 list.
![]()
History of cluster building
The era of physical machines (2004-2014)
Before 2014, our company's applications were all deployed on the physical machine. In the age of physical machines, we needed to wait an average of one week for the allocation to application coming on-line. Due to the lack of isolation, applications would affected each other, resulting in a lot of potential risks. At that time, the average number of tomcat instances on each physical machine was no more than nine. The resource of physical machine was seriously wasted and the scheduling was inflexible. The time of application migration took hours due to the breakdown of physical machines. And the auto-scaling cannot be achieved. To enhance the efficiency of application deployment, we developed compilation-packaging, automatic deployment, log collection, resource monitoring and some other systems.
Containerized era (2014-2016)
The Infrastructure Platform Department (IPD) led by Liu Haifeng--Chief Architect of JD.COM, sought a new resolution in the fall of 2014. Docker ran into our horizon. At that time, docker had been rising, but was slightly weak and lacked of experience in production environment. We had repeatedly tested docker. In addition, docker was customized to fix a couple of issues, such as system crash caused by device mapper and some Linux kernel bugs. We also added plenty of new features into docker, including disk speed limit, capacity management, and layer merging in image building and so on.
To manage the container cluster properly, we chose the architecture of OpenStack + Novadocker driver. Containers are managed as virtual machines. It is known as the first generation of JD container engine platform--JDOS1.0 (JD Datacenter Operating System). The main purpose of JDOS 1.0 is to containerize the infrastructure. All applications run in containers rather than physical machines since then. As for the operation and maintenance of applications, we took full advantage of existing tools. The time for developers to request computing resources in production environment reduced to several minutes rather than a week. After the pooling of computing resources, even the scaling of 1,000 containers would be finished in seconds. Application instances had been isolated from each other. Both the average deployment density of applications and the physical machine utilization had increased by three times, which brought great economic benefits.
We deployed clusters in each IDC and provided unified global APIs to support deployment across the IDC. There are 10,000 compute nodes at most and 4,000 at least in a single OpenStack distributed container cluster in our production environment. The first generation of container engine platform (JDOS 1.0) successfully supported the “6.18” and “11.11” promotional activities in both 2015 and 2016. There are already 150,000 running containers online by November 2016.
“6.18” and “11.11” are known as the two most popular online promotion of JD.COM, similar to the black Friday promotions. Fulfilled orders in November 11, 2016 reached 30 million.
In the practice of developing and promoting JDOS 1.0, applications were migrated directly from physical machines to containers. Essentially, JDOS 1.0 was an implementation of IaaS. Therefore, deployment of applications was still heavily dependent on compilation-packaging and automatic deployment tools. However, the practice of JDOS1.0 is very meaningful. Firstly, we successfully moved business into containers. Secondly, we have a deep understanding of container network and storage, and know how to polish them to the best. Finally, all the experiences lay a solid foundation for us to develop a brand new application container platform.
New container engine platform (JDOS 2.0)
Platform architecture
When JDOS 1.0 grew from 2,000 containers to 100,000, we launched a new container engine platform (JDOS 2.0). The goal of JDOS 2.0 is not just an infrastructure management platform, but also a container engine platform faced to applications. On the basic of JDOS 1.0 and Kubernetes, JDOS 2.0 integrates the storage and network of JDOS 1.0, gets through the process of CI/CD from the source to the image, and finally to the deployment. Also, JDOS 2.0 provides one-stop service such as log, monitor, troubleshooting, terminal and orchestration. The platform architecture of JDOS 2.0 is shown below.

| Function | Product |
|---|---|
| Source Code Management | Gitlab |
| Container Tool | Docker |
| Container Networking | Cane |
| Container Engine | Kubernetes |
| Image Registry | Harbor |
| CI Tool | Jenkins |
| Log Management | Logstash + Elastic Search |
| Monitor | Prometheus |
In JDOS 2.0, we define two levels, system and application. A system consists of several applications and an application consists of several Pods which provide the same service. In general, a department can apply for one or more systems which directly corresponds to the namespace of Kubernetes. This means that the Pods of the same system will be in the same namespace.
Most of the JDOS 2.0 components (GitLab / Jenkins / Harbor / Logstash / Elastic Search / Prometheus) are also containerized and deployed on the Kubernetes platform.
One Stop Solution

- 1.JDOS 2.0 takes docker image as the core to implement continuous integration and continuous deployment.
- 2.Developer pushes code to git.
- 3.Git triggers the jenkins master to generate build job.
- 4.Jenkins master invokes Kubernetes to create jenkins slave Pod.
- 5.Jenkins slave pulls the source code, compiles and packs.
- 6.Jenkins slave sends the package and the Dockerfile to the image build node with docker.
- 7.The image build node builds the image.
- 8.The image build node pushes the image to the image registry Harbor.
- 9.User creates or updates app Pods in different zone.
The docker image in JDOS 1.0 consisted primarily of the operating system and the runtime software stack of the application. So, the deployment of applications was still dependent on the auto-deployment and some other tools. While in JDOS 2.0, the deployment of the application is done during the image building. And the image contains the complete software stack, including App. With the image, we can achieve the goal of running applications as designed in any environment.

Networking and External Service Load Balancing
JDOS 2.0 takes the network solution of JDOS 1.0, which is implemented with the VLAN model of OpenStack Neutron. This solution enables highly efficient communication between containers, making it ideal for a cluster environment within a company. Each Pod occupies a port in Neutron, with a separate IP. Based on the Container Network Interface standard (CNI) standard, we have developed a new project Cane for integrating kubelet and Neutron.

At the same time, Cane is also responsible for the management of LoadBalancer in Kubernetes service. When a LoadBalancer is created / deleted / modified, Cane will call the creating / removing / modifying interface of the lbaas service in Neutron. In addition, the Hades component in the Cane project provides an internal DNS resolution service for the Pods.
The source code of the Cane project is currently being finished and will be released on GitHub soon.
Flexible Scheduling

Summary
The rich functionality of Kubernetes allows us to pay more attention to the entire ecosystem of the platform, such as network performance, rather than the platform itself. In particular, the SREs highly appreciated the functionality of replication controller. With it, the scaling of the applications is achieved in several seconds. JDOS 2.0 now has accessed about 20% of the applications, and deployed 2 clusters with about 20,000 Pods running daily. We plan to access more applications of our company, to replace the current JDOS 1.0. And we are also glad to share our experience in this process with the community.
Thank you to all the contributors of Kubernetes and the other open source projects.
--Infrastructure Platform Department team at JD.com
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Download Kubernetes
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Run Deep Learning with PaddlePaddle on Kubernetes
Editor's note: Today's post is a joint post from the deep learning team at Baidu and the etcd team at CoreOS.
**![]() **
**
What is PaddlePaddle
PaddlePaddle is an easy-to-use, efficient, flexible and scalable deep learning platform originally developed at Baidu for applying deep learning to Baidu products since 2014.
There have been more than 50 innovations created using PaddlePaddle supporting 15 Baidu products ranging from the search engine, online advertising, to Q&A and system security.
In September 2016, Baidu open sourced PaddlePaddle, and it soon attracted many contributors from outside of Baidu.
Why Run PaddlePaddle on Kubernetes
PaddlePaddle is designed to be slim and independent of computing infrastructure. Users can run it on top of Hadoop, Spark, Mesos, Kubernetes and others.. We have a strong interest with Kubernetes because of its flexibility, efficiency and rich features.
While we are applying PaddlePaddle in various Baidu products, we noticed two main kinds of PaddlePaddle usage -- research and product. Research data does not change often, and the focus is fast experiments to reach the expected scientific measurement. Products data changes often. It usually comes from log messages generated from the Web services.
A successful deep learning project includes both the research and the data processing pipeline. There are many parameters to be tuned. A lot of engineers work on the different parts of the project simultaneously.
To ensure the project is easy to manage and utilize hardware resource efficiently, we want to run all parts of the project on the same infrastructure platform.
The platform should provide:
-
fault-tolerance. It should abstract each stage of the pipeline as a service, which consists of many processes that provide high throughput and robustness through redundancy.
-
auto-scaling. In the daytime, there are usually many active users, the platform should scale out online services. While during nights, the platform should free some resources for deep learning experiments.
-
job packing and isolation. It should be able to assign a PaddlePaddle trainer process requiring the GPU, a web backend service requiring large memory, and a CephFS process requiring disk IOs to the same node to fully utilize its hardware.
What we want is a platform which runs the deep learning system, the Web server (e.g., Nginx), the log collector (e.g., fluentd), the distributed queue service (e.g., Kafka), the log joiner and other data processors written using Storm, Spark, and Hadoop MapReduce on the same cluster. We want to run all jobs -- online and offline, production and experiments -- on the same cluster, so we could make full utilization of the cluster, as different kinds of jobs require different hardware resource.
We chose container based solutions since the overhead introduced by VMs is contradictory to our goal of efficiency and utilization.
Based on our research of different container based solutions, Kubernetes fits our requirement the best.
Distributed Training on Kubernetes
PaddlePaddle supports distributed training natively. There are two roles in a PaddlePaddle cluster: parameter server and trainer. Each parameter server process maintains a shard of the global model. Each trainer has its local copy of the model, and uses its local data to update the model. During the training process, trainers send model updates to parameter servers, parameter servers are responsible for aggregating these updates, so that trainers can synchronize their local copy with the global model.
| 
Some other approaches use a set of parameter servers to collectively hold a very large model in the CPU memory space on multiple hosts. But in practice, it is not often that we have such big models, because it would be very inefficient to handle very large model due to the limitation of GPU memory. In our configuration, multiple parameter servers are mostly for fast communications. Suppose there is only one parameter server process working with all trainers, the parameter server would have to aggregate gradients from all trainers and becomes a bottleneck. In our experience, an experimentally efficient configuration includes the same number of trainers and parameter servers. And we usually run a pair of trainer and parameter server on the same node. In the following Kubernetes job configuration, we start a job that runs N Pods, and in each Pod there are a parameter server and a trainer process.
yaml
apiVersion: batch/v1
kind: Job
metadata:
name: PaddlePaddle-cluster-job
spec:
parallelism: 3
completions: 3
template:
metadata:
name: PaddlePaddle-cluster-job
spec:
volumes:
- name: jobpath
hostPath:
path: /home/admin/efs
containers:
- name: trainer
image: your\_repo/paddle:mypaddle
command: ["bin/bash", "-c", "/root/start.sh"]
env:
- name: JOB\_NAME
value: paddle-cluster-job
- name: JOB\_PATH
value: /home/jobpath
- name: JOB\_NAMESPACE
value: default
volumeMounts:
- name: jobpath
mountPath: /home/jobpath
restartPolicy: Never
We can see from the config that parallelism, completions are both set to 3. So this job will simultaneously start up 3 PaddlePaddle pods, and this job will be finished when all 3 pods finishes.
| 
Figure 2: Job A of three pods and Job B of one pod running on two nodes. |
The entrypoint of each pod is start.sh. It downloads data from a storage service, so that trainers can read quickly from the pod-local disk space. After downloading completes, it runs a Python script, start_paddle.py, which starts a parameter server, waits until parameter servers of all pods are ready to serve, and then starts the trainer process in the pod.
This waiting is necessary because each trainer needs to talk to all parameter servers, as shown in Figure. 1. Kubernetes API enables trainers to check the status of pods, so the Python script could wait until all parameter servers’ status change to "running" before it triggers the training process.
Currently, the mapping from data shards to pods/trainers is static. If we are going to run N trainers, we would need to partition the data into N shards, and statically assign each shard to a trainer. Again we rely on the Kubernetes API to enlist pods in a job so could we index pods / trainers from 1 to N. The i-th trainer would read the i-th data shard.
Training data is usually served on a distributed filesystem. In practice we use CephFS on our on-premise clusters and Amazon Elastic File System on AWS. If you are interested in building a Kubernetes cluster to run distributed PaddlePaddle training jobs, please follow this tutorial.
What’s Next
We are working on running PaddlePaddle with Kubernetes more smoothly.
As you might notice the current trainer scheduling fully relies on Kubernetes based on a static partition map. This approach is simple to start, but might cause a few efficiency problems.
First, slow or dead trainers block the entire job. There is no controlled preemption or rescheduling after the initial deployment. Second, the resource allocation is static. So if Kubernetes has more available resources than we anticipated, we have to manually change the resource requirements. This is tedious work, and is not aligned with our efficiency and utilization goal.
To solve the problems mentioned above, we will add a PaddlePaddle master that understands Kubernetes API, can dynamically add/remove resource capacity, and dispatches shards to trainers in a more dynamic manner. The PaddlePaddle master uses etcd as a fault-tolerant storage of the dynamic mapping from shards to trainers. Thus, even if the master crashes, the mapping is not lost. Kubernetes can restart the master and the job will keep running.
Another potential improvement is better PaddlePaddle job configuration. Our experience of having the same number of trainers and parameter servers was mostly collected from using special-purpose clusters. That strategy was observed performant on our clients' clusters that run only PaddlePaddle jobs. However, this strategy might not be optimal on general-purpose clusters that run many kinds of jobs.
PaddlePaddle trainers can utilize multiple GPUs to accelerate computations. GPU is not a first class resource in Kubernetes yet. We have to manage GPUs semi-manually. We would love to work with Kubernetes community to improve GPU support to ensure PaddlePaddle runs the best on Kubernetes.
--Yi Wang, Baidu Research and Xiang Li, CoreOS
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Highly Available Kubernetes Clusters
Today’s post shows how to set-up a reliable, highly available distributed Kubernetes cluster. The support for running such clusters on Google Compute Engine (GCE) was added as an alpha feature in Kubernetes 1.5 release.
Motivation
We will create a Highly Available Kubernetes cluster, with master replicas and worker nodes distributed among three zones of a region. Such setup will ensure that the cluster will continue operating during a zone failure.
Setting Up HA cluster
The following instructions apply to GCE. First, we will setup a cluster that will span over one zone (europe-west1-b), will contain one master and three worker nodes and will be HA-compatible (will allow adding more master replicas and more worker nodes in multiple zones in future). To implement this, we’ll export the following environment variables:
$ export KUBERNETES\_PROVIDER=gce
$ export NUM\_NODES=3
$ export MULTIZONE=true
$ export ENABLE\_ETCD\_QUORUM\_READ=true
and run kube-up script (note that the entire cluster will be initially placed in zone europe-west1-b):
$ KUBE\_GCE\_ZONE=europe-west1-b ./cluster/kube-up.sh
Now, we will add two additional pools of worker nodes, each of three nodes, in zones europe-west1-c and europe-west1-d (more details on adding pools of worker nodes can be find here):
$ KUBE\_USE\_EXISTING\_MASTER=true KUBE\_GCE\_ZONE=europe-west1-c ./cluster/kube-up.sh
$ KUBE\_USE\_EXISTING\_MASTER=true KUBE\_GCE\_ZONE=europe-west1-d ./cluster/kube-up.sh
To complete setup of HA cluster, we will add two master replicase, one in zone europe-west1-c, the other in europe-west1-d:
$ KUBE\_GCE\_ZONE=europe-west1-c KUBE\_REPLICATE\_EXISTING\_MASTER=true ./cluster/kube-up.sh
$ KUBE\_GCE\_ZONE=europe-west1-d KUBE\_REPLICATE\_EXISTING\_MASTER=true ./cluster/kube-up.sh
Note that adding the first replica will take longer (~15 minutes), as we need to reassign the IP of the master to the load balancer in front of replicas and wait for it to propagate (see design doc for more details).
Verifying in HA cluster works as intended
We may now list all nodes present in the cluster:
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 48m
kubernetes-master-2d4 Ready,SchedulingDisabled 5m
kubernetes-master-85f Ready,SchedulingDisabled 32s
kubernetes-minion-group-6s52 Ready 39m
kubernetes-minion-group-cw8e Ready 48m
kubernetes-minion-group-fw91 Ready 48m
kubernetes-minion-group-h2kn Ready 31m
kubernetes-minion-group-ietm Ready 39m
kubernetes-minion-group-j6lf Ready 31m
kubernetes-minion-group-soj7 Ready 31m
kubernetes-minion-group-tj82 Ready 39m
kubernetes-minion-group-vd96 Ready 48m
As we can see, we have 3 master replicas (with disabled scheduling) and 9 worker nodes.
We will deploy a sample application (nginx server) to verify that our cluster is working correctly:
$ kubectl run nginx --image=nginx --expose --port=80
After waiting for a while, we can verify that both the deployment and the service were correctly created and are running:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
...
nginx-3449338310-m7fjm 1/1 Running 0 4s
...
$ kubectl run -i --tty test-a --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
# wget -q -O- http://nginx.default.svc.cluster.local
...
\<title\>Welcome to nginx!\</title\>
...
Now, let’s simulate failure of one of master’s replicas by executing halt command on it (kubernetes-master-137, zone europe-west1-c):
$ gcloud compute ssh kubernetes-master-2d4 --zone=europe-west1-c
...
$ sudo halt
After a while the master replica will be marked as NotReady:
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 51m
kubernetes-master-2d4 NotReady,SchedulingDisabled 8m
kubernetes-master-85f Ready,SchedulingDisabled 4m
...
However, the cluster is still operational. We may verify it by checking if our nginx server works correctly:
$ kubectl run -i --tty test-b --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
# wget -q -O- http://nginx.default.svc.cluster.local
...
\<title\>Welcome to nginx!\</title\>
...
We may also run another nginx server:
$ kubectl run nginx-next --image=nginx --expose --port=80
The new server should be also working correctly:
$ kubectl run -i --tty test-c --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
# wget -q -O- http://nginx-next.default.svc.cluster.local
...
\<title\>Welcome to nginx!\</title\>
...
Let’s now reset the broken replica:
$ gcloud compute instances start kubernetes-master-2d4 --zone=europe-west1-c
After a while, the replica should be re-attached to the cluster:
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 57m
kubernetes-master-2d4 Ready,SchedulingDisabled 13m
kubernetes-master-85f Ready,SchedulingDisabled 9m
...
Shutting down HA cluster
To shutdown the cluster, we will first shut down master replicas in zones D and E:
$ KUBE\_DELETE\_NODES=false KUBE\_GCE\_ZONE=europe-west1-c ./cluster/kube-down.sh
$ KUBE\_DELETE\_NODES=false KUBE\_GCE\_ZONE=europe-west1-d ./cluster/kube-down.sh
Note that the second removal of replica will take longer (~15 minutes), as we need to reassign the IP of the load balancer in front of replicas to the remaining master and wait for it to propagate (see design doc for more details).
Then, we will remove the additional worker nodes from zones europe-west1-c and europe-west1-d:
$ KUBE\_USE\_EXISTING\_MASTER=true KUBE\_GCE\_ZONE=europe-west1-c ./cluster/kube-down.sh
$ KUBE\_USE\_EXISTING\_MASTER=true KUBE\_GCE\_ZONE=europe-west1-d ./cluster/kube-down.sh
And finally, we will shutdown the remaining master with the last group of nodes (zone europe-west1-b):
$ KUBE\_GCE\_ZONE=europe-west1-b ./cluster/kube-down.sh
Conclusions
We have shown how, by adding worker node pools and master replicas, a Highly Available Kubernetes cluster can be created. As of Kubernetes version 1.5.2, it is supported in kube-up/kube-down scripts for GCE (as alpha). Additionally, there is a support for HA cluster on AWS in kops scripts (see this article for more details).
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
--Jerzy Szczepkowski, Software Engineer, Google
Fission: Serverless Functions as a Service for Kubernetes
Editor's note: Today’s post is by Soam Vasani, Software Engineer at Platform9 Systems, talking about a new open source Serverless Function (FaaS) framework for Kubernetes.
Fission is a Functions as a Service (FaaS) / Serverless function framework built on Kubernetes.
Fission allows you to easily create HTTP services on Kubernetes from functions. It works at the source level and abstracts away container images (in most cases). It also simplifies the Kubernetes learning curve, by enabling you to make useful services without knowing much about Kubernetes.
To use Fission, you simply create functions and add them with a CLI. You can associate functions with HTTP routes, Kubernetes events, or other triggers. Fission supports NodeJS and Python today.
Functions are invoked when their trigger fires, and they only consume CPU and memory when they're running. Idle functions don't consume any resources except storage.
Why make a FaaS framework on Kubernetes?
We think there's a need for a FaaS framework that can be run on diverse infrastructure, both in public clouds and on-premise infrastructure. Next, we had to decide whether to build it from scratch, or on top of an existing orchestration system. It was quickly clear that we shouldn't build it from scratch -- we would just end up having to re-invent cluster management, scheduling, network management, and lots more.
Kubernetes offered a powerful and flexible orchestration system with a comprehensive API backed by a strong and growing community. Building on it meant Fission could leave container orchestration functionality to Kubernetes, and focus on FaaS features.
The other reason we don't want a separate FaaS cluster is that FaaS works best in combination with other infrastructure. For example, it may be the right fit for a small REST API, but it needs to work with other services to store state. FaaS also works great as a mechanism for event handlers to handle notifications from storage, databases, and from Kubernetes itself. Kubernetes is a great platform for all these services to interoperate on top of.
Deploying and Using Fission
Fission can be installed with a kubectl create command: see the project README for instructions.
Here's how you’d write a "hello world" HTTP service:
$ cat \> hello.py
def main(context):
print "Hello, world!"
$ fission function create --name hello --env python --code hello.py --route /hello
$ curl http://\<fission router\>/hello
Hello, world!
Fission takes care of loading the function into a container, routing the request to it, and so on. We go into more details in the next section.
How Fission Is Implemented on Kubernetes
At its core, a FaaS framework must (1) turn functions into services and (2) manage the lifecycle of these services.
There are a number of ways to achieve these goals, and each comes with different tradeoffs. Should the framework operate at the source-level, or at the level of Docker images (or something in-between, like "buildpacks")? What's an acceptable amount of overhead the first time a function runs? Choices made here affect platform flexibility, ease of use, resource usage and costs, and of course, performance.
Packaging, source code, and images
One of our goals is to make Fission very easy to use for new users. We chose to operate
at the source level, so that users can avoid having to deal with container image building, pushing images to registries, managing registry credentials, image versioning, and so on.
However, container images are the most flexible way to package apps. A purely source-level interface wouldn't allow users to package binary dependencies, for example.
So, Fission goes with a hybrid approach -- container images that contain a dynamic loader for functions. This approach allows most users to use Fission purely at the source level, but enables them to customize the container image when needed.
These images, called "environment images" in Fission, contain the runtime for the language (such as NodeJS or Python), a set of commonly used dependencies and a dynamic loader for functions. If these dependencies are sufficient for the function the user is writing, no image rebuilding is needed. Otherwise, the list of dependencies can be modified, and the image rebuilt.
These environment images are the only language-specific parts of Fission. They present a uniform interface to the rest of the framework. This design allows Fission to be easily extended to more languages.
Cold start performance
One of the goals of the serverless functions is that functions use CPU/memory resources only when running. This optimizes the resource cost of functions, but it comes at the cost of some performance overhead when starting from idle (the "cold start" overhead).
Cold start overhead is important in many use cases. In particular, with functions used in an interactive use case -- like a web or mobile app, where a user is waiting for the action to complete -- several-second cold start latencies would be unacceptable.
To optimize cold start overheads, Fission keeps a running pool of containers for each environment. When a request for a function comes in, Fission doesn't have to deploy a new container -- it just chooses one that's already running, copies the function into the container, loads it dynamically, and routes the request to that instance. The overhead of this process takes on the order of 100msec for NodeJS and Python functions.
How Fission works on Kubernetes

routes, event triggers, and environment images. A Pool Manager manages pools of idle environment containers, the loading of functions into these containers, and the killing of function instances when they're idle. A Router receives HTTP requests and routes them to function instances, requesting an instance from the Pool Manager if necessary.
The controller serves the fission API. All the other components watch the controller for updates. The router is exposed as a Kubernetes Service of the LoadBalancer or NodePort type, depending on where the Kubernetes cluster is hosted.
When the router gets a request, it looks up a cache to see if this request already has a service it should be routed to. If not, it looks up the function to map the request to, and requests the poolmgr for an instance. The poolmgr has a pool of idle pods; it picks one, loads the function into it (by sending a request into a sidecar container in the pod), and returns the address of the pod to the router. The router proxies over the request to this pod. The pod is cached for subsequent requests, and if it's been idle for a few minutes, it is killed.
(For now, Fission maps one function to one container; autoscaling to multiple instances is planned for a later release. Re-using function pods to host multiple functions is also planned, for cases where isolation isn't a requirement.)
Use Cases for Fission
Bots, Webhooks, REST APIs
Fission is a good framework to make small REST APIs, implement webhooks, and write chatbots for Slack or other services.
As an example of a simple REST API, we've made a small guestbook app that uses functions for reading and writing to guestbook, and works with a redis instance to keep track of state. You can find the app in the Fission GitHub repo.
The app contains two end points -- the GET endpoint lists out guestbook entries from redis and renders them into HTML. The POST endpoint adds a new entry to the guestbook list in redis. That’s all there is -- there’s no Dockerfile to manage, and updating the app is as simple as calling fission function update.
Handling Kubernetes Events
Fission also supports triggering functions based on Kubernetes watches. For example, you can setup a function to watch for all pods in a certain namespace matching a certain label. The function gets the serialized object and the watch event type (added/removed/updated) in its context.
These event handler functions could be used for simple monitoring -- for example, you could send a slack message whenever a new service is added to the cluster. There are also more complex use cases, such as writing a custom controller by watching Kubernetes' Third Party Resources.
Status and Roadmap
Fission is in early alpha for now (Jan 2017). It's not ready for production use just yet. We're looking for early adopters and feedback.
What's ahead for Fission? We're working on making FaaS on Kubernetes more convenient, easy to use and easier to integrate with. In the coming months we're working on adding support for unit testing, integration with Git, function monitoring and log aggregation. We're also working on integration with other sources of events.
Creating more language environments is also in the works. NodeJS and Python are supported today. Preliminary support for C# .NET has been contributed by Klavs Madsen.
You can find our current roadmap on our GitHub issues and projects.
Get Involved
Fission is open source and developed in the open by Platform9 Systems. Check us out on GitHub, and join our slack channel if you’d like to chat with us. We're also on twitter at @fissionio.
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
--Soam Vasani, Software Engineer, Platform9 Systems
Running MongoDB on Kubernetes with StatefulSets
Editor's note: Today’s post is by Sandeep Dinesh, Developer Advocate, Google Cloud Platform, showing how to run a database in a container.
Conventional wisdom says you can’t run a database in a container. “Containers are stateless!” they say, and “databases are pointless without state!”
Of course, this is not true at all. At Google, everything runs in a container, including databases. You just need the right tools. Kubernetes 1.5 includes the new StatefulSet API object (in previous versions, StatefulSet was known as PetSet). With StatefulSets, Kubernetes makes it much easier to run stateful workloads such as databases.
If you’ve followed my previous posts, you know how to create a MEAN Stack app with Docker, then migrate it to Kubernetes to provide easier management and reliability, and create a MongoDB replica set to provide redundancy and high availability.
While the replica set in my previous blog post worked, there were some annoying steps that you needed to follow. You had to manually create a disk, a ReplicationController, and a service for each replica. Scaling the set up and down meant managing all of these resources manually, which is an opportunity for error, and would put your stateful application at risk In the previous example, we created a Makefile to ease the management of these resources, but it would have been great if Kubernetes could just take care of all of this for us.
With StatefulSets, these headaches finally go away. You can create and manage your MongoDB replica set natively in Kubernetes, without the need for scripts and Makefiles. Let’s take a look how.
Note: StatefulSets are currently a beta resource. The sidecar container used for auto-configuration is also unsupported.
Prerequisites and Setup
Before we get started, you’ll need a Kubernetes 1.5+ and the Kubernetes command line tool. If you want to follow along with this tutorial and use Google Cloud Platform, you also need the Google Cloud SDK.
Once you have a Google Cloud project created and have your Google Cloud SDK setup (hint: gcloud init), we can create our cluster.
To create a Kubernetes 1.5 cluster, run the following command:
gcloud container clusters create "test-cluster"
This will make a three node Kubernetes cluster. Feel free to customize the command as you see fit.
Then, authenticate into the cluster:
gcloud container clusters get-credentials test-cluster
Setting up the MongoDB replica set
To set up the MongoDB replica set, you need three things: A StorageClass, a Headless Service, and a StatefulSet.
I’ve created the configuration files for these already, and you can clone the example from GitHub:
git clone https://github.com/thesandlord/mongo-k8s-sidecar.git
cd /mongo-k8s-sidecar/example/StatefulSet/
To create the MongoDB replica set, run these two commands:
kubectl apply -f googlecloud\_ssd.yaml
kubectl apply -f mongo-statefulset.yaml
That's it! With these two commands, you have launched all the components required to run an highly available and redundant MongoDB replica set.
At an high level, it looks something like this:

Let’s examine each piece in more detail.
StorageClass
The storage class tells Kubernetes what kind of storage to use for the database nodes. You can set up many different types of StorageClasses in a ton of different environments. For example, if you run Kubernetes in your own datacenter, you can use GlusterFS. On GCP, your storage choices are SSDs and hard disks. There are currently drivers for AWS, Azure, Google Cloud, GlusterFS, OpenStack Cinder, vSphere, Ceph RBD, and Quobyte.
The configuration for the StorageClass looks like this:
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
This configuration creates a new StorageClass called “fast” that is backed by SSD volumes. The StatefulSet can now request a volume, and the StorageClass will automatically create it!
Deploy this StorageClass:
kubectl apply -f googlecloud\_ssd.yaml
Headless Service
Now you have created the Storage Class, you need to make a Headless Service. These are just like normal Kubernetes Services, except they don’t do any load balancing for you. When combined with StatefulSets, they can give you unique DNS addresses that let you directly access the pods! This is perfect for creating MongoDB replica sets, because our app needs to connect to all of the MongoDB nodes individually.
The configuration for the Headless Service looks like this:
apiVersion: v1
kind: Service
metadata:
name: mongo
labels:
name: mongo
spec:
ports:
- port: 27017
targetPort: 27017
clusterIP: None
selector:
role: mongo
You can tell this is a Headless Service because the clusterIP is set to “None.” Other than that, it looks exactly the same as any normal Kubernetes Service.
StatefulSet
The pièce de résistance. The StatefulSet actually runs MongoDB and orchestrates everything together. StatefulSets differ from Kubernetes ReplicaSets (not to be confused with MongoDB replica sets!) in certain ways that makes them more suited for stateful applications. Unlike Kubernetes ReplicaSets, pods created under a StatefulSet have a few unique attributes. The name of the pod is not random, instead each pod gets an ordinal name. Combined with the Headless Service, this allows pods to have stable identification. In addition, pods are created one at a time instead of all at once, which can help when bootstrapping a stateful system. You can read more about StatefulSets in the documentation.
Just like before, this “sidecar” container will configure the MongoDB replica set automatically. A “sidecar” is a helper container which helps the main container do its work.
The configuration for the StatefulSet looks like this:
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: mongo
spec:
selector:
matchLabels:
role: mongo
environment: test
serviceName: "mongo"
replicas: 3
template:
metadata:
labels:
role: mongo
environment: test
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mongo
image: mongo
command:
- mongod
- "--replSet"
- rs0
- "--smallfiles"
- "--noprealloc"
ports:
- containerPort: 27017
volumeMounts:
- name: mongo-persistent-storage
mountPath: /data/db
- name: mongo-sidecar
image: cvallance/mongo-k8s-sidecar
env:
- name: MONGO_SIDECAR_POD_LABELS
value: "role=mongo,environment=test"
volumeClaimTemplates:
- metadata:
name: mongo-persistent-storage
spec:
storageClassName: "fast"
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 100Gi
It’s a little long, but fairly straightforward.
The first second describes the StatefulSet object. Then, we move into the Metadata section, where you can specify labels and the number of replicas.
Next comes the pod spec. The terminationGracePeriodSeconds is used to gracefully shutdown the pod when you scale down the number of replicas, which is important for databases! Then the configurations for the two containers is shown. The first one runs MongoDB with command line flags that configure the replica set name. It also mounts the persistent storage volume to /data/db, the location where MongoDB saves its data. The second container runs the sidecar.
Finally, there is the volumeClaimTemplates. This is what talks to the StorageClass we created before to provision the volume. It will provision a 100 GB disk for each MongoDB replica.
Using the MongoDB replica set
At this point, you should have three pods created in your cluster. These correspond to the three nodes in your MongoDB replica set. You can see them with this command:
kubectl get pods
NAME READY STATUS RESTARTS AGE
mongo-0 2/2 Running 0 3m
mongo-1 2/2 Running 0 3m
mongo-2 2/2 Running 0 3m
Each pod in a StatefulSet backed by a Headless Service will have a stable DNS name. The template follows this format: <pod-name>.<service-name>
This means the DNS names for the MongoDB replica set are:
mongo-0.mongo
mongo-1.mongo
mongo-2.mongo
You can use these names directly in the connection string URI of your app.
In this case, the connection string URI would be:
mongodb://mongo-0.mongo,mongo-1.mongo,mongo-2.mongo:27017/dbname\_?
That’s it!
Scaling the MongoDB replica set
A huge advantage of StatefulSets is that you can scale them just like Kubernetes ReplicaSets. If you want 5 MongoDB Nodes instead of 3, just run the scale command:
kubectl scale --replicas=5 statefulset mongo
The sidecar container will automatically configure the new MongoDB nodes to join the replica set.
Include the two new nodes (mongo-3.mongo & mongo-4.mongo) in your connection string URI and you are good to go. Too easy!
Cleaning Up
To clean up the deployed resources, delete the StatefulSet, Headless Service, and the provisioned volumes.
Delete the StatefulSet:
kubectl delete statefulset mongo
Delete the Service:
kubectl delete svc mongo
Delete the Volumes:
kubectl delete pvc -l role=mongo
Finally, you can delete the test cluster:
gcloud container clusters delete "test-cluster"
Happy Hacking!
For more cool Kubernetes and Container blog posts, follow me on Twitter and Medium.
--Sandeep Dinesh, Developer Advocate, Google Cloud Platform.
How we run Kubernetes in Kubernetes aka Kubeception
Editor's note: Today’s post is by the team at Giant Swarm, showing how they run Kubernetes in Kubernetes.
Giant Swarm’s container infrastructure started out with the goal to be an easy way for developers to deploy containerized microservices. Our first generation was extensively using fleet as a base layer for our infrastructure components as well as for scheduling user containers.
In order to give our users a more powerful way to manage their containers we introduced Kubernetes into our stack in early 2016. However, as we needed a quick way to flexibly spin up and manage different users’ Kubernetes clusters resiliently we kept the underlying fleet layer.
As we insist on running all our underlying infrastructure components in containers, fleet gave us the flexibility of using systemd unit files to define our infrastructure components declaratively. Our self-developed deployment tooling allowed us to deploy and manage the infrastructure without the need for imperative configuration management tools.
However, fleet is just a distributed init and not a complete scheduling and orchestration system. Next to a lot of work on our tooling, it required significant improvements in terms of communication between peers, its reconciliation loop, and stability that we had to work on. Also the uptake in Kubernetes usage would ensure that issues are found and fixed faster.
As we had made good experience with introducing Kubernetes on the user side and with recent developments like rktnetes and stackanetes it felt like time for us to also move our base layer to Kubernetes.
Why Kubernetes in Kubernetes
Now, you could ask, why would anyone want to run multiple Kubernetes clusters inside of a Kubernetes cluster? Are we crazy? The answer is advanced multi-tenancy use cases as well as operability and automation thereof.
Kubernetes comes with its own growing feature set for multi-tenancy use cases. However, we had the goal of offering our users a fully-managed Kubernetes without any limitations to the functionality they would get using any vanilla Kubernetes environment, including privileged access to the nodes. Further, in bigger enterprise scenarios a single Kubernetes cluster with its inbuilt isolation mechanisms is often not sufficient to satisfy compliance and security requirements. More advanced (firewalled) zoning or layered security concepts are tough to reproduce with a single installation. With namespace isolation both privileged access as well as firewalled zones can hardly be implemented without sidestepping security measures.
Now you could go and set up multiple completely separate (and federated) installations of Kubernetes. However, automating the deployment and management of these clusters would need additional tooling and complex monitoring setups. Further, we wanted to be able to spin clusters up and down on demand, scale them, update them, keep track of which clusters are available, and be able to assign them to organizations and teams flexibly. In fact this setup can be combined with a federation control plane to federate deployments to the clusters over one API endpoint.
And wouldn’t it be nice to have an API and frontend for that?
Enter Giantnetes
Based on the above requirements we set out to build what we call Giantnetes - or if you’re into movies, Kubeception. At the most basic abstraction it is an outer Kubernetes cluster (the actual Giantnetes), which is used to run and manage multiple completely isolated user Kubernetes clusters.

The physical machines are bootstrapped by using our CoreOS Container Linux bootstrapping tool, Mayu. The Giantnetes components themselves are self-hosted, i.e. a kubelet is in charge of automatically bootstrapping the components that reside in a manifests folder. You could call this the first level of Kubeception.
Once the Giantnetes cluster is running we use it to schedule the user Kubernetes clusters as well as our tooling for managing and securing them.
We chose Calico as the Giantnetes network plugin to ensure security, isolation, and the right performance for all the applications running on top of Giantnetes.
Then, to create the inner Kubernetes clusters, we initiate a few pods, which configure the network bridge, create certificates and tokens, and launch virtual machines for the future cluster. To do so, we use lightweight technologies such as KVM and qemu to provision CoreOS Container Linux VMs that become the nodes of an inner Kubernetes cluster. You could call this the second level of Kubeception.
Currently this means we are starting Pods with Docker containers that in turn start VMs with KVM and qemu. However, we are looking into doing this with rkt qemu-kvm, which would result in using a rktnetes setup for our Giantnetes.

The networking solution for the inner Kubernetes clusters has two levels. It on a combination of flannel’s server/client architecture model and Calico BGP. While a flannel client is used to create the network bridge between the VMs of each virtualized inner Kubernetes cluster, Calico is running inside the virtual machines to connect the different Kubernetes nodes and create a single network for the inner Kubernetes. By using Calico, we mimic the Giantnetes networking solution inside of each Kubernetes cluster and provide the primitives to secure and isolate workloads through the Kubernetes network policy API.
Regarding security, we aim for separating privileges as much as possible and making things auditable. Currently this means we use certificates to secure access to the clusters and encrypt communication between all the components that form a cluster is (i.e. VM to VM, Kubernetes components to each other, etcd master to Calico workers, etc). For this we create a PKI backend per cluster and then issue certificates per service in Vault on-demand. Every component uses a different certificate, thus, avoiding to expose the whole cluster if any of the components or nodes gets compromised. We further rotate the certificates on a regular basis.
For ensuring access to the API and to services of each inner Kubernetes cluster from the outside we run a multi-level HAproxy ingress controller setup in the Giantnetes that connects the Kubernetes VMs to hardware load balancers.
Looking into Giantnetes with kubectl
Let’s have a look at a minimal sample deployment of Giantnetes.

In the above example you see a user Kubernetes cluster customera running in VM-containers on top of Giantnetes. We currently use Jobs for the network and certificate setups.
Peeking inside the user cluster, you see the DNS pods and a helloworld running.

Each one of these user clusters can be scheduled and used independently. They can be spun up and down on-demand.
Conclusion
To sum up, we could show how Kubernetes is able to easily not only self-host but also flexibly schedule a multitude of inner Kubernetes clusters while ensuring higher isolation and security aspects. A highlight in this setup is the composability and automation of the installation and the robust coordination between the Kubernetes components. This allows us to easily create, destroy, and reschedule clusters on-demand without affecting users or compromising the security of the infrastructure. It further allows us to spin up clusters with varying sizes and configurations or even versions by just changing some arguments at cluster creation.
This setup is still in its early days and our roadmap is planning for improvements in many areas such as transparent upgrades, dynamic reconfiguration and scaling of clusters, performance improvements, and (even more) security. Furthermore, we are looking forward to improve on our setup by making use of the ever advancing state of Kubernetes operations tooling and upcoming features, such as Init Containers, Scheduled Jobs, Pod and Node affinity and anti-affinity, etc.
Most importantly, we are working on making the inner Kubernetes clusters a third party resource that can then be managed by a custom controller. The result would be much like the Operator concept by CoreOS. And to ensure that the community at large can benefit from this project we will be open sourcing this in the near future.
-- Hector Fernandez, Software Engineer & Puja Abbassi, Developer Advocate, Giant Swarm
Scaling Kubernetes deployments with Policy-Based Networking
Editor's note: Today’s post is by Harmeet Sahni, Director of Product Management, at Nuage Networks, writing about their contributions to Kubernetes and insights on policy-based networking.
Although it’s just been eighteen-months since Kubernetes 1.0 was released, we’ve seen Kubernetes emerge as the leading container orchestration platform for deploying distributed applications. One of the biggest reasons for this is the vibrant open source community that has developed around it. The large number of Kubernetes contributors come from diverse backgrounds means we, and the community of users, are assured that we are investing in an open platform. Companies like Google (Container Engine), Red Hat (OpenShift), and CoreOS (Tectonic) are developing their own commercial offerings based on Kubernetes. This is a good thing since it will lead to more standardization and offer choice to the users.
Networking requirements for Kubernetes applications
For companies deploying applications on Kubernetes, one of biggest questions is how to deploy and orchestrate containers at scale. They’re aware that the underlying infrastructure, including networking and storage, needs to support distributed applications. Software-defined networking (SDN) is a great fit for such applications because the flexibility and agility of the networking infrastructure can match that of the applications themselves. The networking requirements of such applications include:
- Network automation
- Distributed load balancing and service discovery
- Distributed security with fine-grained policies
- QoS Policies
- Scalable Real-time Monitoring
- Hybrid application environments with Services spread across Containers, VMs and Bare Metal Servers
- Service Insertion (e.g. firewalls)
- Support for Private and Public Cloud deployments
Kubernetes Networking
Kubernetes provides a core set of platform services exposed through APIs. The platform can be extended in several ways through the extensions API, plugins and labels. This has allowed a wide variety integrations and tools to be developed for Kubernetes. Kubernetes recognizes that the network in each deployment is going to be unique. Instead of trying to make the core system try to handle all those use cases, Kubernetes chose to make the network pluggable.
With Nuage Networks we provide a scalable policy-based SDN platform. The platform is managed by a Network Policy Engine that abstracts away the complexity associated with configuring the system. There is a separate SDN Controller that comes with a very rich routing feature set and is designed to scale horizontally. Nuage uses the open source Open vSwitch (OVS) for the data plane with some enhancements in the OVS user space. Just like Kubernetes, Nuage has embraced openness as a core tenet for its platform. Nuage provides open APIs that allow users to orchestrate their networks and integrate network services such as firewalls, load balancers, IPAM tools etc. Nuage is supported in a wide variety of cloud platforms like OpenStack and VMware as well as container platforms like Kubernetes and others.
The Nuage platform implements a Kubernetes network plugin that creates VXLAN overlays to provide seamless policy-based networking between Kubernetes Pods and non-Kubernetes environments (VMs and bare metal servers). Each Pod is given an IP address from a network that belongs to a Namespace and is not tied to the Kubernetes node.
As cloud applications are built using microservices, the ability to control traffic among these microservices is a fundamental requirement. It is important to point out that these network policies also need to control traffic that is going to/coming from external networks and services. Nuage’s policy abstraction model makes it easy to declare fine-grained ingress/egress policies for applications. Kubernetes has a beta Network Policy API implemented using the Kubernetes Extensions API. Nuage implements this Network Policy API to address a wide variety of policy use cases such as:
- Kubernetes Namespace isolation
- Inter-Namespace policies
- Policies between groups of Pods (Policy Groups) for Pods in same or different Namespaces
- Policies between Kubernetes Pods/Namespaces and external Networks/Services

A key question for users to consider is the scalability of the policy implementation. Some networking setups require creating access control list (ACL) entries telling Pods how they can interact with one another. In most cases, this eventually leads to an n-squared pileup of ACL entries. The Nuage platform avoids this problem and can quickly assign a policy that applies to a whole group of Pods. The Nuage platform implements these policies using a fully distributed stateful firewall based on OVS.
Being able to monitor the traffic flowing between Kubernetes Pods is very useful to both development and operations teams. The Nuage platform’s real-time analytics engine enables visibility and security monitoring for Kubernetes applications. Users can get a visual representation of the traffic flows between groups of Pods, making it easy to see how the network policies are taking effect. Users can also get a rich set of traffic and policy statistics. Further, users can set alerts to be triggered based on policy event thresholds.

Conclusion
Even though we started working on our integration with Kubernetes over a year ago, it feels we are just getting started. We have always felt that this is a truly open community and we want to be an integral part of it. You can find out more about our Kubernetes integration on our GitHub page.
--Harmeet Sahni, Director of Product Management, Nuage Networks
A Stronger Foundation for Creating and Managing Kubernetes Clusters
Editor's note: Today’s post is by Lucas Käldström an independent Kubernetes maintainer and SIG-Cluster-Lifecycle member, sharing what the group has been building and what’s upcoming.
Last time you heard from us was in September, when we announced kubeadm. The work on making kubeadm a first-class citizen in the Kubernetes ecosystem has continued and evolved. Some of us also met before KubeCon and had a very productive meeting where we talked about what the scopes for our SIG, kubeadm, and kops are.
Continuing to Define SIG-Cluster-Lifecycle
What is the scope for kubeadm?
We want kubeadm to be a common set of building blocks for all Kubernetes deployments; the piece that provides secure and recommended ways to bootstrap Kubernetes. Since there is no one true way to setup Kubernetes, kubeadm will support more than one method for each phase. We want to identify the phases every deployment of Kubernetes has in common and make configurable and easy-to-use kubeadm commands for those phases. If your organization, for example, requires that you distribute the certificates in the cluster manually or in a custom way, skip using kubeadm just for that phase. We aim to keep kubeadm usable for all other phases in that case. We want you to be able to pick which things you want kubeadm to do and let you do the rest yourself.
Therefore, the scope for kubeadm is to be easily extendable, modular and very easy to use. Right now, with this v1.5 release we have, kubeadm can only do the “full meal deal” for you. In future versions that will change as kubeadm becomes more componentized, while still leaving the opportunity to do everything for you. But kubeadm will still only handle the bootstrapping of Kubernetes; it won’t ever handle provisioning of machines for you since that can be done in many more ways. In addition, we want kubeadm to work everywhere, even on multiple architectures, therefore we built in multi-architecture support from the beginning.
What is the scope for kops?
The scope for kops is to automate full cluster operations: installation, reconfiguration of your cluster, upgrading kubernetes, and eventual cluster deletion. kops has a rich configuration model based on the Kubernetes API Machinery, so you can easily customize some parameters to your needs. kops (unlike kubeadm) handles provisioning of resources for you. kops aims to be the ultimate out-of-the-box experience on AWS (and perhaps other providers in the future). In the future kops will be adopting more and more of kubeadm for the bootstrapping phases that exist. This will move some of the complexity inside kops to a central place in the form of kubeadm.
What is the scope for SIG-Cluster-Lifecycle?
The SIG-Cluster-Lifecycle actively tries to simplify the Kubernetes installation and management story. This is accomplished by modifying Kubernetes itself in many cases, and factoring out common tasks. We are also trying to address common problems in the cluster lifecycle (like the name says!). We maintain and are responsible for kubeadm and kops. We discuss problems with the current way to bootstrap clusters on AWS (and beyond) and try to make it easier. We hangout on Slack in the #sig-cluster-lifecycle and #kubeadm channels. We meet and discuss current topics once a week on Zoom. Feel free to come and say hi! Also, don’t be shy to contribute; we’d love your comments and insight!
Looking forward to v1.6
Our goals for v1.6 are centered around refactoring, stabilization and security.
First and foremost, we want to get kubeadm and its composable configuration experience to beta. We will refactor kubeadm so each phase in the bootstrap process is invokable separately. We want to bring the TLS Bootstrap API, the Certificates API and the ComponentConfig API to beta, and to get kops (and other tools) using them.
We will also graduate the token discovery we’re using now (aka. the gcr.io/google_containers/kube-discovery:1.0 image) to beta by adding a new controller to the controller manager: the BootstrapSigner. Using tokens managed as Secrets, that controller will sign the contents (a kubeconfig file) of a well known ConfigMap in a new kube-public namespace. This object will be available to unauthenticated users in order to enable a secure bootstrap with a simple and short shared token.You can read the full proposal here.
In addition to making it possible to invoke phases separately, we will also add a new phase for bringing up the control plane in a self-hosted mode (as opposed to the current static pod technique). The self-hosted technique was developed by CoreOS in the form of bootkube, and will now be incorporated as an alternative into an official Kubernetes product. Thanks to CoreOS for pushing that paradigm forward! This will be done by first setting up a temporary control plane with static pods, injecting the Deployments, ConfigMaps and DaemonSets as necessary, and lastly turning down the temporary control plane. For now, etcd will still be in a static pod by default.
We are supporting self hosting, initially, because we want to support doing patch release upgrades with kubeadm. It should be easy to upgrade from v1.6.2 to v1.6.4 for instance. We consider the built-in upgrade support a critical capability for a real cluster lifecycle tool. It will still be possible to upgrade without self-hosting but it will require more manual work.
On the stabilization front, we want to start running kubeadm e2e tests. In this v1.5 timeframe, we added unit tests and we will continue to increase that coverage. We want to expand this to per-PR e2e tests as well that spin up a cluster with kubeadm init and kubeadm join; runs some kubeadm-specific tests and optionally the Conformance test suite.
Finally, on the security front, we also want to kubeadm to be as secure as possible by default. We look to enable RBAC for v1.6, lock down what kubelet and built-in services like kube-dns and kube-proxy can do, and maybe create specific user accounts that have different permissions.
Regarding releasing, we want to have the official kubeadm v1.6 binary in the kubernetes v1.6 tarball. This means syncing our release with the official one. More details on what we’ve done so far can be found here. As it becomes possible, we aim to move the kubeadm code out to the kubernetes/kubeadm repo (This is blocked on some Kubernetes code-specific infrastructure issues that may take some time to resolve.)
Nice-to-haves for v1.6 would include an official CoreOS Container Linux installer container that does what the debs/rpms are doing for Ubuntu/CentOS. In general, it would be nice to extend the distro support. We also want to adopt Kubelet Dynamic Settings so configuration passed to kubeadm init flows down to nodes automatically (it requires manual configuration currently). We want it to be possible to test Kubernetes from HEAD by using kubeadm.
Through 2017 and beyond
Apart from everything mentioned above, we want kubeadm to simply be a production grade (GA) tool you can use for bootstrapping a Kubernetes cluster. We want HA/multi-master to be much easier to achieve generally than it is now across platforms (though kops makes this easy on AWS today!). We want cloud providers to be out-of-tree and installable separately. kubectl apply -f my-cloud-provider-here.yaml should just work. The documentation should be more robust and should go deeper. Container Runtime Interface (CRI) and Federation should work well with kubeadm. Outdated getting started guides should be removed so new users aren’t mislead.
Refactoring the cloud provider integration plugins
Right now, the cloud provider integrations are built into the controller-manager, the kubelet and the API Server. This combined with the ever-growing interest for Kubernetes makes it unmaintainable to have the cloud provider integrations compiled into the core. Features that are clearly vendor-specific should not be a part of the core Kubernetes project, rather available as an addon from third party vendors. Everything cloud-specific should be moved into one controller, or a few if there’s need. This controller will be maintained by a third-party (usually the company behind the integration) and will implement cloud-specific features. This migration from in-core to out-of-core is disruptive yes, but it has very good side effects: leaner core, making it possible for more than the seven existing clouds to be integrated with Kubernetes and much easier installation. For example, you could run the cloud controller binary in a Deployment and install it with kubectl apply easily.
The plan for v1.6 is to make it possible to:
- Create and run out-of-core cloud provider integration controllers
- Ship a new and temporary binary in the Kubernetes release: the cloud-controller-manager. This binary will include the seven existing cloud providers and will serve as a way of validating, testing and migrating to the new flow.
In a future release (v1.9 is proposed), the
--cloud-providerflag will stop working, and the temporary cloud-controller-manager binary won’t be shipped anymore. Instead, a repository called something like kubernetes/cloud-providers will serve as a place for officially-validated cloud providers to evolve and exist, but all providers there will be independent to each other. (issue #2770; proposal #128; code #3473.)
Changelogs from v1.4 to v1.5
kubeadm
v1.5 is a stabilization release for kubeadm. We’ve worked on making kubeadm more user-friendly, transparent and stable. Some new features have been added making it more configurable.
Here’s a very short extract of what’s changed:
- Made the console output of kubeadm cleaner and more user-friendly #37568
- Implemented kubeadm reset and to drain and cleanup a node #34807 and #37831
- Preflight checks implementation that fails fast if the environment is invalid #34341 and #36334
- kubectl logs and kubectl exec can now be used with kubeadm #37568
- and a lot of other improvements, please read the full changelog.
kops
Here’s a short extract of what’s changed:
- Support for CNI network plugins (Weave, Calico, Kope.io)
- Fully private deployments, where nodes and masters do not have public IPs
- Improved rolling update of clusters, in particular of HA clusters
- OS support for CentOS / RHEL / Ubuntu along with Debian, and support for sysdig & perf tools
Go and check out the kops releases page in order to get information about the latest and greatest kops release.
Summary
In short, we're excited on the roadmap ahead in bringing a lot of these improvements to you in the coming releases. Which we hope will make the experience to start much easier and lead to increased adoption of Kubernetes.
Thank you for all the feedback and contributions. I hope this has given you some insight in what we’re doing and encouraged you to join us at our meetings to say hi!
-- Lucas Käldström, Independent Kubernetes maintainer and SIG-Cluster-Lifecycle member
Kubernetes UX Survey Infographic
Editor's note: Today’s post is by Dan Romlein, UX Designer at Apprenda and member of the SIG-UI, sharing UX survey results from the Kubernetes community.
The following infographic summarizes the findings of a survey that the team behind Dashboard, the official web UI for Kubernetes, sent during KubeCon in November 2016. Following the KubeCon launch of the survey, it was promoted on Twitter and various Slack channels over a two week period and generated over 100 responses. We’re delighted with the data it provides us to now make feature and roadmap decisions more in-line with the needs of you, our users.
Satisfaction with Dashboard

Less than a year old, Dashboard is still very early in its development and we realize it has a long way to go, but it was encouraging to hear it’s tracking on the axis of MVP and even with its basic feature set is adding value for people. Respondents indicated that they like how quickly the Dashboard project is moving forward and the activity level of its contributors. Specific appreciation was given for the value Dashboard brings to first-time Kubernetes users and encouraging exploration. Frustration voiced around Dashboard centered on its limited capabilities: notably, the lack of RBAC and limited visualization of cluster objects and their relationships.
Respondent Demographics

Kubernetes Usage

People are using Dashboard in production, which is fantastic; it’s that setting that the team is focused on optimizing for.
Feature Priority

In building Dashboard, we want to continually make alignments between the needs of Kubernetes users and our product. Feature areas have intentionally been kept as high-level as possible, so that UX designers on the Dashboard team can creatively transform those use cases into specific features. While there’s nothing wrong with “faster horses”, we want to make sure we’re creating an environment for the best possible innovation to flourish.
Troubleshooting & Debugging as a strong frontrunner in requested feature area is consistent with the previous KubeCon survey, and this is now our top area of investment. Currently in-progress is the ability to be able to exec into a Pod, and next up will be providing aggregated logs views across objects. One of a UI’s strengths over a CLI is its ability to show things, and the troubleshooting and debugging feature area is a prime application of this capability.
In addition to a continued ongoing investment in troubleshooting and debugging functionality, the other focus of the Dashboard team’s efforts currently is RBAC / IAM within Dashboard. Though #4 on the ranking of feature areas, In various conversations at KubeCon and the days following, this emerged as a top-requested feature of Dashboard, and the one people were most passionate about. This is a deal-breaker for many companies, and we’re confident its enablement will open many doors for Dashboard’s use in production.
Conclusion
It’s invaluable to have data from Kubernetes users on how they’re putting Dashboard to use and how well it’s serving their needs. If you missed the survey response window but still have something you’d like to share, we’d love to connect with you and hear feedback or answer questions:
- Email us at the SIG-UI mailing list
- Chat with us on the Kubernetes Slack #SIG-UI channel
- Join our weekly meetings at 4PM CEST. See the SIG-UI calendar for details.
Kubernetes supports OpenAPI
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.5
OpenAPI allows API providers to define their operations and models, and enables developers to automate their tools and generate their favorite language’s client to talk to that API server. Kubernetes has supported swagger 1.2 (older version of OpenAPI spec) for a while, but the spec was incomplete and invalid, making it hard to generate tools/clients based on it.
In Kubernetes 1.4, we introduced alpha support for the OpenAPI spec (formerly known as swagger 2.0 before it was donated to the Open API Initiative) by upgrading the current models and operations. Beginning in Kubernetes 1.5, the support for the OpenAPI spec has been completed by auto-generating the spec directly from Kubernetes source, which will keep the spec--and documentation--completely in sync with future changes in operations/models.
The new spec enables us to have better API documentation and we have even introduced a supported python client.
The spec is modular, divided by GroupVersion: this is future-proof, since we intend to allow separate GroupVersions to be served out of separate API servers.
The structure of spec is explained in detail in OpenAPI spec definition. We used operation’s tags to separate each GroupVersion and filled as much information as we can about paths/operations and models. For a specific operation, all parameters, method of call, and responses are documented.
For example, OpenAPI spec for reading a pod information is:
{
...
"paths": {
"/api/v1/namespaces/{namespace}/pods/{name}": {
"get": {
"description": "read the specified Pod",
"consumes": [
"\*/\*"
],
"produces": [
"application/json",
"application/yaml",
"application/vnd.kubernetes.protobuf"
],
"schemes": [
"https"
],
"tags": [
"core\_v1"
],
"operationId": "readCoreV1NamespacedPod",
"parameters": [
{
"uniqueItems": true,
"type": "boolean",
"description": "Should the export be exact. Exact export maintains cluster-specific fields like 'Namespace'.",
"name": "exact",
"in": "query"
},
{
"uniqueItems": true,
"type": "boolean",
"description": "Should this value be exported. Export strips fields that a user can not specify.",
"name": "export",
"in": "query"
}
],
"responses": {
"200": {
"description": "OK",
"schema": {
"$ref": "#/definitions/v1.Pod"
}
},
"401": {
"description": "Unauthorized"
}
}
},
…
}
…
Using this information and the URL of kube-apiserver, one should be able to make the call to the given url (/api/v1/namespaces/{namespace}/pods/{name}) with parameters such as name, exact, export, etc. to get pod’s information. Client libraries generators would also use this information to create an API function call for reading pod’s information. For example, python client makes it easy to call this operation like this:
from kubernetes import client
ret = client.CoreV1Api().read\_namespaced\_pod(name="pods\_name", namespace="default")
A simplified version of generated read_namespaced_pod, can be found here.
Swagger-codegen document generator would also be able to create documentation using the same information:
GET /api/v1/namespaces/{namespace}/pods/{name}
(readCoreV1NamespacedPod)
read the specified Pod
Path parameters
name (required)
Path Parameter — name of the Pod
namespace (required)
Path Parameter — object name and auth scope, such as for teams and projects
Consumes
This API call consumes the following media types via the Content-Type request header:
-
\*/\*
Query parameters
pretty (optional)
Query Parameter — If 'true', then the output is pretty printed.
exact (optional)
Query Parameter — Should the export be exact. Exact export maintains cluster-specific fields like 'Namespace'.
export (optional)
Query Parameter — Should this value be exported. Export strips fields that a user can not specify.
Return type
v1.Pod
Produces
This API call produces the following media types according to the Accept request header; the media type will be conveyed by the Content-Type response header.
-
application/json
-
application/yaml
-
application/vnd.kubernetes.protobuf
Responses
200
OK v1.Pod
401
Unauthorized
There are two ways to access OpenAPI spec:
- From
kuber-apiserver/swagger.json. This file will have all enabled GroupVersions routes and models and would be most up-to-date file with an specifickube-apiserver. - From Kubernetes GitHub repository with all core GroupVersions enabled. You can access it on master or an specific release (for example 1.5 release).
There are numerous tools that works with this spec. For example, you can use the swagger editor to open the spec file and render documentation, as well as generate clients; or you can directly use swagger codegen to generate documentation and clients. The clients this generates will mostly work out of the box--but you will need some support for authorization and some Kubernetes specific utilities. Use python client as a template to create your own client.
If you want to get involved in development of OpenAPI support, client libraries, or report a bug, you can get in touch with developers at SIG-API-Machinery.
--Mehdy Bohlool, Software Engineer, Google
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Cluster Federation in Kubernetes 1.5
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.5
In the latest Kubernetes 1.5 release, you’ll notice that support for Cluster Federation is maturing. That functionality was introduced in Kubernetes 1.3, and the 1.5 release includes a number of new features, including an easier setup experience and a step closer to supporting all Kubernetes API objects.
A new command line tool called ‘kubefed’ was introduced to make getting started with Cluster Federation much simpler. Also, alpha level support was added for Federated DaemonSets, Deployments and ConfigMaps. In summary:
- DaemonSets are Kubernetes deployment rules that guarantee that a given pod is always present at every node, as new nodes are added to the cluster (more info).
- Deployments describe the desired state of Replica Sets (more info).
- ConfigMaps are variables applied to Replica Sets (which greatly improves image reusability as their parameters can be externalized - more info). Federated DaemonSets , Federated Deployments , Federated ConfigMaps take the qualities of the base concepts to the next level. For instance, Federated DaemonSets guarantee that a pod is deployed on every node of the newly added cluster.
But what actually is “federation”? Let’s explain it by what needs it satisfies. Imagine a service that operates globally. Naturally, all its users expect to get the same quality of service, whether they are located in Asia, Europe, or the US. What this means is that the service must respond equally fast to requests at each location. This sounds simple, but there’s lots of logic involved behind the scenes. This is what Kubernetes Cluster Federation aims to do.
How does it work? One of the Kubernetes clusters must become a master by running a Federation Control Plane. In practice, this is a controller that monitors the health of other clusters, and provides a single entry point for administration. The entry point behaves like a typical Kubernetes cluster. It allows creating Replica Sets, Deployments, Services, but the federated control plane passes the resources to underlying clusters. This means that if we request the federation control plane to create a Replica Set with 1,000 replicas, it will spread the request across all underlying clusters. If we have 5 clusters, then by default each will get its share of 200 replicas.
This on its own is a powerful mechanism. But there’s more. It’s also possible to create a Federated Ingress. Effectively, this is a global application-layer load balancer. Thanks to an understanding of the application layer, it allows load balancing to be “smarter” -- for instance, by taking into account the geographical location of clients and servers, and routing the traffic between them in an optimal way.
In summary, with Kubernetes Cluster Federation, we can facilitate administration of all the clusters (single access point), but also optimize global content delivery around the globe. In the following sections, we will show how it works.
Creating a Federation Plane
In this exercise, we will federate a few clusters. For convenience, all commands have been grouped into 6 scripts available here:
- 0-settings.sh
- 1-create.sh
- 2-getcredentials.sh
- 3-initfed.sh
- 4-joinfed.sh
- 5-destroy.sh First we need to define several variables (0-settings.sh)
$ cat 0-settings.sh && . 0-settings.sh
# this project create 3 clusters in 3 zones. FED\_HOST\_CLUSTER points to the one, which will be used to deploy federation control plane
export FED\_HOST\_CLUSTER=us-east1-b
# Google Cloud project name
export FED\_PROJECT=\<YOUR PROJECT e.g. company-project\>
# DNS suffix for this federation. Federated Service DNS names are published with this suffix. This must be a real domain name that you control and is programmable by one of the DNS providers (Google Cloud DNS or AWS Route53)
export FED\_DNS\_ZONE=\<YOUR DNS SUFFIX e.g. example.com\>
And get kubectl and kubefed binaries. (for installation instructions refer to guides here and here).
Now the setup is ready to create a few Google Container Engine (GKE) clusters with gcloud container clusters create (1-create.sh). In this case one is in US, one in Europe and one in Asia.
$ cat 1-create.sh && . 1-create.sh
gcloud container clusters create gce-us-east1-b --project=${FED\_PROJECT} --zone=us-east1-b --scopes cloud-platform,storage-ro,logging-write,monitoring-write,service-control,service-management,https://www.googleapis.com/auth/ndev.clouddns.readwrite
gcloud container clusters create gce-europe-west1-b --project=${FED\_PROJECT} --zone=europe-west1-b --scopes cloud-platform,storage-ro,logging-write,monitoring-write,service-control,service-management,https://www.googleapis.com/auth/ndev.clouddns.readwrite
gcloud container clusters create gce-asia-east1-a --project=${FED\_PROJECT} --zone=asia-east1-a --scopes cloud-platform,storage-ro,logging-write,monitoring-write,service-control,service-management,https://www.googleapis.com/auth/ndev.clouddns.readwrite
The next step is fetching kubectl configuration with gcloud -q container clusters get-credentials (2-getcredentials.sh). The configurations will be used to indicate the current context for kubectl commands.
$ cat 2-getcredentials.sh && . 2-getcredentials.sh
gcloud -q container clusters get-credentials gce-us-east1-b --zone=us-east1-b --project=${FED\_PROJECT}
gcloud -q container clusters get-credentials gce-europe-west1-b --zone=europe-west1-b --project=${FED\_PROJECT}
gcloud -q container clusters get-credentials gce-asia-east1-a --zone=asia-east1-a --project=${FED\_PROJECT}
Let’s verify the setup:
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
\*
gke\_container-solutions\_europe-west1-b\_gce-europe-west1-b
gke\_container-solutions\_europe-west1-b\_gce-europe-west1-b
gke\_container-solutions\_europe-west1-b\_gce-europe-west1-b
gke\_container-solutions\_us-east1-b\_gce-us-east1-b
gke\_container-solutions\_us-east1-b\_gce-us-east1-b
gke\_container-solutions\_us-east1-b\_gce-us-east1-b
gke\_container-solutions\_asia-east1-a\_gce-asia-east1-a
gke\_container-solutions\_asia-east1-a\_gce-asia-east1-a
gke\_container-solutions\_asia-east1-a\_gce-asia-east1-a
We have 3 clusters. One, indicated by the FED_HOST_CLUSTER environment variable, will be used to run the federation plane. For this, we will use the kubefed init federation command (3-initfed.sh).
$ cat 3-initfed.sh && . 3-initfed.sh
kubefed init federation --host-cluster-context=gke\_${FED\_PROJECT}\_${FED\_HOST\_CLUSTER}\_gce-${FED\_HOST\_CLUSTER} --dns-zone-name=${FED\_DNS\_ZONE}
You will notice that after executing the above command, a new kubectl context has appeared:
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
...
federation
federation
The federation context will become our administration entry point. Now it’s time to join clusters (4-joinfed.sh):
$ cat 4-joinfed.sh && . 4-joinfed.sh
kubefed --context=federation join cluster-europe-west1-b --cluster-context=gke\_${FED\_PROJECT}\_europe-west1-b\_gce-europe-west1-b --host-cluster-context=gke\_${FED\_PROJECT}\_${FED\_HOST\_CLUSTER}\_gce-${FED\_HOST\_CLUSTER}
kubefed --context=federation join cluster-asia-east1-a --cluster-context=gke\_${FED\_PROJECT}\_asia-east1-a\_gce-asia-east1-a --host-cluster-context=gke\_${FED\_PROJECT}\_${FED\_HOST\_CLUSTER}\_gce-${FED\_HOST\_CLUSTER}
kubefed --context=federation join cluster-us-east1-b --cluster-context=gke\_${FED\_PROJECT}\_us-east1-b\_gce-us-east1-b --host-cluster-context=gke\_${FED\_PROJECT}\_${FED\_HOST\_CLUSTER}\_gce-${FED\_HOST\_CLUSTER}
Note that cluster gce-us-east1-b is used here to run the federation control plane and also to work as a worker cluster. This circular dependency helps to use resources more efficiently and it can be verified by using the kubectl --context=federation get clusters command:
$ kubectl --context=federation get clusters
NAME STATUS AGE
cluster-asia-east1-a Ready 7s
cluster-europe-west1-b Ready 10s
cluster-us-east1-b Ready 10s
We are good to go.
Using Federation To Run An Application
In our repository you will find instructions on how to build a docker image with a web service that displays the container’s hostname and the Google Cloud Platform (GCP) zone.
An example output might look like this:
{"hostname":"k8shserver-6we2u","zone":"europe-west1-b"}
Now we will deploy the Replica Set (k8shserver.yaml):
$ kubectl --context=federation create -f rs/k8shserver
And a Federated Service (k8shserver.yaml):
$ kubectl --context=federation create -f service/k8shserver
As you can see, the two commands refer to the “federation” context, i.e. to the federation control plane. After a few minutes, you will realize that underlying clusters run the Replica Set and the Service.
Creating The Ingress
After the Service is ready, we can create Ingress - the global load balancer. The command is like this:
kubectl --context=federation create -f ingress/k8shserver.yaml
The contents of the file point to the service we created in the previous step:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: k8shserver
spec:
backend:
serviceName: k8shserver
servicePort: 80
After a few minutes, we should get a global IP address:
$ kubectl --context=federation get ingress
NAME HOSTS ADDRESS PORTS AGE
k8shserver \* 130.211.40.125 80 20m
Effectively, the response of:
$ curl 130.211.40.125
depends on the location of client. Something like this would be expected in the US:
{"hostname":"k8shserver-w56n4","zone":"us-east1-b"}
Whereas in Europe, we might have:
{"hostname":"k8shserver-z31p1","zone":"eu-west1-b"}
Please refer to this issue for additional details on how everything we've described works.
Demo
Summary
Cluster Federation is actively being worked on and is still not fully General Available. Some APIs are in beta and others are in alpha. Some features are missing, for instance cross-cloud load balancing is not supported (federated ingress currently only works on Google Cloud Platform as it depends on GCP HTTP(S) Load Balancing).
Nevertheless, as the functionality matures, it will become an enabler for all companies that aim at global markets, but currently cannot afford sophisticated administration techniques as used by the likes of Netflix or Amazon. That’s why we closely watch the technology, hoping that it soon fulfills its promise.
PS. When done, remember to destroy your clusters:
$ . 5-destroy.sh
-__-Lukasz Guminski, Software Engineer at Container Solutions. Allan Naim, Product Manager, Google
Windows Server Support Comes to Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.5
Extending on the theme of giving users choice, Kubernetes 1.5 release includes the support for Windows Servers. WIth more than 80% of enterprise apps running Java on Linux or .Net on Windows, Kubernetes is previewing capabilities that extends its reach to the mass majority of enterprise workloads.
The new Kubernetes Windows Server 2016 and Windows Container support includes public preview with the following features:
-
Containerized Multiplatform Applications - Applications developed in operating system neutral languages like Go and .NET Core were previously impossible to orchestrate between Linux and Windows. Now, with support for Windows Server 2016 in Kubernetes, such applications can be deployed on both Windows Server as well as Linux, giving the developer choice of the operating system runtime. This capability has been desired by customers for almost two decades.
-
Support for Both Windows Server Containers and Hyper-V Containers - There are two types of containers in Windows Server 2016. Windows Containers is similar to Docker containers on Linux, and uses kernel sharing. The other, called Hyper-V Containers, is more lightweight than a virtual machine while at the same time offering greater isolation, its own copy of the kernel, and direct memory assignment. Kubernetes can orchestrate both these types of containers.
-
Expanded Ecosystem of Applications - One of the key drivers of introducing Windows Server support in Kubernetes is to expand the ecosystem of applications supported by Kubernetes: IIS, .NET, Windows Services, ASP.NET, .NET Core, are some of the application types that can now be orchestrated by Kubernetes, running inside a container on Windows Server.
-
Coverage for Heterogeneous Data Centers - Organizations already use Kubernetes to host tens of thousands of application instances across Global 2000 and Fortune 500. This will allow them to expand Kubernetes to the large footprint of Windows Server.
The process to bring Windows Server to Kubernetes has been a truly multi-vendor effort and championed by the Windows Special Interest Group (SIG) - Apprenda, Google, Red Hat and Microsoft were all involved in bringing Kubernetes to Windows Server. On the community effort to bring Kubernetes to Windows Server, Taylor Brown, Principal Program Manager at Microsoft stated that “This new Kubernetes community work furthers Windows Server container support options for popular orchestrators, reinforcing Microsoft’s commitment to choice and flexibility for both Windows and Linux ecosystems.”
Guidance for Current Usage
| Where to use Windows Server support? | Right now organizations should start testing Kubernetes on Windows Server and provide feedback. Most organizations take months to set up hardened production environments and general availability should be available in next few releases of Kubernetes. | | What works? | Most of the Kubernetes constructs, such as Pods, Services, Labels, etc. work with Windows Containers. | | What doesn’t work yet? |
- Pod abstraction is not same due to networking namespaces. Net result is that Windows containers in a single POD cannot communicate over localhost. Linux containers can share networking stack by placing them in the same network namespace.
- DNS capabilities are not fully implemented
- UDP is not supported inside a container
| | When will it be ready for all production workloads (general availability)? | The goal is to refine the networking and other areas that need work to get Kubernetes users a production version of Windows Server 2016 - including with Windows Nano Server and Windows Server Core installation options - support in the next couple releases. |
Technical Demo
Roadmap
Support for Windows Server-based containers is in alpha release mode for Kubernetes 1.5, but the community is not stopping there. Customers want enterprise hardened container scheduling and management for their entire tech portfolio. That has to include full parity of features among Linux and Windows Server in production. The Windows Server SIG will deliver that parity within the next one or two releases of Kubernetes through a few key areas of investment:
- Networking - the SIG will continue working side by side with Microsoft to enhance the networking backbone of Windows Server Containers, specifically around lighting up container mode networking and native network overlay support for container endpoints.
- OOBE - Improving the setup, deployment, and diagnostics for a Windows Server node, including the ability to deploy to any cloud (Azure, AWS, GCP)
- Runtime Operations - the SIG will play a key part in defining the monitoring interface of the Container Runtime Interface (CRI), leveraging it to provide deep insight and monitoring for Windows Server-based containers Get Started
To get started with Kubernetes on Windows Server 2016, please visit the GitHub guide for more details.
If you want to help with Windows Server support, then please connect with the Windows Server SIG or connect directly with Michael Michael, the SIG lead, on GitHub.
--Michael Michael, Senior Director of Product Management, Apprenda
| 
StatefulSet: Run and Scale Stateful Applications Easily in Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.5
In the latest release, Kubernetes 1.5, we’ve moved the feature formerly known as PetSet into beta as StatefulSet. There were no major changes to the API Object, other than the community selected name, but we added the semantics of “at most one pod per index” for deployment of the Pods in the set. Along with ordered deployment, ordered termination, unique network names, and persistent stable storage, we think we have the right primitives to support many containerized stateful workloads. We don’t claim that the feature is 100% complete (it is software after all), but we believe that it is useful in its current form, and that we can extend the API in a backwards-compatible way as we progress toward an eventual GA release.
When is StatefulSet the Right Choice for my Storage Application?
Deployments and ReplicaSets are a great way to run stateless replicas of an application on Kubernetes, but their semantics aren’t really right for deploying stateful applications. The purpose of StatefulSet is to provide a controller with the correct semantics for deploying a wide range of stateful workloads. However, moving your storage application onto Kubernetes isn’t always the correct choice. Before you go all in on converging your storage tier and your orchestration framework, you should ask yourself a few questions.
Can your application run using remote storage or does it require local storage media?
Currently, we recommend using StatefulSets with remote storage. Therefore, you must be ready to tolerate the performance implications of network attached storage. Even with storage optimized instances, you won’t likely realize the same performance as locally attached, solid state storage media. Does the performance of network attached storage, on your cloud, allow your storage application to meet its SLAs? If so, running your application in a StatefulSet provides compelling benefits from the perspective of automation. If the node on which your storage application is running fails, the Pod containing the application can be rescheduled onto another node, and, as it’s using network attached storage media, its data are still available after it’s rescheduled.
Do you need to scale your storage application?
What is the benefit you hope to gain by running your application in a StatefulSet? Do you have a single instance of your storage application for your entire organization? Is scaling your storage application a problem that you actually have? If you have a few instances of your storage application, and they are successfully meeting the demands of your organization, and those demands are not rapidly increasing, you’re already at a local optimum.
If, however, you have an ecosystem of microservices, or if you frequently stamp out new service footprints that include storage applications, then you might benefit from automation and consolidation. If you’re already using Kubernetes to manage the stateless tiers of your ecosystem, you should consider using the same infrastructure to manage your storage applications.
How important is predictable performance?
Kubernetes doesn’t yet support isolation for network or storage I/O across containers. Colocating your storage application with a noisy neighbor can reduce the QPS that your application can handle. You can mitigate this by scheduling the Pod containing your storage application as the only tenant on a node (thus providing it a dedicated machine) or by using Pod anti-affinity rules to segregate Pods that contend for network or disk, but this means that you have to actively identify and mitigate hot spots.
If squeezing the absolute maximum QPS out of your storage application isn’t your primary concern, if you’re willing and able to mitigate hotspots to ensure your storage applications meet their SLAs, and if the ease of turning up new "footprints" (services or collections of services), scaling them, and flexibly re-allocating resources is your primary concern, Kubernetes and StatefulSet might be the right solution to address it.
Does your application require specialized hardware or instance types?
If you run your storage application on high-end hardware or extra-large instance sizes, and your other workloads on commodity hardware or smaller, less expensive images, you may not want to deploy a heterogenous cluster. If you can standardize on a single instance size for all types of apps, then you may benefit from the flexible resource reallocation and consolidation, that you get from Kubernetes.
A Practical Example - ZooKeeper
ZooKeeper is an interesting use case for StatefulSet for two reasons. First, it demonstrates that StatefulSet can be used to run a distributed, strongly consistent storage application on Kubernetes. Second, it's a prerequisite for running workloads like Apache Hadoop and Apache Kakfa on Kubernetes. An in-depth tutorial on deploying a ZooKeeper ensemble on Kubernetes is available in the Kubernetes documentation, and we’ll outline a few of the key features below.
Creating a ZooKeeper Ensemble
Creating an ensemble is as simple as using kubectl create to generate the objects stored in the manifest.
$ kubectl create -f [http://k8s.io/docs/tutorials/stateful-application/zookeeper.yaml](https://raw.githubusercontent.com/kubernetes/kubernetes.github.io/master/docs/tutorials/stateful-application/zookeeper.yaml)
service "zk-headless" created
configmap "zk-config" created
poddisruptionbudget "zk-budget" created
statefulset "zk" created
When you create the manifest, the StatefulSet controller creates each Pod, with respect to its ordinal, and waits for each to be Running and Ready prior to creating its successor.
$ kubectl get -w -l app=zk
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 7s
zk-0 0/1 ContainerCreating 0 7s
zk-0 0/1 Running 0 38s
zk-0 1/1 Running 0 58s
zk-1 0/1 Pending 0 1s
zk-1 0/1 Pending 0 1s
zk-1 0/1 ContainerCreating 0 1s
zk-1 0/1 Running 0 33s
zk-1 1/1 Running 0 51s
zk-2 0/1 Pending 0 0s
zk-2 0/1 Pending 0 0s
zk-2 0/1 ContainerCreating 0 0s
zk-2 0/1 Running 0 25s
zk-2 1/1 Running 0 40s
Examining the hostnames of each Pod in the StatefulSet, you can see that the Pods’ hostnames also contain the Pods’ ordinals.
$ for i in 0 1 2; do kubectl exec zk-$i -- hostname; done
zk-0
zk-1
zk-2
ZooKeeper stores the unique identifier of each server in a file called “myid”. The identifiers used for ZooKeeper servers are just natural numbers. For the servers in the ensemble, the “myid” files are populated by adding one to the ordinal extracted from the Pods’ hostnames.
$ for i in 0 1 2; do echo "myid zk-$i";kubectl exec zk-$i -- cat /var/lib/zookeeper/data/myid; done
myid zk-0
1
myid zk-1
2
myid zk-2
3
Each Pod has a unique network address based on its hostname and the network domain controlled by the zk-headless Headless Service.
$ for i in 0 1 2; do kubectl exec zk-$i -- hostname -f; done
zk-0.zk-headless.default.svc.cluster.local
zk-1.zk-headless.default.svc.cluster.local
zk-2.zk-headless.default.svc.cluster.local
The combination of a unique Pod ordinal and a unique network address allows you to populate the ZooKeeper servers’ configuration files with a consistent ensemble membership.
$ kubectl exec zk-0 -- cat /opt/zookeeper/conf/zoo.cfg
clientPort=2181
dataDir=/var/lib/zookeeper/data
dataLogDir=/var/lib/zookeeper/log
tickTime=2000
initLimit=10
syncLimit=2000
maxClientCnxns=60
minSessionTimeout= 4000
maxSessionTimeout= 40000
autopurge.snapRetainCount=3
autopurge.purgeInteval=1
server.1=zk-0.zk-headless.default.svc.cluster.local:2888:3888
server.2=zk-1.zk-headless.default.svc.cluster.local:2888:3888
server.3=zk-2.zk-headless.default.svc.cluster.local:2888:3888
StatefulSet lets you deploy ZooKeeper in a consistent and reproducible way. You won’t create more than one server with the same id, the servers can find each other via a stable network addresses, and they can perform leader election and replicate writes because the ensemble has consistent membership.
The simplest way to verify that the ensemble works is to write a value to one server and to read it from another. You can use the “zkCli.sh” script that ships with the ZooKeeper distribution, to create a ZNode containing some data.
$ kubectl exec zk-0 zkCli.sh create /hello world
...
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
Created /hello
You can use the same script to read the data from another server in the ensemble.
$ kubectl exec zk-1 zkCli.sh get /hello
...
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
world
...
You can take the ensemble down by deleting the zk StatefulSet.
$ kubectl delete statefulset zk
statefulset "zk" deleted
The cascading delete destroys each Pod in the StatefulSet, with respect to the reverse order of the Pods’ ordinals, and it waits for each to terminate completely before terminating its predecessor.
$ kubectl get pods -w -l app=zk
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 0 14m
zk-1 1/1 Running 0 13m
zk-2 1/1 Running 0 12m
NAME READY STATUS RESTARTS AGE
zk-2 1/1 Terminating 0 12m
zk-1 1/1 Terminating 0 13m
zk-0 1/1 Terminating 0 14m
zk-2 0/1 Terminating 0 13m
zk-2 0/1 Terminating 0 13m
zk-2 0/1 Terminating 0 13m
zk-1 0/1 Terminating 0 14m
zk-1 0/1 Terminating 0 14m
zk-1 0/1 Terminating 0 14m
zk-0 0/1 Terminating 0 15m
zk-0 0/1 Terminating 0 15m
zk-0 0/1 Terminating 0 15m
You can use kubectl apply to recreate the zk StatefulSet and redeploy the ensemble.
$ kubectl apply -f [http://k8s.io/docs/tutorials/stateful-application/zookeeper.yaml](https://raw.githubusercontent.com/kubernetes/kubernetes.github.io/master/docs/tutorials/stateful-application/zookeeper.yaml)
service "zk-headless" configured
configmap "zk-config" configured
statefulset "zk" created
If you use the “zkCli.sh” script to get the value entered prior to deleting the StatefulSet, you will find that the ensemble still serves the data.
$ kubectl exec zk-2 zkCli.sh get /hello
...
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
world
...
StatefulSet ensures that, even if all Pods in the StatefulSet are destroyed, when they are rescheduled, the ZooKeeper ensemble can elect a new leader and continue to serve requests.
Tolerating Node Failures
ZooKeeper replicates its state machine to different servers in the ensemble for the explicit purpose of tolerating node failure. By default, the Kubernetes Scheduler could deploy more than one Pod in the zk StatefulSet to the same node. If the zk-0 and zk-1 Pods were deployed on the same node, and that node failed, the ZooKeeper ensemble couldn’t form a quorum to commit writes, and the ZooKeeper service would experience an outage until one of the Pods could be rescheduled.
You should always provision headroom capacity for critical processes in your cluster, and if you do, in this instance, the Kubernetes Scheduler will reschedule the Pods on another node and the outage will be brief.
If the SLAs for your service preclude even brief outages due to a single node failure, you should use a PodAntiAffinity annotation. The manifest used to create the ensemble contains such an annotation, and it tells the Kubernetes Scheduler to not place more than one Pod from the zk StatefulSet on the same node.
Tolerating Planned Maintenance
The manifest used to create the ZooKeeper ensemble also creates a PodDistruptionBudget, zk-budget. The zk-budget informs Kubernetes about the upper limit of disruptions (unhealthy Pods) that the service can tolerate.
{
"podAntiAffinity": {
"requiredDuringSchedulingRequiredDuringExecution": [{
"labelSelector": {
"matchExpressions": [{
"key": "app",
"operator": "In",
"values": ["zk-headless"]
}]
},
"topologyKey": "kubernetes.io/hostname"
}]
}
}
}
$ kubectl get poddisruptionbudget zk-budget
NAME MIN-AVAILABLE ALLOWED-DISRUPTIONS AGE
zk-budget 2 1 2h
zk-budget indicates that at least two members of the ensemble must be available at all times for the ensemble to be healthy. If you attempt to drain a node prior taking it offline, and if draining it would terminate a Pod that violates the budget, the drain operation will fail. If you use kubectl drain, in conjunction with PodDisruptionBudgets, to cordon your nodes and to evict all Pods prior to maintenance or decommissioning, you can ensure that the procedure won’t be disruptive to your stateful applications.
Looking Forward
As the Kubernetes development looks towards GA, we are looking at a long list of suggestions from users. If you want to dive into our backlog, checkout the GitHub issues with the stateful label. However, as the resulting API would be hard to comprehend, we don't expect to implement all of these feature requests. Some feature requests, like support for rolling updates, better integration with node upgrades, and using fast local storage, would benefit most types of stateful applications, and we expect to prioritize these. The intention of StatefulSet is to be able to run a large number of applications well, and not to be able to run all applications perfectly. With this in mind, we avoided implementing StatefulSets in a way that relied on hidden mechanisms or inaccessible features. Anyone can write a controller that works similarly to StatefulSets. We call this "making it forkable."
Over the next year, we expect many popular storage applications to each have their own community-supported, dedicated controllers or "operators". We've already heard of work on custom controllers for etcd, Redis, and ZooKeeper. We expect to write some more ourselves and to support the community in developing others.
The Operators for etcd and Prometheus from CoreOS, demonstrate an approach to running stateful applications on Kubernetes that provides a level of automation and integration beyond that which is possible with StatefulSet alone. On the other hand, using a generic controller like StatefulSet or Deployment means that a wide range of applications can be managed by understanding a single config object. We think Kubernetes users will appreciate having the choice of these two approaches.
--Kenneth Owens & Eric Tune, Software Engineers, Google
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Five Days of Kubernetes 1.5
With the help of our growing community of 1,000 contributors, we pushed some 5,000 commits to extend support for production workloads and deliver Kubernetes 1.5. While many improvements and new features have been added, we selected few to highlight in a series of in-depths posts listed below.
This progress is our commitment in continuing to make Kubernetes best way to manage your production workloads at scale.
| Five Days of Kubernetes 1.5 | |
|---|---|
| Day 1 | Introducing Container Runtime Interface (CRI) in Kubernetes |
| Day 2 | StatefulSet: Run and Scale Stateful Applications Easily in Kubernetes |
| Day 3 | Windows Server Support Comes to Kubernetes |
| Day 4 | Cluster Federation in Kubernetes 1.5 |
| Day 5 | Kubernetes supports OpenAPI |
Connect
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Introducing Container Runtime Interface (CRI) in Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.5
At the lowest layers of a Kubernetes node is the software that, among other things, starts and stops containers. We call this the “Container Runtime”. The most widely known container runtime is Docker, but it is not alone in this space. In fact, the container runtime space has been rapidly evolving. As part of the effort to make Kubernetes more extensible, we've been working on a new plugin API for container runtimes in Kubernetes, called "CRI".
What is the CRI and why does Kubernetes need it?
Each container runtime has it own strengths, and many users have asked for Kubernetes to support more runtimes. In the Kubernetes 1.5 release, we are proud to introduce the Container Runtime Interface (CRI) -- a plugin interface which enables kubelet to use a wide variety of container runtimes, without the need to recompile. CRI consists of a protocol buffers and gRPC API, and libraries, with additional specifications and tools under active development. CRI is being released as Alpha in Kubernetes 1.5.
Supporting interchangeable container runtimes is not a new concept in Kubernetes. In the 1.3 release, we announced the rktnetes project to enable rkt container engine as an alternative to the Docker container runtime. However, both Docker and rkt were integrated directly and deeply into the kubelet source code through an internal and volatile interface. Such an integration process requires a deep understanding of Kubelet internals and incurs significant maintenance overhead to the Kubernetes community. These factors form high barriers to entry for nascent container runtimes. By providing a clearly-defined abstraction layer, we eliminate the barriers and allow developers to focus on building their container runtimes. This is a small, yet important step towards truly enabling pluggable container runtimes and building a healthier ecosystem.
Overview of CRI
Kubelet communicates with the container runtime (or a CRI shim for the runtime) over Unix sockets using the gRPC framework, where kubelet acts as a client and the CRI shim as the server.
The protocol buffers API includes two gRPC services, ImageService, and RuntimeService. The ImageService provides RPCs to pull an image from a repository, inspect, and remove an image. The RuntimeService contains RPCs to manage the lifecycle of the pods and containers, as well as calls to interact with containers (exec/attach/port-forward). A monolithic container runtime that manages both images and containers (e.g., Docker and rkt) can provide both services simultaneously with a single socket. The sockets can be set in Kubelet by --container-runtime-endpoint and --image-service-endpoint flags.
Pod and container lifecycle management
service RuntimeService {
// Sandbox operations.
rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {}
rpc StopPodSandbox(StopPodSandboxRequest) returns (StopPodSandboxResponse) {}
rpc RemovePodSandbox(RemovePodSandboxRequest) returns (RemovePodSandboxResponse) {}
rpc PodSandboxStatus(PodSandboxStatusRequest) returns (PodSandboxStatusResponse) {}
rpc ListPodSandbox(ListPodSandboxRequest) returns (ListPodSandboxResponse) {}
// Container operations.
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {}
rpc ListContainers(ListContainersRequest) returns (ListContainersResponse) {}
rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse) {}
...
}
A Pod is composed of a group of application containers in an isolated environment with resource constraints. In CRI, this environment is called PodSandbox. We intentionally leave some room for the container runtimes to interpret the PodSandbox differently based on how they operate internally. For hypervisor-based runtimes, PodSandbox might represent a virtual machine. For others, such as Docker, it might be Linux namespaces. The PodSandbox must respect the pod resources specifications. In the v1alpha1 API, this is achieved by launching all the processes within the pod-level cgroup that kubelet creates and passes to the runtime.
Before starting a pod, kubelet calls RuntimeService.RunPodSandbox to create the environment. This includes setting up networking for a pod (e.g., allocating an IP). Once the PodSandbox is active, individual containers can be created/started/stopped/removed independently. To delete the pod, kubelet will stop and remove containers before stopping and removing the PodSandbox.
Kubelet is responsible for managing the lifecycles of the containers through the RPCs, exercising the container lifecycles hooks and liveness/readiness checks, while adhering to the restart policy of the pod.
Why an imperative container-centric interface?
Kubernetes has a declarative API with a Pod resource. One possible design we considered was for CRI to reuse the declarative Pod object in its abstraction, giving the container runtime freedom to implement and exercise its own control logic to achieve the desired state. This would have greatly simplified the API and allowed CRI to work with a wider spectrum of runtimes. We discussed this approach early in the design phase and decided against it for several reasons. First, there are many Pod-level features and specific mechanisms (e.g., the crash-loop backoff logic) in kubelet that would be a significant burden for all runtimes to reimplement. Second, and more importantly, the Pod specification was (and is) still evolving rapidly. Many of the new features (e.g., init containers) would not require any changes to the underlying container runtimes, as long as the kubelet manages containers directly. CRI adopts an imperative container-level interface so that runtimes can share these common features for better development velocity. This doesn't mean we're deviating from the "level triggered" philosophy - kubelet is responsible for ensuring that the actual state is driven towards the declared state.
Exec/attach/port-forward requests
service RuntimeService {
...
// ExecSync runs a command in a container synchronously.
rpc ExecSync(ExecSyncRequest) returns (ExecSyncResponse) {}
// Exec prepares a streaming endpoint to execute a command in the container.
rpc Exec(ExecRequest) returns (ExecResponse) {}
// Attach prepares a streaming endpoint to attach to a running container.
rpc Attach(AttachRequest) returns (AttachResponse) {}
// PortForward prepares a streaming endpoint to forward ports from a PodSandbox.
rpc PortForward(PortForwardRequest) returns (PortForwardResponse) {}
...
}
Kubernetes provides features (e.g. kubectl exec/attach/port-forward) for users to interact with a pod and the containers in it. Kubelet today supports these features either by invoking the container runtime’s native method calls or by using the tools available on the node (e.g., nsenter and socat). Using tools on the node is not a portable solution because most tools assume the pod is isolated using Linux namespaces. In CRI, we explicitly define these calls in the API to allow runtime-specific implementations.
Another potential issue with the kubelet implementation today is that kubelet handles the connection of all streaming requests, so it can become a bottleneck for the network traffic on the node. When designing CRI, we incorporated this feedback to allow runtimes to eliminate the middleman. The container runtime can start a separate streaming server upon request (and can potentially account the resource usage to the pod!), and return the location of the server to kubelet. Kubelet then returns this information to the Kubernetes API server, which opens a streaming connection directly to the runtime-provided server and connects it to the client.
There are many other aspects of CRI that are not covered in this blog post. Please see the list of design docs and proposals for all the details.
Current status
Although CRI is still in its early stages, there are already several projects under development to integrate container runtimes using CRI. Below are a few examples:
- cri-o: OCI conformant runtimes.
- rktlet: the rkt container runtime.
- frakti: hypervisor-based container runtimes.
- docker CRI shim.
If you are interested in trying these alternative runtimes, you can follow the individual repositories for the latest progress and instructions.
For developers interested in integrating a new container runtime, please see the developer guide for the known limitations and issues of the API. We are actively incorporating feedback from early developers to improve the API. Developers should expect occasional API breaking changes (it is Alpha, after all).
Try the new CRI-Docker integration
Kubelet does not yet use CRI by default, but we are actively working on making this happen. The first step is to re-integrate Docker with kubelet using CRI. In the 1.5 release, we extended kubelet to support CRI, and also added a built-in CRI shim for Docker. This allows kubelet to start the gRPC server on Docker’s behalf. To try out the new kubelet-CRI-Docker integration, you simply have to start the Kubernetes API server with --feature-gates=StreamingProxyRedirects=true to enable the new streaming redirect feature, and then start the kubelet with --experimental-cri=true.
Besides a few missing features, the new integration has consistently passed the main end-to-end tests. We plan to expand the test coverage soon and would like to encourage the community to report any issues to help with the transition.
CRI with Minikube
If you want to try out the new integration, but don’t have the time to spin up a new test cluster in the cloud yet, minikube is a great tool to quickly spin up a local cluster. Before you start, follow the instructions to download and install minikube.
- Check the available Kubernetes versions and pick the latest 1.5.x version available. We will use v1.5.0-beta.1 as an example.
$ minikube get-k8s-versions
- Start a minikube cluster with the built-in docker CRI integration.
$ minikube start --kubernetes-version=v1.5.0-beta.1 --extra-config=kubelet.EnableCRI=true --network-plugin=kubenet --extra-config=kubelet.PodCIDR=10.180.1.0/24 --iso-url=http://storage.googleapis.com/minikube/iso/buildroot/minikube-v0.0.6.iso
--extra-config=kubelet.EnableCRI=true` turns on the CRI implementation in kubelet. --network-plugin=kubenet and --extra-config=kubelet.PodCIDR=10.180.1.0/24 sets the network plugin to kubenet and ensures a PodCIDR is assigned to the node. Alternatively, you can use the cni plugin which does not rely on the PodCIDR. --iso-url sets an iso image for minikube to launch the node with. The image used in the example
- Check the minikube log to check that CRI is enabled.
$ minikube logs | grep EnableCRI
I1209 01:48:51.150789 3226 localkube.go:116] Setting EnableCRI to true on kubelet.
- Create a pod and check its status. You should see a “SandboxReceived” event as a proof that Kubelet is using CRI!
$ kubectl run foo --image=gcr.io/google\_containers/pause-amd64:3.0
deployment "foo" created
$ kubectl describe pod foo
...
... From Type Reason Message
... ----------------- ----- --------------- -----------------------------
...{default-scheduler } Normal Scheduled Successfully assigned foo-141968229-v1op9 to minikube
...{kubelet minikube} Normal SandboxReceived Pod sandbox received, it will be created.
...
_Note that kubectl attach/exec/port-forward does not work with CRI enabled in minikube yet, but this will be addressed in the newer version of minikube. _
Community
CRI is being actively developed and maintained by the Kubernetes SIG-Node community. We’d love to hear feedback from you. To join the community:
- Post issues or feature requests on GitHub
- Join the #sig-node channel on Slack
- Subscribe to the SIG-Node mailing list
- Follow us on Twitter @Kubernetesio for latest updates
--Yu-Ju Hong, Software Engineer, Google
Kubernetes 1.5: Supporting Production Workloads
Today we’re announcing the release of Kubernetes 1.5. This release follows close on the heels of KubeCon/CloundNativeCon, where users gathered to share how they’re running their applications on Kubernetes. Many of you expressed interest in running stateful applications in containers with the eventual goal of running all applications on Kubernetes. If you have been waiting to try running a distributed database on Kubernetes, or for ways to guarantee application disruption SLOs for stateful and stateless apps, this release has solutions for you.
StatefulSet and PodDisruptionBudget are moving to beta. Together these features provide an easier way to deploy and scale stateful applications, and make it possible to perform cluster operations like node upgrade without violating application disruption SLOs.
You will also find usability improvements throughout the release, starting with the kubectl command line interface you use so often. For those who have found it hard to set up a multi-cluster federation, a new command line tool called ‘kubefed’ is here to help. And a much requested multi-zone Highly Available (HA) master setup script has been added to kube-up.
Did you know the Kubernetes community is working to support Windows containers? If you have .NET developers, take a look at the work on Windows containers in this release. This work is in early stage alpha and we would love your feedback.
Lastly, for those interested in the internals of Kubernetes, 1.5 introduces Container Runtime Interface or CRI, which provides an internal API abstracting the container runtime from kubelet. This decoupling of the runtime gives users choice in selecting a runtime that best suits their needs. This release also introduces containerized node conformance tests that verify that the node software meets the minimum requirements to join a Kubernetes cluster.
What’s New
StatefulSet beta (formerly known as PetSet) allows workloads that require persistent identity or per-instance storage to be created, scaled, deleted and repaired on Kubernetes. You can use StatefulSets to ease the deployment of any stateful service, and tutorial examples are available in the repository. In order to ensure that there are never two pods with the same identity, the Kubernetes node controller no longer force deletes pods on unresponsive nodes. Instead, it waits until the old pod is confirmed dead in one of several ways: automatically when the kubelet reports back and confirms the old pod is terminated; automatically when a cluster-admin deletes the node; or when a database admin confirms it is safe to proceed by force deleting the old pod. Users are now warned if they try to force delete pods via the CLI. For users who will be migrating from PetSets to StatefulSets, please follow the upgrade guide.
PodDisruptionBudget beta is an API object that specifies the minimum number or minimum percentage of replicas of a collection of pods that must be up at any time. With PodDisruptionBudget, an application deployer can ensure that cluster operations that voluntarily evict pods will never take down so many simultaneously as to cause data loss, an outage, or an unacceptable service degradation. In Kubernetes 1.5 the “kubectl drain” command supports PodDisruptionBudget, allowing safe draining of nodes for maintenance activities, and it will soon also be used by node upgrade and cluster autoscaler (when removing nodes). This can be useful for a quorum based application to ensure the number of replicas running is never below the number needed for quorum, or for a web front end to ensure the number of replicas serving load never falls below a certain percentage.
Kubefed alpha is a new command line tool to help you manage federated clusters, making it easy to deploy new federation control planes and add or remove clusters from existing federations. Also new in cluster federation is the addition of ConfigMaps alpha and DaemonSets alpha and deployments alpha to the federation API allowing you to create, update and delete these objects across multiple clusters from a single endpoint.
HA Masters alpha provides the ability to create and delete clusters with highly available (replicated) masters on GCE using the kube-up/kube-down scripts. Allows setup of zone distributed HA masters, with at least one etcd replica per zone, at least one API server per zone, and master-elected components like scheduler and controller-manager distributed across zones.
Windows server containers alpha provides initial support for Windows Server 2016 nodes and scheduling Windows Server Containers.
Container Runtime Interface (CRI) alpha introduces the v1 CRI API to allow pluggable container runtimes; an experimental docker-CRI integration is ready for testing and feedback.
Node conformance test beta is a containerized test framework that provides a system verification and functionality test for nodes. The test validates whether the node meets the minimum requirements for Kubernetes; a node that passes the tests is qualified to join a Kubernetes. Node conformance test is available at: gcr.io/google_containers/node-test:0.2 for users to verify node setup.
These are just some of the highlights in our last release for the year. For a complete list please visit the release notes.
Availability
Kubernetes 1.5 is available for download here on GitHub and via get.k8s.io. To get started with Kubernetes, try one of the new interactive tutorials. Don’t forget to take 1.5 for a spin before the holidays!
User Adoption
It’s been a year-and-a-half since GA, and the rate of Kubernetes user adoption continues to surpass estimates. Organizations running production workloads on Kubernetes include the world's largest companies, young startups, and everything in between. Since Kubernetes is open and runs anywhere, we’ve seen adoption on a diverse set of platforms; Pokémon Go (Google Cloud), Ticketmaster (AWS), SAP (OpenStack), Box (bare-metal), and hybrid environments that mix-and-match the above. Here are a few user highlights:
- Yahoo! JAPAN -- built an automated tool chain making it easy to go from code push to deployment, all while running OpenStack on Kubernetes.
- Walmart -- will use Kubernetes with OneOps to manage its incredible distribution centers, helping its team with speed of delivery, systems uptime and asset utilization.
- Monzo -- a European startup building a mobile first bank, is using Kubernetes to power its core platform that can handle extreme performance and consistency requirements.
Kubernetes Ecosystem
The Kubernetes ecosystem is growing rapidly, including Microsoft's support for Kubernetes in Azure Container Service, VMware's integration of Kubernetes in its Photon Platform, and Canonical’s commercial support for Kubernetes. This is in addition to the thirty plus Technology & Service Partners that already provide commercial services for Kubernetes users.
The CNCF recently announced the Kubernetes Managed Service Provider (KMSP) program, a pre-qualified tier of service providers with experience helping enterprises successfully adopt Kubernetes. Furthering the knowledge and awareness of Kubernetes, The Linux Foundation, in partnership with CNCF, will develop and operate the Kubernetes training and certification program -- the first course designed is Kubernetes Fundamentals.
Community Velocity
In the past three months we’ve seen more than a hundred new contributors join the project with some 5,000 commits pushed, reaching new milestones by bringing the total for the core project to 1,000+ contributors and 40,000+ commits. This incredible momentum is only possible by having an open design, being open to new ideas, and empowering an open community to be welcoming to new and senior contributors alike. A big thanks goes out to the release team for 1.5 -- Saad Ali of Google, Davanum Srinivas of Mirantis, and Caleb Miles of CoreOS for their work bringing the 1.5 release to light.
Offline, the community can be found at one of the many Kubernetes related meetups around the world. The strength and scale of the community was visible in the crowded halls of CloudNativeCon/KubeCon Seattle (the recorded user talks are here). The next CloudNativeCon + KubeCon is in Berlin March 29-30, 2017, be sure to get your ticket and submit your talk before the CFP deadline of Dec 16th.
Ready to start contributing? Share your voice at our weekly community meeting.
- Post questions (or answer questions) on Stack Overflow
- Follow us on Twitter @Kubernetesio for latest updates
- Connect with the community on Slack
Thank you for your contributions and support!
-- Aparna Sinha, Senior Product Manager, Google
From Network Policies to Security Policies
Editor's note: Today’s post is by Bernard Van De Walle, Kubernetes Lead Engineer, at Aporeto, showing how they took a new approach to the Kubernetes network policy enforcement.
Kubernetes Network Policies
Kubernetes supports a new API for network policies that provides a sophisticated model for isolating applications and reducing their attack surface. This feature, which came out of the SIG-Network group, makes it very easy and elegant to define network policies by using the built-in labels and selectors Kubernetes constructs.
Kubernetes has left it up to third parties to implement these network policies and does not provide a default implementation.
We want to introduce a new way to think about “Security” and “Network Policies”. We want to show that security and reachability are two different problems, and that security policies defined using endpoints (pods labels for example) do not specifically need to be implemented using network primitives.
Most of us at Aporeto come from a Network/SDN background, and we knew how to implement those policies by using traditional networking and firewalling: Translating the pods identity and policy definitions to network constraints, such as IP addresses, subnets, and so forth.
However, we also knew from past experiences that using an external control plane also introduces a whole new set of challenges: This distribution of ACLs requires very tight synchronization between Kubernetes workers; and every time a new pod is instantiated, ACLs need to be updated on all other pods that have some policy related to the new pod. Very tight synchronization is fundamentally a quadratic state problem and, while shared state mechanisms can work at a smaller scale, they often have convergence, security, and eventual consistency issues in large scale clusters.
From Network Policies to Security Policies
At Aporeto, we took a different approach to the network policy enforcement, by actually decoupling the network from the policy. We open sourced our solution as Trireme, which translates the network policy to an authorization policy, and it implements a transparent authentication and authorization function for any communication between pods. Instead of using IP addresses to identify pods, it defines a cryptographically signed identity for each pod as the set of its associated labels. Instead of using ACLs or packet filters to enforce policy, it uses an authorization function where a container can only receive traffic from containers with an identity that matches the policy requirements.
The authentication and authorization function in Trireme is overlaid on the TCP negotiation sequence. Identity (i.e. set of labels) is captured as a JSON Web Token (JWT), signed by local keys, and exchanged during the Syn/SynAck negotiation. The receiving worker validates that the JWTs are signed by a trusted authority (authentication step) and validates against a cached copy of the policy that the connection can be accepted. Once the connection is accepted, the rest of traffic flows through the Linux kernel and all of the protections that it can potentially offer (including conntrack capabilities if needed). The current implementation uses a simple user space process that captures the initial negotiation packets and attaches the authorization information as payload. The JWTs include nonces that are validated during the Ack packet and can defend against man-in-the-middle or replay attacks.

The Trireme implementation talks directly to the Kubernetes master without an external controller and receives notifications on policy updates and pod instantiations so that it can maintain a local cache of the policy and update the authorization rules as needed. There is no requirement for any shared state between Trireme components that needs to be synchronized. Trireme can be deployed either as a standalone process in every worker or by using Daemon Sets. In the latter case, Kubernetes takes ownership of the lifecycle of the Trireme pods.
Trireme's simplicity is derived from the separation of security policy from network transport. Policy enforcement is linked directly to the labels present on the connection, irrespective of the networking scheme used to make the pods communicate. This identity linkage enables tremendous flexibility to operators to use any networking scheme they like without tying security policy enforcement to network implementation details. Also, the implementation of security policy across the federated clusters becomes simple and viable.
Kubernetes and Trireme deployment
Kubernetes is unique in its ability to scale and provide an extensible security support for the deployment of containers and microservices. Trireme provides a simple, secure, and scalable mechanism for enforcing these policies.
You can deploy and try Trireme on top of Kubernetes by using a provided Daemon Set. You'll need to modify some of the YAML parameters based on your cluster architecture. All the steps are described in detail in the deployment GitHub folder. The same folder contains an example 3-tier policy that you can use to test the traffic pattern.
To learn more, download the code, and engage with the project, visit:
--Bernard Van De Walle, Kubernetes lead engineer, Aporeto
Kompose: a tool to go from Docker-compose to Kubernetes
Editor's note: Today’s post is by Sebastien Goasguen, Founder of Skippbox, showing a new tool to move from ‘docker-compose’ to Kubernetes.
At Skippbox, we developed kompose a tool to automatically transform your Docker Compose application into Kubernetes manifests. Allowing you to start a Compose application on a Kubernetes cluster with a single kompose up command. We’re extremely happy to have donated kompose to the Kubernetes Incubator. So here’s a quick introduction about it and some motivating factors that got us to develop it.
Docker is terrific for developers. It allows everyone to get started quickly with an application that has been packaged in a Docker image and is available on a Docker registry. To build a multi-container application, Docker has developed Docker-compose (aka Compose). Compose takes in a yaml based manifest of your multi-container application and starts all the required containers with a single command docker-compose up. However Compose only works locally or with a Docker Swarm cluster.
But what if you wanted to use something else than Swarm? Like Kubernetes of course.
The Compose format is not a standard for defining distributed applications. Hence you are left re-writing your application manifests in your container orchestrator of choice.
We see kompose as a terrific way to expose Kubernetes principles to Docker users as well as to easily migrate from Docker Swarm to Kubernetes to operate your applications in production.
Over the summer, Kompose has found a new gear with help from Tomas Kral and Suraj Deshmukh from Red Hat, and Janet Kuo from Google. Together with our own lead kompose developer Nguyen An-Tu they are making kompose even more exciting. We proposed Kompose to the Kubernetes Incubator within the SIG-apps and we received approval from the general Kubernetes community; you can now find kompose in the Kubernetes Incubator.
Kompose now supports Docker-compose v2 format, persistent volume claims have been added recently, as well as multiple container per pods. It can also be used to target OpenShift deployments, by specifying a different provider than the default Kubernetes. Kompose is also now available in Fedora packages and we look forward to see it in CentOS distributions in the coming weeks.
kompose is a single Golang binary that you build or install from the release on GitHub. Let’s skip the build instructions and dive straight into an example.
Let's take it for a spin!
Guestbook application with Docker
The Guestbook application has become the canonical example for Kubernetes. In Docker-compose format, the guestbook can be started with this minimal file:
version: "2"
services:
redis-master:
image: gcr.io/google\_containers/redis:e2e
ports:
- "6379"
redis-slave:
image: gcr.io/google\_samples/gb-redisslave:v1
ports:
- "6379"
environment:
- GET\_HOSTS\_FROM=dns
frontend:
image: gcr.io/google-samples/gb-frontend:v4
ports:
- "80:80"
environment:
- GET\_HOSTS\_FROM=dns
It consists of three services. A redis-master node, a set of redis-slave that can be scaled and find the redis-master via its DNS name. And a PHP frontend that exposes itself on port 80. The resulting application allows you to leave short messages which are stored in the redis cluster.
To get it started with docker-compose on a vanilla Docker host do:
$ docker-compose -f docker-guestbook.yml up -d
Creating network "examples\_default" with the default driver
Creating examples\_redis-slave\_1
Creating examples\_frontend\_1
Creating examples\_redis-master\_1
So far so good, this is plain Docker usage. Now let’s see how to get this on Kubernetes without having to re-write anything.
Guestbook with 'kompose'
Kompose currently has three main commands up, down and convert. Here for simplicity we will show a single usage to bring up the Guestbook application.
Similarly to docker-compose, we can use the kompose up command pointing to the Docker-compose file representing the Guestbook application. Like so:
$ kompose -f ./examples/docker-guestbook.yml up
We are going to create Kubernetes deployment and service for your dockerized application.
If you need more kind of controllers, use 'kompose convert' and 'kubectl create -f' instead.
INFO[0000] Successfully created service: redis-master
INFO[0000] Successfully created service: redis-slave
INFO[0000] Successfully created service: frontend
INFO[0000] Successfully created deployment: redis-master
INFO[0000] Successfully created deployment: redis-slave
INFO[0000] Successfully created deployment: frontend
Application has been deployed to Kubernetes. You can run 'kubectl get deployment,svc' for details.
kompose automatically converted the Docker-compose file into Kubernetes objects. By default, it created one deployment and one service per compose services. In addition it automatically detected your current Kubernetes endpoint and created the resources onto it. A set of flags can be used to generate Replication Controllers, Replica Sets or Daemon Sets instead of Deployments.
And that's it! Nothing else to do, the conversion happened automatically.
Now, if you already now Kubernetes a bit, you’re familiar with the client kubectl and you can check what was created on your cluster.
$ kubectl get pods,svc,deployments
NAME READY STATUS RESTARTS AGE
frontend-3780173733-0ayyx 1/1 Running 0 1m
redis-master-3028862641-8miqn 1/1 Running 0 1m
redis-slave-3788432149-t3ejp 1/1 Running 0 1m
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend 10.0.0.34 \<none\> 80/TCP 1m
redis-master 10.0.0.219 \<none\> 6379/TCP 1m
redis-slave 10.0.0.84 \<none\> 6379/TCP 1m
NAME DESIRED CURRENT UP-TO-DATE
AVAILABLE AGE
frontend 1 1 1 1 1m
redis-master 1 1 1 1 1m
redis-slave 1 1 1 1 1m
Indeed you see the three services, the three deployments and the resulting three pods. To access the application quickly, access the frontend service locally and enjoy the Guestbook application, but this time started from a Docker-compose file.

Hopefully this gave you a quick tour of kompose and got you excited. They are more exciting features, like creating different type of resources, creating Helm charts and even using the experimental Docker bundle format as input. Check Lachlan Evenson’s blog on using a Docker bundle with Kubernetes. For an overall demo, see our talk from KubeCon
Head over to the Kubernetes Incubator and check out kompose, it will help you move easily from your Docker compose applications to Kubernetes clusters in production.
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Kubernetes Containers Logging and Monitoring with Sematext
Editor's note: Today’s post is by Stefan Thies, Developer Evangelist, at Sematext, showing key Kubernetes metrics and log elements to help you troubleshoot and tune Docker and Kubernetes.
Managing microservices in containers is typically done with Cluster Managers and Orchestration tools. Each container platform has a slightly different set of options to deploy containers or schedule tasks on each cluster node. Because we do container monitoring and logging at Sematext, part of our job is to share our knowledge of these tools, especially as it pertains to container observability and devops. Today we’ll show a tutorial for Container Monitoring and Log Collection on Kubernetes.
Dynamic Deployments Require Dynamic Monitoring
The high level of automation for the container and microservice lifecycle makes the monitoring of Kubernetes more challenging than in more traditional, more static deployments. Any static setup to monitor specific application containers would not work because Kubernetes makes its own decisions according to the defined deployment rules. It is not only the deployed microservices that need to be monitored. It is equally important to watch metrics and logs for Kubernetes core services themselves, such as Kubernetes Master running etcd, controller-manager, scheduler and apiserver and Kubernetes Workers (fka minions) running kubelet and proxy service. Having a centralized place to keep an eye on all these services, their metrics and logs helps one spot problems in the cluster infrastructure. Kubernetes core services could be installed on bare metal, in virtual machines or as containers using Docker. Deploying Kubernetes core services in containers could be helpful with deployment and monitoring operations - tools for container monitoring would cover both core services and application containers. So how does one monitor such a complex and dynamic environment?
Agent for Kubernetes Metrics and Logs
There are a number of open source docker monitoring and logging projects one can cobble together to build a monitoring and log collection system (or systems). The advantage is that the code is all free. The downside is that this takes times - both initially when setting it up and later when maintaining. That’s why we built Sematext Docker Agent - a modern, Docker-aware metrics, events, and log collection agent. It runs as a tiny container on every Docker host and collects logs, metrics and events for all cluster nodes and all containers. It discovers all containers (one pod might contain multiple containers) including containers for Kubernetes core services, if core services are deployed in Docker containers. Let’s see how to deploy this agent.
**Deploying Agent to all Kubernetes Nodes **
Kubernetes provides DaemonSets, which ensure pods are added to nodes as nodes are added to the cluster. We can use this to easily deploy Sematext Agent to each cluster node!
Configure Sematext Docker Agent for Kubernetes
Let’s assume you’ve created an SPM app for your Kubernetes metrics and events, and a Logsene app for your Kubernetes logs, each of which comes with its own token. The Sematext Docker Agent README lists all configurations (e.g. filter for specific pods/images/containers), but we’ll keep it simple here.
- Grab the latest sematext-agent-daemonset.yml (raw plain-text) template (also shown below)
- Save it somewhere on disk
- Replace the SPM_TOKEN and LOGSENE_TOKEN placeholders with your SPM and Logsene App tokens
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: sematext-agent
spec:
template:
metadata:
labels:
app: sematext-agent
spec:
selector: {}
dnsPolicy: "ClusterFirst"
restartPolicy: "Always"
containers:
- name: sematext-agent
image: sematext/sematext-agent-docker:latest
imagePullPolicy: "Always"
env:
- name: SPM\_TOKEN
value: "REPLACE THIS WITH YOUR SPM TOKEN"
- name: LOGSENE\_TOKEN
value: "REPLACE THIS WITH YOUR LOGSENE TOKEN"
- name: KUBERNETES
value: "1"
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock
- mountPath: /etc/localtime
name: localtime
volumes:
- name: docker-sock
hostPath:
path: /var/run/docker.sock
- name: localtime
hostPath:
path: /etc/localtime
Run Agent as DaemonSet
Activate Sematext Agent Docker with kubectl:
\> kubectl create -f sematext-agent-daemonset.yml
daemonset "sematext-agent-daemonset" created
Now let’s check if the agent got deployed to all nodes:
\> kubectl get pods
NAME READY STATUS RESTARTS AGE
sematext-agent-nh4ez 0/1 ContainerCreating 0 6s
sematext-agent-s47vz 0/1 ImageNotReady 0 6s
The status “ImageNotReady” or “ContainerCreating” might be visible for a short time because Kubernetes must download the image for sematext/sematext-agent-docker first. The setting imagePullPolicy: "Always" specified in sematext-agent-daemonset.yml makes sure that Sematext Agent gets updated automatically using the image from Docker-Hub.
If we check again we’ll see Sematext Docker Agent got deployed to (all) cluster nodes:
\> kubectl get pods -l sematext-agent
NAME READY STATUS RESTARTS AGE
sematext-agent-nh4ez 1/1 Running 0 8s
sematext-agent-s47vz 1/1 Running 0 8s
Less than a minute after the deployment you should see your Kubernetes metrics and logs! Below are screenshots of various out of the box reports and explanations of various metrics’ meanings.
Interpretation of Kubernetes Metrics
The metrics from all Kubernetes nodes are collected in a single SPM App, which aggregates metrics on several levels:
- Cluster - metrics aggregated over all nodes displayed in SPM overview
- Host / node level - metrics aggregated per node
- Docker Image level - metrics aggregated by image name, e.g. all nginx webserver containers
- Docker Container level - metrics aggregated for a single container
| 
Each detailed chart has filter options for Node, Docker Image, and Docker Container. As Kubernetes uses the pod name in the name of the Docker Containers a search by pod name in the Docker Container filter makes it easy to select all containers for a specific pod.
Let’s have a look at a few Kubernetes (and Docker) key metrics provided by SPM.
Host Metrics such as CPU, Memory and Disk space usage. Docker images and containers consume more disk space than regular processes installed on a host. For example, an application image might include a Linux operating system and might have a size of 150-700 MB depending on the size of the base image and installed tools in the container. Data containers consume disk space on the host as well. In our experience watching the disk space and using cleanup tools is essential for continuous operations of Docker hosts.

Container count - represents the number of running containers per host
| 
Container Memory and Memory Fail Counters. These metrics are important to watch and very important to tune applications. Memory limits should fit the footprint of the deployed pod (application) to avoid situations where Kubernetes uses default limits (e.g. defined for a namespace), which could lead to OOM kills of containers. Memory fail counters reflect the number of failed memory allocations in a container, and in case of OOM kills a Docker Event is triggered. This event is then displayed in SPM because Sematext Docker Agents collects all Docker Events. The best practice is to tune memory setting in a few iterations:
- Monitor memory usage of the application container
- Set memory limits according to the observations
- Continue monitoring of memory, memory fail counters, and Out-Of-Memory events. If OOM events happen, the container memory limits may need to be increased, or debugging is required to find the reason for the high memory consumptions.
| 
Container CPU usage and throttled CPU time. The CPU usage can be limited by CPU shares - unlike memory, CPU usage it is not a hard limit. Containers might use more CPU as long the resource is available, but in situations where other containers need the CPU limits apply and the CPU gets throttled to the limit.

There are more docker metrics to watch, like disk I/O throughput, network throughput and network errors for containers, but let’s continue by looking at Kubernetes Logs next.
Understand Kubernetes Logs
Kubernetes containers’ logs are not much different from Docker container logs. However, Kubernetes users need to view logs for the deployed pods. That’s why it is very useful to have Kubernetes-specific information available for log search, such as:
- Kubernetes name space
- Kubernetes pod name
- Kubernetes container name
- Docker image name
- Kubernetes UID
Sematext Docker Agent extracts this information from the Docker container names and tags all logs with the information mentioned above. Having these data extracted in individual fields makes it is very easy to watch logs of deployed pods, build reports from logs, quickly narrow down to problematic pods while troubleshooting, and so on! If Kubernetes core components (such as kubelet, proxy, api server) are deployed via Docker the Sematext Docker Agent will collect Kubernetes core components logs as well.
| 
There are many other useful features Logsene and Sematext Docker Agent give you out of the box, such as:
-
Automatic format detection and parsing of logs
- Sematext Docker Agent includes patterns to recognize and parse many log formats
-
Custom pattern definitions for specific images and application types
-
Filtering logs e.g. to exclude noisy services
-
Masking of sensitive data in specific log fields (phone numbers, payment information, authentication tokens)
-
Alerts and scheduled reports based on logs
-
Analytics for structured logs e.g. in Kibana or Grafana
Most of those topics are described in our Docker Log Management post and are relevant for Kubernetes log management as well. If you want to learn more about Docker monitoring, read more on our blog.
--Stefan Thies, Developer Evangelist, at Sematext
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Visualize Kubelet Performance with Node Dashboard
Since this article was published, the Node Performance Dashboard was retired and is no longer available.
This retirement happened in early 2019, as part of the kubernetes/contrib
repository deprecation.
In Kubernetes 1.4, we introduced a new node performance analysis tool, called the node performance dashboard, to visualize and explore the behavior of the Kubelet in much richer details. This new feature will make it easy to understand and improve code performance for Kubelet developers, and lets cluster maintainer set configuration according to provided Service Level Objectives (SLOs).
Background
A Kubernetes cluster is made up of both master and worker nodes. The master node manages the cluster’s state, and the worker nodes do the actual work of running and managing pods. To do so, on each worker node, a binary, called Kubelet, watches for any changes in pod configuration, and takes corresponding actions to make sure that containers run successfully. High performance of the Kubelet, such as low latency to converge with new pod configuration and efficient housekeeping with low resource usage, is essential for the entire Kubernetes cluster. To measure this performance, Kubernetes uses end-to-end (e2e) tests to continuously monitor benchmark changes of latest builds with new features.
Kubernetes SLOs are defined by the following benchmarks :
* API responsiveness : 99% of all API calls return in less than 1s.
* Pod startup time : 99% of pods and their containers (with pre-pulled images) start within 5s.
Prior to 1.4 release, we’ve only measured and defined these at the cluster level, opening up the risk that other factors could influence the results. Beyond these, we also want to have more performance related SLOs such as the maximum number of pods for a specific machine type allowing maximum utilization of your cluster. In order to do the measurement correctly, we want to introduce a set of tests isolated to just a node’s performance. In addition, we aim to collect more fine-grained resource usage and operation tracing data of Kubelet from the new tests.
Data Collection
The node specific density and resource usage tests are now added into e2e-node test set since 1.4. The resource usage is measured by a standalone cAdvisor pod for flexible monitoring interval (comparing with Kubelet integrated cAdvisor). The performance data, such as latency and resource usage percentile, are recorded in persistent test result logs. The tests also record time series data such as creation time, running time of pods, as well as real-time resource usage. Tracing data of Kubelet operations are recorded in its log stored together with test results.
Node Performance Dashboard
Since Kubernetes 1.4, we are continuously building the newest Kubelet code and running node performance tests. The data is collected by our new performance dashboard available at node-perf-dash.k8s.io. Figure 1 gives a preview of the dashboard. You can start to explore it by selecting a test, either using the drop-down list of short test names (region (a)) or by choosing test options one by one (region (b)). The test details show up in region (c) containing the full test name from Ginkgo (the Go test framework used by Kubernetes). Then select a node type (image and machine) in region (d).
| 
The "BUILDS" page exhibits the performance data across different builds (Figure 2). The plots include pod startup latency, pod creation throughput, and CPU/memory usage of Kubelet and runtime (currently Docker). In this way it’s easy to monitor the performance change over time as new features are checked in.
| 
Compare Different Node Configurations
It’s always interesting to compare the performance between different configurations, such as comparing startup latency of different machine types, different numbers of pods, or comparing resource usage of hosting different number of pods. The dashboard provides a convenient way to do this. Just click the "Compare it" button the right up corner of test selection menu (region (e) in Figure 1). The selected tests will be added to a comparison list in the "COMPARISON" page, as shown in Figure 3. Data across a series of builds are aggregated to a single value to facilitate comparison and are displayed in bar charts.
| 
Time Series and Tracing: Diving Into Performance Data
Pod startup latency is an important metric for Kubelet, especially when creating a large number of pods per node. Using the dashboard you can see the change of latency, for example, when creating 105 pods, as shown in Figure 4. When you see the highly variable lines, you might expect that the variance is due to different builds. However, as these test here were run against the same Kubernetes code, we can conclude the variance is due to performance fluctuation. The variance is close to 40s when we compare the 99% latency of build #162 and #173, which is very large. To drill into the source of the fluctuation, let’s check out the "TIME SERIES" page.
| 
Looking specifically at build #162, we are able to see that the tracing data plotted in the pod creation latency chart (Figure 5). Each curve is an accumulated histogram of the number of pod operations which have already arrive at a certain tracing probe. The timestamp of tracing pod is either collected from the performance tests or by parsing the Kubelet log. Currently we collect the following tracing data:
- "create" (in test): the test creates pods through API client;
- "running" (in test): the test watches that pods are running from API server;
- "pod_config_change": pod config change detected by Kubelet SyncLoop;
- "runtime_manager": runtime manager starts to create containers;
- "infra_container_start": the infra container of a pod starts;
- "container_start': the container of a pod starts;
- "pod_running": a pod is running;
- "pod_status_running": status manager updates status for a running pod;
The time series chart illustrates that it is taking a long time for the status manager to update pod status (the data of "running" is not shown since it overlaps with "pod_status_running"). We figure out this latency is introduced due to the query per second (QPS) limits of Kubelet to the API server (default is 5). After being aware of this, we find in additional tests that by increasing QPS limits, curve "running" gradually converges with "pod_running', and results in much lower latency. Therefore the previous e2e test pod startup results reflect the combined latency of both Kubelet and time of uploading status, the performance of Kubelet is thus under-estimated.
| 
Further, by comparing the time series data of build #162 (Figure 5) and build #173 (Figure 6), we find that the performance pod startup latency fluctuation actually happens during updating pod statuses. Build #162 has several straggler "pod_status_running" events with a long latency tails. It thus provides useful ideas for future optimization.
| 
In future we plan to use events in Kubernetes which has a fixed log format to collect tracing data more conveniently. Instead of extracting existing log entries, then you can insert your own tracing probes inside Kubelet and obtain the break-down latency of each segment.
You can check the latency between any two probes across different builds in the “TRACING” page, as shown in Figure 7. For example, by selecting "pod_config_change" as the start probe, and "pod_status_running' as the end probe, it gives the latency variance of Kubelet over continuous builds without status updating overhead. With this feature, developers are able to monitor the performance change of a specific part of code inside Kubelet.
| 
Future Work
The node performance dashboard is a brand new feature. It is still alpha version under active development. We will keep optimizing the data collecting and visualization, providing more tests, metrics and tools to the developers and the cluster maintainers.
Please join our community and help us build the future of Kubernetes! If you’re particularly interested in nodes or performance testing, participate by chatting with us in our Slack channel or join our meeting which meets every Tuesday at 10 AM PT on this SIG-Node Hangout.
--Zhou Fang, Software Engineering Intern, Google
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
CNCF Partners With The Linux Foundation To Launch New Kubernetes Certification, Training and Managed Service Provider Program
Today the CNCF is pleased to launch a new training, certification and Kubernetes Managed Service Provider (KMSP) program.
The goal of the program is to ensure enterprises get the support they’re looking for to get up to speed and roll out new applications more quickly and more efficiently. The Linux Foundation, in partnership with CNCF, will develop and operate the Kubernetes training and certification.
Interested in this course? Sign up here to pre-register. The course, expected to be available in early 2017, is open now at the discounted price of $99 (regularly $199) for a limited time, and the certification program is expected to be available in the second quarter of 2017.
The KMSP program is a pre-qualified tier of highly vetted service providers who have deep experience helping enterprises successfully adopt Kubernetes. The KMSP partners offer SLA-backed Kubernetes support, consulting, professional services and training for organizations embarking on their Kubernetes journey. In contrast to the Kubernetes Service Partners program outlined recently in this blog, to become a Kubernetes Managed Service Provider the following additional requirements must be met: three or more certified engineers, an active contributor to Kubernetes, and a business model to support enterprise end users.
As part of the program, a new CNCF Certification Working Group is starting up now. The group will help define the program's open source curriculum, which will be available under the Creative Commons By Attribution 4.0 International license for anyone to use. Any Kubernetes expert can join the working group via this link. Google has committed to assist, and many others, including Apprenda, Container Solutions, CoreOS, Deis and Samsung SDS, have expressed interest in participating in the Working Group.
To learn more about the new program and the first round of KMSP partners that we expect to grow weekly, check out today's announcement here.
Bringing Kubernetes Support to Azure Container Service
Editor's note: Today’s post is by Brendan Burns, Partner Architect, at Microsoft & Kubernetes co-founder talking about bringing Kubernetes to Azure Container Service.
With more than a thousand people coming to KubeCon in my hometown of Seattle, nearly three years after I helped start the Kubernetes project, it’s amazing and humbling to see what a small group of people and a radical idea have become after three years of hard work from a large and growing community. In July of 2014, scarcely a month after Kubernetes became publicly available, Microsoft announced its initial support for Azure. The release of Kubernetes 1.4, brought support for native Microsoft networking, load-balancer and disk integration.
Today, Microsoft announced the next step in Kubernetes on Azure: the introduction of Kubernetes as a supported orchestrator in Azure Container Service (ACS). It’s been really exciting for me to join the ACS team and help build this new addition. The integration of Kubernetes into ACS means that with a few clicks in the Azure portal, or by running a single command in the new python-based Azure command line tool, you will be able to create a fully functional Kubernetes cluster that is integrated with the rest of your Azure resources.
Kubernetes is available in public preview in Azure Container Service today. Community participation has always been an important part of the Kubernetes experience. Over the next few months, I hope you’ll join us and provide your feedback on the experience as we bring it to general availability.
In the spirit of community, we are also excited to announce a new open source project: ACS Engine. The goal of ACS Engine is to provide an open, community driven location to develop and share best practices for orchestrating containers on Azure. All of our knowledge of running containers in Azure has been captured in that repository, and we look forward to improving and extending it as we move forward with the community. Going forward, the templates in ACS Engine will be the basis for clusters deployed via the ACS API, and thus community driven improvements, features and more will have a natural path into the Azure Container Service. We’re excited to invite you to join us in improving ACS. Prior to the creation of ACS Engine, customers with unique requirements not supported by the ACS API needed to maintain variations on our templates. While these differences start small, they grew larger over time as the mainline template was improved and users also iterated their templates. These differences and drift really impact the ability for users to collaborate, since their templates are all different. Without the ability to share and collaborate, it’s difficult to form a community since every user is siloed in their own variant.
To solve this problem, the core of ACS Engine is a template processor, built in Go, that enables you to dynamically combine different pieces of configuration together to form a final template that can be used to build up your cluster. Thus, each user can mix and match the pieces build the final container cluster that suits their needs. At the same time, each piece can be built and maintained collaboratively by the community. We’ve been beta testing this approach with some customers and the feedback we’ve gotten so far has been really positive.
Beyond services to help you run containers on Azure, I think it’s incredibly important to improve the experience of developing and deploying containerized applications to Kubernetes. To that end, I’ve been doing a bunch of work lately to build a Kubernetes extension for the really excellent, open source, Visual Studio Code. The Kubernetes extension enables you to quickly deploy JSON or YAML files you are editing onto a Kubernetes cluster. Additionally, it enables you to import existing Kubernetes objects into Code for easy editing. Finally, it enables synchronization between your running containers and the source code that you are developing for easy debugging of issues you are facing in production.
But really, a demo is worth a thousand words, so please have a look at this video:
Of course, like everything else in Kubernetes it’s released as open source, and I look forward to working on it further with the community. Thanks again, I look forward to seeing everyone at the OpenShift Gathering today, as well as at the Microsoft Azure booth during KubeCon tomorrow and Wednesday. Welcome to Seattle!
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Modernizing the Skytap Cloud Micro-Service Architecture with Kubernetes
Editor's note: Today’s guest post is by the Tools and Infrastructure Engineering team at Skytap, a public cloud provider focused on empowering DevOps workflows, sharing their experience on adopting Kubernetes.
Skytap is a global public cloud that provides our customers the ability to save and clone complex virtualized environments in any given state. Our customers include enterprise organizations running applications in a hybrid cloud, educational organizations providing virtual training labs, users who need easy-to-maintain development and test labs, and a variety of organizations with diverse DevOps workflows.
Some time ago, we started growing our business at an accelerated pace — our user base and our engineering organization continue to grow simultaneously. These are exciting, rewarding challenges! However, it's difficult to scale applications and organizations smoothly, and we’re approaching the task carefully. When we first began looking at improvements to scale our toolset, it was very clear that traditional OS virtualization was not going to be an effective way to achieve our scaling goals. We found that the persistent nature of VMs encouraged engineers to build and maintain bespoke ‘pet’ VMs; this did not align well with our desire to build reusable runtime environments with a stable, predictable state. Fortuitously, growth in the Docker and Kubernetes communities has aligned with our growth, and the concurrent explosion in community engagement has (from our perspective) helped these tools mature.
In this article we’ll explore how Skytap uses Kubernetes as a key component in services that handle production workloads growing the Skytap Cloud.
As we add engineers, we want to maintain our agility and continue enabling ownership of components throughout the software development lifecycle. This requires a lot of modularization and consistency in key aspects of our process. Previously, we drove reuse with systems-level packaging through our VM and environment templates, but as we scale, containers have become increasingly important as a packaging mechanism due to their comparatively lightweight and precise control of the runtime environment.
In addition to this packaging flexibility, containers help us establish more efficient resource utilization, and they head off growing complexity arising from the natural inclination of teams to mix resources into large, highly-specialized VMs. For example, our operations team would install tools for monitoring health and resource utilization, a development team would deploy a service, and the security team might install traffic monitoring; combining all of that into a single VM greatly increases the test burden and often results in surprises—oops, you pulled in a new system-level Ruby gem!
Containerization of individual components in a service is pretty trivial with Docker. Getting started is easy, but as anyone who has built a distributed system with more than a handful of components knows, the real difficulties are deployment, scaling, availability, consistency, and communication between each unit in the cluster.
Let’s containerize!
We’d begun to trade a lot of our heavily-loved pet VMs for, as the saying goes, cattle.
_____
/ Moo \
\---- /
\ ^__^
\ (oo)\_______
(__)\ )\/\
||-----w |
|| ||
The challenges of distributed systems aren’t simplified by creating a large herd of free-range containers, though. When we started using containers, we recognized the need for a container management framework. We evaluated Docker Swarm, Mesosphere, and Kubernetes, but we found that the Mesosphere usage model didn’t match our needs — we need the ability to manage discrete VMs; this doesn’t match the Mesosphere ‘distributed operating system’ model — and Docker Swarm was still not mature enough. So, we selected Kubernetes.
Launching Kubernetes and building a new distributed service is relatively easy (inasmuch as this can be said for such a service: you can’t beat CAP theorem). However, we need to integrate container management with our existing platform and infrastructure. Some components of the platform are better served by VMs, and we need the ability to containerize services iteratively.
We broke this integration problem down into four categories:
- 1.Service control and deployment
- 2.Inter-service communication
- 3.Infrastructure integration
- 4.Engineering support and education
Service Control and Deployment
We use a custom extension of Capistrano (we call it ‘Skycap’) to deploy services and manage those services at runtime. It is important for us to manage both containerized and classic services through a single, well-established framework. We also need to isolate Skycap from the inevitable breaking changes inherent in an actively-developed tool like Kubernetes.
To handle this, we use wrappers in to our service control framework that isolate kubectl behind Skycap and handle issues like ignoring spurious log messages.
Deployment adds a layer of complexity for us. Docker images are a great way to package software, but historically, we’ve deployed from source, not packages. Our engineering team expects that making changes to source is sufficient to get their work released; devs don’t expect to handle additional packaging steps. Rather than rebuild our entire deployment and orchestration framework for the sake of containerization, we use a continuous integration pipeline for our containerized services. We automatically build a new Docker image for every commit to a project, and then we tag it with the Mercurial (Hg) changeset number of that commit. On the Skycap side, a deployment from a specific Hg revision will then pull the Docker images that are tagged with that same revision number.
We reuse container images across multiple environments. This requires environment-specific configuration to be injected into each container instance. Until recently, we used similar source-based principles to inject these configuration values: each container would copy relevant configuration files from Hg by cURL-ing raw files from the repo at run time. Network availability and variability are a challenge best avoided, though, so we now load the configuration into Kubernetes’ ConfigMap feature. This not only simplifies our Docker images, but it also makes pod startup faster and more predictable (because containers don’t have to download files from Hg).
Inter-service communication
Our services communicate using two primary methods. The first, message brokering, is typical for process-to-process communication within the Skytap platform. The second is through direct point-to-point TCP connections, which are typical for services that communicate with the outside world (such as web services). We’ll discuss the TCP method in the next section, as a component of infrastructure integration.
Managing direct connections between pods in a way that services can understand is complicated. Additionally, our containerized services need to communicate with classic VM-based services. To mitigate this complexity, we primarily use our existing message queueing system. This helped us avoid writing a TCP-based service discovery and load balancing system for handling traffic between pods and non-Kubernetes services.
This reduces our configuration load—services only need to know how to talk to the message queues, rather than to every other service they need to interact with. We have additional flexibility for things like managing the run-state of pods; messages buffer in the queue while nodes are restarting, and we avoid the overhead of re-configuring TCP endpoints each time a pod is added or removed from the cluster. Furthermore, the MQ model allows us to manage load balancing with a more accurate ‘pull’ based approach, in which recipients determine when they are ready to process a new message, instead of using heuristics like ‘least connections’ that simply count the number of open sockets to estimate load.
Migrating MQ-enabled services to Kubernetes is relatively straightforward compared to migrating services that use the complex TCP-based direct or load balanced connections. Additionally, the isolation provided by the message broker means that the switchover from a classic service to a container-based service is essentially transparent to any other MQ-enabled service.
Infrastructure Integration
As an infrastructure provider, we face some unique challenges in configuring Kubernetes for use with our platform. AWS & GCP provide out-of-box solutions that simplify Kubernetes provisioning but make assumptions about the underlying infrastructure that do not match our reality. Some organizations have purpose-built data centers. This option would have required us to abandon our existing load balancing infrastructure, our Puppet based provisioning system and the expertise we’d built up around these tools. We weren’t interested in abandoning the tools or our vested experience, so we needed a way to manage Kubernetes that could integrate with our world instead of rebuild it.
So, we use Puppet to provision and configure VMs that, in turn, run the Skytap Platform. We wrote custom deployment scripts to install Kubernetes on these, and we coordinate with our operations team to do capacity planning for Kube-master and Kube-node hosts.
In the previous section, we mentioned point-to-point TCP-based communication. For customer-facing services, the pods need a way to interface with Skytap’s layer 3 network infrastructure. Examples at Skytap include our web applications and API over HTTPS, Remote Desktop over Web Sockets, FTP, TCP/UDP port forwarding services, full public IPs, etc. We need careful management of network ingress and egress for this external traffic, and have historically used F5 load balancers. The MQ infrastructure for internal services is inadequate for handling this workload because the protocols used by various clients (like web browsers) are very specific and TCP is the lowest common denominator.
To get our load balancers communicating with our Kubernetes pods, we run the kube-proxy on each node. Load balancers route to the node, and kube-proxy handles the final handoff to the appropriate pod.
We mustn’t forget that Kubernetes needs to route traffic between pods (for both TCP-based and MQ-based messaging). We use the Calico plugin for Kubernetes networking, with a specialized service to reconfigure the F5 when Kubernetes launches or reaps pods. Calico handles route advertisement with BGP, which eases integration with the F5.
F5s also need to have their load balancing pool reconfigured when pods enter or leave the cluster. The F5 appliance maintains a pool of load-balanced back-ends; ingress to a containerized service is directed through this pool to one of the nodes hosting a service pod. This is straightforward for static network configurations – but since we're using Kubernetes to manage pod replication and availability, our networking situation becomes dynamic. To handle changes, we have a 'load balancer' pod that monitors the Kubernetes svc object for changes; if a pod is removed or added, the ‘load balancer’ pod will detect this change through the svc object, and then update the F5 configuration through the appliance's web API. This way, Kubernetes transparently handles replication and failover/recovery, and the dynamic load balancer configuration lets this process remain invisible to the service or user who originated the request. Similarly, the combination of the Calico virtual network plus the F5 load balancer means that TCP connections should behave consistently for services that are running on both the traditional VM infrastructure, or that have been migrated to containers.

With dynamic reconfiguration of the network, the replication mechanics of Kubernetes make horizontal scaling and (most) failover/recovery very straightforward. We haven’t yet reached the reactive scaling milestone, but we've laid the groundwork with the Kubernetes and Calico infrastructure, making one avenue to implement it straightforward:
- Configure upper and lower bounds for service replication
- Build a load analysis and scaling service (easy, right?)
- If load patterns match the configured triggers in the scaling service (for example, request rate or volume above certain bounds), issue: kubectl scale --replicas=COUNT rc NAME
This would allow us fine-grained control of autoscaling at the platform level, instead of from the applications themselves – but we’ll also evaluate Horizontal Pod Autoscaling in Kubernetes; which may suit our need without a custom service.
Keep an eye on our GitHub account and the Skytap blog; as our solutions to problems like these mature, we hope to share what we’ve built with the open source community.
Engineering Support
A transition like our containerization project requires the engineers involved in maintaining and contributing to the platform change their workflow and learn new methods for creating and troubleshooting services.
Because a variety of learning styles require a multi-faceted approach, we handle this in three ways: with documentation, with direct outreach to engineers (that is, brownbag sessions or coaching teams), and by offering easy-to-access, ad-hoc support.
We continue to curate a collection of documents that provide guidance on transitioning classic services to Kubernetes, creating new services, and operating containerized services. Documentation isn’t for everyone, and sometimes it’s missing or incomplete despite our best efforts, so we also run an internal #kube-help Slack channel, where anyone can stop in for assistance or arrange a more in-depth face-to-face discussion.
We have one more powerful support tool: we automatically construct and test prod-like environments that include this Kubernetes infrastructure, which allows engineers a lot of freedom to experiment and work with Kubernetes hands-on. We explore the details of automated environment delivery in more detail in this post.
Final Thoughts
We’ve had great success with Kubernetes and containerization in general, but we’ve certainly found that integrating with an existing full-stack environment has presented many challenges. While not exactly plug-and-play from an enterprise lifecycle standpoint, the flexibility and configurability of Kubernetes still remains a very powerful tool for building our modularized service ecosystem.
We love application modernization challenges. The Skytap platform is well suited for these sorts of migration efforts – we run Skytap in Skytap, of course, which helped us tremendously in our Kubernetes integration project. If you’re planning modernization efforts of your own, connect with us, we’re happy to help.
--Shawn Falkner-Horine and Joe Burchett, Tools and Infrastructure Engineering, Skytap
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Introducing Kubernetes Service Partners program and a redesigned Partners page
Kubernetes has become a leading container orchestration system by being a powerful and flexible way to run distributed systems at scale. Through our very active open source community, equating to hundreds of person years of work, Kubernetes achieved four major releases in just one year to become a critical part of thousands of companies infrastructures. However, even with all that momentum, adopting cloud native computing is a significant transition for many organizations. It can be challenging to adopt a new methodology, and many teams are looking for advice and support through that journey.
Today, we’re excited to launch the Kubernetes Service Partners program. A Service Partner is a company that provides support and consulting for customers building applications on Kubernetes. This program is an addition to our existing Kubernetes Technology Partners who provide software and offer support services for their software.
The Service Partners provide hands-on best practice guidance for running your apps on Kubernetes, and are available to work with companies of all sizes to get started; the first batch of participants includes: Apprenda, Container Solutions, Deis, Livewyer, ReactiveOps and Samsung SDS. You’ll find their listings along with our existing Technology Partners on the newly redesigned Partners Page, giving you a single view into the Kubernetes ecosystem.
The list of partners will grow weekly, and we look forward to collaborating with the community to build a vibrant Kubernetes ecosystem.
--Allan Naim, Product Manager, Google, on behalf of the Kubernetes team.
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Tail Kubernetes with Stern
Editor’s note: today’s post is by Antti Kupila, Software Engineer, at Wercker, about building a tool to tail multiple pods and containers on Kubernetes.
We love Kubernetes here at Wercker and build all our infrastructure on top of it. When deploying anything you need to have good visibility to what's going on and logs are a first view into the inner workings of your application. Good old tail -f has been around for a long time and Kubernetes has this too, built right into kubectl.
I should say that tail is by no means the tool to use for debugging issues but instead you should feed the logs into a more persistent place, such as Elasticsearch. However, there's still a place for tail where you need to quickly debug something or perhaps you don't have persistent logging set up yet (such as when developing an app in Minikube).
Multiple Pods
Kubernetes has the concept of Replication Controllers which ensure that n pods are running at the same time. This allows rolling updates and redundancy. Considering they're quite easy to set up there's really no reason not to do so.
However now there are multiple pods running and they all have a unique id. One issue here is that you'll need to know the exact pod id (kubectl get pods) but that changes every time a pod is created so you'll need to do this every time. Another consideration is the fact that Kubernetes load balances the traffic so you won't know at which pod the request ends up at. If you're tailing pod A but the traffic ends up at pod B you'll miss what happened.
Let's say we have a pod called service with 3 replicas. Here's what that would look like:
$ kubectl get pods # get pods to find pod ids
$ kubectl log -f service-1786497219-2rbt1 # pod 1
$ kubectl log -f service-1786497219-8kfbp # pod 2
$ kubectl log -f service-1786497219-lttxd # pod 3
Multiple containers
We're heavy users gRPC for internal services and expose the gRPC endpoints over REST using gRPC Gateway. Typically we have server and gateway living as two containers in the same pod (same binary that sets the mode by a cli flag). The gateway talks to the server in the same pod and both ports are exposed to Kubernetes. For internal services we can talk directly to the gRPC endpoint while our website communicates using standard REST to the gateway.
This poses a problem though; not only do we now have multiple pods but we also have multiple containers within the pod. When this is the case the built-in logging of kubectl requires you to specify which containers you want logs from.
If we have 3 replicas of a pod and 2 containers in the pod you'll need 6 kubectl log -f <pod id> <container id>. We work with big monitors but this quickly gets out of hand…
If our service pod has a server and gateway container we'd be looking at something like this:
$ kubectl get pods # get pods to find pod ids
$ kubectl describe pod service-1786497219-2rbt1 # get containers in pod
$ kubectl log -f service-1786497219-2rbt1 server # pod 1
$ kubectl log -f service-1786497219-2rbt1 gateway # pod 1
$ kubectl log -f service-1786497219-8kfbp server # pod 2
$ kubectl log -f service-1786497219-8kfbp gateway # pod 2
$ kubectl log -f service-1786497219-lttxd server # pod 3
$ kubectl log -f service-1786497219-lttxd gateway # pod 3
Stern
To get around this we built Stern. It's a super simple utility that allows you to specify both the pod id and the container id as regular expressions. Any match will be followed and the output is multiplexed together, prefixed with the pod and container id, and color-coded for human consumption (colors are stripped if piping to a file).
Here's how the service example would look:
$ stern service
This will match any pod containing the word service and listen to all containers within it. If you only want to see traffic to the server container you could do stern --container server service and it'll stream the logs of all the server containers from the 3 pods.
The output would look something like this:
$ stern service
+ service-1786497219-2rbt1 › server
+ service-1786497219-2rbt1 › gateway
+ service-1786497219-8kfbp › server
+ service-1786497219-8kfbp › gateway
+ service-1786497219-lttxd › server
+ service-1786497219-lttxd › gateway
+ service-1786497219-8kfbp server Log message from server
+ service-1786497219-2rbt1 gateway Log message from gateway
+ service-1786497219-8kfbp gateway Log message from gateway
+ service-1786497219-lttxd gateway Log message from gateway
+ service-1786497219-lttxd server Log message from server
+ service-1786497219-2rbt1 server Log message from server
In addition, if a pod is killed and recreated during a deployment Stern will stop listening to the old pod and automatically hook into the new one. There's no more need to figure out what the id of that newly created pod is.
Configuration options
Stern was deliberately designed to be minimal so there's not much to it. However, there are still a couple configuration options we can highlight here. They're very similar to the ones built into kubectl so if you're familiar with that you should feel right at home.
- timestamps adds the timestamp to each line
- since shows log entries since a certain time (for instance --since 15min)
- kube-config allows you to specify another Kubernetes config. Defaults to ~/.kube/config
- namespace allows you to only limit the search to a certain namespaceRun stern --help for all options.
Examples
Tail the gateway container running inside of the envvars pod on staging
+ stern --context staging --container gateway envvars
Show auth activity from 15min ago with timestamps
+ stern -t --since 15m auth
Follow the development of some-new-feature in minikube
+ stern --context minikube some-new-feature
View pods from another namespace
+ stern --namespace kube-system kubernetes-dashboard
Get Stern
Stern is open source and available on GitHub, we'd love your contributions or ideas. If you don't want to build from source you can also download a precompiled binary from GitHub releases.

How We Architected and Run Kubernetes on OpenStack at Scale at Yahoo! JAPAN
Editor’s note: today’s post is by the Infrastructure Engineering team at Yahoo! JAPAN, talking about how they run OpenStack on Kubernetes. This post has been translated and edited for context with permission -- originally published on the Yahoo! JAPAN engineering blog.
Intro
This post outlines how Yahoo! JAPAN, with help from Google and Solinea, built an automation tool chain for “one-click” code deployment to Kubernetes running on OpenStack.
We’ll also cover the basic security, networking, storage, and performance needs to ensure production readiness.
Finally, we will discuss the ecosystem tools used to build the CI/CD pipeline, Kubernetes as a deployment platform on VMs/bare metal, and an overview of Kubernetes architecture to help you architect and deploy your own clusters.
Preface
Since our company started using OpenStack in 2012, our internal environment has changed quickly. Our initial goal of virtualizing hardware was achieved with OpenStack. However, due to the progress of cloud and container technology, we needed the capability to launch services on various platforms. This post will provide our example of taking applications running on OpenStack and porting them to Kubernetes.
Coding Lifecycle
The goal of this project is to create images for all required platforms from one application code, and deploy those images onto each platform. For example, when code is changed at the code registry, bare metal images, Docker containers and VM images are created by CI (continuous integration) tools, pushed into our image registry, then deployed to each infrastructure platform.

We use following products in our CICD pipeline:
| Function | Product |
|---|---|
| Code registry | GitHub Enterprise |
| CI tools | Jenkins |
| Image registry | Artifactory |
| Bug tracking system | JIRA |
| deploying Bare metal platform | OpenStack Ironic |
| deploying VM platform | OpenStack |
| deploying container platform | Kubernetes |
Image Creation. Each image creation workflow is shown in the next diagram.
VM Image Creation :

- 1.push code to GitHub
- 2.hook to Jenkins master
- 3.Launch job at Jenkins slave
- 4.checkout Packer repository
- 5.Run Service Job
- 6.Execute Packer by build script
- 7.Packer start VM for OpenStack Glance
- 8.Configure VM and install required applications
- 9.create snapshot and register to glance 10.10.Download the new created image from Glance 11.11.Upload the image to Artifactory
Bare Metal Image Creation:

- 1.push code to GitHub
- 2.hook to Jenkins master
- 3.Launch job at Jenkins slave
- 4.checkout Packer repository
- 5.Run Service Job
- 6.Download base bare metal image by build script
- 7.build script execute diskimage-builder with Packer to create bare metal image
- 8.Upload new created image to Glance
- 9.Upload the image to Artifactory
Container Image Creation:

- 1.push code to GitHub
- 2.hook to Jenkins master
- 3.Launch job at Jenkins slave
- 4.checkout Dockerfile repository
- 5.Run Service Job
- 6.Download base docker image from Artifactory
- 7.If no docker image found at Artifactory, download from Docker Hub
- 8.Execute docker build and create image
- 9.Upload the image to Artifactory
Platform Architecture.
Let’s focus on the container workflow to walk through how we use Kubernetes as a deployment platform. This platform architecture is as below.

| Function | Product |
|---|---|
| Infrastructure Services | OpenStack |
| Container Host | CentOS |
| Container Cluster Manager | Kubernetes |
| Container Networking | Project Calico |
| Container Engine | Docker |
| Container Registry | Artifactory |
| Service Registry | etcd |
| Source Code Management | GitHub Enterprise |
| CI tool | Jenkins |
| Infrastructure Provisioning | Terraform |
| Logging | Fluentd, Elasticsearch, Kibana |
| Metrics | Heapster, Influxdb, Grafana |
| Service Monitoring | Prometheus |
We use CentOS for Container Host (OpenStack instances) and install Docker, Kubernetes, Calico, etcd and so on. Of course, it is possible to run various container applications on Kubernetes. In fact, we run OpenStack as one of those applications. That's right, OpenStack on Kubernetes on OpenStack. We currently have more than 30 OpenStack clusters, that quickly become hard to manage and operate. As such, we wanted to create a simple, base OpenStack cluster to provide the basic functionality needed for Kubernetes and make our OpenStack environment easier to manage.
Kubernetes Architecture
Let me explain Kubernetes architecture in some more detail. The architecture diagram is below.
|Product |Description | |OpenStack Keystone|Kubernetes Authentication and Authorization | |OpenStack Cinder |External volume used from Pod (grouping of multiple containers) | |kube-apiserver |Configure and validate objects like Pod or Services (definition of access to services in container) through REST API| |kube-scheduler |Allocate Pods to each node | |kube-controller-manager |Execute Status management, manage replication controller | |kubelet |Run on each node as agent and manage Pod | |calico |Enable inter-Pod connection using BGP | |kube-proxy |Configure iptable NAT tables to configure IP and load balance (ClusterIP) | |etcd |Distribute KVS to store Kubernetes and Calico information | |etcd-proxy |Run on each node and transfer client request to etcd clusters|
Tenant Isolation To enable multi-tenant usage like OpenStack, we utilize OpenStack Keystone for authentication and authorization.
Authentication With a Kubernetes plugin, OpenStack Keystone can be used for Authentication. By Adding authURL of Keystone at startup Kubernetes API server, we can use OpenStack OS_USERNAME and OS_PASSWORD for Authentication. Authorization We currently use the ABAC (Attribute-Based Access Control) mode of Kubernetes Authorization. We worked with a consulting company, Solinea, who helped create a utility to convert OpenStack Keystone user and tenant information to Kubernetes JSON policy file that maps Kubernetes ABAC user and namespace information to OpenStack tenants. We then specify that policy file when launching Kubernetes API Server. This utility also creates namespaces from tenant information. These configurations enable Kubernetes to authenticate with OpenStack Keystone and operate in authorized namespaces. Volumes and Data Persistence Kubernetes provides “Persistent Volumes” subsystem which works as persistent storage for Pods. “Persistent Volumes” is capable to support cloud-provider storage, it is possible to utilize OpenStack cinder-volume by using OpenStack as cloud provider. Networking Flannel and various networking exists as networking model for Kubernetes, we used Project Calico for this project. Yahoo! JAPAN recommends to build data center with pure L3 networking like redistribute ARP validation or IP CLOS networking, Project Calico matches this direction. When we apply overlay model like Flannel, we cannot access to Pod IP from outside of Kubernetes clusters. But Project Calico makes it possible. We also use Project Calico for Load Balancing we describe later.
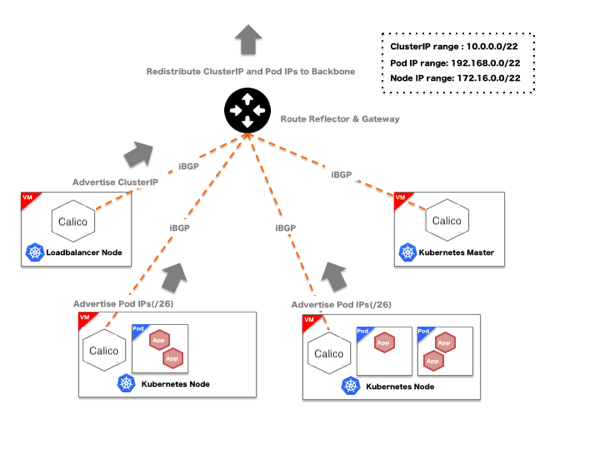
In Project Calico, broadcast production IP by BGP working on BIRD containers (OSS routing software) launched on each nodes of Kubernetes. By default, it broadcast in cluster only. By setting peering routers outside of clusters, it makes it possible to access a Pod from outside of the clusters. External Service Load Balancing
There are multiple choices of external service load balancers (access to services from outside of clusters) for Kubernetes such as NodePort, LoadBalancer and Ingress. We could not find solution which exactly matches our requirements. However, we found a solution that almost matches our requirements by broadcasting Cluster IP used for Internal Service Load Balancing (access to services from inside of clusters) with Project Calico BGP which enable External Load Balancing at Layer 4 from outside of clusters.

Service Discovery
Service Discovery is possible at Kubernetes by using SkyDNS addon. This is provided as cluster internal service, it is accessible in cluster like ClusterIP. By broadcasting ClusterIP by BGP, name resolution works from outside of clusters. By combination of Image creation workflow and Kubernetes, we built the following tool chain which makes it easy from code push to deployment.
Summary
In summary, by combining Image creation workflows and Kubernetes, Yahoo! JAPAN, with help from Google and Solinea, successfully built an automated tool chain which makes it easy to go from code push to deployment, while taking multi-tenancy, authn/authz, storage, networking, service discovery and other necessary factors for production deployment. We hope you found the discussion of ecosystem tools used to build the CI/CD pipeline, Kubernetes as a deployment platform on VMs/bare-metal, and the overview of Kubernetes architecture to help you architect and deploy your own clusters. Thank you to all of the people who helped with this project. --Norifumi Matsuya, Hirotaka Ichikawa, Masaharu Miyamoto and Yuta Kinoshita. This post has been translated and edited for context with permission -- originally published on the Yahoo! JAPAN engineer blog where this was one in a series of posts focused on Kubernetes.
Building Globally Distributed Services using Kubernetes Cluster Federation
Editor's note: Today’s post is by Allan Naim, Product Manager, and Quinton Hoole, Staff Engineer at Google, showing how to deploy a multi-homed service behind a global load balancer and have requests sent to the closest cluster.
In Kubernetes 1.3, we announced Kubernetes Cluster Federation and introduced the concept of Cross Cluster Service Discovery, enabling developers to deploy a service that was sharded across a federation of clusters spanning different zones, regions or cloud providers. This enables developers to achieve higher availability for their applications, without sacrificing quality of service, as detailed in our previous blog post.
In the latest release, Kubernetes 1.4, we've extended Cluster Federation to support Replica Sets, Secrets, Namespaces and Ingress objects. This means that you no longer need to deploy and manage these objects individually in each of your federated clusters. Just create them once in the federation, and have its built-in controllers automatically handle that for you.
Federated Replica Sets leverage the same configuration as non-federated Kubernetes Replica Sets and automatically distribute Pods across one or more federated clusters. By default, replicas are evenly distributed across all clusters, but for cases where that is not the desired behavior, we've introduced Replica Set preferences, which allow replicas to be distributed across only some clusters, or in non-equal proportions (define annotations).
Starting with Google Cloud Platform (GCP), we’ve introduced Federated Ingress as a Kubernetes 1.4 alpha feature which enables external clients point to a single IP address and have requests sent to the closest cluster with usable capacity in any region, zone of the Federation.
Federated Secrets automatically create and manage secrets across all clusters in a Federation, automatically ensuring that these are kept globally consistent and up-to-date, even if some clusters are offline when the original updates are applied.
Federated Namespaces are similar to the traditional Kubernetes Namespaces providing the same functionality. Creating them in the Federation control plane ensures that they are synchronized across all the clusters in Federation.
Federated Events are similar to the traditional Kubernetes Events providing the same functionality. Federation Events are stored only in Federation control plane and are not passed on to the underlying kubernetes clusters.
Let’s walk through how all this stuff works. We’re going to provision 3 clusters per region, spanning 3 continents (Europe, North America and Asia).

The next step is to federate these clusters. Kelsey Hightower developed a tutorial for setting up a Kubernetes Cluster Federation. Follow the tutorial to configure a Cluster Federation with clusters in 3 zones in each of the 3 GCP regions, us-central1, europe-west1 and asia-east1. For the purpose of this blog post, we’ll provision the Federation Control Plane in the us-central1-b zone. Note that more highly available, multi-cluster deployments are also available, but not used here in the interests of simplicity.
The rest of the blog post assumes that you have a running Kubernetes Cluster Federation provisioned.
Let’s verify that we have 9 clusters in 3 regions running.
$ kubectl --context=federation-cluster get clusters
NAME STATUS AGE
gce-asia-east1-a Ready 17m
gce-asia-east1-b Ready 15m
gce-asia-east1-c Ready 10m
gce-europe-west1-b Ready 7m
gce-europe-west1-c Ready 7m
gce-europe-west1-d Ready 4m
gce-us-central1-a Ready 1m
gce-us-central1-b Ready 53s
gce-us-central1-c Ready 39s
| You can download the source used in this blog post here. The source consists of the following files: | |
|---|---|
| configmaps/zonefetch.yaml | retrieves the zone from the instance metadata server and concatenates into volume mount path |
| replicasets/nginx-rs.yaml | deploys a Pod consisting of an nginx and busybox container |
| ingress/ingress.yaml | creates a load balancer with a global VIP that distributes requests to the closest nginx backend |
| services/nginx.yaml | exposes the nginx backend as an external service |
In our example, we’ll be deploying the service and ingress object using the federated control plane. The ConfigMap object isn’t currently supported by Federation, so we’ll be deploying it manually in each of the underlying Federation clusters. Our cluster deployment will look as follows:
We’re going to deploy a Service that is sharded across our 9 clusters. The backend deployment will consist of a Pod with 2 containers:
- busybox container that fetches the zone and outputs an HTML with the zone embedded in it into a Pod volume mount path
- nginx container that reads from that Pod volume mount path and serves an HTML containing the zone it’s running in
Let’s start by creating a federated service object in the federation-cluster context.
$ kubectl --context=federation-cluster create -f services/nginx.yaml
It will take a few minutes for the service to propagate across the 9 clusters.
$ kubectl --context=federation-cluster describe services nginx
Name: nginx
Namespace: default
Labels: app=nginx
Selector: app=nginx
Type: LoadBalancer
IP:
LoadBalancer Ingress: 108.59.xx.xxx, 104.199.xxx.xxx, ...
Port: http 80/TCP
NodePort: http 30061/TCP
Endpoints: <none>
Session Affinity: None
Let’s now create a Federated Ingress. Federated Ingresses are created in much that same way as traditional Kubernetes Ingresses: by making an API call which specifies the desired properties of your logical ingress point. In the case of Federated Ingress, this API call is directed to the Federation API endpoint, rather than a Kubernetes cluster API endpoint. The API for Federated Ingress is 100% compatible with the API for traditional Kubernetes Services.
$ cat ingress/ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx
spec:
backend:
serviceName: nginx
servicePort: 80
$ kubectl --context=federation-cluster create -f ingress/ingress.yaml
ingress "nginx" created
Once created, the Federated Ingress controller automatically:
- 1.creates matching Kubernetes Ingress objects in every cluster underlying your Cluster Federation
- 2.ensures that all of these in-cluster ingress objects share the same logical global L7 (i.e. HTTP(S)) load balancer and IP address
- 3.monitors the health and capacity of the service “shards” (i.e. your Pods) behind this ingress in each cluster
- 4.ensures that all client connections are routed to an appropriate healthy backend service endpoint at all times, even in the event of Pod, cluster, availability zone or regional outages We can verify the ingress objects are matching in the underlying clusters. Notice the ingress IP addresses for all 9 clusters is the same.
$ for c in $(kubectl config view -o jsonpath='{.contexts[*].name}'); do kubectl --context=$c get ingress; done
NAME HOSTS ADDRESS PORTS AGE
nginx \* 80 1h
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 40m
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 1h
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 26m
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 1h
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 25m
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 38m
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 3m
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 57m
NAME HOSTS ADDRESS PORTS AGE
nginx \* 130.211.40.xxx 80 56m
Note that in the case of Google Cloud Platform, the logical L7 load balancer is not a single physical device (which would present both a single point of failure, and a single global network routing choke point), but rather a truly global, highly available load balancing managed service, globally reachable via a single, static IP address.
Clients inside your federated Kubernetes clusters (i.e. Pods) will be automatically routed to the cluster-local shard of the Federated Service backing the Ingress in their cluster if it exists and is healthy, or the closest healthy shard in a different cluster if it does not. Note that this involves a network trip to the HTTP(S) load balancer, which resides outside your local Kubernetes cluster but inside the same GCP region.
The next step is to schedule the service backends. Let’s first create the ConfigMap in each cluster in the Federation.
We do this by submitting the ConfigMap to each cluster in the Federation.
$ for c in $(kubectl config view -o jsonpath='{.contexts[\*].name}'); do kubectl --context=$c create -f configmaps/zonefetch.yaml; done
Let’s have a quick peek at our Replica Set:
$ cat replicasets/nginx-rs.yaml
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: nginx
labels:
app: nginx
type: demo
spec:
replicas: 9
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: frontend
ports:
- containerPort: 80
volumeMounts:
- name: html-dir
mountPath: /usr/share/nginx/html
- image: busybox
name: zone-fetcher
command:
- "/bin/sh"
- "-c"
- "/zonefetch/zonefetch.sh"
volumeMounts:
- name: zone-fetch
mountPath: /zonefetch
- name: html-dir
mountPath: /usr/share/nginx/html
volumes:
- name: zone-fetch
configMap:
defaultMode: 0777
name: zone-fetch
- name: html-dir
emptyDir:
medium: ""
The Replica Set consists of 9 replicas, spread evenly across 9 clusters within the Cluster Federation. Annotations can also be used to control which clusters Pods are scheduled to. This is accomplished by adding annotations to the Replica Set spec, as follows:
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: nginx-us
annotations:
federation.kubernetes.io/replica-set-preferences: ```
{
"rebalance": true,
"clusters": {
"gce-us-central1-a": {
"minReplicas": 2,
"maxReplicas": 4,
"weight": 1
},
"gce-us-central10b": {
"minReplicas": 2,
"maxReplicas": 4,
"weight": 1
}
}
}
For the purpose of our demo, we’ll keep things simple and spread our Pods evenly across the Cluster Federation.
Let’s create the federated Replica Set:
$ kubectl --context=federation-cluster create -f replicasets/nginx-rs.yaml
Verify the Replica Sets and Pods were created in each cluster:
$ for c in $(kubectl config view -o jsonpath='{.contexts[\*].name}'); do kubectl --context=$c get rs; done
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 42s
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 14m
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 45s
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 46s
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 47s
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 48s
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 49s
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 49s
NAME DESIRED CURRENT READY AGE
nginx 1 1 1 49s
$ for c in $(kubectl config view -o jsonpath='{.contexts[\*].name}'); do kubectl --context=$c get po; done
NAME READY STATUS RESTARTS AGE
nginx-ph8zx 2/2 Running 0 25s
NAME READY STATUS RESTARTS AGE
nginx-sbi5b 2/2 Running 0 27s
NAME READY STATUS RESTARTS AGE
nginx-pf2dr 2/2 Running 0 28s
NAME READY STATUS RESTARTS AGE
nginx-imymt 2/2 Running 0 30s
NAME READY STATUS RESTARTS AGE
nginx-9cd5m 2/2 Running 0 31s
NAME READY STATUS RESTARTS AGE
nginx-vxlx4 2/2 Running 0 33s
NAME READY STATUS RESTARTS AGE
nginx-itagl 2/2 Running 0 33s
NAME READY STATUS RESTARTS AGE
nginx-u7uyn 2/2 Running 0 33s
NAME READY STATUS RESTARTS AGE
nginx-i0jh6 2/2 Running 0 34s
Below is an illustration of how the nginx service and associated ingress deployed. To summarize, we have a global VIP (130.211.23.176) exposed using a Global L7 load balancer that forwards requests to the closest cluster with available capacity.

To test this out, we’re going to spin up 2 Google Cloud Engine (GCE) instances, one in us-west1-b and the other in asia-east1-a. All client requests are automatically routed, via the shortest network path, to a healthy Pod in the closest cluster to the origin of the request. So for example, HTTP(S) requests from Asia will be routed directly to the closest cluster in Asia that has available capacity. If there are no such clusters in Asia, the request will be routed to the next closest cluster (in this case the U.S.). This works irrespective of whether the requests originate from a GCE instance or anywhere else on the internet. We only use a GCE instance for simplicity in the demo.

We can SSH directly into the VMs using the Cloud Console or by issuing a gcloud SSH command.
$ gcloud compute ssh test-instance-asia --zone asia-east1-a
-----
user@test-instance-asia:~$ curl 130.211.40.186
<!DOCTYPE html>
<html>
<head>
<title>Welcome to the global site!</title>
</head>
<body>
<h1>Welcome to the global site! You are being served from asia-east1-b</h1>
<p>Congratulations!</p>
user@test-instance-asia:~$ exit
----
$ gcloud compute ssh test-instance-us --zone us-west1-b
----
user@test-instance-us:~$ curl 130.211.40.186
<!DOCTYPE html>
<html>
<head>
<title>Welcome to the global site!</title>
</head>
<body>
<h1>Welcome to the global site! You are being served from us-central1-b</h1>
<p>Congratulations!</p>
----
Federations of Kubernetes Clusters can include clusters running in different cloud providers (e.g. GCP, AWS), and on-premises (e.g. on OpenStack). However, in Kubernetes 1.4, Federated Ingress is only supported across Google Cloud Platform clusters. In future versions we intend to support hybrid cloud Ingress-based deployments.
To summarize, we walked through leveraging the Kubernetes 1.4 Federated Ingress alpha feature to deploy a multi-homed service behind a global load balancer. External clients point to a single IP address and are sent to the closest cluster with usable capacity in any region, zone of the Federation, providing higher levels of availability without sacrificing latency or ease of operation.
We'd love to hear feedback on Kubernetes Cross Cluster Services. To join the community:
- Post issues or feature requests on GitHub
- Join us in the #federation channel on Slack
- Participate in the Cluster Federation SIG
- Download Kubernetes
- Follow Kubernetes on Twitter @Kubernetesio for latest updates
Helm Charts: making it simple to package and deploy common applications on Kubernetes
There are thousands of people and companies packaging their applications for deployment on Kubernetes. This usually involves crafting a few different Kubernetes resource definitions that configure the application runtime, as well as defining the mechanism that users and other apps leverage to communicate with the application. There are some very common applications that users regularly look for guidance on deploying, such as databases, CI tools, and content management systems. These types of applications are usually not ones that are developed and iterated on by end users, but rather their configuration is customized to fit a specific use case. Once that application is deployed users can link it to their existing systems or leverage their functionality to solve their pain points.
For best practices on how these applications should be configured, users could look at the many resources available such as: the examples folder in the Kubernetes repository, the Kubernetes contrib repository, the Helm Charts repository, and the Bitnami Charts repository. While these different locations provided guidance, it was not always formalized or consistent such that users could leverage similar installation procedures across different applications.
So what do you do when there are too many places for things to be found?

In this case, we’re not creating Yet Another Place for Applications, rather promoting an existing one as the canonical location. As part of the Special Interest Group Apps (SIG Apps) work for the Kubernetes 1.4 release, we began to provide a home for these Kubernetes deployable applications that provides continuous releases of well documented and user friendly packages. These packages are being created as Helm Charts and can be installed using the Helm tool. Helm allows users to easily templatize their Kubernetes manifests and provide a set of configuration parameters that allows users to customize their deployment.
Helm is the package manager (analogous to yum and apt) and Charts are packages (analogous to debs and rpms). The home for these Charts is the Kubernetes Charts repository which provides continuous integration for pull requests, as well as automated releases of Charts in the master branch.
There are two main folders where charts reside. The stable folder hosts those applications which meet minimum requirements such as proper documentation and inclusion of only Beta or higher Kubernetes resources. The incubator folder provides a place for charts to be submitted and iterated on until they’re ready for promotion to stable at which time they will automatically be pushed out to the default repository. For more information on the repository structure and requirements for being in stable, have a look at this section in the README.
The following applications are now available:
| Stable repository | Incubating repository |
|---|---|
| Drupal | Consul |
| Jenkins | Elasticsearch |
| MariaDB | etcd |
| MySQL | Grafana |
| Redmine | MongoDB |
| Wordpress | Patroni |
| Prometheus | |
| Spark | |
| ZooKeeper |
Example workflow for a Chart developer
- Create a chart
- Developer provides parameters via the values.yaml file allowing users to customize their deployment. This can be seen as the API between chart devs and chart users.
- A README is written to help describe the application and its parameterized values.
- Once the application installs properly and the values customize the deployment appropriately, the developer adds a NOTES.txt file that is shown as soon as the user installs. This file generally points out the next steps for the user to connect to or use the application.
- If the application requires persistent storage, the developer adds a mechanism to store the data such that pod restarts do not lose data. Most charts requiring this today are using dynamic volume provisioning to abstract away underlying storage details from the user which allows a single configuration to work against Kubernetes installations.
- Submit a Pull Request to the Kubernetes Charts repo. Once tested and reviewed, the PR will be merged.
- Once merged to the master branch, the chart will be packaged and released to Helm’s default repository and available for users to install.
Example workflow for a Chart user
$ helm search
NAME VERSION DESCRIPTION stable/drupal 0.3.1 One of the most versatile open source content m...stable/jenkins 0.1.0 A Jenkins Helm chart for Kubernetes. stable/mariadb 0.4.0 Chart for MariaDB stable/mysql 0.1.0 Chart for MySQL stable/redmine 0.3.1 A flexible project management web application. stable/wordpress 0.3.0 Web publishing platform for building blogs and ...
$ helm install stable/jenkins
- 5.After the install
Notes:
1. Get your 'admin' user password by running:
printf $(printf '\%o' `kubectl get secret --namespace default brawny-frog-jenkins -o jsonpath="{.data.jenkins-admin-password[*]}"`);echo
2. Get the Jenkins URL to visit by running these commands in the same shell:
\*\*\*\* NOTE: It may take a few minutes for the LoadBalancer IP to be available. \*\*\*\*
\*\*\*\* You can watch the status of by running 'kubectl get svc -w brawny-frog-jenkins' \*\*\*\*
export SERVICE\_IP=$(kubectl get svc --namespace default brawny-frog-jenkins -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
echo http://$SERVICE\_IP:8080/login
- Login with the password from step 1 and the username: admin
For more information on running Jenkins on Kubernetes, visit here.
Conclusion
Now that you’ve seen workflows for both developers and users, we hope that you’ll join us in consolidating the breadth of application deployment knowledge into a more centralized place. Together we can raise the quality bar for both developers and users of Kubernetes applications. We’re always looking for feedback on how we can better our process. Additionally, we’re looking for contributions of new charts or updates to existing ones. Join us in the following places to get engaged:
- SIG Apps - Slack Channel
- SIG Apps - Weekly Meeting
- Submit a Kubernetes Charts Issue A big thank you to the folks at Bitnami, Deis, Google and the other contributors who have helped get the Charts repository to where it is today. We still have a lot of work to do but it's been wonderful working together as a community to move this effort forward.
--Vic Iglesias, Cloud Solutions Architect, Google
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Dynamic Provisioning and Storage Classes in Kubernetes
Storage is a critical part of running containers, and Kubernetes offers some powerful primitives for managing it. Dynamic volume provisioning, a feature unique to Kubernetes, allows storage volumes to be created on-demand. Without dynamic provisioning, cluster administrators have to manually make calls to their cloud or storage provider to create new storage volumes, and then create PersistentVolume objects to represent them in Kubernetes. The dynamic provisioning feature eliminates the need for cluster administrators to pre-provision storage. Instead, it automatically provisions storage when it is requested by users. This feature was introduced as alpha in Kubernetes 1.2, and has been improved and promoted to beta in the latest release, 1.4. This release makes dynamic provisioning far more flexible and useful.
What’s New?
The alpha version of dynamic provisioning only allowed a single, hard-coded provisioner to be used in a cluster at once. This meant that when Kubernetes determined storage needed to be dynamically provisioned, it always used the same volume plugin to do provisioning, even if multiple storage systems were available on the cluster. The provisioner to use was inferred based on the cloud environment - EBS for AWS, Persistent Disk for Google Cloud, Cinder for OpenStack, and vSphere Volumes on vSphere. Furthermore, the parameters used to provision new storage volumes were fixed: only the storage size was configurable. This meant that all dynamically provisioned volumes would be identical, except for their storage size, even if the storage system exposed other parameters (such as disk type) for configuration during provisioning.
Although the alpha version of the feature was limited in utility, it allowed us to “get some miles” on the idea, and helped determine the direction we wanted to take.
The beta version of dynamic provisioning, new in Kubernetes 1.4, introduces a new API object, StorageClass. Multiple StorageClass objects can be defined each specifying a volume plugin (aka provisioner) to use to provision a volume and the set of parameters to pass to that provisioner when provisioning. This design allows cluster administrators to define and expose multiple flavors of storage (from the same or different storage systems) within a cluster, each with a custom set of parameters. This design also ensures that end users don’t have to worry about the complexity and nuances of how storage is provisioned, but still have the ability to select from multiple storage options.
How Do I use It?
Below is an example of how a cluster administrator would expose two tiers of storage, and how a user would select and use one. For more details, see the reference and example docs.
Admin Configuration
The cluster admin defines and deploys two StorageClass objects to the Kubernetes cluster:
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
This creates a storage class called “slow” which will provision standard disk-like Persistent Disks.
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
This creates a storage class called “fast” which will provision SSD-like Persistent Disks.
User Request
Users request dynamically provisioned storage by including a storage class in their PersistentVolumeClaim. For the beta version of this feature, this is done via the volume.beta.kubernetes.io/storage-class annotation. The value of this annotation must match the name of a StorageClass configured by the administrator.
To select the “fast” storage class, for example, a user would create the following PersistentVolumeClaim:
{
"kind": "PersistentVolumeClaim",
"apiVersion": "v1",
"metadata": {
"name": "claim1",
"annotations": {
"volume.beta.kubernetes.io/storage-class": "fast"
}
},
"spec": {
"accessModes": [
"ReadWriteOnce"
],
"resources": {
"requests": {
"storage": "30Gi"
}
}
}
}
This claim will result in an SSD-like Persistent Disk being automatically provisioned. When the claim is deleted, the volume will be destroyed.
Defaulting Behavior
Dynamic Provisioning can be enabled for a cluster such that all claims are dynamically provisioned without a storage class annotation. This behavior is enabled by the cluster administrator by marking one StorageClass object as “default”. A StorageClass can be marked as default by adding the storageclass.beta.kubernetes.io/is-default-class annotation to it.
When a default StorageClass exists and a user creates a PersistentVolumeClaim without a storage-class annotation, the new DefaultStorageClass admission controller (also introduced in v1.4), automatically adds the class annotation pointing to the default storage class.
Can I Still Use the Alpha Version?
Kubernetes 1.4 maintains backwards compatibility with the alpha version of the dynamic provisioning feature to allow for a smoother transition to the beta version. The alpha behavior is triggered by the existance of the alpha dynamic provisioning annotation (volume. alpha.kubernetes.io/storage-class). Keep in mind that if the beta annotation (volume. beta.kubernetes.io/storage-class) is present, it takes precedence, and triggers the beta behavior.
Support for the alpha version is deprecated and will be removed in a future release.
What’s Next?
Dynamic Provisioning and Storage Classes will continue to evolve and be refined in future releases. Below are some areas under consideration for further development.
Standard Cloud Provisioners
For deployment of Kubernetes to cloud providers, we are considering automatically creating a provisioner for the cloud’s native storage system. This means that a standard deployment on AWS would result in a StorageClass that provisions EBS volumes, a standard deployment on Google Cloud would result in a StorageClass that provisions GCE PDs. It is also being debated whether these provisioners should be marked as default, which would make dynamic provisioning the default behavior (no annotation required).
Out-of-Tree Provisioners
There has been ongoing discussion about whether Kubernetes storage plugins should live “in-tree” or “out-of-tree”. While the details for how to implement out-of-tree plugins is still in the air, there is a proposal introducing a standardized way to implement out-of-tree dynamic provisioners.
How Do I Get Involved?
If you’re interested in getting involved with the design and development of Kubernetes Storage, join the Kubernetes Storage Special-Interest-Group (SIG). We’re rapidly growing and always welcome new contributors.
-- Saad Ali, Software Engineer, Google
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
How we improved Kubernetes Dashboard UI in 1.4 for your production needs
With the release of Kubernetes 1.4 last week, Dashboard – the official web UI for Kubernetes – has a number of exciting updates and improvements of its own. The past three months have been busy ones for the Dashboard team, and we’re excited to share the resulting features of that effort here. If you’re not familiar with Dashboard, the GitHub repo is a great place to get started.
A quick recap before unwrapping our shiny new features: Dashboard was initially released March 2016. One of the focuses for Dashboard throughout its lifetime has been the onboarding experience; it’s a less intimidating way for Kubernetes newcomers to get started, and by showing multiple resources at once, it provides contextualization lacking in kubectl (the CLI). After that initial release though, the product team realized that fine-tuning for a beginner audience was getting ahead of ourselves: there were still fundamental product requirements that Dashboard needed to satisfy in order to have a productive UX to onboard new users too. That became our mission for this release: closing the gap between Dashboard and kubectl by showing more resources, leveraging a web UI’s strengths in monitoring and troubleshooting, and architecting this all in a user friendly way.
Monitoring Graphs
Real time visualization is a strength that UI’s have over CLI’s, and with 1.4 we’re happy to capitalize on that capability with the introduction of real-time CPU and memory usage graphs for all workloads running on your cluster. Even with the numerous third-party solutions for monitoring, Dashboard should include at least some basic out-of-the box functionality in this area. Next up on the roadmap for graphs is extending the timespan the graph represents, adding drill-down capabilities to reveal more details, and improving the UX of correlating data between different graphs.

Logs
Based on user research with Kubernetes’ predecessor Borg and continued community feedback, we know logs are tremendously important to users. For this reason we’re constantly looking for ways to improve these features in Dashboard. This release includes a fix for an issue wherein large numbers of logs would crash the system, as well as the introduction of the ability to view logs by date.
Showing More Resources
The previous release brought all workloads to Dashboard: Pods, Pet Sets, Daemon Sets, Replication Controllers, Replica Set, Services, & Deployments. With 1.4, we expand upon that set of objects by including Services, Ingresses, Persistent Volume Claims, Secrets, & Config Maps. We’ve also introduced an “Admin” section with the Namespace-independent global objects of Namespaces, Nodes, and Persistent Volumes. With the addition of roles, these will be shown only to cluster operators, and developers’ side nav will begin with the Namespace dropdown.
Like glue binding together a loose stack of papers into a book, we needed some way to impose order on these resources for their value to be realized, so one of the features we’re most excited to announce in 1.4 is navigation.
Navigation
In 1.1, all resources were simply stacked on top of each other in a single page. The introduction of a side nav provides quick access to any aspect of your cluster you’d like to check out. Arriving at this solution meant a lot of time put toward thinking about the hierarchy of Kubernetes objects – a difficult task since by design things fit together more like a living organism than a nested set of linear relationships. The solution we’ve arrived at balances the organizational need for grouping and desire to retain a bird’s-eye view of as much relevant information as possible. The design of the side nav is simple and flexible, in order to accommodate more resources in the future. Its top level objects (e.g. “Workloads”, “Services and Discovery”) roll up their child objects and will eventually include aggregated data for said objects.

Closer Alignment with Material Design
Dashboard follows Google’s Material design system, and the implementation of those principles is refined in the new UI: the global create options have been reduced from two choices to one initial “Create” button, the official Kubernetes logo is displayed as an SVG rather than simply as text, and cards were introduced to help better group different types of content (e.g. a table of Replication Controllers and a table of Pods on your “Workloads” page). Material’s guidelines around desktop-focused enterprise-level software are currently limited (and instead focus on a mobile-first context), so we’ve had to improvise with some aspects of the UI and have worked closely with the UX team at Google Cloud Platform to do this – drawing on their expertise in implementing Material in a more information-dense setting.
Sample Use Case
To showcase Dashboard 1.4’s new suite of features and how they’ll make users’ lives better in the real world, let’s imagine the following scenario:
I am a cluster operator and a customer pings me warning that their app, Kubernetes Dashboard, is suffering performance issues. My first step in addressing the issue is to switch to the correct Namespace, kube-system, to examine what could be going on.

Once in the relevant Namespace, I check out my Deployments to see if anything seems awry. Sure enough, I notice a spike in CPU usage.

I realize we need to perform a rolling update to a newer version of that app that can handle the increased requests it’s evidently getting, so I update this Deployment’s image, which in turn creates a new Replica Set.

Now that Replica Set’s been created, I can open the logs for one of its pods to confirm that it’s been successfully connected to the API server.

Easy as that, we’ve debugged our issue. Dashboard provided us a centralized location to scan for the origin of the problem, and once we had that identified we were able to drill down and address the root of the problem.
Why the Skipped Versions?
If you’ve been following along with Dashboard since 1.0, you may have been confused by the jump in our versioning; we went 1.0, 1.1...1.4. We did this to synchronize with the main Kubernetes distro, and hopefully going forward this will make that relationship easier to understand.
There’s a Lot More Where That Came From
Dashboard is gaining momentum, and these early stages are a very exciting and rewarding time to be involved. If you’d like to learn more about contributing, check out SIG UI. Chat with us Kubernetes Slack: #sig-ui channel.
--Dan Romlein, UX designer, Apprenda
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
How we made Kubernetes insanely easy to install
Editor's note: Today’s post is by Luke Marsden, Head of Developer Experience, at Weaveworks, showing the Special Interest Group Cluster-Lifecycle’s recent work on kubeadm, a tool to make installing Kubernetes much simpler.
Over at SIG-cluster-lifecycle, we've been hard at work the last few months on kubeadm, a tool that makes Kubernetes dramatically easier to install. We've heard from users that installing Kubernetes is harder than it should be, and we want folks to be focused on writing great distributed apps not wrangling with infrastructure!
There are three stages in setting up a Kubernetes cluster, and we decided to focus on the second two (to begin with):
- Provisioning : getting some machines
- Bootstrapping : installing Kubernetes on them and configuring certificates
- Add-ons : installing necessary cluster add-ons like DNS and monitoring services, a pod network, etc We realized early on that there's enormous variety in the way that users want to provision their machines.
They use lots of different cloud providers, private clouds, bare metal, or even Raspberry Pi's, and almost always have their own preferred tools for automating provisioning machines: Terraform or CloudFormation, Chef, Puppet or Ansible, or even PXE booting bare metal. So we made an important decision: kubeadm would not provision machines. Instead, the only assumption it makes is that the user has some computers running Linux.
Another important constraint was we didn't want to just build another tool that "configures Kubernetes from the outside, by poking all the bits into place". There are many external projects out there for doing this, but we wanted to aim higher. We chose to actually improve the Kubernetes core itself to make it easier to install. Luckily, a lot of the groundwork for making this happen had already been started.
We realized that if we made Kubernetes insanely easy to install manually, it should be obvious to users how to automate that process using any tooling.
So, enter kubeadm. It has no infrastructure dependencies, and satisfies the requirements above. It's easy to use and should be easy to automate. It's still in alpha , but it works like this:
- You install Docker and the official Kubernetes packages for you distribution.
- Select a master host, run kubeadm init.
- This sets up the control plane and outputs a kubeadm join [...] command which includes a secure token.
- On each host selected to be a worker node, run the kubeadm join [...] command from above.
- Install a pod network. Weave Net is a great place to start here. Install it using just kubectl apply -f https://git.io/weave-kube Presto! You have a working Kubernetes cluster! Try kubeadm today.
For a video walkthrough, check this out:
Follow the kubeadm getting started guide to try it yourself, and please give us feedback on GitHub, mentioning @kubernetes/sig-cluster-lifecycle!
Finally, I want to give a huge shout-out to so many people in the SIG-cluster-lifecycle, without whom this wouldn't have been possible. I'll mention just a few here:
- Joe Beda kept us focused on keeping things simple for the user.
- Mike Danese at Google has been an incredible technical lead and always knows what's happening. Mike also tirelessly kept up on the many code reviews necessary.
- Ilya Dmitrichenko, my colleague at Weaveworks, wrote most of the kubeadm code and also kindly helped other folks contribute.
- Lucas Käldström from Finland has got to be the youngest contributor in the group and was merging last-minute pull requests on the Sunday night before his school math exam.
- Brandon Philips and his team at CoreOS led the development of TLS bootstrapping, an essential component which we couldn't have done without.
- Devan Goodwin from Red Hat built the JWS discovery service that Joe imagined and sorted out our RPMs.
- Paulo Pires from Portugal jumped in to help out with external etcd support and picked up lots of other bits of work.
- And many other contributors!
This truly has been an excellent cross-company and cross-timezone achievement, with a lovely bunch of people. There's lots more work to do in SIG-cluster-lifecycle, so if you’re interested in these challenges join our SIG. Looking forward to collaborating with you all!
--Luke Marsden, Head of Developer Experience at Weaveworks
- Try kubeadm to install Kubernetes today
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
How Qbox Saved 50% per Month on AWS Bills Using Kubernetes and Supergiant
Editor’s Note: Today’s post is by the team at Qbox, a hosted Elasticsearch provider sharing their experience with Kubernetes and how it helped save them fifty-percent off their cloud bill.
A little over a year ago, we at Qbox faced an existential problem. Just about all of the major IaaS providers either launched or acquired services that competed directly with our Hosted Elasticsearch service, and many of them started offering it for free. The race to zero was afoot unless we could re-engineer our infrastructure to be more performant, more stable, and less expensive than the VM approach we had had before, and the one that is in use by our IaaS brethren. With the help of Kubernetes, Docker, and Supergiant (our own hand-rolled layer for managing distributed and stateful data), we were able to deliver 50% savings, a mid-five figure sum. At the same time, support tickets plummeted. We were so pleased with the results that we decided to open source Supergiant as its own standalone product. This post will demonstrate how we accomplished it.
Back in 2013, when not many were even familiar with Elasticsearch, we launched our as-a-service offering with a dedicated, direct VM model. We hand-selected certain instance types optimized for Elasticsearch, and users configured single-tenant, multi-node clusters running on isolated virtual machines in any region. We added a markup on the per-compute-hour price for the DevOps support and monitoring, and all was right with the world for a while as Elasticsearch became the global phenomenon that it is today.
Background
As we grew to thousands of clusters, and many more thousands of nodes, it wasn’t just our AWS bill getting out of hand. We had 4 engineers replacing dead nodes and answering support tickets all hours of the day, every day. What made matters worse was the volume of resources allocated compared to the usage. We had thousands of servers with a collective CPU utilization under 5%. We were spending too much on processors that were doing absolutely nothing.
How we got there was no great mystery. VM’s are a finite resource, and with a very compute-intensive, burstable application like Elasticsearch, we would be juggling the users that would either undersize their clusters to save money or those that would over-provision and overspend. When the aforementioned competitive pressures forced our hand, we had to re-evaluate everything.
Adopting Docker and Kubernetes
Our team avoided Docker for a while, probably on the vague assumption that the network and disk performance we had with VMs wouldn't be possible with containers. That assumption turned out to be entirely wrong.
To run performance tests, we had to find a system that could manage networked containers and volumes. That's when we discovered Kubernetes. It was alien to us at first, but by the time we had familiarized ourselves and built a performance testing tool, we were sold. It was not just as good as before, it was better.
The performance improvement we observed was due to the number of containers we could “pack” on a single machine. Ironically, we began the Docker experiment wanting to avoid “noisy neighbor,” which we assumed was inevitable when several containers shared the same VM. However, that isolation also acted as a bottleneck, both in performance and cost. To use a real-world example, If a machine has 2 cores and you need 3 cores, you have a problem. It’s rare to come across a public-cloud VM with 3 cores, so the typical solution is to buy 4 cores and not utilize them fully.
This is where Kubernetes really starts to shine. It has the concept of requests and limits, which provides granular control over resource sharing. Multiple containers can share an underlying host VM without the fear of “noisy neighbors”. They can request exclusive control over an amount of RAM, for example, and they can define a limit in anticipation of overflow. It’s practical, performant, and cost-effective multi-tenancy. We were able to deliver the best of both the single-tenant and multi-tenant worlds.
Kubernetes + Supergiant
We built Supergiant originally for our own Elasticsearch customers. Supergiant solves Kubernetes complications by allowing pre-packaged and re-deployable application topologies. In more specific terms, Supergiant lets you use Components, which are somewhat similar to a microservice. Components represent an almost-uniform set of Instances of software (e.g., Elasticsearch, MongoDB, your web application, etc.). They roll up all the various Kubernetes and cloud operations needed to deploy a complex topology into a compact entity that is easy to manage.
For Qbox, we went from needing 1:1 nodes to approximately 1:11 nodes. Sure, the nodes were larger, but the utilization made a substantial difference. As in the picture below, we could cram a whole bunch of little instances onto one big instance and not lose any performance. Smaller users would get the added benefit of higher network throughput by virtue of being on bigger resources, and they would also get greater CPU and RAM bursting.

Adding Up the Cost Savings
The packing algorithm in Supergiant, with its increased utilization, resulted in an immediate 25% drop in our infrastructure footprint. Remember, this came with better performance and fewer support tickets. We could dial up the packing algorithm and probably save even more money. Meanwhile, because our nodes were larger and far more predictable, we could much more fully leverage the economic goodness that is AWS Reserved Instances. We went with 1-year partial RI’s, which cut the remaining costs by 40%, give or take. Our customers still had the flexibility to spin up, down, and out their Elasticsearch nodes, without forcing us to constantly juggle, combine, split, and recombine our reservations. At the end of the day, we saved 50%. That is $600k per year that can go towards engineering salaries instead of enriching our IaaS provider.
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Kubernetes 1.4: Making it easy to run on Kubernetes anywhere
Today we’re happy to announce the release of Kubernetes 1.4.
Since the release to general availability just over 15 months ago, Kubernetes has continued to grow and achieve broad adoption across the industry. From brand new startups to large-scale businesses, users have described how big a difference Kubernetes has made in building, deploying and managing distributed applications. However, one of our top user requests has been making Kubernetes itself easier to install and use. We’ve taken that feedback to heart, and 1.4 has several major improvements.
These setup and usability enhancements are the result of concerted, coordinated work across the community - more than 20 contributors from SIG-Cluster-Lifecycle came together to greatly simplify the Kubernetes user experience, covering improvements to installation, startup, certificate generation, discovery, networking, and application deployment.
Additional product highlights in this release include simplified cluster deployment on any cloud, easy installation of stateful apps, and greatly expanded Cluster Federation capabilities, enabling a straightforward deployment across multiple clusters, and multiple clouds.
What’s new:
Cluster creation with two commands - To get started with Kubernetes a user must provision nodes, install Kubernetes and bootstrap the cluster. A common request from users is to have an easy, portable way to do this on any cloud (public, private, or bare metal).
- Kubernetes 1.4 introduces ‘kubeadm’ which reduces bootstrapping to two commands, with no complex scripts involved. Once kubernetes is installed, kubeadm init starts the master while kubeadm join joins the nodes to the cluster.
- Installation is also streamlined by packaging Kubernetes with its dependencies, for most major Linux distributions including Red Hat and Ubuntu Xenial. This means users can now install Kubernetes using familiar tools such as apt-get and yum.
- Add-on deployments, such as for an overlay network, can be reduced to one command by using a DaemonSet.
- Enabling this simplicity is a new certificates API and its use for kubelet TLS bootstrap, as well as a new discovery API.
Expanded stateful application support - While cloud-native applications are built to run in containers, many existing applications need additional features to make it easy to adopt containers. Most commonly, these include stateful applications such as batch processing, databases and key-value stores. In Kubernetes 1.4, we have introduced a number of features simplifying the deployment of such applications, including:
- ScheduledJob is introduced as Alpha so users can run batch jobs at regular intervals.
- Init-containers are Beta, addressing the need to run one or more containers before starting the main application, for example to sequence dependencies when starting a database or multi-tier app.
- Dynamic PVC Provisioning moved to Beta. This feature now enables cluster administrators to expose multiple storage provisioners and allows users to select them using a new Storage Class API object.
- Curated and pre-tested Helm charts for common stateful applications such as MariaDB, MySQL and Jenkins will be available for one-command launches using version 2 of the Helm Package Manager.
Cluster federation API additions - One of the most requested capabilities from our global customers has been the ability to build applications with clusters that span regions and clouds.
- Federated Replica Sets Beta - replicas can now span some or all clusters enabling cross region or cross cloud replication. The total federated replica count and relative cluster weights / replica counts are continually reconciled by a federated replica-set controller to ensure you have the pods you need in each region / cloud.
- Federated Services are now Beta, and secrets, events and namespaces have also been added to the federation API.
- Federated Ingress Alpha - starting with Google Cloud Platform (GCP), users can create a single L7 globally load balanced VIP that spans services deployed across a federation of clusters within GCP. With Federated Ingress in GCP, external clients point to a single IP address and are sent to the closest cluster with usable capacity in any region or zone of the federation in GCP.
Container security support - Administrators of multi-tenant clusters require the ability to provide varying sets of permissions among tenants, infrastructure components, and end users of the system.
- Pod Security Policy is a new object that enables cluster administrators to control the creation and validation of security contexts for pods/containers. Admins can associate service accounts, groups, and users with a set of constraints to define a security context.
- AppArmor support is added, enabling admins to run a more secure deployment, and provide better auditing and monitoring of their systems. Users can configure a container to run in an AppArmor profile by setting a single field.
Infrastructure enhancements - We continue adding to the scheduler, storage and client capabilities in Kubernetes based on user and ecosystem needs.
- Scheduler - introducing inter-pod affinity and anti-affinity Alpha for users who want to customize how Kubernetes co-locates or spreads their pods. Also priority scheduling capability for cluster add-ons such as DNS, Heapster, and the Kube Dashboard.
- Disruption SLOs - Pod Disruption Budget is introduced to limit impact of pods deleted by cluster management operations (such as node upgrade) at any one time.
- Storage - New volume plugins for Quobyte and Azure Data Disk have been added.
- Clients - Swagger 2.0 support is added, enabling non-Go clients.
Kubernetes Dashboard UI - lastly, a great looking Kubernetes Dashboard UI with 90% CLI parity for at-a-glance management.
For a complete list of updates see the release notes on GitHub. Apart from features the most impressive aspect of Kubernetes development is the community of contributors. This is particularly true of the 1.4 release, the full breadth of which will unfold in upcoming weeks.
Availability
Kubernetes 1.4 is available for download at get.k8s.io and via the open source repository hosted on GitHub. To get started with Kubernetes try the Hello World app.
To get involved with the project, join the weekly community meeting or start contributing to the project here (marked help).
Users and Case Studies
Over the past fifteen months since the Kubernetes 1.0 GA release, the adoption and enthusiasm for this project has surpassed everyone's imagination. Kubernetes runs in production at hundreds of organization and thousands more are in development. Here are a few unique highlights of companies running Kubernetes:
- Box -- accelerated their time to delivery from six months to launch a service to less than a week. Read more on how Box runs mission critical production services on Kubernetes.
- Pearson -- minimized complexity and increased their engineer productivity. Read how Pearson is using Kubernetes to reinvent the world’s largest educational company.
- OpenAI -- a non-profit artificial intelligence research company, built infrastructure for deep learning with Kubernetes to maximize productivity for researchers allowing them to focus on the science.
We’re very grateful to our community of over 900 contributors who contributed more than 5,000 commits to make this release possible. To get a closer look on how the community is using Kubernetes, join us at the user conference KubeCon to hear directly from users and contributors.
Connect
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Thank you for your support!
-- Aparna Sinha, Product Manager, Google
High performance network policies in Kubernetes clusters
Editor's note: today’s post is by Juergen Brendel, Pritesh Kothari and Chris Marino co-founders of Pani Networks, the sponsor of the Romana project, the network policy software used for these benchmark tests.
Network Policies
Since the release of Kubernetes 1.3 back in July, users have been able to define and enforce network policies in their clusters. These policies are firewall rules that specify permissible types of traffic to, from and between pods. If requested, Kubernetes blocks all traffic that is not explicitly allowed. Policies are applied to groups of pods identified by common labels. Labels can then be used to mimic traditional segmented networks often used to isolate layers in a multi-tier application: You might identify your front-end and back-end pods by a specific “segment” label, for example. Policies control traffic between those segments and even traffic to or from external sources.
Segmenting traffic
What does this mean for the application developer? At last, Kubernetes has gained the necessary capabilities to provide "defence in depth". Traffic can be segmented and different parts of your application can be secured independently. For example, you can very easily protect each of your services via specific network policies: All the pods identified by a Replication Controller behind a service are already identified by a specific label. Therefore, you can use this same label to apply a policy to those pods.
Defense in depth has long been recommended as best practice. This kind of isolation between different parts or layers of an application is easily achieved on AWS and OpenStack by applying security groups to VMs.
However, prior to network policies, this kind of isolation for containers was not possible. VXLAN overlays can provide simple network isolation, but application developers need more fine grained control over the traffic accessing pods. As you can see in this simple example, Kubernetes network policies can manage traffic based on source and origin, protocol and port.
apiVersion: extensions/v1beta1
kind: NetworkPolicy
metadata:
name: pol1
spec:
podSelector:
matchLabels:
role: backend
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: tcp
port: 80
Not all network backends support policies
Network policies are an exciting feature, which the Kubernetes community has worked on for a long time. However, it requires a networking backend that is capable of applying the policies. By themselves, simple routed networks or the commonly used flannel network driver, for example, cannot apply network policy.
There are only a few policy-capable networking backends available for Kubernetes today: Romana, Calico, and Canal; with Weave indicating support in the near future. Red Hat’s OpenShift includes network policy features as well.
We chose Romana as the back-end for these tests because it configures pods to use natively routable IP addresses in a full L3 configuration. Network policies, therefore, can be applied directly by the host in the Linux kernel using iptables rules. This results is a high performance, easy to manage network.
Testing performance impact of network policies
After network policies have been applied, network packets need to be checked against those policies to verify that this type of traffic is permissible. But what is the performance penalty for applying a network policy to every packet? Can we use all the great policy features without impacting application performance? We decided to find out by running some tests.
Before we dive deeper into these tests, it is worth mentioning that ‘performance’ is a tricky thing to measure, network performance especially so.
Throughput (i.e. data transfer speed measured in Gpbs) and latency (time to complete a request) are common measures of network performance. The performance impact of running an overlay network on throughput and latency has been examined previously here and here. What we learned from these tests is that Kubernetes networks are generally pretty fast, and servers have no trouble saturating a 1G link, with or without an overlay. It's only when you have 10G networks that you need to start thinking about the overhead of encapsulation.
This is because during a typical network performance benchmark, there’s no application logic for the host CPU to perform, leaving it available for whatever network processing is required. For this reason we ran our tests in an operating range that did not saturate the link, or the CPU. This has the effect of isolating the impact of processing network policy rules on the host. For these tests we decided to measure latency as measured by the average time required to complete an HTTP request across a range of response sizes.
Test setup
- Hardware: Two servers with Intel Core i5-5250U CPUs (2 core, 2 threads per core) running at 1.60GHz, 16GB RAM and 512GB SSD. NIC: Intel Ethernet Connection I218-V (rev 03)
- Ubuntu 14.04.5
- Kubernetes 1.3 for data collection (verified samples on v1.4.0-beta.5)
- Romana v0.9.3.1
- Client and server load test software
For the tests we had a client pod send 2,000 HTTP requests to a server pod. HTTP requests were sent by the client pod at a rate that ensured that neither the server nor network ever saturated. We also made sure each request started a new TCP session by disabling persistent connections (i.e. HTTP keep-alive). We ran each test with different response sizes and measured the average request duration time (how long does it take to complete a request of that size). Finally, we repeated each set of measurements with different policy configurations.
Romana detects Kubernetes network policies when they’re created, translates them to Romana’s own policy format, and then applies them on all hosts. Currently, Kubernetes network policies only apply to ingress traffic. This means that outgoing traffic is not affected.
First, we conducted the test without any policies to establish a baseline. We then ran the test again, increasing numbers of policies for the test's network segment. The policies were of the common “allow traffic for a given protocol and port” format. To ensure packets had to traverse all the policies, we created a number of policies that did not match the packet, and finally a policy that would result in acceptance of the packet.
The table below shows the results, measured in milliseconds for different request sizes and numbers of policies:
Response Size
|Policies |.5k |1k |10k |100k |1M | |---|---|---|---|---| |0 |0.732 |0.738 |1.077 |2.532 |10.487 | |10 |0.744 |0.742 |1.084 |2.570 |10.556 | |50 |0.745 |0.755 |1.086 |2.580 |10.566 | |100 |0.762 |0.770 |1.104 |2.640 |10.597 | |200 |0.783 |0.783 |1.147 |2.652 |10.677 |
What we see here is that, as the number of policies increases, processing network policies introduces a very small delay, never more than 0.2ms, even after applying 200 policies. For all practical purposes, no meaningful delay is introduced when network policy is applied. Also worth noting is that doubling the response size from 0.5k to 1.0k had virtually no effect. This is because for very small responses, the fixed overhead of creating a new connection dominates the overall response time (i.e. the same number of packets are transferred).

Note: .5k and 1k lines overlap at ~.8ms in the chart above
Even as a percentage of baseline performance, the impact is still very small. The table below shows that for the smallest response sizes, the worst case delay remains at 7%, or less, up to 200 policies. For the larger response sizes the delay drops to about 1%.
Response Size
| Policies | .5k | 1k | 10k | 100k | 1M |
|---|---|---|---|---|---|
| 0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| 10 | -1.6% | -0.5% | -0.6% | -1.5% | -0.7% |
| 50 | -1.8% | -2.3% | -0.8% | -1.9% | -0.8% |
| 100 | -4.1% | -4.3% | -2.5% | -4.3% | -1.0% |
| 200 | -7.0% | -6.1% | -6.5% | -4.7% | -1.8% |

What is also interesting in these results is that as the number of policies increases, we notice that larger requests experience a smaller relative (i.e. percentage) performance degradation.
This is because when Romana installs iptables rules, it ensures that packets belonging to established connection are evaluated first. The full list of policies only needs to be traversed for the first packets of a connection. After that, the connection is considered ‘established’ and the connection’s state is stored in a fast lookup table. For larger requests, therefore, most packets of the connection are processed with a quick lookup in the ‘established’ table, rather than a full traversal of all rules. This iptables optimization results in performance that is largely independent of the number of network policies.
Such ‘flow tables’ are common optimizations in network equipment and it seems that iptables uses the same technique quite effectively.
Its also worth noting that in practise, a reasonably complex application may configure a few dozen rules per segment. It is also true that common network optimization techniques like Websockets and persistent connections will improve the performance of network policies even further (especially for small request sizes), since connections are held open longer and therefore can benefit from the established connection optimization.
These tests were performed using Romana as the backend policy provider and other network policy implementations may yield different results. However, what these tests show is that for almost every application deployment scenario, network policies can be applied using Romana as a network back end without any negative impact on performance.
If you wish to try it for yourself, we invite you to check out Romana. In our GitHub repo you can find an easy to use installer, which works with AWS, Vagrant VMs or any other servers. You can use it to quickly get you started with a Romana powered Kubernetes or OpenStack cluster.
Creating a PostgreSQL Cluster using Helm
Editor’s note: Today’s guest post is by Jeff McCormick, a developer at Crunchy Data, showing how to deploy a PostgreSQL cluster using Helm, a Kubernetes package manager.
Crunchy Data supplies a set of open source PostgreSQL and PostgreSQL related containers. The Crunchy PostgreSQL Container Suite includes containers that deploy, monitor, and administer the open source PostgreSQL database, for more details view this GitHub repository.
In this post we’ll show you how to deploy a PostgreSQL cluster using Helm, a Kubernetes package manager. For reference, the Crunchy Helm Chart examples used within this post are located here, and the pre-built containers can be found on DockerHub at this location.
This example will create the following in your Kubernetes cluster:
- postgres master service
- postgres replica service
- postgres 9.5 master database (pod)
- postgres 9.5 replica database (replication controller)

This example creates a simple Postgres streaming replication deployment with a master (read-write), and a single asynchronous replica (read-only). You can scale up the number of replicas dynamically.
Contents
The example is made up of various Chart files as follows:
| values.yaml | This file contains values which you can reference within the database templates allowing you to specify in one place values like database passwords |
| templates/master-pod.yaml | The postgres master database pod definition. This file causes a single postgres master pod to be created. |
| templates/master-service.yaml | The postgres master database has a service created to act as a proxy. This file causes a single service to be created to proxy calls to the master database. |
| templates/replica-rc.yaml | The postgres replica database is defined by this file. This file causes a replication controller to be created which allows the postgres replica containers to be scaled up on-demand. |
| templates/replica-service.yaml | This file causes the service proxy for the replica database container(s) to be created. |
Installation
Install Helm according to their GitHub documentation and then install the examples as follows:
helm init
cd crunchy-containers/examples/kubehelm
helm install ./crunchy-postgres
Testing
After installing the Helm chart, you will see the following services:
kubectl get services
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
crunchy-master 10.0.0.171 \<none\> 5432/TCP 1h
crunchy-replica 10.0.0.31 \<none\> 5432/TCP 1h
kubernetes 10.0.0.1 \<none\> 443/TCP 1h
It takes about a minute for the replica to begin replicating with the master. To test out replication, see if replication is underway with this command, enter password for the password when prompted:
psql -h crunchy-master -U postgres postgres -c 'table pg\_stat\_replication'
If you see a line returned from that query it means the master is replicating to the slave. Try creating some data on the master:
psql -h crunchy-master -U postgres postgres -c 'create table foo (id int)'
psql -h crunchy-master -U postgres postgres -c 'insert into foo values (1)'
Then verify that the data is replicated to the slave:
psql -h crunchy-replica -U postgres postgres -c 'table foo'
You can scale up the number of read-only replicas by running the following kubernetes command:
kubectl scale rc crunchy-replica --replicas=2
It takes 60 seconds for the replica to start and begin replicating from the master.
The Kubernetes Helm and Charts projects provide a streamlined way to package up complex applications and deploy them on a Kubernetes cluster. Deploying PostgreSQL clusters can sometimes prove challenging, but the task is greatly simplified using Helm and Charts.
--Jeff McCormick, Developer, Crunchy Data
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Deploying to Multiple Kubernetes Clusters with kit
Editor’s note: today’s guest post is by Chesley Brown, Full-Stack Engineer, at InVision, talking about how they build and open sourced kit to help them to continuously deploy updates to multiple clusters.
Our Docker journey at InVision may sound familiar. We started with Docker in our development environments, trying to get consistency there first. We wrangled our legacy monolith application into Docker images and streamlined our Dockerfiles to minimize size and amp the efficiency. Things were looking good. Did we learn a lot along the way? For sure. But at the end of it all, we had our entire engineering team working with Docker locally for their development environments. Mission accomplished! Well, not quite. Development was one thing, but moving to production was a whole other ballgame.
Along Came Kubernetes
Kubernetes came into our lives during our evaluation of orchestrators and schedulers last December. AWS ECS was still fresh and Docker had just released 1.9 (networking overlay release). We spent the month evaluating our choices, narrowing it down to native Docker tooling (Machine, Swarm, Compose), ECS and Kubernetes. Well, needless to say, Kubernetes was our clear winner and we started the new year moving headlong to leverage Kubernetes to get us to production. But it wasn't long when we ran into a tiny complication...
Automated Deployments With A Catch
Here at InVision, we have a unique challenge. We just don’t have a single production environment running Kubernetes, but several, all needing automated updates via our CI/CD process. And although the code running on these environments was similar, the configurations were not. Things needed to work smoothly, automatically, as we couldn't afford to add friction to the deploy process or encumber our engineering teams.
Having several near duplicate clusters could easily turn into a Kubernetes manifest nightmare. Anti-patterns galore, as we copy and paste 95% of the manifests to get a new cluster. Scalable? No. Headache? Yes. Keeping those manifests up-to-date and accurate would be a herculean (and error-prone) task. We needed something easier, something that allows reuse, keeping the maintenance low, and that we could incorporate into our CI/CD system.
So after looking for a project or tooling that could fit our needs, we came up empty. At InVision, we love to create tools to help us solve problems, and figuring we may not be the only team in this situation we decided to roll up our sleeves and created something of our own. The result is our open-source tool, kit! (short for Kubernetes + git)
Hello kit!
![]()
kit is a suite of components that, when plugged into your CI/CD system and source control, allows you to continuously deploy updates (or entirely new services!) to as many clusters as needed, all leveraging webhooks and without having to host an external service.
Using kit’s templating format, you can define your service files once and have them reused across multiple clusters. It works by building on top of your usual Kubernetes manifest files allowing them to be defined once and then reused across clusters by only defining the unique configuration needed for that specific cluster. This allows you to easily build the orchestration for your application and deploy it to as many clusters as needed. It also allows the ability to group variations of your application so you could have clusters that run the “development” version of your application while others run the “production” version and so on.
Developers simply commit code to their branches as normal and kit deploys to all clusters running that service. Kit then manages updating the image and tag that is used for a given service directly to the repository containing all your kit manifest templates. This means any and all changes to your clusters, from environment variables, or configurations to image updates are all tracked under source control history providing you with an audit trail for every cluster you have.
We made all of this Open Source so you can check out the kit repo!
Is kit Right For Us?
If you are running Kubernetes across several clusters (or namespaces) all needing to continuously deploy, you bet! Because using kit doesn’t require hosting any external server, your team can leverage the webhooks you probably already have with github and your CI/CD system to get started. From there you create a repo to host your Kubernetes manifest files which tells what services are deployed to which clusters. Complexity of these files is greatly simplified thanks to kit’s templating engine.The kit-image-deployer component is incorporated into the CI/CD process and whenever a developer commits code to master and the build passes, it’s automatically deployed to all configured clusters.
So What Are The Components?

kit is comprised of several components each building on the next. The general flow is a developer commits code to their repository, an image is built and then kit-image-deployer commits the new image and tag to your manifests repository. From there the kit-deploymentizer runs, parsing all your manifest templates to generate the raw Kubernetes manifest files. Finally the kit-deployer runs and takes all the built manifest files and deploys them to all the appropriate clusters. Here is a summary of the components and the flow:
kit-image-deployer
A service that can be used to update given yaml files within a git repository with a new Docker image path. This can be used in collaboration with kit-deploymentizer and kit-deployer to automatically update the images used for a service across multiple clusters.
kit-deploymentizer
This service intelligently builds deployment files as to allow reusability of environment variables and other forms of configuration. It also supports aggregating these deployments for multiple clusters. In the end, it generates a list of clusters and a list of deployment files for each of these clusters. Best used in collaboration with kit-deployer and kit-image-deployer to achieve a continuous deployment workflow.
kit-deployer
Use this service to deploy files to multiple Kubernetes clusters. Just organize your manifest files into directories that match the names of your clusters (the name defined in your kubeconfig files). Then you provide a directory of kubeconfig files and the kit-deployer will asynchronously send all manifests up to their corresponding clusters.
So What's Next?
In the near future, we want to make deployments even smarter so as to handle updating things like mongo replicasets. We also want to add in smart monitoring to further improve on the self-healing nature of Kubernetes. We’re also working on adding additional integrations (such as Slack) and notification methods. And most importantly we’re working towards shifting more control to the individual developers of each service by allowing the kit manifest templates to exist in each individual service repository instead of a single master manifest repository. This will allow them to manage their service completely from development straight to production across all clusters.
We hope you take a closer look at kit and tell us what you think! Check out our InVision Engineering blog for more posts about the cool things we are up to at InVision. If you want to work on kit or other interesting things like this, click through to our jobs page. We'd love to hear from you!
--Chesley Brown, Full-Stack Engineer, at InVision.
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Cloud Native Application Interfaces
Standard Interfaces (or, the Thirteenth Factor)
--by Brian Grant and Craig Mcluckie, Google
When you say we need ‘software standards’ in erudite company, you get some interesting looks. Most concede that software standards have been central to the success of the boldest and most successful projects out there (like the Internet). Most are also skeptical about how they apply to the innovative world we live in today. Our projects are executed in week increments, not years. Getting bogged down behind mega-software-corporation-driven standards practices would be the death knell in this fluid, highly competitive world.
This isn’t about ‘those’ standards. The ones that emerge after years of deep consideration and negotiation that are eventually published by a body with a four-letter acronym for a name. This is about a different approach: finding what is working in the real world, and acting as a community to embrace it.
Let’s go back to first principles. To describe Cloud Native in one word, we'd choose "automatable".
Most existing applications are not.
Applications have many interfaces with their environment, whether with management infrastructure, shared services, or other applications. For us to remove the operator from patching, scaling, migrating an app from one environment to another, changing out dependencies, and handling of failure conditions, a set of well structured common interfaces is essential. It goes without saying that these interfaces must be designed for machines, not just humans. Machine-friendly interfaces allow automation systems to understand the systems under management, and create the loose coupling needed for applications to live in automated environments.
As containerized infrastructure gets built there are a set of critical interfaces available to applications that go far beyond what is available to a single node today. The adoption of ‘serverless patterns’ (meaning ephemeral, event driven function execution) will further compound the need to make sense of running code in an environment that is completely decoupled from the node. The services needed will start with application configuration and extend to monitoring, logging, autoscaling and beyond. The set of capabilities will only grow as applications continue to adapt to be fuller citizens in a "cloud native" world.
Exploring one example a little further, a number of service-discovery solutions have been developed but are often tied to a particular storage implementation, a particular programming language, a non-standard protocol, and/or are opinionated in some other way (e.g., dictating application naming structure). This makes them unsuitable for general-purpose use. While DNS has limitations (that will eventually need to be addressed), it's at least a standard protocol with room for innovation in its implementation. This is demonstrated by CoreDNS and other cloud-native DNS implementations.
When we look inside the systems at Google, we have been able to achieve very high levels of automation without formal interface definitions thanks to a largely homogeneous software and hardware environment. Adjacent systems can safely make assumptions about interfaces, and by providing a set of universally used libraries we can skirt the issue. A good example of this is our log format doesn’t need to be formally specified because the libraries that generate logs are maintained by the teams that maintain the logs processing systems. This means that we have been able to get by to date without something like fluentd (which is solving the problem in the community of interfacing with logging systems).
Even though Google has managed to get by this way, it hurts us. One way is when we acquire a company. Porting their technology to run in our automation systems requires a spectacular amount of work. Doing that work while continuing to innovate is particularly tough. Even more significant though, there’s a lot of innovation happening in the open source world that isn’t easy for us to tap into. When new technology emerges, we would like to be able to experiment with it, adopt it piecemeal, and perhaps contribute back to it. When you run a vertically integrated, bespoke stack, that is a hard thing to do.
The lack of standard interfaces leaves customers with three choices:
- Live with high operations cost (the status quo), and accept that your developers in many cases will spend the majority of their time dealing with the care and feeding of applications.
- Sign-up to be like Google (build your own everything, down to the concrete in the floor).
- Rely on a single, or a small collection of vendors to provide a complete solution and accept some degree of lock-in. Few in companies of any size (from enterprise to startup) find this appealing. It is our belief that an open community is more powerful and that customers benefit when there is competition at every layer of the stack. It should be possible to pull together a stack with best-of-breed capabilities at every level -- logging, monitoring, orchestration, container runtime environment, block and file-system storage, SDN technology, etc.
Standardizing interfaces (at least by convention) between the management system and applications is critical. One might consider the use of common conventions for interfaces as a thirteenth factor (expanding on the 12-factor methodology) in creating modern systems that work well in the cloud and at scale.
Kubernetes and Cloud Native Computing Foundation (CNCF) represent a great opportunity to support the emergence of standard interfaces, and to support the emergence of a fully automated software world. We’d love to see this community embrace the ideal of promoting standard interfaces from working technology. The obvious first step is to identify the immediate set of critical interfaces, and establish working groups in CNCF to start assess what exists in this area as candidates, and to sponsor work to start developing standard interfaces that work across container formats, orchestrators, developer tools and the myriad other systems that are needed to deliver on the Cloud Native vision.
--Brian Grant and Craig Mcluckie, Google
Security Best Practices for Kubernetes Deployment
Note: some of the recommendations in this post are no longer current. Current cluster hardening options are described in this documentation.
Editor’s note: today’s post is by Amir Jerbi and Michael Cherny of Aqua Security, describing security best practices for Kubernetes deployments, based on data they’ve collected from various use-cases seen in both on-premises and cloud deployments.
Kubernetes provides many controls that can greatly improve your application security. Configuring them requires intimate knowledge with Kubernetes and the deployment’s security requirements. The best practices we highlight here are aligned to the container lifecycle: build, ship and run, and are specifically tailored to Kubernetes deployments. We adopted these best practices in our own SaaS deployment that runs Kubernetes on Google Cloud Platform.
The following are our recommendations for deploying a secured Kubernetes application:
**Ensure That Images Are Free of Vulnerabilities **
Having running containers with vulnerabilities opens your environment to the risk of being easily compromised. Many of the attacks can be mitigated simply by making sure that there are no software components that have known vulnerabilities.
-
Implement Continuous Security Vulnerability Scanning -- Containers might include outdated packages with known vulnerabilities (CVEs). This cannot be a ‘one off’ process, as new vulnerabilities are published every day. An ongoing process, where images are continuously assessed, is crucial to insure a required security posture.
-
Regularly Apply Security Updates to Your Environment -- Once vulnerabilities are found in running containers, you should always update the source image and redeploy the containers. Try to avoid direct updates (e.g. ‘apt-update’) to the running containers, as this can break the image-container relationship. Upgrading containers is extremely easy with the Kubernetes rolling updates feature - this allows gradually updating a running application by upgrading its images to the latest version.
Ensure That Only Authorized Images are Used in Your Environment
Without a process that ensures that only images adhering to the organization’s policy are allowed to run, the organization is open to risk of running vulnerable or even malicious containers. Downloading and running images from unknown sources is dangerous. It is equivalent to running software from an unknown vendor on a production server. Don’t do that.
Use private registries to store your approved images - make sure you only push approved images to these registries. This alone already narrows the playing field, reducing the number of potential images that enter your pipeline to a fraction of the hundreds of thousands of publicly available images. Build a CI pipeline that integrates security assessment (like vulnerability scanning), making it part of the build process.
The CI pipeline should ensure that only vetted code (approved for production) is used for building the images. Once an image is built, it should be scanned for security vulnerabilities, and only if no issues are found then the image would be pushed to a private registry, from which deployment to production is done. A failure in the security assessment should create a failure in the pipeline, preventing images with bad security quality from being pushed to the image registry.
There is work in progress being done in Kubernetes for image authorization plugins (expected in Kubernetes 1.4), which will allow preventing the shipping of unauthorized images. For more info see this pull request.
Limit Direct Access to Kubernetes Nodes
You should limit SSH access to Kubernetes nodes, reducing the risk for unauthorized access to host resource. Instead you should ask users to use "kubectl exec", which will provide direct access to the container environment without the ability to access the host.
You can use Kubernetes Authorization Plugins to further control user access to resources. This allows defining fine-grained-access control rules for specific namespace, containers and operations.
Create Administrative Boundaries between Resources
Limiting the scope of user permissions can reduce the impact of mistakes or malicious activities. A Kubernetes namespace allows you to partition created resources into logically named groups. Resources created in one namespace can be hidden from other namespaces. By default, each resource created by a user in Kubernetes cluster runs in a default namespace, called default. You can create additional namespaces and attach resources and users to them. You can use Kubernetes Authorization plugins to create policies that segregate access to namespace resources between different users.
For example: the following policy will allow ‘alice’ to read pods from namespace ‘fronto’.
{
"apiVersion": "abac.authorization.kubernetes.io/v1beta1",
"kind": "Policy",
"spec": {
"user": "alice",
"namespace": "fronto",
"resource": "pods",
"readonly": true
}
}
Define Resource Quota
An option of running resource-unbound containers puts your system in risk of DoS or “noisy neighbor” scenarios. To prevent and minimize those risks you should define resource quotas. By default, all resources in Kubernetes cluster are created with unbounded CPU and memory requests/limits. You can create resource quota policies, attached to Kubernetes namespace, in order to limit the CPU and memory a pod is allowed to consume.
The following is an example for namespace resource quota definition that will limit number of pods in the namespace to 4, limiting their CPU requests between 1 and 2 and memory requests between 1GB to 2GB.
compute-resources.yaml:
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "4"
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
Assign a resource quota to namespace:
kubectl create -f ./compute-resources.yaml --namespace=myspace
Implement Network Segmentation
Running different applications on the same Kubernetes cluster creates a risk of one compromised application attacking a neighboring application. Network segmentation is important to ensure that containers can communicate only with those they are supposed to.
One of the challenges in Kubernetes deployments is creating network segmentation between pods, services and containers. This is a challenge due to the “dynamic” nature of container network identities (IPs), along with the fact that containers can communicate both inside the same node or between nodes.
Users of Google Cloud Platform can benefit from automatic firewall rules, preventing cross-cluster communication. A similar implementation can be deployed on-premises using network firewalls or SDN solutions. There is work being done in this area by the Kubernetes Network SIG, which will greatly improve the pod-to-pod communication policies. A new network policy API should address the need to create firewall rules around pods, limiting the network access that a containerized can have.
The following is an example of a network policy that controls the network for “backend” pods, only allowing inbound network access from “frontend” pods:
POST /apis/net.alpha.kubernetes.io/v1alpha1/namespaces/tenant-a/networkpolicys
{
"kind": "NetworkPolicy",
"metadata": {
"name": "pol1"
},
"spec": {
"allowIncoming": {
"from": [{
"pods": { "segment": "frontend" }
}],
"toPorts": [{
"port": 80,
"protocol": "TCP"
}]
},
"podSelector": {
"segment": "backend"
}
}
}
Read more about Network policies here.
Apply Security Context to Your Pods and Containers
When designing your containers and pods, make sure that you configure the security context for your pods, containers and volumes. A security context is a property defined in the deployment yaml. It controls the security parameters that will be assigned to the pod/container/volume. Some of the important parameters are:
| Security Context Setting | Description |
|---|---|
| SecurityContext->runAsNonRoot | Indicates that containers should run as non-root user |
| SecurityContext->Capabilities | Controls the Linux capabilities assigned to the container. |
| SecurityContext->readOnlyRootFilesystem | Controls whether a container will be able to write into the root filesystem. |
| PodSecurityContext->runAsNonRoot | Prevents running a container with 'root' user as part of the pod |
The following is an example for pod definition with security context parameters:
apiVersion: v1
kind: Pod
metadata:
name: hello-world
spec:
containers:
# specification of the pod’s containers
# ...
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
Reference here.
In case you are running containers with elevated privileges (--privileged) you should consider using the “DenyEscalatingExec” admission control. This control denies exec and attach commands to pods that run with escalated privileges that allow host access. This includes pods that run as privileged, have access to the host IPC namespace, and have access to the host PID namespace. For more details on admission controls, see the Kubernetes documentation.
Log Everything
Kubernetes supplies cluster-based logging, allowing to log container activity into a central log hub. When a cluster is created, the standard output and standard error output of each container can be ingested using a Fluentd agent running on each node into either Google Stackdriver Logging or into Elasticsearch and viewed with Kibana.
Summary
Kubernetes supplies many options to create a secured deployment. There is no one-size-fit-all solution that can be used everywhere, so a certain degree of familiarity with these options is required, as well as an understanding of how they can enhance your application’s security.
We recommend implementing the best practices that were highlighted in this blog, and use Kubernetes flexible configuration capabilities to incorporate security processes into the continuous integration pipeline, automating the entire process with security seamlessly “baked in”.
--Michael Cherny, Head of Security Research, and Amir Jerbi, CTO and co-founder Aqua Security
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Scaling Stateful Applications using Kubernetes Pet Sets and FlexVolumes with Datera Elastic Data Fabric
Editor’s note: today’s guest post is by Shailesh Mittal, Software Architect and Ashok Rajagopalan, Sr Director Product at Datera Inc, talking about Stateful Application provisioning with Kubernetes on Datera Elastic Data Fabric.
Introduction
Persistent volumes in Kubernetes are foundational as customers move beyond stateless workloads to run stateful applications. While Kubernetes has supported stateful applications such as MySQL, Kafka, Cassandra, and Couchbase for a while, the introduction of Pet Sets has significantly improved this support. In particular, the procedure to sequence the provisioning and startup, the ability to scale and associate durably by Pet Sets has provided the ability to automate to scale the “Pets” (applications that require consistent handling and durable placement).
Datera, elastic block storage for cloud deployments, has seamlessly integrated with Kubernetes through the FlexVolume framework. Based on the first principles of containers, Datera allows application resource provisioning to be decoupled from the underlying physical infrastructure. This brings clean contracts (aka, no dependency or direct knowledge of the underlying physical infrastructure), declarative formats, and eventually portability to stateful applications.
While Kubernetes allows for great flexibility to define the underlying application infrastructure through yaml configurations, Datera allows for that configuration to be passed to the storage infrastructure to provide persistence. Through the notion of Datera AppTemplates, in a Kubernetes environment, stateful applications can be automated to scale.
Deploying Persistent Storage
Persistent storage is defined using the Kubernetes PersistentVolume subsystem. PersistentVolumes are volume plugins and define volumes that live independently of the lifecycle of the pod that is using it. They are implemented as NFS, iSCSI, or by cloud provider specific storage system. Datera has developed a volume plugin for PersistentVolumes that can provision iSCSI block storage on the Datera Data Fabric for Kubernetes pods.
The Datera volume plugin gets invoked by kubelets on minion nodes and relays the calls to the Datera Data Fabric over its REST API. Below is a sample deployment of a PersistentVolume with the Datera plugin:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-datera-0
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
flexVolume:
driver: "datera/iscsi"
fsType: "xfs"
options:
volumeID: "kube-pv-datera-0"
size: “100"
replica: "3"
backstoreServer: "[tlx170.tlx.daterainc.com](http://tlx170.tlx.daterainc.com/):7717”
This manifest defines a PersistentVolume of 100 GB to be provisioned in the Datera Data Fabric, should a pod request the persistent storage.
[root@tlx241 /]# kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv-datera-0 100Gi RWO Available 8s
pv-datera-1 100Gi RWO Available 2s
pv-datera-2 100Gi RWO Available 7s
pv-datera-3 100Gi RWO Available 4s
Configuration
The Datera PersistenceVolume plugin is installed on all minion nodes. When a pod lands on a minion node with a valid claim bound to the persistent storage provisioned earlier, the Datera plugin forwards the request to create the volume on the Datera Data Fabric. All the options that are specified in the PersistentVolume manifest are sent to the plugin upon the provisioning request.
Once a volume is provisioned in the Datera Data Fabric, volumes are presented as an iSCSI block device to the minion node, and kubelet mounts this device for the containers (in the pod) to access it.

Using Persistent Storage
Kubernetes PersistentVolumes are used along with a pod using PersistentVolume Claims. Once a claim is defined, it is bound to a PersistentVolume matching the claim’s specification. A typical claim for the PersistentVolume defined above would look like below:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pv-claim-test-petset-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
When this claim is defined and it is bound to a PersistentVolume, resources can be used with the pod specification:
[root@tlx241 /]# kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv-datera-0 100Gi RWO Bound default/pv-claim-test-petset-0 6m
pv-datera-1 100Gi RWO Bound default/pv-claim-test-petset-1 6m
pv-datera-2 100Gi RWO Available 7s
pv-datera-3 100Gi RWO Available 4s
[root@tlx241 /]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pv-claim-test-petset-0 Bound pv-datera-0 0 3m
pv-claim-test-petset-1 Bound pv-datera-1 0 3m
A pod can use a PersistentVolume Claim like below:
apiVersion: v1
kind: Pod
metadata:
name: kube-pv-demo
spec:
containers:
- name: data-pv-demo
image: nginx
volumeMounts:
- name: test-kube-pv1
mountPath: /data
ports:
- containerPort: 80
volumes:
- name: test-kube-pv1
persistentVolumeClaim:
claimName: pv-claim-test-petset-0
The result is a pod using a PersistentVolume Claim as a volume. It in-turn sends the request to the Datera volume plugin to provision storage in the Datera Data Fabric.
[root@tlx241 /]# kubectl describe pods kube-pv-demo
Name: kube-pv-demo
Namespace: default
Node: tlx243/172.19.1.243
Start Time: Sun, 14 Aug 2016 19:17:31 -0700
Labels: \<none\>
Status: Running
IP: 10.40.0.3
Controllers: \<none\>
Containers:
data-pv-demo:
Container ID: [docker://ae2a50c25e03143d0dd721cafdcc6543fac85a301531110e938a8e0433f74447](about:blank)
Image: nginx
Image ID: [docker://sha256:0d409d33b27e47423b049f7f863faa08655a8c901749c2b25b93ca67d01a470d](about:blank)
Port: 80/TCP
State: Running
Started: Sun, 14 Aug 2016 19:17:34 -0700
Ready: True
Restart Count: 0
Environment Variables: \<none\>
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
test-kube-pv1:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: pv-claim-test-petset-0
ReadOnly: false
default-token-q3eva:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-q3eva
QoS Tier: BestEffort
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
43s 43s 1 {default-scheduler } Normal Scheduled Successfully assigned kube-pv-demo to tlx243
42s 42s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Pulling pulling image "nginx"
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Pulled Successfully pulled image "nginx"
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Created Created container with docker id ae2a50c25e03
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Started Started container with docker id ae2a50c25e03
The persistent volume is presented as iSCSI device at minion node (tlx243 in this case):
[root@tlx243 ~]# lsscsi
[0:2:0:0] disk SMC SMC2208 3.24 /dev/sda
[11:0:0:0] disk DATERA IBLOCK 4.0 /dev/sdb
[root@tlx243 datera~iscsi]# mount ``` grep sdb
/dev/sdb on /var/lib/kubelet/pods/6b99bd2a-628e-11e6-8463-0cc47ab41442/volumes/datera~iscsi/pv-datera-0 type xfs (rw,relatime,attr2,inode64,noquota)
Containers running in the pod see this device mounted at /data as specified in the manifest:
[root@tlx241 /]# kubectl exec kube-pv-demo -c data-pv-demo -it bash
root@kube-pv-demo:/# mount ``` grep data
/dev/sdb on /data type xfs (rw,relatime,attr2,inode64,noquota)
Using Pet Sets
Typically, pods are treated as stateless units, so if one of them is unhealthy or gets superseded, Kubernetes just disposes it. In contrast, a PetSet is a group of stateful pods that has a stronger notion of identity. The goal of a PetSet is to decouple this dependency by assigning identities to individual instances of an application that are not anchored to the underlying physical infrastructure.
A PetSet requires {0..n-1} Pets. Each Pet has a deterministic name, PetSetName-Ordinal, and a unique identity. Each Pet has at most one pod, and each PetSet has at most one Pet with a given identity. A PetSet ensures that a specified number of “pets” with unique identities are running at any given time. The identity of a Pet is comprised of:
- a stable hostname, available in DNS
- an ordinal index
- stable storage: linked to the ordinal & hostname
A typical PetSet definition using a PersistentVolume Claim looks like below:
# A headless service to create DNS records
apiVersion: v1
kind: Service
metadata:
name: test-service
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1alpha1
kind: PetSet
metadata:
name: test-petset
spec:
serviceName: "test-service"
replicas: 2
template:
metadata:
labels:
app: nginx
annotations:
[pod.alpha.kubernetes.io/initialized:](http://pod.alpha.kubernetes.io/initialized:) "true"
spec:
terminationGracePeriodSeconds: 0
containers:
- name: nginx
image: [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
ports:
- containerPort: 80
name: web
volumeMounts:
- name: pv-claim
mountPath: /data
volumeClaimTemplates:
- metadata:
name: pv-claim
annotations:
[volume.alpha.kubernetes.io/storage-class:](http://volume.alpha.kubernetes.io/storage-class:) anything
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 100Gi
We have the following PersistentVolume Claims available:
[root@tlx241 /]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pv-claim-test-petset-0 Bound pv-datera-0 0 41m
pv-claim-test-petset-1 Bound pv-datera-1 0 41m
pv-claim-test-petset-2 Bound pv-datera-2 0 5s
pv-claim-test-petset-3 Bound pv-datera-3 0 2s
When this PetSet is provisioned, two pods get instantiated:
[root@tlx241 /]# kubectl get pods
NAMESPACE NAME READY STATUS RESTARTS AGE
default test-petset-0 1/1 Running 0 7s
default test-petset-1 1/1 Running 0 3s
Here is how the PetSet test-petset instantiated earlier looks like:
[root@tlx241 /]# kubectl describe petset test-petset
Name: test-petset
Namespace: default
Image(s): [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
Selector: app=nginx
Labels: app=nginx
Replicas: 2 current / 2 desired
Annotations: \<none\>
CreationTimestamp: Sun, 14 Aug 2016 19:46:30 -0700
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
No volumes.
No events.
Once a PetSet is instantiated, such as test-petset below, upon increasing the number of replicas (i.e. the number of pods started with that PetSet), more pods get instantiated and more PersistentVolume Claims get bound to new pods:
[root@tlx241 /]# kubectl patch petset test-petset -p'{"spec":{"replicas":"3"}}'
"test-petset” patched
[root@tlx241 /]# kubectl describe petset test-petset
Name: test-petset
Namespace: default
Image(s): [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
Selector: app=nginx
Labels: app=nginx
Replicas: 3 current / 3 desired
Annotations: \<none\>
CreationTimestamp: Sun, 14 Aug 2016 19:46:30 -0700
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
No volumes.
No events.
[root@tlx241 /]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test-petset-0 1/1 Running 0 29m
test-petset-1 1/1 Running 0 28m
test-petset-2 1/1 Running 0 9s
Now the PetSet is running 3 pods after patch application.
When the above PetSet definition is patched to have one more replica, it introduces one more pod in the system. This in turn results in one more volume getting provisioned on the Datera Data Fabric. So volumes get dynamically provisioned and attached to a pod upon the PetSet scaling up.
To support the notion of durability and consistency, if a pod moves from one minion to another, volumes do get attached (mounted) to the new minion node and detached (unmounted) from the old minion to maintain persistent access to the data.
Conclusion
This demonstrates Kubernetes with Pet Sets orchestrating stateful and stateless workloads. While the Kubernetes community is working on expanding the FlexVolume framework’s capabilities, we are excited that this solution makes it possible for Kubernetes to be run more widely in the datacenters.
Join and contribute: Kubernetes Storage SIG.
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on the k8s Slack
- Follow us on Twitter @Kubernetesio for latest updates
Kubernetes Namespaces: use cases and insights
“Who's on first, What's on second, I Don't Know's on third”
Who's on First? by Abbott and Costello
Introduction
Kubernetes is a system with several concepts. Many of these concepts get manifested as “objects” in the RESTful API (often called “resources” or “kinds”). One of these concepts is Namespaces. In Kubernetes, Namespaces are the way to partition a single Kubernetes cluster into multiple virtual clusters. In this post we’ll highlight examples of how our customers are using Namespaces.
But first, a metaphor: Namespaces are like human family names. A family name, e.g. Wong, identifies a family unit. Within the Wong family, one of its members, e.g. Sam Wong, is readily identified as just “Sam” by the family. Outside of the family, and to avoid “Which Sam?” problems, Sam would usually be referred to as “Sam Wong”, perhaps even “Sam Wong from San Francisco”.
Namespaces are a logical partitioning capability that enable one Kubernetes cluster to be used by multiple users, teams of users, or a single user with multiple applications without concern for undesired interaction. Each user, team of users, or application may exist within its Namespace, isolated from every other user of the cluster and operating as if it were the sole user of the cluster. (Furthermore, Resource Quotas provide the ability to allocate a subset of a Kubernetes cluster’s resources to a Namespace.)
For all but the most trivial uses of Kubernetes, you will benefit by using Namespaces. In this post, we’ll cover the most common ways that we’ve seen Kubernetes users on Google Cloud Platform use Namespaces, but our list is not exhaustive and we’d be interested to learn other examples from you.
Use-cases covered
- Roles and Responsibilities in an enterprise for namespaces
- Partitioning landscapes: dev vs. test vs. prod
- Customer partitioning for non-multi-tenant scenarios
- When not to use namespaces
Use-case #1: Roles and Responsibilities in an Enterprise
A typical enterprise contains multiple business/technology entities that operate independently of each other with some form of overarching layer of controls managed by the enterprise itself. Operating a Kubernetes clusters in such an environment can be done effectively when roles and responsibilities pertaining to Kubernetes are defined.
Below are a few recommended roles and their responsibilities that can make managing Kubernetes clusters in a large scale organization easier.
- Designer/Architect role: This role will define the overall namespace strategy, taking into account product/location/team/cost-center and determining how best to map these to Kubernetes Namespaces. Investing in such a role prevents namespace proliferation and “snowflake” Namespaces.
- Admin role: This role has admin access to all Kubernetes clusters. Admins can create/delete clusters and add/remove nodes to scale the clusters. This role will be responsible for patching, securing and maintaining the clusters. As well as implementing Quotas between the different entities in the organization. The Kubernetes Admin is responsible for implementing the namespaces strategy defined by the Designer/Architect.
These two roles and the actual developers using the clusters will also receive support and feedback from the enterprise security and network teams on issues such as security isolation requirements and how namespaces fit this model, or assistance with networking subnets and load-balancers setup.
Anti-patterns
- Isolated Kubernetes usage “Islands” without centralized control: Without the initial investment in establishing a centralized control structure around Kubernetes management there is a risk of ending with a “mushroom farm” topology i.e. no defined size/shape/structure of clusters within the org. The result is a difficult to manage, higher risk and elevated cost due to underutilization of resources.
- Old-world IT controls choking usage and innovation: A common tendency is to try and transpose existing on-premises controls/procedures onto new dynamic frameworks .This results in weighing down the agile nature of these frameworks and nullifying the benefits of rapid dynamic deployments.
- Omni-cluster: Delaying the effort of creating the structure/mechanism for namespace management can result in one large omni-cluster that is hard to peel back into smaller usage groups.
Use-case #2: Using Namespaces to partition development landscapes
Software development teams customarily partition their development pipelines into discrete units. These units take various forms and use various labels but will tend to result in a discrete dev environment, a testing|QA environment, possibly a staging environment and finally a production environment. The resulting layouts are ideally suited to Kubernetes Namespaces. Each environment or stage in the pipeline becomes a unique namespace.
The above works well as each namespace can be templated and mirrored to the next subsequent environment in the dev cycle, e.g. dev->qa->prod. The fact that each namespace is logically discrete allows the development teams to work within an isolated “development” namespace. DevOps (The closest role at Google is called Site Reliability Engineering “SRE”) will be responsible for migrating code through the pipelines and ensuring that appropriate teams are assigned to each environment. Ultimately, DevOps is solely responsible for the final, production environment where the solution is delivered to the end-users.
A major benefit of applying namespaces to the development cycle is that the naming of software components (e.g. micro-services/endpoints) can be maintained without collision across the different environments. This is due to the isolation of the Kubernetes namespaces, e.g. serviceX in dev would be referred to as such across all the other namespaces; but, if necessary, could be uniquely referenced using its full qualified name serviceX.development.mycluster.com in the development namespace of mycluster.com.
Anti-patterns
- Abusing the namespace benefit resulting in unnecessary environments in the development pipeline. So; if you don’t do staging deployments, don’t create a “staging” namespace.
- Overcrowding namespaces e.g. having all your development projects in one huge “development” namespace. Since namespaces attempt to partition, use these to partition by your projects as well. Since Namespaces are flat, you may wish something similar to: projectA-dev, projectA-prod as projectA’s namespaces.
Use-case #3: Partitioning of your Customers
If you are, for example, a consulting company that wishes to manage separate applications for each of your customers, the partitioning provided by Namespaces aligns well. You could create a separate Namespace for each customer, customer project or customer business unit to keep these distinct while not needing to worry about reusing the same names for resources across projects.
An important consideration here is that Kubernetes does not currently provide a mechanism to enforce access controls across namespaces and so we recommend that you do not expose applications developed using this approach externally.
Anti-patterns
- Multi-tenant applications don’t need the additional complexity of Kubernetes namespaces since the application is already enforcing this partitioning.
- Inconsistent mapping of customers to namespaces. For example, you win business at a global corporate, you may initially consider one namespace for the enterprise not taking into account that this customer may prefer further partitioning e.g. BigCorp Accounting and BigCorp Engineering. In this case, the customer’s departments may each warrant a namespace.
When Not to use Namespaces
In some circumstances Kubernetes Namespaces will not provide the isolation that you need. This may be due to geographical, billing or security factors. For all the benefits of the logical partitioning of namespaces, there is currently no ability to enforce the partitioning. Any user or resource in a Kubernetes cluster may access any other resource in the cluster regardless of namespace. So, if you need to protect or isolate resources, the ultimate namespace is a separate Kubernetes cluster against which you may apply your regular security|ACL controls.
Another time when you may consider not using namespaces is when you wish to reflect a geographically distributed deployment. If you wish to deploy close to US, EU and Asia customers, a Kubernetes cluster deployed locally in each region is recommended.
When fine-grained billing is required perhaps to chargeback by cost-center or by customer, the recommendation is to leave the billing to your infrastructure provider. For example, in Google Cloud Platform (GCP), you could use a separate GCP Project or Billing Account and deploy a Kubernetes cluster to a specific-customer’s project(s).
In situations where confidentiality or compliance require complete opaqueness between customers, a Kubernetes cluster per customer/workload will provide the desired level of isolation. Once again, you should delegate the partitioning of resources to your provider.
Work is underway to provide (a) ACLs on Kubernetes Namespaces to be able to enforce security; (b) to provide Kubernetes Cluster Federation. Both mechanisms will address the reasons for the separate Kubernetes clusters in these anti-patterns.
An easy to grasp anti-pattern for Kubernetes namespaces is versioning. You should not use Namespaces as a way to disambiguate versions of your Kubernetes resources. Support for versioning is present in the containers and container registries as well as in Kubernetes Deployment resource. Multiple versions should coexist by utilizing the Kubernetes container model which also provides for auto migration between versions with deployments. Furthermore versions scope namespaces will cause massive proliferation of namespaces within a cluster making it hard to manage.
Caveat Gubernator
You may wish to, but you cannot create a hierarchy of namespaces. Namespaces cannot be nested within one another. You can’t, for example, create my-team.my-org as a namespace but could perhaps have team-org.
Namespaces are easy to create and use but it’s also easy to deploy code inadvertently into the wrong namespace. Good DevOps hygiene suggests documenting and automating processes where possible and this will help. The other way to avoid using the wrong namespace is to set a kubectl context.
As mentioned previously, Kubernetes does not (currently) provide a mechanism to enforce security across Namespaces. You should only use Namespaces within trusted domains (e.g. internal use) and not use Namespaces when you need to be able to provide guarantees that a user of the Kubernetes cluster or ones its resources be unable to access any of the other Namespaces resources. This enhanced security functionality is being discussed in the Kubernetes Special Interest Group for Authentication and Authorization, get involved at SIG-Auth.
--Mike Altarace & Daz Wilkin, Strategic Customer Engineers, Google Cloud Platform
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
SIG Apps: build apps for and operate them in Kubernetes
Editor’s note: This post is by the Kubernetes SIG-Apps team sharing how they focus on the developer and devops experience of running applications in Kubernetes.
Kubernetes is an incredible manager for containerized applications. Because of this, numerous companies have started to run their applications in Kubernetes.
Kubernetes Special Interest Groups (SIGs) have been around to support the community of developers and operators since around the 1.0 release. People organized around networking, storage, scaling and other operational areas.
As Kubernetes took off, so did the need for tools, best practices, and discussions around building and operating cloud native applications. To fill that need the Kubernetes SIG Apps came into existence.
SIG Apps is a place where companies and individuals can:
- see and share demos of the tools being built to enable app operators
- learn about and discuss needs of app operators
- organize around efforts to improve the experience
Since the inception of SIG Apps we’ve had demos of projects like KubeFuse, KPM, and StackSmith. We’ve also executed on a survey of those operating apps in Kubernetes.
From the survey results we’ve learned a number of things including:
- That 81% of respondents want some form of autoscaling
- To store secret information 47% of respondents use built-in secrets. At reset these are not currently encrypted. (If you want to help add encryption there is an issue for that.)
- The most responded questions had to do with 3rd party tools and debugging
- For 3rd party tools to manage applications there were no clear winners. There are a wide variety of practices
- An overall complaint about a lack of useful documentation. (Help contribute to the docs here.)
- There’s a lot of data. Many of the responses were optional so we were surprised that 935 of all questions across all candidates were filled in. If you want to look at the data yourself it’s available online.
When it comes to application operation there’s still a lot to be figured out and shared. If you've got opinions about running apps, tooling to make the experience better, or just want to lurk and learn about what's going please come join us.
- Chat with us on SIG-Apps Slack channel
- Email as at SIG-Apps mailing list
- Join our open meetings: weekly at 9AM PT on Wednesdays, full details here.
--Matt Farina, Principal Engineer, Hewlett Packard Enterprise
Create a Couchbase cluster using Kubernetes
Editor’s note: today’s guest post is by Arun Gupta, Vice President Developer Relations at Couchbase, showing how to setup a Couchbase cluster with Kubernetes.
Couchbase Server is an open source, distributed NoSQL document-oriented database. It exposes a fast key-value store with managed cache for submillisecond data operations, purpose-built indexers for fast queries and a query engine for executing SQL queries. For mobile and Internet of Things (IoT) environments, Couchbase Lite runs native on-device and manages sync to Couchbase Server.
Couchbase Server 4.5 was recently announced, bringing many new features, including production certified support for Docker. Couchbase is supported on a wide variety of orchestration frameworks for Docker containers, such as Kubernetes, Docker Swarm and Mesos, for full details visit this page.
This blog post will explain how to create a Couchbase cluster using Kubernetes. This setup is tested using Kubernetes 1.3.3, Amazon Web Services, and Couchbase 4.5 Enterprise Edition.
Like all good things, this post is standing on the shoulder of giants. The design pattern used in this blog was defined in a Friday afternoon hack with @saturnism. A working version of the configuration files was contributed by @r_schmiddy.
Couchbase Cluster
A cluster of Couchbase Servers is typically deployed on commodity servers. Couchbase Server has a peer-to-peer topology where all the nodes are equal and communicate to each other on demand. There is no concept of master nodes, slave nodes, config nodes, name nodes, head nodes, etc, and all the software loaded on each node is identical. It allows the nodes to be added or removed without considering their “type”. This model works particularly well with cloud infrastructure in general. For Kubernetes, this means that we can use the exact same container image for all Couchbase nodes.
A typical Couchbase cluster creation process looks like:
- Start Couchbase: Start n Couchbase servers
- Create cluster: Pick any server, and add all other servers to it to create the cluster
- Rebalance cluster: Rebalance the cluster so that data is distributed across the cluster
In order to automate using Kubernetes, the cluster creation is split into a “master” and “worker” Replication Controller (RC).
The master RC has only one replica and is also published as a Service. This provides a single reference point to start the cluster creation. By default services are visible only from inside the cluster. This service is also exposed as a load balancer. This allows the Couchbase Web Console to be accessible from outside the cluster.
The worker RC use the exact same image as master RC. This keeps the cluster homogenous which allows to scale the cluster easily.

Configuration files used in this blog are available here. Let’s create the Kubernetes resources to create the Couchbase cluster.
Create Couchbase “master” Replication Controller
Couchbase master RC can be created using the following configuration file:
apiVersion: v1
kind: ReplicationController
metadata:
name: couchbase-master-rc
spec:
replicas: 1
selector:
app: couchbase-master-pod
template:
metadata:
labels:
app: couchbase-master-pod
spec:
containers:
- name: couchbase-master
image: arungupta/couchbase:k8s
env:
- name: TYPE
value: MASTER
ports:
- containerPort: 8091
----
apiVersion: v1
kind: Service
metadata:
name: couchbase-master-service
labels:
app: couchbase-master-service
spec:
ports:
- port: 8091
selector:
app: couchbase-master-pod
type: LoadBalancer
This configuration file creates a couchbase-master-rc Replication Controller. This RC has one replica of the pod created using the arungupta/couchbase:k8s image. This image is created using the Dockerfile here. This Dockerfile uses a configuration script to configure the base Couchbase Docker image. First, it uses Couchbase REST API to setup memory quota, setup index, data and query services, security credentials, and loads a sample data bucket. Then, it invokes the appropriate Couchbase CLI commands to add the Couchbase node to the cluster or add the node and rebalance the cluster. This is based upon three environment variables:
- TYPE: Defines whether the joining pod is worker or master
- AUTO_REBALANCE: Defines whether the cluster needs to be rebalanced
- COUCHBASE_MASTER: Name of the master service
For this first configuration file, the TYPE environment variable is set to MASTER and so no additional configuration is done on the Couchbase image.
Let’s create and verify the artifacts.
Create Couchbase master RC:
kubectl create -f cluster-master.yml
replicationcontroller "couchbase-master-rc" created
service "couchbase-master-service" created
List all the services:
kubectl get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
couchbase-master-service 10.0.57.201 8091/TCP 30s
kubernetes 10.0.0.1 \<none\> 443/TCP 5h
Output shows that couchbase-master-service is created.
Get all the pods:
kubectl get po
NAME READY STATUS RESTARTS AGE
couchbase-master-rc-97mu5 1/1 Running 0 1m
A pod is created using the Docker image specified in the configuration file.
Check the RC:
kubectl get rc
NAME DESIRED CURRENT AGE
couchbase-master-rc 1 1 1m
It shows that the desired and current number of pods in the RC are matching.
Describe the service:
kubectl describe svc couchbase-master-service
Name: couchbase-master-service
Namespace: default
Labels: app=couchbase-master-service
Selector: app=couchbase-master-pod
Type: LoadBalancer
IP: 10.0.57.201
LoadBalancer Ingress: a94f1f286590c11e68e100283628cd6c-1110696566.us-west-2.elb.amazonaws.com
Port: \<unset\> 8091/TCP
NodePort: \<unset\> 30019/TCP
Endpoints: 10.244.2.3:8091
Session Affinity: None
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
2m 2m 1 {service-controller } Normal CreatingLoadBalancer Creating load balancer
2m 2m 1 {service-controller } Normal CreatedLoadBalancer Created load balancer
Among other details, the address shown next to LoadBalancer Ingress is relevant for us. This address is used to access the Couchbase Web Console.
Wait for ~3 mins for the load balancer to be ready to receive requests. Couchbase Web Console is accessible at <ip>:8091 and looks like:

The image used in the configuration file is configured with the Administrator username and password password. Enter the credentials to see the console:

Click on Server Nodes to see how many Couchbase nodes are part of the cluster. As expected, it shows only one node:

Click on Data Buckets to see a sample bucket that was created as part of the image:

This shows the travel-sample bucket is created and has 31,591 JSON documents.
Create Couchbase “worker” Replication Controller
Now, let’s create a worker replication controller. It can be created using the configuration file:
apiVersion: v1
kind: ReplicationController
metadata:
name: couchbase-worker-rc
spec:
replicas: 1
selector:
app: couchbase-worker-pod
template:
metadata:
labels:
app: couchbase-worker-pod
spec:
containers:
- name: couchbase-worker
image: arungupta/couchbase:k8s
env:
- name: TYPE
value: "WORKER"
- name: COUCHBASE\_MASTER
value: "couchbase-master-service"
- name: AUTO\_REBALANCE
value: "false"
ports:
- containerPort: 8091
This RC also creates a single replica of Couchbase using the same arungupta/couchbase:k8s image. The key differences here are:
- TYPE environment variable is set to WORKER. This adds a worker Couchbase node to be added to the cluster.
- COUCHBASE_MASTER environment variable is passed the value of couchbase-master-service. This uses the service discovery mechanism built into Kubernetes for pods in the worker and the master to communicate.
- AUTO_REBALANCE environment variable is set to false. This ensures that the node is only added to the cluster but the cluster itself is not rebalanced. Rebalancing is required to re-distribute data across multiple nodes of the cluster. This is the recommended way as multiple nodes can be added first, and then cluster can be manually rebalanced using the Web Console. Let’s create a worker:
kubectl create -f cluster-worker.yml
replicationcontroller "couchbase-worker-rc" created
Check the RC:
kubectl get rc
NAME DESIRED CURRENT AGE
couchbase-master-rc 1 1 6m
couchbase-worker-rc 1 1 22s
A new couchbase-worker-rc is created where the desired and the current number of instances are matching.
Get all pods:
kubectl get po
NAME READY STATUS RESTARTS AGE
couchbase-master-rc-97mu5 1/1 Running 0 6m
couchbase-worker-rc-4ik02 1/1 Running 0 46s
An additional pod is now created. Each pod’s name is prefixed with the corresponding RC’s name. For example, a worker pod is prefixed with couchbase-worker-rc.
Couchbase Web Console gets updated to show that a new Couchbase node is added. This is evident by red circle with the number 1 on the Pending Rebalance tab.

Clicking on the tab shows the IP address of the node that needs to be rebalanced:

Scale Couchbase cluster
Now, let’s scale the Couchbase cluster by scaling the replicas for worker RC:
kubectl scale rc couchbase-worker-rc --replicas=3
replicationcontroller "couchbase-worker-rc" scaled
Updated state of RC shows that 3 worker pods have been created:
kubectl get rc
NAME DESIRED CURRENT AGE
couchbase-master-rc 1 1 8m
couchbase-worker-rc 3 3 2m
This can be verified again by getting the list of pods:
kubectl get po
NAME READY STATUS RESTARTS AGE
couchbase-master-rc-97mu5 1/1 Running 0 8m
couchbase-worker-rc-4ik02 1/1 Running 0 2m
couchbase-worker-rc-jfykx 1/1 Running 0 53s
couchbase-worker-rc-v8vdw 1/1 Running 0 53s
Pending Rebalance tab of Couchbase Web Console shows that 3 servers have now been added to the cluster and needs to be rebalanced.

Rebalance Couchbase Cluster
Finally, click on Rebalance button to rebalance the cluster. A message window showing the current state of rebalance is displayed:

Once all the nodes are rebalanced, Couchbase cluster is ready to serve your requests:

In addition to creating a cluster, Couchbase Server supports a range of high availability and disaster recovery (HA/DR) strategies. Most HA/DR strategies rely on a multi-pronged approach of maximizing availability, increasing redundancy within and across data centers, and performing regular backups.
Now that your Couchbase cluster is ready, you can run your first sample application.
For further information check out the Couchbase Developer Portal and Forums, or see questions on Stack Overflow.
--Arun Gupta, Vice President Developer Relations at Couchbase
- Download Kubernetes
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stack Overflow
- Connect with the community on Slack
- Follow @Kubernetesio on Twitter for latest updates
Challenges of a Remotely Managed, On-Premises, Bare-Metal Kubernetes Cluster
Today's post is written by Bich Le, chief architect at Platform9, describing how their engineering team overcame challenges in remotely managing bare-metal Kubernetes clusters.
Introduction
The recently announced Platform9 Managed Kubernetes (PMK) is an on-premises enterprise Kubernetes solution with an unusual twist: while clusters run on a user’s internal hardware, their provisioning, monitoring, troubleshooting and overall life cycle is managed remotely from the Platform9 SaaS application. While users love the intuitive experience and ease of use of this deployment model, this approach poses interesting technical challenges. In this article, we will first describe the motivation and deployment architecture of PMK, and then present an overview of the technical challenges we faced and how our engineering team addressed them.
Multi-OS bootstrap model
Like its predecessor, Managed OpenStack, PMK aims to make it as easy as possible for an enterprise customer to deploy and operate a “private cloud”, which, in the current context, means one or more Kubernetes clusters. To accommodate customers who standardize on a specific Linux distro, our installation process uses a “bare OS” or “bring your own OS” model, which means that an administrator deploys PMK to existing Linux nodes by installing a simple RPM or Deb package on their favorite OS (Ubuntu-14, CentOS-7, or RHEL-7). The package, which the administrator downloads from their Platform9 SaaS portal, starts an agent which is preconfigured with all the information and credentials needed to securely connect to and register itself with the customer’s Platform9 SaaS controller running on the WAN.
Node management
The first challenge was configuring Kubernetes nodes in the absence of a bare-metal cloud API and SSH access into nodes. We solved it using the node pool concept and configuration management techniques. Every node running the agent automatically shows up in the SaaS portal, which allows the user to authorize the node for use with Kubernetes. A newly authorized node automatically enters a node pool, indicating that it is available but not used in any clusters. Independently, the administrator can create one or more Kubernetes clusters, which start out empty. At any later time, he or she can request one or more nodes to be attached to any cluster. PMK fulfills the request by transferring the specified number of nodes from the pool to the cluster. When a node is authorized, its agent becomes a configuration management agent, polling for instructions from a CM server running in the SaaS application and capable of downloading and configuring software.
Cluster creation and node attach/detach operations are exposed to administrators via a REST API, a CLI utility named qb, and the SaaS-based Web UI. The following screenshot shows the Web UI displaying one 3-node cluster named clus100, one empty cluster clus101, and the three nodes.

Cluster initialization
The first time one or more nodes are attached to a cluster, PMK configures the nodes to form a complete Kubernetes cluster. Currently, PMK automatically decides the number and placement of Master and Worker nodes. In the future, PMK will give administrators an “advanced mode” option allowing them to override and customize those decisions. Through the CM server, PMK then sends to each node a configuration and a set of scripts to initialize each node according to the configuration. This includes installing or upgrading Docker to the required version; starting 2 docker daemons (bootstrap and main), creating the etcd K/V store, establishing the flannel network layer, starting kubelet, and running the Kubernetes appropriate for the node’s role (master vs. worker). The following diagram shows the component layout of a fully formed cluster.

Containerized kubelet?
Another hurdle we encountered resulted from our original decision to run kubelet as recommended by the Multi-node Docker Deployment Guide. We discovered that this approach introduces complexities that led to many difficult-to-troubleshoot bugs that were sensitive to the combined versions of Kubernetes, Docker, and the node OS. Example: kubelet’s need to mount directories containing secrets into containers to support the Service Accounts mechanism. It turns out that doing this from inside of a container is tricky, and requires a complex sequence of steps that turned out to be fragile. After fixing a continuing stream of issues, we finally decided to run kubelet as a native program on the host OS, resulting in significantly better stability.
Overcoming networking hurdles
The Beta release of PMK currently uses flannel with UDP back-end for the network layer. In a Kubernetes cluster, many infrastructure services need to communicate across nodes using a variety of ports (443, 4001, etc..) and protocols (TCP and UDP). Often, customer nodes intentionally or unintentionally block some or all of the traffic, or run existing services that conflict with the required ports, resulting in non-obvious failures. To address this, we try to detect configuration problems early and inform the administrator immediately. PMK runs a “preflight” check on all nodes participating in a cluster before installing the Kubernetes software. This means running small test programs on each node to verify that (1) the required ports are available for binding and listening; and (2) nodes can connect to each other using all required ports and protocols. These checks run in parallel and take less than a couple of seconds before cluster initialization.
Monitoring
One of the values of a SaaS-managed private cloud is constant monitoring and early detection of problems by the SaaS team. Issues that can be addressed without intervention by the customer are handled automatically, while others trigger proactive communication with the customer via UI alerts, email, or real-time channels. Kubernetes monitoring is a huge topic worthy of its own blog post, so we’ll just briefly touch upon it. We broadly classify the problem into layers: (1) hardware & OS, (2) Kubernetes core (e.g. API server, controllers and kubelets), (3) add-ons (e.g. SkyDNS & ServiceLoadbalancer) and (4) applications. We are currently focused on layers 1-3. A major source of issues we’ve seen is add-on failures. If either DNS or the ServiceLoadbalancer reverse http proxy (soon to be upgraded to an Ingress Controller) fails, application services will start failing. One way we detect such failures is by monitoring the components using the Kubernetes API itself, which is proxied into the SaaS controller, allowing the PMK support team to monitor any cluster resource. To detect service failure, one metric we pay attention to is pod restarts. A high restart count indicates that a service is continually failing.
Future topics
We faced complex challenges in other areas that deserve their own posts: (1) Authentication and authorization with Keystone, the identity manager used by Platform9 products; (2) Software upgrades, i.e. how to make them brief and non-disruptive to applications; and (3) Integration with customer’s external load-balancers (in the absence of good automation APIs).
Conclusion
Platform9 Managed Kubernetes uses a SaaS-managed model to try to hide the complexity of deploying, operating and maintaining bare-metal Kubernetes clusters in customers’ data centers. These requirements led to the development of a unique cluster deployment and management architecture, which in turn led to unique technical challenges.This article described an overview of some of those challenges and how we solved them. For more information on the motivation behind PMK, feel free to view Madhura Maskasky's blog post.
--Bich Le, Chief Architect, Platform9
Why OpenStack's embrace of Kubernetes is great for both communities
Today, Mirantis, the leading contributor to OpenStack, announced that it will re-write its private cloud platform to use Kubernetes as its underlying orchestration engine. We think this is a great step forward for both the OpenStack and Kubernetes communities. With Kubernetes under the hood, OpenStack users will benefit from the tremendous efficiency, manageability and resiliency that Kubernetes brings to the table, while positioning their applications to use more cloud-native patterns. The Kubernetes community, meanwhile, can feel confident in their choice of orchestration framework, while gaining the ability to manage both container- and VM-based applications from a single platform.
The Path to Cloud Native
Google spent over ten years developing, applying and refining the principles of cloud native computing. A cloud-native application is:
- Container-packaged. Applications are composed of hermetically sealed, reusable units across diverse environments;
- Dynamically scheduled, for increased infrastructure efficiency and decreased operational overhead; and
- Microservices-based. Loosely coupled components significantly increase the overall agility, resilience and maintainability of applications.
These principles have enabled us to build the largest, most efficient, most powerful cloud infrastructure in the world, which anyone can access via Google Cloud Platform. They are the same principles responsible for the recent surge in popularity of Linux containers. Two years ago, we open-sourced Kubernetes to spur adoption of containers and scalable, microservices-based applications, and the recently released Kubernetes version 1.3 introduces a number of features to bridge enterprise and cloud native workloads. We expect that adoption of cloud-native principles will drive the same benefits within the OpenStack community, as well as smoothing the path between OpenStack and the public cloud providers that embrace them.
Making OpenStack better
We hear from enterprise customers that they want to move towards cloud-native infrastructure and application patterns. Thus, it is hardly surprising that OpenStack would also move in this direction [1], with large OpenStack users such as eBay and GoDaddy adopting Kubernetes as key components of their stack. Kubernetes and cloud-native patterns will improve OpenStack lifecycle management by enabling rolling updates, versioning, and canary deployments of new components and features. In addition, OpenStack users will benefit from self-healing infrastructure, making OpenStack easier to manage and more resilient to the failure of core services and individual compute nodes. Finally, OpenStack users will realize the developer and resource efficiencies that come with a container-based infrastructure.
OpenStack is a great tool for Kubernetes users
Conversely, incorporating Kubernetes into OpenStack will give Kubernetes users access to a robust framework for deploying and managing applications built on virtual machines. As users move to the cloud-native model, they will be faced with the challenge of managing hybrid application architectures that contain some mix of virtual machines and Linux containers. The combination of Kubernetes and OpenStack means that they can do so on the same platform using a common set of tools.
We are excited by the ever increasing momentum of the cloud-native movement as embodied by Kubernetes and related projects, and look forward to working with Mirantis, its partner Intel, and others within the OpenStack community to brings the benefits of cloud-native to their applications and infrastructure.
--Martin Buhr, Product Manager, Strategic Initiatives, Google
[1] Check out the announcement of Kubernetes-OpenStack Special Interest Group here, and a great talk about OpenStack on Kubernetes by CoreOS CEO Alex Polvi at the most recent OpenStack summit here.
A Very Happy Birthday Kubernetes
Last year at OSCON, I got to reconnect with a bunch of friends and see what they have been working on. That turned out to be the Kubernetes 1.0 launch event. Even that day, it was clear the project was supported by a broad community -- a group that showed an ambitious vision for distributed computing.
Today, on the first anniversary of the Kubernetes 1.0 launch, it’s amazing to see what a community of dedicated individuals can do. Kubernauts have collectively put in 237 person years of coding effort since launch to bring forward our most recent release 1.3. However the community is much more than simply coding effort. It is made up of people -- individuals that have given their expertise and energy to make this project flourish. With more than 830 diverse contributors, from independents to the largest companies in the world, it’s their work that makes Kubernetes stand out. Here are stories from a couple early contributors reflecting back on the project:
- Sam Ghods, services architect and co-founder at Box
- Justin Santa Barbara, independent Kubernetes contributor
- Clayton Coleman, contributor and architect on Kubernetes on OpenShift at Red Hat
The community is also more than online GitHub and Slack conversation; year one saw the launch of KubeCon, the Kubernetes user conference, which started as a grassroot effort that brought together 1,000 individuals between two events in San Francisco and London. The advocacy continues with users globally. There are more than 130 Meetup groups that mention Kubernetes, many of which are helping celebrate Kubernetes’ birthday. To join the celebration, participate at one of the 20 #k8sbday parties worldwide: Austin, Bangalore, Beijing, Boston, Cape Town, Charlotte, Cologne, Geneva, Karlsruhe, Kisumu, Montreal, Portland, Raleigh, Research Triangle, San Francisco, Seattle, Singapore, SF Bay Area, or Washington DC.
The Kubernetes community continues to work to make our project more welcoming and open to our kollaborators. This spring, Kubernetes and KubeCon moved to the Cloud Native Compute Foundation (CNCF), a Linux Foundation Project, to accelerate the collaborative vision outlined only a year ago at OSCON …. lifting a glass to another great year.

-- Sarah Novotny, Kubernetes Community Wonk
Happy Birthday Kubernetes. Oh, the places you’ll go!
Editor’s note, Today’s guest post is from an independent Kubernetes contributor, Justin Santa Barbara, sharing his reflection on growth of the project from inception to its future.
Dear K8s,
It’s hard to believe you’re only one - you’ve grown up so fast. On the occasion of your first birthday, I thought I would write a little note about why I was so excited when you were born, why I feel fortunate to be part of the group that is raising you, and why I’m eager to watch you continue to grow up!
--Justin
You started with an excellent foundation - good declarative functionality, built around a solid API with a well defined schema and the machinery so that we could evolve going forwards. And sure enough, over your first year you grew so fast: autoscaling, HTTP load-balancing support (Ingress), support for persistent workloads including clustered databases (PetSets). You’ve made friends with more clouds (welcome Azure & OpenStack to the family), and even started to span zones and clusters (Federation). And these are just some of the most visible changes - there’s so much happening inside that brain of yours!
I think it’s wonderful you’ve remained so open in all that you do - you seem to write down everything on GitHub - for better or worse. I think we’ve all learned a lot about that on the way, like the perils of having engineers make scaling statements that are then weighed against claims made without quite the same framework of precision and rigor. But I’m proud that you chose not to lower your standards, but rose to the challenge and just ran faster instead - it might not be the most realistic approach, but it is the only way to move mountains!
And yet, somehow, you’ve managed to avoid a lot of the common dead-ends that other open source software has fallen into, particularly as those projects got bigger and the developers end up working on it more than they use it directly. How did you do that? There’s a probably-apocryphal story of an employee at IBM that makes a huge mistake, and is summoned to meet with the big boss, expecting to be fired, only to be told “We just spent several million dollars training you. Why would we want to fire you?”. Despite all the investment google is pouring into you (along with Redhat and others), I sometimes wonder if the mistakes we are avoiding could be worth even more. There is a very open development process, yet there’s also an “oracle” that will sometimes course-correct by telling us what happens two years down the road if we make a particular design decision. This is a parent you should probably listen to!
And so although you’re only a year old, you really have an old soul. I’m just one of the many people raising you, but it’s a wonderful learning experience for me to be able to work with the people that have built these incredible systems and have all this domain knowledge. Yet because we started from scratch (rather than taking the existing Borg code) we’re at the same level and can still have genuine discussions about how to raise you. Well, at least as close to the same level as we could ever be, but it’s to their credit that they are all far too nice ever to mention it!
If I would pick just two of the wise decisions those brilliant people made:
- Labels & selectors give us declarative “pointers”, so we can say “why” we want things, rather than listing the things directly. It’s the secret to how you can scale to great heights; not by naming each step, but saying “a thousand more steps just like that first one”.
- Controllers are state-synchronizers: we specify the goals, and your controllers will indefatigably work to bring the system to that state. They work through that strongly-typed API foundation, and are used throughout the code, so Kubernetes is more of a set of a hundred small programs than one big one. It’s not enough to scale to thousands of nodes technically; the project also has to scale to thousands of developers and features; and controllers help us get there.
And so on we will go! We’ll be replacing those controllers and building on more, and the API-foundation lets us build anything we can express in that way - with most things just a label or annotation away! But your thoughts will not be defined by language: with third party resources you can express anything you choose. Now we can build Kubernetes without building in Kubernetes, creating things that feel as much a part of Kubernetes as anything else. Many of the recent additions, like ingress, DNS integration, autoscaling and network policies were done or could be done in this way. Eventually it will be hard to imagine you before these things, but tomorrow’s standard functionality can start today, with no obstacles or gatekeeper, maybe even for an audience of one.
So I’m looking forward to seeing more and more growth happen further and further from the core of Kubernetes. We had to work our way through those phases; starting with things that needed to happen in the kernel of Kubernetes - like replacing replication controllers with deployments. Now we’re starting to build things that don’t require core changes. But we’re still still talking about infrastructure separately from applications. It’s what comes next that gets really interesting: when we start building applications that rely on the Kubernetes APIs. We’ve always had the Cassandra example that uses the Kubernetes API to self-assemble, but we haven’t really even started to explore this more widely yet. In the same way that the S3 APIs changed how we build things that remember, I think the k8s APIs are going to change how we build things that think.
So I’m looking forward to your second birthday: I can try to predict what you’ll look like then, but I know you’ll surpass even the most audacious things I can imagine. Oh, the places you’ll go!
-- Justin Santa Barbara, Independent Kubernetes Contributor
The Bet on Kubernetes, a Red Hat Perspective
Editor’s note: Today’s guest post is from a Kubernetes contributor Clayton Coleman, Architect on OpenShift at Red Hat, sharing their adoption of the project from its beginnings.
Two years ago, Red Hat made a big bet on Kubernetes. We bet on a simple idea: that an open source community is the best place to build the future of application orchestration, and that only an open source community could successfully integrate the diverse range of capabilities necessary to succeed. As a Red Hatter, that idea is not far-fetched - we’ve seen it successfully applied in many communities, but we’ve also seen it fail, especially when a broad reach is not supported by solid foundations. On the one year anniversary of Kubernetes 1.0, two years after the first open-source commit to the Kubernetes project, it’s worth asking the question:
Was Kubernetes the right bet?
The success of software is measured by the successes of its users - whether that software enables for them new opportunities or efficiencies. In that regard, Kubernetes has succeeded beyond our wildest dreams. We know of hundreds of real production deployments of Kubernetes, in the enterprise through Red Hat’s multi-tenant enabled OpenShift distribution, on Google Container Engine (GKE), in heavily customized versions run by some of the world's largest software companies, and through the education, entertainment, startup, and do-it-yourself communities. Those deployers report improved time to delivery, standardized application lifecycles, improved resource utilization, and more resilient and robust applications. And that’s just from customers or contributors to the community - I would not be surprised if there were now thousands of installations of Kubernetes managing tens of thousands of real applications out in the wild.
I believe that reach to be a validation of the vision underlying Kubernetes: to build a platform for all applications by providing tools for each of the core patterns in distributed computing. Those patterns:
- simple replicated web software
- distributed load balancing and service discovery
- immutable images run in containers
- co-location of related software into pods
- simplified consumption of network attached storage
- flexible and powerful resource scheduling
- running batch and scheduled jobs alongside service workloads
- managing and maintaining clustered software like databases and message queues
Allow developers and operators to move to the next scale of abstraction, just like they have enabled Google and others in the tech ecosystem to scale to datacenter computers and beyond. From Kubernetes 1.0 to 1.3 we have continually improved the power and flexibility of the platform while ALSO improving performance, scalability, reliability, and usability. The explosion of integrations and tools that run on top of Kubernetes further validates core architectural decisions to be composable, to expose open and flexible APIs, and to deliberately limit the core platform and encourage extension.
Today Kubernetes has one of the largest and most vibrant communities in the open source ecosystem, with almost a thousand contributors, one of the highest human-generated commit rates of any single-repository project on GitHub, over a thousand projects based around Kubernetes, and correspondingly active Stack Overflow and Slack channels. Red Hat is proud to be part of this ecosystem as the largest contributor to Kubernetes after Google, and every day more companies and individuals join us. The idea of Kubernetes found fertile ground, and you, the community, provided the excitement and commitment that made it grow.
So, did we bet correctly? For all the reasons above, and hundreds more: Yes.
What’s next?
Happy as we are with the success of Kubernetes, this is no time to rest! While there are many more features and improvements we want to build into Kubernetes, I think there is a general consensus that we want to focus on the only long term goal that matters - a healthy, successful, and thriving technical community around Kubernetes. As John F. Kennedy probably said:
> Ask not what your community can do for you, but what you can do for your community
In a recent post to the kubernetes-dev list, Brian Grant laid out a great set of near term goals - goals that help grow the community, refine how we execute, and enable future expansion. In each of the Kubernetes Special Interest Groups we are trying to build sustainable teams that can execute across companies and communities, and we are actively working to ensure each of these SIGs is able to contribute, coordinate, and deliver across a diverse range of interests under one vision for the project.
Of special interest to us is the story of extension - how the core of Kubernetes can become the beating heart of the datacenter operating system, and enable even more patterns for application management to build on top of Kubernetes, not just into it. Work done in the 1.2 and 1.3 releases around third party APIs, API discovery, flexible scheduler policy, external authorization and authentication (beyond those built into Kubernetes) is just the start. When someone has a need, we want them to easily find a solution, and we also want it to be easy for others to consume and contribute to that solution. Likewise, the best way to prove ideas is to prototype them against real needs and to iterate against real problems, which should be easy and natural.
By Kubernetes’ second birthday, I hope to reflect back on a long year of refinement, user success, and community participation. It has been a privilege and an honor to contribute to Kubernetes, and it still feels like we are just getting started. Thank you, and I hope you come along for the ride!
-- Clayton Coleman, Contributor and Architect on Kubernetes and OpenShift at Red Hat. Follow him on Twitter and GitHub: @smarterclayton
Bringing End-to-End Kubernetes Testing to Azure (Part 2)
Editor’s Note: Today’s guest post is Part II from a series by Travis Newhouse, Chief Architect at AppFormix, writing about their contributions to Kubernetes.
Historically, Kubernetes testing has been hosted by Google, running e2e tests on Google Compute Engine (GCE) and Google Container Engine (GKE). In fact, the gating checks for the submit-queue are a subset of tests executed on these test platforms. Federated testing aims to expand test coverage by enabling organizations to host test jobs for a variety of platforms and contribute test results to benefit the Kubernetes project. Members of the Kubernetes test team at Google and SIG-Testing have created a Kubernetes test history dashboard that publishes the results from all federated test jobs (including those hosted by Google).
In this blog post, we describe extending the e2e test jobs for Azure, and show how to contribute a federated test to the Kubernetes project.
END-TO-END INTEGRATION TESTS FOR AZURE
After successfully implementing “development distro” scripts to automate deployment of Kubernetes on Azure, our next goal was to run e2e integration tests and share the results with the Kubernetes community.
We automated our workflow for executing e2e tests of Kubernetes on Azure by defining a nightly job in our private Jenkins server. Figure 2 shows the workflow that uses kube-up.sh to deploy Kubernetes on Ubuntu virtual machines running in Azure, then executes the e2e tests. On completion of the tests, the job uploads the test results and logs to a Google Cloud Storage directory, in a format that can be processed by the scripts that produce the test history dashboard. Our Jenkins job uses the hack/jenkins/e2e-runner.sh and hack/jenkins/upload-to-gcs.sh scripts to produce the results in the correct format.
| 
HOW TO CONTRIBUTE AN E2E TEST
Throughout our work to create the Azure e2e test job, we have collaborated with members of SIG-Testing to find a way to publish the results to the Kubernetes community. The results of this collaboration are documentation and a streamlined process to contribute results from a federated test job. The steps to contribute e2e test results can be summarized in 4 steps.
- Create a Google Cloud Storage bucket in which to publish the results.
- Define an automated job to run the e2e tests. By setting a few environment variables, hack/jenkins/e2e-runner.sh deploys Kubernetes binaries and executes the tests.
- Upload the results using hack/jenkins/upload-to-gcs.sh.
- Incorporate the results into the test history dashboard by submitting a pull-request with modifications to a few files in kubernetes/test-infra.
The federated tests documentation describes these steps in more detail. The scripts to run e2e tests and upload results simplifies the work to contribute a new federated test job. The specific steps to set up an automated test job and an appropriate environment in which to deploy Kubernetes are left to the reader’s preferences. For organizations using Jenkins, the jenkins-job-builder configurations for GCE and GKE tests may provide helpful examples.
RETROSPECTIVE
The e2e tests on Azure have been running for several weeks now. During this period, we have found two issues in Kubernetes. Weixu Zhuang immediately published fixes that have been merged into the Kubernetes master branch.
The first issue happened when we wanted to bring up the Kubernetes cluster using SaltStack on Azure using Ubuntu VMs. A commit (07d7cfd3) modified the OpenVPN certificate generation script to use a variable that was only initialized by scripts in the cluster/ubuntu. Strict checking on existence of parameters by the certificate generation script caused other platforms that use the script to fail (e.g. our changes to support Azure). We submitted a pull-request that fixed the issue by initializing the variable with a default value to make the certificate generation scripts more robust across all platform types.
The second pull-request cleaned up an unused import in the Daemonset unit test file. The import statement broke the unit tests with golang 1.4. Our nightly Jenkins job helped us find this error and we promptly pushed a fix for it.
CONCLUSION AND FUTURE WORK
The addition of a nightly e2e test job for Kubernetes on Azure has helped to define the process to contribute a federated test to the Kubernetes project. During the course of the work, we also saw the immediate benefit of expanding test coverage to more platforms when our Azure test job identified compatibility issues.
We want to thank Aaron Crickenberger, Erick Fejta, Joe Finney, and Ryan Hutchinson for their help to incorporate the results of our Azure e2e tests into the Kubernetes test history. If you’d like to get involved with testing to create a stable, high quality releases of Kubernetes, join us in the Kubernetes Testing SIG (sig-testing).
--Travis Newhouse, Chief Architect at AppFormix
Dashboard - Full Featured Web Interface for Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.3
Kubernetes Dashboard is a project that aims to bring a general purpose monitoring and operational web interface to the Kubernetes world. Three months ago we released the first production ready version, and since then the dashboard has made massive improvements. In a single UI, you’re able to perform majority of possible interactions with your Kubernetes clusters without ever leaving your browser. This blog post breaks down new features introduced in the latest release and outlines the roadmap for the future.
Full-Featured Dashboard
Thanks to a large number of contributions from the community and project members, we were able to deliver many new features for Kubernetes 1.3 release. We have been carefully listening to all the great feedback we have received from our users (see the summary infographics) and addressed the highest priority requests and pain points.
The Dashboard UI now handles all workload resources. This means that no matter what workload type you run, it is visible in the web interface and you can do operational changes on it. For example, you can modify your stateful MySQL installation with Pet Sets, do a rolling update of your web server with Deployments or install cluster monitoring with DaemonSets.

In addition to viewing resources, you can create, edit, update, and delete them. This feature enables many use cases. For example, you can kill a failed Pod, do a rolling update on a Deployment, or just organize your resources. You can also export and import YAML configuration files of your cloud apps and store them in a version control system.

The release includes a beta view of cluster nodes for administration and operational use cases. The UI lists all nodes in the cluster to allow for overview analysis and quick screening for problematic nodes. The details view shows all information about the node and links to pods running on it.

There are also many smaller scope new features that the we shipped with the release, namely: support for namespaced resources, internationalization, performance improvements, and many bug fixes (find out more in the release notes). All these improvements result in a better and simpler user experience of the product.
Future Work
The team has ambitious plans for the future spanning across multiple use cases. We are also open to all feature requests, which you can post on our issue tracker.
Here is a list of our focus areas for the following months:
- Handle more Kubernetes resources - To show all resources that a cluster user may potentially interact with. Once done, Dashboard can act as a complete replacement for CLI.
- Monitoring and troubleshooting - To add resource usage statistics/graphs to the objects shown in Dashboard. This focus area will allow for actionable debugging and troubleshooting of cloud applications.
- Security, auth and logging in - Make Dashboard accessible from networks external to a Cluster and work with custom authentication systems.
Connect With Us
We would love to talk with you and hear your feedback!
- Email us at the SIG-UI mailing list
- Chat with us on the Kubernetes Slack #SIG-UI channel
- Join our meetings: 4PM CEST. See the SIG-UI calendar for details.
-- Piotr Bryk, Software Engineer, Google
Steering an Automation Platform at Wercker with Kubernetes
Editor’s note: today’s guest post is by Andy Smith, the CTO of Wercker, sharing how Kubernetes helps them save time and speed up development.
At Wercker we run millions of containers that execute our users’ CI/CD jobs. The vast majority of them are ephemeral and only last as long as builds, tests and deploys take to run, the rest are ephemeral, too -- aren't we all --, but tend to last a bit longer and run our infrastructure. As we are running many containers across many nodes, we were in need of a highly scalable scheduler that would make our lives easier, and as such, decided to implement Kubernetes.
Wercker is a container-centric automation platform that helps developers build, test and deploy their applications. We support any number of pipelines, ranging from building code, testing API-contracts between microservices, to pushing containers to registries, and deploying to schedulers. All of these pipeline jobs run inside Docker containers and each artifact can be a Docker container.
And of course we use Wercker to build Wercker, and deploy itself onto Kubernetes!
Overview
Because we are a platform for running multi-service cloud-native code we've made many design decisions around isolation. On the base level we use CoreOS and cloud-init to bootstrap a cluster of heterogeneous nodes which I have named Patricians, Peasants, as well as controller nodes that don't have a cool name and are just called Controllers. Maybe we should switch to Constables.

Patrician nodes are where the bulk of our infrastructure runs. These nodes have appropriate network interfaces to communicate with our backend services as well as be routable by various load balancers. This is where our logging is aggregated and sent off to logging services, our many microservices for reporting and processing the results of job runs, and our many microservices for handling API calls.
On the other end of the spectrum are the Peasant nodes where the public jobs are run. Public jobs consist of worker pods reading from a job queue and dynamically generating new runner pods to handle execution of the job. The job itself is an incarnation of our open source CLI tool, the same one you can run on your laptop with Docker installed. These nodes have very limited access to the rest of the infrastructure and the containers the jobs themselves run in are even further isolated.
Controllers are controllers, I bet ours look exactly the same as yours.
Dynamic Pods
Our heaviest use of the Kubernetes API is definitely our system of creating dynamic pods to serve as the runtime environment for our actual job execution. After pulling job descriptions from the queue we define a new pod containing all the relevant environment for checking out code, managing a cache, executing a job and uploading artifacts. We launch the pod, monitor its progress, and destroy it when the job is done.
Ingresses
In order to provide a backend for HTTP API calls and allow self-registration of handlers we make use of the Ingress system in Kubernetes. It wasn't the clearest thing to set up, but reading through enough of the nginx example eventually got us to a good spot where it is easy to connect services to the frontend.
Upcoming Features in 1.3
While we generally treat all of our pods and containers as ephemeral and expect rapid restarts on failures, we are looking forward to Pet Sets and Init Containers as ways to optimize some of our processes. We are also pleased with official support for Minikube coming along as it improves our local testing and development.
Conclusion
Kubernetes saves us the non-trivial task of managing many, many containers across many nodes. It provides a robust API and tooling for introspecting these containers, and it includes much built in support for logging, metrics, monitoring and debugging. Service discovery and networking alone saves us so much time and speeds development immensely.
Cheers to you Kubernetes, keep up the good work :)
-- Andy Smith, CTO, Wercker
Citrix + Kubernetes = A Home Run
Editor’s note: today’s guest post is by Mikko Disini, a Director of Product Management at Citrix Systems, sharing their collaboration experience on a Kubernetes integration.
Technical collaboration is like sports. If you work together as a team, you can go down the homestretch and pull through for a win. That’s our experience with the Google Cloud Platform team.
Recently, we approached Google Cloud Platform (GCP) to collaborate on behalf of Citrix customers and the broader enterprise market looking to migrate workloads. This migration required including the NetScaler Docker load balancer, CPX, into Kubernetes nodes and resolving any issues with getting traffic into the CPX proxies.
Why NetScaler and Kubernetes?
- Citrix customers want the same Layer 4 to Layer 7 capabilities from NetScaler that they have on-prem as they move to the cloud as they begin deploying their container and microservices architecture with Kubernetes
- Kubernetes provides a proven infrastructure for running containers and VMs with automated workload delivery
- NetScaler CPX provides Layer 4 to Layer 7 services and highly efficient telemetry data to a logging and analytics platform, NetScaler Management and Analytics System
I wish all our experiences working together with a technical partner were as good as working with GCP. We had a list of issues to enable our use cases and were able to collaborate swiftly on a solution. To resolve these, GCP team offered in depth technical assistance, working with Citrix such that NetScaler CPX can spin up and take over as a client-side proxy running on each host.
Next, NetScaler CPX needed to be inserted in the data path of GCP ingress load balancer so that NetScaler CPX can spread traffic to front end web servers. The NetScaler team made modifications so that NetScaler CPX listens to API server events and configures itself to create a VIP, IP table rules and server rules to take ingress traffic and load balance across front end applications. Google Cloud Platform team provided feedback and assistance to verify modifications made to overcome the technical hurdles. Done!
NetScaler CPX use case is supported in Kubernetes 1.3. Citrix customers and the broader enterprise market will have the opportunity to leverage NetScaler with Kubernetes, thereby lowering the friction to move workloads to the cloud.
You can learn more about NetScaler CPX here.
-- Mikko Disini, Director of Product Management - NetScaler, Citrix Systems
Cross Cluster Services - Achieving Higher Availability for your Kubernetes Applications
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.3
As Kubernetes users scale their production deployments we’ve heard a clear desire to deploy services across zone, region, cluster and cloud boundaries. Services that span clusters provide geographic distribution, enable hybrid and multi-cloud scenarios and improve the level of high availability beyond single cluster multi-zone deployments. Customers who want their services to span one or more (possibly remote) clusters, need them to be reachable in a consistent manner from both within and outside their clusters.
In Kubernetes 1.3, our goal was to minimize the friction points and reduce the management/operational overhead associated with deploying a service with geographic distribution to multiple clusters. This post explains how to do this.
Note: Though the examples used here leverage Google Container Engine (GKE) to provision Kubernetes clusters, they work anywhere you want to deploy Kubernetes.
Let’s get started. The first step is to create is to create Kubernetes clusters into 4 Google Cloud Platform (GCP) regions using GKE.
- asia-east1-b
- europe-west1-b
- us-east1-b
- us-central1-b
Let’s run the following commands to build the clusters:
gcloud container clusters create gce-asia-east1 \
--scopes cloud-platform \
--zone asia-east1-b
gcloud container clusters create gce-europe-west1 \
--scopes cloud-platform \
--zone=europe-west1-b
gcloud container clusters create gce-us-east1 \
--scopes cloud-platform \
--zone=us-east1-b
gcloud container clusters create gce-us-central1 \
--scopes cloud-platform \
--zone=us-central1-b
Let’s verify the clusters are created:
gcloud container clusters list
NAME ZONE MASTER\_VERSION MASTER\_IP NUM\_NODES STATUS
gce-asia-east1 asia-east1-b 1.2.4 104.XXX.XXX.XXX 3 RUNNING
gce-europe-west1 europe-west1-b 1.2.4 130.XXX.XX.XX 3 RUNNING
gce-us-central1 us-central1-b 1.2.4 104.XXX.XXX.XX 3 RUNNING
gce-us-east1 us-east1-b 1.2.4 104.XXX.XX.XXX 3 RUNNING

The next step is to bootstrap the clusters and deploy the federation control plane on one of the clusters that has been provisioned. If you’d like to follow along, refer to Kelsey Hightower’s tutorial which walks through the steps involved.
Federated Services
Federated Services are directed to the Federation API endpoint and specify the desired properties of your service.
Once created, the Federated Service automatically:
- creates matching Kubernetes Services in every cluster underlying your cluster federation,
- monitors the health of those service "shards" (and the clusters in which they reside), and
- manages a set of DNS records in a public DNS provider (like Google Cloud DNS, or AWS Route 53), thus ensuring that clients of your federated service can seamlessly locate an appropriate healthy service endpoint at all times, even in the event of cluster, availability zone or regional outages.
Clients inside your federated Kubernetes clusters (i.e. Pods) will automatically find the local shard of the federated service in their cluster if it exists and is healthy, or the closest healthy shard in a different cluster if it does not.
Federations of Kubernetes Clusters can include clusters running in different cloud providers (e.g. GCP, AWS), and on-premise (e.g. on OpenStack). All you need to do is create your clusters in the appropriate cloud providers and/or locations, and register each cluster's API endpoint and credentials with your Federation API Server.
In our example, we have clusters created in 4 regions along with a federated control plane API deployed in one of our clusters, that we’ll be using to provision our service. See diagram below for visual representation.

Creating a Federated Service
Let’s list out all the clusters in our federation:
kubectl --context=federation-cluster get clusters
NAME STATUS VERSION AGE
gce-asia-east1 Ready 1m
gce-europe-west1 Ready 57s
gce-us-central1 Ready 47s
gce-us-east1 Ready 34s
Let’s create a federated service object:
kubectl --context=federation-cluster create -f services/nginx.yaml
The '--context=federation-cluster' flag tells kubectl to submit the request to the Federation API endpoint, with the appropriate credentials. The federated service will automatically create and maintain matching Kubernetes services in all of the clusters underlying your federation.
You can verify this by checking in each of the underlying clusters, for example:
kubectl --context=gce-asia-east1a get svc nginx
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx 10.63.250.98 104.199.136.89 80/TCP 9m
The above assumes that you have a context named 'gce-asia-east1a' configured in your client for your cluster in that zone. The name and namespace of the underlying services will automatically match those of the federated service that you created above.
The status of your Federated Service will automatically reflect the real-time status of the underlying Kubernetes services, for example:
kubectl --context=federation-cluster describe services nginx
Name: nginx
Namespace: default
Labels: run=nginx
Selector: run=nginx
Type: LoadBalancer
IP:
LoadBalancer Ingress: 104.XXX.XX.XXX, 104.XXX.XX.XXX, 104.XXX.XX.XXX, 104.XXX.XXX.XX
Port: http 80/TCP
Endpoints: \<none\>
Session Affinity: None
No events.
The 'LoadBalancer Ingress' addresses of your federated service corresponds with the 'LoadBalancer Ingress' addresses of all of the underlying Kubernetes services. For inter-cluster and inter-cloud-provider networking between service shards to work correctly, your services need to have an externally visible IP address. Service Type: Loadbalancer is typically used here.
Note also what we have not yet provisioned any backend Pods to receive the network traffic directed to these addresses (i.e. 'Service Endpoints'), so the federated service does not yet consider these to be healthy service shards, and has accordingly not yet added their addresses to the DNS records for this federated service.
Adding Backend Pods
To render the underlying service shards healthy, we need to add backend Pods behind them. This is currently done directly against the API endpoints of the underlying clusters (although in future the Federation server will be able to do all this for you with a single command, to save you the trouble). For example, to create backend Pods in our underlying clusters:
for CLUSTER in asia-east1-a europe-west1-a us-east1-a us-central1-a
do
kubectl --context=$CLUSTER run nginx --image=nginx:1.11.1-alpine --port=80
done
Verifying Public DNS Records
Once the Pods have successfully started and begun listening for connections, Kubernetes in each cluster (via automatic health checks) will report them as healthy endpoints of the service in that cluster. The cluster federation will in turn consider each of these service 'shards' to be healthy, and place them in serving by automatically configuring corresponding public DNS records. You can use your preferred interface to your configured DNS provider to verify this. For example, if your Federation is configured to use Google Cloud DNS, and a managed DNS domain 'example.com':
$ gcloud dns managed-zones describe example-dot-com
creationTime: '2016-06-26T18:18:39.229Z'
description: Example domain for Kubernetes Cluster Federation
dnsName: example.com.
id: '3229332181334243121'
kind: dns#managedZone
name: example-dot-com
nameServers:
- ns-cloud-a1.googledomains.com.
- ns-cloud-a2.googledomains.com.
- ns-cloud-a3.googledomains.com.
- ns-cloud-a4.googledomains.com.
$ gcloud dns record-sets list --zone example-dot-com
NAME TYPE TTL DATA
example.com. NS 21600 ns-cloud-e1.googledomains.com., ns-cloud-e2.googledomains.com.
example.com. SOA 21600 ns-cloud-e1.googledomains.com. cloud-dns-hostmaster.google.com. 1 21600 3600 1209600 300
nginx.mynamespace.myfederation.svc.example.com. A 180 104.XXX.XXX.XXX, 130.XXX.XX.XXX, 104.XXX.XX.XXX, 104.XXX.XXX.XX
nginx.mynamespace.myfederation.svc.us-central1-a.example.com. A 180 104.XXX.XXX.XXX
nginx.mynamespace.myfederation.svc.us-central1.example.com.
nginx.mynamespace.myfederation.svc.us-central1.example.com. A 180 104.XXX.XXX.XXX, 104.XXX.XXX.XXX, 104.XXX.XXX.XXX
nginx.mynamespace.myfederation.svc.asia-east1-a.example.com. A 180 130.XXX.XX.XXX
nginx.mynamespace.myfederation.svc.asia-east1.example.com.
nginx.mynamespace.myfederation.svc.asia-east1.example.com. A 180 130.XXX.XX.XXX, 130.XXX.XX.XXX
nginx.mynamespace.myfederation.svc.europe-west1.example.com. CNAME 180 nginx.mynamespace.myfederation.svc.example.com.
... etc.
Note: If your Federation is configured to use AWS Route53, you can use one of the equivalent AWS tools, for example:
$aws route53 list-hosted-zones
and
$aws route53 list-resource-record-sets --hosted-zone-id Z3ECL0L9QLOVBX
Whatever DNS provider you use, any DNS query tool (for example 'dig' or 'nslookup') will of course also allow you to see the records created by the Federation for you.
Discovering a Federated Service from pods Inside your Federated Clusters
By default, Kubernetes clusters come preconfigured with a cluster-local DNS server ('KubeDNS'), as well as an intelligently constructed DNS search path which together ensure that DNS queries like "myservice", "myservice.mynamespace", "bobsservice.othernamespace" etc issued by your software running inside Pods are automatically expanded and resolved correctly to the appropriate service IP of services running in the local cluster.
With the introduction of Federated Services and Cross-Cluster Service Discovery, this concept is extended to cover Kubernetes services running in any other cluster across your Cluster Federation, globally. To take advantage of this extended range, you use a slightly different DNS name (e.g. myservice.mynamespace.myfederation) to resolve federated services. Using a different DNS name also avoids having your existing applications accidentally traversing cross-zone or cross-region networks and you incurring perhaps unwanted network charges or latency, without you explicitly opting in to this behavior.
So, using our NGINX example service above, and the federated service DNS name form just described, let's consider an example: A Pod in a cluster in the us-central1-a availability zone needs to contact our NGINX service. Rather than use the service's traditional cluster-local DNS name ("nginx.mynamespace", which is automatically expanded to"nginx.mynamespace.svc.cluster.local") it can now use the service's Federated DNS name, which is"nginx.mynamespace.myfederation". This will be automatically expanded and resolved to the closest healthy shard of my NGINX service, wherever in the world that may be. If a healthy shard exists in the local cluster, that service's cluster-local (typically 10.x.y.z) IP address will be returned (by the cluster-local KubeDNS). This is exactly equivalent to non-federated service resolution.
If the service does not exist in the local cluster (or it exists but has no healthy backend pods), the DNS query is automatically expanded to "nginx.mynamespace.myfederation.svc.us-central1-a.example.com". Behind the scenes, this is finding the external IP of one of the shards closest to my availability zone. This expansion is performed automatically by KubeDNS, which returns the associated CNAME record. This results in a traversal of the hierarchy of DNS records in the above example, and ends up at one of the external IP's of the Federated Service in the local us-central1 region.
It is also possible to target service shards in availability zones and regions other than the ones local to a Pod by specifying the appropriate DNS names explicitly, and not relying on automatic DNS expansion. For example, "nginx.mynamespace.myfederation.svc.europe-west1.example.com" will resolve to all of the currently healthy service shards in Europe, even if the Pod issuing the lookup is located in the U.S., and irrespective of whether or not there are healthy shards of the service in the U.S. This is useful for remote monitoring and other similar applications.
Discovering a Federated Service from Other Clients Outside your Federated Clusters
For external clients, automatic DNS expansion described is no longer possible. External clients need to specify one of the fully qualified DNS names of the federated service, be that a zonal, regional or global name. For convenience reasons, it is often a good idea to manually configure additional static CNAME records in your service, for example:
eu.nginx.acme.com CNAME nginx.mynamespace.myfederation.svc.europe-west1.example.com.
us.nginx.acme.com CNAME nginx.mynamespace.myfederation.svc.us-central1.example.com.
nginx.acme.com CNAME nginx.mynamespace.myfederation.svc.example.com.
That way your clients can always use the short form on the left, and always be automatically routed to the closest healthy shard on their home continent. All of the required failover is handled for you automatically by Kubernetes Cluster Federation.
Handling Failures of Backend Pods and Whole Clusters
Standard Kubernetes service cluster-IP's already ensure that non-responsive individual Pod endpoints are automatically taken out of service with low latency. The Kubernetes cluster federation system automatically monitors the health of clusters and the endpoints behind all of the shards of your federated service, taking shards in and out of service as required. Due to the latency inherent in DNS caching (the cache timeout, or TTL for federated service DNS records is configured to 3 minutes, by default, but can be adjusted), it may take up to that long for all clients to completely fail over to an alternative cluster in in the case of catastrophic failure. However, given the number of discrete IP addresses which can be returned for each regional service endpoint (see e.g. us-central1 above, which has three alternatives) many clients will fail over automatically to one of the alternative IP's in less time than that given appropriate configuration.
Community
We'd love to hear feedback on Kubernetes Cross Cluster Services. To join the community:
- Post issues or feature requests on GitHub
- Join us in the #federation channel on Slack
- Participate in the Cluster Federation SIG
Please give Cross Cluster Services a try, and let us know how it goes!
-- Quinton Hoole, Engineering Lead, Google and Allan Naim, Product Manager, Google
Stateful Applications in Containers!? Kubernetes 1.3 Says “Yes!”
Editor's note: today’s guest post is from Mark Balch, VP of Products at Diamanti, who’ll share more about the contributions they’ve made to Kubernetes.
Congratulations to the Kubernetes community on another value-packed release. A focus on stateful applications and federated clusters are two reasons why I’m so excited about 1.3. Kubernetes support for stateful apps such as Cassandra, Kafka, and MongoDB is critical. Important services rely on databases, key value stores, message queues, and more. Additionally, relying on one data center or container cluster simply won’t work as apps grow to serve millions of users around the world. Cluster federation allows users to deploy apps across multiple clusters and data centers for scale and resiliency.
You may have heard me say before that containers are the next great application platform. Diamanti is accelerating container adoption for stateful apps in production - where performance and ease of deployment really matter.
Apps Need More Than Cattle
Beyond stateless containers like web servers (so-called “cattle” because they are interchangeable), users are increasingly deploying stateful workloads with containers to benefit from “build once, run anywhere” and to improve bare metal efficiency/utilization. These “pets” (so-called because each requires special handling) bring new requirements including longer life cycle, configuration dependencies, stateful failover, and performance sensitivity. Container orchestration must address these needs to successfully deploy and scale apps.
Enter Pet Set, a new object in Kubernetes 1.3 for improved stateful application support. Pet Set sequences through the startup phase of each database replica (for example), ensuring orderly master/slave configuration. Pet Set also simplifies service discovery by leveraging ubiquitous DNS SRV records, a well-recognized and long-understood mechanism.
Diamanti’s FlexVolume contribution to Kubernetes enables stateful workloads by providing persistent volumes with low-latency storage and guaranteed performance, including enforced quality-of-service from container to media.
A Federalist
Users who are planning for application availability must contend with issues of failover and scale across geography. Cross-cluster federated services allows containerized apps to easily deploy across multiple clusters. Federated services tackles challenges such as managing multiple container clusters and coordinating service deployment and discovery across federated clusters.
Like a strictly centralized model, federation provides a common app deployment interface. With each cluster retaining autonomy, however, federation adds flexibility to manage clusters locally during network outages and other events. Cross-cluster federated services also applies consistent service naming and adoption across container clusters, simplifying DNS resolution.
It’s easy to imagine powerful multi-cluster use cases with cross-cluster federated services in future releases. An example is scheduling containers based on governance, security, and performance requirements. Diamanti’s scheduler extension was developed with this concept in mind. Our first implementation makes the Kubernetes scheduler aware of network and storage resources local to each cluster node. Similar concepts can be applied in the future to broader placement controls with cross-cluster federated services.
Get Involved
With interest growing in stateful apps, work has already started to further enhance Kubernetes storage. The Storage Special Interest Group is discussing proposals to support local storage resources. Diamanti is looking forward to extend FlexVolume to include richer APIs that enable local storage and storage services including data protection, replication, and reduction. We’re also working on proposals for improved app placement, migration, and failover across container clusters through Kubernetes cross-cluster federated services.
Join the conversation and contribute! Here are some places to get started:
- Product Management group
- Kubernetes Storage SIG
- Kubernetes Cluster Federation SIG
-- Mark Balch, VP Products, Diamanti. Twitter @markbalch
Thousand Instances of Cassandra using Kubernetes Pet Set
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.3
Running The Greek Pet Monster Races
For the Kubernetes 1.3 launch, we wanted to put the new Pet Set through its paces. By testing a thousand instances of Cassandra, we could make sure that Kubernetes 1.3 was production ready. Read on for how we adapted Cassandra to Kubernetes, and had our largest deployment ever.
It’s fairly straightforward to use containers with basic stateful applications today. Using a persistent volume, you can mount a disk in a pod, and ensure that your data lasts beyond the life of your pod. However, with deployments of distributed stateful applications, things can become more tricky. With Kubernetes 1.3, the new Pet Set component makes everything much easier. To test this new feature out at scale, we decided to host the Greek Pet Monster Races! We raced Centaurs and other Ancient Greek Monsters over hundreds of thousands of races across multiple availability zones.

As many of you know Kubernetes is from the Ancient Greek: κυβερνήτης. This means helmsman, pilot, steersman, or ship master. So in order to keep track of race results, we needed a data store, and we choose Cassandra. Κασσάνδρα, Cassandra who was the daughter of King of Priam and Queen Hecuba of Troy. With multiple references to the ancient Greek language, we thought it would be appropriate to race ancient Greek monsters.
From there the story kinda goes sideways because Cassandra was actually the Pets as well. Read on and we will explain.
One of the new exciting features in Kubernetes 1.3 is Pet Set. In order to organize the deployment of containers inside of Kubernetes, different deployment mechanisms are available. Examples of these components include Resource Controllers and Daemon Set. Pet Sets is a new feature that delivers the capability to deploy containers, as Pets, inside of Kubernetes. Pet Sets provide a guarantee of identity for various aspects of the pet / pod deployment: DNS name, consistent storage, and ordered pod indexing. Previously, using components like Deployments and Replication Controllers, would only deploy an application with a weak uncoupled identity. A weak identity is great for managing applications such as microservices, where service discovery is important, the application is stateless, and the naming of individual pods does not matter. Many software applications do require strong identity, including many different types of distributed stateful systems. Cassandra is a great example of a distributed application that requires consistent network identity, and stable storage.
Pet Sets provides the following capabilities:
- A stable hostname, available to others in DNS. Number is based off of the Pet Set name and starts at zero. For example cassandra-0.
- An ordinal index of Pets. 0, 1, 2, 3, etc.
- Stable storage linked to the ordinal and hostname of the Pet.
- Peer discovery is available via DNS. With Cassandra the names of the peers are known before the Pets are created.
- Startup and Teardown ordering. Which numbered Pet is going to be created next is known, and which Pet will be destroyed upon reducing the Pet Set size. This feature is useful for such admin tasks as draining data from a Pet, when reducing the size of a cluster.
If your application has one or more of these requirements, then it may be a candidate for Pet Set.
A relevant analogy is that a Pet Set is composed of Pet dogs. If you have a white, brown or black dog and the brown dog runs away, you can replace it with another brown dog no one would notice. If over time you can keep replacing your dogs with only white dogs then someone would notice. Pet Set allows your application to maintain the unique identity or hair color of your Pets.
Example workloads for Pet Set:
- Clustered software like Cassandra, Zookeeper, etcd, or Elastic require stable membership.
- Databases like MySQL or PostgreSQL that require a single instance attached to a persistent volume at any time.
Only use Pet Set if your application requires some or all of these properties. Managing pods as stateless replicas is vastly easier.
So back to our races!
As we have mentioned, Cassandra was a perfect candidate to deploy via a Pet Set. A Pet Set is much like a Replica Controller with a few new bells and whistles. Here's an example YAML manifest:
Headless service to provide DNS lookup
apiVersion: v1
kind: Service
metadata:
labels:
app: cassandra
name: cassandra
spec:
clusterIP: None
ports:
- port: 9042
selector:
app: cassandra-data
----
# new API name
apiVersion: "apps/v1alpha1"
kind: PetSet
metadata:
name: cassandra
spec:
serviceName: cassandra
# replicas are the same as used by Replication Controllers
# except pets are deployed in order 0, 1, 2, 3, etc
replicas: 5
template:
metadata:
annotations:
pod.alpha.kubernetes.io/initialized: "true"
labels:
app: cassandra-data
spec:
# just as other component in Kubernetes one
# or more containers are deployed
containers:
- name: cassandra
image: "cassandra-debian:v1.1"
imagePullPolicy: Always
ports:
- containerPort: 7000
name: intra-node
- containerPort: 7199
name: jmx
- containerPort: 9042
name: cql
resources:
limits:
cpu: "4"
memory: 11Gi
requests:
cpu: "4"
memory: 11Gi
securityContext:
privileged: true
env:
- name: MAX\_HEAP\_SIZE
value: 8192M
- name: HEAP\_NEWSIZE
value: 2048M
# this is relying on guaranteed network identity of Pet Sets, we
# will know the name of the Pets / Pod before they are created
- name: CASSANDRA\_SEEDS
value: "cassandra-0.cassandra.default.svc.cluster.local,cassandra-1.cassandra.default.svc.cluster.local"
- name: CASSANDRA\_CLUSTER\_NAME
value: "OneKDemo"
- name: CASSANDRA\_DC
value: "DC1-Data"
- name: CASSANDRA\_RACK
value: "OneKDemo-Rack1-Data"
- name: CASSANDRA\_AUTO\_BOOTSTRAP
value: "false"
# this variable is used by the read-probe looking
# for the IP Address in a `nodetool status` command
- name: POD\_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
readinessProbe:
exec:
command:
- /bin/bash
- -c
- /ready-probe.sh
initialDelaySeconds: 15
timeoutSeconds: 5
# These volume mounts are persistent. They are like inline claims,
# but not exactly because the names need to match exactly one of
# the pet volumes.
volumeMounts:
- name: cassandra-data
mountPath: /cassandra\_data
# These are converted to volume claims by the controller
# and mounted at the paths mentioned above. Storage can be automatically
# created for the Pets depending on the cloud environment.
volumeClaimTemplates:
- metadata:
name: cassandra-data
annotations:
volume.alpha.kubernetes.io/storage-class: anything
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 380Gi
You may notice that these containers are on the rather large size, and it is not unusual to run Cassandra in production with 8 CPU and 16GB of ram. There are two key new features that you will notice above; dynamic volume provisioning, and of course Pet Set. The above manifest will create 5 Cassandra Pets / Pods starting with the number 0: cassandra-data-0, cassandra-data-1, etc.
In order to generate data for the races, we used another Kubernetes feature called Jobs. Simple python code was written to generate the random speed of the monster for every second of the race. Then that data, position information, winners, other data points, and metrics were stored in Cassandra. To visualize the data, we used JHipster to generate a AngularJS UI with Java services, and then used D3 for graphing.
An example of one of the Jobs:
apiVersion: batch/v1
kind: Job
metadata:
name: pet-race-giants
labels:
name: pet-races
spec:
parallelism: 2
completions: 4
template:
metadata:
name: pet-race-giants
labels:
name: pet-races
spec:
containers:
- name: pet-race-giants
image: py3numpy-job:v1.0
command: ["pet-race-job", --length=100", "--pet=Giants", "--scale=3"]
resources:
limits:
cpu: "2"
requests:
cpu: "2"
restartPolicy: Never
 Since we are talking about Monsters, we had to go big. We deployed 1,009 minion nodes to Google Compute Engine (GCE), spread across 4 zones, running a custom version of the Kubernetes 1.3 beta. We ran this demo on beta code since the demo was being set up before the 1.3 release date. For the minion nodes, GCE virtual machine n1-standard-8 machine size was chosen, which is vm with 8 virtual CPUs and 30GB of memory. It would allow for a single instance of Cassandra to run on one node, which is recommended for disk I/O.
Since we are talking about Monsters, we had to go big. We deployed 1,009 minion nodes to Google Compute Engine (GCE), spread across 4 zones, running a custom version of the Kubernetes 1.3 beta. We ran this demo on beta code since the demo was being set up before the 1.3 release date. For the minion nodes, GCE virtual machine n1-standard-8 machine size was chosen, which is vm with 8 virtual CPUs and 30GB of memory. It would allow for a single instance of Cassandra to run on one node, which is recommended for disk I/O.
Then the pets were deployed! One thousand of them, in two different Cassandra Data Centers. Cassandra distributed architecture is specifically tailored for multiple-data center deployment. Often multiple Cassandra data centers are deployed inside the same physical or virtual data center, in order to separate workloads. Data is replicated across all data centers, but workloads can be different between data centers and thus application tuning can be different. Data centers named 'DC1-Analytics' and ‘DC1-Data’ where deployed with 500 pets each. The race data was created by the python Batch Jobs connected to DC1-Data, and the JHipster UI was connected DC1-Analytics.
Here are the final numbers:
- 8,072 Cores. The master used 24, minion nodes used the rest
- 1,009 IP addresses
- 1,009 routes setup by Kubernetes on Google Cloud Platform
- 100,510 GB persistent disk used by the Minions and the Master
- 380,020 GB SSD disk persistent disk. 20 GB for the master and 340 GB per Cassandra Pet.
- 1,000 deployed instances of Cassandra Yes we deployed 1,000 pets, but one really did not want to join the party! Technically with the Cassandra setup, we could have lost 333 nodes without service or data loss.
Limitations with Pet Sets in 1.3 Release
- Pet Set is an alpha resource not available in any Kubernetes release prior to 1.3.
- The storage for a given pet must either be provisioned by a dynamic storage provisioner based on the requested storage class, or pre-provisioned by an admin.
- Deleting the Pet Set will not delete any pets or Pet storage. You will need to delete your Pets and possibly its storage by hand.
- All Pet Sets currently require a "governing service", or a Service responsible for the network identity of the pets. The user is responsible for this Service.
- Updating an existing Pet Set is currently a manual process. You either need to deploy a new Pet Set with the new image version or orphan Pets one by one and update their image, which will join them back to the cluster.
Resources and References
- The source code for the demo is available on GitHub: (Pet Set examples will be merged into the Kubernetes Cassandra Examples).
- More information about Jobs
- Documentation for Pet Set
- Image credits: Cassandra image and Cyclops image
-- Chris Love, Senior DevOps Open Source Consultant for Datapipe. Twitter @chrislovecnm
Autoscaling in Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.3
Customers using Kubernetes respond to end user requests quickly and ship software faster than ever before. But what happens when you build a service that is even more popular than you planned for, and run out of compute? In Kubernetes 1.3, we are proud to announce that we have a solution: autoscaling. On Google Compute Engine (GCE) and Google Container Engine (GKE) (and coming soon on AWS), Kubernetes will automatically scale up your cluster as soon as you need it, and scale it back down to save you money when you don’t.
Benefits of Autoscaling
To understand better where autoscaling would provide the most value, let’s start with an example. Imagine you have a 24/7 production service with a load that is variable in time, where it is very busy during the day in the US, and relatively low at night. Ideally, we would want the number of nodes in the cluster and the number of pods in deployment to dynamically adjust to the load to meet end user demand. The new Cluster Autoscaling feature together with Horizontal Pod Autoscaler can handle this for you automatically.
Setting Up Autoscaling on GCE
The following instructions apply to GCE. For GKE please check the autoscaling section in cluster operations manual available here.
Before we begin, we need to have an active GCE project with Google Cloud Monitoring, Google Cloud Logging and Stackdriver enabled. For more information on project creation, please read our Getting Started Guide. We also need to download a recent version of Kubernetes project (version v1.3.0 or later).
First, we set up a cluster with Cluster Autoscaler turned on. The number of nodes in the cluster will start at 2, and autoscale up to a maximum of 5. To implement this, we’ll export the following environment variables:
export NUM\_NODES=2
export KUBE\_AUTOSCALER\_MIN\_NODES=2
export KUBE\_AUTOSCALER\_MAX\_NODES=5
export KUBE\_ENABLE\_CLUSTER\_AUTOSCALER=true
and start the cluster by running:
./cluster/kube-up.sh
The kube-up.sh script creates a cluster together with Cluster Autoscaler add-on. The autoscaler will try to add new nodes to the cluster if there are pending pods which could schedule on a new node.
Let’s see our cluster, it should have two nodes:
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 2m
kubernetes-minion-group-de5q Ready 2m
kubernetes-minion-group-yhdx Ready 1m
Run & Expose PHP-Apache Server
To demonstrate autoscaling we will use a custom docker image based on php-apache server. The image can be found here. It defines index.php page which performs some CPU intensive computations.
First, we’ll start a deployment running the image and expose it as a service:
$ kubectl run php-apache \
--image=gcr.io/google\_containers/hpa-example \
--requests=cpu=500m,memory=500M --expose --port=80
service "php-apache" createddeployment "php-apache" created
Now, we will wait some time and verify that both the deployment and the service were correctly created and are running:
$ kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
php-apache 1 1 1 1 49s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
php-apache-2046965998-z65jn 1/1 Running 0 30s
We may now check that php-apache server works correctly by calling wget with the service's address:
$ kubectl run -i --tty service-test --image=busybox /bin/sh
Hit enter for command prompt
$ wget -q -O- http://php-apache.default.svc.cluster.local
OK!
Starting Horizontal Pod Autoscaler
Now that the deployment is running, we will create a Horizontal Pod Autoscaler for it. To create it, we will use kubectl autoscale command, which looks like this:
$ kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
This defines a Horizontal Ppod Autoscaler that maintains between 1 and 10 replicas of the Pods controlled by the php-apache deployment we created in the first step of these instructions. Roughly speaking, the horizontal autoscaler will increase and decrease the number of replicas (via the deployment) so as to maintain an average CPU utilization across all Pods of 50% (since each pod requests 500 milli-cores by kubectl run, this means average CPU usage of 250 milli-cores). See here for more details on the algorithm.
We may check the current status of autoscaler by running:
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
php-apache Deployment/php-apache/scale 50% 0% 1 20 14s
Please note that the current CPU consumption is 0% as we are not sending any requests to the server (the CURRENT column shows the average across all the pods controlled by the corresponding replication controller).
Raising the Load
Now, we will see how our autoscalers (Cluster Autoscaler and Horizontal Pod Autoscaler) react on the increased load of the server. We will start two infinite loops of queries to our server (please run them in different terminals):
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
Hit enter for command prompt
$ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
We need to wait a moment (about one minute) for stats to propagate. Afterwards, we will examine status of Horizontal Pod Autoscaler:
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
php-apache Deployment/php-apache/scale 50% 310% 1 20 2m
$ kubectl get deployment php-apache
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
php-apache 7 7 7 3 4m
Horizontal Pod Autoscaler has increased the number of pods in our deployment to 7. Let’s now check, if all the pods are running:
jsz@jsz-desk2:~/k8s-src$ kubectl get pods
php-apache-2046965998-3ewo6 0/1 Pending 0 1m
php-apache-2046965998-8m03k 1/1 Running 0 1m
php-apache-2046965998-ddpgp 1/1 Running 0 5m
php-apache-2046965998-lrik6 1/1 Running 0 1m
php-apache-2046965998-nj465 0/1 Pending 0 1m
php-apache-2046965998-tmwg1 1/1 Running 0 1m
php-apache-2046965998-xkbw1 0/1 Pending 0 1m
As we can see, some pods are pending. Let’s describe one of pending pods to get the reason of the pending state:
$ kubectl describe pod php-apache-2046965998-3ewo6
Name: php-apache-2046965998-3ewo6
Namespace: default
...
Events:
FirstSeen From SubobjectPath Type Reason Message
1m {default-scheduler } Warning FailedScheduling pod (php-apache-2046965998-3ewo6) failed to fit in any node
fit failure on node (kubernetes-minion-group-yhdx): Insufficient CPU
fit failure on node (kubernetes-minion-group-de5q): Insufficient CPU
1m {cluster-autoscaler } Normal TriggeredScaleUp pod triggered scale-up, mig: kubernetes-minion-group, sizes (current/new): 2/3
The pod is pending as there was no CPU in the system for it. We see there’s a TriggeredScaleUp event connected with the pod. It means that the pod triggered reaction of Cluster Autoscaler and a new node will be added to the cluster. Now we’ll wait for the reaction (about 3 minutes) and list all nodes:
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 9m
kubernetes-minion-group-6z5i Ready 43s
kubernetes-minion-group-de5q Ready 9m
kubernetes-minion-group-yhdx Ready 9m
As we see a new node kubernetes-minion-group-6z5i was added by Cluster Autoscaler. Let’s verify that all pods are now running:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
php-apache-2046965998-3ewo6 1/1 Running 0 3m
php-apache-2046965998-8m03k 1/1 Running 0 3m
php-apache-2046965998-ddpgp 1/1 Running 0 7m
php-apache-2046965998-lrik6 1/1 Running 0 3m
php-apache-2046965998-nj465 1/1 Running 0 3m
php-apache-2046965998-tmwg1 1/1 Running 0 3m
php-apache-2046965998-xkbw1 1/1 Running 0 3m
After the node addition all php-apache pods are running!
Stop Load
We will finish our example by stopping the user load. We’ll terminate both infinite while loops sending requests to the server and verify the result state:
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
php-apache Deployment/php-apache/scale 50% 0% 1 10 16m
$ kubectl get deployment php-apache
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
php-apache 1 1 1 1 14m
As we see, in the presented case CPU utilization dropped to 0, and the number of replicas dropped to 1.
After deleting pods most of the cluster resources are unused. Scaling the cluster down may take more time than scaling up because Cluster Autoscaler makes sure that the node is really not needed so that short periods of inactivity (due to pod upgrade etc) won’t trigger node deletion (see cluster autoscaler doc). After approximately 10-12 minutes you can verify that the number of nodes in the cluster dropped:
$ kubectl get nodes
NAME STATUS AGE
kubernetes-master Ready,SchedulingDisabled 37m
kubernetes-minion-group-de5q Ready 36m
kubernetes-minion-group-yhdx Ready 36m
The number of nodes in our cluster is now two again as node kubernetes-minion-group-6z5i was removed by Cluster Autoscaler.
Other use cases
As we have shown, it is very easy to dynamically adjust the number of pods to the load using a combination of Horizontal Pod Autoscaler and Cluster Autoscaler.
However Cluster Autoscaler alone can also be quite helpful whenever there are irregularities in the cluster load. For example, clusters related to development or continuous integration tests can be less needed on weekends or at night. Batch processing clusters may have periods when all jobs are over and the new will only start in couple hours. Having machines that do nothing is a waste of money.
In all of these cases Cluster Autoscaler can reduce the number of unused nodes and give quite significant savings because you will only pay for these nodes that you actually need to run your pods. It also makes sure that you always have enough compute power to run your tasks.
-- Jerzy Szczepkowski and Marcin Wielgus, Software Engineers, Google
Kubernetes in Rancher: the further evolution
Editor’s note: today's guest post is from Alena Prokharchyk, Principal Software Engineer at Rancher Labs, who’ll share how they are incorporating new Kubernetes features into their platform.
Kubernetes was the first external orchestration platform supported by Rancher, and since its release, it has become one of the most widely used among our users, and continues to grow rapidly in adoption. As Kubernetes has evolved, so has Rancher in terms of adapting new Kubernetes features. We’ve started with supporting Kubernetes version 1.1, then switched to 1.2 as soon as it was released, and now we’re working on supporting the exciting new features in 1.3. I’d like to walk you through the features that we’ve been adding support for during each of these stages.
Rancher and Kubernetes 1.2
Kubernetes 1.2 introduced enhanced Ingress object to simplify allowing inbound connections to reach the cluster services: here’s an excellent blog post about ingress policies. Ingress resource allows users to define host name routing rules and TLS config for the Load Balancer in a user friendly way. Then it should be backed up by an Ingress controller that would configure a corresponding cloud provider’s Load Balancer with the Ingress rules. Since Rancher already included a software defined Load Balancer based on HAproxy, we already supported all of the configuration requirements of the Ingress resource, and didn’t have to do any changes on the Rancher side to adopt Ingress. What we had to do was write an Ingress controller that would listen to Kubernetes ingress specific events, configure the Rancher Load Balancer accordingly, and propagate the Load Balancer public entry point back to Kubernetes:

Now, the ingress controller gets deployed as a part of our Rancher Kubernetes system stack, and is managed by Rancher. Rancher monitors Ingress controller health, and recreates it in case of any failures. In addition to standard ingress features, Rancher also lets you to horizontally scale the Load Balancer supporting the ingress service by specifying scale via Ingress annotations. For example:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: scalelb
annotations:
scale: "2"
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: nginx-service
servicePort: 80
As a result of the above, 2 instances of Rancher Load Balancer will get started on separate hosts, and Ingress will get updated with 2 public ip addresses:
kubectl get ingress
NAME RULE BACKEND ADDRESS
scalelb - 104.154.107.202, 104.154.107.203 // hosts ip addresses where Rancher LB instances are deployed
foo.bar.com
/foo nginx-service:80
More details on Rancher Ingress Controller implementation for Kubernetes can be found here:
Rancher and Kubernetes 1.3
We’ve very excited about Kubernetes 1.3 release, and all the new features that are included with it. There are two that we are especially interested in: Stateful Apps and Cluster Federation.
Kubernetes Stateful Apps
Stateful Apps is a new resource to Kubernetes to represent a set of pods in stateful application. This is an alternative to the using Replication Controllers, which are best leveraged for running stateless apps. This feature is specifically useful for apps that rely on quorum with leader election (such as MongoDB, Zookeeper, etcd) and decentralized quorum (Cassandra). Stateful Apps create and maintains a set of pods, each of which have a stable network identity. In order to provide the network identity, it must be possible to have a resolvable DNS name for the pod that is tied to the pod identity as per Kubernetes design doc:
# service mongo pointing to pods created by PetSet mdb, with identities mdb-1, mdb-2, mdb-3
dig mongodb.namespace.svc.cluster.local +short A
172.130.16.50
dig mdb-1.mongodb.namespace.svc.cluster.local +short A
# IP of pod created for mdb-1
dig mdb-2.mongodb.namespace.svc.cluster.local +short A
# IP of pod created for mdb-2
dig mdb-3.mongodb.namespace.svc.cluster.local +short A
# IP of pod created for mdb-3
The above is implemented via an annotation on pods, which is surfaced to endpoints, and finally surfaced as DNS on the service that exposes those pods. Currently Rancher simplifies DNS configuration by leveraging Rancher DNS as a drop-in replacement for SkyDNS. Rancher DNS is fast, stable, and scalable - every host in cluster gets DNS server running. Kubernetes services get programmed to Rancher DNS, and being resolved to either service’s cluster IP from 10,43.x.x address space, or to set of Pod ip addresses for headless service. To make PetSet work with Kubernetes via Rancher, we’ll have to add support for Pod Identities to Rancher DNS configuration. We’re working on this now and should have it supported in one of the upcoming Rancher releases.
Cluster Federation
Cluster Federation is a control plane of cluster federation in Kubernetes. It offers improved application availability by spreading applications across multiple clusters (the image below is a courtesy of Kubernetes):

Each Kubernetes cluster exposes an API endpoint and gets registered to Cluster Federation as a part of Federation object. Then using Cluster Federation API, you can create federated services. Those objects are comprised of multiple equivalent underlying Kubernetes resources. Assuming that the 3 clusters on the picture above belong to the same Federation object, each Service created via Cluster Federation, will get equivalent service created in each of the clusters. Besides that, a Cluster Federation service will get publicly resolvable DNS name resolvable to Kubernetes service’s public ip addresses (DNS record gets programmed to a one of the public DNS providers below):

To support Cluster Federation via Kubernetes in Rancher, certain changes need to be done. Today each Kubernetes cluster is represented as a Rancher environment. In each Kubernetes environment, we create a full Kubernetes system stack comprised of several services: Kubernetes API server, Scheduler, Ingress controller, persistent etcd, Controller manager, Kubelet and Proxy (2 last ones run on every host). To setup Cluster Federation, we will create one extra environment where Cluster Federation stack is going to run:

Then every underlying Kubernetes cluster represented by Rancher environment, should be registered to a specific Cluster Federation. Potentially each cluster can be auto-discovered by Rancher Cluster Federation environment via label representing federation name on Kubernetes cluster. We’re still working through finalizing our design, but we’re very excited by this feature, and see a lot of use cases it can solve. Cluster Federation doc references:
- Kubernetes cluster federation design doc
- Kubernetes blog post on multi zone clusters
- Kubernetes federated services design doc
Plans for Kubernetes 1.4
When we launched Kubernetes support in Rancher we decided to maintain our own distribution of Kubernetes in order to support Rancher’s native networking. We were aware that by having our own distribution, we’d need to update it every time there were changes made to Kubernetes, but we felt it was necessary to support the use cases we were working on for users. As part of our work for 1.4 we looked at our networking approach again, and re-analyzed the initial need for our own fork of Kubernetes. Other than the networking integration, all of the work we’ve done with Kubernetes has been developed as a Kubernetes plugin:
- Rancher as a CloudProvider (to support Load Balancers).
- Rancher as a CredentialProvider (to support Rancher private registries).
- Rancher Ingress controller to back up Kubernetes ingress resource.
So we’ve decided to eliminate the need of Rancher Kubernetes distribution, and try to upstream all our changes to the Kubernetes repo. To do that, we will be reworking our networking integration, and support Rancher networking as a CNI plugin for Kubernetes. More details on that will be shared as soon as the feature design is finalized, but expect it to come in the next 2-3 months. We will also continue investing in Rancher’s core capabilities integrated with Kubernetes, including, but not limited to:
- Access rights management via Rancher environment that represents Kubernetes cluster
- Credential management and easy web-based access to standard kubectl cli
- Load Balancing support
- Rancher internal DNS support
- Catalog support for Kubernetes templates
- Enhanced UI to represent even more Kubernetes objects like: Deployment, Ingress, Daemonset.
All of that is to make Kubernetes experience even more powerful and user intuitive. We’re so excited by all of the progress in the Kubernetes community, and thrilled to be participating. Kubernetes 1.3 is an incredibly significant release, and you’ll be able to upgrade to it very soon within Rancher.
-- Alena Prokharchyk, Principal Software Engineer, Rancher Labs. Twitter @lemonjet & GitHub alena1108

Five Days of Kubernetes 1.3
Last week we released Kubernetes 1.3, two years from the day when the first Kubernetes commit was pushed to GitHub. Now 30,000+ commits later from over 800 contributors, this 1.3 releases is jam packed with updates driven by feedback from users.
While many new improvements and features have been added in the latest release, we’ll be highlighting several that stand-out. Follow along and read these in-depth posts on what’s new and how we continue to make Kubernetes the best way to manage containers at scale.
| Day 1 |
* Minikube: easily run Kubernetes locally
* rktnetes: brings rkt container engine to Kubernetes
|
|
Day 2
|
* Autoscaling in Kubernetes
* Partner post: Kubernetes in Rancher, the further evolution
|
|
Day 3
|
* Deploying thousand instances of Cassandra using Pet Set
* Partner post: Stateful Applications in Containers, by Diamanti
|
|
Day 4
|
* Cross Cluster Services
* Partner post: Citrix and NetScaler CPX
|
|
Day 5
|
* Dashboard - Full Featured Web Interface for Kubernetes
* Partner post: Steering an Automation Platform at Wercker with Kubernetes
|
|
Bonus
|
* Updates to Performance and Scalability
|
Connect
We’d love to hear from you and see you participate in this growing community:
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stackoverflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Minikube: easily run Kubernetes locally
Editor's note: This is the first post in a series of in-depth articles on what's new in Kubernetes 1.3
While Kubernetes is one of the best tools for managing containerized applications available today, and has been production-ready for over a year, Kubernetes has been missing a great local development platform.
For the past several months, several of us from the Kubernetes community have been working to fix this in the Minikube repository on GitHub. Our goal is to build an easy-to-use, high-fidelity Kubernetes distribution that can be run locally on Mac, Linux and Windows workstations and laptops with a single command.
Thanks to lots of help from members of the community, we're proud to announce the official release of Minikube. This release comes with support for Kubernetes 1.3, new commands to make interacting with your local cluster easier and experimental drivers for xhyve (on macOS) and KVM (on Linux).
Using Minikube
Minikube ships as a standalone Go binary, so installing it is as simple as downloading Minikube and putting it on your path:
Minikube currently requires that you have VirtualBox installed, which you can download here.
_(This is for Mac, for Linux substitute “minikube-darwin-amd64” with “minikube-linux-amd64”)curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-darwin-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
To start a Kubernetes cluster in Minikube, use the minikube start command:
$ minikube start
Starting local Kubernetes cluster...
Kubernetes is available at https://192.168.99.100:443
Kubectl is now configured to use the cluster

At this point, you have a running single-node Kubernetes cluster on your laptop! Minikube also configures kubectl for you, so you're also ready to run containers with no changes.
Minikube creates a Host-Only network interface that routes to your node. To interact with running pods or services, you should send traffic over this address. To find out this address, you can use the minikube ip command:

Minikube also comes with the Kubernetes Dashboard. To open this up in your browser, you can use the built-in minikube dashboard command:


In general, Minikube supports everything you would expect from a Kubernetes cluster. You can use kubectl exec to get a bash shell inside a pod in your cluster. You can use the kubectl port-forward and kubectl proxy commands to forward traffic from localhost to a pod or the API server.
Since Minikube is running locally instead of on a cloud provider, certain provider-specific features like LoadBalancers and PersistentVolumes will not work out-of-the-box. However, you can use NodePort LoadBalancers and HostPath PersistentVolumes.
Architecture
Minikube is built on top of Docker's libmachine, and leverages the driver model to create, manage and interact with locally-run virtual machines.
RedSpread was kind enough to donate their localkube codebase to the Minikube repo, which we use to spin up a single-process Kubernetes cluster inside a VM. Localkube bundles etcd, DNS, the Kubelet and all the Kubernetes master components into a single Go binary, and runs them all via separate goroutines.
Upcoming Features
Minikube has been a lot of fun to work on so far, and we're always looking to improve Minikube to make the Kubernetes development experience better. If you have any ideas for features, don't hesitate to let us know in the issue tracker.
Here's a list of some of the things we're hoping to add to Minikube soon:
- Native hypervisor support for macOS and Windows
- We're planning to remove the dependency on Virtualbox, and integrate with the native hypervisors included in macOS and Windows (Hypervisor.framework and Hyper-v, respectively).
- Improved support for Kubernetes features
- We're planning to increase the range of supported Kubernetes features, to include things like Ingress.
- Configurable versions of Kubernetes
- Today Minikube only supports Kubernetes 1.3. We're planning to add support for user-configurable versions of Kubernetes, to make it easier to match what you have running in production on your laptop.
Community
We'd love to hear feedback on Minikube. To join the community:
Please give Minikube a try, and let us know how it goes!
--Dan Lorenc, Software Engineer, Google
rktnetes brings rkt container engine to Kubernetes
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.3
As part of Kubernetes 1.3, we’re happy to report that our work to bring interchangeable container engines to Kubernetes is bearing early fruit. What we affectionately call “rktnetes” is included in the version 1.3 Kubernetes release, and is ready for development use. rktnetes integrates support for CoreOS rkt into Kubernetes as the container runtime on cluster nodes, and is now part of the mainline Kubernetes source code. Today it’s easier than ever for developers and ops pros with container portability in mind to try out running Kubernetes with a different container engine.
"We find CoreOS’s rkt a compelling container engine in Kubernetes because of how rkt is composed with the underlying systemd,” said Mark Petrovic, senior MTS and architect at Xoom, a PayPal service. “The rkt runtime assumes only the responsibility it needs to, then delegates to other system services where appropriate. This separation of concerns is important to us.”
What’s rktnetes?
rktnetes is the nickname given to the code that enables Kubernetes nodes to execute application containers with the rkt container engine, rather than with Docker. This change adds new abilities to Kubernetes, for instance running containers under flexible levels of isolation. rkt explores an alternative approach to container runtime architecture, aimed to reflect the Unix philosophy of cleanly separated, modular tools. Work done to support rktnetes also opens up future possibilities for Kubernetes, such as multiple container image format support, and the integration of other container runtimes tailored for specific use cases or platforms.
Why does Kubernetes need rktnetes?
rktnetes is about more than just rkt. It’s also about refining and exercising Kubernetes interfaces, and paving the way for other modular runtimes in the future. While the Docker container engine is well known, and is currently the default Kubernetes container runtime, a number of benefits derive from pluggable container environments. Some clusters may call for very specific container engine implementations, for example, and ensuring the Kubernetes design is flexible enough to support alternate runtimes, starting with rkt, helps keep the interfaces between components clean and simple.
Separation of concerns: Decomposing the monolithic container daemon
The current container runtime used by Kubernetes imposes a number of design decisions. Experimenting with other container execution architectures is worthwhile in such a rapidly evolving space. Today, when Kubernetes sends a request to a node to start running a pod, it communicates through the kubelet on each node with the default container runtime’s central daemon, responsible for managing all of the node’s containers.
rkt does not implement a monolithic container management daemon. (It is worth noting that the default container runtime is in the midst of refactoring its original monolithic architecture.) The rkt design has from day one tried to apply the principle of modularity to the fullest, including reusing well-tested system components, rather than reimplementing them.
The task of building container images is abstracted away from the container runtime core in rkt, and implemented by an independent utility. The same approach is taken to ongoing container lifecycle management. A single binary, rkt, configures the environment and prepares container images for execution, then sets the container application and its isolation environment running. At this point, the rkt program has done its “one job”, and the container isolator takes over.
The API for querying container engine and pod state, used by Kubernetes to track cluster work on each node, is implemented in a separate service, isolating coordination and orchestration features from the core container runtime. While the API service does not fully implement all the API features of the current default container engine, it already helps isolate containers from failures and upgrades in the core runtime, and provides the read-only parts of the expected API for querying container metadata.
Modular container isolation levels
With rkt managing container execution, Kubernetes can take advantage of the CoreOS container engine’s modular stage1 isolation mechanism. The typical container runs under rkt in a software-isolated environment constructed from Linux kernel namespaces, cgroups, and other facilities. Containers isolated in this common way nevertheless share a single kernel with all the other containers on a system, making for lightweight isolation of running apps.
However, rkt features pluggable isolation environments, referred to as stage1s, to change how containers are executed and isolated. For example, the rkt fly stage1 runs containers in the host namespaces (PID, mount, network, etc), granting containers greater power on the host system. Fly is used for containerizing lower-level system and network software, like the kubelet itself. At the other end of the isolation spectrum, the KVM stage1 runs standard app containers as individual virtual machines, each above its own Linux kernel, managed by the KVM hypervisor. This isolation level can be useful for high security and multi-tenant cluster workloads.

Currently, rktnetes can use the KVM stage1 to execute all containers on a node with VM isolation by setting the kubelet’s --rkt-stage1-image option. Experimental work exists to choose the stage1 isolation regime on a per-pod basis with a Kubernetes annotation declaring the pod’s appropriate stage1. KVM containers and standard Linux containers can be mixed together in the same cluster.
How rkt works with Kubernetes
Kubernetes today talks to the default container engine over an API provided by the Docker daemon. rktnetes communicates with rkt a little bit differently. First, there is a distinction between how Kubernetes changes the state of a node’s containers – how it starts and stops pods, or reschedules them for failover or scaling – and how the orchestrator queries pod metadata for regular, read-only bookkeeping. Two different facilities implement these two different cases.

Managing microservice lifecycles
The kubelet on each cluster node communicates with rkt to prepare containers and their environments into pods, and with systemd, the linux service management framework, to invoke and manage the pod processes. Pods are then managed as systemd services, and the kubelet sends systemd commands over dbus to manipulate them. Lifecycle management, such as restarting failed pods and killing completed processes, is handled by systemd, at the kubelet’s behest.
The API service for reading pod data
A discrete rkt api-service implements the pod introspection mechanisms expected by Kubernetes. While each node’s kubelet uses systemd to start, stop, and restart pods as services, it contacts the API service to read container runtime metadata. This includes basic orchestration information such as the number of pods running on the node, the names and networks of those pods, and the details of pod configuration, resource limits and storage volumes (think of the information shown by the kubectl describe subcommand).
Pod logs, having been written to journal files, are made available for kubectl logs and other forensic subcommands by the API service as well, which reads from log files to provide pod log data to the kubelet for answering control plane requests.
This dual interface to the container environment is an area of very active development, and plans are for the API service to expand to provide methods for the pod manipulation commands. The underlying mechanism will continue to keep separation of concerns in mind, but will hide more of this from the kubelet. The methods the kubelet uses to control the rktnetes container engine will grow less different from the default container runtime interface over time.
Try rktnetes
So what can you do with rktnetes today? Currently, rktnetes passes all of the applicable Kubernetes “end-to-end” (aka “e2e”) tests, provides standard metrics to cAdvisor, manages networks using CNI, handles per-container/pod logs, and automatically garbage collects old containers and images. Kubernetes running on rkt already provides more than the basics of a modular, flexible container runtime for Kubernetes clusters, and it is already a functional part of our development environment at CoreOS.
Developers and early adopters can follow the known issues in the rktnetes notes to get an idea of the wrinkles and bumps test-drivers can expect to encounter. This list groups the high-level pieces required to bring rktnetes to feature parity with the existing container runtime and API. We hope you’ll try out rktnetes in your Kubernetes clusters, too.
Use rkt with Kubernetes Today
The introductory guide Running Kubernetes on rkt walks through the steps to spin up a rktnetes cluster, from kubelet --container-runtime=rkt to networking and starting pods. This intro also sketches the configuration you’ll need to start a cluster on GCE with the Kubernetes kube-up.sh script.
Recent work aims to make rktnetes cluster creation much easier, too. While not yet merged, an in-progress pull request creates a single rktnetes configuration toggle to select rkt as the container engine when deploying a Kubernetes cluster with the coreos-kubernetes configuration tools. You can also check out the rktnetes workshop project, which launches a single-node rktnetes cluster on just about any developer workstation with one vagrant up command.
We’re excited to see the experiments the wider Kubernetes and CoreOS communities devise to put rktnetes to the test, and we welcome your input – and pull requests!
--Yifan Gu and Josh Wood, rktnetes Team, CoreOS. Twitter @CoreOSLinux.
Updates to Performance and Scalability in Kubernetes 1.3 -- 2,000 node 60,000 pod clusters
We are proud to announce that with the release of version 1.3, Kubernetes now supports 2000-node clusters with even better end-to-end pod startup time. The latency of our API calls are within our one-second Service Level Objective (SLO) and most of them are even an order of magnitude better than that. It is possible to run larger deployments than a 2,000 node cluster, but performance may be degraded and it may not meet our strict SLO.
In this blog post we discuss the detailed performance results from Kubernetes 1.3 and what changes we made from version 1.2 to achieve these results. We also describe Kubemark, a performance testing tool that we’ve integrated into our continuous testing framework to detect performance and scalability regressions.
Evaluation Methodology
We have described our test scenarios in a previous blog post. The biggest change since the 1.2 release is that in our API responsiveness tests we now create and use multiple namespaces. In particular for the 2000-node/60000 pod cluster tests we create 8 namespaces. The change was done because we believe that users of such very large clusters are likely to use many namespaces, certainly at least 8 in the cluster in total.
Metrics from Kubernetes 1.3
So, what is the performance of Kubernetes version 1.3? The following graph shows the end-to-end pod startup latency with a 2000 and 1000 node cluster. For comparison we show the same metric from Kubernetes 1.2 with a 1000-node cluster.



How did we achieve these improvements?
The biggest change that we made for scalability in Kubernetes 1.3 was adding an efficient Protocol Buffer-based serialization format to the API as an alternative to JSON. It is primarily intended for communication between Kubernetes control plane components, but all API server clients can use this format. All Kubernetes control plane components now use it for their communication, but the system continues to support JSON for backward compatibility.
We didn’t change the format in which we store cluster state in etcd to Protocol Buffers yet, as we’re still working on the upgrade mechanism. But we’re very close to having this ready, and we expect to switch the storage format to Protocol Buffers in Kubernetes 1.4. Our experiments show that this should reduce pod startup end-to-end latency by another 30%.
How do we test Kubernetes at scale?
Spawning clusters with 2000 nodes is expensive and time-consuming. While we need to do this at least once for each release to collect real-world performance and scalability data, we also need a lighter-weight mechanism that can allow us to quickly evaluate our ideas for different performance improvements, and that we can run continuously to detect performance regressions. To address this need we created a tool call “Kubemark.”
What is “Kubemark”?
Kubemark is a performance testing tool which allows users to run experiments on emulated clusters. We use it for measuring performance in large clusters.
A Kubemark cluster consists of two parts: a real master node running the normal master components, and a set of “hollow” nodes. The prefix “hollow” means an implementation/instantiation of a component with some “moving parts” mocked out. The best example is hollow-kubelet, which pretends to be an ordinary Kubelet, but doesn’t start any containers or mount any volumes. It just claims it does, so from master components’ perspective it behaves like a real Kubelet.
Since we want a Kubemark cluster to be as similar to a real cluster as possible, we use the real Kubelet code with an injected fake Docker client. Similarly hollow-proxy (KubeProxy equivalent) reuses the real KubeProxy code with injected no-op Proxier interface (to avoid mutating iptables).
Thanks to those changes
- many hollow-nodes can run on a single machine, because they are not modifying the environment in which they are running
- without real containers running and the need for a container runtime (e.g. Docker), we can run up to 14 hollow-nodes on a 1-core machine.
- yet hollow-nodes generate roughly the same load on the API server as their “whole” counterparts, so they provide a realistic load for performance testing [the only fundamental difference is that we are not simulating any errors that can happens in reality (e.g. failing containers) - adding support for this is a potential extension to the framework in the future]
How do we set up Kubemark clusters?
To create a Kubemark cluster we use the power the Kubernetes itself gives us - we run Kubemark clusters on Kubernetes. Let’s describe this in detail.
In order to create a N-node Kubemark cluster, we:
- create a regular Kubernetes cluster where we can run N hollow-nodes [e.g. to create 2000-node Kubemark cluster, we create a regular Kubernetes cluster with 22 8-core nodes]
- create a dedicated VM, where we start all master components for our Kubemark cluster (etcd, apiserver, controllers, scheduler, …).
- schedule N “hollow-node” pods on the base Kubernetes cluster. Those hollow-nodes are configured to talk to the Kubemark API server running on the dedicated VM
- finally, we create addon pods (currently just Heapster) by scheduling them on the base cluster and configuring them to talk to the Kubemark API server Once this done, you have a usable Kubemark cluster that you can run your (performance) tests on. We have scripts for doing all of this on Google Compute Engine (GCE). For more details, take a look at our guide.
One thing worth mentioning here is that while running Kubemark, underneath we’re also testing Kubernetes correctness. Obviously your Kubemark cluster will not work correctly if the base Kubernetes cluster under it doesn’t work.
Performance measured in real clusters vs Kubemark
Crucially, the performance of Kubemark clusters is mostly similar to the performance of real clusters. For the pod startup end-to-end latency, as shown in the graph below, the difference is negligible:

For the API-responsiveness, the differences are higher, though generally less than 2x. However, trends are exactly the same: an improvement/regression in a real cluster is visible as a similar percentage drop/increase in metrics in Kubemark.

We continue to improve the performance and scalability of Kubernetes. In this blog post we
showed that the 1.3 release scales to 2000 nodes while meeting our responsiveness SLOs
explained the major change we made to improve scalability from the 1.2 release, and
described Kubemark, our emulation framework that allows us to quickly evaluate the performance impact of code changes, both when experimenting with performance improvement ideas and to detect regressions as part of our continuous testing infrastructure.
Please join our community and help us build the future of Kubernetes! If you’re particularly interested in scalability, participate by:
- chatting with us on our Slack channel
- joining the scalability Special Interest Group, which meets every Thursday at 9 AM Pacific Time on this SIG-Scale Hangout
For more information about the Kubernetes project, visit kubernetes.io and follow us on Twitter @Kubernetesio.
-- Wojciech Tyczynski, Software Engineer, Google
Kubernetes 1.3: Bridging Cloud Native and Enterprise Workloads
Nearly two years ago, when we officially kicked off the Kubernetes project, we wanted to simplify distributed systems management and provide the core technology required to everyone. The community’s response to this effort has blown us away. Today, thousands of customers, partners and developers are running clusters in production using Kubernetes and have joined the cloud native revolution.
Thanks to the help of over 800 contributors, we are pleased to announce today the availability of Kubernetes 1.3, our most robust and feature-rich release to date.
As our users scale their production deployments we’ve heard a clear desire to deploy services across cluster, zone and cloud boundaries. We’ve also heard a desire to run more workloads in containers, including stateful services. In this release, we’ve worked hard to address these two problems, while making it easier for new developers and enterprises to use Kubernetes to manage distributed systems at scale.
Product highlights in Kubernetes 1.3 include the ability to bridge services across multiple clouds (including on-prem), support for multiple node types, integrated support for stateful services (such as key-value stores and databases), and greatly simplified cluster setup and deployment on your laptop. Now, developers at organizations of all sizes can build production scale apps more easily than ever before.
What’s new:
-
Increased scale and automation - Customers want to scale their services up and down automatically in response to application demand. In 1.3 we have made it easier to autoscale clusters up and down while doubling the maximum number of nodes per cluster. Customers no longer need to think about cluster size, and can allow the underlying cluster to respond to demand.
-
Cross-cluster federated services - Customers want their services to span one or more (possibly remote) clusters, and for them to be reachable in a consistent manner from both within and outside their clusters. Services that span clusters have higher availability, provide geographic distribution and enable hybrid and multi-cloud scenarios. Kubernetes 1.3 introduces cross-cluster service discovery so containers, and external clients can consistently resolve to services irrespective of whether they are running partially or completely in other clusters.
-
Stateful applications - Customers looking to use containers for stateful workloads (such as databases or key value stores) will find a new ‘PetSet’ object with raft of alpha features, including:
- Permanent hostnames that persist across restarts
- Automatically provisioned persistent disks per container that live beyond the life of a container
- Unique identities in a group to allow for clustering and leader election
- Initialization containers which are critical for starting up clustered applications
-
Ease of use for local development - Developers want an easy way to learn to use Kubernetes. In Kubernetes 1.3 we are introducing Minikube, where with one command a developer can start a local Kubernetes cluster on their laptop that is API compatible with a full Kubernetes cluster. This enable developers to test locally, and push to their Kubernetes clusters when they are ready.
-
Support for rkt and container standards OCI & CNI - Kubernetes is an extensible and modular orchestration platform. Part of what has made Kubernetes successful is our commitment to giving customers access to the latest container technologies that best suit their environment. In Kubernetes 1.3 we support emerging standards such as the Container Network Interface (CNI) natively, and have already taken steps to the Open Container Initiative (OCI), which is still being ratified. We are also introducing rkt as an alternative container runtime in Kubernetes node, with a first-class integration between rkt and the kubelet. This allows Kubernetes users to take advantage of some of rkt's unique features.
-
Updated Kubernetes dashboard UI - Customers can now use the Kubernetes open source dashboard for the majority of interactions with their clusters, rather than having to use the CLI. The updated UI lets users control, edit and create all workload resources (including Deployments and PetSets).
-
And many more. For a complete list of updates, see the release notes on GitHub.
Community
We could not have achieved this milestone without the tireless effort of countless people that are part of the Kubernetes community. We have 19 different Special Interest Groups, and over 100 meetups around the world. Kubernetes is a community project, built in the open, and it truly would not be possible without the over 233 person-years of effort the community has put in to date. Woot!
Availability
Kubernetes 1.3 is available for download at get.k8s.io and via the open source repository hosted on GitHub. To get started with Kubernetes try our Hello World app.
To learn the latest about the project, we encourage everyone to join the weekly community meeting or watch a recorded hangout.
Connect
We’d love to hear from you and see you participate in this growing community:
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stackoverflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Thank you for your support!
-- Aparna Sinha, Product Manager, Google
Container Design Patterns
Kubernetes automates deployment, operations, and scaling of applications, but our goals in the Kubernetes project extend beyond system management -- we want Kubernetes to help developers, too. Kubernetes should make it easy for them to write the distributed applications and services that run in cloud and datacenter environments. To enable this, Kubernetes defines not only an API for administrators to perform management actions, but also an API for containerized applications to interact with the management platform.
Our work on the latter is just beginning, but you can already see it manifested in a few features of Kubernetes. For example:
- The “graceful termination” mechanism provides a callback into the container a configurable amount of time before it is killed (due to a rolling update, node drain for maintenance, etc.). This allows the application to cleanly shut down, e.g. persist in-memory state and cleanly conclude open connections.
- Liveness and readiness probes check a configurable application HTTP endpoint (other probe types are supported as well) to determine if the container is alive and/or ready to receive traffic. The response determines whether Kubernetes will restart the container, include it in the load-balancing pool for its Service, etc.
- ConfigMap allows applications to read their configuration from a Kubernetes resource rather than using command-line flags.
More generally, we see Kubernetes enabling a new generation of design patterns, similar to object oriented design patterns, but this time for containerized applications. That design patterns would emerge from containerized architectures is not surprising -- containers provide many of the same benefits as software objects, in terms of modularity/packaging, abstraction, and reuse. Even better, because containers generally interact with each other via HTTP and widely available data formats like JSON, the benefits can be provided in a language-independent way.
This week Kubernetes co-founder Brendan Burns is presenting a paper outlining our thoughts on this topic at the 8th Usenix Workshop on Hot Topics in Cloud Computing (HotCloud ‘16), a venue where academic researchers and industry practitioners come together to discuss ideas at the forefront of research in private and public cloud technology. The paper describes three classes of patterns: management patterns (such as those described above), patterns involving multiple cooperating containers running on the same node, and patterns involving containers running across multiple nodes. We don’t want to spoil the fun of reading the paper, but we will say that you’ll see that the Pod abstraction is a key enabler for the last two types of patterns.
As the Kubernetes project continues to bring our decade of experience with Borg to the open source community, we aim not only to make application deployment and operations at scale simple and reliable, but also to make it easy to create “cloud-native” applications in the first place. Our work on documenting our ideas around design patterns for container-based services, and Kubernetes’s enabling of such patterns, is a first step in this direction. We look forward to working with the academic and practitioner communities to identify and codify additional patterns, with the aim of helping containers fulfill the promise of bringing increased simplicity and reliability to the entire software lifecycle, from development, to deployment, to operations.
To learn more about the Kubernetes project visit kubernetes.io or chat with us on Slack at slack.kubernetes.io.
--Brendan Burns and David Oppenheimer, Software Engineers, Google
The Illustrated Children's Guide to Kubernetes
Kubernetes is an open source project with a growing community. We love seeing the ways that our community innovates inside and on top of Kubernetes. Deis is an excellent example of company who understands the strategic impact of strong container orchestration. They contribute directly to the project; in associated subprojects; and, delightfully, with a creative endeavor to help our user community understand more about what Kubernetes is. Want to contribute to Kubernetes? One way is to get involved here and help us with code. But, please don’t consider that the only way to contribute. This little adventure that Deis takes us is an example of how open source isn’t only code.
Have your own Kubernetes story you’d like to tell, let us know!
-- @sarahnovotny Community Wonk, Kubernetes project.
Guest post is by Beau Vrolyk, CEO of Deis, the open source Kubernetes-native PaaS.
Over at Deis, we’ve been busy building open source tools for Kubernetes. We’re just about to finish up moving our easy-to-use application platform to Kubernetes and couldn’t be happier with the results. In the Kubernetes project we’ve found not only a growing and vibrant community but also a well-architected system, informed by years of experience running containers at scale.
But that’s not all! As we’ve decomposed, ported, and reborn our PaaS as a Kubernetes citizen; we found a need for tools to help manage all of the ephemera that comes along with building and running Kubernetes-native applications. The result has been open sourced as Helm and we’re excited to see increasing adoption and growing excitement around the project.
There’s fun in the Deis offices too -- we like to add some character to our architecture diagrams and pull requests. This time, literally. Meet Phippy--the intrepid little PHP app--and her journey to Kubernetes. What better way to talk to your parents, friends, and co-workers about this Kubernetes thing you keep going on about, than a little story time. We give to you The Illustrated Children's Guide to Kubernetes, conceived of and narrated by our own Matt Butcher and lovingly illustrated by Bailey Beougher. Join the fun on YouTube and tweet @opendeis to win your own copy of the book or a squishy little Phippy of your own.
Bringing End-to-End Kubernetes Testing to Azure (Part 1)
Today’s guest post is by Travis Newhouse, Chief Architect at AppFormix, writing about their experiences bringing Kubernetes to Azure.
At AppFormix, continuous integration testing is part of our culture. We see many benefits to running end-to-end tests regularly, including minimizing regressions and ensuring our software works together as a whole. To ensure a high quality experience for our customers, we require the ability to run end-to-end testing not just for our application, but for the entire orchestration stack. Our customers are adopting Kubernetes as their container orchestration technology of choice, and they demand choice when it comes to where their containers execute, from private infrastructure to public providers, including Azure. After several weeks of work, we are pleased to announce we are contributing a nightly, continuous integration job that executes e2e tests on the Azure platform. After running the e2e tests each night for only a few weeks, we have already found and fixed two issues in Kubernetes. We hope our contribution of an e2e job will help the community maintain support for the Azure platform as Kubernetes evolves.
In this blog post, we describe the journey we took to implement deployment scripts for the Azure platform. The deployment scripts are a prerequisite to the e2e test job we are contributing, as the scripts make it possible for our e2e test job to test the latest commits to the Kubernetes master branch. In a subsequent blog post, we will describe details of the e2e tests that will help maintain support for the Azure platform, and how to contribute federated e2e test results to the Kubernetes project.
BACKGROUND
While Kubernetes is designed to operate on any IaaS, and solution guides exist for many platforms including Google Compute Engine, AWS, Azure, and Rackspace, the Kubernetes project refers to these as “versioned distros,” as they are only tested against a particular binary release of Kubernetes. On the other hand, “development distros” are used daily by automated, e2e tests for the latest Kubernetes source code, and serve as gating checks to code submission.
When we first surveyed existing support for Kubernetes on Azure, we found documentation for running Kubernetes on Azure using CoreOS and Weave. The documentation includes scripts for deployment, but the scripts do not conform to the cluster/kube-up.sh framework for automated cluster creation required by a “development distro.” Further, there did not exist a continuous integration job that utilized the scripts to validate Kubernetes using the end-to-end test scenarios (those found in test/e2e in the Kubernetes repository).
With some additional investigation into the project history (side note: git log --all --grep='azure' --oneline was quite helpful), we discovered that there previously existed a set of scripts that integrated with the cluster/kube-up.sh framework. These scripts were discarded on October 16, 2015 (commit 8e8437d) because the scripts hadn’t worked since before Kubernetes version 1.0. With these commits as a starting point, we set out to bring the scripts up to date, and create a supported continuous integration job that will aid continued maintenance.
CLUSTER DEPLOYMENT SCRIPTS
To setup a Kubernetes cluster with Ubuntu VMs on Azure, we followed the groundwork laid by the previously abandoned commit, and tried to leverage the existing code as much as possible. The solution uses SaltStack for deployment and OpenVPN for networking between the master and the minions. SaltStack is also used for configuration management by several other solutions, such as AWS, GCE, Vagrant, and Vsphere. Resurrecting the discarded commit was a starting point, but we soon realized several key elements that needed attention:
- Install Docker and Kubernetes on the nodes using SaltStack
- Configure authentication for services
- Configure networking
The cluster setup scripts ensure Docker is installed, copy the Kubernetes Docker images to the master and minions nodes, and load the images. On the master node, SaltStack launches kubelet, which in turn launches the following Kubernetes services running in containers: kube-api-server, kube-scheduler, and kube-controller-manager. On each of the minion nodes, SaltStack launches kubelet, which starts kube-proxy.
Kubernetes services must authenticate when communicating with each other. For example, minions register with the kube-api service on the master. On the master node, scripts generate a self-signed certificate and key that kube-api uses for TLS. Minions are configured to skip verification of the kube-api’s (self-signed) TLS certificate. We configure the services to use username and password credentials. The username and password are generated by the cluster setup scripts, and stored in the kubeconfig file on each node.
Finally, we implemented the networking configuration. To keep the scripts parameterized and minimize assumptions about the target environment, the scripts create a new Linux bridge device (cbr0), and ensure that all containers use that interface to access the network. To configure networking, we use OpenVPN to establish tunnels between master and minion nodes. For each minion, we reserve a /24 subnet to use for its pods. Azure assigned each node its own IP address. We also added the necessary routing table entries for this bridge to use OpenVPN interfaces. This is required to ensure pods in different hosts can communicate with each other. The routes on the master and minion are the following:
master
Destination Gateway Genmask Flags Metric Ref Use Iface
10.8.0.0 10.8.0.2 255.255.255.0 UG 0 0 0 tun0
10.8.0.2 0.0.0.0 255.255.255.255 UH 0 0 0 tun0
10.244.1.0 10.8.0.2 255.255.255.0 UG 0 0 0 tun0
10.244.2.0 10.8.0.2 255.255.255.0 UG 0 0 0 tun0
172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 cbr0
minion-1
10.8.0.0 10.8.0.5 255.255.255.0 UG 0 0 0 tun0
10.8.0.5 0.0.0.0 255.255.255.255 UH 0 0 0 tun0
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cbr0
10.244.2.0 10.8.0.5 255.255.255.0 UG 0 0 0 tun0
minion-2
10.8.0.0 10.8.0.9 255.255.255.0 UG 0 0 0 tun0
10.8.0.9 0.0.0.0 255.255.255.255 UH 0 0 0 tun0
10.244.1.0 10.8.0.9 255.255.255.0 UG 0 0 0 tun0
10.244.2.0 0.0.0.0 255.255.255.0 U 0 0 0 cbr0
 |
| Figure 1 - OpenVPN network configuration |
|
| Figure 1 - OpenVPN network configuration |
FUTURE WORK With the deployment scripts implemented, a subset of e2e test cases are passing on the Azure platform. Nightly results are published to the Kubernetes test history dashboard. Weixu Zhuang made a pull request on Kubernetes GitHub, and we are actively working with the Kubernetes community to merge the Azure cluster deployment scripts necessary for a nightly e2e test job. The deployment scripts provide a minimal working environment for Kubernetes on Azure. There are several next steps to continue the work, and we hope the community will get involved to achieve them.
- Only a subset of the e2e scenarios are passing because some cloud provider interfaces are not yet implemented for Azure, such as load balancer and instance information. To this end, we seek community input and help to define an Azure implementation of the cloudprovider interface (pkg/cloudprovider/). These interfaces will enable features such as Kubernetes pods being exposed to the external network and cluster DNS.
- Azure has new APIs for interacting with the service. The submitted scripts currently use the Azure Service Management APIs, which are deprecated. The Azure Resource Manager APIs should be used in the deployment scripts. The team at AppFormix is pleased to contribute support for Azure to the Kubernetes community. We look forward to feedback about how we can work together to improve Kubernetes on Azure.
Editor's Note: Want to contribute to Kubernetes, get involved here. Have your own Kubernetes story you’d like to tell, let us know!
Part II is available here.
Hypernetes: Bringing Security and Multi-tenancy to Kubernetes
Today’s guest post is written by Harry Zhang and Pengfei Ni, engineers at HyperHQ, describing a new hypervisor based container called HyperContainer
While many developers and security professionals are comfortable with Linux containers as an effective boundary, many users need a stronger degree of isolation, particularly for those running in a multi-tenant environment. Sadly, today, those users are forced to run their containers inside virtual machines, even one VM per container.
Unfortunately, this results in the loss of many of the benefits of a cloud-native deployment: slow startup time of VMs; a memory tax for every container; low utilization resulting in wasting resources.
In this post, we will introduce HyperContainer, a hypervisor based container and see how it naturally fits into the Kubernetes design, and enables users to serve their customers directly with virtualized containers, instead of wrapping them inside of full blown VMs.
HyperContainer
HyperContainer is a hypervisor-based container, which allows you to launch Docker images with standard hypervisors (KVM, Xen, etc.). As an open-source project, HyperContainer consists of an OCI compatible runtime implementation, named runV, and a management daemon named hyperd. The idea behind HyperContainer is quite straightforward: to combine the best of both virtualization and container.
We can consider containers as two parts (as Kubernetes does). The first part is the container runtime, where HyperContainer uses virtualization to achieve execution isolation and resource limitation instead of namespaces and cgroups. The second part is the application data, where HyperContainer leverages Docker images. So in HyperContainer, virtualization technology makes it possible to build a fully isolated sandbox with an independent guest kernel (so things like top and /proc all work), but from developer’s view, it’s portable and behaves like a standard container.
HyperContainer as Pod
The interesting part of HyperContainer is not only that it is secure enough for multi-tenant environments (such as a public cloud), but also how well it fits into the Kubernetes philosophy.
One of the most important concepts in Kubernetes is Pods. The design of Pods is a lesson learned (Borg paper section 8.1) from real world workloads, where in many cases people want an atomic scheduling unit composed of multiple containers (please check this example for further information). In the context of Linux containers, a Pod wraps and encapsulates several containers into a logical group. But in HyperContainer, the hypervisor serves as a natural boundary, and Pods are introduced as first-class objects:

HyperContainer wraps a Pod of light-weight application containers and exposes the container interface at Pod level. Inside the Pod, a minimalist Linux kernel called HyperKernel is booted. This HyperKernel is built with a tiny Init service called HyperStart. It will act as the PID 1 process and creates the Pod, setup Mount namespace, and launch apps from the loaded images.
This model works nicely with Kubernetes. The integration of HyperContainer with Kubernetes, as we indicated in the title, is what makes up the Hypernetes project.
Hypernetes
One of the best parts of Kubernetes is that it is designed to support multiple container runtimes, meaning users are not locked-in to a single vendor. We are very pleased to announce that we have already begun working with the Kubernetes team to integrate HyperContainer into Kubernetes upstream. This integration involves:
- container runtime optimizing and refactoring
- new client-server mode runtime interface
- containerd integration to support runV
The OCI standard and kubelet’s multiple runtime architecture make this integration much easier even though HyperContainer is not based on Linux container technology stack.
On the other hand, in order to run HyperContainers in multi-tenant environment, we also created a new network plugin and modified an existing volume plugin. Since Hypernetes runs Pod as their own VMs, it can make use of your existing IaaS layer technologies for multi-tenant network and persistent volumes. The current Hypernetes implementation uses standard Openstack components.
Below we go into further details about how all those above are implemented.
Identity and Authentication
In Hypernetes we chose Keystone to manage different tenants and perform identification and authentication for tenants during any administrative operation. Since Keystone comes from the OpenStack ecosystem, it works seamlessly with the network and storage plugins we used in Hypernetes.
Multi-tenant Network Model
For a multi-tenant container cluster, each tenant needs to have strong network isolation from each other tenant. In Hypernetes, each tenant has its own Network. Instead of configuring a new network using OpenStack, which is complex, with Hypernetes, you just create a Network object like below.
apiVersion: v1
kind: Network
metadata:
name: net1
spec:
tenantID: 065f210a2ca9442aad898ab129426350
subnets:
subnet1:
cidr: 192.168.0.0/24
gateway: 192.168.0.1
Note that the tenantID is supplied by Keystone. This yaml will automatically create a new Neutron network with a default router and a subnet 192.168.0.0/24.
A Network controller will be responsible for the life-cycle management of any Network instance created by the user. This Network can be assigned to one or more Namespaces, and any Pods belonging to the same Network can reach each other directly through IP address.
apiVersion: v1
kind: Namespace
metadata:
name: ns1
spec:
network: net1
If a Namespace does not have a Network spec, it will use the default Kubernetes network model instead, including the default kube-proxy. So if a user creates a Pod in a Namespace with an associated Network, Hypernetes will follow the Kubernetes Network Plugin Model to set up a Neutron network for this Pod. Here is a high level example:

Hypernetes uses a standalone gRPC handler named kubestack to translate the Kubernetes Pod request into the Neutron network API. Moreover, kubestack is also responsible for handling another important networking feature: a multi-tenant Service proxy.
In a multi-tenant environment, the default iptables-based kube-proxy can not reach the individual Pods, because they are isolated into different networks. Instead, Hypernetes uses a built-in HAproxy in every HyperContainer as the portal. This HAproxy will proxy all the Service instances in the namespace of that Pod. Kube-proxy will be responsible for updating these backend servers by following the standard OnServiceUpdate and OnEndpointsUpdate processes, so that users will not notice any difference. A downside of this method is that HAproxy has to listen to some specific ports which may conflicts with user’s containers.That’s why we are planning to use LVS to replace this proxy in the next release.
With the help of the Neutron based network plugin, the Hypernetes Service is able to provide an OpenStack load balancer, just like how the “external” load balancer does on GCE. When user creates a Service with external IPs, an OpenStack load balancer will be created and endpoints will be automatically updated through the kubestack workflow above.
Persistent Storage
When considering storage, we are actually building a tenant-aware persistent volume in Kubernetes. The reason we decided not to use existing Cinder volume plugin of Kubernetes is that its model does not work in the virtualization case. Specifically:
The Cinder volume plugin requires OpenStack as the Kubernetes provider.
The OpenStack provider will find on which VM the target Pod is running on
Cinder volume plugin will mount a Cinder volume to a path inside the host VM of Kubernetes.
The kubelet will bind mount this path as a volume into containers of target Pod.
But in Hypernetes, things become much simpler. Thanks to the physical boundary of Pods, HyperContainer can mount Cinder volumes directly as block devices into Pods, just like a normal VM. This mechanism eliminates extra time to query Nova to find out the VM of target Pod in the existing Cinder volume workflow listed above.
The current implementation of the Cinder plugin in Hypernetes is based on Ceph RBD backend, and it works the same as all other Kubernetes volume plugins, one just needs to remember to create the Cinder volume (referenced by volumeID below) beforehand.
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: nginx-persistent-storage
mountPath: /var/lib/nginx
volumes:
- name: nginx-persistent-storage
cinder:
volumeID: 651b2a7b-683e-47e1-bdd6-e3c62e8f91c0
fsType: ext4
So when the user provides a Pod yaml with a Cinder volume, Hypernetes will check if kubelet is using the Hyper container runtime. If so, the Cinder volume can be mounted directly to the Pod without any extra path mapping. Then the volume metadata will be passed to the Kubelet RunPod process as part of HyperContainer spec. Done!
Thanks to the plugin model of Kubernetes network and volume, we can easily build our own solutions above for HyperContainer though it is essentially different from the traditional Linux container. We also plan to propose these solutions to Kubernetes upstream by following the CNI model and volume plugin standard after the runtime integration is completed.
We believe all of these open source projects are important components of the container ecosystem, and their growth depends greatly on the open source spirit and technical vision of the Kubernetes team.
Conclusion
This post introduces some of the technical details about HyperContainer and the Hypernetes project. We hope that people will be interested in this new category of secure container and its integration with Kubernetes. If you are looking to try out Hypernetes and HyperContainer, we have just announced the public beta of our new secure container cloud service (Hyper_), which is built on these technologies. But even if you are running on-premise, we believe that Hypernetes and HyperContainer will let you run Kubernetes in a more secure way.
~Harry Zhang and Pengfei Ni, engineers at HyperHQ
CoreOS Fest 2016: CoreOS and Kubernetes Community meet in Berlin (& San Francisco)
CoreOS Fest 2016 will bring together the container and open source distributed systems community, including many thought leaders in the Kubernetes space. It is the second annual CoreOS community conference, held for the first time in Berlin on May 9th and 10th. CoreOS believes Kubernetes is the container orchestration component to deliver GIFEE (Google’s Infrastructure for Everyone Else).
At this year’s CoreOS Fest, there are tracks dedicated to Kubernetes where you’ll hear about various topics ranging from Kubernetes performance and scalability, continuous delivery and Kubernetes, rktnetes, stackanetes and more. In addition, there will be a variety of talks, from introductory workshops to deep-dives into all things containers and related software.
Don’t miss these great speaker sessions at the conference in Berlin :
- Kubernetes Performance & Scalability Deep-Dive by Filip Grzadkowski, Senior Software Engineer at Google
- Launching a complex application in a Kubernetes cloud by Thomas Fricke and Jannis Rake-Revelant, Operations & Infrastructure Lead, immmr Gmbh (a service developed by the Deutsche Telekom’s R&D department)
- I have Kubernetes, now what? by Gabriel Monroy, CTO of Engine Yard and creator of Deis
- When rkt meets Kubernetes: a troubleshooting tale by Luca Marturana, Software Engineer at Sysdig
- Use Kubernetes to deploy telecom applications by Victor Hu, Senior Engineer at Huawei Technologies
- Continuous Delivery, Kubernetes and You by Micha Hernandez van Leuffen, CEO and founder of Wercker
- #GIFEE, More Containers, More Problems by Ed Rooth, Head of Tectonic at CoreOS
- Kubernetes Access Control with dex by Eric Chiang, Software Engineer at CoreOS
If you can’t make it to Berlin, Kubernetes is also a focal point at the CoreOS Fest San Franciscosatellite event, a one day event dedicated to CoreOS and Kubernetes. In fact, Tim Hockin, senior staff engineer at Google and one of the creators of Kubernetes, will be kicking off the day with a keynote dedicated to Kubernetes updates.
San Francisco sessions dedicated to Kubernetes include:
- Tim Hockin’s keynote address, Senior Staff Engineer at Google
- When rkt meets Kubernetes: a troubleshooting tale by Loris Degioanni, CEO of Sysdig
- rktnetes: what's new with container runtimes and Kubernetes by Derek Gonyeo, Software Engineer at CoreOS
- Magical Security Sprinkles: Secure, Resilient Microservices on CoreOS and Kubernetes by Oliver Gould, CTO of Buoyant
Kubernetes Workshop in SF : Getting Started with Kubernetes, hosted at Google San Francisco office (345 Spear St - 7th floor) by Google Developer Program Engineers Carter Morgan and Bill Prin on Tuesday May 10th from 9:00am to 1:00pm, lunch will be served afterwards. Limited seats, please RSVP for free here.
Get your tickets :
- CoreOS Fest - Berlin, at the Berlin Congress Center (hotel option)
- satellite event in San Francisco, at the 111 Minna Gallery
Learn more at: coreos.com/fest/ and on Twitter @CoreOSFest #CoreOSFest
-- Sarah Novotny, Kubernetes Community Manager
Introducing the Kubernetes OpenStack Special Interest Group
Editor’s note: This week we’re featuring Kubernetes Special Interest Groups; Today’s post is by the SIG-OpenStack team about their mission to facilitate ideas between the OpenStack and Kubernetes communities.
The community around the Kubernetes project includes a number of Special Interest Groups (SIGs) for the purposes of facilitating focused discussions relating to important subtopics between interested contributors. Today we would like to highlight the Kubernetes OpenStack SIG focused on the interaction between Kubernetes and OpenStack, the Open Source cloud computing platform.
There are two high level scenarios that are being discussed in the SIG:
- Using Kubernetes to manage containerized workloads running on top of OpenStack
- Using Kubernetes to manage containerized OpenStack services themselves
In both cases the intent is to help facilitate the inter-pollination of ideas between the growing Kubernetes and OpenStack communities. The OpenStack community itself includes a number of projects broadly aimed at assisting with both of these use cases including:
- Kolla - Provides OpenStack service containers and deployment tooling for operating OpenStack clouds.
- Kuryr - Provides bridges between container networking/storage framework models and OpenStack infrastructure services.
- Magnum - Provides containers as a service for OpenStack.
- Murano - Provides an Application Catalog service for OpenStack including support for Kubernetes itself, and for containerized applications, managed by Kubernetes.
There are also a number of example templates available to assist with using the OpenStack Orchestration service (Heat) to deploy and configure either Kubernetes itself or offerings built around Kubernetes such as OpenShift. While each of these approaches has their own pros and cons the common theme is the ability, or potential ability, to use Kubernetes and where available leverage deeper integration between it and the OpenStack services themselves.
Current SIG participants represent a broad array of organizations including but not limited to: CoreOS, eBay, GoDaddy, Google, IBM, Intel, Mirantis, OpenStack Foundation, Rackspace, Red Hat, Romana, Solinea, VMware.
The SIG is currently working on collating information about these approaches to help Kubernetes users navigate the OpenStack ecosystem along with feedback on which approaches to the requirements presented work best for operators.
Kubernetes at OpenStack Summit Austin
The OpenStack Summit is in Austin from April 25th to 29th and is packed with sessions related to containers and container management using Kubernetes. If you plan on joining us in Austin you can review the schedule online where you will find a number of sessions, both in the form of presentations and hands on workshops, relating to Kubernetes and containerization at large. Folks from the Kubernetes OpenStack SIG are particularly keen to get the thoughts of operators in the “Ops: Containers on OpenStack” and “Ops: OpenStack in Containers” working sessions.
Kubernetes community experts will also be on hand in the Container Expert Lounge to answer your burning questions. You can find the lounge on the 4th floor of the Austin Convention Center.
Follow @kubernetesio and #OpenStackSummit to keep up with the latest updates on Kubernetes at OpenStack Summit throughout the week.
Connect With Us
If you’re interested in Kubernetes and OpenStack, there are several ways to participate:
- Email us at the SIG-OpenStack mailing list
- Chat with us on the Kubernetes Slack: #sig-openstack channel and #openstack-kubernetes on freenode
- Join our meeting occurring every second Tuesday at 2 PM PDT; attend via the zoom videoconference found in our meeting notes.
-- Steve Gordon, Principal Product Manager at Red Hat, and Ihor Dvoretskyi, OpenStack Operations Engineer at Mirantis
SIG-UI: the place for building awesome user interfaces for Kubernetes
Editor’s note: This week we’re featuring Kubernetes Special Interest Groups; Today’s post is by the SIG-UI team describing their mission and showing the cool projects they work on.
Kubernetes has been handling production workloads for a long time now (see case studies). It runs on public, private and hybrid clouds as well as bare metal. It can handle all types of workloads (web serving, batch and mixed) and enable zero-downtime rolling updates. It abstracts service discovery, load balancing and storage so that applications running on Kubernetes aren’t restricted to a specific cloud provider or environment.
The abundance of features that Kubernetes offers is fantastic, but implementing a user-friendly, easy-to-use user interface is quite challenging. How shall all the features be presented to users? How can we gradually expose the Kubernetes concepts to newcomers, while empowering experts? There are lots of other challenges like these that we’d like to solve. This is why we created a special interest group for Kubernetes user interfaces.
Meet SIG-UI: the place for building awesome user interfaces for Kubernetes
The SIG UI mission is simple: we want to radically improve the user experience of all Kubernetes graphical user interfaces. Our goal is to craft UIs that are used by devs, ops and resource managers across their various environments, that are simultaneously intuitive enough for newcomers to Kubernetes to understand and use.
SIG UI members have been independently working on a variety of UIs for Kubernetes. So far, the projects we’ve seen have been either custom internal tools coupled to their company workflows, or specialized API frontends. We have realized that there is a need for a universal UI that can be used standalone or be a standard base for custom vendors. That’s how we started the Dashboard UI project. Version 1.0 has been recently released and is included with Kubernetes as a cluster addon. The Dashboard project was recently featured in a talk at KubeCon EU, and we have ambitious plans for the future!
| 
Since the initial release of the Dashboard UI we have been thinking hard about what to do next and what users of UIs for Kubernetes think about our plans. We’ve had many internal discussions on this topic, but most importantly, reached out directly to our users. We created a questionnaire asking a few demographic questions as well as questions for prioritizing use cases. We received more than 200 responses from a wide spectrum of user types, which in turn helped to shape the Dashboard UI’s current roadmap. Our members from LiveWyer summarised the results in a nice infographic.
Connect with us
We believe that collaboration is the key to SIG UI success, so we invite everyone to connect with us. Whether you’re a Kubernetes user who wants to provide feedback, develop your own UIs, or simply want to collaborate on the Dashboard UI project, feel free to get in touch. There are many ways you can contact us:
- Email us at the sig-ui mailing list
- Chat with us on the Kubernetes Slack: #sig-ui channel
- Join our meetings: biweekly on Wednesdays 9AM PT (US friendly) and weekly 10AM CET (Europe friendly). See the SIG-UI calendar for details.
-- Piotr Bryk, Software Engineer, Google
SIG-ClusterOps: Promote operability and interoperability of Kubernetes clusters
Editor’s note: This week we’re featuring Kubernetes Special Interest Groups; Today’s post is by the SIG-ClusterOps team whose mission is to promote operability and interoperability of Kubernetes clusters -- to listen, help & escalate.
We think Kubernetes is an awesome way to run applications at scale! Unfortunately, there's a bootstrapping problem: we need good ways to build secure & reliable scale environments around Kubernetes. While some parts of the platform administration leverage the platform (cool!), there are fundamental operational topics that need to be addressed and questions (like upgrade and conformance) that need to be answered.
Enter Cluster Ops SIG – the community members who work under the platform to keep it running.
Our objective for Cluster Ops is to be a person-to-person community first, and a source of opinions, documentation, tests and scripts second. That means we dedicate significant time and attention to simply comparing notes about what is working and discussing real operations. Those interactions give us data to form opinions. It also means we can use real-world experiences to inform the project.
We aim to become the forum for operational review and feedback about the project. For Kubernetes to succeed, operators need to have a significant voice in the project by weekly participation and collecting survey data. We're not trying to create a single opinion about ops, but we do want to create a coordinated resource for collecting operational feedback for the project. As a single recognized group, operators are more accessible and have a bigger impact.
What about real world deliverables?
We've got plans for tangible results too. We’re already driving toward concrete deliverables like reference architectures, tool catalogs, community deployment notes and conformance testing. Cluster Ops wants to become the clearing house for operational resources. We're going to do it based on real world experience and battle tested deployments.
Connect with us.
Cluster Ops can be hard work – don't do it alone. We're here to listen, to help when we can and escalate when we can't. Join the conversation at:
- Chat with us on the Cluster Ops Slack channel
- Email us at the Cluster Ops SIG email list
The Cluster Ops Special Interest Group meets weekly at 13:00PT on Thursdays, you can join us via the video hangout and see latest meeting notes for agendas and topics covered.
--Rob Hirschfeld, CEO, RackN
SIG-Networking: Kubernetes Network Policy APIs Coming in 1.3
Editor’s note: This week we’re featuring Kubernetes Special Interest Groups; Today’s post is by the Network-SIG team describing network policy APIs coming in 1.3 - policies for security, isolation and multi-tenancy.
The Kubernetes network SIG has been meeting regularly since late last year to work on bringing network policy to Kubernetes and we’re starting to see the results of this effort.
One problem many users have is that the open access network policy of Kubernetes is not suitable for applications that need more precise control over the traffic that accesses a pod or service. Today, this could be a multi-tier application where traffic is only allowed from a tier’s neighbor. But as new Cloud Native applications are built by composing microservices, the ability to control traffic as it flows among these services becomes even more critical.
In most IaaS environments (both public and private) this kind of control is provided by allowing VMs to join a ‘security group’ where traffic to members of the group is defined by a network policy or Access Control List (ACL) and enforced by a network packet filter.
The Network SIG started the effort by identifying specific use case scenarios that require basic network isolation for enhanced security. Getting the API right for these simple and common use cases is important because they are also the basis for the more sophisticated network policies necessary for multi-tenancy within Kubernetes.
From these scenarios several possible approaches were considered and a minimal policy specification was defined. The basic idea is that if isolation were enabled on a per namespace basis, then specific pods would be selected where specific traffic types would be allowed.
The simplest way to quickly support this experimental API is in the form of a ThirdPartyResource extension to the API Server, which is possible today in Kubernetes 1.2.
If you’re not familiar with how this works, the Kubernetes API can be extended by defining ThirdPartyResources that create a new API endpoint at a specified URL.
third-party-res-def.yaml
kind: ThirdPartyResource
apiVersion: extensions/v1beta1
metadata:
name: network-policy.net.alpha.kubernetes.io
description: "Network policy specification"
versions:
- name: v1alpha1
$kubectl create -f third-party-res-def.yaml
This will create an API endpoint (one for each namespace):
/net.alpha.kubernetes.io/v1alpha1/namespace/default/networkpolicys/
Third party network controllers can now listen on these endpoints and react as necessary when resources are created, modified or deleted. Note: With the upcoming release of Kubernetes 1.3 - when the Network Policy API is released in beta form - there will be no need to create a ThirdPartyResource API endpoint as shown above.
Network isolation is off by default so that all pods can communicate as they normally do. However, it’s important to know that once network isolation is enabled, all traffic to all pods, in all namespaces is blocked, which means that enabling isolation is going to change the behavior of your pods
Network isolation is enabled by defining the network-isolation annotation on namespaces as shown below:
net.alpha.kubernetes.io/network-isolation: [on | off]
Once network isolation is enabled, explicit network policies must be applied to enable pod communication.
A policy specification can be applied to a namespace to define the details of the policy as shown below:
POST /apis/net.alpha.kubernetes.io/v1alpha1/namespaces/tenant-a/networkpolicys/
{
"kind": "NetworkPolicy",
"metadata": {
"name": "pol1"
},
"spec": {
"allowIncoming": {
"from": [
{ "pods": { "segment": "frontend" } }
],
"toPorts": [
{ "port": 80, "protocol": "TCP" }
]
},
"podSelector": { "segment": "backend" }
}
}
In this example, the ‘ tenant-a ’ namespace would get policy ‘ pol1 ’ applied as indicated. Specifically, pods with the segment label ‘ backend ’ would allow TCP traffic on port 80 from pods with the segment label ‘ frontend ’ to be received.
Today, Romana, OpenShift, OpenContrail and Calico support network policies applied to namespaces and pods. Cisco and VMware are working on implementations as well. Both Romana and Calico demonstrated these capabilities with Kubernetes 1.2 recently at KubeCon. You can watch their presentations here: Romana (slides), Calico (slides).
How does it work?
Each solution has their their own specific implementation details. Today, they rely on some kind of on-host enforcement mechanism, but future implementations could also be built that apply policy on a hypervisor, or even directly by the network itself.
External policy control software (specifics vary across implementations) will watch the new API endpoint for pods being created and/or new policies being applied. When an event occurs that requires policy configuration, the listener will recognize the change and a controller will respond by configuring the interface and applying the policy. The diagram below shows an API listener and policy controller responding to updates by applying a network policy locally via a host agent. The network interface on the pods is configured by a CNI plugin on the host (not shown).

If you’ve been holding back on developing applications with Kubernetes because of network isolation and/or security concerns, these new network policies go a long way to providing the control you need. No need to wait until Kubernetes 1.3 since network policy is available now as an experimental API enabled as a ThirdPartyResource.
If you’re interested in Kubernetes and networking, there are several ways to participate - join us at:
- Our Networking slack channel
- Our Kubernetes Networking Special Interest Group email list
The Networking “Special Interest Group,” which meets bi-weekly at 3pm (15h00) Pacific Time at SIG-Networking hangout.
--Chris Marino, Co-Founder, Pani Networks
How to deploy secure, auditable, and reproducible Kubernetes clusters on AWS
Today’s guest post is written by Colin Hom, infrastructure engineer at CoreOS, the company delivering Google’s Infrastructure for Everyone Else (#GIFEE) and running the world's containers securely on CoreOS Linux, Tectonic and Quay.
Join us at CoreOS Fest Berlin, the Open Source Distributed Systems Conference, and learn more about CoreOS and Kubernetes.
At CoreOS, we're all about deploying Kubernetes in production at scale. Today we are excited to share a tool that makes deploying Kubernetes on Amazon Web Services (AWS) a breeze. Kube-aws is a tool for deploying auditable and reproducible Kubernetes clusters to AWS, currently used by CoreOS to spin up production clusters.
Today you might be putting the Kubernetes components together in a more manual way. With this helpful tool, Kubernetes is delivered in a streamlined package to save time, minimize interdependencies and quickly create production-ready deployments.
A simple templating system is leveraged to generate cluster configuration as a set of declarative configuration templates that can be version controlled, audited and re-deployed. Since the entirety of the provisioning is by AWS CloudFormation and cloud-init, there’s no need for external configuration management tools on your end. Batteries included!
To skip the talk and go straight to the project, check out the latest release of kube-aws, which supports Kubernetes 1.2.x. To get your cluster running, check out the documentation.
Why kube-aws? Security, auditability and reproducibility
Kube-aws is designed with three central goals in mind.
Secure : TLS assets are encrypted via the AWS Key Management Service (KMS) before being embedded in the CloudFormation JSON. By managing IAM policy for the KMS key independently, an operator can decouple operational access to the CloudFormation stack from access to the TLS secrets.
Auditable : kube-aws is built around the concept of cluster assets. These configuration and credential assets represent the complete description of the cluster. Since KMS is used to encrypt TLS assets, you can feel free to check your unencrypted stack JSON into version control as well!
Reproducible : The --export option packs your parameterized cluster definition into a single JSON file which defines a CloudFormation stack. This file can be version controlled and submitted directly to the CloudFormation API via existing deployment tooling, if desired.
How to get started with kube-aws
On top of this foundation, kube-aws implements features that make Kubernetes deployments on AWS easier to manage and more flexible. Here are some examples.
Route53 Integration : Kube-aws can manage your cluster DNS records as part of the provisioning process.
cluster.yaml
externalDNSName: my-cluster.kubernetes.coreos.com
createRecordSet: true
hostedZone: kubernetes.coreos.com
recordSetTTL: 300
Existing VPC Support : Deploy your cluster to an existing VPC.
cluster.yaml
vpcId: vpc-xxxxx
routeTableId: rtb-xxxxx
Validation : Kube-aws supports validation of cloud-init and CloudFormation definitions, along with any external resources that the cluster stack will integrate with. For example, here’s a cloud-config with a misspelled parameter:
userdata/cloud-config-worker
#cloud-config
coreos:
flannel:
interrface: $private\_ipv4
etcd\_endpoints: {{ .ETCDEndpoints }}
$ kube-aws validate
> Validating UserData...
Error: cloud-config validation errors:
UserDataWorker: line 4: warning: unrecognized key "interrface"
To get started, check out the kube-aws documentation.
Future Work
As always, the goal with kube-aws is to make deployments that are production ready. While we use kube-aws in production on AWS today, this project is pre-1.0 and there are a number of areas in which kube-aws needs to evolve.
Fault tolerance : At CoreOS we believe Kubernetes on AWS is a potent platform for fault-tolerant and self-healing deployments. In the upcoming weeks, kube-aws will be rising to a new challenge: surviving the Chaos Monkey – control plane and all!
Zero-downtime updates : Updating CoreOS nodes and Kubernetes components can be done without downtime and without interdependency with the correct instance replacement strategy.
A github issue tracks the work towards this goal. We look forward to seeing you get involved with the project by filing issues or contributing directly.
Learn more about Kubernetes and meet the community at CoreOS Fest Berlin - May 9-10, 2016
– Colin Hom, infrastructure engineer, CoreOS
Adding Support for Kubernetes in Rancher
Today’s guest post is written by Darren Shepherd, Chief Architect at Rancher Labs, an open-source software platform for managing containers.
Over the last year, we’ve seen a tremendous increase in the number of companies looking to leverage containers in their software development and IT organizations. To achieve this, organizations have been looking at how to build a centralized container management capability that will make it simple for users to get access to containers, while centralizing visibility and control with the IT organization. In 2014 we started the open-source Rancher project to address this by building a management platform for containers.
Recently we shipped Rancher v1.0. With this latest release, Rancher, an open-source software platform for managing containers, now supports Kubernetes as a container orchestration framework when creating environments. Now, launching a Kubernetes environment with Rancher is fully automated, delivering a functioning cluster in just 5-10 minutes.
We created Rancher to provide organizations with a complete management platform for containers. As part of that, we’ve always supported deploying Docker environments natively using the Docker API and Docker Compose. Since its inception, we’ve been impressed with the operational maturity of Kubernetes, and with this release, we’re making it possible to deploy a variety of container orchestration and scheduling frameworks within the same management platform.
Adding Kubernetes gives users access to one of the fastest growing platforms for deploying and managing containers in production. We’ll provide first-class Kubernetes support in Rancher going forward and continue to support native Docker deployments.
Bringing Kubernetes to Rancher

Our platform was already extensible for a variety of different packaging formats, so we were optimistic about embracing Kubernetes. We were right, working with the Kubernetes project has been a fantastic experience as developers. The design of the project made this incredibly easy, and we were able to utilize plugins and extensions to build a distribution of Kubernetes that leveraged our infrastructure and application services. For instance, we were able to plug in Rancher’s software defined networking, storage management, load balancing, DNS and infrastructure management functions directly into Kubernetes, without even changing the code base.
Even better, we have been able to add a number of services around the core Kubernetes functionality. For instance, we implemented our popular application catalog on top of Kubernetes. Historically we’ve used Docker Compose to define application templates, but with this release, we now support Kubernetes services, replication controllers and pods to deploy applications. With the catalog, users connect to a git repo and automate deployment and upgrade of an application deployed as Kubernetes services. Users then configure and deploy a complex multi-node enterprise application with one click of a button. Upgrades are fully automated as well, and pushed out centrally to users.
Giving Back
Like Kubernetes, Rancher is an open-source software project, free to use by anyone, and given to the community without any restrictions. You can find all of the source code, upcoming releases and issues for Rancher on GitHub. We’re thrilled to be joining the Kubernetes community, and look forward to working with all of the other contributors. View a demo of the new Kubernetes support in Rancher here.
-- Darren Shepherd, Chief Architect, Rancher Labs
Container survey results - March 2016
Last month, we had our third installment of our container survey and today we look at the results. (raw data is available here)
Looking at the headline number, “how many people are using containers” we see a decrease in the number of people currently using containers from 89% to 80%. Obviously, we can’t be certain for the cause of this decrease, but it’s my believe that the previous number was artificially high due to sampling biases and we did a better job getting a broader reach of participants in the March survey and so the March numbers more accurately represent what is going on in the world.
Along the lines of getting an unbiased sample, I’m excited to announce that going forward, we will be partnering with The New Stack and theCloud Native Compute Foundation to publicize and distribute this container survey. This partnership will enable us to reach a broader audience than we are reaching and thus obtain a significantly more unbiased sample and representative portrayal of current container usage. I’m really excited about this collaboration!
But without further ado, more on the data.
For the rest of the numbers, the March survey shows steady continuation of the numbers that we saw in February. Most of the container usage is still in Development and Testing, though a solid majority (60%) are using it for production as well. For the remaining folks using containers there continues to be a plan to bring containers to production as the “I am planning to” number for production use matches up nearly identically with the numbers for people currently in testing.
Physical and virtual machines continue to be the most popular places to deploy containers, though the March survey shows a fairly substantial drop (48% -> 35%) in people deploying to physical machines.
Likewise hosted container services show growth, with nearly every service showing some growth. Google Container Engine continues to be the most popular in the survey, followed by the Amazon EC2 Container Service. It will be interesting to see how those numbers change as we move to the New Stack survey.
Finally, Kubernetes is still the favorite for container manager, with Bash scripts are still in second place. As with the container service provider numbers I’ll be quite interested to see what this looks like with a broader sample set.
Finally, the absolute use of containers appears to be ticking up. The number of people running more than 250 containers has grown from 12% to nearly 20%. And the number people running containers on 50 or more machines has grown from 10% to 18%.
As always, the raw data is available for you to analyze here.
--Brendan Burns, Software Engineer, Google
Configuration management with Containers
Editor’s note: this is our seventh post in a series of in-depth posts on what's new in Kubernetes 1.2
A good practice when writing applications is to separate application code from configuration. We want to enable application authors to easily employ this pattern within Kubernetes. While the Secrets API allows separating information like credentials and keys from an application, no object existed in the past for ordinary, non-secret configuration. In Kubernetes 1.2, we've added a new API resource called ConfigMap to handle this type of configuration data.
The basics of ConfigMap
The ConfigMap API is simple conceptually. From a data perspective, the ConfigMap type is just a set of key-value pairs. Applications are configured in different ways, so we need to be flexible about how we let users store and consume configuration data. There are three ways to consume a ConfigMap in a pod:
- Command line arguments
- Environment variables
- Files in a volume
These different methods lend themselves to different ways of modeling the data being consumed. To be as flexible as possible, we made ConfigMap hold both fine- and/or coarse-grained data. Further, because applications read configuration settings from both environment variables and files containing configuration data, we built ConfigMap to support either method of access. Let’s take a look at an example ConfigMap that contains both types of configuration:
apiVersion: v1
kind: ConfigMap
metadata:
Name: example-configmap
data:
# property-like keys
game-properties-file-name: game.properties
ui-properties-file-name: ui.properties
# file-like keys
game.properties: |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
Users that have used Secrets will find it easy to begin using ConfigMap — they’re very similar. One major difference in these APIs is that Secret values are stored as byte arrays in order to support storing binaries like SSH keys. In JSON and YAML, byte arrays are serialized as base64 encoded strings. This means that it’s not easy to tell what the content of a Secret is from looking at the serialized form. Since ConfigMap is intended to hold only configuration information and not binaries, values are stored as strings, and thus are readable in the serialized form.
We want creating ConfigMaps to be as flexible as storing data in them. To create a ConfigMap object, we’ve added a kubectl command called kubectl create configmap that offers three different ways to specify key-value pairs:
- Specify literal keys and value
- Specify an individual file
- Specify a directory to create keys for each file
These different options can be mixed, matched, and repeated within a single command:
$ kubectl create configmap my-config \
--from-literal=literal-key=literal-value \
--from-file=ui.properties \
--from=file=path/to/config/dir
Consuming ConfigMaps is simple and will also be familiar to users of Secrets. Here’s an example of a Deployment that uses the ConfigMap above to run an imaginary game server:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: configmap-example-deployment
labels:
name: configmap-example-deployment
spec:
replicas: 1
selector:
matchLabels:
name: configmap-example
template:
metadata:
labels:
name: configmap-example
spec:
containers:
- name: game-container
image: imaginarygame
command: ["game-server", "--config-dir=/etc/game/cfg"]
env:
# consume the property-like keys in environment variables
- name: GAME\_PROPERTIES\_NAME
valueFrom:
configMapKeyRef:
name: example-configmap
key: game-properties-file-name
- name: UI\_PROPERTIES\_NAME
valueFrom:
configMapKeyRef:
name: example-configmap
key: ui-properties-file-name
volumeMounts:
- name: config-volume
mountPath: /etc/game
volumes:
# consume the file-like keys of the configmap via volume plugin
- name: config-volume
configMap:
name: example-configmap
items:
- key: ui.properties
path: cfg/ui.properties
- key: game.properties
path: cfg/game.properties
restartPolicy: Never
In the above example, the Deployment uses keys of the ConfigMap via two of the different mechanisms available. The property-like keys of the ConfigMap are used as environment variables to the single container in the Deployment template, and the file-like keys populate a volume. For more details, please see the ConfigMap docs.
We hope that these basic primitives are easy to use and look forward to seeing what people build with ConfigMaps. Thanks to the community members that provided feedback about this feature. Special thanks also to Tamer Tas who made a great contribution to the proposal and implementation of ConfigMap.
If you’re interested in Kubernetes and configuration, you’ll want to participate in:
- Our Configuration Slack channel
- Our Kubernetes Configuration Special Interest Group email list
- The Configuration “Special Interest Group,” which meets weekly on Wednesdays at 10am (10h00) Pacific Time at SIG-Config hangout
And of course for more information about the project in general, go to www.kubernetes.io and follow us on Twitter @Kubernetesio.
-- Paul Morie, Senior Software Engineer, Red Hat
Using Deployment objects with Kubernetes 1.2
Editor's note: this is the seventh post in a series of in-depth posts on what's new in Kubernetes 1.2
Kubernetes has made deploying and managing applications very straightforward, with most actions a single API or command line away, including rolling out new applications, canary testing and upgrading. So why would we need Deployments?
Deployment objects automate deploying and rolling updating applications. Compared with kubectl rolling-update, Deployment API is much faster, is declarative, is implemented server-side and has more features (for example, you can rollback to any previous revision even after the rolling update is done).
In today’s blogpost, we’ll cover how to use Deployments to:
- Deploy/rollout an application
- Update the application declaratively and progressively, without a service outage
- Rollback to a previous revision, if something’s wrong when you’re deploying/updating the application

Without further ado, let’s start playing around with Deployments!
Getting started
If you want to try this example, basically you’ll need 3 things:
- A running Kubernetes cluster : If you don’t already have one, check the Getting Started guides for a list of solutions on a range of platforms, from your laptop, to VMs on a cloud provider, to a rack of bare metal servers.
- Kubectl, the Kubernetes CLI : If you see a URL response after running kubectl cluster-info, you’re ready to go. Otherwise, follow the instructions to install and configure kubectl; or the instructions for hosted solutions if you have a Google Container Engine cluster.
- The configuration files for this demo. If you choose not to run this example yourself, that’s okay. Just watch this video to see what’s going on in each step.
Diving in
The configuration files contain a static website. First, we want to start serving its static content. From the root of the Kubernetes repository, run:
$ kubectl proxy --www=docs/user-guide/update-demo/local/ &
Starting to serve on …
This runs a proxy on the default port 8001. You may now visit http://localhost:8001/static/ the demo website (and it should be a blank page for now). Now we want to run an app and show it on the website.
$ kubectl run update-demo
--image=gcr.io/google\_containers/update-demo:nautilus --port=80 -l name=update-demo
deployment “update-demo” created
This deploys 1 replica of an app with the image “update-demo:nautilus” and you can see it visually on http://localhost:8001/static/.1

The card showing on the website represents a Kubernetes pod, with the pod’s name (ID), status, image, and labels.
Getting bigger
Now we want more copies of this app!
$ kubectl scale deployment/update-demo --replicas=4
deployment "update-demo" scaled

Updating your application
How about updating the app?
$ kubectl edit deployment/update-demo
This opens up your default editor, and you can update the deployment on the fly. Find .spec.template.spec.containers[0].image and change nautilus to kitty. Save the file, and you’ll see:
deployment "update-demo" edited
You’re now updating the image of this app from “update-demo:nautilus” to “update-demo:kitty”. Deployments allow you to update the app progressively, without a service outage.

After a while, you’ll find the update seems stuck. What happened?
Debugging your rollout
If you look closer, you’ll find that the pods with the new “kitty” tagged image stays pending. The Deployment automatically stops the rollout if it’s failing. Let’s look at one of the new pod to see what happened:
$ kubectl describe pod/update-demo-1326485872-a4key
Looking at the events of this pod, you’ll notice that Kubernetes failed to pull the image because the “kitty” tag wasn’t found:
Failed to pull image "gcr.io/google_containers/update-demo:kitty": Tag kitty not found in repository gcr.io/google_containers/update-demo
Rolling back
Ok, now we want to undo the changes and then take our time to figure out which image tag we should use.
$ kubectl rollout undo deployment/update-demo
deployment "update-demo" rolled back
Everything’s back to normal, phew!
To learn more about rollback, visit rolling back a Deployment.
Updating your application (for real)
After a while, we finally figure that the right image tag is “kitten”, instead of “kitty”. Now change .spec.template.spec.containers[0].image tag from “nautilus“ to “kitten“.
$ kubectl edit deployment/update-demo
deployment "update-demo" edited

Now you see there are 4 cute kittens on the demo website, which means we’ve updated the app successfully! If you want to know the magic behind this, look closer at the Deployment:
$ kubectl describe deployment/update-demo
From the events section, you’ll find that the Deployment is managing another resource called Replica Set, each controls the number of replicas of a different pod template. The Deployment enables progressive rollout by scaling up and down Replica Sets of new and old pod templates.
Conclusion
Now, you’ve learned the basic use of Deployment objects:
- Deploy an app with a Deployment, using kubectl run
- Updating the app by updating the Deployment with kubectl edit
- Rolling back to a previously deployed app with kubectl rollout undo But there’s so much more in Deployment that this article didn’t cover! To discover more, continue reading Deployment’s introduction.
Note: In Kubernetes 1.2, Deployment (beta release) is now feature-complete and enabled by default. For those of you who have tried Deployment in Kubernetes 1.1, please delete all Deployment 1.1 resources (including the Replication Controllers and Pods they manage) before trying out Deployments in 1.2. This is necessary because we made some non-backward-compatible changes to the API.
If you’re interested in Kubernetes and configuration, you’ll want to participate in:
- Our Configuration slack channel
- Our Kubernetes Configuration Special Interest Group email list
- The Configuration “Special Interest Group,” which meets weekly on Wednesdays at 10am (10h00) Pacific Time at SIG-Config hangout And of course for more information about the project in general, go to www.kubernetes.io.
-- Janet Kuo, Software Engineer, Google
1 “kubectl run” outputs the type and name of the resource(s) it creates. In 1.2, it now creates a deployment resource. You can use that in subsequent commands, such as "kubectl get deployment ", or "kubectl expose deployment ". If you want to write a script to do that automatically, in a forward-compatible manner, use "-o name" flag with "kubectl run", and it will generate short output "deployments/", which can also be used on subsequent command lines. The "--generator" flag can be used with "kubectl run" to generate other types of resources, for example, set it to "run/v1" to create a Replication Controller, which was the default in 1.1 and 1.0, and to "run-pod/v1" to create a Pod, such as for --restart=Never pods.
Kubernetes 1.2 and simplifying advanced networking with Ingress
Editor's note: This is the sixth post in a series of in-depth posts on what's new in Kubernetes 1.2.
Ingress is currently in beta and under active development.
In Kubernetes, Services and Pods have IPs only routable by the cluster network, by default. All traffic that ends up at an edge router is either dropped or forwarded elsewhere. In Kubernetes 1.2, we’ve made improvements to the Ingress object, to simplify allowing inbound connections to reach the cluster services. It can be configured to give services externally-reachable URLs, load balance traffic, terminate SSL, offer name based virtual hosting and lots more.
Ingress controllers
Today, with containers or VMs, configuring a web server or load balancer is harder than it should be. Most web server configuration files are very similar. There are some applications that have weird little quirks that tend to throw a wrench in things, but for the most part, you can apply the same logic to them and achieve a desired result. In Kubernetes 1.2, the Ingress resource embodies this idea, and an Ingress controller is meant to handle all the quirks associated with a specific "class" of Ingress (be it a single instance of a load balancer, or a more complicated setup of frontends that provide GSLB, CDN, DDoS protection etc). An Ingress Controller is a daemon, deployed as a Kubernetes Pod, that watches the ApiServer's /ingresses endpoint for updates to the Ingress resource. Its job is to satisfy requests for ingress.
Your Kubernetes cluster must have exactly one Ingress controller that supports TLS for the following example to work. If you’re on a cloud-provider, first check the “kube-system” namespace for an Ingress controller RC. If there isn’t one, you can deploy the nginx controller, or write your own in < 100 lines of code.
Please take a minute to look over the known limitations of existing controllers (gce, nginx).
TLS termination and HTTP load-balancing
Since the Ingress spans Services, it’s particularly suited for load balancing and centralized security configuration. If you’re familiar with the go programming language, Ingress is like net/http’s “Server” for your entire cluster. The following example shows you how to configure TLS termination. Load balancing is not optional when dealing with ingress traffic, so simply creating the object will configure a load balancer.
First create a test Service. We’ll run a simple echo server for this example so you know exactly what’s going on. The source is here.
$ kubectl run echoheaders
--image=gcr.io/google\_containers/echoserver:1.3 --port=8080
$ kubectl expose deployment echoheaders --target-port=8080
--type=NodePort
If you’re on a cloud-provider, make sure you can reach the Service from outside the cluster through its node port.
$ NODE_IP=$(kubectl get node `kubectl get po -l run=echoheaders
--template '{{range .items}}{{.spec.nodeName}}{{end}}'` --template
'{{range $i, $n := .status.addresses}}{{if eq $n.type
"ExternalIP"}}{{$n.address}}{{end}}{{end}}')
$ NODE_PORT=$(kubectl get svc echoheaders --template '{{range $i, $e
:= .spec.ports}}{{$e.nodePort}}{{end}}')
$ curl $NODE_IP:$NODE_PORT
This is a sanity check that things are working as expected. If the last step hangs, you might need a firewall rule.
Now lets create our TLS secret:
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout
/tmp/tls.key -out /tmp/tls.crt -subj "/CN=echoheaders/O=echoheaders"
$ echo "
apiVersion: v1
kind: Secret
metadata:
name: tls
data:
tls.crt: `base64 -w 0 /tmp/tls.crt`
tls.key: `base64 -w 0 /tmp/tls.key`
" | kubectl create -f
And the Ingress:
$ echo "
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
spec:
tls:
- secretName: tls
backend:
serviceName: echoheaders
servicePort: 8080
" | kubectl create -f -
You should get a load balanced IP soon:
$ kubectl get ing
NAME RULE BACKEND ADDRESS AGE
test - echoheaders:8080 130.X.X.X 4m
And if you wait till the Ingress controller marks your backends as healthy, you should see requests to that IP on :80 getting redirected to :443 and terminated using the given TLS certificates.
$ curl 130.X.X.X
\<html\>
\<head\>\<title\>301 Moved Permanently\</title\>\</head\>\<body bgcolor="white"\>\<center\>\<h1\>301 Moved Permanently\</h1\>\</center\>
$ curl https://130.X.X.X -kCLIENT VALUES:client\_address=10.48.0.1command=GETreal path=/
$ curl 130.X.X.X -Lk
CLIENT VALUES:client\_address=10.48.0.1command=GETreal path=/
Future work
You can read more about the Ingress API or controllers by following the links. The Ingress is still in beta, and we would love your input to grow it. You can contribute by writing controllers or evolving the API. All things related to the meaning of the word “ingress” are in scope, this includes DNS, different TLS modes, SNI, load balancing at layer 4, content caching, more algorithms, better health checks; the list goes on.
There are many ways to participate. If you’re particularly interested in Kubernetes and networking, you’ll be interested in:
- Our Networking slack channel
- Our Kubernetes Networking Special Interest Group email list
- The Big Data “Special Interest Group,” which meets biweekly at 3pm (15h00) Pacific Time at SIG-Networking hangout
And of course for more information about the project in general, go towww.kubernetes.io
-- Prashanth Balasubramanian, Software Engineer
Using Spark and Zeppelin to process big data on Kubernetes 1.2
Editor's note: this is the fifth post in a series of in-depth posts on what's new in Kubernetes 1.2
With big data usage growing exponentially, many Kubernetes customers have expressed interest in running Apache Spark on their Kubernetes clusters to take advantage of the portability and flexibility of containers. Fortunately, with Kubernetes 1.2, you can now have a platform that runs Spark and Zeppelin, and your other applications side-by-side.
Why Zeppelin?
Apache Zeppelin is a web-based notebook that enables interactive data analytics. As one of its backends, Zeppelin connects to Spark. Zeppelin allows the user to interact with the Spark cluster in a simple way, without having to deal with a command-line interpreter or a Scala compiler.
Why Kubernetes?
There are many ways to run Spark outside of Kubernetes:
- You can run it using dedicated resources, in Standalone mode
- You can run it on a YARN cluster, co-resident with Hadoop and HDFS
- You can run it on a Mesos cluster alongside other Mesos applications
So why would you run Spark on Kubernetes?
- A single, unified interface to your cluster: Kubernetes can manage a broad range of workloads; no need to deal with YARN/HDFS for data processing and a separate container orchestrator for your other applications.
- Increased server utilization: share nodes between Spark and cloud-native applications. For example, you may have a streaming application running to feed a streaming Spark pipeline, or a nginx pod to serve web traffic — no need to statically partition nodes.
- Isolation between workloads: Kubernetes' Quality of Service mechanism allows you to safely co-schedule batch workloads like Spark on the same nodes as latency-sensitive servers.
Launch Spark
For this demo, we’ll be using Google Container Engine (GKE), but this should work anywhere you have installed a Kubernetes cluster. First, create a Container Engine cluster with storage-full scopes. These Google Cloud Platform scopes will allow the cluster to write to a private Google Cloud Storage Bucket (we’ll get to why you need that later):
$ gcloud container clusters create spark --scopes storage-full
--machine-type n1-standard-4
Note: We’re using n1-standard-4 (which are larger than the default node size) to demonstrate some features of Horizontal Pod Autoscaling. However, Spark works just fine on the default node size of n1-standard-1.
After the cluster’s created, you’re ready to launch Spark on Kubernetes using the config files in the Kubernetes GitHub repo:
$ git clone https://github.com/kubernetes/kubernetes.git
$ kubectl create -f kubernetes/examples/spark
‘kubernetes/examples/spark’ is a directory, so this command tells kubectl to create all of the Kubernetes objects defined in all of the YAML files in that directory. You don’t have to clone the entire repository, but it makes the steps of this demo just a little easier.
The pods (especially Apache Zeppelin) are somewhat large, so may take some time for Docker to pull the images. Once everything is running, you should see something similar to the following:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
spark-master-controller-v4v4y 1/1 Running 0 21h
spark-worker-controller-7phix 1/1 Running 0 21h
spark-worker-controller-hq9l9 1/1 Running 0 21h
spark-worker-controller-vwei5 1/1 Running 0 21h
zeppelin-controller-t1njl 1/1 Running 0 21h
You can see that Kubernetes is running one instance of Zeppelin, one Spark master and three Spark workers.
Set up the Secure Proxy to Zeppelin
Next you’ll set up a secure proxy from your local machine to Zeppelin, so you can access the Zeppelin instance running in the cluster from your machine. (Note: You’ll need to change this command to the actual Zeppelin pod that was created on your cluster.)
$ kubectl port-forward zeppelin-controller-t1njl 8080:8080
This establishes a secure link to the Kubernetes cluster and pod (zeppelin-controller-t1njl) and then forwards the port in question (8080) to local port 8080, which will allow you to use Zeppelin safely.
Now that I have Zeppelin up and running, what do I do with it?
For our example, we’re going to show you how to build a simple movie recommendation model. This is based on the code on the Spark website, modified slightly to make it interesting for Kubernetes.
Now that the secure proxy is up, visit http://localhost:8080/. You should see an intro page like this:

Click “Import note,” give it an arbitrary name (e.g. “Movies”), and click “Add from URL.” For a URL, enter:
https://gist.githubusercontent.com/zmerlynn/875fed0f587d12b08ec9/raw/6
eac83e99caf712482a4937800b17bbd2e7b33c4/movies.json
Then click “Import Note.” This will give you a ready-made Zeppelin note for this demo. You should now have a “Movies” notebook (or whatever you named it). If you click that note, you should see a screen similar to this:

You can now click the Play button, near the top-right of the PySpark code block, and you’ll create a new, in-memory movie recommendation model! In the Spark application model, Zeppelin acts as a Spark Driver Program, interacting with the Spark cluster master to get its work done. In this case, the driver program that’s running in the Zeppelin pod fetches the data and sends it to the Spark master, which farms it out to the workers, which crunch out a movie recommendation model using the code from the driver. With a larger data set in Google Cloud Storage (GCS), it would be easy to pull the data from GCS as well. In the next section, we’ll talk about how to save your data to GCS.
Working with Google Cloud Storage (Optional)
For this demo, we’ll be using Google Cloud Storage, which will let us store our model data beyond the life of a single pod. Spark for Kubernetes is built with the Google Cloud Storage connector built-in. As long as you can access your data from a virtual machine in the Google Container Engine project where your Kubernetes nodes are running, you can access your data with the GCS connector on the Spark image.
If you want, you can change the variables at the top of the note so that the example will actually save and restore a model for the movie recommendation engine — just point those variables at a GCS bucket that you have access to. If you want to create a GCS bucket, you can do something like this on the command line:
$ gsutil mb gs://my-spark-models
You’ll need to change this URI to something that is unique for you. This will create a bucket that you can use in the example above.
Using Horizontal Pod Autoscaling with Spark (Optional)
Spark is somewhat elastic to workers coming and going, which means we have an opportunity: we can use use Kubernetes Horizontal Pod Autoscaling to scale-out the Spark worker pool automatically, setting a target CPU threshold for the workers and a minimum/maximum pool size. This obviates the need for having to configure the number of worker replicas manually.
Create the Autoscaler like this (note: if you didn’t change the machine type for the cluster, you probably want to limit the --max to something smaller):
$ kubectl autoscale --min=1 --cpu-percent=80 --max=10 \
rc/spark-worker-controller
To see the full effect of autoscaling, wait for the replication controller to settle back to one replica. Use ‘kubectl get rc’ and wait for the “replicas” column on spark-worker-controller to fall back to 1.
The workload we ran before ran too quickly to be terribly interesting for HPA. To change the workload to actually run long enough to see autoscaling become active, change the “rank = 100” line in the code to “rank = 200.” After you hit play, the Spark worker pool should rapidly increase to 20 pods. It will take up to 5 minutes after the job completes before the worker pool falls back down to one replica.
Conclusion
In this article, we showed you how to run Spark and Zeppelin on Kubernetes, as well as how to use Google Cloud Storage to store your Spark model and how to use Horizontal Pod Autoscaling to dynamically size your Spark worker pool.
This is the first in a series of articles we’ll be publishing on how to run big data frameworks on Kubernetes — so stay tuned!
Please join our community and help us build the future of Kubernetes! There are many ways to participate. If you’re particularly interested in Kubernetes and big data, you’ll be interested in:
- Our Big Data slack channel
- Our Kubernetes Big Data Special Interest Group email list
- The Big Data “Special Interest Group,” which meets every Monday at 1pm (13h00) Pacific Time at SIG-Big-Data hangout And of course for more information about the project in general, go to www.kubernetes.io.
-- Zach Loafman, Software Engineer, Google
AppFormix: Helping Enterprises Operationalize Kubernetes
Today’s guest post is written Sumeet Singh, founder and CEO of AppFormix, a cloud infrastructure performance optimization service helping enterprise operators streamline their cloud operations on any OpenStack or Kubernetes cloud.
If you run clouds for a living, you’re well aware that the tools we've used since the client/server era for monitoring, analytics and optimization just don’t cut it when applied to the agile, dynamic and rapidly changing world of modern cloud infrastructure.
And, if you’re an operator of enterprise clouds, you know that implementing containers and container cluster management is all about giving your application developers a more agile, responsive and efficient cloud infrastructure. Applications are being rewritten and new ones developed – not for legacy environments where relatively static workloads are the norm, but for dynamic, scalable cloud environments. The dynamic nature of cloud native applications coupled with the shift to continuous deployment means that the demands placed by the applications on the infrastructure are constantly changing.
This shift necessitates infrastructure transparency and real-time monitoring and analytics. Without these key pieces, neither applications nor their underlying plumbing can deliver the low-latency user experience end users have come to expect.
AppFormix Architectural Review
From an operational standpoint, it is necessary to understand how applications are consuming infrastructure resources in order to maximize ROI and guarantee SLAs. AppFormix software empowers operators and developers to monitor, visualize, and control how physical resources are utilized by cloud workloads.
At the center of the software, the AppFormix Data Platform provides a distributed analysis engine that performs configurable, real-time evaluation of in-depth, high-resolution metrics. On each host, the resource-efficient AppFormix Agent collects and evaluates multi-layer metrics from the hardware, virtualization layer, and up to the application. Intelligent agents offer sub-second response times that make it possible to detect and solve problems before they start to impact applications and users. The raw data is associated with the elements that comprise a cloud-native environment: applications, virtual machines, containers, hosts. The AppFormix Agent then publishes metrics and events to a Data Manager that stores and forwards the data to Analytics modules. Events are based on predefined or dynamic conditions set by users or infrastructure operators to make sure that SLAs and policies are being met.
| 
| 
Additional subsystems are the Policy Controller and Analytics. The Policy Controller manages policies for resource monitoring, analysis, and control. It also provides role-based access control. The Analytics modules analyze metrics and events produced by Data Platform, enabling correlation across multiple elements to provide higher-level information to operators and developers. The Analytics modules may also configure policies in Policy Controller in response to conditions in the infrastructure.
AppFormix organizes elements of cloud infrastructure around hosts and instances (either containers or virtual machines), and logical groups of such elements. AppFormix integrates with cloud platforms using Adapter modules that discover the physical and virtual elements in the environment and configure those elements into the Policy Controller.
Integrating AppFormix with Kubernetes
Enterprises often run many environments located on- or off-prem, as well as running different compute technologies (VMs, containers, bare metal). The analytics platform we’ve developed at AppFormix gives Kubernetes users a single pane of glass from which to monitor and manage container clusters in private and hybrid environments.
The AppFormix Kubernetes Adapter leverages the REST-based APIs of Kubernetes to discover nodes, pods, containers, services, and replication controllers. With the relational information about each element, Kubernetes Adapter is able to represent all of these elements in our system. A pod is a group of containers. A service and a replication controller are both different types of pod groups. In addition, using the watch endpoint, Kubernetes Adapter stays aware of changes to the environment.
DevOps in the Enterprise with AppFormix
With AppFormix, developers and operators can work collaboratively to optimize applications and infrastructure. Users can access a self-service IT experience that delivers visibility into CPU, memory, storage, and network consumption by each layer of the stack: physical hardware, platform, and application software.
- Real-time multi-layer performance metrics - In real-time, developers can view multi-layer metrics that show container resource consumption in context of the physical node on which it executes. With this context, developers can determine if application performance is limited by the physical infrastructure, due to contention or resource exhaustion, or by application design.
- Proactive resource control - AppFormix Health Analytics provides policy-based actions in response to conditions in the cluster. For example, when resource consumption exceeds threshold on a worker node, Health Analytics can remove the node from the scheduling pool by invoking Kubernetes REST APIs. This dynamic control is driven by real-time monitoring at each node.
- Capacity planning - Kubernetes will schedule workloads, but operators need to understand how the resources are being utilized. What resources have the most demand? How is demand trending over time? Operators can generate reports that provide necessary data for capacity planning.
As you can see, we’re working hard to give Kubernetes users a useful, performant toolset for both OpenStack and Kubernetes environments that allows operators to deliver self-service IT to their application developers. We’re excited to be partner contributing to the Kubernetes ecosystem and community.
-- Sumeet Singh, Founder and CEO, AppFormix
Building highly available applications using Kubernetes new multi-zone clusters (a.k.a. 'Ubernetes Lite')
Editor's note: this is the third post in a series of in-depth posts on what's new in Kubernetes 1.2
Introduction
One of the most frequently-requested features for Kubernetes is the ability to run applications across multiple zones. And with good reason — developers need to deploy applications across multiple domains, to improve availability in thxe advent of a single zone outage.
Kubernetes 1.2, released two weeks ago, adds support for running a single cluster across multiple failure zones (GCP calls them simply "zones," Amazon calls them "availability zones," here we'll refer to them as "zones"). This is the first step in a broader effort to allow federating multiple Kubernetes clusters together (sometimes referred to by the affectionate nickname "Ubernetes"). This initial version (referred to as "Ubernetes Lite") offers improved application availability by spreading applications across multiple zones within a single cloud provider.
Multi-zone clusters are deliberately simple, and by design, very easy to use — no Kubernetes API changes were required, and no application changes either. You simply deploy your existing Kubernetes application into a new-style multi-zone cluster, and your application automatically becomes resilient to zone failures.
Now into some details . . .
Ubernetes Lite works by leveraging the Kubernetes platform’s extensibility through labels. Today, when nodes are started, labels are added to every node in the system. With Ubernetes Lite, the system has been extended to also add information about the zone it's being run in. With that, the scheduler can make intelligent decisions about placing application instances.
Specifically, the scheduler already spreads pods to minimize the impact of any single node failure. With Ubernetes Lite, via SelectorSpreadPriority, the scheduler will make a best-effort placement to spread across zones as well. We should note, if the zones in your cluster are heterogenous (e.g., different numbers of nodes or different types of nodes), you may not be able to achieve even spreading of your pods across zones. If desired, you can use homogenous zones (same number and types of nodes) to reduce the probability of unequal spreading.
This improved labeling also applies to storage. When persistent volumes are created, the PersistentVolumeLabel admission controller automatically adds zone labels to them. The scheduler (via the VolumeZonePredicate predicate) will then ensure that pods that claim a given volume are only placed into the same zone as that volume, as volumes cannot be attached across zones.
Walkthrough
We're now going to walk through setting up and using a multi-zone cluster on both Google Compute Engine (GCE) and Amazon EC2 using the default kube-up script that ships with Kubernetes. Though we highlight GCE and EC2, this functionality is available in any Kubernetes 1.2 deployment where you can make changes during cluster setup. This functionality will also be available in Google Container Engine (GKE) shortly.
Bringing up your cluster
Creating a multi-zone deployment for Kubernetes is the same as for a single-zone cluster, but you’ll need to pass an environment variable ("MULTIZONE”) to tell the cluster to manage multiple zones. We’ll start by creating a multi-zone-aware cluster on GCE and/or EC2.
GCE:
curl -sS https://get.k8s.io | MULTIZONE=true KUBERNETES_PROVIDER=gce
KUBE_GCE_ZONE=us-central1-a NUM_NODES=3 bash
EC2:
curl -sS https://get.k8s.io | MULTIZONE=true KUBERNETES_PROVIDER=aws
KUBE_AWS_ZONE=us-west-2a NUM_NODES=3 bash
At the end of this command, you will have brought up a cluster that is ready to manage nodes running in multiple zones. You’ll also have brought up NUM_NODES nodes and the cluster's control plane (i.e., the Kubernetes master), all in the zone specified by KUBE_{GCE,AWS}_ZONE. In a future iteration of Ubernetes Lite, we’ll support a HA control plane, where the master components are replicated across zones. Until then, the master will become unavailable if the zone where it is running fails. However, containers that are running in all zones will continue to run and be restarted by Kubelet if they fail, thus the application itself will tolerate such a zone failure.
Nodes are labeled
To see the additional metadata added to the node, simply view all the labels for your cluster (the example here is on GCE):
$ kubectl get nodes --show-labels
NAME STATUS AGE LABELS
kubernetes-master Ready,SchedulingDisabled 6m
beta.kubernetes.io/instance-type=n1-standard-1,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-master
kubernetes-minion-87j9 Ready 6m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-minion-87j9
kubernetes-minion-9vlv Ready 6m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-minion-9vlv
kubernetes-minion-a12q Ready 6m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-minion-a12q
The scheduler will use the labels attached to each of the nodes (failure-domain.beta.kubernetes.io/region for the region, and failure-domain.beta.kubernetes.io/zone for the zone) in its scheduling decisions.
Add more nodes in a second zone
Let's add another set of nodes to the existing cluster, but running in a different zone (us-central1-b for GCE, us-west-2b for EC2). We run kube-up again, but by specifying KUBE_USE_EXISTING_MASTER=1 kube-up will not create a new master, but will reuse one that was previously created.
GCE:
KUBE_USE_EXISTING_MASTER=true MULTIZONE=true KUBERNETES_PROVIDER=gce
KUBE_GCE_ZONE=us-central1-b NUM_NODES=3 kubernetes/cluster/kube-up.sh
On EC2, we also need to specify the network CIDR for the additional subnet, along with the master internal IP address:
KUBE_USE_EXISTING_MASTER=true MULTIZONE=true KUBERNETES_PROVIDER=aws
KUBE_AWS_ZONE=us-west-2b NUM_NODES=3 KUBE_SUBNET_CIDR=172.20.1.0/24
MASTER_INTERNAL_IP=172.20.0.9 kubernetes/cluster/kube-up.sh
View the nodes again; 3 more nodes will have been launched and labelled (the example here is on GCE):
$ kubectl get nodes --show-labels
NAME STATUS AGE LABELS
kubernetes-master Ready,SchedulingDisabled 16m
beta.kubernetes.io/instance-type=n1-standard-1,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-master
kubernetes-minion-281d Ready 2m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-b,kub
ernetes.io/hostname=kubernetes-minion-281d
kubernetes-minion-87j9 Ready 16m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-minion-87j9
kubernetes-minion-9vlv Ready 16m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-minion-9vlv
kubernetes-minion-a12q Ready 17m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-minion-a12q
kubernetes-minion-pp2f Ready 2m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-b,kub
ernetes.io/hostname=kubernetes-minion-pp2f
kubernetes-minion-wf8i Ready 2m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-b,kub
ernetes.io/hostname=kubernetes-minion-wf8i
Let’s add one more zone:
GCE:
KUBE_USE_EXISTING_MASTER=true MULTIZONE=true KUBERNETES_PROVIDER=gce
KUBE_GCE_ZONE=us-central1-f NUM_NODES=3 kubernetes/cluster/kube-up.sh
EC2:
KUBE_USE_EXISTING_MASTER=true MULTIZONE=true KUBERNETES_PROVIDER=aws
KUBE_AWS_ZONE=us-west-2c NUM_NODES=3 KUBE_SUBNET_CIDR=172.20.2.0/24
MASTER_INTERNAL_IP=172.20.0.9 kubernetes/cluster/kube-up.sh
Verify that you now have nodes in 3 zones:
kubectl get nodes --show-labels
Highly available apps, here we come.
Deploying a multi-zone application
Create the guestbook-go example, which includes a ReplicationController of size 3, running a simple web app. Download all the files from here, and execute the following command (the command assumes you downloaded them to a directory named “guestbook-go”:
kubectl create -f guestbook-go/
You’re done! Your application is now spread across all 3 zones. Prove it to yourself with the following commands:
$ kubectl describe pod -l app=guestbook | grep Node
Node: kubernetes-minion-9vlv/10.240.0.5
Node: kubernetes-minion-281d/10.240.0.8
Node: kubernetes-minion-olsh/10.240.0.11
$ kubectl get node kubernetes-minion-9vlv kubernetes-minion-281d
kubernetes-minion-olsh --show-labels
NAME STATUS AGE LABELS
kubernetes-minion-9vlv Ready 34m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-a,kub
ernetes.io/hostname=kubernetes-minion-9vlv
kubernetes-minion-281d Ready 20m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-b,kub
ernetes.io/hostname=kubernetes-minion-281d
kubernetes-minion-olsh Ready 3m
beta.kubernetes.io/instance-type=n1-standard-2,failure-domain.beta.kubernetes.
io/region=us-central1,failure-domain.beta.kubernetes.io/zone=us-central1-f,kub
ernetes.io/hostname=kubernetes-minion-olsh
Further, load-balancers automatically span all zones in a cluster; the guestbook-go example includes an example load-balanced service:
$ kubectl describe service guestbook | grep LoadBalancer.Ingress
LoadBalancer Ingress: 130.211.126.21
ip=130.211.126.21
$ curl -s http://${ip}:3000/env | grep HOSTNAME
"HOSTNAME": "guestbook-44sep",
$ (for i in `seq 20`; do curl -s http://${ip}:3000/env | grep HOSTNAME; done)
| sort | uniq
"HOSTNAME": "guestbook-44sep",
"HOSTNAME": "guestbook-hum5n",
"HOSTNAME": "guestbook-ppm40",
The load balancer correctly targets all the pods, even though they’re in multiple zones.
Shutting down the cluster
When you're done, clean up:
GCE:
KUBERNETES_PROVIDER=gce KUBE_USE_EXISTING_MASTER=true
KUBE_GCE_ZONE=us-central1-f kubernetes/cluster/kube-down.sh
KUBERNETES_PROVIDER=gce KUBE_USE_EXISTING_MASTER=true
KUBE_GCE_ZONE=us-central1-b kubernetes/cluster/kube-down.sh
KUBERNETES_PROVIDER=gce KUBE_GCE_ZONE=us-central1-a
kubernetes/cluster/kube-down.sh
EC2:
KUBERNETES_PROVIDER=aws KUBE_USE_EXISTING_MASTER=true KUBE_AWS_ZONE=us-west-2c
kubernetes/cluster/kube-down.sh
KUBERNETES_PROVIDER=aws KUBE_USE_EXISTING_MASTER=true KUBE_AWS_ZONE=us-west-2b
kubernetes/cluster/kube-down.sh
KUBERNETES_PROVIDER=aws KUBE_AWS_ZONE=us-west-2a
kubernetes/cluster/kube-down.sh
Conclusion
A core philosophy for Kubernetes is to abstract away the complexity of running highly available, distributed applications. As you can see here, other than a small amount of work at cluster spin-up time, all the complexity of launching application instances across multiple failure domains requires no additional work by application developers, as it should be. And we’re just getting started!
Please join our community and help us build the future of Kubernetes! There are many ways to participate. If you’re particularly interested in scalability, you’ll be interested in:
- Our federation slack channel
- The federation “Special Interest Group,” which meets every Thursday at 9:30 a.m. Pacific Time at SIG-Federation hangout
And of course for more information about the project in general, go to www.kubernetes.io
-- Quinton Hoole, Staff Software Engineer, Google, and Justin Santa Barbara
1000 nodes and beyond: updates to Kubernetes performance and scalability in 1.2
Editor's note: this is the first in a series of in-depth posts on what's new in Kubernetes 1.2
We're proud to announce that with the release of 1.2, Kubernetes now supports 1000-node clusters, with a reduction of 80% in 99th percentile tail latency for most API operations. This means in just six months, we've increased our overall scale by 10 times while maintaining a great user experience — the 99th percentile pod startup times are less than 3 seconds, and 99th percentile latency of most API operations is tens of milliseconds (the exception being LIST operations, which take hundreds of milliseconds in very large clusters).
Words are fine, but nothing speaks louder than a demo. Check this out!
In the above video, you saw the cluster scale up to 10 M queries per second (QPS) over 1,000 nodes, including a rolling update, with zero downtime and no impact to tail latency. That’s big enough to be one of the top 100 sites on the Internet!
In this blog post, we’ll cover the work we did to achieve this result, and discuss some of our future plans for scaling even higher.
Methodology
We benchmark Kubernetes scalability against the following Service Level Objectives (SLOs):
- API responsiveness 1 99% of all API calls return in less than 1s
- Pod startup time : 99% of pods and their containers (with pre-pulled images) start within 5s. We say Kubernetes scales to a certain number of nodes only if both of these SLOs are met. We continuously collect and report the measurements described above as part of the project test framework. This battery of tests breaks down into two parts: API responsiveness and Pod Startup Time.
API responsiveness for user-level abstractions2
Kubernetes offers high-level abstractions for users to represent their applications. For example, the ReplicationController is an abstraction representing a collection of pods. Listing all ReplicationControllers or listing all pods from a given ReplicationController is a very common use case. On the other hand, there is little reason someone would want to list all pods in the system — for example, 30,000 pods (1000 nodes with 30 pods per node) represent ~150MB of data (~5kB/pod * 30k pods). So this test uses ReplicationControllers.
For this test (assuming N to be number of nodes in the cluster), we:
-
Create roughly 3xN ReplicationControllers of different sizes (5, 30 and 250 replicas), which altogether have 30xN replicas. We spread their creation over time (i.e. we don’t start all of them at once) and wait until all of them are running.
-
Perform a few operations on every ReplicationController (scale it, list all its instances, etc.), spreading those over time, and measuring the latency of each operation. This is similar to what a real user might do in the course of normal cluster operation.
-
Stop and delete all ReplicationControllers in the system. For results of this test see the “Metrics for Kubernetes 1.2” section below.
For the v1.3 release, we plan to extend this test by also creating Services, Deployments, DaemonSets, and other API objects.
Pod startup end-to-end latency3
Users are also very interested in how long it takes Kubernetes to schedule and start a pod. This is true not only upon initial creation, but also when a ReplicationController needs to create a replacement pod to take over from one whose node failed.
We (assuming N to be the number of nodes in the cluster):
-
Create a single ReplicationController with 30xN replicas and wait until all of them are running. We are also running high-density tests, with 100xN replicas, but with fewer nodes in the cluster.
-
Launch a series of single-pod ReplicationControllers - one every 200ms. For each, we measure “total end-to-end startup time” (defined below).
-
Stop and delete all pods and replication controllers in the system. We define “total end-to-end startup time” as the time from the moment the client sends the API server a request to create a ReplicationController, to the moment when “running & ready” pod status is returned to the client via watch. That means that “pod startup time” includes the ReplicationController being created and in turn creating a pod, scheduler scheduling that pod, Kubernetes setting up intra-pod networking, starting containers, waiting until the pod is successfully responding to health-checks, and then finally waiting until the pod has reported its status back to the API server and then API server reported it via watch to the client.
While we could have decreased the “pod startup time” substantially by excluding for example waiting for report via watch, or creating pods directly rather than through ReplicationControllers, we believe that a broad definition that maps to the most realistic use cases is the best for real users to understand the performance they can expect from the system.
Metrics from Kubernetes 1.2
So what was the result?We run our tests on Google Compute Engine, setting the size of the master VM based on the size of the Kubernetes cluster. In particular for 1000-node clusters we use a n1-standard-32 VM for the master (32 cores, 120GB RAM).
API responsiveness
The following two charts present a comparison of 99th percentile API call latencies for the Kubernetes 1.2 release and the 1.0 release on 100-node clusters. (Smaller bars are better)

We present results for LIST operations separately, since these latencies are significantly higher. Note that we slightly modified our tests in the meantime, so running current tests against v1.0 would result in higher latencies than they used to.

We also ran these tests against 1000-node clusters. Note: We did not support clusters larger than 100 on GKE, so we do not have metrics to compare these results to. However, customers have reported running on 1,000+ node clusters since Kubernetes 1.0.

Since LIST operations are significantly larger, we again present them separately: All latencies, in both cluster sizes, are well within our 1 second SLO.

Pod startup end-to-end latency
The results for “pod startup latency” (as defined in the “Pod-Startup end-to-end latency” section) are presented in the following graph. For reference we are presenting also results from v1.0 for 100-node clusters in the first part of the graph.

As you can see, we substantially reduced tail latency in 100-node clusters, and now deliver low pod startup latency up to the largest cluster sizes we have measured. It is noteworthy that the metrics for 1000-node clusters, for both API latency and pod startup latency, are generally better than those reported for 100-node clusters just six months ago!
How did we make these improvements?
To make these significant gains in scale and performance over the past six months, we made a number of improvements across the whole system. Some of the most important ones are listed below.
- _ Created a “read cache” at the API server level _
(https://github.com/kubernetes/kubernetes/issues/15945 )
Since most Kubernetes control logic operates on an ordered, consistent snapshot kept up-to-date by etcd watches (via the API server), a slight delay in that arrival of that data has no impact on the correct operation of the cluster. These independent controller loops, distributed by design for extensibility of the system, are happy to trade a bit of latency for an increase in overall throughput.
In Kubernetes 1.2 we exploited this fact to improve performance and scalability by adding an API server read cache. With this change, the API server’s clients can read data from an in-memory cache in the API server instead of reading it from etcd. The cache is updated directly from etcd via watch in the background. Those clients that can tolerate latency in retrieving data (usually the lag of cache is on the order of tens of milliseconds) can be served entirely from cache, reducing the load on etcd and increasing the throughput of the server. This is a continuation of an optimization begun in v1.1, where we added support for serving watch directly from the API server instead of etcd:https://github.com/kubernetes/kubernetes/blob/master/docs/proposals/apiserver-watch.md.
Thanks to contributions from Wojciech Tyczynski at Google and Clayton Coleman and Timothy St. Clair at Red Hat, we were able to join careful system design with the unique advantages of etcd to improve the scalability and performance of Kubernetes.
- Introduce a “Pod Lifecycle Event Generator” (PLEG) in the Kubelet (https://github.com/kubernetes/kubernetes/blob/master/docs/proposals/pod-lifecycle-event-generator.md)
Kubernetes 1.2 also improved density from a pods-per-node perspective — for v1.2 we test and advertise up to 100 pods on a single node (vs 30 pods in the 1.1 release). This improvement was possible because of diligent work by the Kubernetes community through an implementation of the Pod Lifecycle Event Generator (PLEG).
The Kubelet (the Kubernetes node agent) has a worker thread per pod which is responsible for managing the pod’s lifecycle. In earlier releases each worker would periodically poll the underlying container runtime (Docker) to detect state changes, and perform any necessary actions to ensure the node’s state matched the desired state (e.g. by starting and stopping containers). As pod density increased, concurrent polling from each worker would overwhelm the Docker runtime, leading to serious reliability and performance issues (including additional CPU utilization which was one of the limiting factors for scaling up).
To address this problem we introduced a new Kubelet subcomponent — the PLEG — to centralize state change detection and generate lifecycle events for the workers. With concurrent polling eliminated, we were able to lower the steady-state CPU usage of Kubelet and the container runtime by 4x. This also allowed us to adopt a shorter polling period, so as to detect and react to changes more quickly.


-
Improved scheduler throughput Kubernetes community members from CoreOS (Hongchao Deng and Xiang Li) helped to dive deep into the Kubernetes scheduler and dramatically improve throughput without sacrificing accuracy or flexibility. They cut total time to schedule 30,000 pods by nearly 1400%! You can read a great blog post on how they approached the problem here: https://coreos.com/blog/improving-kubernetes-scheduler-performance.html
-
A more efficient JSON parser Go’s standard library includes a flexible and easy-to-use JSON parser that can encode and decode any Go struct using the reflection API. But that flexibility comes with a cost — reflection allocates lots of small objects that have to be tracked and garbage collected by the runtime. Our profiling bore that out, showing that a large chunk of both client and server time was spent in serialization. Given that our types don’t change frequently, we suspected that a significant amount of reflection could be bypassed through code generation.
After surveying the Go JSON landscape and conducting some initial tests, we found the ugorji codec library offered the most significant speedups - a 200% improvement in encoding and decoding JSON when using generated serializers, with a significant reduction in object allocations. After contributing fixes to the upstream library to deal with some of our complex structures, we switched Kubernetes and the go-etcd client library over. Along with some other important optimizations in the layers above and below JSON, we were able to slash the cost in CPU time of almost all API operations, especially reads.
-
Other notable changes led to significant wins, including:
- Reducing the number of broken TCP connections, which were causing unnecessary new TLS sessions: https://github.com/kubernetes/kubernetes/issues/15664

- Improving the performance of ReplicationController in large clusters:https://github.com/kubernetes/kubernetes/issues/21672
In both cases, the problem was debugged and/or fixed by Kubernetes community members, including Andy Goldstein and Jordan Liggitt from Red Hat, and Liang Mingqiang from NetEase.
Kubernetes 1.3 and Beyond
Of course, our job is not finished. We will continue to invest in improving Kubernetes performance, as we would like it to scale to many thousands of nodes, just like Google’s Borg. Thanks to our investment in testing infrastructure and our focus on how teams use containers in production, we have already identified the next steps on our path to improving scale.
On deck for Kubernetes 1.3:
-
Our main bottleneck is still the API server, which spends the majority of its time just marshaling and unmarshaling JSON objects. We plan to add support for protocol buffers to the API as an optional path for inter-component communication and for storing objects in etcd. Users will still be able to use JSON to communicate with the API server, but since the majority of Kubernetes communication is intra-cluster (API server to node, scheduler to API server, etc.) we expect a significant reduction in CPU and memory usage on the master.
-
Kubernetes uses labels to identify sets of objects; For example, identifying which pods belong to a given ReplicationController requires iterating over all pods in a namespace and choosing those that match the controller’s label selector. The addition of an efficient indexer for labels that can take advantage of the existing API object cache will make it possible to quickly find the objects that match a label selector, making this common operation much faster.
-
Scheduling decisions are based on a number of different factors, including spreading pods based on requested resources, spreading pods with the same selectors (e.g. from the same Service, ReplicationController, Job, etc.), presence of needed container images on the node, etc. Those calculations, in particular selector spreading, have many opportunities for improvement — see https://github.com/kubernetes/kubernetes/issues/22262 for just one suggested change.
-
We are also excited about the upcoming etcd v3.0 release, which was designed with Kubernetes use case in mind — it will both improve performance and introduce new features. Contributors from CoreOS have already begun laying the groundwork for moving Kubernetes to etcd v3.0 (see https://github.com/kubernetes/kubernetes/pull/22604). While this list does not capture all the efforts around performance, we are optimistic we will achieve as big a performance gain as we saw going from Kubernetes 1.0 to 1.2.
Conclusion
In the last six months we’ve significantly improved Kubernetes scalability, allowing v1.2 to run 1000-node clusters with the same excellent responsiveness (as measured by our SLOs) as we were previously achieving only on much smaller clusters. But that isn’t enough — we want to push Kubernetes even further and faster. Kubernetes v1.3 will improve the system’s scalability and responsiveness further, while continuing to add features that make it easier to build and run the most demanding container-based applications.
Please join our community and help us build the future of Kubernetes! There are many ways to participate. If you’re particularly interested in scalability, you’ll be interested in:
-
The scalability “Special Interest Group”, which meets every Thursday at 9 AM Pacific Time at SIG-Scale hangout And of course for more information about the project in general, go to www.kubernetes.io
-
Wojciech Tyczynski, Software Engineer, Google
1We exclude operations on “events” since these are more like system logs and are not required for the system to operate properly.
2This is test/e2e/load.go from the Kubernetes github repository.
3This is test/e2e/density.go test from the Kubernetes github repository
4We are looking into optimizing this in the next release, but for now using a smaller master can result in significant (order of magnitude) performance degradation. We encourage anyone running benchmarking against Kubernetes or attempting to replicate these findings to use a similarly sized master, or performance will suffer.
Five Days of Kubernetes 1.2
The Kubernetes project has had some huge milestones over the past few weeks. We released Kubernetes 1.2, had our first conference in Europe, and were accepted into the Cloud Native Computing Foundation. While we catch our breath, we would like to take a moment to highlight some of the great work contributed by the community since our last milestone, just four months ago.
Our mission is to make building distributed systems easy and accessible for all. While Kubernetes 1.2 has LOTS of new features, there are a few that really highlight the strides we’re making towards that goal. Over the course of the next week, we’ll be publishing a series of in-depth posts covering what’s new, so come back daily this week to read about the new features that continue to make Kubernetes the easiest way to run containers at scale. Thanks, and stay tuned!
|
3/28
|
* 1000 nodes and Beyond: Updates to Kubernetes performance and scalability in 1.2
* Guest post by Sysdig: How container metadata changes your point of view
|
|
3/29
|
* Building highly available applications using Kubernetes new multi-zone clusters (a.k.a. Ubernetes Lite")
* Guest post by AppFormix: Helping Enterprises Operationalize Kubernetes
|
|
3/30
|
* Using Spark and Zeppelin to process big data on Kubernetes 1.2.
|
|
3/31
|
* Kubernetes 1.2 and simplifying advanced networking with Ingress
|
|
4/1
|
* Using Deployment Objects with Kubernetes 1.2
|
|
BONUS
|
* ConfigMap API Configuration management with Containers
|
You can follow us on twitter here @Kubernetesio
--David Aronchick, Senior Product Manager for Kubernetes, Google
How container metadata changes your point of view
Today’s guest post is brought to you by Apurva Davé, VP of Marketing at Sysdig, who’ll discuss using Kubernetes metadata & Sysdig to understand what’s going on in your Kubernetes cluster.
Sure, metadata is a fancy word. It actually means “data that describes other data.” While that definition isn’t all that helpful, it turns out metadata itself is especially helpful in container environments. When you have any complex system, the availability of metadata helps you sort and process the variety of data coming out of that system, so that you can get to the heart of an issue with less headache.
In a Kubernetes environment, metadata can be a crucial tool for organizing and understanding the way containers are orchestrated across your many services, machines, availability zones or (in the future) multiple clouds. This metadata can also be consumed by other services running on top of your Kubernetes system and can help you manage your applications.
We’ll take a look at some examples of this below, but first...
A quick intro to Kubernetes metadata Kubernetes metadata is abundant in the form of labels and annotations. Labels are designed to be identifying metadata for your infrastructure, whereas annotations are designed to be non-identifying. For both, they’re simply generic key:value pairs that look like this:
"labels": {
"key1" : "value1",
"key2" : "value2"
}
Labels are not designed to be unique; you can expect any number of objects in your environment to carry the same label, and you can expect that an object could have many labels.
What are some examples of labels you might use? Here are just a few. WARNING: Once you start, you might find more than a few ways to use this functionality!
- Environment: Dev, Prod, Test, UAT
- Customer: Cust A, Cust B, Cust C
- Tier: Frontend, Backend
- App: Cache, Web, Database, Auth
In addition to custom labels you might define, Kubernetes also automatically applies labels to your system with useful metadata. Default labels supply key identifying information about your entire Kubernetes hierarchy: Pods, Services, Replication Controllers,and Namespaces.
Putting your metadata to work
Once you spend a little time with Kubernetes, you’ll see that labels have one particularly powerful application that makes them essential:
Kubernetes labels allows you to easily move between a “physical” view of your hosts and containers, and a “logical” view of your applications and micro-services.
At its core, a platform like Kubernetes is designed to orchestrate the optimal use of underlying physical resources. This is a powerful way to consume private or public cloud resources very efficiently, and sometimes you need to visualize those physical resources. In reality, however, most of the time you care about the performance of the service first and foremost.
But in a Kubernetes world, achieving that high utilization means a service’s containers may be scattered all over the place! So how do you actually measure the service’s performance? That’s where the metadata comes in. With Kubernetes metadata, you can create a deep understanding of your service’s performance, regardless of where the underlying containers are physically located.
Paint me a picture
Let’s look at a quick example to make this more concrete: monitoring your application. Let’s work with a small, 3 node deployment running on GKE. For visualizing the environment we’ll use Sysdig Cloud. Here’s a list of the nodes — note the “gke” prepended to the name of each host. We see some basic performance details like CPU, memory and network.

Each of these hosts has a number of containers running on it. Drilling down on the hosts, we see the containers associated with each:

Simply scanning this list of containers on a single host, I don’t see much organization to the responsibilities of these objects. For example, some of these containers run Kubernetes services (like kube-ui) and we presume others have to do with the application running (like javaapp.x).
Now let’s use some of the metadata provided by Kubernetes to take an application-centric view of the system. Let’s start by creating a hierarchy of components based on labels, in this order:
Kubernetes namespace -> replication controller -> pod -> container
This aggregates containers at corresponding levels based on the above labels. In the app UI below, this aggregation and hierarchy are shown in the grey “grouping” bar above the data about our hosts. As you can see, we have a “prod” namespace with a group of services (replication controllers) below it. Each of those replication controllers can then consist of multiple pods, which are in turn made up of containers.

In addition to organizing containers via labels, this view also aggregates metrics across relevant containers, giving a singular view into the performance of a namespace or replication controller.
In other words, with this aggregated view based on metadata, you can now start by monitoring and troubleshooting services, and drill into hosts and containers only if needed.
Let’s do one more thing with this environment — let’s use the metadata to create a visual representation of services and the topology of their communications. Here you see our containers organized by services, but also a map-like view that shows you how these services relate to each other.

The boxes represent services that are aggregates of containers (the number in the upper right of each box tells you how many containers), and the lines represent communications between services and their latencies.
This kind of view provides yet another logical, instead of physical, view of how these application components are working together. From here I can understand service performance, relationships and underlying resource consumption (CPU in this example).
Metadata: love it, use it
This is a pretty quick tour of metadata, but I hope it inspires you to spend a little time thinking about the relevance to your own system and how you could leverage it. Here we built a pretty simple example — apps and services — but imagine collecting metadata across your apps, environments, software components and cloud providers. You could quickly assess performance differences across any slice of this infrastructure effectively, all while Kubernetes is efficiently scheduling resource usage.
Get started with metadata for visualizing these resources today, and in a followup post we’ll talk about the power of adaptive alerting based on metadata.
-- Apurva Davé is a closet Kubernetes fanatic, loves data, and oh yeah is also the VP of Marketing at Sysdig.
Scaling neural network image classification using Kubernetes with TensorFlow Serving
In 2011, Google developed an internal deep learning infrastructure called DistBelief, which allowed Googlers to build ever larger neural networks and scale training to thousands of cores. Late last year, Google introduced TensorFlow, its second-generation machine learning system. TensorFlow is general, flexible, portable, easy-to-use and, most importantly, developed with the open source community.

The process of introducing machine learning into your product involves creating and training a model on your dataset, and then pushing the model to production to serve requests. In this blog post, we’ll show you how you can use Kubernetes with TensorFlow Serving, a high performance, open source serving system for machine learning models, to meet the scaling demands of your application.
Let’s use image classification as an example. Suppose your application needs to be able to correctly identify an image across a set of categories. For example, given the cute puppy image below, your system should classify it as a retriever.
|  |
| Image via Wikipedia |
|
| Image via Wikipedia |
You can implement image classification with TensorFlow using the Inception-v3 model trained on the data from the ImageNet dataset. This dataset contains images and their labels, which allows the TensorFlow learner to train a model that can be used for by your application in production.
 Once the model is trained and exported, TensorFlow Serving uses the model to perform inference — predictions based on new data presented by its clients. In our example, clients submit image classification requests over gRPC, a high performance, open source RPC framework from Google.
Once the model is trained and exported, TensorFlow Serving uses the model to perform inference — predictions based on new data presented by its clients. In our example, clients submit image classification requests over gRPC, a high performance, open source RPC framework from Google.
Inference can be very resource intensive. Our server executes the following TensorFlow graph to process every classification request it receives. The Inception-v3 model has over 27 million parameters and runs 5.7 billion floating point operations per inference.
|  |
| Schematic diagram of Inception-v3 |
|
| Schematic diagram of Inception-v3 |
Fortunately, this is where Kubernetes can help us. Kubernetes distributes inference request processing across a cluster using its External Load Balancer. Each pod in the cluster contains a TensorFlow Serving Docker image with the TensorFlow Serving-based gRPC server and a trained Inception-v3 model. The model is represented as a set of files describing the shape of the TensorFlow graph, model weights, assets, and so on. Since everything is neatly packaged together, we can dynamically scale the number of replicated pods using the Kubernetes Replication Controller to keep up with the service demands.
To help you try this out yourself, we’ve written a step-by-step tutorial, which shows you how to create the TensorFlow Serving Docker container to serve the Inception-v3 image classification model, configure a Kubernetes cluster and run classification requests against it. We hope this will make it easier for you to integrate machine learning into your own applications and scale it with Kubernetes! To learn more about TensorFlow Serving, check out tensorflow.github.io/serving.
- Fangwei Li, Software Engineer, Google
Kubernetes 1.2: Even more performance upgrades, plus easier application deployment and management
Today we released Kubernetes 1.2. This release represents significant improvements for large organizations building distributed systems. Now with over 680 unique contributors to the project, this release represents our largest yet.
From the beginning, our mission has been to make building distributed systems easy and accessible for all. With the Kubernetes 1.2 release we’ve made strides towards our goal by increasing scale, decreasing latency and overall simplifying the way applications are deployed and managed. Now, developers at organizations of all sizes can build production scale apps more easily than ever before.
What’s new:
-
Significant scale improvements. Increased cluster scale by 400% to 1,000 nodes and 30,000 containers per cluster.
-
Simplified application deployment and management.
- Dynamic Configuration (via the ConfigMap API) enables applications to pull their configuration when they run rather than packaging it in at build time.
- Turnkey Deployments (via the Beta Deployment API) let you declare your application and Kubernetes will do the rest. It handles versioning, multiple simultaneous rollouts, aggregating status across all pods, maintaining application availability and rollback.
-
Automated cluster management :
- Improved reliability through cross-zone failover and multi-zone scheduling
- Simplified One-Pod-Per-Node Applications (via the Beta DaemonSet API) allows you to schedule a service (such as a logging agent) that runs one, and only one, pod per node.
- TLS and L7 support (via the Beta Ingress API) provides a straightforward way to integrate into custom networking environments by supporting TLS for secure communication and L7 for http-based traffic routing.
- Graceful Node Shutdown (aka Node Drain) takes care of transitioning pods off a node and allowing it to be shut down cleanly.
- Custom Metrics for Autoscaling now supports custom metrics, allowing you to specify a set of signals to indicate autoscaling pods.
-
New GUI allows you to get started quickly and enables the same functionality found in the CLI for a more approachable and discoverable interface.

- And many more. For a complete list of updates, see the release notes on github.
Community
All these improvements would not be possible without our enthusiastic and global community. The momentum is astounding. We’re seeing over 400 pull requests per week, a 50% increase since the previous 1.1 release. There are meetups and conferences discussing Kubernetes nearly every day, on top of the 85 Kubernetes related meetup groups around the world. We’ve also seen significant participation in the community in the form of Special Interest Groups, with 18 active SIGs that cover topics from AWS and OpenStack to big data and scalability, to get involved join or start a new SIG. Lastly, we’re proud that Kubernetes is the first project to be accepted to the Cloud Native Computing Foundation (CNCF), read more about the announcement here.
Documentation
With Kubernetes 1.2 comes a relaunch of our website at kubernetes.io. We’ve slimmed down the docs contribution process so that all you have to do is fork/clone and send a PR. And the site works the same whether you’re staging it on your laptop, on github.io, or viewing it in production. It’s a pure GitHub Pages project; no scripts, no plugins.
From now on, our docs are at a new repo: https://github.com/kubernetes/kubernetes.github.io
To entice you even further to contribute, we’re also announcing our new bounty program. For every “bounty bug” you address with a merged pull request, we offer the listed amount in credit for Google Cloud Platform services. Just look for bugs labeled “Bounty” in the new repo for more details.
Roadmap
All of our work is done in the open, to learn the latest about the project join the weekly community meeting or watch a recorded hangout. In keeping with our major release schedule of every three to four months, here are just a few items that are in development for next release and beyond:
- Improved stateful application support (aka Pet Set)
- Cluster Federation (aka Ubernetes)
- Even more (more!) performance improvements
- In-cluster IAM
- Cluster autoscaling
- Scheduled job
- Public dashboard that allows for nightly test runs across multiple cloud providers
- Lots, lots more! Kubernetes 1.2 is available for download at get.k8s.io and via the open source repository hosted on GitHub. To get started with Kubernetes try our new Hello World app.
Connect
We’d love to hear from you and see you participate in this growing community:
- Get involved with the Kubernetes project on GitHub
- Post questions (or answer questions) on Stackoverflow
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
Thank you for your support!
- David Aronchick, Senior Product Manager for Kubernetes, Google
ElasticBox introduces ElasticKube to help manage Kubernetes within the enterprise
Today’s guest post is brought to you by Brannan Matherson, from ElasticBox, who’ll discuss a new open source project to help standardize container deployment and management in enterprise environments. This highlights the advantages of authentication and user management for containerized applications
I’m delighted to share some exciting work that we’re doing at ElasticBox to contribute to the open source community regarding the rapidly changing advancements in container technologies. Our team is kicking off a new initiative called ElasticKube to help solve the problem of challenging container management scenarios within the enterprise. This project is a native container management experience that is specific to Kubernetes and leverages automation to provision clusters for containerized applications based on the latest release of Kubernetes 1.2.
I’ve talked to many enterprise companies, both large and small, and the plethora of cloud offering capabilities is often confusing and makes the evaluation process very difficult, so why Kubernetes? Of the large public cloud players - Amazon Web Services, Microsoft Azure, and Google Cloud Platform - Kubernetes is poised to take an innovative leadership role in framing the container management space. The Kubernetes platform does not restrict or dictate any given technical approach for containers, but encourages the community to collectively solve problems as this container market still takes form. With a proven track record of supporting open source efforts, Kubernetes platform allows my team and me to actively contribute to this fundamental shift in the IT and developer world.
We’ve chosen Kubernetes, not just for the core infrastructure services, but also the agility of Kubernetes to leverage the cluster management layer across any cloud environment - GCP, AWS, Azure, vSphere, and Rackspace. Kubernetes also provides a huge benefit for users to run clusters for containers locally on many popular technologies such as: Docker, Vagrant (and VirtualBox), CoreOS, Mesos and more. This amount of choice enables our team and many others in the community to consider solutions that will be viable for a wide range of enterprise scenarios. In the case of ElasticKube, we’re pleased with Kubernetes 1.2 which includes the full release of the deployment API. This provides the ability for us to perform seamless rolling updates of containerized applications that are running in production. In addition, we’ve been able to support new resource types like ConfigMaps and Horizontal Pod Autoscalers.
Fundamentally, ElasticKube delivers a web console for which compliments Kubernetes for users managing their clusters. The initial experience incorporates team collaboration, lifecycle management and reporting, so organizations can efficiently manage resources in a predictable manner. Users will see an ElasticKube portal that takes advantage of the infrastructure abstraction that enables users to run a container that has already been built. With ElasticKube assuming the cluster has been deployed, the overwhelming value is to provide visibility into who did what and define permissions for access to the cluster with multiple containers running on them. Secondly, by partitioning clusters into namespaces, authorization management is more effective. Finally, by empowering users to build a set of reusable templates in a modern portal, ElasticKube provides a vehicle for delivering a self-service template catalog that can be stored in GitHub (for instance, using Helm templates) and deployed easily.
ElasticKube enables organizations to accelerate adoption by developers, application operations and traditional IT operations teams and shares a mutual goal of increasing developer productivity, driving efficiency in container management and promoting the use of microservices as a modern application delivery methodology. When leveraging ElasticKube in your environment, users need to ensure the following technologies are configured appropriately to guarantee everything runs correctly:
- Configure Google Container Engine (GKE) for cluster installation and management
- Use Kubernetes to provision the infrastructure and clusters for containers
- Use your existing tools of choice to actually build your containers
- Use ElasticKube to run, deploy and manage your containers and services
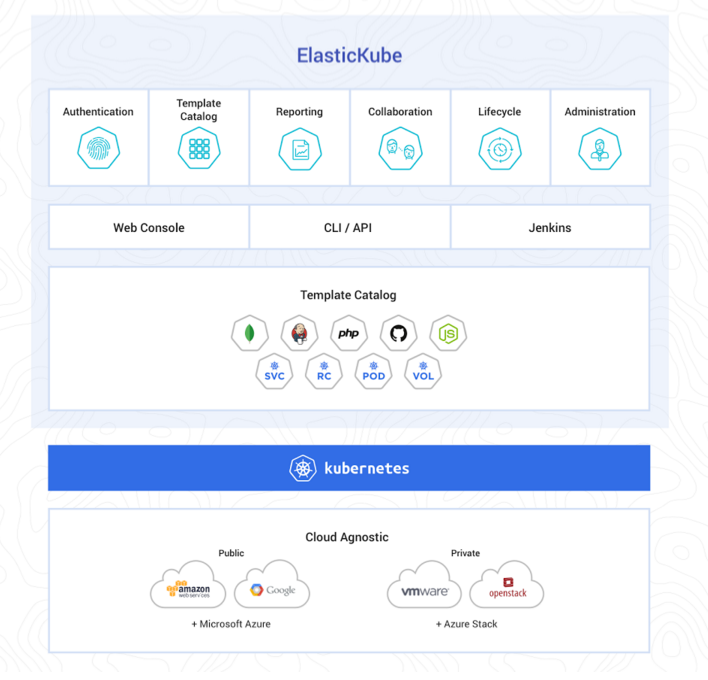
Getting Started with Kubernetes and ElasticKube
(this is a 3min walk through video with the following topics)
- Deploy ElasticKube to a Kubernetes cluster
- Configuration
- Admin: Setup and invite a user
- Deploy an instance
Hear What Others are Saying
“Kubernetes has provided us the level of sophistication required for enterprises to manage containers across complex networking environments and the appropriate amount of visibility into the application lifecycle. Additionally, the community commitment and engagement has been exceptional, and we look forward to being a major contributor to this next wave of modern cloud computing and application management.”
~Alberto Arias Maestro, Co-founder and Chief Technology Officer, ElasticBox
-- Brannan Matherson, Head of Product Marketing, ElasticBox
Kubernetes in the Enterprise with Fujitsu’s Cloud Load Control
Today’s guest post is by Florian Walker, Product Manager at Fujitsu and working on Cloud Load Control, an offering focused on the usage of Kubernetes in an enterprise context. Florian tells us what potential Fujitsu sees in Kubernetes, and how they make it accessible to enterprises.
Earlier this year, Fujitsu released its Kubernetes-based offering Fujitsu ServerViewCloud Load Control (CLC) to the public. Some might be surprised since Fujitsu’s reputation is not necessarily related to software development, but rather to hardware manufacturing and IT services. As a long-time member of the Linux foundation and founding member of the Open Container Initiative and the Cloud Native Computing Foundation, Fujitsu does not only build software, but is committed to open source software, and contributes to several projects, including Kubernetes. But we not only believe in Kubernetes as an open source project, we also chose it as the core of our offering, because it provides the best balance of feature set, resource requirements and complexity to run distributed applications at scale.
Today, we want to take you on a short tour explaining the background of our offering, why we think Kubernetes is the right fit for your customers and what value Cloud Load Control provides on top of it. A long long time ago…
In mid 2014 we looked at the challenges enterprises are facing in the context of digitization, where traditional enterprises experience that more and more competitors from the IT sector are pushing into the core of their markets. A big part of Fujitsu’s customers are such traditional businesses, so we considered how we could help them and came up with three basic principles:
- Decouple applications from infrastructure - Focus on where the value for the customer is: the application.
- Decompose applications - Build applications from smaller, loosely coupled parts. Enable reconfiguration of those parts depending on the needs of the business. Also encourage innovation by low-cost experiments.
- Automate everything - Fight the increasing complexity of the first two points by introducing a high degree of automation.
We found that Linux containers themselves cover the first point and touch the second. But at this time there was little support for creating distributed applications and running them managed automatically. We found Kubernetes as the missing piece. Not a free lunch
The general approach of Kubernetes in managing containerized workload is convincing, but as we looked at it with the eyes of customers, we realized that it’s not a free lunch. Many customers are medium-sized companies whose core business is often bound to strict data protection regulations. The top three requirements we identified are:
- On-premise deployments (with the option for hybrid scenarios)
- Efficient operations as part of a (much) bigger IT infrastructure
- Enterprise-grade support, potentially on global scale
We created Cloud Load Control with these requirements in mind. It is basically a distribution of Kubernetes targeted for on-premise use, primarily focusing on operational aspects of container infrastructure. We are committed to work with the community, and contribute all relevant changes and extensions upstream to the Kubernetes project. On-premise deployments
As Kubernetes core developer Tim Hockin often puts it in histalks, Kubernetes is "a story with two parts" where setting up a Kubernetes cluster is not the easy part and often challenging due to variations in infrastructure. This is in particular true when it comes to production-ready deployments of Kubernetes. In the public cloud space, a customer could choose a service like Google Container Engine (GKE) to do this job. Since customers have less options on-premise, often they have to consider the deployment by themselves.
Cloud Load Control addresses these issues. It enables customers to reliably and readily provision a production grade Kubernetes clusters on their own infrastructure, with the following benefits:
- Proven setup process, lowers risk of problems while setting up the cluster
- Reduction of provisioning time to minutes
- Repeatable process, relevant especially for large, multi-tenant environments
Cloud Load Control delivers these benefits for a range of platforms, starting from selected OpenStack distributions in the first versions of Cloud Load Control, and successively adding more platforms depending on customer demand. We are especially excited about the option to remove the virtualization layer and support Kubernetes bare-metal on Fujitsu servers in the long run. By removing a layer of complexity, the total cost to run the system would be decreased and the missing hypervisor would increase performance.
Right now we are in the process of contributing a generic provider to set up Kubernetes on OpenStack. As a next step in driving multi-platform support, Docker-based deployment of Kubernetes seems to be crucial. We plan to contribute to this feature to ensure it is going to be Beta in Kubernetes 1.3. Efficient operations
Reducing operation costs is the target of any organization providing IT infrastructure. This can be achieved by increasing the efficiency of operations and helping operators to get their job done. Considering large-scale container infrastructures, we found it is important to differentiate between two types of operations:
- Platform-oriented, relates to the overall infrastructure, often including various systems, one of which might be Kubernetes.
- Application-oriented, focusses rather on a single, or a small set of applications deployed on Kubernetes.
Kubernetes is already great for the application-oriented part. Cloud Load Control was created to help platform-oriented operators to efficiently manage Kubernetes as part of the overall infrastructure and make it easy to execute Kubernetes tasks relevant to them.
The first version of Cloud Load Control provides a user interface integrated in the OpenStack Horizon dashboard which enables the Platform ops to create and manage their Kubernetes clusters.

Clusters are treated as first-class citizens of OpenStack. Their creation is as simple as the creation of a virtual machine. Operators do not need to learn a new system or method of provisioning, and the self-service approach enables large organizations to rapidly provide the Kubernetes infrastructure to their tenants.
An intuitive UI is crucial for the simplification of operations. This is why we heavily contributed to theKubernetes Dashboard project and ship it in Cloud Load Control. Especially for operators who don’t know the Kubernetes CLI by heart, because they have to care about other systems too, a great UI is perfectly suitable to get typical operational tasks done, such as checking the health of the system or deploying a new application.
Monitoring is essential. With the dashboard, it is possible to get insights on cluster level. To ensure that the OpenStack operators have a deep understanding of their platform, we will soon add an integration withMonasca, OpenStack’s monitoring-as-a-service project, so metrics of Kubernetes can be analyzed together with OpenStack metrics from a single point of access. Quality and enterprise-grade support
As a Japanese company, quality and customer focus have the highest priority in every product and service we ship. This is where the actual value of Cloud Cloud Control comes from: it provides a specific version of the open source software which has been intensively tested and hardened to ensure stable operations on a particular set of platforms.
Acknowledging that container technology and Kubernetes is new territory for a lot of enterprises, expert assistance is the key for setting up and running a production-grade container infrastructure. Cloud Load Control comes with a support service leveraging Fujitsu’s proven support structure. This enables support also for customers operating Kubernetes in different regions of the world, like Europe and Japan, as part of the same offering. Conclusion
2014 seems to be light years away, we believe the decision for Kubernetes was the right one. It is built from the ground-up to enable the creation of container-based, distributed applications, and best supports this use case.
With Cloud Load Control, we’re excited to enable enterprises to run Kubernetes in production environments and to help their operators to efficiently use it, so DevOps teams can build awesome applications on top of it.
-- Florian Walker, Product Manager, FUJITSU
Kubernetes Community Meeting Notes - 20160225
February 25th - Redspread demo, 1.2 update and planning 1.3, newbie introductions, SIG-networking and a shout out to CoreOS blog post.
The Kubernetes contributing community meets most Thursdays at 10:00PT to discuss the project's status via videoconference. Here are the notes from the latest meeting.
Note taker: [Ilan Rabinovich]
- Quick call out for sharing presentations/slides [JBeda]
- Demo (10 min): Redspread [Mackenzie Burnett, Dan Gillespie]
- 1.2 Release Watch [T.J. Goltermann]
- currently about 80 issues in the queue that need to be addressed before branching.
- currently looks like March 7th may slip to later in the week, but up in the air until flakey tests are resolved.
- non-1.2 changes may be delayed in review/merging until 1.2 stabilization work completes.
- 1.3 release planning
- currently about 80 issues in the queue that need to be addressed before branching.
- Newbie Introductions
- SIG Reports -
- Networking [Tim Hockin]
- Scale [Bob Wise]
- meeting last Friday went very well. Discussed charter AND a working deployment
- moved meeting to Thursdays @ 1 (so in 3 hours!)
- Rob is posting a Cluster Ops announce on TheNewStack to recruit more members
- GSoC participation -- no application submitted. [Sarah Novotny]
- Brian Grant has offered to review PRs that need attention for 1.2
- Dynamic Provisioning
- Currently overlaps a bit with the ubernetes work
- PR in progress.
- Should work in 1.2, but being targeted more in 1.3
- Next meeting is March 3rd.
- Demo from Weave on Kubernetes Anywhere
- Another Kubernetes 1.2 update
- Update from CNCF update
- 1.3 commitments from google
- No meeting on March 10th.
To get involved in the Kubernetes community consider joining our Slack channel, taking a look at the Kubernetes project on GitHub, or join the Kubernetes-dev Google group. If you're really excited, you can do all of the above and join us for the next community conversation — March 3rd, 2016. Please add yourself or a topic you want to know about to the agenda and get a calendar invitation by joining this group.
The full recording is available on YouTube in the growing archive of Kubernetes Community Meetings. -- Kubernetes Community
State of the Container World, February 2016
Hello, and welcome to the second installment of the Kubernetes state of the container world survey. At the beginning of February we sent out a survey about people’s usage of containers, and wrote about the results from the January survey. Here we are again, as before, while we try to reach a large and representative set of respondents, this survey was publicized across the social media account of myself and others on the Kubernetes team, so I expect some pro-container and Kubernetes bias in the data.We continue to try to get as large an audience as possible, and in that vein, please go and take the March survey and share it with your friends and followers everywhere! Without further ado, the numbers...
Containers continue to gain ground
In January, 71% of respondents were currently using containers, in February, 89% of respondents were currently using containers. The percentage of users not even considering containers also shrank from 4% in January to a surprising 0% in February. Will see if that holds consistent in March.Likewise, the usage of containers continued to march across the dev/canary/prod lifecycle. In all parts of the lifecycle, container usage increased:
- Development: 80% -> 88%
- Test: 67% -> 72%
- Pre production: 41% -> 55%
- Production: 50% -> 62%
What is striking in this is that pre-production growth continued, even as workloads were clearly transitioned into true production. Likewise the share of people considering containers for production rose from 78% in January to 82% in February. Again we’ll see if the trend continues into March.
Container and cluster sizes
We asked some new questions in the survey too, around container and cluster sizes, and there were some interesting numbers:
How many containers are you running?

How many machines are you running containers on?

So while container usage continues to grow, the size and scope continues to be quite modest, with more than 50% of users running fewer than 50 containers on fewer than 10 machines.
Things stay the same
Across the orchestration space, things seemed pretty consistent between January and February (Kubernetes is quite popular with folks (54% -> 57%), though again, please see the note at the top about the likely bias in our survey population. Shell scripts likewise are also quite popular and holding steady. You all certainly love your Bash (don’t worry, we do too ;) Likewise people continue to use cloud services both in raw IaaS form (10% on GCE, 30% on EC2, 2% on Azure) as well as cloud container services (16% for GKE, 11% on ECS, 1% on ACS). Though the most popular deployment target by far remains your laptop/desktop at ~53%.
Raw data
As always, the complete raw data is available in a spreadsheet here.
Conclusions
Containers continue to gain in popularity and usage. The world of orchestration is somewhat stabilizing, and cloud services continue to be a common place to run containers, though your laptop is even more popular.
And if you are just getting started with containers (or looking to move beyond your laptop) please visit us at kubernetes.io and Google Container Engine. ‘Till next month, please get your friends, relatives and co-workers to take our March survey!
Thanks!
-- Brendan Burns, Software Engineer, Google
KubeCon EU 2016: Kubernetes Community in London
KubeCon EU 2016 is the inaugural European Kubernetes community conference that follows on the American launch in November 2015. KubeCon is fully dedicated to education and community engagement forKubernetes enthusiasts, production users and the surrounding ecosystem.
Come join us in London and hang out with hundreds from the Kubernetes community and experience a wide variety of deep technical expert talks and use cases.
Don’t miss these great speaker sessions at the conference:
-
“Kubernetes Hardware Hacks: Exploring the Kubernetes API Through Knobs, Faders, and Sliders” by Ian Lewis and Brian Dorsey, Developer Advocate, Google -* http://sched.co/6Bl3
-
“rktnetes: what's new with container runtimes and Kubernetes” by Jonathan Boulle, Developer and Team Lead at CoreOS -* http://sched.co/6BY7
-
“Kubernetes Documentation: Contributing, fixing issues, collecting bounties” by John Mulhausen, Lead Technical Writer, Google -* http://sched.co/6BUP
-
“What is OpenStack's role in a Kubernetes world?” By Thierry Carrez, Director of Engineering, OpenStack Foundation -* http://sched.co/6BYC
-
“A Practical Guide to Container Scheduling” by Mandy Waite, Developer Advocate, Google -* http://sched.co/6BZa
-
“Kubernetes in Production in The New York Times newsroom” Eric Lewis, Web Developer, New York Times -* http://sched.co/67f2
-
“Creating an Advanced Load Balancing Solution for Kubernetes with NGINX” by Andrew Hutchings, Technical Product Manager, NGINX -* http://sched.co/6Bc9
-
And many more http://kubeconeurope2016.sched.org/
Get your KubeCon EU tickets here.
Venue Location: CodeNode * 10 South Pl, London, United Kingdom
Accommodations: hotels
Website: kubecon.io
Twitter: @KubeConio #KubeCon
Google is a proud Diamond sponsor of KubeCon EU 2016. Come to London next month, March 10th & 11th, and visit booth #13 to learn all about Kubernetes, Google Container Engine (GKE) and Google Cloud Platform!
KubeCon is organized by KubeAcademy, LLC, a community-driven group of developers focused on the education of developers and the promotion of Kubernetes.
-* Sarah Novotny, Kubernetes Community Manager, Google
Kubernetes Community Meeting Notes - 20160218
February 18th - kmachine demo, clusterops SIG formed, new k8s.io website preview, 1.2 update and planning 1.3
The Kubernetes contributing community meets most Thursdays at 10:00PT to discuss the project's status via videoconference. Here are the notes from the latest meeting.
- Note taker: Rob Hirschfeld
- Demo (10 min): kmachine [Sebastien Goasguen]
- started :01 intro video
- looking to create mirror of Docker tools for Kubernetes (similar to machine, compose, etc)
- kmachine (forked from Docker Machine, so has the same endpoints)
- Use Case (10 min): started at :15
- SIG Report starter
- Cluster Ops launch meeting Friday (doc). [Rob Hirschfeld]
- Time Zone Discussion [:22]
- This timezone does not work for Asia.
- Considering rotation - once per month
- Likely 5 or 6 PT
- Rob suggested moving the regular meeting up a little
- k8s.io website preview [John Mulhausen] [:27]
- using github for docs. you can fork and do a pull request against the site
- will be its own kubernetes organization BUT not in the code repo
- Google will offer a "doc bounty" where you can get GCP credits for working on docs
- Uses Jekyll to generate the site (e.g. the ToC)
- Principle will be to 100% GitHub Pages; no script trickery or plugins, just fork/clone, edit, and push
- Hope to launch at Kubecon EU
- Home Page Only Preview: http://kub.unitedcreations.xyz
- 1.2 Release Watch [T.J. Goltermann] [:38]
- 1.3 Planning update [T.J. Goltermann]
- GSoC participation -- deadline 2/19 [Sarah Novotny]
- March 10th meeting? [Sarah Novotny]
To get involved in the Kubernetes community consider joining our Slack channel, taking a look at the Kubernetes project on GitHub, or join the Kubernetes-dev Google group. If you're really excited, you can do all of the above and join us for the next community conversation — February 25th, 2016. Please add yourself or a topic you want to know about to the agenda and get a calendar invitation by joining this group.
"https://youtu.be/L5BgX2VJhlY?list=PL69nYSiGNLP1pkHsbPjzAewvMgGUpkCnJ"
-- Kubernetes Community
Kubernetes Community Meeting Notes - 20160211
February 11th - Pangaea Demo, #AWS SIG formed, release automation and documentation team introductions. 1.2 update and planning 1.3.
The Kubernetes contributing community meets most Thursdays at 10:00PT to discuss the project's status via videoconference. Here are the notes from the latest meeting.
Note taker: Rob Hirschfeld
-
Demo: Pangaea [Shahidh K Muhammed, Tanmai Gopal, and Akshaya Acharya]
- Microservices packages
- Focused on Application developers
- Demo at recording +4 minutes
- Single node kubernetes cluster — runs locally using Vagrant CoreOS image
- Single user/system cluster allows use of DNS integration (unlike Compose)
- Can run locally or in cloud
- SIG Report:
- Release Automation and an introduction to David McMahon
- Docs and k8s website redesign proposal and an introduction to John Mulhausen
- This will allow the system to build docs correctly from GitHub w/ minimal effort
- Will be check-in triggered
- Getting website style updates
- Want to keep authoring really light
- There will be some automated checks
- Next week: preview of the new website during the community meeting
-
[@goltermann] 1.2 Release Watch (time +34 minutes)
- code slush * no major features or refactors accepted
- discussion about release criteria: we will hold release date for bugs
-
Testing flake surge is over (one time event and then maintain test stability)
-
1.3 Planning (time +40 minutes)
- working to cleanup the GitHub milestones — they should be a source of truth. you can use GitHub for bug reporting
- push off discussion while 1.2 crunch is under
- Framework
- dates
- prioritization
- feedback
- Design Review meetings
- General discussion about the PRD process — still at the beginning states
- Working on a contributor conference
- Rob suggested tracking relationships between PRD/Mgmr authors
- PLEASE DO REVIEWS — talked about the way people are authorized to +2 reviews.
To get involved in the Kubernetes community consider joining our Slack channel, taking a look at the Kubernetes project on GitHub, or join the Kubernetes-dev Google group. If you're really excited, you can do all of the above and join us for the next community conversation — February 18th, 2016. Please add yourself or a topic you want to know about to the agenda and get a calendar invitation by joining this group.
The full recording is available on YouTube in the growing archive of Kubernetes Community Meetings.
ShareThis: Kubernetes In Production
Today’s guest blog post is by Juan Valencia, Technical Lead at ShareThis, a service that helps website publishers drive engagement and consumer sharing behavior across social networks.
ShareThis has grown tremendously since its first days as a tiny widget that allowed you to share to your favorite social services. It now serves over 4.5 million domains per month, helping publishers create a more authentic digital experience.
Fast growth came with a price. We leveraged technical debt to scale fast and to grow our products, particularly when it came to infrastructure. As our company expanded, the infrastructure costs mounted as well - both in terms of inefficient utilization and in terms of people costs. About 1 year ago, it became clear something needed to change.
TL;DRKubernetes has been a key component for us to reduce technical debt in our infrastructure by:
- Fostering the Adoption of Docker
- Simplifying Container Management
- Onboarding Developers On Infrastructure
- Unlocking Continuous Integration and Delivery We accomplished this by radically adopting Kubernetes and switching our DevOps team to a Cloud Platform team that worked in terms of containers and microservices. This included creating some tools to get around our own legacy debt.
The Problem
Alas, the cloud was new and we were young. We started with a traditional data-center mindset. We managed all of our own services: MySQL, Cassandra, Aerospike, Memcache, you name it. We set up VM’s just like you would traditional servers, installed our applications on them, and managed them in Nagios or Ganglia.
Unfortunately, this way of thinking was antithetical to a cloud-centric approach. Instead of thinking in terms of services, we were thinking in terms of servers. Instead of using modern cloud approaches such as autoscaling, microservices, or even managed VM’s, we were thinking in terms of scripted setups, server deployments, and avoiding vendor lock-in.
These ways of thinking were not bad per se, they were simply inefficient. They weren’t taking advantage of the changes to the cloud that were happening very quickly. It also meant that when changes needed to take place, we were treating those changes as big slow changes to a datacenter, rather than small fast changes to the cloud.
The Solution
Kubernetes As A Tool To Foster Docker Adoption
As Docker became more of a force in our industry, engineers at ShareThis also started experimenting with it to good effect. It soon became obvious that we needed to have a working container for every app in our company just so we could simplify testing in our development environment.
Some apps moved quickly into Docker because they were simple and had few dependencies. For those that had small dependencies, we were able to manage using Fig (Fig was the original name of Docker Compose). Still, many of our data pipelines or interdependent apps were too gnarly to be directly dockerized. We still wanted to do it, but Docker was not enough.
In late 2015, we were frustrated enough with our legacy infrastructure that we finally bit the bullet. We evaluated Docker’s tools, ECS, Kubernetes, and Mesosphere. It was quickly obvious that Kubernetes was in a more stable and user friendly state than its competitors for our infrastructure. As a company, we could solidify our infrastructure on Docker by simply setting the goal of having all of our infrastructure on Kubernetes.
Engineers were skeptical at first. However, once they saw applications scale effortlessly into hundreds of instances per application, they were hooked. Now, not only was there the pain points driving us forward into Docker and by extension Kubernetes, but there was genuine excitement for the technology pulling us in. This has allowed us to make an incredibly difficult migration fairly quickly. We now run Kubernetes in multiple regions on about 65 large VMs and increasing to over 100 in the next couple months. Our Kubernetes cluster currently processes 800 million requests per day with the plan to process over 2 billion requests per day in the coming months.
Kubernetes As A Tool To Manage Containers
Our earliest use of Docker was promising for development, but not so much so for production. The biggest friction point was the inability to manage Docker components at scale. Knowing which containers were running where, what version of a deployment was running, what state an app was in, how to manage subnets and VPCs, etc, plagued any chance of it going to production. The tooling required would have been substantial.
When you look at Kubernetes, there are several key features that were immediately attractive:
- It is easy to install on AWS (where all our apps were running)
- There is a direct path from a Dockerfile to a replication controller through a yaml/json file
- Pods are able to scale in number easily
- We can easily scale the number of VM’s running on AWS in a Kubernetes cluster
- Rolling deployments and rollback are built into the tooling
- Each pod gets monitored through health checks
- Service endpoints are managed by the tool
- There is an active and vibrant community
Unfortunately, one of the biggest pain points was that the tooling didn’t solve our existing legacy infrastructure, it just provided an infrastructure to move onto. There were still a variety of network quirks which disallowed us from directly moving our applications onto a new VPC. In addition, the reworking of so many applications required developers to jump onto problems that have classically been solved by sys admins and operations teams.
Kubernetes As A Tool For Onboarding Developers On Infrastructure
When we decided to make the switch from what was essentially a Chef-run setup to Kubernetes, I do not think we understood all of the pain points that we would hit. We ran our servers in a variety of different ways in a variety of different network configurations that were considerably different than the clean setup that you find on a fresh Kubernetes VPC.
In production we ran in both AWS VPCs and AWS classic across multiple regions. This means that we managed several subnets with different access controls across different applications. Our most recent applications were also very secure, having no public endpoints. This meant that we had a combination of VPC peering, network address translation (NAT), and proxies running in varied configurations.
In the Kubernetes world, there’s only the VPC. All the pods can theoretically talk to each other, and services endpoints are explicitly defined. It’s easy for the developer to gloss over some of the details and it removes the need for operations (mostly).
We made the decision to convert all of our infrastructure / DevOps developers into application developers (really!). We had already started hiring them on the basis of their development skills rather than their operational skills anyway, so perhaps that is not as wild as it sounds.
We then made the decision to onboard our entire engineering organization onto Operations. Developers are flexible, they enjoy challenges, and they enjoy learning. It was remarkable. After 1 month, our organization went from having a few DevOps folks, to having every engineer capable of modifying our architecture.
The training ground for onboarding on networking, productionization, problem solving, root cause analysis, etc, was getting Kubernetes into prod at scale. After the first month, I was biting my nails and worrying about our choices. After 2 months, it looked like it might some day be viable. After 3 months, we were deploying 10 times per week. After 4 months, 40 apps per week. Only 30% of our apps have been migrated, yet the gains are not only remarkable, they are astounding. Kubernetes allowed us to go from an infrastructure-is-slowing-us-down-ugh! organization, to an infrastructure-is-speeding-us-up-yay! organization.
Kubernetes As A Means To Unlock Continuous Integration And Delivery
How did we get to 40+ deployments per week? Put simply, continuous integration and deployment (CI/CD) came as a byproduct of our migration. Our first application in Kubernetes was Jenkins, and every app that went in also was added to Jenkins. As we moved forward, we made Jenkins more automatic until pods were being added and taken from Kubernetes faster than we could keep track.
Interestingly, our problems with scaling are now about wanting to push out too many changes at once and people having to wait until their turn. Our goal is to get 100 deployments per week through the new infrastructure. This is achievable if we can continue to execute on our migration and on our commitment to a CI/CD process on Kubernetes and Jenkins.
Next Steps
We need to finish our migration. At this point the problems are mostly solved, the biggest difficulties are in the tedium of the task at hand. To move things out of our legacy infrastructure meant changing the network configurations to allow access to and from the Kubernetes VPC and across the regions. This is still a very real pain, and one we continue to address.
Some services do not play well in Kubernetes -- think stateful distributed databases. Luckily, we can usually migrate those to a 3rd party who will manage it for us. At the end of this migration, we will only be running pods on Kubernetes. Our infrastructure will become much simpler.
All these changes do not come for free; committing our entire infrastructure to Kubernetes means that we need to have Kubernetes experts. Our team has been unblocked in terms of infrastructure and they are busy adding business value through application development (as they should). However, we do not (yet) have committed engineers to stay up to date with changes to Kubernetes and cloud computing.
As such, we have transferred one engineer to a new “cloud platform team” and will hire a couple of others (have I mentioned we’re hiring!). They will be responsible for developing tools that we can use to interface well with Kubernetes and manage all of our cloud resources. In addition, they will be working in the Kubernetes source code, part of Kubernetes SIGs, and ideally, pushing code into the open source project.
Summary
All in all, while the move to Kubernetes initially seemed daunting, it was far less complicated and disruptive than we thought. And the reward at the other end was a company that could respond as fast as our customers wanted.Editor's note: at a recent Kubernetes meetup, the team at ShareThis gave a talk about their production use of Kubernetes. Video is embedded below.
Kubernetes Community Meeting Notes - 20160204
February 4th - rkt demo (congratulations on the 1.0, CoreOS!), eBay puts k8s on Openstack and considers Openstack on k8s, SIGs, and flaky test surge makes progress.
The Kubernetes contributing community meets most Thursdays at 10:00PT to discuss the project's status via a videoconference. Here are the notes from the latest meeting.
- Note taker: Rob Hirschfeld
- Demo (20 min): CoreOS rkt + Kubernetes [Shaya Potter]
- expect to see integrations w/ rkt & k8s in the coming months ("rkt-netes"). not integrated into the v1.2 release.
- Shaya gave a demo (8 minutes into meeting for video reference)
-
CLI of rkt shown spinning up containers
-
[note: audio is garbled at points]
-
Discussion about integration w/ k8s & rkt
-
rkt community sync next week: https://groups.google.com/forum/#!topic/rkt-dev/FlwZVIEJGbY
-
Dawn Chen:
- The remaining issues of integrating rkt with kubernetes: 1) cadivsor 2) DNS 3) bugs related to logging
- But need more work on e2e test suites
-
- Use Case (10 min): eBay k8s on OpenStack and OpenStack on k8s [Ashwin Raveendran]
- eBay is currently running Kubernetes on OpenStack
- Goal for eBay is to manage the OpenStack control plane w/ k8s. Goal would be to achieve upgrades
- OpenStack Kolla creates containers for the control plane. Uses Ansible+Docker for management of the containers.
- Working on k8s control plan management - Saltstack is proving to be a management challenge at the scale they want to operate. Looking for automated management of the k8s control plane.
- SIG Report
- Testing update [Jeff, Joe, and Erick]
- Working to make the workflow about contributing to K8s easier to understanding
- pull/19714 has flow chart of the bot flow to help users understand
- Need a consistent way to run tests w/ hacking config scripts (you have to fake a Jenkins process right now)
- Want to create necessary infrastructure to make test setup less flaky
- want to decouple test start (single or full) from Jenkins
- goal is to get to point where you have 1 script to run that can be pointed to any cluster
- demo included Google internal views - working to try get that external.
- want to be able to collect test run results
- Bob Wise calls for testing infrastructure to be a blocker on v1.3
- Long discussion about testing practices…
- consensus that we want to have tests work over multiple platforms.
- would be helpful to have a comprehensive state dump for test reports
- "phone-home" to collect stack traces - should be available
- Working to make the workflow about contributing to K8s easier to understanding
- 1.2 Release Watch
- CoC [Sarah]
- GSoC [Sarah]
To get involved in the Kubernetes community consider joining our Slack channel, taking a look at the Kubernetes project on GitHub, or join the Kubernetes-dev Google group. If you're really excited, you can do all of the above and join us for the next community conversation — February 11th, 2016. Please add yourself or a topic you want to know about to the agenda and get a calendar invitation by joining this group.
"https://youtu.be/IScpP8Cj0hw?list=PL69nYSiGNLP1pkHsbPjzAewvMgGUpkCnJ"
Kubernetes Community Meeting Notes - 20160128
January 28 - 1.2 release update, Deis demo, flaky test surge and SIGs
The Kubernetes contributing community meets once a week to discuss the project's status via a videoconference. Here are the notes from the latest meeting.
Note taker: Erin Boyd
- Discuss process around code freeze/code slush (TJ Goltermann)
- Code wind down was happening during holiday (for 1.1)
- Releasing ~ every 3 months
- Build stability is still missing
- Issue on Transparency (Bob Wise)
- Email from Sarah for call to contribute (Monday, January 25)
- Concern over publishing dates / understanding release schedule /etc…
- Email from Sarah for call to contribute (Monday, January 25)
- Release targeted for early March
- Where does one find information on the release schedule with the committed features?
- For 1.2 - Send email / Slack to TJ
- For 1.3 - Working on better process to communicate to the community
- Wiki
- GitHub Milestones
- Where does one find information on the release schedule with the committed features?
- How to better communicate issues discovered in the SIG
- AI: People need to email the kubernetes-dev@ mailing list with summary of findings
- AI: Each SIG needs a note taker
- Release planning vs Release testing
- Testing SIG lead Ike McCreery
- Also part of the testing infrastructure team at Google
- Community being able to integrate into the testing framework
- Federated testing
- Release Manager = David McMahon
- Request to introduce him to the community meeting
- Testing SIG lead Ike McCreery
- Demo: Jason Hansen Deis
- Implemented simple REST API to interact with the platform
- Deis managed application (deployed via)
- Source -> image
- Rolling upgrades -> Rollbacks
- AI: Jason will provide the slides & notes
- Adding an administrative component (dashboard)
- Helm wraps kubectl
- Testing
- Called for community interaction
- Need to understand friction points from community
- Better documentation
- Better communication on how things “should work"
- Internally, Google is having daily calls to resolve test flakes
- Started up SIG testing meetings (Tuesday at 10:30 am PT)
- Everyone wants it, but no one want to pony up the time to make it happen
- Google is dedicating headcount to it (3-4 people, possibly more)
- https://groups.google.com/forum/?hl=en#!forum/kubernetes-sig-testing
- Best practices for labeling
- Are there tools built on top of these to leverage
- AI: Generate artifact for labels and what they do (Create doc)
- Help Wanted Label - good for new community members
- Classify labels for team and area
- User experience, test infrastructure, etc..
- SIG Config (not about deployment)
- Any interest in ansible, etc.. type
- SIG Scale meeting (Bob Wise & Tim StClair)
- Tests related to performance SLA get relaxed in order to get the tests to pass
- exposed process issues
- AI: outline of a proposal for a notice policy if things are being changed that are critical to the system (Bob Wise/Samsung)
- Create a Best Practices of set of constants into well documented place
- Tests related to performance SLA get relaxed in order to get the tests to pass
To get involved in the Kubernetes community consider joining our Slack channel, taking a look at the Kubernetes project on GitHub, or join the Kubernetes-dev Google group. If you’re really excited, you can do all of the above and join us for the next community conversation — February 4th, 2016. Please add yourself or a topic you want to know about to the agenda and get a calendar invitation by joining this group.
The full recording is available on YouTube in the growing archive of Kubernetes Community Meetings.
State of the Container World, January 2016
At the start of the new year, we sent out a survey to gauge the state of the container world. We’re ready to send the February edition, but before we do, let’s take a look at the January data from the 119 responses (thank you for participating!).
A note about these numbers: First, you may notice that the numbers don’t add up to 100%, the choices were not exclusive in most cases and so percentages given are the percentage of all respondents who selected a particular choice. Second, while we attempted to reach a broad cross-section of the cloud community, the survey was initially sent out via Twitter to followers of @brendandburns, @kelseyhightower, @sarahnovotny, @juliaferraioli, @thagomizer_rb, so the audience is likely not a perfect cross-section. We’re working to broaden our sample size (have I mentioned our February survey? Come take it now).
Now, without further ado, the data:
First off, lots of you are using containers! 71% are currently using containers, while 24% of you are considering using them soon. Obviously this indicates a somewhat biased sample set. Numbers for container usage in the broader community vary, but are definitely lower than 71%. Consequently, take all of the rest of these numbers with a grain of salt.
So what are folks using containers for? More than 80% of respondents are using containers for development, while only 50% are using containers for production. But you plan to move to production soon, as 78% of container users said that you were planning on moving to production sometime soon.
Where do you deploy containers? Your laptop was the clear winner here, with 53% of folks deploying to laptops. Next up was 44% of people running on their own VMs (Vagrant? OpenStack? we’ll try dive into this in the February survey), followed by 33% of folks running on physical infrastructure, and 31% on public cloud VMs.
And how are you deploying containers? 54% of you are using Kubernetes, awesome to see, though likely somewhat biased by the sample set (see the notes above), possibly more surprising, 45% of you are using shell scripts. Is it because of the extensive (and awesome) Bash scripting going on in the Kubernetes repository? Go on, you can tell me the truth… Rounding out the numbers, 25% are using CAPS (Chef/Ansible/Puppet/Salt) systems, and roughly 13% are using Docker Swarm, Mesos or other systems.
Finally, we asked people for free-text answers about the challenges of working with containers. Some of the most interesting answers are grouped and reproduced here:
Development Complexity
- “Silo'd development environments / workflows can be fragmented, ease of access to tools like logs is available when debugging containers but not intuitive at times, massive amounts of knowledge is required to grasp the whole infrastructure stack and best practices from say deploying / updating kubernetes, to underlying networking etc.”
- “Migrating developer workflow. People uninitiated with containers, volumes, etc just want to work.”
Security
- “Network Security”
- “Secrets”
Immaturity
- “Lack of a comprehensive non-proprietary standard (i.e. non-Docker) like e.g runC / OCI”
- “Still early stage with few tools and many missing features.”
- “Poor CI support, a lot of tooling still in very early days.”
- "We've never done it that way before."
Complexity
- “Networking support, providing ip per pod on bare metal for kubernetes”
- “Clustering is still too hard”
- “Setting up Mesos and Kubernetes too damn complicated!!”
Data
- “Lack of flexibility of volumes (which is the same problem with VMs, physical hardware, etc)”
- “Persistency”
- “Storage”
- “Persistent Data”
Download the full survey results here (CSV file).
_Up-- Brendan Burns, Software Engineer, Google
Kubernetes Community Meeting Notes - 20160114
January 14 - RackN demo, testing woes, and KubeCon EU CFP.
Note taker: Joe Beda
-
Demonstration: Automated Deploy on Metal, AWS and others w/ Digital Rebar, Rob Hirschfeld and Greg Althaus from RackN
-
Greg Althaus. CTO. Digital Rebar is the product. Bare metal provisioning tool.
-
Detect hardware, bring it up, configure raid, OS and get workload deployed.
-
Been working on Kubernetes workload.
-
Seeing trend to start in cloud and then move back to bare metal.
-
New provider model to use provisioning system on both cloud and bare metal.
-
UI, REST API, CLI
-
Demo: Packet -- bare metal as a service
-
4 nodes running grouped into a "deployment"
-
Functional roles/operations selected per node.
-
Decomposed the kubernetes bring up into units that can be ordered and synchronized. Dependency tree -- things like wait for etcd to be up before starting k8s master.
-
Using the Ansible playbook under the covers.
-
Demo brings up 5 more nodes -- packet will build those nodes
-
Pulled out basic parameters from the ansible playbook. Things like the network config, dns set up, etc.
-
Hierarchy of roles pulls in other components -- making a node a master brings in a bunch of other roles that are necessary for that.
-
Has all of this combined into a command line tool with a simple config file.
-
-
Forward: extending across multiple clouds for test deployments. Also looking to create split/replicated across bare metal and cloud.
-
Q: secrets?
A: using ansible playbooks. Builds own certs and then distributes them. Wants to abstract them out and push that stuff upstream. -
Q: Do you support bringing up from real bare metal with PXE boot?
A: yes -- will discover bare metal systems and install OS, install ssh keys, build networking, etc.
-
-
[from SIG-scalability] Q: What is the status of moving to golang 1.5?
A: At HEAD we are 1.5 but will support 1.4 also. Some issues with flakiness but looks like things are stable now.-
Also looking to use the 1.5 vendor experiment. Move away from godep. But can't do that until 1.5 is the baseline.
-
Sarah: one of the things we are working on is rewards for doing stuff like this. Cloud credits, tshirts, poker chips, ponies.
-
-
[from SIG-scalability] Q: What is the status of cleaning up the jenkins based submit queue? What can the community do to help out?
A: It has been rocky the last few days. There should be issues associated with each of these. There is a flake label on those issues.-
Still working on test federation. More test resources now. Happening slowly but hopefully faster as new people come up to speed. Will be great to having lots of folks doing e2e tests on their environments.
-
Erick Fjeta is the new test lead
-
Brendan is happy to help share details on Jenkins set up but that shouldn't be necessary.
-
Federation may use Jenkins API but doesn't require Jenkins itself.
-
Joe bitches about the fact that running the e2e tests in the way Jenkins is tricky. Brendan says it should be runnable easily. Joe will take another look.
-
Conformance tests? etune did this but he isn't here. - revisit 20150121
-
-
* March 10-11 in London. Venue to be announced this week.-
Please send talks! CFP deadline looks to be Feb 5.
-
Lots of excitement. Looks to be 700-800 people. Bigger than SF version (560 ppl).
-
Buy tickets early -- early bird prices will end soon and price will go up 100 GBP.
-
Accommodations provided for speakers?
-
Q from Bob @ Samsung: Can we get more warning/planning for stuff like this:
-
A: Sarah -- I don't hear about this stuff much in advance but will try to pull together a list. Working to make the events page on kubernetes.io easier to use.
-
A: JJ -- we'll make sure we give more info earlier for the next US conf.
-
-
-
Scale tests [Rob Hirschfeld from RackN] -- if you want to help coordinate on scale tests we'd love to help.
-
Bob invited Rob to join the SIG-scale group.
-
There is also a big bare metal cluster through the CNCF (from Intel) that will be useful too. No hard dates yet on that.
-
-
Notes/video going to be posted on k8s blog. (Video for 20150114 wasn't recorded. Fail.)
To get involved in the Kubernetes community consider joining our Slack channel, taking a look at the Kubernetes project on GitHub, or join the Kubernetes-dev Google group. If you're really excited, you can do all of the above and join us for the next community conversation - January 27th, 2016. Please add yourself or a topic you want to know about to the agenda and get a calendar invitation by joining this group.
Kubernetes Community Meeting Notes - 20160121
January 21 - Configuration, Federation and Testing, oh my.
Note taker: Rob Hirshfeld
-
Use Case (10 min): SFDC Paul Brown
-
SIG Report - SIG-config and the story of #18215.
- Application config IN K8s not deployment of K8s
- Topic has been reuse of configuration,specifically parameterization(aka templates). Needs:
- include scoping(cluster namespace)
- slight customization (naming changes, but not major config)
- multiple positions on how todo this including allowing external or simple extensions
- PetSet creates instances w/stable namespace
-
Workflow proposal
- Distributed Chron. Challenge is that configs need to create multiple objects in sequence
- Trying to figure out how balance the many config options out there (compose, terraform,ansible/etc)
- Goal is to “meet people where they are” to keep it simple
- Q: is there an opinion for the keystore sizing
- large size / data blob would not be appropriate
- you can pull data(config) from another store for larger objects
-
SIG Report - SIG-federation - progress on Ubernetes-Lite & Ubernetes design
-
Goal is to be able to have a cluster manager, so you can federate clusters. They will automatically distribute the pods.
-
Plan is to use the same API for the master cluster
-
Conformance testing Q+A Isaac Hollander McCreery
- status on conformance testing for release process
- expect to be forward compatible but not backwards
- is there interest for a sig-testing meeting
- testing needs to a higher priority for the project
- lots of focus on trying to make this a higher priority To get involved in the Kubernetes community consider joining our Slack channel, taking a look at the Kubernetes project on GitHub, or join the Kubernetes-dev Google group. If you’re really excited, you can do all of the above and join us for the next community conversation -- January 27th, 2016. Please add yourself or a topic you want to know about to the agenda and get a calendar invitation by joining this group.
Still want more Kubernetes? Check out the recording of this meeting and the growing of the archive of Kubernetes Community Meetings.
Why Kubernetes doesn’t use libnetwork
Kubernetes has had a very basic form of network plugins since before version 1.0 was released — around the same time as Docker's libnetwork and Container Network Model (CNM) was introduced. Unlike libnetwork, the Kubernetes plugin system still retains its "alpha" designation. Now that Docker's network plugin support is released and supported, an obvious question we get is why Kubernetes has not adopted it yet. After all, vendors will almost certainly be writing plugins for Docker — we would all be better off using the same drivers, right?
Before going further, it's important to remember that Kubernetes is a system that supports multiple container runtimes, of which Docker is just one. Configuring networking is a facet of each runtime, so when people ask "will Kubernetes support CNM?" what they really mean is "will kubernetes support CNM drivers with the Docker runtime?" It would be great if we could achieve common network support across runtimes, but that’s not an explicit goal.
Indeed, Kubernetes has not adopted CNM/libnetwork for the Docker runtime. In fact, we’ve been investigating the alternative Container Network Interface (CNI) model put forth by CoreOS and part of the App Container (appc) specification. Why? There are a number of reasons, both technical and non-technical.
First and foremost, there are some fundamental assumptions in the design of Docker's network drivers that cause problems for us.
Docker has a concept of "local" and "global" drivers. Local drivers (such as "bridge") are machine-centric and don’t do any cross-node coordination. Global drivers (such as "overlay") rely on libkv (a key-value store abstraction) to coordinate across machines. This key-value store is a another plugin interface, and is very low-level (keys and values, no semantic meaning). To run something like Docker's overlay driver in a Kubernetes cluster, we would either need cluster admins to run a whole different instance of consul, etcd or zookeeper (see multi-host networking), or else we would have to provide our own libkv implementation that was backed by Kubernetes.
The latter sounds attractive, and we tried to implement it, but the libkv interface is very low-level, and the schema is defined internally to Docker. We would have to either directly expose our underlying key-value store or else offer key-value semantics (on top of our structured API which is itself implemented on a key-value system). Neither of those are very attractive for performance, scalability and security reasons. The net result is that the whole system would significantly be more complicated, when the goal of using Docker networking is to simplify things.
For users that are willing and able to run the requisite infrastructure to satisfy Docker global drivers and to configure Docker themselves, Docker networking should "just work." Kubernetes will not get in the way of such a setup, and no matter what direction the project goes, that option should be available. For default installations, though, the practical conclusion is that this is an undue burden on users and we therefore cannot use Docker's global drivers (including "overlay"), which eliminates a lot of the value of using Docker's plugins at all.
Docker's networking model makes a lot of assumptions that aren’t valid for Kubernetes. In docker versions 1.8 and 1.9, it includes a fundamentally flawed implementation of "discovery" that results in corrupted /etc/hosts files in containers (docker #17190) — and this cannot be easily turned off. In version 1.10 Docker is planning to bundle a new DNS server, and it’s unclear whether this will be able to be turned off. Container-level naming is not the right abstraction for Kubernetes — we already have our own concepts of service naming, discovery, and binding, and we already have our own DNS schema and server (based on the well-established SkyDNS). The bundled solutions are not sufficient for our needs but are not disableable.
Orthogonal to the local/global split, Docker has both in-process and out-of-process ("remote") plugins. We investigated whether we could bypass libnetwork (and thereby skip the issues above) and drive Docker remote plugins directly. Unfortunately, this would mean that we could not use any of the Docker in-process plugins, "bridge" and "overlay" in particular, which again eliminates much of the utility of libnetwork.
On the other hand, CNI is more philosophically aligned with Kubernetes. It's far simpler than CNM, doesn't require daemons, and is at least plausibly cross-platform (CoreOS’s rkt container runtime supports it). Being cross-platform means that there is a chance to enable network configurations which will work the same across runtimes (e.g. Docker, Rocket, Hyper). It follows the UNIX philosophy of doing one thing well.
Additionally, it's trivial to wrap a CNI plugin and produce a more customized CNI plugin — it can be done with a simple shell script. CNM is much more complex in this regard. This makes CNI an attractive option for rapid development and iteration. Early prototypes have proven that it's possible to eject almost 100% of the currently hard-coded network logic in kubelet into a plugin.
We investigated writing a "bridge" CNM driver for Docker that ran CNI drivers. This turned out to be very complicated. First, the CNM and CNI models are very different, so none of the "methods" lined up. We still have the global vs. local and key-value issues discussed above. Assuming this driver would declare itself local, we have to get info about logical networks from Kubernetes.
Unfortunately, Docker drivers are hard to map to other control planes like Kubernetes. Specifically, drivers are not told the name of the network to which a container is being attached — just an ID that Docker allocates internally. This makes it hard for a driver to map back to any concept of network that exists in another system.
This and other issues have been brought up to Docker developers by network vendors, and are usually closed as "working as intended" (libnetwork #139, libnetwork #486, libnetwork #514, libnetwork #865, docker #18864), even though they make non-Docker third-party systems more difficult to integrate with. Throughout this investigation Docker has made it clear that they’re not very open to ideas that deviate from their current course or that delegate control. This is very worrisome to us, since Kubernetes complements Docker and adds so much functionality, but exists outside of Docker itself.
For all of these reasons we have chosen to invest in CNI as the Kubernetes plugin model. There will be some unfortunate side-effects of this. Most of them are relatively minor (for example, docker inspect will not show an IP address), but some are significant. In particular, containers started by docker run might not be able to communicate with containers started by Kubernetes, and network integrators will have to provide CNI drivers if they want to fully integrate with Kubernetes. On the other hand, Kubernetes will get simpler and more flexible, and a lot of the ugliness of early bootstrapping (such as configuring Docker to use our bridge) will go away.
As we proceed down this path, we’ll certainly keep our eyes and ears open for better ways to integrate and simplify. If you have thoughts on how we can do that, we really would like to hear them — find us on slack or on our network SIG mailing-list.
Tim Hockin, Software Engineer, Google
Simple leader election with Kubernetes and Docker
Overview
Kubernetes simplifies the deployment and operational management of services running on clusters. However, it also simplifies the development of these services. In this post we'll see how you can use Kubernetes to easily perform leader election in your distributed application. Distributed applications usually replicate the tasks of a service for reliability and scalability, but often it is necessary to designate one of the replicas as the leader who is responsible for coordination among all of the replicas.
Typically in leader election, a set of candidates for becoming leader is identified. These candidates all race to declare themselves the leader. One of the candidates wins and becomes the leader. Once the election is won, the leader continually "heartbeats" to renew their position as the leader, and the other candidates periodically make new attempts to become the leader. This ensures that a new leader is identified quickly, if the current leader fails for some reason.
Implementing leader election usually requires either deploying software such as ZooKeeper, etcd or Consul and using it for consensus, or alternately, implementing a consensus algorithm on your own. We will see below that Kubernetes makes the process of using leader election in your application significantly easier.
Implementing leader election in Kubernetes
The first requirement in leader election is the specification of the set of candidates for becoming the leader. Kubernetes already uses Endpoints to represent a replicated set of pods that comprise a service, so we will re-use this same object. (aside: You might have thought that we would use ReplicationControllers, but they are tied to a specific binary, and generally you want to have a single leader even if you are in the process of performing a rolling update)
To perform leader election, we use two properties of all Kubernetes API objects:
- ResourceVersions - Every API object has a unique ResourceVersion, and you can use these versions to perform compare-and-swap on Kubernetes objects
- Annotations - Every API object can be annotated with arbitrary key/value pairs to be used by clients.
Given these primitives, the code to use master election is relatively straightforward, and you can find it here. Let's run it ourselves.
$ kubectl run leader-elector --image=gcr.io/google_containers/leader-elector:0.4 --replicas=3 -- --election=example
This creates a leader election set with 3 replicas:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
leader-elector-inmr1 1/1 Running 0 13s
leader-elector-qkq00 1/1 Running 0 13s
leader-elector-sgwcq 1/1 Running 0 13s
To see which pod was chosen as the leader, you can access the logs of one of the pods, substituting one of your own pod's names in place of
${pod_name}, (e.g. leader-elector-inmr1 from the above)
$ kubectl logs -f ${name}
leader is (leader-pod-name)
… Alternately, you can inspect the endpoints object directly:
'example' is the name of the candidate set from the above kubectl run … command
$ kubectl get endpoints example -o yaml
Now to validate that leader election actually works, in a different terminal, run:
$ kubectl delete pods (leader-pod-name)
This will delete the existing leader. Because the set of pods is being managed by a replication controller, a new pod replaces the one that was deleted, ensuring that the size of the replicated set is still three. Via leader election one of these three pods is selected as the new leader, and you should see the leader failover to a different pod. Because pods in Kubernetes have a grace period before termination, this may take 30-40 seconds.
The leader-election container provides a simple webserver that can serve on any address (e.g. http://localhost:4040). You can test this out by deleting the existing leader election group and creating a new one where you additionally pass in a --http=(host):(port) specification to the leader-elector image. This causes each member of the set to serve information about the leader via a webhook.
# delete the old leader elector group
$ kubectl delete rc leader-elector
# create the new group, note the --http=localhost:4040 flag
$ kubectl run leader-elector --image=gcr.io/google_containers/leader-elector:0.4 --replicas=3 -- --election=example --http=0.0.0.0:4040
# create a proxy to your Kubernetes api server
$ kubectl proxy
You can then access:
http://localhost:8001/api/v1/proxy/namespaces/default/pods/(leader-pod-name):4040/
And you will see:
{"name":"(name-of-leader-here)"}
Leader election with sidecars
Ok, that's great, you can do leader election and find out the leader over HTTP, but how can you use it from your own application? This is where the notion of sidecars come in. In Kubernetes, Pods are made up of one or more containers. Often times, this means that you add sidecar containers to your main application to make up a Pod. (for a much more detailed treatment of this subject see my earlier blog post).
The leader-election container can serve as a sidecar that you can use from your own application. Any container in the Pod that's interested in who the current master is can simply access http://localhost:4040 and they'll get back a simple JSON object that contains the name of the current master. Since all containers in a Pod share the same network namespace, there's no service discovery required!
For example, here is a simple Node.js application that connects to the leader election sidecar and prints out whether or not it is currently the master. The leader election sidecar sets its identifier to hostname by default.
var http = require('http');
// This will hold info about the current master
var master = {};
// The web handler for our nodejs application
var handleRequest = function(request, response) {
response.writeHead(200);
response.end("Master is " + master.name);
};
// A callback that is used for our outgoing client requests to the sidecar
var cb = function(response) {
var data = '';
response.on('data', function(piece) { data = data + piece; });
response.on('end', function() { master = JSON.parse(data); });
};
// Make an async request to the sidecar at http://localhost:4040
var updateMaster = function() {
var req = http.get({host: 'localhost', path: '/', port: 4040}, cb);
req.on('error', function(e) { console.log('problem with request: ' + e.message); });
req.end();
};
/ / Set up regular updates
updateMaster();
setInterval(updateMaster, 5000);
// set up the web server
var www = http.createServer(handleRequest);
www.listen(8080);
Of course, you can use this sidecar from any language that you choose that supports HTTP and JSON.
Conclusion
Hopefully I've shown you how easy it is to build leader election for your distributed application using Kubernetes. In future installments we'll show you how Kubernetes is making building distributed systems even easier. In the meantime, head over to Google Container Engine or kubernetes.io to get started with Kubernetes.
Creating a Raspberry Pi cluster running Kubernetes, the installation (Part 2)
At Devoxx Belgium and Devoxx Morocco, Ray Tsang and I (Arjen Wassink) showed a Raspberry Pi cluster we built at Quintor running HypriotOS, Docker and Kubernetes. While we received many compliments on the talk, the most common question was about how to build a Pi cluster themselves! We’ll be doing just that, in two parts. The first part covered the shopping list for the cluster, and this second one will show you how to get kubernetes up and running . . .
Now you got your Raspberry Pi Cluster all setup, it is time to run some software on it. As mentioned in the previous blog I based this tutorial on the Hypriot linux distribution for the ARM processor. Main reason is the bundled support for Docker. I used this version of Hypriot for this tutorial, so if you run into trouble with other versions of Hypriot, please consider the version I’ve used.
First step is to make sure every Pi has Hypriot running, if not yet please check the getting started guide of them. Also hook up the cluster switch to a network so that Internet is available and every Pi get an IP-address assigned via DHCP. Because we will be running multiple Pi’s it is practical to give each Pi a unique hostname. I renamed my Pi’s to rpi-master, rpi-node-1, rpi-node-2, etc for my convenience. Note that on Hypriot the hostname is set by editing the /boot/occidentalis.txt file, not the /etc/hostname. You could also set the hostname using the Hypriot flash tool.
The most important thing about running software on a Pi is the availability of an ARM distribution. Thanks to Brendan Burns, there are Kubernetes components for ARM available in the Google Cloud Registry. That’s great. The second hurdle is how to install Kubernetes. There are two ways; directly on the system or in a Docker container. Although the container support has an experimental status, I choose to go for that because it makes it easier to install Kubernetes for you. Kubernetes requires several processes (etcd, flannel, kubectl, etc) to run on a node, which should be started in a specific order. To ease that, systemd services are made available to start the necessary processes in the right way. Also the systemd services make sure that Kubernetes is spun up when a node is (re)booted. To make the installation real easy I created an simple install script for the master node and the worker nodes. All is available at GitHub. So let’s get started now!
Installing the Kubernetes master node
First we will be installing Kubernetes on the master node and add the worker nodes later to the cluster. It comes basically down to getting the git repository content and executing the installation script.
$ curl -L -o k8s-on-rpi.zip https://github.com/awassink/k8s-on-rpi/archive/master.zip
$ apt-get update
$ apt-get install unzip
$ unzip k8s-on-rpi.zip
$ k8s-on-rpi-master/install-k8s-master.sh
The install script will install five services:
- docker-bootstrap.service - is a separate Docker daemon to run etcd and flannel because flannel needs to be running before the standard Docker daemon (docker.service) because of network configuration.
- k8s-etcd.service - is the etcd service for storing flannel and kubelet data.
- k8s-flannel.service - is the flannel process providing an overlay network over all nodes in the cluster.
- docker.service - is the standard Docker daemon, but with flannel as a network bridge. It will run all Docker containers.
- k8s-master.service - is the kubernetes master service providing the cluster functionality.
The basic details of this installation procedure is also documented in the Getting Started Guide of Kubernetes. Please check it to get more insight on how a multi node Kubernetes cluster is setup.
Let’s check if everything is working correctly. Two docker daemon processes must be running.
$ ps -ef|grep docker
root 302 1 0 04:37 ? 00:00:14 /usr/bin/docker daemon -H unix:///var/run/docker-bootstrap.sock -p /var/run/docker-bootstrap.pid --storage-driver=overlay --storage-opt dm.basesize=10G --iptables=false --ip-masq=false --bridge=none --graph=/var/lib/docker-bootstrap
root 722 1 11 04:38 ? 00:16:11 /usr/bin/docker -d -bip=10.0.97.1/24 -mtu=1472 -H fd:// --storage-driver=overlay -D
The etcd and flannel containers must be up.
$ docker -H unix:///var/run/docker-bootstrap.sock ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4855cc1450ff andrewpsuedonym/flanneld "flanneld --etcd-endp" 2 hours ago Up 2 hours k8s-flannel
ef410b986cb3 andrewpsuedonym/etcd:2.1.1 "/bin/etcd --addr=127" 2 hours ago Up 2 hours k8s-etcd
The hyperkube kubelet, apiserver, scheduler, controller and proxy must be up.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a17784253dd2 gcr.io/google\_containers/hyperkube-arm:v1.1.2 "/hyperkube controller" 2 hours ago Up 2 hours k8s\_controller-manager.7042038a\_k8s-master-127.0.0.1\_default\_43160049df5e3b1c5ec7bcf23d4b97d0\_2174a7c3
a0fb6a169094 gcr.io/google\_containers/hyperkube-arm:v1.1.2 "/hyperkube scheduler" 2 hours ago Up 2 hours k8s\_scheduler.d905fc61\_k8s-master-127.0.0.1\_default\_43160049df5e3b1c5ec7bcf23d4b97d0\_511945f8
d93a94a66d33 gcr.io/google\_containers/hyperkube-arm:v1.1.2 "/hyperkube apiserver" 2 hours ago Up 2 hours k8s\_apiserver.f4ad1bfa\_k8s-master-127.0.0.1\_default\_43160049df5e3b1c5ec7bcf23d4b97d0\_b5b4936d
db034473b334 gcr.io/google\_containers/hyperkube-arm:v1.1.2 "/hyperkube kubelet -" 2 hours ago Up 2 hours k8s-master
f017f405ff4b gcr.io/google\_containers/hyperkube-arm:v1.1.2 "/hyperkube proxy --m" 2 hours ago Up 2 hours k8s-master-proxy
Deploying the first pod and service on the cluster
When that’s looking good we’re able to access the master node of the Kubernetes cluster with kubectl. Kubectl for ARM can be downloaded from googleapis storage. kubectl get nodes shows which cluster nodes are registered with its status. The master node is named 127.0.0.1.
$ curl -fsSL -o /usr/bin/kubectl https://storage.googleapis.com/kubernetes-release/release/v1.1.2/bin/linux/arm/kubectl
$ kubectl get nodes
NAME LABELS STATUS AGE
127.0.0.1 kubernetes.io/hostname=127.0.0.1 Ready 1h
An easy way to test the cluster is by running a busybox docker image for ARM. kubectl run can be used to run the image as a container in a pod. kubectl get pods shows the pods that are registered with its status.
$ kubectl run busybox --image=hypriot/rpi-busybox-httpd
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE NODE
busybox-fry54 1/1 Running 1 1h 127.0.0.1
k8s-master-127.0.0.1 3/3 Running 6 1h 127.0.0.1
Now the pod is running but the application is not generally accessible. That can be achieved by creating a service. The cluster IP-address is the IP-address the service is avalailable within the cluster. Use the IP-address of your master node as external IP and the service becomes available outside of the cluster (e.g. at http://192.168.192.161 in my case).
$ kubectl expose rc busybox --port=90 --target-port=80 --external-ip=\<ip-address-master-node\>
$ kubectl get svc
NAME CLUSTER\_IP EXTERNAL\_IP PORT(S) SELECTOR AGE
busybox 10.0.0.87 192.168.192.161 90/TCP run=busybox 1h
kubernetes 10.0.0.1 \<none\> 443/TCP \<none\> 2h
$ curl http://10.0.0.87:90/
\<html\>
\<head\>\<title\>Pi armed with Docker by Hypriot\</title\>
\<body style="width: 100%; background-color: black;"\>
\<div id="main" style="margin: 100px auto 0 auto; width: 800px;"\>
\<img src="pi\_armed\_with\_docker.jpg" alt="pi armed with docker" style="width: 800px"\>
\</div\>
\</body\>
\</html\>
Installing the Kubernetes worker nodes
The next step is installing Kubernetes on each worker node and add it to the cluster. This also comes basically down to getting the git repository content and executing the installation script. Though in this installation the k8s.conf file needs to be copied on forehand and edited to contain the IP-address of the master node.
$ curl -L -o k8s-on-rpi.zip https://github.com/awassink/k8s-on-rpi/archive/master.zip
$ apt-get update
$ apt-get install unzip
$ unzip k8s-on-rpi.zip
$ mkdir /etc/kubernetes
$ cp k8s-on-rpi-master/rootfs/etc/kubernetes/k8s.conf /etc/kubernetes/k8s.conf
Change the ip-address in /etc/kubernetes/k8s.conf to match the master node
$ k8s-on-rpi-master/install-k8s-worker.sh
The install script will install four services. These are the quite similar to ones on the master node, but with the difference that no etcd service is running and the kubelet service is configured as worker node.
Once all the services on the worker node are up and running we can check that the node is added to the cluster on the master node.
$ kubectl get nodes
NAME LABELS STATUS AGE
127.0.0.1 kubernetes.io/hostname=127.0.0.1 Ready 2h
192.168.192.160 kubernetes.io/hostname=192.168.192.160 Ready 1h
$ kubectl scale --replicas=2 rc/busybox
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE NODE
busybox-fry54 1/1 Running 1 1h 127.0.0.1
busybox-j2slu 1/1 Running 0 1h 192.168.192.160
k8s-master-127.0.0.1 3/3 Running 6 2h 127.0.0.1
Enjoy your Kubernetes cluster!
Congratulations! You now have your Kubernetes Raspberry Pi cluster running and can start playing with Kubernetes and start learning. Checkout the Kubernetes User Guide to find out what you all can do. And don’t forget to pull some plugs occasionally like Ray and I do :-)
Arjen Wassink, Java Architect and Team Lead, Quintor
Managing Kubernetes Pods, Services and Replication Controllers with Puppet
Today’s guest post is written by Gareth Rushgrove, Senior Software Engineer at Puppet Labs, a leader in IT automation. Gareth tells us about a new Puppet module that helps manage resources in Kubernetes.
People familiar with Puppet might have used it for managing files, packages and users on host computers. But Puppet is first and foremost a configuration management tool, and config management is a much broader discipline than just managing host-level resources. A good definition of configuration management is that it aims to solve four related problems: identification, control, status accounting and verification and audit. These problems exist in the operation of any complex system, and with the new Puppet Kubernetes module we’re starting to look at how we can solve those problems for Kubernetes.
The Puppet Kubernetes Module
The Puppet Kubernetes module currently assumes you already have a Kubernetes cluster up and running;Its focus is on managing the resources in Kubernetes, like Pods, Replication Controllers and Services, not (yet) on managing the underlying kubelet or etcd services. Here’s a quick snippet of code describing a Pod in Puppet’s DSL.
kubernetes_pod { 'sample-pod':
ensure => present,
metadata => {
namespace => 'default',
},
spec => {
containers => [{
name => 'container-name',
image => 'nginx',
}]
},
}
If you’re familiar with the YAML file format, you’ll probably recognise the structure immediately. The interface is intentionally identical to aid conversion between different formats — in fact, the code powering this is autogenerated from the Kubernetes API Swagger definitions. Running the above code, assuming we save it as pod.pp, is as simple as:
puppet apply pod.pp
Authentication uses the standard kubectl configuration file. You can find complete installation instructions in the module's README.
Kubernetes has several resources, from Pods and Services to Replication Controllers and Service Accounts. You can see an example of the module managing these resources in the Kubernetes guestbook sample in Puppet post. This demonstrates converting the canonical hello-world example to use Puppet code.
One of the main advantages of using Puppet for this, however, is that you can create your own higher-level and more business-specific interfaces to Kubernetes-managed applications. For instance, for the guestbook, you could create something like the following:
guestbook { 'myguestbook':
redis_slave_replicas => 2,
frontend_replicas => 3,
redis_master_image => 'redis',
redis_slave_image => 'gcr.io/google_samples/gb-redisslave:v1',
frontend_image => 'gcr.io/google_samples/gb-frontend:v3',
}
You can read more about using Puppet’s defined types, and see lots more code examples, in the Puppet blog post, Building Your Own Abstractions for Kubernetes in Puppet.
Conclusions
The advantages of using Puppet rather than just the standard YAML files and kubectl are:
- The ability to create your own abstractions to cut down on repetition and craft higher-level user interfaces, like the guestbook example above.
- Use of Puppet’s development tools for validating code and for writing unit tests.
- Integration with other tools such as Puppet Server, for ensuring that your model in code matches the state of your cluster, and with PuppetDB for storing reports and tracking changes.
- The ability to run the same code repeatedly against the Kubernetes API, to detect any changes or remediate configuration drift.
It’s also worth noting that most large organisations will have very heterogenous environments, running a wide range of software and operating systems. Having a single toolchain that unifies those discrete systems can make adopting new technology like Kubernetes much easier.
It’s safe to say that Kubernetes provides an excellent set of primitives on which to build cloud-native systems. And with Puppet, you can address some of the operational and configuration management issues that come with running any complex system in production. Let us know what you think if you try the module out, and what else you’d like to see supported in the future.
- Gareth Rushgrove, Senior Software Engineer, Puppet Labs
How Weave built a multi-deployment solution for Scope using Kubernetes
Today we hear from Peter Bourgon, Software Engineer at Weaveworks, a company that provides software for developers to network, monitor and control microservices-based apps in docker containers. Peter tells us what was involved in selecting and deploying Kubernetes
Earlier this year at Weaveworks we launched Weave Scope, an open source solution for visualization and monitoring of containerised apps and services. Recently we released a hosted Scope service into an Early Access Program. Today, we want to walk you through how we initially prototyped that service, and how we ultimately chose and deployed Kubernetes as our platform.
A cloud-native architecture
Scope already had a clean internal line of demarcation between data collection and user interaction, so it was straightforward to split the application on that line, distribute probes to customers, and host frontends in the cloud. We built out a small set of microservices in the 12-factor model, which includes:
- A users service, to manage and authenticate user accounts
- A provisioning service, to manage the lifecycle of customer Scope instances
- A UI service, hosting all of the fancy HTML and JavaScript content
- A frontend service, to route requests according to their properties
- A monitoring service, to introspect the rest of the system
All services are built as Docker images, FROM scratch where possible. We knew that we wanted to offer at least 3 deployment environments, which should be as near to identical as possible.
- An "Airplane Mode" local environment, on each developer's laptop
- A development or staging environment, on the same infrastructure that hosts production, with different user credentials
- The production environment itself
These were our application invariants. Next, we had to choose our platform and deployment model.
Our first prototype
There are a seemingly infinite set of choices, with an infinite set of possible combinations. After surveying the landscape in mid-2015, we decided to make a prototype with
- Amazon EC2 as our cloud platform, including RDS for persistence
- Docker Swarm as our "scheduler"
- Consul for service discovery when bootstrapping Swarm
- Weave Net for our network and service discovery for the application itself
- Terraform as our provisioner
This setup was fast to define and fast to deploy, so it was a great way to validate the feasibility of our ideas. But we quickly hit problems.
- Terraform's support for Docker as a provisioner is barebones, and we uncovered some bugs when trying to use it to drive Swarm.
- Largely as a consequence of the above, managing a zero-downtime deploy of Docker containers with Terraform was very difficult.
- Swarm's raison d'être is to abstract the particulars of multi-node container scheduling behind the familiar Docker CLI/API commands. But we concluded that the API is insufficiently expressive for the kind of operations that are necessary at scale in production.
- Swarm provides no fault tolerance in the case of e.g. node failure.
We also made a number of mistakes when designing our workflow.
- We tagged each container with its target environment at build time, which simplified our Terraform definitions, but effectively forced us to manage our versions via image repositories. That responsibility belongs in the scheduler, not the artifact store.
- As a consequence, every deploy required artifacts to be pushed to all hosts. This made deploys slow, and rollbacks unbearable.
- Terraform is designed to provision infrastructure, not cloud applications. The process is slower and more deliberate than we’d like. Shipping a new version of something to prod took about 30 minutes, all-in.
When it became clear that the service had potential, we re-evaluated the deployment model with an eye towards the long-term.
Rebasing on Kubernetes
It had only been a couple of months, but a lot had changed in the landscape.
- HashiCorp released Nomad
- Kubernetes hit 1.0
- Swarm was soon to hit 1.0
While many of our problems could be fixed without making fundamental architectural changes, we wanted to capitalize on the advances in the industry, by joining an existing ecosystem, and leveraging the experience and hard work of its contributors.
After some internal deliberation, we did a small-scale audition of Nomad and Kubernetes. We liked Nomad a lot, but felt it was just too early to trust it with our production service. Also, we found the Kubernetes developers to be the most responsive to issues on GitHub. So, we decided to go with Kubernetes.
Local Kubernetes
First, we would replicate our Airplane Mode local environment with Kubernetes. Because we have developers on both Mac and Linux laptops, it’s important that the local environment is containerised. So, we wanted the Kubernetes components themselves (kubelet, API server, etc.) to run in containers.
We encountered two main problems. First, and most broadly, creating Kubernetes clusters from scratch is difficult, as it requires deep knowledge of how Kubernetes works, and quite some time to get the pieces to fall in place together. local-cluster-up.sh seems like a Kubernetes developer’s tool and didn’t leverage containers, and the third-party solutions we found, like Kubernetes Solo, require a dedicated VM or are platform-specific.
Second, containerised Kubernetes is still missing several important pieces. Following the official Kubernetes Docker guide yields a barebones cluster without certificates or service discovery. We also encountered a couple of usability issues (#16586, #17157), which we resolved by submitting a patch and building our own hyperkube image from master.
In the end, we got things working by creating our own provisioning script. It needs to do things like generate the PKI keys and certificates and provision the DNS add-on, which took a few attempts to get right. We’ve also learned of a commit to add certificate generation to the Docker build, so things will likely get easier in the near term.
Kubernetes on AWS
Next, we would deploy Kubernetes to AWS, and wire it up with the other AWS components. We wanted to stand up the service in production quickly, and we only needed to support Amazon, so we decided to do so without Weave Net and to use a pre-existing provisioning solution. But we’ll definitely revisit this decision in the near future, leveraging Weave Net via Kubernetes plugins.
Ideally we would have used Terraform resources, and we found a couple: kraken (using Ansible), kubestack (coupled to GCE), kubernetes-coreos-terraform (outdated Kubernetes) and coreos-kubernetes. But they all build on CoreOS, which was an extra moving part we wanted to avoid in the beginning. (On our next iteration, we’ll probably audition CoreOS.) If you use Ansible, there are playbooks available in the main repo. There are also community-drive Chef cookbooks and Puppet modules. I’d expect the community to grow quickly here.
The only other viable option seemed to be kube-up, which is a collection of scripts that provision Kubernetes onto a variety of cloud providers. By default, kube-up onto AWS puts the master and minion nodes into their own VPC, or Virtual Private Cloud. But our RDS instances were provisioned in the region-default VPC, which meant that communication from a Kubernetes minion to the DB would be possible only via VPC peering or by opening the RDS VPC's firewall rules manually.
To get traffic to traverse a VPC peer link, your destination IP needs to be in the target VPC's private address range. But it turns out that resolving the RDS instance's hostname from anywhere outside the same VPC will yield the public IP. And performing the resolution is important, because RDS reserves the right to change the IP for maintenance. This wasn't ever a concern in the previous infrastructure, because our Terraform scripts simply placed everything in the same VPC. So I thought I'd try the same with Kubernetes; the kube-up script ostensibly supports installing to an existing VPC by specifying a VPC_ID environment variable, so I tried installing Kubernetes to the RDS VPC. kube-up appeared to succeed, but service integration via ELBs broke andteardown via kube-down stopped working. After some time, we judged it best to let kube-up keep its defaults, and poked a hole in the RDS VPC.
This was one hiccup among several that we encountered. Each one could be fixed in isolation, but the inherent fragility of using a shell script to provision remote state seemed to be the actual underlying cause. We fully expect the Terraform, Ansible, Chef, Puppet, etc. packages to continue to mature, and hope to switch soon.
Provisioning aside, there are great things about the Kubernetes/AWS integration. For example, Kubernetes services of the correct type automatically generate ELBs, and Kubernetes does a great job of lifecycle management there. Further, the Kubernetes domain model—services, pods, replication controllers, the labels and selector model, and so on—is coherent, and seems to give the user the right amount of expressivity, though the definition files do tend to stutter needlessly. The kubectl tool is good, albeit daunting at first glance. The rolling-update command in particular is brilliant: exactly the semantics and behavior I'd expect from a system like this. Indeed, once Kubernetes was up and running, it just worked, and exactly as I expected it to. That’s a huge thing.
Conclusions
After a couple weeks of fighting with the machines, we were able to resolve all of our integration issues, and have rolled out a reasonably robust Kubernetes-based system to production.
- Provisioning Kubernetes is difficult , owing to a complex architecture and young provisioning story. This shows all signs of improving.
- Kubernetes’ non-optional security model takes time to get right.
- The Kubernetes domain language is a great match to the problem domain.
- We have a lot more confidence in operating our application (It's a lot faster, too.).
- And we're very happy to be part of a growing Kubernetes userbase , contributing issues and patches as we can and benefitting from the virtuous cycle of open-source development that powers the most exciting software being written today. - Peter Bourgon, Software Engineer at Weaveworks
Weave Scope is an open source solution for visualization and monitoring of containerised apps and services. For a hosted Scope service, request an invite to Early Access program at scope.weave.works.
Creating a Raspberry Pi cluster running Kubernetes, the shopping list (Part 1)
At Devoxx Belgium and Devoxx Morocco, Ray Tsang and I showed a Raspberry Pi cluster we built at Quintor running HypriotOS, Docker and Kubernetes. For those who did not see the talks, you can check out an abbreviated version of the demo or the full talk by Ray on developing and deploying Java-based microservices in Kubernetes. While we received many compliments on the talk, the most common question was about how to build a Pi cluster themselves! We’ll be doing just that, in two parts. This first post will cover the shopping list for the cluster, and the second will show you how to get it up and running . . .
Wait! Why the heck build a Raspberry Pi cluster running Kubernetes?
We had two big reasons to build the Pi cluster at Quintor. First of all we wanted to experiment with container technology at scale on real hardware. You can try out container technology using virtual machines, but Kubernetes runs great on bare metal too. To explore what that’d be like, we built a Raspberry Pi cluster just like we would build a cluster of machines in a production datacenter. This allowed us to understand and simulate how Kubernetes would work when we move it to our data centers.
Secondly, we did not want to blow the budget to do this exploration. And what is cheaper than a Raspberry Pi! If you want to build a cluster comprising many nodes, each node should have a good cost to performance ratio. Our Pi cluster has 20 CPU cores, which is more than many servers, yet cost us less than $400. Additionally, the total power consumption is low and the form factor is small, which is great for these kind of demo systems.
So, without further ado, let’s get to the hardware.
The Shopping List:
| 5 | Raspberry Pi 2 model B | ~$200 |
| 5 | 16 GB micro SD-card class 10 | ~ $45 |
| 1 | D-Link Switch GO-SW-8E 8-Port | ~$15 |
| 1 | Anker 60W 6-Port PowerPort USB Charger (white) | ~$35 |
| 3 | ModMyPi Multi-Pi Stackable Raspberry Pi Case | ~$60 |
| 1 | ModMyPi Multi-Pi Stackable Raspberry Pi Case - Bolt Pack | ~$7 |
| 5 | Micro USB cable (white) 1ft long | ~ $10 |
| 5 | UTP cat5 cable (white) 1ft long | ~ $10 |
For a total of approximately $380 you will have a building set to create a Raspberry Pi cluster like we built! [1](#1)
Some of our considerations
We used the Raspberry Pi 2 model B boards in our cluster rather than the Pi 1 boards because of the CPU power (quadcore @ 900MHz over a dualcore @ 700MHz) and available memory (1 GB over 512MB). These specs allowed us to run multiple containers on each Pi to properly experiment with Kubernetes.
We opted for a 16GB SD-card in each Pi to be at the save side on filesystem storage. In hindsight, 8GB seemed to be enough.
Note the GeauxRobot Stackable Case looks like an alternative for the ModMyPi Stackable Case, but it’s smaller which can cause a problem fitting in the Anker USB Adapter and placing the D-Link Network Switch. So, we stuck with the ModMyPi case.
Putting it together
Building the Raspberry Pi cluster is pretty straight forward. Most of the work is putting the stackable casing together and mounting the Pi boards on the plexiglass panes. We mounted the network switch and USB Adapter using double side foam tape, which feels strong enough for most situations. Finally, we connected the USB and UTP cables. Next, we installed HypriotOS on every Pi. HypriotOS is a Raspbian based Linux OS for Raspberry Pi’s extended with Docker support. The Hypriot team has an excellent tutorial on Getting started with Docker on your Raspberry Pi. Follow this tutorial to get Linux and Docker running on all Pi’s.
With that, you’re all set! Next up will be running Kubernetes on the Raspberry Pi cluster. We’ll be covering this the next post, so stay tuned!
Arjen Wassink, Java Architect and Team Lead, Quintor
** ## [1] ## ** **[1] **To save ~$90 by making a stack of four Pi’s (instead of five). This also means you can use a 5-Port Anker USB Charger instead of the 6-Port one.
Monitoring Kubernetes with Sysdig
Today we’re sharing a guest post by Chris Crane from Sysdig about their monitoring integration into Kubernetes.
Kubernetes offers a full environment to write scalable and service-based applications. It takes care of things like container grouping, discovery, load balancing and healing so you don’t have to worry about them. The design is elegant, scalable and the APIs are a pleasure to use.
And like any new infrastructure platform, if you want to run Kubernetes in production, you’re going to want to be able to monitor and troubleshoot it. We’re big fans of Kubernetes here at Sysdig, and, well: we’re here to help.
Sysdig offers native visibility into Kubernetes across the full Sysdig product line. That includes sysdig, our open source, CLI system exploration tool, and Sysdig Cloud, the first and only monitoring platform designed from the ground up to support containers and microservices.
At a high level, Sysdig products are aware of the entire Kubernetes cluster hierarchy, including namespaces, services, replication controllers and labels. So all of the rich system and application data gathered is now available in the context of your Kubernetes infrastructure. What does this mean for you? In a nutshell, we believe Sysdig can be your go-to tool for making Kubernetes environments significantly easier to monitor and troubleshoot!
In this post I will quickly preview the Kubernetes visibility in both open source sysdig and Sysdig Cloud, and show off a couple interesting use cases. Let’s start with the open source solution.
Exploring a Kubernetes Cluster with csysdig
The easiest way to take advantage of sysdig’s Kubernetes support is by launching csysdig, the sysdig ncurses UI:
> csysdig -k http://127.0.0.1:8080
*Note: specify the address of your Kubernetes API server with the -k command, and sysdig will poll all the relevant information, leveraging both the standard and the watch API.
Now that csysdig is running, hit F2 to bring up the views panel, and you'll notice the presence of a bunch of new views. The k8s Namespaces view can be used to see the list of namespaces and observe the amount of CPU, memory, network and disk resources each of them is using on this machine:

Similarly, you can select k8s Services to see the same information broken up by service:

or k8s Controllers to see the replication controllers:

or k8s Pods to see the list of pods running on this machine and the resources they use:

Drill Down-Based Navigation
A cool feature in csysdig is the ability to drill down: just select an element, click on enter and – boom – now you're looking inside it. Drill down is also aware of the Kubernetes hierarchy, which means I can start from a service, get the list of its pods, see which containers run inside one of the pods, and go inside one of the containers to explore files, network connections, processes or even threads. Check out the video below.

Actions!
One more thing about csysdig. As recently announced, csysdig also offers “control panel” functionality, making it possible to use hotkeys to execute command lines based on the element currently selected. So we made sure to enrich the Kubernetes views with a bunch of useful hotkeys. For example, you can delete a namespace or a service by pressing "x," or you can describe them by pressing "d."
My favorite hotkeys, however, are "f," to follow the logs that a pod is generating, and "b," which leverages kubectl exec to give you a shell inside a pod. Being brought into a bash prompt for the pod you’re observing is really useful and, frankly, a bit magic. :-)
So that’s a quick preview of Kubernetes in sysdig. Note though, that all of this functionality is only for a single machine. What happens if you want to monitor a distributed Kubernetes cluster? Enter Sysdig Cloud.
Monitoring Kubernetes with Sysdig Cloud
Let’s start with a quick review of Kubernetes’ architecture. From the physical/infrastructure point of view, a Kubernetes cluster is made up of a set of minion machines overseen by a master machine. The master’s tasks include orchestrating containers across minions, keeping track of state and exposing cluster control through a REST API and a UI.
On the other hand, from the logical/application point of view, Kubernetes clusters are arranged in the hierarchical fashion shown in this picture:

- All containers run inside pods. A pod can host a single container, or multiple cooperating containers; in the latter case, the containers in the pod are guaranteed to be co-located on the same machine and can share resources.
- Pods typically sit behind services , which take care of balancing the traffic, and also expose the set of pods as a single discoverable IP address/port.
- Services are scaled horizontally by replication controllers (“RCs”) which create/destroy pods for each service as needed.
- Namespaces are virtual clusters that can include one or more services.
So just to be clear, multiple services and even multiple namespaces can be scattered across the same physical infrastructure.
After talking to hundreds of Kubernetes users, it seems that the typical cluster administrator is often interested in looking at things from the physical point of view, while service/application developers tend to be more interested in seeing things from the logical point of view.
With both these use cases in mind, Sysdig Cloud’s support for Kubernetes works like this:
- By automatically connecting to a Kubernetes’ cluster API Server and querying the API (both the regular and the watch API), Sysdig Cloud is able to infer both the physical and the logical structure of your microservice application.
- In addition, we transparently extract important metadata such as labels.
- This information is combined with our patent-pending ContainerVision technology, which makes it possible to inspect applications running inside containers without requiring any instrumentation of the container or application. Based on this, Sysdig Cloud can provide rich visibility and context from both an infrastructure-centric and an application-centric point of view. Best of both worlds! Let’s check out what this actually looks like.
One of the core features of Sysdig Cloud is groups, which allow you to define the hierarchy of metadata for your applications and infrastructure. By applying the proper groups, you can explore your containers based on their physical hierarchy (for example, physical cluster > minion machine > pod > container) or based on their logical microservice hierarchy (for example, namespace > replication controller > pod > container – as you can see in this example).
If you’re interested in the utilization of your underlying physical resource – e.g., identifying noisy neighbors – then the physical hierarchy is great. But if you’re looking to explore the performance of your applications and microservices, then the logical hierarchy is often the best place to start.

For example: here you can see the overall performance of our WordPress service:

Keep in mind that the pods implementing this service are scattered across multiple machines, but we can still total request counts, response times and URL statistics aggregated together for this service. And don’t forget: this doesn’t require any configuration or instrumentation of wordpress, apache, or the underlying containers!
And from this view, I can now easily create alerts for these service-level metrics, and I can dig down into any individual container for deep inspection - down to the process level – whenever I want, including back in time!
Visualizing Your Kubernetes Services
We’ve also included Kubernetes awareness in Sysdig Cloud’s famous topology view, at both the physical and logical level.


The two pictures below show the exact same infrastructure and services. But the first one depicts the physical hierarchy, with a master node and three minion nodes; while the second one groups containers into namespaces, services and pods, while abstracting the physical location of the containers.
Hopefully it’s self-evident how much more natural and intuitive the second (services-oriented) view is. The structure of the application and the various dependencies are immediately clear. The interactions between various microservices become obvious, despite the fact that these microservices are intermingled across our machine cluster!
Conclusion
I’m pretty confident that what we’re delivering here represents a huge leap in visibility into Kubernetes environments and it won’t disappoint you. I also hope it can be a useful tool enabling you to use Kubernetes in production with a little more peace of mind. Thanks, and happy digging!
Chris Crane, VP Product, Sysdig
You can find open source sysdig on github and at sysdig.org, and you can sign up for free trial of Sysdig Cloud at sysdig.com.
To see a live demo and meet some of the folks behind the project join us this Thursday for a Kubernetes and Sysdig Meetup in San Francisco.
One million requests per second: Dependable and dynamic distributed systems at scale
Recently, I’ve gotten in the habit of telling people that building a reliable service isn’t that hard. If you give me two Compute Engine virtual machines, a Cloud Load balancer, supervisord and nginx, I can create you a static web service that will serve a static web page, effectively forever.
The real challenge is building agile AND reliable services. In the new world of software development it's trivial to spin up enormous numbers of machines and push software to them. Developing a successful product must also include the ability to respond to changes in a predictable way, to handle upgrades elegantly and to minimize downtime for users. Missing on any one of these elements results in an unsuccessful product that's flaky and unreliable. I remember a time, not that long ago, when it was common for websites to be unavailable for an hour around midnight each day as a safety window for software upgrades. My bank still does this. It’s really not cool.
Fortunately, for developers, our infrastructure is evolving along with the requirements that we’re placing on it. Kubernetes has been designed from the ground up to make it easy to design, develop and deploy dependable, dynamic services that meet the demanding requirements of the cloud native world.
To demonstrate exactly what we mean by this, I've developed a simple demo of a Container Engine cluster serving 1 million HTTP requests per second. In all honesty, serving 1 million requests per second isn’t really that exciting. In fact, it’s really so very 2013.

What is exciting is that while successfully handling 1 million HTTP requests per second with uninterrupted availability, we have Kubernetes perform a zero-downtime rolling upgrade of the service to a new version of the software while we're still serving 1 million requests per second.

This is only possible due to a large number of performance tweaks and enhancements that have gone into the Kubernetes 1.1 release. I’m incredibly proud of all of the features that our community has built into this release. Indeed in addition to making it possible to serve 1 million requests per second, we’ve also added an auto-scaler, so that you won’t even have to wake up in the middle of the night to scale your service in response to load or memory pressures.
If you want to try this out on your own cluster (or use the load test framework to test your own service) the code for the demo is available on github. And the full video is available.
I hope I’ve shown you how Kubernetes can enable developers of distributed systems to achieve both reliability and agility at scale, and as always, if you’re interested in learning more, head over to kubernetes.io or github and connect with the community on our Slack channel.
"https://www.youtube.com/embed/7TOWLerX0Ps"
- Brendan Burns, Senior Staff Software Engineer, Google, Inc.
Kubernetes 1.1 Performance upgrades, improved tooling and a growing community
Since the Kubernetes 1.0 release in July, we’ve seen tremendous adoption by companies building distributed systems to manage their container clusters. We’re also been humbled by the rapid growth of the community who help make Kubernetes better everyday. We have seen commercial offerings such as Tectonic by CoreOS and RedHat Atomic Host emerge to deliver deployment and support of Kubernetes. And a growing ecosystem has added Kubernetes support including tool vendors such as Sysdig and Project Calico.
With the help of hundreds of contributors, we’re proud to announce the availability of Kubernetes 1.1, which offers major performance upgrades, improved tooling, and new features that make applications even easier to build and deploy.
Some of the work we’d like to highlight includes:
-
Substantial performance improvements : We have architected Kubernetes from day one to handle Google-scale workloads, and our customers have put it through their paces. In Kubernetes 1.1, we have made further investments to ensure that you can run in extremely high-scale environments; later this week, we will be sharing examples of running thousand node clusters, and running over a million QPS against a single cluster.
-
Significant improvement in network throughput : Running Google-scale workloads also requires Google-scale networking. In Kubernetes 1.1, we have included an option to use native IP tables offering an 80% reduction in tail latency, an almost complete elimination of CPU overhead and improvements in reliability and system architecture ensuring Kubernetes can handle high-scale throughput well into the future.
-
Horizontal pod autoscaling (Beta): Many workloads can go through spiky periods of utilization, resulting in uneven experiences for your users. Kubernetes now has support for horizontal pod autoscaling, meaning your pods can scale up and down based on CPU usage. Read more about Horizontal pod autoscaling.
-
HTTP load balancer (Beta): Kubernetes now has the built-in ability to route HTTP traffic based on the packets introspection. This means you can have ‘http://foo.com/bar’ go to one service, and ‘http://foo.com/meep’ go to a completely independent service. Read more about the Ingress object.
-
Job objects (Beta): We’ve also had frequent request for integrated batch jobs, such as processing a batch of images to create thumbnails or a particularly large data file that has been broken down into many chunks. Job objects introduces a new API object that runs a workload, restarts it if it fails, and keeps trying until it’s successfully completed. Read more about theJob object.
-
New features to shorten the test cycle for developers : We continue to work on making developing for applications for Kubernetes quick and easy. Two new features that speeds developer’s workflows include the ability to run containers interactively, and improved schema validation to let you know if there are any issues with your configuration files before you deploy them.
-
Rolling update improvements : Core to the DevOps movement is being able to release new updates without any affect on a running service. Rolling updates now ensure that updated pods are healthy before continuing the update.
-
And many more. For a complete list of updates, see the 1.1. release notes on GitHub
Today, we’re also proud to mark the inaugural Kubernetes conference, KubeCon, where some 400 community members along with dozens of vendors are in attendance supporting the Kubernetes project.
We’d love to highlight just a few of the many partners making Kubernetes better:
“We are betting our major product, Tectonic – which enables any company to deploy, manage and secure its containers anywhere – on Kubernetes because we believe it is the future of the data center. The release of Kubernetes 1.1 is another major milestone that will create more widespread adoption of distributed systems and containers, and puts us on a path that will inevitably lead to a whole new generation of products and services.” – Alex Polvi, CEO, CoreOS.
“Univa’s customers are looking for scalable, enterprise-caliber solutions to simplify managing container and non-container workloads in the enterprise. We selected Kubernetes as a foundational element of our new Navops suite which will help IT and DevOps rapidly integrate containerized workloads into their production systems and extend these workloads into cloud services.” – Gary Tyreman, CEO, Univa.
“The tremendous customer demand we’re seeing to run containers at scale with Kubernetes is a critical element driving growth in our professional services business at Redapt. As a trusted advisor, it’s great to have a tool like Kubernetes in our tool belt to help our customers achieve their objectives.” – Paul Welch, SR VP Cloud Solutions, Redapt
As we mentioned above, we would love your help:
- Get involved with the Kubernetes project on GitHub
- Connect with the community on Slack
- Follow us on Twitter @Kubernetesio for latest updates
- Post questions (or answer questions) on Stackoverflow
- Get started running, deploying, and using Kubernetes guides;
But, most of all, just let us know how you are transforming your business using Kubernetes, and how we can help you do it even faster. Thank you for your support!
- David Aronchick, Senior Product Manager for Kubernetes and Google Container Engine
Kubernetes as Foundation for Cloud Native PaaS
With Kubernetes continuing to gain momentum as a critical tool for building and scaling container based applications, we’ve been thrilled to see a growing number of platform as a service (PaaS) offerings adopt it as a foundation. PaaS developers have been drawn to Kubernetes by its rapid rate of maturation, the soundness of its core architectural concepts, and the strength of its contributor community. The Kubernetes ecosystem continues to grow, and these PaaS projects are great additions to it.

“Deis is the leading Docker PaaS with over a million downloads, actively used by companies like Mozilla, The RealReal, ShopKeep and Coinbase. Deis provides software teams with a turn-key platform for running containers in production, featuring the ability to build and store Docker images, production-grade load balancing, a streamlined developer interface and an ops-ready suite of logging and monitoring infrastructure backed by world-class 24x7x365 support. After a community-led evaluation of alternative orchestrators, it was clear that Kubernetes represents a decade of experience running containers at scale inside Google. The Deis project is proud to be rebasing onto Kubernetes and is thrilled to join its vibrant community." - Gabriel Monroy, CTO of Engine Yard, Inc.

OpenShift by Red Hat helps organizations accelerate application delivery by enabling development and IT operations teams to be more agile, responsive and efficient. OpenShift Enterprise 3 is the first fully supported, enterprise-ready, web-scale container application platform that natively integrates the Docker container runtime and packaging format, Kubernetes container orchestration and management engine, on a foundation of Red Hat Enterprise Linux 7, all fully supported by Red Hat from the operating system to application runtimes.
“Kubernetes provides OpenShift users with a powerful model for application orchestration, leveraging concepts like pods and services, to deploy (micro)services that inherently span multiple containers and application topologies that will require wiring together multiple services. Pods can be optionally mapped to storage, which means you can run both stateful and stateless services in OpenShift. Kubernetes also provides a powerful declarative management model to manage the lifecycle of application containers. Customers can then use Kubernetes’ integrated scheduler to deploy and manage containers across multiple hosts. As a leading contributor to both the Docker and Kubernetes open source projects, Red Hat is not just adopting these technologies but actively building them upstream in the community.” - Joe Fernandes, Director of Product Management for Red Hat OpenShift.

Huawei, a leading global ICT technology solution provider, will offer container as a service (CaaS) built on Kubernetes in the public cloud for customers with Docker based applications. Huawei CaaS services will manage multiple clusters across data centers, and deploy, monitor and scale containers with high availability and high resource utilization for their customers. For example, one of Huawei’s current software products for their telecom customers utilizes tens of thousands of modules and hundreds of instances in virtual machines. By moving to a container based PaaS platform powered by Kubernetes, Huawei is migrating this product into a micro-service based, cloud native architecture. By decoupling the modules, they’re creating a high performance, scalable solution that runs hundreds, even thousands of containers in the system. Decoupling existing heavy modules could have been a painful exercise. However, using several key concepts introduced by Kubernetes, such as pods, services, labels, and proxies, Huawei has been able to re-architect their software with great ease.
Huawei has made Kubernetes the core runtime engine for container based applications/services, and they’ve been building other PaaS components or capabilities around Kubernetes, such as user access management, composite API, Portal and multiple cluster management. Additionally, as part of the migration to the new platform, they’re enhancing their PaaS solution in the areas of advanced scheduling algorithm, multi tenant support and enhanced container network communication to support customer needs.
“Huawei chose Kubernetes as the foundation for our offering because we like the abstract concepts of services, pod and label for modeling and distributed applications. We developed an application model based on these concepts to model existing complex applications which works well for moving legacy applications into the cloud. In addition, Huawei intends for our PaaS platform to support many scenarios, and Kubernetes’ flexible architecture with its plug-in capability is key to our platform architecture.”- Ying Xiong, Chief Architect of PaaS at Huawei.

Gondoris a PaaS with a focus on application hosting throughout the lifecycle, from development to testing to staging to production. It supports Python, Go, and Node.js applications as well as technologies such as Postgres, Redis and Elasticsearch. The Gondor team recently re-architected Gondor to incorporate Kubernetes, and discussed this in a blog post.
“There are two main reasons for our move to Kubernetes: One, by taking care of the lower layers in a truly scalable fashion, Kubernetes lets us focus on providing a great product at the application layer. Two, the portability of Kubernetes allows us to expand our PaaS offering to on-premises, private cloud and a multitude of alternative infrastructure providers.” - Brian Rosner, Chief Architect at Eldarion (the driving force behind Gondor)
- Martin Buhr, Google Business Product Manager
Some things you didn’t know about kubectl
kubectl is the command line tool for interacting with Kubernetes clusters. Many people use it every day to deploy their container workloads into production clusters. But there’s more to kubectl than just kubectl create -f or kubectl rolling-update. kubectl is a veritable multi-tool of container orchestration and management. Below we describe some of the features of kubectl that you may not have seen.
Important Note : Most of these features are part of the upcoming 1.1 release of Kubernetes. They are not present in the current stable 1.0.x release series.
Run interactive commands
kubectl run has been in kubectl since the 1.0 release, but recently we added the ability to run interactive containers in your cluster. That means that an interactive shell in your Kubernetes cluster is as close as:
$> kubectl run -i --tty busybox --image=busybox --restart=Never -- sh
Waiting for pod default/busybox-tv9rm to be running, status is Pending, pod ready: false
Waiting for pod default/busybox-tv9rm to be running, status is Running, pod ready: false
$> # ls
bin dev etc home proc root sys tmp usr var
$> # exit
The above kubectl command is equivalent to docker run -i -t busybox sh. Sadly we mistakenly used -t for template in kubectl 1.0, so we need to retain backwards compatibility with existing CLI user. But the existing use of -t is deprecated and we’ll eventually shorten --tty to -t.
In this example, -i indicates that you want an allocated stdin for your container and indicates that you want an interactive session, --restart=Never indicates that the container shouldn’t be restarted after you exit the terminal and --tty requests that you allocate a TTY for that session.
View your Pod’s logs
Sometimes you just want to watch what’s going on in your server. For this, kubectl logs is the subcommand to use. Adding the -f flag lets you live stream new logs to your terminal, just like tail -f.
$> kubectl logs -f redis-izl09
Attach to existing containers
In addition to interactive execution of commands, you can now also attach to any running process. Like kubectl logs, you’ll get stderr and stdout data, but with attach, you’ll also be able to send stdin from your terminal to the program. Awesome for interactive debugging, or even just sending ctrl-c to a misbehaving application.
$> kubectl attach redis -i
1:C 12 Oct 23:05:11.848 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
_._
_.-``__''-._
_.-`` `. `_. ''-._ Redis 3.0.3 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 1
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
1:M 12 Oct 23:05:11.849 # Server started, Redis version 3.0.3
Forward ports from Pods to your local machine
Often times you want to be able to temporarily communicate with applications in your cluster without exposing them to the public internet for security reasons. To achieve this, the port-forward command allows you to securely forward a port on your local machine through the kubernetes API server to a Pod running in your cluster. For example:
$> kubectl port-forward redis-izl09 6379
Opens port 6379 on your local machine and forwards communication to that port to the Pod or Service in your cluster. For example, you can use the ‘telnet’ command to poke at a Redis service in your cluster:
$> telnet localhost 6379
INCR foo
:1
INCR foo
:2
Execute commands inside an existing container
In addition to being able to attach to existing processes inside a container, the “exec” command allows you to spawn new processes inside existing containers. This can be useful for debugging, or examining your pods to see what’s going on inside without interrupting a running service. kubectl exec is different from kubectl run, because it runs a command inside of an existing container, rather than spawning a new container for execution.
$> kubectl exec redis-izl09 -- ls /
bin
boot
data
dev
entrypoint.sh
etc
home
Add or remove Labels
Sometimes you want to dynamically add or remove labels from a Pod, Service or Replication controller. Maybe you want to add an existing Pod to a Service, or you want to remove a Pod from a Service. No matter what you want, you can easily and dynamically add or remove labels using the kubectl label subcommand:
$> kubectl label pods redis-izl09 mylabel=awesome
pod "redis-izl09" labeled
Add annotations to your objects
Just like labels, you can add or remove annotations from API objects using the kubectl annotate subcommand. Unlike labels, annotations are there to help describe your object, but aren’t used to identify pods via label queries (more details on annotations). For example, you might add an annotation of an icon for a GUI to use for displaying your pods.
$> kubectl annotate pods redis-izl09 icon-url=http://goo.gl/XXBTWq
pod "redis-izl09" annotated
Output custom format
Sometimes, you want to customize the fields displayed when kubectl summarizes an object from your cluster. To do this, you can use the custom-columns-file format. custom-columns-file takes in a template file for rendering the output. Again, JSONPath expressions are used in the template to specify fields in the API object. For example, the following template first shows the number of restarts, and then the name of the object:
$> cat cols.tmpl
RESTARTS NAME
.status.containerStatuses[0].restartCount .metadata.name
If you pass this template to the kubectl get pods command you get a list of pods with the specified fields displayed.
$> kubectl get pods redis-izl09 -o=custom-columns-file --template=cols.tmpl RESTARTS NAME
0 redis-izl09
1 redis-abl42
Easily manage multiple Kubernetes clusters
If you’re running multiple Kubernetes clusters, you know it can be tricky to manage all of the credentials for the different clusters. Using the kubectl config subcommands, switching between different clusters is as easy as:
$> kubectl config use-context
Not sure what clusters are available? You can view currently configured clusters with:
$> kubectl config view
Phew, that outputs a lot of text. To restrict it down to only the things we’re interested in, we can use a JSONPath template:
$> kubectl config view -o jsonpath="{.context[*].name}"
Ahh, that’s better.
Conclusion
So there you have it, nine new and exciting things you can do with your Kubernetes cluster and the kubectl command line. If you’re just getting started with Kubernetes, check out Google Container Engine or other ways to get started with Kubernetes.
- Brendan Burns, Google Software Engineer
Kubernetes Performance Measurements and Roadmap
No matter how flexible and reliable your container orchestration system is, ultimately, you have some work to be done, and you want it completed quickly. For big problems, a common answer is to just throw more machines at the problem. After all, more compute = faster, right?
Interestingly, adding more nodes is a little like the tyranny of the rocket equation - in some systems, adding more machines can actually make your processing slower. However, unlike the rocket equation, we can do better. Kubernetes in v1.0 version supports clusters with up to 100 nodes. However, we have a goal to 10x the number of nodes we will support by the end of 2015. This blog post will cover where we are and how we intend to achieve the next level of performance.
What do we measure?
The first question we need to answer is: “what does it mean that Kubernetes can manage an N-node cluster?” Users expect that it will handle all operations “reasonably quickly,” but we need a precise definition of that. We decided to define performance and scalability goals based on the following two metrics:
-
1.“API-responsiveness”: 99% of all our API calls return in less than 1 second
-
2.“Pod startup time”: 99% of pods (with pre-pulled images) start within 5 seconds
Note that for “pod startup time” we explicitly assume that all images necessary to run a pod are already pre-pulled on the machine where it will be running. In our experiments, there is a high degree of variability (network throughput, size of image, etc) between images, and these variations have little to do with Kubernetes’ overall performance.
The decision to choose those metrics was made based on our experience spinning up 2 billion containers a week at Google. We explicitly want to measure the latency of user-facing flows since that’s what customers will actually care about.
How do we measure?
To monitor performance improvements and detect regressions we set up a continuous testing infrastructure. Every 2-3 hours we create a 100-node cluster from HEAD and run our scalability tests on it. We use a GCE n1-standard-4 (4 cores, 15GB of RAM) machine as a master and n1-standard-1 (1 core, 3.75GB of RAM) machines for nodes.
In scalability tests, we explicitly focus only on the full-cluster case (full N-node cluster is a cluster with 30 * N pods running in it) which is the most demanding scenario from a performance point of view. To reproduce what a customer might actually do, we run through the following steps:
-
Populate pods and replication controllers to fill the cluster
-
Generate some load (create/delete additional pods and/or replication controllers, scale the existing ones, etc.) and record performance metrics
-
Stop all running pods and replication controllers
-
Scrape the metrics and check whether they match our expectations
It is worth emphasizing that the main parts of the test are done on full clusters (30 pods per node, 100 nodes) - starting a pod in an empty cluster, even if it has 100 nodes will be much faster.
To measure pod startup latency we are using very simple pods with just a single container running the “gcr.io/google_containers/pause:go” image, which starts and then sleeps forever. The container is guaranteed to be already pre-pulled on nodes (we use it as the so-called pod-infra-container).
Performance data
The following table contains percentiles (50th, 90th and 99th) of pod startup time in 100-node clusters which are 10%, 25%, 50% and 100% full.
| 10%-full | 25%-full | 50%-full | 100%-full | |
|---|---|---|---|---|
| 50th percentile | .90s | 1.08s | 1.33s | 1.94s |
| 90th percentile | 1.29s | 1.49s | 1.72s | 2.50s |
| 99th percentile | 1.59s | 1.86s | 2.56s | 4.32s |
As for api-responsiveness, the following graphs present 50th, 90th and 99th percentiles of latencies of API calls grouped by kind of operation and resource type. However, note that this also includes internal system API calls, not just those issued by users (in this case issued by the test itself).





Some resources only appear on certain graphs, based on what was running during that operation (e.g. no namespace was put at that time).
As you can see in the results, we are ahead of target for our 100-node cluster with pod startup time even in a fully-packed cluster occurring 14% faster in the 99th percentile than 5 seconds. It’s interesting to point out that LISTing pods is significantly slower than any other operation. This makes sense: in a full cluster there are 3000 pods and each of pod is roughly few kilobytes of data, meaning megabytes of data that need to processed for each LIST.
#####Work done and some future plans
The initial performance work to make 100-node clusters stable enough to run any tests on them involved a lot of small fixes and tuning, including increasing the limit for file descriptors in the apiserver and reusing tcp connections between different requests to etcd.
However, building a stable performance test was just step one to increasing the number of nodes our cluster supports by tenfold. As a result of this work, we have already taken on significant effort to remove future bottlenecks, including:
-
Rewriting controllers to be watch-based: Previously they were relisting objects of a given type every few seconds, which generated a huge load on the apiserver.
-
Using code generators to produce conversions and deep-copy functions: Although the default implementation using Go reflections are very convenient, they proved to be extremely slow, as much as 10X in comparison to the generated code.
-
Adding a cache to apiserver to avoid deserialization of the same data read from etcd multiple times
-
Reducing frequency of updating statuses: Given the slow changing nature of statutes, it only makes sense to update pod status only on change and node status only every 10 seconds.
-
Implemented watch at the apiserver instead of redirecting the requests to etcd: We would prefer to avoid watching for the same data from etcd multiple times, since, in many cases, it was filtered out in apiserver anyway.
Looking further out to our 1000-node cluster goal, proposed improvements include:
-
Moving events out from etcd: They are more like system logs and are neither part of system state nor are crucial for Kubernetes to work correctly.
-
Using better json parsers: The default parser implemented in Go is very slow as it is based on reflection.
-
Rewriting the scheduler to make it more efficient and concurrent
-
Improving efficiency of communication between apiserver and Kubelets: In particular, we plan to reduce the size of data being sent on every update of node status.
This is by no means an exhaustive list. We will be adding new elements (or removing existing ones) based on the observed bottlenecks while running the existing scalability tests and newly-created ones. If there are particular use cases or scenarios that you’d like to see us address, please join in!
- We have weekly meetings for our Kubernetes Scale Special Interest Group on Thursdays 11am PST where we discuss ongoing issues and plans for performance tracking and improvements.
- If you have specific performance or scalability questions before then, please join our scalability special interest group on Slack: https://kubernetes.slack.com/messages/sig-scale
- General questions? Feel free to join our Kubernetes community on Slack: https://kubernetes.slack.com/messages/kubernetes-users/
- Submit a pull request or file an issue! You can do this in our GitHub repository. Everyone is also enthusiastically encouraged to contribute with their own experiments (and their result) or PR contributions improving Kubernetes. - Wojciech Tyczynski, Google Software Engineer
Using Kubernetes Namespaces to Manage Environments
One of the advantages that Kubernetes provides is the ability to manage various environments easier and better than traditional deployment strategies. For most nontrivial applications, you have test, staging, and production environments. You can spin up a separate cluster of resources, such as VMs, with the same configuration in staging and production, but that can be costly and managing the differences between the environments can be difficult.
Kubernetes includes a cool feature called [namespaces][4], which enable you to manage different environments within the same cluster. For example, you can have different test and staging environments in the same cluster of machines, potentially saving resources. You can also run different types of server, batch, or other jobs in the same cluster without worrying about them affecting each other.
The Default Namespace
Specifying the namespace is optional in Kubernetes because by default Kubernetes uses the "default" namespace. If you've just created a cluster, you can check that the default namespace exists using this command:
$ kubectl get namespaces
NAME LABELS STATUS
default Active
kube-system Active
Here you can see that the default namespace exists and is active. The status of the namespace is used later when turning down and deleting the namespace.
Creating a New Namespace
You create a namespace in the same way you would any other resource. Create a my-namespace.yaml file and add these contents:
kind: Namespace
apiVersion: v1
metadata:
name: my-namespace
labels:
name: my-namespace
Then you can run this command to create it:
$ kubectl create -f my-namespace.yaml
Service Names
With namespaces you can have your apps point to static service endpoints that don't change based on the environment. For instance, your MySQL database service could be named mysql in production and staging even though it runs on the same infrastructure.
This works because each of the resources in the cluster will by default only "see" the other resources in the same namespace. This means that you can avoid naming collisions by creating pods, services, and replication controllers with the same names provided they are in separate namespaces. Within a namespace, short DNS names of services resolve to the IP of the service within that namespace. So for example, you might have an Elasticsearch service that can be accessed via the DNS name elasticsearch as long as the containers accessing it are located in the same namespace.
You can still access services in other namespaces by looking it up via the full DNS name which takes the form of SERVICE-NAME.NAMESPACE-NAME. So for example, elasticsearch.prod or elasticsearch.canary for the production and canary environments respectively.
An Example
Lets look at an example application. Let’s say you want to deploy your music store service MyTunes in Kubernetes. You can run the application production and staging environment as well as some one-off apps running in the same cluster. You can get a better idea of what’s going on by running some commands:
~$ kubectl get namespaces
NAME LABELS STATUS
default Active
mytunes-prod Active
mytunes-staging Active
my-other-app Active
Here you can see a few namespaces running. Next let’s list the services in staging:
~$ kubectl get services --namespace=mytunes-staging
NAME LABELS SELECTOR IP(S) PORT(S)
mytunes name=mytunes,version=1 name=mytunes 10.43.250.14 80/TCP
104.185.824.125
mysql name=mysql name=mysql 10.43.250.63 3306/TCP
Next check production:
~$ kubectl get services --namespace=mytunes-prod
NAME LABELS SELECTOR IP(S) PORT(S)
mytunes name=mytunes,version=1 name=mytunes 10.43.241.145 80/TCP
104.199.132.213
mysql name=mysql name=mysql 10.43.245.77 3306/TCP
Notice that the IP addresses are different depending on which namespace is used even though the names of the services themselves are the same. This capability makes configuring your app extremely easy—since you only have to point your app at the service name—and has the potential to allow you to configure your app exactly the same in your staging or test environments as you do in production.
Caveats
While you can run staging and production environments in the same cluster and save resources and money by doing so, you will need to be careful to set up resource limits so that your staging environment doesn't starve production for CPU, memory, or disk resources. Setting resource limits properly, and testing that they are working takes a lot of time and effort so unless you can measurably save money by running production in the same cluster as staging or test, you may not really want to do that.
Whether or not you run staging and production in the same cluster, namespaces are a great way to partition different apps within the same cluster. Namespaces will also serve as a level where you can apply resource limits so look for more resource management features at the namespace level in the future.
- Posted by Ian Lewis, Developer Advocate at Google
Weekly Kubernetes Community Hangout Notes - July 31 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Here are the notes from today's meeting:
-
Private Registry Demo - Muhammed
-
Run docker-registry as an RC/Pod/Service
-
Run a proxy on every node
-
Access as localhost:5000
-
Discussion:
-
Should we back it by GCS or S3 when possible?
-
Run real registry backed by $object_store on each node
-
DNS instead of localhost?
-
disassemble image strings?
-
more like DNS policy?
-
-
-
-
Running Large Clusters - Joe
-
Samsung keen to see large scale O(1000)
- Starting on AWS
-
RH also interested - test plan needed
-
Plan for next week: discuss working-groups
-
If you are interested in joining conversation on cluster scalability send mail to [joe@0xBEDA.com][4]
-
-
Resource API Proposal - Clayton
-
New stuff wants more info on resources
-
Proposal for resources API - ask apiserver for info on pods
-
Send feedback to: #11951
-
Discussion on snapshot vs time-series vs aggregates
-
-
Containerized kubelet - Clayton
-
Open pull
-
Docker mount propagation - RH carries patches
-
Big issues around whole bootstrap of the system
- dual: boot-docker/system-docker
-
Kube-in-docker is really nice, but maybe not critical
-
Do the small stuff to make progress
-
Keep pressure on docker
-
-
-
Web UI (preilly)
-
Where does web UI stand?
-
OK to split it back out
-
Use it as a container image
-
Build image as part of kube release process
-
Vendor it back in? Maybe, maybe not.
-
-
Will DNS be split out?
- Probably more tightly integrated, instead
-
Other potential spin-outs:
-
apiserver
-
clients
-
-
The Growing Kubernetes Ecosystem
Over the past year, we’ve seen fantastic momentum in the Kubernetes project, culminating with the release of Kubernetes v1 earlier this week. We’ve also witnessed the ecosystem around Kubernetes blossom, and wanted to draw attention to some of the cooler offerings we’ve seen.
| ----- | |

|
CloudBees and the Jenkins community have created a Kubernetes plugin, allowing Jenkins slaves to be built as Docker images and run in Docker hosts managed by Kubernetes, either on the Google Cloud Platform or on a more local Kubernetes instance. These elastic slaves are then brought online as Jenkins schedules jobs for them and destroyed after their builds are complete, ensuring masters have steady access to clean workspaces and minimizing builds’ resource footprint.
|
|

|
CoreOS has created launched Tectonic, an opinionated enterprise distribution of Kubernetes, CoreOS and Docker. Tectonic includes a management console for workflows and dashboards, an integrated registry to build and share containers, and additional tools to automate deployment and customize rolling updates. At KuberCon, CoreOS launched Tectonic Preview, giving users easy access to Kubernetes 1.0, 24x7 enterprise ready support, Kubernetes guides and Kubernetes training to help enterprises begin experiencing the power of Kubernetes, CoreOS and Docker.
|
|

|
Hitachi Data Systems has announced that Kubernetes now joins the list of solutions validated to run on their enterprise Unified Computing Platform. With this announcement Hitachi has validated Kubernetes and VMware running side-by-side on the UCP platform, providing an enterprise solution for container-based applications and traditional virtualized workloads.
|
|

|
Kismatic is providing enterprise support for pure play open source Kubernetes. They have announced open source and commercially supported Kubernetes plug-ins specifically built for production-grade enterprise environments. Any Kubernetes deployment can now benefit from modular role-based access controls (RBAC), Kerberos for bedrock authentication, LDAP/AD integration, rich auditing and platform-agnostic Linux distro packages.
|
|

|
Meteor Development Group, creators of Meteor, a JavaScript App Platform, are using Kubernetes to build Galaxy to run Meteor apps in production. Galaxy will scale from free test apps to production-suitable high-availability hosting.
|
|

|
Mesosphere has incorporated Kubernetes into its Data Center Operating System (DCOS) platform as a first class citizen. Using DCOS, enterprises can deploy Kubernetes across thousands of nodes, both bare-metal and virtualized machines that can run on-premise and in the cloud. Mesosphere also launched a beta of their Kubernetes Training Bootcamp and will be offering more in the future.
|
|

|
Mirantis is enabling hybrid cloud applications across OpenStack and other clouds supporting Kubernetes. An OpenStack Murano app package supports full application lifecycle actions such as deploy, create cluster, create pod, add containers to pods, scale up and scale down.
|
|

|
OpenContrail is creating a kubernetes-contrail plugin designed to stitch the cluster management capabilities of Kubernetes with the network service automation capabilities of OpenContrail. Given the event-driven abstractions of pods and services inherent in Kubernetes, it is a simple extension to address network service enforcement by leveraging OpenContrail’s Virtual Network policy approach and programmatic API’s.
|
|

|
Pachyderm is a containerized data analytics engine which provides the broad functionality of Hadoop with the ease of use of Docker. Users simply provide containers with their data analysis logic and Pachyderm will distribute that computation over the data. They have just released full deployment on Kubernetes for on premise deployments, and on Google Container Engine, eliminating all the operational overhead of running a cluster yourself.
|
|

|
Platalytics, Inc. and announced the release of one-touch deploy-anywhere feature for its Spark Application Platform. Based on Kubernetes, Docker, and CoreOS, it allows simple and automated deployment of Apache Hadoop, Spark, and Platalytics platform, with a single click, to all major public clouds, including Google, Amazon, Azure, DigitalOcean, and private on-premise clouds. It also enables hybrid cloud scenarios, where resources on public and private clouds can be mixed.
|
|
|
Rackspace has created Corekube as a simple, quick way to deploy Kubernetes on OpenStack. By using a decoupled infrastructure that is coordinated by etcd, fleet and flannel, it enables users to try Kubernetes and CoreOS without all the fuss of setting things up by hand.
|
|
|
Red Hat is a long time proponent of Kubernetes, and a significant contributor to the project. In their own words, “From Red Hat Enterprise Linux 7 and Red Hat Enterprise Linux Atomic Host to OpenShift Enterprise 3 and the forthcoming Red Hat Atomic Enterprise Platform, we are well-suited to bring container innovations into the enterprise, leveraging Kubernetes as the common backbone for orchestration.”
|
|

|
Redapt has launching a variety of turnkey, on-premises Kubernetes solutions co-engineered with other partners in the Kubernetes partner ecosystem. These include appliances built to leverage the CoreOS/Tectonic, Mirantis OpenStack, and Mesosphere platforms for management and provisioning. Redapt also offers private, public, and multi-cloud solutions that help customers accelerate their Kubernetes deployments successfully into production.
|
| ----- | |
|
|
We’ve also seen a community of services partners spring up to assist in adopting Kubernetes and containers:
| ----- | |

|
Biarca is using Kubernetes to ease application deployment and scale on demand across available hybrid and multi-cloud clusters through strategically managed policy. A video on their website illustrates how to use Kubernetes to deploy applications in a private cloud infrastructure based on OpenStack and use a public cloud like GCE to address bursting demand for applications.
|
|

|
Cloud Technology Partners has developed a Container Services Offering featuring Kubernetes to assist enterprises with container best practices, adoption and implementation. This offering helps organizations understand how containers deliver competitive edge.
|
|

|
DoIT International is offering a Kubernetes Bootcamp which consists of a series of hands-on exercises interleaved with mini-lectures covering hands on topics such as Container Basics, Using Docker, Kubernetes and Google Container Engine.
|
|

|
OpenCredo provides a practical, lab style container and scheduler course in addition to consulting and solution delivery. The three-day course allows development teams to quickly ramp up and make effective use of containers in real world scenarios, covering containers in general along with Docker and Kubernetes.
|
|

|
Pythian focuses on helping clients design, implement, and manage systems that directly contribute to revenue and business success. They provide small, dedicated teams of highly trained and experienced data experts have the deep Kubernetes and container experience necessary to help companies solve Big Data problems with containers.
|
- Martin Buhr, Product Manager at Google
Weekly Kubernetes Community Hangout Notes - July 17 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Here are the notes from today's meeting:
-
Eric Paris: replacing salt with ansible (if we want)
-
In contrib, there is a provisioning tool written in ansible
-
The goal in the rewrite was to eliminate as much of the cloud provider stuff as possible
-
The salt setup does a bunch of setup in scripts and then the environment is setup with salt
- This means that things like generating certs is done differently on GCE/AWS/Vagrant
-
For ansible, everything must be done within ansible
-
Background on ansible
- Does not have clients
- Provisioner ssh into the machine and runs scripts on the machine
- You define what you want your cluster to look like, run the script, and it sets up everything at once
- If you make one change in a config file, ansible re-runs everything (which isn’t always desirable)
- Uses a jinja2 template
-
Create machines with minimal software, then use ansible to get that machine into a runnable state
- Sets up all of the add-ons
-
Eliminates the provisioner shell scripts
-
Full cluster setup currently takes about 6 minutes
- CentOS with some packages
- Redeploy to the cluster takes 25 seconds
-
Questions for Eric
-
Where does the provider-specific configuration go?
- The only network setup that the ansible config does is flannel; you can turn it off
-
What about init vs. systemd?
- Should be able to support in the code w/o any trouble (not yet implemented)
-
-
Discussion
-
Why not push the setup work into containers or kubernetes config?
- To bootstrap a cluster drop a kubelet and a manifest
-
Running a kubelet and configuring the network should be the only things required. We can cut a machine image that is preconfigured minus the data package (certs, etc)
- The ansible scripts install kubelet & docker if they aren’t already installed
-
Each OS (RedHat, Debian, Ubuntu) could have a different image. We could view this as part of the build process instead of the install process.
-
There needs to be solution for bare metal as well.
-
In favor of the overall goal -- reducing the special configuration in the salt configuration
-
Everything except the kubelet should run inside a container (eventually the kubelet should as well)
- Running in a container doesn’t cut down on the complexity that we currently have
- But it does more clearly define the interface about what the code expects
-
These tools (Chef, Puppet, Ansible) conflate binary distribution with configuration
- Containers more clearly separate these problems
-
The mesos deployment is not completely automated yet, but the mesos deployment is completely different: kubelets get put on top on an existing mesos cluster
- The bash scripts allow the mesos devs to see what each cloud provider is doing and re-use the relevant bits
- There was a large reverse engineering curve, but the bash is at least readable as opposed to the salt
-
Openstack uses a different deployment as well
-
We need a well documented list of steps (e.g. create certs) that are necessary to stand up a cluster
- This would allow us to compare across cloud providers
- We should reduce the number of steps as much as possible
- Ansible has 241 steps to launch a cluster
-
-
-
1.0 Code freeze
-
How are we getting out of code freeze?
-
This is a topic for next week, but the preview is that we will move slowly rather than totally opening the firehose
- We want to clear the backlog as fast as possible while maintaining stability both on HEAD and on the 1.0 branch
- The backlog of almost 300 PRs but there are also various parallel feature branches that have been developed during the freeze
-
Cutting a cherry pick release today (1.0.1) that fixes a few issues
-
Next week we will discuss the cadence for patch releases
-
Strong, Simple SSL for Kubernetes Services
Hi, I’m Evan Brown (@evandbrown) and I work on the solutions architecture team for Google Cloud Platform. I recently wrote an article and tutorial about using Jenkins on Kubernetes to automate the Docker and GCE image build process. Today I’m going to discuss how I used Kubernetes services and secrets to add SSL to the Jenkins web UI. After reading this, you’ll be able to add SSL termination (and HTTP->HTTPS redirects + basic auth) to your public HTTP Kubernetes services.
In the beginning
In the spirit of minimum viability, the first version of Jenkins-on-Kubernetes I built was very basic but functional:
- The Jenkins leader was just a single container in one pod, but it was managed by a replication controller, so if it failed it would automatically respawn.
- The Jenkins leader exposes two ports - TCP 8080 for the web UI and TCP 50000 for build agents to register - and those ports are made available as a Kubernetes service with a public load balancer.
Here’s a visual of that first version:

This works, but I have a few problems with it. First, authentication isn’t configured in a default Jenkins installation. The leader is sitting on the public Internet, accessible to anyone, until you connect and configure authentication. And since there’s no encryption, configuring authentication is kind of a symbolic gesture. We need SSL, and we need it now!
Do what you know
For a few milliseconds I considered trying to get SSL working directly on Jenkins. I’d never done it before, and I caught myself wondering if it would be as straightforward as working with SSL on Nginx, something I do have experience with. I’m all for learning new things, but this seemed like a great place to not invent a new wheel: SSL on Nginx is straightforward and well documented (as are its reverse-proxy capabilities), and Kubernetes is all about building functionality by orchestrating and composing containers. Let’s use Nginx, and add a few bonus features that Nginx makes simple: HTTP->HTTPS redirection, and basic access authentication.
SSL termination proxy as an nginx service
I started by putting together a Dockerfile that inherited from the standard nginx image, copied a few Nginx config files, and added a custom entrypoint (start.sh). The entrypoint script checks an environment variable (ENABLE_SSL) and activates the correct Nginx config accordingly (meaning that unencrypted HTTP reverse proxy is possible, but that defeats the purpose). The script also configures basic access authentication if it’s enabled (the ENABLE_BASIC_AUTH env var).
Finally, start.sh evaluates the SERVICE_HOST_ENV_NAME and SERVICE_PORT_ENV_NAME env vars. These variables should be set to the names of the environment variables for the Kubernetes service you want to proxy to. In this example, the service for our Jenkins leader is cleverly named jenkins, which means pods in the cluster will see an environment variable named JENKINS_SERVICE_HOST and JENKINS_SERVICE_PORT_UI (the port that 8080 is mapped to on the Jenkins leader). SERVICE_HOST_ENV_NAME and SERVICE_PORT_ENV_NAME simply reference the correct service to use for a particular scenario, allowing the image to be used generically across deployments.
Defining the Controller and Service
LIke every other pod in this example, we’ll deploy Nginx with a replication controller, allowing us to scale out or in, and recover automatically from container failures. This excerpt from acomplete descriptor in the sample app shows some relevant bits of the pod spec:
spec:
containers:
-
name: "nginx-ssl-proxy"
image: "gcr.io/cloud-solutions-images/nginx-ssl-proxy:latest"
env:
-
name: "SERVICE\_HOST\_ENV\_NAME"
value: "JENKINS\_SERVICE\_HOST"
-
name: "SERVICE\_PORT\_ENV\_NAME"
value: "JENKINS\_SERVICE\_PORT\_UI"
-
name: "ENABLE\_SSL"
value: "true"
-
name: "ENABLE\_BASIC\_AUTH"
value: "true"
ports:
-
name: "nginx-ssl-proxy-http"
containerPort: 80
-
name: "nginx-ssl-proxy-https"
containerPort: 443
The pod will have a service exposing TCP 80 and 443 to a public load balancer. Here’s the service descriptor (also available in the sample app):
kind: "Service"
apiVersion: "v1"
metadata:
name: "nginx-ssl-proxy"
labels:
name: "nginx"
role: "ssl-proxy"
spec:
ports:
-
name: "https"
port: 443
targetPort: "nginx-ssl-proxy-https"
protocol: "TCP"
-
name: "http"
port: 80
targetPort: "nginx-ssl-proxy-http"
protocol: "TCP"
selector:
name: "nginx"
role: "ssl-proxy"
type: "LoadBalancer"
And here’s an overview with the SSL termination proxy in place. Notice that Jenkins is no longer directly exposed to the public Internet:

Now, how did the Nginx pods get ahold of the super-secret SSL key/cert and htpasswd file (for basic access auth)?
Keep it secret, keep it safe
Kubernetes has an API and resource for Secrets. Secrets “are intended to hold sensitive information, such as passwords, OAuth tokens, and ssh keys. Putting this information in a secret is safer and more flexible than putting it verbatim in a pod definition or in a docker image.”
You can create secrets in your cluster in 3 simple steps:
Base64-encode your secret data (i.e., SSL key pair or htpasswd file)
$ cat ssl.key | base64
LS0tLS1CRUdJTiBDRVJUS...
Create a json document describing your secret, and add the base64-encoded values:
apiVersion: "v1"
kind: "Secret"
metadata:
name: "ssl-proxy-secret"
namespace: "default"
data:
proxycert: "LS0tLS1CRUd..."
proxykey: "LS0tLS1CR..."
htpasswd: "ZXZhb..."
Create the secrets resource:
$ kubectl create -f secrets.json
To access the secrets from a container, specify them as a volume mount in your pod spec. Here’s the relevant excerpt from the Nginx proxy template we saw earlier:
spec:
containers:
-
name: "nginx-ssl-proxy"
image: "gcr.io/cloud-solutions-images/nginx-ssl-proxy:latest"
env: [...]
ports: ...[]
volumeMounts:
-
name: "secrets"
mountPath: "/etc/secrets"
readOnly: true
volumes:
-
name: "secrets"
secret:
secretName: "ssl-proxy-secret"
A volume of type secret that points to the ssl-proxy-secret secret resource is defined, and then mounted into /etc/secrets in the container. The secrets spec in the earlier example defined data.proxycert, data.proxykey, and data.htpasswd, so we would see those files appear (base64-decoded) in /etc/secrets/proxycert, /etc/secrets/proxykey, and /etc/secrets/htpasswd for the Nginx process to access.
All together now
I have “containers and Kubernetes are fun and cool!” moments all the time, like probably every day. I’m beginning to have “containers and Kubernetes are extremely useful and powerful and are adding value to what I do by helping me do important things with ease” more frequently. This SSL termination proxy with Nginx example is definitely one of the latter. I didn’t have to waste time learning a new way to use SSL. I was able to solve my problem using well-known tools, in a reusable way, and quickly (from idea to working took about 2 hours).
Check out the complete Automated Image Builds with Jenkins, Packer, and Kubernetes repo to see how the SSL termination proxy is used in a real cluster, or dig into the details of the proxy image in the nginx-ssl-proxy repo (complete with a Dockerfile and Packer template so you can build the image yourself).
Weekly Kubernetes Community Hangout Notes - July 10 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Here are the notes from today's meeting:
- Eric Paris: replacing salt with ansible (if we want)
- In contrib, there is a provisioning tool written in ansible
- The goal in the rewrite was to eliminate as much of the cloud provider stuff as possible
- The salt setup does a bunch of setup in scripts and then the environment is setup with salt
- This means that things like generating certs is done differently on GCE/AWS/Vagrant
- For ansible, everything must be done within ansible
- Background on ansible
- Does not have clients
- Provisioner ssh into the machine and runs scripts on the machine
- You define what you want your cluster to look like, run the script, and it sets up everything at once
- If you make one change in a config file, ansible re-runs everything (which isn’t always desirable)
- Uses a jinja2 template
- Create machines with minimal software, then use ansible to get that machine into a runnable state
- Sets up all of the add-ons
- Eliminates the provisioner shell scripts
- Full cluster setup currently takes about 6 minutes
- CentOS with some packages
- Redeploy to the cluster takes 25 seconds
- Questions for Eric
- Where does the provider-specific configuration go?
- The only network setup that the ansible config does is flannel; you can turn it off
- What about init vs. systemd?
- Should be able to support in the code w/o any trouble (not yet implemented)
- Where does the provider-specific configuration go?
- Discussion
- Why not push the setup work into containers or kubernetes config?
- To bootstrap a cluster drop a kubelet and a manifest
- Running a kubelet and configuring the network should be the only things required. We can cut a machine image that is preconfigured minus the data package (certs, etc)
- The ansible scripts install kubelet & docker if they aren’t already installed
- Each OS (RedHat, Debian, Ubuntu) could have a different image. We could view this as part of the build process instead of the install process.
- There needs to be solution for bare metal as well.
- In favor of the overall goal -- reducing the special configuration in the salt configuration
- Everything except the kubelet should run inside a container (eventually the kubelet should as well)
- Running in a container doesn’t cut down on the complexity that we currently have
- But it does more clearly define the interface about what the code expects
- These tools (Chef, Puppet, Ansible) conflate binary distribution with configuration
- Containers more clearly separate these problems
- The mesos deployment is not completely automated yet, but the mesos deployment is completely different: kubelets get put on top on an existing mesos cluster
- The bash scripts allow the mesos devs to see what each cloud provider is doing and re-use the relevant bits
- There was a large reverse engineering curve, but the bash is at least readable as opposed to the salt
- Openstack uses a different deployment as well
- We need a well documented list of steps (e.g. create certs) that are necessary to stand up a cluster
- This would allow us to compare across cloud providers
- We should reduce the number of steps as much as possible
- Ansible has 241 steps to launch a cluster
- Why not push the setup work into containers or kubernetes config?
- 1.0 Code freeze
- How are we getting out of code freeze?
- This is a topic for next week, but the preview is that we will move slowly rather than totally opening the firehose
- We want to clear the backlog as fast as possible while maintaining stability both on HEAD and on the 1.0 branch
- The backlog of almost 300 PRs but there are also various parallel feature branches that have been developed during the freeze
- Cutting a cherry pick release today (1.0.1) that fixes a few issues
- Next week we will discuss the cadence for patch releases
Announcing the First Kubernetes Enterprise Training Course
At Google we rely on Linux application containers to run our core infrastructure. Everything from Search to Gmail runs in containers. In fact, we like containers so much that even our Google Compute Engine VMs run in containers! Because containers are critical to our business, we have been working with the community on many of the basic container technologies (from cgroups to Docker’s LibContainer) and even decided to build the next generation of Google’s container scheduling technology, Kubernetes, in the open.
One year into the Kubernetes project, and on the eve of our planned V1 release at OSCON, we are pleased to announce the first-ever formal Kubernetes enterprise-focused training session organized by a key Kubernetes contributor, Mesosphere. The inaugural session will be taught by Zed Shaw and Michael Hausenblas from Mesosphere, and will take place on July 20 at OSCON in Portland. Pre-registration is free for early registrants, but space is limited so act soon!
This one-day course will cover the basics of building and deploying containerized applications using Kubernetes. It will walk attendees through the end-to-end process of creating a Kubernetes application architecture, building and configuring Docker images, and deploying them on a Kubernetes cluster. Users will also learn the fundamentals of deploying Kubernetes applications and services on our Google Container Engine and Mesosphere’s Datacenter Operating System.
The upcoming Kubernetes bootcamp will be a great way to learn how to apply Kubernetes to solve long-standing deployment and application management problems. This is just the first of what we hope are many, and from a broad set of contributors.
How did the Quake demo from DockerCon Work?
Shortly after its release in 2013, Docker became a very popular open source container management tool for Linux. Docker has a rich set of commands to control the execution of a container. Commands such as start, stop, restart, kill, pause, and unpause. However, what is still missing is the ability to Checkpoint and Restore (C/R) a container natively via Docker itself.
We’ve been actively working with upstream and community developers to add support in Docker for native C/R and hope that checkpoint and restore commands will be introduced in Docker 1.8. As of this writing, it’s possible to C/R a container externally because this functionality was recently merged in libcontainer.
External container C/R was demo’d at DockerCon 2015:

Container C/R offers many benefits including the following:
- Stop and restart the Docker daemon (say for an upgrade) without having to kill the running containers and restarting them from scratch, losing precious work they had done when they were stopped
- Reboot the system without having to restart the containers from scratch. Same benefits as use case 1 above
- Speed up the start time of slow-start applications
- “Forensic debugging" of processes running in a container by examining their checkpoint images (open files, memory segments, etc.)
- Migrate containers by restoring them on a different machine
CRIU
Implementing C/R functionality from scratch is a major undertaking and a daunting task. Fortunately, there is a powerful open source tool written in C that has been used in production for checkpointing and restoring entire process trees in Linux. The tool is called CRIU which stands for Checkpoint Restore In Userspace (http://criu.org). CRIU works by:
- Freezing a running application.
- Checkpointing the address space and state of the entire process tree to a collection of “image” files.
- Restoring the process tree from checkpoint image files.
- Resuming application from the point it was frozen.
In April 2014, we decided to find out if CRIU could checkpoint and restore Docker containers to facilitate container migration.
Phase 1 - External C/R
The first phase of this effort invoking CRIU directly to dump a process tree running inside a container and determining why the checkpoint or restore operation failed. There were quite a few issues that caused CRIU failure. The following three issues were among the more challenging ones.
External Bind Mounts
Docker sets up /etc/{hostname,hosts,resolv.conf} as targets with source files outside the container's mount namespace.
The --ext-mount-map command line option was added to CRIU to specify the path of the external bind mounts. For example, assuming default Docker configuration, /etc/hostname in the container's mount namespace is bind mounted from the source at /var/lib/docker/containers/<container-id>/hostname. When checkpointing, we tell CRIU to record /etc/hostname's "map" as, say, etc_hostname. When restoring, we tell CRIU that the file previously recorded as etc_hostname should be mapped from the external bind mount at /var/lib/docker/containers/<container-id>/hostname.

AUFS Pathnames
Docker initially used AUFS as its preferred filesystem which is still in wide usage (the preferred filesystem is now OverlayFS).. Due to a bug, the AUFS symbolic link paths of /proc/<pid>/map_files point inside AUFS branches instead of their pathnames relative to the container's root. This problem has been fixed in AUFS source code but hasn't made it to all the distros yet. CRIU would get confused seeing the same file in its physical location (in the branch) and its logical location (from the root of mount namespace).
The --root command line option that was used only during restore was generalized to understand the root of the mount namespace during checkpoint and automatically "fix" the exposed AUFS pathnames.
Cgroups
After checkpointing, the Docker daemon removes the container’s cgroups subdirectories (because the container has “exited”). This causes restore to fail.
The --manage-cgroups command line option was added to CRIU to dump and restore the process's cgroups along with their properties.
The CRIU command lines are a simple container are shown below:
$ docker run -d busybox:latest /bin/sh -c 'i=0; while true; do echo $i \>\> /foo; i=$(expr $i + 1); sleep 3; done'
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS
168aefb8881b busybox:latest "/bin/sh -c 'i=0; 6 seconds ago Up 4 seconds
$ sudo criu dump -o dump.log -v4 -t 17810 \
-D /tmp/img/\<container\_id\> \
--root /var/lib/docker/aufs/mnt/\<container\_id\> \
--ext-mount-map /etc/resolv.conf:/etc/resolv.conf \
--ext-mount-map /etc/hosts:/etc/hosts \
--ext-mount-map /etc/hostname:/etc/hostname \
--ext-mount-map /.dockerinit:/.dockerinit \
--manage-cgroups \
--evasive-devices
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS
168aefb8881b busybox:latest "/bin/sh -c 'i=0; 6 minutes ago Exited (-1) 4 minutes ago
$ sudo mount -t aufs -o br=\
/var/lib/docker/aufs/diff/\<container\_id\>:\
/var/lib/docker/aufs/diff/\<container\_id\>-init:\
/var/lib/docker/aufs/diff/a9eb172552348a9a49180694790b33a1097f546456d041b6e82e4d7716ddb721:\
/var/lib/docker/aufs/diff/120e218dd395ec314e7b6249f39d2853911b3d6def6ea164ae05722649f34b16:\
/var/lib/docker/aufs/diff/42eed7f1bf2ac3f1610c5e616d2ab1ee9c7290234240388d6297bc0f32c34229:\
/var/lib/docker/aufs/diff/511136ea3c5a64f264b78b5433614aec563103b4d4702f3ba7d4d2698e22c158:\
none /var/lib/docker/aufs/mnt/\<container\_id\>
$ sudo criu restore -o restore.log -v4 -d
-D /tmp/img/\<container\_id\> \
--root /var/lib/docker/aufs/mnt/\<container\_id\> \
--ext-mount-map /etc/resolv.conf:/var/lib/docker/containers/\<container\_id\>/resolv.conf \
--ext-mount-map /etc/hosts:/var/lib/docker/containers/\<container\_id\>/hosts \
--ext-mount-map /etc/hostname:/var/lib/docker/containers/\<container\_id\>/hostname \
--ext-mount-map /.dockerinit:/var/lib/docker/init/dockerinit-1.0.0 \
--manage-cgroups \
--evasive-devices
$ ps -ef | grep /bin/sh
root 18580 1 0 12:38 ? 00:00:00 /bin/sh -c i=0; while true; do echo $i \>\> /foo; i=$(expr $i + 1); sleep 3; done
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS
168aefb8881b busybox:latest "/bin/sh -c 'i=0; 7 minutes ago Exited (-1) 5 minutes ago
docker\_cr.sh
Since the command line arguments to CRIU were long, a helper script called docker_cr.sh was provided in the CRIU source tree to simplify the process. So, for the above container, one would simply C/R the container as follows (for details see http://criu.org/Docker):
$ sudo docker\_cr.sh -c 4397
dump successful
$ sudo docker\_cr.sh -r 4397
restore successful
At the end of Phase 1, it was possible to externally checkpoint and restore a Docker 1.0 container using either VFS, AUFS, or UnionFS storage drivers with CRIU v1.3.
Phase 2 - Native C/R
While external C/R served as a successful proof of concept for container C/R, it had the following limitations:
- State of a checkpointed container would show as "Exited".
- Docker commands such as logs, kill, etc. will not work on a restored container.
- The restored process tree will be a child of /etc/init instead of the Docker daemon.
Therefore, the second phase of the effort concentrated on adding native checkpoint and restore commands to Docker.
libcontainer, nsinit
Libcontainer is Docker’s native execution driver. It provides a set of APIs to create and manage containers. The first step of adding native support was the introduction of two methods, checkpoint() and restore(), to libcontainer and the corresponding checkpoint and restore subcommands to nsinit. Nsinit is a simple utility that is used to test and debug libcontainer.
docker checkpoint, docker restore
With C/R support in libcontainer, the next step was adding checkpoint and restore subcommands to Docker itself. A big challenge in this step was to rebuild the “plumbing” between the container and the daemon. When the daemon initially starts a container, it sets up individual pipes between itself (parent) and the standard input, output, and error file descriptors of the container (child). This is how docker logs can show the output of a container.
When a container exits after being checkpointed, the pipes between it and the daemon are deleted. During container restore, it’s actually CRIU that is the parent. Therefore, setting up a pipe between the child (container) and an unrelated process (Docker daemon) required is not a bit of challenge.
To address this issue, the --inherit-fd command line option was added to CRIU. Using this option, the Docker daemon tells CRIU to let the restored container “inherit” certain file descriptors passed from the daemon to CRIU.
The first version of native C/R was demo'ed at the Linux Plumbers Conference (LPC) in October 2014 (http://linuxplumbersconf.org/2014/ocw/proposals/1899).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The LPC demo was done with a simple container that did not require network connectivity. Support for restoring network connections was done in early 2015 and demonstrated in this 2-minute video clip.
Current Status of Container C/R
In May 2015, the criu branch of libcontainer was merged into master. Using the newly-introduced lightweight runC container runtime, container migration was demo’ed at DockerCon15. In this
 (minute 23:00), a container running Quake was checkpointed and restored on a different machine, effectively implementing container migration.
(minute 23:00), a container running Quake was checkpointed and restored on a different machine, effectively implementing container migration.
At the time of this writing, there are two repos on GitHub that have native C/R support in Docker:
- Docker 1.5 (old libcontainer, relatively stable)
- Docker 1.7 (newer, less stable)
Work is underway to merge C/R functionality into Docker. You can use either of the above repositories to experiment with Docker C/R. If you are using OverlayFS or your container workload uses AIO, please note the following:
OverlayFS
When OverlayFS support was officially merged into the Linux kernel version 3.18, it became the preferred storage driver (instead of AUFS) . However, OverlayFS in 3.18 has the following issues:
- /proc/<pid>/fdinfo/<fd> contains mnt_id which isn’t in /proc/<pid>/mountinfo
- /proc/<pid>/fd/<fd> does not contain an absolute path to the opened file
Both issues are fixed in this patch but the patch has not been merged upstream yet.
AIO
If you are using a kernel older than 3.19 and your container uses AIO, you need the following kernel patches from 3.19:
-
torvalds: bd9b51e7 by Al Viro
-
torvalds: e4a0d3e72 by Pavel Emelyanov
-
Saied Kazemi, Software Engineer at Google
Kubernetes 1.0 Launch Event at OSCON
In case you haven't heard, the Kubernetes project team & community have some awesome stuff lined up for our release event at OSCON in a few weeks.
If you haven't already registered for in person or live stream, please do it now! check out kuberneteslaunch.com for all the details. You can also find out there how to get a free expo pass for OSCON which you'll need to attend in person.
We'll have talks from Google executives Brian Stevens, VP of Cloud Product, and Eric Brewer, VP of Google Infrastructure. They will share their perspective on where Kubernetes is and where it's going that you won't want to miss.
Several of our community partners will be there including CoreOS, Redapt, Intel, Mesosphere, Mirantis, the OpenStack Foundation, CloudBees, Kismatic and Bitnami.
And real life users of Kubernetes will be there too. We've announced that zulily Principal Engineer Steve Reed is speaking, and we will let you know about others over the next few days. Let's just say it's a pretty cool list.
Check it out now - kuberneteslaunch.com
The Distributed System ToolKit: Patterns for Composite Containers
Having had the privilege of presenting some ideas from Kubernetes at DockerCon 2015, I thought I would make a blog post to share some of these ideas for those of you who couldn’t be there.
Over the past two years containers have become an increasingly popular way to package and deploy code. Container images solve many real-world problems with existing packaging and deployment tools, but in addition to these significant benefits, containers offer us an opportunity to fundamentally re-think the way we build distributed applications. Just as service oriented architectures (SOA) encouraged the decomposition of applications into modular, focused services, containers should encourage the further decomposition of these services into closely cooperating modular containers. By virtue of establishing a boundary, containers enable users to build their services using modular, reusable components, and this in turn leads to services that are more reliable, more scalable and faster to build than applications built from monolithic containers.
In many ways the switch from VMs to containers is like the switch from monolithic programs of the 1970s and early 80s to modular object-oriented programs of the late 1980s and onward. The abstraction layer provided by the container image has a great deal in common with the abstraction boundary of the class in object-oriented programming, and it allows the same opportunities to improve developer productivity and application quality. Just like the right way to code is the separation of concerns into modular objects, the right way to package applications in containers is the separation of concerns into modular containers. Fundamentally this means breaking up not just the overall application, but also the pieces within any one server into multiple modular containers that are easy to parameterize and re-use. In this way, just like the standard libraries that are ubiquitous in modern languages, most application developers can compose together modular containers that are written by others, and build their applications more quickly and with higher quality components.
The benefits of thinking in terms of modular containers are enormous, in particular, modular containers provide the following:
- Speed application development, since containers can be re-used between teams and even larger communities
- Codify expert knowledge, since everyone collaborates on a single containerized implementation that reflects best-practices rather than a myriad of different home-grown containers with roughly the same functionality
- Enable agile teams, since the container boundary is a natural boundary and contract for team responsibilities
- Provide separation of concerns and focus on specific functionality that reduces spaghetti dependencies and un-testable components
Building an application from modular containers means thinking about symbiotic groups of containers that cooperate to provide a service, not one container per service. In Kubernetes, the embodiment of this modular container service is a Pod. A Pod is a group of containers that share resources like file systems, kernel namespaces and an IP address. The Pod is the atomic unit of scheduling in a Kubernetes cluster, precisely because the symbiotic nature of the containers in the Pod require that they be co-scheduled onto the same machine, and the only way to reliably achieve this is by making container groups atomic scheduling units.
When you start thinking in terms of Pods, there are naturally some general patterns of modular application development that re-occur multiple times. I’m confident that as we move forward in the development of Kubernetes more of these patterns will be identified, but here are three that we see commonly:
Example #1: Sidecar containers
Sidecar containers extend and enhance the "main" container, they take existing containers and make them better. As an example, consider a container that runs the Nginx web server. Add a different container that syncs the file system with a git repository, share the file system between the containers and you have built Git push-to-deploy. But you’ve done it in a modular manner where the git synchronizer can be built by a different team, and can be reused across many different web servers (Apache, Python, Tomcat, etc). Because of this modularity, you only have to write and test your git synchronizer once and reuse it across numerous apps. And if someone else writes it, you don’t even need to do that.
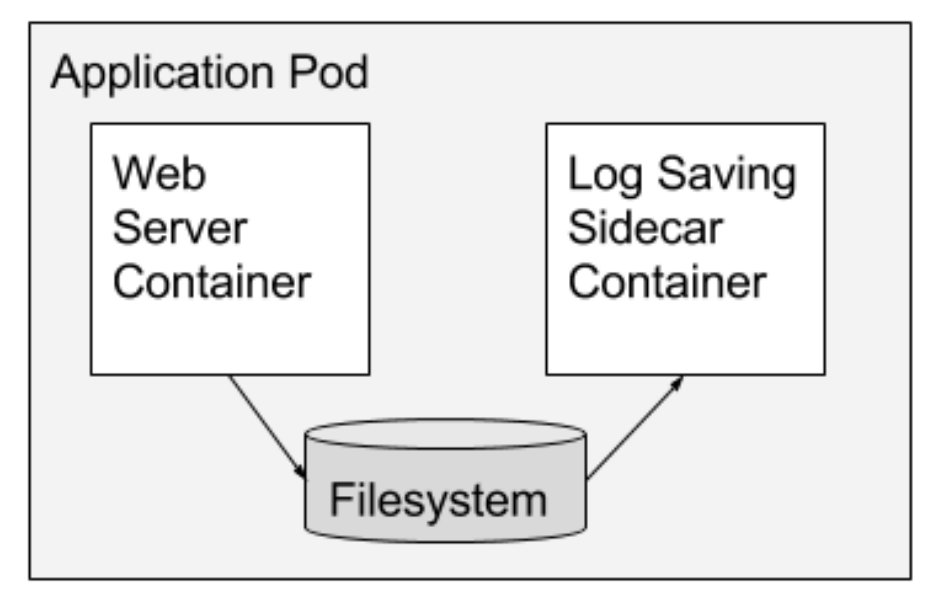
Example #2: Ambassador containers
Ambassador containers proxy a local connection to the world. As an example, consider a Redis cluster with read-replicas and a single write master. You can create a Pod that groups your main application with a Redis ambassador container. The ambassador is a proxy is responsible for splitting reads and writes and sending them on to the appropriate servers. Because these two containers share a network namespace, they share an IP address and your application can open a connection on “localhost” and find the proxy without any service discovery. As far as your main application is concerned, it is simply connecting to a Redis server on localhost. This is powerful, not just because of separation of concerns and the fact that different teams can easily own the components, but also because in the development environment, you can simply skip the proxy and connect directly to a Redis server that is running on localhost.
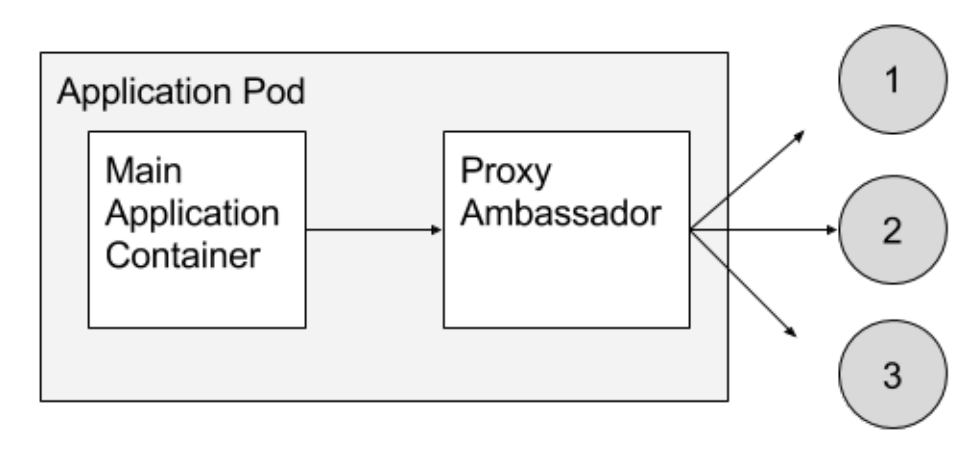
Example #3: Adapter containers
Adapter containers standardize and normalize output. Consider the task of monitoring N different applications. Each application may be built with a different way of exporting monitoring data. (e.g. JMX, StatsD, application specific statistics) but every monitoring system expects a consistent and uniform data model for the monitoring data it collects. By using the adapter pattern of composite containers, you can transform the heterogeneous monitoring data from different systems into a single unified representation by creating Pods that groups the application containers with adapters that know how to do the transformation. Again because these Pods share namespaces and file systems, the coordination of these two containers is simple and straightforward.
In all of these cases, we've used the container boundary as an encapsulation/abstraction boundary that allows us to build modular, reusable components that we combine to build out applications. This reuse enables us to more effectively share containers between different developers, reuse our code across multiple applications, and generally build more reliable, robust distributed systems more quickly. I hope you’ve seen how Pods and composite container patterns can enable you to build robust distributed systems more quickly, and achieve container code re-use. To try these patterns out yourself in your own applications. I encourage you to go check out open source Kubernetes or Google Container Engine.
- Brendan Burns, Software Engineer at Google
Slides: Cluster Management with Kubernetes, talk given at the University of Edinburgh
On Friday 5 June 2015 I gave a talk called Cluster Management with Kubernetes to a general audience at the University of Edinburgh. The talk includes an example of a music store system with a Kibana front end UI and an Elasticsearch based back end which helps to make concrete concepts like pods, replication controllers and services.
Cluster Level Logging with Kubernetes
A Kubernetes cluster will typically be humming along running many system and application pods. How does the system administrator collect, manage and query the logs of the system pods? How does a user query the logs of their application which is composed of many pods which may be restarted or automatically generated by the Kubernetes system? These questions are addressed by the Kubernetes cluster level logging services.
Cluster level logging for Kubernetes allows us to collect logs which persist beyond the lifetime of the pod’s container images or the lifetime of the pod or even cluster. In this article we assume that a Kubernetes cluster has been created with cluster level logging support for sending logs to Google Cloud Logging. This is an option when creating a Google Container Engine (GKE) cluster, and is enabled by default for the open source Google Compute Engine (GCE) Kubernetes distribution. After a cluster has been created you will have a collection of system pods running that support monitoring, logging and DNS resolution for names of Kubernetes services:
$ kubectl get pods
NAME READY REASON RESTARTS AGE
fluentd-cloud-logging-kubernetes-minion-0f64 1/1 Running 0 32m
fluentd-cloud-logging-kubernetes-minion-27gf 1/1 Running 0 32m
fluentd-cloud-logging-kubernetes-minion-pk22 1/1 Running 0 31m
fluentd-cloud-logging-kubernetes-minion-20ej 1/1 Running 0 31m
kube-dns-v3-pk22 3/3 Running 0 32m
monitoring-heapster-v1-20ej 0/1 Running 9 32m
Here is the same information in a picture which shows how the pods might be placed on specific nodes.

Here is a close up of what is running on each node.




The first diagram shows four nodes created on a GCE cluster with the name of each VM node on a purple background. The internal and public IPs of each node are shown on gray boxes and the pods running in each node are shown in green boxes. Each pod box shows the name of the pod and the namespace it runs in, the IP address of the pod and the images which are run as part of the pod’s execution. Here we see that every node is running a fluentd-cloud-logging pod which is collecting the log output of the containers running on the same node and sending them to Google Cloud Logging. A pod which provides a cluster DNS service runs on one of the nodes and a pod which provides monitoring support runs on another node.
To help explain how cluster level logging works let’s start off with a synthetic log generator pod specification counter-pod.yaml:
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : ubuntu:14.04
args : [bash, -c,
'for ((i = 0; ; i++)); do echo "$i: $(date)"; sleep 1; done']
This pod specification has one container which runs a bash script when the container is born. This script simply writes out the value of a counter and the date once per second and runs indefinitely. Let’s create the pod.
$ kubectl create -f counter-pod.yaml
pods/counter
We can observe the running pod:
$ kubectl get pods
NAME READY REASON RESTARTS AGE
counter 1/1 Running 0 5m
fluentd-cloud-logging-kubernetes-minion-0f64 1/1 Running 0 55m
fluentd-cloud-logging-kubernetes-minion-27gf 1/1 Running 0 55m
fluentd-cloud-logging-kubernetes-minion-pk22 1/1 Running 0 55m
fluentd-cloud-logging-kubernetes-minion-20ej 1/1 Running 0 55m
kube-dns-v3-pk22 3/3 Running 0 55m
monitoring-heapster-v1-20ej 0/1 Running 9 56m
This step may take a few minutes to download the ubuntu:14.04 image during which the pod status will be shown as Pending.
One of the nodes is now running the counter pod:

When the pod status changes to Running we can use the kubectl logs command to view the output of this counter pod.
$ kubectl logs counter
0: Tue Jun 2 21:37:31 UTC 2015
1: Tue Jun 2 21:37:32 UTC 2015
2: Tue Jun 2 21:37:33 UTC 2015
3: Tue Jun 2 21:37:34 UTC 2015
4: Tue Jun 2 21:37:35 UTC 2015
5: Tue Jun 2 21:37:36 UTC 2015
This command fetches the log text from the Docker log file for the image that is running in this container. We can connect to the running container and observe the running counter bash script.
$ kubectl exec -i counter bash
ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 17976 2888 ? Ss 00:02 0:00 bash -c for ((i = 0; ; i++)); do echo "$i: $(date)"; sleep 1; done
root 468 0.0 0.0 17968 2904 ? Ss 00:05 0:00 bash
root 479 0.0 0.0 4348 812 ? S 00:05 0:00 sleep 1
root 480 0.0 0.0 15572 2212 ? R 00:05 0:00 ps aux
What happens if for any reason the image in this pod is killed off and then restarted by Kubernetes? Will we still see the log lines from the previous invocation of the container followed by the log lines for the started container? Or will we lose the log lines from the original container’s execution and only see the log lines for the new container? Let’s find out. First let’s stop the currently running counter.
$ kubectl stop pod counter
pods/counter
Now let’s restart the counter.
$ kubectl create -f counter-pod.yaml
pods/counter
Let’s wait for the container to restart and get the log lines again.
$ kubectl logs counter
0: Tue Jun 2 21:51:40 UTC 2015
1: Tue Jun 2 21:51:41 UTC 2015
2: Tue Jun 2 21:51:42 UTC 2015
3: Tue Jun 2 21:51:43 UTC 2015
4: Tue Jun 2 21:51:44 UTC 2015
5: Tue Jun 2 21:51:45 UTC 2015
6: Tue Jun 2 21:51:46 UTC 2015
7: Tue Jun 2 21:51:47 UTC 2015
8: Tue Jun 2 21:51:48 UTC 2015
Oh no! We’ve lost the log lines from the first invocation of the container in this pod! Ideally, we want to preserve all the log lines from each invocation of each container in the pod. Furthermore, even if the pod is restarted we would still like to preserve all the log lines that were ever emitted by the containers in the pod. But don’t fear, this is the functionality provided by cluster level logging in Kubernetes. When a cluster is created, the standard output and standard error output of each container can be ingested using a Fluentd agent running on each node into either Google Cloud Logging or into Elasticsearch and viewed with Kibana. This blog article focuses on Google Cloud Logging.
When a Kubernetes cluster is created with logging to Google Cloud Logging enabled, the system creates a pod called fluentd-cloud-logging on each node of the cluster to collect Docker container logs. These pods were shown at the start of this blog article in the response to the first get pods command.
This log collection pod has a specification which looks something like this fluentd-gcp.yaml:
apiVersion: v1
kind: Pod
metadata:
name: fluentd-cloud-logging
spec:
containers:
- name: fluentd-cloud-logging
image: gcr.io/google\_containers/fluentd-gcp:1.6
env:
- name: FLUENTD\_ARGS
value: -qq
volumeMounts:
- name: containers
mountPath: /var/lib/docker/containers
volumes:
- name: containers
hostPath:
path: /var/lib/docker/containers
This pod specification maps the directory on the host containing the Docker log files, /var/lib/docker/containers, to a directory inside the container which has the same path. The pod runs one image, gcr.io/google_containers/fluentd-gcp:1.6, which is configured to collect the Docker log files from the logs directory and ingest them into Google Cloud Logging. One instance of this pod runs on each node of the cluster. Kubernetes will notice if this pod fails and automatically restart it.
We can click on the Logs item under the Monitoring section of the Google Developer Console and select the logs for the counter container, which will be called kubernetes.counter_default_count. This identifies the name of the pod (counter), the namespace (default) and the name of the container (count) for which the log collection occurred. Using this name we can select just the logs for our counter container from the drop down menu:
(image-counter-new-logs.png)
When we view the logs in the Developer Console we observe the logs for both invocations of the container.
(image-screenshot-2015-06-02)
Note the first container counted to 108 and then it was terminated. When the next container image restarted the counting process resumed from 0. Similarly if we deleted the pod and restarted it we would capture the logs for all instances of the containers in the pod whenever the pod was running.
Logs ingested into Google Cloud Logging may be exported to various other destinations including Google Cloud Storage buckets and BigQuery. Use the Exports tab in the Cloud Logging console to specify where logs should be streamed to (or follow this link to the settings tab).
We could query the ingested logs from BigQuery using the SQL query which reports the counter log lines showing the newest lines first.
SELECT metadata.timestamp, structPayload.log FROM [mylogs.kubernetes_counter_default_count_20150611] ORDER BY metadata.timestamp DESC
Here is some sample output:
(image-bigquery-log-new.png)
We could also fetch the logs from Google Cloud Storage buckets to our desktop or laptop and then search them locally. The following command fetches logs for the counter pod running in a cluster which is itself in a GCE project called myproject. Only logs for the date 2015-06-11 are fetched.
$ gsutil -m cp -r gs://myproject/kubernetes.counter\_default\_count/2015/06/11 .
Now we can run queries over the ingested logs. The example below uses thejq program to extract just the log lines.
$ cat 21\:00\:00\_21\:59\:59\_S0.json | jq '.structPayload.log'
"0: Thu Jun 11 21:39:38 UTC 2015\n"
"1: Thu Jun 11 21:39:39 UTC 2015\n"
"2: Thu Jun 11 21:39:40 UTC 2015\n"
"3: Thu Jun 11 21:39:41 UTC 2015\n"
"4: Thu Jun 11 21:39:42 UTC 2015\n"
"5: Thu Jun 11 21:39:43 UTC 2015\n"
"6: Thu Jun 11 21:39:44 UTC 2015\n"
"7: Thu Jun 11 21:39:45 UTC 2015\n"
This article has touched briefly on the underlying mechanisms that support gathering cluster level logs on a Kubernetes deployment. The approach here only works for gathering the standard output and standard error output of the processes running in the pod’s containers. To gather other logs that are stored in files one can use a sidecar container to gather the required files as described at the page Collecting log files within containers with Fluentd and sending them to the Google Cloud Logging service.
Weekly Kubernetes Community Hangout Notes - May 22 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Discussion / Topics
- Code Freeze
- Upgrades of cluster
- E2E test issues
Code Freeze process starts EOD 22-May, including
- Code Slush -- draining PRs that are active. If there are issues for v1 to raise, please do so today.
- Community PRs -- plan is to reopen in ~6 weeks.
- Key areas for fixes in v1 -- docs, the experience.
E2E issues and LGTM process
-
Seen end-to-end tests go red.
-
Plan is to limit merging to on-call. Quinton to communicate.
-
Can we expose Jenkins runs to community? (Paul)
-
Question/concern to work out is securing Jenkins. Short term conclusion: Will look at pushing Jenkins logs into GCS bucket. Lavalamp will follow up with Jeff Grafton.
-
Longer term solution may be a merge queue, where e2e runs for each merge (as opposed to multiple merges). This exists in OpenShift today.
-
Cluster Upgrades for Kubernetes as final v1 feature
-
GCE will use Persistent Disk (PD) to mount new image.
-
OpenShift will follow a tradition update model, with "yum update".
-
A strawman approach is to have an analog of "kube-push" to update the master, in-place. Feedback in the meeting was
-
Upgrading Docker daemon on the master will kill the master's pods. Agreed. May consider an 'upgrade' phase or explicit step.
-
How is this different than HA master upgrade? See HA case as a superset. The work to do an upgrade would be a prerequisite for HA master upgrade.
-
-
Mesos scheduler implements a rolling node upgrade.
Attention requested for v1 in the Hangout
-
-
Discussed that it's an eventually consistent design.*
- In the meeting, the outcome was: seeking a pattern for atomicity of update across multiple piece. Paul to ping Tim when ready to review.
-
-
Regression in e2e #8499 (Eric Paris)
-
Asking for review of direction, if not review. #8334 (Mark)
-
Handling graceful termination (e.g. sigterm to postgres) is not implemented. #2789 (Clayton)
-
Need is to bump up grace period or finish plumbing. In API, client tools, missing is kubelet does use and we don't set the timeout (>0) value.
-
Brendan will look into this graceful term issue.
-
-
Load balancer almost ready by JustinSB.
Kubernetes on OpenStack

Today, the OpenStack foundation made it even easier for you deploy and manage clusters of Docker containers on OpenStack clouds by including Kubernetes in its Community App Catalog. At a keynote today at the OpenStack Summit in Vancouver, Mark Collier, COO of the OpenStack Foundation, and Craig Peters, Mirantis product line manager, demonstrated the Community App Catalog workflow by launching a Kubernetes cluster in a matter of seconds by leveraging the compute, storage, networking and identity systems already present in an OpenStack cloud.
The entries in the catalog include not just the ability to start a Kubernetes cluster, but also a range of applications deployed in Docker containers managed by Kubernetes. These applications include:
- Apache web server
- Nginx web server
- Crate - The Distributed Database for Docker
- GlassFish - Java EE 7 Application Server
- Tomcat - An open-source web server and servlet container
- InfluxDB - An open-source, distributed, time series database
- Grafana - Metrics dashboard for InfluxDB
- Jenkins - An extensible open source continuous integration server
- MariaDB database
- MySql database
- Redis - Key-value cache and store
- PostgreSQL database
- MongoDB NoSQL database
- Zend Server - The Complete PHP Application Platform
This list will grow, and is curated here. You can examine (and contribute to) the YAML file that tells Murano how to install and start the Kubernetes cluster here.
The Kubernetes open source project has continued to see fantastic community adoption and increasing momentum, with over 11,000 commits and 7,648 stars on GitHub. With supporters ranging from Red Hat and Intel to CoreOS and Box.net, it has come to represent a range of customer interests ranging from enterprise IT to cutting edge startups. We encourage you to give it a try, give us your feedback, and get involved in our growing community.
- Martin Buhr, Product Manager, Kubernetes Open Source Project
Docker and Kubernetes and AppC
Recently we announced the intent in Kubernetes, our open source cluster manager, to support AppC and RKT, an alternative container format that has been driven by CoreOS with input from many companies (including Google). This announcement has generated a surprising amount of buzz and has been construed as a move from Google to support Appc over Docker. Many have taken it as signal that Google is moving away from supporting Docker. I would like to take a moment to clarify Google’s position in this.
Google has consistently supported the Docker initiative and has invested heavily in Docker. In the early days of containers, we decided to de-emphasize our own open source offering (LMCTFY) and to instead focus on Docker. As a result of that we have two engineers that are active maintainers of LibContainer, a critical piece of the Docker ecosystem and are working closely with Docker to add many additional features and capabilities. Docker is currently the only supported runtime in GKE (Google Container Engine) our commercial containers product, and in GAE (Google App Engine), our Platform-as-a-Service product.
While we may introduce AppC support at some point in the future to GKE based on our customers demand, we intend to continue to support the Docker project and product, and Docker the company indefinitely. To date Docker is by far the most mature and widely used container offering in the market, with over 400 million downloads. It has been production ready for almost a year and seen widespread use in industry, and also here inside Google.
Beyond the obvious traction Docker has in the market, we are heartened by many of Docker’s recent initiatives to open the project and support ‘batteries included, but swappable options across the stack and recognize that it offers a great developer experience for engineers new to the containers world. We are encouraged, for example, by the separation of the Docker Machine and Swarm projects from the core runtime, and are glad to see support for Docker Machine emerging for Google Compute Engine.
Our intent with our announcement for AppC and RKT support was to establish Kubernetes (our open source project) as a neutral ground in the world of containers. Customers should be able to pick their container runtime and format based solely on its technical merits, and we do see AppC as offering some legitimate potential merits as the technology matures. Somehow this was misconstrued as an ‘a vs b’ selection which is simply untrue. The world is almost always better for having choice, and it is perfectly natural that different tools should be available for different purposes.
Stepping back a little, one must recognize that Docker has done remarkable work in democratizing container technologies and making them accessible to everyone. We believe that Docker will continue to drive great experiences for developers looking to use containers and plan to support this technology and its burgeoning community indefinitely. We, for one, are looking forward to the upcoming Dockercon where Brendan Burns (a Kubernetes co-founder) will be talking about the role of Docker in modern distributed systems design.
-- Craig McLuckie
Google Group Product Manager, and Kubernetes Project Co-Founder
Weekly Kubernetes Community Hangout Notes - May 15 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
- v1 API - what's in, what's out
- We're trying to fix critical issues we discover with v1beta3
- Would like to make a number of minor cleanups that will be expensive to do later
- defaulting replication controller spec default to 1
- deduplicating security context
- change id field to name
- rename host
- inconsistent times
- typo in container states terminated (termination vs. terminated)
- flatten structure (requested by heavy API user)
- pod templates - could be added after V1, field is not implemented, remove template ref field
- in general remove any fields not implemented (can be added later)
- if we want to change any of the identifier validation rules, should do it now
- recently changed label validation rules to be more precise
- Bigger changes
- generalized label selectors
- service - change the fields in a way that we can add features in a forward compatible manner if possible
- public IPs - what to do from a security perspective
- Support aci format - there is an image field - add properties to signify the image, or include it in a string
- inconsistent on object use / cross reference - needs design discussion
- Things to do later
- volume source cleanup
- multiple API prefixes
- watch changes - watch client is not notified of progress
- A few other proposals
- swagger spec fixes - ongoing
- additional field selectors - additive, backward compatible
- additional status - additive, backward compatible
- elimination of phase - won't make it for v1
- Service discussion - Public IPs
- with public IPs as it exists we can't go to v1
- Tim has been developing a mitigation if we can't get Justin's overhaul in (but hopefully we will)
- Justin's fix will describe public IPs in a much better way
- The general problem is it's too flexible and you can do things that are scary, the mitigation is to restrict public ip usage to specific use cases -- validated public IPs would be copied to status, which is what kube-proxy would use
- public IPs used for -
- binding to nodes / node
- request a specific load balancer IP (GCE only)
- emulate multi-port services -- now we support multi-port services, so no longer necessary
- This is a large change, 70% code complete, Tim & Justin working together, parallel code review and updates, need to reconcile and test
- Do we want to allow people to request host ports - is there any value in letting people ask for a public port? or should we assign you one?
- Tim: we should assign one
- discussion of what to do with status - if users set to empty then probably their intention
- general answer to the pattern is binding
- post v1: if we can make portal ip a non-user settable field, then we need to figure out the transition plan. need to have a fixed ip for dns.
- we should be able to just randomly assign services a new port and everything should adjust, but this is not feasible for v1
- next iteration of the proposal: PR is being iterated on, testing over the weekend, so PR hopefully ready early next week - gonna be a doozie!
- API transition
- actively removing all dependencies on v1beta1 and v1beta2, announced their going away
- working on a script that will touch everything in the system and will force everything to flip to v1beta3
- a release with both APIs supported and with this script can make sure clusters are moved over and we can move the API
- Should be gone by 0.19
- Help is welcome, especially for trivial things and will try to get as much done as possible in next few weeks
- Release candidate targeting mid june
- The new kubectl will not work for old APIs, will be a problem for GKE for clusters pinned to old version. Will be a problem for k8s users as well if they update kubectl
- Since there's no way to upgrade a GKE cluster, users are going to have to tear down and upgrade their cluster
- we're going to stop testing v1beta1 very soon, trying to streamline the testing paths in our CI pipelines
- Did we decide we are not going to do namespace autoprovisioning?
- Brian would like to turn it off - no objections
- Documentation should include creating namepspaces
- Would like to impose a default CPU for the default namespace
- would cap the number of pods, would reduce the resource exhaustion issue
- would eliminate need to explicitly cap the number of pods on a node due to IP exhaustion
- could add resources as arguments to the porcelain commands
- kubectl run is a simplified command, but it could include some common things (image, command, ports). but could add resources
- Kubernetes 1.0 Launch Event
- Save the * Blog posts, whitepapers, etc. welcome to be published
- Event will be live streamed, mostly demos & customer talks, keynote
- Big launch party in the evening
- Kit to send more info in next couple weeks
Kubernetes Release: 0.17.0
Release Notes:
-
Cleanups
-
v1beta3
- update example/walkthrough to v1beta3 #7940 (caesarxuchao)
- update example/rethinkdb to v1beta3 #7946 (caesarxuchao)
- verify the v1beta3 yaml files all work; merge the yaml files #7917 (caesarxuchao)
- update examples/cassandra to api v1beta3 #7258 (caesarxuchao)
- update service.json in persistent-volume example to v1beta3 #7899 (caesarxuchao)
- update mysql-wordpress example to use v1beta3 API #7864 (caesarxuchao)
- Update examples/meteor to use API v1beta3 #7848 (caesarxuchao)
- update node-selector example to API v1beta3 #7872 (caesarxuchao)
- update logging-demo to use API v1beta3; modify the way to access Elasticsearch and Kibana services #7824 (caesarxuchao)
- Convert the skydns rc to use v1beta3 and add a health check to it #7619 (a-robinson)
- update the hazelcast example to API version v1beta3 #7728 (caesarxuchao)
- Fix YAML parsing for v1beta3 objects in the kubelet for file/http #7515 (brendandburns)
- Updated kubectl cluster-info to show v1beta3 addresses #7502 (piosz)
-
Kubelet
- kubelet: Fix racy kubelet tests. #7980 (yifan-gu)
- kubelet/container: Move prober.ContainerCommandRunner to container. #8079 (yifan-gu)
- Kubelet: set host field in the pending pod status #6127 (yujuhong)
- Fix the kubelet node watch #6442 (yujuhong)
- Kubelet: recreate mirror pod if the static pod changes #6607 (yujuhong)
- Kubelet: record the timestamp correctly in the runtime cache #7749 (yujuhong)
- Kubelet: wait until container runtime is up #7729 (yujuhong)
- Kubelet: replace DockerManager with the Runtime interface #7674 (yujuhong)
- Kubelet: filter out terminated pods in SyncPods #7301 (yujuhong)
- Kubelet: parallelize cleaning up containers in unwanted pods #7048 (yujuhong)
- kubelet: Add container runtime option for rkt. #7952 (yifan-gu)
- kubelet/rkt: Remove build label. #7916 (yifan-gu)
- kubelet/metrics: Move instrumented_docker.go to dockertools. #7327 (yifan-gu)
- kubelet/rkt: Add GetPods() for rkt. #7599 (yifan-gu)
- kubelet/rkt: Add KillPod() and GetPodStatus() for rkt. #7605 (yifan-gu)
- pkg/kubelet: Fix logging. #4755 (yifan-gu)
- kubelet: Refactor RunInContainer/ExecInContainer/PortForward. #6491 (yifan-gu)
- kubelet/DockerManager: Fix returning empty error from GetPodStatus(). #6609 (yifan-gu)
- kubelet: Move pod infra container image setting to dockertools. #6634 (yifan-gu)
- kubelet/fake_docker_client: Use self's PID instead of 42 in testing. #6653 (yifan-gu)
- kubelet/dockertool: Move Getpods() to DockerManager. #6778 (yifan-gu)
- kubelet/dockertools: Add puller interfaces in the containerManager. #6776 (yifan-gu)
- kubelet: Introduce PodInfraContainerChanged(). #6608 (yifan-gu)
- kubelet/container: Replace DockerCache with RuntimeCache. #6795 (yifan-gu)
- kubelet: Clean up computePodContainerChanges. #6844 (yifan-gu)
- kubelet: Refactor prober. #7009 (yifan-gu)
- kubelet/container: Update the runtime interface. #7466 (yifan-gu)
- kubelet: Refactor isPodRunning() in runonce.go #7477 (yifan-gu)
- kubelet/rkt: Add basic rkt runtime routines. #7465 (yifan-gu)
- kubelet/rkt: Add podInfo. #7555 (yifan-gu)
- kubelet/container: Add GetContainerLogs to runtime interface. #7488 (yifan-gu)
- kubelet/rkt: Add routines for converting kubelet pod to rkt pod. #7543 (yifan-gu)
- kubelet/rkt: Add RunPod() for rkt. #7589 (yifan-gu)
- kubelet/rkt: Add RunInContainer()/ExecInContainer()/PortForward(). #7553 (yifan-gu)
- kubelet/container: Move ShouldContainerBeRestarted() to runtime. #7613 (yifan-gu)
- kubelet/rkt: Add SyncPod() to rkt. #7611 (yifan-gu)
- Kubelet: persist restart count of a container #6794 (yujuhong)
- kubelet/container: Move pty*.go to container runtime package. #7951 (yifan-gu)
- kubelet: Add container runtime option for rkt. #7900 (yifan-gu)
- kubelet/rkt: Add docker prefix to image string. #7803 (yifan-gu)
- kubelet/rkt: Inject dependencies to rkt. #7849 (yifan-gu)
- kubelet/rkt: Remove dependencies on rkt.store #7859 (yifan-gu)
- Kubelet talks securely to apiserver #2387 (erictune)
- Rename EnvVarSource.FieldPath -> FieldRef and add example #7592 (pmorie)
- Add containerized option to kubelet binary #7741 (pmorie)
- Ease building kubelet image #7948 (pmorie)
- Remove unnecessary bind-mount from dockerized kubelet run #7854 (pmorie)
- Add ability to dockerize kubelet in local cluster #7798 (pmorie)
- Create docker image for kubelet #7797 (pmorie)
- Security context - types, kubelet, admission #7343 (pweil-)
- Kubelet: Add rkt as a runtime option #7743 (vmarmol)
- Fix kubelet's docker RunInContainer implementation #7746 (vishh)
-
AWS
- AWS: Don't try to copy gce_keys in jenkins e2e job #8018 (justinsb)
- AWS: Copy some new properties from config-default => config.test #7992 (justinsb)
- AWS: make it possible to disable minion public ip assignment #7928 (manolitto)
- update AWS CloudFormation template and cloud-configs #7667 (antoineco)
- AWS: Fix variable naming that meant not all tokens were written #7736 (justinsb)
- AWS: Change apiserver to listen on 443 directly, not through nginx #7678 (justinsb)
- AWS: Improving getting existing VPC and subnet #6606 (gust1n)
- AWS EBS volume support #5138 (justinsb)
-
Introduce an 'svc' segment for DNS search #8089 (thockin)
-
Adds ability to define a prefix for etcd paths #5707 (kbeecher)
-
Add kubectl log --previous support to view last terminated container log #7973 (dchen1107)
-
Add a flag to disable legacy APIs #8083 (brendandburns)
-
make the dockerkeyring handle mutiple matching credentials #7971 (deads2k)
-
Convert Fluentd to Cloud Logging pod specs to YAML #8078 (satnam6502)
-
Use etcd to allocate PortalIPs instead of in-mem #7704 (smarterclayton)
-
eliminate auth-path #8064 (deads2k)
-
Record failure reasons for image pulling #7981 (yujuhong)
-
Rate limit replica creation #7869 (bprashanth)
-
Upgrade to Kibana 4 for cluster logging #7995 (satnam6502)
-
Added name to kube-dns service #8049 (piosz)
-
Fix validation by moving it into the resource builder. #7919 (brendandburns)
-
Add cache with multiple shards to decrease lock contention #8050 (fgrzadkowski)
-
Delete status from displayable resources #8039 (nak3)
-
Refactor volume interfaces to receive pod instead of ObjectReference #8044 (pmorie)
-
fix kube-down for provider gke #7565 (jlowdermilk)
-
Service port names are required for multi-port #7786 (thockin)
-
Increase disk size for kubernetes master. #8051 (fgrzadkowski)
-
expose: Load input object for increased safety #7774 (kargakis)
-
Improments to conversion methods generator #7896 (wojtek-t)
-
Added displaying external IPs to kubectl cluster-info #7557 (piosz)
-
Add missing Errorf formatting directives #8037 (shawnps)
-
Add startup code to apiserver to migrate etcd keys #7567 (kbeecher)
-
Use error type from docker go-client instead of string #8021 (ddysher)
-
Accurately get hardware cpu count in Vagrantfile. #8024 (BenTheElder)
-
Stop setting a GKE specific version of the kubeconfig file #7921 (roberthbailey)
-
Make the API server deal with HEAD requests via the service proxy #7950 (satnam6502)
-
GlusterFS Critical Bug Resolved - Removing warning in README #7983 (wattsteve)
-
Don't use the first token
uname -nas the hostname #7967 (yujuhong) -
Call kube-down in test-teardown for vagrant. #7982 (BenTheElder)
-
defaults_tests: verify defaults when converting to an API object #6235 (yujuhong)
-
Use the full hostname for mirror pod name. #7910 (yujuhong)
-
Removes RunPod in the Runtime interface #7657 (yujuhong)
-
Clean up dockertools/manager.go and add more unit tests #7533 (yujuhong)
-
Adapt pod killing and cleanup for generic container runtime #7525 (yujuhong)
-
Fix pod filtering in replication controller #7198 (yujuhong)
-
Print container statuses in
kubectl get pods#7116 (yujuhong) -
Prioritize deleting the non-running pods when reducing replicas #6992 (yujuhong)
-
Fix locking issue in pod manager #6872 (yujuhong)
-
Limit the number of concurrent tests in integration.go #6655 (yujuhong)
-
Fix typos in different config comments #7931 (pmorie)
-
Update cAdvisor dependency. #7929 (vmarmol)
-
Ubuntu-distro: deprecate & merge ubuntu single node work to ubuntu cluster node stuff#5498 (resouer)
-
Add control variables to Jenkins E2E script #7935 (saad-ali)
-
Check node status as part of validate-cluster.sh. #7932 (fabioy)
-
Add old endpoint cleanup function #7821 (lavalamp)
-
Support recovery from in the middle of a rename. #7620 (brendandburns)
-
Update Exec and Portforward client to use pod subresource #7715 (csrwng)
-
Added NFS to PV structs #7564 (markturansky)
-
Fix environment variable error in Vagrant docs #7904 (posita)
-
Adds a simple release-note builder that scrapes the GitHub API for recent PRs #7616(brendandburns)
-
Scheduler ignores nodes that are in a bad state #7668 (bprashanth)
-
Set GOMAXPROCS for etcd #7863 (fgrzadkowski)
-
Auto-generated conversion methods calling one another #7556 (wojtek-t)
-
Bring up a kuberenetes cluster using coreos image as worker nodes #7445 (dchen1107)
-
Godep: Add godep for rkt. #7410 (yifan-gu)
-
Add volumeGetter to rkt. #7870 (yifan-gu)
-
Update cAdvisor dependency. #7897 (vmarmol)
-
DNS: expose 53/TCP #7822 (thockin)
-
Set NodeReady=False when docker is dead #7763 (wojtek-t)
-
Ignore latency metrics for events #7857 (fgrzadkowski)
-
SecurityContext admission clean up #7792 (pweil-)
-
Support manually-created and generated conversion functions #7832 (wojtek-t)
-
Add latency metrics for etcd operations #7833 (fgrzadkowski)
-
Update errors_test.go #7885 (hurf)
-
Change signature of container runtime PullImage to allow pull w/ secret #7861 (pmorie)
-
Fix bug in Service documentation: incorrect location of "selector" in JSON [#7873]146
-
Fix controller-manager manifest for providers that don't specify CLUSTER_IP_RANGE[#7876][147] (cjcullen)
-
Fix controller unittests [#7867][148] (bprashanth)
-
Enable GCM and GCL instead of InfluxDB on GCE [#7751][149] (saad-ali)
-
Remove restriction that cluster-cidr be a class-b [#7862][150] (cjcullen)
-
Fix OpenShift example [#7591][151] (derekwaynecarr)
-
API Server - pass path name in context of create request for subresource [#7718][152] (csrwng)
-
Rolling Updates: Add support for --rollback. [#7575][153] (brendandburns)
-
Update to container-vm-v20150505 (Also updates GCE to Docker 1.6) [#7820][154] (zmerlynn)
-
Fix metric label [#7830][155] (rhcarvalho)
-
Fix v1beta1 typos in v1beta2 conversions [#7838][156] (pmorie)
-
skydns: use the etcd-2.x native syntax, enable IANA attributed ports. [#7764]157
-
Added port 6443 to kube-proxy default IP address for api-server [#7794][158] (markllama)
-
Added client header info for authentication doc. [#7834][159] (ashcrow)
-
Clean up safe_format_and_mount spam in the startup logs [#7827][160] (zmerlynn)
-
Set allocate_node_cidrs to be blank by default. [#7829][161] (roberthbailey)
-
Fix sync problems in [#5246][162] [#7799][163] (cjcullen)
-
Fix event doc link [#7823][164] (saad-ali)
-
Cobra update and bash completions fix [#7776][165] (eparis)
-
Fix kube2sky flakes. Fix tools.GetEtcdVersion to work with etcd > 2.0.7 [#7675][166] (cjcullen)
-
Change kube2sky to use token-system-dns secret, point at https endpoint ... [#7154]167
-
replica: serialize created-by reference [#7468][168] (simon3z)
-
Inject mounter into volume plugins [#7702][169] (pmorie)
-
bringing CoreOS cloud-configs up-to-date (against 0.15.x and latest OS' alpha) [#6973]170
-
Update kubeconfig-file doc. [#7787][171] (jlowdermilk)
-
Throw an API error when deleting namespace in termination [#7780][172] (derekwaynecarr)
-
Fix command field PodExecOptions [#7773][173] (csrwng)
-
Start ImageManager housekeeping in Run(). [#7785][174] (vmarmol)
-
fix DeepCopy to properly support runtime.EmbeddedObject [#7769][175] (deads2k)
-
fix master service endpoint system for multiple masters [#7273][176] (lavalamp)
-
Add genbashcomp to KUBE_TEST_TARGETS [#7757][177] (nak3)
-
Change the cloud provider TCPLoadBalancerExists function to GetTCPLoadBalancer...[#7669][178] (a-robinson)
-
Add containerized option to kubelet binary [#7772][179] (pmorie)
-
Fix swagger spec [#7779][180] (pmorie)
-
FIX: Issue [#7750][181] - Hyperkube docker image needs certificates to connect to cloud-providers[#7755][182] (viklas)
-
Add build labels to rkt [#7752][183] (vmarmol)
-
Check license boilerplate for python files [#7672][184] (eparis)
-
Reliable updates in rollingupdate [#7705][185] (bprashanth)
-
Don't exit abruptly if there aren't yet any minions right after the cluster is created. [#7650]186
-
Make changes suggested in [#7675][166] [#7742][187] (cjcullen)
-
A guide to set up kubernetes multiple nodes cluster with flannel on fedora [#7357]188
-
Setup generators in factory [#7760][189] (kargakis)
-
Reduce usage of time.After [#7737][190] (lavalamp)
-
Remove node status from "componentstatuses" call. [#7735][191] (fabioy)
-
React to failure by growing the remaining clusters [#7614][192] (tamsky)
-
Fix typo in runtime_cache.go [#7725][193] (pmorie)
-
Update non-GCE Salt distros to 1.6.0, fallback to ContainerVM Docker version on GCE[#7740][194] (zmerlynn)
-
Skip SaltStack install if it's already installed [#7744][195] (zmerlynn)
-
Expose pod name as a label on containers. [#7712][196] (rjnagal)
-
Log which SSH key is used in e2e SSH test [#7732][197] (mbforbes)
-
Add a central simple getting started guide with kubernetes guide. [#7649][198] (brendandburns)
-
Explicitly state the lack of support for 'Requests' for the purposes of scheduling [#7443]199
-
Select IPv4-only from host interfaces [#7721][200] (smarterclayton)
-
Metrics tests can't run on Mac [#7723][201] (smarterclayton)
-
Add step to API changes doc for swagger regen [#7727][202] (pmorie)
-
Add NsenterMounter mount implementation [#7703][203] (pmorie)
-
add StringSet.HasAny [#7509][204] (deads2k)
-
Add an integration test that checks for the metrics we expect to be exported from the master [#6941][205] (a-robinson)
-
Minor bash update found by shellcheck.net [#7722][206] (eparis)
-
Add --hostport to run-container. [#7536][207] (rjnagal)
-
Have rkt implement the container Runtime interface [#7659][208] (vmarmol)
-
Change the order the different versions of API are registered [#7629][209] (caesarxuchao)
-
expose: Create objects in a generic way [#7699][210] (kargakis)
-
Requeue rc if a single get/put retry on status.Replicas fails [#7643][211] (bprashanth)
-
logs for master components [#7316][212] (ArtfulCoder)
-
cloudproviders: add ovirt getting started guide [#7522][213] (simon3z)
-
Make rkt-install a oneshot. [#7671][214] (vmarmol)
-
Provide container_runtime flag to Kubelet in CoreOS. [#7665][215] (vmarmol)
-
Boilerplate speedup [#7654][216] (eparis)
-
Log host for failed pod in Density test [#7700][217] (wojtek-t)
-
Removes spurious quotation mark [#7655][218] (alindeman)
-
Add kubectl_label to custom functions in bash completion [#7694][219] (nak3)
-
Enable profiling in kube-controller [#7696][220] (wojtek-t)
-
Set vagrant test cluster default NUM_MINIONS=2 [#7690][221] (BenTheElder)
-
Add metrics to measure cache hit ratio [#7695][222] (fgrzadkowski)
-
Change IP to IP(S) in service columns for kubectl get [#7662][223] (jlowdermilk)
-
annotate required flags for bash_completions [#7076][224] (eparis)
-
(minor) Add pgrep debugging to etcd error [#7685][225] (jayunit100)
-
Fixed nil pointer issue in describe when volume is unbound [#7676][226] (markturansky)
-
Removed unnecessary closing bracket [#7691][227] (piosz)
-
Added TerminationGracePeriod field to PodSpec and grace-period flag to kubectl stop[#7432][228] (piosz)
-
Fix boilerplate in test/e2e/scale.go [#7689][229] (wojtek-t)
-
Update expiration timeout based on observed latencies [#7628][230] (bprashanth)
-
Output generated conversion functions/names [#7644][231] (liggitt)
-
Moved the Scale tests into a scale file. [#7645][232] [#7646][233] (rrati)
-
Truncate GCE load balancer names to 63 chars [#7609][234] (brendandburns)
-
Add SyncPod() and remove Kill/Run InContainer(). [#7603][235] (vmarmol)
-
Merge release 0.16 to master [#7663][236] (brendandburns)
-
Update license boilerplate for examples/rethinkdb [#7637][237] (eparis)
-
First part of improved rolling update, allow dynamic next replication controller generation.[#7268][238] (brendandburns)
-
Add license boilerplate to examples/phabricator [#7638][239] (eparis)
-
Use generic copyright holder name in license boilerplate [#7597][240] (eparis)
-
Retry incrementing quota if there is a conflict [#7633][241] (derekwaynecarr)
-
Remove GetContainers from Runtime interface [#7568][242] (yujuhong)
-
Add image-related methods to DockerManager [#7578][243] (yujuhong)
-
Remove more docker references in kubelet [#7586][244] (yujuhong)
-
Add KillContainerInPod in DockerManager [#7601][245] (yujuhong)
-
Kubelet: Add container runtime option. [#7652][246] (vmarmol)
-
bump heapster to v0.11.0 and grafana to v0.7.0 [#7626][247] (idosh)
-
Build github.com/onsi/ginkgo/ginkgo as a part of the release [#7593][248] (ixdy)
-
Do not automatically decode runtime.RawExtension [#7490][249] (smarterclayton)
-
Update changelog. [#7500][250] (brendandburns)
-
Add SyncPod() to DockerManager and use it in Kubelet [#7610][251] (vmarmol)
-
Build: Push .md5 and .sha1 files for every file we push to GCS [#7602][252] (zmerlynn)
-
Fix rolling update --image [#7540][253] (bprashanth)
-
Update license boilerplate for docs/man/md2man-all.sh [#7636][254] (eparis)
-
Include shell license boilerplate in examples/k8petstore [#7632][255] (eparis)
-
Add --cgroup_parent flag to Kubelet to set the parent cgroup for pods [#7277][256] (guenter)
-
change the current dir to the config dir [#7209][257] (you-n-g)
-
Set Weave To 0.9.0 And Update Etcd Configuration For Azure [#7158][258] (idosh)
-
Augment describe to search for matching things if it doesn't match the original resource.[#7467][259] (brendandburns)
-
Add a simple cache for objects stored in etcd. [#7559][260] (fgrzadkowski)
-
Rkt gc [#7549][261] (yifan-gu)
-
Rkt pull [#7550][262] (yifan-gu)
-
Implement Mount interface using mount(8) and umount(8) [#6400][263] (ddysher)
-
Trim Fleuntd tag for Cloud Logging [#7588][264] (satnam6502)
-
GCE CoreOS cluster - set master name based on variable [#7569][265] (bakins)
-
Capitalization of KubeProxyVersion wrong in JSON [#7535][266] (smarterclayton)
-
Make nodes report their external IP rather than the master's. [#7530][267] (mbforbes)
-
Trim cluster log tags to pod name and container name [#7539][268] (satnam6502)
-
Handle conversion of boolean query parameters with a value of "false" [#7541][269] (csrwng)
-
Add image-related methods to Runtime interface. [#7532][270] (vmarmol)
-
Test whether auto-generated conversions weren't manually edited [#7560][271] (wojtek-t)
-
Mention :latest behavior for image version tag [#7484][272] (colemickens)
-
readinessProbe calls livenessProbe.Exec.Command which cause "invalid memory address or nil pointer dereference". [#7487][273] (njuicsgz)
-
Add RuntimeHooks to abstract Kubelet logic [#7520][274] (vmarmol)
-
Expose URL() on Request to allow building URLs [#7546][275] (smarterclayton)
-
Add a simple cache for objects stored in etcd [#7288][276] (fgrzadkowski)
-
Prepare for chaining autogenerated conversion methods [#7431][277] (wojtek-t)
-
Increase maxIdleConnection limit when creating etcd client in apiserver. [#7353][278] (wojtek-t)
-
Improvements to generator of conversion methods. [#7354][279] (wojtek-t)
-
Code to automatically generate conversion methods [#7107][280] (wojtek-t)
-
Support recovery for anonymous roll outs [#7407][281] (brendandburns)
-
Bump kube2sky to 1.2. Point it at https endpoint (3rd try). [#7527][282] (cjcullen)
-
cluster/gce/coreos: Add metadata-service in node.yaml [#7526][283] (yifan-gu)
-
Move ComputePodChanges to the Docker runtime [#7480][284] (vmarmol)
-
Cobra rebase [#7510][285] (eparis)
-
Adding system oom events from kubelet [#6718][286] (vishh)
-
Move Prober to its own subpackage [#7479][287] (vmarmol)
-
Fix parallel-e2e.sh to work on my macbook (bash v3.2) [#7513][288] (cjcullen)
-
Move network plugin TearDown to DockerManager [#7449][289] (vmarmol)
-
Fixes [#7498][290] - CoreOS Getting Started Guide had invalid cloud config [#7499][291] (elsonrodriguez)
-
Fix invalid character '"' after object key:value pair [#7504][292] (resouer)
-
Fixed kubelet deleting data from volumes on stop ([#7317][293]). [#7503][294] (jsafrane)
-
Fixing hooks/description to catch API fields without description tags [#7482][295] (nikhiljindal)
-
cadvisor is obsoleted so kubelet service does not require it. [#7457][296] (aveshagarwal)
-
Set the default namespace for events to be "default" [#7408][297] (vishh)
-
Fix typo in namespace conversion [#7446][298] (liggitt)
-
Convert Secret registry to use update/create strategy, allow filtering by Type [#7419][299] (liggitt)
-
Use pod namespace when looking for its GlusterFS endpoints. [#7102][300] (jsafrane)
-
Fixed name of kube-proxy path in deployment scripts. [#7427][301] (jsafrane)
To download, please visit https://github.com/GoogleCloudPlatform/kubernetes/releases/tag/v0.17.0
Simple theme. Powered by [Blogger][385].
[ ![][327] ][386]
[146]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7873 "Fix bug in Service documentation: incorrect location of "selector" in JSON" [147]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7876 "Fix controller-manager manifest for providers that don't specify CLUSTER_IP_RANGE" [148]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7867 "Fix controller unittests" [149]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7751 "Enable GCM and GCL instead of InfluxDB on GCE" [150]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7862 "Remove restriction that cluster-cidr be a class-b" [151]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7591 "Fix OpenShift example" [152]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7718 "API Server - pass path name in context of create request for subresource" [153]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7575 "Rolling Updates: Add support for --rollback." [154]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7820 "Update to container-vm-v20150505 (Also updates GCE to Docker 1.6)" [155]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7830 "Fix metric label" [156]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7838 "Fix v1beta1 typos in v1beta2 conversions" [157]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7764 "skydns: use the etcd-2.x native syntax, enable IANA attributed ports." [158]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7794 "Added port 6443 to kube-proxy default IP address for api-server" [159]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7834 "Added client header info for authentication doc." [160]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7827 "Clean up safe_format_and_mount spam in the startup logs" [161]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7829 "Set allocate_node_cidrs to be blank by default." [162]: https://github.com/GoogleCloudPlatform/kubernetes/pull/5246 "Make nodecontroller configure nodes' pod IP ranges" [163]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7799 "Fix sync problems in #5246" [164]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7823 "Fix event doc link" [165]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7776 "Cobra update and bash completions fix" [166]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7675 "Fix kube2sky flakes. Fix tools.GetEtcdVersion to work with etcd > 2.0.7" [167]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7154 "Change kube2sky to use token-system-dns secret, point at https endpoint ..." [168]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7468 "replica: serialize created-by reference" [169]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7702 "Inject mounter into volume plugins" [170]: https://github.com/GoogleCloudPlatform/kubernetes/pull/6973 "bringing CoreOS cloud-configs up-to-date (against 0.15.x and latest OS' alpha) " [171]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7787 "Update kubeconfig-file doc." [172]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7780 "Throw an API error when deleting namespace in termination" [173]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7773 "Fix command field PodExecOptions" [174]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7785 "Start ImageManager housekeeping in Run()." [175]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7769 "fix DeepCopy to properly support runtime.EmbeddedObject" [176]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7273 "fix master service endpoint system for multiple masters" [177]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7757 "Add genbashcomp to KUBE_TEST_TARGETS" [178]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7669 "Change the cloud provider TCPLoadBalancerExists function to GetTCPLoadBalancer..." [179]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7772 "Add containerized option to kubelet binary" [180]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7779 "Fix swagger spec" [181]: https://github.com/GoogleCloudPlatform/kubernetes/issues/7750 "Hyperkube image requires root certificates to work with cloud-providers (at least AWS)" [182]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7755 "FIX: Issue #7750 - Hyperkube docker image needs certificates to connect to cloud-providers" [183]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7752 "Add build labels to rkt" [184]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7672 "Check license boilerplate for python files" [185]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7705 "Reliable updates in rollingupdate" [186]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7650 "Don't exit abruptly if there aren't yet any minions right after the cluster is created." [187]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7742 "Make changes suggested in #7675" [188]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7357 "A guide to set up kubernetes multiple nodes cluster with flannel on fedora" [189]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7760 "Setup generators in factory" [190]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7737 "Reduce usage of time.After" [191]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7735 "Remove node status from "componentstatuses" call." [192]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7614 "React to failure by growing the remaining clusters" [193]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7725 "Fix typo in runtime_cache.go" [194]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7740 "Update non-GCE Salt distros to 1.6.0, fallback to ContainerVM Docker version on GCE" [195]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7744 "Skip SaltStack install if it's already installed" [196]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7712 "Expose pod name as a label on containers." [197]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7732 "Log which SSH key is used in e2e SSH test" [198]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7649 "Add a central simple getting started guide with kubernetes guide." [199]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7443 "Explicitly state the lack of support for 'Requests' for the purposes of scheduling" [200]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7721 "Select IPv4-only from host interfaces" [201]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7723 "Metrics tests can't run on Mac" [202]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7727 "Add step to API changes doc for swagger regen" [203]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7703 "Add NsenterMounter mount implementation" [204]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7509 "add StringSet.HasAny" [205]: https://github.com/GoogleCloudPlatform/kubernetes/pull/6941 "Add an integration test that checks for the metrics we expect to be exported from the master" [206]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7722 "Minor bash update found by shellcheck.net" [207]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7536 "Add --hostport to run-container." [208]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7659 "Have rkt implement the container Runtime interface" [209]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7629 "Change the order the different versions of API are registered " [210]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7699 "expose: Create objects in a generic way" [211]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7643 "Requeue rc if a single get/put retry on status.Replicas fails" [212]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7316 "logs for master components" [213]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7522 "cloudproviders: add ovirt getting started guide" [214]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7671 "Make rkt-install a oneshot." [215]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7665 "Provide container_runtime flag to Kubelet in CoreOS." [216]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7654 "Boilerplate speedup" [217]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7700 "Log host for failed pod in Density test" [218]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7655 "Removes spurious quotation mark" [219]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7694 "Add kubectl_label to custom functions in bash completion" [220]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7696 "Enable profiling in kube-controller" [221]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7690 "Set vagrant test cluster default NUM_MINIONS=2" [222]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7695 "Add metrics to measure cache hit ratio" [223]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7662 "Change IP to IP(S) in service columns for kubectl get" [224]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7076 "annotate required flags for bash_completions" [225]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7685 "(minor) Add pgrep debugging to etcd error" [226]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7676 "Fixed nil pointer issue in describe when volume is unbound" [227]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7691 "Removed unnecessary closing bracket" [228]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7432 "Added TerminationGracePeriod field to PodSpec and grace-period flag to kubectl stop" [229]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7689 "Fix boilerplate in test/e2e/scale.go" [230]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7628 "Update expiration timeout based on observed latencies" [231]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7644 "Output generated conversion functions/names" [232]: https://github.com/GoogleCloudPlatform/kubernetes/issues/7645 "Move the scale tests into a separate file" [233]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7646 "Moved the Scale tests into a scale file. #7645" [234]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7609 "Truncate GCE load balancer names to 63 chars" [235]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7603 "Add SyncPod() and remove Kill/Run InContainer()." [236]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7663 "Merge release 0.16 to master" [237]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7637 "Update license boilerplate for examples/rethinkdb" [238]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7268 "First part of improved rolling update, allow dynamic next replication controller generation." [239]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7638 "Add license boilerplate to examples/phabricator" [240]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7597 "Use generic copyright holder name in license boilerplate" [241]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7633 "Retry incrementing quota if there is a conflict" [242]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7568 "Remove GetContainers from Runtime interface" [243]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7578 "Add image-related methods to DockerManager" [244]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7586 "Remove more docker references in kubelet" [245]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7601 "Add KillContainerInPod in DockerManager" [246]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7652 "Kubelet: Add container runtime option." [247]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7626 "bump heapster to v0.11.0 and grafana to v0.7.0" [248]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7593 "Build github.com/onsi/ginkgo/ginkgo as a part of the release" [249]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7490 "Do not automatically decode runtime.RawExtension" [250]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7500 "Update changelog." [251]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7610 "Add SyncPod() to DockerManager and use it in Kubelet" [252]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7602 "Build: Push .md5 and .sha1 files for every file we push to GCS" [253]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7540 "Fix rolling update --image " [254]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7636 "Update license boilerplate for docs/man/md2man-all.sh" [255]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7632 "Include shell license boilerplate in examples/k8petstore" [256]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7277 "Add --cgroup_parent flag to Kubelet to set the parent cgroup for pods" [257]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7209 "change the current dir to the config dir" [258]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7158 "Set Weave To 0.9.0 And Update Etcd Configuration For Azure" [259]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7467 "Augment describe to search for matching things if it doesn't match the original resource." [260]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7559 "Add a simple cache for objects stored in etcd." [261]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7549 "Rkt gc" [262]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7550 "Rkt pull" [263]: https://github.com/GoogleCloudPlatform/kubernetes/pull/6400 "Implement Mount interface using mount(8) and umount(8)" [264]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7588 "Trim Fleuntd tag for Cloud Logging" [265]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7569 "GCE CoreOS cluster - set master name based on variable" [266]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7535 "Capitalization of KubeProxyVersion wrong in JSON" [267]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7530 "Make nodes report their external IP rather than the master's." [268]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7539 "Trim cluster log tags to pod name and container name" [269]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7541 "Handle conversion of boolean query parameters with a value of "false"" [270]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7532 "Add image-related methods to Runtime interface." [271]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7560 "Test whether auto-generated conversions weren't manually edited" [272]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7484 "Mention :latest behavior for image version tag" [273]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7487 "readinessProbe calls livenessProbe.Exec.Command which cause "invalid memory address or nil pointer dereference"." [274]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7520 "Add RuntimeHooks to abstract Kubelet logic" [275]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7546 "Expose URL() on Request to allow building URLs" [276]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7288 "Add a simple cache for objects stored in etcd" [277]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7431 "Prepare for chaining autogenerated conversion methods " [278]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7353 "Increase maxIdleConnection limit when creating etcd client in apiserver." [279]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7354 "Improvements to generator of conversion methods." [280]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7107 "Code to automatically generate conversion methods" [281]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7407 "Support recovery for anonymous roll outs" [282]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7527 "Bump kube2sky to 1.2. Point it at https endpoint (3rd try)." [283]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7526 "cluster/gce/coreos: Add metadata-service in node.yaml" [284]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7480 "Move ComputePodChanges to the Docker runtime" [285]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7510 "Cobra rebase" [286]: https://github.com/GoogleCloudPlatform/kubernetes/pull/6718 "Adding system oom events from kubelet" [287]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7479 "Move Prober to its own subpackage" [288]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7513 "Fix parallel-e2e.sh to work on my macbook (bash v3.2)" [289]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7449 "Move network plugin TearDown to DockerManager" [290]: https://github.com/GoogleCloudPlatform/kubernetes/issues/7498 "CoreOS Getting Started Guide not working" [291]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7499 "Fixes #7498 - CoreOS Getting Started Guide had invalid cloud config" [292]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7504 "Fix invalid character '"' after object key:value pair" [293]: https://github.com/GoogleCloudPlatform/kubernetes/issues/7317 "GlusterFS Volume Plugin deletes the contents of the mounted volume upon Pod deletion" [294]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7503 "Fixed kubelet deleting data from volumes on stop (#7317)." [295]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7482 "Fixing hooks/description to catch API fields without description tags" [296]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7457 "cadvisor is obsoleted so kubelet service does not require it." [297]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7408 "Set the default namespace for events to be "default"" [298]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7446 "Fix typo in namespace conversion" [299]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7419 "Convert Secret registry to use update/create strategy, allow filtering by Type" [300]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7102 "Use pod namespace when looking for its GlusterFS endpoints." [301]: https://github.com/GoogleCloudPlatform/kubernetes/pull/7427 "Fixed name of kube-proxy path in deployment scripts." [
Resource Usage Monitoring in Kubernetes
Understanding how an application behaves when deployed is crucial to scaling the application and providing a reliable service. In a Kubernetes cluster, application performance can be examined at many different levels: containers, pods, services, and whole clusters. As part of Kubernetes we want to provide users with detailed resource usage information about their running applications at all these levels. This will give users deep insights into how their applications are performing and where possible application bottlenecks may be found. In comes Heapster, a project meant to provide a base monitoring platform on Kubernetes.
Overview
Heapster is a cluster-wide aggregator of monitoring and event data. It currently supports Kubernetes natively and works on all Kubernetes setups. Heapster runs as a pod in the cluster, similar to how any Kubernetes application would run. The Heapster pod discovers all nodes in the cluster and queries usage information from the nodes’ Kubelets, the on-machine Kubernetes agent. The Kubelet itself fetches the data from cAdvisor. Heapster groups the information by pod along with the relevant labels. This data is then pushed to a configurable backend for storage and visualization. Currently supported backends include InfluxDB (with Grafana for visualization), Google Cloud Monitoring and many others described in more details here. The overall architecture of the service can be seen below:

Let’s look at some of the other components in more detail.
cAdvisor
cAdvisor is an open source container resource usage and performance analysis agent. It is purpose built for containers and supports Docker containers natively. In Kubernetes, cadvisor is integrated into the Kubelet binary. cAdvisor auto-discovers all containers in the machine and collects CPU, memory, filesystem, and network usage statistics. cAdvisor also provides the overall machine usage by analyzing the ‘root’? container on the machine.
On most Kubernetes clusters, cAdvisor exposes a simple UI for on-machine containers on port 4194. Here is a snapshot of part of cAdvisor’s UI that shows the overall machine usage:

Kubelet
The Kubelet acts as a bridge between the Kubernetes master and the nodes. It manages the pods and containers running on a machine. Kubelet translates each pod into its constituent containers and fetches individual container usage statistics from cAdvisor. It then exposes the aggregated pod resource usage statistics via a REST API.
STORAGE BACKENDS
InfluxDB and Grafana
A Grafana setup with InfluxDB is a very popular combination for monitoring in the open source world. InfluxDB exposes an easy to use API to write and fetch time series data. Heapster is setup to use this storage backend by default on most Kubernetes clusters. A detailed setup guide can be found here. InfluxDB and Grafana run in Pods. The pod exposes itself as a Kubernetes service which is how Heapster discovers it.
The Grafana container serves Grafana’s UI which provides an easy to configure dashboard interface. The default dashboard for Kubernetes contains an example dashboard that monitors resource usage of the cluster and the pods inside of it. This dashboard can easily be customized and expanded. Take a look at the storage schema for InfluxDB here.
Here is a video showing how to monitor a Kubernetes cluster using heapster, InfluxDB and Grafana:

Here is a snapshot of the default Kubernetes Grafana dashboard that shows the CPU and Memory usage of the entire cluster, individual pods and containers:

Google Cloud Monitoring
Google Cloud Monitoring is a hosted monitoring service that allows you to visualize and alert on important metrics in your application. Heapster can be setup to automatically push all collected metrics to Google Cloud Monitoring. These metrics are then available in the Cloud Monitoring Console. This storage backend is the easiest to setup and maintain. The monitoring console allows you to easily create and customize dashboards using the exported data.
Here is a video showing how to setup and run a Google Cloud Monitoring backed Heapster: "https://youtube.com/embed/xSMNR2fcoLs" Here is a snapshot of the a Google Cloud Monitoring dashboard showing cluster-wide resource usage.

Try it out!
Now that you’ve learned a bit about Heapster, feel free to try it out on your own clusters! The Heapster repository is available on GitHub. It contains detailed instructions to setup Heapster and its storage backends. Heapster runs by default on most Kubernetes clusters, so you may already have it! Feedback is always welcome. Please let us know if you run into any issues via the troubleshooting channels.
-- Vishnu Kannan and Victor Marmol, Google Software Engineers
Kubernetes Release: 0.16.0
Release Notes:
- Bring up a kuberenetes cluster using coreos image as worker nodes #7445 (dchen1107)
- Cloning v1beta3 as v1 and exposing it in the apiserver #7454 (nikhiljindal)
- API Conventions for Late-initializers #7366 (erictune)
- Upgrade Elasticsearch to 1.5.2 for cluster logging #7455 (satnam6502)
- Make delete actually stop resources by default. #7210 (brendandburns)
- Change kube2sky to use token-system-dns secret, point at https endpoint ... #7154(cjcullen)
- Updated CoreOS bare metal docs for 0.15.0 #7364 (hvolkmer)
- Print named ports in 'describe service' #7424 (thockin)
- AWS
- Return public & private addresses in GetNodeAddresses #7040 (justinsb)
- Improving getting existing VPC and subnet #6606 (gust1n)
- Set hostname_override for minions, back to fully-qualified name #7182 (justinsb)
- Conversion to v1beta3
- Convert node level logging agents to v1beta3 #7274 (satnam6502)
- Removing more references to v1beta1 from pkg/ #7128 (nikhiljindal)
- update examples/cassandra to api v1beta3 #7258 (caesarxuchao)
- Convert Elasticsearch logging to v1beta3 and de-salt #7246 (satnam6502)
- Update examples/storm for v1beta3 #7231 (bcbroussard)
- Update examples/spark for v1beta3 #7230 (bcbroussard)
- Update Kibana RC and service to v1beta3 #7240 (satnam6502)
- Updating the guestbook example to v1beta3 #7194 (nikhiljindal)
- Update Phabricator to v1beta3 example #7232 (bcbroussard)
- Update Kibana pod to speak to Elasticsearch using v1beta3 #7206 (satnam6502)
- Validate Node IPs; clean up validation code #7180 (ddysher)
- Add PortForward to runtime API. #7391 (vmarmol)
- kube-proxy uses token to access port 443 of apiserver #7303 (erictune)
- Move the logging-related directories to where I think they belong #7014 (a-robinson)
- Make client service requests use the default timeout now that external load balancers are created asynchronously #6870 (a-robinson)
- Fix bug in kube-proxy of not updating iptables rules if a service's public IPs change #6123(a-robinson)
- PersistentVolumeClaimBinder #6105 (markturansky)
- Fixed validation message when trying to submit incorrect secret #7356 (soltysh)
- First step to supporting multiple k8s clusters #6006 (justinsb)
- Parity for namespace handling in secrets E2E #7361 (pmorie)
- Add cleanup policy to RollingUpdater #6996 (ironcladlou)
- Use narrowly scoped interfaces for client access #6871 (ironcladlou)
- Warning about Critical bug in the GlusterFS Volume Plugin #7319 (wattsteve)
- Rolling update
- First part of improved rolling update, allow dynamic next replication controller generation. #7268 (brendandburns)
- Further implementation of rolling-update, add rename #7279 (brendandburns)
- Added basic apiserver authz tests. #7293 (ashcrow)
- Retry pod update on version conflict error in e2e test. #7297 (quinton-hoole)
- Add "kubectl validate" command to do a cluster health check. #6597 (fabioy)
- coreos/azure: Weave version bump, various other enhancements #7224 (errordeveloper)
- Azure: Wait for salt completion on cluster initialization #6576 (jeffmendoza)
- Tighten label parsing #6674 (kargakis)
- fix watch of single object #7263 (lavalamp)
- Upgrade go-dockerclient dependency to support CgroupParent #7247 (guenter)
- Make secret volume plugin idempotent #7166 (pmorie)
- Salt reconfiguration to get rid of nginx on GCE #6618 (roberthbailey)
- Revert "Change kube2sky to use token-system-dns secret, point at https e... #7207 (fabioy)
- Pod templates as their own type #5012 (smarterclayton)
- iscsi Test: Add explicit check for attach and detach calls. #7110 (swagiaal)
- Added field selector for listing pods #7067 (ravigadde)
- Record an event on node schedulable changes #7138 (pravisankar)
- Resolve #6812, limit length of load balancer names #7145 (caesarxuchao)
- Convert error strings to proper validation errors. #7131 (rjnagal)
- ResourceQuota add object count support for secret and volume claims #6593(derekwaynecarr)
- Use Pod.Spec.Host instead of Pod.Status.HostIP for pod subresources #6985 (csrwng)
- Prioritize deleting the non-running pods when reducing replicas #6992 (yujuhong)
- Kubernetes UI with Dashboard component #7056 (preillyme)
To download, please visit https://github.com/GoogleCloudPlatform/kubernetes/releases/tag/v0.16.0
Weekly Kubernetes Community Hangout Notes - May 1 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
-
Simple rolling update - Brendan
-
Rolling update = nice example of why RCs and Pods are good.
-
...pause… (Brendan needs demo recovery tips from Kelsey)
-
Rolling update has recovery: Cancel update and restart, update continues from where it stopped.
-
New controller gets name of old controller, so appearance is pure update.
-
Can also name versions in update (won't do rename at the end).
-
-
Rocket demo - CoreOS folks
-
2 major differences between rocket & docker: Rocket is daemonless & pod-centric.
-
Rocket has AppContainer format as native, but also supports docker image format.
-
Can run AppContainer and docker containers in same pod.
-
Changes are close to merged.
-
-
demo service accounts and secrets being added to pods - Jordan
-
Problem: It's hard to get a token to talk to the API.
-
New API object: "ServiceAccount"
-
ServiceAccount is namespaced, controller makes sure that at least 1 default service account exists in a namespace.
-
Typed secret "ServiceAccountToken", controller makes sure there is at least 1 default token.
-
DEMO
-
* Can create new service account with ServiceAccountToken. Controller will create token for it. -
Can create a pod with service account, pods will have service account secret mounted at /var/run/secrets/kubernetes.io/…
-
-
Kubelet running in a container - Paul
- Kubelet successfully ran pod w/ mounted secret.
AppC Support for Kubernetes through RKT
We very recently accepted a pull request to the Kubernetes project to add appc support for the Kubernetes community. Appc is a new open container specification that was initiated by CoreOS, and is supported through CoreOS rkt container runtime.
This is an important step forward for the Kubernetes project and for the broader containers community. It adds flexibility and choice to the container-verse and brings the promise of compelling new security and performance capabilities to the Kubernetes developer.
Container based runtimes (like Docker or rkt) when paired with smart orchestration technologies (like Kubernetes and/or Apache Mesos) are a legitimate disruption to the way that developers build and run their applications. While the supporting technologies are relatively nascent, they do offer the promise of some very powerful new ways to assemble, deploy, update, debug and extend solutions. I believe that the world has not yet felt the full potential of containers and the next few years are going to be particularly exciting! With that in mind it makes sense for several projects to emerge with different properties and different purposes. It also makes sense to be able to plug together different pieces (whether it be the container runtime or the orchestrator) based on the specific needs of a given application.
Docker has done an amazing job of democratizing container technologies and making them accessible to the outside world, and we expect Kubernetes to support Docker indefinitely. CoreOS has also started to do interesting work with rkt to create an elegant, clean, simple and open platform that offers some really interesting properties. It looks poised deliver a secure and performant operating environment for containers. The Kubernetes team has been working with the appc team at CoreOS for a while and in many ways they built rkt with Kubernetes in mind as a simple pluggable runtime component.
The really nice thing is that with Kubernetes you can now pick the container runtime that works best for you based on your workloads’ needs, change runtimes without having the replace your cluster environment, or even mix together applications where different parts are running in different container runtimes in the same cluster. Additional choices can’t help but ultimately benefit the end developer.
-- Craig McLuckie
Google Product Manager and Kubernetes co-founder
Weekly Kubernetes Community Hangout Notes - April 24 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Agenda:
- Flocker and Kubernetes integration demo
Notes:
- flocker and kubernetes integration demo
-
-
Flocker Q/A
-
Does the file still exists on node1 after migration?
-
Brendan: Any plan this to make it a volume? So we don't need powerstrip?
-
Luke: Need to figure out interest to decide if we want to make it a first-class persistent disk provider in kube.
-
Brendan: Removing need for powerstrip would make it simple to use. Totally go for it.
-
Tim: Should take no more than 45 minutes to add it to kubernetes:)
-
-
Derek: Contrast this with persistent volumes and claims?
-
Luke: Not much difference, except for the novel ZFS based backend. Makes workloads really portable.
-
Tim: very different than network-based volumes. Its interesting that it is the only offering that allows upgrading media.
-
Brendan: claims, how does it look for replicated claims? eg Cassandra wants to have replicated data underneath. It would be efficient to scale up and down. Create storage on the fly based on load dynamically. Its step beyond taking snapshots - programmatically creating replicas with preallocation.
-
Tim: helps with auto-provisioning.
-
-
Brian: Does flocker requires any other component?
-
Kai: Flocker control service co-located with the master. (dia on blog post). Powerstrip + Powerstrip Flocker. Very interested in mpersisting state in etcd. It keeps metadata about each volume.
-
Brendan: In future, flocker can be a plugin and we'll take care of persistence. Post v1.0.
-
Brian: Interested in adding generic plugin for services like flocker.
-
Luke: Zfs can become really valuable when scaling to lot of containers on a single node.
-
-
Alex: Can flocker service can be run as a pod?
-
Kai: Yes, only requirement is the flocker control service should be able to talk to zfs agent. zfs agent needs to be installed on the host and zfs binaries need to be accessible.
-
Brendan: In theory, all zfs bits can be put it into a container with devices.
-
Luke: Yes, still working through cross-container mounting issue.
-
Tim: pmorie is working through it to make kubelet work in a container. Possible re-use.
-
-
Kai: Cinder support is coming. Few days away.
-
-
- Bob: What's the process of pushing kube to GKE? Need more visibility for confidence.
Borg: The Predecessor to Kubernetes
Google has been running containerized workloads in production for more than a decade. Whether it's service jobs like web front-ends and stateful servers, infrastructure systems like Bigtable and Spanner, or batch frameworks like MapReduce and Millwheel, virtually everything at Google runs as a container. Today, we took the wraps off of Borg, Google’s long-rumored internal container-oriented cluster-management system, publishing details at the academic computer systems conference Eurosys. You can find the paper here.
Kubernetes traces its lineage directly from Borg. Many of the developers at Google working on Kubernetes were formerly developers on the Borg project. We've incorporated the best ideas from Borg in Kubernetes, and have tried to address some pain points that users identified with Borg over the years.
To give you a flavor, here are four Kubernetes features that came from our experiences with Borg:
- Pods. A pod is the unit of scheduling in Kubernetes. It is a resource envelope in which one or more containers run. Containers that are part of the same pod are guaranteed to be scheduled together onto the same machine, and can share state via local volumes.
Borg has a similar abstraction, called an alloc (short for “resource allocation”). Popular uses of allocs in Borg include running a web server that generates logs alongside a lightweight log collection process that ships the log to a cluster filesystem (not unlike fluentd or logstash); running a web server that serves data from a disk directory that is populated by a process that reads data from a cluster filesystem and prepares/stages it for the web server (not unlike a Content Management System); and running user-defined processing functions alongside a storage shard. Pods not only support these use cases, but they also provide an environment similar to running multiple processes in a single VM -- Kubernetes users can deploy multiple co-located, cooperating processes in a pod without having to give up the simplicity of a one-application-per-container deployment model.
-
Services. Although Borg’s primary role is to manage the lifecycles of tasks and machines, the applications that run on Borg benefit from many other cluster services, including naming and load balancing. Kubernetes supports naming and load balancing using the service abstraction: a service has a name and maps to a dynamic set of pods defined by a label selector (see next section). Any container in the cluster can connect to the service using the service name. Under the covers, Kubernetes automatically load-balances connections to the service among the pods that match the label selector, and keeps track of where the pods are running as they get rescheduled over time due to failures.
-
Labels. A container in Borg is usually one replica in a collection of identical or nearly identical containers that correspond to one tier of an Internet service (e.g. the front-ends for Google Maps) or to the workers of a batch job (e.g. a MapReduce). The collection is called a Job, and each replica is called a Task. While the Job is a very useful abstraction, it can be limiting. For example, users often want to manage their entire service (composed of many Jobs) as a single entity, or to uniformly manage several related instances of their service, for example separate canary and stable release tracks. At the other end of the spectrum, users frequently want to reason about and control subsets of tasks within a Job -- the most common example is during rolling updates, when different subsets of the Job need to have different configurations.
Kubernetes supports more flexible collections than Borg by organizing pods using labels, which are arbitrary key/value pairs that users attach to pods (and in fact to any object in the system). Users can create groupings equivalent to Borg Jobs by using a “job:<jobname>” label on their pods, but they can also use additional labels to tag the service name, service instance (production, staging, test), and in general, any subset of their pods. A label query (called a “label selector”) is used to select which set of pods an operation should be applied to. Taken together, labels and replication controllers allow for very flexible update semantics, as well as for operations that span the equivalent of Borg Jobs.
- IP-per-Pod. In Borg, all tasks on a machine use the IP address of that host, and thus share the host’s port space. While this means Borg can use a vanilla network, it imposes a number of burdens on infrastructure and application developers: Borg must schedule ports as a resource; tasks must pre-declare how many ports they need, and take as start-up arguments which ports to use; the Borglet (node agent) must enforce port isolation; and the naming and RPC systems must handle ports as well as IP addresses.
Thanks to the advent of software-defined overlay networks such as flannel or those built into public clouds, Kubernetes is able to give every pod and service its own IP address. This removes the infrastructure complexity of managing ports, and allows developers to choose any ports they want rather than requiring their software to adapt to the ones chosen by the infrastructure. The latter point is crucial for making it easy to run off-the-shelf open-source applications on Kubernetes--pods can be treated much like VMs or physical hosts, with access to the full port space, oblivious to the fact that they may be sharing the same physical machine with other pods.
With the growing popularity of container-based microservice architectures, the lessons Google has learned from running such systems internally have become of increasing interest to the external DevOps community. By revealing some of the inner workings of our cluster manager Borg, and building our next-generation cluster manager as both an open-source project (Kubernetes) and a publicly available hosted service (Google Container Engine), we hope these lessons can benefit the broader community outside of Google and advance the state-of-the-art in container scheduling and cluster management.
Kubernetes and the Mesosphere DCOS
Kubernetes and the Mesosphere DCOS
Today Mesosphere announced the addition of Kubernetes as a standard part of their DCOS offering. This is a great step forwards in bringing cloud native application management to the world, and should lay to rest many questions we hear about 'Kubernetes or Mesos, which one should I use?'. Now you can have your cake and eat it too: use both. Today's announcement extends the reach of Kubernetes to a new class of users, and add some exciting new capabilities for everyone.
By way of background, Kubernetes is a cluster management framework that was started by Google nine months ago, inspired by the internal system known as Borg. You can learn a little more about Borg by checking out this paper. At the heart of it Kubernetes offers what has been dubbed 'cloud native' application management. To us, there are three things that together make something 'cloud native':
- Container oriented deployments Package up your application components with all their dependencies and deploy them using technologies like Docker or Rocket. Containers radically simplify the deployment process, making rollouts repeatable and predictable.
- Dynamically managed Rely on modern control systems to make moment-to-moment decisions around the health management and scheduling of applications to radically improve reliability and efficiency. There are some things that just machines do better than people, and actively running applications is one of those things.
- Micro-services oriented Tease applications apart into small semi-autonomous services that can be consumed easily so that the resulting systems are easier to understand, extend and adapt.
Kubernetes was designed from the start to make these capabilities available to everyone, and built by the same engineers that built the system internally known as Borg. For many users the promise of 'Google style app management' is interesting, but they want to run these new classes of applications on the same set of physical resources as their existing workloads like Hadoop, Spark, Kafka, etc. Now they will have access to commercially supported offering that brings the two worlds together.
Mesosphere, one of the earliest supporters of the Kubernetes project, has been working closely with the core Kubernetes team to create a natural experience for users looking to get the best of both worlds, adding Kubernetes to every Mesos deployment they instantiate, whether it be in the public cloud, private cloud, or in a hybrid deployment model. This is well aligned with the overall Kubernetes vision of creating ubiquitous management framework that runs anywhere a container can. It will be interesting to see how you blend together the old world and the new on a commercially supported, versatile platform.
Craig McLuckie
Product Manager, Google and Kubernetes co-founder
Weekly Kubernetes Community Hangout Notes - April 17 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Agenda
- Mesos Integration
- High Availability (HA)
- Adding performance and profiling details to e2e to track regressions
- Versioned clients
Notes
-
Mesos integration
-
Mesos integration proposal:
-
No blockers to integration.
-
Documentation needs to be updated.
-
-
HA
-
Proposal should land today.
-
Etcd cluster.
-
Load-balance apiserver.
-
Cold standby for controller manager and other master components.
-
-
Adding performance and profiling details to e2e to track regression
-
Want red light for performance regression
-
Need a public DB to post the data
- See
-
Justin working on multi-platform e2e dashboard
-
-
Versioned clients
-
Client library currently uses internal API objects.
-
Nobody reported that frequent changes to types.go have been painful, but we are worried about it.
-
Structured types are useful in the client. Versioned structs would be ok.
-
If start with json/yaml (kubectl), shouldn’t convert to structured types. Use swagger.
-
-
Security context
-
Administrators can restrict who can run privileged containers or require specific unix uids
-
Kubelet will be able to get pull credentials from apiserver
-
Policy proposal coming in the next week or so
-
-
Discussing upstreaming of users, etc. into Kubernetes, at least as optional
-
1.0 Roadmap
-
Focus is performance, stability, cluster upgrades
-
TJ has been making some edits to roadmap.md but hasn’t sent out a PR yet
-
-
Kubernetes UI
-
Dependencies broken out into third-party
-
@lavalamp is reviewer
-
[*[3:27 PM]: 2015-04-17T15:27:00-07:00
Introducing Kubernetes API Version v1beta3
We've been hard at work on cleaning up the API over the past several months (see https://github.com/GoogleCloudPlatform/kubernetes/issues/1519 for details). The result is v1beta3, which is considered to be the release candidate for the v1 API.
We would like you to move to this new API version as soon as possible. v1beta1 and v1beta2 are deprecated, and will be removed by the end of June, shortly after we introduce the v1 API.
As of the latest release, v0.15.0, v1beta3 is the primary, default API. We have changed the default kubectl and client API versions as well as the default storage version (which means objects persisted in etcd will be converted from v1beta1 to v1beta3 as they are rewritten).
You can take a look at v1beta3 examples such as:
https://github.com/GoogleCloudPlatform/kubernetes/tree/master/examples/guestbook/v1beta3
https://github.com/GoogleCloudPlatform/kubernetes/tree/master/examples/walkthrough/v1beta3
https://github.com/GoogleCloudPlatform/kubernetes/tree/master/examples/update-demo/v1beta3
To aid the transition, we've also created a conversion tool and put together a list of important different API changes.
- The resource
idis now calledname. name,labels,annotations, and other metadata are now nested in a map calledmetadatadesiredStateis now calledspec, andcurrentStateis now calledstatus/minionshas been moved to/nodes, and the resource has kindNode- The namespace is required (for all namespaced resources) and has moved from a URL parameter to the path:
/api/v1beta3/namespaces/{namespace}/{resource_collection}/{resource_name} - The names of all resource collections are now lower cased - instead of
replicationControllers, usereplicationcontrollers. - To watch for changes to a resource, open an HTTP or Websocket connection to the collection URL and provide the
?watch=trueURL parameter along with the desiredresourceVersionparameter to watch from. - The container
entrypointhas been renamed tocommand, andcommandhas been renamed toargs. - Container, volume, and node resources are expressed as nested maps (e.g.,
resources{cpu:1}) rather than as individual fields, and resource values support scaling suffixes rather than fixed scales (e.g., milli-cores). - Restart policy is represented simply as a string (e.g., "Always") rather than as a nested map ("always{}").
- The volume
sourceis inlined intovolumerather than nested. - Host volumes have been changed to hostDir to hostPath to better reflect that they can be files or directories
And the most recently generated Swagger specification of the API is here:
http://kubernetes.io/third_party/swagger-ui/#!/v1beta3
More details about our approach to API versioning and the transition can be found here:
https://github.com/GoogleCloudPlatform/kubernetes/blob/master/docs/api.md
Another change we discovered is that with the change to the default API version in kubectl, commands that use "-o template" will break unless you specify "--api-version=v1beta1" or update to v1beta3 syntax. An example of such a change can be seen here:
https://github.com/GoogleCloudPlatform/kubernetes/pull/6377/files
If you use "-o template", I recommend always explicitly specifying the API version rather than relying upon the default. We may add this setting to kubeconfig in the future.
Let us know if you have any questions. As always, we're available on IRC (#google-containers) and github issues.
Kubernetes Release: 0.15.0
Release Notes:
- Enables v1beta3 API and sets it to the default API version (#6098)
- Added multi-port Services (#6182)
- Added a controller framework (#5270, #5473)
- The Kubelet now listens on a secure HTTPS port (#6380)
- Made kubectl errors more user-friendly (#6338)
- The apiserver now supports client cert authentication (#6190)
- The apiserver now limits the number of concurrent requests it processes (#6207)
- Added rate limiting to pod deleting (#6355)
- Implement Balanced Resource Allocation algorithm as a PriorityFunction in scheduler package (#6150)
- Enabled log collection from master (#6396)
- Added an api endpoint to pull logs from Pods (#6497)
- Added latency metrics to scheduler (#6368)
- Added latency metrics to REST client (#6409)
- etcd now runs in a pod on the master (#6221)
- nginx now runs in a container on the master (#6334)
- Began creating Docker images for master components (#6326)
- Updated GCE provider to work with gcloud 0.9.54 (#6270)
- Updated AWS provider to fix Region vs Zone semantics (#6011)
- Record event when image GC fails (#6091)
- Add a QPS limiter to the kubernetes client (#6203)
- Decrease the time it takes to run make release (#6196)
- New volume support
- Updated to heapster version to v0.10.0 (#6331)
- Updated to etcd 2.0.9 (#6544)
- Updated to Kibana to v1.2 (#6426)
- Bug Fixes
To download, please visit https://github.com/GoogleCloudPlatform/kubernetes/releases/tag/v0.15.0
Weekly Kubernetes Community Hangout Notes - April 10 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Agenda:
- kubectl tooling, rolling update, deployments, imperative commands.
- Downward API / env. substitution, and maybe preconditions/dependencies.
Notes from meeting:
1. kubectl improvements
-
make it simpler to use, finish rolling update, higher-level deployment concepts.
-
rolling update
-
today
-
can replace one rc by another rc specified by a file.
-
no explicit support for rollback, can sort of do it by doing rolling update to old version.
-
we keep annotations on rcs to keep track of desired # instances; won't work for rollback case b/c not symmetric.
-
-
need immutable image ids; currently no uuid that corresponds to image,version so if someone pushes on top you'll re-pull that; in API server we should translate images into uuids (as close to edge as possible).
-
would be nice to auto-gen new rc instead of having user update it (e.g. when change image tag for container, etc.; currently need to change rc name and label value; could automate generating new rc).
-
treating rcs as pets vs. cattle.
-
"roll me from v1 to v2" (or v2 to v1) - good enough for most people. don't care about record of what happened in the past.
-
we're providing the module ansible can call to make something happen.
-
how do you keep track of multiple templates; today we use multiple RCs.
-
if we had a deployment controller; deployment config spawns pos that runs rolling update; trigger is level-based update of image repository.
-
alternative short-term proposal: create new rc as clone of old one, futz with counts so new one is old one and vv, bring prev-named one (pet) down to zero and bring it back up with new template (this is very similar to how Borg does job updates).
- is it worthwhile if we want to have the deployments anyway? Yes b/c we have lots of concepts already; need to simplify.
-
deployment controller keeps track of multiple templates which is what you need for rolling updates and canaries.
-
only reason for new thing is to move the process into the server instead of the client?
-
may not need to make it an API object; should provide experience where it's not an API object and is just something client side.
-
need an experience now so need to do it in client because object won't land before 1.0.
-
having simplified experience for people who only want to enageg w/ RCs.
-
how does rollback work: ctrl-c, rollout v2 v1. rollback pattern can be in person's head. 2 kinds of rollback: i'm at steady state and want to go back, and i've got canary deployment and hit ctrl-c how do i get rid of the canary deployment (e.g. new is failing). ctrl-c might not work. delete canary controller and its pods. wish there was a command to also delete pods (there is -- kbectl stop). argument for not reusing name: when you move fwd you can stop the new thing and you're ok, vs. if you replace the old one and you've created a copy if you hit ctrl-c you don't have anything you can stop. but you could wait to flip the name until the end, use naming convention so can figure out what is going on, etc.
-
two different experiences: (1) i'm using version control, have version history of last week rollout this week, rolling update with two files -> create v2, ??? v1, don't have a pet - moved into world of version control where have cumulative history and; (1) imperative kubectl v1 v2 where sys takes care of details, that's where we use the snapshot pattern.
-
-
other imperative commands
-
run-container (or just run): spec command on command line which makes it more similar to docker run; but not multi-container pods.
-
--forever vs. not (one shot exec via simple command).
-
would like it go interactive - run -it and runs in cluster but you have interactive terminal to your process.
-
how do command line args work. could say --image multiple times. will cobra support? in openshift we have clever syntax for grouping arguments together. doesn't work for real structured parameters.
-
alternative: create pod; add container add container ...; run pod -- build and don't run object until 'run pod'.
-
-- to separate container args.
-
create a pod, mutate it before you run it - like initializer pattern.
-
-
-
kind discovery
-
if we have run and sometimes it creates an rc and sometimes it doesn't, how does user know what to delete if they want to delete whatever they created with run.
-
bburns has proposal for don't specify kind if you do command like stop, delete; let kubectl figure it out.
-
alternative: allow you to define alias from name to set of resource types, eg. delete all which would follow that alias (all could mean everything in some namespace, or unscoped, etc.) - someone explicitly added something to a set vs. accidentally showed up like nodes.
-
would like to see extended to allow tools to specify their own aliases (not just users); e.g. resize can say i can handle RCs, delete can say I can handle everything, et.c so we can automatically do these things w/o users have to specify stuff. but right mechanism.
-
resourcebuilder has concept of doing that kind of expansion depending on how we fit in targeted commands. for instance if you want to add a volume to pods and rcs, you need something to go find the pod template and change it. there's the search part of it (delete nginx -> you have to figure out what object they are referring to) and then command can say i got a pod i know what to do with a pod.
-
alternative heuristic: what if default target of all commands was deployments. kubectl run -> deployment. too much work, easier to clean up existing CLI. leave door open for that. macro objects OK but a lot more work to make that work. eventually will want index to make these efficient. could rely more on swagger to tell us types.
-
2. paul/downward api: env substitution
- create ad-hoc env var like strings, e.g. k8s_pod_name that would get sub'd by system in objects.
- allow people to create env vars that refer to fields of k8s objects w/o query api from inside their container; in some cases enables query api from their container (e.g. pass obj names, namespaces); e.g. sidecar containers need this for pulling things from api server.
- another proposal similar: instead of env var like names, have JSON-path-like syntax for referring to object field names; e.g. $.metadata.name to refer to name of current object, maybe have some syntax for referring to related objects like node that a pod is on. advantage of JSON path-like syntax is that it's less ad hoc. disadvantage is that you can only refer to things that are fields of objects.
- for both, if you populate env vars then you have drawback that fields only set when container is created. but least degree of coupling -- off the shelf containers, containers don't need to know how to talk to k8s API. keeps the k8s concepts in the control plane.
- we were converging on JSON path like approach. but need prototype or at least deeper proposal to demo.
- paul: one variant is for env vars in addition to value field have different sources which is where you would plug in e.g. syntax you use to describe a field of an object; another source would be a source that described info about the host. have partial prototype. clean separation between what's in image vs. control plane. could use source idea for volume plugin.
- use case: provide info for sidecar container to contact API server.
- use case: pass down unique identifiers or things like using UID as unique identifier.
- clayton: for rocket or gce metadata service being available for every pod for more sophisticated things; most containers want to find endpoint of service.
3. preconditions/dependencies
- when you create pods that talk to services, the service env vars only get populated if you create the objs in the right order. if you use dns it's less of a problem but some apps are fragile. may crash if svc they depend on is not there, may take a long time to restart. proposal to have preconds that block starting pods until objs they depend on exist.
- infer automatically if we ask people to declare which env vars they wanted, or have dep mech at pod or rc or obj level to say this obj doesn't become active until this other thing exists.
- can use event hook? only app owner knows their dependency or when service is ready to serve.
- one proposal is to use pre-start hook. another is precondition probe - pre-start hook could do a probe. does anything respond when i hit this svc address or ip, then probe fails. could be implemented in pre-start hook. more useful than post-start. is part of rkt spec. has stages 0, 1, 2. hard to do in docker today, easy in rocket.
- pre-start hook in container: how will affect readiness probe since the container might have a lock until some arbitrary condition is met if you implement with prestart hook. there has to be some compensation on when kubelet runs readiness/liveness probes if you have a hook. Systemd has timeouts around the stages of process lifecycle.
- if we go to black box model of container pre-start makes sense; if container spec becomes more descriptive of process model like systemd, then does kubelet need to know more about process model to do the right thing.
- ideally msg from inside the container to say i've done all of my pre-start actions. sdnotify for systemd does this. you tell systemd that you're done, it will communicate to other deps that you're alive.
- but... someone could just implement preconds inside their container. makes it easier to adapt an app w/o having to change their image. alternative is just have a pattern how they do it themselves but we don't do it for them.
Faster than a speeding Latte
Check out Brendan Burns racing Kubernetes.
Weekly Kubernetes Community Hangout Notes - April 3 2015
Kubernetes: Weekly Kubernetes Community Hangout Notes
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Agenda:
- Quinton - Cluster federation
- Satnam - Performance benchmarking update
Notes from meeting:
- Quinton - Cluster federation
- Ideas floating around after meetup in SF
-
- Please read and comment
- Not 1.0, but put a doc together to show roadmap
- Can be built outside of Kubernetes
- API to control things across multiple clusters, include some logic
-
Auth(n)(z)
-
Scheduling Policies
-
…
- Different reasons for cluster federation
-
Zone (un) availability : Resilient to zone failures
-
Hybrid cloud: some in cloud, some on prem. for various reasons
-
Avoid cloud provider lock-in. For various reasons
-
"Cloudbursting" - automatic overflow into the cloud
- Hard problems
-
Location affinity. How close do pods need to be?
-
Workload coupling
-
Absolute location (e.g. eu data needs to be in eu)
-
-
Cross cluster service discovery
- How does service/DNS work across clusters
-
Cross cluster workload migration
- How do you move an application piece by piece across clusters?
-
Cross cluster scheduling
-
How do know enough about clusters to know where to schedule
-
Possibly use a cost function to achieve affinities with minimal complexity
-
Can also use cost to determine where to schedule (under used clusters are cheaper than over-used clusters)
-
- Implicit requirements
-
Cross cluster integration shouldn't create cross-cluster failure modes
- Independently usable in a disaster situation where Ubernetes dies.
-
Unified visibility
- Want to have unified monitoring, alerting, logging, introspection, ux, etc.
-
Unified quota and identity management
- Want to have user database and auth(n)/(z) in a single place
- Important to note, most causes of software failure are not the infrastructure
-
Botched software upgrades
-
Botched config upgrades
-
Botched key distribution
-
Overload
-
Failed external dependencies
- Discussion:
-
Where do you draw the "ubernetes" line
- Likely at the availability zone, but could be at the rack, or the region
-
Important to not pigeon hole and prevent other users
-
Satnam - Soak Test
- Want to measure things that run for a long time to make sure that the cluster is stable over time. Performance doesn't degrade, no memory leaks, etc.
- github.com/GoogleCloudPlatform/kubernetes/test/soak/…
- Single binary, puts lots of pods on each node, and queries each pod to make sure that it is running.
- Pods are being created much, much more quickly (even in the past week) to make things go more quickly.
- Once the pods are up running, we hit the pods via the proxy. Decision to hit the proxy was deliberate so that we test the kubernetes apiserver.
- Code is already checked in.
- Pin pods to each node, exercise every pod, make sure that you get a response for each node.
- Single binary, run forever.
- Brian - v1beta3 is enabled by default, v1beta1 and v1beta2 deprecated, turned off in June. Should still work with upgrading existing clusters, etc.
Participate in a Kubernetes User Experience Study
We need your help in shaping the future of Kubernetes and Google Container Engine, and we'd love to have you participate in a remote UX research study to help us learn about your experiences! If you're interested in participating, we invite you to take this brief survey to see if you qualify. If you’re selected to participate, we’ll follow up with you directly.
- Length: 60 minute interview
- Date: April 7th-15th
- Location: Remote
- Your gift: $100 Perks gift code*
- Study format: Interview with our researcher
Interested in participating? Take this brief survey.
* Perks gift codes can be redeemed for gift certificates from VISA and used at a number of online retailers (http://www.google.com/forms/perks/index1.html). Gift codes are only for participants who successfully complete the study session. You’ll be emailed the gift code after you complete the study session.
Weekly Kubernetes Community Hangout Notes - March 27 2015
Every week the Kubernetes contributing community meet virtually over Google Hangouts. We want anyone who's interested to know what's discussed in this forum.
Agenda:
- Andy - demo remote execution and port forwarding
- Quinton - Cluster federation - Postponed
- Clayton - UI code sharing and collaboration around Kubernetes
Notes from meeting:
1. Andy from RedHat:
-
Demo remote execution
-
kubectl exec -p $POD -- $CMD
-
Makes a connection to the master as proxy, figures out which node the pod is on, proxies connection to kubelet, which does the interesting bit. via nsenter.
-
Multiplexed streaming over HTTP using SPDY
-
Also interactive mode:
-
Assumes first container. Can use -c $CONTAINER to pick a particular one.
-
If have gdb pre-installed in container, then can interactively attach it to running process
- backtrace, symbol tbles, print, etc. Most things you can do with gdb.
-
Can also with careful flag crafting run rsync over this or set up sshd inside container.
-
Some feedback via chat:
-
-
Andy also demoed port forwarding
-
nsenter vs. docker exec
-
want to inject a binary under control of the host, similar to pre-start hooks
-
socat, nsenter, whatever the pre-start hook needs
-
-
would be nice to blog post on this
-
version of nginx in wheezy is too old to support needed master-proxy functionality
2. Clayton: where are we wrt a community organization for e.g. kubernetes UI components?
- google-containers-ui IRC channel, mailing list.
- Tim: google-containers prefix is historical, should just do "kubernetes-ui"
- also want to put design resources in, and bower expects its own repo.
- General agreement
3. Brian Grant:
- Testing v1beta3, getting that ready to go in.
- Paul working on changes to commandline stuff.
- Early to mid next week, try to enable v1beta3 by default?
- For any other changes, file issue and CC thockin.
4. General consensus that 30 minutes is better than 60
- Shouldn't artificially try to extend just to fill time.
Kubernetes Gathering Videos
If you missed the Kubernetes Gathering in SF last month, fear not! Here are the videos from the evening presentations organized into a playlist on YouTube

Welcome to the Kubernetes Blog!
Welcome to the new Kubernetes Blog. Follow this blog to learn about the Kubernetes Open Source project. We plan to post release notes, how-to articles, events, and maybe even some off topic fun here from time to time.
If you are using Kubernetes or contributing to the project and would like to do a guest post, please let me know.
To start things off, here's a roundup of recent Kubernetes posts from other sites:
- Scaling MySQL in the cloud with Vitess and Kubernetes
- Container Clusters on VMs
- Everything you wanted to know about Kubernetes but were afraid to ask
- What makes a container cluster?
- Integrating OpenStack and Kubernetes with Murano
- An introduction to containers, Kubernetes, and the trajectory of modern cloud computing
- What is Kubernetes and how to use it?
- OpenShift V3, Docker and Kubernetes Strategy
- An Introduction to Kubernetes
Happy cloud computing!
- Kit Merker - Product Manager, Google Cloud Platform